1. Introduction
Owing to the increasing market share of the autonomous vehicle industry, fundamental technologies for driving assistants and artificial intelligence have been increasingly studied [
1]. One of the most crucial technologies for Advanced Driver Assistance Systems (ADAS), including self-driving, forward collision warning, or pedestrian recognition, is contextual awareness of road environments [
2]. In particular, traffic sign recognition systems are core methods for providing vital instructions in safety-critical road regulations and should perform at highly stringent confidence levels.
Many autonomous vehicles utilize high-definition (HD) maps to provide richer information for road environments [
3,
4]. However, because of the manual and time-consuming efforts in production, the usage of HD maps is costly [
5]. More importantly, HD maps can suffer from the discrepancies between the stored traffic signs and real-time changes [
6]. In addition to assisting drivers, intelligent object recognition systems can facilitate the maintenance of road surroundings, such as traffic signs, lane lines, and guard rails [
7]. For instance, traffic sign recognition systems can effectively analyze damage or defects through autonomous vehicles for monitoring purposes because it is nontrivial to inspect an entire road scene using human resources [
8]. Therefore, the traffic sign recognition technique is an important component both for decision-making systems in vehicles and for monitoring road management systems.
A traffic sign recognition system should provide stable support in real-time driving vehicles, but faces two major challenges. The first problem is the low quality of images owing to diverse environmental conditions, such as weather, illuminance, and occlusion [
9,
10]. Given that blurred and contaminated images can severely deteriorate recognition performance, a recognition model should be robust to the noise from various causes. Secondly, another critical issue for the traffic sign recognition technique is to detect and recognize signs in real-time. Therefore, to respond to the frequent changes in driving car scenarios, the model should guarantee a short processing time for the recognition systems.
Conventional traffic sign recognition methods have been developed in the context of studying salient features to capture traffic signs. The feature-based models such as color- or shape-based methods have been proposed to extract candidate regions and classify the signs in road scene images [
11]. However, these feature-based methods are illumination-sensitive. A recent trend in traffic sign recognition systems is to employ deep learning-based object detection models, especially Convolutional Neural Networks (CNNs) [
2,
12]. Deep learning-based object detection approaches including YOLO models facilitate accurate traffic sign recognition in several benchmark datasets because they are capable of flexible and expressible nonlinear representation. Indeed, studies [
2,
13,
14] based on YOLO models have achieved state-of-the-art performances for publicly available benchmark datasets (e.g., GTSDB [
15], GTSRB [
16], and RTSD [
17]) for traffic sign recognition.
Although the recent studies for traffic sign recognition systems outperform the conventional methods, they have three prominent limitations. Firstly, there are limited studies to demonstrate the performance of deep learning-based traffic sign recognition methods in real-world urban road environments with various noise. Because there can be significant differences in the quality between benchmark images and urban road scenes, it is crucial to inspect the types of noise and to verify the recognition results of the models. Secondly, deep learning-based approaches for traffic sign recognition systems barely consider object tracking models coupled with detection models for practical usage. Lastly, there is a lack of studies with respect to the processing time or frames per second (FPS) of the recent deep learning-based models in driving cars coupled with intelligent cameras. To evaluate a traffic sign recognition system, it is necessary to implement the entire edge system, from an edge camera to an edge computing system (e.g., NVIDIA Jetson) in a driving car, rather than only assessing the performance of models in laboratories.
