


Bio-Signal-Guided Robot Adaptive Stiffness Learning via Human-Teleoperated Demonstrations

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
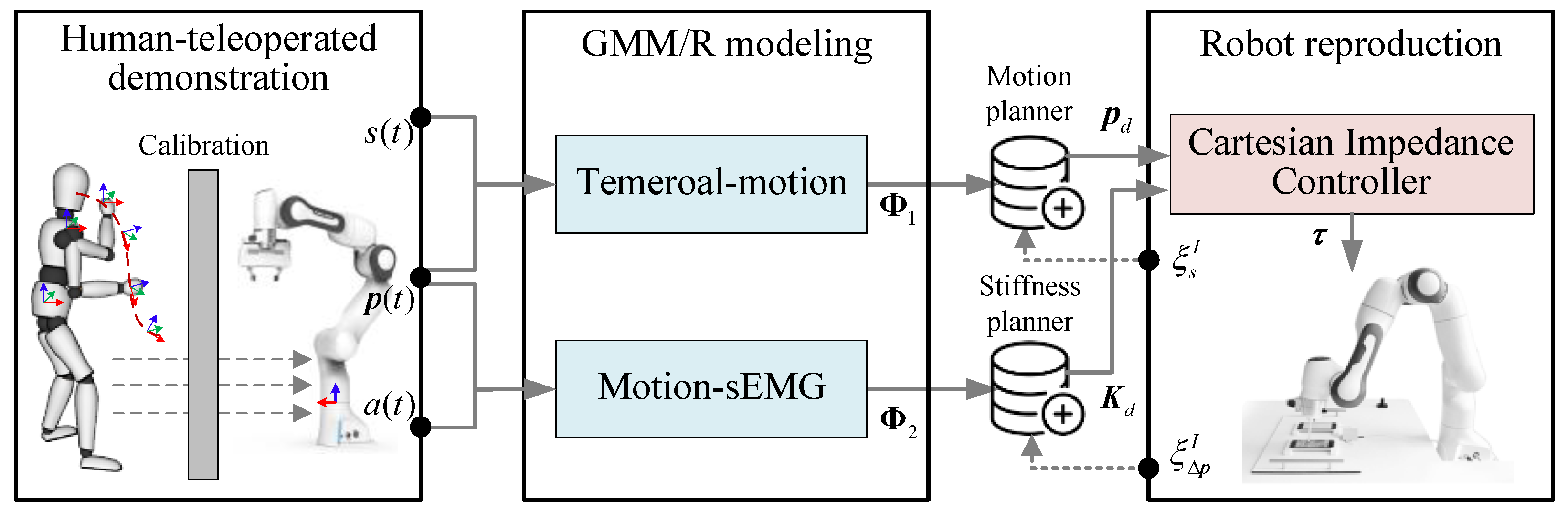
2. Methodology
2.1. Human-Teleoperated Demonstration
2.1.1. sEMG Preprocessing and Feature Extraction
2.1.2. Motion Calibration
2.1.3. Stiffness Calibration
2.2. Motion/Stiffness Modeling Through GMM/R
2.2.1. Gmm Modeling
2.2.2. Em Optimization
2.2.3. Gmr Generation
2.3. Robot Cartesian Impedance Control Law
2.3.1. Robot Dynamics
2.3.2. Classical Impedance Model
2.3.3. Cartesian Impedance Control Law
3. Experiment
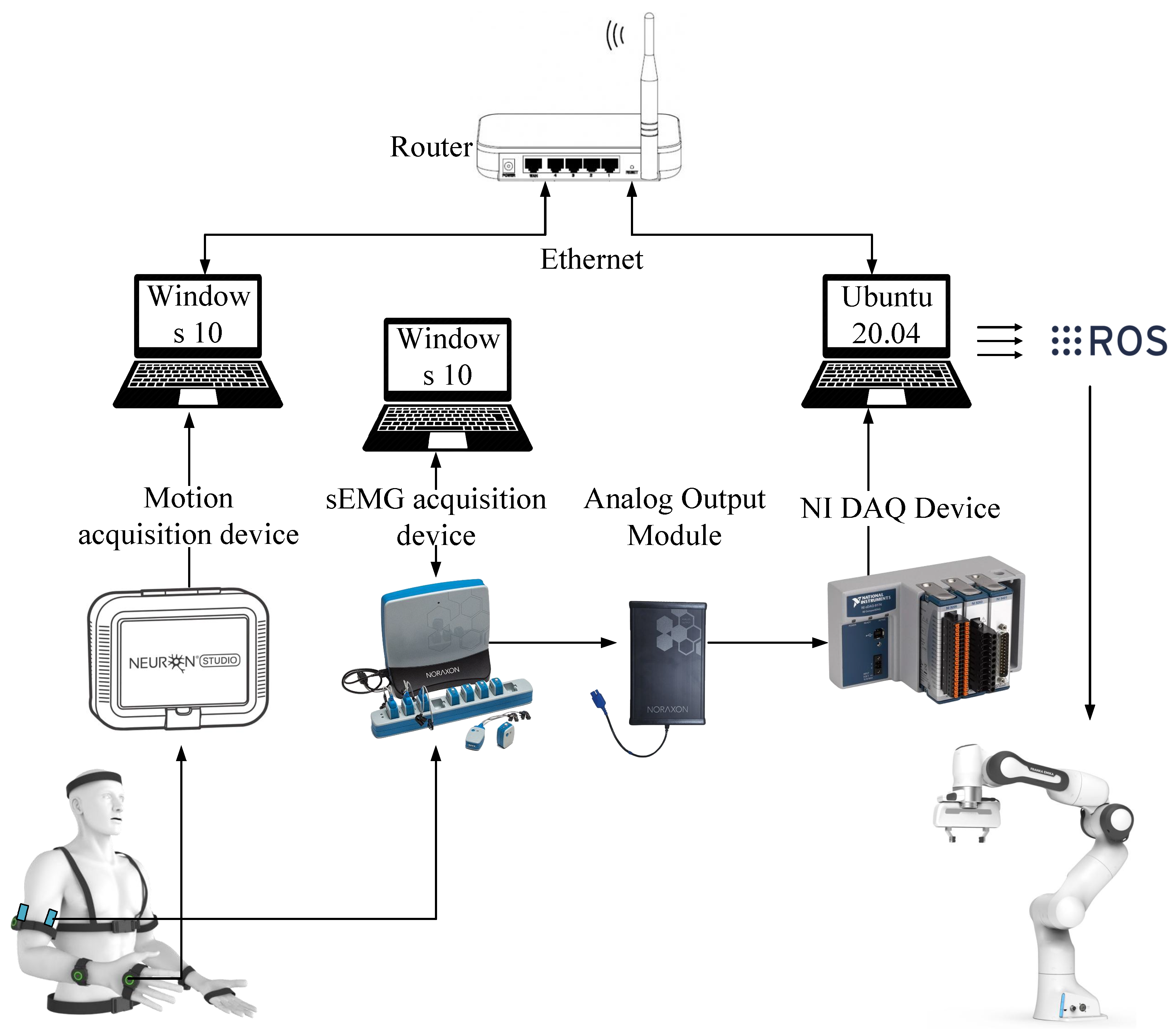
3.1. Experimental Setup and Protocols
3.1.1. Human-Teleoperated Demonstration Platform
3.1.2. Robot Control Scheme
3.2. Parameters Settings
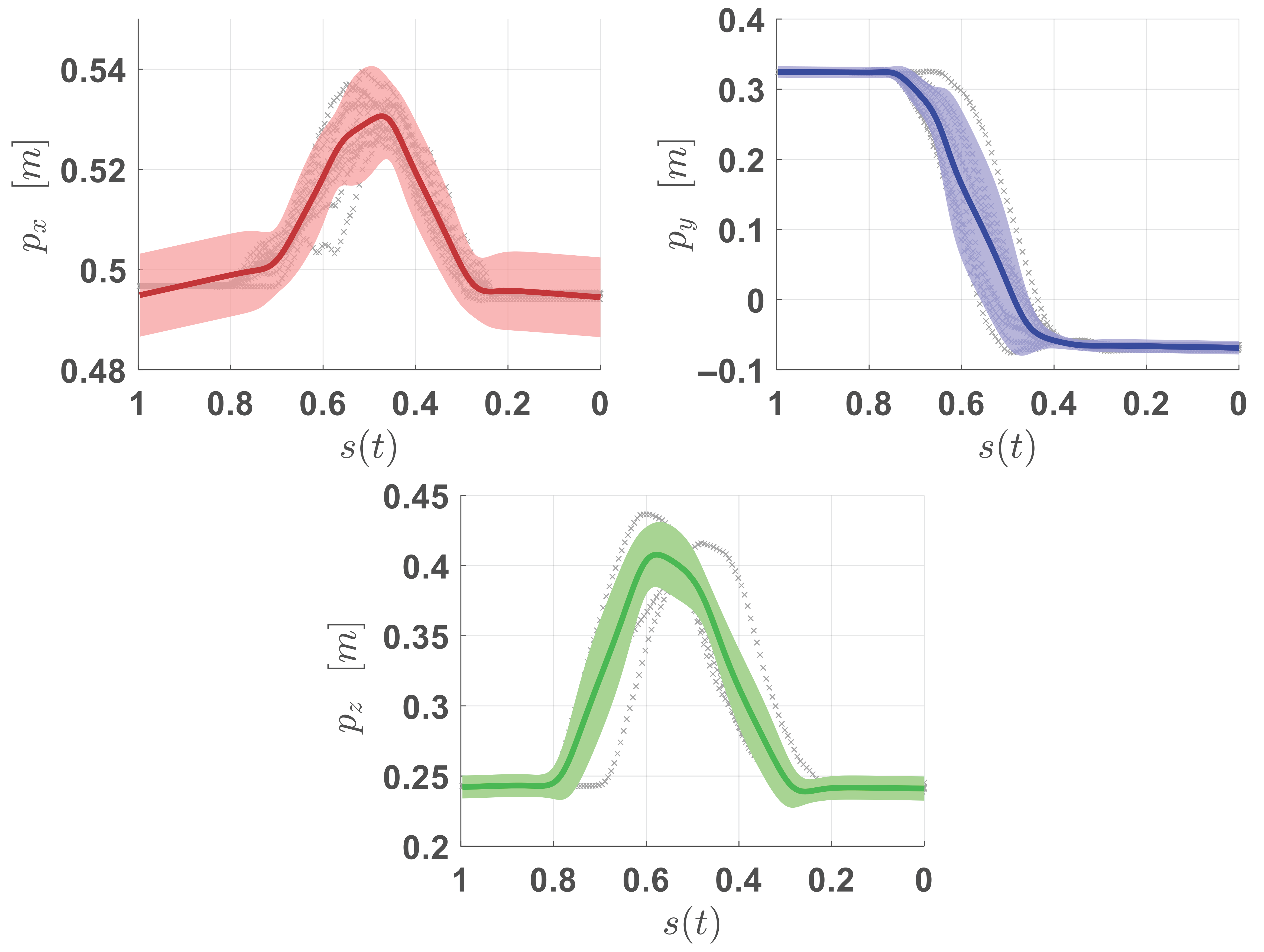
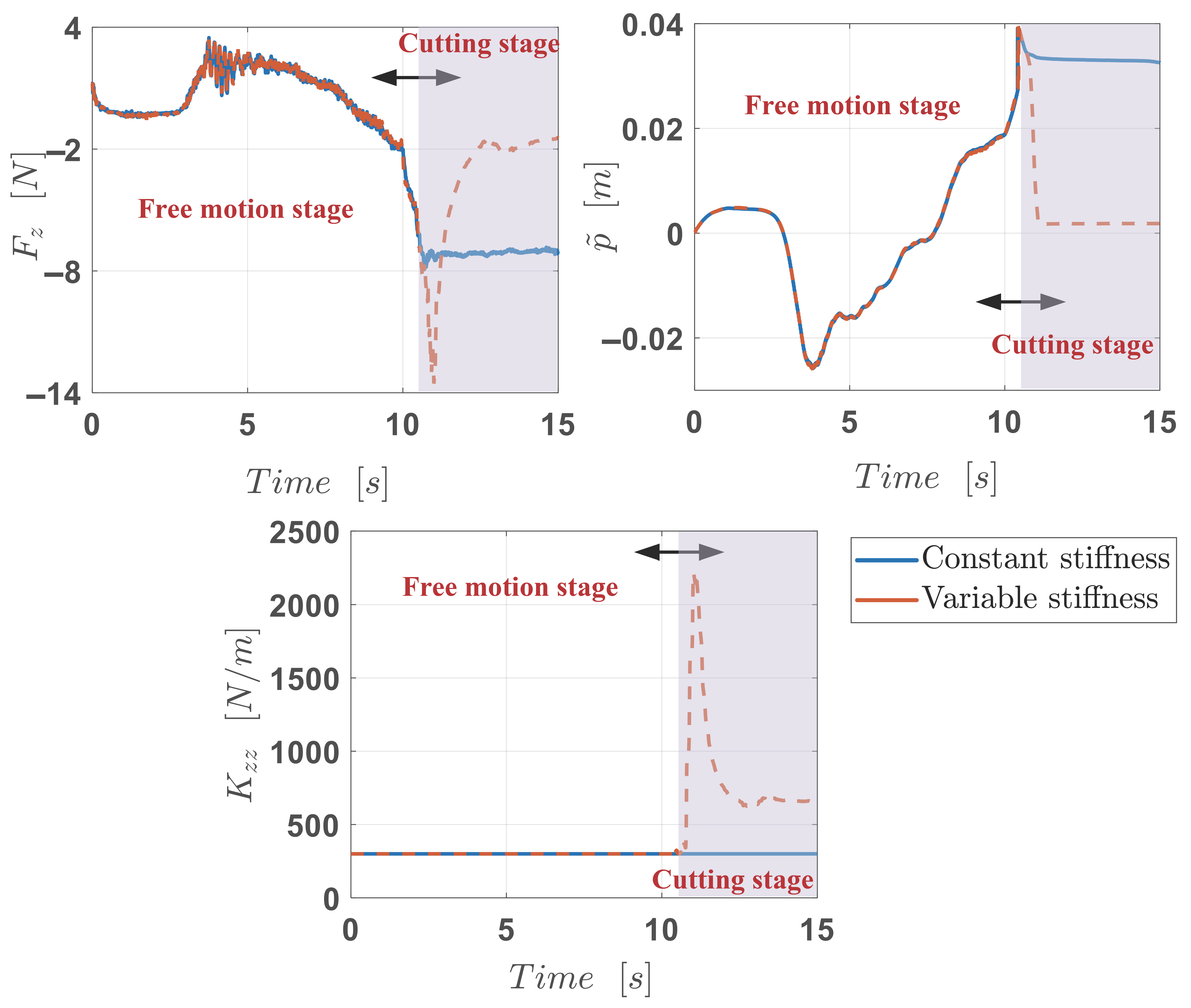
3.3. Experimental Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Billard, A.; Kragic, D. Trends and challenges in robot manipulation. Science 2019, 364, eaat8414. [Google Scholar] [CrossRef] [PubMed]
- Abu-Dakka, F.J.; Saveriano, M. Variable impedance control and learning—A review. Front. Robot. AI 2020, 7, 590681. [Google Scholar] [CrossRef] [PubMed]
- Knežević, N.; Petrović, M.; Jovanović, K. Cartesian stiffness shaping of compliant robots—Incremental learning and optimization based on sequential quadratic programming. Actuators 2024, 13, 32. [Google Scholar] [CrossRef]
- Knežević, N.; Lukić, B.; Petrič, T.; Jovanovič, K. A Geometric Approach to Task-Specific Cartesian Stiffness Shaping. J. Intell. Robot. Syst. 2024, 110, 14. [Google Scholar] [CrossRef]
