Non-Intrusive Load Monitoring of Residential Water-Heating Circuit Using Ensemble Machine Learning Techniques




Abstract
1. Introduction
1.1. Motivation
1.2. Literature Review
1.3. Contributions
- To realize the real-world implementation, the proposed approach is,
- Thoroughly evaluated on real-world load measurements acquired at low data granularity of 1/60 Hz, i.e., 1-min interval measurements;
- Based on only a single input variable, i.e., mean power (in Watts).
- Event Detection: As an extension of our previously proposed event detection algorithm [41], a post-processing criterion is incorporated to further improve the event detection performance. The extracted results are validated using an extensive sensitivity analysis.
- Load Features: Four distinct load features are extracted for each detected event and further analyzed using correlation-based feature selection methodology to identify the most significant load features.
- Classification: To facilitate the classification performance, this research work introduces two diverse ensemble learning techniques, based on a combination of machine learning and artificial neural network models, in the context of the NILM domain and comprehensive performance evaluation and comparative analysis are presented.
- A brief outlook in the context of real-world applications of the proposed approach is presented.
2. System Formulation
2.1. Problem Statement
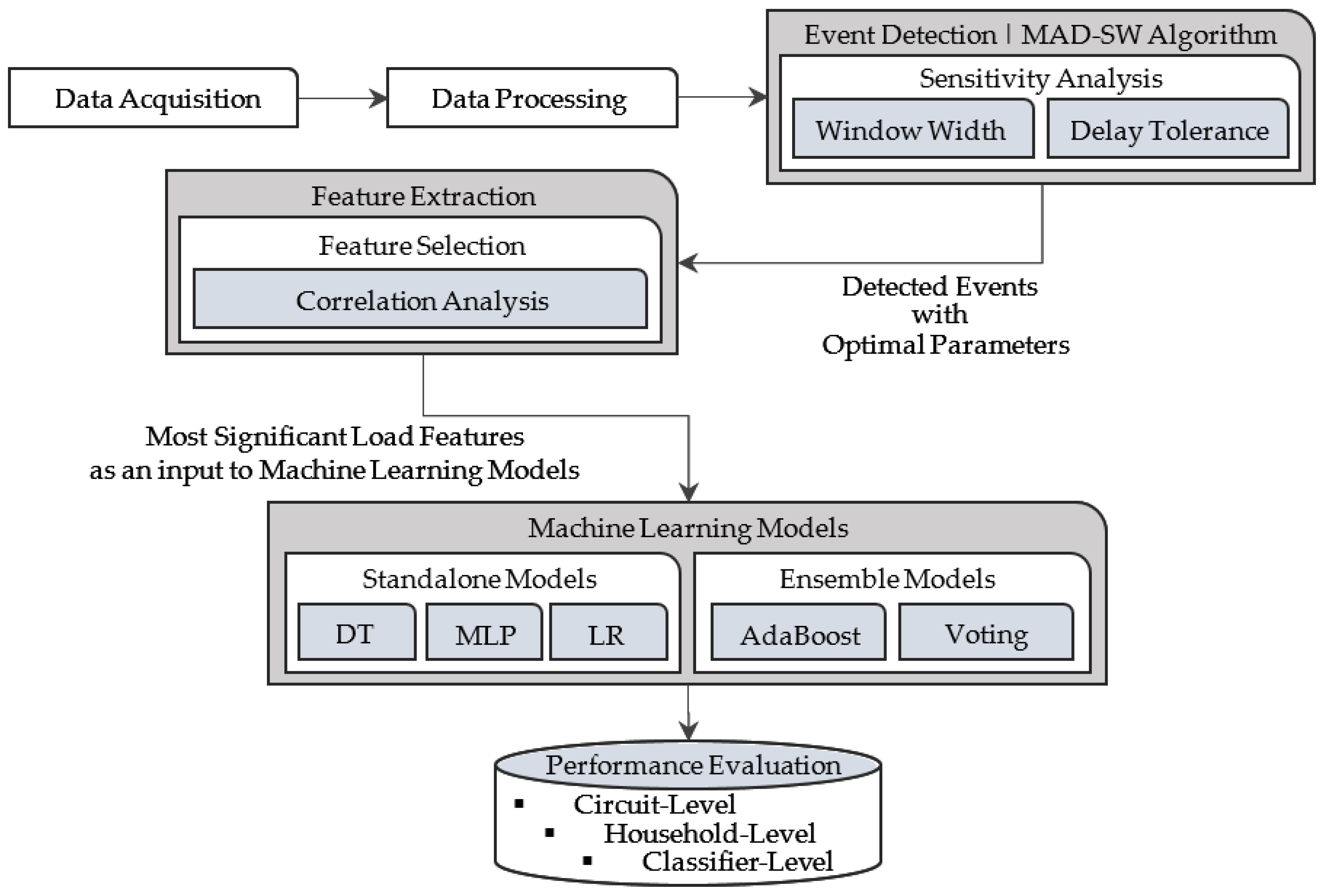
2.2. Methodology
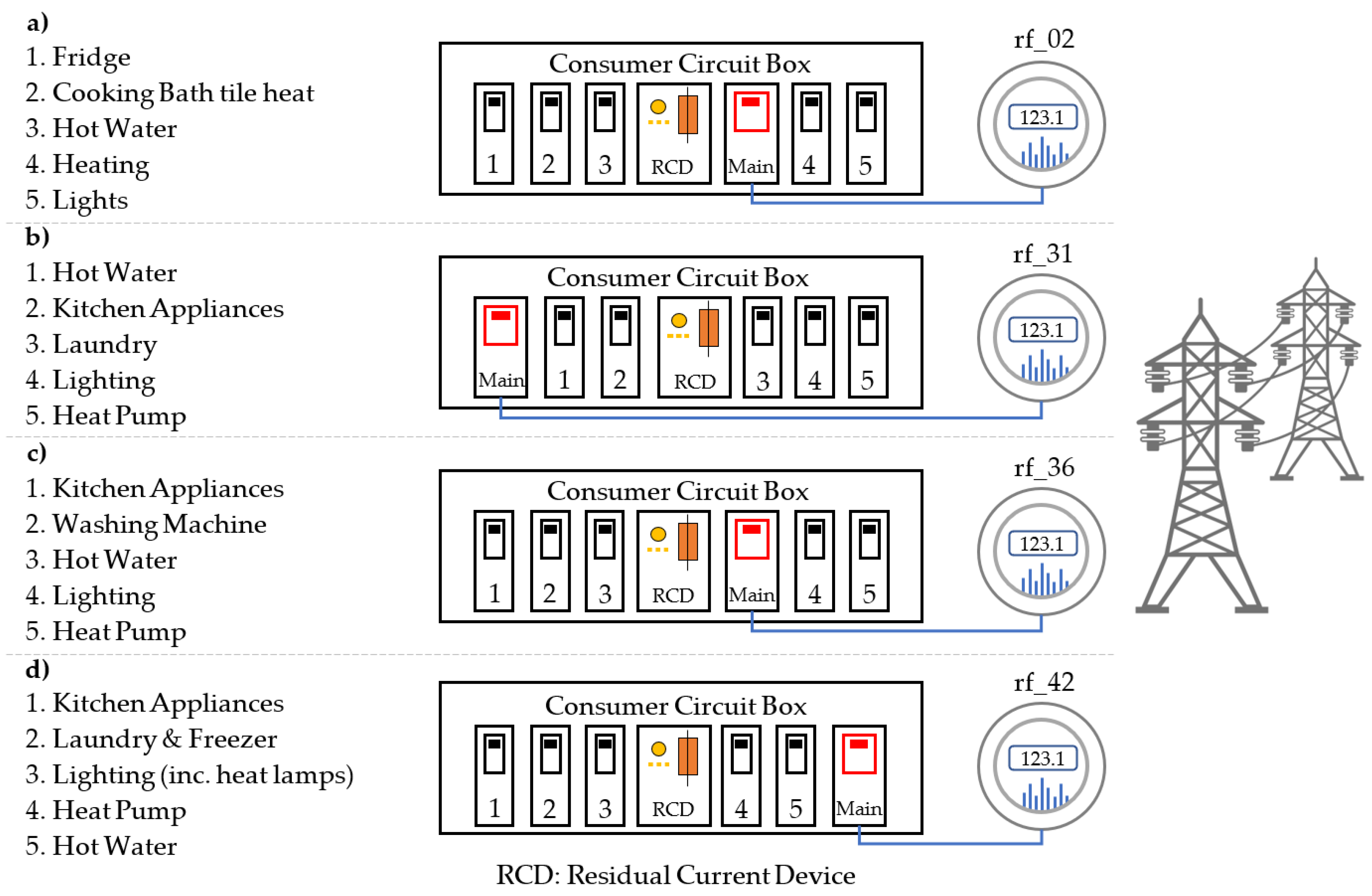
2.2.1. Data Acquisition and Preprocessing
2.2.2. Event Detection
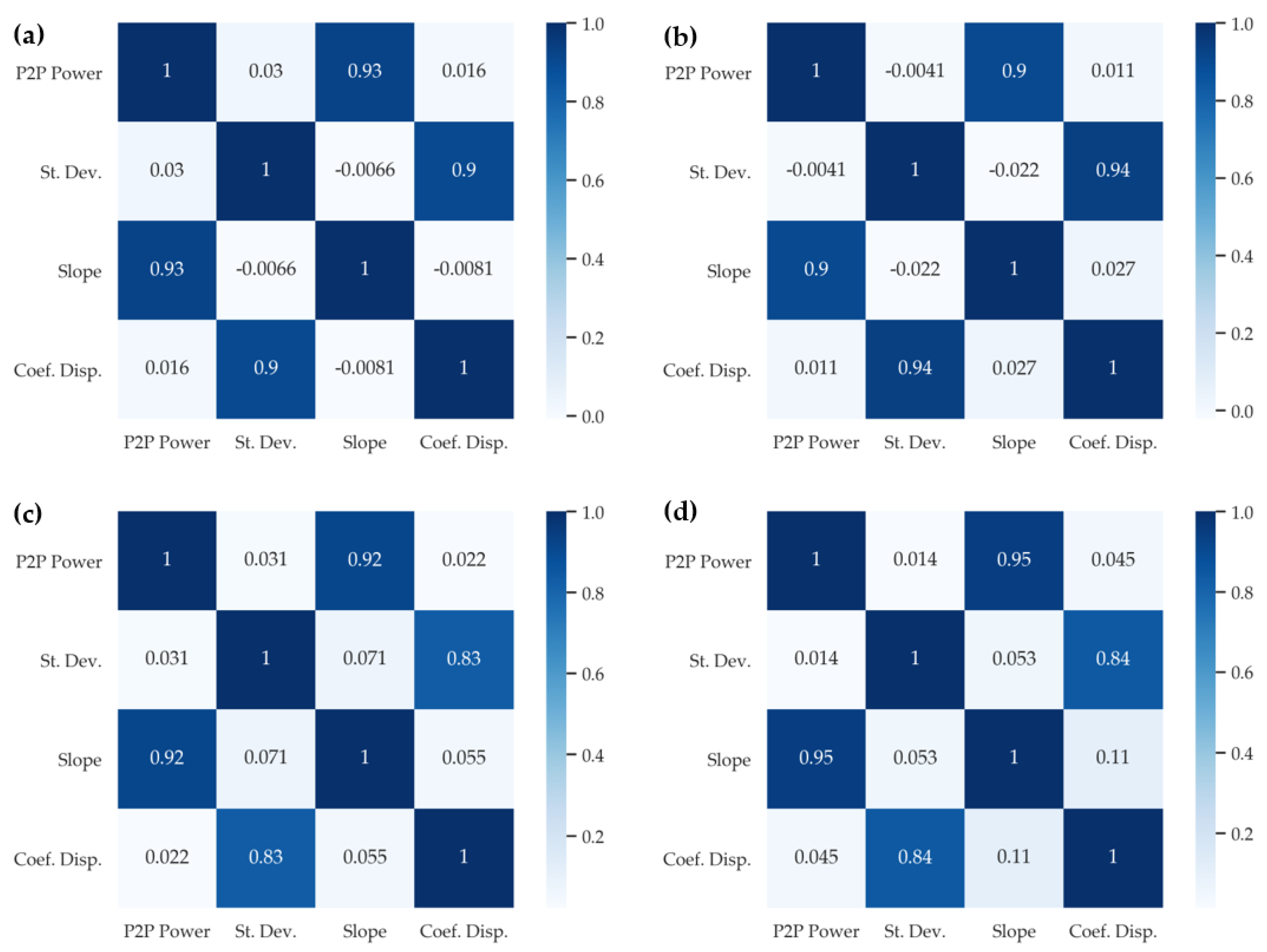
2.2.3. Feature Extraction and Selection
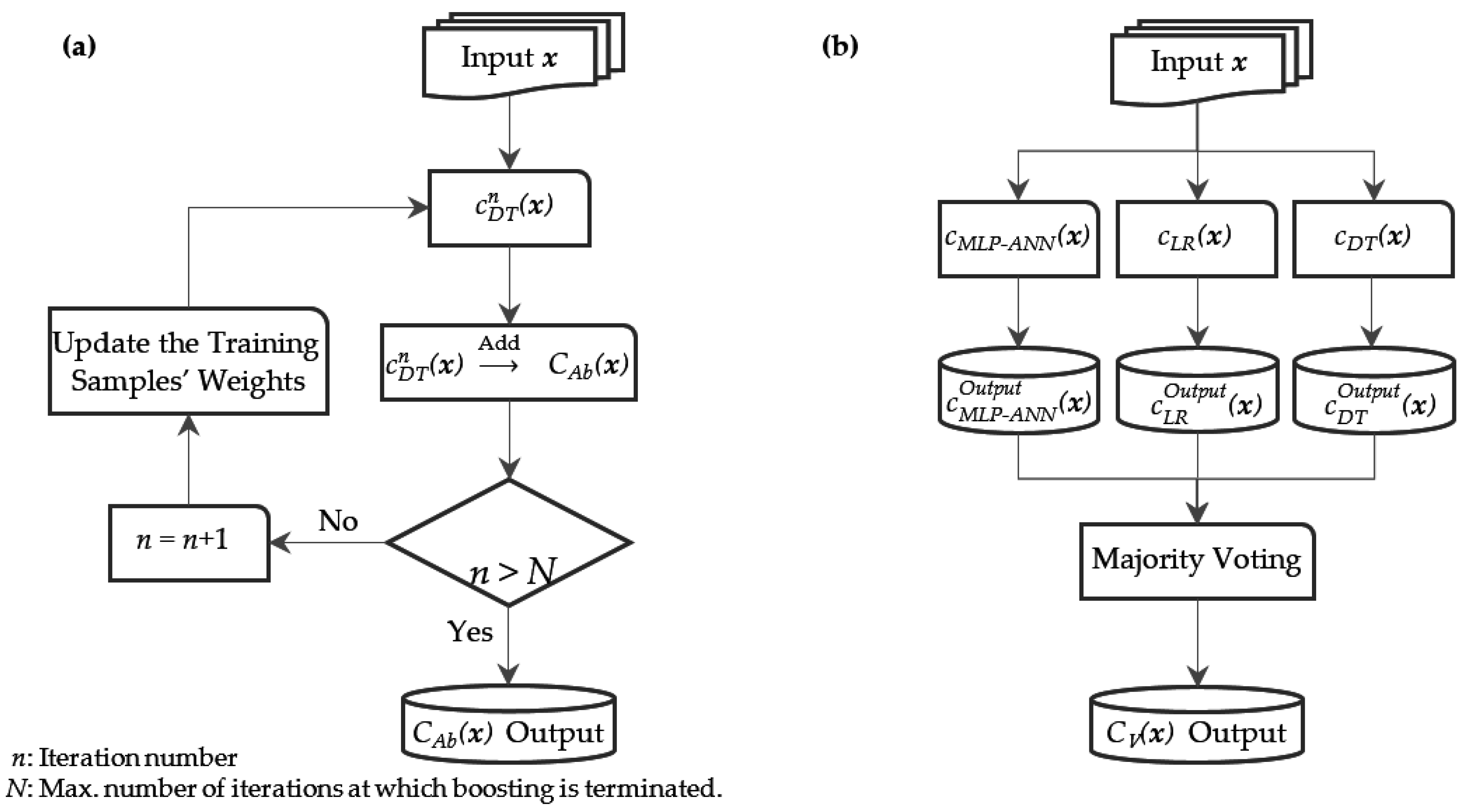
2.2.4. Classification
2.3. Performance Evaluation
3. Simulations and Results
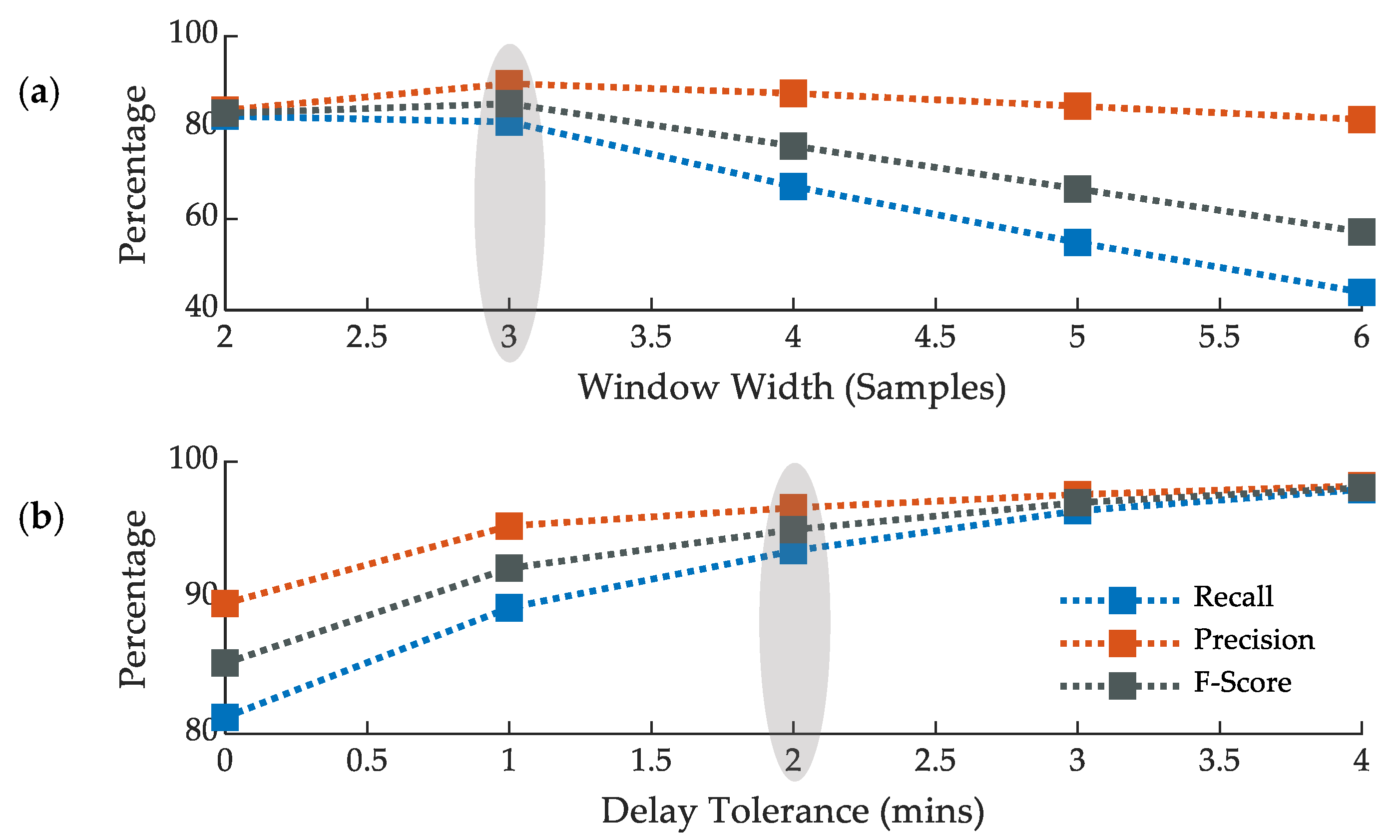
3.1. Event Detection Results
3.2. Feature Extraction and Selection Results
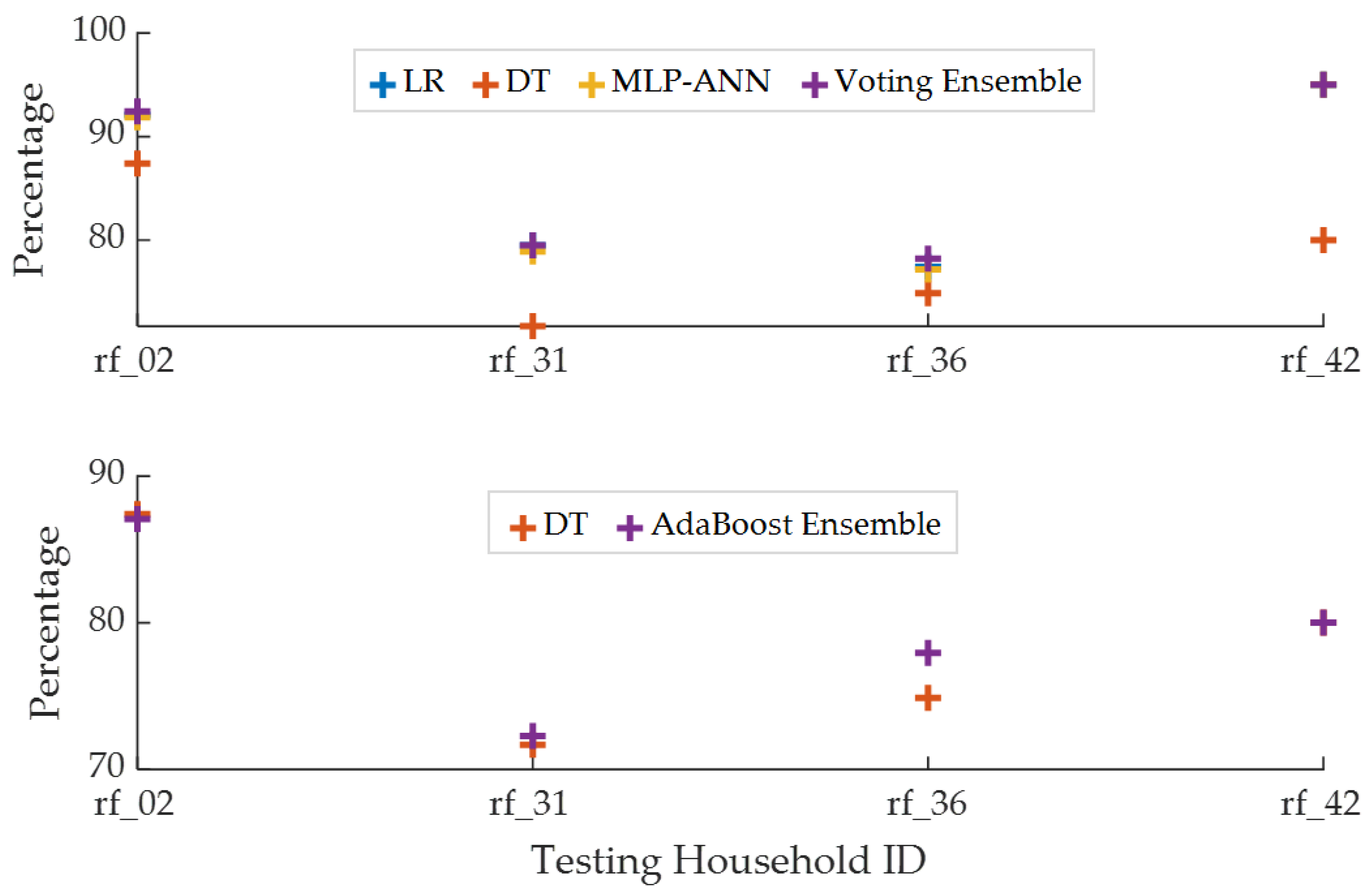
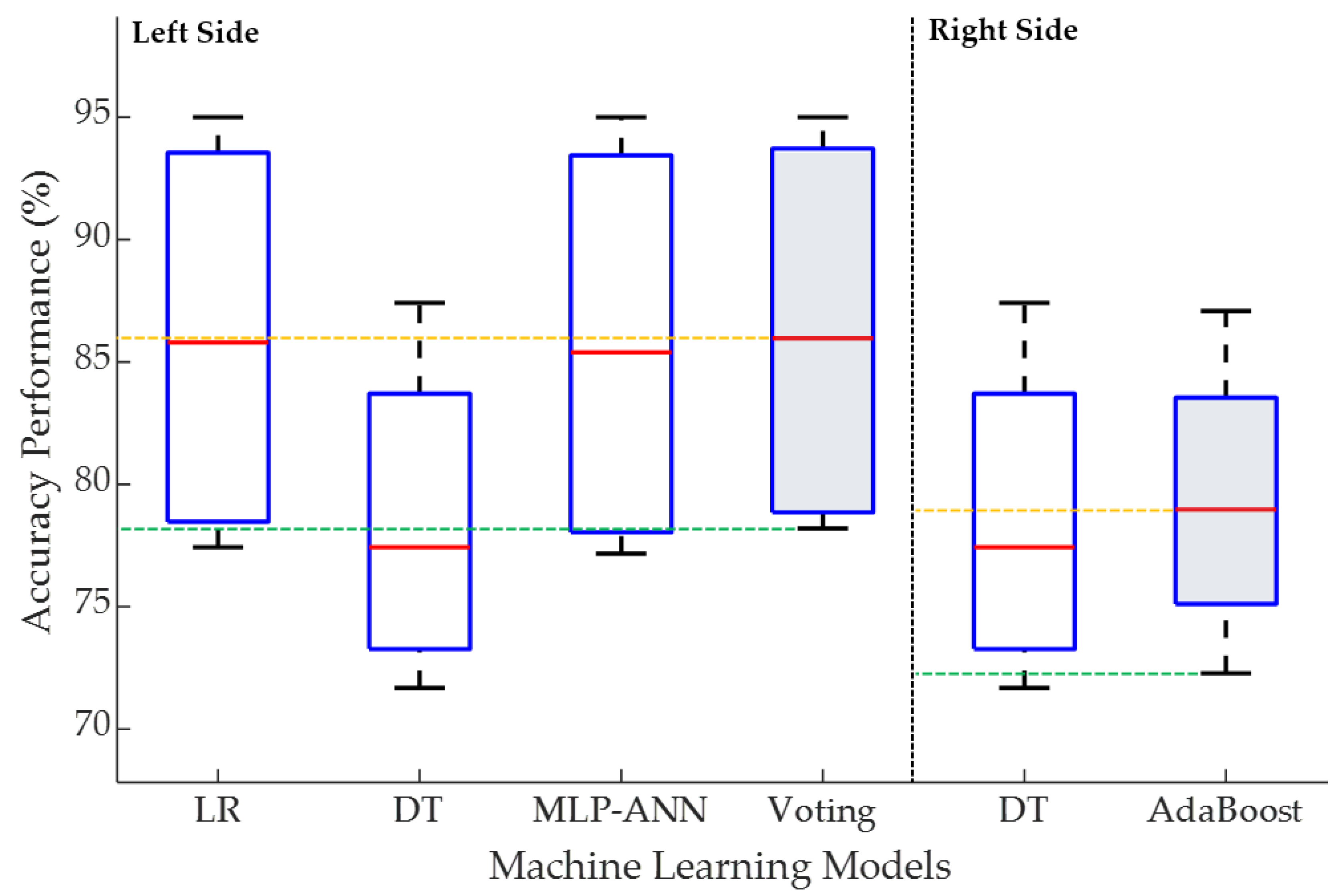
3.3. Classification Results
4. Outlook
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mohassel, R.R.; Fung, A.; Mohammadi, F.; Raahemifar, K. A survey on advanced metering infrastructure. Int. J. Electr. Power Energy Syst. 2014, 63, 473–484. [Google Scholar] [CrossRef]
- Egarter, D.; Bhuvana, V.P.; Elmenreich, W. PALDi: Online Load Disaggregation via Particle Filtering. IEEE Trans. Instrum. Meas. 2015, 64, 467–477. [Google Scholar] [CrossRef]
- Chang, H.; Lin, L.; Chen, N.; Lee, W. Particle-Swarm-Optimization-Based Nonintrusive Demand Monitoring and Load Identification in Smart Meters. IEEE Trans. Ind. Appl. 2013, 49, 2229–2236. [Google Scholar] [CrossRef]
- Zoha, A.; Gluhak, A.; Imran, M.A.; Rajasegarar, S. Non-intrusive load monitoring approaches for disaggregated energy sensing: A survey. Sensors 2012, 12, 16838–16866. [Google Scholar] [CrossRef] [PubMed]
