1. Introduction
Aquatic organism recognition is increasingly being applied in aquaculture, such as in automated fishing and aquatic organism statistics. In automated fishing, this technology enables systems to accurately identify target species, allowing for selective harvesting. In aquatic organism statistics, recognition technology allows automated systems to monitor population numbers and distribution, ensuring the sustainability of fishery resources. Additionally, some marine biologists have begun using this technology to study the abundance and species diversity of aquatic animals.
However, due to light absorption and scattering effects, underwater images and videos often exhibit color distortion and fine blurring, reducing the ability to distinguish features. Underwater images also tend to have significant noise, such as tiny algae or floating particles in the water. Moreover, the clustering behavior of aquatic organisms can cause occlusion, leading to missed detections. As a result, accurately identifying aquatic organisms remains a significant challenge.
In recent years, deep learning models have gained increasing popularity in the fields of fisheries and aquaculture, due to their efficient feature learning capabilities and their ability to effectively capture complex patterns. The research in [
1] deepened the model’s architecture and proposed a novel neck structure, embedding a new module. The results indicated that this model could better monitor fishery resources and enhance aquaculture efficiency. Monitoring feed pellet utilization in aquaculture is crucial for effective resource management [
2]. A new framework, was introduced, which integrates underwater object detection and image reconstruction using YOLO-V5. Addressing the issues of shallow network layers and insufficient feature extraction in the YOLO-V3-Tiny network [
3], a network combining YOLO-V3-Tiny with MobileNet was proposed. Compared to traditional shore-based fishing vessel detection methods, this real-time monitoring approach offers timely warnings to fishing operators, which is more advantageous for fisheries ecological protection. The method [
4] proposed a multi-stage R-CNN (region-based convolutional neural network) target detection network linked by sequential LSTM (long short-term memory), aimed at accurately counting fish in diverse benthic backgrounds and lighting conditions in the ocean. However, the accuracy of this method does not meet practical demands, and its computational complexity increases as the number of cascaded R-CNN structures rises. Another study [
5] integrated deformable convolution modules (DCM) and adaptive thresholding modules (ATM) into the YOLOv5 framework to precisely detect and count red-finned triggerfish in aquaculture ponds. The DCM reduced background blur interference, while the ATM minimized detection misses in densely occluded scenes. The model achieved an accuracy of 97.53% and a recall rate of 98.09% on a real aquaculture pond dataset. In [
6], a single-stage CNN detector, RetinaNet, was used for fish detection in underwater video frames, while a simple online real-time tracker (SORT) was employed to link detections of the same fish, achieving a 74% average precision (AP). Ref. [
7] applied Mask R-CNN and the GOTURN (generic object tracking using regression networks) tracking algorithm to detect and track fish in videos captured by UAVs (unmanned aerial vehicles) above fish tanks, achieving an F1 score of 91% and 16 frames per second (FPS). Lastly, ref. [
8] used three R-CNN architectures based on NASNet, ResNet-101, and MobileNet to detect mullets onshore, and estimated their total length based on per-pixel real length provided by ArUco benchmark markers. To overcome challenges posed by low-quality underwater images and the presence of small-sized feed pellets [
9], an improved YOLO-V4 network was designed to accurately detect uneaten feed pellets in the underwater environments of Atlantic salmon seawater cages.
The aforementioned literature primarily focuses on improving model accuracy but overlooks the design and processing of models for mobile platforms. One study [
10] proposed a lightweight Underwater-YOLO architecture for real-time fish school detection in unconstrained marine environments, specifically designed for underwater robot embedded systems. Another study [
9] developed a lightweight deep learning architecture, YOLOv3-Lite, for the automatic detection of hunger and oxygen supply behaviors in crucian carp and catfish within fish tanks, utilizing MobileNetv2 as the backbone to simplify detection. A modified YOLOv3 model for fish detection [
11] based on MobileNetV1 was developed to provide real-time detection and counting of red-finned triggerfish in aquaculture ponds, replacing conventional convolution operations in CNNs with depthwise separable convolutions to reduce model parameters. In [
12], an intermediate-layer feature distillation method using CWD (class-weighted dice) loss was proposed, with a large YOLOv8s-FG as the teacher network and a small YOLOv8n-FG as the student network. The resulting YOLOv8n-DFG model demonstrated superior accuracy and real-time performance in experiments on a dataset containing six morphologically similar fish species, effectively meeting the requirements for real-time fine-grained fish recognition. Ref. [
13] introduced a lightweight real-time detection method, YOLOv5s-SGC, for deck crew and fishing net detection. This method, based on the YOLOv5s model, uses surveillance cameras to capture fishing vessel operation videos and enhances the dataset. YOLOv5s-SGC replaced the YOLOv5s backbone with ShuffleNetV2, substituted the feature fusion network with an improved generalized FPN (feature pyramid network), and added a CBAM (convolutional block attention module) attention module before the detection head. Ref. [
14] developed a real-time high-accuracy fish detection algorithm based on YOLOv5s. The model incorporated attention mechanisms and gated convolutions to enhance channel representations and spatial interactions, while introducing GhostNet to reduce the model weight size. The Light-YOLO model [
15] proposed a network optimized for complex underwater lighting and visual conditions by integrating an attention mechanism based on sparse connections and deformable convolutions. The study also introduced a lightweight network architecture containing deformable convolutions, called Deformable FishNet [
16]. This model incorporated an efficient global coordinate attention module (EGCA) and an EGCA-based deformable convolution network (EDCN/EC2f) to address fish body deformations caused by swimming movements. In [
17], a lightweight backbone network was generated using YOLOv4 to ensure fast computation, with an attention mechanism introduced to suppress irrelevant features. Finally, ref. [
18] proposed a novel lightweight module, the Sparse Ghost Module, designed specifically for accurate and real-time underwater organism detection. By replacing standard convolutions with the proposed convolutions, this approach significantly reduces the network complexity and enhances the inference speed, with minimal loss in detection accuracy.
Most existing studies focus either solely on improving accuracy [
19,
20,
21,
22] or solely on achieving lightweight design [
23,
24], while neglecting the trade-off between the two. This often results in models with improved accuracy but sharply increased complexity or lightweight models that sacrifice precision. Moreover, the datasets [
25,
26] used in these studies are often limited in scope, with simple categories and homogeneous environments. In contrast, our dataset is collected from complex underwater environments characterized by significant noise and diverse backgrounds. The four types of aquatic organisms considered in our study are particularly susceptible to interference from noise and background variations. Overly lightweight models may lack sufficient fitting capacity, leading to inadequate learning of discriminative features in such challenging conditions and ultimately resulting in reduced accuracy. In our study, we proposed a lightweight object detection model for aquatic organism recognition. Our model achieved 82.1% mAP, 416.7 FPS, with Params of only 2.04 M, FLOPs of just 5.8 G, and weights of only 4.13 MB. These characteristics make our model highly suitable for deployment on mobile devices. Our research advances the study of aquatic organism recognition models. The main contributions of our work are as follows:
(1) We propose a lightweight object detection model designed for aquatic organism recognition.