- Ravichandar, H.; Polydoros, A.S.; Chernova, S.; Billard, A. Recent advances in robot learning from demonstration. Annu. Rev. Control. Robot. Auton. Syst. 2020, 3, 297–330. [Google Scholar] [CrossRef]
- Batzianoulis, I.; Iwane, F.; Wei, S.; Correia, C.G.P.R.; Chavarriaga, R.; Millán, J.d.R.; Billard, A. Customizing skills for assistive robotic manipulators, an inverse reinforcement learning approach with error-related potentials. Commun. Biol. 2021, 4, 1406. [Google Scholar] [CrossRef]
- Tugal, H.; Gautier, B.; Tang, B.; Nabi, G.; Erden, M.S. Hand-impedance measurements with robots during laparoscopy training. Robot. Auton. Syst. 2022, 154, 104130. [Google Scholar] [CrossRef]
- Luo, J.; Solowjow, E.; Wen, C.; Ojea, J.A.; Agogino, A.M.; Tamar, A.; Abbeel, P. Reinforcement learning on variable impedance controller for high-precision robotic assembly. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 3080–3087. [Google Scholar]
- Roveda, L.; Maskani, J.; Franceschi, P.; Abdi, A.; Braghin, F.; Molinari Tosatti, L.; Pedrocchi, N. Model-based reinforcement learning variable impedance control for human-robot collaboration. J. Intell. Robot. Syst. 2020, 100, 417–433. [Google Scholar] [CrossRef]
- Roveda, L.; Testa, A.; Shahid, A.A.; Braghin, F.; Piga, D. Q-Learning-based model predictive variable impedance control for physical human-robot collaboration. Artif. Intell. 2022, 312, 103771. [Google Scholar] [CrossRef]
- Karim, M.F.; Bollimuntha, S.; Hashmi, M.S.; Das, A.; Singh, G.; Sridhar, S.; Singh, A.K.; Govindan, N.; Krishna, K.M. DA-VIL: Adaptive Dual-Arm Manipulation with Reinforcement Learning and Variable Impedance Control. arXiv 2024, arXiv:2410.19712. [Google Scholar]
- Anand, A.S.; Gravdahl, J.T.; Abu-Dakka, F.J. Model-based variable impedance learning control for robotic manipulation. Robot. Auton. Syst. 2023, 170, 104531. [Google Scholar] [CrossRef]