- Amenta, V.; Tina, G.M. Load Demand Disaggregation based on Simple Load Signature and User’s Feedback. Energy Procedia 2015, 83, 380–388. [Google Scholar] [CrossRef]
- Carrie Armel, K.; Gupta, A.; Shrimali, G.; Albert, A. Is disaggregation the holy grail of energy efficiency? The case of electricity. Energy Policy 2013, 52, 213–234. [Google Scholar] [CrossRef]
- Ehrhardt-Martinez, K.; Donnelly, K.A.; Laitner, S. Advanced Metering Initiatives and Residential Feedback Programs: A Meta-Review for Household Electricity-Saving Opportunities; American Council for an Energy-Efficient Economy: Washington, DC, USA, 2010. [Google Scholar]
- Ebrahim, A.F.; Mohammed, O.A. Pre-processing of energy demand disaggregation based data mining techniques for household load demand forecasting. Inventions 2018, 3, 45. [Google Scholar] [CrossRef]
- Liao, J.; Elafoudi, G.; Stankovic, L.; Stankovic, V. Power disaggregation for low-sampling rate data. In Proceedings of the 2nd International Non-intrusive Appliance Load Monitoring Workshop, Austin, TX, USA, 3 June 2014. [Google Scholar]
- Shaw, S.R.; Leeb, S.B.; Norford, L.K.; Cox, R.W. Nonintrusive load monitoring and diagnostics in power systems. IEEE Trans. Instrum. Meas. 2008, 57, 1445–1454. [Google Scholar] [CrossRef]
