A Three-Feature Model to Predict Colour Change Blindness


Abstract
1. Introduction
2. Related Work
- A new publicly available benchmark for change blindness research which includes observer experience.
- A new predictive model of change blindness based on low-level image features and user experience.
3. User Study
3.1. Participants and Instructions
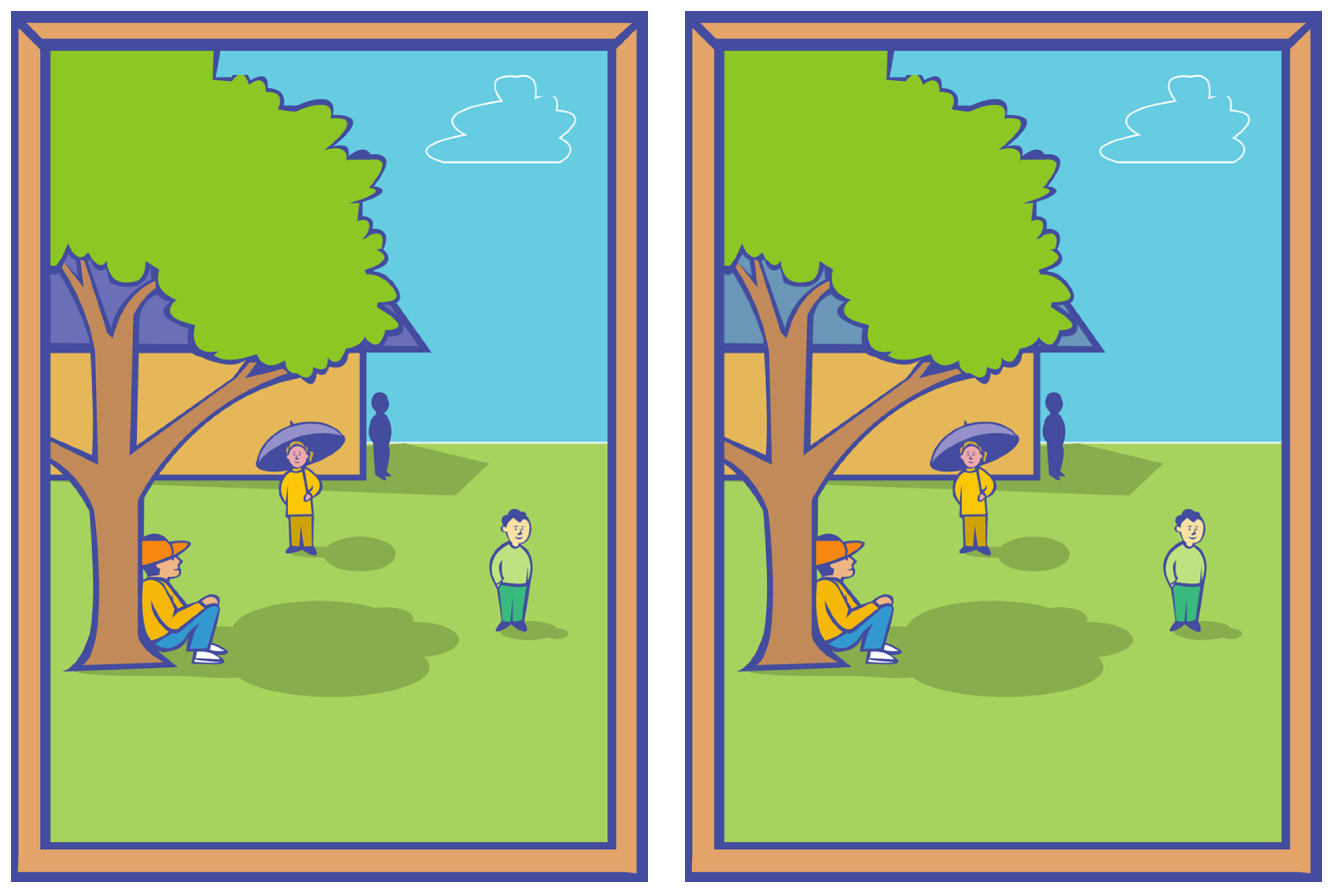
- Your task is to spot the differences in pairs of images which will be displayed on the screen. Each pair contains a single difference.
