1. Introduction
Recent developments in remote sensing (RS) data and technologies deliver the ability of highly accessible, cheap and real time advantages [
1]. In recent years, a massive quantity of global coverage RS images have been openly available [
2]. In particular, Landsat 8 satellite offers high-resolution multispectral datasets including wealthy data on agricultural vegetation development which is easily accessible. It allows us to examine the vegetation growth and forecast the changes over time from past to present [
3]. RS is an effective data collection technology, and it is broadly employed in agriculture, for example, to monitor crop conditions, crop distribution, and to predict upcoming food production under various situations [
4]. Though current agricultural RSs generally use sensors from satellite environments like Landsat and MODIS, they combine and integrate the data acquired from the aerial or ground-based sensors [
5,
6]. Even if satellite-borne sensors cover a larger range from a local to a national scale, precision agriculture needs remotely sensed data with high efficiency, knowledge, and high resolution to sufficiently study crop conditions, hence giving support to national food provision security.
Aerial or airborne RS that uses classical aerial photography taken from aircraft, light aircraft or unmanned aerial vehicles (UAVs) as its platform, and gets a higher ground resolution of a few centimeters than the satellite image resolution of a few to hundreds of meters provides two important advantages: Primarily, significant biochemical and biophysical variables can be calculated finely at most of the levels of an individual plant, and its images are without mixed pixel effects. Next, important phases of crop development can be finely noticed with the use of active and current crop height created by classical aerial triangulation technology [
7]. Additionally, the highly accurate cropland mask, crop-specific categorization and circulation gained from airborne sensors provide extra training and validation data for satellite observation and additionally increase the respective outcome. Successful integration of various sensor sources, wavebands, and time-stamped RS images gives extensive feature data about crops [
8]. Thus, it is a reasonable and significant study to discover the crop classification based on RS images.
Classical RS-based image classification procedures of ML were slowly used in the classification and detection of RS images. These models can be classified as supervised and unsupervised classes. The first holds minimum distance, maximum likelihood, and support vector machine (SVM). In this phase, the SVM is extensively applied in RS image classification, even though few problems exist. DL, referring to a deep neural network, is a type of ML technique, and because of its data expression and dominant feature extraction capability, it has been widely adopted. Over the years, the identification rate of DL on most classical identification processes has enhanced considerably [
9]. Numerous studies have exhibited that DL can extract features from RS imagery and enhance the classifier performance.
This article develops a remote sensing imagery data analysis using the marine predators algorithm with deep learning for food crop classification (RSMPA-DLFCC) method. The RSMPA-DLFCC technique mainly investigates the RS data and determines the variety of food crops. In the RSMPA-DLFCC technique, the SimAM-EfficientNet model is utilized for the feature extraction process. The MPA is applied for the optimal parameter selection to optimize the accuracy of SimAM-EfficientNet architecture. MPA, inspired by the foraging behaviors of marine predators, perceptively explores hyperparameter configurations to optimize the hyperparameters, thereby improving the classification accuracy and generalization capabilities. For crop type detection and classification, an extreme learning machine (ELM) model can be used. The simulation analysis of the RSMPA-DLFCC method takes place on the UAV image dataset.
The rest of the paper is organized as follows.
Section 2 provides the related works and
Section 3 offers the proposed model. Then,
Section 4 gives the result analysis and
Section 5 concludes the paper.
2. Literature Review
Kwak and Park [
10] examined self training with domain adversarial networks (STDAN) to classify crop types. The main function of STDAN is to integrate adversarial training for improving spectral discrepancy issues with self training in order to create novel trained data in the targeted field, utilizing present ground truth details. In [
11], a unique structure based on deep CNN (DCNN) and the dual attention module (DAM) makes utilization of the Sentinel 2 time series dataset which was projected for crop identification. Fresh DAM was applied to the removal of enlightened deep features using the advantages of spatial and spectral features of Sentinel 2 datasets. Reedha et al. [
12] targeted the design of attention-related DL networks in a significant technique to state the earlier mentioned complications regarding weeds and crop detection with drone systems. The objective is to inspect visual transformers (ViT) and implement them in the identification of plants in UAV images. In [
13], the results of accurate recognition were tested to associate the phenology of vegetation products by time series of Landsat8, digital elevation model (DEM), and Sentinel 1. Next, based on the agricultural phenology of crops, radar Sentinel1 and optical Landsat8 time-series data with DEM were used to enhance the performance classification.
