Abstract
Objectives: to assess the ability of high-performing open-weight large language models (LLMs) in extracting key radiological features from prostate MRI reports. Methods: Five LLMs (Llama3.3, DeepSeek-R1-Llama3.3, Phi4, Gemma-2, and Qwen2.5-14B) were used to analyze free-text MRI reports retrieved from clinical practice. Each LLM processed reports three times using specialized prompts to extract (1) dimensions, (2) volume and PSA density, and (3) lesion characteristics. An experienced radiologist manually annotated the dataset, defining entities (Exam) and sub-entities (Lesion, Dimension). Feature- and physician-level performance were then assessed. Results: 250 MRI exams reported by 7 radiologists were analyzed by the LLMs. Feature-level performances showed that DeepSeek-R1-Llama3.3 exhibited the highest average score (98.6% ± 2.1%), followed by Phi4 (98.1% ± 2.2%), Llama3.3 (98.0% ± 3.0%), Qwen2.5 (97.5% ± 3.9%), and Gemma2 (96.0% ± 3.4%). All models excelled in extracting PSA density (100%) and volume (≥98.4%), while lesions’ extraction showed greater variability (88.4–94.0%). LLMs’ performance varied among radiologists: Physician B’s reports yielded the highest mean score (99.9% ± 0.2%), while Physician C’s resulted in the lowest (94.4% ± 2.3%). Conclusions: LLMs showed promising results in automated feature-extraction from radiology reports, with DeepSeek-R1-Llama3.3 achieving the highest overall score. These models can improve clinical workflows by structuring unstructured medical text. However, a preliminary analysis of reporting styles is necessary to identify potential challenges and optimize prompt design to better align with individual physician reporting styles. This approach can further enhance the robustness and adaptability of LLM-driven clinical data extraction.
1. Introduction
Structured reporting has been widely endorsed by leading radiological societies, such as the Radiology Society of North America (RSNA) and European Society of Radiology (ESR), to standardize reporting, enhance clinical communication, and enable data-driven research [1,2,3]. Despite these recommendations, many institutions continue to rely on unstructured, free-text radiology reports, which often impede the consistent extraction of clinically relevant data and limit the ability to build large-scale, queryable databases for both research and quality improvement purposes.
Efforts to promote structured report templates have met with partial success, partly due to the additional time and effort required for manual data entry into predefined fields [1]. As a result, large-scale retrospective analyses, epidemiological studies, and the development of advanced imaging biomarkers remain constrained by incomplete or inconsistently documented information.
Natural Language Processing (NLP) has long been a cornerstone in the effort to extract and analyze information from unstructured radiology reports. For example, Trivedi et al. [4] introduced an interactive NLP tool designed to identify incidental findings in radiology reports. In a study involving 15 physicians, the tool demonstrated significant improvements in model performance and a significant reduction in time spent reviewing. Banerjee et al. [5] obtained ClinicalBERT++ by fine-tuning the BERT model on 3 million radiology reports to improve the detection and follow-up of critical findings in radiology reports, achieving high performance in both internal and external validation datasets and offering a scalable solution for automated alert notifications and retrospective tracking of critical findings [6].
More recently, Large Language Models (LLMs) have emerged as a transformative tool in radiology, enhancing report readability, improving patient-provider communication, and streamlining non-interpretive tasks. Recent studies have demonstrated the ability of LLMs to simplify complex medical terminology in radiology reports, making them more accessible to patients. For instance, one study found that four LLMs (GPT-3.5, GPT-4, Bard, and Bing) significantly reduced the reading grade level of radiology report impressions across various imaging modalities when prompted to simplify the language [7]. Similarly, another study highlighted the efficacy of an LLM in improving the readability of foot and ankle radiology reports, achieving statistically significant improvements in Flesch Reading Ease and Flesch-Kincaid Grade Level scores [8]. Additionally, LLMs have shown promise in enhancing the clarity of knee and spine MRI reports, further underscoring their potential to bridge the gap between technical jargon and patient understanding [9]. Beyond simplifying reports, LLMs have been utilized to enhance MRI request forms and automate protocol suggestions, reducing the burden on radiologists while maintaining high accuracy [10]. Other authors have investigated the use of LLMs in improving radiology reporting accuracy. A study by Gertz et al. evaluated GPT-4’s ability to detect common errors in radiology reports, such as omissions, insertions, and spelling mistakes, achieving an error detection rate of 82.7%, which was comparable to the performance of radiologists across all experience levels [11].
Despite these advancements, challenges remain in using LLMs to extract structured data from unstructured reports, particularly in specialized clinical contexts [12]. For instance, a study evaluating ChatGPT’s performance in determining LI-RADS scores based on MRI reports revealed poor accuracy (53% for unstructured reports and 44% for structured reports) [13].
Given these challenges, our study focuses on addressing a critical gap in the application of LLMs to radiology reporting: the extraction of structured data from unstructured MRI reports. While applicable to various radiological exams, we focused on multiparametric prostate MRI due to its clinical complexity and relevance to prostate cancer biomarkers. Thus, the aim of this study was to develop and validate an automated pipeline using open-weight LLMs and rule-based parsing to convert free-text prostate MRI reports into standardized, queryable formats. This approach enhances data utilization for research, quality improvement, and patient care, addressing a critical need in clinical workflows.
2. Materials and Methods
2.1. Data Acquisition, Cleaning, and Categorization
In this retrospective study, we used a set of unstructured, clinically generated, Italian-language prostate MRI reports. The ethic approval was obtained on September 11, 2024, by CET Lombardia 3 Ethical Committee (Study ID: 5105). One expert data scientist (L.D.P., with 2 years of experience working with LLMs) revised the reports in order to manage the dataset. Only minor changes were made; for example, many radiologists had appended a fixed legend at the end of the report to explain the meaning of each PI-RADS value. These common strings were removed before processing the reports with the LLM. The dataset was cleaned in a balanced manner across multiple radiologists. All medical reports used were standalone text reports that did not contain any personally identifiable information. Specifically, the reports included no names, patient IDs, dates of birth, or other direct or indirect identifiers. As such, the dataset was fully de-identified before any processing. To further protect data privacy, all processing was performed locally within the institution’s secure computing environment. No data were transmitted to external services or cloud-based platforms at any point during the study, thereby eliminating the risk of external exposure.
2.2. Feature Extraction by Radiologist
One radiologist performed manual extractions of key information, according to a list of predefined features referring to 3 entities: Exam, the main entity containing the sub-entities, Lesion, and Dimension.
The Exam entity is composed of:
- Volume (float)
- PSA density (float)
- Lesions (List of Lesion elements)
- Dimensions (Dimension element)
Where each Lesion is composed of:
- PI-RADS score (int)
- Location (str): allowed values are “Transition zone”, “Peripheral zone”, “Transition zone and peripheral zone”
While Dimension is composed of:
- Longitudinal dimension (float)
- Transverse dimension (float)
- Antero-posterior dimension (float)
- Unit of measurements (str): allowed values are “mm” and “cm”
These manually curated data served as the ground truth for subsequent model evaluation. Examples of reports and filled templates are presented in Table 1 and Table 2.

Table 1.
Examples of free-text MRI reports and corresponding structured-output versions.
Table 2.
Examples of free-text MRI reports and corresponding structured-output versions. Values which are not indicated remain empty (-) in the structured report.
2.3. Model Validation
2.3.1. Architecture
A diverse set of high-performing open-weight LLMs was selected to process unstructured medical text. The models varied in architecture and parameter size, allowing a comprehensive comparison. Specifically, we included:
- Llama3.3 70B parameters (Meta, Menlo Park, CA, USA), known for strong language understanding, performing similarly to Llama 3.1 405B [14].