- Unlike what you may expect, images will not appear side by side. They will be shown one after the other in a flickering fashion. As soon as you spot the difference, please click on it as quickly as possible. You can click only once. After clicking, the solution will be displayed whether you were correct or not. If after one minute you have not noticed any difference, the solution will be displayed anyway and it will move to the next pair.
- After each sequence of five images, you will have the opportunity to take a short break. Make it as long as you need and feel free to stop the experiment at any time, especially if you feel your focus is drifting away from the task.
- All stimuli had to be seen by an approximately equal number of observers.
- Some scenes had to be seen earlier than others so that the average rank (position in sequence) across all observers follows approximately a uniform distribution. This allowed studying the influence of experience in change detection performance.
3.2. Apparatus
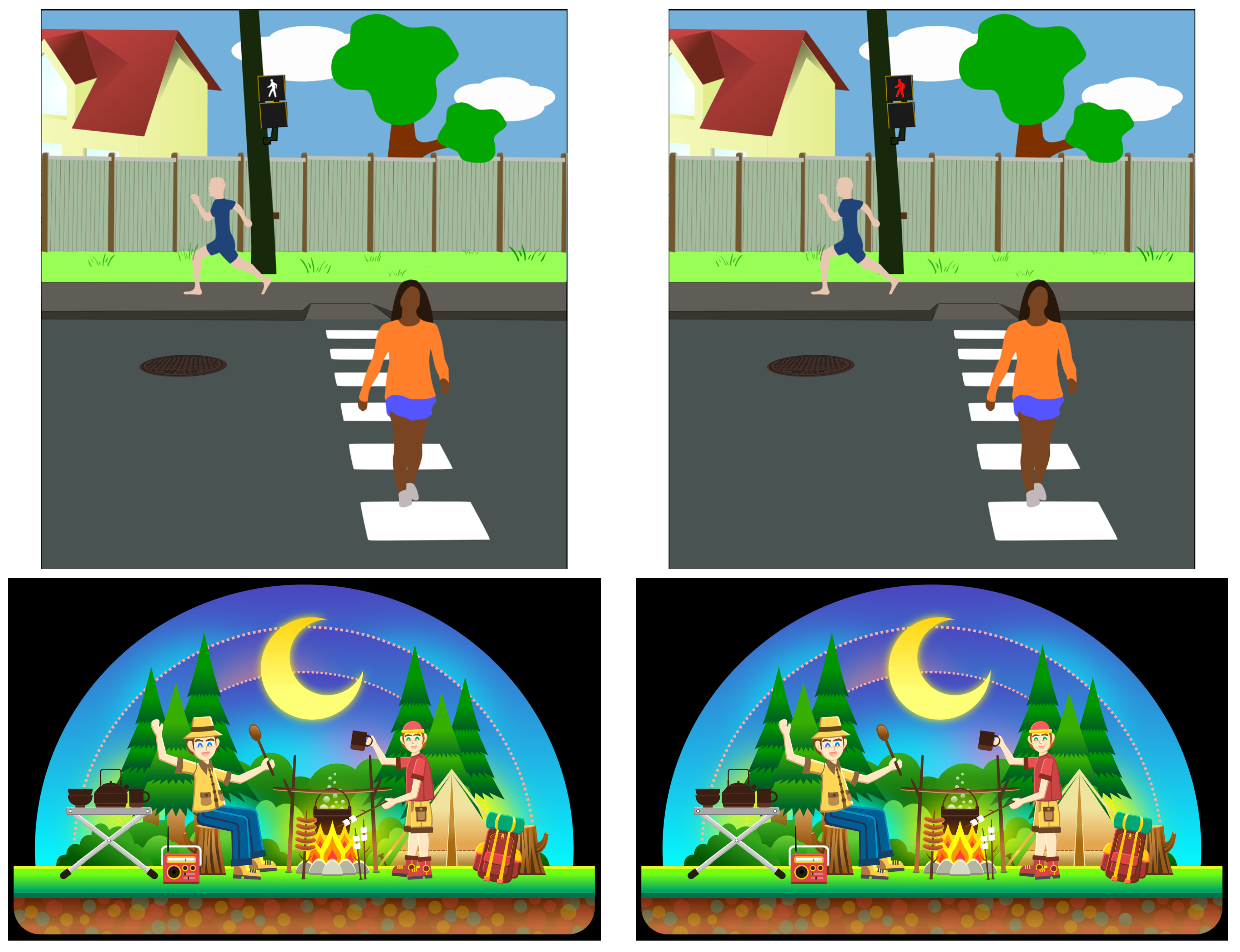
3.3. Stimuli
3.4. Screening
4. Prediction of Change Blindness
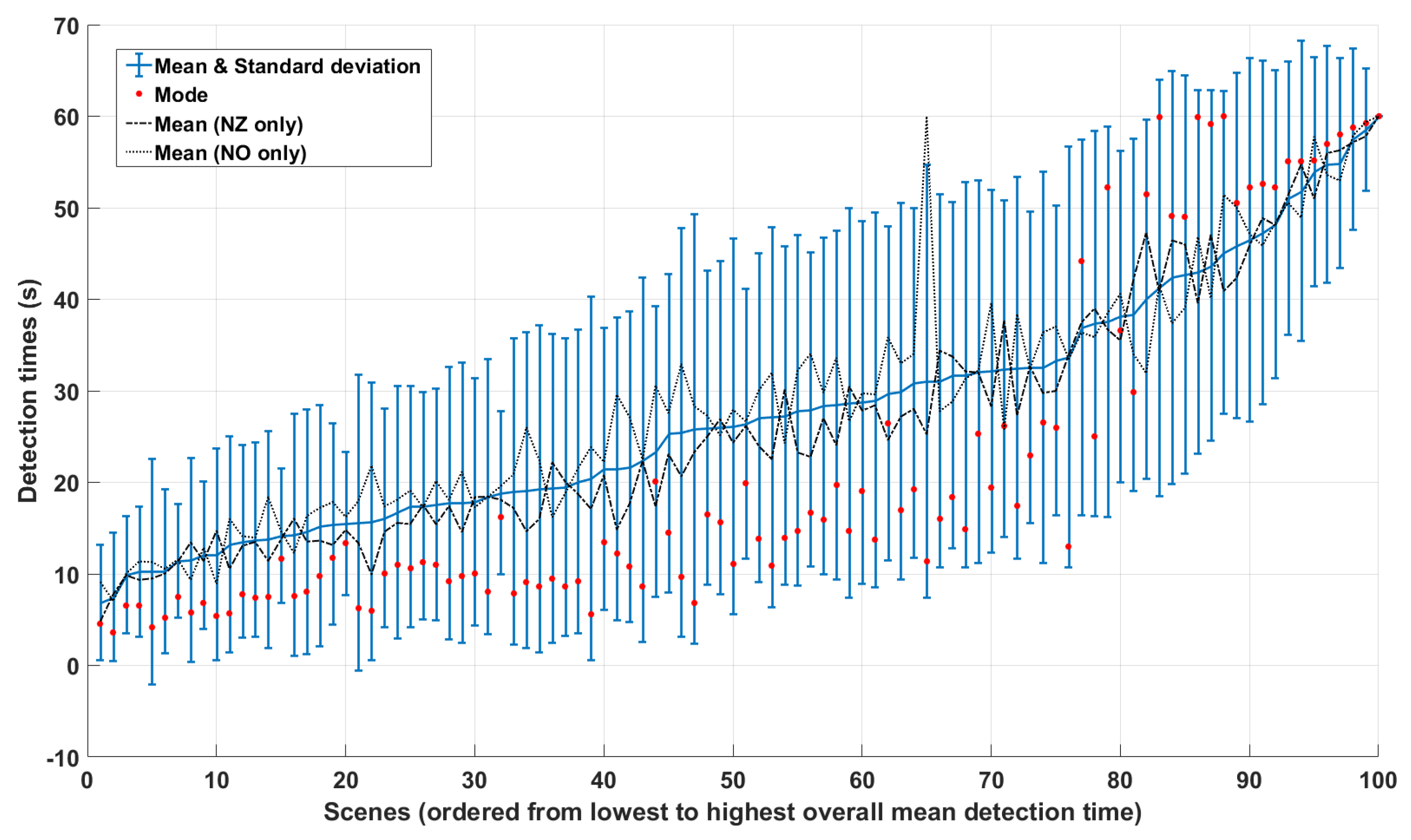
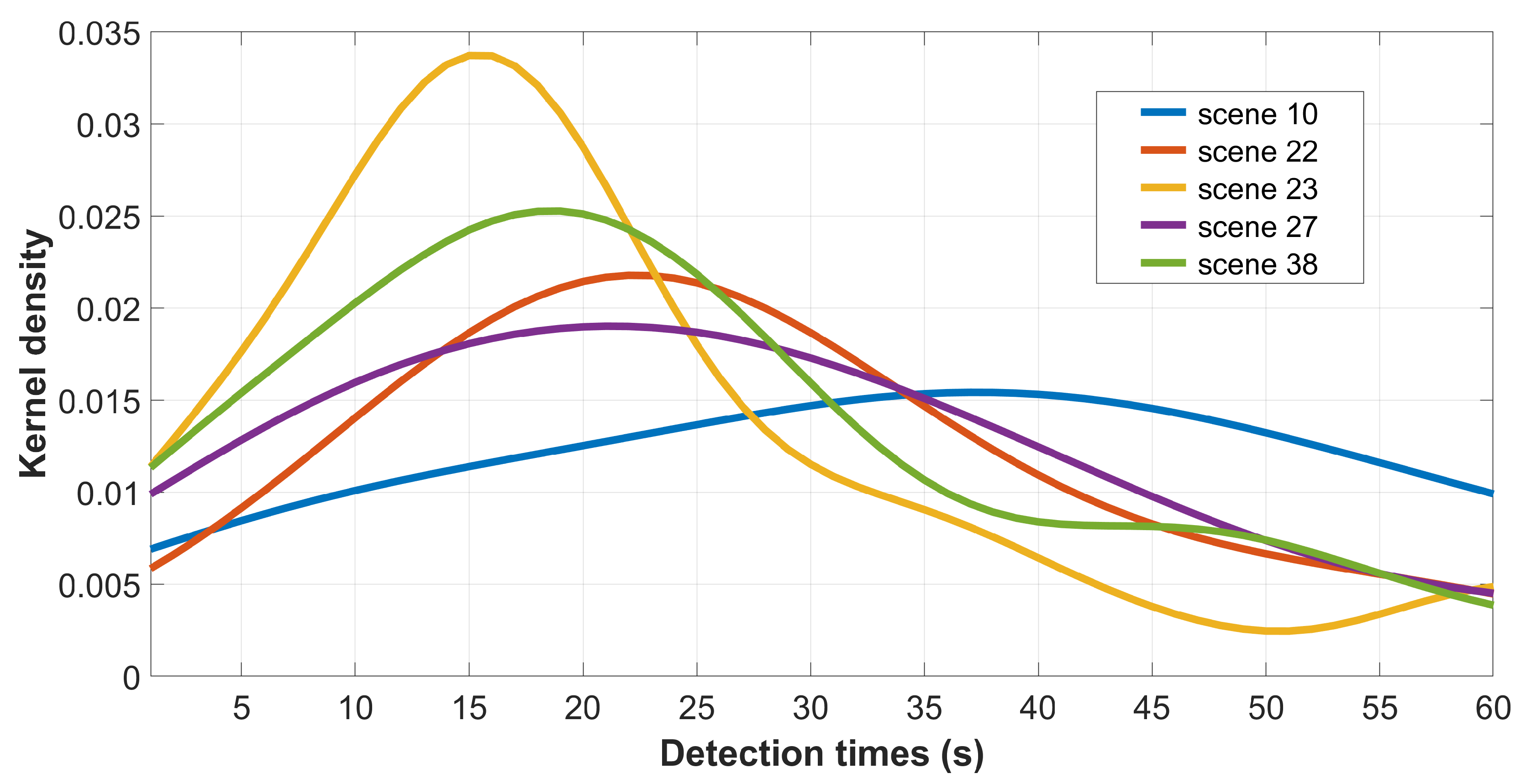
4.1. Observer Variability and Consistency
4.2. Proposed Model
- Change Magnitude (),
- Salience Imbalance (),
- User Experience ().
