

A Gaussian Mixture Model-Based Unsupervised Dendritic Artificial Visual System for Motion Direction Detection
 , and
, and
Abstract
1. Introduction
2. Materials and Methods
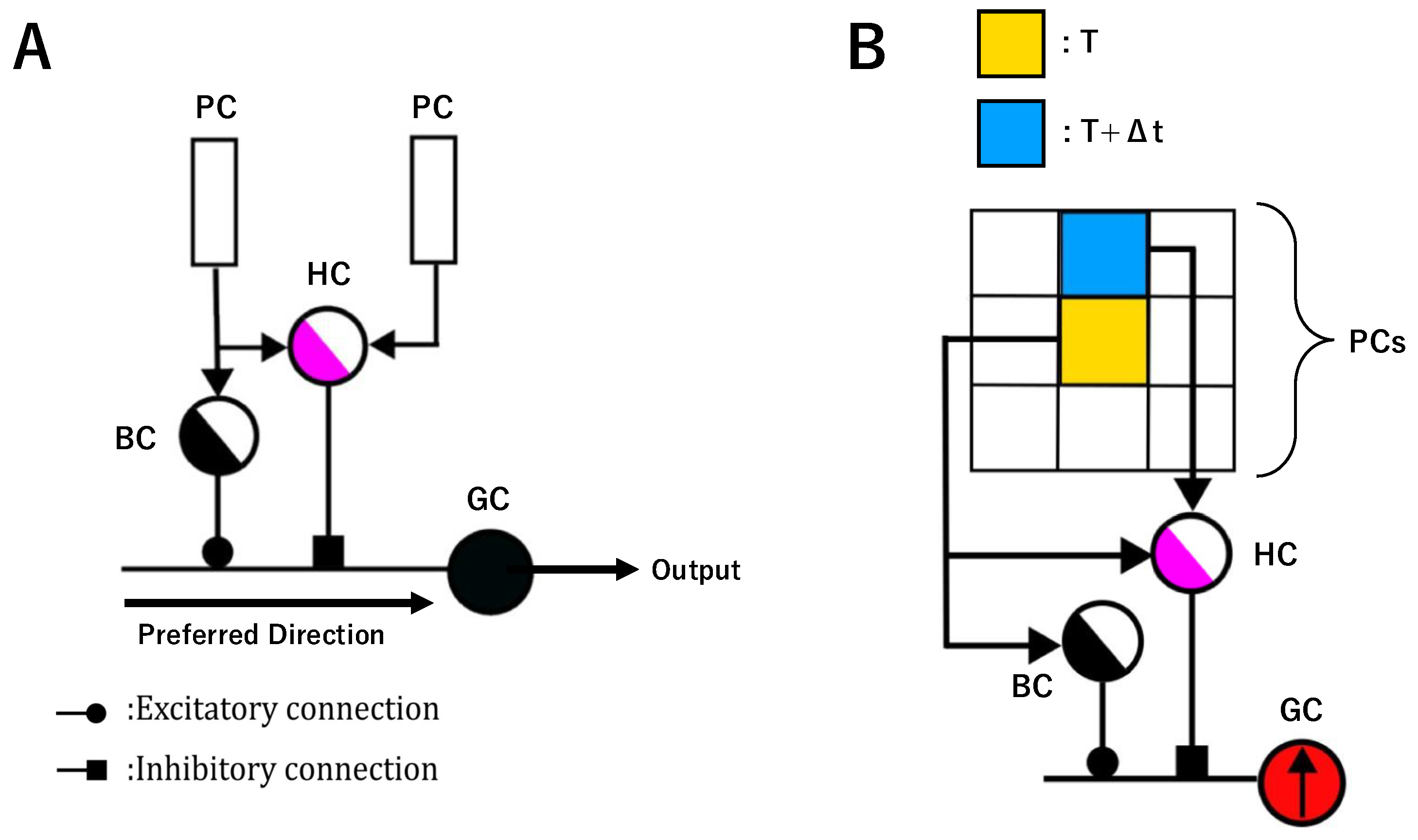
2.1. Dendritic Neuron Model for Motion Direction Detection
2.2. GMM-Based Unsupervised AVS
- Mean Update Equation:The mean of each Gaussian component is updated based on the weighted sum of all input vectors, where represents the effective number of data points assigned to the kth Gaussian component. This concept reflects the soft clustering nature of the GMM, where data points are not assigned to a single cluster but distributed across components with associated probabilities.