(2) We optimized the object detection model for lightweight performance and accuracy by using a Mobile-Nano backbone network, a lightweight detection head, the Dysample technique, and the HWD method.
(3) The experiments show that our model outperforms many excellent models, reaching a state-of-the-art level.
2. Materials and Methods
2.1. Dataset Introduction
The dataset adopted in this paper was collected from the waters near Zhangzi Island in Dalian, Liaoning Province, China. It came from the URPC underwater object detection algorithm competition co-hosted by the National Natural Science Foundation of China, the Dalian Municipal Government, and Pengcheng Laboratory. As shown in
Table 1, this dataset is a multi-class dataset, consisting of four common types of aquatic fishery targets in total. Among them, the targets labeled as “echinus” have 17,735 ground-truth bounding boxes, which is the largest number and exceeds the sum of the other three types. The targets labeled as “holothurian” have 4488 ground-truth bounding boxes, those labeled as “scallop” have 5345 ground-truth bounding boxes, and the targets labeled as “starfish” have 5391 ground-truth bounding boxes.
We divided the dataset into a training set, a validation set, and a testing set. The training set is used for training to learn the features of the targets. The validation set is employed to quantify the learning ability during the training process and assist us in selecting the best model for testing. The testing set is utilized for the final testing to obtain the object detection evaluation metrics of the model and assess its generalization ability. The division situation of our dataset can be seen in
Table 2. We provide a detailed description of the numerical composition of the training set. Specifically, the dataset contains 15,686 annotated bounding boxes for echinus, 3948 for holothurian, 4784 for scallop, and 4814 for starfish.
Specifically, the training set contains 3880 underwater images, the validation set has 554 images, and the testing set includes 1109 images.
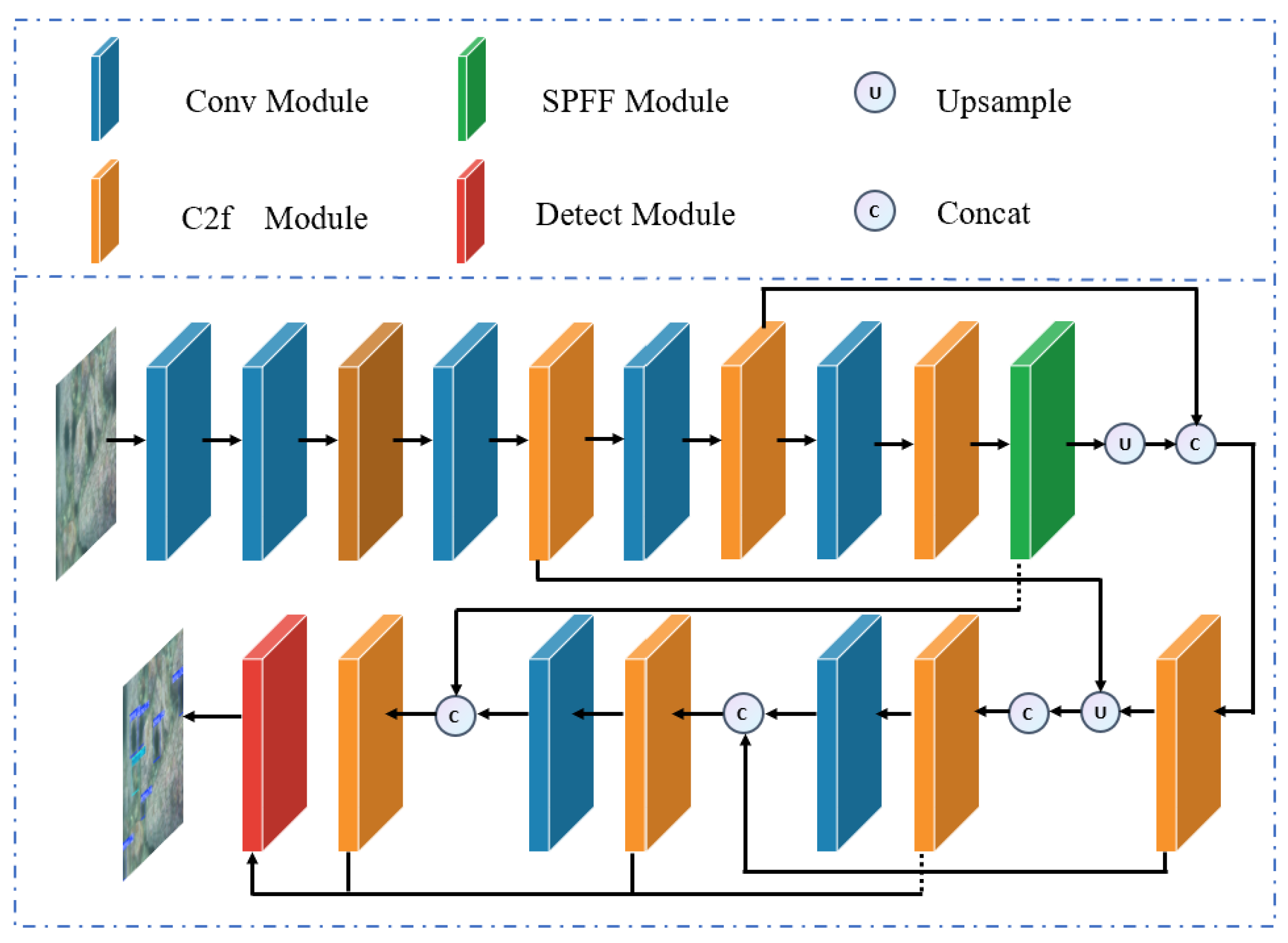
2.2. YOLOv8 Object Detection Network
YOLOv8 is an efficient single-stage object detection model, which is divided into five versions, namely n, s, m, l, and x. The depth and width of each version increase successively, while their architectures remain the same. The architecture diagram can be seen in
Figure 1.
The backbone network of YOLOv8 utilizes Conv and C2f modules to extract lightweight and information-rich gradient flow features at different scales. Through the Conv module, the feature maps are continuously downsampled, and the feature maps keep shrinking. Meanwhile, the backbone network also obtains features at large, medium, and small scales. The C2f module is an improvement on the C3 module in the YOLOv5 model. It incorporates the advantages of the ELAN structure in YOLOv7 and optimizes the extraction of gradient flow features. The compressed feature maps are sent to the SPFF module, where pooling operations with different kernel sizes are used to comprehensively capture and extract features. Then, these feature maps are sent to the subsequent head network for feature fusion and upsampling processing. In terms of the detection head structure, a decoupled head design is adopted, separating the classification head from the detection head. It has transitioned from the anchor-based design of the YOLOv5 model to the anchor-free design of YOLOv8, enhancing the flexibility of the model. However, this also introduces a large number of parameters and complexity as a result.
