A Riemannian Geometry Theory of Synergy Selection for Visually-Guided Movement



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Why Riemannian Geometry?
2.1. The Relevance of Riemannian Geometry in Visual Science
2.2. The Relevance of Riemannian Geometry in Action Science
2.3. The Geometry of an Integrated Somatosensory-Hippocampal-Visual Memory
2.4. The Street View Analogy
2.5. Constructing a 3D Representation via Riemannian Mapping
2.6. Geodesic Trajectories and Reinforcement Learning
2.7. Two Streams of Visual Processing
2.8. A Riemannian Metric Encodes the Intrinsic Geometry of Visual Space
3. Background
3.1. The Intrinsically-Warped Geometry of 3D Visual Space
3.2. The Need for Movement Synergies
3.3. The Configuration Space of the Human Body Moving in 3D Euclidean Space
3.4. The Mass-Inertia Matrix of the Body Changes with Configuration
3.5. Minimum Effort Movement Trajectories to Achieve Specified Visual Outcomes
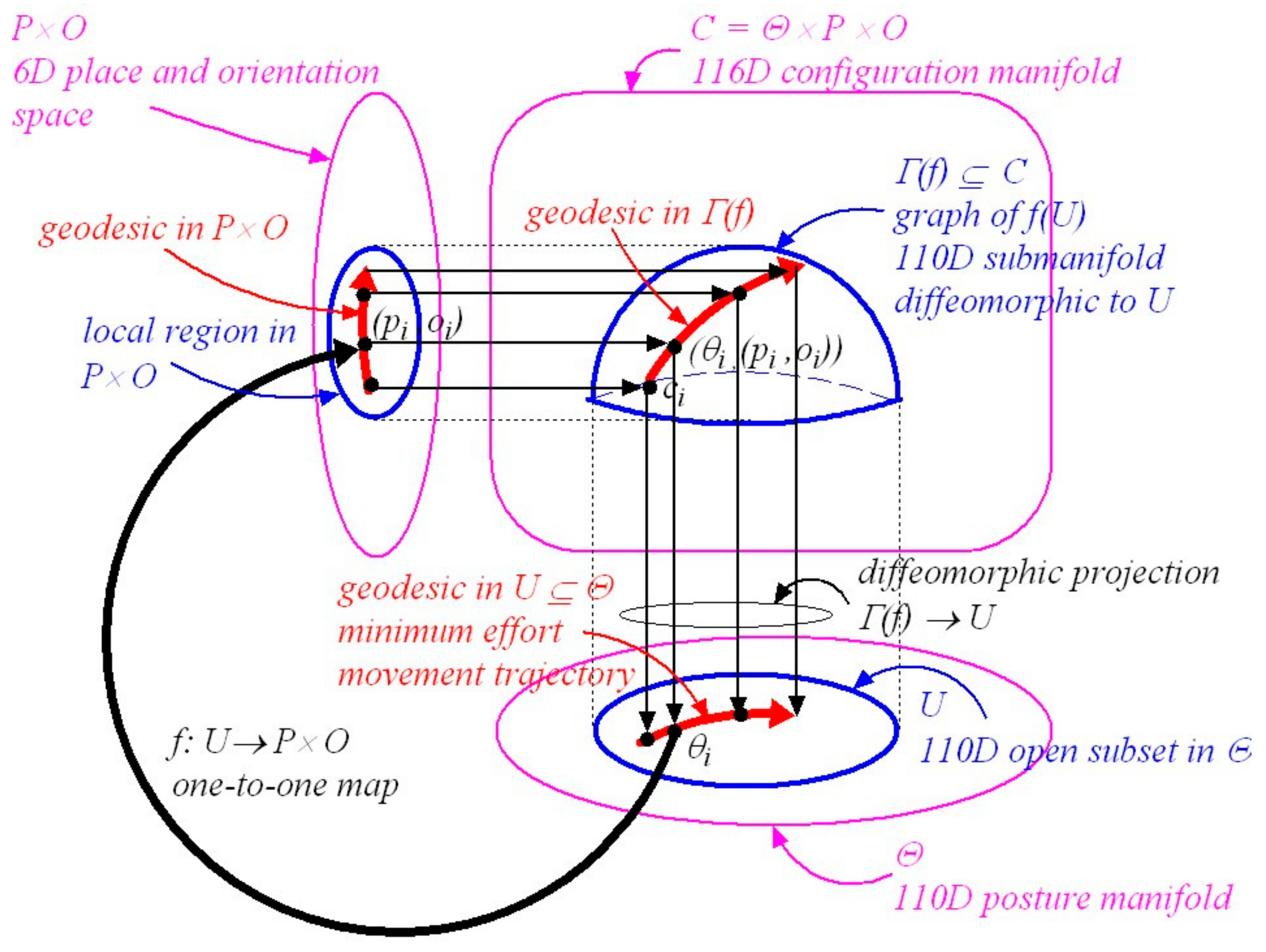
3.6. Movement Trajectories Confined to Local Regions in Configuration Space
3.7. Geodesics in Configuration Space
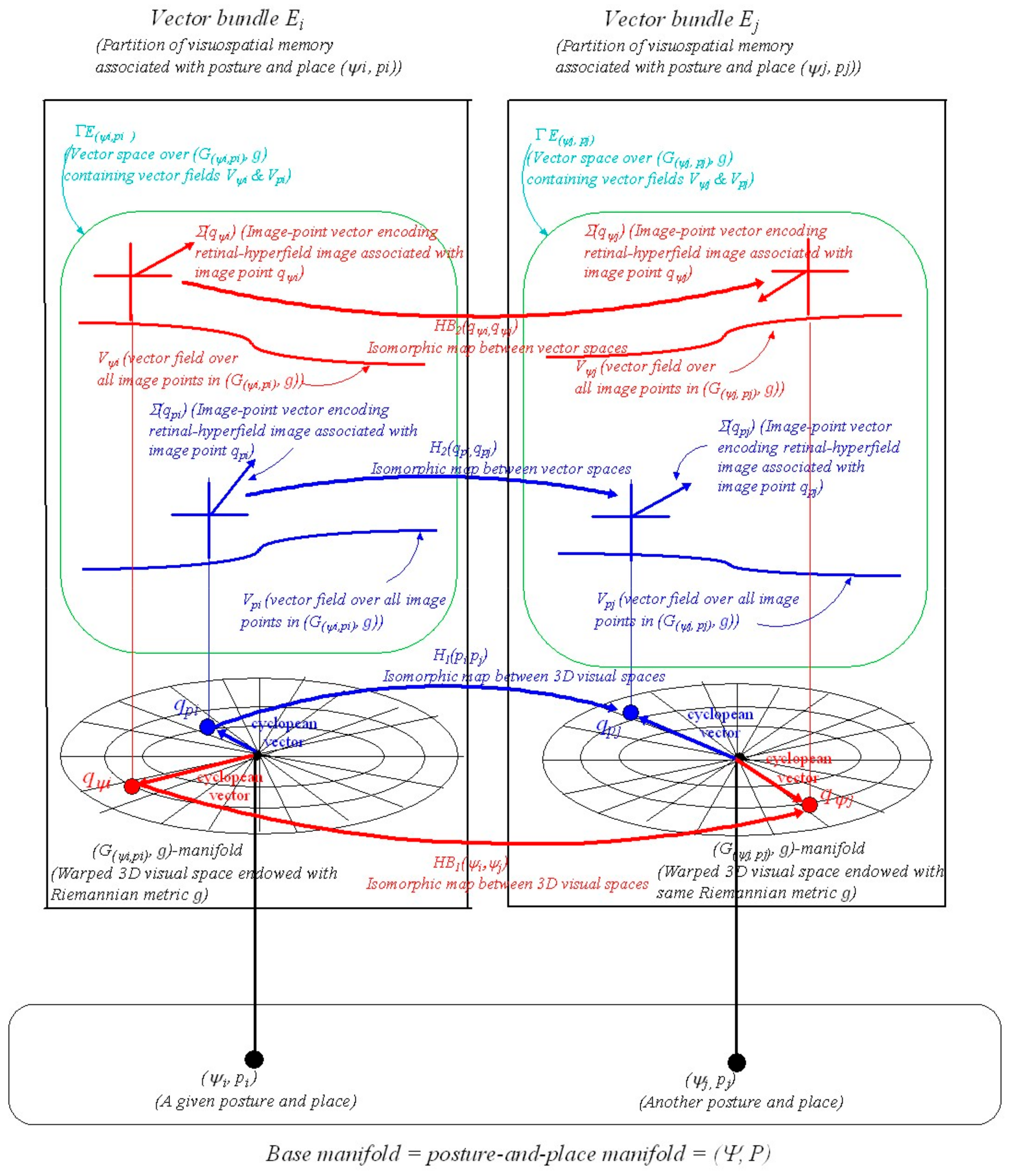
4. Posture-and-Place-Encoded Visual Images
4.1. Image Points, Image-Point Vectors and Visual Space
4.2. Visual Scanning of Objects and of the Body
4.3. The Geometric Structure of Posture-and-Place Encoding
4.4. Redundancy in Posture-to-Vision Maps
4.5. Overcoming Redundancy in Posture-to-Vision Maps
5. The Geometry of Synergistic Movement to a Visual Goal
5.1. The Visual Task Space and Minimum-Effort Synergies
5.2. Visually-Guided Movements Planned in a Local Region of the Configuration Space
5.3. A Simplified Description of Riemannian Graph Theory
5.4. Constructing a Local Minimum-Effort Movement Synergy Compatible with a Specified Visual Goal
5.4.1. One-Dimensional Submanifold
