1. Introduction
Monitoring and predicting defects on civil and infrastructure systems play a crucial role in asset management. The current version of ISO 55000 (Asset Management) and the guidelines on condition assessment issued by the Asset Management Institute (AIM) have highlighted that aside from using conventional visual inspection and detection methods, the use of Artificial Intelligence (AI) with modern machine-learning algorithms should be potentially applied where possible to save the cost of the monitoring activities, as well as to increase the level of accuracy.
As components of infrastructure systems deteriorate over time, the severity of deterioration should be measured and captured. The severity is often expressed as condition state, either using binary state or multiple-condition state, depending on the types of components [
1,
2]. By employing smart technologies for data collection and analysis, they can detect these issues early, enabling prompt maintenance and preventing further damage. This proactive strategy prolongs the lifespan of the city’s infrastructure, lowers overall maintenance expenses, and ensures a smooth and safe transportation network for all users [
3,
4].
Over the last few decades, within the context of transportation and road and bridge management, the monitoring of defects has relied heavily on manual visual inspection or high-speed inspection cars [
3,
5]. While these methods provided some level of information, they were both time-consuming and expensive. This inefficiency led to challenges in pinpointing the emergence and severity of defects, hindering timely interventions. As a result, repairs often occurred when problems became severe, leading to higher overall costs and disruptions to traffic flow [
6].
Recently, the field of defect monitoring has been revolutionized by the application of Artificial Intelligence (AI) and machine-learning techniques. TensorFlow (TensorFlow
https://www.tensorflow.org/) accessed on 1 December 2024, a popular open-source software library, is being used to develop powerful Neural Network algorithms. These algorithms are trained on vast datasets of images containing various defect types, like cracks. By employing statistical modeling techniques, the AI learns to identify and classify these defects with high accuracy. This paves the way for automated inspections, significantly reducing the need for manual labor and high-speed inspection cars.
In developing countries, due to a shortage of investments and, sometimes, lack of proper asset management, defects pose a significant challenge. Due to budget limitations, these defects deteriorate quickly, creating a vicious cycle. In reports published by the World Bank [
7,
8] and the Asian Development Bank [
9], it was stated that 30–50% of paved roads in low- and middle-income countries are classified as being in poor condition. Maintenance backlogs are due to chronic underinvestment, and many developing nations spend less than 1% GDP on road maintenance, whilst in developed nations, the recommended value is between 2 and 3%. The report did emphasize that delays in maintenance increase future repair costs by 4–5 times compared to yearly interventions. For example, in pavement management, cracks, potholes, and uneven surfaces emerge rapidly on roads subjected to heavy traffic loads. Unfortunately, addressing these issues promptly is often hindered by limited funds for repairs and maintenance [
7,
8,
9]. This quick deterioration of pavements not only creates a bumpy and unsafe ride for commuters but also shortens the lifespan of roads, ultimately leading to even greater costs down the line. Finding innovative solutions for cost-effective pavement maintenance and exploring alternative funding mechanisms are crucial steps for developing countries to overcome this hurdle.
Convolutional Neural Networks (CNNs) have proven to be among the most powerful methods for image recognition, with applications in various fields, including civil and structural health monitoring within infrastructure asset management [
10,
11]. State-of-the-Art (SOTA) CNN models are now available as open-source models and can be accessed on several Artificial Intelligence (AI) platforms, with TensorFlow being particularly popular [
12]. In addition to CNN models, Vision Transformers (ViTs) have recently emerged as a strong alternative. Numerous studies have shown that ViT models often outperform current SOTA CNNs by nearly four times in both computational efficiency and accuracy [
13,
14].
This study explores defect detection in civil and structural components using both a CNN model and a ViT model accessible via TensorFlow. An empirical analysis utilized a database of cracks, categorizing them based on severity (e.g., width and pattern) to create distinct subsets for accuracy testing. Results confirmed that when cracks are classified in binary terms (crack or no crack), CNN and ViT models show similar accuracies. However, with multiple classification states, the CNN model exhibits greater sensitivity, but significantly lower accuracy compared to the ViT model.