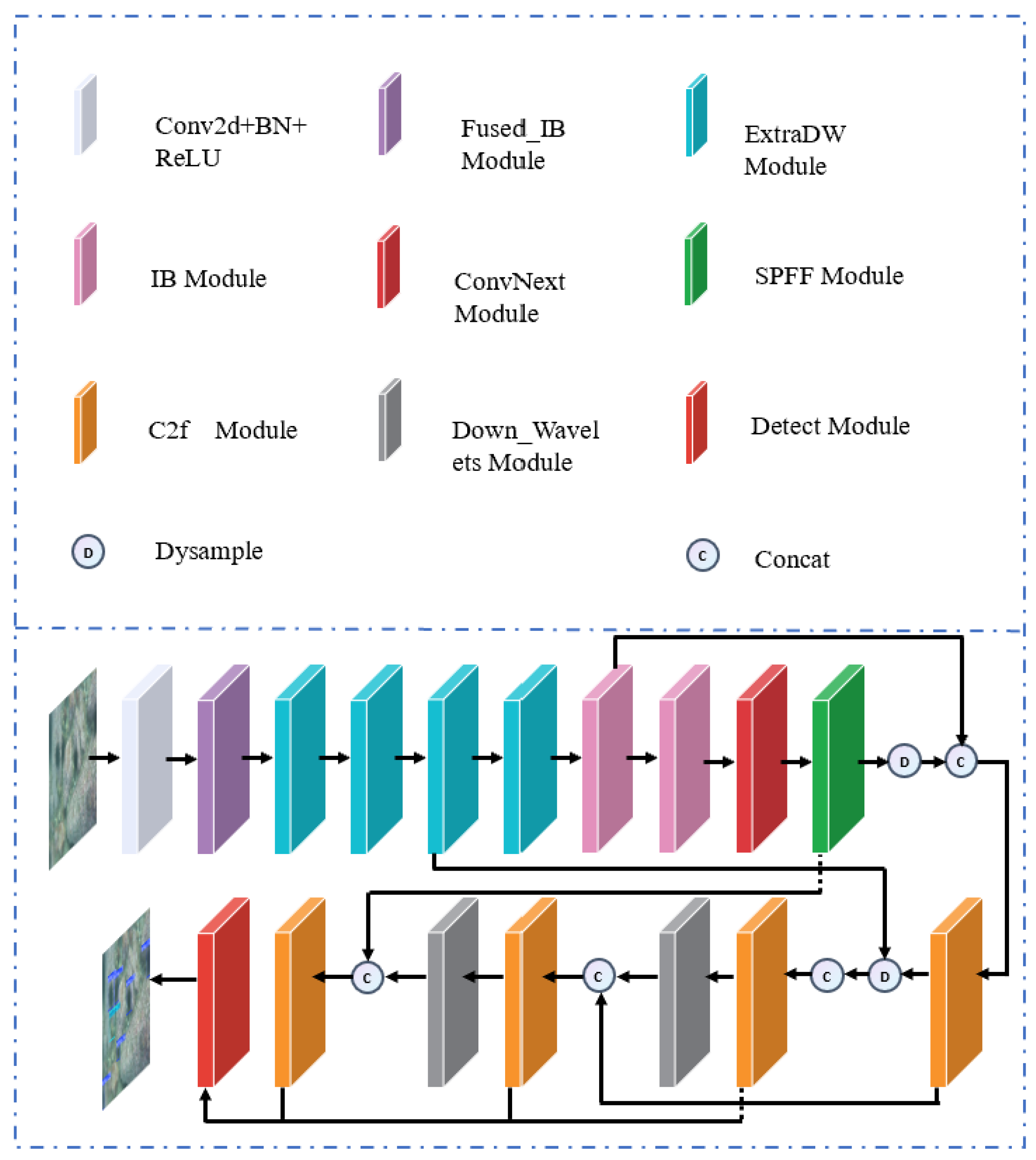
2.3. Mobile-YOLO Object Detection Network
In practical applications, especially in resource-constrained mobile devices, the lightweight nature of the model is of particular importance. A lightweight model can enhance the inference speed, reduce the dependence on hardware and the power consumption requirements, and also decrease the storage pressure, facilitating deployment and update. Based on this fundamental fact, we propose an object detection model suitable for mobile devices and name this lightweight, yet highly efficient and accurate, deep learning model Mobile-YOLO. Its detailed structure diagram can be seen in
Figure 2.
In our work, based on MobileNetv4 which is suitable for mobile platforms [
27], we have developed an even more lightweight backbone. This backbone is lighter than the small version in the paper and has a remarkable effect on our detection task. We name this backbone Mobile-Nano. Mobile-Nano consists of the Fused_IB module, ExtraDW module, IB module, and SPFF module. Compared with the backbone of YOLOv8, it is lighter, has a better feature extraction effect, and has a simpler structure. In addition, after comparing the structures of YOLOv5 and YOLOv8, we found that a large number of parameters and computational complexity were introduced after replacing the coupled head with a decoupled head. Accordingly, we simplified the decoupled head of YOLOv8 to further achieve lightweighting. In the head part of YOLOv8, the task of feature fusion needs to be completed. However, due to the inevitable loss of detailed features in the ordinary downsampling and upsampling processes, the fusion effect is not satisfactory. Therefore, we introduced Dysample [
28], formulating upsampling from the perspective of point sampling, which is more resource-efficient and brings an impressive performance improvement. Moreover, we introduced the HWD [
29] module. This module applies the Haar wavelet transform to reduce the spatial resolution of the feature map while retaining as much information as possible. By using this special downsampling method, we further lightweighted the model and improved the model’s accuracy at the same time.
