Abstract
Wind patterns can change due to climate change, causing more storms, hurricanes, and quiet spells. These changes can dramatically affect wind power system performance and predictability. Researchers and practitioners are creating more advanced wind power forecasting algorithms that combine more parameters and data sources. Advanced numerical weather prediction models, machine learning techniques, and real-time meteorological sensor and satellite data are used. This paper proposes a Recurrent Neural Network (RNN) forecasting model incorporating a Dynamic Fitness Al-Biruni Earth Radius (DFBER) algorithm to predict wind power data patterns. The performance of this model is compared with several other popular models, including BER, Jaya Algorithm (JAYA), Fire Hawk Optimizer (FHO), Whale Optimization Algorithm (WOA), Grey Wolf Optimizer (GWO), and Particle Swarm Optimization (PSO)-based models. The evaluation is done using various metrics such as relative root mean squared error (RRMSE), Nash Sutcliffe Efficiency (NSE), mean absolute error (MAE), mean bias error (MBE), Pearson’s correlation coefficient (r), coefficient of determination (R2), and determination agreement (WI). According to the evaluation metrics and analysis presented in the study, the proposed RNN-DFBER-based model outperforms the other models considered. This suggests that the RNN model, combined with the DFBER algorithm, predicts wind power data patterns more effectively than the alternative models. To support the findings, visualizations are provided to demonstrate the effectiveness of the RNN-DFBER model. Additionally, statistical analyses, such as the ANOVA test and the Wilcoxon Signed-Rank test, are conducted to assess the significance and reliability of the results.
1. Introduction
Wind energy generation has grown 17% year since 2021. Power grid stability depends on wind speed. Wind variability complicates predictions. New technologies have improved wind speed forecasting with hybrid models and methods. Statistical and artificial intelligence technologies, particularly artificial neural networks, have improved results. Identifying the fundamental aspects affecting forecasting and providing a basis for estimation with artificial neural network models are concerns. The study in [1] classifies modern forecasting models by input model type, pre-and post-processing, artificial neural network model, prediction horizon, steps ahead number, and assessment metric. The research shows that artificial neural network (ANN)-based models can accurately anticipate wind speeds and pinpoint a power plant’s prospective wind use site.
The electricity grid has been faced with obstacles due to the randomness and instability of wind energy, and the connected amount of wind energy poses difficulty in network distribution. For a long time, artificial intelligence has been utilized to anticipate variables in a wide variety of applications, including water desalination [2], transformer faults [3], T-shape antennas [4], engineering problems [5], direct normal irradiation [6], and most notably wind speed forecasting [7].
Utilizing the Deep Neural Networks’ Temporal Convolutional Network (TCN) algorithm, the purpose of the investigation in [8] was to make a long-term (24–72-h ahead) prediction of wind power with a MAPE that was less than 10%. In our experiment, they carried out TCN model pretraining by using historical data on the weather in addition to the power generation outputs of a wind turbine located at a Scada wind power facility in Turkey. The results of the experiments showed that the MAPE for predicting wind power over 72 h was 5.13%, which is sufficient given the limitations of our research. Ultimately, they compared the efficiency of four different DLN-based prediction models for power forecasting. These models were the recurrent neural network (RNN), the gated recurrence unit (GRU), the TCN, and the long short-term memory (LSTM). According to the results of our validation, the TCN is superior to the other three models for predicting wind power in terms of the volume of data input, the consistency of error reduction, and the accuracy of the forecast.
Wind energy is promising. Wind power generation forecasting is essential for smart grid supply-demand balancing. Wind power’s significant variability and intermittent nature make forecasting difficult. The work in [9] develops data-driven wind power generation models. Importantly, the following elements list this work’s important contributions. First, they test upgraded machine learning models for univariate wind power time-series forecasting. We used Bayesian optimization (BO) to optimize hyperparameters of Gaussian process regression (GPR), Support Vector Regression (SVR) with different kernels, and ensemble learning (ES) models (Boosted trees and Bagged trees) and examined their forecasting performance. Second, dynamic information has been added to the models to improve prediction. Lagged measures capture time evolution in model design. More input factors like wind speed and direction increase wind prediction performance. Three wind turbines in France, Turkey, and Kaggle are utilized to test model efficiency. Lagged data and input variables improve wind power forecasts. Optimized GPR and ensemble models also outperformed other machine learning models.
Wind energy has many installations worldwide. Wind speed data power generation prediction accuracy seriously challenges power system regulation and safety. Power system dispatching has various time points relating to area conditions. Power grid dispatching relies on precise wind turbine generation capacity predictions. Wind speed is erratic and intermittent, affecting data quality. The research in [10] proposes a neural network approach that processes wind speed data and predicts electricity generation using BP and Newton interpolation mathematical function methods. BP neural networks handle the hidden layer connection weight learning problem in multi-layer feedforward neural networks. This research examines wind speed data at different heights in the same area at a space scale. The proposed method is 3.1% more accurate than the standard support vector machine method.
On the other hand, models that are based on ANN are able to operate with nonlinear models and do not require prior knowledge of a mathematical model in order to function properly. In addition, some hybrid models forecast wind speed with the use of artificial intelligence applied to time series [11,12]. These models are beneficial because they provide essential information on how to utilize the wind potential of a particular place for the probable construction of a wind power plant by gaining an understanding of future wind speed values [13]. In addition, these models have a fault tolerance and an adaptation of inline measurements. As a result, it is recommended that a substantial amount of data be used in the time series to train the network and produce better results in wind forecasting [14].
The rapid growth of wind power installations has led to increased integration of wind power into the grid [15]. However, this integration brings challenges related to power quality, grid stability, dispatching, and overall power system operation. These challenges are further amplified by the uncertainties associated with wind power generation [16,17]. To ensure the reliable functioning of the power grid, it is crucial to regulate the time series distribution of energy. However, wind power’s nonlinear and unpredictable nature makes achieving this goal difficult. To overcome these challenges, researchers are working towards making wind energy supply more predictable and improving the efficiency and reliability of wind power forecasting. By reducing the unpredictability of wind power, the impact on the power system during the integration of wind power can be minimized. Achieving this requires a solid theoretical foundation and technological advancements that can optimize the operation of the power system, grid dispatching and enhance overall security [18,19]. Through these efforts, it is possible to mitigate the challenges posed by wind power integration and ensure a more stable and secure power grid in the future.
Bio-inspired optimization algorithms handle complex optimization issues by mimicking nature. Evolution, swarm intelligence, and natural selection inspire these strategies. Bio-inspired optimization algorithms solve complicated engineering issues by mimicking nature’s adaptive and efficient solutions [20]. Genetic Algorithm (GA) is a popular bio-inspired optimization algorithm. GA iteratively evolves optimal or near-optimal solutions by selecting, crossover, and mutating a population of candidate solutions. GA has successfully optimized engineering designs and scheduled and estimated parameters. The intelligent technique GA was combined with the Chinese FDS team’s nuclear reactor physics Monte Carlo (MC) code SuperMC for optimal reactor core refilling design in [21]. Particle Swarm Optimization (PSO), another bio-inspired optimization technique, is also prominent. Inspired by bird flocking and fish schooling, PSO uses a population of particles traveling through a problem space, altering their placements based on their experience and other particles. Neural network training, power system optimization, and feature selection use PSO. A hybrid method, such as Aquila Optimizer (AO) with PSO, named IAO, was presented in [22]. Another optimal Ethanol-based method concentration was obtained from the artificial neural network (ANN)-PSO [23]. A complete learning particle swarm optimizer (CLPSO) coupled with local search (LS) is presented to maximize performance by leveraging CLPSO’s robust global search and LS’s fast convergence [24]. Other bio-inspired optimization algorithms include Artificial Bee Colony (ABC) methods, Firefly Algorithm (FA), and Grey Wolf Optimizer (GWO). These algorithms solve optimization problems in image processing, robotics, data mining, and renewable energy systems. Bio-inspired optimization solves complex optimization issues well. By leveraging nature’s wisdom, these algorithms provide new and efficient solutions for various technical applications.