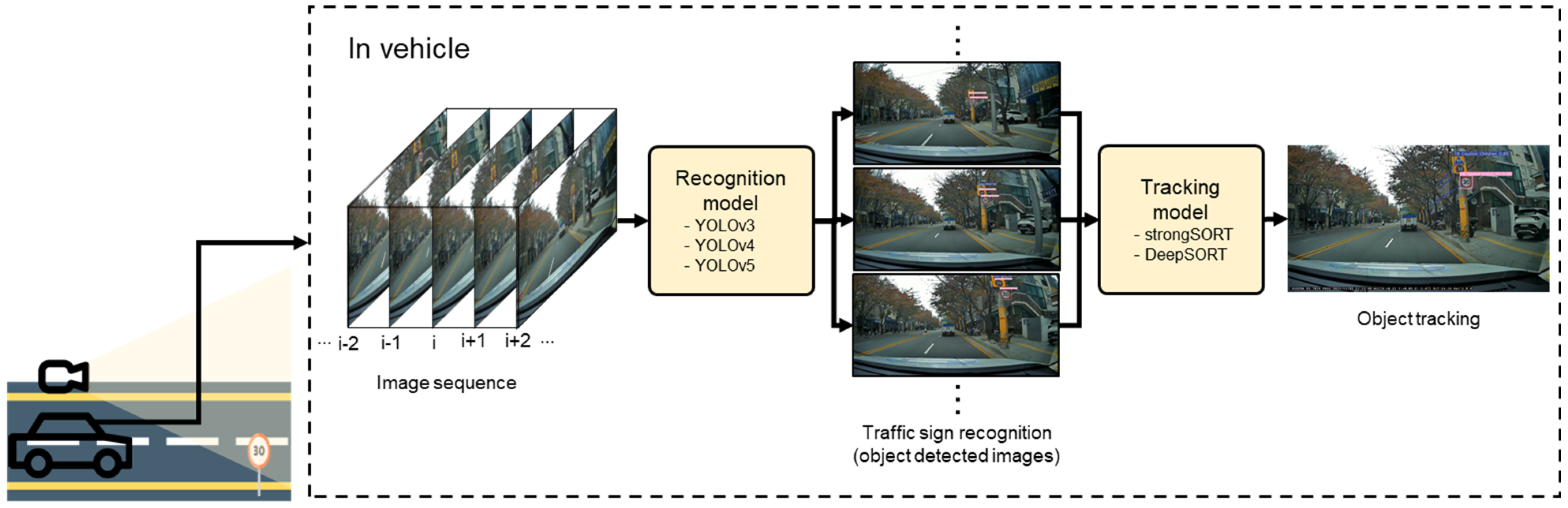
To address these issues, we propose a traffic sign recognition framework based on deep learning models to implement the entire system from cameras to processing units and to validate the accuracy and latency of the proposed system architecture. As our main goal is to evaluate the traffic sign recognition performance in a driving car, we install the entire system inside a car, including a camera device, an edge computing unit, and a standalone server. We categorize the urban road environments based on diverse noise types and group road images with the corresponding settings [
18]. We train several versions of object detection models and examine the framework with respect to the defined categories of environmental conditions in terms of accuracy and latency. In addition, we evaluate the real-time performance of two object tracking models with a detection model. From our experimental results, we identify the possible obstacles in traffic sign recognition tasks with extensive discussion to facilitate future research.
The main contributions of this study are as follows:
We propose a traffic sign recognition framework coupled with deep learning-based object detection models. Furthermore, we collect real-world road scene images from a driving car and define the main categories of noise for the environmental conditions;
We evaluate and prove the efficiency of deep learning-based object detection and tracking models through in-depth experiments considering model types and environmental conditions;
We derive the candidate issues from the experimental results and provide insightful analyses to facilitate future research on traffic sign recognition systems.
The remainder of the paper is organized as follows.
Section 2 briefly reviews related works on traffic sign recognition tasks. In
Section 3, we introduce the proposed framework and then describe data collection and categorization methods for urban road scene images.
Section 4 includes the experimental setup and evaluation metrics. In
Section 5 and
Section 6, we present comprehensive results and provide a detailed discussion through in-depth ablation studies. Finally,
Section 7 provides a conclusion and considers future research directions.
2. Related Work
In the last decade, extensive research has been conducted to detect and recognize traffic signs as well as moving objects in road scenes. Among the intelligent object detection tasks, the traffic sign recognition method is core because it is the most critical in safety-critical road applications. The various types of urban environments (e.g., downtown, residential areas) are relevant to traffic sign recognition because different types of traffic signs tend to occur in different environments and traffic signs are also different in size and location [
7]. The core challenge in detecting and recognizing traffic signs on roads is the low quality of images owing to variable urban environments including the influence of weather, the time of day, and driving of vehicles at high speed. Alongside environmental effects, it is still problematic to develop intelligent recognition systems because the installation methods of devices can prompt vibrations in vehicles and result in a restricted view of the surrounding objects [
10]. To reduce the impact of these problems, various image preprocessing methods are being studied: one approach is based on traditional feature-based methods, and another approach uses deep learning-based methods.
