1. Introduction
China is a vast maritime nation with an abundance of marine resources, and the total value of fishery production plays a crucial role in the Chinese economy [
1]. The significance of the total value of fisheries production to the agricultural sector cannot be overstated. At present, the marine economy has become one of the favorable engines of the national economy, but the rapid growth of the market demand for aquatic products has caused many fishing vessels to operate illegally during the fishing moratorium and in foreign waters, which has damaged the ecological balance of the sea and seriously undermined the sustainable and healthy development of the ecological environment of fishing waters [
2]. Some fishermen in the coastal areas have been working illegally during the closed season. In addition, they are influenced by the traditional idea of “Living by the Sea” and exploit the loopholes of supervision, with “vessels with different certificates”, illegal new “three-noes” vessels, and illegal fishing at sea. This is especially true during the fishing moratorium, which can severely disrupt the order of fisheries production and harm the ecological equilibrium of the ocean [
3]. In recent years, as the number of fishing vessels and the degree of mechanization and automation of fishing vessels have increased, so has the intensity of fishing, and irresponsible fishing practices have caused a severe decline in marine fishery resources and a crisis in marine fishery production [
4,
5]. To advance the modernization of the fishing industry and improve the intelligence and information technology on fishing vessels, it is necessary to identify the operational status of fishing vessels at sea. China’s maritime rights and interests can be effectively safeguarded by advancing the level of fisheries informatization management construction and eliminating the retrograde development situation [
6]. Consequently, it is imperative to investigate onboard camera technology to autonomously identify fishing vessels’ operational status. The onboard camera allows for the rapid and accurate identification of deck crew and fishing nets on fishing vessels, which is essential for the automatic identification of the operating status of fishing vessels. The operational status of fishing vessels is identified based on the identification results of the onboard camera.
Manual detection, satellite monitoring, and shipboard video surveillance are the primary methods for identifying the operational status of a fishing vessel. The manual inspection method is primarily applied by law enforcement officers who board fishing vessels to identify their operational status. This manual judgment method is highly accurate and can promptly find out if a fishing vessel has engaged in illegal fishing in a restricted area. But it also requires a significant amount of human labor, and when there are too many fishing boats, there may not be enough staff to monitor the operational status of all fishing boats. The primary method of satellite detection involves deploying a monitoring system for fishing vessels on the fishing vessel. This system transmits the fishing vessel’s current status data to the satellite, which then conveys it to the ground-based base station. However, the data capacity on land is limited and costly, and the real-time efficacy is poor. For example, the price and communication fee of Inmarsat equipment is high, and the terminal equipment is large. In some areas such as China’s large number of small vessels, the operating sea area is basically not extensive, poor economic capacity, and other characteristics, promoting the application of such fishing vessels in a large area is significantly difficult [
