

T5 for Hate Speech, Augmented Data, and Ensemble



Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
3.1. Preprocessing
- URLs are removed.
- Emails are removed.
- IP addresses are removed.
- Numbers are removed.
- All characters are changed to lowercase.
- Excess spaces are removed.
- Special characters, such as hashtags(#) and mention symbols (@), are removed.
3.2. Data
- 1.
- HASOC 2020
- 2.
- HASOC 2021
- 3.
- HatEval 2019
- 4.
- OLID 2019
- 5.
- Hate Speech and Offensive HSO
- 6.
- Trolling, Aggression, and Cyberbullying (TRAC)
3.3. Models
- 1.
- The Bi-LSTM is one form of Recurrent Neural Network (RNN) [39]. It is an improved variant of the vanilla RNN. Its input text flows forward and backward, providing more contextual information, and thereby improving the network performance [40]. We used 2 bi-directional layers and pre-trained Glove [41] word embeddings of 100 dimensions. We also applied a dropout layer to prevent overfitting. This model has 1,317,721 parameters. Word and subword embeddings have been shown to improve the performance of downstream tasks [41,42,43].
- 2.
- The CNN is common in computer vision or image processing. The author of [44] shows the effectiveness of CNNs in capturing text local patterns on different NLP tasks. Both the Bi-LSTM and CNN architectures are used as feature-based models, where for each tweet, we computed embeddings using the pre-trained Glove, before using the embeddings as an input to the baseline model. The CNN model is composed of 3 convolution layers with 100 filters each. The filter size for the first layer is , the filter size for the second layer is , and the filter size is for the third layer. We use the ReLU activation function and max-pooling after each convolution layer. We perform dropout for regularization. The total trainable parameters for the CNN are 1,386,201.
- 3.
- RoBERTa is based on the replication study of BERT. It differs from BERT in the following ways: (1) training for longer over more data, (2) removing the next sentence prediction objective, and (3) using longer sequences for training [29]. The base version of the model, which we use, has 12 layers and 110 M parameters. For our study, we use a batch size of 32, an initial learning rate of , and a maximum sequence length of 256. We restricted the number of tasks to only binary tasks for this model.