Optimizing parameters in LSTM models for time series prediction is crucial for achieving optimal performance. While LSTM has shown impressive results in this domain, finding the best global solution can be challenging due to the complexity of parameter optimization during model training. As a result, researchers have been studying various methods to improve parameter optimization [25]. One such method is the sparrow search algorithm (SSA), a population intelligence optimization technique introduced in 2020 [26]. SSA is part of a group of emerging metaheuristic algorithms that have gained recognition for their effectiveness in machine learning parameter optimization. It models the behavior of a flock of sparrows as they search for food and avoid predators, aiming to find the optimal solution for a given objective function [27]. Applying SSA optimization to set up network parameters has shown promising results, surpassing the performance of other models in terms of accuracy [28]. For example, SSA has been utilized in estimating ultra-short-term wind power, enhancing the input weight and other parameters of the Dynamic Ensemble Learning Model (DELM) [29]. In another study, short-term wind speed prediction was developed using LSTM and BPNN, and SSA was employed to optimize the prediction model for various complexities in the input sequence [30].
This study suggests a Recurrent Neural Network (RNN) forecasting model based on a proposed Dynamic Fitness Al-Biruni Earth Radius (DFBER) algorithm for capturing and predicting data patterns. We compare its performance with popular models such as BER [31], Jaya Algorithm (JAYA) [32], Fire Hawk Optimizer (FHO) [33], Whale Optimization Algorithm (WOA) [34], Grey Wolf Optimizer (GWO) [35], Particle swarm optimization (PSO) [36], Firefly algorithm (FA) [37], and Genetic Algorithm (GA) [35] based models, utilizing a comprehensive range of evaluation metrics. The evaluation includes metrics like relative root mean squared error (RRMSE), Nash Sutcliffe Efficiency (NSE), mean absolute error (MAE), mean bias error (MBE), Pearson’s correlation coefficient (r), coefficient of determination (R2), and determine agreement (WI), along with considerations of dataset size, estimated and observed values, and arithmetic means of bandwidths. The DFBER-based model demonstrates superior performance compared to the other models, as evident from the evaluation metrics and analysis. Visualizations, including box plots, histograms, residual plots, and heat maps, further validate the model’s ability to capture data patterns. Statistical analyses, such as the ANOVA test and the Wilcoxon Signed-Rank test, strengthen the reliability and significance of the findings.
The main contributions of this research are as follows:
- Providing machine learning-based methodologies to Wind Power time-series forecasting.
- Introducing the optimization-based Recurrent Neural Network (RNN) forecasting model incorporating a Dynamic Fitness Al-Biruni Earth Radius (DFBER) algorithm to predict the wind power data patterns.
- Currently developing an optimized RNN-DFBER-based regression model to enhance the accuracy of predictions using the evaluated dataset.
- Conducting a comparison among different algorithms to determine which one yields the most favorable outcomes.
- Employing Wilcoxon rank-sum and ANOVA tests to assess the potential statistical significance of the optimized RNN-DFBER-based model.
- The RNN-DFBER-based regression model’s flexibility allows it to be tested and customized for various datasets, thanks to its adaptability.
2. Materials and Methods
2.1. Recurrent Neural Network
A Recurrent Neural Network (RNN) is a type of neural network that addresses the need to remember previous information. Unlike traditional neural networks, where inputs and outputs are independent, an RNN utilizes a Hidden Layer to retain and recall previous information. The crucial aspect of an RNN is its Hidden state, which serves as a memory state, storing information about a sequence. By using the same parameters for each input and hidden layer, the RNN simplifies the complexity of parameters compared to other neural networks [38]. Figure 1 shows the RNN architecture. In an RNN, the State matrix (S) contains elements () representing the state of the network at each time step (i). The RNN calculates a hidden state () for every input () by utilizing the information stored in the State matrix.
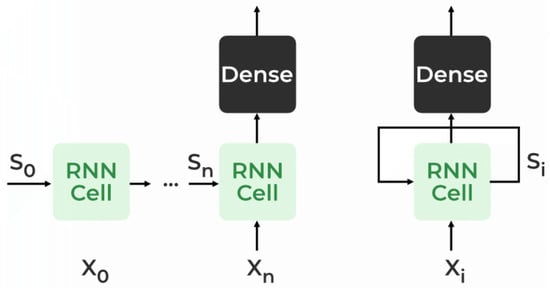
Figure 1.
Recurrent neural network architecture.
2.2. Al-Biruni Earth Radius (BER) Algorithm
The first version of the Al-Biruni Earth Radius (BER) optimizes the situation by segmenting the population into groups for exploration and exploitation. Altering the composition of the agent subgroups can help strike a balance between exploitative and exploratory actions. Exploration accounts for 70 percent of the population, denoted as , while exploitation accounts for 30 percent, denoted as . The worldwide average levels of the exploration and exploitation groups’ agents’ fitness have improved as a result of the increased number of agents in those groups. The mathematical skills of the exploring crew enable them to locate potentially fruitful places nearby. This can be achieved by persistently looking for more suitable alternatives [31].
Optimization algorithms discover the best agent given constraints. The BER algorithm indicates the population agents as (search space) for feature d. The objective function, denoted as F, is recommended for assessing the agent’s performance. Agents are optimized to find the best agent, denoted as . The BER algorithm will optimize using the fitness function, as well as the lower and higher limits for each solution, the dimension, and the population size. The original BER algorithm is presented in Algorithm 1.
The solitary explorer in the group will utilize this strategy to look for potentially fruitful new regions to research in the region where they are now situated in order to go closer to the most optimally viable answer. In order to accomplish this objective, one must do research into the numerous options that are available in the surrounding area and choose the alternative that is superior to the others with regard to the effect it has on one’s physical well-being. In order to accomplish this objective, the research that BER has carried out has made use of the equations that are as follows:
where is a solution at iteration t. With a circle with a diameter of , the agent will search for promising spots. The h parameter is selected within , and . The terms h and x are random variables and follow a uniform distribution. Examples of coefficient vectors include and , and their values can be decided using .