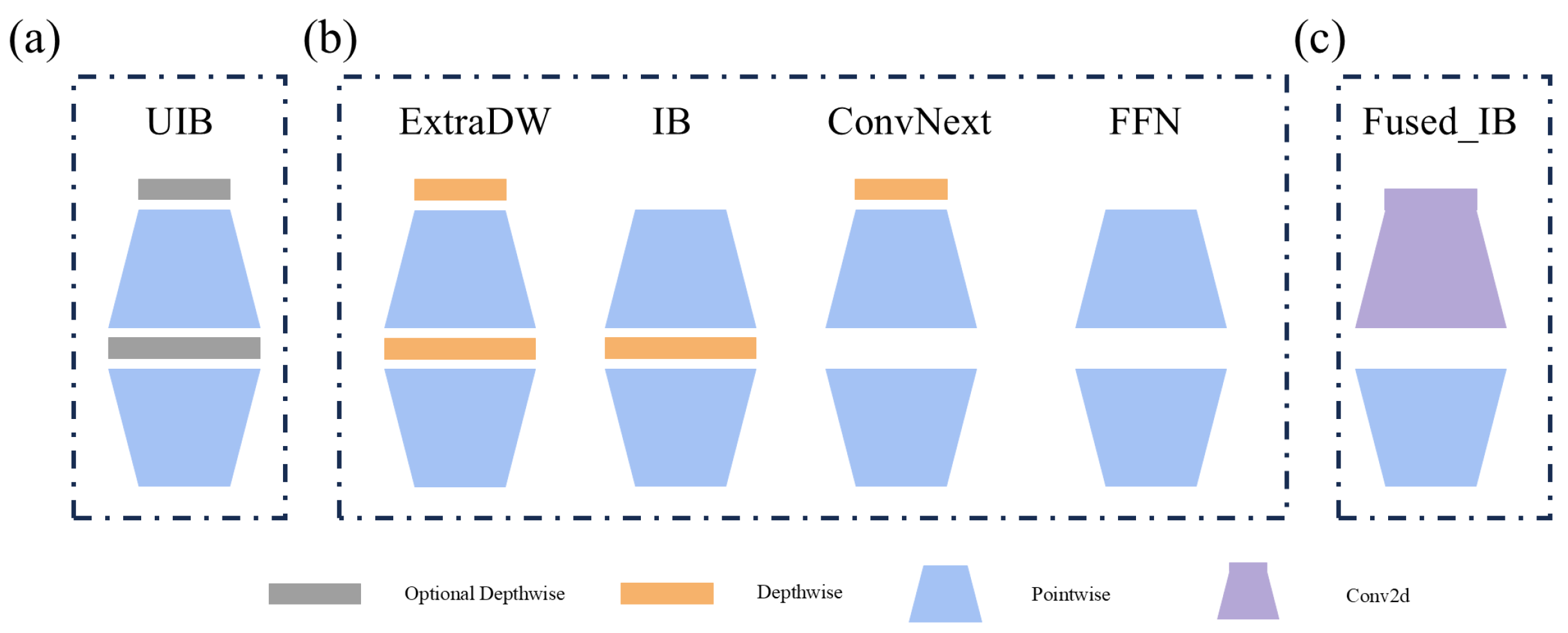
2.4. Mobile-Nano Backbone Network
The foundation of MobileNetv4 is constructed by the universal inverted bottleneck (UIB) block and other components. Here, we will focus on introducing the UIB module and the Fused_IB module, as these two modules are the core components of our Mobile-Nano. The detailed design can be seen in
Figure 3.
Firstly, the UIB module is a building block for efficient network design. It can adapt to various optimization objectives while remaining simple enough. The UIB extends the IB module proposed in MobileNetv2 [
30], and this IB module has become a standard building block for efficient networks and is widely used in various neural networks. The UIB module has four possible structures, namely ExtraDW, IB, ConvNext, and FFN. These are generated due to the permutations and combinations of the depthwise components. Scholars further use Fused_IB to improve the efficiency: a k × k Fused_IB module is equivalent to an ordinary convolution with a convolution kernel of K and a pointwise convolution. Since the lightest version of MobileNetv4, MNv4-Conv-S, has a deeper depth than the original backbone network of YOLOv8, and the feature map transformation is quite different from that of the original backbone network, we hope to make fewer modifications to the rest of the YOLOv8 structure, because this can reduce the determination and optimization of parameters. Therefore, based on the core components of MobileNetv4, we have created a network that is shallower and lighter than MNv4-Conv-S. The detailed design of our Mobile-Nano can be seen in
Table 3.