7]. The application of intelligent fishing vessels is very difficult. Because of the abundant space for the implementation of intelligent transformation of fishing vessels, the artificial intelligence of fishing vessel operation mode identification technology based on shipboard video is considered, combined with multi-source data to achieve the monitoring of fishing gear and fishing methods, and to improve the level of intelligent control of fishing vessel compliance operations. Zhang Jiaze [
8] achieved 95.35% accuracy in the behavioral recognition method of the fishing vessel by installing high-definition camera equipment at four fixed locations on a mackerel fishing vessel and building a 3-2D fusion convolutional neural network to extract and classify the behavioral features of the fishing vessel. Shuxian Wang [
9] attached cameras, built a convolutional neural network, and added pooling layers, LSTM long short-term memory modules, and attention modules on Japanese mackerel fishing boats. In the behavior recognition test set of Japanese mackerel fishing vessels, they received an F1 score of 97.12%.
Deep learning algorithms have shown outstanding performance and promising application prospects in the fields of object detection and recognition [
10,
11,
12,
13,
14,
15]. In boat-based video identification systems, deep learning algorithms have produced greater results in terms of accuracy and real-time performance. But the following issues continue to exist: the computing platform of the fishing vessel’s on-board equipment has limited computing power resources and the operating environment of the fishing vessel is complex, with issues such as light changes and field of view occlusion affecting the final detection results, yet the detection speed of complex models cannot meet the real-time requirements of the task, and the network models are too large to be deployed. Most deep learning algorithms with high accuracy require more model parameters and high computational complexity, requiring high computational power of hardware devices and slow detection speed; while deep learning models with fast detection speed are lacking in accuracy. Not much research has been performed on the lightweight detection model for deck crew and the use of fishing nets that balance detection accuracy and detection speed well. To solve this problem, many excellent lightweight and efficient network structures have been proposed such as MobileNet [
16,
17,
18], EfficientNet [
19], PP-LCNet [
20], etc. This study proposes a real-time detection algorithm YOLOv5s-SGC based on the YOLOv5s model, using the lightweight network ShuffleNetV2 [
21] 0.5× replaces the YOLOv5s backbone network CSP-Darknet53 [
22] to reduce the number of parameters and increase the speed of operation while maintaining accuracy. We used Generalized-FPN [
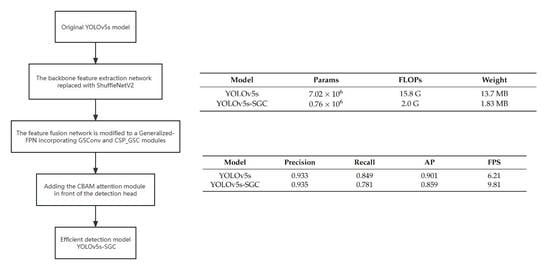