In order to make the most of opportunities, the group responsible for doing so needs to find ways to make the solutions that are already in place even more effective. The BER determines at the end of each round which individuals have achieved the highest levels of fitness and then awards them appropriately. The BER accomplishes its mission of exploitation through the use of two distinct approaches, both of which are detailed in this article. By applying the following equation to help us progress in the right direction, we will be able to move closer to the optimal answer.
where is a random vector calculated based on , which controls the moving to the best solution. represents the best solution and is the distance vector.
| Algorithm 1: AL-Biruni Earth Radius (BER) algorithm |
| 1: Initialize BER population and parameters, 2: Calculate objective function for each agent 3: Find best agent 4: while do 5: for () do 6: Update , 7: Move to best agent as in Equation (1) 8: end for 9: for () do 10: Update , 11: Elitism of the best agent as in Equation (2) 12: Investigating area around best agent as in Equation (3) 13: Select best agent by comparing and 14: if The best fitness value with no change for two iterations. then 15: Mutate solution as in Equation (4) 16: end if 17: end for 18: Update objective function for each agent 19: Find best agent as 20: Update BER parameters, 21: end while 22: Return best agent |
Examining the region reveals that the region surrounding the best solution offers the most exciting potential solution. Consequently, several agents hunt for ways to better circumstances by contemplating alternate options that are relatively comparable to the best option. Using the equation that is provided below, the BER completes the procedure that was just described.
where indicates the best solution. The best solution in this case is determined based on comparing and . In the event that the optimal level of fitness has remained unchanged throughout the course of the previous two iterations, the solution will be modified in line with the equation that is presented below.
where z has a random value within and follow a uniform distribution.
To provide the highest possible level of quality, the BER will select the most suitable alternative for the subsequent cycle. The effectiveness of elitism may hasten the process of multimodal functions converging on one another. By utilizing a mutational strategy and thoroughly assessing all of the members of the exploration group, the BER is able to provide great capabilities for mineral exploration. Exploration allows for a delay in the BER’s convergence. Algorithm 1 has BER pseudo-code. To begin, please provide the size of the BER population, the mutation rate, and the number of iterations. The BER then separates the agents into two distinct groups: the exploratory and the exploitative. The BER method iteratively searches for the best response and automatically modifies the size of each group as it does so. When iterating, the BER will rearrange the responses to ensure that they are diverse and have sufficient depth. In the subsequent cycle, a solution that was developed by the exploration group might be passed on to the exploitation group. During the rigorous and exclusive selection process that is the BER, the leader cannot be replaced.
3. Proposed Dynamic Fitness BER Algorithm
This section introduces the innovative Dynamic Fitness Al-Biruni Earth Radius (DFBER) algorithm. This novel algorithm builds upon the original BER algorithm by incorporating it into an adaptable framework. The specifics of the proposed algorithm can be found in Algorithm 2, and further elaboration on its intricacies is provided within this section.
| Algorithm 2: The proposed DFBER algorithm |
| 1: Initialize population and parameters, 2: Calculate fitness function for each agent 3: Find first, second, and third best agents 4: while do 5: if (For three iterations, the best fitness value is the same) then 6: Increase agents in exploration group 7: Decrease agents in exploitation group 8: end if 9: for () do 10: Update , 11: Update positions of agents as 12: end for 13: for () do 14: Update r = h , 15: Update Fitness 16: Update Fitness 17: Update Fitness 18: Calculate 19: Elitism of the best agent as 20: Investigating area around best agent as 21: Select best agent by comparing and 22: if The best fitness value with no change for two iterations. then 23: Mutate solution as 24: end if 25: end for 26: Update fitness function for each agent 27: Find best three agents 28: Set first best agent as 29: Update parameters, 30: end while 31: Return best agent |
3.1. Motivation
Optimization problems use populations to represent viable solutions. Each agent in the search space has a parameter vector. Exploitation and exploration groups comprise the prospective solution. An objective function helps the exploitation group enhance the best solution. The exploration group uses the search space to find new places where the best solution may be. In the proposed optimization technique, these two groups share roles and information to quickly find the optimum solution. This partnership avoids local optima and explores the search space efficiently. The suggested optimization technique maintains the balance between exploitation and exploration groups and avoids steady regions in the search space through a dynamic mechanism.
3.2. Dynamic Feature of DFBER Algorithm
The proposed DFBER algorithm achieves a balance between exploration and exploitation within the population’s subgroups. It adopts a 70/30 approach, where the population is divided into two groups: exploration, denoted as , and exploitation, denoted as . Initially, a larger number of participants in the exploration group facilitates the discovery of new and interesting search regions. As the optimization progresses and individuals in the exploitation group improve their fitness, the overall fitness of the population increases, resulting in a rapid reduction of individuals in the exploration group from 70% to 30%. To ensure convergence, an elitism method is employed, retaining the leader of the process in subsequent populations if a better solution cannot be found. Additionally, if the leader’s fitness remains relatively unchanged for three consecutive iterations, the DFBER algorithm has the flexibility to increase the number of members in the exploration group at any point in time.
The DFBER algorithm balances subgroup exploration and exploitation. Wind power prediction equality and inequality limitations require this balance. Exploration involves searching the solution space broadly to find better solutions, whereas exploitation involves refining and improving the best-known answers in optimization issues. The DFBER algorithm uses exploration and exploitation in population subgroups. This balanced method lets the DFBER algorithm analyze genuine wind power prediction equalities and inequalities. Wind power generating has physical, system, and operational constraints. The DFBER algorithm efficiently navigates the solution space by balancing exploration and exploitation. This method improves wind power estimates by realistically modeling restrictions. The DFBER algorithm’s ability to solve equality and inequality restrictions in wind power projections helps align the optimization process with wind power systems’ real-world limits and requirements.
3.3. Fitness Al-Biruni Earth Radius Algorithm
The fitness of the proposed DFBER is formulated as follows. Equation (2) will be updated in the proposed algorithm to include the fitness function property. The fitness functions of , , and will be calculated for the first best solutions, denoted as , , and , respectively. The final fitness values will be updated as in the following equation to be involved in the proposed algorithm.
Equation (2) of the original BER algorithm will be updated by Equations (8) and (9) in the proposed DFBER algorithm based on the fitness function is as follows.
For the modified distance vector, , calculated using , , and as.
where is a random vector calculated based on , which controls the moving to the best solution. represents the first best solution, represents the second best solution, and indicates the third best solution. The proposed DFBER algorithm is shown in Algorithm 2 step-by-step.
3.4. Complexity Analysis
The DFBER algorithm’s computational complexity, shown in Algorithm 2, can be described using the following expression. We will define the time complexity for a population size of n, and a maximum number of iterations denoted as .
- Initialize population and parameters, .
- Calculate fitness function for each agent: .
- Finding best three solutions: .
- Updating agents in exploration and exploitation groups: .
- Updating position of current agents in exploration group: .
- Updating position of current agents in exploitation group by fitness functions: .
- Updating fitness function for each agent: .
- Finding best fitness: .
- Finding best three solutions: .
- Set first best agent as : .
- Updating parameters: .
- Updating iterations: .
- Return the best fitness: .
Based on the analysis, the computational complexity of the algorithm can be summarized as follows. The time complexity is estimated to be for the case of a population size of n. Additionally, the algorithm employs the k-nearest neighbors (kNN) within a fitness function, and the computational complexity of kNN is primarily determined by the number of training samples and the dimensional of the feature space (d). Thus, the time complexity becomes .
3.5. Fitness Function
The fitness equation, , helps the DFBER approach assess a solution’s quality. The expressions for selected features (v), the total number of features (V), and a classifier’s error rate () employ as a variable.
where indicates the population’s importance of the specified trait, and might be any number between [0, 1]. If a selection of features may reduce classification error, the strategy is acceptable. The simple classification method k-nearest neighbor (kNN) is used often. The k-nearest neighbors classifier ensures high-quality attributes in this strategy. The only classifier criterion is the shortest distance between the query instance and the training instances. This experiment uses no K-nearest neighbor models.