- Martín-Martín, R.; Lee, M.A.; Gardner, R.; Savarese, S.; Bohg, J.; Garg, A. Variable impedance control in end-effector space: An action space for reinforcement learning in contact-rich tasks. In Proceedings of the 2019 IEEE/RSJ international conference on intelligent robots and systems (IROS), Macau, China, 3–8 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1010–1017. [Google Scholar]
- Meng, Y.; Su, J.; Wu, J. Reinforcement learning based variable impedance control for high precision human-robot collaboration tasks. In Proceedings of the 2021 6th IEEE International Conference on Advanced Robotics and Mechatronics (ICARM), Chongqing, China, 3–5 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 560–565. [Google Scholar]
- Zhang, X.; Sun, L.; Kuang, Z.; Tomizuka, M. Learning variable impedance control via inverse reinforcement learning for force-related tasks. IEEE Robot. Autom. Lett. 2021, 6, 2225–2232. [Google Scholar] [CrossRef]
- Li, Z.; Zeng, C.; Deng, Z.; Xu, Q.; He, B.; Zhang, J. Learning variable impedance control for robotic massage with deep reinforcement learning: A novel learning framework. IEEE Syst. Man, Cybern. Mag. 2024, 10, 17–27. [Google Scholar] [CrossRef]
- Zhang, H.; Solak, G.; Lahr, G.J.; Ajoudani, A. Srl-vic: A variable stiffness-based safe reinforcement learning for contact-rich robotic tasks. IEEE Robot. Autom. Lett. 2024, 9, 5631–5638. [Google Scholar] [CrossRef]
- Li, Y.; Wang, Y.; Li, Z.; Lv, Y.; Chai, J.; Dong, E. Deep reinforcement learning-based variable impedance control for grinding workpieces with complex geometry. Robot. Intell. Autom. 2025, 45, 159–172. [Google Scholar] [CrossRef]