Sun et al. [
14] proposed a technique for attaining deduction of fine-scale crops by combining RS information from different satellite images by construction of chronological scale crop features inside the parcels employing Sentinel 2A, Gaofen-6, and Landsat 8. The authors adopted a feature-equivalent technique to fill in the missing values in the time series feature-building methods to prevent problems with unidentified crops. Li et al. [
15] introduced a scale sequence object-based CNN (SS-OCNN) that identifies images at the object phase by taking segmented object crop parcels as the primary unit of analysis, therefore providing the limits between crop parcels that were defined precisely. Next, the segmented object was identified utilizing the CNN approach combined with an automated generating scale structure of input patch sizes.
Zhai et al. [
16] examined the contribution of the data to rice planting area mapping. Specifically, the introduction of the red-edge band was to build a red-edge agricultural index derived from Sentinel 2 data. C band quad pol Radar sat 2 data was also utilized. The authors employed the random forest technique and finally collaborated with radar and optical data to plot rice-planted regions. In [
17], the authors designed an enhanced crop planting structure to plot the structure for rainy and cloudy regions using collective optical data and SAR data. First, the author removed geo parcels from optical images with high dimensional resolution. Next, the authors made an RNN-based classification appropriate for remote detecting images on a geo parcel scale.
3. The Proposed Model
This manuscript offered the development of automated food crop classification using the RSMPA-DLFCC technique. The RSMPA-DLFCC technique mainly investigates the RS data and determines different types of food crops. In the RSMPA-DLFCC technique, three major phases of operations are involved, namely the SimAM-EfficientNet feature extractor, MPA-based hyperparameter tuning, and ELM classification.
Figure 1 represents the entire process of the RSMPA-DLFCC approach.
3.1. Feature Extraction Using SimAM-EfficientNet Model
The RSMPA-DLFCC technique applies the SimAM-EfficientNet model to derive feature vectors. A novel CNN called EfficientNet was launched by Google researchers [
18]. The study uses a multi-dimensional hybrid method scaling model making them consider the speed and accuracy of the model even though the existing network has advanced considerably in speed and accuracy. Through compound scaling factors, ResNet raises the network depth to optimize the performance. By improving accuracy and ensuring speed, EfficientNet balances the network depth, width, and resolution. EfficientNet-B0 is the initial EfficientNet model. The most basic model B0 is: concerning resolution, layers, and channels, B1-B7 overall of 7 models adapted from B0.
Many existing attention modules generate 1D or 2D weights. Next, the weights created are extended for channel and spatial attention. Generally, the present attention module faces the two subsequent challenges. The former is the attention module could extract features through channel and space that results in the flexibility of attention weight. Moreover, CNN is influenced by a series of factors and has a complex structure. SimAM considers these spaces and channels in contrast to them. Without adding parameters, it presents 3D attention weights to the original network. Based on neuroscience theory, an energy function can be defined and, in turn, derive a solution that converges faster. This operation is executed in ten lines of code. An additional benefit of SimAM is that it prevents excessive adjustment to the network architecture. Hence, SimAM is lightweight, more flexible, and modular. In numerous instances, SimAM is better than the conventional CBAM and SE attention models.
Figure 2 illustrates the architecture of SimAM-EfficientNet.
The SimAM model defines an energy function and looks for important neurons. It adds regular terms and uses binary labels. At last, the minimal energy is evaluated by the following expression:
where
and
are the mean and variance of each neuron.
is the target neuron.
indicates the regularization coefficient. Using
, the neuron count on that channel is attained. Finally, the dissimilarity between neurons and peripheral neurons is associated with the energy used. The implication of all the neurons is evaluated by
. The scaling operator is used to refine the feature and it can be formulated as follows:
The function is used to limit the size of the value. In Equation (3), group each across the channel and spatial sizes.
EfficientNet-B0 has a total of nine phases. The initial phase is convolutional layers. The second to the eighth phases are MBConv, which is the building block of these network models. The last phase is made up of a pooling layer, a convolutional layer, and the FC layer. MBConv has five different parts. The initial part is a convolutional layer. The next part is a depth-wise convolution layer. The third part is the SE attention mechanism. The fourth part is a convolutional layer for reduction dimension. Lastly, the dropout layer lessens the over-fitting problem. After the first convolutional layer, the SimAM module was added to increase channel and spatial weights. The original EfficientNet comprises the SE attention mechanism.
The SimAM-EfficientNet is made up of seven SimAM-MBConv models, one FC layer, two convolution layers, and one pooling layer. At first, the images with dimensions are ascended by the convolution layers. The dimensions of the images obtained with features are . Next, the image features are extracted by the SimAM-Conv. The connection will be deactivated when both SimAM-Convs are the same, and the input will connect. The FC layer is utilized for classification and the original channel is restored after point-wise convolutional layer.