23] to replace the original FPN + PAN in the feature fusion network and the general convolution and C3 modules in the feature fusion network were replaced with GSConv and CSP_GSC modules to further reduce the complexity of the model and the number of parameters, and finally the CBAM attention module was introduced in front of the detection layer to strengthen the feature representation capability of the network. The problem of detection accuracy degradation due to the reduced number of parameters is increased at the cost of a small amount of computation. To provide a real-time and effective detection method for deck crew and the use of fishing net detection of fishing vessels, experiments were conducted on the data set of fishing vessels out at sea operations suggested in this paper, and the detection performance was compared with other lightweight improvement methods.
3. Proposed Methods
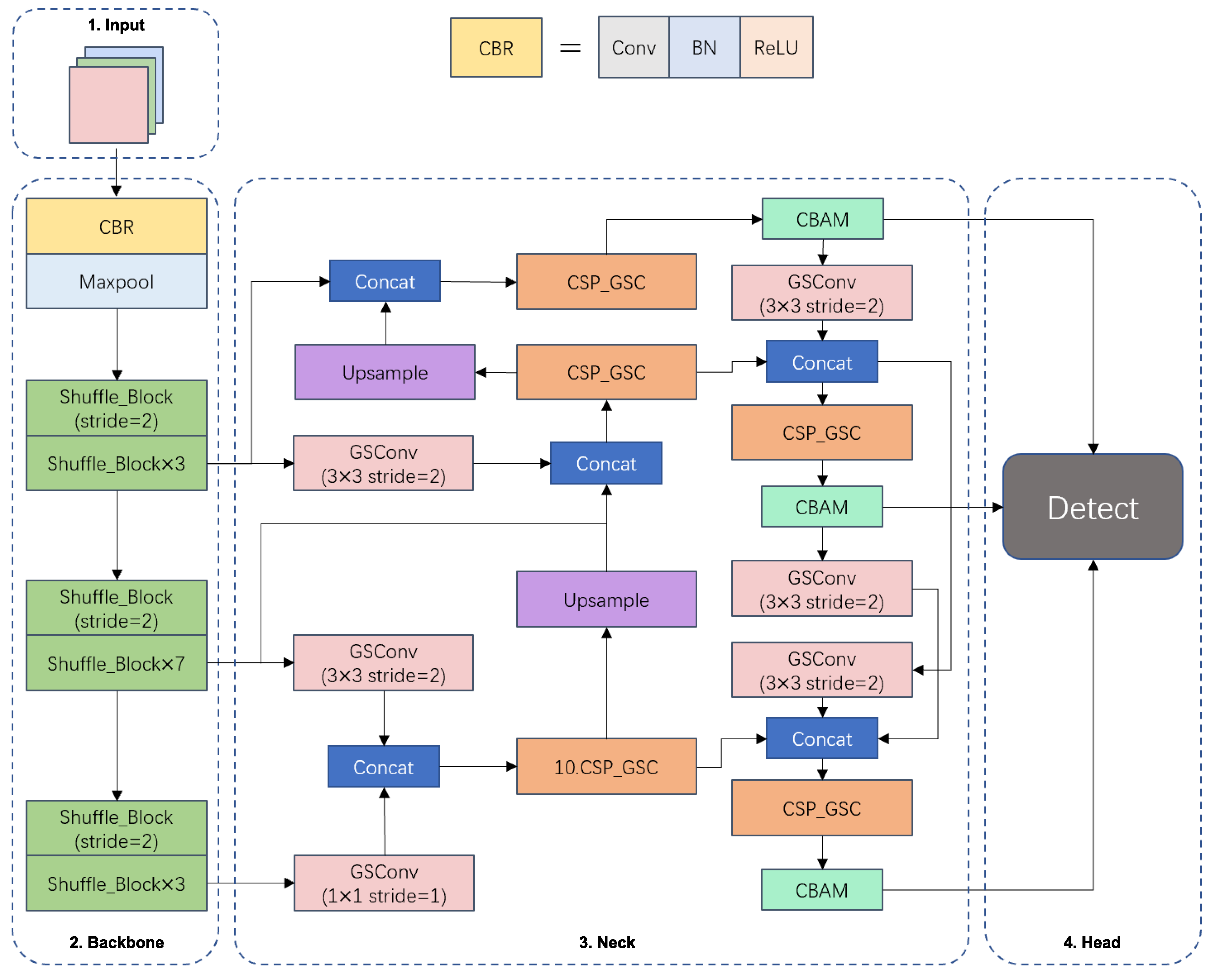
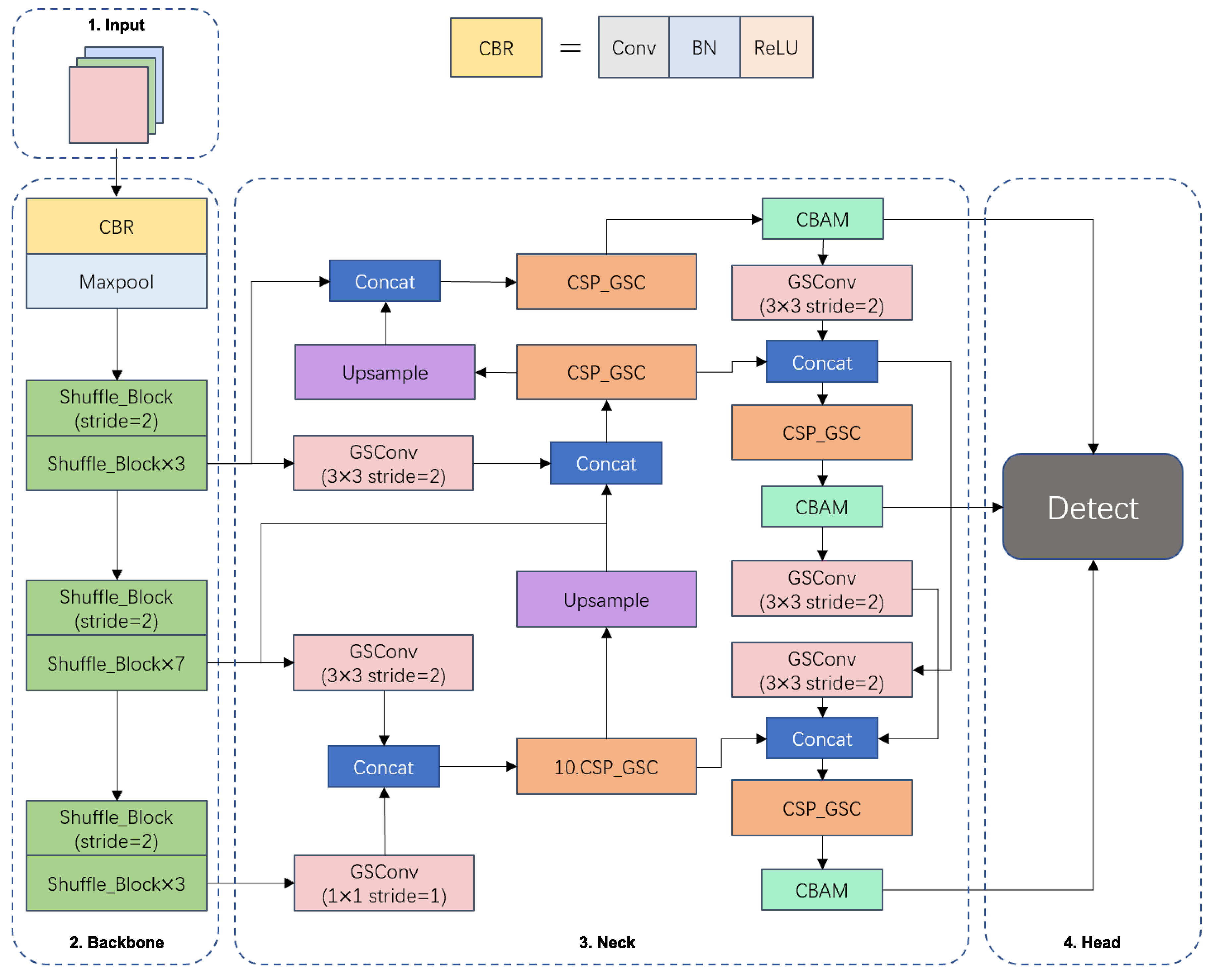
In this study, ShuffleNetV2 is introduced to replace the original backbone network CSP-Darknet53, and deep separable convolution is used instead of traditional convolution to efficiently utilize the feature channels and network capacity while reducing the number of parameters. In the feature fusion network, GhostNet’s Ghost module is introduced to reduce the number of parameters and operations of the model by converting the normal convolution operation to generate only some highly differentiated feature maps, and then transforming these feature maps based on cheap linear operations to obtain other similar feature maps. Although the above methods will significantly reduce the number of parameters of the model and speed up the operation speed of the detection network, they will also make the accuracy of detection decrease, so in order to compensate for the loss of accuracy due to the reduction of model parameters, this study introduces a CBAM attention module in front of the detection head. CBAM is an attention mechanism module that combines space and channel to extract positive and effective features in the image, thus improving the accuracy of the network.
3.1. YOLOv5s Model
The YOLOv5 model, the current dominant deep learning framework, can be used for state detection to provide real-time deck crew and the use of fishing net detection on fishing vessels. YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x are four variations of a one-stage structural target detection network that are all essentially the same structurally and have networks that go wider and deeper in that order. The YOLOv5s, the lightest model size, and the fastest detection speed is used in this study as the fundamental model due to the low computational power of hardware devices on fishing vessels. The input, backbone, neck, and head components make up the bulk of the YOLOv5 algorithm.
Although YOLOv5 performs admirably on publicly available datasets and is excellent at feature extraction and target detection, there is still room to improve the performance of its model files on devices with limited processing power. Additionally, it frequently confuses the target with the background of the fishing boat when images taken by the onboard camera are dimly lit or have uneven illumination, leading to false alarms. The network can maintain high-precision target detection while reducing the model’s weight size and improving its processing speed by making lightweight modifications and incorporating attention modules, As a result, it can be deployed and perform real-time detection of deck crew and fishing net operations even on low-intelligence fishing vessels.
3.2. The Backbone Based on ShufflenetV2
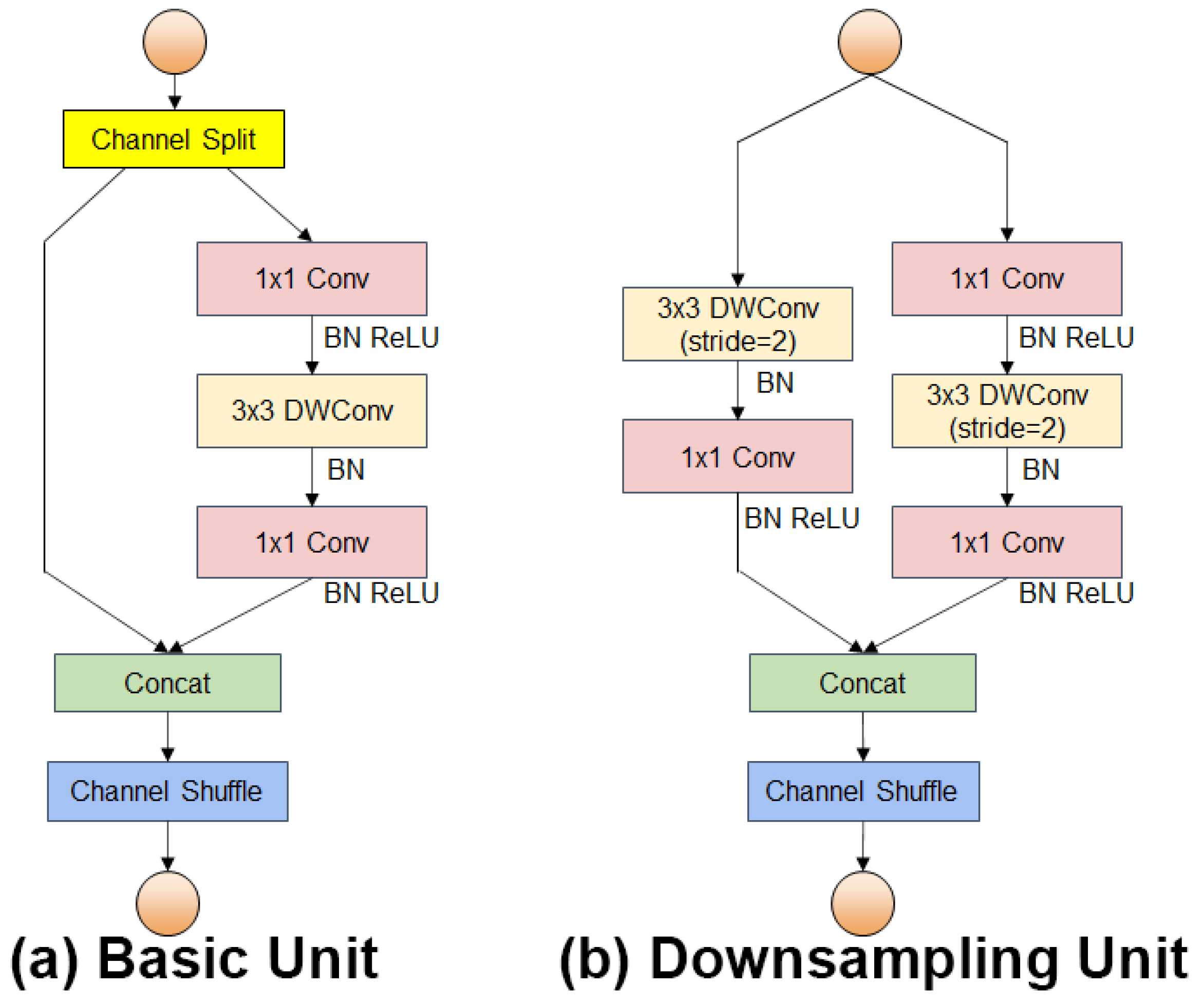
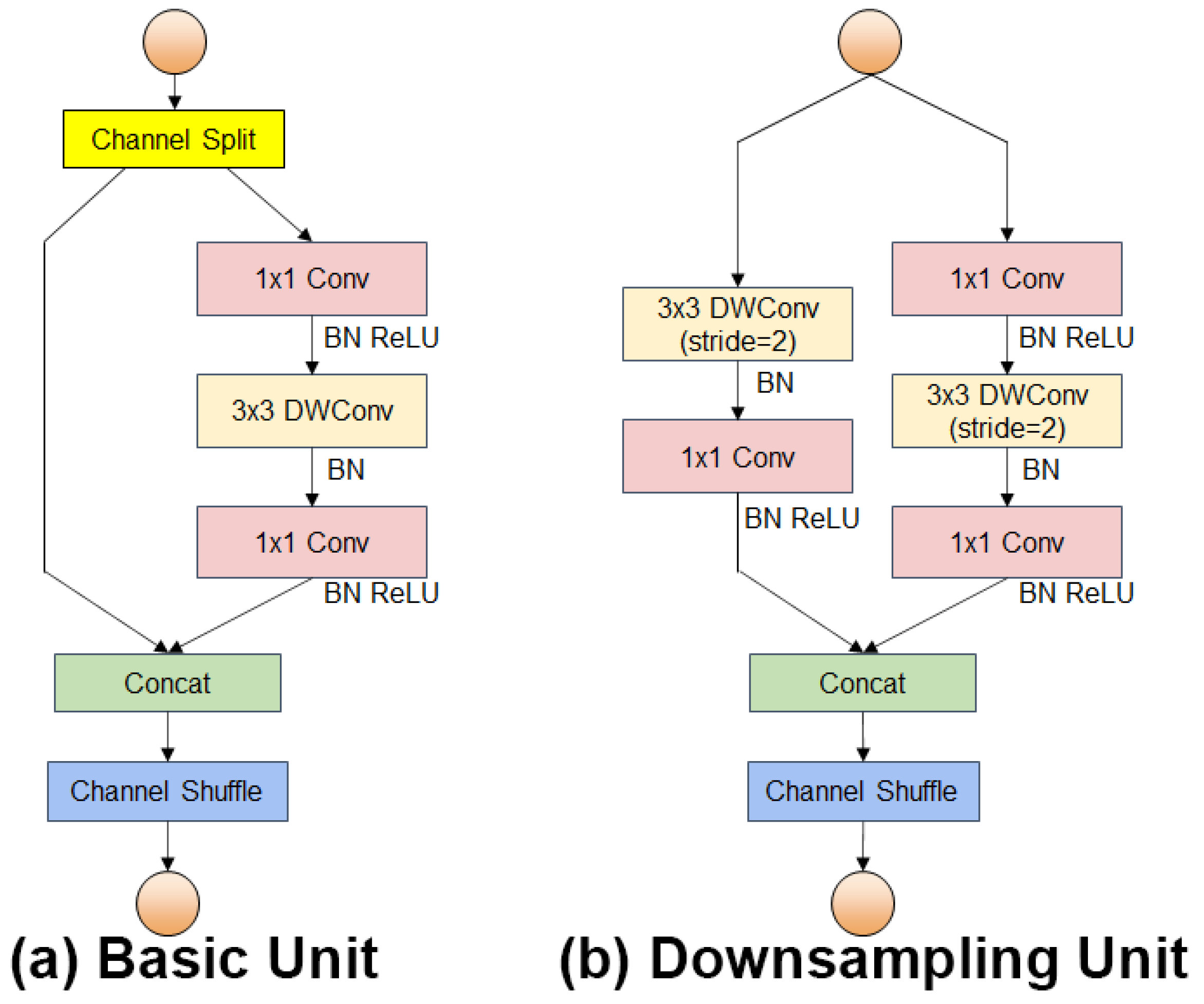