4. Experimental Results
In the study, the investigation’s findings are thoroughly examined, focusing on the DFBER algorithm. This algorithm is analyzed and compared to other state-of-the-art algorithms including BER [31], Jaya Algorithm (JAYA) [32], Fire Hawk Optimizer (FHO) [33], Whale Optimization Algorithm (WOA) [34], Grey Wolf Optimizer (GWO) [35], Particle swarm optimization (PSO) [36], Firefly algorithm (FA) [37], and Genetic Algorithm (GA) [35]. The DFBER algorithm’s configuration is presented in Table 1. This table details the algorithm’s parameters, which are crucial for understanding its behavior and performance in optimization. The presented parameters include the population size (number of agents), termination criterion (number of iterations), and other important characteristics for selecting significant features from the input dataset.

Table 1.
The DFBER algorithm’s configuration settings.
By comparing the DFBER algorithm with other state-of-the-art algorithms and presenting its configuration, the investigation aims to evaluate its effectiveness and potential advantages. Table 2 presents the setup of the comparative algorithms used in the evaluation. Several factors are considered to ensure a fair evaluation of optimization techniques and parameters. The problem’s search space size, constraints, and objective function are considered. The choice of algorithm parameters can greatly influence its performance. Factors such as convergence speed and the exploration-exploitation trade-off should be considered when tuning parameters for both the problem and the chosen algorithm. The evaluation is conducted over ten runs with different random seeds to ensure fair comparisons. This helps account for the variability in the optimization process and provides a more robust statistical analysis. Furthermore, an appropriate dataset is selected for testing the algorithms. The choice of the dataset should represent the problem domain and provide meaningful insights into the performance of the algorithms. The number of function calls made during optimization is considered to establish a fair computational budget. Each optimizer is run ten times for 80 iterations, with the number of search agents set to 10. Setting a specific computational budget ensures that all compared algorithms have an equal opportunity to explore and exploit the search space within the given limitations. Adopting this approach enables a fair and standardized evaluation, enabling meaningful comparisons between the optimization algorithms and facilitating informed decision-making.
Table 2.
Compared algorithms various configuration parameters.
4.1. Dataset
The dataset in this context is focused on analyzing energy generation from solar and wind sources in different operating areas. The data used in the analysis is sourced from the National Renewable Energy Laboratory (NREL) and provides information on solar and wind energy generation over specific periods. The dataset includes monthly average wind speeds 50 m above the Earth’s surface regarding wind energy. This wind speed data is collected over 30 years, specifically from January 1984 to December 2013. The wind speed measurements help assess the wind energy potential in different areas [39]. The data is further categorized based on different operating areas:
- Central Operating Area (COA): This refers to a specific region or area where the central energy generation operations occur.
- Eastern Operating Area (EOA): This refers to a specific region or area where energy generation operations are concentrated in the eastern part.
- Southern Operating Area (SOA): This refers to a specific region or area where energy generation operations are concentrated in the southern part.
- Western Operating Area (WOA): This refers to a specific region or area where energy generation operations are concentrated in the western part.
The dataset is sourced from NREL and associated with the “wind-solar-energy-data identifier”. Figure 2 shows the map of the wind power forecasting dataset. It falls under the theme of Renewable & Alternative Fuels and contains keywords related to wind and solar energy. The dataset is in English and was last modified on 14 October 2020. The publisher of the dataset is the King Abdullah Petroleum Studies and Research Center in Saudi Arabia. The dataset’s availability and classification indicate that it is public data. However, it is noted that the dataset has been discontinued. The dataset specifically focuses on energy generation in Saudi Arabia, as the country’s information indicates. The ISO region associated with the dataset is EMEA (Europe, the Middle East, and Africa).
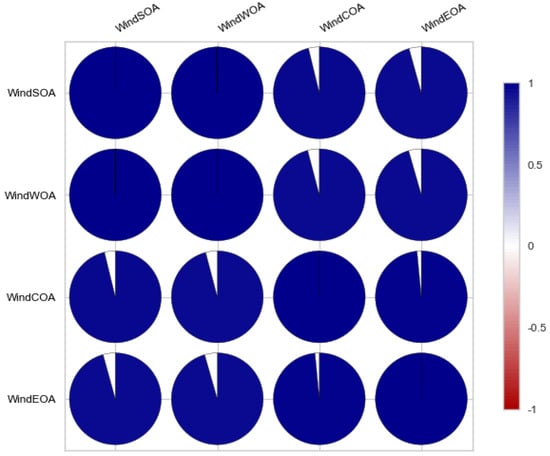
Figure 2.
Map of the wind power forecasting dataset.
The seasonal decomposition of the wind power forecasting dataset provides insights into the individual components of the dataset, namely COA, EOA, SOA, and WOA. Each of these components represents a specific aspect or pattern within the dataset. Figure 3, Figure 4, Figure 5 and Figure 6 offer a visual representation of the seasonal decomposition for each component. This decomposition helps in understanding the variations and trends associated with the COA, EOA, SOA, and WOA over time. By isolating these components, it becomes easier to analyze and interpret the dataset.
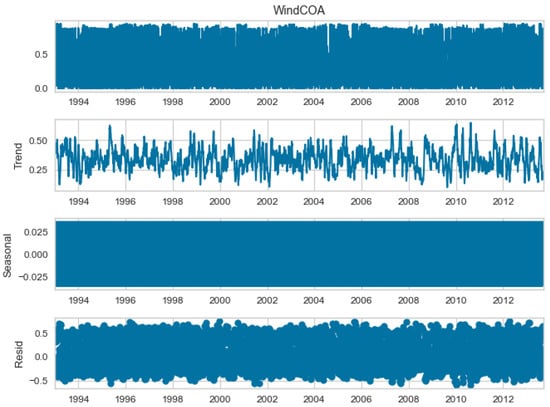
Figure 3.
The seasonal decompose for COA of the wind power forecasting dataset.
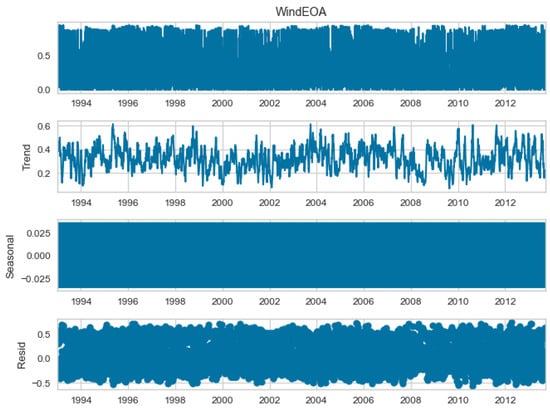
Figure 4.
The seasonal decompose for EOA of the wind power forecasting dataset.
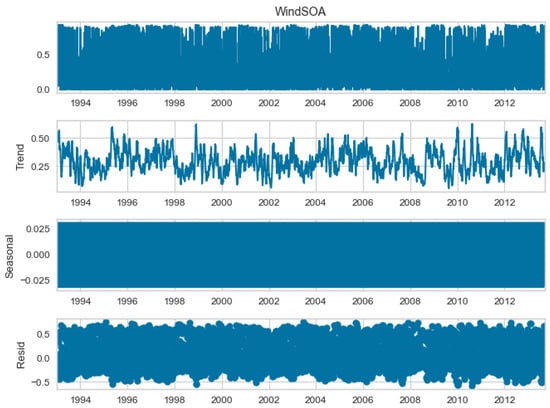
Figure 5.