The traditional feature-based methods typically gather specifically engineered visual features including Histogram of Oriented Gradient (HOG) features and use those features to classify traffic signs [
1,
19,
20]. A method based on HOG features [
21] was proposed for object detection purposes in computer vision and image processing; HOG descriptors are calculated on dense grids of cells placed at uniform intervals and are designed to use nested local contrast normalization to improve accuracy. These methods have been used as improvements to balance scale-invariant characteristic transformations with descriptor and shape contexts, feature-invariance (e.g., illumination, translation, and scale), and nonlinearity. HOG methods, however, mainly utilize manual features to capture significant characteristics in images; hence, they often fail to model complex surroundings in road scene images.
On the other hand, methods utilizing features from the color and shape of a given image have been proposed for traffic sign recognition tasks [
11,
22,
23,
24,
25]. The main steps of these methods are to extract visual information contained in candidate areas, capture and segment traffic signs within an image, and correctly classify the signs through pattern classification [
26]. The color-based methods typically segment specific colors to generate a color map. These methods find solid color regions and then determine the candidate regions that are computationally efficient [
27]; however, they usually require delicate color and shape information to increase recognition accuracy. The intrinsic issues of the environment, such as color fading, subtle illumination change, and occlusion of traffic signs, are critical in these methods [
2]. For instance, color-based methods are dependent on specific characteristics (e.g., solid colors) of traffic signs; hence they show significant performance degradation with contaminated images. Similarly, shape-based methods fail to recognize objects with unclear shapes in blurred images.
Prominent traffic sign recognition methods have used machine learning models including Support Vector Machine [
28,
29,
30] and AdaBoost based traffic signs detection [
31]. These approaches result in relatively fair recognition performances when coupled with specific image features (e.g., HOG, color- or shape-features). However, they are heavily reliant on hand manual feature engineering. For this reason, they fail to model complex urban road surroundings, which is a similar shortcoming inherited from features-based methods. Moreover, different feature engineering is required for different environmental settings.
Deep learning models, specifically CNN-based models, have achieved rapid advances in computer vision tasks [
32,
33,
34]. Similar to object detection tasks, computer vision processing tasks in intelligent transportation systems are also following this trend, and these tasks are being used practically in ADAS as well as in autonomous vehicles. Accordingly, several researchers have tried to solve the traffic sign recognition problem using a CNN-based object detection framework [
2,
11]. These studies mainly employ object detection models that can be represented by Faster R-CNN [
34] and YOLO models [
32,
33]. In particular, Faster R-CNN combines the regression of bounding boxes and object classification. It uses end-to-end methods to detect visual objects, which not only improve the accuracy of object detection but also improve the speed of object recognition. Visual object detection consists of classification and positioning. Before the advent of YOLO, these two tasks differed in visual object detection. In YOLO models, object detection is simply transformed into a regression problem. In addition, YOLO follows the end-to-end structure of the neural network for visual object detection, and thus simultaneously obtains the coordinates of the predicted boundary box, the reliability of the target, and the probability of the class to which the target belongs through one image input [
35].
Recently, three versions of YOLO have been proposed: YOLOv3 [
32], YOLOv4 [
33], and YOLOv5; YOLOv4 succeeded the Darknet and obtained a remarkable performance improvement based on the Microsoft COCO dataset [
36]. Compared with YOLOv3, accuracy and speed have been effectively improved in YOLOv4. Furthermore, it can be considered a real-time object detection model for traffic sign recognition tasks on Tesla V100 [
37], which has strong computational resources. The most recent model, YOLOv5, outperformed the previously models both in accuracy and efficiency. It uses several techniques, including efficient CNN blocks, adversarial training, and augmentation. Compared with YOLOv3, the detection accuracy of YOLOv5 increased by 4.30%, indicating that the performance was superior to that of the previous model [
38].
Object tracking is another technology that has been actively researched recently. Object tracking is an algorithm that assigns a unique ID to a detected object and maintains the ID value unchanged even as frames flow. One of the most successful object tracking methods is Simple Online and Realtime Tracking (SORT) [
39], which employs Kalman filters [
40] and the Hungarian algorithm [
40,
41]. SORT is proposed for a multiple object tracking task that efficiently associates detected objects for real-time tracking. Based on the position information of objects using noise and speed information, SORT obtains the position information of objects to come in the next frame. DeepSORT [
42] has been proposed to utilize expressive CNN features to the existing SORT method. DeepSORT has advanced the tracking accuracy because the model uses more informative features than SORT. Recently, [
43] proposed StrongSORT which extends DeepSORT. StrongSORT outperformed the previous models by introducing an appearance-free link model to generate efficient trajectories and Gaussian-smoothed interpolation to compensate missing detections.
