Meaning and Attentional Guidance in Scenes: A Review of the Meaning Map Approach


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
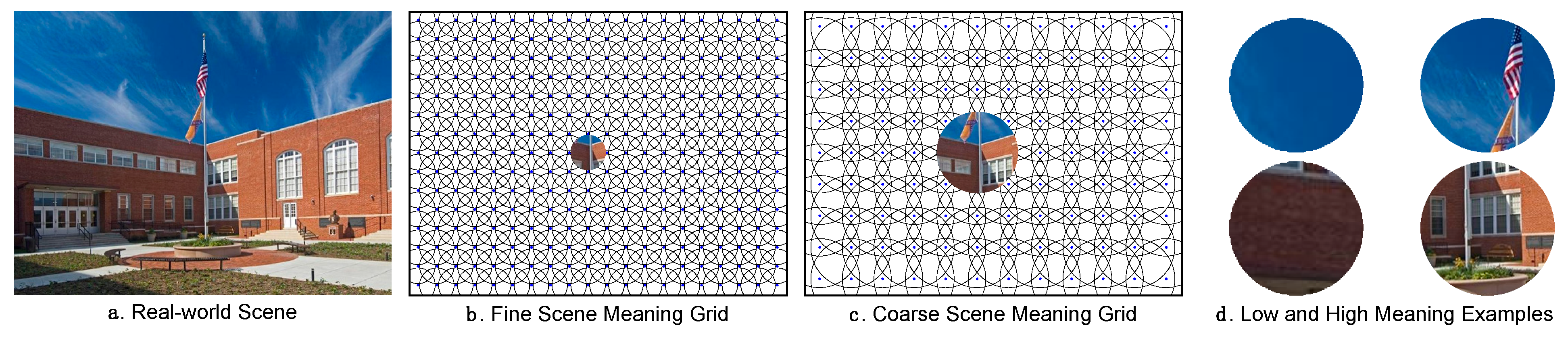
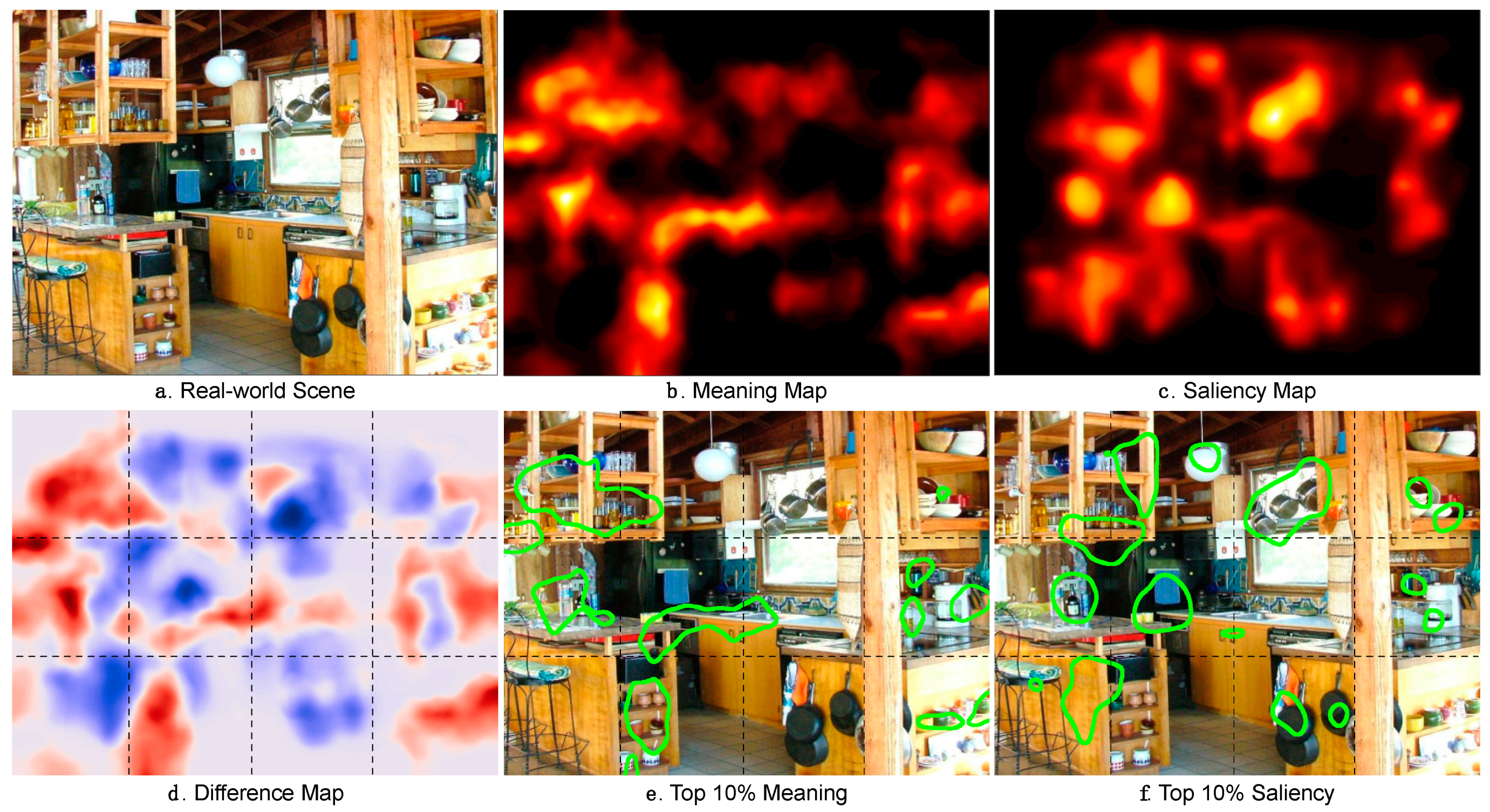
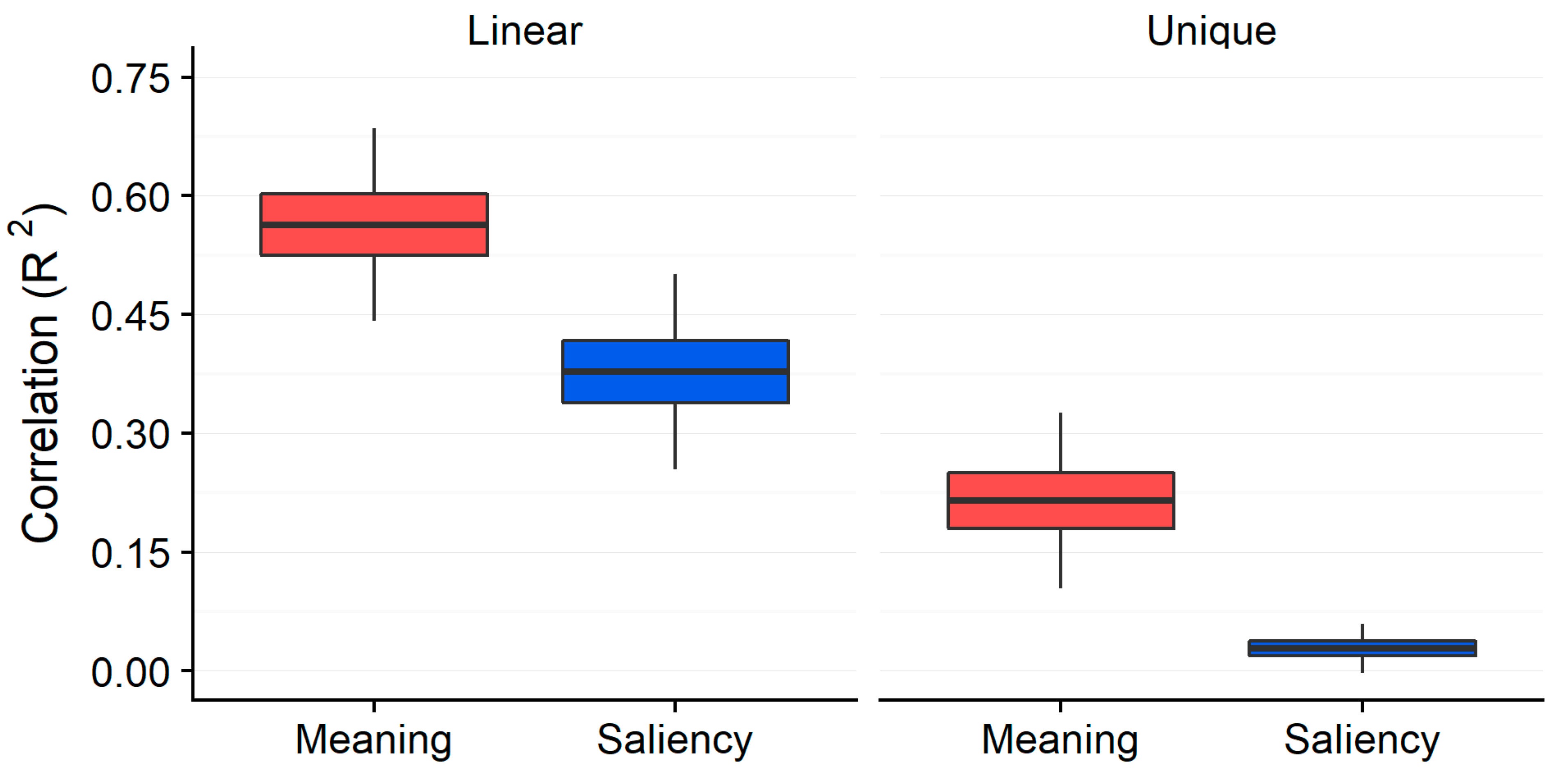
2. Review of Results
3. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Land, M.F.; Hayhoe, M.M. In what ways do eye movements contribute to everyday activities? Vis. Res. 2001, 41, 3559–3565. [Google Scholar] [CrossRef]
- Hayhoe, M.M.; Ballard, D. Eye movements in natural behavior. Trends Cogn. Sci. 2005, 9, 188–194. [Google Scholar] [CrossRef]
- Henderson, J.M. Human gaze control during real-world scene perception. Trends Cogn. Sci. 2003, 7, 498–504. [Google Scholar] [CrossRef] [PubMed]
- Henderson, J.M. Gaze Control as Prediction. Trends Cogn. Sci. 2017, 21, 15–23. [Google Scholar] [CrossRef]
- Buswell, G.T. How People Look at Pictures; University of Chicago Press: Chicago, IL, USA, 1935. [Google Scholar]
- Yarbus, A.L. Eye Movements and Vision; Plenum Press: New York, NY, USA, 1967; ISBN 0306302985. [Google Scholar]
- Henderson, J.M.; Hollingworth, A. High-level scene perception. Ann. Rev. Psychol. 1999, 50, 243–271. [Google Scholar] [CrossRef] [PubMed]
- Rayner, K. The 35th Sir Frederick Bartlett Lecture: Eye movements and attention in reading, scene perception, and visual search. Q. J. Exp. Psychol. 2009, 62, 1457–1506. [Google Scholar] [CrossRef]
- Liversedge, S.P.; Findlay, J.M. Saccadic eye movements and cognition. Trends Cogn. Sci. 2000, 4, 6–14. [Google Scholar] [CrossRef]
- Henderson, J.M. Regarding scenes. Curr. Dir. Psychol. Sci. 2007, 16, 219–222. [Google Scholar] [CrossRef]
- Henderson, J.M. Eye movements and scene perception. In The Oxford Handbook of Eye Movements; Liversedge, S.P., Gilchrist, I.D., Everling, S., Eds.; Oxford University Press: New York, NY, USA, 2011; pp. 593–606. [Google Scholar]
- Treisman, A.M.; Gelade, G. A Feature-Integration Theory of Attention. Cogn. Psychol. 1980, 12, 97–136. [Google Scholar] [CrossRef]
- Wolfe, J.M. Guided Search 2.0. A revised model of visual search. Psychon. Bull. Rev. 1994, 1, 202–238. [Google Scholar] [CrossRef] [PubMed]