3.2. Hyperparameter Tuning Using MPA
For the optimal hyperparameter selection process, the MPA is applied. The MPA is derived from the foraging tactics of the ocean predator [
19]. MPA is a population-based metaheuristic approach. The optimization technique begins with the arbitrary solution.
where
and
denotes the lower and upper boundaries, and
is a randomly generated integer in the range
. In the MPA, Prey and Elite are two different matrices with similar dimensions. The optimum solution is selected as the fittest predator while creating the Elite matrix.
The finding of and search for prey is checked through these matrices.
indicates the dominant predator vector,
is the searching agent, and
, the dimension. Both prey and predator are the search agents.
where
dimension of
prey is represented as
. The optimization method is connected to both matrices. Predator uses these matrices for updating the position.
In the MPA, there are three stages discussed in detail.
Phase 1 occurs if
.
and
denote the existing and maximal iteration counter.
shows the constant number with the value of 0.5. The appropriate tactic is one where the predator should stop. In Equation (7) of stage 1, vector
portrays the Brownian motion and uniformly distributed random number in [0,1].
Phase 2 realized if
. Once the prey movement is Lévy, then the predator movement should be Brownian. The prey is responsible for exploitation, and the predator is responsible for exploration. The multiplication of
and
represent the prey movement, and the prey movement can be exemplified by adding the
to the prey position. The
vector is a random number representing Lévy motion. CF denotes an adaptive parameter.
for the predator movement can be controlled by the CF.
Phase 3 occurs If
. As the optimum strategy, the predator movement is Lévy.
The factors including fish aggregating devices (FADs) or eddy formation may affect the predator strategy are called the FADs effect.
is a randomly generated value within [0,1].
shows the
vector with an array of
and 1.
and
depict the random indexes of prey matrices.
and
denote the lower and upper boundaries of the dimension.
The fitness selection is a major factor in the MPA technique. An encoded solution is used for evaluating the outcome of the solution candidate. The accuracy values are the foremost conditions used to design an FF.
where
and
represent the true and false positive values.
3.3. Classification Using ELM Model
The ELM algorithm is applied for the automated detection and classification of food crops. The ELM model is used to generate the weight between the hidden and the input layers at random, and during the training process, it does not need to be adjusted and only needs to set the number of HL neurons in order to attain an optimum result [
20]. Assume
arbitrary sample
, where
R is formulated by
The weight of
neurons in the input layer and HL is
, chosen at random. The resultant weight is
, and the learning objective is to obtain the fittest
The
input vector is
. The inner product of
and
is
The bias of
HL neuron is
. The set non-linear activation function is
. The output vector of the
neurons is
. The target vector attained from the
input vector is
. It can be represented in the matrix form:
The output of the HL node is
, the output weight is
, and the desired output is
. The following equation is used to get
as follows:
As shown in Equation (17), this corresponds to minimalizing the loss function,
Since the HL offset and the input weight
are determined randomly, then the output matrix of HL is also defined. As shown in Equation (18), the training purpose is transmuted into resolving a linear formula
:
where the optimum output weight is
. The Moore–Penrose generalized the inverse of
matrix is
, and it is shown that the norm of the obtained solution is unique and minimal. Thus, ELM has better robustness and generalization.
4. Results Analysis
The proposed model is simulated using the Python 3.8.5 tool. The proposed model is experimented on PC i5-8600k, GeForce 1050Ti 4 GB, 16 GB RAM, 250 GB SSD, and 1 TB HDD. The food crop classification performance of the RSMPA-DLFCC system is validated on the UAV image dataset [
21], comprising 6450 samples with six classes. For experimental validation, we have used 80:20 and 70:30 of training (TR)/testing (TS) set.
Figure 3 demonstrates the confusion matrices produced by the RSMPA-DLFCC technique under 80:20 and 70:30 of the TR phase/TS phase. The experimental values specified the efficient recognition of all six classes.