5. Results
5.1. Regression
5.2. Classification
- a small and a large ,
- a large , large and small .
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Simons, D.J.; Levin, D.T. Change blindness. Trends Cogn. Sci. 1997, 1, 261–267. [Google Scholar] [CrossRef]
- Jensen, M.; Yao, R.; Street, W.; Simons, D. Change blindness and inattentional blindness. Wiley Interdiscip. Rev. Cognit. Sci. 2011, 2, 529–546. [Google Scholar] [CrossRef] [PubMed]
- Cohen, M.A.; Dennett, D.C.; Kanwisher, N. What is the Bandwidth of Perceptual Experience? Trends Cogn. Sci. 2016, 20, 324–335. [Google Scholar] [CrossRef] [PubMed]
- Loussouarn, A.; Gabriel, D.; Proust, J. Exploring the informational sources of metaperception: The case of Change Blindness Blindness. Conscious. Cogn. 2011, 20, 1489–1501. [Google Scholar] [CrossRef]
- Galpin, A.; Underwood, G.; Crundall, D. Change blindness in driving scenes. Transp. Res. Part F Traffic Psychol. Behav. 2009, 12, 179–185. [Google Scholar] [CrossRef]
- Hallett, C.; Lambert, A.; Regan, M.A. Cell phone conversing while driving in New Zealand: Prevalence, risk perception and legislation. Accid. Anal. Prev. 2011, 43, 862–869. [Google Scholar] [CrossRef]
- Liu, P.; Lyu, X.; Qiu, Y.; Hu, J.; Tong, J.; Li, Z. Identifying macrocognitive function failures from accident reports: A case study. In Advances in Human Factors in Energy: Oil, Gas, Nuclear and Electric Power Industries; Springer: Berlin/Heidelberg, Germany, 2017; pp. 29–40. [Google Scholar]
- Sciolino, E. Military in curb on civilian visits. New York Times, 2 February 2001. [Google Scholar]
- Davies, G.; Hine, S. Change blindness and eyewitness testimony. J. Psychol. 2007, 141, 423–434. [Google Scholar] [CrossRef]
- Cater, K.; Chalmers, A.; Dalton, C. Varying rendering fidelity by exploiting human change blindness. In Proceedings of the 1st International Conference on Computer Graphics and Interactive Techniques in Australasia and South East Asia, Melbourne, Australia, 11–14 February 2003; ACM: New York, NY, USA, 2003; pp. 39–46. [Google Scholar]
- Suma, E.A.; Clark, S.; Krum, D.; Finkelstein, S.; Bolas, M.; Warte, Z. Leveraging change blindness for redirection in virtual environments. In Proceedings of the Virtual Reality Conference (VR), Singapore, 19–23 March 2011; pp. 159–166. [Google Scholar]
- Le Moan, S.; Farup, I.; Blahová, J. Towards exploiting change blindness for image processing. J. Vis. Commun. Image Represent. 2018, 54, 31–38. [Google Scholar] [CrossRef]
- Wilson, A.D.; Williams, S. Autopager: Exploiting change blindness for gaze-assisted reading. In Proceedings of the 2018 ACM Symposium on Eye Tracking Research & Applications, Warsaw, Poland, 14–17 June 2018; ACM: New York, NY, USA, 2018; p. 46. [Google Scholar]
- Brock, M.; Quigley, A.; Kristensson, P.O. Change blindness in proximity-aware mobile interfaces. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; ACM: New York, NY, USA, 2018; p. 43. [Google Scholar]
