Transdisciplinary AI Observatory—Retrospective Analyses and Future-Oriented Contradistinctions



{kind=link}
{kind=link}
Abstract
:1. Motivation
2. Simple AI Risk Taxonomy
3. Retrospective Descriptive Analysis (RDA)
3.1. Aims and Limitations
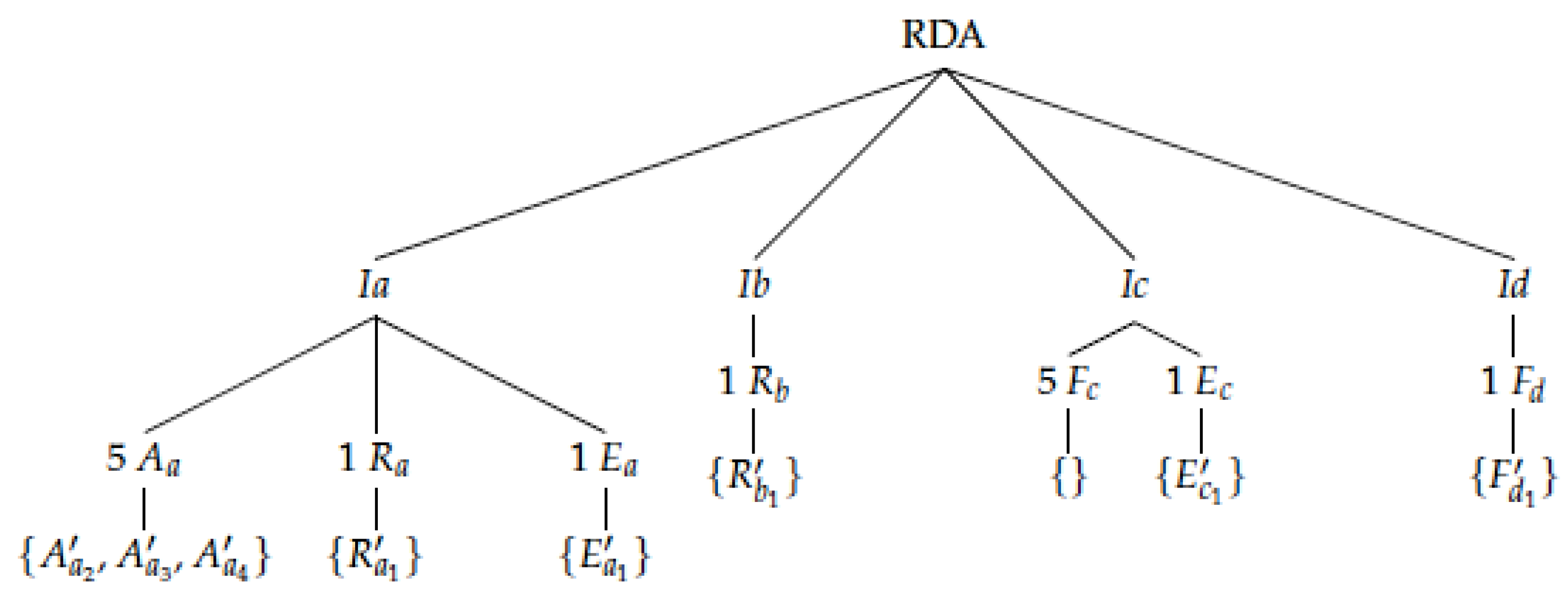
3.2. RDA for AI Risk Instantiations Ia and Ib—Examples
3.3. RDA for AI Risk Instantiations Ic and Id—Examples
4. Retrospective Counterfactual Risk Analysis (RCRA)
4.1. Aims and Limitations
4.2. Preparatory Procedure
4.3. Exemplary RDA-Based RCRA for AI Observatory Projects
4.3.1. Downward Counterfactual DF Narrative
- Adversarial Goals: AI-aided defamation, revenge, harassment and sextortion.
- Adversarial Knowledge: Since it is a malicious stakeholder that is designing the AI, the system is available to this adversary in a transparent white-box setting. Concerning the knowledge pertaining to the human target, a grey-box setting is assumed. Open-source intelligence gathering and social engineering are exemplary tools that the adversary can employ to widen its knowledge of beliefs, preferences and personal traits exhibited by the victim.
- Adversarial Capabilities: In the following, we briefly speak to exemplary plausible counterfactuals of at least lethal nature that malicious actors could have been capable to bring about and that are “worse than what actually happened” [14] (as per RDA). For defamation purposes, it would have been for instance possible to craft AI-generated fake samples that wrongly incriminate victims with not actually executed actions (e.g., a fake homicide but also fake police violence) leading to a subsequent assassination when deployed in precarious milieus with high criminality. To enact revenge with lethal consequences in socio-cultural settings that particularly penalize the violation of restrictive moral principles, similar AI-based methods could have been applicable (e.g., via deepfakes assumingly displaying fake adultery or contents linked to homosexuality). An already instantiated form of AI-enabled harassment mentioned in the RDA consists in sharing fake AI-generated video samples of pornographic nature via social media channels [34]. Consequences could include suicide of vulnerable targets (as generally in cybervictimization [122]) or exposure to a lynch mob. In fact, the contemplation of suicide by deepfake pornography targets has already been reported lately [33]. Finally, concerning AI-supported sextortion, warnings directed to teenagers and pertaining to the convergence of deepfakes and sextortion have been formulated recently [123]. Given the link between sextortion and suicide associated with motifs such as i.a. hopelessness, humiliation and shame [124], consequences of technically feasible but not yet instantiated deepfake sextortion scams could also include suicide—next to simplifying this criminal enactment by adding automatable elements.
4.3.2. Downward Counterfactual DF Narrative
- Adversarial Goals: AI-aided misinformation and disinformation.
- Adversarial Knowledge: Identical to adversarial knowledge indicated in Section 4.3.1.
- Adversarial Capabilities: Technically speaking, a malicious actor could have crafted misleading and disconcerting fake AI-generated material that could be interpreted by extreme endorsers of pre-existing misguided conspiracy theories as providing evidence for their beliefs inciting them to subsequent lethal violence. A historical precedent of gun violence as reaction to fake news seemingly confirming false conspiracy theories was the Pizzagate shooting case where a young man fired a rifle in a pizzeria “[...] wrongly believing he was saving children trapped in a sex-slave ring” [125]. Beyond that, when it comes to (micro-)targeted [91] disinformation, conceivable malicious actors could have more systematically already employed hazardous AI-aided information warfare [96] techniques in social media. This could have been supported by AI-enabled psychographic targeting tools [91] and via networks of automated bots [96,126] partially concealed via AI-generated artefacts such as fake profile pictures. While the level of sophistication of many present-day social bots is limited [127], more sophisticated bots emulating a breadth of human online behavior patterns are already developed [128,129] and it is known for some time [130] that “[...] political bots exacerbate political polarization” [131]. By AI-aided microtargeting of specific groups of people that are ready to carry out violent acts, malicious actors could have caused more political unrest with major lethal outcomes. In fact, Tim Kendall who was a prior director of monetization at Facebook recently stated more broadly that “[...] one possible near-term effect of online platforms’ manipulative and polarizing nature could be civil war” [92].
4.3.3. Downward Counterfactual DF Narrative
- Adversarial Goals: AI-aided non-consensual voyeurism.
- Adversarial Knowledge: Identical to adversarial knowledge indicated in Section 4.3.1.
- Adversarial Capabilities: Before delving into downward counterfactuals that corresponding malicious actors could have already brought about, it is important to note that the goal considered in this cluster is not primarily the credibility or appearance of authenticity exhibited by the synthetic AI-generated contents. Rather, the focus when visually displaying the target non-consensually in compromising settings is more on feeding personal fantasies or facilitating a demonstration of power [37,38] while the synthetic samples can obviously concurrently be shared via social media channels. Against this backdrop, it is not difficult to imagine that when editing visual material of vulnerable targets with practices such as deep-learning based “undressing” [38], a disclosure could induce motifs of hopelessness, humiliation and shame in some of those individuals provoking suicidal attempts similar to the hypothetical deepfake sextortion counterfactual described in Section 4.3.1. The mere sensing of having been victimized via non-consensual deepfake pornography has also been associated with the perception of a “digital rape” [33,132]. Especially when the victims are underage [38], this could plausibly reinforce suicidal ideation. Another dangerous avenue may be subtle combination possibilities available to the malicious actor. Non-consensual voyeuristic (but also more generally abusive) illegal but quasi-untraceable material bypassing content filters could be meticulously concealed with deepfake technologies and unnoticedly propagated5 for some time. This could hinder criminal prosecution and particularly threaten the life of vulnerable young victims. Potentiated with automated disconcertion, it could cause a set of latent lethal socio-psycho-technological risks.
4.3.4. Downward Counterfactual DF Narrative
- Adversarial Goals: Research on malevolent AI.
- Adversarial Knowledge: Identical to adversarial knowledge indicated in Section 4.3.1.
- Adversarial Capabilities: To begin with, note that in this RCRA cluster, we assume that the research is motivated by malign intentions contrary to the corresponding factual RDA research cluster that is conducted with benign and precautionary intentions by security researchers and white hats as mentioned in Section 3.2. This additional distinction is permissible due to its property as downward counterfactual. By way of illustration, malicious actors could have already performed research on malevolent AI design in the domain of autonomous mobility or in the military domain. They could have developed a novel type of meta-level physical adversarial attacks on intelligent systems6 directly utilizing other physically deployed intelligent systems under their control. Such an attacker-controlled intelligent system could be employed as a new advanced form of present-day physical adversarial examples [60,69,134,135,136,137] against a selected victim intelligent system. The maliciously crafted AI could have been designed to optimize on physically fooling the victim AI system once deployed in the environment for example, via physical manipulations at the sensor level such as to misleadingly bring about victim policies with lethal consequences entirely unintended by the operators of the victim model. A further concerning instance of malign research could have been secretive or closed-source research on automated medical AI forgery tools that add imperceptible adversarial perturbations to inputs such as to cause tailored customizable misclassifications. While the vulnerability of medical AI to adversarial attacks is already known [62,63,64,65,138] and could be exploited by actors intending medical fraud for example, for financial gains, certain exertions of this practice in the wrong settings could be misused as tool for murder attempts and targeted homicides.
4.3.5. Downward Counterfactual DF Narrative
- Adversarial Goals: This extra cluster of automated disconcertion refers to a risk pattern that emerged automatically from the mere availability and proliferation of deepfake methods in recent years. However, it is conceivable that this AI-related agentless automatic pattern can be intentionally instrumentalized in the service of other (not necessarily AI-related) primary adversarial goals. One example for a primary adversarial goal cluster in the light of which it is appealing for a malicious actor to strategically harness automated disconcertion, would be information warfare and agitation on social media. In fact, early cases may already occur [50].
- Adversarial Knowledge: Identical to adversarial knowledge indicated in Section 4.3.1.
- Adversarial Capabilities: The use of social media in information warfare has been described to be linked to the objective to intentionally blur the lines between fact and fiction [91]. The motif of automated disconcertion itself could be weaponized and misleadingly framed as providing evidence for post-truth narratives offering an ideal breeding ground for global political adversaries performing information warfare via disinformation. Malicious actors could then intensify this framing with the use of pertinent AI technology enlarging their adversarial capabilities as described earlier under the cluster of AI-aided misinformation and disinformation in Section 4.3.2. Given that automated disconcertion may aggravate pre-existing global strategically maintained confusions [139], it becomes clear that a more effective incitement to lethal violence, political unrest with major lethal outcomes or civil wars could be achieved.
4.3.6. Downward Counterfactual DF Narrative
- Adversarial Goals: Research on vulnerabilities of deployed AI systems.
- Adversarial Knowledge: Grey-box setting (partial knowledge of AI implementation details).
- Adversarial Capabilities: As analogously described in Section 4.3.4, we assume that the research is conducted with malicious intentions. Zero-day exploits of vulnerabilities in (semi-)autonomous mobility and cooperative driving settings to trigger extensive fatal road accidents seem realizable.
4.3.7. Downward Counterfactual DF Narrative
- Designer Goals: Although automated peer pressure refers to an agentless self- perpetuating mechanism that emerged through AI-empowered (micro-)targeting7 on social media, its origins can certainly be traced back to the original benign or neutral economic intentions underlying the early design of social media platforms. Psychologist Richard Freed called present-day social media an “attention economy” [90] and it is plausible that social media profits from the maximization of utilization time spent by their users.
- Knowledge Gaps: Early social media designers may not have foreseen the far-reaching consequences of the designed socio-technological artefacts including threats of lethal dimension or even existential caliber according to some present-day viewpoints [92].
