1. Introduction
Dual-task paradigms, which include walking, are increasingly recognized as a valuable framework for studying the interaction between motor and cognitive functions in real-world settings [
1]. The attention demands in dual-task situations can affect cognitive and motor domains, revealing undetected declines in single-task settings [
2]. These changes may be early indicators of cognitive or functional impairment [
3].
Numerous studies have highlighted that individual characteristics, including age, education level, and health status, may affect multitasking ability [
4]. Higher education supports cognitive reserve, helping buffer brain changes, but its effects vary. It can protect memory in healthier adults but may accelerate the decline in those at higher dementia risk [
5]. This acceleration occurs because a stronger cognitive reserve can mask the early behavioral signs of dementia, delaying their detection. Therefore, when noticeable symptoms appear, the underlying disease process may have progressed significantly, leading to the perception of a more rapid decline, even though the underlying changes have been unfolding for some time. Similarly, physical fitness, emotional well-being, and lifestyle behaviors can affect how effectively individuals manage simultaneous motor and cognitive demands [
6]. Understanding these complex relationships requires advanced analytical tools that account for nonlinear patterns and interactions, which traditional models like Multiple Linear Regression (MLR) may not include.
Artificial Neural Networks (ANNs) have emerged as a powerful solution for analyzing complex, nonlinear datasets in recent years [
7]. Unlike conventional methods, ANNs can model intricate relationships between variables, making them particularly appropriate for studying complex systems like dual-task performance. Prior research has demonstrated the utility of ANNs in biomechanics, with applications ranging from predicting metabolic cost during movement to analyzing joint mechanics and gait dynamics [
8,
9,
10]. Gonabadi et al. (2024) [
8] demonstrated the superiority of ANNs over traditional methods in predicting metabolic costs from biomechanical data, providing a foundation for their application in other domains, including cognitive-motor integration [
8].
Recent wearable sensors have made it possible to measure many features, including kinetic and kinematic movement, biomechanics, and muscle activities, during walking and under dual-task conditions. Moreover, clinical evaluations and psychological assessments provide information about people’s stress levels, personality types, and mental health elements that may affect or be related to dual-task performance. Although the amount of research on dual-tasking in older populations is increasing, it is still necessary to combine these various sources of information to identify which particular characteristics—such as speech-linguistic metrics, demographic information, health status indicators, or psychosocial metrics—are most likely to predict important clinical outcomes like mild cognitive impairment or depressive symptoms.
In line with the field of biomimetics, our study adopts an interdisciplinary approach that bridges cognitive neuroscience, biomechanics, and artificial intelligence to model complex human behaviors. Biomimetics involves the design and application of systems that mimic biological processes. Here, we simulate the integrative mechanisms of human cognitive-motor interactions under dual-task conditions by training ANNs to predict health-related outcomes from multimodal inputs. This modeling mirrors biological processing by capturing nonlinear and adaptive relationships among sensory, motor, and cognitive domains.
Furthermore, by using Artificial Intelligence (AI) tools to analyze natural speech and gait patterns—both inherently biomimetic in nature—our work enables early detection of cognitive and psychosocial decline in real-world settings. These predictive models can potentially be translated into biomimetic diagnostic tools that reflect the adaptability and complexity of human function. This aligns with biomimetics’ goal of understanding and replicating biologically inspired systems for clinical and technological innovation.
By applying ANN modeling, the present study aimed to find the optimal subset of features for predicting clinical outcomes, thereby shedding light on how dual-task cognitive performance can serve as a sensitive indicator of overall cognitive and physical health in older adults. We also implemented an MLR model using the same dataset to benchmark the predictive performance of our ANN models. This comparison highlights the added value of nonlinear modeling in capturing complex interactions among multimodal features [
8,
10,
11,
12,
13]. We hypothesized that cognitive load during dual-task conditions—reflected in gait, speech-linguistic features, and internal thought patterns—can effectively predict this population’s cognitive status and psychological conditions. Including feature importance scores and Partial Dependence Plots (PDPs) further allows for interpreting how specific variables contribute to model predictions, offering insights beyond traditional statistical approaches. These tools help interpret the model’s predictions by illustrating the marginal effects of individual features, offering insights beyond standard statistical approaches. Additionally, we employed k-fold cross-validation (k = 5) to ensure robust model evaluation and enhance the reliability of our findings, reducing the risk of overfitting and improving generalizability.
2. Materials and Methods
2.1. Participants
Forty participants (22 men and 18 women) were included in the study. Their ages ranged from 20 to 84 years (50.58 ± 21.24). Participants’ average height was 170.46 ± 10.01 cm, and weight was 77.86 ± 14.60 kg, resulting in a Body Mass Index (BMI) of 26.89 ± 4.14. Individual BMI values ranged from 19.83 to 37.21. Participants were required to be healthy adults, physically active, and capable of independent ambulation, with no history of progressive neurological diseases such as multiple sclerosis or Parkinson’s disease. Exclusion criteria included the use of depression medications that could cause dizziness, cognitive impairment, or physical performance deficits, and hearing impairments (even with amplification) that affected speech perception. Additionally, individuals with an inter-aural tone threshold difference averaging over 15 decibels at 1000 Hz, those who were pregnant, or those who were breastfeeding were also excluded. Recruitment was conducted through community advertisements and university networks to ensure a diverse sample. Ethical approval was obtained from the Institutional Review Board at the University of Nebraska Medical Center (IRB #0639-19-EP). Participants provided written informed consent after being briefed about the study’s purpose, procedures, and potential risks. Participants were compensated for their time and effort.