- Zitnick, C.; Vedantam, R.; Parikh, D. Adopting abstract images for semantic scene understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 627–638. [Google Scholar] [CrossRef]
- James, W. The Principles of Psychology; Henry Holt and Company: New York, NY, USA, 1890; Volume 2. [Google Scholar]
- Alam, M.M.; Vilankar, K.P.; Field, D.J.; Chandler, D.M. Local masking in natural images: A database and analysis. J. Vis. 2014, 14, 22. [Google Scholar] [CrossRef]
- Lavoué, G.; Langer, M.; Peytavie, A.; Poulin, P. A Psychophysical Evaluation of Texture Compression Masking Effects. IEEE Trans. Vis. Comput. Graph. 2018, 25, 1336–1346. [Google Scholar] [CrossRef] [PubMed]
- Henderson, J.M.; Hollingworth, A. Global transsaccadic change blindness during scene perception. Psychol. Sci. 2003, 14, 493–497. [Google Scholar] [CrossRef] [PubMed]
- O’Regan, J.K.; Rensink, R.A.; Clark, J.J. Change-blindness as a result of ‘mudsplashes’. Nature 1999, 398, 34. [Google Scholar] [CrossRef] [PubMed]
- Yao, R.; Wood, K.; Simons, D.J. As if by Magic: An Abrupt Change in Motion Direction Induces Change Blindness. Psychol. Sci. 2019, 30, 436–443. [Google Scholar] [CrossRef]
- Simons, D.J.; Franconeri, S.L.; Reimer, R.L. Change blindness in the absence of a visual disruption. Perception 2000, 29, 1143–1154. [Google Scholar] [CrossRef]
- Simons, D.J.; Chabris, C.F. Gorillas in our midst: Sustained inattentional blindness for dynamic events. Perception 1999, 28, 1059–1074. [Google Scholar] [CrossRef]
- Tseng, P.; Hsu, T.Y.; Muggleton, N.G.; Tzeng, O.J.; Hung, D.L.; Juan, C.H. Posterior parietal cortex mediates encoding and maintenance processes in change blindness. Neuropsychologia 2010, 48, 1063–1070. [Google Scholar] [CrossRef]
- Kelly, D. Information capacity of a single retinal channel. IRE Trans. Inf. Theory 1962, 8, 221–226. [Google Scholar] [CrossRef]
- Koch, K.; McLean, J.; Segev, R.; Freed, M.A.; Berry II, M.J.; Balasubramanian, V.; Sterling, P. How much the eye tells the brain. Curr. Biol. 2006, 16, 1428–1434. [Google Scholar] [CrossRef]
- Sziklai, G. Some studies in the speed of visual perception. IRE Trans. Inf. Theory 1956, 2, 125–128. [Google Scholar] [CrossRef]
- Freeman, J.; Simoncelli, E.P. Metamers of the ventral stream. Nat. Neurosci. 2011, 14, 1195–1201. [Google Scholar] [CrossRef]
- Pessoa, L.; Ungerleider, L.G. Neural correlates of change detection and change blindness in a working memory task. Cereb. Cortex 2004, 14, 511–520. [Google Scholar] [CrossRef]
- Yamins, D.L.; Hong, H.; Cadieu, C.F.; Solomon, E.A.; Seibert, D.; DiCarlo, J.J. Performance-optimized hierarchical models predict neural responses in higher visual cortex. Proc. Natl. Acad. Sci. USA 2014, 111, 8619–8624. [Google Scholar] [CrossRef]
- Ma, L.Q.; Xu, K.; Wong, T.T.; Jiang, B.Y.; Hu, S.M. Change blindness images. IEEE Trans. Vis. Comput. Graph. 2013, 19, 1808–1819. [Google Scholar]
- Jin, J.H.; Shin, H.J.; Choi, J.J. SPOID: A system to produce spot-the-difference puzzle images with difficulty. Vis. Comput. 2013, 29, 481–489. [Google Scholar] [CrossRef]