2. Literature Review
Over the last few decades, within the context of transportation, road, and bridge management, the monitoring of defects has heavily relied on manual visual inspections and high-speed inspection vehicles (HSVs). Although these methods have provided valuable information, they exhibit significant limitations in terms of time, cost, and accuracy. Manual inspections are notably labor-intensive and subjective, often missing between 20 and 30% of surface defects depending on inspector experience and environmental conditions [
15]. Furthermore, rating inconsistencies between inspectors can vary by as much as 25%, undermining the reliability of condition assessments [
3].
While HSVs offer improvements by inspecting approximately 100–150 km per day compared to only 5–10 km/day with manual inspections [
5], they come with substantial costs, averaging between USD 1000 and 2000 per lane-mile [
16]. Moreover, HSVs primarily detect macro-surface defects and are often unable to capture micro-cracks below 1 mm in width, which are critical indicators of early-stage deterioration [
3]. Their operation also heavily depends on sophisticated technology typically manufactured in developed countries, making maintenance and calibration challenging for infrastructure agencies in developing nations [
8]. This inefficiency in conventional methods leads to delays in defect identification and intervention, often resulting in repairs being carried out only after significant deterioration has occurred, causing higher overall costs and major disruptions to traffic flow.
Traditional pavement defect detection methods pose significant challenges for developing countries, primarily due to substantial costs [
7,
8,
9]. High-tech inspection systems are often exclusive to affluent nations with multi-million-dollar road maintenance budgets. Developing countries struggle to afford these technologies, causing delays in defect identification and remediation. This results in accelerated deterioration, increased maintenance costs, and unsafe road conditions. A cost-effective, efficient alternative is crucial for developing nations to address this challenge and extend their road networks’ lifespan.
Machine learning has significantly transformed the field of engineering, particularly in structural health monitoring and infrastructure asset management [
11,
12]. Traditional condition assessment methods, such as manual visual inspections and expensive dense sensor networks, were time-consuming, costly, and often limited in spatial or temporal resolution [
3,
5,
16]. Today, machine-learning algorithms can efficiently analyze vast datasets collected from cost-effective sources like wireless sensor networks, UAV-mounted cameras, and IoT devices. Applications are widespread: vibration-based anomaly detection models, using supervised and unsupervised learning, help identify early-stage damage in bridges and tall structures [
17,
18]; deep-learning methods such as Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) are extensively used for crack detection, corrosion assessment, and pavement distress classification [
19,
20]; and predictive maintenance systems powered by Recurrent Neural Networks (RNNs) and long short-term memory (LSTM) architectures are employed to forecast the remaining useful life of infrastructure assets, enabling proactive maintenance scheduling [
21]. These technologies enable early defect detection, optimize maintenance interventions, reduce lifecycle costs, and improve the overall safety and resilience of civil infrastructure systems.
This enables early detection of subtle changes, facilitating preventative maintenance and extending infrastructure lifespan. Machine learning also predicts future issues based on historical data and trends, allowing proactive asset management and resource allocation. This shift from reactive to predictive maintenance optimizes costs, ensures safety and functionality, and transforms engineering practices [
12].
The emergence of AI, particularly machine learning, revolutionizes pavement defect detection. Trained on extensive datasets of pavement images, Convolutional Neural Networks (CNNs) and Vision Transformer (ViT) accurately identify and classify defects like cracks, potholes, and roughness. This technology offers numerous benefits, including automation, objectivity, and scalability. AI-powered systems automate inspections, reducing manual labor while providing consistent and objective assessments, thus minimizing human error. Additionally, they efficiently analyze large pavement areas captured by drone imagery, making them an ideal solution for efficient and accurate defect detection [
5,
6,
20].
In recent years, defect detection research has been dominated by the use of Convolutional Neural Networks (CNNs). However, a key limitation of this research has been its focus on proprietary, non-open-source algorithms. While CNNs have achieved impressive results in identifying cracks, the emphasis has primarily been on this specific defect type [
4,
19,
20]. This narrow focus leaves other critical distresses, like potholes, rutting, and edge raveling, under-represented in the research landscape. To achieve a more comprehensive approach to pavement health assessment, further research efforts need to explore the potential of CNNs, along with potentially open-source alternatives, for the detection of a wider range of defects. Aside from CNN algorithms, the Vision Transformer (ViT) model is another powerful and prominent alternative which has emerged recently and has been found to be compatible with the CNN model.