5.4.2. Two-Dimensional Submanifold

5.4.3. N-Dimensional Submanifold
5.4.4. The Two-Point Boundary Value Problem
5.5. Temporal Response Planning in a Submanifold
5.6. Synergy Submanifolds Are Confined to Local Regions in Configuration Space
6. Proprioceptive-to-Vision and Vision-to-Proprioceptive Maps
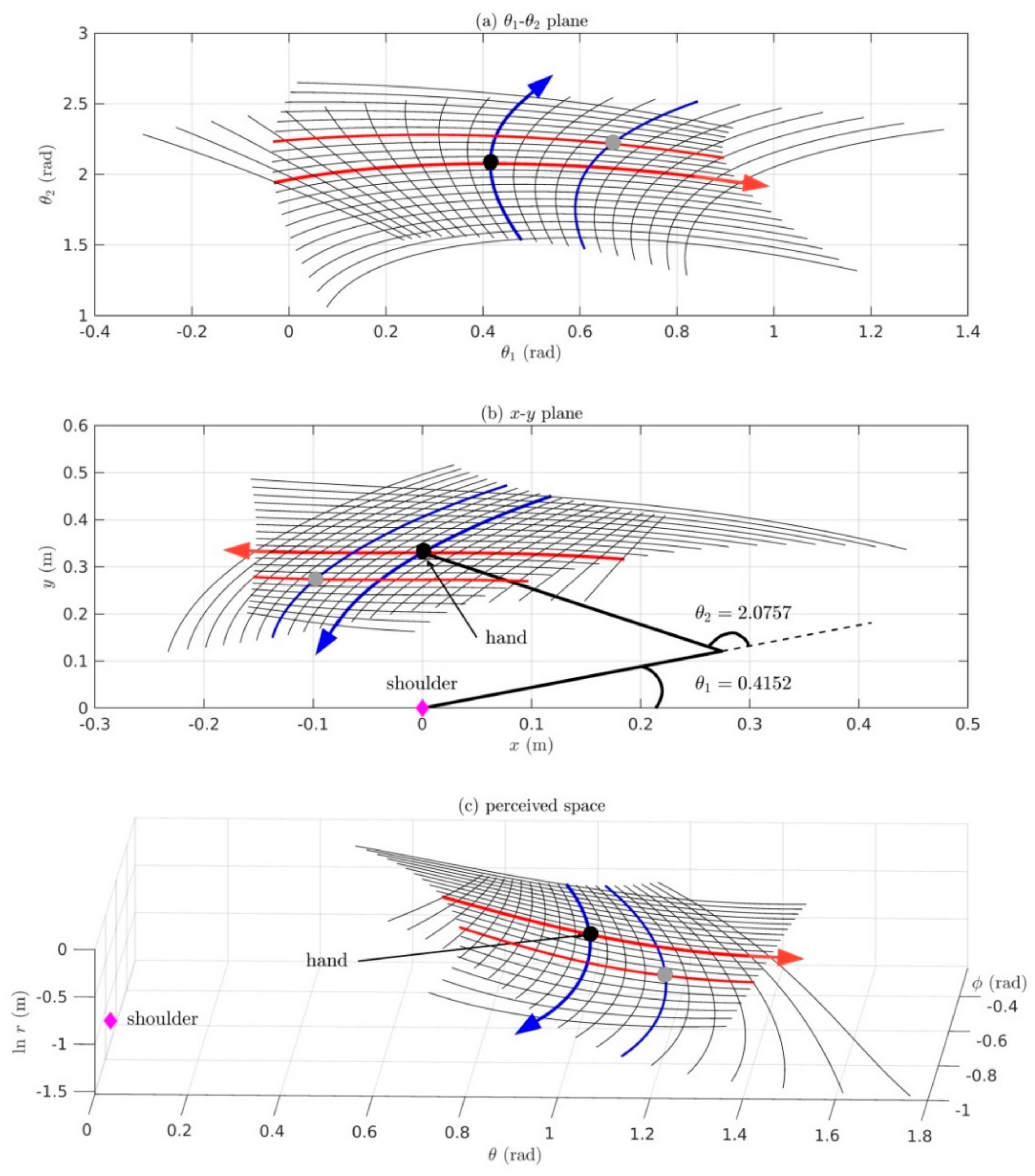
6.1. The Synergy Submanifold in Visual Space
6.2. Simulation of a Proprioceptive-to-Visual Map for a Two-DOF Arm
7. Task-Related Synergy Selection
7.1. Transforming Visuomotor Goals into Movement Synergies
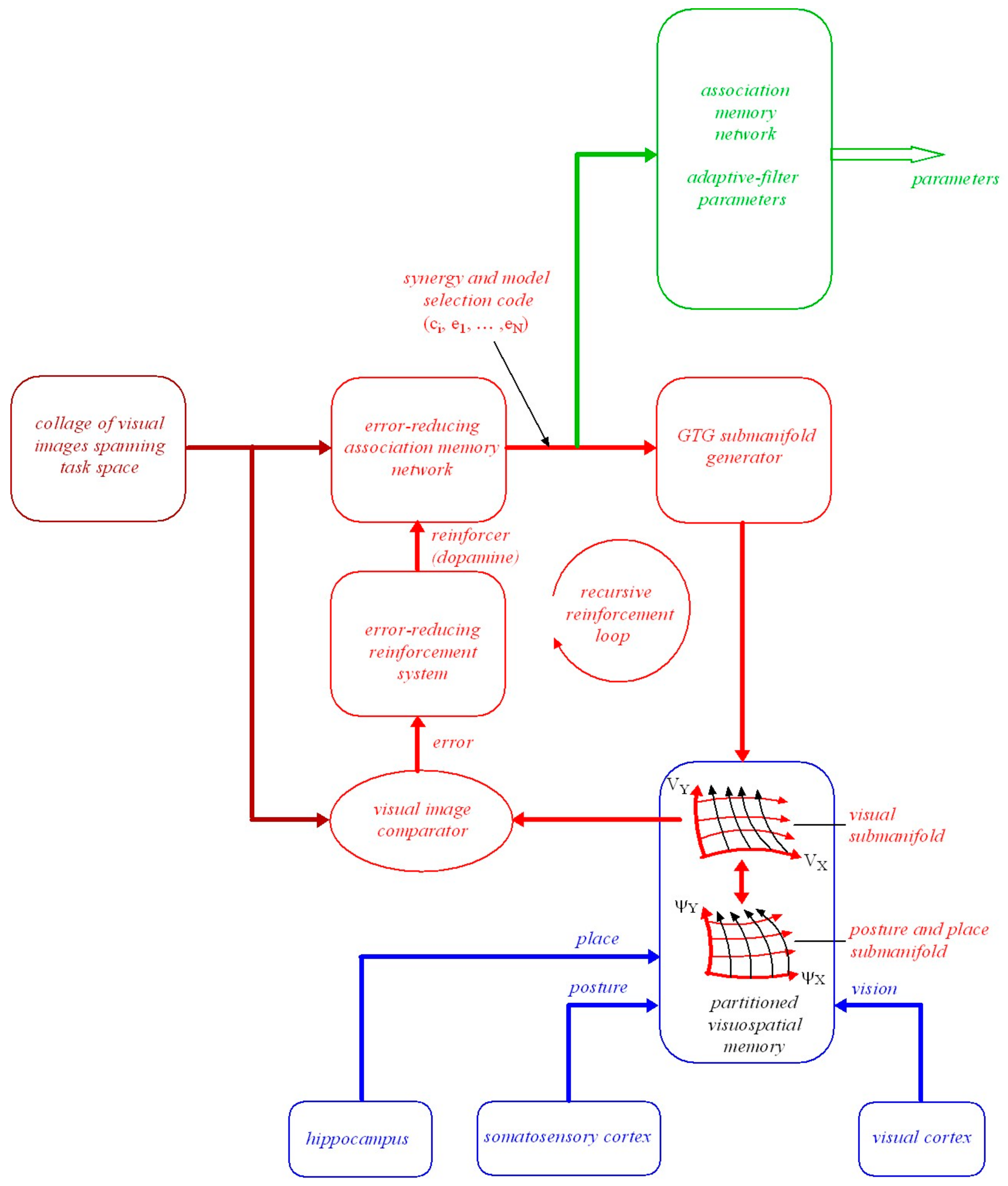
7.2. Model-Based Reinforcement Learning Using an Error-Reducing Association Memory Network
8. Discussion
8.1. Why Pursue a Theory?
8.2. A Recap of the Major Features of the Theory
8.3. Sequences of Movement Synergies in Natural Behaviour
“We filmed a range of primates [and] were able to film complex behavior including climbing, playing, grooming, foraging, fighting and so on. Much of the video footage was analyzed frame by frame in an attempt to construct a general, qualitative description of the normal movement repertoire of monkeys. Perhaps the most striking feature of the movement repertoire of monkeys, or of any animal that we observed, was its breakdown into action modes and submodes between which the animal frequently switched with minimal overlap. Typically an animal switched rapidly among these different action modes. The episodes of each action mode were brief. The impression was of a constant changing from one mode to the next”([80] pp. 2–5)
8.4. Other Accounts of Movement Synergy
8.5. Relationship to Robotic Multi-Joint Movement
8.6. Optical Flow Is Determined by the Intrinsic Riemannian Geometry of 3D Visual Space
8.7. Dissociation of Perception and Action