- Wu, Y.; Zhao, F.; Tao, T.; Ajoudani, A. A framework for autonomous impedance regulation of robots based on imitation learning and optimal control. IEEE Robot. Autom. Lett. 2020, 6, 127–134. [Google Scholar] [CrossRef]
- Wu, R.; Billard, A. Learning from demonstration and interactive control of variable-impedance to cut soft tissues. IEEE/ASME Trans. Mechatron. 2021, 27, 2740–2751. [Google Scholar] [CrossRef]
- Liao, Z.; Jiang, G.; Zhao, F.; Wu, Y.; Yue, Y.; Mei, X. Dynamic skill learning from human demonstration based on the human arm stiffness estimation model and Riemannian DMP. IEEE/ASME Trans. Mechatron. 2022, 28, 1149–1160. [Google Scholar] [CrossRef]
- Zeng, C.; Yang, C.; Jin, Z.; Zhang, J. Hierarchical impedance, force, and manipulability control for robot learning of skills. IEEE/ASME Trans. Mechatron. 2024. early access. [Google Scholar] [CrossRef]
- Liao, Z.; Tassi, F.; Gong, C.; Leonori, M.; Zhao, F.; Jiang, G.; Ajoudani, A. Simultaneously learning of motion, stiffness, and force from human demonstration based on riemannian dmp and qp optimization. IEEE Trans. Autom. Sci. Eng. 2024, 22, 7773–7785. [Google Scholar] [CrossRef]
- Zhai, X.; Jiang, L.; Wu, H.; Zheng, H.; Liu, D.; Wu, X.; Xu, Z.; Zhou, X. Learning target-directed skill and variable impedance control from interactive demonstrations for robot-assisted soft tissue puncture tasks. IEEE Trans. Autom. Sci. Eng. 2024, 22, 5238–5250. [Google Scholar] [CrossRef]
- Kronander, K.; Billard, A. Learning compliant manipulation through kinesthetic and tactile human-robot interaction. IEEE Trans. Haptics 2013, 7, 367–380. [Google Scholar] [CrossRef] [PubMed]