- DeepSeek-R1-Llama3.3 70B parameters (DeepSeek, Hangzhou, Cina), a distilled version of DeepSeek-R1 on Llama3.3, demonstrating performance comparable to OpenAI models [15].
- Phi4 14B parameters (Microsoft, Redmond, WA, USA), a state-of-the-art open model balancing efficiency and performance [16].
- Gemma-2 27B parameters (Alphabet, Mountain View, CA, USA), excelling in multi-turn conversations and reasoning [17].
- Qwen2.5-14B 14B parameters (Alibaba Cloud, Hangzhou, China), offering specialized models and broad language support [18,19].
All models were tested with uniform inference settings: zero temperature (deterministic outputs) and unlimited token length (avoiding truncation), ensuring fair assessment of their clinical text interpretation capabilities.
2.3.2. Prompting
A structured three-step zero-shot prompting technique was adopted for all models to extract relevant information systematically (Figure 1). While each LLM utilized its own prompt format, a consistent system-prompt and user-prompt structure was applied to ensure fair comparison. This standardized approach preserved the unique prompt designs of individual models while maintaining an equitable evaluation framework. The extraction process was divided into three sequential steps:
- Dimension extraction: the first prompt focused on identifying and extracting prostate dimensions (longitudinal, transverse, antero-posterior, and measurement unit) from the provided medical report.
- Volume and PSA density extraction: the second prompt extracted the prostate volume and PSA density.
- Lesion extraction: the third prompt identified and extracted lesion details (PI-RADS and location).
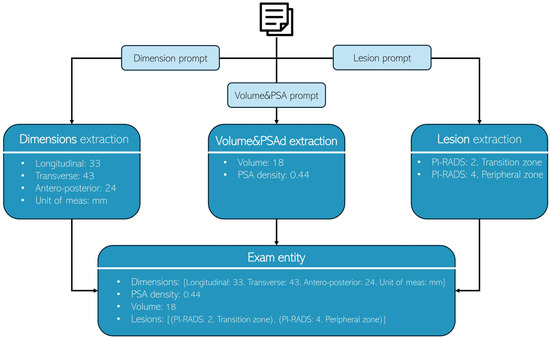
Figure 1.
Each radiology report undergoes processing three times, with each iteration utilizing a distinct prompt to extract specific information: Dimensions, Volume & PSA, and lesion characteristics, respectively.
Figure 1.
Each radiology report undergoes processing three times, with each iteration utilizing a distinct prompt to extract specific information: Dimensions, Volume & PSA, and lesion characteristics, respectively.
The prompts used were:
- System Prompt:“You are a highly skilled radiologist with extensive experience in prostate imaging and diagnostics, as well as proficiency in Python programming. Your task is to analyze the provided medical report and generate a comprehensive, professional radiology report following the provided instructions.”
- User Prompt for dimension extraction:
“Here is the report that you have to process:
[START REPORT]
- report here -
[END REPORT]
Instructions:
- -
- Extract the dimensions mentioned in the report.
- -
- Assign each dimension to its corresponding category: Anteroposterior (AP), Latero-lateral (LL), or Craniocaudal (CC, or Longitudinal).
- -
- If the report does not explicitly specify which dimension corresponds to AP, LL, or CC, or if the dimension names are not clearly stated, set dimensionOrder to: [NA, NA, NA].
- -
- Do not infer or assume dimension assignments based on context; rely solely on explicit information provided in the report.
Answer:
{{“dimensions”: Optional[List[float]],
“dimensionsOrder”: Optional[List[str]],
“measurement_unit”: Optional[Literal[“mm”, “cm”]]}}”
- User Prompt for volume and PSA density extraction:
“Here is the report that you have to process:
[START REPORT]
- report here -
[END REPORT]
Instructions:
- -
- If the report explicitly specifies the prostate volume (e.g., “volume: 35 mL” or “volume: 35 cc”), extract that value and assign it to the ‘volume’ field.
- -
- If the report provides only linear dimensions (e.g., “AAxBBxCC mm”) without explicitly stating the volume, leave the ‘volume’ field empty.
- -
- If the report explicitly specifies PSA density (e.g., “PSA density: 0.15 ng/mL/cm3”), extract that value and assign it to the ‘psa_density’ field.
- -
- If the report does not explicitly specify PSA density, leave the ‘psa_density’ field empty.
- -
- Do not infer or calculate volume or PSA density based on provided dimensions or other context; rely solely on explicit information stated in the report.
Answer:
{{‘volume’: Optional[float], ‘psa_density’: Optional[float]}}”
- User Prompt for lesion extraction:
“Here is the report that you have to process:
[START REPORT]
- report here -
[END REPORT]
Instructions:
- -
- Extract the lesions mentioned in the report.
- -
- Assign to each lesion its corresponding pirads and location (peripheral zone, transition zone, peripheral and transition zone).
Answer:
{{‘lesions’: Optional[list[pydanticLesion]]}},
where pydanticLesion is defined as:
{{‘pirads’: Optional[int], ‘location’: Optional[Literal[“Transition zone”, “Peripheral zone”, “Peripheral and transition zone”]]}}”
The complete prompt configurations used for each model can be found in Table 3.
Table 3.
Each LLM includes special tokens unique to the model, which it uses to mark the beginning and end of structured components in its generation. These tokens help indicate the start or conclusion of a sequence, message, or response.
2.3.3. Structured Output Schema
The same structured schema, mirroring the manually curated data, was utilized by the LLM to ensure consistency in feature extraction. The schema adheres to the predefined entities and their respective attributes, such that the LLM-generated data aligns with the ground truth established by the radiologist, facilitating accurate model evaluation.
2.4. Evaluation Metrics
The performances of each LLM were assessed using distinct evaluation matrices based on the extracted features:
- For longitudinal, transverse, antero-posterior, unit of measurements, volume, PSA density:
- ○
- Accuracy: the proportion of correctly extracted entities compared to manual annotations. A prediction was considered correct when:
- ▪
- both prediction and ground truth were empty or
- ▪
- prediction and ground truth were equal.
- For lesions (example is shown in Table 4):
Table 4. Example illustrating the methodology used to compute the lesion score, detailing the individual parameters, their respective weightings, and the final score calculation.
- ○
- F1-Score: a more granular evaluation was performed to account for partial matches in lesion PI-RADS and location. The process involved calculating true positives (TP), false positives (FP), and false negatives (FN) as follows:
- For each examination, a blank set of new lesions was created based on the lesion ground truth.
- Each prediction was matched with the ground truth:
- ○
- Complete match: predictions were first matched to the blank schema where both the PI-RADS score and lesion location matched the ground truth.
- ○
- Partial match: remaining predictions were matched if at least one field (PI-RADS or location) matched the ground truth, reflecting cases where the model identified the correct lesion but made an error in one of the two fields.
- For the remaining predictions, any unmatched ones were used to fill blank spaces, with excess predictions classified as FP.
- For each lesion:
- If there was a match in lesion PI-RADS: TP was incremented by 0.5.
- If there was a match in lesion location: TP was incremented by 0.5.
- If there was no match in lesion PI-RADS: FN was incremented by 0.5, and FP was incremented by 0.5.
- If there was no match in lesion location: FN was incremented by 0.5, and FP was incremented by 0.5.
- Final exam score: The F1-score for each examination was computed using the formula:
- Processing time: the time required to process all reports. During the construction of the ground truth dataset, the time required for manual data extraction from scratch and the time for manual review of pre-filled templates were evaluated using a sample of examinations.
