


Decentralized Multi-Robot Navigation Based on Deep Reinforcement Learning and Trajectory Optimization

Abstract
1. Introduction
- A novel GNN-RL-based decentralized multi-robot navigation framework using path generation is proposed, which is trained with deep reinforcement learning.
- An APF and nonlinear optimization are integrated into the optimization of the generated trajectory to ensure the safety of the multi-robot system.
- The scalability experiment of the multi-robot system and the obstacle avoidance experiment of a random obstacle scene are carried out to verify the effectiveness of the proposed method.
2. Related Work
3. Problem Statement
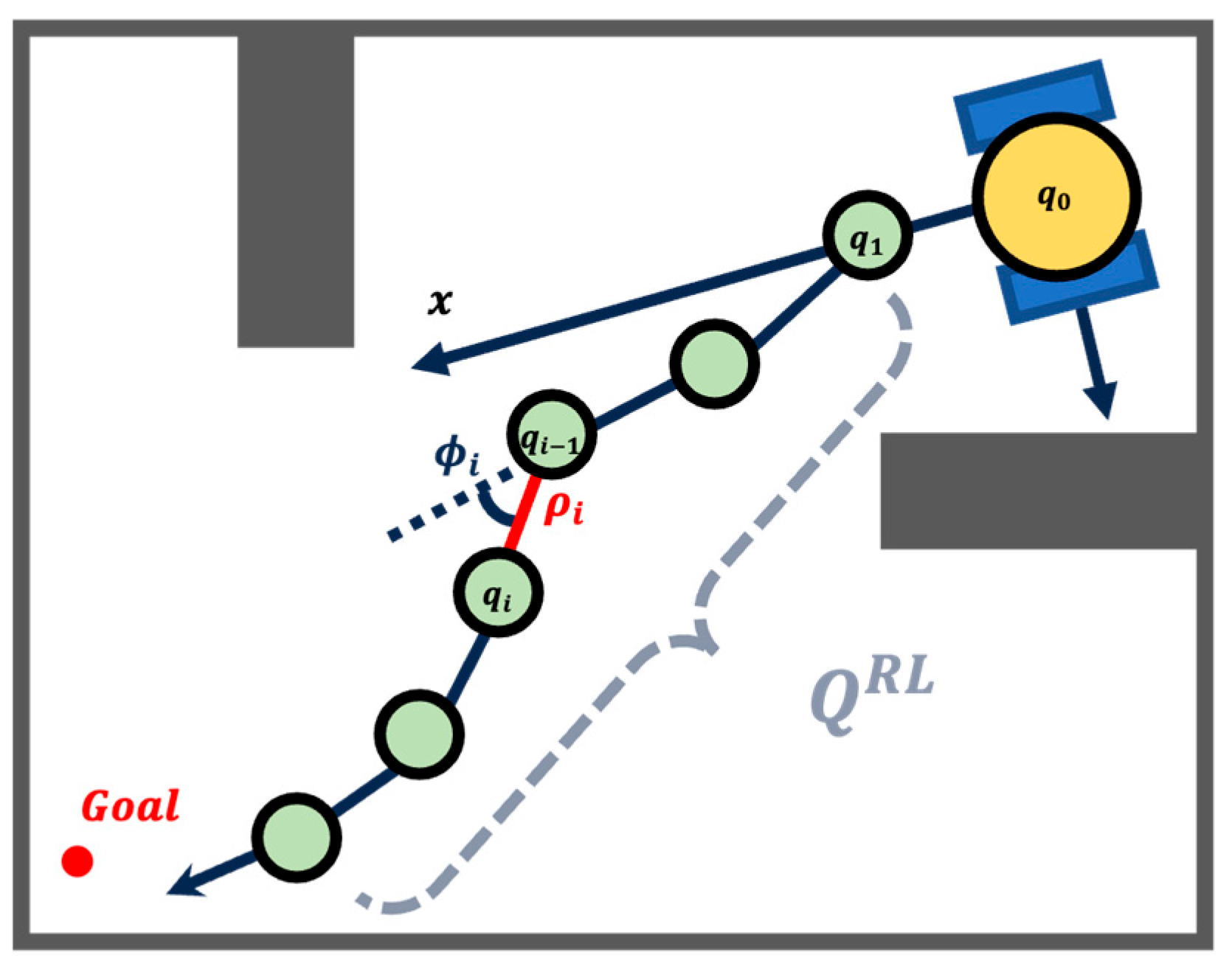
3.1. Trajectory Representation
3.2. Multi-Robot Weighted Adjacency Matrix
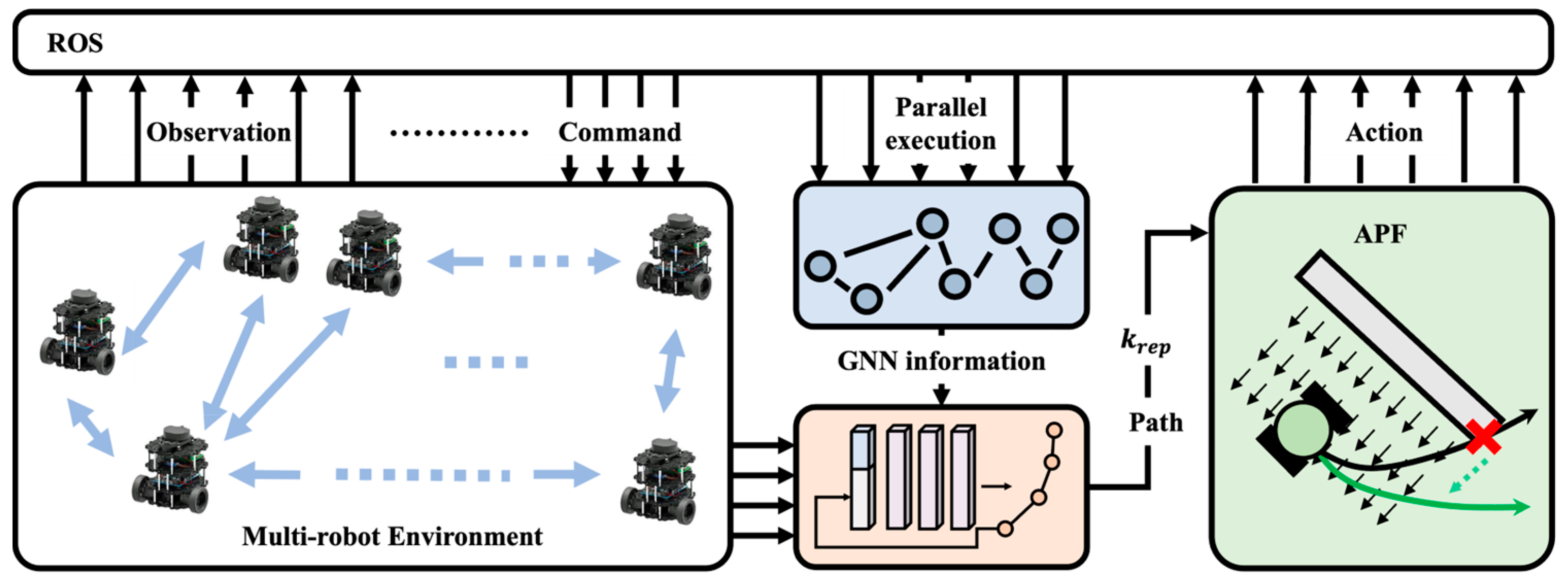
4. Approach
4.1. Multi-Robot Path Generation
- (1)
- Observation Space: The observation for each robot consists of 3 parts: the latest 3 frames of the 2D laser scan data , the relative goal position and the positions of other robots in group. The 2D laser scan data sampled 180 measurements from a LIDAR with the orientation of the robot as zero. The position information is Cartesian coordinate, converted from the world coordinate system to the local robot coordinate system.
- (2)
- Action Space: At each time step, a path was generated for the robot to follow. The action therefore is represented by the generated path , which consists of points. All these points are represented as polar coordinates and were also transformed into the local robotic coordinate system as mentioned in Section 3.1.
