Integrated Big Data Analytics Technique for Real-Time Prognostics, Fault Detection and Identification for Complex Systems


Abstract
1. Introduction
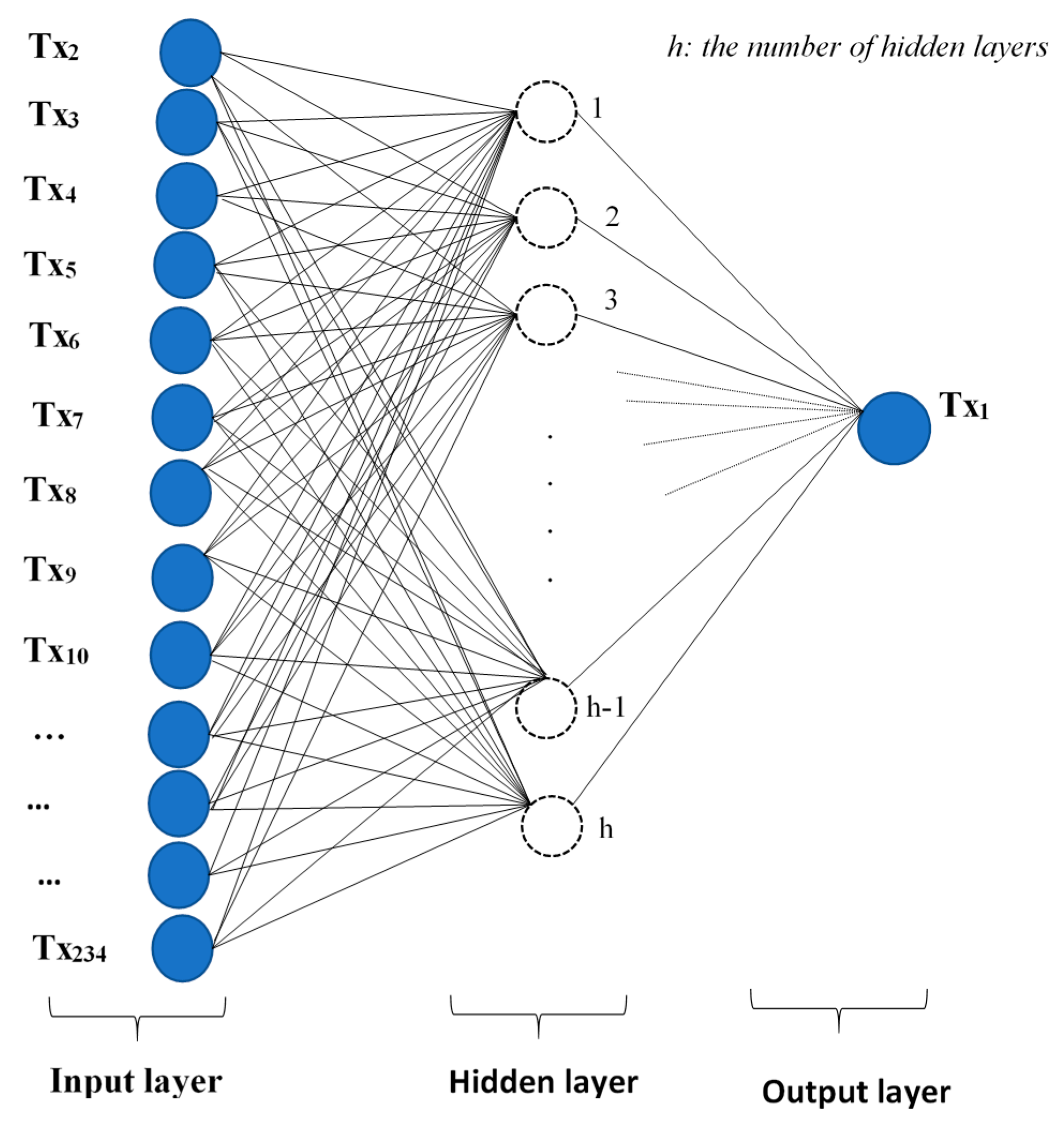
2. Artificial Neural Network Concept
3. Frameworks for Complex System’s Prognosis
4. Fault Detection and Identification with ANN
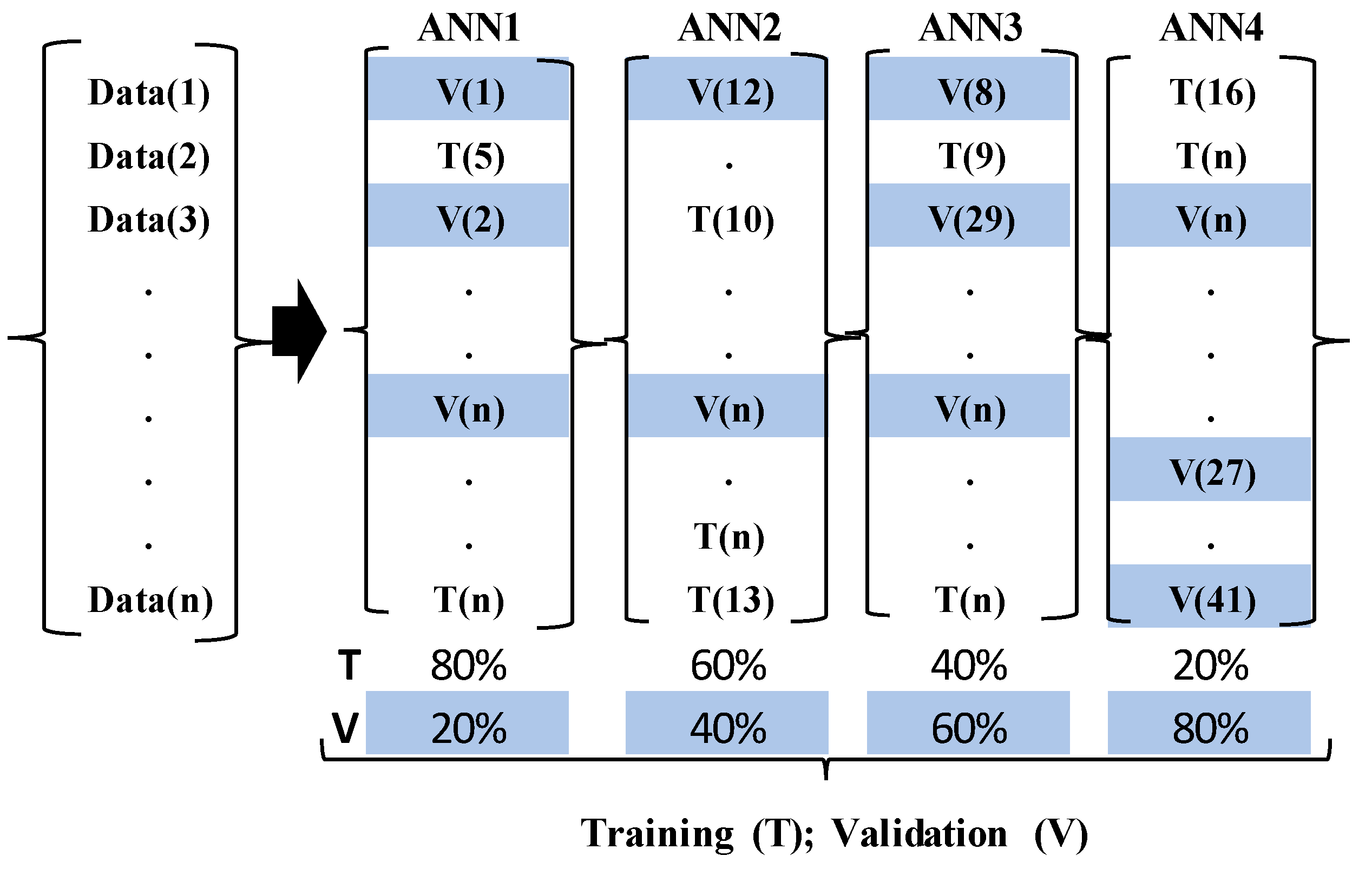
Cross-Validation Ensemble
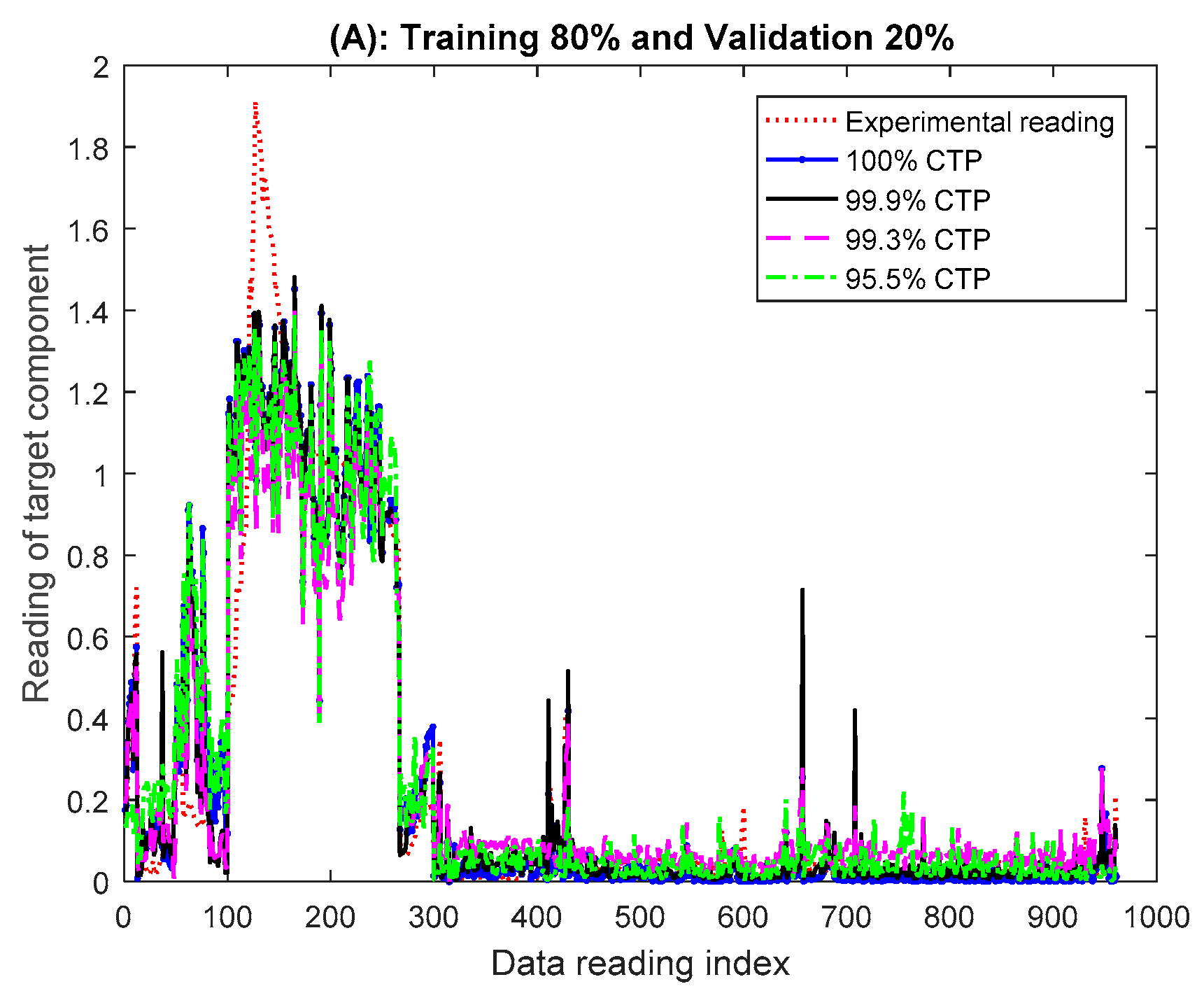
5. Illustrative Example and Results
- -
- 80% training and 20% validation {100% CTP: 0.0359, 99.9% CTP: 0.0483, 99.3% CTP: 0.0565 and 95.5% CTP:0.0484}
- -
- 60% training and 40% validation {100% CTP: 0.0419, 99.9% CTP:0.0393, 99.3% CTP:0.0386 and 95.5% CTP:0.050}
- -
- 40% training and 60% validation {100% CTP: 0.044, 99.9% CTP: 0.0365, 99.3% CTP: 0.0391 and 95.5% CTP: 0.0515}
- -
- 20% training and 80% validation {100% CTP: 0.0455, 99.9% CTP: 0.0384, 99.3% CTP: 0.0407 and 95.5% CTP: 0.093}.
Comparison of Cross-Validation Ensemble ANN with Classic ANN and other Techniques
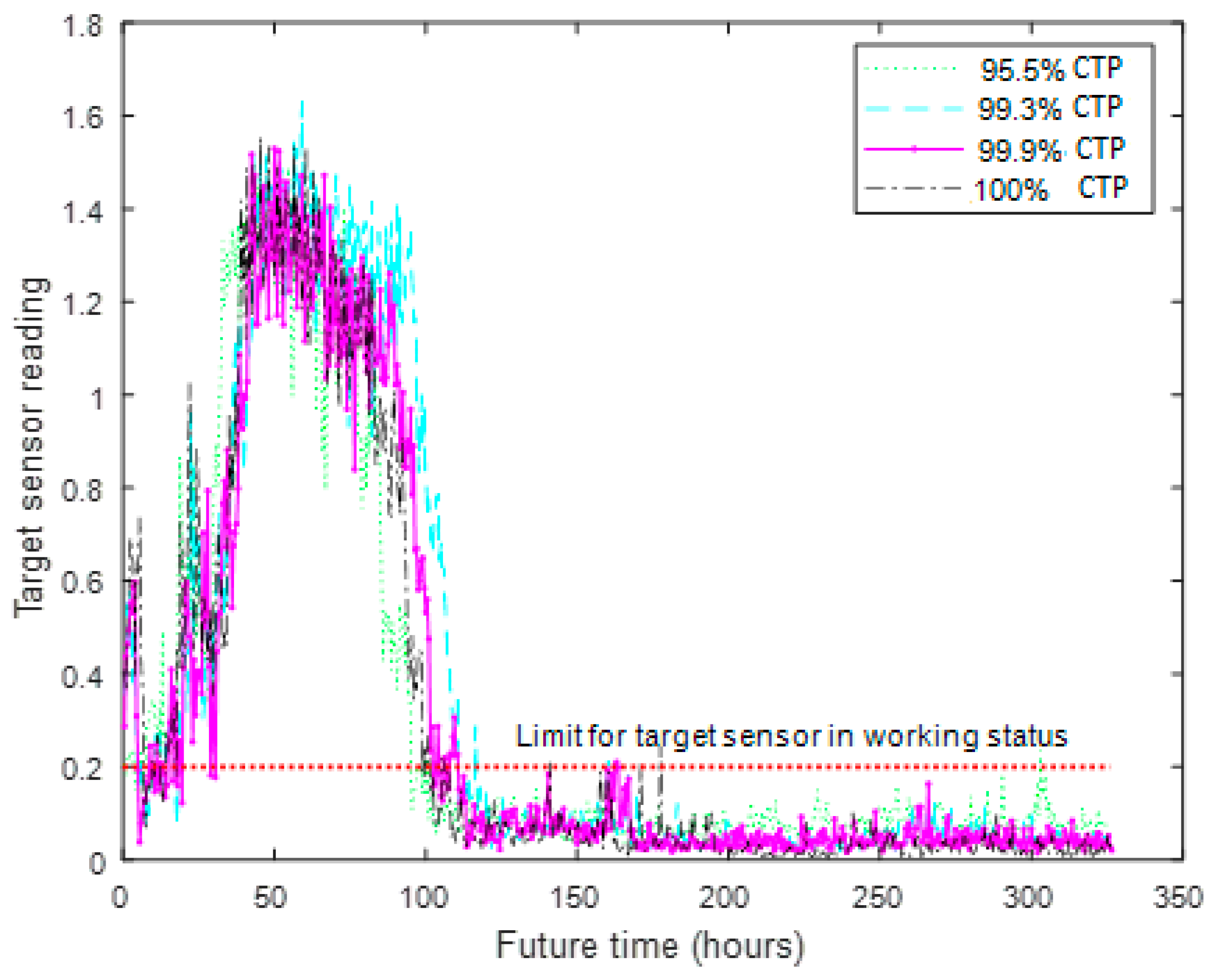
6. Predicting Future Behavior of the Target Component
7. Conclusions
Acknowledgments
Conflicts of Interest
References
- Lee, J.; Ni, J.; Djurdjanovic, D.; Qiu, H.; Liao, H. Intelligent prognostics tools and e-maintenance. Comput. Ind. 2006, 57, 476–489. [Google Scholar] [CrossRef]