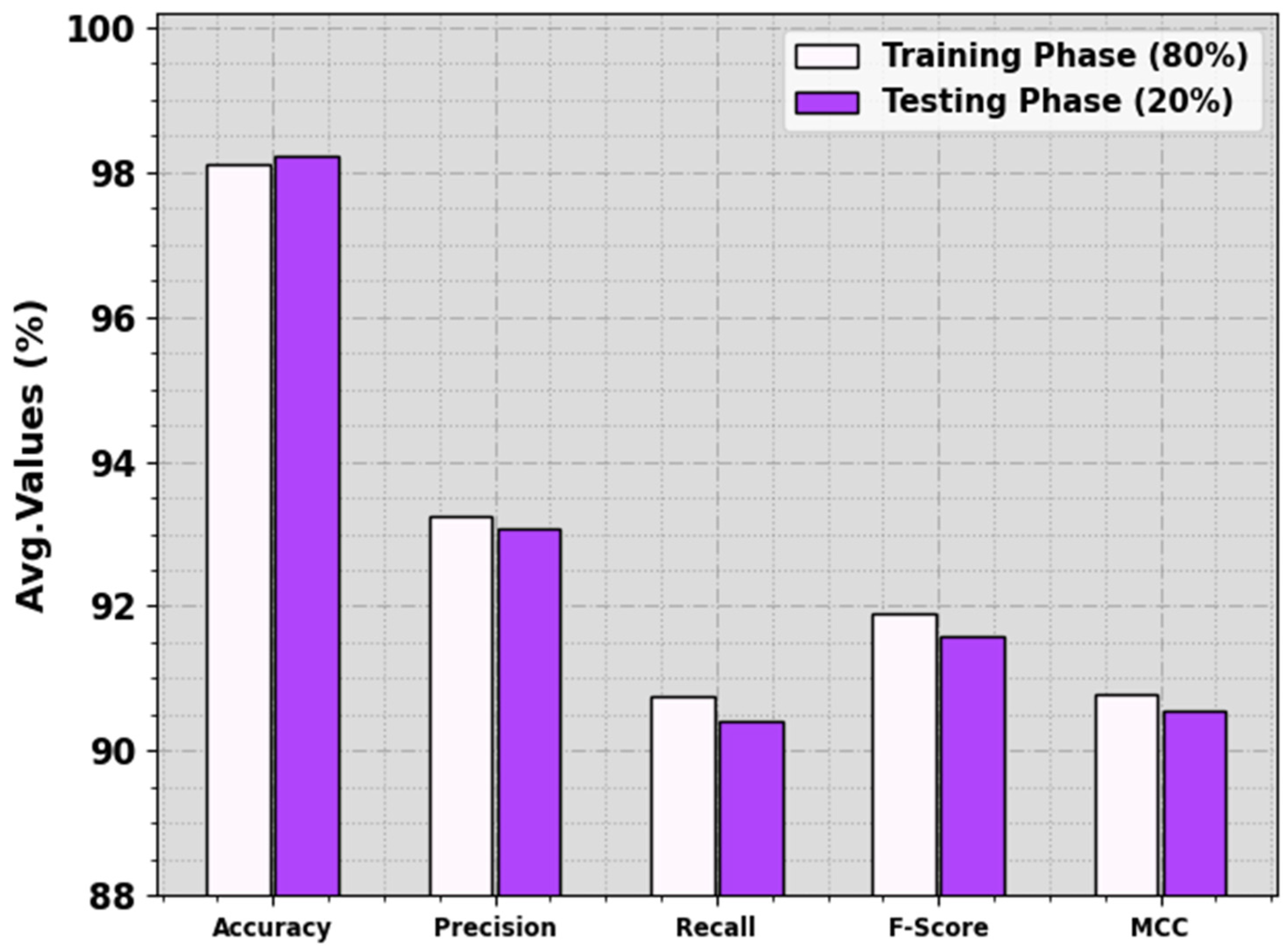
In
Table 1 and
Figure 4, the food crop classification analysis of the RSMPA-DLFCC methodology is calculated at 80:20 of the TR phase/TS phase. The observational data specified that the RSMPA-DLFCC system properly categorizes seven types of crops. With 80% of the TR phase, the RSMPA-DLFCC technique offers an average
of 98.12%,
of 93.23%,
of 90.76%,
of 91.89%, and MCC of 90.77%. Additionally, with 20% of TS phase, the RSMPA-DLFCC method offers an average
of 98.22%,
of 93.06%,
of 90.42%,
of 91.57%, and MCC of 90.56%, respectively.