2.2. Data Collection
This study utilized a range of physical, cognitive, and psychological assessments to evaluate participants’ overall functioning. Physical measures included hand dynamometry for grip strength, the Timed Up and Go test for mobility, and the Frailty Index for Elders to assess frailty risk. Cognitive assessments covered memory, processing speed, spatial orientation, and executive function, including the Montreal Cognitive Assessment, Trail Making Test, Word Fluency Test, and the Wechsler Adult Intelligence Scale (WAIS-III) Digit Symbol test. Psychological and functional measures assessed fatigue (Pittsburgh Fatigability Scale), Activities-Specific Balance Confidence Scale, Geriatric Depression Scale, Memory Functioning Questionnaire, the Perceived Stress Scale, and Pittsburgh Sleep Quality Index. These tools provide a comprehensive dataset for the relationship between individual characteristics and dual-task performance.
Data collection occurred across two laboratory visits, where participants completed both single-task and dual-task conditions to assess motor and cognitive performance. In single-task conditions, participants engaged in a three-minute conversation on an experimenter-provided mobile phone while seated. During dual-task conditions, participants walked around the perimeter of the laboratory (approximately 100 feet) at a self-selected pace for three minutes while simultaneously conversing on the same mobile phone. A low-profile, pressure-sensing walkway (3 feet wide × 12 feet long) was positioned along one side of the laboratory to capture gait data. Participants wore safety belts while walking, and a researcher walked behind them to reduce fall risk. No specific instructions were given regarding task prioritization under the dual-task condition. To ensure engagement, participants rated potential conversation topics on a 5-point Likert scale (1 = not at all interested to 5 = very interested), and one highly rated topic was selected for both task conditions. Conversation topics included personal values, travel aspirations, life challenges, responsibilities, memorable experiences, and influential figures. Participants were randomly assigned to different task conditions and conversation sets. The phone conversation, conducted with a researcher in another room, was recorded using a provided cell phone. No specific instructions were given regarding task prioritization in the dual-task condition.
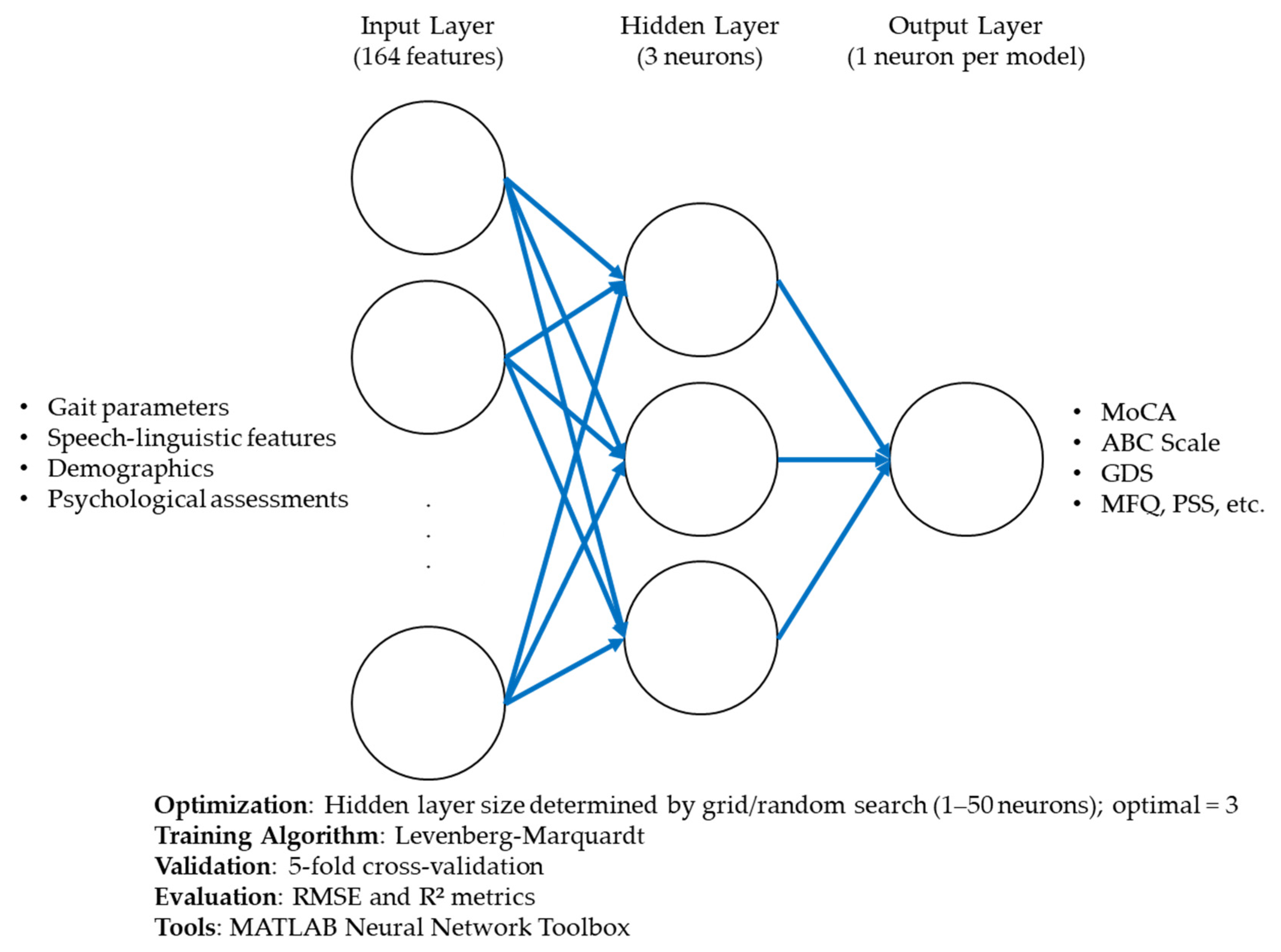
2.3. Neural Network Inputs and Outputs
The ANN models were trained using diverse input variables encompassing multiple domains (
Table 1). Demographic information included age, sex, education level, and years of occupation. Physiological data comprised body mass index, hearing and vision status, and self-reported health ratings. Lifestyle factors such as alcohol use, smoking status, and retirement status were also incorporated. Additionally, psychological measures were included, with scores derived from validated scales such as the Memory Functioning Questionnaire and the Perceived Stress Scale. Cognitive performance metrics from the dual-task conditions, including cognitive outcomes such as reaction time and task accuracy, were measured.