The sizes of fishing nets and deck crew in the collected fishing vessel operation images in this study belong to large and medium targets in the image. The backbone network CSP-DarkNet53 of YOLOv5s has a deeper network depth and larger model capacity, which provides higher performance in terms of accuracy, but its number of parameters and computational complexity are also larger. To meet the requirements of high accuracy, real-time operation on low computing power devices, and fewer model parameters, the YOLOv5s backbone feature extraction network is replaced by the ShuffleNetV2 network. ShuffleNetV2 introduces the concept of “channel split” based on ShuffleNetV1 [
24], and redesigns the basic structure module into two types: the basic unit and the downsampling unit, as shown in
Figure 3.
The primary design idea of ShuffleNet is to execute a channel shuffle operation on several channels to address the issue of non-communication between the layers of network feature information produced by group convolution, thereby reducing the computational effort of the network.
In the YOLOv5s-SGC backbone network, to meet the requirements of detection speed and hardware device computing power, a lighter version of ShuffleNetV2 0.5× was used to build a lightweight and efficient feature extraction network to replace the CSP-DarkNet53 feature extraction network in YOLOv5s model. The ShuffleNetV2 0.5× has a total of 18 layers. The structure and parameter settings of the backbone are shown in
Table 1. This approach will lose a small amount of model accuracy, but can significantly reduce the number of parameters and operations of the backbone network.
3.3. Generalized-FPN Structure
In a feature pyramid network, the purpose of multi-scale feature fusion is to aggregate features extracted from the backbone network at different resolutions. The structure of FPN + PAN of YOLOv5s only focuses on feature extraction and does not consider the connection of internal modules. Therefore, we use the modified Generalized-FPN as the feature fusion network for YOLOv5s-SGC, thus reducing the number of network operations and increasing the detection speed while enhancing the crew and fishing net detection accuracy. The Generalized-FPN uses -link to extend the depth while retaining effective feature reuse and adopts a Queen-fusion structure to add more feature fusion, where each node receives inputs at both the same level and neighbor level, and finally, the feature fusion is performed by Concat.
3.4. The Ghost Module
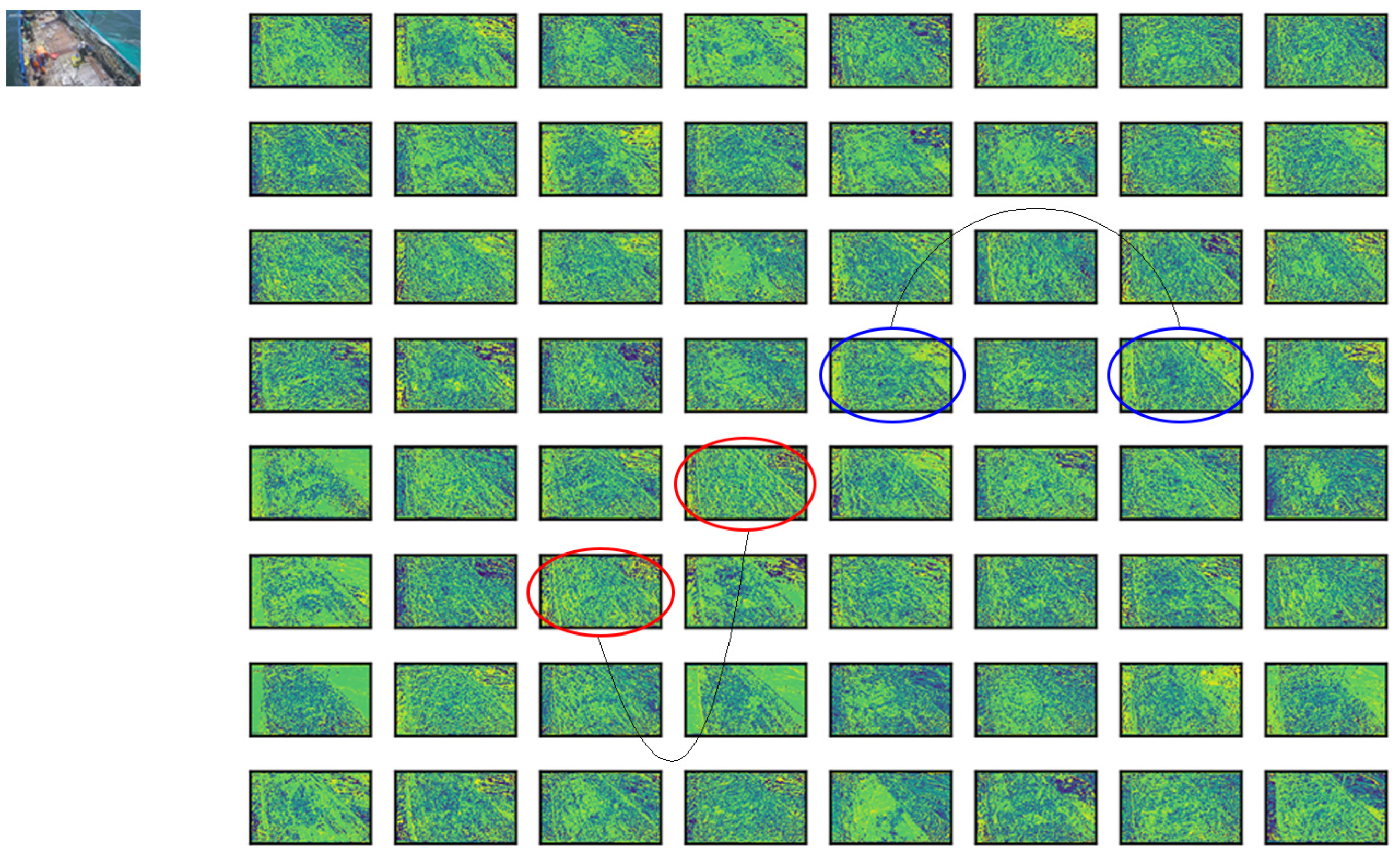
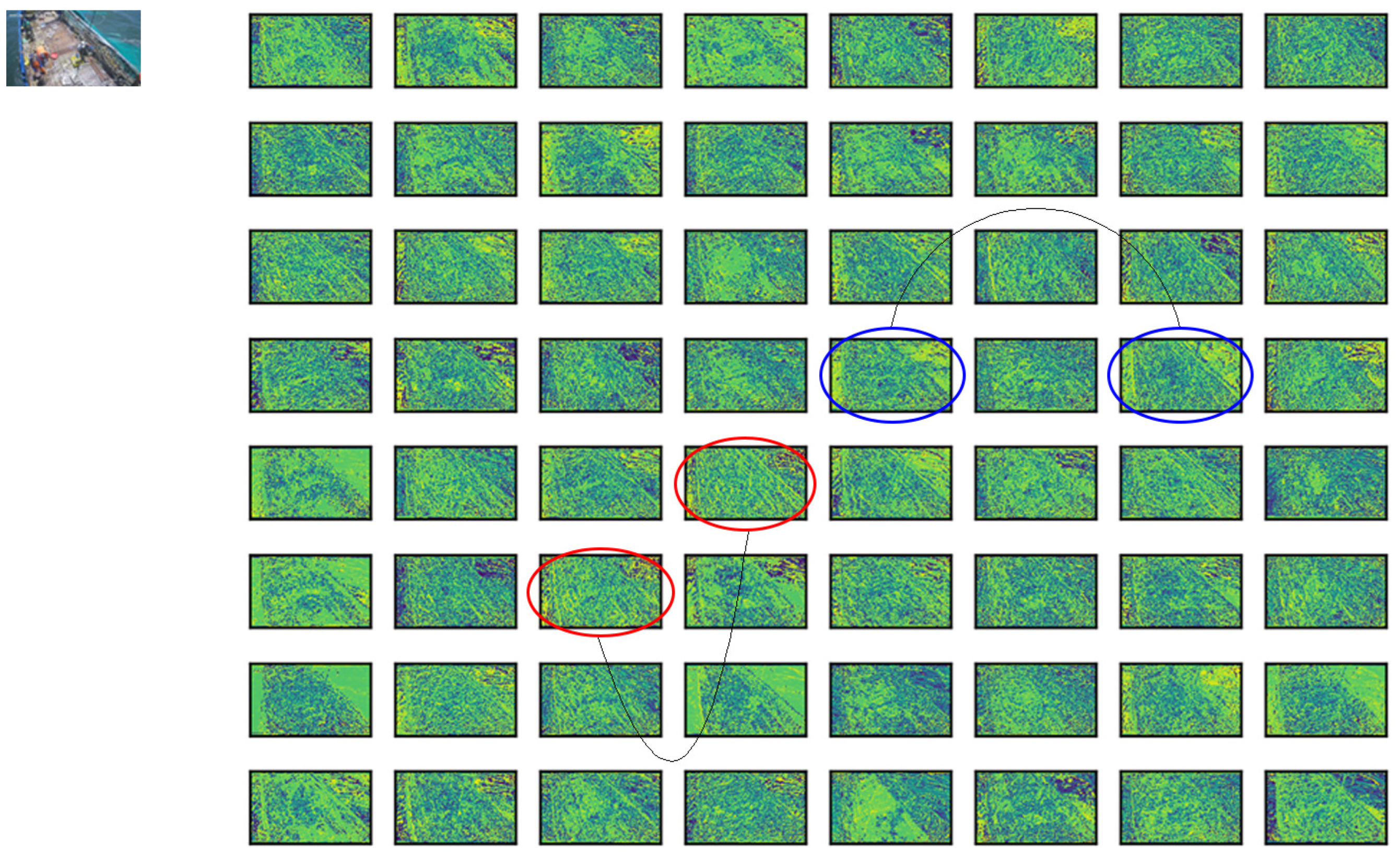
After the feature extraction network, the feature maps for detecting the deck crew and fishing net need to undergo further processing in the feature fusion network. As shown in
Figure 4, there will be some photos with high similarity among these feature maps, which is feature map redundancy in the neural network, leading to wasteful computation and parameter increase, from a single image following feature extraction by the neural network. In response to this situation, we introduced GhostNet [
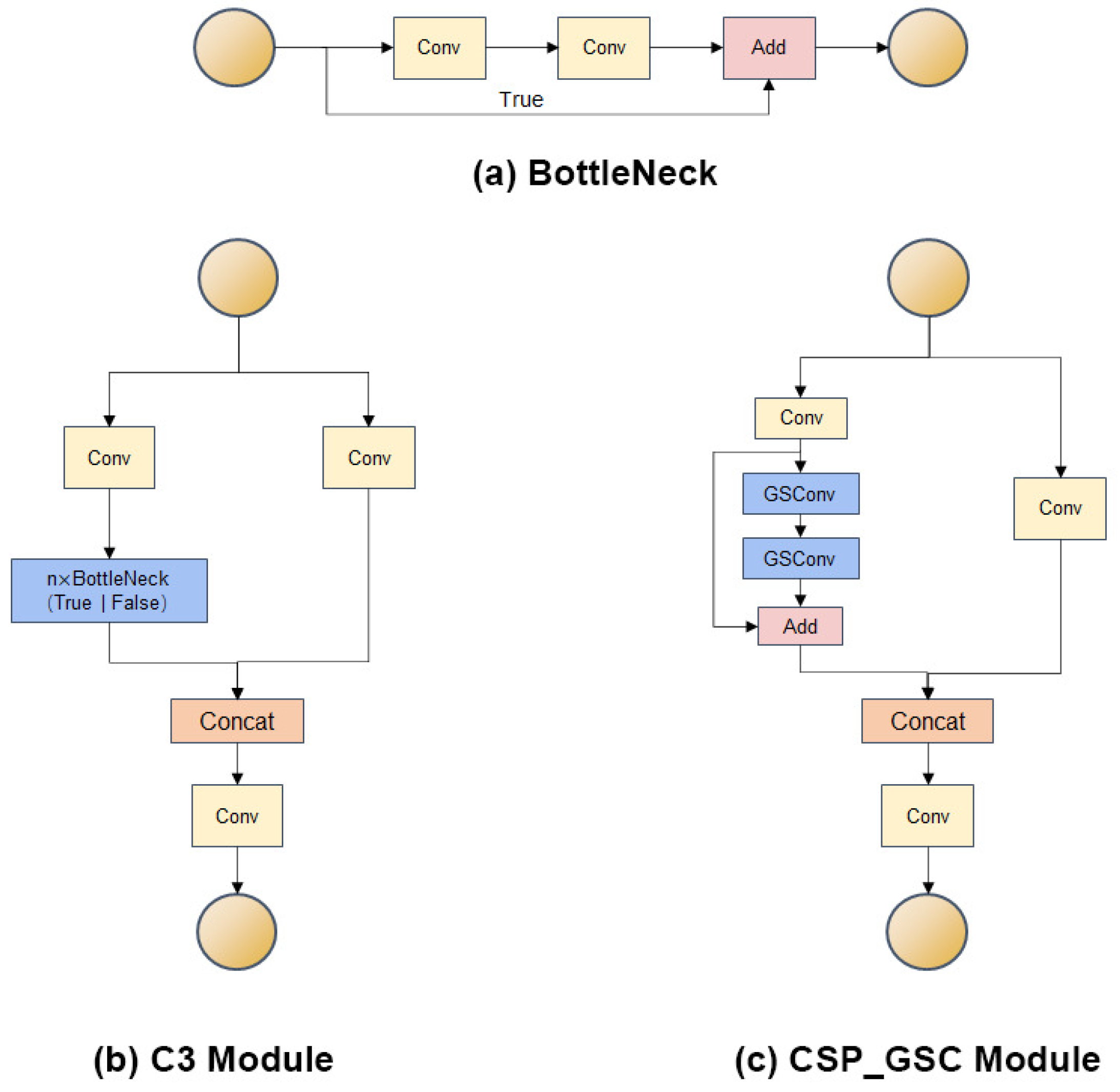
25] in the feature fusion section module in GhostNet. In the Ghost module, the first step is to generate a part of the feature map by a small amount of traditional convolution, after which a linear operation is performed on these feature maps, and the newly generated feature map becomes the Ghost feature map. Finally, the two parts of the feature map before and after the linear operation are stitched together to produce the final feature map, and this structure is called Ghost convolution GSConv.