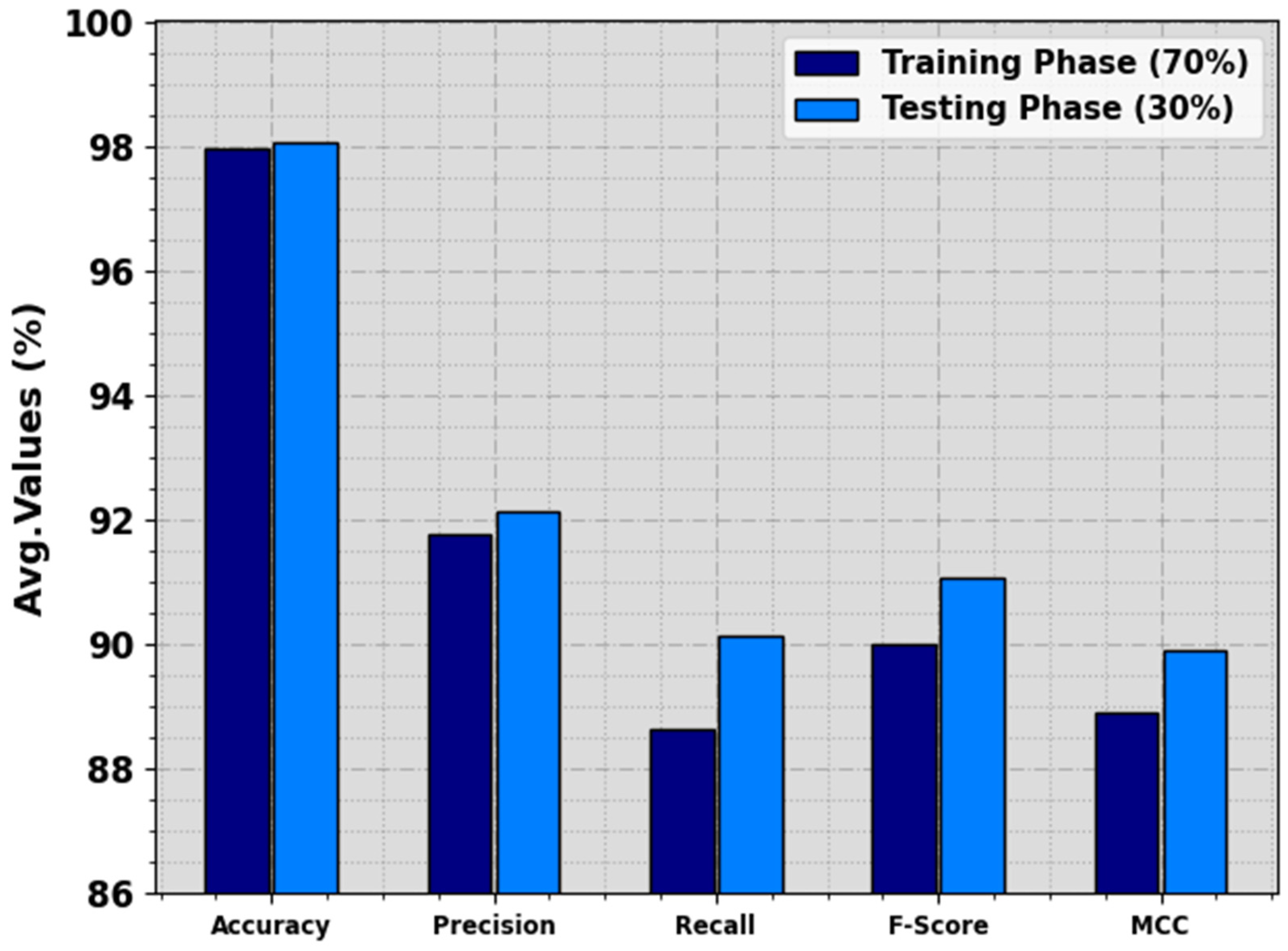
In
Table 2 and
Figure 5, the food crop classification analysis of the RSMPA-DLFCC technique is calculated at 70:30 of TR Phase/TS Phase. The experimental values indicate that the RSMPA-DLFCC technique appropriately categorizes seven types of crops. With 70% of the TR phase, the RSMPA-DLFCC algorithm offers an average
of 97.98%,
of 91.79%,
of 88.64%,
of 90.02%, and MCC of 88.90%, respectively. In addition, with 30% of TS phase, the RSMPA-DLFCC system offers average
of 98.07%,
of 92.13%,
of 90.13%,
of 91.06%, and MCC of 89.92%, correspondingly.