Recent deep learning-based traffic sign recognition studies [
2,
13,
14] have shown significant improvement by outperforming state-of-the-art scores on several benchmark datasets [
15,
16,
17]. However, there are limited studies on real-world urban road environments with the diverse noise types. Since urban road scenes can have different aspects from benchmark images, it is crucial to investigate deep learning models for real-world application. Additionally, deep learning-based approaches for traffic sign recognition systems barely consider object tracking models, which are essential for practical implementation. In this study, we develop a traffic sign recognition framework using different YOLO models followed by two tracking methods (DeepSORT and StrongSORT), and explore those models on urban roads in a driving car to ensure real-time applicability.
5. Experimental Results
In this section, we validate the recognition performances of the proposed framework for various environments during road driving. We first compare performance for three different detection models trained with the same dataset, and then derive an applicable model for real-time traffic sign recognition system. We also investigate the proposed categorization method for environmental conditions through in-depth ablation studies, including different weather and light conditions.
5.1. Comparison of Detection Models
We trained the three different YOLO models for the comparison: YOLOv3 (
https://github.com/ultralytics/yolov3, 10 November 2022), YOLOv4 (
https://github.com/AlexeyAB/darknet, 10 November 2022), and YOLOv5 (
https://github.com/ultralytics/yolov5, 10 November 2022). The models were trained using the same training set. We employed the original source codes without modification from the official GitHub pages. The YOLOv4 model is built in C language, whereas the other models are implemented in Python. After training all the models, we employed the trained YOLOv5-S model for inference during a test drive, while collecting a test set. The test set comprises the proposed categories in
Section 3.2. To be specific, we additionally collected 1740 Clean, 244 Cloud, 377 Rain, 179 Sunlight, 1309 Night, and 168 Tunnel images for the test set. Except for YOLOv5-S, which was already evaluated in a driving car, the other models were evaluated using this test set.
Table 3 reports the training results obtained with different YOLO models. Note that the training epochs are set to 300, except for YOLOv5-L, which is trained for 200 epochs because it needs much longer GPU days owing to the heavy computation for large layers inside the model. It could be an unfair comparison with other models because the YOLOv5-L model does not have enough training iteration. Aside from the accuracy performance of YOLOv5-L, it shows the second slowest inference speed of 76 FPS. From this result, we conclude that YOLOv5-L model is not suitable for real-time application.
In terms of accuracy performance, YOLOv5-S achieved the best performance with an mAP@.5:.95 score of 0.850, followed by YOLOv3. The YOLOv4 model shows the worst performance when the model is trained with a smaller input size (416 × 416), but it has slightly improved performance with a similar input size (608 × 608). We could obtain a higher accuracy value because of the higher resolution, but it has a lower FPS because of the complexity. One can confirm that the size of a road scene image should be at least 608 × 608.
Based on the FPS performance, YOLOv5-S also shows the best performance followed by YOLOv4, and YOLOv3. Therefore, we choose YOLOv5-S as the preferred detection model, because it achieves both the highest mAP and FPS. In addition, if we consider applying the object tracking algorithm, one can conclude that YOLOv5-S can be used in real-time applications with 133 FPS.
5.2. Effect of Weather Conditions
It is possible to have diverse weather conditions, such as clouds and rain, as well as sunlight in summer because of the four distinct seasons. To evaluate traffic sign recognition in such environments, we conducted an ablation test for Clean, Cloud, and Rain.
Table 4 compares the results for the different weather conditions. Clean shows the best results in Precision (0.856) and F1 (0.86). Surprisingly, the performance in the Rain condition has a better mAP@.5:.95 than that in Clean, where the exact Precision is higher than that of Rain. By definition, the mAP@.5:.95 measure averages several precisions while changing the thresholds. Therefore, the objects are detected with high confidence scores when it is Clean weather. However, the objects could still be detected in other conditions, though with slightly lower confidence scores.