- Yam, R.C.M.; Tse, P.W.; Li, L.; Tu, P. Intelligent predictive decision support system for condition-based maintenance. Int. J. Adv. Manuf. Technol. 2001, 17, 383–391. [Google Scholar] [CrossRef]
- Montgomery, R.L.; Serratella, C. Risk-based maintenance: A new vision for asset integrity management. In Proceedings of the ASME 2002 Pressure Vessels and Piping Conference, Vancouver, BC, Canada, 5–9 August 2002; American Society of Mechanical Engineers: New York, NY, USA, 2002; pp. 151–165. [Google Scholar]
- Mohanty, S.; Jagadeesh, M.; Srivatsa, H. Big Data Imperatives: Enterprise ‘Big Data’ Warehouse, ‘BI’ Implementations and Analytics; Apress: New York, NY, USA, 2013. [Google Scholar]
- Ratnayake, R.C. Modelling of asset integrity management process: A case study for computing operational integrity preference weights. Int. J. Comput. Syst. Eng. 2012, 1, 3–12. [Google Scholar] [CrossRef]
- Rastegari, A.; Mobin, M. Maintenance decision making, supported by computerized maintenance management system. In Proceedings of the 2016 IEEE Annual Reliability and Maintainability Symposium (RAMS), Tucson, AZ, USA, 25–28 January 2016; pp. 1–8. [Google Scholar]
- Misra, K.B. Maintenance engineering and maintainability: An introduction. In Handbook of Performability Engineering; Springer: London, UK, 2008; pp. 755–772. [Google Scholar]