- (3)
- Reward Design: To enable multi-robot group to navigate to the target locations while maintaining the formation and avoiding the collision, we designed the reward function to estimate the generated path and the robot’s current state:
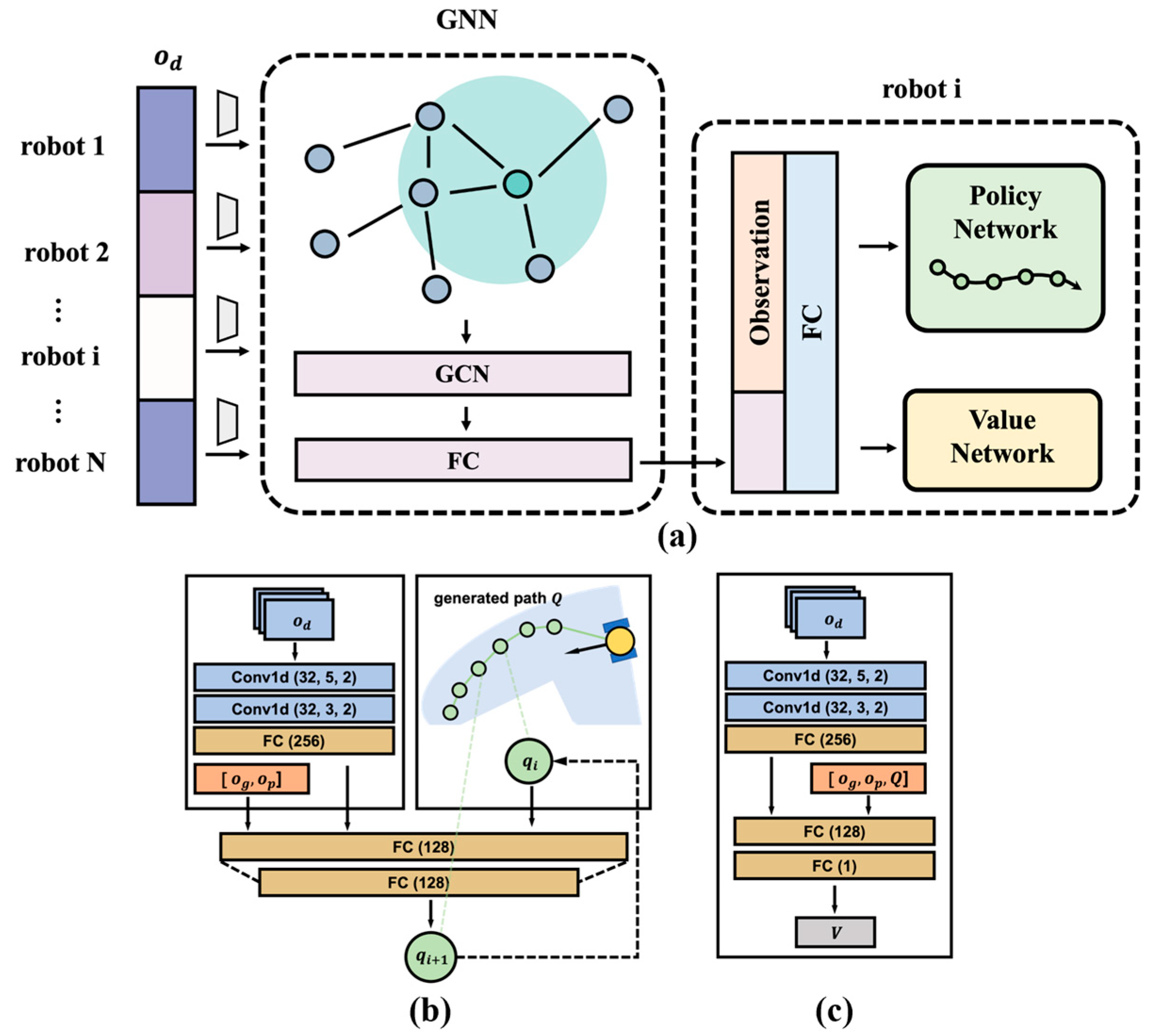
4.2. Learning Local Information Based on GCN
4.3. Trajectory Optimization Based on APF