In the case of Cloud, in
Table 4 we observe the lowest performance in all indicators except Precision. To further investigate this result, we report sample images for each condition in
Figure 5. In
Figure 5c,d, we can see that Cloud has lower image quality than the other two conditions. Furthermore, the overall environment appears dark, and the boundaries between objects are not clear. For these reasons, we evaluate that the Cloud environment adversely affects recognition of traffic signs, resulting in poor performance indicators. To improve the performance in cloud weather conditions, we suggest using bright lighting or post-processing of images to aid the discrimination of objects. In addition, removal of rainwater formed on the lens during rainfall will elevate the confidence levels for precision and lead to better results.
Figure 5g,h show the failure results of traffic sign recognition. In particular, in
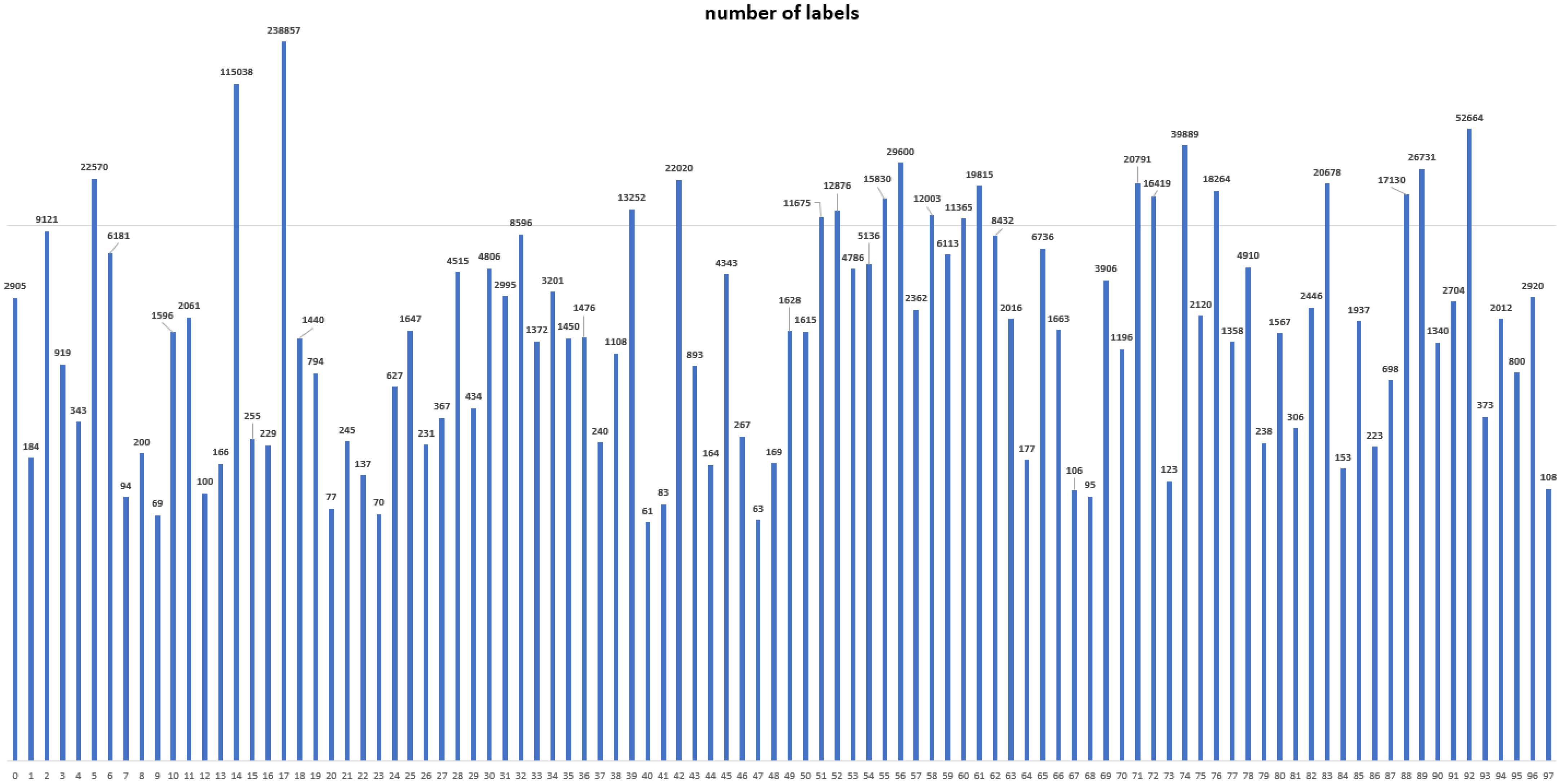
Figure 5h, one can expect a class named Left-Merge, but we obtain Right-Merge. The possible explanation is that those classes have a similar shape but an imbalanced number of samples. Note that the Right-Merge class has as twice many samples as Left-Merge (i.e., Left-Merge: 794, Right-Merge: 1440). To solve this problem, one could consider setting the number of samples similarly for each class by data augmentation or oversampling.