- Shafiee, M.; Finkelstein, M. An optimal age-based group maintenance policy for multi-unit degrading systems. Reliab. Eng. Syst. Saf. 2015, 134, 230–238. [Google Scholar] [CrossRef]
- Boone, C.A.; Skipper, J.B.; Hazen, B.T. A framework for investigating the role of big data in service parts management. J. Clean. Prod. 2017, 153, 687–691. [Google Scholar] [CrossRef]
- Daneshkhah, A.; Hosseinian-Far, A.; Chatrabgoun, O. Sustainable Maintenance Strategy Under Uncertainty in the Lifetime Distribution of Deteriorating Assets. In Strategic Engineering for Cloud Computing and Big Data Analytics; Springer: Cham, Swizerland, 2017; pp. 29–50. [Google Scholar]
- Lapworth, J.A.; Wilson, A. The asset health review for managing reliability risks associated with ongoing use of ageing system power transformers. In Proceedings of the CMD 2008 IEEE International Conference on Condition Monitoring and Diagnosis, Beijing, China, 21–24 April 2008; pp. 605–608. [Google Scholar]
- Remy, E.; Corset, F.; Despréaux, S.; Doyen, L.; Gaudoin, O. An example of integrated approach to technical and economic optimization of maintenance. Reliab. Eng. Syst. Saf. 2013, 116, 8–19. [Google Scholar] [CrossRef]
- Volovoi, V.; Valenzuela, R.C. On compact modeling of coupling effects in maintenance processes of complex systems. Int. J. Eng. Sci. 2012, 59, 193–210. [Google Scholar] [CrossRef]