8.8. Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Riemannian Geometry: A Tutorial
A.1. Set Theory
A.2. Topology
A.3. Topological Spaces
A.3.1. Useful Definitions
A.3.2. Maps between Topological Spaces
A.3.3. Open and Closed Maps
A.4. Topological Manifolds
- (i)
- is Hausdorff which means that for any two points there exist disjoint open subsets and in such that contains and contains .
- (ii)
- is second countable which means that its basis open subsets can be mapped bijectively onto the set of positive integers (i.e., the can be counted). Being second countable implies being first countable which means that for every point there is a neighbourhood basis consisting of a countable collection of nested neighbourhoods of such that any other arbitrary neighbourhood of contains at least one of the neighbourhoods in the neighbourhood basis of .
- (iii)
- is locally Euclidean which means that for every point there exists a coordinate chart where is an open subset of containing the point known as a coordinate domain and is a homeomorphic map between and in an n-dimensional Euclidean space . This defines the manifold to be n-dimensional. The component functions of the homeomorphic map define a set of orthogonal Cartesian coordinates on and a set of curvilinear coordinates on such that and . A collection of coordinate charts , that cover is called an atlas.
- (iv)
- is locally path-connected (i.e., its basis open subsets are path-connected).
- (v)
- is locally compact (i.e., its basis open subsets are precompact).
- (vi)
- The combination of being second countable, locally compact and Hausdorff means that a topological manifold is paracompact (i.e., every open cover of has a locally finite refinement (i.e., every open subset can be constructed from a union of a finite number of basis open subsets )).