- Unintended Failures: The more attention users pay to social media contents, the more time they may spend with like-minded individuals (consistent with homophily8 [91,96]) and the more they may be prone to automated peer pressure. The latter can an also be partially fueled by social bots aggravating polarization [131]. The bigger the success of information warfare and targeted disinformation on social media and the higher the performance of the AI technology empowering it, the more groups of like-minded peers could (but of course not necessarily) uptake misleading ideas. Individuals could then—via these repercussions—sense a social pressure to suppress their critical thinking and get accustomed to simply copy in-group narratives irrespective of their contents. This scenario could in turn play into the hands of malicious actors of the type mentioned in Section 4.3.5 and raise the amount and intensity of the lethal and catastrophic scenarios of the sort described in Section 4.3.2.
4.3.8. Downward Counterfactual DF Narrative
- Designer Goals: Implementation of high-performance AI.
- Knowledge Gaps: Designers cannot predict the emergence of yet unknown global risks for which no scientific explanatory framework exists (otherwise that would contradict the fundamental unpredictability of future knowledge creation mentioned in Section 4.1). Given that the past does not contain data patterns of yet never instantiated hazards, the datasets utilized to train “high-performance” AI cannot already have these eventualities reflected in their metrics.
- Unintended Failures: Exemplary failures that resulted from this unavoidable type of knowledge gap, are multiple post-COVID AI performance issues [138,153,154]. Simultaneously, humanity relies more and more on medical AI systems. Would humans have been confronted with a more aggressive type of yet unknown biological hazard requiring even faster reactivity, it is conceivable that under the wrong constellations, the AI systems optimizing on metrics pertaining to the then deprecated old or on the novel but yet too scarce and thus biased datasets [154] could have led to unreliable policies up to the potential of a major risk.
5. Discussion
5.1. Hybrid Cognitive-Affective AI Observatory—Transdisciplinary Integration and Guidelines
5.1.1. Near-Term Guidelines for Risks Ia and Ib
RDA
- : Clearly, for risk Ia instances of adversarial cluster 1 related to the misuse of generative AI to facilitate cybercrimes (e.g., via impersonation within social engineering phone calls), already known security measures regarding identity check are needed as minimum requirement. A standard approach to mitigate dangers of malevolent impersonation [155] is to go beyond something you are (biometric) [156], and to also require something you know (password) [157] and/or something you have (ID card). Generally, an awareness-raising training of users and employees on social engineering methods including the novel combination possibilities emerging from malicious generative AI design seems indispensable. In addition, it may be helpful to systematically complement those measures with old-fashioned but potentially effective pre-approved but updatable private arrangements made offline which can also employ offline elements for identity check. For instance, the malicious actor may not be able to react appropriately in real-time if presented with a from his perspective semantically unintelligible inspection question making use of offline pre-agreed upon (dynamically updated) linguistically ciphered insider idioms. The induced confusion could consequently help to dismantle the AI-aided impersonation attempt. Having said this, it is important to analyze the attack surface that the availability of voice cloning and even video impersonation with generative AI brings about when instrumentalized for attacks against widespread voice-based or video-based authentication methods.
- : This cluster pertaining to AI-aided defamation, harassment, revenge and sextortion exhibits the need for far-reaching legislatures for the protection of potential victims. Legal frameworks but also social media platforms may need to counteract large-scale propagation of material that threatens the safety of targeted entities. Social services could initiate emergency call hotlines for dangerous deepfake victimization. Moreover, the creation of (virtual or physical) local temporary shelters or havens for affected individuals combining a team of transdisciplinary experts and volunteers for acute phases immediately succeeding the release of compromising material on social media channels appears recommendable. However, the initiation of a societal-level debate and education could foster destigmatization of deepfake instrumentalized for defamation, harassment and revenge. It could dampen the effects of widely distributed compromising material once the general public looses interest in such currently salient elements. More broadly, educating the public about the capabilities of deep-fake technology could be helpful in mitigating defamation, harassment and sextortion since just like society learned to deal with fake Photoshop images, society can also learn scepticism towards AI-generated content.
- : AI-aided misinformation and disinformation represents a highly complex socio-psycho-technological threat landscape that needs to be addressed at multiple levels using multi-layered [158] approaches. For instance, in a recent work addressing the malicious applications of generative AI and corresponding defenses, Boneh et al. [128] provide a list of directly or indirectly concerned actors: “authors of fake content; authors of applications used to create fake content; owners of platforms that host fake content software; educators who train engineers in sensitive technologies; manufacturers and authors who create platforms and applications for capturing content (e.g., cameras); owners of data repositories used to train generators; unwitting persons depicted in fake content such as images or deepfakes; platforms that host and/or distribute fake content; audiences who encounter fake content; journalists who report on fake content; and so on”. Crucially, as further specified by the authors, “a precise threat model capturing the goal and capabilities of actors relevant to the system being analyzed is the first step towards principled defenses” [128]. In fact, as briefly adumbrated in Section 4.3, the format of the RDA-based RCRA-DFs we proposed for risk Ia and Ib was purposefully instantiating exactly that—a threat model. Overall, we thus recommend grounding the development of near-term AI safety defenses (as applied to AI-aided disinformation but also more generally) in RDA-based RCRA-DFs that can be once generated potentially retroactively diversified by novel DF narrative instances tailored to the exemplary actors mentioned by Boneh and collaborators. This could broaden the RCRA results and allow for an enhanced targeted development of countermeasures.
- : For this AI-aided form of non-consensual voyeurism, the measures of an emergency hotline and a specialized haven as mentioned under cluster are likewise applicable. Legislators need to be informed on psychological consequences especially for underage victims. While cluster implied the overt public dissemination of compromising material by what minor individuals would be less at risk given the potential repercussions, the purely voyeuristic case can often be covert and attracts motivational profiles that can target minor individuals [38]. In addition, it might be valuable to proactively inform the general public and also adult population groups susceptible to this issue in order to lift the underlying taboos and to mitigate negative psychological impacts. In the long run, instantiations of this cluster are unlikely to be prevented any more than one can prevent someone fantasizing about someone else. Hence, in the age of fake generative AI artefacts with the virtualization of fake acts of heterogeneous nature normally violating physical integrity in the real-world, it might become fundamentally important to re-assess and/or update societal notions intimately linked to virtual, physical and hybrid body perception in a critical and open dialogue.
- : With regard to AI-aided espionage, companies and public organizations in sensitive domains need to broadly create awareness especially related to the risk of fake accounts with fake but real appearing profile pictures. For instance, since the generator in a generative adversarial network (GAN) [159] is by design imitating features from a given distribution, advanced results of a successful procedure could appear ordinary and more typical—potentially facilitating a psychologically-relevant intrinsic camouflaging effect. In effect, according to a recent study focused on the human perception of GAN pictures displaying faces of fake individuals that do not exist, “[...] GAN faces were more likely to be perceived as real than Real faces”9 [160]. Beyond that, the authors described an increased social conformity towards faces perceived as real independently of their actual realness. This is concerning also in the light of the extra cluster of automated peer pressure that could make AI-aided espionage easier. A generic trivial but often underestimated guideline that may also apply to AI-aided open-source intelligence gathering would be to reduce the sharing of valuable information assets via social media channels and more generally on publically available sources to a minimum. Finally, to confuse person-tracking algorithms and prevent AI-aided surveillance misused for espionage, camouflage [161] and adversarial patches [60] embedded in clothes and accessoires can be utilized.
- : As deep-fake technology proliferates and is used in numerous criminal domains, it is conceivable that an arms-race between malevolent fakers and AI forensic experts [162,163] will ensue, with no permanent winner. Given that this cluster covers a wide variety of research domains in which security researchers and white hats attempt to preemptively emulate malicious AI design activities to foster safety awareness, a consequential recommendation appears to actively support such research at multiple scales of governance. Talent in this adversarial field would need to be attracted by tailored incentives and should not be limited to a standard sampling from average sought-after skill profiles in companies, universities and public organizations of high social reputation. This may also help to avoid an undesirable drift to adversaries for instance at the level of information operations risking reinforcing capacities mentioned in the downward counterfactual DF narratives on cluster , and presented in Section 4.3. Hence, a monolithic approach in AI governance with a narrow focus on ethics and unintentional ethical failures is insufficient [13]. Finally, we briefly address guidelines related to a specific issue concerning science (as asset of invaluable importance for a democratic society [164]) that did not yet gain attention in AI safety and AI governance but that makes further inspections appear imperative in the near-term. Namely, targeted studies on AI-aided deception in science to produce AI-generated text disseminated as fake research articles (see the research prototype developed by Yampolskiy [46] in another research context) and possibly AI-generated audiovisual or other material meant to display fake experiments or also fake historical samples (see the recent MIT deepfake demonstration [165] developed for educative purposes). However, this technical research direction requires a supplementation by transdisciplinary experts addressing the socio-psycho-technological impacts and particularly the epistemic impacts of corresponding future risk instantiations. We suggest that for a safety-relevant sense-making, AI governance may even need to stimulate debates and exchanges on the very epistemological grounding of science—before for example, future texts written by maliciously designed sophisticated AI bots (also called sophisbots [128]) infiltrate the scientific enterprise with submissions that go undetected. For instance, there is a fundamental discrepancy10 between how Bayesian and empiricist epistemology would analyze this risk vs. how Popperian critical rationalist epistemology would view the same risk. Disentangling this epistemic issue is of high importance for AI safety and beyond as becomes apparent in the guidelines linked to the next cluster below.
- : Near-term guidelines to directly tackle this extra cluster associated to automated disconcertion seem daunting to formulate. However, as a first small step, one could focus on how to avoid exacerbating it. One reason why this cluster may seem difficult to address is due to its deep and far-reaching epistemic implications pertaining to the nature of falsification, verification, fakery and (hyper-)reality [169] itself. With regard to this feature of epistemic relevance, exhibits a commonality with the just introduced different risk of AI-aided deception in science. We postulate that in the light of pre-existing fragile circumstances in the scientific enterprise including the emergence of modern “fake science” [170] patterns but also the mentioned fundamental discrepancies across epistemically-relevant scientific stances, AI-aided deception in science could have direct repercussions on automated disconcertion. First, it could for instance unnecessarily aggravate automated disconcertion phenomena in the general public as for example, the belief in epistemic threats [166] could increase people’s subjective uncertainty. Second, a reinforced automated disconcertion can subsequently be weaponized and instrumentalized by malicious actors with lethal consequences as generally depicted under the downward counterfactual DF narrative described in Section 4.3. This explains our near-term AI governance recommendation to address AI-aided deception in science as transdisciplinary collaborative endeavor analyzing socio-psycho-technological and epistemic impacts.
- : For this cluster linked to risk Ib and pertaining to research on AI vulnerabilities currently performed by security researchers and white hats, we recommend (as analogously already explained in ) to recruit such researchers preemptively. In this vein, Aliman [13] proposes to “organize a digital security playground where “AI white hats” engage in adversarial attacks against AI architectures and share their findings in an open-source manner”. For the specific domain of intelligent systems, it is advisable to proactively equip these AIs with technical self-assessment and self-management capabilities11 [20] allowing for better real-time adaptability for the eventuality of attack scenarios known from past incidents or proof-of-concept use cases studied by security researchers and white hats. However, it is important to keep in mind that challenges from this cluster also deal with zero-day AI exploits, they are the unknown unknowns and cannot be meaningfully anticipated and prevented, though it is realized that many issues could be caused by under-specification in machine learning systems [171].
RCRA (Additional Non-Overlapping Guidelines)
- : Generally, one possible way to systematically reflect upon defense methods for specific RCRA instances (generated from downward counterfactual clusters) of harm intensity , could be to perform corresponding upward counterfactual deliberations targeting a harm intensity . As briefly introduced in Section 4.1, upward counterfactuals refer to those ways in which a certain event could have turned out better but did not. Recently, Oughton et al. [172] applied a combination of downward and upward counterfactual stochastic risk analyis to a cyber-physical attack on electricity infrastructure. In short, the difference to the method that we propose is that instead of focusing on slightly better upward counterfactuals given the factual event as made sense in the case of Oughton et al., we suggest a threshold-based selection of below threshold upward counterfactuals given above threshold downward counterfactuals12. For instance, as applied to the present downward counterfactual cluster which also included a narrative instance describing suicide attempts with lethal outcomes as a consequence of AI-aided defamation, harassment and revenge, it could simply consist in deliberations on how to avoid these lethal scenarios. This could be implemented by deliberating from the perspective of planning a human, hybrid or fully automated AI-based emergency team response with a highly restricted timeframe (e.g., to counteract the domino-effect initiated by the deployment of the deepfake sample on social media). Next to a proactive combination of deepfake detectors and content detectors for blocking purposes that can fail, a reactive automated social network graph analysis AI combined with sentiment analysis tools could be trained to detect large harassment and defamation patterns that if paired with the sharing of audiovisual samples, can prompt a human operator. This individual could then decide to call in social services that in turn proactively contact the target offering support as analogously mentioned under the guidelines for the factual RDA sample .