4.4. Neural Network Structure
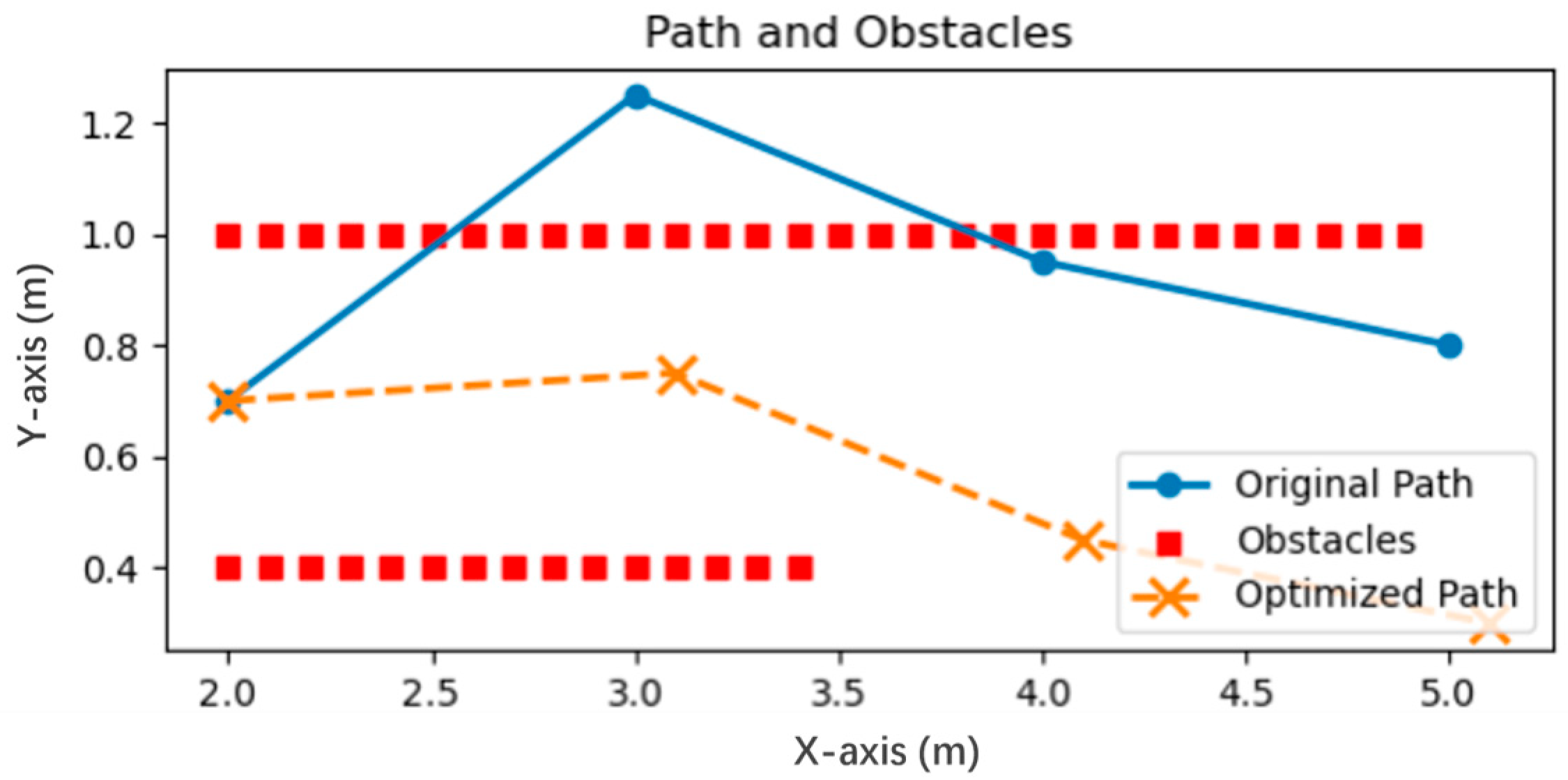
4.5. Path Adjustment Based on Nonlinear Optimization
4.6. Policy Training
5. Experiment
5.1. Evaluation Metrics
- Success Rate: The rate of the robot team to reach the goal position without collision. If a collision occurs, the current test is immediately terminated and marked as a failure.