This backbone network utilizes the core components of MobileNetv4. Finally, under the action of the SPFF module in YOLOv8, pooling operations with different kernel sizes are used to comprehensively capture and extract features. The feature map transformation process of this backbone network is the same as that of the YOLOv8 backbone network; so, the subsequent relevant feature fusion structures do not need to undergo significant adjustments, thus shortening our development process. Meanwhile, due to the lightweight design and efficient feature extraction ability of Mobile-Nano, we also obtained a lighter model and higher accuracy.
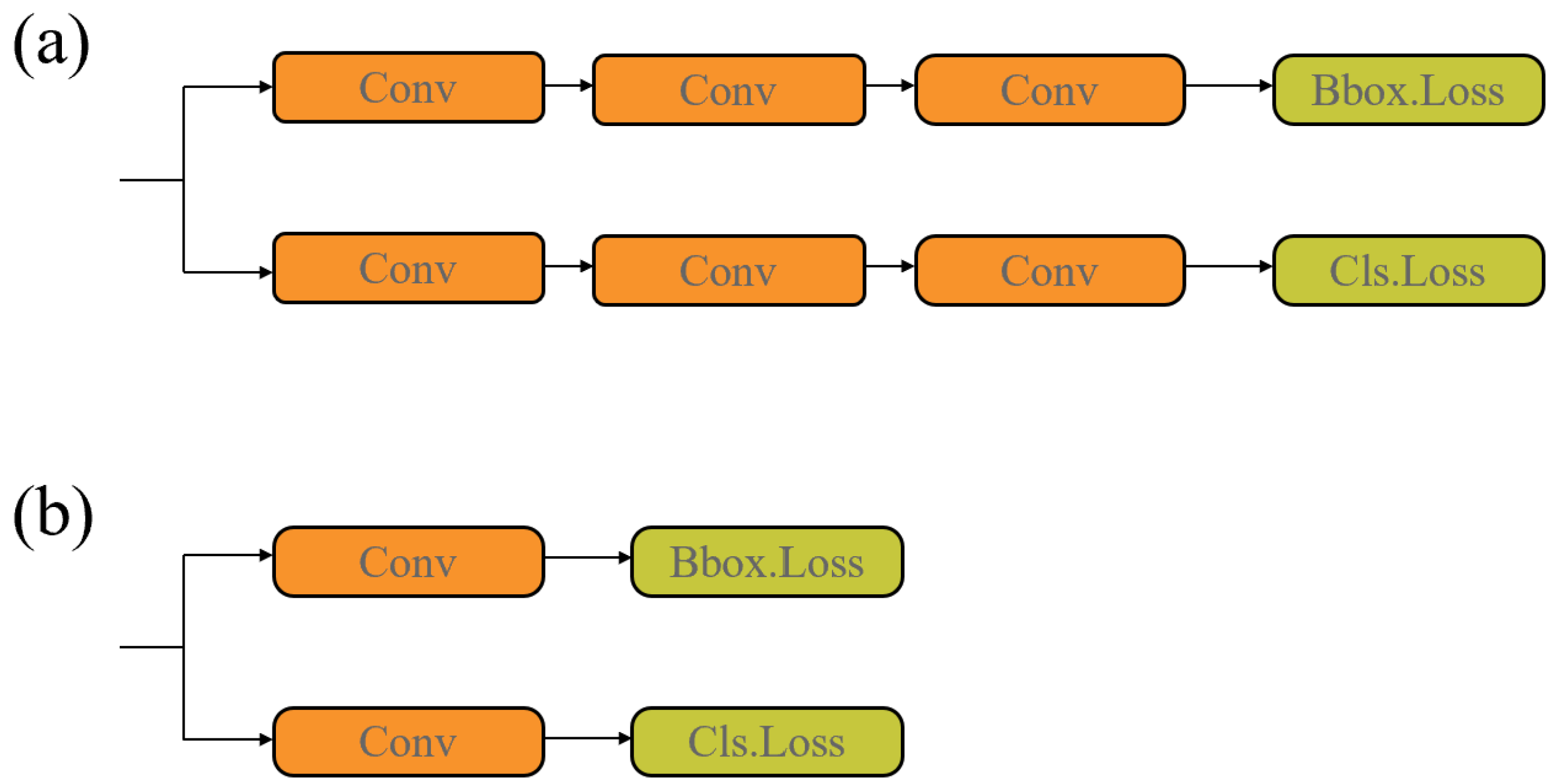
2.5. Lightweight Detection Head
Compared with YOLOv5, YOLOv8 replaces the coupled head with a decoupled head. This brings an improvement in accuracy but also leads to a sharp increase in network complexity and the number of parameters [
31,
32]. As shown in
Figure 4a, both the upper and lower branches of the decoupled head in YOLOv8 are composed of three convolutional layers. However, the high-channel feature maps located in the top layer of the network result in an extremely large number of parameters and computational complexity. Moreover, we believe that multiple stacked convolutional layers are actually overly redundant. Therefore, we only retain the last convolutional layer, thus achieving a lightweight detection head, with only a slight decrease in accuracy. This lightweight detection head is referred to as LDtect in the following text. As shown in Table 7, the model equipped with the original non-simplified detection head has 2.76 M parameters and 7.7 G FLOPs. After replacing it with LDect, the parameter count is reduced to 2.13 M, and the FLOPs decrease to 5.9 G, representing reductions of 22.83% and 28.57%, respectively. Meanwhile, the drop in accuracy remains within an acceptable range.
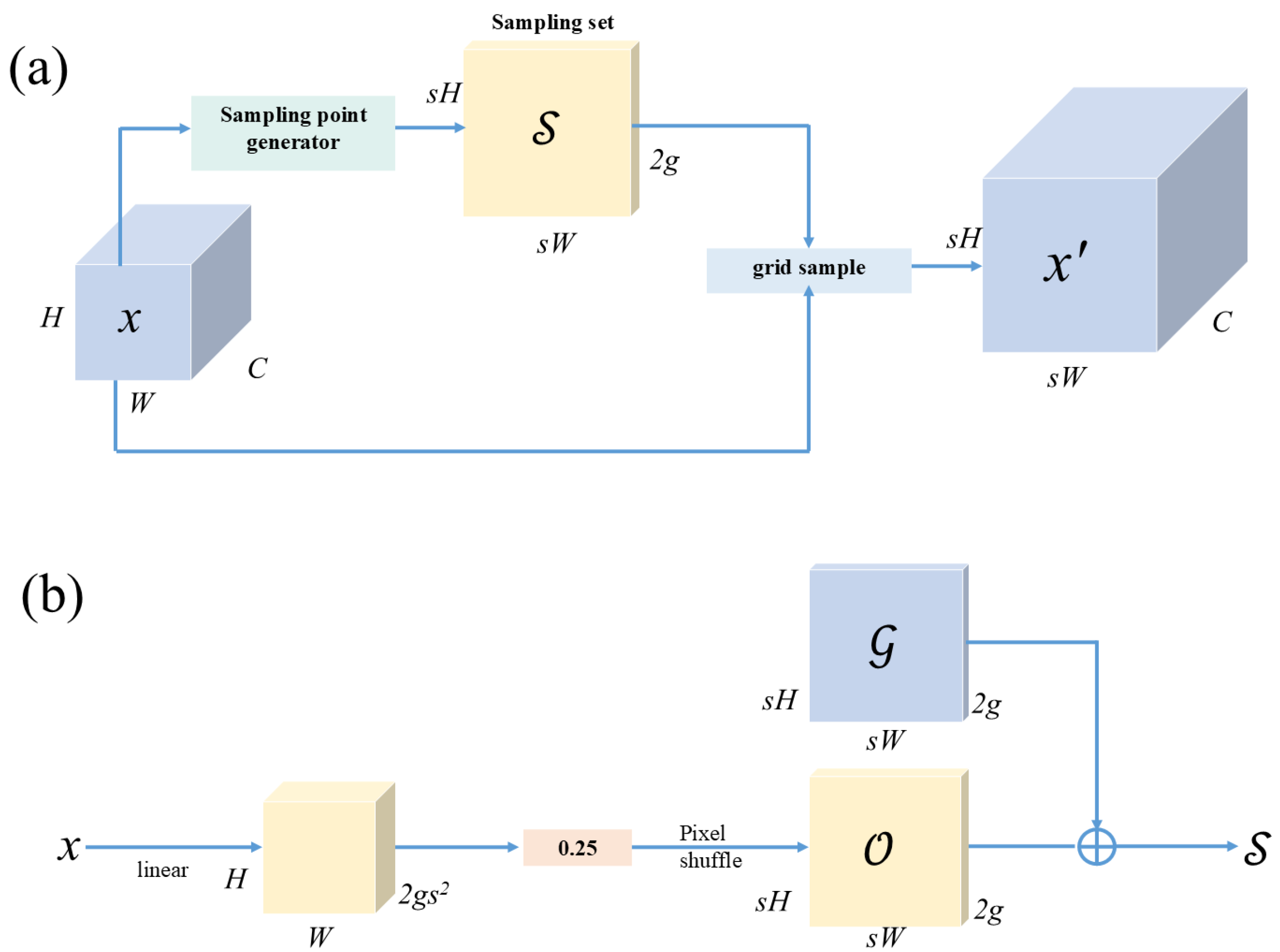
2.6. Dysample
The specific process of Dysample [
28] is shown in
Figure 5.