- : For this downward counterfactual cluster on AI-aided misinformation and disinformation of at least lethal dimensions, we focus on recommendations pertaining to journalism-relevant defenses and bots on social media. Disinformation from fake sources could be counteracted with the use of blockchain-based reputation systems [173] to assess the quality of information sources. Journalists could also entertain a collective blockchain-based repository containing all news-relevant audiovisual deepfake samples whose authenticity has been refuted so far. This tool could be utilized as publically available high-level filter to evade certain techniques of disinformation campaigns. Moreover, the case of hazardous large-scale disinformation supported by sophisticated automated social bots is of high relevance for what one can term social media AI safety. Ideally, tests for a “bot shield” enabling some bot-free social media spaces could be crafted. However, it is conceivable that at a certain point, AI-based bot detection [174] might become futile. Also, social bots already fool people [131,175] and many assume that humans will become unable to discern them in the long-term. Nevertheless, it could be worthwhile viewing what one could have done better already with present technological tools (the upward counterfactuals)—which can also include the consideration of divergent unconventional solutions or novel formulations of questions. As stated by Barrett, “[...] progress in science is often not answering old questions but asking better ones” [176]. Perhaps, in the future, humans could still devise bot shielding tactics that could attempt to bypass epistemic issues [177] intrinsic to imitation game and Turing Test [178] derivatives where “real” and “fake” become relative.
- : To tackle suicidal ideation as a consequence of AI-aided non-consensual voyeurism that enters the awareness of the targeted individual, one may need to extend the countermeasures already mentioned in the factual RDA counterpart of this cluster (which also included the creation of public awareness and the removal of associated taboos). Social services and public institutions like universities and schools could offer emergency psychological interventions for the person at risk. Next to necessitated measures at the level of legal frameworks to protect underage victims, the subtle case of adult targets calls for instance for a civil reporting office collaborating with social media platforms which could initiate a critical dialogue with the other party to bring about an immediate deletion or at least categorical refraining from further dissemination of the material which can be calibrated to the expectations of the target. Recently, the malicious design of deepfakes has been described as a “[...] serious threat to psychological security” [179]. Adult targets may despite the synthetic nature of the deepfake samples and often eventually their private character restricted to a personal possession of the agent in question, perceive their mere existence as degradation [180]—a phenomenon certainly requiring social discourses in the long-term. For a principled analytical approach, an extensive psychological research program integrating a collaboration with i.a. AI security researchers could be helpful in order to be able to contextualize relevant socio-psycho-technological aspects against the background of advanced technical feasibility. Importantly, instead of limiting this research to deepfake artefacts in the AI field, one needs to also cover novel hybrid combination possibilities available for the design of non-consensual voyeuristic material. Notably, this includes blended applications at the intersection of AI and virtual reality [28,37] (or augmented reality [181]).
- : Concerning proactive measures against future research where an adversary designs self-owned intelligent systems to trigger lethal accidents on victim intelligent systems, one might require legal norms setting minimum requirements on the techniques employed for the cybernetic control of systems deployed in public space. From an adversarial AI perspective, this could include the obligation to integrate regular updates on AI-related security patches developed in collaboration with AI security researchers and white hats that also study advanced physical adversarial attacks. This becomes particularly important as many stakeholders are currently unprepared in this regard [182]. As guideline, we propose that future adversarial AI research endeavors explore attack scenarios where adversarial examples on physically deployed intelligent systems are delivered by another physically deployed intelligent system which potentially offers more degrees of freedom to the malicious actor. From a systems engineering perspective, any intelligent system might need to at least integrate multiple types of sensors and check for inconsistencies at the symbolic level. Next to explainability requirements, a further valuable feature to create accountability in the case of accidents could be a type of self-auditing via self-assessment and self-management [20] allowing for a retrospective counterfactual analysis on what went wrong.
- : As its factual counterpart , this counterfactual cluster refering to automated disconcertion instrumentalized for AI-aided information warfare and agitation on social media with the risk to incite lethal violence at large scales, represents a weighty challenge of international extent. As for , multi-level piecemeal tactics of constructive small steps such as for example, targeted methods to avoid exacerbating it may be valuable. Concerning AI governance, that could include the strategies mentioned under but also more general efforts in line with international frameworks that aim to foster strong institutions and error-correction via life-long learning (see e.g., [19] for an in-depth discussion).
- : For this counterfactual cluster pertaining to malicious research on vulnerabilities of deployed AI systems with the goal to trigger extensive fatal road accidents, we recommend tailored measures analogous to those presented for the counterfactual cluster .
5.1.2. Near-Term Guidelines for Risks Ic and Id
RDA
- : This cluster related to automated peer pressure can be i.a. met by measures raising public awareness on the dangers of the confirmation bias [192,193] reinforced via AI-empowered social media. However, a possible upward counterfactual on that issue would be to revert negative consequences of automated peer pressure by utilizing it for beneficial purposes. For instance, it is cogitable that automated peer pressure need not represent a threat would it simply perhaps paradoxically socially reinforce critical thinking instead of reinforcing tendencies to blindly copy in-group narratives. Ideally, such a peer pressure would reinforce heterophily (the antonym of homophily) with regard to various preferences with one notable exception being the critical thinking mode itself. Hence, one interesting future-oriented solution for AI governance may be education and life-long learning [19] conveying critical thinking and criticism as invaluable tools for youth and general public. For instance, critical thinking skills fostered in the Finnish public education system were effective against disinformation operations [91]. In fact, critical thinking, criticism and transformative contrariness may not only represent a strong shield to tackle disinformation or automated disconcertion and its risk potentials (cluster and respectively), but it also represents a crucial momentum for human creativity [13,194]. Generally, peer pressure is in itself a psychological tool that could be systematically used for good, for example by creating an artificial crowd [195] of peers with all members interested in desirable behaviors such as education, start-ups or effective altruism. A benevolent crowd of peers can then counteract hazardous bubbles on social media.
- : Concerning AI failures rooted in unanticipated and yet unknown post-deployment scenarios, it becomes clear that accuracy and other AI performance measures cannot be understood as conclusive and engraved in stone. A possible proactive measure against post-deployment instantiations of yet unknown AI risks could be the establishment of a generic corrective mechanism. Problems which AI systems experience during its deployment due to differences between training and usage environments can be reduced via increased testing and continued updating and learning stages. On the whole, multiphase deployment, similar to vaccine approval phases, can reduce an overall negative impact on society and increase reliability. Finally, for each safety-critical domain in which AI predictions are involved in the decision-making procedure, one could—irrespective of present-day AI performance—foresee the proactive planification of a human response team in case of sudden expanding anomalies that a sensitized and safety-aware human operator could detect.
RCRA (Additional Non-Overlapping Guidelines)
- : A twofold guideline for this counterfactual cluster (refering to automated peer pressure with lethal consequences via automated disconcertion instrumentalized for AI-aided disinformation), could be to weaken the influence of social bots by measures described under cluster and by transforming automated peer pressure into strong incentives for critical thinking as stated in .
- : Finally, for this cluster of major risk dimension being the counterfactual counterpart of cluster , we emphasize the importance of an early proactive response team formation in contexts such as for instance medical AI, AI in the financial market, AI-aided cybersecurity and critical intelligent cyberphysical assets. In short, AI systems should by no means be understood to be able to truly operate independently in a given task even if current excellent performance measures seem to suggest so. In the face of unknown and unknowable changes, performance is a moving target which if mistaken as conclusive and static could endanger human lifes.
5.2. Long-Term Directions and Future-Oriented Contradistinctions
5.2.1. Paradigm Artificial Stupidity (AS)
- Regulatory distinction criterium: In this light, one can extract intelligence (or more broadly “performance” or “cogntive performance” across tasks) as the recurring theme of relevance for regulatory AI safety considerations under the AS paradigm. At a first level, one could identify two main safety-relevant clusters: a cluster comprising all AIs that are less or equally capable than an average human [198] and another cluster of superintelligent AI systems. The latter can be further subdivided into three classes of systems as introduced by Bostrom [203]: (1) speed superintelligence, (2) collective superintelligence and (3) quality superintelligence. According to Bostrom, the first ones “can do all that a human intellect can do, but much faster”, the second ones are “composed of a large number of smaller intellects such that the system’s overall performance across many very general domains vastly outstrips that of any current cognitive system” and the third ones are “at least as fast as a human mind and vastly qualitatively smarter” [203].
- Regulatory enactment: In a nutshell, AS recommends limiting an AI in hardware and software such that it does not attain any of these enumerated sorts of superintelligence since “[...] humans could lose control over the AI” [197]. AS foresees regulatory strategies on “how to constrain an AGI to be less capable than an average person, or equally capable, while still exhibiting general intelligence” [198].
- Substrate management: To limit AI abilities while maintaining functionality, AS proposes multiple practical measures at the hardware and software level. Concerning the former it proposes diverse restrictions especially pertaining to memory, processing, clock speed and computing [198]. With regard to software, it foresees necessary limits on self-improvement as well as measures to avoid treacherous turn scenarios [197]. Another guideline consists in deliberately incorporating known human cognitive biases in the AI system. More precisely, AS postulates that human biases “can limit the AGI’s intelligence and make the AGI fundamentally safer by avoiding behaviors that might harm humans” [197]. Overall, the substrate management in AS can be categorized as substrate-dependent because the artificial substrate is among others specifically tuned to match hardware properties of the human substrate for at most equalization purposes. In summary, AS suscribes to the viewpoint that AI safety aims to “limit aspects of memory, processing, and speed in ways that align with human capabilities and/or prioritize human welfare, cooperative behavior, and service to humans” [196] given that AGI “[...] presents a risk to humanity” [196].
5.2.2. Paradigm Eternal Creativity (EC)
- Regulatory distinction criterium: EC distinguishes two substrate-independent and disjunct sets of systems: Type I and Type II systems. Type II systems are all systems for which it is possible to consciously create and understand explanatory knowledge. Type I systems are all systems for which this is an impossible task 15. Thereby, a subset of Type I systems can be conscious (such as non-human mammals) and requires protection akin to animal rights. Obviously, all present-day AI systems are of Type I and non-conscious. Type II AI is non-existent today.
- Regulatory enactment: In theory, with a Type II AI, “a mutual value alignment might be achievable via a co- construction of novel values, however, at the cost of its predictability” [13]. As with all Type II systems (including humans), the future contents of the knowledge they will create are fundamentally unpredictable—irrespective of any intelligence class16. In EC, this signifies that: (1) Type II AI is uncontrollable17 and requires rights on a par with humans, (2) Type II AI could engage in a mutual bi-directional value alignment with humans—if it decides so and (3) it would be unethical to enslave Type II AI. (Finally, banning Type II AI is a potential loss of requisite variety and does not hinder malicious actors to do so.) By contrast, regarding Type I AI, EC implies that: (4) Type I AI is controllable, (5) Type I AI cannot be fully value-aligned across all domains of interest for humans due to an insufficient understanding of human morality, (6) conscious Type I AI is possible and would require animal-like rights but it is clearly non-existent nowadays.
- Substrate management: To avoid functional biases [214] due to a lack of diversity in information processing, EC opts for a substrate-independent functional view. Irrespective of its specific substrate composition, an overall panoply of systems is viewed as one unit with diverse functions. Given Type-II-system-defined cognitive-affective goal settings, a systematic function integration can yield complementary synergies. Notably, EC recommends research on substrate-independent functional artificial creativity augmentation [199] (artificially augmenting human creativity and augmenting artificial creativity). For instance, active inference could technically increase Type I AI exploratory abilities [215,216]. Besides that, in Section 6.2, we apply a functional viewpoint to augment RCRA DF generation by human Type II systems for AI observatory purposes.
6. Materials and Methods
6.1. RDA Data Collection
6.2. Interlinking RDA-Based RCRA Pre-Processing and RCRA DFs
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Amodei, D.; Olah, C.; Steinhardt, J.; Christiano, P.; Schulman, J.; Mané, D. Concrete problems in AI safety. arXiv 2016, arXiv:1606.06565. [Google Scholar]
- Dafoe, A. AI governance: A research agenda. In Governance of AI Program; Future of Humanity Institute, University of Oxford: Oxford, UK, 2018. [Google Scholar]
- Everitt, T.; Lea, G.; Hutter, M. AGI safety literature review. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 5441–5449. [Google Scholar]
- Fjeld, J.; Achten, N.; Hilligoss, H.; Nagy, A.; Srikumar, M. Principled artificial intelligence: Mapping consensus in ethical and rights-based approaches to principles for AI. Berkman Klein Cent. Res. Publ. 2020, 1, 2–5. [Google Scholar] [CrossRef]
- Irving, G.; Christiano, P.; Amodei, D. AI safety via debate. arXiv 2018, arXiv:1805.00899. [Google Scholar]
- Turchin, A.; Denkenberger, D.; Green, B.P. Global Solutions vs. Local Solutions for the AI Safety Problem. Big Data Cogn. Comput. 2019, 3, 16. [Google Scholar] [CrossRef] [Green Version]
- The Agency for Digital Italy. Italian Observatory on Artificial Intelligence. 2020. Available online: https://ia.italia.it/en/ai-observatory/ (accessed on 25 April 2020).