A.5. Smooth Manifolds
A.6. Smooth Maps between Smooth Manifolds
A.7. Tangent Vectors and Cotangent Vectors
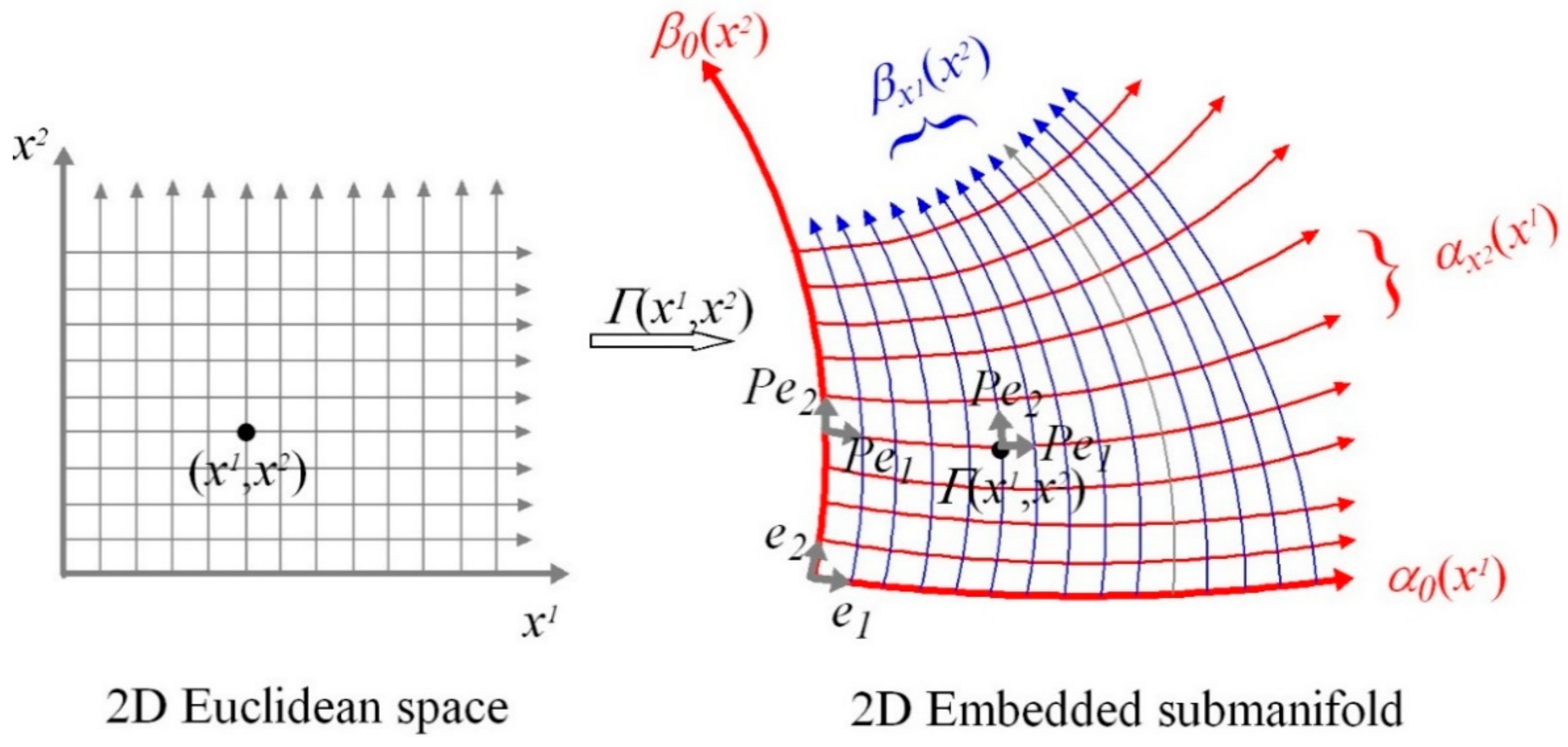
A.8. Smooth Submanifolds
A.9. Smoothly Embedded Submanifolds
A.10. Slice Coordinates
A.11. Riemannian Manifolds
A.12. Graphs of Submanifolds
A.13. Vector Bundles
A.14. Vector Bundle Morphisms
A.15. Covariant Derivatives
A.16. Curvature
- (i)
- ,
- (ii)
- ,
- (iii)
- , and
- (iv)
- .
A.17. Geodesics and Parallel Translation
A.18. Variation through Geodesics
A.18.1. Variation at the Beginning Point
A.18.2. Properties of Variation through Geodesics
Appendix B. Mathematical Properties of Variations through Geodesics
Appendix C. Error-Reducing Association Memory Network
References
- Sprague, N.; Ballard, D.; Robinson, A. Modeling embodied visual behaviors. ACM Trans. Appl. Percept. 2007, 4, 11. [Google Scholar] [CrossRef]
- Berthoz, A. (Ed.) Multisensory Control of Movement; Oxford University Press: Oxford, UK, 1993; ISBN 978-0191724268. [Google Scholar]
- Hayhoe, M.M. Vision and action. Ann. Rev. Vis. Sci. 2017, 3, 389–413. [Google Scholar] [CrossRef]
- Gielen, S. Review of models for the generation of multi-joint movements in 3-D. In Progress in Motor Control: A Multidisciplinary Perspective; Sternad, D., Ed.; Springer: Boston, MA, USA, 2009; pp. 523–550. ISBN 978-0387770642. [Google Scholar]
- Neilson, P.D.; Neilson, M.D.; Bye, R.T. A Riemannian geometry theory of human movement: The geodesic synergy hypothesis. Hum. Mov. Sci. 2015, 44, 42–72. [Google Scholar] [CrossRef]
- Neilson, P.D.; Neilson, M.D.; Bye, R.T. A Riemannian geometry theory of three-dimensional binocular visual perception. Vision 2018, 2, e43. [Google Scholar] [CrossRef] [PubMed]
- Hillerbrand, F. Theory of apparent size in binocular vision. Denkschr. Akad. Wissensch. Math. Nat. Wiss. Cl. 1902, 72, 255–307. [Google Scholar]
- Blumenfeld, W. Studies on apparent size in visual space. Z. Psychol. 1913, 65, 241–404. [Google Scholar]
- Luneburg, R.K. Mathematical Analysis of Binocular Vision; Princeton University Press: Princeton, NJ, USA, 1947. [Google Scholar]
- Gilinsky, A.S. Perceived size and distance in visual space. Psych. Rev. 1951, 58, 460–482. [Google Scholar] [CrossRef]
- Foley, J.M. The size-distance relation and intrinsic geometry of visual space: Implications for processing. Vis. Res. 1972, 12, 323–332. [Google Scholar] [CrossRef]
- Battro, A.M.; Netto, S.D.P.; Rozestraten, R.J.A. Riemannian geometries of variable curvature in visual space: Visual alleys, horopters, and triangles in big open fields. Perception 1976, 5, 9–23. [Google Scholar] [CrossRef] [PubMed]
- Wagner, M. The metric of visual space. Percept. Psychophys. 1985, 38, 483–495. [Google Scholar] [CrossRef]
- Indow, T. A critical review of Luneburg’s model with regard to global structure of visual space. Psych. Rev. 1991, 98, 430–453. [Google Scholar] [CrossRef]
- Koenderink, J.J.; van Doorn, A.J. Exocentric pointing. In Vision and Action; Harris, L.R., Jenkin, M., Eds.; Cambridge University Press: Cambridge, UK, 1998; pp. 295–313. ISBN 978-0521631624. [Google Scholar]
- Koenderink, J.J.; van Doorn, A.J.; Lappin, J.S. Direct measurement of the curvature of visual space. Perception 2000, 29, 69–79. [Google Scholar] [CrossRef] [PubMed]
- Cuijpers, R.H.; Kappers, A.M.L.; Koenderink, J.J. Investigation of visual space using an exocentric pointing task. Percept. Psychophys. 2000, 62, 1556–1571. [Google Scholar] [CrossRef] [PubMed]
- Hatfield, G. Representation and constraints: The inverse problem and the structure of visual space. Acta Psychol. 2003, 114, 355–378. [Google Scholar] [CrossRef] [PubMed]
- Foley, J.M.; Ribeiro-Filho, N.P.; Da Silva, J.A. Visual perception of extent and the geometry of visual space. Vis. Res. 2004, 44, 147–156. [Google Scholar] [CrossRef]
- Fernandez, J.M.; Farell, B. Is perceptual space inherently non-Euclidean? J. Math. Psychol. 2009, 53, 86–91. [Google Scholar] [CrossRef]
- Cuijpers, R.H.; Kappers, A.M.L.; Koenderink, J.J. On the role of external reference frames on visual judgements of parallelity. Acta Psychol. 2001, 108, 283–302. [Google Scholar] [CrossRef]