The C3 module and the CSP_GSC module are shown in
Figure 5. The C3 module of YOLOv5s consists of a bottleneck and contains a large number of parameters, which makes it computationally intensive. In order to reduce the number of parameters of the neck network and improve the detection speed of the model. The study replaces the normal convolution and C3 modules in the YOLOv5s feature fusion network with the GSConv and CSP_GSC modules to reduce the size of the model. The CSP_GSC module is a replacement of the Conv module of BottleNeck in the C3 module with the GSConv module, so the parameters and computational effort in the CSP_GSC module are reduced. Note that since the Ghost module has two normal convolutions and two depth-wise convolutions in its bottleneck structure, if used extensively and without special optimization, the speed in hardware will be reduced, offsetting the advantages of reducing the number of parameters and FLOPs. As the computing power of the platform grows, the advantages of GSConv become less obvious.GSConv is better suited for edge computing devices due to its smaller computing consumption and memory footprint. By changing the original operation of generating feature maps using convolutional kernels to retaining only a small number of convolutional kernels and replacing the rest of the convolutional operations with linear operations, the amount of computation and time required to generate feature maps can be significantly reduced [
26].
3.5. The CBAM Module
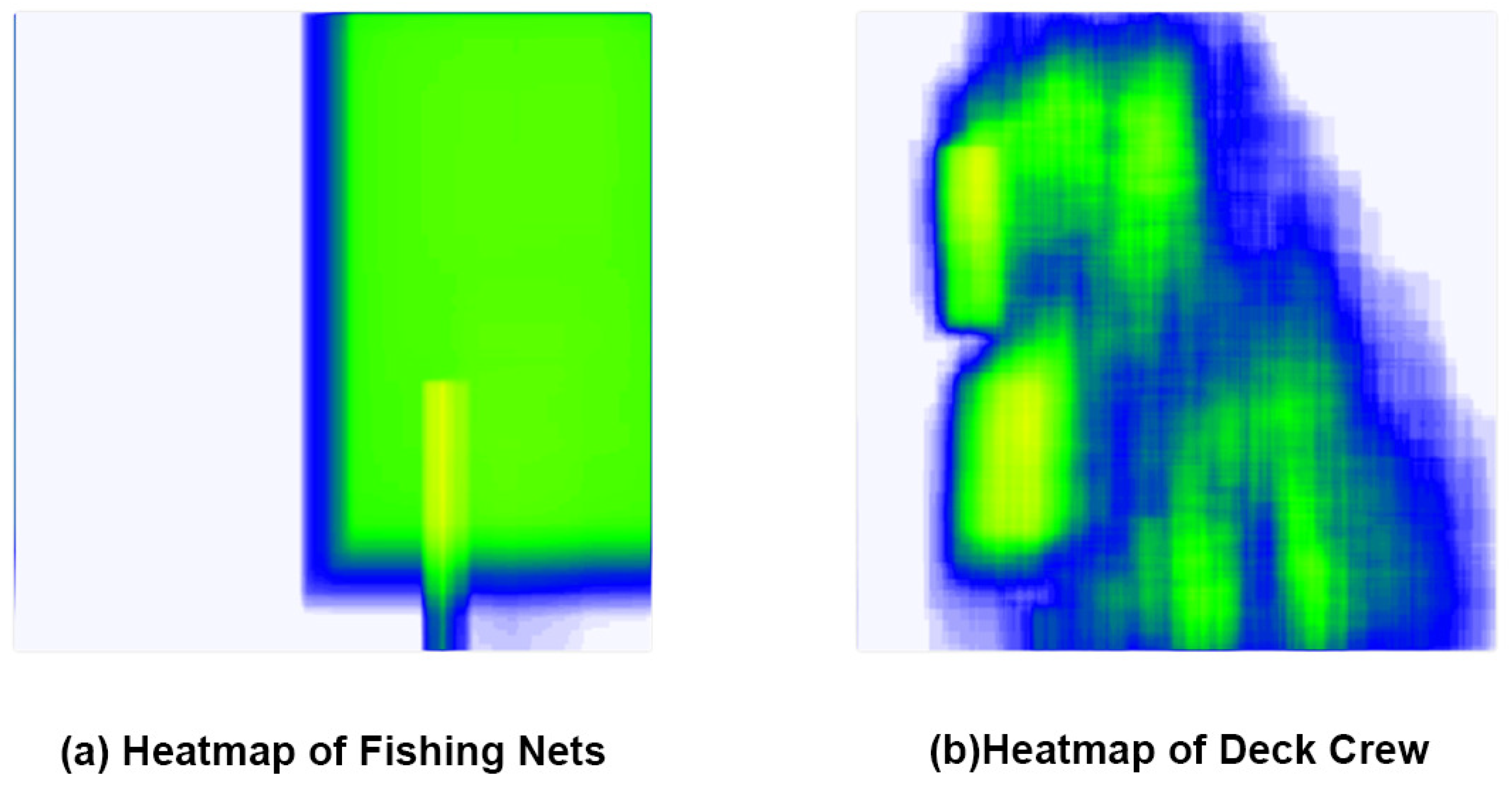
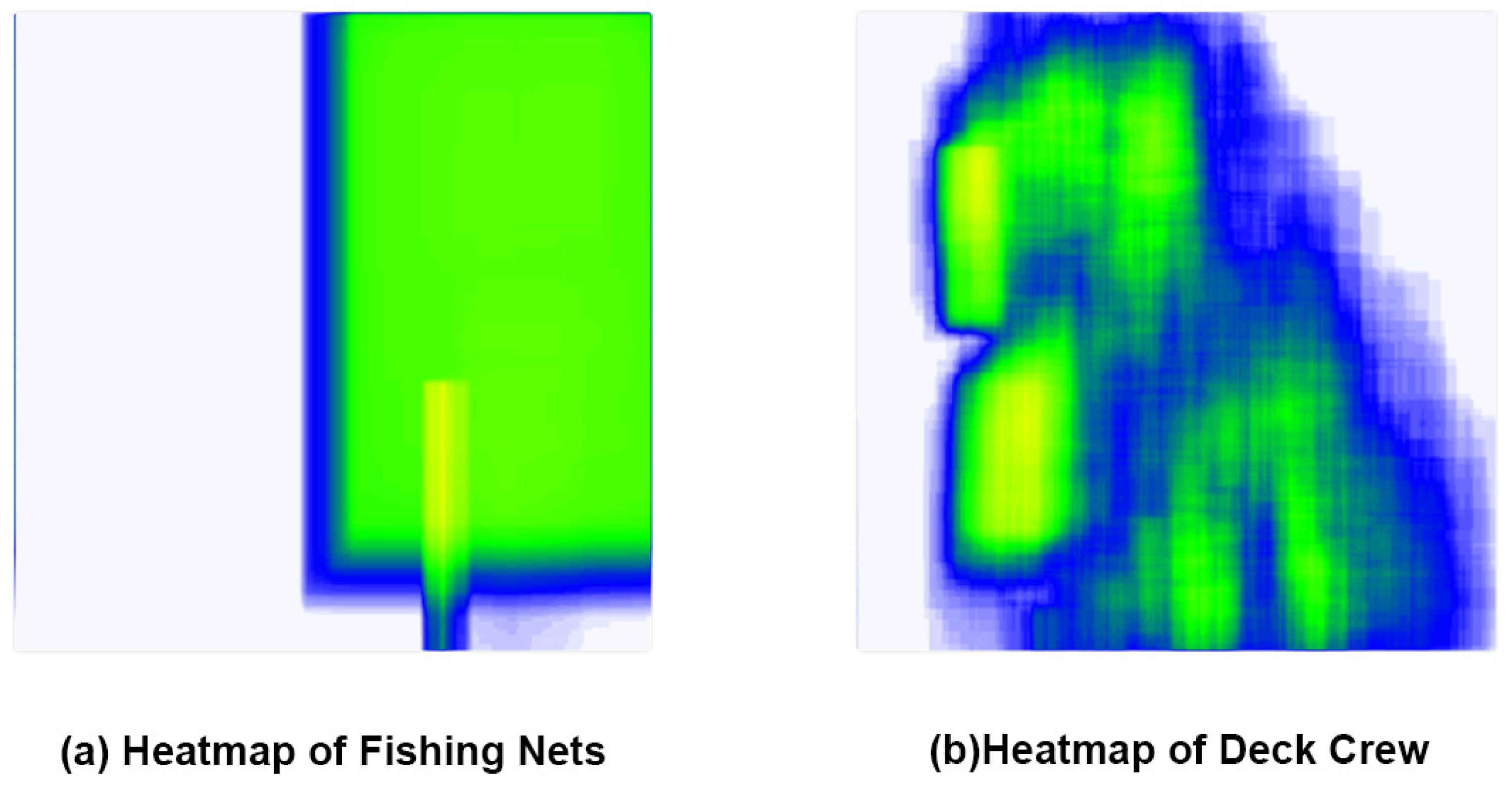
Significantly reducing the number of parameters and computational effort of the backbone feature extraction network and the feature fusion network also reduces the detection accuracy of the model. As shown in
Figure 6, the heat map of the dataset reveals that the accuracy of the model’s target detection can be enhanced by incorporating an attention mechanism into the network, as the fishing nets are primarily located at the periphery or outside of the deck and the crew is primarily located on the deck.
This study introduces the CBAM attention module [
27] into the feature network to accurately obtain the relative position information of the target in the fishing vessel operation image, and to focus on the feature part of the fishing net and crew, thereby reducing the influence of information unrelated to the target, while also increasing the accuracy of target detection [
27]. The CBAM module is an efficient and straightforward attention module for feed-forward convolutional neural networks. Given an intermediate feature map, the CBAM module sequentially infers the attention map along two separate dimensions, channel, and space, and finally multiplies the attention map with the input feature map to perform adaptive feature optimization, thereby enhancing the extraction of important features and suppressing target-irrelevant information.