- 4.
- The T5 [32] is based on the transformer architecture by Vaswani et al. [16]. However, a different layer normalization is applied, in which there is no additive bias applied, and the activations are only rescaled. Causal or autoregressive self-attention is used in the decoder for it to attend to past outputs. The T5-Base model has about twice the number of parameters as that of BERT-Base. It has 220 M parameters and 12 layers each in the encoder and decoder blocks, while the smaller version has 60 M parameters [32]. The T5 training method uses teacher forcing (i.e., standard maximum likelihood) and a cross-entropy loss. T5-Base required more memory and would not fit on a single V100 GPU for the batch size of 64; hence, we lowered the batch size to 16 but kept the batch size at 64 for T5-Small. The task prefix we use is ‘classification’ for all the tasks, as the model takes a hyperparameter called a task prefix.
3.4. Solving OoC Predictions in T5
3.5. Data Augmentation
3.6. The Ensemble
4. Results
4.1. Cross-Task Training
4.2. HASOC 2021 Annotation Issues
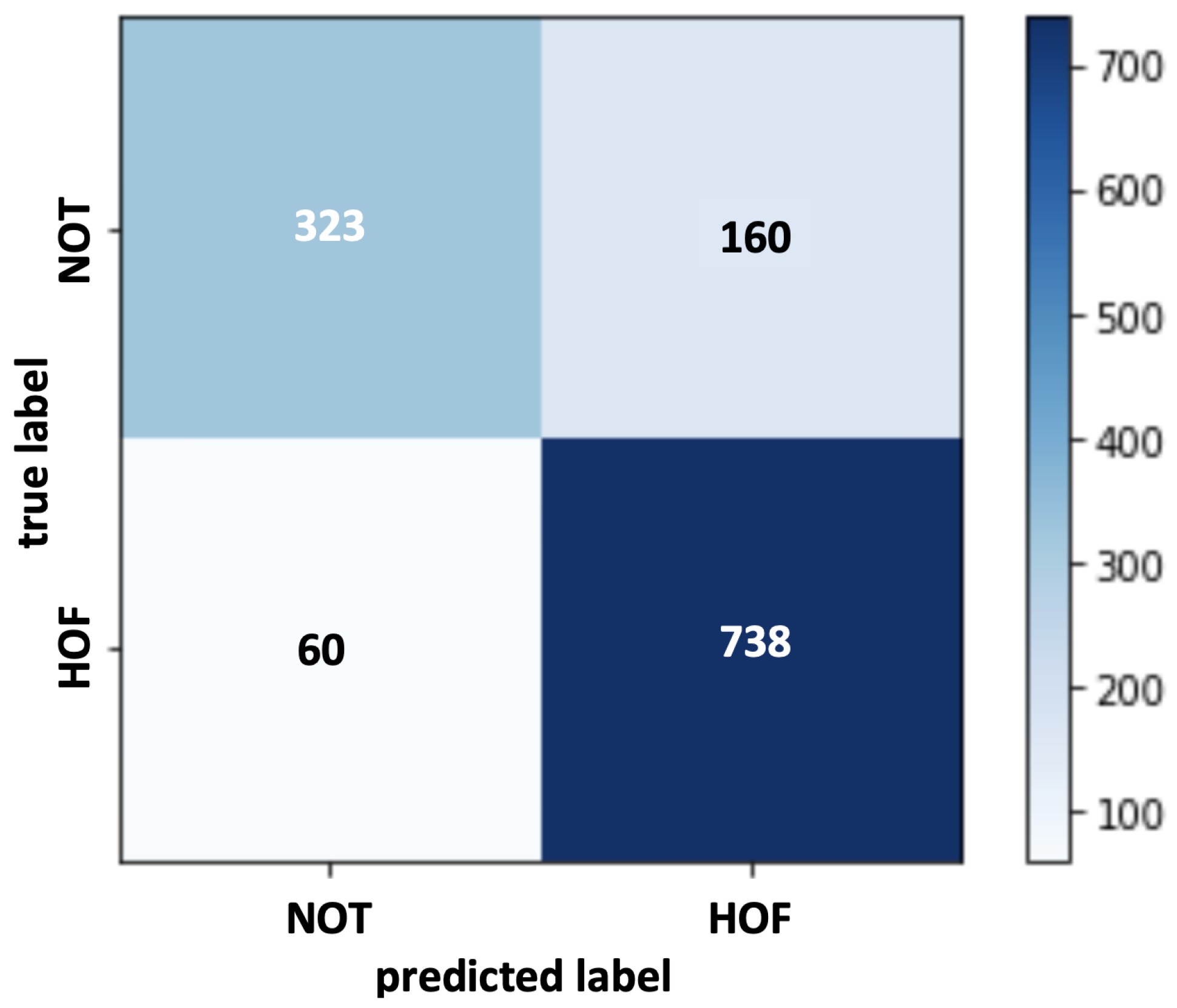
4.3. Error Analysis
4.4. Explainable Artificial Intelligence (XAI)
5. Conclusions
Limitations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Appendix A
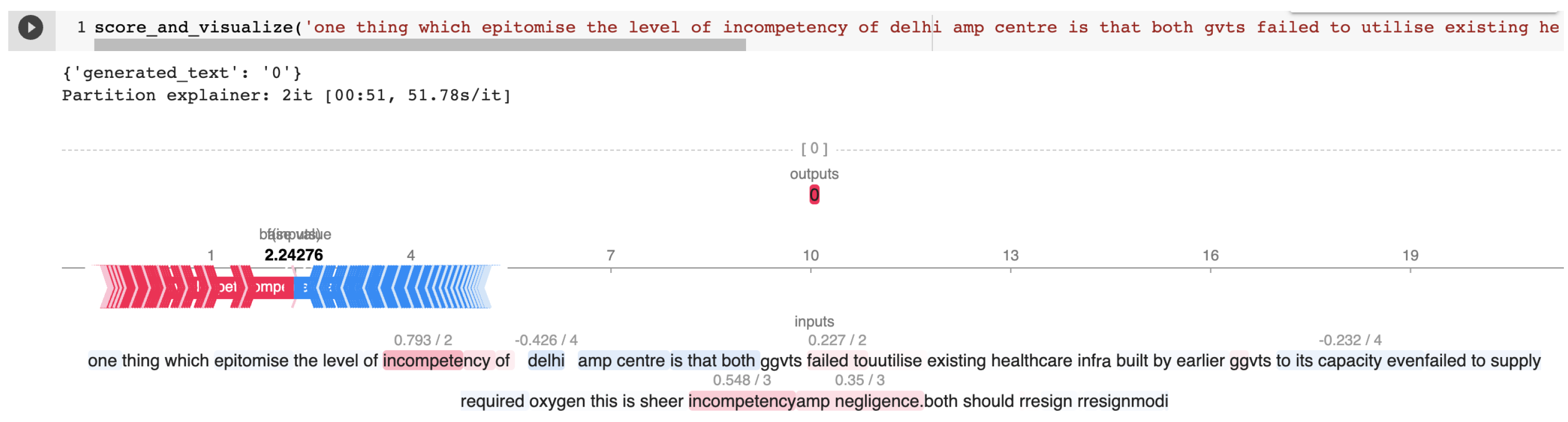
Appendix A.1. SHAP Explanations
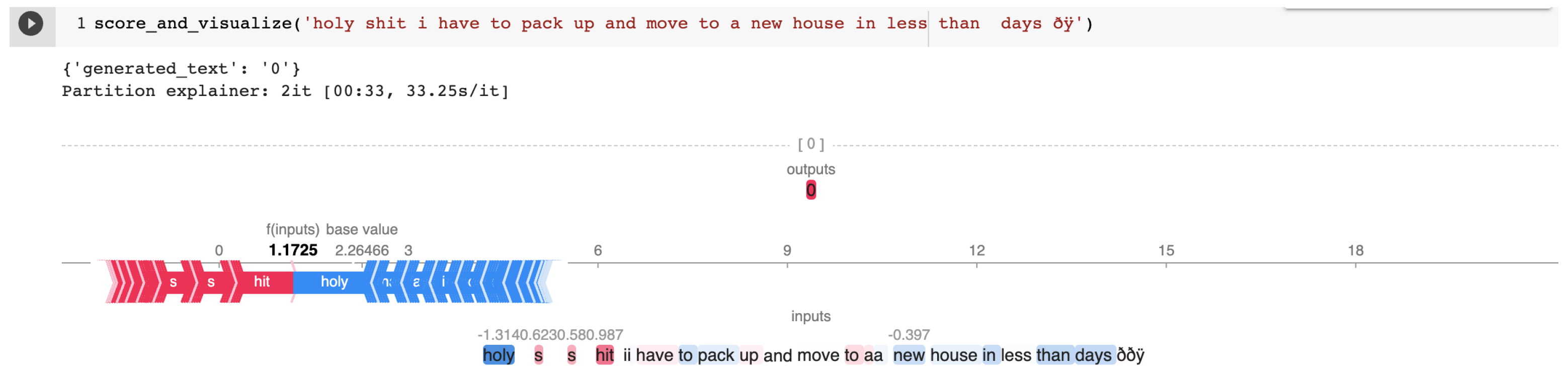
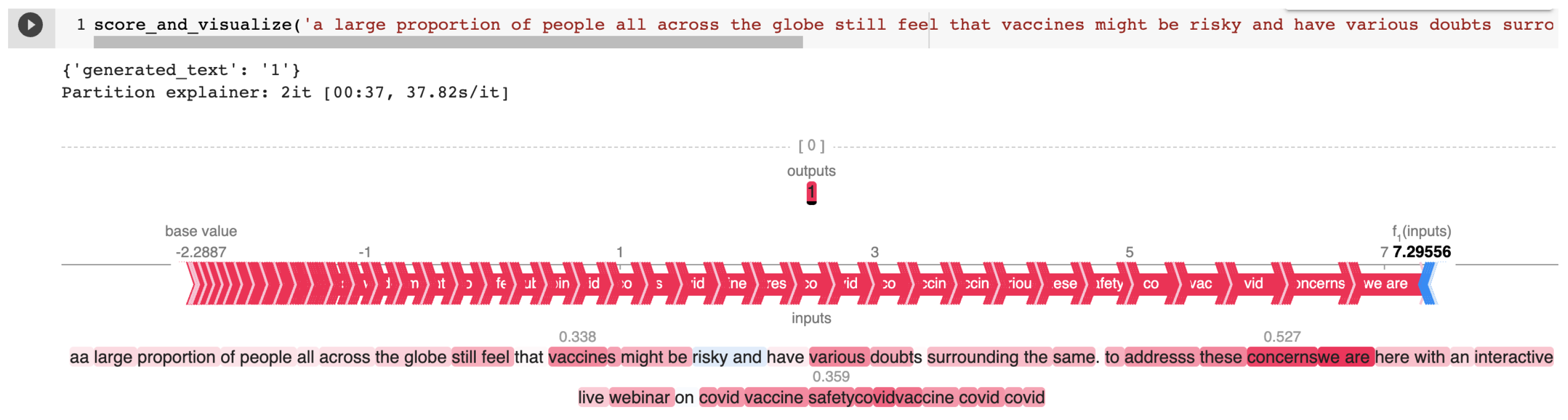


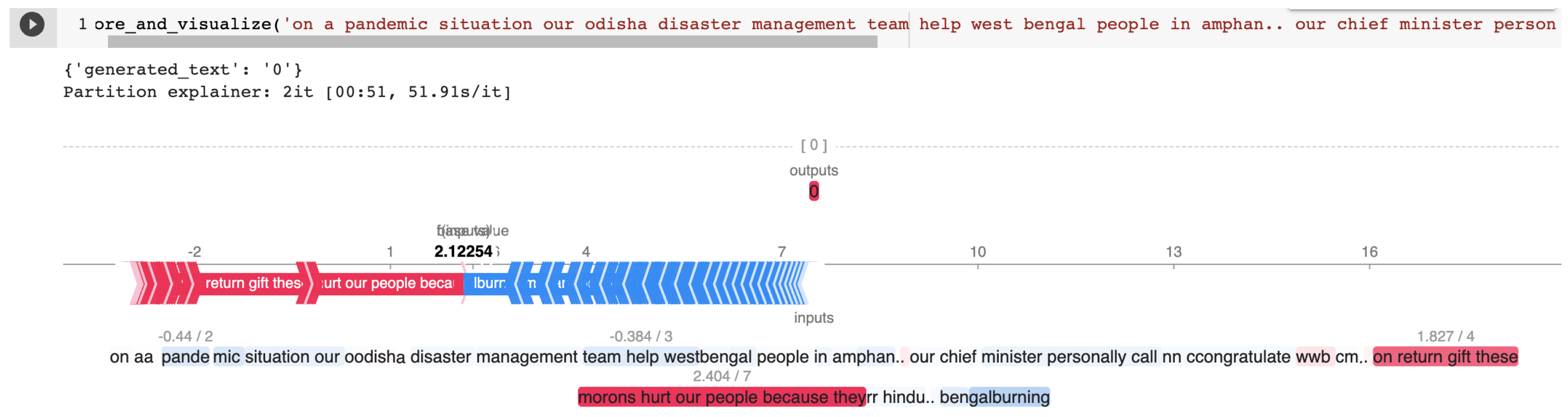
Appendix A.2. Cross-Task Training
Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cross-Task | Weighted F1 (%) | Macro F1 (%) | ||
|---|---|---|---|---|
| Dev (sd) | Test (sd) | Dev (sd) | Test (sd) | |
| Hasoc 2020 A -> OLID A | 90.35 (0.01) | 83.94 (0.72) | 88.82 (0.01) | 79.81 (0.85) |
| Hasoc 2021 A -> OLID A | 91.82 (0.01) | 83.52 (0.48) | 90.57 (0.01) | 79.22 (1.01) |
| Hasoc 2021 A -> Hasoc 2020 A | 95.87 (0) | 90.14 (0.85) | 95.87 (0) | 90.13 (0.85) |
| OLID A -> Hasoc 2020 A | 96.59 (0.68) | 91.73 (0.25) | 96.58 (0.68) | 91.73 (0.26) |
| OLID A -> Hasoc 2021 A | 86.82 (0.01) | 80.91 (0.53) | 84.91 (0.02) | 79.32 (0.55) |
| Hasoc 2020 A -> Hasoc 2021 A | 87.2 (0.03) | 81.75 (0.29) | 87.37 (0.01) | 80.4 (0.3) |
| Task | Weighted F1 (%) | Macro F1(%) | ||
|---|---|---|---|---|
| Dev (sd) | Test (sd) | Dev (sd) | Test (sd) | |