- Wolfe, J.M.; Horowitz, T.S. Five factors that guide attention in visual search. Nat. Hum. Behav. 2017, 1, 1–8. [Google Scholar] [CrossRef]
- Borji, A.; Parks, D.; Itti, L. Complementary effects of gaze direction and early saliency in guiding fixations during free viewing. J. Vis. 2014, 14, 3. [Google Scholar] [CrossRef]
- Borji, A.; Sihite, D.N.; Itti, L. Quantitative analysis of human-model agreement in visual saliency modeling: A comparative study. IEEE Trans. Image Proc. 2013, 22, 55–69. [Google Scholar] [CrossRef]
- Harel, J.; Koch, C.; Perona, P. Graph-Based Visual Saliency. Adv. Neural Inf. Proc. Syst. 2006, 1–8. [Google Scholar]
- Itti, L.; Koch, C. Computational modelling of visual attention. Nat. Rev. Neurosci. 2001, 2, 194–203. [Google Scholar] [CrossRef]
- Koch, C.; Ullman, S. Shifts in Selective Visual Attention: Towards the Underlying Neural Circuitry. Hum. Neurobiol. 1985, 4, 219–227. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Parkhurst, D.; Law, K.; Niebur, E. Modeling the role of salience in the allocation of overt visual attention. Vis. Res. 2002, 42, 107–123. [Google Scholar] [CrossRef]
- Loftus, G.R.; Mackworth, N.H. Cognitive determinants of fixation location during picture viewing. J. Exp. Psychol. 1978, 4, 565–572. [Google Scholar] [CrossRef]
- Antes, J.R. The time course of picture viewing. J. Exp. Psychol. 1974, 103, 62–70. [Google Scholar] [CrossRef]
- Mackworth, N.H.; Morandi, A.J. The gaze selects informative details within pictures. Percept. Psychophy. 1967, 2, 547–552. [Google Scholar] [CrossRef]
- Wu, C.C.; Wick, F.A.; Pomplun, M. Guidance of visual attention by semantic information in real-world scenes. Front. Psychol. 2014, 5, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Tatler, B.W.; Hayhoe, M.M.; Land, M.F.; Ballard, D.H. Eye guidance in natural vision: Reinterpreting salience. J. Vis. 2011, 11, 5. [Google Scholar] [CrossRef] [PubMed]
- Rothkopf, C.A.; Ballard, D.H.; Hayhoe, M.M. Task and context determine where you look. J. Vis. 2007, 7, 16.1-20. [Google Scholar] [CrossRef] [PubMed]
- Hayhoe, M.M.; Ballard, D. Modeling Task Control of Eye Movements Minireview. Curr. Biol. 2014, 24, R622–R628. [Google Scholar] [CrossRef]