In this paper, the CBAM attention module is added in front of the detection head, which improves the detection accuracy of the model, although it slightly increases the computational complexity and the number of parameters.
After the backbone feature extraction network is replaced with ShuffleNetV2, the feature fusion network is modified to a Generalized-FPN incorporating GSConv and CSP_GSC modules, and the CBAM attention module is added in front of the detection head, the structure of the lightweight real-time detection algorithm YOLOv5s-SGC based on the modified YOLOv5s network for fishing vessel personnel and retrieval nets is shown in
Figure 7.
4. Experiments
4.1. Evaluation Metrics
In this paper, we use common evaluation metrics to judge target detection models: , , (mean Average Precision), weight size, FLOPs, and detection speed.
The accuracy rate equals the number of samples correctly identified as positive cases by the network; the recall rate equals the ratio of the number of samples correctly identified as positive cases by the network to the total number of positive samples.
equals the area under the PR (Precision–Recall) curve, where P is Precision and R is Recall, as calculated as follows:
represents “the number of positive samples identified by the network as positive”,
represents “the number of negative samples identified by the network as positive”, and
represents “the number of positive samples identified by the network as negative”.
represents “the number of positive samples identified as negative by the network”. The
of each category is obtained by integrating its PR curve. The
is obtained by integrating the PR curves of each category, and the
is obtained by averaging the
of each category:
In this paper, we use FPS to evaluate the detection speed of the model. Moreover, the number of parameters and FLOPS are also used to evaluate the model. The larger the number of parameters, the higher the capability of the model on the hardware. the FLOPs are used to evaluate the computational power of the model, and the larger the FLOPs, the higher the computational power of the model is required.
4.2. Environment
The operating system used for model training is Windows 10, the CPU model is AMD_Ryzen_7_5800H, the GPU model is NVIDIA GeForce RTX 3070 Laptop, the video memory size is 8G, the memory size is 32G, the deep learning framework used is Pytorch 1.12.0, the programming language is Python 3.7, and the GPU acceleration libraries are CUDA 11.6 and CUDNN 8.3.2.
The operating system used during the running speed test was Windows 11. To simulate running the inspection program on a low computing power fishing boat hardware device, the CPU model was AMD_Ryzen_7_5800H, the memory size was 16 G, the deep learning framework used was Pytorch 1.12.1, and the programming language was Python 3.7.3.
4.3. Model Training
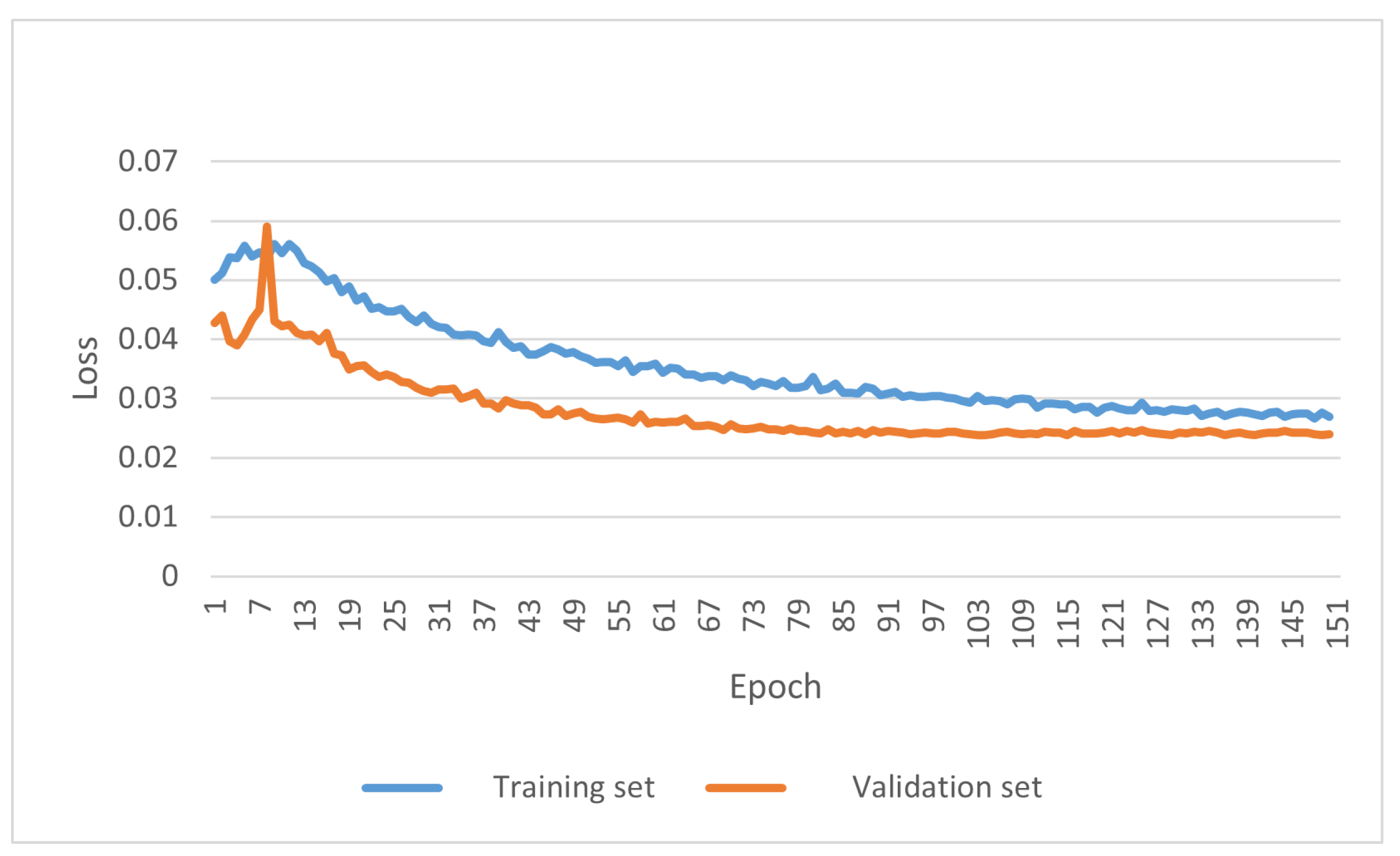
In the model training session, the number of training rounds was set to 150, the Adam optimizer was used, the batch size was set to 16, no pre-training weights were used, the initial learning rate was set to 0.001, the network input image size was
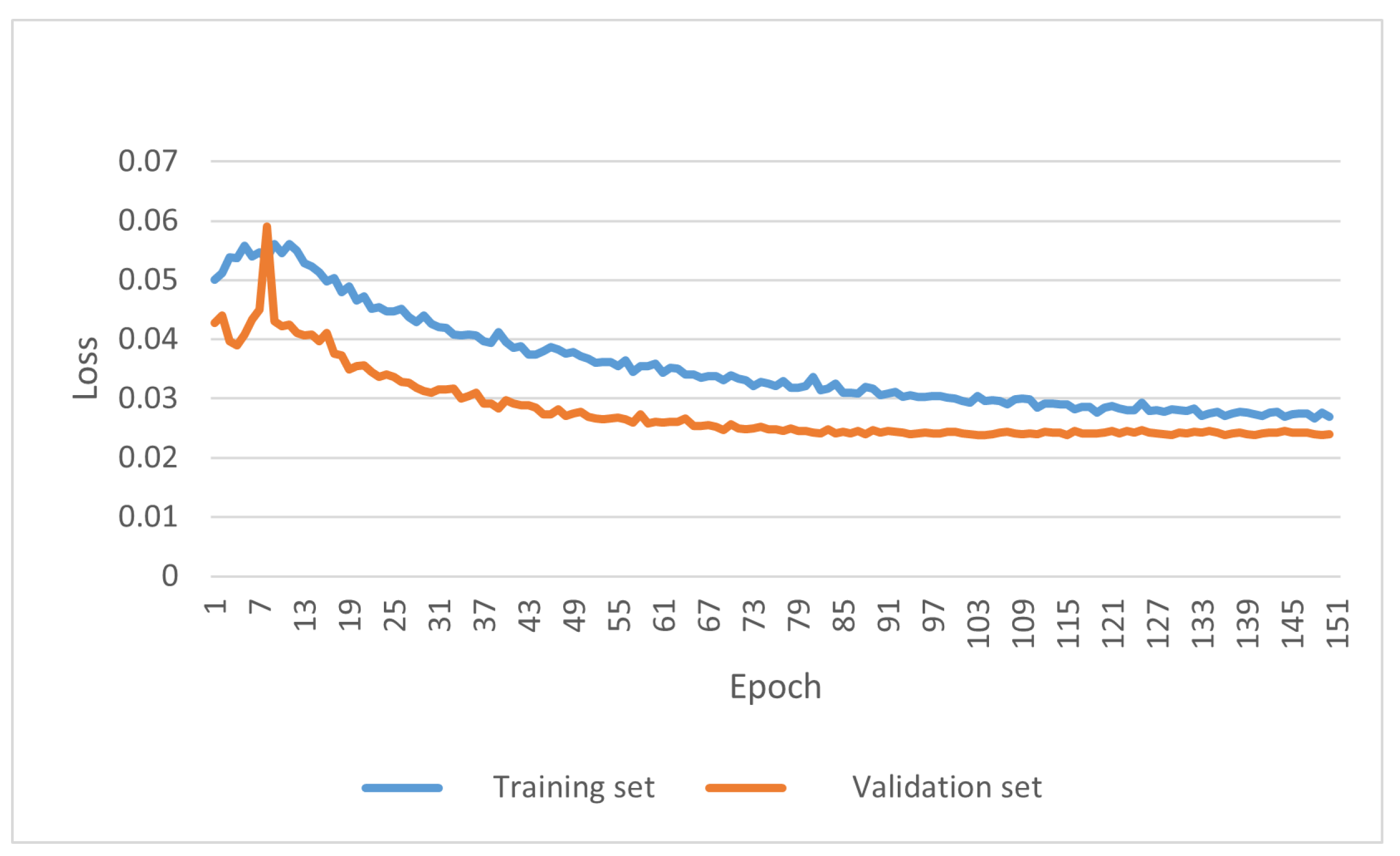
, using cosine annealing to reduce the learning rate. train_loss and val_losss changes during the training process are shown in
Figure 8. The model was trained to 130 rounds when convergence was reached.