- Lin, Y.H.; Tsai, M.S. An Advanced Home Energy Management System Facilitated by Nonintrusive Load Monitoring With Automated Multiobjective Power Scheduling. IEEE Trans. Smart Grid 2015, 6, 1839–1851. [Google Scholar] [CrossRef]
- Wang, H.; Yang, W.; Chen, T.; Yang, Q. An optimal load disaggregation method based on power consumption pattern for low sampling data. Sustainability 2019, 11, 251. [Google Scholar] [CrossRef]
- Kwak, Y.; Hwang, J.; Lee, T. Load disaggregation via pattern recognition: A feasibility study of a novel method in residential building. Energies 2018, 11, 1008. [Google Scholar] [CrossRef]
- Wong, Y.F.; Şekercioğlu, Y.A.; Drummond, T.; Wong, V.S. Recent approaches to non-intrusive load monitoring techniques in residential settings. In Proceedings of the 2013 IEEE Computational Intelligence Applications in Smart Grid (CIASG), Singapore, 16–19 April 2013; pp. 73–79. [Google Scholar]
- Hernández, Á.; Ruano, A.; Ureña, J.; Ruano, M.; Garcia, J. Applications of NILM Techniques to Energy Management and Assisted Living. IFAC-PapersOnLine 2019, 52, 164–171. [Google Scholar]
- Ruano, A.; Hernandez, A.; Ureña, J.; Ruano, M.; Garcia, J. NILM Techniques for intelligent home energy management and ambient assisted living: A review. Energies 2019, 12, 2203. [Google Scholar] [CrossRef]