5.3. Effect of the Amount of Light
In this subsection, we conduct a test to determine the degree of traffic sign recognition with a vision camera. In places with dim light, it is difficult to recognize traffic signs with human eyes. Similarly, the vision camera system and the accompanying detection model could be heavily affected by the amount of light. To evaluate Daytime, we use the same test samples as Clean in
Table 4 because of similar environmental conditions.
Table 5 shows that the Night condition results in significantly lower performance than Daytime in all indicators: Precision (0.815), Recall (0.838), mAP@.5 (0.886), mAP@.5:.95 (0.635), and F1 (0.78), as we expected. Although we conducted the test with a similar number of images, the difference between the two results is significant. We also observe significant qualitative differences between the two conditions in terms of the amount of light, as visualized in
Figure 6. One can confirm that it is difficult to recognize traffic signs at night because of the dim light. To improve the recognition of traffic signs in an environment where there is little light, we propose to install a device that provides illumination to aid the recognition of objects. In addition, we suggest equipping the traffic signs with LEDs to enable them to be well recognized at night. On the other hand, we can see the low confidence results of traffic sign recognition in
Figure 6e,f because the number of samples for learning is not sufficient (e.g., Bypass: 108, Right Turn: 223). To alleviate this issue, it is important to obtain a lot of high-quality data for training.
5.4. Effect of the Type of Light
In this subsection, we investigate how the type of light affects the vision cameras used to recognize traffic signs. We define natural light as the amount of light during the daytime that does not cause discomfort in daily life. We use test samples of natural light on the same test set as Clean in
Table 4 because of similar environmental conditions. We also evaluate Sunlight, which is the amount of light that is intense, as defined in
Table 1. Finally, we conduct a test on Tunnel, which has artificial light sources.
Table 6 compares the results for the different types of light. Tunnel shows the best results in all metrics, except for mAP@.5:.95. It can be observed that Tunnel condition has almost no blurred effect caused by direct sunlight entering the camera; hence, this results in the best performance scores.
On the other hand, we observe that the performance in the Sunlight condition shows better results than in the Natural light condition, contrary to our expectations. As shown in
Figure 7, objects in the Sunlight condition have boundaries to their background and show distinct shapes or colors. One can conclude that the YOLOv5-S model is powerful enough to classify these small deviations as an object. Nonetheless, to improve traffic sign recognition, we propose to install filtering to reduce the influence of light interference on the vision camera.
Figure 7e,f report the failure results of traffic sign recognition. In
Figure 7e, we can confirm that the class name No Automobiles Allowed has a low recognition result of 0.26. Note that there is a small number of samples for the class (i.e., 267 samples), but the sign contains relatively complicated images (small cars and automobiles).
Figure 7f shows that Left Lane Ends is recognized as another class, Right Lane Ends, despite the recognition result value of 0.8. It should be noted that both classes are similar shapes but include small differences in directions. To alleviate these problems, one could use an extra classifier for detailed classification to improve the accuracy.
5.5. Evaluation of Real-Time and Tracking Performance
In this subsection, we analyze the detailed real-time performance of the YOLO models and conduct an additional experiment to evaluate real-time performance for the object tracking algorithms DeepSORT and StrongSORT. To validate real-time performance, it is necessary to implement an edge computing system, and we employ Jetson AGX Xavier. For the test video, we recorded a 36 s video during an additional test drive on urban roads in Seoul, Korea. While driving, the StrongSORT was evaluated and other models were tested using the same video.
Table 7 reports the real-time performance results obtained by the different YOLO models. We report results for two GPU environments: one for the local server with RTX A6000, where the models have been trained; and the other for the edge device installed in vehicle, Jetson AGX Xavier. Obviously, one can confirm that all models have lower FPS results on Jetson AGX Xavier compared with the results on the local server. Nevertheless, in
Table 8, one can see that the FPS performance of YOLOv5-S is remarkably higher in the edge device. YOLOv5-L shows a lower FPS than YOLOv5-S because of the complexity. It indicates that YOLOv5-S is optimized for real-time compared with YOLOv3 and YOLOv4. Based on the results in
Table 8, we conducted the experiments for object tracking using the YOLOv5-S model.