Given a feature map
with dimensions C × H × W (C, H, and W represent the channel, height, and width of the feature map, respectively) and a sampling set
of size 2g × sH × sW (s and g are manually defined parameters), the grid sampling function uses the positions in
to resample the assumed bilinear interpolation into a new feature map
with dimensions C × sH × sW. This process is defined as
Given an upsampling factor s and a feature map
of size C×H×W, a linear layer with input and output channels C and
, respectively, is used to generate an offset
of size
× sH × sW. This offset is then reshaped to 2g × sH × sW using pixel shuffling. The sampling set
is obtained by adding the offset
to the original sampling grid
, as follows:
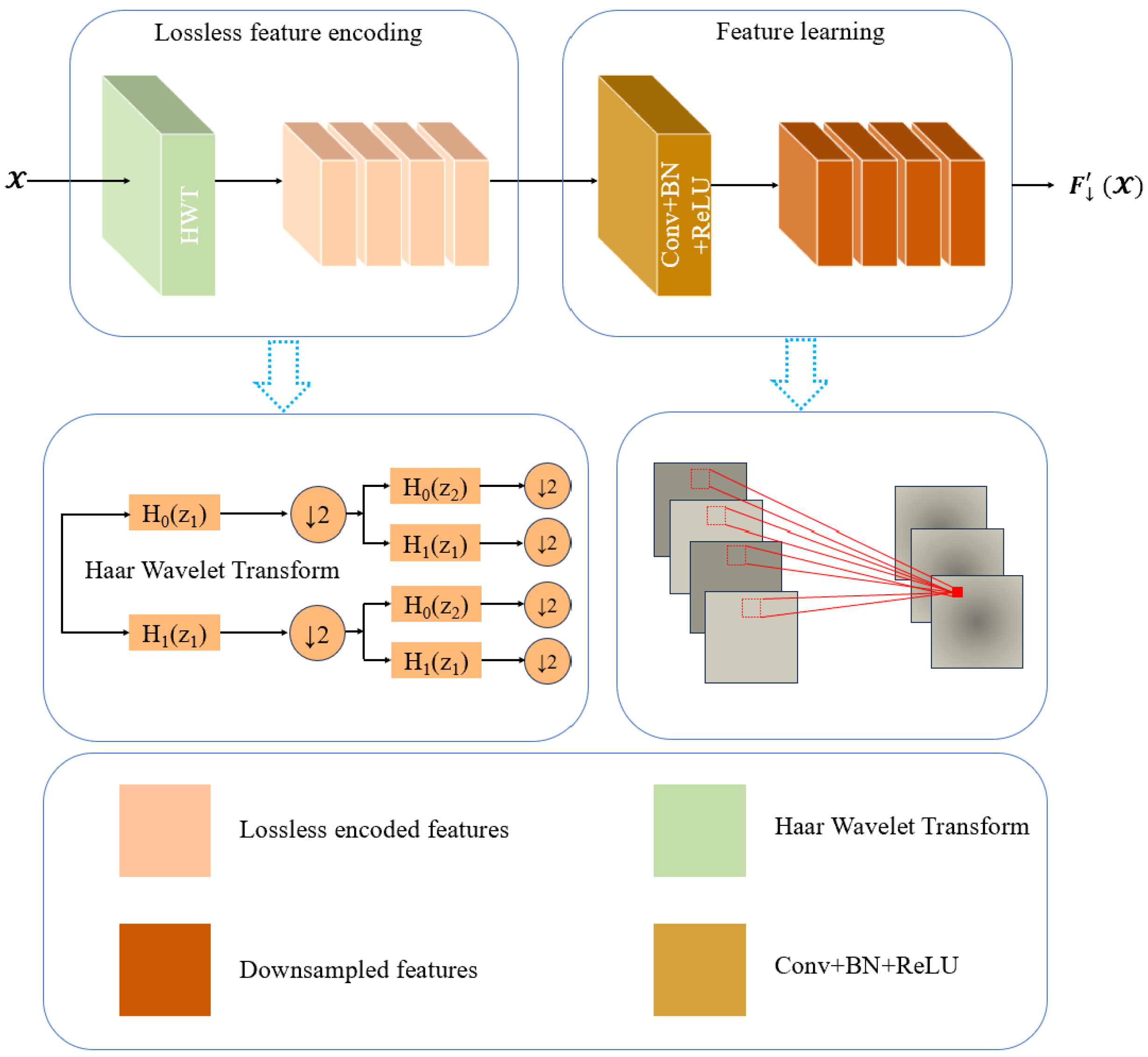
2.7. Haar Wavelet Downsampling
As shown in
Figure 6, the HWD module [
29] used in this paper consists of two blocks: (1) a lossless feature encoding block and (2) a feature representation learning block.
The lossless feature encoding block is responsible for transforming features and reducing spatial resolution. To achieve this, researchers leverage the Haar wavelet transform, a method that efficiently reduces the resolution of feature maps while retaining all information.
The representation learning block consists of a standard convolutional layer, batch normalization, and a ReLU activation layer. It is used to extract discriminative features. By using the wavelet downsampling module, we are able to preserve as much information as possible during downsampling, which enhances the feature fusion process and improves the accuracy.
2.8. Evaluation Metrics
In tasks related to object detection, a set of evaluation metrics is essential. This paper adopts metrics such as the precision, recall, F1-score, and mAP. Precision is defined by the following formula:
Here,
represents the number of correctly detected samples, while
represents the number of samples where the negative class is mistakenly identified as the positive class. Recall is defined by the following formula:
Here,
represents the number of samples where the positive class is erroneously identified as the negative class. Each class has its corresponding precision and recall values. Plotting these two metrics on the same graph yields a precision–recall (P-R) curve. The area under the P-R curve is termed AP, signifying the precision of the object detection algorithm. The mAP is then calculated by averaging the AP values for each class, as shown in the following formula:
Here,
N represents the total number of classes. FPS (frames per second) is a crucial metric for measuring the speed of a model in computer vision tasks, indicating the number of image frames processed per second. In real-time systems, such as object detection or tracking in video streams, FPS serves as a key performance indicator. The calculation of FPS involves measuring the time it takes for the model to process each frame and then determining how many frames can be processed per second. The formula for FPS is as follows:
Here, represents the total time required to process a single image, while , , and denote the time spent on pre-processing, inference, and post-processing, respectively.
3. Experiment and Results
3.1. Training Settings
In the domain of deep learning, the choice of hardware and software can substantially influence experimental outcomes, leading to variations in performance. To facilitate reproducibility and enable other researchers to replicate our experiments, we provide the configuration details utilized in our study, with the results summarized in
Table 4.
Furthermore, the model’s hyperparameters can also affect the experimental results to varying extents [
33,
34]. In our enhanced YOLOv8 model, we trained the network for 200 epochs using a batch size of 16. All input images were resized to 640 × 640 pixels before being fed into the model. The optimizer was set to “auto,” with a random seed of 0, and the close_mosaic parameter was configured to 10.