- Covariance Matrix Update:The covariance matrix of each Gaussian component is updated based on the weighted sum of the squared differences between the input vectors and the updated mean.
- Mixing Coefficient Update:The mixing coefficient, which determines the proportion of data points assigned to each Gaussian component, is updated as follows:where N is the total number of data points.
- Log-Likelihood Computation:To assess the convergence of the EM algorithm, the log-likelihood of the observed data is computed at each iteration. The algorithm iterates until the log-likelihood converges to a stable value.
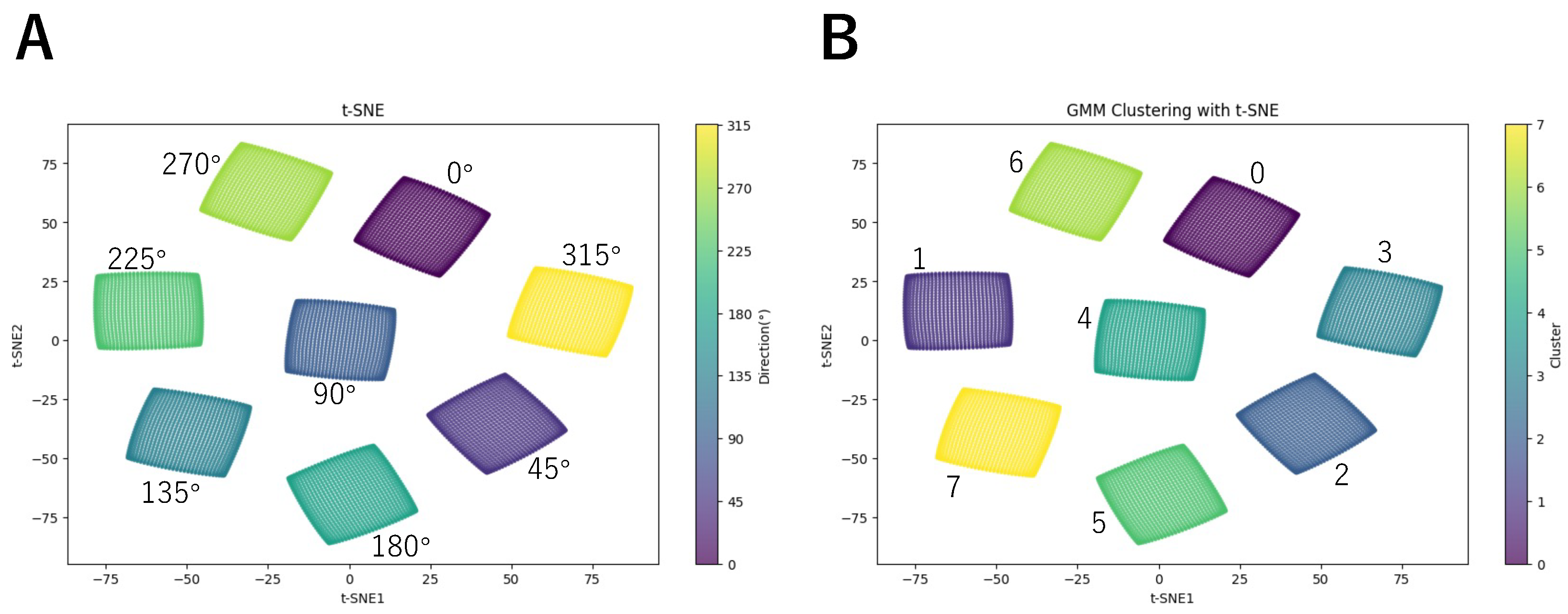
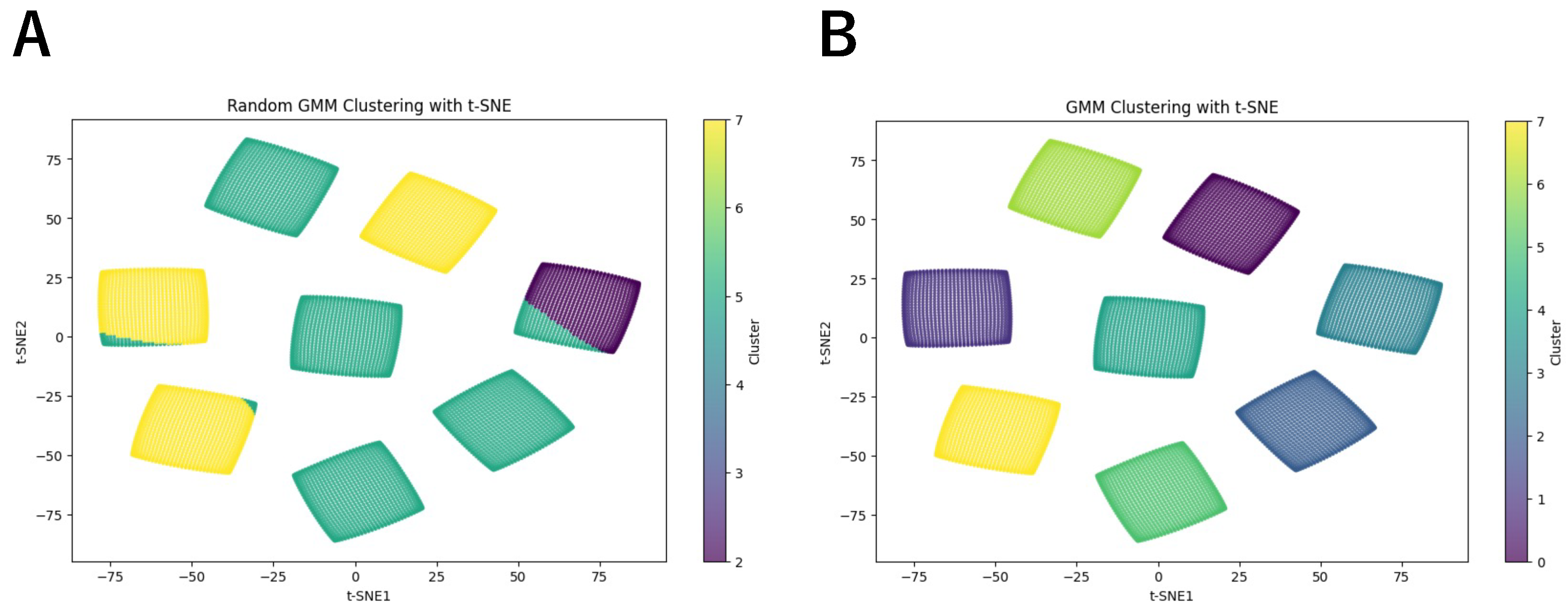
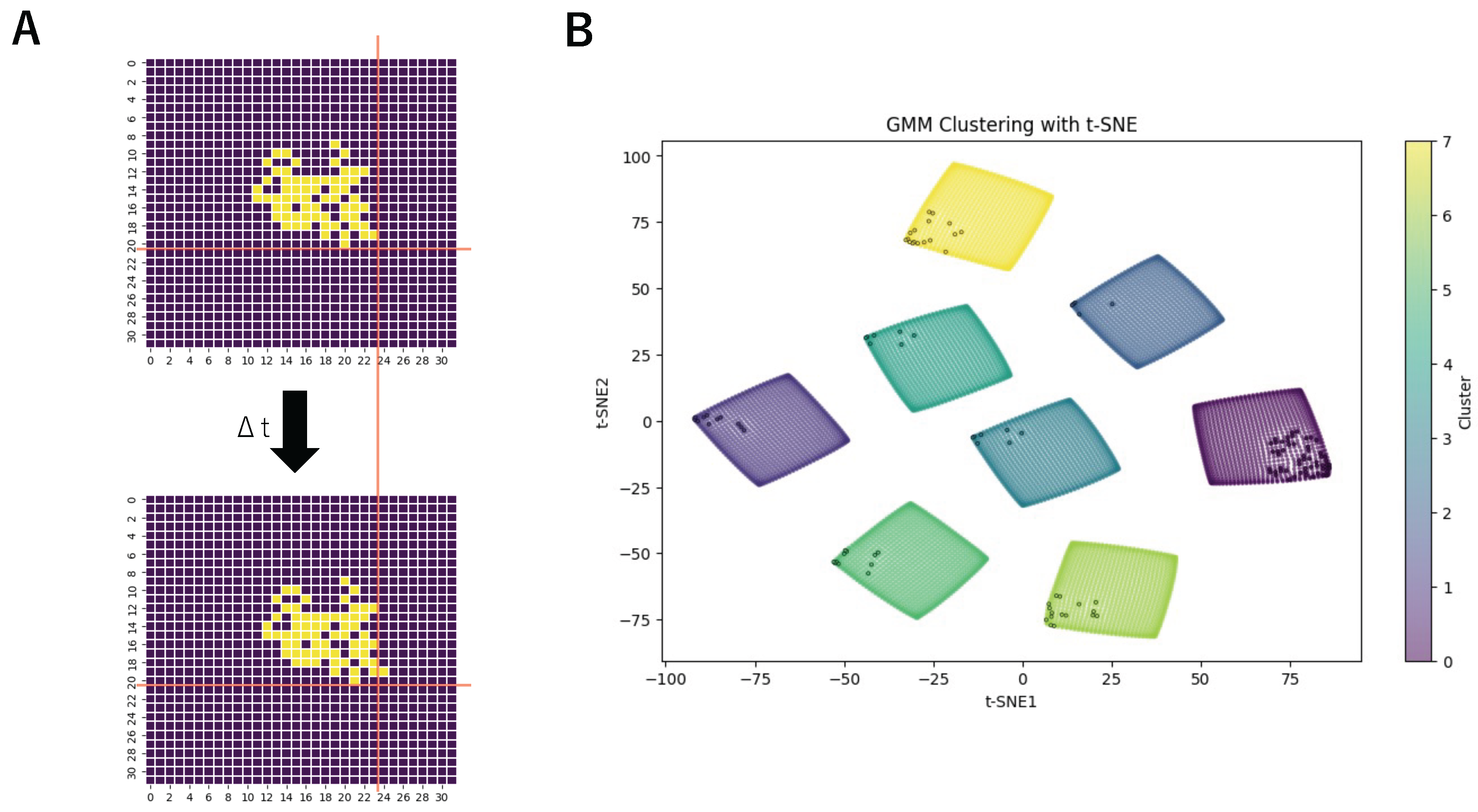
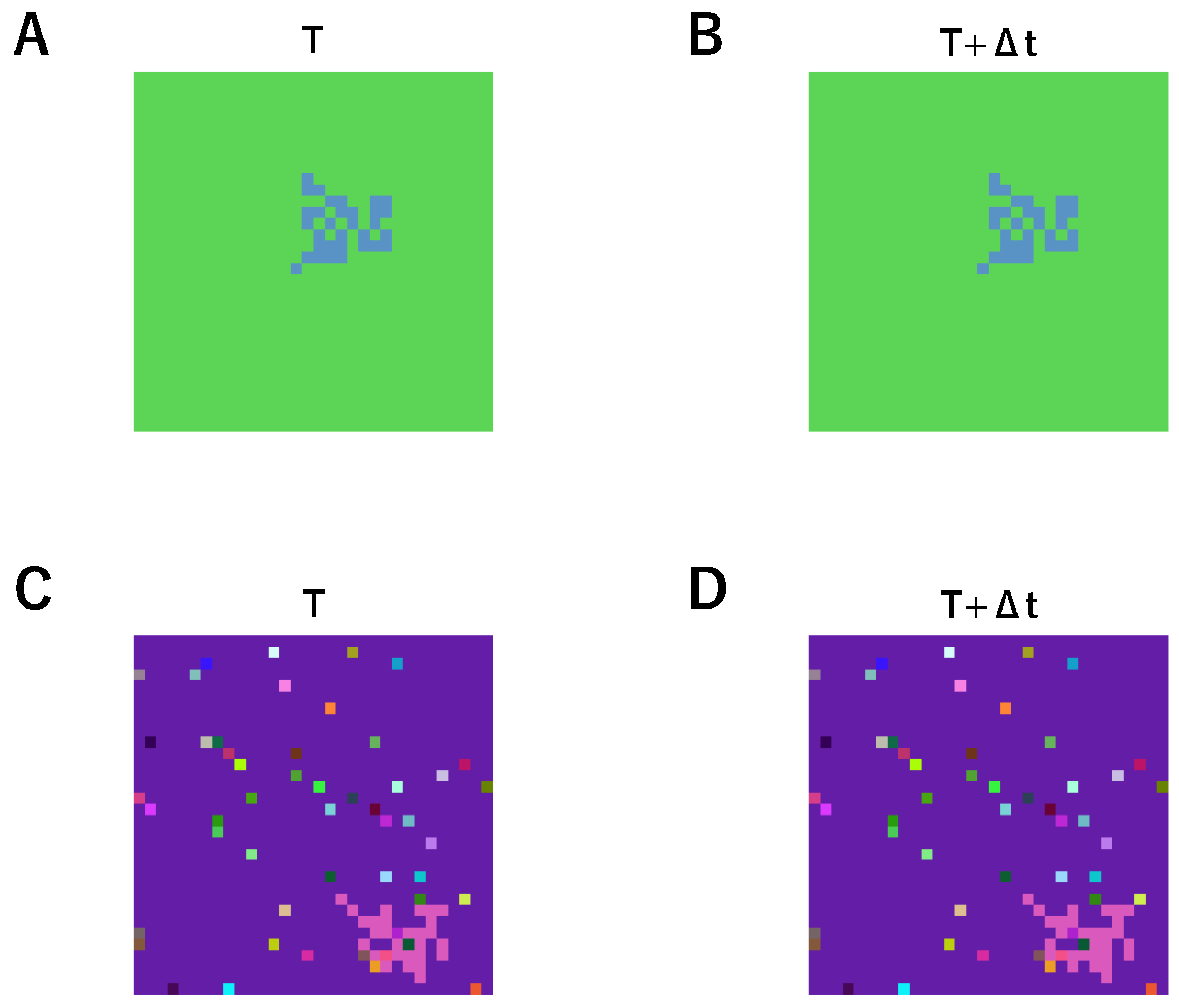
3. Results
4. Summary
- A local motion direction detection layer, which corresponds to the retina and retains the previously established structure and mechanisms.
- A global motion direction detection layer, which was redesigned from a simple summation-based approach to a GMM-based unsupervised learning mechanism.