- Hou, X.; Harel, J.; Koch, C. Image signature: Highlighting sparse salient regions. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 194–201. [Google Scholar]
- Verma, M.; McOwan, P.W. A semi-automated approach to balancing of bottom-up salience for predicting change detection performance. J. Vis. 2010, 10, 3. [Google Scholar] [CrossRef]
- Werner, S.; Thies, B. Is “change blindness” attenuated by domain-specific expertise? An expert-novices comparison of change detection in football images. Vis. Cogn. 2000, 7, 163–173. [Google Scholar] [CrossRef]
- Rizzo, M.; Sparks, J.; McEvoy, S.; Viamonte, S.; Kellison, I.; Vecera, S.P. Change blindness, aging, and cognition. J. Clin. Exp. Neuropsychol. 2009, 31, 245–256. [Google Scholar] [CrossRef]
- Masuda, T.; Nisbett, R.E. Culture and change blindness. Cogn. Sci. 2006, 30, 381–399. [Google Scholar] [CrossRef]
- Andermane, N.; Bosten, J.M.; Seth, A.K.; Ward, J. Individual differences in change blindness are predicted by the strength and stability of visual representations. Neurosci. Conscious. 2019, 2019, niy010. [Google Scholar] [CrossRef] [PubMed]
- Alvarez, G.A.; Cavanagh, P. The capacity of visual short-term memory is set both by visual information load and by number of objects. Psychol. Sci. 2004, 15, 106–111. [Google Scholar] [CrossRef] [PubMed]
- Zuiderbaan, W.; van Leeuwen, J.; Dumoulin, S.O. Change Blindness Is Influenced by Both Contrast Energy and Subjective Importance within Local Regions of the Image. Front. Psychol. 2017, 8, 1718. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Shen, Y.; Li, H. VSI: A Visual Saliency Induced Index for Perceptual Image Quality Assessment. IEEE Trans. Image Process. 2014, 23, 4270–4281. [Google Scholar] [CrossRef] [PubMed]
- Oliva, A.; Schyns, P.G. Diagnostic colors mediate scene recognition. Cogn. Psychol. 2000, 41, 176–210. [Google Scholar] [CrossRef] [PubMed]
- Goffaux, V.; Jacques, C.; Mouraux, A.; Oliva, A.; Schyns, P.; Rossion, B. Diagnostic colours contribute to the early stages of scene categorization: Behavioural and neurophysiological evidence. Vis. Cogn. 2005, 12, 878–892. [Google Scholar] [CrossRef]
- Nijboer, T.C.; Kanai, R.; de Haan, E.H.; van der Smagt, M.J. Recognising the forest, but not the trees: An effect of colour on scene perception and recognition. Conscious. Cogn. 2008, 17, 741–752. [Google Scholar] [CrossRef][Green Version]
- Castelhano, M.S.; Henderson, J.M. The influence of color on the perception of scene gist. J. Exp. Psychol. Hum. Percept. Perform. 2008, 34, 660. [Google Scholar] [CrossRef]
- Caplovitz, G.P.; Fendrich, R.; Hughes, H.C. Failures to see: Attentive blank stares revealed by change blindness. Conscious. Cogn. 2008, 17, 877–886. [Google Scholar] [CrossRef]
- PorubanovÁ, M. Change Blindness and Its Determinants. Ph.D. Thesis, Masarykova Univerzita, Fakulta Sociálních Studií, Brno, Czechia, 2013. [Google Scholar]