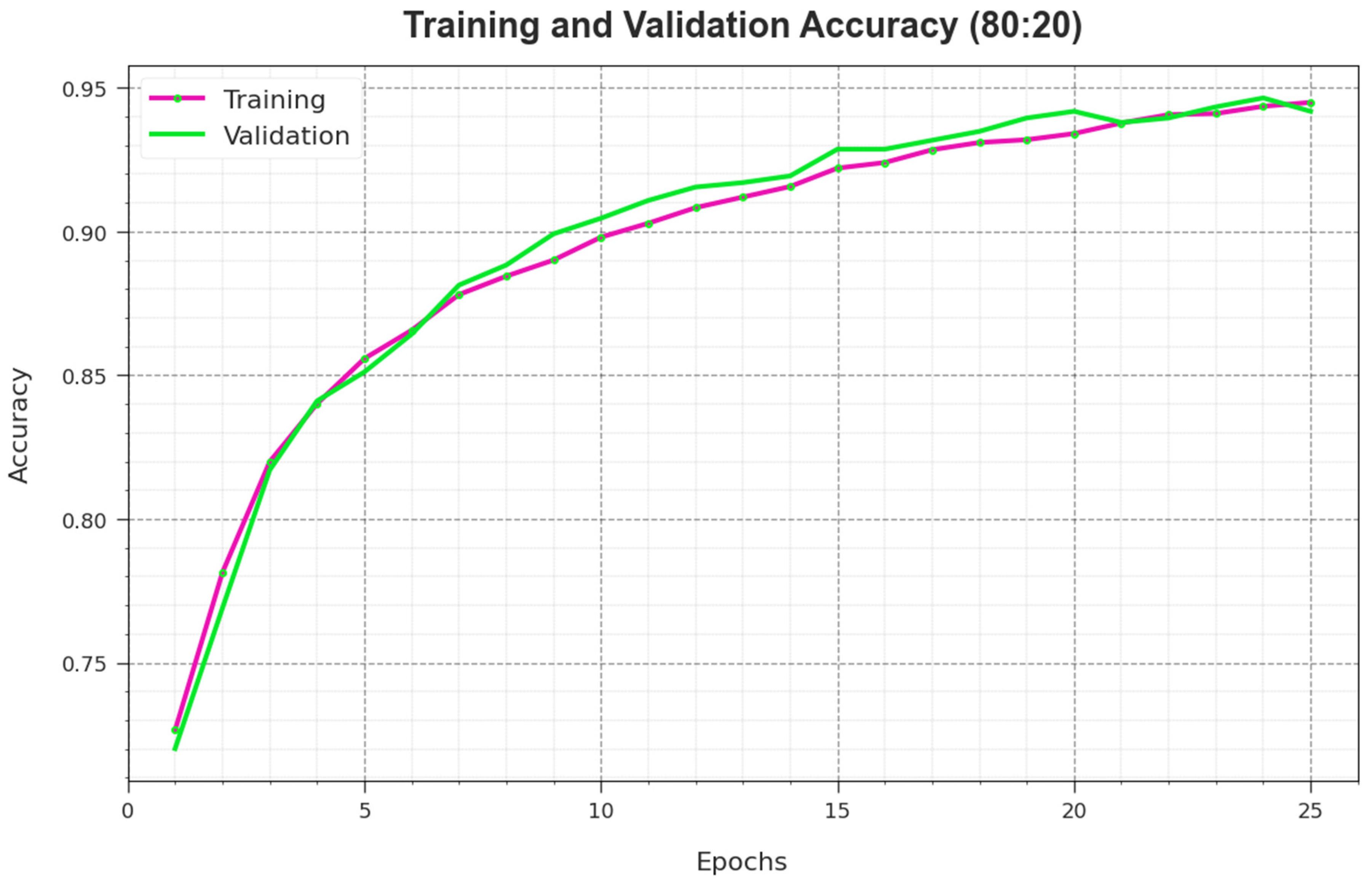
To calculate the performance of the RSMPA-DLFCC methodology on 80:20 of TR Phase/TS Phase, TR and TS
curves are defined, as shown in
Figure 6. The TR and TS
curves demonstrate the performance of the RSMPA-DLFCC technique over numerous epochs. The figure offers the details about the learning task and generalization capabilities of the RSMPA-DLFCC system. With a rise in epoch count, it is observed that the TR and TS
curves attained are enhanced. It is noted that the RSMPA-DLFCC approach enriches testing accuracy that has the ability to identify the patterns in the TR and TS data.
Figure 7 illustrates an overall TR and TS loss value of the RSMPA-DLFCC methodology on 80:20 of TR Phase/TS Phase over epochs. The TR loss shows the model loss acquired reduces over epochs. Mainly, the loss values are decreased as the model adapts the weight to diminish the predicted error on the TR and TS data. The loss analysis illustrates the level where the model is fitting the training data. It is evidenced that the TR and TS loss is progressively minimized and described that the RSMPA-DLFCC technique effectively learns the patterns revealed in the TR and TS data. It is also observed that the RSMPA-DLFCC methodology modifies the parameters for reducing the difference between the predicted and actual training labels.