- Carlos, S.; Sánchez, A.; Martorell, S.; Villanueva, J.F. Particle Swarm Optimization of safety components and systems of nuclear power plants under uncertain maintenance planning. Adv. Eng. Softw. 2012, 50, 12–18. [Google Scholar] [CrossRef]
- Guo, C.; Wang, W.; Guo, B.; Si, X. A maintenance optimization model for mission-oriented systems based on Wiener degradation. Reliab. Eng. Syst. Saf. 2013, 111, 183–194. [Google Scholar] [CrossRef]
- Aven, T.; Castro, I.T. A delay-time model with safety constraint. Reliab. Eng. Syst. Saf. 2009, 94, 261–267. [Google Scholar] [CrossRef]
- Wang, W. A stochastic model for joint spare parts inventory and planned maintenance optimization. Eur. J. Oper. Res. 2012, 216, 127–139. [Google Scholar] [CrossRef]
- Baker, R.D.; Christer, A.H. Review of delay-time OR modelling of engineering aspects of maintenance. Eur. J. Oper. Res. 1994, 73, 407–422. [Google Scholar] [CrossRef]
- Kan, M.S.; Tan, A.C.C.; Mathew, J. A review on prognostic techniques for non-stationary and non-linear rotating systems. Mech. Syst. Signal Process. 2015, 62–63, 1–20. [Google Scholar] [CrossRef]
- Nabati, E.G.; Thoben, K.-D. Data Driven Decision Making in Planning the Maintenance Activities of Off-shore Wind Energy. Procedia CIRP 2017, 59, 160–165. [Google Scholar] [CrossRef]
- Fumeo, E.; Oneto, L.; Anguita, D. Condition Based Maintenance in Railway Transportation Systems Based on Big Data Streaming Analysis. Procedia Comput. Sci. 2015, 53, 437–446. [Google Scholar] [CrossRef]