- Average Trajectory Length: The average length of the trajectory of the robot in the team that successfully moves to the target.
- Average Time Step: The average time steps for the robot to travel to the goal.
- Average Time Cost: The average time cost for the robot to travel to the goal.
5.2. Multi-Robot Mutual Obstacle Avoidance Algorithm Comparative Experiment
5.3. Multi-Robot Large-Scale Mutual Obstacle Avoidance Experiment
5.4. Comparative Experiments on Multi-Robot Mutual Obstacle Avoidance in Complex Environments
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Bi, Q.; Zhang, X.; Wen, J.; Pan, Z.; Zhang, S.; Wang, R.; Yuan, J. Cure: A hierarchical framework for multi-robot autonomous exploration inspired by centroids of unknown regions. IEEE Trans. Autom. Sci. Eng. 2023, 21, 3773–3786. [Google Scholar] [CrossRef]
- Corah, M.; O’Meadhra, C.; Goel, K.; Michael, N. Communication-efficient planning and mapping for multi-robot exploration in large environments. IEEE Robot. Autom. Lett. 2019, 4, 1715–1721. [Google Scholar] [CrossRef]
- Dai, X.; Jiang, L.; Zhao, Y. Cooperative exploration based on supervisory control of multi-robot systems. Appl. Intell. 2016, 45, 18–29. [Google Scholar] [CrossRef]
- Stump, E.; Michael, N. Multi-robot persistent surveillance planning as a vehicle routing problem. In Proceedings of the 2011 IEEE International Conference on Automation Science and Engineering, Trieste, Italy, 24–27 August 2011; pp. 569–575. [Google Scholar]
- Queralta, J.P.; Taipalmaa, J.; Pullinen, B.C.; Sarker, V.K.; Gia, T.N.; Tenhunen, H.; Gabbouj, M.; Raitoharju, J.; Westerlund, T. Collaborative multi-robot search and rescue: Planning, coordination, perception, and active vision. IEEE Access 2020, 8, 191617–191643. [Google Scholar] [CrossRef]
- Habibi, G.; Kingston, Z.; Xie, W.; Jellins, M.; McLurkin, J. Distributed centroid estimation and motion controllers for collective transport by multi-robot systems. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1282–1288. [Google Scholar]
- Albani, D.; IJsselmuiden, J.; Haken, R.; Trianni, V. Monitoring and mapping with robot swarms for agricultural applications. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Ribeiro, A.; Conesa-Muñoz, J. Multi-robot systems for precision agriculture. In Innovation in Agricultural Robotics for Precision Agriculture: A Roadmap for Integrating Robots in Precision Agriculture; Bechar, A., Ed.; Springer: Cham, Switzerland, 2021; pp. 151–175. [Google Scholar]
- Wagner, G.; Choset, H. M*: A complete multirobot path planning algorithm with performance bounds. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), San Francisco, CA, USA, 25–30 September 2011; pp. 3260–3267. [Google Scholar]
- Yu, J.; LaValle, S.M. Optimal multirobot path planning on graphs: Complete algorithms and effective heuristics. IEEE Trans. Robot. 2016, 32, 1163–1177. [Google Scholar] [CrossRef]
- Chen, L.; Wang, Y.; Miao, Z.; Feng, M.; Zhou, Z.; Wang, H.; Wang, D. Toward safe distributed multi-robot navigation coupled with variational bayesian model. IEEE Trans. Autom. Sci. Eng. 2023, 21, 7583–7598. [Google Scholar] [CrossRef]
- Van Den Berg, J.; Snape, J.; Guy, S.J.; Manocha, D. Reciprocal collision avoidance with acceleration-velocity obstacles. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3475–3482. [Google Scholar]