4.4. Results
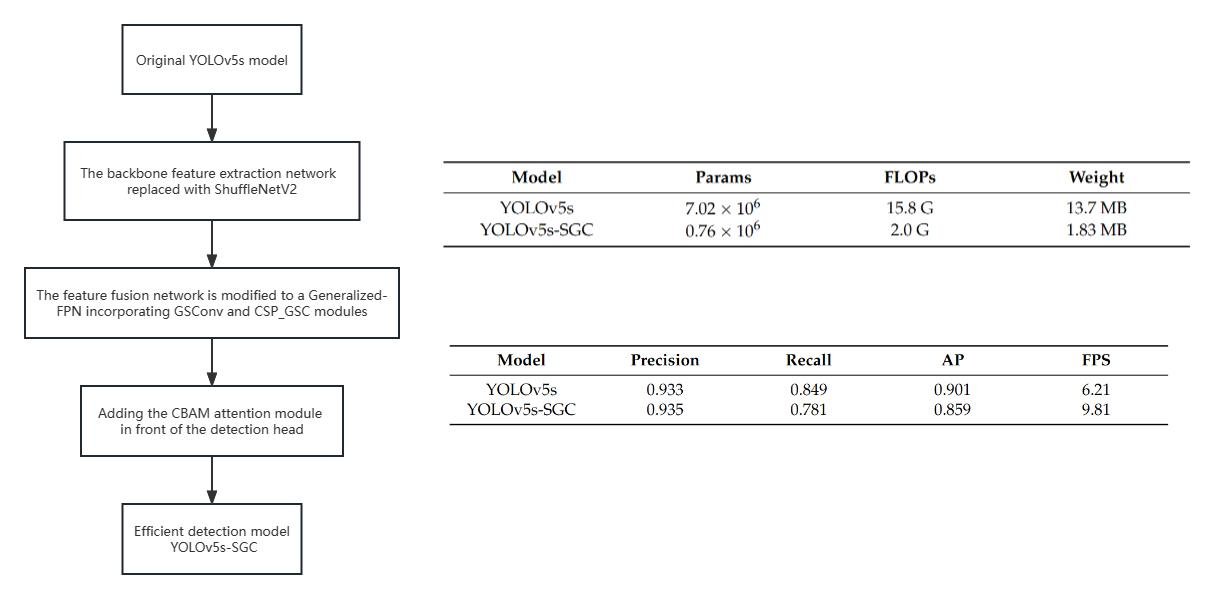
Table 2 presents a comparison of FLOPs, model parameters, and weight sizes between the YOLOv5s-SGC and YOLOv5 models.
Table 3 displays the detection results of the YOLOv5s-SGC and YOLOv5 models on the fishing vessel operation image dataset.
It is evident that YOLOv5s-SGC outperforms YOLOv5s in terms of the number of parameters and floating point operations based on the data in
Table 2 and
Table 3. The weight size of the method presented in this paper is only 1.83 MB, which is 86.64% less than YOLOv5s’s 13.7 MB, and the FLOPs size is only 2.0GFLOPs. With similar accuracy, 6.8% less recall, and 4% less average precision than YOLOv5s, the algorithm presented in this paper obtains 9.81 FPS on CPU devices, a 57.97% improvement in detection speed. The comparative data demonstrates that the algorithm reduces the size and computation of the network model and increases the speed of computation while maintaining a certain level of accuracy, making it more suitable for deployment on hardware devices with limited computational capacity.
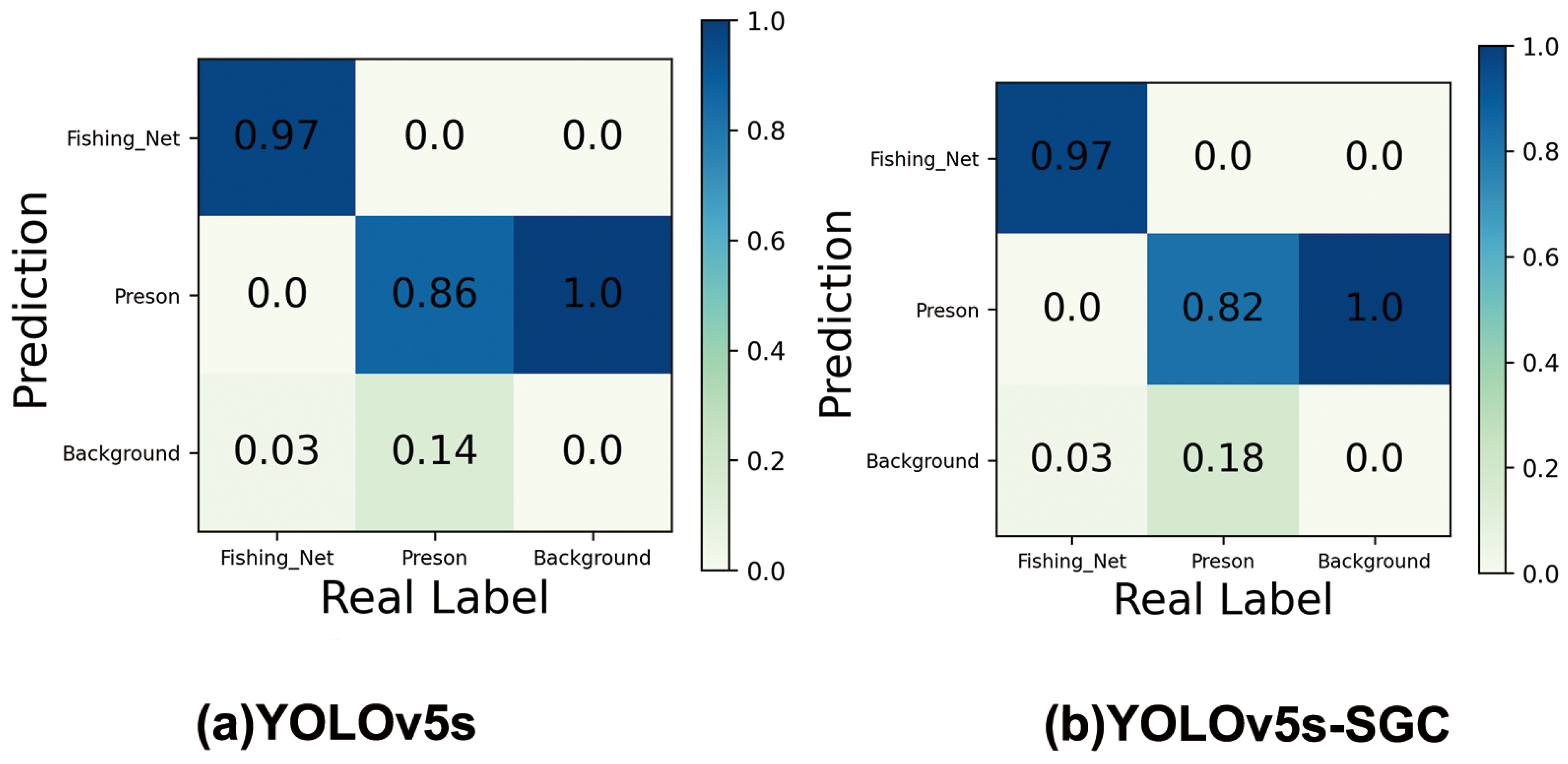
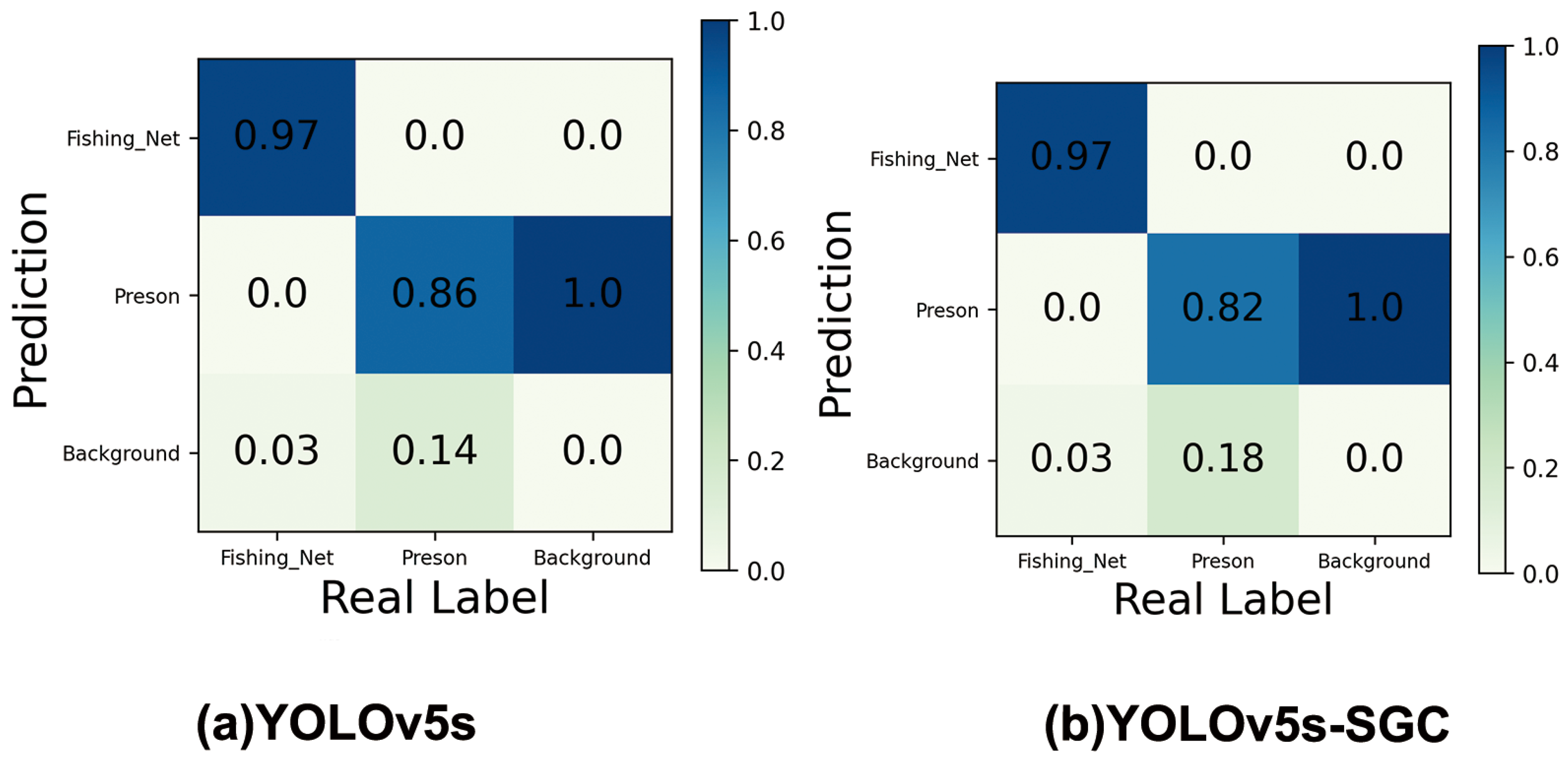
Figure 9 shows the confusion matrix for the YOLOv5s model and the YOLOv5s-SGC model. The horizontal and vertical coordinates indicate the FP and FN of the model, respectively, and the values on the diagonal line are the recall of the model’s predicted targets. From the figure, it can be seen that YOLOv5s has 86% and 97% detection rates for crew and nets, and 14% of crew and 3% of nets are mistakenly detected as background. In contrast, the detection rates of YOLOv5s-SGC for crew and nets were 82% and 97%, with 18% of the crew and 3% of the nets being falsely detected as background. Overall, the difference in classification performance between YOLOv5s-SGC and YOLOv5s is not significant, but YOLOv5s-SGC has reduced the model size by 86.64% and improved the computing speed by 57.97%, which can be better applied to the real ship operation status detection tasks of deck crew and fishing nets usage.
4.5. Performance Comparison of Different Models
This part aims to objectively and accurately evaluate the overall performance of the proposed model on the fishing vessel operation dataset, including detection accuracy, model size, FLOPs, and detection speed, and compare it to six other models.
As seen in
Table 4, the YOLOv5s-SGC model has slightly lower accuracy than other models, but the number of parameters and FLOPS are the smallest among all models. This makes the detection speed of the YOLOv5s-SGC model second only to the YOLOv5n model among the eight models. In terms of detection speed, the YOLOv5s-SGC model is 61.89% of the YOLOv5n model, but in terms of model size and FLOPs it is only 43.18% and 48.78% of YOLOv5n, which is more suitable for deployment on low-computing shipboard devices. YOLOv5s-SGC achieves an FPS of 9.81 on CPU devices, which can satisfy the requirement for real-time target detection on fishing vessels.
The detection results of each model on some of the test images are shown in
Figure 10. These models were all able to identify the crew in the images and fishing net locations, but YOLOv5s-PP_LCNet appeared to misidentify them. The minimal number of parameters and computational effort of YOLOv5s-SGC also caused the model to have a low confidence level for some of the detected targets, but the confidence level was still above 0.5.
From the above experimental results, it can be seen that, compared with other network models, the YOLOv5s-SGC model has a better trade-off between the number of parameters, the number of operations, and the accuracy of the model, and performs better in the detection of the deck crew and the use of fishing nets, which can detect the targets of fishing vessels in real-time and provide a basis for identifying the current operation status of fishing vessels.
4.6. Ablation Experiments
Ablation experiments were conducted on the models in this paper. The dataset and experimental environment were the same. Six models, YOLOv5s, YOLOv5s-ShuffleNetV2, YOLOv5s-GFPN, YOLOv5s-GFPN-S, YOLOv5s-GFPN-SG, and YOLOv5s-SGC were obtained by extending from different dimensions, respectively. The structures of different models are shown in
Table 5 and the experimental results are shown in
Table 6.
The ablation experiments results can be seen from