- Barbini, L.; Ompusunggu, A.P.; Hillis, A.J.; du Bois, J.L.; Bartic, A. Phase editing as a signal pre-processing step for automated bearing fault detection. Mech. Syst. Signal Process. 2017, 91, 407–421. [Google Scholar] [CrossRef]
- Kumar, A.; Shankar, R.; Thakur, L.S. A big data driven sustainable manufacturing framework for condition-based maintenance prediction. J. Comput. Sci. 2017. [Google Scholar] [CrossRef]
- Manco, G.; Ritacco, E.; Rullo, P.; Gallucci, L.; Astill, W.; Kimber, D.; Antonelli, M. Fault detection and explanation through big data analysis on sensor streams. Expert Syst. Appli. 2017, 87, 141–156. [Google Scholar] [CrossRef]
- Cai, J.; Cottis, R.A.; Lyon, S.B. Phenomenological modelling of atmospheric corrosion using an artificial neural network. Corros. Sci. 1999, 41, 2001–2030. [Google Scholar] [CrossRef]
- Wang, S.C. Artificial neural network. In Interdisciplinary Computing in Java Programming; Springer: New York, NY, USA, 2003; pp. 81–100. [Google Scholar]
- Wang, P.; Vachtsevanos, G. Fault prognostics using dynamic wavelet neural networks. AI EDAM 2001, 15, 349–365. [Google Scholar] [CrossRef]
- Horrocks, P.; Mansfield, D.; Parker, K.; Thomson, J.; Atkinson, T.; Worsley, J.; House, W.; Park, B. Managing Ageing Plant; Technical Report; HSE: Warrington, UK, 2010; Volume 823.