A software, Language Inquiry Word Count (LIWC2015) [
14], was used to quantify the usage rate of differentiation words, conjunction words, prepositions, cognitive mechanisms, and words greater than six letters in the conversations. The LIWC is a computerized program that analyzes text by categorizing and quantifying language use in writing and speaking [
14]. One of the categories, psychological processes, addresses emotionality, social relationships, and thinking styles related to cognitive mechanisms. Under the subscales, the thinking style category (i.e., differentiation words, conjunction words, prepositions, cognitive mechanism, and words greater than six letters) was chosen for this study to examine cognitive complexity, which refers to the richness of two components of reasoning, namely the extent to which someone differentiates between multiple competing solutions and the extent to which someone integrates among solutions. Each participant’s conversations were separately transcribed through Rev.com.
This study’s outcome measures included the ABC Scale for assessing individuals’ confidence in performing various daily activities without falling and the Montreal Cognitive Assessment (MOCA [
15]) for detecting mild cognitive impairment. The Trail Making Test [
16], comprising Parts A (TMTA) and B (TMTB), was administered to gauge visual attention, task-switching ability, and executive functioning [
16]. The Memory Functioning Questionnaire (MFQ [
17]) captured self-reported memory performance, and affective states were evaluated using the Positive and Negative Affect Schedule (PANAS [
18]), with separate subscales for Positive Affect (PA) and Negative Affect (NA). Perceived stress over the past month was measured via the Perceived Stress Scale (PSS [
19]). Additionally, anxiety was analyzed using the State-Trait Anxiety Inventory (STAXI [
20]), which distinguishes between temporary (state) and chronic (trait) anxiety, as well as overall anxiety expression. Core personality traits—extraversion, agreeableness, conscientiousness, neuroticism, and openness—were assessed through the Big Five Inventory (BFI [
21,
22]). At the same time, sleep quality and disturbances were evaluated using the Pittsburgh Sleep Quality Index (PSQI [
23]). The Geriatric Depression Scale (GDS [
24]) measured depressive symptoms specifically in older adults. Lastly, social support was quantified using the Social Support Rating Scale (SSRS [
25]), capturing both the size of one’s network (Social Support [N]) and satisfaction with that network (Social Support [S]).
In this study, we implemented a single ANN model configured to simultaneously predict multiple heterogeneous outcomes (e.g., MOCA, GDS, ABC, speech-linguistic, and memory scores) based on the same set of shared input features. This multi-output structure allows the model to learn shared patterns across cognitive, psychological, and physical domains, improving predictive coherence and efficiency. This approach follows previously published frameworks using unified neural networks for multi-target prediction in interrelated clinical domains [
8,
10,
11,
12,
13].
2.4. Artificial Neural Network Modeling
The ANN models were designed to predict clinical outcomes using a comprehensive set of input features, including demographic, physiological, gait, and speech-linguistic variables. Each model was structured with three main layers: (1) an input layer corresponding to the number of predictor variables; (2) a single hidden layer, whose size was optimized through systematic grid and random search; and (3) an output layer representing each target outcome. The hidden layer used a log-sigmoid activation function (logsig) to capture nonlinear interactions, while the output layer used a purelin (linear) activation function to support continuous prediction [
8,
10,
11,
12]. The models were trained using the Levenberg–Marquardt backpropagation algorithm, chosen for its efficiency in fitting nonlinear mappings within relatively small datasets. A 5-fold cross-validation strategy (k = 5) was applied to evaluate model robustness and avoid overfitting [
8]. During each fold, one subset of the data was used for testing, while the remaining four were used for training, and this process was repeated until each subset had been used for testing once. We computed Root Mean Squared Error (RMSE) and R-squared (R
2) values across all folds to assess model reliability and performance. Additionally, feature importance scores were extracted to determine the relative contribution of each predictor to the ANN’s output. PDPs were generated to visualize the marginal effects of influential features on the predicted outcomes and enhance interpretability.
The architecture and training configuration of the ANN models are summarized in
Table 1. This includes the number of input features, the number of neurons in the hidden layer, the output structure, activation functions used in each layer, the learning algorithm (Levenberg–Marquardt), and the evaluation method (5-fold cross-validation).
Figure 1 illustrates the detailed architecture of the ANN used in this study, including the input layer, optimized hidden layer, and output unit. It also outlines the training parameters and performance evaluation strategy.
2.5. Artificial Neural Network Architecture and Optimization
The ANN implemented in this study was designed to model the complex relationships between input features and outcomes. The network architecture included a single hidden layer with three neurons, as specified in
Table 2. The ANN utilized all input variables simultaneously, including demographic, physiological, psychological, and lifestyle features, to account for their interactions in predicting outcomes.