3. Results
3.1. Data Acquisition
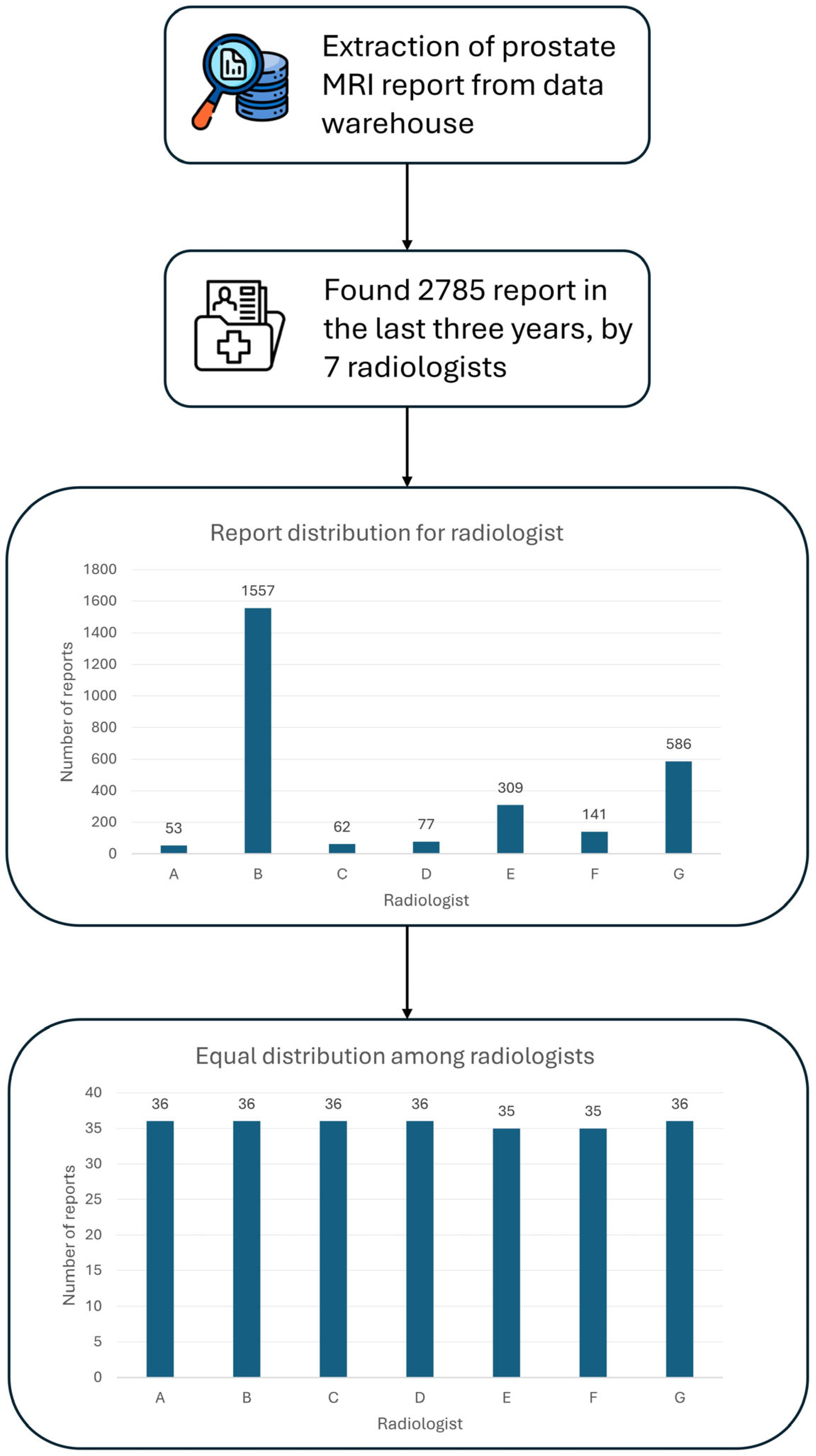
A total of 250 unstructured prostate MRI reports were retrospectively analyzed in this study. These reports were derived from routine clinical practice at our Center, comprising prostate MRI exams conducted over the last three years, amounting to 2785 exams (Figure 2). The minimum number of reports required per radiologist to reach a total of 250 reports and to ensure balanced representation among radiologists was determined. Seven radiologists with at least three years of experience in prostate MRI interpretation were selected. The study population comprised 248 people, ranging in age from 29 to 87 (66 ± 9), with a median prostate volume of 51.5 cc (IQR 37.5–73.5). Regarding anatomical prostate measurements, the median longitudinal dimension was 50 mm (IQR: 43–57 mm), while the transverse dimension measured 53 mm (IQR: 47–58 mm). The median antero-posterior dimension was recorded as 39 mm (IQR: 34–45 mm). However, these measurements were unavailable for 71 cases, corresponding to 28.4% of the total dataset. This missing data resulted from radiology reports in which prostate dimensions were recorded in the format ‘AAxBBxCC’ without specifying which value corresponded to the longitudinal, transverse, or antero-posterior dimension. As it was not possible to accurately determine the correct dimension assignment, these cases were considered missing in the analysis. The median PSA density was 0.09 ng/mL2 (IQR: 0.06–0.14), although data on PSA density were missing (the value was not specified by the radiologist in the original report) for 152 examinations, representing a significant portion (61%) of the cohort (Table 5A).
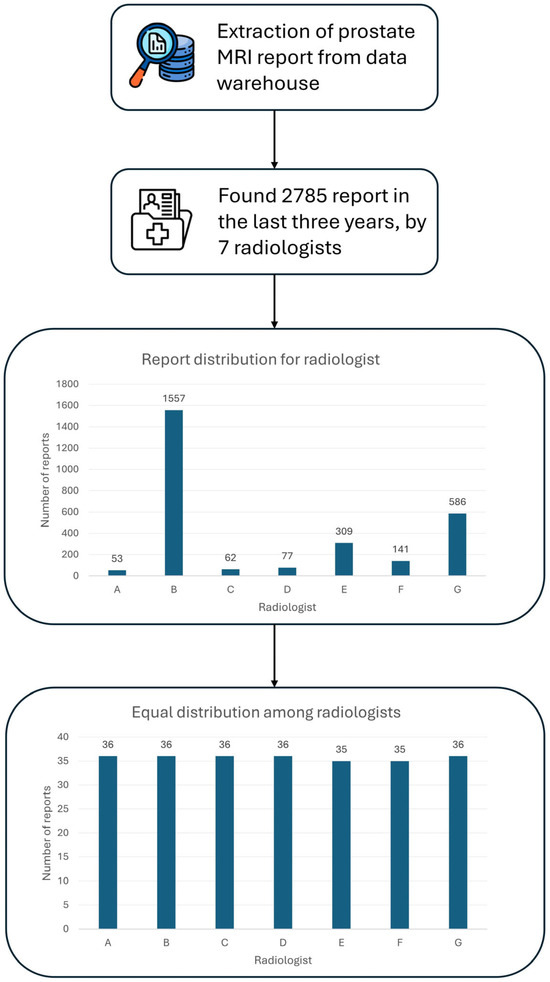
Figure 2.
Workflow for dataset generation. The complete workflow illustrates the steps taken to obtain the final dataset of 250 radiology reports.
Table 5.
(A). Summary of prostate characteristics, including dimensional measurements (longitudinal, transverse, and antero-posterior), volume, and PSA density, along with missing data counts. (B). Distribution of lesions based on PI-RADS score and anatomical location, providing an overview of lesion classification across different prostate zones.