- Rosenholtz, R.; Li, Y.; Nakano, L. Measuring visual clutter. J. Vis. 2007, 7, 17. [Google Scholar] [CrossRef]
- Mack, M.; Oliva, A. Computational estimation of visual complexity. In Proceedings of the 12th Annual Object, Perception, Attention, and Memory Conference, Minneapolis, MN, USA, November 2004. [Google Scholar]
- Lissner, I.; Preiss, J.; Urban, P. Predicting Image Differences Based on Image-Difference Features. In Proceedings of the IS&T/SID, 19th Color and Imaging Conference, San Jose, CA, USA, 7–11 November 2011; pp. 23–28. [Google Scholar]
- Lissner, I.; Urban, P. Toward a unified color space for perception-based image processing. IEEE Trans. Image Process. 2012, 21, 1153–1168. [Google Scholar] [CrossRef] [PubMed]
- Le Moan, S. Can image quality features predict visual change blindness? In Proceedings of the 2017 International Conference on Image and Vision Computing New Zealand (IVCNZ), Christchurch, New Zealand, 4–6 December 2017; pp. 1–5. [Google Scholar]
- Le Meur, O.; Liu, Z. Saccadic model of eye movements for free-viewing condition. Vis. Res. 2015, 116, 152–164. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indiv () | Mode () | |||
|---|---|---|---|---|
| PLCC | SROCC | PLCC | SROCC | |
| Change magnitude | 0.28 | 0.30 | 0.37 | 0.45 |
| Salience imbalance (based on [33]) | −0.29 | −0.29 | −0.39 | −0.46 |
| User experience | 0.08 | 0.18 | 0.42 | 0.30 |
| Age | 0.19 | 0.18 | / | / |
| Subband entropy (global) | 0.12 | 0.13 | 0.15 | 0.19 |
| Subband entropy (local) | 0.16 | 0.20 | 0.21 | 0.21 |
| Edge density (global) | 0.08 | 0.08 | 0.13 | 0.12 |
| Edge density (local) | 0.10 | 0.12 | 0.14 | 0.15 |
| Indiv () | Mode () | |||||
|---|---|---|---|---|---|---|
| PLCC | SROCC | RMSE | PLCC | SROCC | RMSE | |
| Linear regression | 0.29 | 0.29 | 20.0 | 0.62 | 0.63 | 14.8 |
| SVR | 0.34 | 0.36 | 20.2 | 0.61 | 0.62 | 16.3 |
| NN | 0.36 | 0.35 | 19.3 | 0.55 | 0.57 | 15.6 |
| Tree | 0.40 | 0.37 | 19.0 | 0.45 | 0.41 | 17.7 |
| Ma et al. [31] | 0.11 | 0.09 | 35.2 | 0.39 | 0.39 | 22.5 |
| Training on NZ Data | Training on NO Data | |||||
|---|---|---|---|---|---|---|
| PLCC | SROCC | RMSE | PLCC | SROCC | RMSE | |
| Linear regression | 0.59 | 0.56 | 17.5 | 0.55 | 0.55 | 17.1 |
| NN | 0.61 | 0.60 | 15.8 | 0.59 | 0.58 | 16.2 |
| Ma et al. [31] | 0.04 | 0.13 | 39.2 | 0.29 | 0.34 | 24.5 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Le Moan, S.; Pedersen, M. A Three-Feature Model to Predict Colour Change Blindness. Vision 2019, 3, 61. https://doi.org/10.3390/vision3040061
Le Moan S, Pedersen M. A Three-Feature Model to Predict Colour Change Blindness. Vision. 2019; 3(4):61. https://doi.org/10.3390/vision3040061
Chicago/Turabian StyleLe Moan, Steven, and Marius Pedersen. 2019. "A Three-Feature Model to Predict Colour Change Blindness" Vision 3, no. 4: 61. https://doi.org/10.3390/vision3040061
APA StyleLe Moan, S., & Pedersen, M. (2019). A Three-Feature Model to Predict Colour Change Blindness. Vision, 3(4), 61. https://doi.org/10.3390/vision3040061