Table 6. After replacing the backbone network with the ShuffleNetV2 backbone, the model weight was reduced by 7.91 MB and FLOPs by 10.2 G and had a 48.63% increase in detection speed, but the mAP was reduced by 3.9%, respectively, compared to the original YOLOv5s. After replacing the feature fusion network with Generalized-FPN, not only did the model size and FLOPs decrease by 20 and 2.9 G, but the accuracy and mAP also improved by 1.6% and 0.8%, while the detection speed increased by 19%. This shows that the improved feature network can improve the model computing speed and accuracy while ensuring accuracy. YOLOv5s-GFPN-S was improved with both ShuffleNetV2 and Generalized-FPN, the weights and FLOPs of the model decreased significantly, resulting in a 97% increase in computing speed, but also a 2.8% and 4.5% decrease in accuracy and mAP. YOLOv5s-GFPN-SG improves on Generalized-FPN using the Ghost module. Compared with YOLOv5s-GFPN-S, the model size is reduced by 1.2MB while maintaining accuracy, but the runtime speed is reduced by 16.5%. Our proposed model YOLOv5s-SGC added the CBAM attention mechanism before the detection layer on the basis of YOLOv5s-GFPN-SG. Compared to YOlOv5s-SG, the weight of the model and FLOPs were only increased by 0.06 MB and 0.1 G, while precision was increased by 4.5%. Although YOLOv5s has better mAP, considering the parameter size and real-time performance of the model, the improved YOLOv5s-SGC is similar to YOLOv5s in mAP with only 10.83% params and 13.36% model weight, while the FPS results show the real-time performance is much better. In summary, the improved model YOLOv5-SGC in this paper is superior in terms of real-time detection for deck crew and fishing nets.
The above ablation experiments illustrate that replacing the backbone network with ShuffleNetV2 0.5× reduces the number of parameters and increases the running speed by introducing a depth-separable convolution with channel splitting. Replacing the feature fusion network with Generalized-FPN makes it possible to reduce the model size and increase the computational speed while maintaining accuracy. Adding the Ghost module to the feature fusion network and replacing the traditional convolution with cheap linear operations can also significantly reduce the number of parameters and computational complexity of the model and speed up the detection of the model. These methods will make the average accuracy value have a slight decrease, after the introduction of the CBAM attention mechanism, through the space and channel attention module can compensate for the accuracy loss to a certain extent, and finally both make the model lightweight and ensure that the model has high accuracy. Thus, real-time and accurate detection can be performed on low-intelligence fishing vessel equipment to meet the needs of fishing vessel operation status detection.
5. Discussion
Researchers are increasingly using vision methods to detect the operational status of fishing vessels. Combining deep learning techniques with shipboard video surveillance is an important way to achieve the identification of the operational status of fishing vessels. In this study, we incorporate the features of YOLOv5s, ShuffleNetV2, Generalized-FPN, GhostNet, and CBAM attention modules to develop a lightweight target detection model to detect crew and fishing nets on deck and obtain their number and location information. This approach enables real-time target detection with high accuracy even on low computing power shipboard hardware devices.
We extracted pictures from the video of fishing boats out at sea and annotated the deck crew and fishing nets in the pictures to produce the dataset. Considering the fact that the images captured by the camera during the fishing boat’s sea trip may be due to light changes and field of view occlusion, we processed the dataset by data augmentation, using various methods such as Gaussian noise and random rectangular occlusion in random combinations, thus increasing the diversity of the dataset and improving the robustness of the trained model.
Our deployed lightweight target detection model, YOLOv5s-SGC, achieves an FPS value of 9.81 on devices with low computing power and has a significant reduction in the number of parameters, FLOPs, and model size compared to YOLOv5s, with an accuracy of 86%. Based on the current performance of our model, it is expected that the recognition rate and detection speed in practical applications can meet the requirements of real-time detection and provide strong support for the operational status detection of fishing vessels. However, compared with the YOLOv5n model, although the model size and FLOPs are lower, there is still a gap in speed, so there is some room for improvement in our model description. We will further develop a more lightweight target detection model based on our model to better serve the automatic identification of fishing vessel operation status.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}