- Zhuang, M.; Shahidehpour, M.; Li, Z. An Overview of Non-Intrusive Load Monitoring: Approaches, Business Applications, and Challenges. In Proceedings of the 2018 International Conference on Power System Technology (POWERCON), Guangzhou, China, 6–8 November 2018; pp. 4291–4299. [Google Scholar]
- Kolter, J.Z.; Johnson, M.J. REDD: A public data set for energy disaggregation research. In Proceedings of the Workshop on Data Mining Applications in Sustainability (SIGKDD), San Diego, CA, USA, 21 August 2011; pp. 59–62. [Google Scholar]
- Anderson, K.; Ocneanu, A.; Benitez, D.; Carlson, D.; Rowe, A.; Berges, M. BLUED: A fully labeled public dataset for event-based non-intrusive load monitoring research. In Proceedings of the 2nd KDD Workshop on Data Mining Applications in Sustainability (SustKDD), Beijing, China, 12–16 August 2012; pp. 1–5. [Google Scholar]
- Kelly, J.; Knottenbelt, W. The UK-DALE dataset, domestic appliance-level electricity demand and whole-house demand from five UK homes. Sci. Data 2015, 2, 150007. [Google Scholar] [CrossRef] [PubMed]
- Anderson, B.; Eyers, D.; Ford, R.; Ocampo, D.G.; Peniamina, R.; Stephenson, J.; Suomalainen, K.; Wilcocks, L.; Jack, M. New Zealand GREEN Grid Household Electricity Demand Study 2014–2018; UK Data Service: Colchester, UK, 2018. [Google Scholar]
- “Pecan Street Inc. Dataport 2020”, United States of America. Available online: https://www.pecanstreet.org/dataport/ (accessed on 23 November 2020).