| Bi-LSTM | ||||
| HatEval SemEval 2019 A | - | 72.38 (0.54) | - | 72.12 (0.72) |
| HatEval SemEval 2019 B | - | 77.74 (2.8) | - | 73.11 (0.44) |
| Hasoc 2020 A | 88.6 (0.15) | 89.30 (0.15) | 89.47 (1.47) | 90.28 (0.20) |
| Hasoc 2020 B | 75.80 (0.56) | 74.39 (2.31) | 42.99 (0.15) | 42.97 (0.06) |
| HSO | 90.19 (0.03) | - | 68.77 (1.93) | - |
| Trolling, Aggression | 68.69 (0.36) | - | 36.00 (0.27) | - |
| CNN | ||||
| HatEval SemEval 2019 A | - | 73.95 (0.64) | - | 71.67 (0.43) |
| HatEval SemEval 2019 B | - | 78.88 (0.55) | - | 71.13 (0.43) |
| Hasoc 2020 A | 88.06 (0.41) | 89.76 (0.44) | 88.21 (0.41) | 90.08 (0.46) |
| Hasoc 2020 B | 76.38 (0.63) | 76.48 (0.61) | 49.15 (1.25) | 47.58 (0.85) |
| HSO | 88.52 (0.62) | - | 71.27 (0.74) | - |
| TRAC | 71.01 (1.73) | - | 40.24 (0.43) | - |
| T5-Base | ||||
| HatEval SemEval 2019 A | - | 87.07 (4.81) | - | 86.52 (5.11) |
| HatEval SemEval 2019 B | - | 99.93 (0) | - | 99.88 (0) |
| TRAC | 80.84 (3.96) | - | 56.97 (8.34) | - |
| HateBERT | ||||
| HatEval SemEval 2019 A | - | - | - | 0.516 (0.007) |
| _id | Text | Task_1 | Task_2 |
|---|---|---|---|
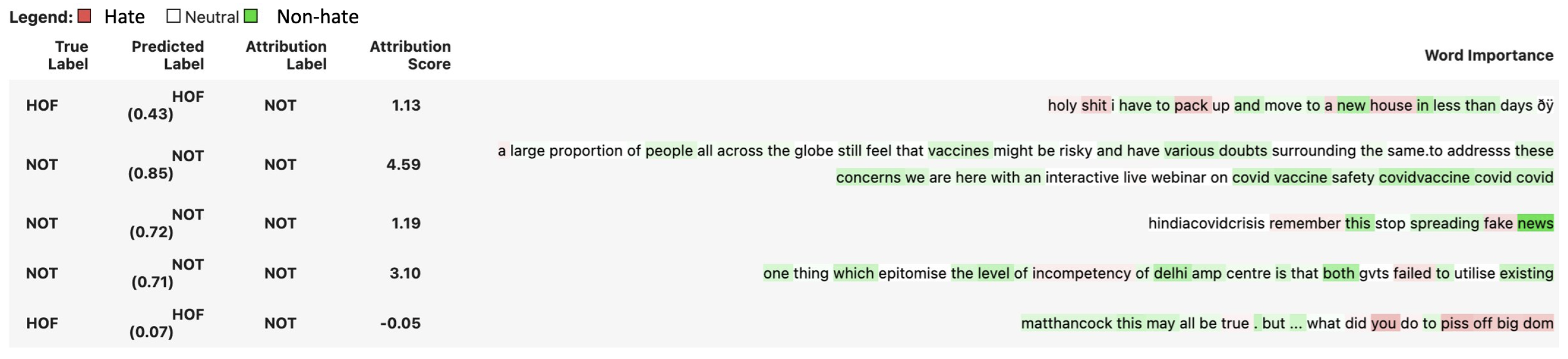
| 60c5d6bf5659ea5e55def475 | holy shit i have to pack up and move to a new house in less than days ðÿ | HOF | PRFN |
| 60c5d6bf5659ea5e55df026b | a large proportion of people all across the globe still feel that vaccines might be risky and have various doubts surrounding the same. to addresss these concerns we are here with an interactive live webinar on covid vaccine safety covidvaccine covid covid | NOT | NONE |
| 60c5d6bf5659ea5e55deff15 | indiacovidcrisis remember this stop spreading fake news | NOT | NONE |
| 60c5d6bf5659ea5e55defc3e | one thing which epitomise the level of incompetency of delhi amp centre is that both gvts failed to utilise existing healthcare infra built by earlier gvts to its capacity even failed to supply required oxygen this is sheer incompetency amp negligence. both should resign resignmodi | NOT | NONE |
| 60c5d6bf5659ea5e55df028c | matthancock this may all be true. but…what did you do to piss off big dom | HOF | PRFN |
| 60c5d6bf5659ea5e55defb7f | on a pandemic situation our odisha disaster management team help west bengal people in amphan.. our chief minister personally call n congratulate wb cm.. on return gift these morons hurt our people because they r hindu.. bengalburning | HOF | HATE |