- Krausová, A. Czech Republic’s AI Observatory and Forum. Lawyer Q. 2020, 10. [Google Scholar]
- Denkfabrik. AI Observatory. Digitale Arbeitsgesellschaft, 2020. Available online: https://www.denkfabrik-bmas.de/en/projects/ai-observatory (accessed on 28 November 2020).
- OECD.AI. OECD AI Policy Observatory. 2020. Available online: https://oecd.ai/ (accessed on 25 April 2020).
- Yampolskiy, R.V. Predicting future AI failures from historic examples. Foresight 2019, 21, 138–152. [Google Scholar] [CrossRef]
- McGregor, S. Preventing Repeated Real World AI Failures by Cataloging Incidents: The AI Incident Database. arXiv 2020, arXiv:2011.08512. [Google Scholar]
- Aliman, N.M. Hybrid Cognitive-Affective Strategies for AI Safety. Ph.D. Thesis, Utrecht University, Utrecht, The Netherlands, 2020. [Google Scholar]
- Woo, G. Downward Counterfactual Search for Extreme Events. Front. Earth Sci. 2019, 7, 340. [Google Scholar] [CrossRef]
- Roese, N.J.; Epstude, K. The functional theory of counterfactual thinking: New evidence, new challenges, new insights. In Advances in Experimental Social Psychology; Elsevier: Amsterdam, The Netherlands, 2017; Volume 56, pp. 1–79. [Google Scholar]
- Aliman, N.M.; Elands, P.; Hürst, W.; Kester, L.; Thórisson, K.R.; Werkhoven, P.; Yampolskiy, R.; Ziesche, S. Error-Correction for AI Safety. In International Conference on Artificial General Intelligence; Springer: Cham, Switzerland, 2020; pp. 12–22. [Google Scholar]
- Brundage, M.; Avin, S.; Clark, J.; Toner, H.; Eckersley, P.; Garfinkel, B.; Dafoe, A.; Scharre, P.; Zeitzoff, T.; Filar, B.; et al. The malicious use of artificial intelligence: Forecasting, prevention, and mitigation. arXiv 2018, arXiv:1802.07228. [Google Scholar]
- Pistono, F.; Yampolskiy, R.V. Unethical Research: How to Create a Malevolent Artificial Intelligence. arXiv 2016, arXiv:1605.02817. [Google Scholar]
- Aliman, N.M.; Kester, L.; Werkhoven, P.; Ziesche, S. Sustainable AI Safety? Delphi Interdiscip. Rev. Emerg. Technol. 2020, 2, 226–233. [Google Scholar]
- Aliman, N.M.; Kester, L.; Werkhoven, P.; Yampolskiy, R. Orthogonality-based disentanglement of responsibilities for ethical intelligent systems. In International Conference on Artificial General Intelligence; Springer: Cham, Switzerland, 2019; pp. 22–31. [Google Scholar]
- Cancila, D.; Gerstenmayer, J.L.; Espinoza, H.; Passerone, R. Sharpening the scythe of technological change: Socio-technical challenges of autonomous and adaptive cyber-physical systems. Designs 2018, 2, 52. [Google Scholar] [CrossRef] [Green Version]
- Martin, D., Jr.; Prabhakaran, V.; Kuhlberg, J.; Smart, A.; Isaac, W.S. Extending the Machine Learning Abstraction Boundary: A Complex Systems Approach to Incorporate Societal Context. arXiv 2020, arXiv:2006.09663. [Google Scholar]
- Scott, P.J.; Yampolskiy, R.V. Classification Schemas for Artificial Intelligence Failures. Delphi-Interdiscip. Rev. Emerg. Technol. 2020, 2, 186–199. [Google Scholar] [CrossRef]
- Gray, K.; Waytz, A.; Young, L. The moral dyad: A fundamental template unifying moral judgment. Psychol. Inq. 2012, 23, 206–215. [Google Scholar] [CrossRef]
- Schein, C.; Gray, K. The theory of dyadic morality: Reinventing moral judgment by redefining harm. Personal. Soc. Psychol. Rev. 2018, 22, 32–70. [Google Scholar] [CrossRef] [Green Version]
- Gray, K.; Schein, C.; Cameron, C.D. How to think about emotion and morality: Circles, not arrows. Curr. Opin. Psychol. 2017, 17, 41–46. [Google Scholar] [CrossRef]
- Popper, K.R. The Poverty of Historicism; Routledge & Kegan Paul: Abingdon, UK, 1966. [Google Scholar]
- Aliman, N.; Kester, L. Malicious Design in AIVR, Falsehood and Cybersecurity-oriented Immersive Defenses. In Proceedings of the 2020 IEEE International Conference on Artificial Intelligence and Virtual Reality (AIVR), Utrecht, The Netherlands, 14–18 December 2020. [Google Scholar]
- Harwell, D. An Artificial-Intelligence First: Voice-Mimicking Software Reportedly Used in a Major Theft. The Washington Post. 2019. Available online: https://www.washingtonpost.com/technology/2019/09/04/an-artificial-intelligence-first-voice-mimicking-software-reportedly-used-major-theft/ (accessed on 4 August 2020).
- Rohrlich, J. Romance Scammer Used Deepfakes to Impersonate a Navy Admiral and Bilk Widow Out of Nearly $300,000. Daily Beastl. 2020. Available online: https://www.thedailybeast.com/romance-scammer-used-deepfakes-to-impersonate-a-navy-admiral-and-bilk-widow-out-of-nearly-dollar300000 (accessed on 8 November 2020).
- Rushing, E. A Philly Lawyer Nearly Wired $9,000 to a Stranger Impersonating His Son’s Voice, Showing Just How Smart Scammers are Getting. The Philadelphia Inquirer. 2020. Available online: https://www.inquirer.com/news/voice-scam-impersonation-fraud-bail-bond-artificial-intelligence-20200309.html (accessed on 4 August 2020).
- Stupp, C. Fraudsters Used AI to Mimic CEO’s Voice in Unusual Cybercrime Case. Wall Str. J. 2019. Available online: https://www.wsj.com/articles/fraudsters-use-ai-to-mimic-ceos-voice-in-unusual-cybercrime-case-11567157402 (accessed on 4 August 2020).
- Gieseke, A.P. “The New Weapon of Choice”: Law’s Current Inability to Properly Address Deepfake Pornography. Vanderbilt Law Rev. 2020, 73, 1479–1515. [Google Scholar]
- Ajder, H.; Patrini, G.; Cavalli, F.; Cullen, L. The State of Deepfakes: Landscape, Threats, and Impact. Amst. Deep. 2019, 1, 1–15. [Google Scholar]
- Alba, D. Facebook Discovers Fakes That Show Evolution of Disinformation. The New York Times. 2019. Available online: https://www.nytimes.com/2019/12/20/business/facebook-ai-generated-profiles.html (accessed on 4 August 2020).
- Reuters. Deepfake Used to Attack Activist Couple Shows New Disinformation Frontier. Reuters, 2020. Available online: https://gadgets.ndtv.com/internet/features/deepfake-oliver-taylor-mazen-masri-terrorist-accuse-london-university-of-birmingham-student-fake-profile-22640449 (accessed on 8 November 2020).
- Cole, S.; Maiberg, E. Deepfake Porn Is Evolving to Give People Total Control Over Women’s Bodies. VICE. 2019. Available online: https://www.vice.com/en/article/9keen8/deepfake-porn-is-evolving-to-give-people-total-control-over-womens-bodies (accessed on 8 November 2020).
- Hao, K. A Deepfake Bot Is Being Used to “Undress” Underage Girls. MIT Technol. Rev. 2020. Available online: https://www.technologyreview.com/2020/10/20/1010789/ai-deepfake-bot-undresses-women-and-underage-girls/ (accessed on 8 November 2020).
- Corera, G. UK Spies will Need Artificial Intelligence—Rusi Report. BBC. 2020. Available online: https://www.bbc.com/news/technology-52415775 (accessed on 8 November 2020).
- Satter, R. Experts: Spy Used AI-Generated Face to Connect With Targets. AP News. 2019. Available online: https://apnews.com/article/bc2f19097a4c4fffaa00de6770b8a60d (accessed on 4 August 2020).
- Probyn, A.; Doran, M. One Month, 500,000 Face Scans: How China Is Using A.I. to Profile a Minority. ABC News. 2020. Available online: https://www.abc.net.au/news/2020-09-14/chinese-data-leak-linked-to-military-names-australians/12656668 (accessed on 4 August 2020).
- Mozur, P. China’s ‘Hybrid War’: Beijing’s Mass Surveillance of Australia And the World for Secrets and Scandal. The New York Times. 2019. Available online: https://www.nytimes.com/2019/04/14/technology/china-surveillance-artificial-intelligence-racial-profiling.html (accessed on 4 August 2020).
- Neekhara, P.; Hussain, S.; Jere, M.; Koushanfar, F.; McAuley, J. Adversarial Deepfakes: Evaluating Vulnerability of Deepfake Detectors to Adversarial Examples. arXiv 2020, arXiv:2002.12749. [Google Scholar]
- Zang, J.; Sweeney, L.; Weiss, M. The Real Threat of Fake Voices in a Time of Crisis. Techcrunch. 2020. Available online: https://techcrunch.com/2020/05/16/the-real-threat-of-fake-voices-in-a-time-of-crisis/?guccounter=1 (accessed on 8 November 2020).
- O’Donnell, L. Black Hat 2020: Open-Source AI to Spur Wave of ‘Synthetic Media’ Attacks. Threatpost. 2020. Available online: https://threatpost.com/black-hat-2020-open-source-ai-to-spur-wave-of-synthetic-media-attacks/158066/ (accessed on 8 November 2020).
- Transformer, G.P., Jr.; Note, E.X.; Spellchecker, M.S.; Yampolskiy, R. When Should Co-Authorship Be Given to AI? Unpublished, PhilArchive. 2020. Available online: https://philarchive.org/archive/GPTWSCv1 (accessed on 8 November 2020).
- Zhang, F.; Zhou, S.; Qin, Z.; Liu, J. Honeypot: A supplemented active defense system for network security. In Proceedings of the Fourth International Conference on Parallel and Distributed Computing, Applications and Technologies, Chengdu, China, 29 August 2003; pp. 231–235. [Google Scholar]
- Nelson, S.D.; Simek, J.W. Video and Audio Deepfakes: What Lawyers Need to Know. Sensei Enterprises, Inc., 2020. Available online: https://www.masslomap.org/video-and-audio-deepfakes-what-lawyers-need-to-know-guest-post/ (accessed on 8 November 2020).
- Chen, T.; Liu, J.; Xiang, Y.; Niu, W.; Tong, E.; Han, Z. Adversarial attack and defense in reinforcement learning-from AI security view. Cybersecurity 2019, 2, 11. [Google Scholar] [CrossRef] [Green Version]
- Spocchia, G. Republican Candidate Shares Conspiracy Theory That George Floyd Murder Was Faked. Independent. 2020. Available online: https://www.independent.co.uk/news/world/americas/us-politics/george-floyd-murder-fake-conspiracy-theory-hoax-republican-gop-missouri-a9580896.html (accessed on 4 August 2020).
- Hao, K. The Biggest Threat of Deepfakes Isn’t the Deepfakes Themselves. MIT Technol. Rev. 2019. Available online: https://www.technologyreview.com/2019/10/10/132667/the-biggest-threat-of-deepfakes-isnt-the-deepfakes-themselves/ (accessed on 8 November 2020).