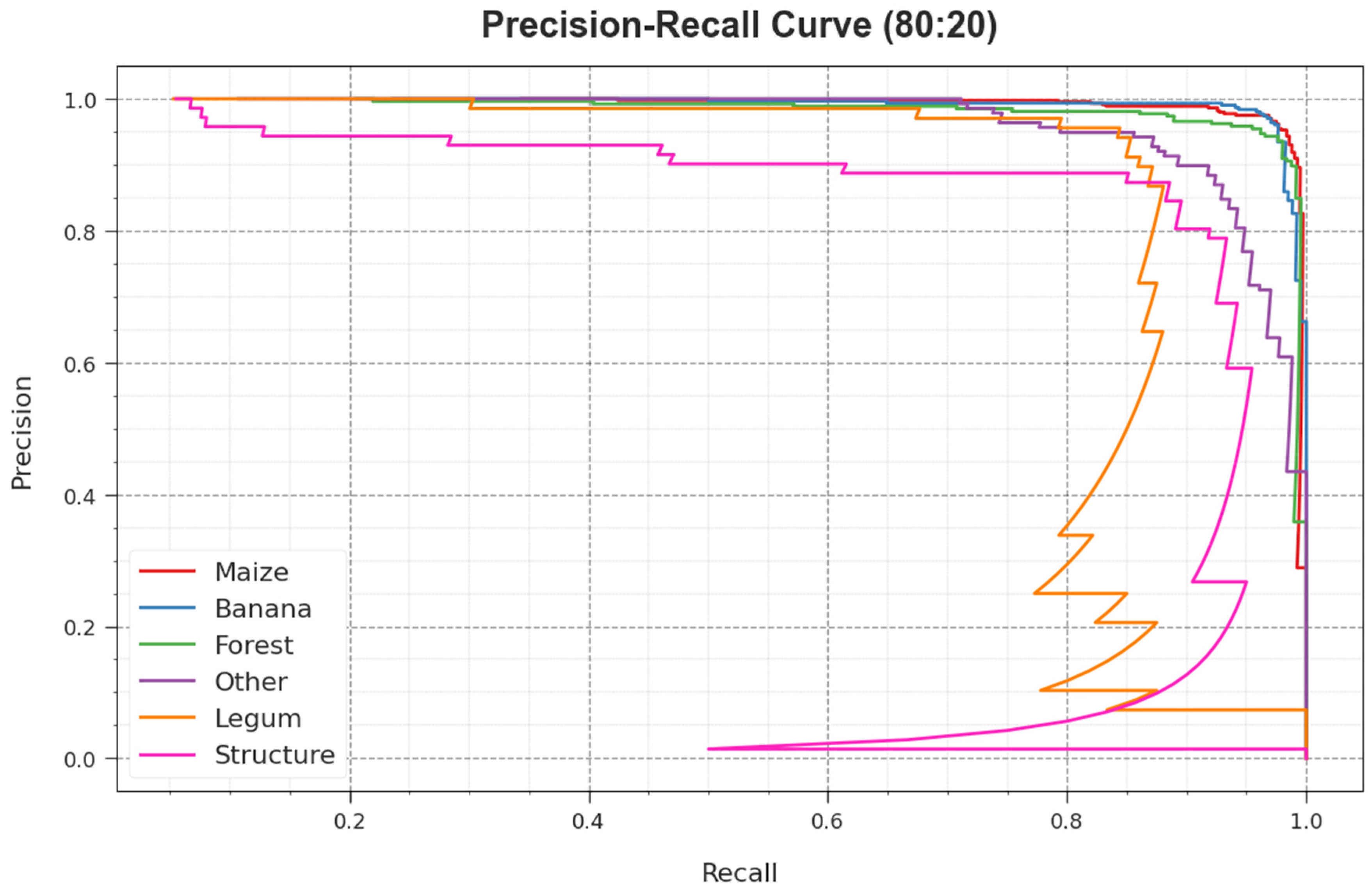
The PR curve of the RSMPA-DLFCC approach on 80:20 of TR phase/TS phase, illustrated by plotting precision against recall as described in
Figure 8, confirms that the RSMPA-DLFCC technique achieves improved PR values under all classes. The figure represents that the model learns to identify different class labels. The RSMPA-DLFCC achieves improved effectiveness in the recognition of positive samples with reduced false positives.
The ROC analysis, provided by the RSMPA-DLFCC system on 80:20 of TR phase/TS phase demonstrated in
Figure 9, has the ability the differentiate between class labels. The figure shows valuable insights into the trade-off between the TPR and FPR rates over dissimilar classification thresholds and differing numbers of epochs. It introduces the accurately predicted performance of the RSMPA-DLFCC methodology on the classification of various classes.
In
Table 3, detailed comparative results of the RSMPA-DLFCC technique are demonstrated with current models [
22,
23].
Figure 10 investigates a comparative analysis of the RSMPA-DLFCC with recent approaches in terms of
. The experimental values highlighted that the RSMPA-DLFCC technique reaches an increased
of 98.22%, whereas the SBODL-FCC, DNN, AlexNet, VGG-16, ResNet, and SVM models obtain decreased
values of 97.43%, 86.23%, 90.49%, 90.35%, 87.70%, and 86.69%, respectively.