| 60c5d6bf5659ea5e55defca7 | diovavl shit | NOT | NONE |
| 60c5d6bf5659ea5e55def240 | cancelthboardexams resign_pm_modi pmoindia because of your overconfidence and ignorance hundreds of indian citizens are dying everyday and now you are ignoring lakhs of students daily plea to cancel exam…cancelthboardexams | NOT | NONE |
| 60c5d6bf5659ea5e55defa7d | china must be punished for unleashing the chinesevirus starting a biological war. ban and boycott everything sources from the animal country covidsecondwave | HOF | HATE |
| 60c5d6bf5659ea5e55def5a2 | globaltimesnews china is not at all a trustworthy nation. the epidemic caused by chinesevirus have wreaked havoc worldwide and not only in india. if china really wants to help it should accept its blunder of creating this chinesevirus and spreading it all over intentionally. boycottchina | HOF | HATE |
Appendix B.1. Cherry-Picked Examples from the HASOC 2021 Test Set for T5 Explained by SHAP
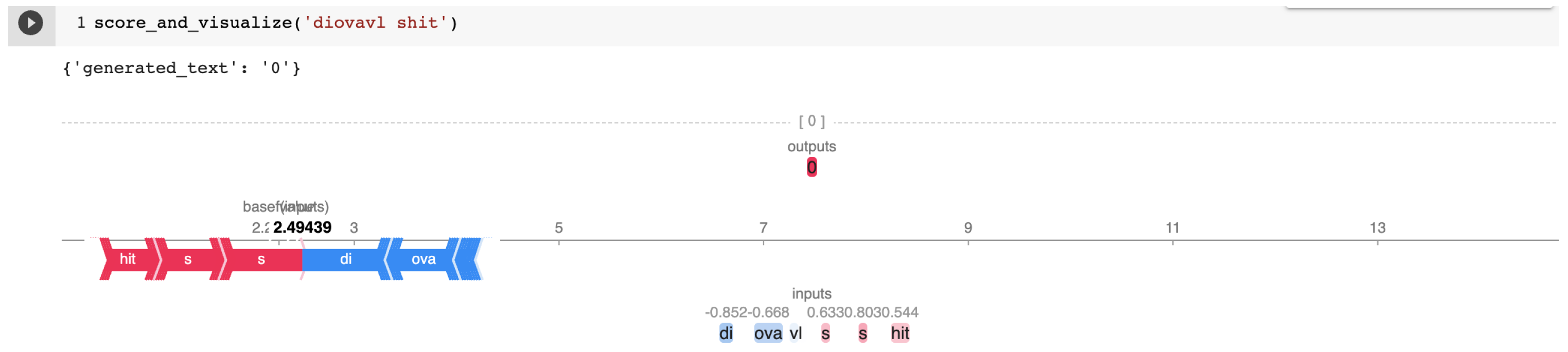


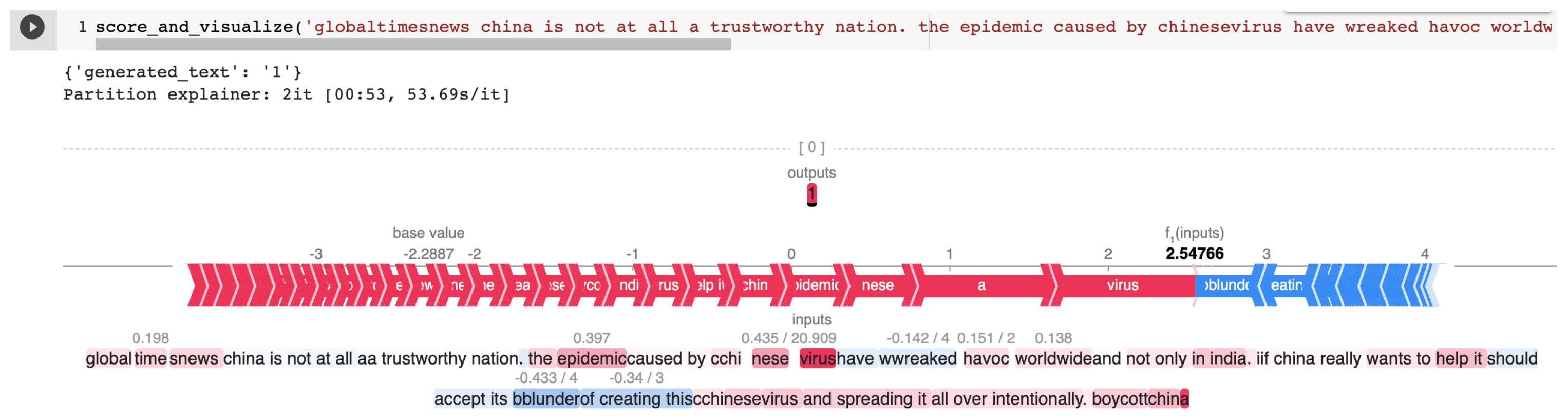
Appendix B.2. Cherry-Picked Examples from the HASOC 2021 Test Set for Bi-LSTM Explained by IG

Appendix B.3. Some Incorrect HASOC 2021 Annotations Correctly Classified by T5 and Explained by SHAP
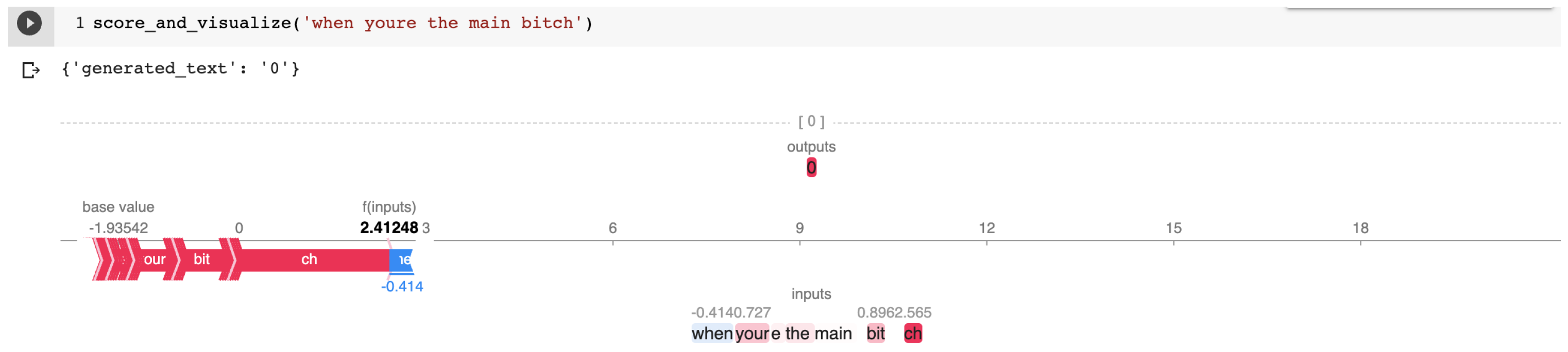

References
- Brison, S.J. The autonomy defense of free speech. Ethics 1998, 108, 312–339. [Google Scholar] [CrossRef]
- Nockleby, J.T. Hate speech. Encycl. Am. Const. 2000, 3, 1277–1279. [Google Scholar]
- Brown, A. What is hate speech? Part 1: The myth of hate. Law Philos. 2017, 36, 419–468. [Google Scholar] [CrossRef]
- Quintel, T.; Ullrich, C. Self-regulation of fundamental rights? The EU Code of Conduct on Hate Speech, related initiatives and beyond. In Fundamental Rights Protection Online; Edward Elgar Publishing: Cheltenham, UK, 2020. [Google Scholar]
- Anderson, L.; Barnes, M. Hate Speech. In The Stanford Encyclopedia of Philosophy, Spring 2022 ed.; Zalta, E.N., Ed.; Metaphysics Research Lab, Stanford University: Stanford, CA, USA, 2022. [Google Scholar]
- Sabry, S.S.; Adewumi, T.; Abid, N.; Kovács, G.; Liwicki, F.; Liwicki, M. HaT5: Hate Language Identification using Text-to-Text Transfer Transformer. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, S.; Galley, M.; Chen, Y.C.; Brockett, C.; Gao, X.; Gao, J.; Liu, J.; Dolan, B. DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Online, 5–10 July 2020; pp. 270–278. [Google Scholar]