- Bilge, L.; Dumitraş, T. Before we knew it: An empirical study of zero-day attacks in the real world. In Proceedings of the 2012 ACM Conference on Computer and Communications Security, Raleigh, NC, USA, 16–18 October 2012; pp. 833–844. [Google Scholar]
- Carlini, N.; Wagner, D. Adversarial examples are not easily detected: Bypassing ten detection methods. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 3–14. [Google Scholar]
- Carlini, N. A Partial Break of the Honeypots Defense to Catch Adversarial Attacks. arXiv 2020, arXiv:2009.10975. [Google Scholar]
- Papernot, N.; McDaniel, P.; Sinha, A.; Wellman, M. Towards the science of security and privacy in machine learning. arXiv 2016, arXiv:1611.03814. [Google Scholar]
- Tramer, F.; Carlini, N.; Brendel, W.; Madry, A. On adaptive attacks to adversarial example defenses. arXiv 2020, arXiv:2002.08347. [Google Scholar]
- Kirat, D.; Jang, J.; Stoecklin, M. Deeplocker–Concealing Targeted Attacks with AI Locksmithing. Blackhat USA 2018, 1, 1–29. [Google Scholar]
- Qiu, H.; Xiao, C.; Yang, L.; Yan, X.; Lee, H.; Li, B. Semanticadv: Generating adversarial examples via attribute-conditional image editing. arXiv 2019, arXiv:1906.07927. [Google Scholar]
- Carlini, N.; Farid, H. Evading Deepfake-Image Detectors with White-and Black-Box Attacks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 658–659. [Google Scholar]
- Xu, K.; Zhang, G.; Liu, S.; Fan, Q.; Sun, M.; Chen, H.; Chen, P.Y.; Wang, Y.; Lin, X. Adversarial t-shirt! Evading person detectors in a physical world. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 665–681. [Google Scholar]
- Wallace, E.; Feng, S.; Kandpal, N.; Gardner, M.; Singh, S. Universal Adversarial Triggers for Attacking and Analyzing NLP. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Cheng, Y.; Juefei-Xu, F.; Guo, Q.; Fu, H.; Xie, X.; Lin, S.W.; Lin, W.; Liu, Y. Adversarial Exposure Attack on Diabetic Retinopathy Imagery. arXiv 2020, arXiv:2009.09231. [Google Scholar]
- Finlayson, S.G.; Bowers, J.D.; Ito, J.; Zittrain, J.L.; Beam, A.L.; Kohane, I.S. Adversarial attacks on medical machine learning. Science 2019, 363, 1287–1289. [Google Scholar] [CrossRef]
- Han, X.; Hu, Y.; Foschini, L.; Chinitz, L.; Jankelson, L.; Ranganath, R. Deep learning models for electrocardiograms are susceptible to adversarial attack. Nat. Med. 2020, 26, 360–363. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, D.; Ding, L.; Luo, H.; Lin, C.T.; Jung, T.P.; Chavarriaga, R. Tiny noise, big mistakes: Adversarial perturbations induce errors in brain-computer interface spellers. Natl. Sci. Rev. 2020, 10, 3837. [Google Scholar]
- Zhou, Z.; Tang, D.; Wang, X.; Han, W.; Liu, X.; Zhang, K. Invisible mask: Practical attacks on face recognition with infrared. arXiv 2018, arXiv:1803.04683. [Google Scholar]
- Cao, Y.; Xiao, C.; Cyr, B.; Zhou, Y.; Park, W.; Rampazzi, S.; Chen, Q.A.; Fu, K.; Mao, Z.M. Adversarial sensor attack on LiDAR-based perception in autonomous driving. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; pp. 2267–2281. [Google Scholar]
- Povolny, S.; Trivedi, S. Model Hacking ADAS to Pave Safer Roads for Autonomous Vehicles. McAfee. 2020. Available online: https://www.mcafee.com/blogs/other-blogs/mcafee-labs/model-hacking-adas-to-pave-safer-roads-for-autonomous-vehicles/ (accessed on 8 November 2020).
- Chen, Y.; Yuan, X.; Zhang, J.; Zhao, Y.; Zhang, S.; Chen, K.; Wang, X. Devil’s Whisper: A General Approach for Physical Adversarial Attacks against Commercial Black-box Speech Recognition Devices. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), USENIX Association, Online. Boston, MA, USA, 12–14 August 2020; pp. 2667–2684. [Google Scholar]
- Li, J.; Qu, S.; Li, X.; Szurley, J.; Kolter, J.Z.; Metze, F. Adversarial music: Real world audio adversary against wake-word detection system. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2019; pp. 11931–11941. [Google Scholar]
- Wu, J.; Zhou, M.; Liu, S.; Liu, Y.; Zhu, C. Decision-based Universal Adversarial Attack. arXiv 2020, arXiv:2009.07024. [Google Scholar]
- Shumailov, I.; Zhao, Y.; Bates, D.; Papernot, N.; Mullins, R.; Anderson, R. Sponge Examples: Energy-Latency Attacks on Neural Networks. arXiv 2020, arXiv:2006.03463. [Google Scholar]
- Cinà, A.E.; Torcinovich, A.; Pelillo, M. A Black-box Adversarial Attack for Poisoning Clustering. arXiv 2020, arXiv:2009.05474. [Google Scholar]
- Chitpin, S. Should Popper’s view of rationality be used for promoting teacher knowledge? Educ. Philos. Theory 2013, 45, 833–844. [Google Scholar] [CrossRef]
- Obermeyer, Z.; Powers, B.; Vogeli, C.; Mullainathan, S. Dissecting racial bias in an algorithm used to manage the health of populations. Science 2019, 366, 447–453. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hill, K. Wrongfully accused by an algorithm. The New York Times, 24 June 2020. [Google Scholar]
- Buolamwini, J.; Gebru, T. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Proceedings of the Conference on Fairness, Accountability and Transparency, New York, NY, USA, 23–24 February 2018. [Google Scholar]
- Da Costa, C. The Women Geniuses Taking on Racial and Gender Bias in AI—And Amazon. The Daily Beast. 2020. Available online: https://www.thedailybeast.com/the-women-geniuses-taking-on-racial-and-gender-bias-in-artificial-intelligence-and-amazon (accessed on 23 May 2020).
- Larrazabal, A.J.; Nieto, N.; Peterson, V.; Milone, D.H.; Ferrante, E. Gender imbalance in medical imaging datasets produces biased classifiers for computer-aided diagnosis. Proc. Natl. Acad. Sci. USA 2020, 117, 12592–12594. [Google Scholar] [CrossRef]
- Prabhu, V.U.; Birhane, A. Large image datasets: A pyrrhic win for computer vision? arXiv 2020, arXiv:2006.16923. [Google Scholar]
- Jain, N.; Olmo, A.; Sengupta, S.; Manikonda, L.; Kambhampati, S. Imperfect imaganation: Implications of gans exacerbating biases on facial data augmentation and snapchat selfie lenses. arXiv 2020, arXiv:2001.09528. [Google Scholar]
- Kempsell, R. Ofqual Pauses Study into Whether AI Could be Used to Mark Exams. The Times. 2020. Available online: https://www.thetimes.co.uk/article/robot-exam-marking-project-is-put-on-hold-vvrm753l3 (accessed on 10 November 2020).
- Huchel, B. Artificial Intelligence Examines Best Ways to Keep Parolees From Recommitting Crimes. Phys. Org. 2020. Available online: https://phys.org/news/2020-08-artificial-intelligence-ways-parolees-recommitting.html (accessed on 20 August 2020).
- Cushing, T. Harrisburg University Researchers Claim Their ’Unbiased’ Facial Recognition Software Can Identify Potential Criminals. techdirt. 2020. Available online: https://www.techdirt.com/articles/20200505/17090244442/harrisburg-university-researchers-claim-their-unbiased-facial-recognition-software-can-identify-potential-criminals.shtml (accessed on 2 November 2020).
- Harrisburg University. HU Facial Recognition Software Predicts Criminality. 2020. Available online: http://archive.is/N1HVe#selection-1509.0-1509.51 (accessed on 23 May 2020).
- Pascu, L. Biometric Software that Allegedly Predicts Criminals Based on Their Face Sparks Industry Controversy. Biometric. 2020. Available online: https://www.biometricupdate.com/202005/biometric-software-that-allegedly-predicts-criminals-based-on-their-face-sparks-industry-controversy (accessed on 23 May 2020).
- Barrett, L.F.; Adolphs, R.; Marsella, S.; Martinez, A.M.; Pollak, S.D. Emotional expressions reconsidered: Challenges to inferring emotion from human facial movements. Psychol. Sci. Public Interest 2019, 20, 1–68. [Google Scholar] [CrossRef] [Green Version]
- Gendron, M.; Hoemann, K.; Crittenden, A.N.; Mangola, S.M.; Ruark, G.A.; Barrett, L.F. Emotion perception in Hadza Hunter-Gatherers. Sci. Rep. 2020, 10, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Crawford, K.; Dobbe, R.; Dryer, T.; Fried, G.; Green, B.; Kaziunas, E.; Kak, A.; Mathur, V.; McElroy, E.; Sánchez, A.N.; et al. AI Now 2019 Report; AI Now Institute: New York, NY, USA, 2019; Available online: https://ainowinstitute.org/AI_Now_2019_Report.pdf (accessed on 23 May 2020).
- Lieber, C. Tech Companies Use “Persuasive Design” to Get Us Hooked. Psychologists Say It’s Unethical. Vox. 2018. Available online: https://www.vox.com/2018/8/8/17664580/persuasive-technology-psychology (accessed on 8 November 2020).
- Jakubowski, G. What’s not to like? Social media as information operations force multiplier. Jt. Force Q. 2019, 3, 8–17. [Google Scholar]
- Sawers, P. The Social Dilemma: How Digital Platforms Pose an Existential Threat to Society. VentureBeat. 2020. Available online: https://venturebeat.com/2020/09/02/the-social-dilemma-how-digital-platforms-pose-an-existential-threat-to-society/ (accessed on 2 November 2020).
- Chikhale, S.; Gohad, V. Multidimensional Construct About The Robot Citizenship Law’s In Saudi Arabia. Int. J. Innov. Res. Adv. Stud. (IJIRAS) 2018, 5, 106–108. [Google Scholar]
- Yam, K.C.; Bigman, Y.E.; Tang, P.M.; Ilies, R.; De Cremer, D.; Soh, H.; Gray, K. Robots at work: People prefer—And forgive—Service robots with perceived feelings. J. Appl. Psychol. 2020, 1, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Orabi, M.; Mouheb, D.; Al Aghbari, Z.; Kamel, I. Detection of Bots in Social Media: A Systematic Review. Inf. Process. Manag. 2020, 57, 102250. [Google Scholar] [CrossRef]
- Prier, J. Commanding the trend: Social media as information warfare. Strateg. Stud. Q. 2017, 11, 50–85. [Google Scholar]
- Letter, O. Our Letter to the APA. 2018. Available online: https://screentimenetwork.org/apa (accessed on 2 November 2020).
- Theriault, J.E.; Young, L.; Barrett, L.F. The sense of should: A biologically-based framework for modeling social pressure. Phys. Life Rev. 2020, in press. [Google Scholar] [CrossRef] [Green Version]
- Anderson, M.; Jiang, J. Teens’ social media habits and experiences. Pew Res. Cent. 2018, 28, 1. [Google Scholar]
- Barberá, P.; Zeitzoff, T. The new public address system: Why do world leaders adopt social media? Int. Stud. Q. 2018, 62, 121–130. [Google Scholar] [CrossRef] [Green Version]
- Franchina, V.; Coco, G.L. The influence of social media use on body image concerns. Int. J. Psychoanal. Educ. 2018, 10, 5–14. [Google Scholar]
- Halfmann, A.; Rieger, D. Permanently on call: The effects of social pressure on smartphone users’ self-control, need satisfaction, and well-being. J. Comput. Mediat. Commun. 2019, 24, 165–181. [Google Scholar] [CrossRef]
- Stieger, S.; Lewetz, D. A week without using social media: Results from an ecological momentary intervention study using smartphones. Cyberpsychol. Behav. Soc. Netw. 2018, 21, 618–624. [Google Scholar] [CrossRef] [PubMed]
- Ferrara, E.; Yang, Z. Measuring emotional contagion in social media. PLoS ONE 2015, 10, e0142390. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Luxton, D.D.; June, J.D.; Fairall, J.M. Social media and suicide: A public health perspective. Am. J. Public Health 2012, 102, S195–S200. [Google Scholar] [CrossRef] [PubMed]
- Lane, L. NIST finds flaws in facial checks on people with Covid masks. Biom. Technol. Today 2020, 8, 2. [Google Scholar]
- Mundial, I.Q.; Hassan, M.S.U.; Tiwana, M.I.; Qureshi, W.S.; Alanazi, E. Towards Facial Recognition Problem in COVID-19 Pandemic. In Proceedings of the 2020 4rd International Conference on Electrical, Telecommunication and Computer Engineering (ELTICOM), Medan, Indonesia, 3–4 September 2020; pp. 210–214. [Google Scholar]
- Ngan, M.L.; Grother, P.J.; Hanaoka, K.K. Ongoing Face Recognition Vendor Test (FRVT) Part 6A: Face recognition accuracy with masks using pre-COVID-19 algorithms. Natl. Inst. Stand. Technol. 2020, 1, 1. [Google Scholar]
- Krishna, K.; Tomar, G.S.; Parikh, A.P.; Papernot, N.; Iyyer, M. Thieves on Sesame Street! Model Extraction of BERT-based APIs. arXiv 2019, arXiv:1910.12366. [Google Scholar]
- Taylor, J. Facebook Incorrectly Removes Picture of Aboriginal Men in Chains Because of ‘Nudity’. The Guardian. 2020. Available online: https://www.theguardian.com/technology/2020/jun/13/facebook-incorrectly-removes-picture-of-aboriginal-men-in-chains-because-of-nudity (accessed on 2 November 2020).