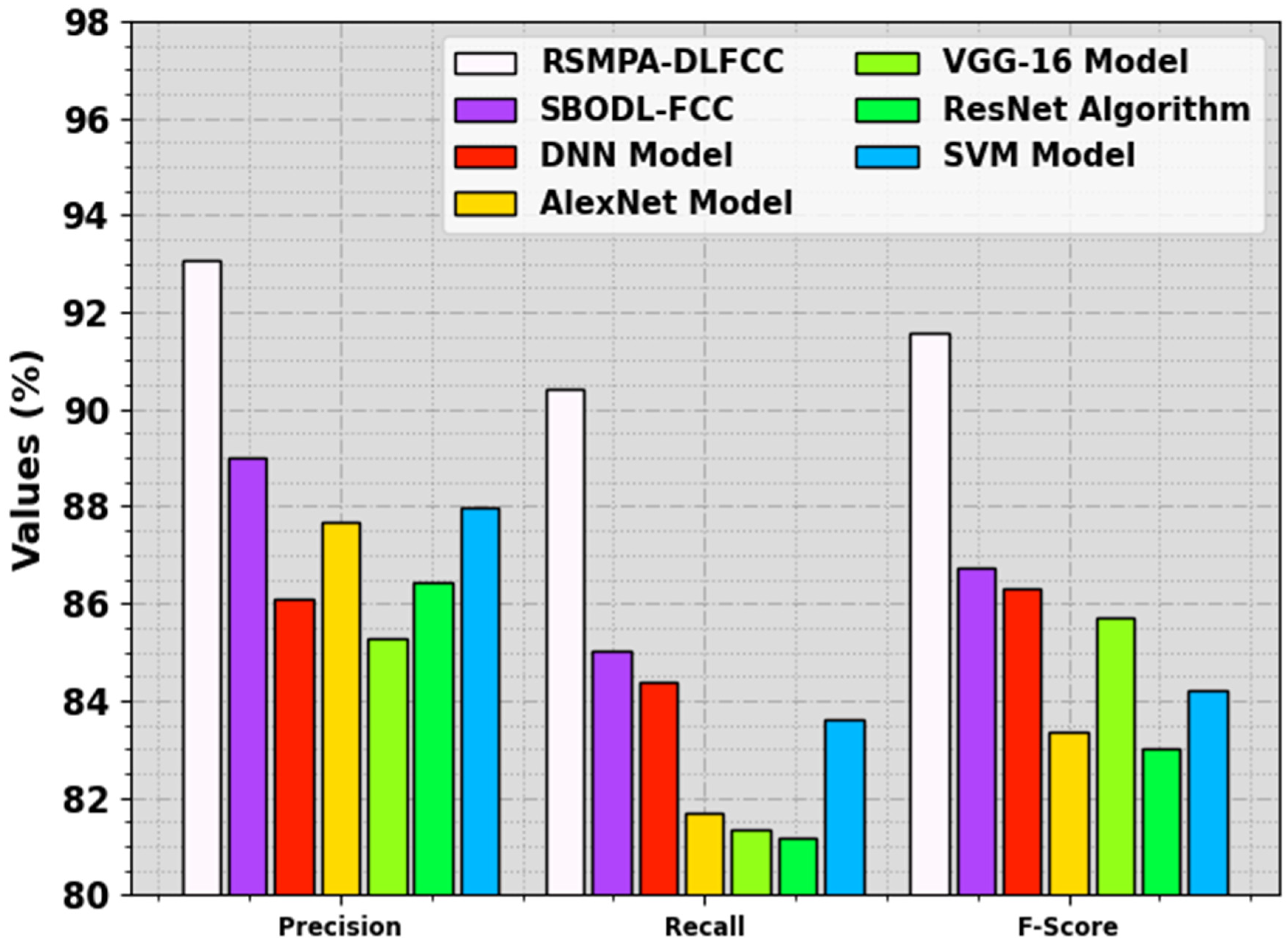
Figure 11 investigates a comparative analysis of the RSMPA-DLFCC system with recent techniques, with respect to
and
. The observational data highlighted that the RSMPA-DLFCC system attains a raised
of 93.06%, while the SBODL-FCC, DNN, AlexNet, VGG-16, ResNet, and SVM methods obtain reduced
values of 89.02%, 86.11%, 87.68%, 85.28%, 86.42%, and 87.99%, correspondingly. In addition, the RSMPA-DLFCC system attains
values of 90.42% whereas SBODL-FCC, DNN, AlexNet, VGG-16, ResNet, and SVM systems get decreased
values of 85.03%, 84.39%, 81.7%, 81.35%, 81.18%, and 83.61%, respectively. These experimental data indicated that the RSMPA-DLFCC methodology reaches the maximum food crop classification process.




 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}