- Einhäuser, W.; Rutishauser, U.; Koch, C. Task-demands can immediately reverse the effects of sensory-driven saliency in complex visual stimuli. J. Vis. 2008, 8, 2.1-19. [Google Scholar] [CrossRef] [PubMed]
- Torralba, A.; Oliva, A.; Castelhano, M.S.; Henderson, J.M. Contextual guidance of eye movements and attention in real-world scenes: The role of global features in object search. Psychol. Rev. 2006, 113, 766–786. [Google Scholar] [CrossRef] [PubMed]
- Castelhano, M.S.; Mack, M.L.; Henderson, J.M. Viewing task influences eye movement control during active scene perception. J. Vis. 2009, 9, 6.1-15. [Google Scholar] [CrossRef] [PubMed]
- Neider, M.B.; Zelinsky, G. Scene context guides eye movements during visual search. Vis. Res. 2006, 46, 614–621. [Google Scholar] [CrossRef] [PubMed]
- Turano, K.A.; Geruschat, D.R.; Baker, F.H. Oculomotor strategies for the direction of gaze tested with a real-world activity. Vis. Res. 2003, 43, 333–346. [Google Scholar] [CrossRef]
- Foulsham, T.; Underwood, G. How does the purpose of inspection influence the potency of visual salience in scene perception? Perception 2007, 36, 1123–1138. [Google Scholar] [CrossRef]
- Henderson, J.M.; Brockmole, J.R.; Castelhano, M.S.; Mack, M. Visual saliency does not account for eye movements during visual search in real-world scenes. In Eye Movements: A Window on Mind and Brain; Van Gompel, R.P.G., Fischer, M.H., Murray, W.S., Hill, R.L., Eds.; Elsevier Ltd.: Oxford, UK, 2007; pp. 537–562. ISBN 9780080449807. [Google Scholar]
- Henderson, J.M.; Malcolm, G.L.; Schandl, C. Searching in the dark: Cognitive relevance drives attention in real-world scenes. Psychon. Bull. Rev. 2009, 16, 850–856. [Google Scholar] [CrossRef]
- Borji, A.; Itti, L. State-of-the-art in visual attention modeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 185–207. [Google Scholar] [CrossRef]
- De Graef, P.; Christiaens, D.; d’Ydewalle, G. Perceptual effects of scene context on object identification. Psychol. Res. 1990, 52, 317–329. [Google Scholar] [CrossRef]
- Henderson, J.M.; Weeks, P.A., Jr.; Hollingworth, A. The effects of semantic consistency on eye movements during complex scene viewing. J. Exp. Psychol. 1999, 25, 210–228. [Google Scholar] [CrossRef]