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Barlow, H.B. Possible principles underlying the transformation of sensory messages. Sens. Commun. 1961, 1, 217–233. [Google Scholar]
- Hubel, D.H.; Wiesel, T.N. Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. J. Physiol. 1962, 160, 106. [Google Scholar] [CrossRef] [PubMed]
- Land, M.F.; Nilsson, D.E. Animal Eyes; Oxford University Press: Oxford, UK, 2012. [Google Scholar]
- Clifford, C.W.; Ibbotson, M.R. Fundamental mechanisms of visual motion detection: Models, cells and functions. Prog. Neurobiol. 2002, 68, 409–437. [Google Scholar] [CrossRef] [PubMed]
- Nakayama, K. Biological image motion processing: A review. Vis. Res. 1985, 25, 625–660. [Google Scholar] [CrossRef]
- Fleishman, L.J. The influence of the sensory system and the environment on motion patterns in the visual displays of anoline lizards and other vertebrates. Am. Nat. 1992, 139, S36–S61. [Google Scholar] [CrossRef]
- Pack, C.C.; Bensmaia, S.J. Seeing and feeling motion: Canonical computations in vision and touch. PLoS Biol. 2015, 13, e1002271. [Google Scholar] [CrossRef]
- Zarei Eskikand, P.; Grayden, D.B.; Kameneva, T.; Burkitt, A.N.; Ibbotson, M.R. Understanding visual processing of motion: Completing the picture using experimentally driven computational models of MT. Rev. Neurosci. 2024, 35, 243–258. [Google Scholar] [CrossRef]
- Mazzia, V.; Angarano, S.; Salvetti, F.; Angelini, F.; Chiaberge, M. Action transformer: A self-attention model for short-time pose-based human action recognition. Pattern Recognit. 2022, 124, 108487. [Google Scholar] [CrossRef]
- Rideaux, R.; Welchman, A.E. Exploring and explaining properties of motion processing in biological brains using a neural network. J. Vis. 2021, 21, 11. [Google Scholar] [CrossRef]
- Fu, Q.; Wang, H.; Hu, C.; Yue, S. Towards computational models and applications of insect visual systems for motion perception: A review. Artif. Life 2019, 25, 263–311. [Google Scholar] [CrossRef]
- Abel, R.; Ullman, S. Biologically Inspired Learning Model for Instructed Vision. Adv. Neural Inf. Process. Syst. 2024, 37, 45315–45358. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Zhou, Y.; Liu, E.; Neubig, G.; Tarr, M.; Wehbe, L. Divergences between Language Models and Human Brains. Adv. Neural Inf. Process. Syst. 2025, 37, 137999–138031. [Google Scholar]
- Song, Y.; Millidge, B.; Salvatori, T.; Lukasiewicz, T.; Xu, Z.; Bogacz, R. Inferring neural activity before plasticity as a foundation for learning beyond backpropagation. Nat. Neurosci. 2024, 27, 348–358. [Google Scholar] [CrossRef]
- Krotov, D.; Hopfield, J.J. Unsupervised learning by competing hidden units. Proc. Natl. Acad. Sci. USA 2019, 116, 7723–7731. [Google Scholar] [CrossRef]
- Chen, L.; Singh, S.; Kailath, T.; Roychowdhury, V. Brain-inspired automated visual object discovery and detection. Proc. Natl. Acad. Sci. USA 2019, 116, 96–105. [Google Scholar] [CrossRef]
- Ligeralde, A.; Kuang, Y.; Yerxa, T.E.; Pitcher, M.N.; Feller, M.; Chung, S. Unsupervised learning on spontaneous retinal activity leads to efficient neural representation geometry. In Proceedings of the UniReps: The First Workshop on Unifying Representations in Neural Models, New Orleans, LA, USA, 15 December 2023. [Google Scholar]