- Adewumi, T.; Abid, N.; Pahlavan, M.; Brännvall, R.; Sabry, S.S.; Liwicki, F.; Liwicki, M. Smaprat: DialoGPT for Natural Language Generation of Swedish Dialogue by Transfer Learning. arXiv 2021, arXiv:2110.06273. [Google Scholar] [CrossRef] [PubMed]
- Zampieri, M.; Malmasi, S.; Nakov, P.; Rosenthal, S.; Farra, N.; Kumar, R. Predicting the Type and Target of Offensive Posts in Social Media. In Proceedings of the NAACL 2019, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Caselli, T.; Basile, V.; Mitrović, J.; Granitzer, M. HateBERT: Retraining BERT for Abusive Language Detection in English. In Proceedings of the 5th Workshop on Online Abuse and Harms (WOAH 2021), Online, 6 August 2021; pp. 17–25. [Google Scholar] [CrossRef]
- Davidson, T.; Warmsley, D.; Macy, M.; Weber, I. Automated hate speech detection and the problem of offensive language. In Proceedings of the International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 15–18 May 2017; Volume 11. [Google Scholar]
- Mathew, B.; Saha1, P.; Yimam, S.M.; Biemann, C.; Goyal1, P.; Mukherjee1, A. HateXplain: A Benchmark Dataset for Explainable Hate Speech Detection. In Proceedings of the 35th Association for the Advancement of Artificial Intelligence Conference on Artificial Intelligence, Online, 2–9 February 2021. [Google Scholar]
- Caselli, T.; Basile, V.; Mitrović, J.; Kartoziya, I.; Granitzer, M. I feel offended, don’t be abusive! implicit/explicit messages in offensive and abusive language. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 6193–6202. [Google Scholar]
- Basile, V.; Bosco, C.; Fersini, E.; Debora, N.; Patti, V.; Pardo, F.M.R.; Rosso, P.; Sanguinetti, M. Semeval-2019 task 5: Multilingual detection of hate speech against immigrants and women in twitter. In Proceedings of the 13th International Workshop on Semantic Evaluation. Association for Computational Linguistics, Minneapolis, MN, USA, 6–7 June 2019; pp. 54–63. [Google Scholar]
- Mutanga, R.T.; Naicker, N.; Olugbara, O.O. Hate speech detection in twitter using transformer methods. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 614–620. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008.