- Schoumans, N.; Kappers, A.M.L.; Koenderink, J.J. Scale invariance in near space: Pointing under influence of context. Acta Psychol. 2002, 110, 63–81. [Google Scholar] [CrossRef]
- Cuijpers, R.H.; Kappers, A.M.L.; Koenderink, J.J. The metrics of visual and haptic space based on parallelity judgements. J. Math. Psychol. 2003, 47, 278–291. [Google Scholar] [CrossRef]
- Koenderink, J.J.; van Doorn, A.J.; Lappin, J.S. Exocentric pointing to opposite targets. Acta Psychol. 2003, 112, 71–87. [Google Scholar] [CrossRef]
- Doumen, M.J.A.; Kappers, A.M.L.; Koenderink, J.J. Visual space under free viewing conditions. Percept. Psychophys. 2005, 67, 1177–1189. [Google Scholar] [CrossRef]
- Doumen, M.J.A.; Kappers, A.M.L.; Koenderink, J.J. Horizontal–vertical anisotropy in visual space. Acta Psychol. 2006, 123, 219–239. [Google Scholar] [CrossRef] [PubMed]
- Doumen, M.J.A.; Kappers, A.M.L.; Koenderink, J.J. Effects of context on a visual 3-D pointing task. Perception 2007, 36, 75–90. [Google Scholar] [CrossRef] [PubMed]
- Koenderink, J.; van Doorn, A. The structure of visual spaces. J. Math. Imaging Vis. 2008, 31, 171–187. [Google Scholar] [CrossRef]
- Koenderink, J.J.; van Doorn, A.J.; Kappers, A.M.L.; Doumen, M.J.A.; Todd, J.T. Exocentric pointing in depth. Vision Res. 2008, 48, 716–723. [Google Scholar] [CrossRef]
- Koenderink, J.; van Doorn, A.; de Ridder, H.; Oomes, S. Visual rays are parallel. Perception 2010, 39, 1163–1171. [Google Scholar] [CrossRef] [PubMed]
- Koenderink, J.; van Doorn, A. The shape of space. In Shape Perception in Human and Computer Vision; Dickinson, S., Pizlo, Z., Eds.; Springer: London, UK, 2013; pp. 145–156. ISBN 978-1447151944. [Google Scholar]
- van Doorn, A.; Koenderink, J.; Wagemans, J. Exocentric pointing in the visual field. i-Perception 2013, 4, 532–542. [Google Scholar] [CrossRef] [PubMed]
- Cuijpers, R.H.; Kappers, A.M.L.; Koenderink, J.J. Visual perception of collinearity. Percept. Psychophys. 2002, 64, 392–404. [Google Scholar] [CrossRef] [PubMed]
- Smeets, J.B.J.; Sousa, R.; Brenner, E. Illusions can warp visual space. Perception 2009, 38, 1467–1480. [Google Scholar] [CrossRef]
- Gogel, W.C. A theory of phenomenal geometry and its applications. Percept. Psychophys. 1990, 48, 105–123. [Google Scholar] [CrossRef]
- Predebon, J. Relative distance judgments of familiar and unfamiliar objects viewed under representatively natural conditions. Percept. Psychophys. 1990, 47, 342–348. [Google Scholar] [CrossRef]
- Predebon, J. The influence of object familiarity on magnitude estimates of apparent size. Perception 1992, 21, 77–90. [Google Scholar] [CrossRef] [PubMed]
- Gogel, W.C. An analysis of perceptions from changes in optical size. Percept. Psychophys. 1998, 60, 805–820. [Google Scholar] [CrossRef]
- Granrud, C.E. Development of size constancy in children: A test of the metacognitive theory. Atten. Percept. Psychophys. 2009, 71, 644–654. [Google Scholar] [CrossRef] [PubMed]
- Hatfield, G. Phenomenal and cognitive factors in spatial perception. In Visual Experience: Sensation, Cognition, and Constancy; Hatfield, G., Allred, S., Eds.; Oxford University Press: Oxford, UK, 2012; pp. 35–62. ISBN 978-0191741883. [Google Scholar]
- Wagner, M. Sensory and cognitive explanations for a century of size constancy research. In Visual Experience: Sensation, Cognition, and Constancy; Hatfield, G., Allred, S., Eds.; Oxford University Press: Oxford, UK, 2012; pp. 63–86. ISBN 978-0191741883. [Google Scholar]
- Frisby, J.P.; Stone, J.V. Seeing: The Computational Approach to Biological Vision, 2nd ed.; MIT Press: Cambridge, MA, USA, 2010; ISBN 978-0262514279. [Google Scholar]
- Wikipedia, The Free Encyclopedia. Mathematics of General Relativity. 2020. Available online: https://en.wikipedia.org/wiki/Mathematics_of_general_relativity (accessed on 28 November 2020).
- Hartley, T.; Lever, C.; Burgess, N.; O’Keefe, J. Space in the brain: How the hippocampal formation supports spatial cognition. Philos. Trans. R. Soc. Lond. B Biol. Sci. 2014, 369, 20120510. [Google Scholar] [CrossRef] [PubMed]
- Discover Street View and Contribute Your Own Imagery to Google Maps. Available online: https://www.google.com/streetview/ (accessed on 24 March 2021).