- Snape, J.; Van Den Berg, J.; Guy, S.J.; Manocha, D. Smooth and collision-free navigation for multiple robots under differential-drive constraints. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 4584–4589. [Google Scholar]
- Alonso-Mora, J.; Breitenmoser, A.; Rufli, M.; Beardsley, P.; Siegwart, R. Optimal reciprocal collision avoidance for multiple non-holonomic robots. In Distributed Autonomous Robotic Systems: The 10th International Symposium; Martinoli, A., Mermoud, G., Mondada, F., Correll, N., Egerstedt, M., Ani Hsieh, M., Parker, L.E., Støy, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 203–216. [Google Scholar]
- Liu, Z.; Liu, Q.; Tang, L.; Jin, K.; Wang, H.; Liu, M.; Wang, H. Visuomotor reinforcement learning for multirobot cooperative navigation. IEEE Trans. Autom. Sci. Eng. 2021, 19, 3234–3245. [Google Scholar] [CrossRef]
- Huang, H.; Zhu, G.; Fan, Z.; Zhai, H.; Cai, Y.; Shi, Z.; Dong, Z.; Hao, Z. Vision-based distributed multi-uav collision avoidance via deep reinforcement learning for navigation. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 13745–13752. [Google Scholar]
- Chen, Y.F.; Liu, M.; Everett, M.; How, J.P. Decentralized non-communicating multiagent collision avoidance with deep reinforcement learning. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 285–292. [Google Scholar]
- Chen, Y.F.; Everett, M.; Liu, M.; How, J.P. Socially aware motion planning with deep reinforcement learning. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1343–1350. [Google Scholar]
- Han, R.; Chen, S.; Wang, S.; Zhang, Z.; Gao, R.; Hao, Q.; Pan, J. Reinforcement learned distributed multi-robot navigation with reciprocal velocity obstacle shaped rewards. IEEE Robot. Autom. Lett. 2022, 7, 5896–5903. [Google Scholar] [CrossRef]
- Cui, Y.; Lin, L.; Huang, X.; Zhang, D.; Wang, Y.; Jing, W.; Chen, J.; Xiong, R.; Wang, Y. Learning observation-based certifiable safe policy for decentralized multi-robot navigation. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 5518–5524. [Google Scholar]
- Thumiger, N.; Deghat, M. A multi-agent deep reinforcement learning approach for practical decentralized uav collision avoidance. IEEE Control Syst. Lett. 2021, 6, 2174–2179. [Google Scholar] [CrossRef]
- Wang, G.; Liu, Z.; Xiao, K.; Xu, Y.; Yang, L.; Wang, X. Collision detection and avoidance for multi-UAV based on deep reinforcement learning. In Proceedings of the 2021 40th Chinese Control Conference (CCC), Shanghai, China, 26–28 July 2021; pp. 7783–7789. [Google Scholar]
- Moon, J.; Papaioannou, S.; Laoudias, C.; Kolios, P.; Kim, S. Deep reinforcement learning multi-UAV trajectory control for target tracking. IEEE Internet Things J. 2021, 8, 15441–15455. [Google Scholar] [CrossRef]
- Ourari, R.; Cui, K.; Elshamanhory, A.; Koeppl, H. Nearest-neighbor-based collision avoidance for quadrotors via reinforcement learning. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 293–300. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Cassandra, A.R. Planning and acting in partially observable stochastic domains. Artif. Intell. 1998, 101, 99–134. [Google Scholar] [CrossRef]
- Zhang, L.; Hou, Z.; Wang, J.; Liu, Z.; Li, W. Robot navigation with reinforcement learned path generation and fine-tuned motion control. arXiv 2022, arXiv:2210.10639. [Google Scholar] [CrossRef]