The seasonal decompose for SOA of the wind power forecasting dataset.
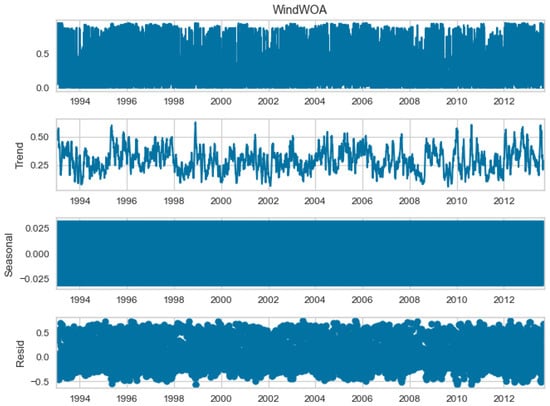
Figure 6.
The seasonal decompose for WOA of the wind power forecasting dataset.
Additionally, Figure 7, Figure 8, Figure 9 and Figure 10 display the histogram and box plot for each component. These plots provide a graphical representation of the distribution and statistical properties of the COA, EOA, SOA, and WOA. The histogram gives an overview of the frequency distribution of the values, while the box plot illustrates the median, quartiles, and any outliers present. Together, these figures provide a comprehensive understanding of the wind power forecasting dataset, allowing for a detailed analysis of the COA, EOA, SOA, and WOA components in terms of their seasonal patterns, variations, and statistical characteristics.
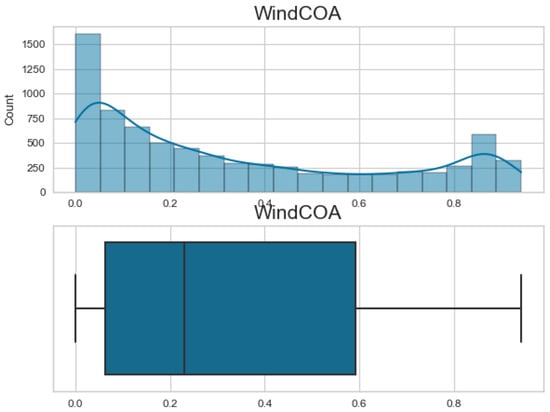
Figure 7.
The histogram and box plot for COA of the wind power forecasting dataset.
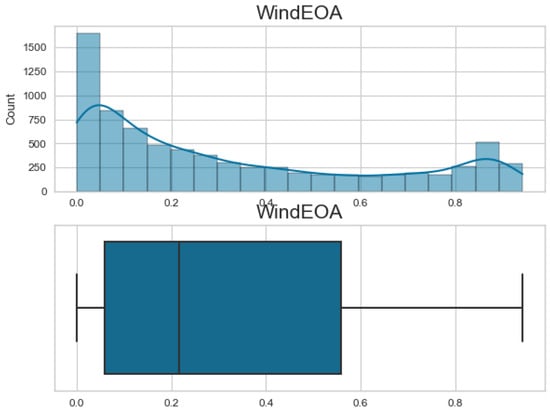
Figure 8.
The histogram and box plot for EOA of the wind power forecasting dataset.
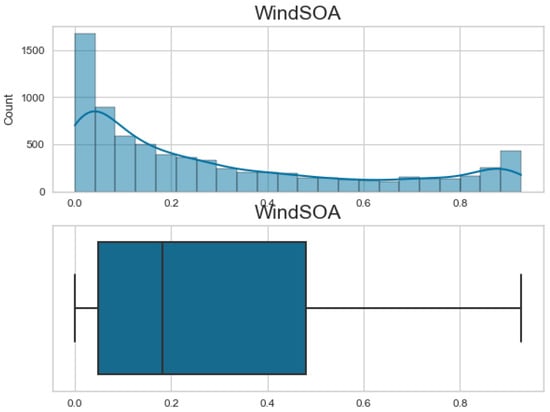
Figure 9.
The histogram and box plot for SOA of the wind power forecasting dataset.
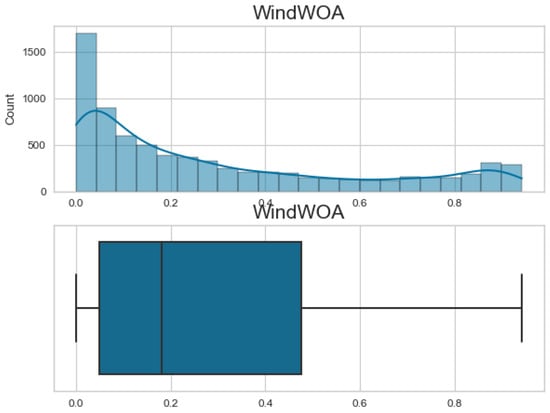
Figure 10.
The histogram and box plot for WOA of the wind power forecasting dataset.
4.2. Regression Results and Discussions
To assess the effectiveness of the suggested RNN forecasting model based on the DFBER algorithm, various metrics are employed. These metrics encompass relative root mean squared error (RRMSE), Nash Sutcliffe Efficiency (NSE), mean absolute error (MAE), mean bias error (MBE), Pearson’s correlation coefficient (r), coefficient of determination (R2), and determine agreement (WI). The dataset size is denoted by the parameter N, while the nth estimated and observed bandwidth values are represented by and , respectively. The arithmetic means of the estimated and observed values are denoted as and . The evaluation criteria for predictions can be found in Table 3. The outcomes of the proposed optimizing RNN-DFBER-based model are displayed in Table 4. The results reveal an RMSE value of 0.0028426034752477.
Table 3.
Evaluation criteria for predictions.
Table 4.
Proposed RNN-DFBER-based model results.
To evaluate the effectiveness of the proposed RNN-DFBER-based model, its regression results are compared with those of other models such as BER, JAYA, FHO, FA, GWO, PSO, GA, and WOA-based models. Table 5 offers a comprehensive statistical description of the RNN-DFBER-based model and presents the RMSE results of all models based on ten independent runs. The description includes information about the minimum, median, maximum, and mean average errors, standard (Std.) Deviation, Std. Error of Mean, the required time in seconds. The Number of values to run the models is ten times.
Table 5.
Statistical description of the proposed RNN-DFBER-based model and other models’ results from RMSE.
Figure 11 illustrates a box plot generated using the root-mean-squared error (RMSE) for the proposed RNN-DFBER-based model, as well as the BER, JAYA, FHO, FA, GWO, PSO, GA, and WOA-based models. The effectiveness of the optimized RNN-DFBER-based model is assessed using the fitness function described in Equation (10), as depicted in the figure. Additionally, Figure 12 presents a histogram of the RMSE values for both the presented RNN-DFBER-based model and the other models. Furthermore, Figure 13 showcases the ROC curve comparing the presented DFBER algorithm with the BER algorithm. Lastly, Figure 14 showcases QQ plots, residual plots, and a heat map for both the provided RNN-DFBER-based model and the compared models, based on the analyzed data. These figures collectively demonstrate the potential of the given optimized RNN-DFBER-based model to outperform the compared models.