The surge in open-source Artificial Intelligence (AI) algorithms, particularly those built on the user-friendly TensorFlow framework, presents a game-changer for pavement defect prediction. These algorithms offer several advantages over traditional, non-open-source methods. Firstly, their open-source nature fosters collaboration and innovation among researchers, accelerating the development and refinement of defect detection models. Secondly, the affordability of open-source tools makes AI-powered infrastructure management more accessible, especially for developing countries with limited budgets.
The following two subsections provide a brief overview of the concepts and modeling approaches of CNN and ViT models. A detailed description of these models is beyond the scope of this paper, as the focus is on their applications using pre-trained CNN and ViT models available through open-source platforms like TensorFlow. Readers interested in exploring the architectural structures and inner workings of these models are encouraged to consult the extensive literature and TensorFlow documentation.
2.1. Brief on CNN Model
Convolutional Neural Networks (CNNs) are a class of deep-learning models specifically designed for processing and analyzing visual data, such as images and videos [
22]. They are structured to automatically and adaptively learn spatial hierarchies of features from the input data through the application of convolutional layers [
10]. CNNs typically consist of multiple layers, including convolutional layers, pooling layers, and fully connected layers.
The core concept behind CNNs is to extract meaningful features from input images through convolutions with learnable filters or kernels [
11]. These filters capture various aspects of the image, such as edges, textures, and more complex patterns, in a hierarchical manner. Pooling layers, often using max or average pooling techniques, reduce the spatial dimensions of the feature maps, retaining important information while minimizing computational complexity [
23]. Finally, fully connected layers aggregate these features and classify the input into different categories based on learned representations.
CNNs have achieved remarkable success in numerous computer vision tasks, including image classification, object detection, and image segmentation [
12]. Their ability to automatically learn hierarchical representations directly from raw pixel data has significantly advanced the State of the Art in visual recognition systems.
2.2. Brief on ViT Model
Vision Transformers (ViTs) represent a recent breakthrough in computer vision, challenging the traditional dominance of Convolutional Neural Networks (CNNs). Unlike CNNs, which process images using sequential convolutional operations, ViT approaches image understanding through a transformer architecture originally developed for natural language processing tasks [
13]. ViT models split an image into fixed-size patches, linearly embedding each patch into a sequence of tokens, which are then processed by transformer layers. This enables ViT to capture global dependencies and long-range interactions within images, facilitating effective feature learning across the entire input space.
The primary innovation of ViT lies in its ability to replace the spatial hierarchy traditionally learned by CNNs with a self-attention mechanism. This mechanism allows ViT to attend to relationships between all pairs of tokens, thereby capturing both local and global context in the image [
14]. Despite its initial adaptation from language models, ViT has shown impressive performance in image classification and other vision tasks, often achieving competitive or superior results compared to CNNs, particularly on datasets with complex visual patterns or large-scale images. As research continues to refine ViT architectures and explore their applications, they hold promise for advancing the State of the Art in computer vision tasks beyond traditional CNN-based approaches.