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Kovács, G.; Alonso, P.; Saini, R. Challenges of Hate Speech Detection in Social Media. SN Comput. Sci. 2021, 2, 95. [Google Scholar] [CrossRef]
- Elsafoury, F.; Katsigiannis, S.; Wilson, S.R.; Ramzan, N. Does BERT pay attention to cyberbullying? In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Online, 11–15 July 2021; pp. 1900–1904. [Google Scholar]
- Alkomah, F.; Ma, X. A literature review of textual hate speech detection methods and datasets. Information 2022, 13, 273. [Google Scholar] [CrossRef]
- Akuma, S.; Lubem, T.; Adom, I.T. Comparing Bag of Words and TF-IDF with different models for hate speech detection from live tweets. Int. J. Inf. Technol. 2022, 14, 3629–3635. [Google Scholar] [CrossRef]
- Gitari, N.D.; Zuping, Z.; Damien, H.; Long, J. A lexicon-based approach for hate speech detection. Int. J. Multimed. Ubiquitous Eng. 2015, 10, 215–230. [Google Scholar] [CrossRef]
- Pitsilis, G.K.; Ramampiaro, H.; Langseth, H. Effective hate-speech detection in Twitter data using recurrent neural networks. Appl. Intell. 2018, 48, 4730–4742. [Google Scholar] [CrossRef]
- Khan, S.; Fazil, M.; Sejwal, V.K.; Alshara, M.A.; Alotaibi, R.M.; Kamal, A.; Baig, A.R. BiCHAT: BiLSTM with deep CNN and hierarchical attention for hate speech detection. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 4335–4344. [Google Scholar] [CrossRef]
- Gambäck, B.; Sikdar, U.K. Using Convolutional Neural Networks to Classify Hate-Speech. In Proceedings of the First Workshop on Abusive Language Online, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 85–90. [Google Scholar] [CrossRef]
- Roy, P.K.; Tripathy, A.K.; Das, T.K.; Gao, X.Z. A framework for hate speech detection using deep convolutional neural network. IEEE Access 2020, 8, 204951–204962. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Mozafari, M.; Farahbakhsh, R.; Crespi, N. A BERT-based transfer learning approach for hate speech detection in online social media. In Proceedings of the Complex Networks and Their Applications VIII: Volume 1 Proceedings of the Eighth International Conference on Complex Networks and Their Applications COMPLEX NETWORKS 2019, Lisbon, Portugal, 10–12 December 2019; Springer: Cham, Switzerland, 2020; pp. 928–940. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- He, P.; Liu, X.; Gao, J.; Chen, W. Deberta: Decoding-enhanced bert with disentangled attention. arXiv 2020, arXiv:2006.03654. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Beltagy, I.; Lo, K.; Cohan, A. SciBERT: A Pretrained Language Model for Scientific Text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3615–3620. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Mandl, T.; Modha, S.; Kumar M, A.; Chakravarthi, B.R. Overview of the hasoc track at fire 2020: Hate speech and offensive language identification in tamil, malayalam, hindi, english and german. In Proceedings of the Forum for Information Retrieval Evaluation, Hyderabad, India, 16 –20 December 2020; pp. 29–32. [Google Scholar]
- Mandl, T.; Modha, S.; Shahi, G.K.; Madhu, H.; Satapara, S.; Majumder, P.; Schaefer, J.; Ranasinghe, T.; Zampieri, M.; Nandini, D.; et al. Overview of the HASOC subtrack at FIRE 2021: Hate speech and offensive content identification in English and Indo-Aryan languages. arXiv 2021, arXiv:2112.09301. [Google Scholar]
- Kumar, R.; Ojha, A.K.; Malmasi, S.; Zampieri, M. Evaluating Aggression Identification in Social Media. In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying, Marseille, France, 11–16 May 2020; pp. 1–5. [Google Scholar]
- Elsafoury, F.; Katsigiannis, S.; Pervez, Z.; Ramzan, N. When the timeline meets the pipeline: A survey on automated cyberbullying detection. IEEE Access 2021, 9, 103541–103563. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef] [PubMed]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 3111–3119. [Google Scholar]
- Adewumi, T.; Liwicki, F.; Liwicki, M. Word2Vec: Optimal hyperparameters and their impact on natural language processing downstream tasks. Open Comput. Sci. 2022, 12, 134–141. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar] [CrossRef]
- Feng, S.Y.; Gangal, V.; Wei, J.; Chandar, S.; Vosoughi, S.; Mitamura, T.; Hovy, E. A Survey of Data Augmentation Approaches for NLP. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; pp. 968–988. [Google Scholar] [CrossRef]
- Eric, M.; Goel, R.; Paul, S.; Sethi, A.; Agarwal, S.; Gao, S.; Kumar, A.; Goyal, A.; Ku, P.; Hakkani-Tur, D. MultiWOZ 2.1: A Consolidated Multi-Domain Dialogue Dataset with State Corrections and State Tracking Baselines. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 422–428. [Google Scholar]