- Võ, M.L.H.; Henderson, J.M. Does gravity matter? Effects of semantic and syntactic inconsistencies on the allocation of attention during scene perception. J. Vis. 2009, 9, 1–15. [Google Scholar] [CrossRef]
- Brockmole, J.R.; Henderson, J.M. Prioritizing new objects for eye fixation in real-world scenes: Effects of object-scene consistency. Vis. Cogn. 2008, 16, 375–390. [Google Scholar] [CrossRef]
- Henderson, J.M.; Hayes, T.R. Meaning-based guidance of attention in scenes as revealed by meaning maps. Nat. Hum. Behav. 2017, 1, 743–747. [Google Scholar] [CrossRef]
- Henderson, J.M.; Pierce, G.L. Eye movements during scene viewing: Evidence for mixed control of fixation durations. Psychon. Bull. Rev. 2008, 15, 566–573. [Google Scholar] [CrossRef]
- Nuthmann, A.; Smith, T.J.; Engbert, R.; Henderson, J.M. CRISP: A computational model of fixation durations in scene viewing. Psychol. Rev. 2010, 117, 382–405. [Google Scholar] [CrossRef]
- Henderson, J.M.; Smith, T.J. How are eye fixation durations controlled during scene viewing? Further evidence from a scene onset delay paradigm. Vis. Cogn. 2009, 17, 1055–1082. [Google Scholar] [CrossRef]
- Glaholt, M.G.; Reingold, E.M. Direct control of fixation times in scene viewing: Evidence from analysis of the distribution of first fixation duration. Vis. Cogn. 2012, 20, 605–626. [Google Scholar] [CrossRef]
- Henderson, J.M.; Nuthmann, A.; Luke, S.G. Eye movement control during scene viewing: Immediate effects of scene luminance on fixation durations. J. Exp. Psychol. 2013, 39, 318–322. [Google Scholar] [CrossRef]
- Van Diepen, P.; Ruelens, L.; d’Ydewalle, G. Brief foveal masking during scene perception. Acta Psychol. 1999, 101, 91–103. [Google Scholar] [CrossRef]
- Luke, S.G.; Nuthmann, A.; Henderson, J.M. Eye movement control in scene viewing and reading: Evidence from the stimulus onset delay paradigm. J. Exp. Psychol. 2013, 39, 10–15. [Google Scholar] [CrossRef] [PubMed]
- Henderson, J.M.; Hayes, T.R. Meaning guides attention in real-world scene images : Evidence from eye movements and meaning maps. J. Vis. 2018, 18. [Google Scholar] [CrossRef] [PubMed]