- Basu, K.; Debusschere, V.; Bacha, S.; Maulik, U.; Bondyopadhyay, S. Nonintrusive Load Monitoring: A Temporal Multilabel Classification Approach. IEEE Trans. Ind. Inform. 2015, 11, 262–270. [Google Scholar] [CrossRef]
- Guillén-García, E.; Morales-Velazquez, L.; Zorita-Lamadrid, A.L.; Duque-Perez, O.; Osornio-Rios, R.A.; de Jesús Romero-Troncoso, R. Identification of the electrical load by C-means from non-intrusive monitoring of electrical signals in non-residential buildings. Int. J. Electr. Power Energy Syst. 2019, 104, 21–28. [Google Scholar] [CrossRef]
- De Baets, L.; Develder, C.; Dhaene, T.; Deschrijver, D. Detection of unidentified appliances in non-intrusive load monitoring using siamese neural networks. Int. J. Electr. Power Energy Syst. 2019, 104, 645–653. [Google Scholar] [CrossRef]
- Gupta, S.; Reynolds, M.S.; Patel, S.N. ElectriSense: Single-point sensing using EMI for electrical event detection and classification in the home. In Proceedings of the 12th ACM International Conference on Ubiquitous Computing, Copenhagen, Denmark, 26–29 September 2010; pp. 139–148. [Google Scholar]
- Chang, H.-H. Non-intrusive demand monitoring and load identification for energy management systems based on transient feature analyses. Energies 2012, 5, 4569–4589. [Google Scholar] [CrossRef]
- Wang, H.; Yang, W. An iterative load disaggregation approach based on appliance consumption pattern. Appl. Sci. 2018, 8, 542. [Google Scholar] [CrossRef]
- Basu, K.; Debusschere, V.; Douzal-Chouakria, A.; Bacha, S. Time series distance-based methods for non-intrusive load monitoring in residential buildings. Energy Build. 2015, 96, 109–117. [Google Scholar] [CrossRef]
- Elafoudi, G.; Stankovic, L.; Stankovic, V. Power disaggregation of domestic smart meter readings using dynamic time warping. In Proceedings of the 2014 6th International Symposium on Communications, Control and Signal Processing (ISCCSP), Athens, Greece, 21–23 May 2014; pp. 36–39. [Google Scholar]
- Egarter, D.; Elmenreich, W. Load disaggregation with metaheuristic optimization. In Proceedings of the 2015 Energieinformatik Conference, Karlsruhe, Germany, 12–13 November 2015; pp. 1–12. [Google Scholar]
- Rehman, A.U.; Lie, T.T.; Vallès, B.; Tito, S.R. Low Complexity Non-Intrusive Load Disaggregation of Air Conditioning Unit and Electric Vehicle Charging. In Proceedings of the 2019 IEEE Innovative Smart Grid Technologies—Asia (ISGT Asia), Chengdu, China, 21–24 May 2019; pp. 2607–2612. [Google Scholar]
- Su, S.; Yan, Y.; Lu, H.; Kangping, L.; Yujing, S.; Fei, W.; Liming, L.; Hui, R. Non-intrusive load monitoring of air conditioning using low-resolution smart meter data. In Proceedings of the 2016 IEEE International Conference on Power System Technology (POWERCON), Wollongong, Australia, 28 September–1 October 2016; pp. 1–5. [Google Scholar]
- Wu, X.; Gao, Y.; Jiao, D. Multi-label classification based on random forest algorithm for non-intrusive load monitoring system. Processes 2019, 7, 337. [Google Scholar] [CrossRef]
- Aiad, M.; Lee, P.H. Unsupervised approach for load disaggregation with devices interactions. Energy Build. 2016, 116, 96–103. [Google Scholar] [CrossRef]
- Yang, C.C.; Soh, C.S.; Yap, V.V. A non-intrusive appliance load monitoring for efficient energy consumption based on Naive Bayes classifier. Sustain. Comput. Inform. Syst. 2017, 14, 34–42. [Google Scholar] [CrossRef]
- Chang, H.; Lian, K.; Su, Y.; Lee, W. Power-Spectrum-Based Wavelet Transform for Nonintrusive Demand Monitoring and Load Identification. IEEE Trans. Ind. Appl. 2014, 50, 2081–2089. [Google Scholar] [CrossRef]
- Cho, J.; Hu, Z.; Sartipi, M. Non-Intrusive A/C Load Disaggregation Using Deep Learning. In Proceedings of the 2018 IEEE/PES Transmission and Distribution Conference and Exposition (T&D), Denver, CO, USA, 16–19 April 2018; pp. 1–5. [Google Scholar]
- Kong, W.; Dong, Z.Y.; Wang, B.; Zhao, J.; Huang, J. A practical solution for non-intrusive type II load monitoring based on deep learning and post-processing. IEEE Trans. Smart Grid 2019, 11, 148–160. [Google Scholar] [CrossRef]
- Azaza, M.; Wallin, F. Evaluation of classification methodologies and Features selection from smart meter data. Energy Procedia 2017, 142, 2250–2256. [Google Scholar] [CrossRef]
- Rehman, A.U.; Lie, T.T.; Vallès, B.; Tito, S.R. Event-Detection Algorithms for Low Sampling Nonintrusive Load Monitoring Systems Based on Low Complexity Statistical Features. IEEE Trans. Instrum. Meas. 2020, 69, 751–759. [Google Scholar] [CrossRef]
- Electricity in New Zealand; Electricity Authority New Zealand: Wellington, New Zealand, November 2018.