We employed the original source codes and pretrained checkpoints for DeepSORT (
https://github.com/nwojke/deep_sort, 10 November 2022) and StrongSORT (
https://github.com/dyhBUPT/StrongSORT, 10 November 2022) from the official GitHub site. Note that our framework first detects traffic signs and then the detected features are fed into the tracking models.
Table 8 reports the FPS results from DeepSORT and StrongSORT coupled with YOLOv5-S. In both GPU environments, one can see that object tracking methods are highly costly because the FPS drops sharply with the tracking methods. Nonetheless, we observed that the FPS of StrongSORT is twice as good as that of DeepSORT. We achieved 23 FPS with StrongSORT for the best speed in the edge device, but this is reduced by half compared with the result before StrongSORT was applied. We can conclude that StrongSORT should be recommended over DeepSORT for real-time traffic sign recognition system.
Figure 8 represents the results of StrongSORT coupled with YOLOv5-S on Jetson AGX Xavier. We confirm the consecutive image frames maintain recognized object information when drawing tracking paths. We also can see that high confidence is maintained while tracking the detected traffic signs (e.g., Caution Children: 0.89, Speed Limit 30: 0.90).
6. Discussion
In this section, we perform an additional experiment for the number of training samples. For deep learning models, the number of training data is one of the most important factors. Although we trained the models using a dataset with one million images, in this study, the number of training data varies for each class. We compare results according to the number of samples in each class.
In
Table 9, we divide the whole class into six clusters, based on the number of class samples. We define each cluster based on the number of samples using the following ranges: less than 100, 100 to 500, 500 to 1000, 1000 to 5000, 5000 to 10,000, and over 10,000. In addition, the mAP@.5:.95 values of each class are classified according to each range and averaged. We can confirm that the larger the number of samples, the greater the value of mAP@.5:.95. Evidently, the model performance increases sharply when we train the model with more samples.
To further investigate,
Table 10 reports the recognition performances for the sampled classes. For instance, Up-Hill shows results significantly lower than for the other classes in all indicators except Recall: Precision (0.54), mAP@.5 (0.556), and mAP@.5:.95 (0.408). We deduce that Up-Hill has the worst results because it used less than 100 samples of data for training. In contrast, Speed Limit 40, Speed Limit 50, and Bicycle Cross Walk all show good results compared with the class with more than 1000 samples. In addition, the Bicycle Cross Walk class presents the best results in all indicators: Precision (0.991), Recall (0.998), mAP@.5 (0.995), and mAP@.5:.95 (0.974).
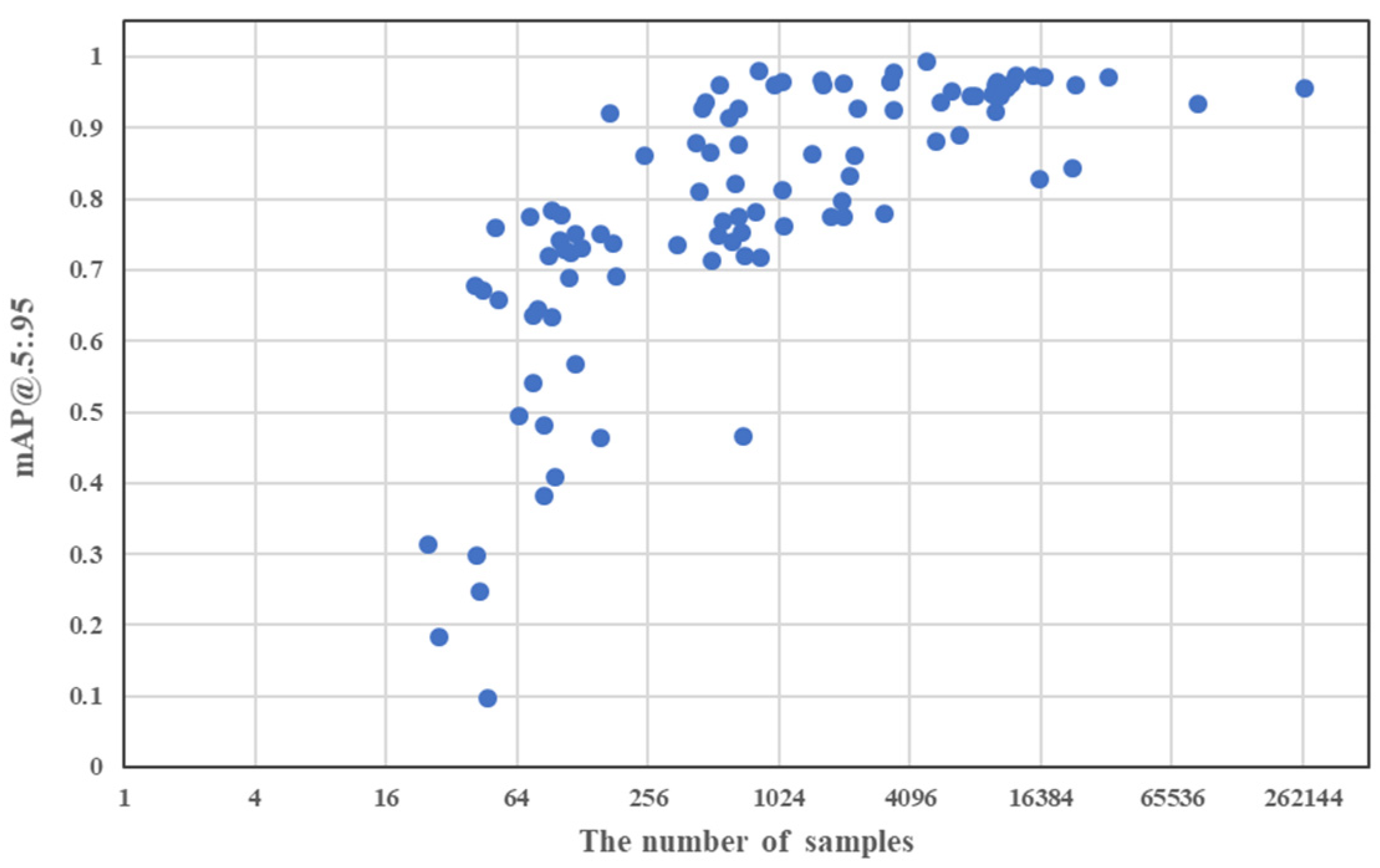