- Peternel, L.; Petrič, T.; Oztop, E.; Babič, J. Teaching robots to cooperate with humans in dynamic manipulation tasks based on multi-modal human-in-the-loop approach. Auton. Robot. 2014, 36, 123–136. [Google Scholar] [CrossRef]
- Peternel, L.; Petrič, T.; Babič, J. Robotic assembly solution by human-in-the-loop teaching method based on real-time stiffness modulation. Auton. Robot. 2018, 42, 1–17. [Google Scholar] [CrossRef]
- Ajoudani, A.; Fang, C.; Tsagarakis, N.; Bicchi, A. Reduced-complexity representation of the human arm active endpoint stiffness for supervisory control of remote manipulation. Int. J. Robot. Res. 2018, 37, 155–167. [Google Scholar] [CrossRef]
- Doornebosch, L.M.; Abbink, D.A.; Peternel, L. Analysis of coupling effect in human-commanded stiffness during bilateral tele-impedance. IEEE Trans. Robot. 2021, 37, 1282–1297. [Google Scholar] [CrossRef]
- Ahn, H.; Michel, Y.; Eiband, T.; Lee, D. Vision-based approximate estimation of muscle activation patterns for tele-impedance. IEEE Robot. Autom. Lett. 2023, 8, 5220–5227. [Google Scholar] [CrossRef]
- Hu, P.; Huang, X.; Wang, Y.; Li, H.; Jiang, Z. A Novel Hand Teleoperation Method with Force and Vibrotactile Feedback Based on Dynamic Compliant Primitives Controller. Biomimetics 2025, 10, 194. [Google Scholar] [CrossRef]
- Ijspeert, A.J.; Nakanishi, J.; Hoffmann, H.; Pastor, P.; Schaal, S. Dynamical movement primitives: Learning attractor models for motor behaviors. Neural Comput. 2013, 25, 328–373. [Google Scholar] [CrossRef]
- Liao, Z.; Zhao, F.; Jiang, G.; Mei, X. Extended DMPs framework for position and decoupled quaternion learning and generalization. Chin. J. Mech. Eng. 2022, 35, 95. [Google Scholar] [CrossRef]