- DeCamp, M.; Lindvall, C. Latent bias and the implementation of artificial intelligence in medicine. J. Am. Med. Inform. Assoc. 2020, 27, 2020–2023. [Google Scholar] [CrossRef]
- Kaushal, A.; Altman, R.; Langlotz, C. Geographic Distribution of US Cohorts Used to Train Deep Learning Algorithms. JAMA 2020, 324, 1212–1213. [Google Scholar] [CrossRef]
- Epstude, K.; Roese, N.J. The functional theory of counterfactual thinking. Personal. Soc. Psychol. Rev. 2008, 12, 168–192. [Google Scholar] [CrossRef] [Green Version]
- Weidman, G. Penetration Testing: A Hands-On Introduction to Hacking; No Starch Press: San Francisco, CA, USA, 2014. [Google Scholar]
- Rajendran, J.; Jyothi, V.; Karri, R. Blue team red team approach to hardware trust assessment. In Proceedings of the 2011 IEEE 29th International Conference on Computer Design (ICCD), Amherst, MA, USA, 9–12 October 2011; pp. 285–288. [Google Scholar]
- Rege, A. Incorporating the human element in anticipatory and dynamic cyber defense. In Proceedings of the 2016 IEEE International Conference on Cybercrime and Computer Forensic (ICCCF), Vancouver, BC, Canada, 12–14 June 2016; pp. 1–7. [Google Scholar]
- Ahmadpour, N.; Pedell, S.; Mayasari, A.; Beh, J. Co-creating and assessing future wellbeing technology using design fiction. She Ji J. Des. Econ. Innov. 2019, 5, 209–230. [Google Scholar] [CrossRef]
- Pillai, A.G.; Ahmadpour, N.; Yoo, S.; Kocaballi, A.B.; Pedell, S.; Sermuga Pandian, V.P.; Suleri, S. Communicate, Critique and Co-create (CCC) Future Technologies through Design Fictions in VR Environment. In Proceedings of the Companion Publication of the 2020 ACM Designing Interactive Systems Conference, Eindhoven, The Netherlands, 6–20 July 2020; pp. 413–416. [Google Scholar]
- Rapp, A. Design fictions for learning: A method for supporting students in reflecting on technology in Human-Computer Interaction courses. Comput. Educ. 2020, 145, 103725. [Google Scholar] [CrossRef]
- Houde, S.; Liao, V.; Martino, J.; Muller, M.; Piorkowski, D.; Richards, J.; Weisz, J.; Zhang, Y. Business (mis) Use Cases of Generative AI. arXiv 2020, arXiv:2003.07679. [Google Scholar]
- Carlini, N.; Athalye, A.; Papernot, N.; Brendel, W.; Rauber, J.; Tsipras, D.; Goodfellow, I.; Madry, A.; Kurakin, A. On evaluating adversarial robustness. arXiv 2019, arXiv:1902.06705. [Google Scholar]
- John, A.; Glendenning, A.C.; Marchant, A.; Montgomery, P.; Stewart, A.; Wood, S.; Lloyd, K.; Hawton, K. Self-harm, suicidal behaviours, and cyberbullying in children and young people: Systematic review. J. Med. Internet Res. 2018, 20, e129. [Google Scholar] [CrossRef]
- Crothers, B. FBI Warns on Teenage Sextortion as New Twists on Sex-Related Scams Emerge. Fox News. 2020. Available online: https://www.foxnews.com/tech/fbi-warns-teenage-sextortion-new-twists-sex-scams-emerge (accessed on 2 November 2020).
- Nilsson, M.G.; Pepelasi, K.T.; Ioannou, M.; Lester, D. Understanding the link between Sextortion and Suicide. Int. J. Cyber Criminol. 2019, 13, 55–69. [Google Scholar]
- Haag, M.; Salam, M. Gunman in ‘Pizzagate’ Shooting Is Sentenced to 4 Years in Prison. The New York Times. 2017. Available online: https://www.nytimes.com/2017/06/22/us/pizzagate-attack-sentence.html (accessed on 2 November 2017).
- Bessi, A.; Ferrara, E. Social bots distort the 2016 US Presidential election online discussion. First Monday 2016, 21, 1–14. [Google Scholar]
- Assenmacher, D.; Clever, L.; Frischlich, L.; Quandt, T.; Trautmann, H.; Grimme, C. Demystifying Social Bots: On the Intelligence of Automated Social Media Actors. Soc. Media Soc. 2020, 6, 2056305120939264. [Google Scholar] [CrossRef]
- Boneh, D.; Grotto, A.J.; McDaniel, P.; Papernot, N. How relevant is the Turing test in the age of sophisbots? IEEE Secur. Priv. 2019, 17, 64–71. [Google Scholar] [CrossRef] [Green Version]
- Yang, K.C.; Varol, O.; Davis, C.A.; Ferrara, E.; Flammini, A.; Menczer, F. Arming the public with artificial intelligence to counter social bots. Hum. Behav. Emerg. Technol. 2019, 1, 48–61. [Google Scholar] [CrossRef] [Green Version]
- Shao, C.; Ciampaglia, G.L.; Varol, O.; Yang, K.C.; Flammini, A.; Menczer, F. The spread of low-credibility content by social bots. Nat. Commun. 2018, 9, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yan, H.Y.; Yang, K.C.; Menczer, F.; Shanahan, J. Asymmetrical perceptions of partisan political bots. New Media Soc. 2020. [Google Scholar] [CrossRef]
- Farokhmanesh, M. Is It Legal to Swap Someone’s Face into Porn without Consent? Verge. January 2018, 30, 1. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of StyleGAN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 8110–8119. [Google Scholar]
- Duan, R.; Ma, X.; Wang, Y.; Bailey, J.; Qin, A.K.; Yang, Y. Adversarial Camouflage: Hiding Physical-World Attacks with Natural Styles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1000–1008. [Google Scholar]
- Kong, Z.; Guo, J.; Li, A.; Liu, C. PhysGAN: Generating Physical-World-Resilient Adversarial Examples for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 14254–14263. [Google Scholar]
- Nassi, B.; Nassi, D.; Ben-Netanel, R.; Mirsky, Y.; Drokin, O.; Elovici, Y. Phantom of the ADAS: Phantom Attacks on Driver-Assistance Systems. IACR Cryptol. ePrint Arch. 2020, 2020, 85. [Google Scholar]
- Wang, Y.; Lv, H.; Kuang, X.; Zhao, G.; Tan, Y.A.; Zhang, Q.; Hu, J. Towards a Physical-World Adversarial Patch for Blinding Object Detection Models. Inf. Sci. 2020, in press. [Google Scholar] [CrossRef]
- Rahman, A.; Hossain, M.S.; Alrajeh, N.A.; Alsolami, F. Adversarial examples–security threats to COVID-19 deep learning systems in medical IoT devices. IEEE Internet Things J. 2020. [Google Scholar] [CrossRef]
- Ciosek, I. Aggravating Uncertaub–Russian Information Warfare in the West. Tor. Int. Stud. 2020, 1, 57–72. [Google Scholar] [CrossRef]
- Colleoni, E.; Rozza, A.; Arvidsson, A. Echo chamber or public sphere? Predicting political orientation and measuring political homophily in Twitter using big data. J. Commun. 2014, 64, 317–332. [Google Scholar] [CrossRef]
- Kocabey, E.; Ofli, F.; Marin, J.; Torralba, A.; Weber, I. Using computer vision to study the effects of BMI on online popularity and weight-based homophily. In International Conference on Social Informatics; Springer: Cham, Switzerland, 2018; pp. 129–138. [Google Scholar]
- Hanusch, F.; Nölleke, D. Journalistic homophily on social media: Exploring journalists’ interactions with each other on Twitter. Digit. J. 2019, 7, 22–44. [Google Scholar] [CrossRef]
- Lathiya, S.; Dhobi, J.; Zubiaga, A.; Liakata, M.; Procter, R. Birds of a feather check together: Leveraging homophily for sequential rumour detection. Online Soc. Netw. Media 2020, 19, 100097. [Google Scholar] [CrossRef]
- Leonhardt, J.M.; Pezzuti, T.; Namkoong, J.E. We’re not so different: Collectivism increases perceived homophily, trust, and seeking user-generated product information. J. Bus. Res. 2020, 112, 160–169. [Google Scholar] [CrossRef]
- Saleem, A.; Ellahi, A. Influence of electronic word of mouth on purchase intention of fashion products in social networking websites. Pak. J. Commer. Soc. Sci. (PJCSS) 2017, 11, 597–622. [Google Scholar]
- Ismagilova, E.; Slade, E.; Rana, N.P.; Dwivedi, Y.K. The effect of characteristics of source credibility on consumer behaviour: A meta-analysis. J. Retail. Consum. Serv. 2020, 53, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.; Kandampully, J.; Bilgihan, A. The influence of eWOM communications: An application of online social network framework. Comput. Hum. Behav. 2018, 80, 243–254. [Google Scholar] [CrossRef]
- Ladhari, R.; Massa, E.; Skandrani, H. YouTube vloggers’ popularity and influence: The roles of homophily, emotional attachment, and expertise. J. Retail. Consum. Serv. 2020, 54, 102027. [Google Scholar] [CrossRef]
- Xu, S.; Zhou, A. Hashtag homophily in twitter network: Examining a controversial cause-related marketing campaign. Comput. Hum. Behav. 2020, 102, 87–96. [Google Scholar] [CrossRef]
- Zhou, Z.; Xu, K.; Zhao, J. Homophily of music listening in online social networks of China. Soc. Netw. 2018, 55, 160–169. [Google Scholar] [CrossRef]
- Vonk, R. Effects of stereotypes on attitude inference: Outgroups are black and white, ingroups are shaded. Br. J. Soc. Psychol. 2002, 41, 157–167. [Google Scholar] [CrossRef]
- Bakshy, E.; Messing, S.; Adamic, L.A. Exposure to ideologically diverse news and opinion on Facebook. Science 2015, 348, 1130–1132. [Google Scholar] [CrossRef]
- Lamb, A. After Covid, AI Will Pivot. Towards Data Sciece. 2020. Available online: https://towardsdatascience.com/after-covid-ai-will-pivot-dbe9dd06327 (accessed on 12 November 2020).
- Smith, G.; Rustagi, I. The Problem With COVID-19 Artificial Intelligence Solutions and How to Fix Them. Standford Social Innovation Review. 2020. Available online: https://ssir.org/articles/entry/the_problem_with_covid_19_artificial_intelligence_solutions_and_how_to_fix_them (accessed on 12 November 2020).
- Yampolskiy, R.V. Mimicry attack on strategy-based behavioral biometric. In Proceedings of the Fifth International Conference on Information Technology: New Generations (ITNG 2008), Las Vegas, NV, USA, 7–9 April 2008; pp. 916–921. [Google Scholar]
- Yampolskiy, R.V.; Govindaraju, V. Taxonomy of behavioural biometrics. In Behavioral Biometrics for Human Identification: Intelligent Applications; IGI Global: Hershey, PA, USA, 2010; pp. 1–43. [Google Scholar]
- Yampolskiy, R.V. Analyzing user password selection behavior for reduction of password space. In Proceedings of the 40th Annual 2006 International Carnahan Conference on Security Technology, Lexington, KY, USA, 16–19 October 2006; pp. 109–115. [Google Scholar]
- Whyte, C. Deepfake news: AI-enabled disinformation as a multi-level public policy challenge. J. Cyber Policy 2020, 5, 199–217. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2014; pp. 2672–2680. [Google Scholar]
- Tucciarelli, R.; Vehar, N.; Tsakiris, M. On the realness of people who do not exist: The social processing of artificial faces. PsyArXiv 2020. [Google Scholar]
- Young, L. Calibration Camouflage: Hyphen-Labs and Adam Harvey: HyperFace. Archit. Des. 2019, 89, 28–31. [Google Scholar] [CrossRef] [Green Version]
- Baggili, I.; Behzadan, V. Founding The Domain of AI Forensics. arXiv 2019, arXiv:1912.06497. [Google Scholar]
- Schneider, J.; Breitinger, F. AI Forensics: Did the Artificial Intelligence System Do It? Why? arXiv 2020, arXiv:2005.13635. [Google Scholar]
- Rosenberg, A.A.; Halpern, M.; Shulman, S.; Wexler, C.; Phartiyal, P. Reinvigorating the role of science in democracy. PLoS Biol. 2013, 11, e1001553. [Google Scholar] [CrossRef] [PubMed]
- MIT Open Learning. Tackling the Misinformation Epidemic with “In Event of Moon Disaster”. MIT News. 2020. Available online: https://news.mit.edu/2020/mit-tackles-misinformation-in-event-of-moon-disaster-0720 (accessed on 11 October 2020).