- Ciampi, L.; Lagani, G.; Amato, G.; Falchi, F. Biologically-inspired Semi-supervised Semantic Segmentation for Biomedical Imaging. arXiv 2024, arXiv:2412.03192. [Google Scholar]
- Yun, Z.; Zhang, J.; Olshausen, B.; LeCun, Y.; Chen, Y. Urlost: Unsupervised representation learning without stationarity or topology. arXiv 2023, arXiv:2310.04496. [Google Scholar]
- Paredes-Vallés, F.; Scheper, K.Y.; De Croon, G.C. Unsupervised learning of a hierarchical spiking neural network for optical flow estimation: From events to global motion perception. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2051–2064. [Google Scholar] [CrossRef]
- Thompson, B.; Tjan, B.S.; Liu, Z. Perceptual learning of motion direction discrimination with suppressed and unsuppressed MT in humans: An fMRI study. PLoS ONE 2013, 8, e53458. [Google Scholar] [CrossRef] [PubMed]
- Wei, W. Neural mechanisms of motion processing in the mammalian retina. Annu. Rev. Vis. Sci. 2018, 4, 165–192. [Google Scholar] [CrossRef] [PubMed]
- Su, C.; Mendes-Platt, R.F.; Alonso, J.M.; Swadlow, H.A.; Bereshpolova, Y. Retinal direction of motion is reliably transmitted to visual cortex through highly selective thalamocortical connections. Curr. Biol. 2025, 35, 217–223. [Google Scholar] [CrossRef] [PubMed]
- Hubel, D.H.; Wiesel, T.N. Receptive fields and functional architecture of monkey striate cortex. J. Physiol. 1968, 195, 215–243. [Google Scholar] [CrossRef]
- Orban, G.A. Higher order visual processing in macaque extrastriate cortex. Physiol. Rev. 2008, 88, 59–89. [Google Scholar] [CrossRef]
- Kohn, A.; Movshon, J.A. Adaptation changes the direction tuning of macaque MT neurons. Nat. Neurosci. 2004, 7, 764–772. [Google Scholar] [CrossRef]
- Sengpiel, F.; Kind, P.C. The role of activity in development of the visual system. Curr. Biol. 2002, 12, R818–R826. [Google Scholar] [CrossRef]
- Bharmauria, V.; Ouelhazi, A.; Lussiez, R.; Molotchnikoff, S. Adaptation-induced plasticity in the sensory cortex. J. Neurophysiol. 2022, 128, 946–962. [Google Scholar] [CrossRef]
- Yan, C.; Todo, Y.; Kobayashi, Y.; Tang, Z.; Li, B. An Artificial Visual System for Motion Direction Detection Based on the Hassenstein–Reichardt Correlator Model. Electronics 2022, 11, 1423. [Google Scholar] [CrossRef]
- Tang, C.; Todo, Y.; Ji, J.; Tang, Z. A novel motion direction detection mechanism based on dendritic computation of direction-selective ganglion cells. Knowl.-Based Syst. 2022, 241, 108205. [Google Scholar] [CrossRef]
- Han, M.; Todo, Y.; Tang, Z. Mechanism of Motion Direction Detection Based on Barlow’s Retina Inhibitory Scheme in Direction-Selective Ganglion Cells. Electronics 2021, 10, 1663. [Google Scholar] [CrossRef]
- Cafaro, J.; Zylberberg, J.; Field, G.D. Global motion processing by populations of direction-selective retinal ganglion cells. J. Neurosci. 2020, 40, 5807–5819. [Google Scholar] [CrossRef]
- Hua, Y.; Yuki, T.; Tao, S.; Tang, Z.; Cheng, T.; Qiu, Z. Bio-inspired computational model for direction and speed detection. Knowl.-Based Syst. 2024, 300, 112195. [Google Scholar] [CrossRef]
- Reynolds, D.A. Gaussian mixture models. In Encyclopedia of Biometrics; Springer: Boston, MA, USA, 2009; p. 3. [Google Scholar]