- Khansari-Zadeh, S.M.; Billard, A. Learning stable nonlinear dynamical systems with gaussian mixture models. IEEE Trans. Robot. 2011, 27, 943–957. [Google Scholar] [CrossRef]
- Calinon, S. Mixture models for the analysis, edition, and synthesis of continuous time series. In Mixture Models and Applications; Springer International Publishing: Cham, Switzerland, 2020; pp. 39–57. [Google Scholar]
- Calinon, S. A tutorial on task-parameterized movement learning and retrieval. Intell. Serv. Robot. 2016, 9, 1–29. [Google Scholar] [CrossRef]
- Paraschos, A.; Daniel, C.; Peters, J.R.; Neumann, G. Probabilistic movement primitives. Adv. Neural Inf. Process. Syst. 2013, 26. [Google Scholar]
- Huang, Y.; Rozo, L.; Silvério, J.; Caldwell, D.G. Kernelized movement primitives. Int. J. Robot. Res. 2019, 38, 833–852. [Google Scholar] [CrossRef]
- Cho, N.J.; Lee, S.H.; Kim, J.B.; Suh, I.H. Learning, improving, and generalizing motor skills for the peg-in-hole tasks based on imitation learning and self-learning. Appl. Sci. 2020, 10, 2719. [Google Scholar] [CrossRef]
- Tanwani, A.K.; Calinon, S. Learning robot manipulation tasks with task-parameterized semitied hidden semi-Markov model. IEEE Robot. Autom. Lett. 2016, 1, 235–242. [Google Scholar] [CrossRef]
- Kadi, H.A.; Terzić, K. Data-driven robotic manipulation of cloth-like deformable objects: The present, challenges and future prospects. Sensors 2023, 23, 2389. [Google Scholar] [CrossRef]
- Lu, G.; Yan, Z.; Luo, J.; Li, W. Integrating Historical Learning and Multi-View Attention with Hierarchical Feature Fusion for Robotic Manipulation. Biomimetics 2024, 9, 712. [Google Scholar] [CrossRef]
- Yang, H.; Zhou, Y.; Wu, J.; Liu, H.; Yang, L.; Lv, C. Human-Guided Continual Learning for Personalized Decision-Making of Autonomous Driving. IEEE Trans. Intell. Transp. Syst. 2025, 26, 5435–5447. [Google Scholar] [CrossRef]