Furthermore,
Figure 9 shows the relationship between the number of samples and mAP@.5:.95 for each class. We observe that the results of mAP@.5:.95 do not exceed 0.8 for the class with less than 200 samples. In general, the higher the number of samples, the better the value of mAP@.5:.95. In particular, when the trained model is applied to images, a class with a small number of samples is not recognized at all or is recognized as a similar but different class. To prevent this problem, a potential guideline for reasonable recognition performance is to exploit as many training samples as possible.
7. Conclusions
In this study, we propose a traffic sign recognition framework based on deep learning from a camera to an edge processing unit to validate an entire system of complex urban road environments in a driving car. Recent traffic sign recognition studies using deep learning-based detection models have shown significant advances in addressing the performance constraints of traffic sign systems resulting from the low quality of images. However, they lack both practical validation on real-world urban road environments including object tracking models, and assessment of the processing time for heavy computation in deep learning models. To alleviate these limitations and provide insightful discussion, we developed a traffic sign recognition system using YOLO models as detectors and SORT-variants models as trackers. We also propose a novel categorization method for the frequently changing urban road environments based on diverse noise types.
We evaluate the proposed framework in a driving car on several expressways to validate the system in terms of accuracy and latency. In particular, we investigate the results from different types of YOLO architectures and tracking models to understand the effect of different road environment conditions on models in terms of mAP performance and inference time. Furthermore, we conduct in-depth ablation studies for a proposed categorization method for complex urban road environments. Additional analyses performed include the effect of weather, light conditions, and the number of traffic signs. Finally, we provide detailed analyses and identify potential issues for recognizing traffic signs in urban road scenes. We believe that this study can become a solid stepping stone and facilitate future research on traffic sign recognition systems. Potential future work includes the identification of broken traffic signs from road scenes. Furthermore, although it is currently difficult to collect data across all environments, we will be able to obtain more informative results if we add various environments (e.g., ice, snow cover, snow fall). Moreover, pretraining the detection models and incorporating them in downstream tasks could also be an interesting future study that maximizes the advantages of knowledge transfer.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