Analysis of lesion frequency per examination revealed that 20 scans (8%) showed no detectable lesions, while the majority of examinations (n = 130, 52%) identified a single lesion. Two lesions were detected in 70 examinations (28%), while 20 scans (8%) revealed three lesions, and 9 scans (3.6%) displayed four lesions. In one examination (0.4%), there was no clear definition of lesions and it was excluded from the count.
A total of 366 lesions were identified across all examinations. Among these, 237 (64.8%) lesions were classified as PI-RADS 2, while 53 (14.5%) were classified as PI-RADS 3. 58 (15.8%) lesions were found to be PI-RADS 4, and a smaller subset of 13 (3.6%) lesions were assigned a PI-RADS 5 classification. The remaining five (1.3%) didn’t have a clearly specified PI-RADS classification. Additional clinical characteristics, including PI-RADS score distribution and lesion localization, are detailed in Table 5B.
3.2. LLMs Output
The LLMs were running locally on our server using the Ollama (version (v) 0.4.6) framework. The output was obtained and validated using Instructor (v. 1.7.2) and Pydantic (2.9.2). Each report was processed 3 times, once for each task with its prompt to extract the different features (dimensions, volume & PSA density, lesions). The outputs of each task were then processed and used to fill the Exam entity. Examples of the expected outputs of each task are shown in Table 6.
Table 6.
Example of output obtained from each task execution.
3.3. Evaluation Metrics
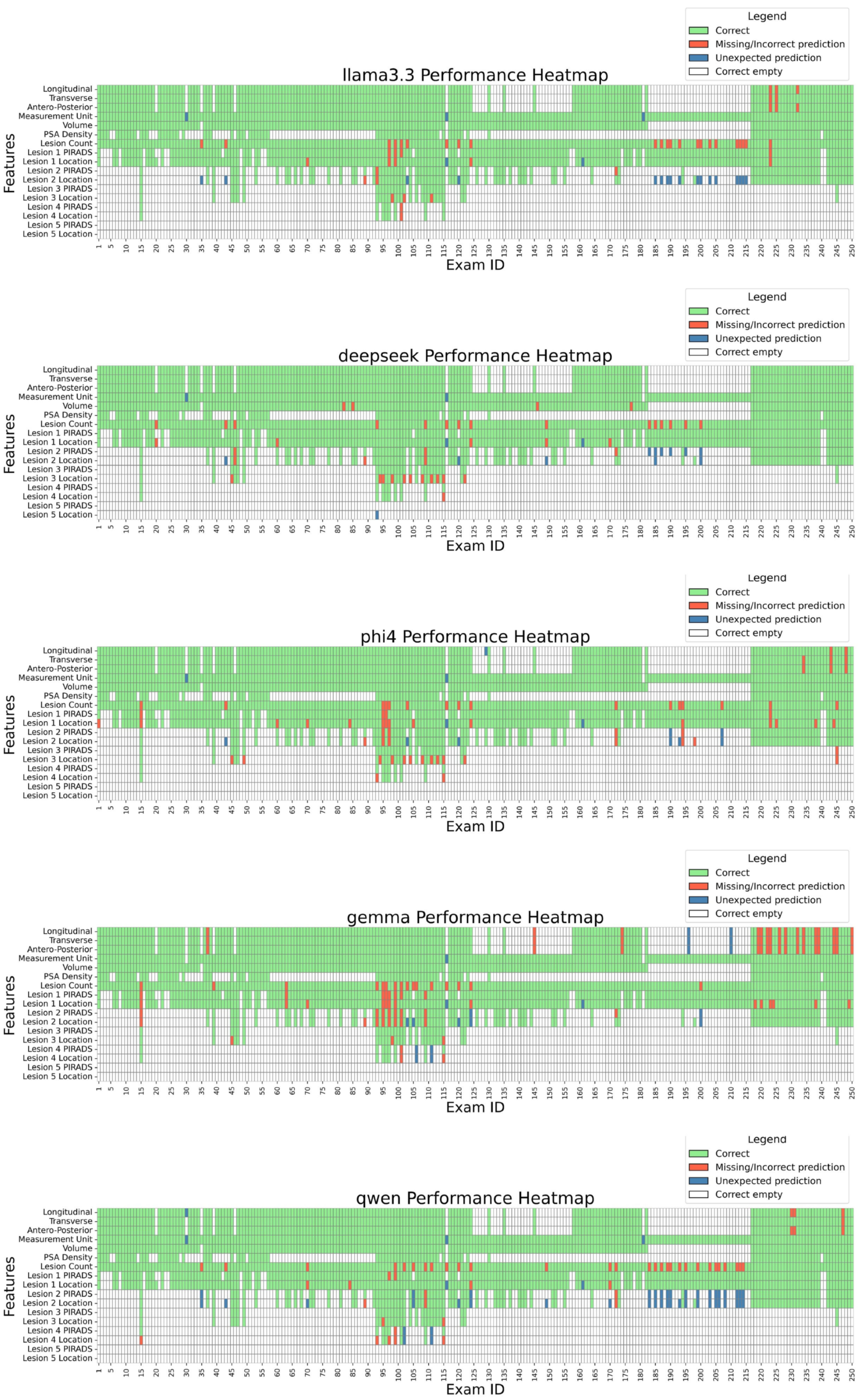
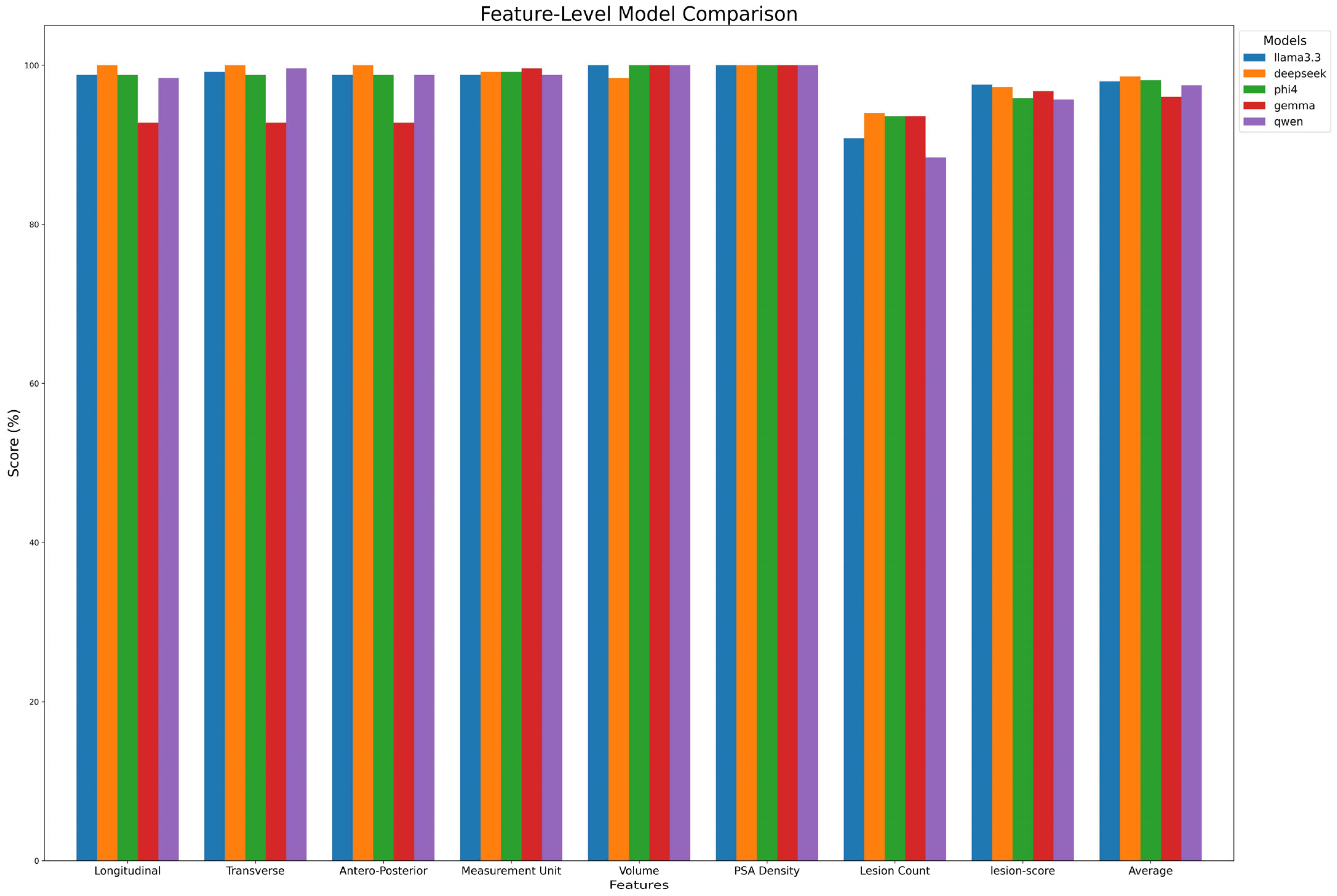
To assess open-source LLMs in extracting values from medical reports, we established a ground truth based on annotations made by Radiologist C. Models’ performances were evaluated by comparing their predictions with this ground truth. Figure 3 details performance case by case, while Table 7A and Figure 4 summarize extraction results across features. DeepSeek-R1-Llama3.3 achieved the highest average score (98.6% ± 1.97%), followed by Phi-4, Llama 3.3, Qwen, and Gemma. While models performed well in extracting Volume and PSA Density (~100%), variability was observed in lesion count extraction, with Qwen scoring the lowest (88.4%). Lesion-score extraction varied by model, ranging from Qwen2.5 (95.7%) to Llama3.3 (97.3%).