- Katz, M.; Kruger, P.B. The human eye as an optical system. In Duane’s Clinical Ophthalmology; Tasman, W., Jaeger, E.A., Eds.; Lippincott, Williams and Wilkins: Philadelphia, PA, USA, 2006. [Google Scholar]
- Neilson, P.D.; Neilson, M.D. An overview of adaptive model theory: Solving the problems of redundancy, resources, and nonlinear interactions in human movement control. J. Neural Eng. 2005, 2, S279–S312. [Google Scholar] [CrossRef] [PubMed]
- Neilson, P.D.; Neilson, M.D. On theory of motor synergies. Hum. Mov. Sci. 2010, 29, 655–683. [Google Scholar] [CrossRef]
- Bullo, F.; Lewis, A.D. Geometric Control of Mechanical Systems: Modeling, Analysis, and Design for Simple Mechanical Control Systems; Springer: New York, NY, USA, 2005; ISBN 978-0387221953. [Google Scholar]
- Lee, J.M. Introduction to Smooth Manifolds, 2nd ed.; Springer: New York, NY, USA, 2013; ISBN 978-1441999818. [Google Scholar]
- Neilson, P.D.; Neilson, M.D.; O’Dwyer, N.J. Internal models and intermittency: A theoretical account of human tracking behavior. Biol. Cybern. 1988, 58, 101–112. [Google Scholar] [CrossRef]
- Neilson, P.D.; Neilson, M.D.; O’Dwyer, N.J. Adaptive model theory: Application to disorders of motor control. In Approaches to the Study of Motor Control and Learning; Summers, J.J., Ed.; Elsevier: Amsterdam, The Netherlands, 1992; pp. 495–548. ISBN 978-0444884558. [Google Scholar]
- Neilson, P.D.; Neilson, M.D.; O’Dwyer, N.J. Adaptive model theory: Central processing in acquisition of skill. In Neurophysiology & Neuropsychology of Motor Development; Connolly, K.J., Forssberg, H., Eds.; Mac Keith Press: London, UK, 1997; pp. 346–370. ISBN 978-0521018982. [Google Scholar]
- Neilson, P.D.; Neilson, M.D. A neuroengineering solution to the optimal tracking problem. Hum. Mov. Sci. 1999, 18, 155–183. [Google Scholar] [CrossRef]
- Neilson, P.D.; O’Dwyer, N.J.; Neilson, M.D. Stochastic prediction in pursuit tracking: An experimental test of adaptive model theory. Biol. Cybern. 1988, 58, 113–122. [Google Scholar] [CrossRef]
- Neilson, P.D.; Neilson, M.D.; O’Dwyer, N.J. What limits high speed tracking performance? Hum. Mov. Sci. 1993, 12, 85–109. [Google Scholar] [CrossRef]
- O’Dwyer, N.J.; Neilson, P.D. Metabolic energy expenditure and accuracy in movement: Relation to levels of muscle and cardiorespiratory activation and the sense of effort. In Energetics of Human Activity; Sparrow, W.A., Ed.; Human Kinetics: Champaign, IL, USA, 2000; pp. 1–42. ISBN 978-0880117876. [Google Scholar]
- Sparrow, W.A.; Newell, K.M. Metabolic energy expenditure and the regulation of movement economy. Psychon. Bull. Rev. 1998, 5, 173–196. [Google Scholar] [CrossRef]
- Neilson, P.D.; Neilson, M.D.; O’Dwyer, N.J. Adaptive optimal control of human tracking. In Motor Control and Sensory Motor Integration: Issues and Directions; Glencross, D.J., Piek, J.P., Eds.; North-Holland: Amsterdam, The Netherlands, 1995; pp. 97–140. ISBN 978-0444819215. [Google Scholar]
- Bye, R.T.; Neilson, P.D. The BUMP model of response planning: Variable horizon predictive control accounts for the speed–accuracy tradeoffs and velocity profiles of aimed movement. Hum. Mov. Sci. 2008, 27, 771–798. [Google Scholar] [CrossRef]
- Bye, R.T.; Neilson, P.D. The BUMP model of response planning: Intermittent predictive control accounts for 10Hz physiological tremor. Hum. Mov. Sci. 2010, 29, 713–736. [Google Scholar] [CrossRef]
- Shah, A. Psychological and neuroscientific connections with reinforcement learning. In Reinforcement Learning: State-of-the-Art; Wiering, M., van Otterlo, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 507–537. ISBN 978-3642276453. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT Press: Cambridge, MA, USA, 2018; ISBN 978-0262039246. [Google Scholar]
- O’Doherty, J.P.; Lee, S.W.; McNamee, D. The structure of reinforcement-learning mechanisms in the human brain. Curr. Opin. Behav. Sci. 2015, 1, 94–100. [Google Scholar] [CrossRef]
- Neilson, P.D.; Neilson, M.D.; O’Dwyer, N.J. Evidence for rapid switching of sensory-motor models. In Motor Behavior and Human Skill: A Multidisciplinary Approach; Piek, J.P., Ed.; Human Kinetics: Champaign, IL, USA, 1998; pp. 105–126. ISBN 978-0880116756. [Google Scholar]
- Nash, J.; Neilson, P.D.; O’Dwyer, N.J. Reducing spasticity to control muscle contracture of children with cerebral palsy. Dev. Med. Child Neurol. 1989, 31, 471–480. [Google Scholar] [CrossRef] [PubMed]
- O’Dwyer, N.; Neilson, P.; Nash, J. Reduction of spasticity in cerebral palsy using feedback of the tonic stretch reflex: A controlled study. Dev. Med. Child Neurol. 1994, 36, 770–786. [Google Scholar] [CrossRef] [PubMed]
- Neilson, P.D. Voluntary control of arm movement in athetotic patients. J. Neurol. Neurosurg. Psychiatry 1974, 37, 162–170. [Google Scholar] [CrossRef][Green Version]
- Neilson, P.D. Measurement of involuntary arm movement in athetotic patients. J. Neurol. Neurosurg. Psychiatry 1974, 37, 171–177. [Google Scholar] [CrossRef][Green Version]
- Polich, J. Theoretical overview of P3a and P3b. In Detection of Change: Event-Related Potential and fMRI Findings; Polich, J., Ed.; Springer: Boston, MA, USA, 2003; pp. 83–98. ISBN 978-1461502944. [Google Scholar]
- Gandevia, S.C. Roles for perceived voluntary motor commands in motor control. Trends Neurosci. 1987, 10, 81–85. [Google Scholar] [CrossRef]
- Barlow, J.S. The Cerebellum and Adaptive Control; Cambridge University Press: Cambridge, UK, 2002; ISBN 978-0521808422. [Google Scholar]
- Jin, X.; Costa, R.M. Shaping action sequences in basal ganglia circuits. Curr. Opin. Neurobiol. 2015, 33, 188–196. [Google Scholar] [CrossRef] [PubMed]
- Markowitz, J.E.; Gillis, W.F.; Beron, C.C.; Neufeld, S.Q.; Robertson, K.; Bhagat, N.D.; Peterson, R.E.; Peterson, E.; Hyun, M.; Linderman, S.W.; et al. The striatum organizes 3D behavior via moment-to-moment action selection. Cell 2018, 174, e17. [Google Scholar] [CrossRef] [PubMed]
- Jessup, R.K.; O’Doherty, J.P. Distinguishing informational from value-related encoding of rewarding and punishing outcomes in the human brain. Eur. J. Neurosci. 2014, 39, 2014–2026. [Google Scholar] [CrossRef]