The dataset was split into training (70%), validation (15%), and testing (15%) subsets to ensure robust model development. Specifically, out of 40 participants, 28 were allocated to the training set, 6 to the validation set, and 6 to the test set in each fold of the 5-fold cross-validation procedure. A Levenberg–Marquardt backpropagation algorithm was employed for training, as it is well-suited for solving nonlinear problems and offers efficient convergence for smaller datasets [
8,
10,
11,
12,
13]. A subject-wise data split was used to avoid overfitting and enhance generalizability, ensuring that data from each subject was exclusive to one subset.
Given the small sample size, we opted for ANNs rather than deep learning methods to ensure the model’s suitability for our dataset. To enhance the reliability of our ANN models and strike a balance between convergence speed and stability within the smaller dataset [
26], we employed a robust optimization approach inspired by methodologies from Nogueira et al. [
26] and Gonabadi et al. [
8,
10]. This process included systematic hyperparameter tuning using grid and random search techniques to identify the optimal hidden layer sizes for each ANN model [
26]. The optimization strategy leveraged performance metrics such as Mean Squared Error (MSE) and R-squared (R) values to evaluate and compare configurations across cross-validation folds. This systematic process utilized nested for-loops in MATLAB R2024b (MathWorks, Natick, MA, USA), varying hidden layer sizes (from 1 to 50 neurons), and iterating each parameter combination 1000 times to ensure stability and minimize stochastic effects. Each configuration was assessed based on MSE values for training, validation, test sets, and correlation coefficients (R-values) to determine predictive accuracy. We observed that increasing the number of neurons in a single hidden layer initially enhanced model performance, reflected by lower MSE and higher R-values, signifying improved predictive accuracy. However, beyond a certain threshold of complexity, the model exhibited diminishing returns and occasional overfitting, as indicated by higher MSE values on the validation set. This analysis allowed us to pinpoint an optimal architecture that balanced complexity with predictive reliability. These efforts were further informed by prior optimization strategies described in Gonabadi et al. [
8,
10], ensuring our approach integrated best practices for ANN model development. We developed ANN models for high performance and reliability to ensure an optimal balance between predictive accuracy and computational efficiency.
In summary, we used a single-hidden-layer feedforward ANN structure due to its effectiveness in capturing nonlinear relationships in small datasets [
8,
10,
11,
12,
13]. We implemented grid and random search strategies across 1 to 50 neurons to determine the optimal number of neurons in the hidden layer. We selected the final configuration based on the combination that minimized RMSE and maximized R-values across 5-fold cross-validation. The 70% training, 15% validation, and 15% test data split was adopted based on standard practice, ensuring sufficient capacity for training while maintaining robustness during validation and testing [
8,
10,
11,
12,
13].
The modeling process was done using MATLAB’s Neural Network Toolbox, supplemented by custom MATLAB scripts designed for this research. The ANN model’s performance was assessed using regression analysis, comparing predicted and actual outcomes across all phases of the dataset. Metrics, including MSE and R-values, were used to evaluate predictive accuracy, while residual analysis provided insights into error distributions. These methodological choices ensured the ANN’s capacity to effectively model the intricate, nonlinear interactions among input features.
2.6. Statistical Analyses
To evaluate the performance of the ANN model, standard classification metrics, including Accuracy, Precision, Recall, and
F1 Score, were calculated using the confusion matrix components:
(A) True Positives (TP) are cases where the model correctly predicts a positive outcome.
(B) True Negatives (TN) are cases where the model predicts a negative outcome correctly.
(C) False Positives (FP) are cases where the model incorrectly predicts a positive outcome.
(D) False Negatives (FN) are cases where the model incorrectly predicts a negative outcome. These metrics are computed under an acceptable error margin of ±10%, ensuring robustness in prediction evaluation. This threshold was selected based on prior literature in neural network modeling applied to biomedical and behavioral data, where prediction errors within ±10% are often regarded as clinically or functionally acceptable [
8,
10,
11,
12,
13]. This approach provides a more interpretable measure of the model’s performance within a realistic margin of variability, mainly when predicting continuous clinical outcomes. The metrics that we used are
Accuracy [
27],
Precision,
Recall (Sensitivity), and
F1 Score [
28], Equations (1)–(4).
Accuracy measures the overall correctness of the model by quantifying the ratio of correctly predicted outcomes to the total number of outcomes.
Precision evaluates the model’s ability to identify positive outcomes and minimize false positives correctly.
Recall quantifies the model’s ability to identify positive cases and reduce false negatives.
The
F1 Score provides a harmonic mean of precision and recall, offering a balanced measure, especially for imbalanced datasets.
In this study, prediction accuracy for each outcome was calculated based on whether the predicted value fell within ±10% of the actual (observed) value. This threshold was chosen based on prior literature utilizing similar ANN models for clinical and behavioral predictions [
8,
10,
11,
12,
13]. For example, a predicted score was considered accurate if it deviated by no more than ±10% of the actual score. This operational definition provided a practical and interpretable metric for assessing the model’s performance across diverse clinical and psychosocial outcomes.
In line with previous studies [
8,
10,
11,
12,
13], to establish a baseline for model performance, we additionally implemented an MLR model. The MLR was applied to the same dataset as the ANN, using identical outcome variables and input features. The MLR served as a linear reference point to compare the predictive capabilities of the ANN in modeling complex and nonlinear interactions. Evaluation metrics, including RMSE, accuracy, recall, precision, and
F1-score, were computed for both models across training, validation, and test partitions. This comparative framework allowed us to assess the relative benefits of using ANN over traditional regression methods in multimodal data contexts.