- Gasimov, R.N. Augmented Lagrangian duality and nondifferentiable optimization methods in nonconvex programming. J. Glob. Optim. 2002, 24, 187–203. [Google Scholar] [CrossRef]
- Fan, T.; Long, P.; Liu, W.; Pan, J. Distributed multi-robot collision avoidance via deep reinforcement learning for navigation in complex scenarios. Int. J. Robot. Res. 2020, 39, 856–892. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aspect | Centralized Methods | Distributed Methods |
|---|---|---|
| Computational Complexity | O(nk) exponential growth | O(n) linear growth |
| Communication Requirements | High (global state sharing) | Low (local information only) |
| Scalability | Limited (<10 robots typically) | High (100 + robots possible) |
| Optimality | Global optimum achievable | Local optimum, good approximation |
| Robustness | Single point of failure | Fault-tolerant |
| Real-time Performance | Poor for large teams | High |
| Number | Methods | Success Rate (%) | Average Trajectory Length (m) | Average Time Step | Average Time Cost (×10 s) |
|---|---|---|---|---|---|
| 2 robots | GNN-RL | 62.50 | 16.422 | 914 | 21.458 |
| GNN-RL-APF | 100.00 | 10.264 | 583 | 14.281 | |
| 3 robots | GNN-RL | 71.67 | 16.639 | 915 | 22.982 |
| GNN-RL-APF | 100.00 | 9.178 | 461 | 12.356 | |
| 4 robots | GNN-RL | 100.00 | 15.979 | 828 | 23.318 |
| GNN-RL-APF | 100.00 | 13.534 | 658 | 19.009 | |
| 6 robots | GNN-RL | 85.00 | 16.213 | 802 | 27.292 |
| GNN-RL-APF | 100.00 | 10.281 | 470 | 16.578 | |
| 8 robots | GNN-RL | 76.82 | 16.162 | 819 | 32.216 |
| GNN-RL-APF | 100.00 | 12.087 | 555 | 22.072 |
| Number | Methods | Success Rate (%) | Average Trajectory Length (m) | Average Time Step | Average Time Cost (×10 s) |
|---|---|---|---|---|---|
| 10 robots | GNN-RL-APF | 95.38 | 18.473 | 918 | 41.668 |
| 20 robots | GNN-RL-APF | 86.67 | 17.441 | 646 | 75.842 |
| 30 robots | GNN-RL-APF | 68.33 | 16.446 | 562 | 138.92 |
| Methods | Success Rate (%) | Average Time Step | Average Trajectory Length (m) | Average Time Cost (×10 s) |
|---|---|---|---|---|
| GNN-RL | 37.50 | 655 | 13.664 | 23.434 |
| GNN-RL-APF | 90.00 | 702 | 15.054 | 24.430 |
| GNN-RL-APF-Lagrangian | 96.43 | 709 | 15.308 | 100.795 |
| Methods | Success Rate (%) | Average Time Step | Average Trajectory Length (m) | Average Time Cost (×10 s) |
|---|---|---|---|---|
| GNN-RL | 29.54 | 977 | 20.680 | 38.792 |
| GNN-RL-APF | 84.09 | 1077 | 20.849 | 30.068 |
| GNN-RL-APF-Lagrangian | 89.77 | 1075 | 20.873 | 104.578 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bi, Y.; Luo, J.; Zhu, J.; Liu, J.; Li, W. Decentralized Multi-Robot Navigation Based on Deep Reinforcement Learning and Trajectory Optimization. Biomimetics 2025, 10, 366. https://doi.org/10.3390/biomimetics10060366
Bi Y, Luo J, Zhu J, Liu J, Li W. Decentralized Multi-Robot Navigation Based on Deep Reinforcement Learning and Trajectory Optimization. Biomimetics. 2025; 10(6):366. https://doi.org/10.3390/biomimetics10060366
Chicago/Turabian StyleBi, Yifei, Jianing Luo, Jiwei Zhu, Junxiu Liu, and Wei Li. 2025. "Decentralized Multi-Robot Navigation Based on Deep Reinforcement Learning and Trajectory Optimization" Biomimetics 10, no. 6: 366. https://doi.org/10.3390/biomimetics10060366
APA StyleBi, Y., Luo, J., Zhu, J., Liu, J., & Li, W. (2025). Decentralized Multi-Robot Navigation Based on Deep Reinforcement Learning and Trajectory Optimization. Biomimetics, 10(6), 366. https://doi.org/10.3390/biomimetics10060366