3.2. Comparison Experiments of Common Lightweight Methods
Currently, there is a large body of research on the lightweight optimization of object detection networks [
35,
36,
37,
38,
39]. Among the most representative approaches are replacing the existing backbone networks with MobileNetv3 and ShuffleNetv2. To highlight the superiority of the backbone network proposed in our Mobile-YOLO, we followed the open-source code provided in [
40] to replace the backbone network of YOLOv8, constructing YOLOv8-MobileNetv3. We then referred to the open-source code in [
41] to build the more lightweight YOLOv8-ShuffleNetv2. Finally, we compared these models with our Mobile-YOLO, and the results are presented in
Table 5.
It can be observed that YOLOv8-MobileNetv3 has the worst lightweight performance, with the lowest mAP and FPS, while its Params and FLOPs are the highest. YOLOv8-ShuffleNetv2 performs better in terms of lightweight optimization, showing excellent results in Params, FLOPs, and FPS. However, our original YOLOv8 already achieves a high mAP value of 80.5%, meaning this lightweight approach significantly impacts accuracy. On the other hand, although our Mobile-YOLO does not perform the best in terms of Params and FLOPs, it achieves a high FPS and an improved mAP compared to YOLOv8. Our method demonstrates a balance between lightweight optimization and accuracy, highlighting the effectiveness of our approach.
In many existing studies, using MobileNetv3 for model lightweighting often yields excellent results. For instance, in [
42], the proposed model was trained and evaluated on a wheat FHB dataset, achieving a high mAP of 97.15% with only 3.64 million parameters and 4.77 billion FLOPs. Compared to the original YOLOv5, these values were reduced by 49.72% and 71.32%, respectively. However, the dataset used in this study was relatively simple, involving only binary classification. As a result, even with significant model lightweighting, it was still possible to retain relatively high accuracy in such straightforward tasks. In contrast, our dataset involves four categories, and the complex underwater environment introduces challenges such as light scattering and a cluttered background, with the targets often exhibiting clustering behaviors. When the number of target categories is too large or when the differences between categories are significant, the model may struggle to effectively learn the features of each category. Our dataset contains morphologically diverse underwater organisms, with targets varying in color, texture, or size. These diverse targets make it difficult for the model to extract features that can sufficiently distinguish between categories. Moreover, the dataset’s background is highly complex, containing many distracting elements or noise, making it harder for the model to extract relevant target information. This background complexity includes natural scenes, cluttered objects, lighting changes, or motion blur, all of which can interfere with target detection, especially when the target-background contrast is low or there is significant occlusion. These factors make our dataset particularly challenging, which is why using MobileNetv3 for lightweighting resulted in poor performance.
ShuffleNetv2 is also widely used in lightweight model research. A previous study [
43] reported that YOLO-WDNet reduced the number of parameters by 82.3%, the model size by 91.6%, and the FLOPs by 82.3%. The proposed method improved the detection mAP by 9.1%, reduced the inference time by 57.14%, and outperformed state-of-the-art algorithms in weed detection. However, similar to MobileNetv3, the dataset used in this study involved binary classification and had relatively low scene noise. One reason ShuffleNetv2 performed poorly on our dataset is the complexity of the data. Another reason is the model’s simplicity, which made it incapable of efficiently extracting and processing features from complex data. A model that is too simple often lacks the capacity to learn the intricate features of complex datasets. Object detection tasks involve extracting features from images and accurately locating and classifying targets, which require a high-performing model. A simple model may fail to capture high-level features such as complex backgrounds, fine details, or varying scales, especially when dealing with tasks involving significant changes in target size or complex image backgrounds. Consequently, a simple model may struggle with such tasks, leading to poor detection performance. Additionally, if the model architecture is too shallow, it may lose significant detail during feature extraction, particularly lower- and mid-level features in the image. Shallow networks often struggle to handle complex visual tasks effectively. The lightweight approaches based on ShuffleNetv2 typically result in shallow networks, which also contributed to the low accuracy observed in our results. In contrast, our Mobile-YOLO model strikes a better balance between accuracy and lightweighting. It achieves high precision while maintaining a lightweight architecture, making it an effective solution for aquatic organism recognition tasks in challenging environments.
3.3. Performance Experiments of Haar Wavelet Downsampling Activation Functions
To achieve better aquaculture monitoring performance while performing lightweight optimization on the model, we conducted a performance comparison of the wavelet downsampling module with various activation functions. The final model tested was our Mobile-YOLO, with the only difference being the activation function used. The test results are shown in
Table 6.
The experimental results indicate that the wavelet downsampling module with the ReLU activation function achieves the highest mAP50 and mAP50-95, as well as the highest FPS. The FPS is the highest for ReLU compared to other activation functions because ReLU is relatively simple. In contrast, the Tanh activation function, due to its complexity, results in the lowest FPS. The other activation functions show varying mAP50 and mAP50-95 values, with FPS remaining similar across them. Due to the outstanding performance of ReLU, we used the ReLU activation function in the wavelet downsampling module for the experiments described in the following sections.
3.4. Ablation Experiments
Table 7 presents the results of the ablation experiments, showing the impact of four components—Mobile-Nano, LDtect, Dysample, and HWD—on the lightweight performance of the model.
The experimental results indicate that the original YOLOv8 achieves the lowest mAP, suggesting that its feature extraction capability is inferior to that of our improved model. Additionally, the original YOLOv8 has the highest number of parameters, the highest complexity, the largest weight file, and the lowest FPS, indicating that it is the most complex model. After replacing the backbone network with Mobile-Nano, the model’s accuracy, i.e., the mAP, improved to 81.9%, while other lightweight metrics were also enhanced. Replacing the detection head with LDtect led to a slight decrease in mAP. This accuracy loss is the cost of reducing the three convolutions in the original detection head to one; however, the lightweight effect was significant, with Params reduced by 29.2%, FLOPs decreased by 27.2%, FPS increased by 51.9%, and Weights reduced by 28.0%. Continuing with the replacement of the feature fusion module’s upsampling block with Dysample, our model’s accuracy increased, but the lightweight performance slightly declined. Finally, replacing the downsampling block in the feature fusion module with HWD achieved the highest accuracy, with an mAP of 82.1%. At the same time, the model achieved the lightest performance, with Params reduced by 32.2%, FLOPs reduced by 28.4%, FPS increased by 95.2%, and Weights reduced by 30.8%.
Overall, our model strikes a balance between accuracy and lightweight performance, reaching an advanced level suitable for mobile devices for aquatic organism recognition.
3.5. Comparison Experiments with Popular Models
To further validate the performance advantages of our proposed model for aquatic organism recognition, we trained several popular neural networks [
44,
45,
46,
47,
48,
49,
50,
51,
52,
53,
54], with the performance of different models shown in
Table 8.