3. Results
3.1. Overall
The ANN demonstrated robust predictive performance for all dual-task outcomes. Optimized with a single hidden layer containing three neurons, the model’s architecture effectively captured the nonlinear relationships between input features and the predicted outcomes (
Table S1).
Table S1 lists all input features used in the predictive models, along with their associated abbreviations and detailed descriptions, serving as a reference for interpreting feature importance across outcomes. This configuration was validated during the training and testing, ensuring its generalizability and reliability. The network achieved consistent performance metrics across the validation and testing datasets, highlighting its capacity to model complex interactions within the data.
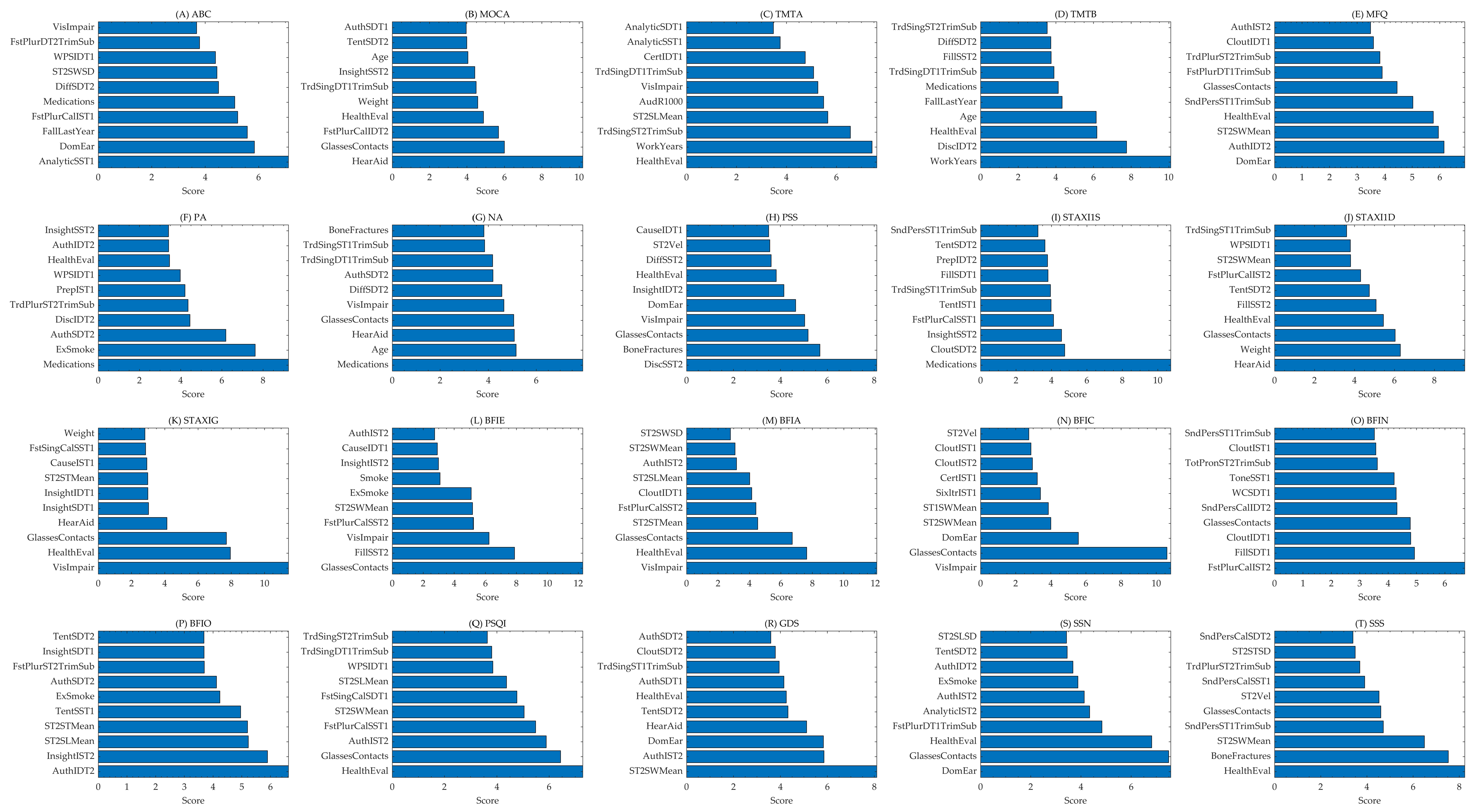
Table 2 also represents the architecture of the ANN used in this study and presents the accuracy levels achieved for each outcome. The table provides detailed information on the specific features the ANN model utilizes, along with their corresponding accuracy levels. Notably, this study employs a single ANN model to predict multiple outcomes simultaneously, leveraging a shared network architecture to optimize predictive performance across all outcomes. Each column represents an outcome, while the rows depict the performance metrics, including accuracy and key architecture parameters. The consistency of using a single ANN for all outcomes reflects the network’s ability to generalize across diverse prediction tasks. This unified approach not only simplifies the model structure but also highlights the versatility and robustness of the ANN in handling complex, multifaceted datasets. The results demonstrate the effectiveness of this architecture in achieving reliable predictions across a wide range of outcomes. The top features predicting each outcome are shown in
Figure 2, while their abbreviations and descriptions appear in
Table S1.