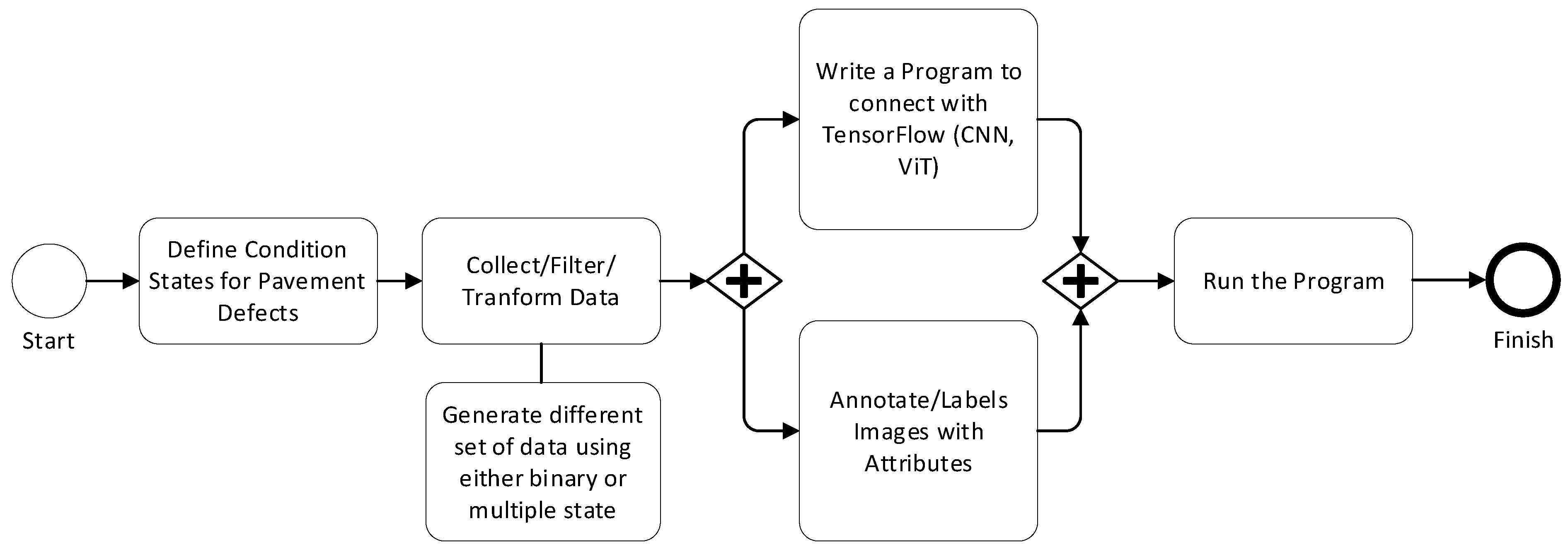
3. Methodologies
The overarching methodology of this study can be briefly explained with the workflow shown in
Figure 1.
Each defect type with its continuous state is transformed to a discrete scale of the condition state, with two ways of defining the severity of the defect (or condition state), either with binary condition states or multiple condition states. Asset managers can define their preferred scale that shall be satisfied also with existing legislation and norms in many practical situations.
Depending on the type of drone and its mounted camera, asset managers and drone pilots need to define appropriate height of flying paths considering local constraints such as trees, buildings, and weather conditions. This also includes data filtering to eliminate possible effects and obstacles such as shadows, tree leaves, and other items.
This step also involves transformation of the image to proper segmentation with a uniform dimension.
Appropriate software used for image annotation and labeling can be utilized. This is a manual task but can also be automated if supervising model is utilized. A simpler method is to save images with the same attributes in folders and use the names of the folders to dictate the attributes.
TensorFlow provides a systematic way to interact with its algorithms, such as Keras. This can be conveniently performed with Python, R, KNIME, or other data analytical platforms.
Run the program on both training data and test data to evaluate and validate the effectiveness of the model.
Readers who are interested in learning machine-learning algorithms available with the TensorFlow platform can read and refer to numerous works from the literature offering a description of mathematical and Neural Network models, as well as coding examples utilizing Keras CNN algorithms and ViT algorithms.
The above steps present a generic methodological framework. The specific methodologies regarding the architectures of CNN and ViT models applied to empirical datasets are further detailed in the following section (“Empirical Example and Discussion”), as different datasets with their own characteristics and attributes may require customized model parameter configurations.
4. Empirical Example and Discussion
4.1. Step 1: Define Condition States for Pavement Defects
For the purpose of this study, the authors focus on using AI models to detect whether an image contains cracks. In other words, the crack is categorized into two states: “with crack” and “without crack”. This simplification is, in many cases, acceptable depending on the expectations of asset managers. The definition of multiple condition states—involving precise measurements of crack width, length, and types—will be addressed in a subsequent study and discussed in a separate paper. Examples of images with cracks and without cracks are shown in
Table 1.
4.2. Step 2: Collect/Filter/Transform Data
We applied the methodology to a dataset comprising 15,000 images showcasing cracks. The dataset is stored in RGB format as JPEG files and was resized to dimensions of 240 × 240 pixels.
This dataset was collected using the DJI Mini 4 Pro, a drone priced at approximately USD 1000 in 2024. The DJI Mini 4 Pro is primarily designed for personal use, weighing only 249 g, and it is equipped with a high-definition camera capable of capturing 48MP photos and recording videos in 4K resolution. For this study, the research team programmed the drone to automatically capture photos of target road sections using a non-DJI third-party drone deployment application which supports pre-program on-route selection using GPS and Google Map. To maintain consistent image resolution, the drone’s altitude was kept at 10 m above the road surface.