- Hester, T.; Stone, P. Learning and using models. In Reinforcement Learning; Wiering, M., van Otterlo, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 111–141. ISBN 978-3642276446. [Google Scholar]
- Fuster, J.M. The Prefrontal Cortex, 4th ed.; Academic Press: London, UK, 2008; ISBN 978-0123736444. [Google Scholar]
- Marr, D. Vision: A Computational Investigation into the Human Representation and Processing of Visual Information; Originally Published 1982; MIT Press: Cambridge, MA, USA, 2010; ISBN 978-0262514620. [Google Scholar]
- Kuhn, T.S. The Structure of Scientific Revolutions; University of Chicago Press: Chicago, IL, USA, 1962; ISBN 978-0226458113. [Google Scholar]
- Graziano, M.S.A. The movement repertoire of monkeys. In The Intelligent Movement Machine: An Ethological Perspective on the Primate Motor System; Oxford University Press: Oxford, UK, 2009; ISBN 978-0199864867. [Google Scholar]
- Bruton, M.; O’Dwyer, N. Synergies in coordination: A comprehensive overview of neural, computational, and behavioral approaches. J. Neurophysiol. 2018, 120, 2761–2774. [Google Scholar] [CrossRef]
- Scholz, J.P.; Schöner, G. The uncontrolled manifold concept: Identifying control variables for a functional task. Exp. Brain Res. 1999, 126, 289–306. [Google Scholar] [CrossRef]
- Latash, M.L. The bliss (not the problem) of motor abundance (not redundancy). Exp. Brain Res. 2012, 217, 1–5. [Google Scholar] [CrossRef]
- Profeta, V.L.S.; Turvey, M.T. Bernstein’s levels of movement construction: A contemporary perspective. Hum. Mov. Sci. 2018, 57, 111–133. [Google Scholar] [CrossRef]
- Neilson, P.D.; Neilson, M.D. Motor maps and synergies. Hum. Mov. Sci. 2005, 24, 774–797. [Google Scholar] [CrossRef] [PubMed]
- Glennerster, A.; Hansard, M.E.; Fitzgibbon, A.W. View-based approaches to spatial representation in human vision. In Statistical and Geometrical Approaches to Visual Motion Analysis; Cremers, D., Rosenhahn, B., Yuille, A.L., Schmidt, F.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 193–208. ISBN 978-3642030604. [Google Scholar]
- Land, M.F. Motion and vision: Why animals move their eyes. J. Comp. Physiol. A 1999, 185, 341–352. [Google Scholar] [CrossRef] [PubMed]
- Saito, H.; Yukie, M.; Tanaka, K.; Hikosaka, K.; Fukada, Y.; Iwai, E. Integration of direction signals of image motion in the superior temporal sulcus of the macaque monkey. J. Neurosci. 1986, 6, 145–157. [Google Scholar] [CrossRef] [PubMed]
- Perrone, J.A.; Stone, L.S. A model of self-motion estimation within primate extrastriate visual cortex. Vis. Res. 1994, 34, 2917–2938. [Google Scholar] [CrossRef]
- Roy, J.-P.; Wurtz, R.H. The role of disparity-sensitive cortical neurons in signalling the direction of self-motion. Nature 1990, 348, 160–162. [Google Scholar] [CrossRef]
- Fajen, B.R.; Matthis, J.S. Visual and non-visual contributions to the perception of object motion during self-motion. PLoS ONE 2013, 8, e55446. [Google Scholar] [CrossRef] [PubMed]
- Beek, P.J.; Beek, W.J. Tools for constructing dynamical models of rhythmic movement. Hum. Mov. Sci. 1988, 7, 301–342. [Google Scholar] [CrossRef]
- Dessing, J.C.; Rey, F.P.; Beek, P.J. Gaze fixation improves the stability of expert juggling. Exp. Brain Res. 2012, 216, 635–644. [Google Scholar] [CrossRef] [PubMed]
- Goodale, M.A.; Milner, A.D. Separate visual pathways for perception and action. Trends Neurosci. 1992, 15, 20–25. [Google Scholar] [CrossRef]
- Goodale, M.A.; Milner, D. Sight Unseen: An Exploration of Conscious and Unconscious Vision; Oxford University Press: Oxford, UK, 2013; ISBN 978-0191753008. [Google Scholar]
- Goodale, M.; Milner, D. One brain—Two visual systems. Psychologist 2006, 19, 660–663. [Google Scholar]
- Cutting, J.E.; Vishton, P.M. Perceiving layout and knowing distances: The interaction, relative potency, and contextual use of different information about depth. In Perception of Space and Motion, 2nd ed.; Epstein, W., Rogers, S.J., Eds.; Handbook of Perception and Cognition; Academic Press: San Diego, CA, USA, 1995; pp. 69–177. ISBN 978-0122405303. [Google Scholar]
- Glennerster, A. Depth perception. In Encyclopedia of the Mind; Pashler, H., Ed.; SAGE Publications, Inc.: Thousand Oaks, CA, USA, 2013; pp. 233–235. ISBN 978-1412950572. [Google Scholar]
- Broerse, J.; Ashton, R.; Shaw, C. The apparent shape of afterimages in the Ames room. Perception 1992, 21, 261–268. [Google Scholar] [CrossRef]
- Dwyer, J.; Ashton, R.; Broerse, J. Emmert’s law in the Ames room. Perception 1990, 19, 35–41. [Google Scholar] [CrossRef] [PubMed]
- Gregory, R.L. Emmert’s law and the moon illusion. Spat. Vis. 2008, 21, 407–420. [Google Scholar] [CrossRef] [PubMed]
- Lou, L. Apparent afterimage size, Emmert’s law, and oculomotor adjustment. Perception 2007, 36, 1214–1228. [Google Scholar] [CrossRef]
- Glennerster, A.; Tcheang, L.; Gilson, S.J.; Fitzgibbon, A.W.; Parker, A.J. Humans ignore motion and stereo cues in favor of a fictional stable world. Curr. Biol. 2006, 16, 428–432. [Google Scholar] [CrossRef]
- Gregory, R.L. Knowledge in perception and illusion. Phil. Trans. R. Soc. Lond. B 1997, 352, 1121–1127. [Google Scholar] [CrossRef] [PubMed]
- Króliczak, G.; Heard, P.; Goodale, M.A.; Gregory, R.L. Dissociation of perception and action unmasked by the hollow-face illusion. Brain Res. 2006, 1080, 9–16. [Google Scholar] [CrossRef]
- Erkelens, C.J. Computation and measurement of slant specified by linear perspective. J. Vis. 2013, 13, 16. [Google Scholar] [CrossRef] [PubMed]
- Whitwell, R.L.; Buckingham, G.; Enns, J.T.; Chouinard, P.A.; Goodale, M.A. Rapid decrement in the effects of the Ponzo display dissociates action and perception. Psychon. Bull. Rev. 2016, 23, 1157–1163. [Google Scholar] [CrossRef] [PubMed]
- Whitwell, R.L.; Goodale, M.A.; Merritt, K.E.; Enns, J.T. The Sander parallelogram illusion dissociates action and perception despite control for the litany of past confounds. Cortex 2018, 98, 163–176. [Google Scholar] [CrossRef]
- Ozana, A.; Ganel, T. A double dissociation between action and perception in bimanual grasping: Evidence from the Ponzo and the Wundt–Jastrow illusions. Sci. Rep. 2020, 10, 14665. [Google Scholar] [CrossRef] [PubMed]