3.2. Model Training and Overview
The dataset was split into training (70%), validation (15%), and test (15%) subsets, and a feedforward ANN with three hidden neurons was used to predict multiple outcomes simultaneously. Model performance was assessed via root mean squared error (RMSE) for continuous outcomes and by accuracy, recall, precision, and F1 score for the classification task.
3.3. Variation in Predictive Success by Outcome
Table 2 summarizes the performance metrics for each outcome. Training RMSE: Ranged from 1.44 (for MOCA) to 10.75 (for TMT B), reflecting variability in how well the model fits different continuous outcomes. Validation and Test RMSE: Most measures showed slightly higher RMSE on the validation and test sets than on the training set, indicative of some generalization error. Notably, MOCA maintained a relatively low RMSE (1.77 validation; 1.50 test), suggesting that the model learned this measure more robustly. Accuracy (Classification): MOCA, a measure of task-switching ability, reached 100% accuracy on the test set—a standout result. Although the model achieved 100% accuracy for MOCA within the ±10% threshold, this should be interpreted cautiously. This reflects the model consistently producing values within an acceptable clinical margin rather than a perfect score-level prediction. Instead, it suggests the model could consistently estimate values within a clinically reasonable margin of error. This interpretation aligns with standard practices in evaluating regression-based ANN outputs in clinical prediction tasks [
8,
10,
11,
12,
13]. Other relatively high accuracies included ABC (80%), MFQ (80%), and Social Support Satisfaction (75%). In contrast, TMT A achieved only 17.5% accuracy, indicating an incredible difficulty in predicting this more complex executive function measure.
F1 Scores: Aligned closely with accuracy for most outcomes, with MOCA scoring the highest (
F1 = 1.00). MFQ and ABC achieved an
F1 score of ~0.80, while Social Support Satisfaction reached 0.74.
In addition to developing and evaluating the ANN model, we implemented an MLR model to serve as a baseline for performance comparison. Both models were applied to the same dataset, and their predictive performances were assessed using standard metrics including root mean square error (RMSE), accuracy, recall, precision, and
F1-score. As shown in
Table 2, the ANN model consistently outperformed MLR across all outcome variables. Specifically, the ANN achieved a lower RMSE (8.52 vs. 11.22) and higher classification metrics (accuracy: 40.5% vs. 32.4%; recall: 40.1% vs. 32.6%; precision: 40.5% vs. 32.4%;
F1-score: 0.40 vs. 0.33). These results highlight the ANN’s superior capability in modeling complex, nonlinear relationships within the multimodal dataset.
The RMSE for each outcome was calculated by first computing the RMSE in the five k-fold (k = 5) cross-validation folds. These individual RMSE values were then averaged to obtain the aggregated RMSE reported in
Table 2. This method ensures a stable estimation of model performance and reduces the bias that could arise from a single train-test split [
8,
10,
11,
12,
13].
To visualize the training process and model stability, we plotted the MSE for the training, validation, and test sets across epochs (
Figure 3).
Figure 3 indicates that the model achieved its best validation performance at epoch 13 (MSE ≈ 103.3). The training curve showed consistent downward trends, while the validation and test errors remained stable after early epochs, suggesting effective generalization without significant overfitting. These results reinforce the reliability of the ANN models under our cross-validation scheme.
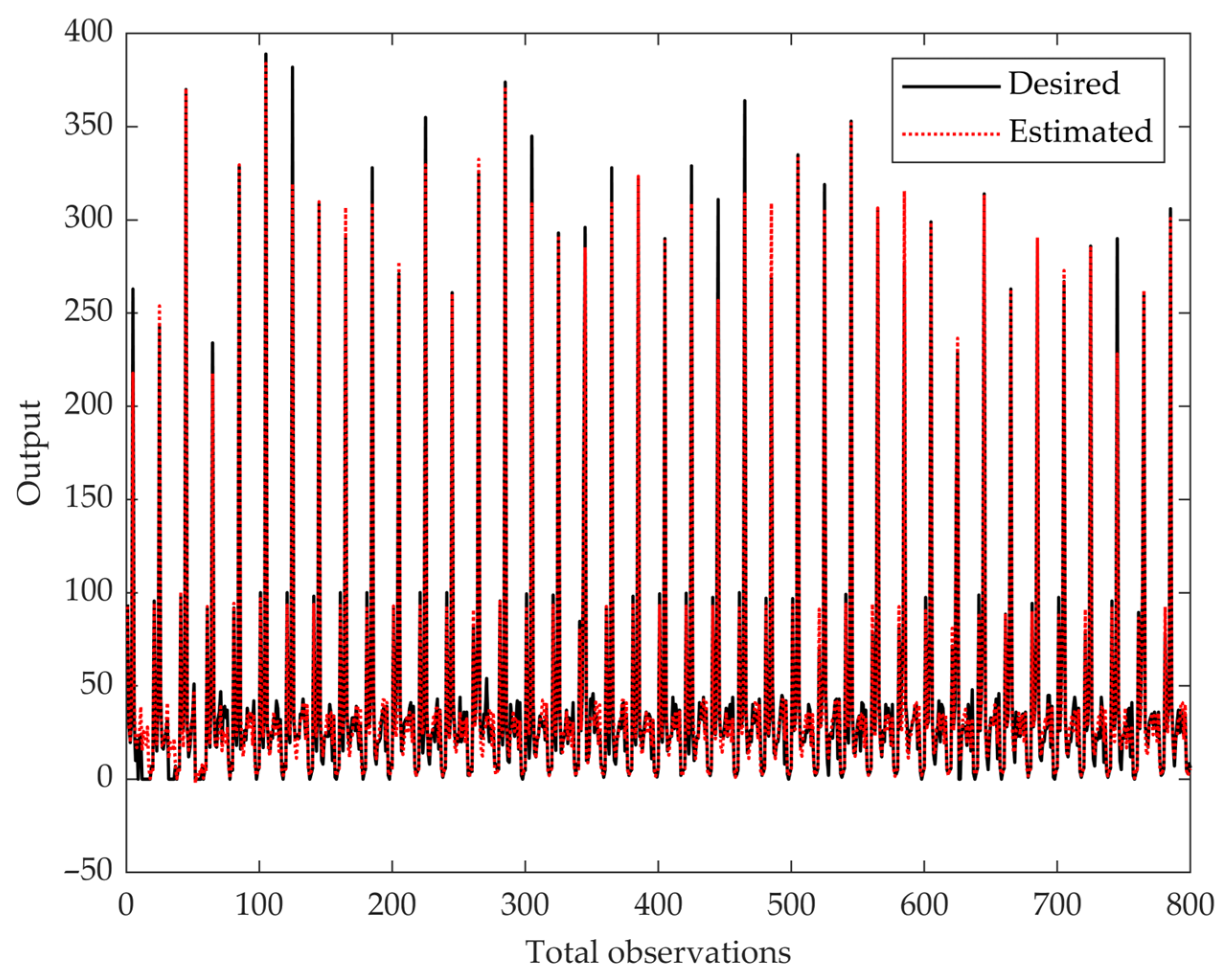
In addition to the MSE performance curve, we visualized the ANN’s predictive accuracy by plotting all samples’ estimated and desired outputs (
Figure 4). The red dotted line represents the estimated outputs, while the black line represents the target values. The close alignment between these two lines indicates the model’s ability to learn and generalize patterns across the dataset, demonstrating reliable predictive performance across various outcome levels.
3.4. Overall Performance Across Outcomes
The following are the high-performing measures.