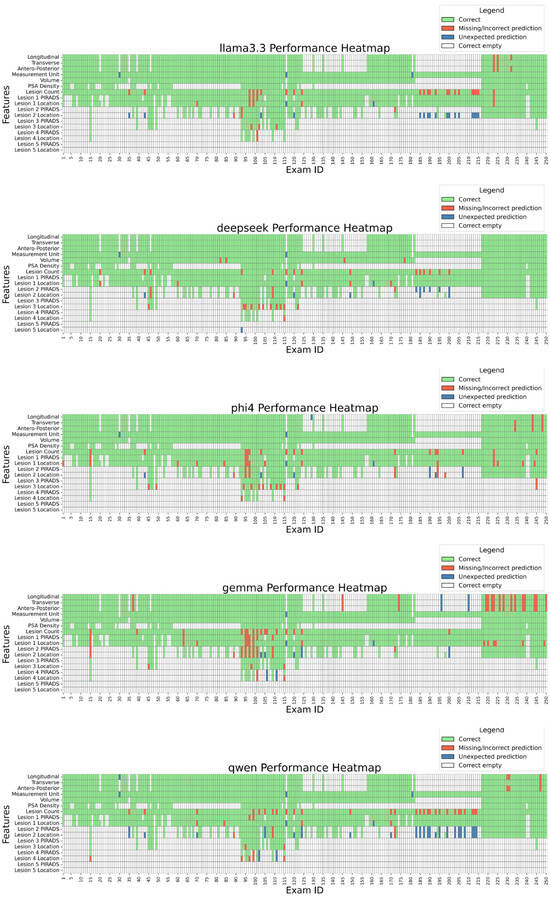
Figure 3.
Model performance by exam and feature. The heatmap displays the performance of each model across individual exams and extracted features. LEGEND: Correct: the prediction matches the ground truth; Missing/Incorrect prediction: the prediction is missing or is different from the ground truth; Unexpected prediction: while the ground truth is missing, the LLM still made a prediction (hallucination). Correct empty: the ground truth was empty, and the LLM correctly left the field empty.
Table 7.
(A). Performances obtained by each model for each extracted feature. In bold, the best performance was highlighted. (B). Performance scores of each model, computed with respect to the physician (A–G). In bold, the best performance was highlighted.
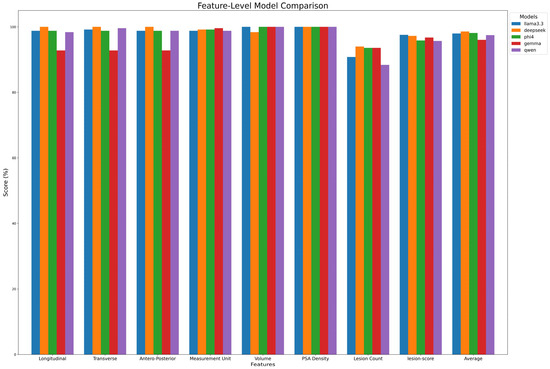
Figure 4.
Model performance on feature extraction. The figure compares the performance of each model in extracting key features from radiology reports.
A qualitative analysis of model errors revealed several common failure modes. For example, some LLMs attempted to infer prostate dimensions (longitudinal, transverse, antero-posterior) even when the associations between the numbers and the dimensions were not explicitly specified in the report, leading to incorrect extractions. In other cases, units of measurement were incorrectly assigned, e.g., by mistakenly associating values with units mentioned elsewhere in the report rather than those relevant to prostate dimensions. Lesion-related errors included missing lesions entirely, misclassifying lesion location when the description was ambiguous, or failing to recognize that two references in the report referred to the same lesion, resulting in overestimation of lesion count.