Since the captured images often included extraneous elements such as roadsides, curbs, or unrelated objects, a post-processing step was necessary. This involved dividing an image into equal squares of 100 cm × 100 cm. The image-slicing process was carried out using GIMP (GIMP—a GNU Image Manipulation Program
https://www.gimp.org/), though other image-processing applications could also be used. The entire process—from capturing images with the drone to slicing the images—spanned one month and covered a total of 100 km of road sections. The mission’s total cost, excluding the reusable drone, was under USD 2000. This translates to an approximate cost of USD 20 per kilometer for drone operations and image processing (for 10 m of road section, the cost is 0.2 cent (~5000 VND), and for each image, the cost is less than 0.008 cent (200 VND)). Comparatively, this cost is minimal when juxtaposed with high-speed inspection cars, which require already upfront a significant investment of around USD 1.5 million for the vehicle, sensors, and associated equipment alone.
4.3. Step 3: Annotate/Labels Images with Attributes
With a binary state classification of “with crack” and “without crack”, annotation and labeling can be easily performed by organizing images into two folders: “Crack” and “Without-Crack”. Attributes corresponding to each image, such as pixel values, are also defined through Step 4 by introducing resizing image function so that all images are loaded onto the GPU with a square shape of 240 × 240 pixels.
4.4. Step 4: Write a Program to Connect and Interact with TensorFlow
The program is with Python programming language, using standard syntax to connect with TensorFlow Keras CNN algorithm and ViT algorithm. The program was executed in Google Colab environment, using L4 GPU to allow for faster computational time compared to executing the code using a laptop.
With CNN model, the following syntax along with its parameters are defined:
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters = 32, kernel_size = (3,3), strides = (2,2), activation = “relu”, padding = “valid”, input_shape = (image_size, image_size,3)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(filters = 32, kernel_size = (3,3), strides = (2,2), activation = “relu”, padding = “valid”),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units = 64, activation = “relu”,
kernel_regularizer = regularizers.L1L2(l1 = 1 × 10−3, l2 = 1 × 10−3),
bias_regularizer = regularizers.L2(1e-2),
activity_regularizer = regularizers.L2(1e-3)),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(units = 1, activation = “sigmoid”),
])
With the ViT model, the following parameters are used:
learning_rate = 0.001
weight_decay = 0.0001
batch_size = 256
num_epochs = 100
image_size = 240 # We will resize input images to this size
patch_size = 20 # Size of the patches to be extracted from the input images
num_patches = (image_size // patch_size) ** 2
projection_dim = 64
num_heads = 4
transformer_units = [
projection_dim * 2,
projection_dim,
] # Size of the transformer layers
transformer_layers = 8
mlp_head_units = [2048, 1024] # Size of the dense layers of the final classifier
Here, an image size of 240 will be sliced to a smaller size, with each size being 20 × 20, resulting in 1200 squares.
For both CNN and ViT, we use Adam optimizer (Adam optimization:
https://keras.io/api/optimizers/adam/) [
24] from Keras (Keras:
https://keras.io/), which is a stochastic gradient descent method that is based on adaptive estimation of first-order and second-order moments, for compilation
4.5. Step 5: Run the Program
4.5.1. Results of CNN Model
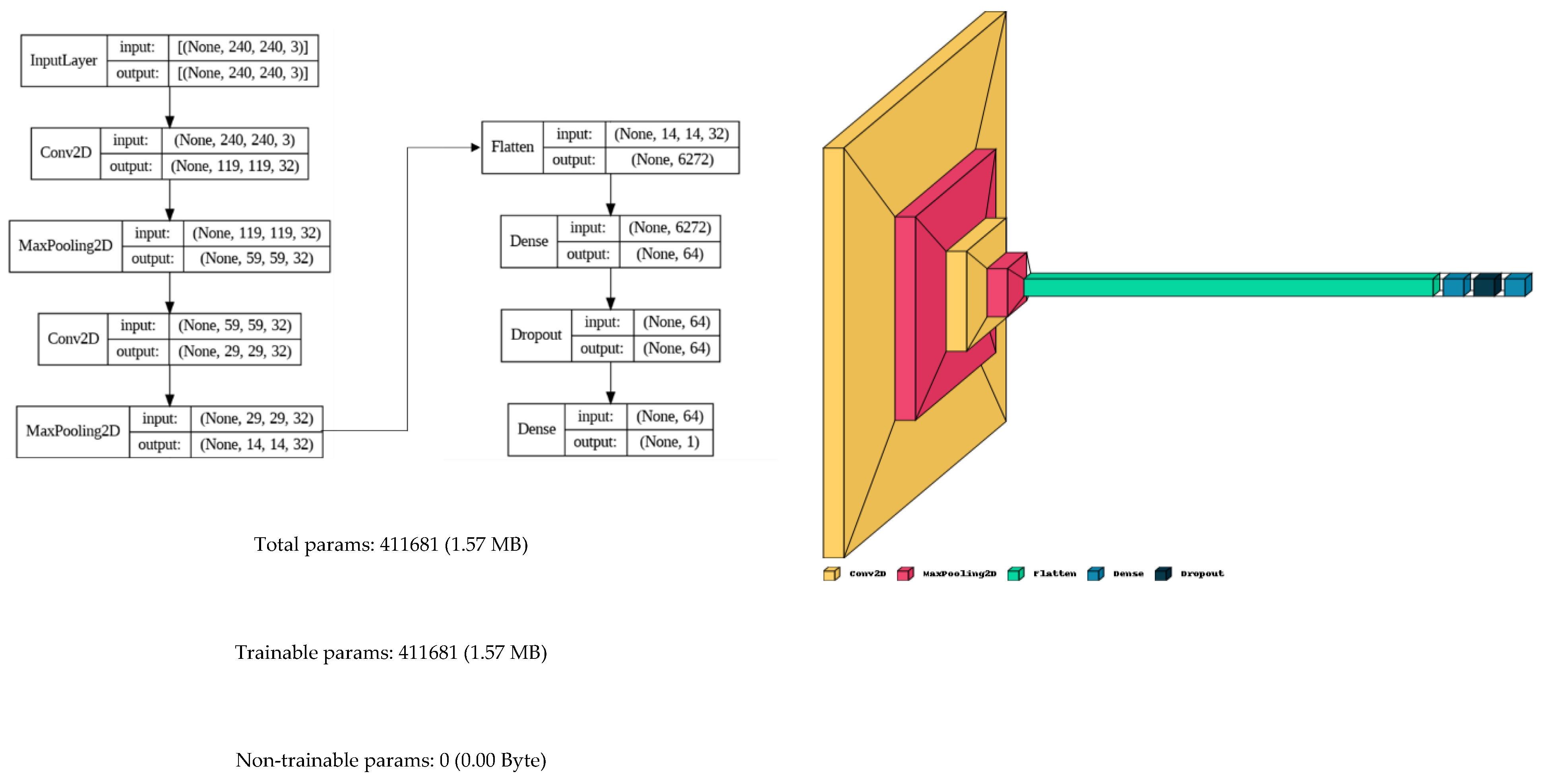
The model was set up with convolutional layers (applying filters to the input image layer to generate a feature map), max pooling layers (reducing the dimension of feature map without affecting the key features, and summarizing the features generated by a convolution layer), a fully connected or flatten layer (connecting every neuron in one layer to every neuron in the next), and a dropout layer (randomly deactivating a fraction of neurons during training to prevent overfitting).
Figure 2 presents a summary of input and output in respective layers of the Neural Network.