- Zou, Y.; Liu, Z.; Hu, X.; Zhang, Q. Thinking Clearly, Talking Fast: Concept-Guided Non-Autoregressive Generation for Open-Domain Dialogue Systems. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online, Dominican Republic, 7–11 November 2021; pp. 2215–2226. [Google Scholar] [CrossRef]
- Adewumi, O. Vector Representations of Idioms in Data-Driven Chatbots for Robust Assistance. Ph.D. Thesis, Luleå University of Technology, Luleå, Sweden, 2022. [Google Scholar]
- Zampieri, M.; Malmasi, S.; Nakov, P.; Rosenthal, S.; Farra, N.; Kumar, R. SemEval-2019 Task 6: Identifying and Categorizing Offensive Language in Social Media (OffensEval). In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 75–86. [Google Scholar] [CrossRef]
- Doshi-Velez, F.; Kim, B. Towards a rigorous science of interpretable machine learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic attribution for deep networks. In Proceedings of the International Conference on Machine Learning. PMLR, Sydney, NSW, Australia, 6–11 August 2017; pp. 3319–3328. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 4765–4774. [Google Scholar]
- Shapley, L.S. Notes on the n-Person Game—II: The Value of an n-Person Game; RAND Corporation: Santa Monica, CA, USA, 1951. [Google Scholar]
- Nguyen, D.Q.; Vu, T.; Tuan Nguyen, A. BERTweet: A pre-trained language model for English Tweets. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 9–14. [Google Scholar] [CrossRef]
| id | Tweet |
|---|---|
| 23352 | @USER Antifa simply wants us to k*ll them. By the way. Most of us carry a back up. And a knife |
| 61110 | @USER @USER Her life is crappy because she is crappy. And she’s threatening to k*ll everyone. Another nut job...Listen up FBI! |
| 68130 | @USER @USER @USER @USER @USER Yes usually in THOSE countries people k*ll gays cuz religion advise them to do it and try to point this out and antifa will beat you. No matter how u try in america to help gay in those countries it will have no effect cuz those ppl hate america. |
| Method | Description with Pros/Cons |
|---|---|
| Bag of Words | This considers the multiplicity of words in a document and is usually applied with some classical ML methods [21]. It does not consider word order or context; hence, it is less effective than modern approaches. |
| Lexicon-based | This is based on a list of keywords that are identified as hateful or offensive [22]. The lack of context makes this approach more prone to false positives. |
| Term Frequency–Inverse Document Frequency (TF-IDF) | TF-IDF is based on the importance of a word or term to a document [20]. Therefore, it gives less frequently used words greater weight compared to common words, e.g., the. It is commonly used together with classical Machine Learning (ML) approaches, such as Random Forest, Decision Trees, Logistic Regression, etc. [21]. It is less effective than modern ML approaches because it does not consider the context of words in a document. |
| Recurrent Neural Network (RNN) | Neural networks based on sequential recurring time-steps are used in automatic HS detection [23,24]. An improved variant of the RNN is the Bi-LSTM. The vanishing gradient problem and the lack of parallelization in RNNs have placed limitations on their performance. |
| Convolutional Neural Network (CNN) | CNNs are typically used in computer vision and are a deep learning approach. They employ filters and pooling [24,25,26]. The architectural design of CNNs seems to make them less efficient for text than the Transformer [16]. |
| Bidirectional Encoder Representations from Transformers (BERT) [27] | BERT has been employed in automatic HS detection in various forms, including hybrid methods [24,28]. Variants of BERT include RoBERTa [29], ALBERT [30], and DeBERTa [31]. These are deep learning models that generate deep contextual representations. They use only the encoder stacks of the Transformer architecture [16], unlike the T5 [32], which uses both encoder and decoder stacks. |
| Type | Sample |
|---|---|
| original | Son of a *** wrong “you’re” |
| augmented | son of a *** wrong youre No, that’s Saint Johns Chop House. I need a taxi to take me from the hotel to the restaurant, leaving the first at 5:45. |
| original | SO EXCITED TO GET MY CovidVaccine I hate you covid! |
| augmented | so excited to get my covidvaccine i hate you covid You should probably get that checked out by a gastroenterology department. |
| original | ModiKaVaccineJumla Who is responsible for oxygen? ModiResign Do you agree with me? Don’t you agree with me? |
| augmented | modikavaccinejumla who is responsible for oxygen modiresign do you agree with me dont you agree with me Yes, I definitely do not want to work with them again. I appreciate your help.. |
| Task | Weighted F1 (%) | Macro F1(%) | ||
|---|---|---|---|---|
| Dev (sd) | Test (sd) | Dev (sd) | Test (sd) | |
| CNN | ||||