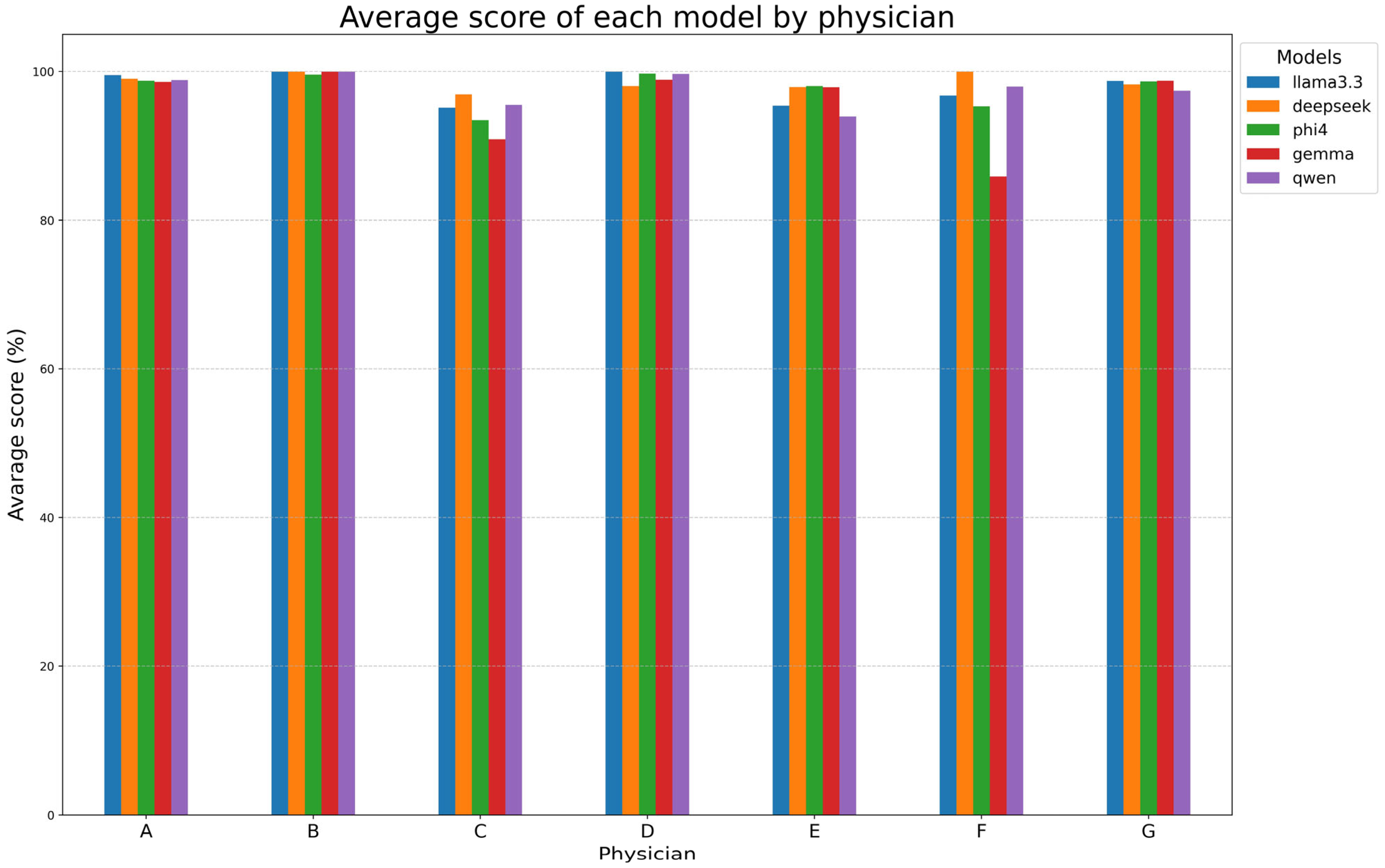
Table 7B and Figure 5 examine the performances of models for each reporting physician, with DeepSeek-R1-Llama3.3 again achieving the highest mean score (98.6% ± 1.1%). Llama 3.3, Phi-4, and Qwen2.5 followed closely, while Gemma-2 had the lowest mean score (95.8% ± 5.5%). Models performed exceptionally well on reports made by radiologists A, B, D, and G (~99%) but showed lower alignment with radiologists C, E, and F. Gemma-2 exhibited the most variability, while DeepSeek-R1-Llama3.3 maintained high consistency.
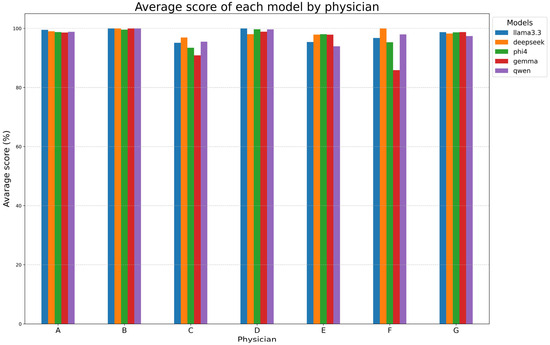
Figure 5.
Model performance at physician-level. This figure evaluates the performance of each model with respect to each physician (A–G).
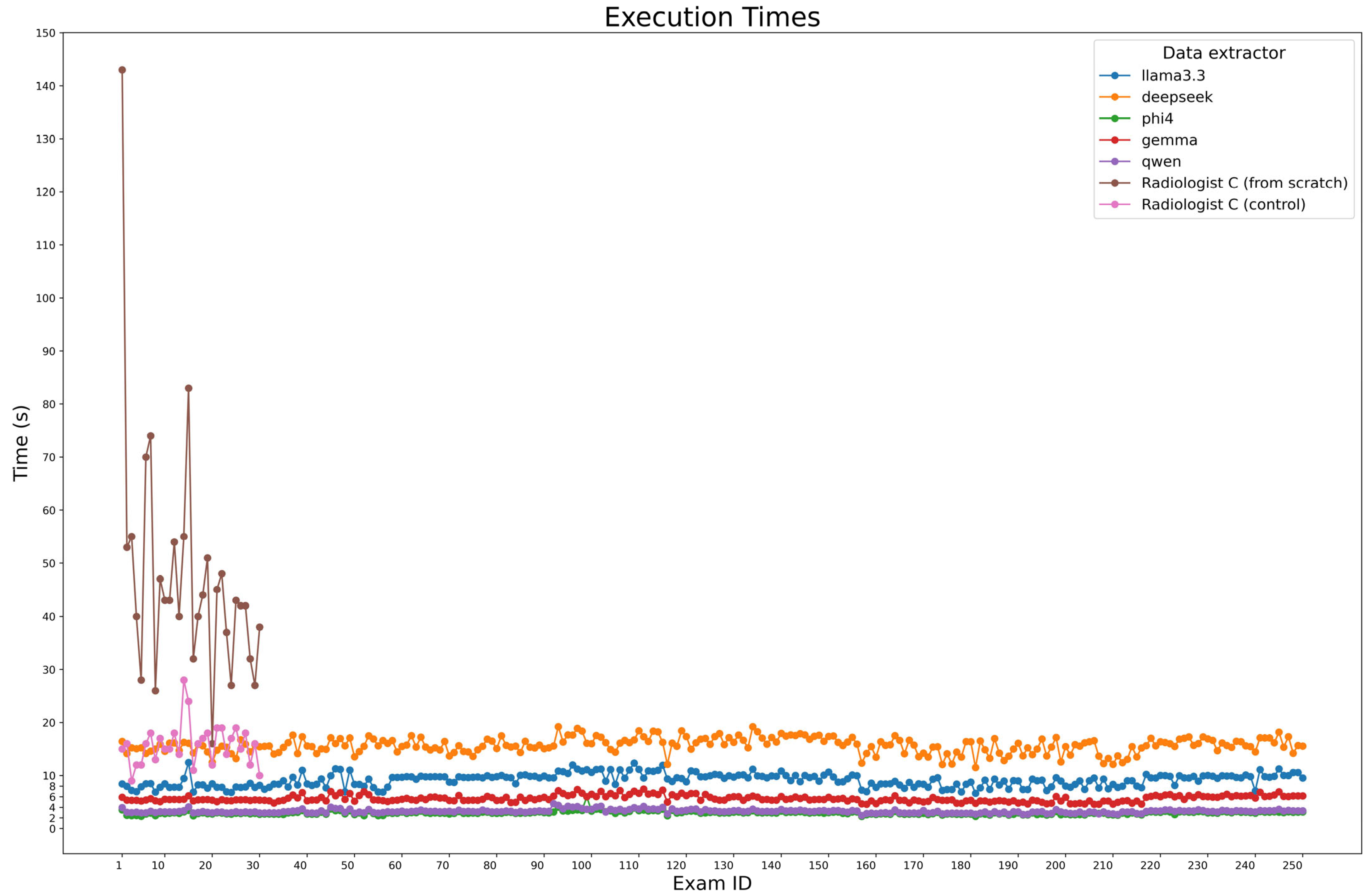
During ground truth evaluation, Radiologist C was observed while compiling a sample of 30 examinations from scratch, achieving a median time of 43 s per report (IQR: 37.25–52.5). The same reports were used for a second examination, where radiologist C didn’t fill the fields from scratch but only corrected the model predictions, in particular DeepSeek-R1-Llama3.3 predictions, obtaining a median time of 16s (IQR: 13.25–18). For automated extraction, the execution times of the model were measured across all 250 cases using Python (v. 3.10.12) timing functions, considering all three steps made for entity extraction, which were executed in series. Figure 6 presents processing times, with Phi-4 being the fastest (2.95 s, IQR: 2.76–3.12), followed by Qwen2.5 (3.23 s, IQR: 3.04–3.38) and Gemma-2 (5.49 s, IQR: 5.27–6.06). Larger models, Llama 3.3 and DeepSeek-R1-Llama3.3, required longer times (9.45 s, IQR: 8.23–9.93 and 15.72 s, IQR: 14.87–16.72, respectively).