- Yang, Y.; Zengqiang, M.; Zheng, X.; Chang, D. Accommodation of curtailed wind power by electric water heaters based on a new hybrid prediction approach. J. Mod. Power Syst. Clean Energy 2019, 7, 525–537. [Google Scholar]
- Wu, M.; Bao, Y.-Q.; Zhang, J.; Ji, T. Multi-objective optimization for electric water heater using mixed integer linear programming. J. Mod. Power Syst. Clean Energy 2019, 7, 1256–1266. [Google Scholar] [CrossRef]
- Haider, Z.M.; Mehmood, K.K.; Rafique, M.K.; Khan, S.U.; Soon-Jeong, L.; Chul-Hwan, K. Water-filling algorithm based approach for management of responsive residential loads. J. Mod. Power Syst. Clean Energy 2018, 6, 118–131. [Google Scholar] [CrossRef]
- Pipattanasomporn, M.; Kuzlu, M.; Rahman, S.; Teklu, Y. Load profiles of selected major household appliances and their demand response opportunities. IEEE Trans. Smart Grid 2013, 5, 742–750. [Google Scholar] [CrossRef]
- Clarke, T.; Slay, T.; Eustis, C.; Bass, R.B. Aggregation of Residential Water Heaters for Peak Shifting and Frequency Response Services. IEEE Open Access J. Power Energy 2019, 7, 22–30. [Google Scholar] [CrossRef]
- Liu, M.; Yong, J.; Wang, X.; Lu, J. A new event detection technique for residential load monitoring. In Proceedings of the 2018 18th International Conference on Harmonics and Quality of Power (ICHQP), Ljubljana, Slovenia, 13–16 May 2018; pp. 1–6. [Google Scholar]
- Wild, B.; Barsim, K.S.; Yang, B. A new unsupervised event detector for non-intrusive load monitoring. In Proceedings of the 2015 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Orlando, FL, USA, 14–16 December 2015; pp. 73–77. [Google Scholar]
- Anderson, K.D.; Bergés, M.E.; Ocneanu, A.; Benitez, D.; Moura, J.M. Event detection for non intrusive load monitoring. In Proceedings of the IECON 2012-38th Annual Conference on IEEE Industrial Electronics Society, Montreal, QC, Canada, 25–28 October 2012; pp. 3312–3317. [Google Scholar]
- Kotsiantis, S.B. Supervised Machine Learning: A Review of Classification Techniques. Emerg. Artif. Intell. Appl. Comput. Eng. 2007, 160, 3–24. [Google Scholar]
- Polikar, R. Ensemble based systems in decision making. IEEE Circuits Syst. Mag. 2006, 6, 21–45. [Google Scholar] [CrossRef]
- Leon, F.; Floria, S.-A.; Bădică, C. Evaluating the effect of voting methods on ensemble-based classification. In Proceedings of the 2017 IEEE International Conference on INnovations in Intelligent SysTems and Applications (INISTA), Gdynia, Poland, 3–5 July 2017; pp. 1–6. [Google Scholar]
- An, T.-K.; Kim, M.-H. A new diverse AdaBoost classifier. In Proceedings of the 2010 International Conference on Artificial Intelligence and Computational Intelligence, Sanya, China, 23–24 October 2010; pp. 359–363. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Kleinbaum, D.G.; Dietz, K.; Gail, M.; Klein, M.; Klein, M. Logistic Regression; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Asres, M.W.; Girmay, A.A.; Camarda, C.; Tesfamariam, G.T. Non-intrusive load composition estimation from aggregate ZIP load models using machine learning. Int. J. Electr. Power Energy Syst. 2019, 105, 191–200. [Google Scholar] [CrossRef]
- Faustine, A.; Mvungi, N.H.; Kaijage, S.; Michael, K. A Survey on Non-Intrusive Load Monitoring Methodies and Techniques for Energy Disaggregation Problem. arXiv 2017, arXiv:1703.00785. [Google Scholar]
- Alcala, J.; Urena, J.; Hernandez, A.; Gualda, D. Event-Based Energy Disaggregation Algorithm for Activity Monitoring From a Single-Point Sensor. IEEE Trans. Instrum. Meas. 2017, 66, 2615–2626. [Google Scholar] [CrossRef]
- Meziane, M.N.; Ravier, P.; Lamarque, G.; Le Bunetel, J.-C.; Raingeaud, Y. High accuracy event detection for Non-Intrusive Load Monitoring. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2452–2456. [Google Scholar]
- Anderson, B.; Eyers, D.; Ford, R.; Ocampo, D.G.; Peniamina, R.; Stephenson, J.; Suomalainen, K.; Wilcocks, L.; Jack, M. NZ GREEN Grid Household Electricity Demand Study: 1 Minute Electricity Power (Version 1.0); Centre for Sustainability, University of Otago: Dunedin, New Zealand, 2018. [Google Scholar]
- Polikar, R. Ensemble learning. In Ensemble Machine Learning; Springer: Berlin/Heidelberg, Germany, 2012; pp. 1–34. [Google Scholar]
- Logenthiran, T.; Srinivasan, D.; Shun, T.Z. Demand Side Management in Smart Grid Using Heuristic Optimization. IEEE Trans. Smart Grid 2012, 3, 1244–1252. [Google Scholar] [CrossRef]
- Rehman, A.U.; Tito, S.R.; Nieuwoudt, P.; Imran, G.; Lie, T.T.; Vallès, B.; Ahmad, W. Applications of Non-Intrusive Load Monitoring Towards Smart and Sustainable Power Grids: A System Perspective. In Proceedings of the 2019 29th Australasian Universities Power Engineering Conference (AUPEC), Nadi, Fiji, 26–29 November 2019; pp. 1–6. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MAD-SW |
| Input |
| Preprocessed aggregated load data, x |
| Process |
|
| Output |
| Starting and Ending time instances of the detected events |
| Household Data ID | rf_01 |
|---|---|