| OLID A | 79.10 (0.26) | 82.47 (0.56) | 77.61 (0.39) | 78.46 (0) |
| OLID B | 82.43 (0.49) | 83.46 (0) | 46.76 (0) | 47.88 (0) |
| OLID C | 47.54 (1.36) | 38.09 (3.91) | 35.65 (0) | 36.85 (0) |
| Hasoc 2021 A | 77.22 (0.52) | 77.63 (0.70) | 74.28 (0.58) | 75.67 (0) |
| Hasoc 2021 B | 55.60 (0.61) | 59.84 (0.41) | 50.41 (0.41) | 54.99 (0) |
| Bi-LSTM | ||||
| OLID A | 79.59 (0.89) | 83.89 (0.57) | 78.48 (1.52) | 79.49 (0) |
| OLID B | 82.50 (1.70) | 83.46 (0) | 46.76 (0) | 47.32 (0) |
| OLID C | 49.75 (3.95) | 43.82 (9.63) | 35.65 (2.81) | 36.82 (0) |
| Hasoc 2021 A | 78.05 (0.85) | 78.43 (0.84) | 77.99 (1.79) | 77.19 (0) |
| Hasoc 2021 B | 50.65 (1.34) | 52.19 (1.95) | 43.19 (2.09) | 42.25 (0) |
| RoBERTa | ||||
| OLID A | 82.70 (0.55) | 84.62 (0) | 80.51 (0.76) | 80.34 (0) |
| OLID B | 82.70 (0.13) | 83.46 (0) | 46.76 (0.04) | 47.02 (0) |
| Hasoc 2021 A | 79.9 (0.57) | 76.2 (0) | 77.77 (0.75) | 74 (0) |
| T5-Base | ||||
| OLID A | 92.90 (1.37) | 85.57 (0) | 92.93 (1.42) | 81.66 (0) |
| OLID B | 99.75 (0.43) | 86.81 (0) | 99.77 (0.44) | 53.78 (0) |
| OLID C | 58.35 (1.22) | 54.99 (0) | 33.09 (0.76) | 43.12 (0) |
| Hasoc 2021 A | 94.60 (1.98) | 82.3 (0) | 94.73 (5.26) | 80.81 (0) |
| Hasoc 2021 B | 65.40 (0.82) | 62.74 (0) | 62.43 (6.32) | 59.21 (0) |
| [49] best scores | ||||
| OLID A | 82.90 (-) | |||
| OLID B | 75.50 (-) | |||
| OLID C | 66 (-) | |||
| Task | Weighted F1 (%) | Macro F1(%) | ||
|---|---|---|---|---|
| Dev (sd) | Test (sd) | Dev (sd) | Test (sd) | |
| T5-Base | ||||
| Hasoc 2020 A | 96.77 (0.54) | 91.12 (0.2) | 96.76 (0.54) | 91.12 (0.2) |
| Hasoc 2020 B | 83.36 (1.59) | 79.08 (1.15) | 56.38 (5.09) | 53.21 (2.87) |
| T5-Base+Augmented Data | ||||
| Hasoc 2021 A | 95.5 (3.27) | 83 (0) | 92.97 (2.20) | 82.54 (0) |
| Hasoc 2021 B | 64.74 (3.84) | 66.85 (0) | 65.56 (1.48) | 62.71 (0) |
| Ensemble | ||||
| Hasoc 2021 A | 80.78 (0) | 79.05 (0) | ||
| [35] best scores | ||||
| Hasoc 2020 A | 51.52 (-) | |||
| Hasoc 2020 B | 26.52 (-) | |||
| [36] best scores | ||||
| Hasoc 2021 A | 83.05 (-) | |||
| Hasoc 2021 B | 66.57 (-) | |||
| _id | Text | Task_1 | Task_2 |
|---|---|---|---|
| 60c5d6bf5659ea5e55def8b3 | When you’re the main b*tch https://t.co//HWlNpEUiwS, accessed on 7 January 2023. | NOT | NONE |
| 60c5d6bf5659ea5e55df0242 | miya four creeps into every thought i have what the f*ck | NOT | NONE |
| 60c5d6bf5659ea5e55defe58 | At least we’re being freed from the shambles of the evangelical, but d*mn y’all couldn’t just go w the flow? Y’all just had to find jebus through crystals and astrology? Smdh | NOT | NONE |
| 60c5d6bf5659ea5e55defe24 | @kumarmbayar @Actor_Siddharth He is mentally Upset, Why he’s not talking about #BengalBurning and why stupid talks about Tejasvi_Surya | NOT | NONE |
| 60c5d6bf5659ea5e55df0210 | @amemoott @Ripple @UCT_news @qz @coinbase @cz_binance låve been holding XRP for years. On Coinbase and binance. If you not going to help shut the f*ck up | NOT | NONE |
| 60c5d6bf5659ea5e55def288 | Like this tweet for a DM SC: jayjayson4225 #dmme #horny #hornydm #nsfwtwitter #nsfw #twitterafterdark #whitedick #whitecock #cockrate #nudes #naughtydm #dmsopen #bwc #cock #dick #nsfwtwt #porn #sex #dickpic #dickpics #cumslut #cum #slut #whore #hotwife | NOT | NONE |
| 60c5d6bf5659ea5e55defdc1 | happy p*ss off old people month! | NOT | NONE |
| 60c5d6bf5659ea5e55defc79 | #China is such a worst country first they unleashed #Chinesevirus on whole world and #ChinaLiedPeopleDied and now india is struggling with #Chinesevirus but they are mocking people who are dieing of #ChinesVirus in India https:/t.coV0AiuJV3lm | NOT | NONE |
| 60c5d6bf5659ea5e55df01aa | @globaltimesnews Communist must feel shame God is watching you what you did with world. #CommunistVirus | NOT | NONE |
| 60c5d6bf5659ea5e55def750 | @RapidWolfReturn @Utd_76 @MenachoManuel1 @ITheKTrainI @UnitedStandMUFC Yeah…sh*t move, but as has been said; heat of the moment, stupid comment he probably doesn’t really back.. should’ve just explained it, owned it, and moved on. He’s a w*nker, regar | NOT | NONE |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adewumi, T.; Sabry, S.S.; Abid, N.; Liwicki, F.; Liwicki, M. T5 for Hate Speech, Augmented Data, and Ensemble. Sci 2023, 5, 37. https://doi.org/10.3390/sci5040037
Adewumi T, Sabry SS, Abid N, Liwicki F, Liwicki M. T5 for Hate Speech, Augmented Data, and Ensemble. Sci. 2023; 5(4):37. https://doi.org/10.3390/sci5040037
Chicago/Turabian StyleAdewumi, Tosin, Sana Sabah Sabry, Nosheen Abid, Foteini Liwicki, and Marcus Liwicki. 2023. "T5 for Hate Speech, Augmented Data, and Ensemble" Sci 5, no. 4: 37. https://doi.org/10.3390/sci5040037
APA StyleAdewumi, T., Sabry, S. S., Abid, N., Liwicki, F., & Liwicki, M. (2023). T5 for Hate Speech, Augmented Data, and Ensemble. Sci, 5(4), 37. https://doi.org/10.3390/sci5040037