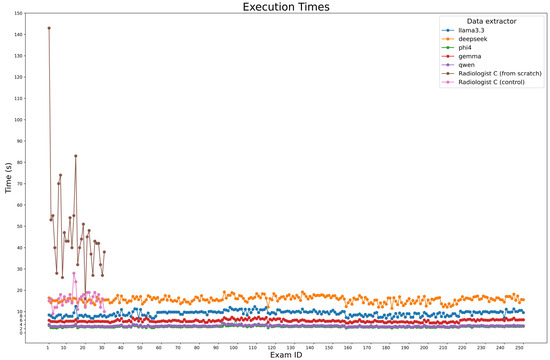
Figure 6.
Execution time comparison. The plot compares the execution times of each model for processing all 250 cases, alongside the time.
4. Discussion
Despite the benefits of structured reporting, adoption remains limited due to workflow challenges and clinician resistance. Addressing these issues could enhance radiology’s efficiency and data-driven capabilities. Recent LLM advancements offer automation opportunities [20,21,22,23], though many rely on closed-source models, raising concerns about patient confidentiality, regulatory compliance, and model oversight [20,21,22,24]. Jiang et al. [20] examined ChatGPT-3.5 and ChatGPT-4.0 for thyroid ultrasound reports, finding that while ChatGPT-3.5 produced satisfactory reports, ChatGPT-4.0 excelled in nodule categorization and management recommendations. Adams et al. [25] demonstrated GPT-4’s ability to convert 170 CT/MRI and 583 chest radiography reports into structured JSON files with 100% accuracy. Other studies explored the usability of open-weights LLMs to create structured reports [23,26,27]. Open-weight LLMs have also been explored for structured reporting. Woznicki et al. [26] assessed Llama-2-70B-chat for converting narrative chest radiograph reports into structured data, achieving human-comparable performance in English and German datasets. Other studies confirm that privacy-preserving open-weight LLMs can match closed models like GPT-4o in extracting structured data, underscoring their potential for automated clinical data processing [23].
Our study developed and validated an automated pipeline using open-weight LLMs and rule-based parsing to convert unstructured prostate MRI reports into structured data. A dataset of 250 reports was carefully curated to ensure diversity and minimize selection bias. The results demonstrated that models like DeepSeek-R1-Llama3.3, Llama3.3, and Phi-4 performed exceptionally well, though extraction accuracy varied for lesion-related data, indicating challenges in complex medical contexts. Variability in model performance across different physicians’ reports suggests that reporting style significantly impacts accuracy, highlighting the need for algorithm adaptation to specific physicians.
The automated approach provided substantial time and cost savings compared to manual reporting. Unlike radiologists, LLMs maintain consistent efficiency without fatigue and can process large volumes of reports daily. A hybrid workflow where AI generates structured reports from free text and radiologists review them could enhance efficiency while maintaining trust and accuracy. This study underscores the transformative potential of structured medical data, improving workflow efficiency, enhancing research, and unlocking valuable clinical insights.
This work has limitations. By centralizing the reference standard with a single radiologist, we aimed to minimize inconsistencies in interpretation while retaining a systematic methodology for extracting relevant clinical details. However, this strategy introduces the risk of subjective bias and precludes assessment of inter-rater reliability, which could offer insight into annotation consistency and model agreement with expert consensus.
Furthermore, all medical reports were sourced from a single institution and authored in Italian. This limits the model’s exposure to the variability in reporting styles that may exist across different clinical environments. Such stylistic differences, along with ambiguities in language and structure, may affect the generalizability and robustness of the model in broader settings. Future work should include datasets from multiple institutions, languages, and reporting styles to evaluate model performance under more diverse conditions.
5. Conclusions
This study demonstrates the strong capability of open-weight LLMs in extracting structured data from unstructured prostate MRI reports with high performance. All models, especially DeepSeek-R1-LLama3.3, Phi-4, and Llama3.3, exhibited exceptional performance across most features. The evaluation across different physicians’ reports revealed that reporting style significantly influences model performance, highlighting the need for prompt adaptation to individual radiologists’ styles to maximize performance. In terms of efficiency, automated extraction significantly reduced the time required for report generation. Compared to the manual process, LLMs operated with remarkable speed, achieving near-instantaneous results while maintaining high fidelity to the ground truth. Furthermore, incorporating an AI-assisted workflow, where radiologists review and modify AI-generated structured reports rather than compiling them from scratch, can be an option. This workflow aligns with real-world clinical practice by balancing automation with human oversight, ensuring reliable and interpretable outcomes.
Beyond workflow efficiency, this study underscores the broader potential of structured reporting in radiology. Converting free-text reports into structured formats unlocks vast amounts of valuable clinical data, facilitating improved patient care, research, and data-driven medical decision-making. Despite these advantages, challenges remain, particularly in ensuring robust generalization across diverse reporting styles and mitigating biases introduced by a centralized reference standard. Future work should explore adaptive prompt engineering and fine-tuning approaches to further optimize model performance across varied radiology practices.
Overall, our findings reinforce the viability of open-weight LLMs as powerful tools for structured reporting in radiology. These models can drive a transformative shift toward a more efficient, standardized, and data-driven radiology ecosystem.
Author Contributions
Conceptualization: L.D.P. and F.D.; Methodology: L.D.P.; Software: L.D.P.; Validation: L.D.P., F.D. and M.A.; Formal analysis: L.D.P.; Investigation: L.D.P.; Data curation: L.D.P.; Writing—original draft preparation: L.D.P.; Writing—review and editing: L.D.P., F.D. and D.F.; Visualization: L.D.P.; Supervision: D.F. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
The ethic approval was obtained on 11 September 2024 by CET Lombardia 3 Ethical Committee (Study ID: 5105).
Informed Consent Statement
A retrospective informed consent statement was obtained.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest related to this work.