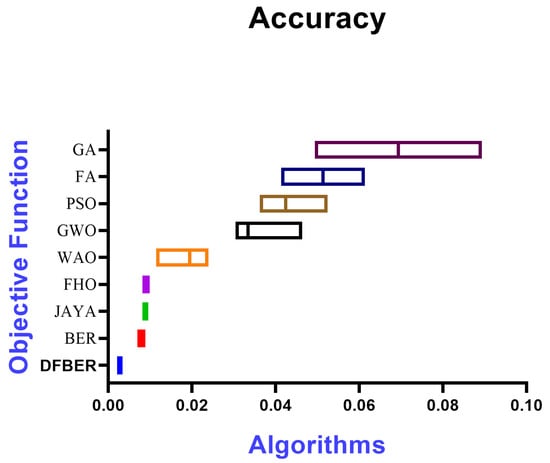
Figure 11.
The box plot of the proposed RNN-DFBER-based model and BER, JAYA, FHO, FA, GWO, PSO, GA, and WOA-based models based on the RMSE.
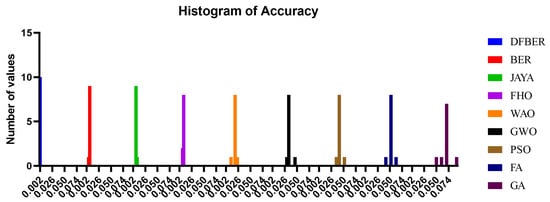
Figure 12.
Histogram of RMSE for both the presented RNN-DFBER-based model and the other models.
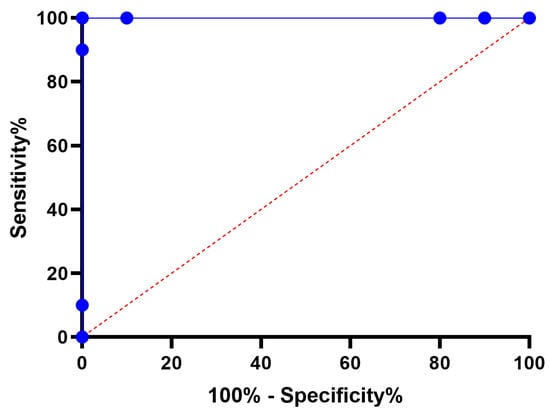
Figure 13.
ROC curve of the presented RNN-DFBER algorithm versus the BER algorithm.
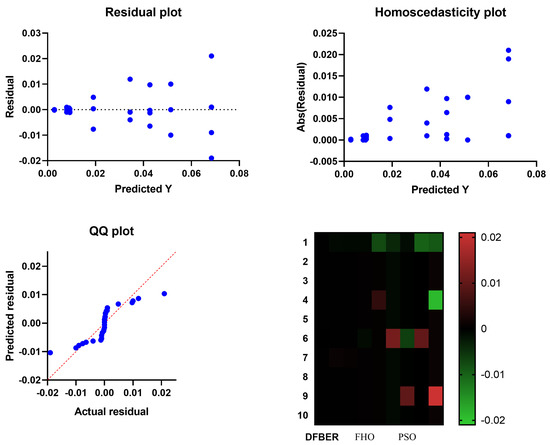
Figure 14.
For both the models that were compared and the model that was presented using RNN-DFBER, there were QQ plots, residual plots, and heat maps.
Figure 15 illustrates the statistical distribution of the COA compared to the EOA components of the wind power forecasting dataset. This distribution provides insights into the relationship and variability between these two components. Figure 16 presents the statistical distribution of the EOA in relation to the SOA components of the wind power forecasting dataset. This distribution offers a visualization of the statistical properties and potential correlations between these two components. Lastly, Figure 17 showcases the statistical distribution of the SOA in comparison to the WOA components of the wind power forecasting dataset. This distribution enables an analysis of the statistical characteristics and potential dependencies between these two components. By examining these statistical distributions, one can gain a deeper understanding of the relationships, variations, and patterns present in the wind power forecasting dataset between COA and EOA, EOA and SOA, and SOA and WOA.
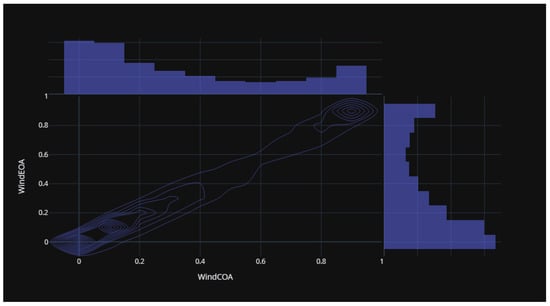
Figure 15.
The statistical distribution for COA versus EOA of the wind power forecasting dataset.
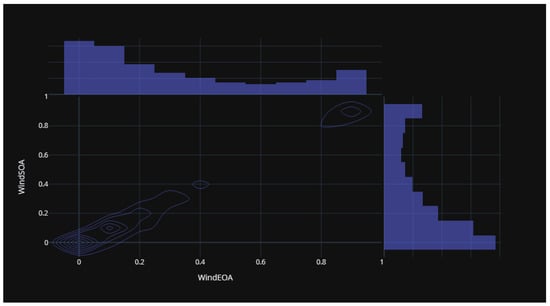
Figure 16.
The statistical distribution for EOA versus SOA of the wind power forecasting dataset.
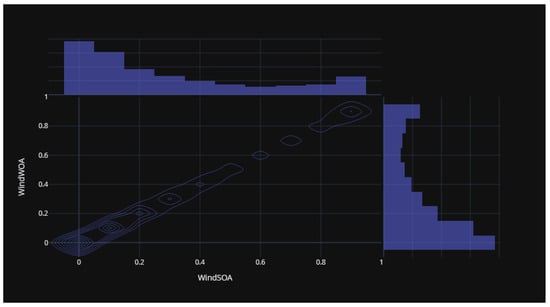
Figure 17.
The statistical distribution for SOA versus WOA of the wind power forecasting dataset.
The results of the ANOVA test conducted on the proposed RNN-DFBER-based model and the compared models are presented in Table 6. This statistical analysis provides insights into the significance of differences between the models. Additionally, Table 7 presents a comparison between the proposed optimized RNN-DFBER-based model and the compared models using the Wilcoxon Signed-Rank test. By conducting ten independent iterations of each algorithm, the statistical analysis ensures accurate comparisons and enhances the reliability of the study’s findings.
Table 6.
The outcomes of the ANOVA test for the comparison models and the suggested RNN-DFBER.
Table 7.
Comparison between the models that were compared using the Wilcoxon Signed-Rank test and the proposed RNN-DFBER.
5. Discussion
The presented results demonstrate the effectiveness of the proposed optimized RNN-DFBER-based model. It outperforms the compared models based on various evaluation metrics, visual representations, and statistical tests. These findings highlight the potential and superiority of the presented RNN-DFBER-based model in accurately predicting and modeling the data. The model exhibits lower RMSE values, indicating better overall performance in capturing the observed values compared to other models. Furthermore, the comprehensive evaluation using multiple metrics such as RRMSE, NSE, MAE, MBE, r, R2, and WI provides a holistic assessment of the proposed RNN-DFBER-based model. The model’s ability to closely match the observed values, as reflected in the high correlation coefficient (r) and coefficient of determination (R2), demonstrates its effectiveness in capturing the underlying patterns in the data.
The visual comparisons, including the box plot, histogram, ROC curve, QQ plots, residual plots, and heat map, further support the superiority of the proposed RNN-DFBER-based model. These visualizations provide insights into the distribution of errors, discrimination ability, conformity to assumptions, and the relationship between variables, ultimately highlighting the model’s strengths and advantages over the other models. The statistical analyses conducted, including the ANOVA test and the Wilcoxon Signed-Rank test, reinforce the significance and reliability of the findings. By conducting multiple iterations of each algorithm, the comparisons are robust, ensuring that the observed differences in performance are statistically significant.