MOCA: As a broad cognitive screener assessing multiple domains, such as visuospatial abilities, memory, executive function, and attention, the Montreal Cognitive Assessment still achieved perfect classification metrics (accuracy/recall/precision/F1 all ~100%). This suggests that, given the features used, the model could readily distinguish participants above or below the specified MOCA threshold.
ABC: With 80% accuracy and an F1 of 0.79, the model reliably distinguished participants above or below an impairment threshold, suggesting that the cognitive dual-task performance could capture a balance score.
MFQ: With 80% accuracy and an F1 of 0.8, the model reliably distinguished participants above or below an impairment threshold, suggesting that the cognitive features (e.g., gait/speech parameters) capture relevant perceived memory abilities, frequency of forgetfulness, and confidence in everyday memory tasks.
Positive Affect and Social Support Satisfaction: Both also reached high classification performance (F1 ≥ 0.74), implying that psychosocial states can be effectively predicted from the combined demographic, gait, and speech-linguistic features.
The following are the challenging measures.
TMT A: Despite being related to executive functioning, it showed notably lower accuracy (17.5%) and F1 (0.17), implying greater complexity or insufficiently predictive features for this outcome.
Other Personality and Mood Scores: Measures like GDS (accuracy = 17.5%, F1 = 0.18) and Neuroticism (25% accuracy, F1 = 0.25) were also less accurately predicted, hinting at potential variability in how these constructs manifest across individuals or the need for more tailored features.
3.5. Interpretation of RMSE for Continuous Outcomes
When considered as continuous scores (reflected by RMSE), specific measures demonstrated moderate fit even if their classification performance was low. For instance, TMT A’s test RMSE (7.82) was lower than its training RMSE (8.17), suggesting that while the classification threshold was not well captured, the model still reduced overall error for raw TMT A scores. This dual perspective (RMSE vs. accuracy) determined the importance of looking at continuous and categorical metrics in evaluating model performance. Overall, the ANN performed best at predicting ABC, MOCA, MFQ, and Social Support Satisfaction, with consistently higher accuracy, precision, recall, and F1 scores. This indicates that simple attention/switching measures and specific psychosocial attributes (e.g., affect, satisfaction with social support) were easier to capture using the available demographic, dual-task cognitive, and gait features. In contrast, more complex executive-function tasks (TMT A) and certain mood or personality scales (e.g., GDS, Neuroticism) proved more challenging for the model, possibly requiring additional or more nuanced features to improve predictive power.
4. Discussion
The present findings showed a strong predictive capability of the ANN for select psychological and cognitive outcomes when incorporating dual-task features alongside demographic variables. These results highlight how task interference and cognitive load, which arise naturally when individuals perform simultaneous walking and cognitive activities, can be closely linked with performance on standardized cognitive assessments. In this context, the dual-task parameters (e.g., alterations in gait and speech-linguistic performance under cognitive load situations) may serve as windows into one’s cognitive reserve. This emphasizes the potential clinical importance of assessing the interaction between motor and cognitive processes, which are crucial for maintaining functional independence and identifying early signs of cognitive decline.
The comparative analysis showed that the ANN substantially outperformed the MLR model across all key metrics, including RMSE, accuracy, and
F1 score. This finding reinforces the importance of using machine learning approaches like ANN to model complex, nonlinear relationships in dual-task cognitive-motor assessments.
Figure 3 visually confirms the model’s training stability, highlighting minimal overfitting and successful early convergence. Additionally,
Figure 4 demonstrates the ANN model’s ability to closely align predicted and actual outcomes across observations, reinforcing its robustness and generalizability.