Abbreviations
The following abbreviations are used in this manuscript:
| MRI | Magnetic Resonance Imaging |
| LLM | Large Language Models |
| IQR | Interquartile Range |
| SD | Standard Deviation |
References
- Kahn, C.E., Jr.; Langlotz, C.P.; Burnside, E.S.; Carrino, J.A.; Channin, D.S.; Hovsepian, D.M.; Rubin, D.L. Toward best practices in radiology reporting. Radiology 2009, 252, 852–856. [Google Scholar] [CrossRef] [PubMed]
- Granata, V.; Faggioni, L.; Fusco, R.; Reginelli, A.; Rega, D.; Maggialetti, N.; Buccicardi, D.; Frittoli, B.; Rengo, M.; Bortolotto, C.; et al. Structured reporting of computed tomography in the staging of colon cancer: A Delphi consensus proposal. Radiol. Med. 2022, 127, 21–29. [Google Scholar] [CrossRef] [PubMed]
- Pesapane, F.; Tantrige, P.; De Marco, P.; Carriero, S.; Zugni, F.; Nicosia, L.; Bozzini, A.C.; Rotili, A.; Latronico, A.; Abbate, F.; et al. Advancements in standardizing radiological reports: A comprehensive review. Med. Kaunas 2023, 59, 1679. [Google Scholar] [CrossRef] [PubMed]
- Trivedi, G.; Dadashzadeh, E.R.; Handzel, R.M.; Chapman, W.W.; Visweswaran, S.; Hochheiser, H. Interactive NLP in clinical care: Identifying incidental findings in radiology reports. Appl. Clin. Inf. 2019, 10, 655–669. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional Transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Banerjee, I.; Davis, M.A.; Vey, B.L.; Mazaheri, S.; Khan, F.; Zavaletta, V.; Gerard, R.; Gichoya, J.W.; Patel, B. Natural language processing model for identifying critical findings-A multi-institutional study. J. Digit. Imaging 2023, 36, 105–113. [Google Scholar] [CrossRef]
- Doshi, R.; Amin, K.S.; Khosla, P.; Bajaj, S.; Chheang, S.; Forman, H.P. Quantitative evaluation of large language models to streamline radiology report impressions: A multimodal retrospective analysis. Radiology 2024, 310, e231593. [Google Scholar] [CrossRef]
- Butler, J.J.; Harrington, M.C.; Tong, Y.; Rosenbaum, A.J.; Samsonov, A.P.; Walls, R.J.; Kennedy, J.G. From jargon to clarity: Improving the readability of foot and ankle radiology reports with an artificial intelligence large language model. Foot Ankle Surg. 2024, 30, 331–337. [Google Scholar] [CrossRef]
- Butler, J.J.; Puleo, J.; Harrington, M.C.; Dahmen, J.; Rosenbaum, A.J.; Kerkhoffs, G.M.M.J.; Kennedy, J.G. From technical to understandable: Artificial Intelligence Large Language Models improve the readability of knee radiology reports. Knee Surg. Sports Traumatol. Arthrosc. 2024, 32, 1077–1086. [Google Scholar] [CrossRef]
- Hallinan, J.T.P.D.; Leow, N.W.; Ong, W.; Lee, A.; Low, Y.X.; Chan, M.D.Z.; Devi, G.K.; Loh, D.D.-L.; He, S.S.; Nor, F.E.M.; et al. MRI spine request form enhancement and auto protocoling using a secure institutional large language model. Spine J. 2025, 25, 505–514. [Google Scholar] [CrossRef]
- Gertz, R.J.; Dratsch, T.; Bunck, A.C.; Lennartz, S.; Iuga, A.-I.; Hellmich, M.G.; Persigehl, T.; Pennig, L.; Gietzen, C.H.; Fervers, P.; et al. Potential of GPT-4 for detecting errors in radiology reports: Implications for reporting accuracy. Radiology 2024, 311, e232714. [Google Scholar] [CrossRef] [PubMed]
- Reichenpfader, D.; Müller, H.; Denecke, K. A scoping review of large language model based approaches for information extraction from radiology reports. NPJ Digit. Med. 2024, 7, 222. [Google Scholar] [CrossRef] [PubMed]
- Fervers, P.; Hahnfeldt, R.; Kottlors, J.; Wagner, A.; Maintz, D.; dos Santos, D.P.; Lennartz, S.; Persigehl, T. ChatGPT yields low accuracy in determining LI-RADS scores based on free-text and structured radiology reports in German language. Front. Radiol. 2024, 4, 1390774. [Google Scholar] [CrossRef]
- Grattafiori, A.; Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Vaughan, A.; et al. The Llama 3 Herd of Models. arXiv 2024, arXiv:2407.21783. [Google Scholar]
- DeepSeek-AI; Guo, D.; Yang, D.; Zhang, H.; Song, J.; Zhang, R.; Xu, R.; Zhu, Q.; Ma, S.; Wang, P.; et al. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv 2025, arXiv:2501.12948. [Google Scholar]
- Abdin, M.; Aneja, J.; Behl, H.; Bubeck, S.; Eldan, R.; Gunasekar, S.; Harrison, M.; Hewett, R.J.; Javaheripi, M.; Kauffmann, P.; et al. Phi-4 Technical Report. arXiv 2024, arXiv:2412.08905. [Google Scholar]
- Riviere, M.; Pathak, S.; Sessa, P.G.; Hardin, C.; Bhupatiraju, S.; Hussenot, L.; Mesnard, T.; Shahriari, B.; Ramé, A.; Ferret, J.; et al. Gemma 2: Improving Open Language Models at a Practical Size. arXiv 2024, arXiv:2408.00118. [Google Scholar]
- Yang, A.; Yang, B.; Zhang, B.; Hui, B.; Zheng, B.; Yu, B.; Li, C.; Liu, D.; Huang, F.; Wei, H.; et al. Qwen2.5 Technical Report. arXiv 2024, arXiv:241215115. [Google Scholar]
- Yang, A.; Yang, B.; Hui, B.; Zheng, B.; Yu, B.; Zhou, C.; Li, C.; Li, C.; Liu, D.; Huang, F.; et al. Qwen2 Technical Report. arXiv 2024, arXiv:240710671. [Google Scholar]
- Jiang, H.; Xia, S.; Yang, Y.; Xu, J.; Hua, Q.; Mei, Z.; Hou, Y.; Wei, M.; Lai, L.; Li, N.; et al. Transforming free-text radiology reports into structured reports using ChatGPT: A study on thyroid ultrasonography. Eur. J. Radiol. 2024, 175, 111458. [Google Scholar] [CrossRef]
- Mallio, C.A.; Sertorio, A.C.; Bernetti, C.; Beomonte Zobel, B. Large language models for structured reporting in radiology: Performance of GPT-4, ChatGPT-3.5, Perplexity and Bing. Radiol. Med. 2023, 128, 808–812. [Google Scholar] [CrossRef] [PubMed]
- Siepmann, R.M.; Baldini, G.; Schmidt, C.S.; Truhn, D.; Müller-Franzes, G.A.; Dada, A.; Kleesiek, J.; Nensa, F.; Hosch, R. An automated information extraction model for unstructured discharge letters using large language models and GPT-4. Healthc. Anal. 2025, 7, 100378. [Google Scholar] [CrossRef]
- Nowak, S.; Wulff, B.; Layer, Y.C.; Theis, M.; Isaak, A.; Salam, B.; Block, W.; Kuetting, D.; Pieper, C.C.; Luetkens, J.A.; et al. Privacy-ensuring open-weights large language models are competitive with closed-weights GPT-4o in extracting chest radiography findings from free-text reports. Radiology 2025, 314, e240895. [Google Scholar] [CrossRef]
- Fink, M.A.; Bischoff, A.; Fink, C.A.; Moll, M.; Kroschke, J.; Dulz, L.; Heußel, C.P.; Kauczor, H.-U.; Weber, T.F. Potential of ChatGPT and GPT-4 for data mining of free-text CT reports on lung cancer. Radiology 2023, 308, e231362. [Google Scholar] [CrossRef]
- Adams, L.C.; Truhn, D.; Busch, F.; Kader, A.; Niehues, S.M.; Makowski, M.R.; Bressem, K.K. Leveraging GPT-4 for post hoc transformation of free-text radiology reports into structured reporting: A multilingual feasibility study. Radiology 2023, 307, e230725. [Google Scholar] [CrossRef]
- Woźnicki, P.; Laqua, C.; Fiku, I.; Hekalo, A.; Truhn, D.; Engelhardt, S.; Kather, J.; Foersch, S.; D’aNtonoli, T.A.; dos Santos, D.P.; et al. Automatic structuring of radiology reports with on-premise open-source large language models. Eur. Radiol. 2024, 35, 2018–2029. [Google Scholar] [CrossRef]
- Mukherjee, P.; Hou, B.; Lanfredi, R.B.; Summers, R.M. Feasibility of using the privacy-preserving Large language model Vicuna for labeling radiology reports. Radiology 2023, 309, e231147. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).