- Lee, J.; Wu, F.; Zhao, W.; Ghaffari, M.; Liao, L.; Siegel, D. Prognostics and health management design for rotary machinery systems—Reviews, methodology and applications. Mech. Syst. Signal Process. 2014, 42, 314–334. [Google Scholar] [CrossRef]
- Peng, Y.; Dong, M.; Zuo, M.J. Current status of machine prognostics in condition-based maintenance: A review. Int. J. Adv. Manuf. Technol. 2010, 50, 297–313. [Google Scholar] [CrossRef]
- Joly, R.B.; Ogaji, S.O.T.; Singh, R.; Probert, S.D. Gas-turbine diagnostics using artificial neural-networks for a high bypass ratio military turbofan engine. Appl. Energy 2004, 78, 397–418. [Google Scholar] [CrossRef]
- Schwabacher, M. A survey of data-driven prognostics. In Infotech@ Aerospace; Mark Schwabacher, NASA Ames Research Center: Arlington, VA, USA, 2005; p. 7002. [Google Scholar]
- Kothamasu, R.; Huang, S.H.; VerDuin, W.H. System health monitoring and prognostics—A review of current paradigms and practices. In Handbook of Maintenance Management and Engineering; Springer: London, UK, 2009; pp. 337–362. [Google Scholar]
- Van Oosterom, C.D.; Elwany, A.H.; Çelebi, D.; Van Houtum, G.J. Optimal policies for a delay time model with postponed replacement. Eur. J. Oper. Res. 2014, 232, 186–197. [Google Scholar] [CrossRef]
- Christer, A.H.; Lee, C.; Wang, W. A data deficiency based parameter estimating problem and case study in delay time PM modeling. Int. J. Prod. Econ. 2000, 67, 63–76. [Google Scholar] [CrossRef]
- Wang, W.; Banjevic, D.; Pecht, M. A multi-component and multi-failure mode inspection model based on the delay time concept. Reliab. Eng. Syst. Saf. 2010, 95, 912–920. [Google Scholar] [CrossRef]
- Dietterich, T. Overfitting and under computing in machine learning. ACM Comput. Surv. (CSUR) 1995, 27, 326–327. [Google Scholar] [CrossRef]
- Donate, J.P.; Cortez, P.; Sanchez, G.G.; De Miguel, A.S. Time series forecasting using a weighted cross-validation evolutionary artificial neural network ensemble. Neurocomputing 2013, 109, 27–32. [Google Scholar] [CrossRef]
- Abyaneh, H.Z. Evaluation of multivariate linear regression and artificial neural networks in prediction of water quality parameters. J. Environ. Health Sci. Eng. 2014, 12, 40. [Google Scholar] [CrossRef] [PubMed]
- Garcia, M.C.; Sanz-Bobi, M.A.; del Pico, J. SIMAP: Intelligent system for predictive maintenance: Application to the health condition monitoring of a windturbine gearbox. Comput. Ind. 2006, 57, 552–568. [Google Scholar] [CrossRef]
- Zaher, A.; McArthur, S.D.J.; Infield, D.G.; Patel, Y. Online wind turbine fault detection through automated SCADA data analysis. Wind Energy 2009, 12, 574–593. [Google Scholar] [CrossRef]
- Bangalore, P.; Tjernberg, L.B. An artificial neural network approach for early fault detection of gearbox bearings. IEEE Trans. Smart Grid 2015, 6, 980–987. [Google Scholar] [CrossRef]
- Illias, H.Z.; Chai, X.R.; Mokhlis, H. Transformer incipient fault prediction using combined artificial neural network and various particle swarm optimisation techniques. PLoS ONE 2015, 10, e0129363. [Google Scholar] [CrossRef] [PubMed]
- Zakaria, F.; Johari, D.; Musirin, I. Optimized Artificial Neural Network for the detection of incipient faults in power transformer. In Proceedings of the 2014 IEEE 8th International Power Engineering and Optimization Conference (PEOCO), Langkawi, Malaysia, 24–25 March 2014; pp. 635–640. [Google Scholar]
- Ahmed, M.R.; Geliel, M.A.; Khalil, A. Power transformer fault diagnosis using fuzzy logic technique based on dissolved gas analysis. In Proceedings of the 2013 IEEE 21st Mediterranean Conference on Control & Automation (MED), Chania, Greece, 25–28 June 2013; pp. 584–589. [Google Scholar]
- Setiawan, N.A.; Adhiarga, Z. Power transformer incipient faults diagnosis using Dissolved Gas Analysis and Rough Set. In Proceedings of the 2012 IEEE International Conference on Condition Monitoring and Diagnosis (CMD), Bali, Indonesia, 23–27 September 2012; pp. 950–953. [Google Scholar]
- Yang, H.T.; Huang, Y.C. Intelligent decision support for diagnosis of incipient transformer faults using self-organizing polynomial networks. IEEE Trans. Power Syst. 1998, 13, 946–952. [Google Scholar] [CrossRef]