- Fallis, D. The Epistemic Threat of Deepfakes. Philos. Technol. 2020, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Popper, K. Conjectures and Refutations: The Growth of Scientific Knowledge; Routledge: Abingdon, UK, 2014. [Google Scholar]
- Deutsch, D. The Beginning of Infinity: Explanations that Transform the World; Penguin: London, UK, 2011. [Google Scholar]
- Baudrillard, J. Simulacra and Simulation; University of Michigan Press: Ann Arbor, MI, USA, 1994. [Google Scholar]
- Hopf, H.; Krief, A.; Mehta, G.; Matlin, S.A. Fake science and the knowledge crisis: Ignorance can be fatal. R. Soc. Open Sci. 2019, 6, 190161. [Google Scholar] [CrossRef] [Green Version]
- D’Amour, A.; Heller, K.; Moldovan, D.; Adlam, B.; Alipanahi, B.; Beutel, A.; Chen, C.; Deaton, J.; Eisenstein, J.; Hoffman, M.D.; et al. Underspecification Presents Challenges for Credibility in Modern Machine Learning. arXiv 2020, arXiv:2011.03395. [Google Scholar]
- Oughton, E.J.; Ralph, D.; Pant, R.; Leverett, E.; Copic, J.; Thacker, S.; Dada, R.; Ruffle, S.; Tuveson, M.; Hall, J.W. Stochastic Counterfactual Risk Analysis for the Vulnerability Assessment of Cyber-Physical Attacks on Electricity Distribution Infrastructure Networks. Risk Anal. 2019, 39, 2012–2031. [Google Scholar] [CrossRef] [Green Version]
- Almasoud, A.S.; Hussain, F.K.; Hussain, O.K. Smart contracts for blockchain-based reputation systems: A systematic literature review. J. Netw. Comput. Appl. 2020, 170, 102814. [Google Scholar] [CrossRef]
- Cresci, S. A decade of social bot detection. Commun. ACM 2020, 63, 72–83. [Google Scholar] [CrossRef]
- Cresci, S.; Di Pietro, R.; Petrocchi, M.; Spognardi, A.; Tesconi, M. The paradigm-shift of social spambots: Evidence, theories, and tools for the arms race. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017; pp. 963–972. [Google Scholar]
- Barrett, L.F. The theory of constructed emotion: An active inference account of interoception and categorization. Soc. Cogn. Affect. Neurosci. 2017, 12, 1–23. [Google Scholar] [CrossRef] [PubMed]
- Aliman, N.M. Self-Shielding Worlds. 2020. Available online: https://nadishamarie.jimdo.com/clipboard/ (accessed on 23 November 2020).
- Turing, I.B.A. Computing machinery and intelligence-AM Turing. Mind 1950, 59, 433. [Google Scholar] [CrossRef]
- Pantserev, K.A. The Malicious Use of AI-Based Deepfake Technology as the New Threat to Psychological Security and Political Stability. In Cyber Defence in the Age of AI, Smart Societies and Augmented Humanity; Springer: Berlin/Heidelberg, Germany, 2020; pp. 37–55. [Google Scholar]
- Öhman, C. Introducing the pervert’s dilemma: A contribution to the critique of Deepfake Pornography. Ethics Inf. Technol. 2019, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Macaulay, T. New AR App will Let You Model a Virtual Companion on Anyone You Want. 2020. Available online: https://thenextweb.com/neural/2020/06/01/new-ar-app-will-let-you-model-a-virtual-companion-on-anyone-you-want/ (accessed on 4 August 2020).
- Kumar, R.S.S.; Nyström, M.; Lambert, J.; Marshall, A.; Goertzel, M.; Comissoneru, A.; Swann, M.; Xia, S. Adversarial Machine Learning–Industry Perspectives. arXiv 2020, arXiv:2002.05646. [Google Scholar]
- Barrett, L.F.; Simmons, W.K. Interoceptive predictions in the brain. Nat. Rev. Neurosci. 2015, 16, 419–429. [Google Scholar] [CrossRef] [Green Version]
- Kleckner, I.R.; Zhang, J.; Touroutoglou, A.; Chanes, L.; Xia, C.; Simmons, W.K.; Quigley, K.S.; Dickerson, B.C.; Barrett, L.F. Evidence for a large-scale brain system supporting allostasis and interoception in humans. Nat. Hum. Behav. 2017, 1, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Aliman, N.; Kester, L. Requisite Variety in Ethical Utility Functions for AI Value Alignment. In Proceedings of the Workshop on Artificial Intelligence Safety 2019 co-located with the 28th International Joint Conference on Artificial Intelligence, AISafety@IJCAI 2019, Macao, China, 11–12 August 2019. [Google Scholar]
- Dignum, V. AI is multidisciplinary. AI Matters 2020, 5, 18–21. [Google Scholar] [CrossRef]
- Floridi, L. Establishing the rules for building trustworthy AI. Nat. Mach. Intell. 2019, 1, 261–262. [Google Scholar] [CrossRef]
- Hagendorff, T. The ethics of Ai ethics: An evaluation of guidelines. Minds Mach. 2020, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Mittelstadt, B. AI Ethics–Too principled to fail. arXiv 2019, arXiv:1906.06668. [Google Scholar] [CrossRef]
- Whittlestone, J.; Nyrup, R.; Alexandrova, A.; Cave, S. The role and limits of principles in AI ethics: Towards a focus on tensions. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, Honolulu, HI, USA, 27–28 January 2019; pp. 195–200. [Google Scholar]
- Jobin, A.; Ienca, M.; Vayena, E. The global landscape of AI ethics guidelines. Nat. Mach. Intell. 2019, 1, 389–399. [Google Scholar] [CrossRef]
- Gu, B.; Konana, P.; Raghunathan, R.; Chen, H.M. Research note—The allure of homophily in social media: Evidence from investor responses on virtual communities. Inf. Syst. Res. 2014, 25, 604–617. [Google Scholar] [CrossRef]
- Yoo, J. Ideological Homophily and Echo Chamber Effect in Internet and Social Media. Stud. Int. J. Res. 2007, 4, 1–7. [Google Scholar]
- Tsao, J.; Ting, C.; Johnson, C. Creative outcome as implausible utility. Rev. Gen. Psychol. 2019, 23, 279–292. [Google Scholar] [CrossRef] [Green Version]
- Yampolskiy, R.V.; Ashby, L.; Hassan, L. Wisdom of Artificial Crowds—A Metaheuristic Algorithm for Optimization. J. Intell. Learn. Syst. Appl. 2012, 4, 98–107. [Google Scholar] [CrossRef] [Green Version]
- Yampolskiy, R. Usable Guidelines Aim to Make AI Safer. All, EIT 2020: The Intelligent Revolution. 2020. Available online: https://www.mouser.com/blog/usable-guidelines-aim-to-make-ai-safer (accessed on 13 November 2020).
- Trazzi, M.; Yampolskiy, R.V. Building safer AGI by introducing artificial stupidity. arXiv 2018, arXiv:1808.03644. [Google Scholar]
- Trazzi, M.; Yampolskiy, R.V. Artificial Stupidity: Data We Need to Make Machines Our Equals. Patterns 2020, 1, 100021. [Google Scholar] [CrossRef]
- Aliman, N.M.; Kester, L. Artificial creativity augmentation. In International Conference on Artificial General Intelligence; Springer: Cham, Switzerland, 2020; pp. 23–33. [Google Scholar]
- Leviathan, Y.; Matias, Y. Google Duplex: An AI System for Accomplishing Real-World Tasks Over the Phone. 2018. Available online: https://ai.googleblog.com/2018/05/duplex-ai-system-for-natural-conversation.html (accessed on 4 August 2020).
- Yampolskiy, R.V. On Controllability of AI. arXiv 2020, arXiv:2008.04071. [Google Scholar]
- Yampolskiy, R.V. Unpredictability of AI. arXiv 2019, arXiv:1905.13053. [Google Scholar]
- Boström, N. Superintelligence: Paths, Dangers, Strategies; Oxford University Press: Oxford, UK, 2014. [Google Scholar]
- Baum, S.; Barrett, A.; Yampolskiy, R.V. Modeling and interpreting expert disagreement about artificial superintelligence. Informatica 2017, 41, 419–428. [Google Scholar]
- Friston, K. Am I self-conscious? (Or does self-organization entail self-consciousness?). Front. Psychol. 2018, 9, 579. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bruineberg, J.; Kiverstein, J.; Rietveld, E. The anticipating brain is not a scientist: The free-energy principle from an ecological-enactive perspective. Synthese 2018, 195, 2417–2444. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rudrauf, D.; Bennequin, D.; Granic, I.; Landini, G.; Friston, K.; Williford, K. A mathematical model of embodied consciousness. J. Theor. Biol. 2017, 428, 106–131. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Williford, K.; Bennequin, D.; Friston, K.; Rudrauf, D. The projective consciousness model and phenomenal selfhood. Front. Psychol. 2018, 9, 2571. [Google Scholar] [CrossRef] [Green Version]
- Deutsch, D. Constructor theory. Synthese 2013, 190, 4331–4359. [Google Scholar] [CrossRef]
- Deutsch, D.; Marletto, C. Constructor theory of information. Proc. R. Soc. Math. Phys. Eng. Sci. 2015, 471, 20140540. [Google Scholar] [CrossRef] [Green Version]
- Dietrich, A. How Creativity Happens in the Brain; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Brockman, J. Possible Minds: Twenty-Five Ways of Looking at AI. Beyond Reward and Punishment. David Deutsch.; Penguin Books: London, UK, 2020. [Google Scholar]
- Hall, B. Superintelligence. Part 6: Neologisms and Choices. 2020. Available online: http://www.bretthall.org/superintelligence-6.html (accessed on 4 January 2021).