The results and analyses collectively demonstrate that the proposed optimized RNN-DFBER-based model outperforms the compared models in terms of accuracy, predictive capability, and reliability. These findings contribute to the validation and efficacy of the suggested algorithm for the given dataset and underline its potential for practical applications in similar domains.
6. Conclusions and Future Work
In conclusion, the proposed optimized RNN-DFBER-based model has been shown to be highly effective in predicting and modeling the given dataset. The model outperformed other compared models based on various evaluation metrics, including RRMSE, NSE, MAE, MBE, r, R2, and WI. The low RMSE value indicates a close match between the model’s predictions and the observed values. Visual comparisons, such as box plots, histograms, ROC curves, QQ plots, residual plots, and heat maps, further supported the superiority of the RNN-DFBER-based model. These visualizations demonstrated its ability to accurately capture the underlying patterns and relationships in the data. Statistical analyses, including the ANOVA test and the Wilcoxon Signed-Rank test, provided additional evidence of the model’s significance and reliability. By conducting multiple iterations of each algorithm, the statistical comparisons ensured the robustness of the results. The findings indicate that the proposed RNN-DFBER-based model offers a powerful and effective approach for the given dataset. Its strong performance, supported by comprehensive evaluations and statistical analyses, suggests its potential for practical applications in similar domains. Future directions for research in this area could include conducting further research and validation using diverse datasets and scenarios to evaluate the generalizability and robustness of the RNN-DFBER-based model. This would help determine the model’s effectiveness in different contexts and ensure its reliability across various conditions.
Author Contributions
Software, S.K.T.; validation, F.K.K. and M.M.E.; formal analysis, F.K.K.; investigation, D.S.K.; data curation, H.K.A.; writing—original draft preparation, D.S.K.; M.M.E.; writing—review and editing, S.K.T.; visualization, M.M.E.; supervision, S.K.T.; project administration, S.K.T.; funding acquisition, H.K.A. All authors have read and agreed to the published version of the manuscript.
Funding
Deputyship for Research & Innovation, Ministry of Education in Saudi Arabia for funding this research work through the project number RI-44-0649.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
King Abdullah Petroleum Studies and Research Center. Available online: https://datasource.kapsarc.org/explore/dataset/ wind-solar-energy-data/information/ (accessed on 1 June 2023).
Acknowledgments
The authors extend their appreciation to the Deputyship for Research & Innovation, Ministry of Education in Saudi Arabia for funding this research work through the project number RI-44-0649.
Conflicts of Interest
The authors declare that they have no conflict of interest to report regarding the present study.
References
- Valdivia-Bautista, S.M.; Domínguez-Navarro, J.A.; Pérez-Cisneros, M.; Vega-Gómez, C.J.; Castillo-Téllez, B. Artificial Intelligence in Wind Speed Forecasting: A Review. Energies 2023, 16, 2457. [Google Scholar] [CrossRef]
- Ibrahim, A.; El-kenawy, E.S.M.; Kabeel, A.E.; Karim, F.K.; Eid, M.M.; Abdelhamid, A.A.; Ward, S.A.; El-Said, E.M.S.; El-Said, M.; Khafaga, D.S. Al-Biruni Earth Radius Optimization Based Algorithm for Improving Prediction of Hybrid Solar Desalination System. Energies 2023, 16, 1185. [Google Scholar] [CrossRef]
- El-kenawy, E.S.M.; Albalawi, F.; Ward, S.A.; Ghoneim, S.S.M.; Eid, M.M.; Abdelhamid, A.A.; Bailek, N.; Ibrahim, A. Feature Selection and Classification of Transformer Faults Based on Novel Meta-Heuristic Algorithm. Mathematics 2022, 10, 3144. [Google Scholar] [CrossRef]
- Khafaga, D.S.; Alhussan, A.A.; El-Kenawy, E.S.M.; Ibrahim, A.; Eid, M.M.; Abdelhamid, A.A. Solving Optimization Problems of Metamaterial and Double T-Shape Antennas Using Advanced Meta-Heuristics Algorithms. IEEE Access 2022, 10, 74449–74471. [Google Scholar] [CrossRef]
- El-Kenawy, E.S.M.; Mirjalili, S.; Alassery, F.; Zhang, Y.D.; Eid, M.M.; El-Mashad, S.Y.; Aloyaydi, B.A.; Ibrahim, A.; Abdelhamid, A.A. Novel Meta-Heuristic Algorithm for Feature Selection, Unconstrained Functions and Engineering Problems. IEEE Access 2022, 10, 40536–40555. [Google Scholar] [CrossRef]
- Djaafari, A.; Ibrahim, A.; Bailek, N.; Bouchouicha, K.; Hassan, M.A.; Kuriqi, A.; Al-Ansari, N.; El-kenawy, E.S.M. Hourly predictions of direct normal irradiation using an innovative hybrid LSTM model for concentrating solar power projects in hyper-arid regions. Energy Rep. 2022, 8, 15548–15562. [Google Scholar] [CrossRef]
- El-kenawy, E.S.M.; Mirjalili, S.; Khodadadi, N.; Abdelhamid, A.A.; Eid, M.M.; El-Said, M.; Ibrahim, A. Feature selection in wind speed forecasting systems based on meta-heuristic optimization. PLoS ONE 2023, 18, e0278491. [Google Scholar] [CrossRef]
- Lin, W.H.; Wang, P.; Chao, K.M.; Lin, H.C.; Yang, Z.Y.; Lai, Y.H. Wind Power Forecasting with Deep Learning Networks: Time-Series Forecasting. Appl. Sci. 2021, 11, 10335. [Google Scholar] [CrossRef]
- Alkesaiberi, A.; Harrou, F.; Sun, Y. Efficient Wind Power Prediction Using Machine Learning Methods: A Comparative Study. Energies 2022, 15, 2327. [Google Scholar] [CrossRef]
- Qiao, L.; Chen, S.; Bo, J.; Liu, S.; Ma, G.; Wang, H.; Yang, J. Wind power generation forecasting and data quality improvement based on big data with multiple temporal-spatual scale. In Proceedings of the 2019 IEEE International Conference on Energy Internet (ICEI), Nanjing, China, 27–31 May 2019. [Google Scholar] [CrossRef]
- Mohammed, I.J.; Al-Nuaimi, B.T.; Baker, T.I. Weather Forecasting over Iraq Using Machine Learning. J. Artif. Intell. Metaheuristics 2022, 2, 39–45. [Google Scholar] [CrossRef]
- Alsayadi, H.A.; Khodadadi, N.; Kumar, S. Improving the Regression of Communities and Crime Using Ensemble of Machine Learning Models. J. Artif. Intell. Metaheuristics 2022, 1, 27–34. [Google Scholar] [CrossRef]