- Antoni, J. The spectral kurtosis: A useful tool for characterising non-stationary signals. Mech. Syst. Signal Process. 2006, 20, 282–307. [Google Scholar] [CrossRef]
- Borghesani, P.; Pennacchi, P.; Randall, R.; Sawalhi, N.; Ricci, R. Application of cepstrum pre-whitening for the diagnosis of bearing faults under variable speed conditions. Mech. Syst. Signal Process. 2013, 36, 370–384. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, Y.; Griffin, P.J. A combined ANN and expert system tool for transformer fault diagnosis. IEEE Trans. Power Deliv. 1998, 13, 1224–1229. [Google Scholar] [CrossRef]
- Shintemirov, A.; Tang, W.; Wu, Q.H. Power transformer fault classification based on dissolved gas analysis by implementing bootstrap and genetic programming. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2009, 39, 69–79. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Descript. | Tx_1 | Tx_3 | Tx_18 | Tx_37 | Tx_94 | Tx_160 | Tx_197 | Tx_216 | Tx_232 | Tx_234 |
|---|---|---|---|---|---|---|---|---|---|---|
| min | 0.0000 | 1.9998 | 0.0000 | 9.6552 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 1.9998 | 0.0000 |
| max | 1.9247 | 8.1290 | 912.8352 | 100.0000 | 99.9546 | 1.0000 | 100.0000 | 1199.7422 | 8.1979 | 912.8352 |
| range | 1.9247 | 6.1292 | 912.8352 | 90.3448 | 99.9546 | 1.0000 | 100.0000 | 1199.7422 | 6.1981 | 912.8352 |
| median | 0.0269 | 7.4863 | 487.3383 | 40.0000 | 31.6343 | 0.0000 | 13.5617 | 600.0000 | 7.6996 | 487.3383 |
| mean | 0.2230 | 7.4596 | 362.3406 | 53.4006 | 24.4100 | 0.2227 | 11.5449 | 514.5615 | 7.6864 | 362.3406 |
| Std. | 0.4188 | 0.2081 | 308.2417 | 25.5838 | 23.5495 | 0.4069 | 6.9333 | 282.3706 | 0.2626 | 308.2417 |
| COV | 1.8778 | 0.0279 | 0.8507 | 0.4791 | 0.9647 | 1.8275 | 0.6006 | 0.5488 | 0.0342 | 0.8507 |
| CTP | Number of Source Components |
|---|---|
| 95.50% | 10 |
| 99.30% | 27 |
| 99.90% | 46 |
| 100% | 82 |
| TD:VD (%) | Training Dataset (TD) | Validation Dataset (VD) | CTP | ||||
|---|---|---|---|---|---|---|---|
| R2 | MSE | R2 | MSE | HR | MR | ||
| 80:20 | 0.856 | 0.0254 | 0.848 | 0.0277 | 90.53% | 9.47% | 95.50% |
| 60:40 | 0.852 | 0.0266 | 0.839 | 0.0282 | 90.53% | 9.47% | |
| 40:60 | 0.836 | 0.0301 | 0.833 | 0.0289 | 91.88% | 8.12% | |
| 20:80 | 0.87 | 0.0236 | 0.862 | 0.0289 | 89.87% | 10.13% | |
| Average | 0.853 | 0.0264 | 0.845 | 0.0284 | 90.70% | 9.30% | |
| 80:20 | 0.886 | 0.0224 | 0.878 | 0.0245 | 94.59% | 5.41% | 99.30% |
| 60:40 | 0.886 | 0.0211 | 0.877 | 0.0227 | 92.19% | 7.81% | |
| 40:60 | 0.884 | 0.0214 | 0.881 | 0.0204 | 94.86% | 5.14% | |
| 20:80 | 0.889 | 0.0176 | 0.876 | 0.0232 | 93.65% | 6.35% | |
| Average | 0.886 | 0.021 | 0.878 | 0.023 | 93.80% | 6.18% | |
| 80:20 | 0.89 | 0.0192 | 0.881 | 0.0216 | 94.69% | 5.31% | 99.90% |
| 60:40 | 0.889 | 0.021 | 0.879 | 0.0216 | 95.26% | 4.74% | |
| 40:60 | 0.887 | 0.0214 | 0.881 | 0.0205 | 96.18% | 3.82% | |
| 20:80 | 0.889 | 0.0176 | 0.876 | 0.0233 | 94.85% | 5.15% | |
| Average | 0.889 | 0.02 | 0.879 | 0.022 | 95.20% | 4.76% | |
| 80:20 | 0.881 | 0.0208 | 0.873 | 0.023 | 94.38% | 5.62% | 100% |
| 60:40 | 0.887 | 0.0201 | 0.877 | 0.0212 | 94.12% | 5.88% | |
| 40:60 | 0.879 | 0.0227 | 0.877 | 0.0226 | 94.59% | 5.41% | |
| 20:80 | 0.884 | 0.0175 | 0.869 | 0.0238 | 94.87% | 5.13% | |
| Average | 0.883 | 0.02 | 0.874 | 0.023 | 94.50% | 5.51% | |
| CTP | Classic ANN Dataset (70% Training, 30% Validation) | Cross-Validation Ensemble ANN | ||
|---|---|---|---|---|
| Hit Ratio (HR) | Miss Ratio (MR) | Hit Ratio (HR) | Miss Ratio (MR) | |
| 95.50% | 89.45% | 10.55% | 90.7% | 9.3% |
| 99.30% | 91.95% | 8.05% | 93.8% | 6.18% |
| 99.90% | 94.10% | 5.90% | 95.2% | 4.76% |
| 100% | 93.89% | 6.11% | 94.5% | 5.51% |
| Technique | Accuracy | Variation from CVEANN | Ref |
|---|---|---|---|
| ANN (classic) | 95% | −0.20% | [43] |
| Artificial Neural Network with Particle Swarm Optimization (ANN-PSO) | 96% | 0.80% | [43] |
| Artificial Neural Network with Iterative Particle Swarm Optimization (ANN-IPSO) | 97% | 1.80% | [43] |