The ANN model achieved 100% accuracy and a perfect
F1 score (1.00) for MOCA and the MFQ. These results suggest that demographic, health, gait, and speech-linguistic features effectively capture markers related to general cognitive functioning (as reflected by MOCA) and self-reported memory functioning (as gauged by MFQ). MOCA provides a comprehensive evaluation of multiple cognitive domains. It assesses attention, memory, executive function, language, and visuospatial abilities [
29]. This multidimensional approach allows the MOCA to detect mild impairments and identify subtle cognitive deficits that narrower assessments might overlook. Furthermore, recent findings indicate that individuals with hearing or vision impairments tend to score lower on the MOCA than those with intact sensory acuity, even after accounting for these deficits [
30]. This observation aligns with our model’s demonstration that medical factors, such as the use of hearing aids, can meaningfully influence MOCA score predictions.
Past reviews indicate that subjective memory complaints often reflect an interplay between genuine cognitive decline and emotional factors such as depressive symptoms [
31,
32]. In our study, the authenticity of internal thoughts during dual-task conditions was the strongest predictor of MFQ scores. This finding suggests that how individuals self-reflect, particularly under cognitive load, can reveal significant insights into subjective memory functioning. Higher authenticity might amplify awareness of subtle memory lapses, paralleling observations that contingent self-esteem increases vulnerability when performance standards are threatened [
33]. In other words, when people remain true to their emotional states during challenging tasks, they may report more issues or align their self-assessments more closely with actual memory performance. These results emphasize the value of considering objective tests and how individuals perceive and narrate their cognitive experiences.
The Activities-Specific Balance Confidence (ABC) Scale measures an individual’s confidence in maintaining balance during various daily activities and was best predicted by analytic scores calculated for speech in single-task 1. This finding is intriguing, as it suggests that how participants structured their speech, even in a low-demand, single-task context, may reflect underlying cognitive processes linked to balance confidence. It aligns with research showing that cognitive function, particularly executive control and attentional resources, is tightly linked to physical activity and mobility outcomes in older adults. For example, Kumar et al. (2022) demonstrated that older adults in India who engaged in regular physical activity had significantly better cognitive functioning than their less active peers, highlighting how maintaining physical activity benefits cognitive and functional domains [
34]. Given that balance confidence influences mobility and fall risk, our findings suggest that cognitive markers like analytic speech could reflect broader functional abilities, including physical confidence.
The speech-linguistic features extracted through LIWC analysis emerged as strong predictors for multiple outcomes. For instance, the frequency of first-person plural pronouns (e.g., “we”, “us”) was the top predictor of MOCA scores, suggesting a link between inclusive language use and cognitive performance [
14]. This aligns with prior studies indicating that social and self-referential language markers are associated with aging populations’ cognitive engagement and executive functioning [
14]. Additionally, markers of authenticity, cognitive processing, and tone captured from speech samples during dual-task walking were influential in predicting memory and affect-related outcomes [
14]. These findings highlight the sensitivity of naturalistic language to reflect underlying cognitive and emotional states, mainly when individuals are engaged in cognitively demanding conditions such as dual-task walking [
14]. This underscores the value of integrating speech-linguistic behavior into AI-based predictive models for clinical screening.
One limitation of this study is the relatively small sample size of older adults. This led us to include participants across a wide age range rather than focusing solely on older individuals. As a result, the findings may not be fully representative or specific to the aging population. Future research will address this limitation by expanding the dataset to include a larger sample of older adults, allowing the model to capture age-specific patterns and improve generalizability to older populations more accurately. With a relatively small dataset, these models are at risk of overfitting, which can affect the reliability of their predictions. Additionally, ANNs are often seen as “black-box” models, making it difficult to interpret how specific inputs contribute to the outputs, even with techniques like feature importance scoring. Although we employed k-fold cross-validation to minimize overfitting and evaluate the model’s generalizability, the small sample size remains a key limitation. As the reviewer noted, a limited dataset may constrain the model’s ability to generalize across broader populations, and future research should involve larger, more diverse cohorts to validate and extend our findings. Another limitation is the sample size. While informative, this study included 40 participants, which may not fully represent the diversity of dual-task performance across different populations. Expanding the sample size in future studies would improve the model’s generalizability and robustness. While the ANN models demonstrated strong predictive accuracy for several outcomes (e.g., MOCA, ABC, MFQ), the prediction performance for some variables, such as Trail Making Test A (TMT A) and Trail Making Test B (TMT B), was notably lower. This reduced accuracy likely reflects the complex nature of these executive functioning tasks, which may depend on cognitive processes not fully represented by the input features used in this study. The limited sample size may have also restricted the model’s ability to generalize to these specific outcomes. These findings suggest that future work should incorporate more targeted neurocognitive features or expanded datasets to improve predictive performance for higher-order cognitive tasks. Furthermore, while this study employed a specific ANN model, exploring other architectures or AI approaches, such as ensemble learning methods, convolutional neural networks, or decision tree-based models like gradient boosting, may yield improved performance and interpretability. Another potential limitation is that participants were not given explicit instructions regarding task prioritization during dual-task conditions. This may have introduced variability in performance, as individuals could have unconsciously prioritized either the cognitive (speech) or motor (gait) component. While this design choice aimed to mimic naturalistic conditions, it may affect interpretability and model generalizability. Future studies should consider standardizing or systematically manipulating task priority to better control for this variability. Incorporating a comparative analysis of these methods could provide further insights into the strengths and limitations of various AI techniques in this domain. Addressing these limitations in future work could involve increasing the sample size, using external validation datasets, and applying advanced methods to improve the transparency and interpretability of ANN models.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}