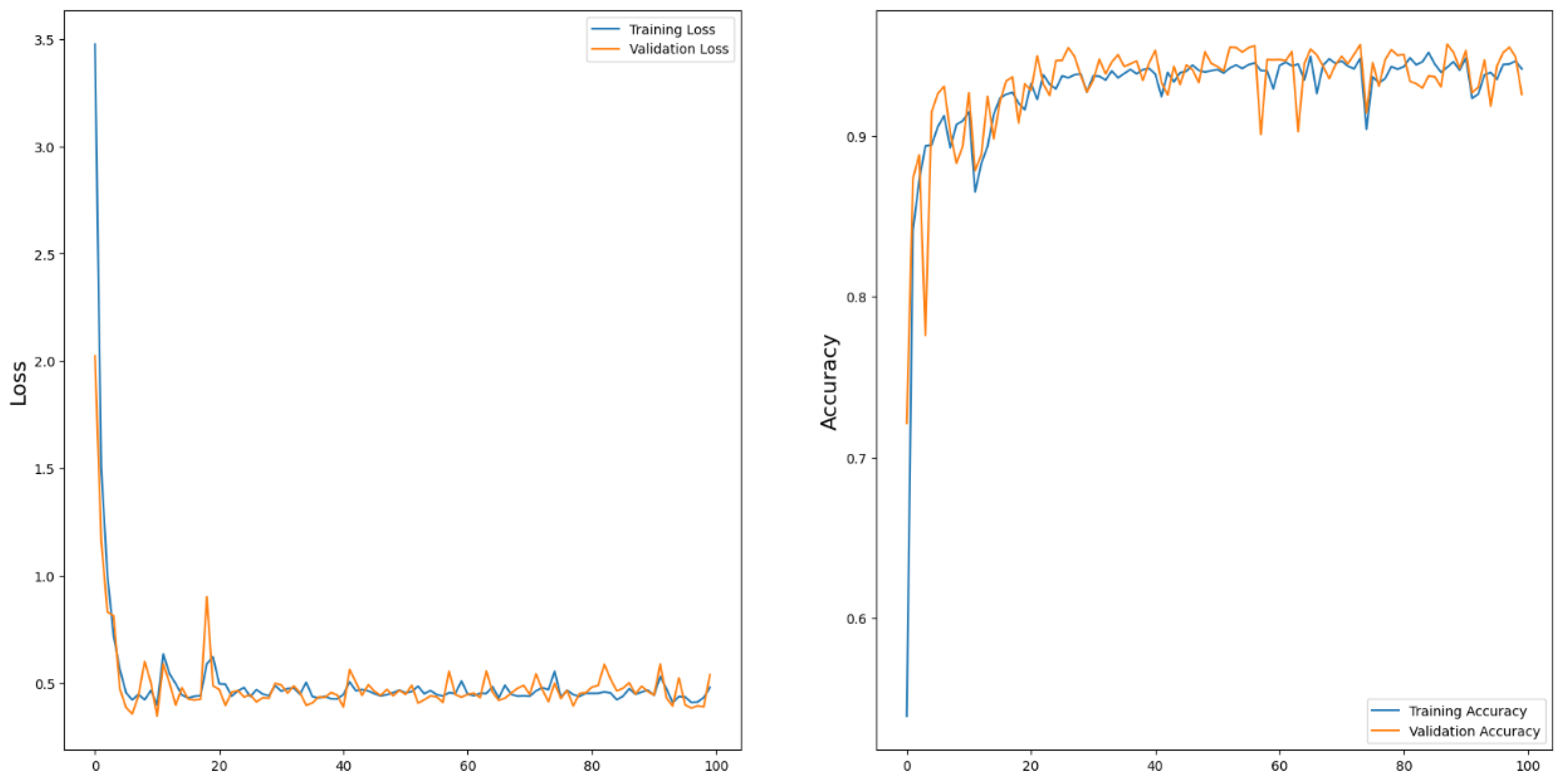
The model produces a result of approximately 95% accuracy (in contrast to the loss), as depicted in
Figure 3 and
Table 2. Notably, as can be seen in
Figure 3 and
Table 2, the level of accuracy gets to more than 90% only after the first five epochs.
4.5.2. Results of ViT Model
The model produces a result of approximately 98% accuracy (in contrast to the loss), as depicted in
Figure 4 and
Table 3. Notably, as can be seen in
Figure 4 and
Table 3, the level of accuracy gets to more than 90% only after the first three epochs.
5. Conclusions
This research investigates defect detection in civil and structural components using both a CNN model and a ViT model available through TensorFlow. The study conducted an empirical analysis using a database of cracks. The findings indicate that when cracks are classified simply as binary (crack or no crack), both CNN and ViT models demonstrate comparable levels of accuracy.
Although it has been shown that the methodology with the models is effective to be used for the detection of cracks with a high accuracy level for this example; however, the example is relatively simple, with only two condition states of crack being defined: one without cracks and another with cracks. In practical situations, asset managers might wish to define the condition states into more than two (2) to capture the severity and damage level of cracks in order to make a proper preventive or corrective intervention. This limitation will be addressed by the team in the upcoming research work that covers the multiple condition states of pavement defects, including cracks and other types of distress, such as potholes, roughness, and rutting.
It is confirmed from the work that the open-source approach with use of TensorFlow algorithm is effective and significantly reducing the cost of implementation while still maintaining a good level of accuracy. In addition, suffice it to say that this method can be extended to other types of defects on infrastructure systems.




{kind=link}
{kind=link}
{kind=link}
{kind=link}