- Zhang, Z.; Hong, J.; Enayati, A.M.S.; Najjaran, H. Using implicit behavior cloning and dynamic movement primitive to facilitate reinforcement learning for robot motion planning. IEEE Trans. Robot. 2024, 40, 4733–4749. [Google Scholar] [CrossRef]
- Qi, W.; Fan, H.; Zheng, C.; Su, H.; Alfayad, S. Human-like Dexterous Grasping Through Reinforcement Learning and Multimodal Perception. Biomimetics 2025, 10, 186. [Google Scholar] [CrossRef] [PubMed]
- Calinon, S.; Kormushev, P.; Caldwell, D.G. Compliant skills acquisition and multi-optima policy search with EM-based reinforcement learning. Robot. Auton. Syst. 2013, 61, 369–379. [Google Scholar] [CrossRef]
- Ott, C. Cartesian Impedance Control of Redundant and Flexible-Joint Robots; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xia, W.; Liao, Z.; Lu, Z.; Yao, L. Bio-Signal-Guided Robot Adaptive Stiffness Learning via Human-Teleoperated Demonstrations. Biomimetics 2025, 10, 399. https://doi.org/10.3390/biomimetics10060399
Xia W, Liao Z, Lu Z, Yao L. Bio-Signal-Guided Robot Adaptive Stiffness Learning via Human-Teleoperated Demonstrations. Biomimetics. 2025; 10(6):399. https://doi.org/10.3390/biomimetics10060399
Chicago/Turabian StyleXia, Wei, Zhiwei Liao, Zongxin Lu, and Ligang Yao. 2025. "Bio-Signal-Guided Robot Adaptive Stiffness Learning via Human-Teleoperated Demonstrations" Biomimetics 10, no. 6: 399. https://doi.org/10.3390/biomimetics10060399
APA StyleXia, W., Liao, Z., Lu, Z., & Yao, L. (2025). Bio-Signal-Guided Robot Adaptive Stiffness Learning via Human-Teleoperated Demonstrations. Biomimetics, 10(6), 399. https://doi.org/10.3390/biomimetics10060399