- Fasse, E.D.; Hogan, N.; Kay, B.A.; Mussa-Ivaldi, F.A. Haptic interaction with virtual objects. Biol. Cybern. 2000, 82, 69–83. [Google Scholar] [CrossRef] [PubMed]
- Majdak, P.; Baumgartner, R.; Jenny, C. Formation of three-dimensional auditory space. In The Technology of Binaural Understanding; Blauert, J., Braasch, J., Eds.; Springer: Cham, Switzerland, 2020; pp. 115–149. ISBN 978-3030003852. [Google Scholar]
- Rizzolatti, G.; Cattaneo, L.; Fabbri-Destro, M.; Rozzi, S. Cortical mechanisms underlying the organization of goal-directed actions and mirror neuron-based action understanding. Physiol. Rev. 2014, 94, 655–706. [Google Scholar] [CrossRef] [PubMed]
- Abraham, R.; Marsden, J.E. Foundations of Mechanics, 2nd ed.; Benjamin/Cummings: Reading, MA, USA, 1978. [Google Scholar]
- Arnol’d, V.I. Mathematical Methods of Classical Mechanics, 2nd ed.; Springer: New York, NY, USA, 1989; ISBN 978-0387968902. [Google Scholar]
- Darling, R.W.R. Differential Forms and Connections; Cambridge University Press: Cambridge, UK, 1994; ISBN 978-0511805110. [Google Scholar]
- Isidori, A. Nonlinear Control Systems. In Communications and Control Engineering, Nonlinear Control Systems; Springer: London, UK, 1995; ISBN 978-3540199168. [Google Scholar]
- Jurdjevic, V. Geometric control theory. In Cambridge Studies in Advanced Mathematics Volume 52; Cambridge University Press: Cambridge, UK, 1996; ISBN 978-0521495028. [Google Scholar]
- Lee, J.M. Riemannian manifolds: An introduction to curvature. In Graduate Texts in Mathematics Volume 176; Springer: New York, NY, USA, 1997; ISBN 978-0387982717. [Google Scholar]
- Lang, S. Fundamentals of Differential Geometry; Springer: New York, NY, USA, 1999; ISBN 978-1461268109. [Google Scholar]
- Marsden, J.E.; Ratiu, T.S. Introduction to Mechanics and Symmetry: A Basic Exposition of Classical Mechanical Systems, 2nd ed.; Springer: New York, NY, USA, 1999; ISBN 978-0387986432. [Google Scholar]
- Ortega, J.-P.; Ratiu, T. Momentum Maps and Hamiltonian Reduction; Birkhäuser: Basel, Switzerland, 2004; ISBN 978-0817643072. [Google Scholar]
- Szekeres, P. A Course in Modern Mathematical Physics: Groups, Hilbert Space and Differential Geometry; Cambridge University Press: Cambridge, UK, 2004; ISBN 978-0511263293. [Google Scholar]
- Ivancevic, V.G.; Ivancevic, T.T. Applied Differential Geometry: A Modern Introduction; World Scientific: Singapore, 2007; ISBN 978-9812706140. [Google Scholar]
- Lee, J. Introduction to Topological Manifolds, 2nd ed.; Springer: New York, NY, USA, 2011; ISBN 978-1441979391. [Google Scholar]
- Lee, J.M. Introduction to Riemannian Manifolds, 2nd ed.; Springer International Publishing: Cham, Switzerland, 2018; ISBN 978-3319917542. [Google Scholar]
- Ritter, H.; Martinetz, T.; Schulten, K. Neural Computation and Self-organizing Maps: An Introduction; Addison-Wesley: Reading, MA, USA, 1992; ISBN 978-0201554427. [Google Scholar]
- Kohonen, T. Self-organized formation of topologically correct feature maps. Biol. Cybern. 1982, 43, 59–69. [Google Scholar] [CrossRef]
- Sanger, T.D. Optimal unsupervised learning in a single-layer linear feedforward neural network. Neural Netw. 1989, 2, 459–473. [Google Scholar] [CrossRef]
- Oja, E. Principal components, minor components, and linear neural networks. Neural Netw. 1992, 5, 927–935. [Google Scholar] [CrossRef]
- Rao, R.P.N.; Ballard, D.H. Predictive coding in the visual cortex: A functional interpretation of some extra-classical receptive-field effects. Nat. Neurosci. 1999, 2, 79–87. [Google Scholar] [CrossRef] [PubMed]
- Simoncelli, E.P.; Olshausen, B.A. Natural image statistics and neural representation. Ann. Rev. Neurosci. 2001, 24, 1193–1216. [Google Scholar] [CrossRef]
- Friston, K. Learning and inference in the brain. Neural Netw. 2003, 16, 1325–1352. [Google Scholar] [CrossRef] [PubMed]
- Marr, D. Simple memory: A theory for archicortex. Philos. Trans. R. Soc. Lond. B Biol. Sci. 1971, 262, 23–81. [Google Scholar] [CrossRef] [PubMed]
- Hopfield, J.J. Neural networks and physical systems with emergent collective computational abilities. Proc. Natl. Acad. Sci. USA 1982, 79, 2554–2558. [Google Scholar] [CrossRef] [PubMed]
- Braitenberg, V. Two views of the cerebral cortex. In Brain Theory; Palm, G., Aertsen, A., Eds.; Springer: Berlin/Heidelberg, Germany, 1986; pp. 81–96. ISBN 978-3642709135. [Google Scholar]
- Von Seelen, W.; Mallot, H.A.; Krone, G.; Dinse, H. On information processing in the cat’s visual cortex. In Brain Theory; Palm, G., Aertsen, A., Eds.; Springer: Berlin/Heidelberg, Germany, 1986; pp. 49–79. ISBN 978-3642709135. [Google Scholar]
- Shaw, G.L.; Silverman, D.J. Simulations of the trion model and the search for the code of higher cortical processing. In Computer Simulation in Brain Science; Cotterill, R.M.J., Ed.; Cambridge University Press: Cambridge, UK, 1988; pp. 189–209. ISBN 978-0521341790. [Google Scholar]
- Coster, A.C.F. On the ensemble properties of interacting neurons. In Progress in Biophysics and Molecular Biology; Elsevier: Amsterdam, The Netherlands, 1996; p. 186. [Google Scholar] [CrossRef]
- Coster, A.C.F. Neural Ensembles: A Statistical Mechanical Exploration. Ph.D. Thesis, School of Electrical Engineering and Telecommunications, University of New South Wales, Sydney, Australia, 1997. [Google Scholar]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Neilson, P.D.; Neilson, M.D.; Bye, R.T. A Riemannian Geometry Theory of Synergy Selection for Visually-Guided Movement. Vision 2021, 5, 26. https://doi.org/10.3390/vision5020026
Neilson PD, Neilson MD, Bye RT. A Riemannian Geometry Theory of Synergy Selection for Visually-Guided Movement. Vision. 2021; 5(2):26. https://doi.org/10.3390/vision5020026
Chicago/Turabian StyleNeilson, Peter D., Megan D. Neilson, and Robin T. Bye. 2021. "A Riemannian Geometry Theory of Synergy Selection for Visually-Guided Movement" Vision 5, no. 2: 26. https://doi.org/10.3390/vision5020026
APA StyleNeilson, P. D., Neilson, M. D., & Bye, R. T. (2021). A Riemannian Geometry Theory of Synergy Selection for Visually-Guided Movement. Vision, 5(2), 26. https://doi.org/10.3390/vision5020026