The results demonstrate that among these models, our Mobile-YOLO achieves the highest accuracy and FPS, while the Params, FLOPs, and Weights metrics are the second-best. The model with the smallest Params is YOLOv9t; however, its FPS is relatively low in this comparison. The model with the smallest FLOPs is EfficientDet, but its accuracy is quite low, with an mAP of only 56.42%. This is because our dataset contains a significant amount of underwater noise, and the EfficientDet model struggles to capture key features, mistaking noise for targets, leading to lower accuracy. YOLOv5n has the smallest Weights, and its other lightweight metrics also perform well, but its accuracy is not high enough.
Among these popular models, our Mobile-YOLO achieves high accuracy along with excellent lightweight metrics, highlighting its significant potential for aquatic organism recognition applications.
3.6. Model Detection Performance
The primary function of heatmaps is to provide interpretability for deep learning models, helping us understand the basis behind the model’s decision-making. In the visualized heatmaps, the intensity of the colors indicates which parts of the image contributed to the prediction of a specific classification label.
Figure 7 illustrates several heatmaps generated from our detection results.
In the first column, based on the ground-truth labels, it is clear that the YOLOv8 model failed to focus on two of the objects, as these objects are represented with a color intensity of zero in the heatmap. This indicates that the model did not successfully attend to these two objects, resulting in missed detections. This issue primarily arose because the objects blended into the background, making them hard to distinguish. Specifically, the model misclassified a starfish as a rock and an urchin as a shadowed area formed between rocks. In contrast, Mobile-YOLO successfully attended to all four objects in the image, differentiating the targets from the background and effectively avoiding missed detections. In the second column, the YOLOv8 model showed insufficient focus on the target, which could result in lower confidence scores since the model’s certainty about the target’s presence would be reduced. Furthermore, although the ground truth indicates only one target, the model generated additional attention outside of the target, suggesting a false positive. The lower color intensity in the heatmap is due to the similarity between the sea cucumber and the soil, making it difficult to distinguish. While the model did identify the target, the low certainty led to a lower confidence score. We believe that this false positive was caused by the model’s inadequate feature extraction capabilities and significant background interference, both contributing to the error. In contrast, the heatmap generated by our Mobile-YOLO model displayed deeper colors, predominantly red, indicating a much stronger focus on the target, which results in higher confidence in the detection outcome. Additionally, our model did not generate any extra attention outside of the ground-truth label, thereby avoiding false positives. This demonstrates the model’s superior feature extraction ability and its robust capability to distinguish between objects and the background. In the third column, neither our model nor the YOLOv8 model successfully attended to all the targets, and both incorrectly generated attention on the background, leading to varying degrees of false positives.
Figure 8 illustrates the detection results of different models.
From
Figure 8, it can be observed that in the first column, the YOLOv8 model exhibited a significant number of missed detections, while our model successfully detected all the targets. The number of missed detections in
Figure 8 is inconsistent with those in
Figure 7, where
Figure 7 shows more missed detections, though in reality, only one target was missed. This discrepancy might be due to less distinct color mapping, causing the target to blend into the background. However, the deeper color in our model’s heatmap indicates that it has a higher level of confidence for this target, as evidenced by the higher confidence scores in
Figure 8. In the second column, the YOLOv8 model produced a false detection, whereas our model avoided this issue. Furthermore, the deeper color of the target in
Figure 7 corresponds to the higher confidence score shown in the detection result in
Figure 8. In the third column, neither model successfully detected the target. We believe this is due to the presence of noise. In the future, we plan to investigate methods to denoise underwater images to ensure more accurate detection results. Finally, in
Figure 9, we present several detection results from our model.
In
Figure 10, we present several failure cases. In the first column of comparison images, our model successfully identified all true targets but mistakenly classified a portion of the background as potential objects. A similar issue occurred in the second column, where false positives and missed detections were observed. The third column also demonstrates a case of missed detection. We attribute these failures to the visual similarity between the background and the target objects. For instance, shadows or other background elements may share similar shapes and colors with Echinus, leading the model to make inevitable false or missed detections—errors that even experienced fishermen might encounter. In the missed detection shown in the second column, the target object exhibits relatively distinct features, which suggests that the feature extraction capability of our model still has room for improvement. In future work, we plan to explore more effective feature extraction architectures to reduce the occurrence of such failures.
5. Conclusions and Future Work
In response to the challenge of real-time aquatic organism recognition in underwater environments, this paper proposes a lightweight yet highly accurate Mobile-YOLO model. We introduced the lightweight Mobile-Nano backbone network, which is more efficient and capable of stronger feature extraction compared to the original YOLOv8 backbone. We simplified YOLOv8’s complex detection head by optimizing its redundant convolutional structures, resulting in a more lightweight detection head, LDtect. Additionally, we optimized the feature fusion structure of YOLOv8 by incorporating a more advanced upsampling strategy, Dysample, which designs upsampling from a point-sampling perspective, enhancing the resource efficiency and yielding impressive performance improvements. We also employed Haar wavelet downsampling (HWD) to reduce the spatial resolution of feature maps while preserving as much information as possible. Our model achieved an mAP of 82.1%, an FPS of 416.7, with only 2.04 M Params, 5.8 G FLOPs, and a weight size of 4.13 MB. These results indicate that our model is well-suited for mobile deployment and contributes significantly to the research on lightweight models for aquatic organism recognition. Meanwhile, the improvement in accuracy contributes to producing higher-quality results in tasks such as marine species monitoring, conservation efforts, and biodiversity assessment.
The method proposed in this study demonstrates not only strong performance metrics in experimental evaluations but also considerable practical value and engineering feasibility. In future work, this approach can be further extended to support a broader range of object categories and multimodal information fusion, thereby enhancing its environmental adaptability and detection robustness. With the continued advancement of embedded hardware and edge computing technologies, the proposed method holds great promise for deployment on intelligent underwater equipment, unmanned surface platforms, and remote environmental monitoring systems, enabling real-time and efficient automated perception tasks. Moreover, it offers wide application potential in areas such as marine ecological monitoring, intelligent aquaculture management, autonomous underwater robotic fishing, and aquatic species population studies, indicating a broad development prospect and strong potential for real-world adoption.
Our study still has certain limitations. First, the dataset we used contains only a little over 5000 images, and there is room for further expansion. Demonstrating the mAP improvement of our model on a larger dataset would provide more statistically significant results. Second, we lack practical deployment experiments. In future work, we will focus on addressing these two aspects. Finally, the mAP of our model was improved by 1.6%; however, due to time constraints, we were unable to conduct a statistical significance analysis. In future work, we plan to strengthen our investigation in this area.
In future work, we plan to explore how to leverage large amounts of unannotated RGB images for depth estimation, as well as develop data augmentation techniques to improve underwater image quality.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}