- Henderson, J.M.; Hayes, T.R.; Rehrig, G.; Ferreira, F. Meaning Guides Attention during Real-World Scene Description. Sci. Rep. 2018, 8, 1–9. [Google Scholar] [CrossRef]
- Ferreira, F.; Swets, B. How incremental is language production? Evidence from the production of utterances requiring the computation of arithmetic sums. J. Mem. Lang. 2002, 46, 57–84. [Google Scholar] [CrossRef]
- Peacock, C.E.; Hayes, T.R.; Henderson, J.M. Meaning guides attention during scene viewing, even when it is irrelevant. Atten. Percept. Psychophy. 2019, 81, 20–34. [Google Scholar] [CrossRef]
- Huettig, F.; McQueen, J.M. The tug of war between phonological, semantic and shape information in language-mediated visual search. J. Mem. Lang. 2007, 57, 460–482. [Google Scholar] [CrossRef]
- Shomstein, S.; Malcolm, G.L.; Nah, J.C. Intrusive Effects of Task-Irrelevant Information on Visual Selective Attention: Semantics and Size. Curr. Opin. Psychol. 2019. [Google Scholar] [CrossRef] [PubMed]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. 2008 LabelMe. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Kummerer, M.; Wallis, T.S.A.; Gatys, L.A.; Bethge, M. Understanding Low- and High-Level Contributions to Fixation Prediction. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy,, 22–29 October 2007; pp. 4799–4808. [Google Scholar]




© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Henderson, J.M.; Hayes, T.R.; Peacock, C.E.; Rehrig, G. Meaning and Attentional Guidance in Scenes: A Review of the Meaning Map Approach. Vision 2019, 3, 19. https://doi.org/10.3390/vision3020019
Henderson JM, Hayes TR, Peacock CE, Rehrig G. Meaning and Attentional Guidance in Scenes: A Review of the Meaning Map Approach. Vision. 2019; 3(2):19. https://doi.org/10.3390/vision3020019
Chicago/Turabian StyleHenderson, John M., Taylor R. Hayes, Candace E. Peacock, and Gwendolyn Rehrig. 2019. "Meaning and Attentional Guidance in Scenes: A Review of the Meaning Map Approach" Vision 3, no. 2: 19. https://doi.org/10.3390/vision3020019
APA StyleHenderson, J. M., Hayes, T. R., Peacock, C. E., & Rehrig, G. (2019). Meaning and Attentional Guidance in Scenes: A Review of the Meaning Map Approach. Vision, 3(2), 19. https://doi.org/10.3390/vision3020019