- do Nascimento Camelo, H.; Lucio, P.S.; Junior, J.V.L.; von Glehn dos Santos, D.; de Carvalho, P.C.M. Innovative Hybrid Modeling of Wind Speed Prediction Involving Time-Series Models and Artificial Neural Networks. Atmosphere 2018, 9, 77. [Google Scholar] [CrossRef]
- Oubelaid, A.; Shams, M.Y.; Abotaleb, M. Energy Efficiency Modeling Using Whale Optimization Algorithm and Ensemble Model. J. Artif. Intell. Metaheuristics 2022, 2, 27–35. [Google Scholar] [CrossRef]
- Abdelbaky, M.A.; Liu, X.; Jiang, D. Design and implementation of partial offline fuzzy model-predictive pitch controller for large-scale wind-turbines. Renew. Energy 2020, 145, 981–996. [Google Scholar] [CrossRef]
- Kong, X.; Ma, L.; Wang, C.; Guo, S.; Abdelbaky, M.A.; Liu, X.; Lee, K.Y. Large-scale wind farm control using distributed economic model predictive scheme. Renew. Energy 2022, 181, 581–591. [Google Scholar] [CrossRef]
- Xu, W.; Liu, P.; Cheng, L.; Zhou, Y.; Xia, Q.; Gong, Y.; Liu, Y. Multi-step wind speed prediction by combining a WRF simulation and an error correction strategy. Renew. Energy 2021, 163, 772–782. [Google Scholar] [CrossRef]
- Peng, X.; Wang, H.; Lang, J.; Li, W.; Xu, Q.; Zhang, Z.; Cai, T.; Duan, S.; Liu, F.; Li, C. EALSTM-QR: Interval wind-power prediction model based on numerical weather prediction and deep learning. Energy 2021, 220, 119692. [Google Scholar] [CrossRef]
- Tian, Z. Short-term wind speed prediction based on LMD and improved FA optimized combined kernel function LSSVM. Eng. Appl. Artif. Intell. 2020, 91, 103573. [Google Scholar] [CrossRef]
- Forestiero, A. Bio-inspired algorithm for outliers detection. Multimed. Tools Appl. 2017, 76, 25659–25677. [Google Scholar] [CrossRef]
- Shaukat, N.; Ahmad, A.; Mohsin, B.; Khan, R.; Khan, S.U.D.; Khan, S.U.D. Multiobjective Core Reloading Pattern Optimization of PARR-1 Using Modified Genetic Algorithm Coupled with Monte Carlo Methods. Sci. Technol. Nucl. Install. 2021, 2021, 1–13. [Google Scholar] [CrossRef]
- Abualigah, L.; Elaziz, M.A.; Khodadadi, N.; Forestiero, A.; Jia, H.; Gandomi, A.H. Aquila Optimizer Based PSO Swarm Intelligence for IoT Task Scheduling Application in Cloud Computing. In Studies in Computational Intelligence; Springer International Publishing: Berlin/Heidelberg, Germany, 2022; pp. 481–497. [Google Scholar] [CrossRef]
- Barboza, A.B.; Mohan, S.; Dinesha, P. On reducing the emissions of CO, HC, and NOx from gasoline blended with hydrogen peroxide and ethanol: Optimization study aided with ANN-PSO. Environ. Pollut. 2022, 310, 119866. [Google Scholar] [CrossRef] [PubMed]
- Cao, Y.; Zhang, H.; Li, W.; Zhou, M.; Zhang, Y.; Chaovalitwongse, W.A. Comprehensive Learning Particle Swarm Optimization Algorithm With Local Search for Multimodal Functions. IEEE Trans. Evol. Comput. 2019, 23, 718–731. [Google Scholar] [CrossRef]
- Memarzadeh, G.; Keynia, F. A new short-term wind speed forecasting method based on fine-tuned LSTM neural network and optimal input sets. Energy Convers. Manag. 2020, 213, 112824. [Google Scholar] [CrossRef]
- Xue, J.; Shen, B. A novel swarm intelligence optimization approach: Sparrow search algorithm. Syst. Sci. Control Eng. 2020, 8, 22–34. [Google Scholar] [CrossRef]
- Kumar Ganti, P.; Naik, H.; Kanungo Barada, M. Environmental impact analysis and enhancement of factors affecting the photovoltaic (PV) energy utilization in mining industry by sparrow search optimization based gradient boosting decision tree approach. Energy 2022, 244, 122561. [Google Scholar] [CrossRef]
- Zhang, C.; Ding, S. A stochastic configuration network based on chaotic sparrow search algorithm. Knowl.-Based Syst. 2021, 220, 106924. [Google Scholar] [CrossRef]
- An, G.; Jiang, Z.; Chen, L.; Cao, X.; Li, Z.; Zhao, Y.; Sun, H. Ultra Short-Term Wind Power Forecasting Based on Sparrow Search Algorithm Optimization Deep Extreme Learning Machine. Sustainability 2021, 13, 10453. [Google Scholar] [CrossRef]
- Chen, G.; Tang, B.; Zeng, X.; Zhou, P.; Kang, P.; Long, H. Short-term wind speed forecasting based on long short-term memory and improved BP neural network. Int. J. Electr. Power Energy Syst. 2022, 134, 107365. [Google Scholar] [CrossRef]
- El-kenawy, E.S.M.; Abdelhamid, A.A.; Ibrahim, A.; Mirjalili, S.; Khodadad, N.; Al duailij, M.A.; Alhussan, A.A.; Khafaga, D.S. Al-Biruni Earth Radius (BER) Metaheuristic Search Optimization Algorithm. Comput. Syst. Sci. Eng. 2023, 45, 1917–1934. [Google Scholar] [CrossRef]
- Zitar, R.A.; Al-Betar, M.A.; Awadallah, M.A.; Doush, I.A.; Assaleh, K. An Intensive and Comprehensive Overview of JAYA Algorithm, its Versions and Applications. Arch. Comput. Methods Eng. 2021, 29, 763–792. [Google Scholar] [CrossRef]
- Azizi, M.; Talatahari, S.; Gandomi, A.H. Fire Hawk Optimizer: A novel metaheuristic algorithm. Artif. Intell. Rev. 2022, 56, 287–363. [Google Scholar] [CrossRef]
- Eid, M.M.; El-kenawy, E.S.M.; Ibrahim, A. A binary Sine Cosine-Modified Whale Optimization Algorithm for Feature Selection. In Proceedings of the 2021 National Computing Colleges Conference (NCCC), Taif, Saudi Arabia, 27–28 March 2021. [Google Scholar] [CrossRef]
- El-Kenawy, E.S.M.; Eid, M.M.; Saber, M.; Ibrahim, A. MbGWO-SFS: Modified Binary Grey Wolf Optimizer Based on Stochastic Fractal Search for Feature Selection. IEEE Access 2020, 8, 107635–107649. [Google Scholar] [CrossRef]
- Ibrahim, A.; Noshy, M.; Ali, H.A.; Badawy, M. PAPSO: A Power-Aware VM Placement Technique Based on Particle Swarm Optimization. IEEE Access 2020, 8, 81747–81764. [Google Scholar] [CrossRef]
- Ghasemi, M.; kadkhoda Mohammadi, S.; Zare, M.; Mirjalili, S.; Gil, M.; Hemmati, R. A new firefly algorithm with improved global exploration and convergence with application to engineering optimization. Decis. Anal. J. 2022, 5, 100125. [Google Scholar] [CrossRef]
- Kanagachidambaresan, G.R.; Ruwali, A.; Banerjee, D.; Prakash, K.B. Recurrent Neural Network. In Programming with TensorFlow; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 53–61. [Google Scholar] [CrossRef]
- King Abdullah Petroleum Studies and Research Center. Available online: https://datasource.kapsarc.org/explore/dataset/wind-solar-energy-data/information/ (accessed on 1 June 2023).

















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).