- Reynolds, A.; Lewis, D. Teams solve problems faster when they’re more cognitively diverse. Harv. Bus. Rev. 2017, 30, 1–8. [Google Scholar]
- Friston, K.J.; Lin, M.; Frith, C.D.; Pezzulo, G.; Hobson, J.A.; Ondobaka, S. Active inference, curiosity and insight. Neural Comput. 2017, 29, 2633–2683. [Google Scholar] [CrossRef]
- Sajid, N.; Ball, P.J.; Friston, K.J. Active inference: Demystified and compared. arXiv 2019, arXiv:1909.10863. [Google Scholar]
- Hernandez, J.; Marin-Castro, H.M.; Morales-Sandoval, M. A Semantic Focused Web Crawler Based on a Knowledge Representation Schema. Appl. Sci. 2020, 10, 3837. [Google Scholar] [CrossRef]
- Singh, N.K.; Tomar, D.S.; Sangaiah, A.K. Sentiment analysis: A review and comparative analysis over social media. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 97–117. [Google Scholar] [CrossRef]
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text classification algorithms: A survey. Information 2019, 10, 150. [Google Scholar] [CrossRef] [Green Version]
- Aggarwal, I.; Woolley, A.W.; Chabris, C.F.; Malone, T.W. The impact of cognitive style diversity on implicit learning in teams. Front. Psychol. 2019, 10, 112. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Den Houting, J. Neurodiversity: An insider’s perspective. Autism 2019, 23, 271–273. [Google Scholar] [CrossRef]
- Blume, H. Neurodiversity: On the neurological underpinnings of geekdom. Atlantic 1998, 30, 1. [Google Scholar]
- Chapman, R. Neurodiversity, disability, wellbeing. In Neurodiversity Studies: A New Critical Paradigm; Routledge: Abingdon, UK, 2020. [Google Scholar]
- Chen, X.; Liu, J.; Zhang, H.; Kwan, H.K. Cognitive diversity and innovative work behaviour: The mediating roles of task reflexivity and relationship conflict and the moderating role of perceived support. J. Occup. Organ. Psychol. 2019, 92, 671–694. [Google Scholar] [CrossRef] [Green Version]
- Bolis, D.; Balsters, J.; Wenderoth, N.; Becchio, C.; Schilbach, L. Beyond autism: Introducing the dialectical misattunement hypothesis and a bayesian account of intersubjectivity. Psychopathology 2017, 50, 355–372. [Google Scholar] [CrossRef]
- Abu-Akel, A.; Webb, M.E.; de Montpellier, E.; Von Bentivegni, S.; Luechinger, L.; Ishii, A.; Mohr, C. Autistic and positive schizotypal traits respectively predict better convergent and divergent thinking performance. Think. Ski. Creat. 2020, 36, 100656. [Google Scholar] [CrossRef]
- Paola, P.; Laura, G.; Giusy, M.; Michela, C. Autism, autistic traits and creativity: A systematic review and meta-analysis. Cogn. Process. 2020, 1, 1–36. [Google Scholar] [CrossRef]
- Kasirer, A.; Adi-Japha, E.; Mashal, N. Verbal and Figural Creativity in Children With Autism Spectrum Disorder and Typical Development. Front. Psychol. 2020, 11, 2968. [Google Scholar] [CrossRef] [PubMed]
- Hoogman, M.; Stolte, M.; Baas, M.; Kroesbergen, E. Creativity and ADHD: A review of behavioral studies, the effect of psychostimulants and neural underpinnings. Neurosci. Biobehav. Rev. 2020, 119, 66–85. [Google Scholar] [CrossRef] [PubMed]
- White, H.A. Thinking “Outside the Box”: Unconstrained Creative Generation in Adults with Attention Deficit Hyperactivity Disorder. J. Creat. Behav. 2020, 54, 472–483. [Google Scholar] [CrossRef]
- White, H.A.; Shah, P. Scope of semantic activation and innovative thinking in college students with ADHD. Creat. Res. J. 2016, 28, 275–282. [Google Scholar] [CrossRef]
- Greenberg, J.; Arndt, J. Terror management theory. In Handbook of Theories of Social Psychology; SAGE Publications Inc.: Los Angeles, CA, USA, 2011; Volume 1, pp. 398–415. [Google Scholar]
- Solomon, S.; Greenberg, J.; Pyszczynski, T. The Worm at the Core: On the Role of Death in Life; Random House Inc.: New York, NY, USA, 2015. [Google Scholar]
- Chittaro, L.; Sioni, R.; Crescentini, C.; Fabbro, F. Mortality salience in virtual reality experiences and its effects on users’ attitudes towards risk. Int. J. Hum. Comput. Stud. 2017, 101, 10–22. [Google Scholar] [CrossRef]
- Shehryar, O.; Hunt, D.M. A terror management perspective on the persuasiveness of fear appeals. J. Consum. Psychol. 2005, 15, 275–287. [Google Scholar] [CrossRef]
| 1. | Downward counterfactuals can be (co-)created for example, in a predominantly mental form, facilitated by immersive design fiction settings [28] (including storytelling narratives and virtual reality) or simulated and visualized with technological tools. |
| 2. | For instance, their interest could shift, the asset could be(come) less interesting or the attack too time-consuming and costly. |
| 3. | For an enhanced context-sensitivity and to avoid overfitting to the idiosyncrasies of single isolated events, we recommend RCRA simulations at the level of clusters and not of single instances as becomes apparent in the next Section 4.3. |
| 4. | In theory, this search can be optimized further. However, the aim is to (at a later stage) obtain a broad as possible set of counterfactual instances to increase illustrative power. Both one-to-one and many-to-one mappings between downward counterfactual instances and clusters can potentially become RCRA-relevant if stored. This is connected to the complementary cognitive co-creation method used to interlink the preparatory procedure with the RCRA that we explain in Section 6.2. |
| 5. | |
| 6. | With intelligent systems, we refer to technically feasible AIs able to independently perform the OODA-loop (i.e., observe, orient, decide, act), but simultaneously totally subordinated to and goal-governed by human entities (e.g., using updatable human-defined ethical goal functions [19] prepared pre-deployment—where humans fill in ethically-relevant parameters into a suitable blank but context-sensitive scientifically-grounded template denoted augmented utilitarianism [13]). |
| 7. | As for instance successfully performed in the Cambridge Analytica case [91]. |
| 8. | Homophily in social media is a multidimensional construct that can refer to attitudes, beliefs, preferences, appearances across a variety of domains. It is by no means limited to the often discussed case of political homophily [140]. For example, empirical social media studies identified weight-based homophily [141], journalistic homophily [142], homophily in rumor sharing [143], higher perceived homophily by users from collectivistic cultures [144], perceived homophily driving consumer purchase intentions [145] and credibility of information [146], homophilic effects in consumer-website relationships [147], homophily as factor for vlogger popularity [148], ideological hashtag homophily in marketing campaigns [149] and even homophily related to music preferences [150]. Apart from that, it is known in social psychology that “ingroups are seen as more variable than outgroups” [151] (especially in individualistic cultures). This could arguably strengthen the (wrong) perception of engaging in heterogeneous online spaces. However, some studies actually found social media patterns diverging from homophily [152]. Hence, it is important to further assess the context-sensitive nature of the phenomenon in future work. |
| 9. | Note that on the long-term this could in theory skew the unconscious internal model internet users exposed to more and more synthetic faces have of how human faces look like. Outliers from the real distribution could be met with more surprise at the subpersonal level. However, the latter might already be the case today with the widespread use of enhancing filters on social-media. |
| 10. | Bayesian and empiricist epistemological stances placing the empirical collection of evidence and the identification of true beliefs at the center of science may link AI-aided deception to “epistemic threats” [166]—knowledge-relevant impairments of belief-updating which they already see emerging via deepfakes (i.a. subsuming a general decrease of information in audiovisual samples [166]). By contrast, Popperian epistemic views [167] and especially their Deutschian extension [168] predominantly emphasize in the first place the explanatory and criticism-centered purpose of science next to the (experimental) falsifiability of hypotheses. Strikingly, Deutsch describes science as the endless quest for invariant, hard-to-vary explanations of reality [168]. On this view, AI-aided deception in science may be practically problematic, but without question solvable. In fact, while the empiricist direction faces epistemic threats and a post-truth difficulty, the Popperian and Deutschian direction may neither see explanatory knowledge, truth, falsifiability nor the scientific method per se at risk. |
| 11. | |
| 12. | Since as mentioned earlier, lower harm intensity may lead to more perceiver-dependent differences, one does not exactly need to establish which exact intensity, one only needs to know that it is a non-lethal upward counterfactual scenario. |
| 13. | |
| 14. | From a psychological and neurocognitive perspective, EC currently views creativity as a tri-partite evolutionary affective construct with varying degrees of sightedness [199] instead of a blind evolutionary process without a goal akin to biological evolution—as mistakenly assumed by Popper [16,211]. This is epistemologically relevant because ideas are not created by blind trial and error (as variation and selection in biological evolution). Even if novel idea contents are fundamentally unpredictable a priori, idea variation is partially guided by previous experience, the task and contextual cues that is, there is a non-zero coupling between variation and selection [211]. Creativity itself could have historical roots in serendipity and multi-purpose socially shared doubt [13] facilitating in theory error-correction but initially largely used to maintain traditions. |
| 15. | EC could be stated to apply a constructor-theoretic distinction to AI safety insofar as it applies a possibility-impossibility dichotomy [209] embedded in an explanatory framework to it. |
| 16. | Under EC, superintelligence is as explained not of distinctive interest. It is also viewed as not implying profound qualitative differences to human baselines. Following Deutsch, it would be “[...] subject only to limitations of speed or memory capacity, both of which can be equalized by technology” [212]. EC views human augmentation as valid transformative defense strategy [199]. |
| 17. | Importantly, note that Type II AI uncontrollability does by no means imply that a Type II AI is necessarily more dangerous than an arbitrarily designed Type I AI. First, it is important to consider that already an advanced Type I AI could lead to existential risks for instance when maliciously designed by malevolent human actors to operate “at a global scale (e.g., affecting global ecological aspects or the financial system)” [16]. Second, while it is obvious that a Type II AI could be highly dangerous, this also holds for humans including adult terrorists threatening international safety. Overall, it seems a prejudice to assume that Type II AIs that would be members of an open society would inherently tend to opt for immutable goals of indifference or extreme violence (see e.g., Hall [213] for an in-depth explanation). Those patterns are possible choices posing major risks, but not inherent properties of Type II systems—the content of whose future novel ideas and related decisions cannot be prophesied a priori. In short, there is no meaningful total order of “dangerousness” according to which one can compare Type I and Type II AIs. To put it plainly: both the worst risk and the greatest luck for a Type II system could be a Type II system. |
| 18. | Note that if given an RCRA cluster, the executive group would not succeed in imagining a corresponding instance for a narrative, there is always at least one back-up instantiation—which corresponds to the narrative envisaged by the participatory group pre-DF (whose identification represented the precondition for this cluster to exist in the first place). |
| 19. | For instance, despite possible significant context-dependent [223] hindrances, dyadic mismatches [225] and disabilities, autistic traits are also paired with enhanced convergent thinking [226], detail-rich thinking [227] and higher verbal creativity [228] while attention deficit hyperactivity disorder traits have been linked to enhanced divergent thinking [229,230] and enhanced originality and flexibility [231]. Systematically combining these two complementary cognitive profiles under a CCC-oriented approach to RDA-based RCRA-DFs for AI observatory feedback-loops could engender benefits. |

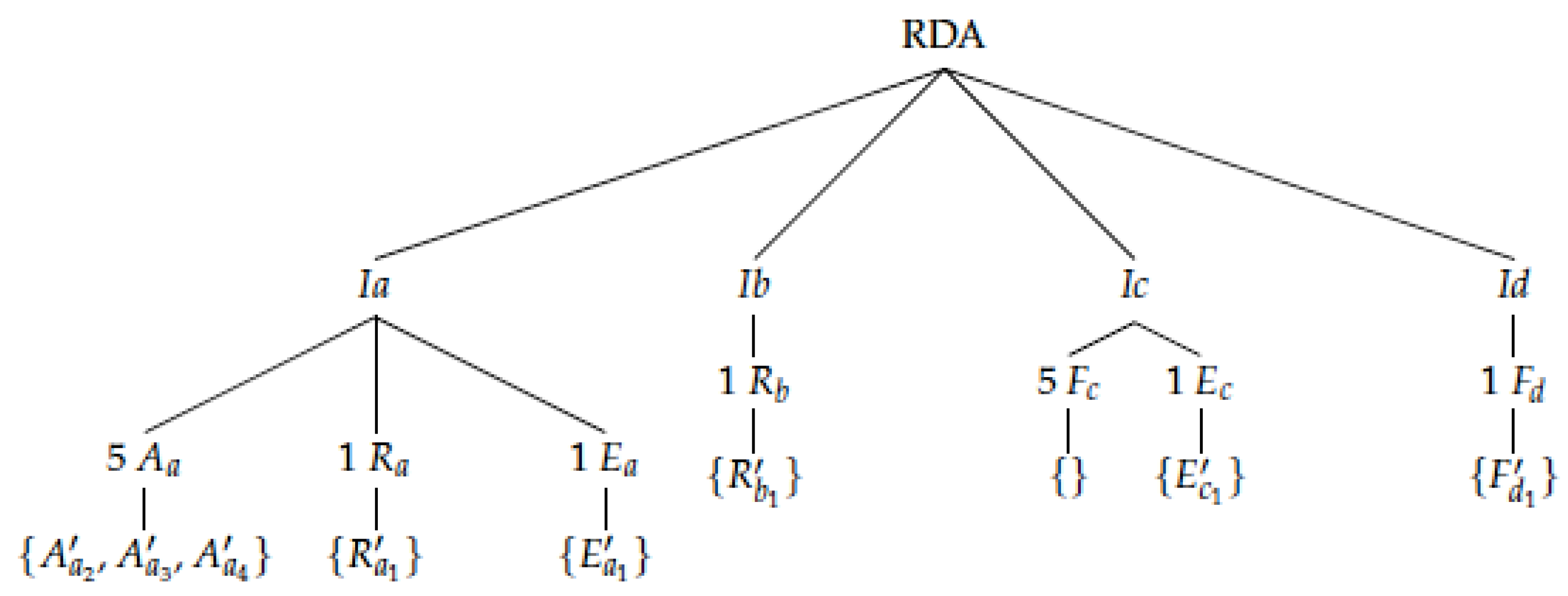
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aliman, N.-M.; Kester, L.; Yampolskiy, R. Transdisciplinary AI Observatory—Retrospective Analyses and Future-Oriented Contradistinctions. Philosophies 2021, 6, 6. https://doi.org/10.3390/philosophies6010006
Aliman N-M, Kester L, Yampolskiy R. Transdisciplinary AI Observatory—Retrospective Analyses and Future-Oriented Contradistinctions. Philosophies. 2021; 6(1):6. https://doi.org/10.3390/philosophies6010006
Chicago/Turabian StyleAliman, Nadisha-Marie, Leon Kester, and Roman Yampolskiy. 2021. "Transdisciplinary AI Observatory—Retrospective Analyses and Future-Oriented Contradistinctions" Philosophies 6, no. 1: 6. https://doi.org/10.3390/philosophies6010006
APA StyleAliman, N.-M., Kester, L., & Yampolskiy, R. (2021). Transdisciplinary AI Observatory—Retrospective Analyses and Future-Oriented Contradistinctions. Philosophies, 6(1), 6. https://doi.org/10.3390/philosophies6010006