| Artificial Neural Network with Evolutionary Particle Swarm Optimization (ANN-EPSO) | 98% | 2.80% | [43] |
| Evolutionary Programming Artificial Neural Network (EPANN) | 95% | −0.20% | [44] |
| Fussy logic | 89% | −6.20% | [45] |
| Rough set theory | 92.11% | −3.09% | [46] |
| Support Vector Machine (SVM) | 92% | −3.20% | [47] |
| Phase editing | 79% | −16.20% | [22] |
| Cepstral editing | 69%, 72% | −26.2%, −23.2% | [48,49] |
| Artificial Neural Network with Expert System (ANN-EPS) | 90.40% | −4.8% | [50] |
| Bootstrap Genetic Programming and K-Nearest Neighbor (GP-KNN) | 92.11% | −3.09% | [51] |
| Date/Time (Start) | Date/Time (End) | Duration (h) | System Status | Required Maintenance | Duration (h) | System Status | Required Maintenance |
|---|---|---|---|---|---|---|---|
| 16 May 2016 9:30 | 16 May 2016 1:30 | 4.00 | faulty | minor | 0.5–4.5 | faulty | minor |
| 16 May 2016 14:00 | 16 May 2016 17:30 | 3.50 | working | 5–8.5 | working | ||
| 16 May 2016 18:00 | 16 May 2016 18:00 | 0.50 | faulty | minor | 9 | faulty | minor |
| 16 May 2016 18:30 | 16 May 2016 18:30 | 0.50 | working | 9.5 | working | ||
| 16 May 2016 19:00 | 16 May 2016 19:00 | 0.50 | faulty | minor | 10 | faulty | minor |
| 16 May 2016 19:30 | 16 May 2016 19:30 | 0.50 | working | 10.5 | working | ||
| 16 May 2016 20:00 | 16 May 2016 20:00 | 0.50 | faulty | minor | 11 | faulty | minor |
| 16 May 2016 20:30 | 16 May 2016 21:00 | 1.00 | working | 11.5–12 | working | ||
| 16 May 2016 21:30 | 16 May 2016 22:00 | 1.00 | faulty | minor | 12.5–13 | faulty | minor |
| 16 May 2016 22:30 | 16 May 2016 23:30 | 1.50 | working | 13.5–14.5 | working | ||
| 17 May 2016 0:00 | 17 May 2016 1:00 | 1.00 | faulty | minor | 15–16 | faulty | minor |
| 17 May 2016 1:30 | 17 May 2016 1:30 | 0.50 | working | 16.5 | working | ||
| 17 May 2016 2:00 | 17 May 2016 2:30 | 1.00 | faulty | minor | 17–17.5 | faulty | minor |
| 17 May 2016 3:00 | 17 May 2016 3:00 | 0.50 | working | 18 | working | ||
| 17 May 2016 3:30 | 17 May 2016 4:00 | 1.00 | faulty | minor | 18.5–19 | faulty | minor |
| 17 May 2016 4:30 | 17 May 2016 4:30 | 0.50 | working | 19.5 | working | ||
| 17 May 2016 5:00 | 17 May 2016 13:30 | 8.50 | faulty | major | 20–28.5 | faulty | major |
| 17 May 2016 14:00 | 17 May 2016 14:00 | 0.50 | working | 29 | working | ||
| 17 May 2016 14:30 | 17 May 2016 15:00 | 1.00 | faulty | minor | 29.5–30 | faulty | minor |
| 17 May 2016 15:30 | 17 May 2016 15:30 | 0.50 | working | 30.5 | working | ||
| 17 May 2016 16:00 | 20 May 2016 15:00 | 71.00 | faulty | shutdown | 31–102 | faulty | shutdown |
| 20 May 2016 15:30 | 20 May 2016 16:00 | 1.00 | working | 102.5–103 | working | ||
| 20 May 2016 16:30 | 20 May 2016 17:00 | 1.00 | faulty | minor | 103.5–104 | faulty | minor |
| 20 May 2016 17:30 | 20 May 2016 18:30 | 1.50 | working | 104.5–105.5 | working | ||
| 20 May 2016 21:00 | 20 May 2016 23:30 | 3.50 | faulty | minor | 108–110.5 | faulty | minor |
| 21 May 2016 0:00 | 23 May 2016 3:30 | 51.50 | working | 111–162.5 | working | ||
| 23 May 2016 4:00 | 23 May 2016 4:00 | 0.50 | faulty | minor | 163 | faulty | minor |
| 23 May 2016 4:30 | 31 May 2016 7:00 | 194.50 | working | 163.5–358 | working |
© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ossai, C.I. Integrated Big Data Analytics Technique for Real-Time Prognostics, Fault Detection and Identification for Complex Systems. Infrastructures 2017, 2, 20. https://doi.org/10.3390/infrastructures2040020
Ossai CI. Integrated Big Data Analytics Technique for Real-Time Prognostics, Fault Detection and Identification for Complex Systems. Infrastructures. 2017; 2(4):20. https://doi.org/10.3390/infrastructures2040020
Chicago/Turabian StyleOssai, Chinedu I. 2017. "Integrated Big Data Analytics Technique for Real-Time Prognostics, Fault Detection and Identification for Complex Systems" Infrastructures 2, no. 4: 20. https://doi.org/10.3390/infrastructures2040020
APA StyleOssai, C. I. (2017). Integrated Big Data Analytics Technique for Real-Time Prognostics, Fault Detection and Identification for Complex Systems. Infrastructures, 2(4), 20. https://doi.org/10.3390/infrastructures2040020