| Data Timeframe (In 2014) | 11–15 March; 11–13 April; 12–13 May 12–15 June; 14–15 July; 11–15 August 11–14 September; 11–15 October |
| Duration; No. of Data Samples | 30 Days; 43,200 |
| Threshold Value | 150 W |
| Delay Tolerance (mins) | 0 | ||||
|---|---|---|---|---|---|
| Window Width (Samples) | 2 * | 3 | 4 | 5 | 6 |
| Total Detected Events | 3651 | 3367 | 2853 | 2412 | 2005 |
| True Positive | 3058 | 3016 | 2495 | 2042 | 1639 |
| False Positive | 593 | 351 | 358 | 370 | 366 |
| False Negative | 651 | 698 | 1224 | 1684 | 2093 |
| Precision % | 83.76 | 89.58 | 87.45 | 84.66 | 81.75 |
| Recall % | 82.45 | 81.21 | 67.09 | 54.80 | 43.92 |
| F-Score % | 83.10 | 85.19 | 75.93 | 66.54 | 57.14 |
| Window Width (Samples) | 3 | ||||
|---|---|---|---|---|---|
| Delay Tolerance (mins) | 0 | 1 | 2 | 3 | 4 |
| True Positive | 3016 | 3208 | 3253 | 3286 | 3307 |
| False Positive | 351 | 159 | 114 | 81 | 60 |
| False Negative | 698 | 386 | 228 | 123 | 69 |
| Precision (%) | 89.58 | 95.28 | 96.61 | 97.59 | 98.22 |
| Recall (%) | 81.21 | 89.26 | 93.45 | 96.39 | 97.96 |
| F-Score (%) | 85.19 | 92.17 | 95.01 | 96.99 | 98.09 |
| Training Data | Testing Data | ||||
|---|---|---|---|---|---|
| Data ID | rf_02 | rf_02 | rf_31 | rf_36 | rf_42 |
| Data Timeframe | 11–30 May 2014 | 1–10 July 2014 | 1–7 September 2016 | 21–27 June 2017 | 7–13 January 2017 |
| No. of Days/Samples | 20/28,800 | 10/14,400 | 7/10,080 | 7/10,800 | 7/10,800 |
| Detected Events | 1504 | 898 | 166 | 390 | 60 |
| Models | Parameter * |
|---|---|
| MLP-ANN | activation = ‘relu’; solver = ‘sgd’; hidden_layer_size = (100) |
| DT | criterion = ‘gini’; splitter = ‘best’ |
| Voting Ensemble | voting = ‘hard’ |
| AdaBoost Ensemble | N = 50; algorithm = ‘SAMME.R’ |
| Standalone Models | Ensemble Model | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LR | DT | MLP-ANN | ||||||||||||||
| ID | Status | P | R | F | P | R | F | P | R | F | P | R | F | P | R | F |
| rf_02 | WHOFF | 94 | 88 | 91 | 85 | 88 | 87 | 94 | 85 | 90 | 94 | 88 | 91 | 85 | 87 | 86 |
| WHON | 90 | 85 | 88 | 79 | 84 | 81 | 90 | 87 | 88 | 90 | 87 | 88 | 79 | 84 | 81 | |
| Misc.ON | 91 | 94 | 93 | 90 | 86 | 88 | 92 | 94 | 93 | 92 | 94 | 93 | 90 | 86 | 88 | |
| Misc.OFF | 93 | 97 | 95 | 93 | 91 | 92 | 91 | 97 | 94 | 93 | 97 | 95 | 92 | 90 | 91 | |
| Weighted Avg. | 92 | 92 | 92 | 88 | 87 | 87 | 92 | 92 | 92 | 92 | 92 | 92 | 87 | 87 | 87 | |
| rf_31 | WHOFF | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| WHON | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Misc.ON | 100 | 83 | 91 | 100 | 73 | 84 | 100 | 82 | 90 | 100 | 83 | 91 | 100 | 73 | 84 | |
| Misc.OFF | 100 | 72 | 84 | 100 | 69 | 82 | 100 | 72 | 84 | 100 | 72 | 84 | 100 | 71 | 83 | |
| Weighted Avg. | 100 | 80 | 88 | 100 | 72 | 83 | 100 | 79 | 88 | 100 | 80 | 88 | 100 | 72 | 84 | |
| rf_36 | WHOFF | 87 | 72 | 79 | 72 | 83 | 77 | 86 | 72 | 78 | 87 | 73 | 80 | 78 | 85 | 82 |
| WHON | 79 | 69 | 74 | 74 | 79 | 76 | 78 | 70 | 74 | 80 | 71 | 75 | 75 | 78 | 77 | |
| Misc.ON | 72 | 82 | 77 | 77 | 72 | 75 | 72 | 81 | 76 | 73 | 82 | 77 | 77 | 74 | 76 | |
| Misc.OFF | 74 | 88 | 81 | 78 | 64 | 70 | 74 | 87 | 80 | 75 | 88 | 81 | 82 | 74 | 78 | |
| Weighted Avg. | 78 | 77 | 77 | 75 | 75 | 75 | 78 | 77 | 77 | 79 | 78 | 78 | 78 | 78 | 78 | |
| rf_42 | WHOFF | 71 | 100 | 83 | 38 | 100 | 56 | 71 | 100 | 83 | 71 | 100 | 83 | 38 | 100 | 56 |
| WHON | 83 | 100 | 91 | 56 | 100 | 71 | 83 | 100 | 91 | 83 | 100 | 91 | 56 | 100 | 71 | |
| Misc.ON | 100 | 96 | 98 | 100 | 84 | 91 | 100 | 96 | 98 | 100 | 96 | 98 | 100 | 84 | 91 | |
| Misc.OFF | 100 | 92 | 96 | 100 | 68 | 81 | 100 | 92 | 96 | 100 | 92 | 96 | 100 | 68 | 81 | |
| Weighted Avg. | 96 | 95 | 95 | 91 | 80 | 82 | 96 | 95 | 95 | 96 | 95 | 95 | 91 | 80 | 82 | |
| Voting Based Ensemble | AdaBoost Ensemble | |||||
|---|---|---|---|---|---|---|
| Testing Households IDs | LR | DT | MLP-ANN | DT | ||
| rf_02 | 92.09 | 87.41 | 91.87 | 92.42 | 87.41 | 87.08 |
| rf_31 | 79.51 | 71.68 | 78.91 | 79.51 | 71.68 | 72.28 |
| rf_36 | 77.43 | 74.87 | 77.17 | 78.20 | 74.87 | 77.94 |
| rf_42 | 95 | 80 | 95 | 95 | 80 | 80 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rehman, A.U.; Lie, T.T.; Vallès, B.; Tito, S.R. Non-Intrusive Load Monitoring of Residential Water-Heating Circuit Using Ensemble Machine Learning Techniques. Inventions 2020, 5, 57. https://doi.org/10.3390/inventions5040057
Rehman AU, Lie TT, Vallès B, Tito SR. Non-Intrusive Load Monitoring of Residential Water-Heating Circuit Using Ensemble Machine Learning Techniques. Inventions. 2020; 5(4):57. https://doi.org/10.3390/inventions5040057
Chicago/Turabian StyleRehman, Attique Ur, Tek Tjing Lie, Brice Vallès, and Shafiqur Rahman Tito. 2020. "Non-Intrusive Load Monitoring of Residential Water-Heating Circuit Using Ensemble Machine Learning Techniques" Inventions 5, no. 4: 57. https://doi.org/10.3390/inventions5040057
APA StyleRehman, A. U., Lie, T. T., Vallès, B., & Tito, S. R. (2020). Non-Intrusive Load Monitoring of Residential Water-Heating Circuit Using Ensemble Machine Learning Techniques. Inventions, 5(4), 57. https://doi.org/10.3390/inventions5040057