- Simoncelli, E.P.; Heeger, D.J. A model of neuronal responses in visual area MT. Vis. Res. 1998, 38, 743–761. [Google Scholar] [CrossRef]
- Orbán, G.; Berkes, P.; Fiser, J.; Lengyel, M. Neural variability and sampling-based probabilistic representations in the visual cortex. Neuron 2016, 92, 530–543. [Google Scholar] [CrossRef]
- Barlow, H.; Levick, W.R. The mechanism of directionally selective units in rabbit’s retina. J. Physiol. 1965, 178, 477. [Google Scholar] [CrossRef]
- Hassenstein, B.; Reichardt, W. Systemtheoretische analyse der zeit-, reihenfolgen-und vorzeichenauswertung bei der bewegungsperzeption des rüsselkäfers chlorophanus. Z. Naturforschung B 1956, 11, 513–524. [Google Scholar] [CrossRef]
- Zhou, T.; Gao, S.; Wang, J.; Chu, C.; Todo, Y.; Tang, Z. Financial time series prediction using a dendritic neuron model. Knowl.-Based Syst. 2016, 105, 214–224. [Google Scholar] [CrossRef]
- Borst, A.; Egelhaaf, M. Principles of visual motion detection. Trends Neurosci. 1989, 12, 297–306. [Google Scholar] [CrossRef]
- Joesch, M.; Plett, J.; Borst, A.; Reiff, D.F. Response properties of motion-sensitive visual interneurons in the lobula plate of Drosophila melanogaster. Curr. Biol. 2008, 18, 368–374. [Google Scholar] [CrossRef]
- de Polavieja, G.G. Neuronal algorithms that detect the temporal order of events. Neural Comput. 2006, 18, 2102–2121. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Han, S.; Gao, H.; Wang, T. A Gaussian mixture based hidden Markov model for motion recognition with 3D vision device. Comput. Electr. Eng. 2020, 83, 106603. [Google Scholar] [CrossRef]
- Huang, H.; Ye, H.; Sun, Y.; Liu, M. Gmmloc: Structure consistent visual localization with gaussian mixture models. IEEE Robot. Autom. Lett. 2020, 5, 5043–5050. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| Random | 0 | 0 | 788 | 0 | 0 | 4450 | 0 | 2954 |
| Trained | 1024 | 1024 | 1024 | 1024 | 1024 | 1024 | 1024 | 1024 |
| Label | 0 | 1 | 2 | 3 |
| Direction | Rightward | Left-Lower | Right-Upper | Right-Lower |
| Angle | 0° | 225° | 45° | 315° |
| Label | 4 | 5 | 6 | 7 |
| Direction | Upward | Leftward | Downward | Left-Upper |
| Angle | 90° | 180° | 270° | 135° |
| Label | 0 | 1 | 2 | 3 |
| Direction | Rightward | Left-Lower | Right-Upper | Right-Lower |
| Activations | 56 | 11 | 5 | 7 |
| Label | 4 | 5 | 6 | 7 |
| Direction | Upward | Leftward | Downward | Left-Upper |
| Activations | 7 | 11 | 16 | 17 |
| Size/Noise | 0% | 1% | 5% | 10% |
|---|---|---|---|---|
| 1 | 97.50% | 97.63% | 94.75% | 92.25% |
| 2 | 98.75% | 97.88% | 97.00% | 93.63% |
| 4 | 99.13% | 99.75% | 98.50% | 97.38% |
| 8 | 100% | 100% | 100% | 99.38% |
| 16 | 100% | 100% | 100% | 100% |
| 32 | 100% | 100% | 100% | 100% |
| 64 | 100% | 100% | 100% | 100% |
| 128 | 100% | 100% | 100% | 100% |
| 256 | 100% | 100% | 100% | 100% |
| 512 | 100% | 100% | 100% | 100% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, Z.; Hua, Y.; Chen, T.; Todo, Y.; Tang, Z.; Qiu, D.; Chu, C. A Gaussian Mixture Model-Based Unsupervised Dendritic Artificial Visual System for Motion Direction Detection. Biomimetics 2025, 10, 332. https://doi.org/10.3390/biomimetics10050332
Qiu Z, Hua Y, Chen T, Todo Y, Tang Z, Qiu D, Chu C. A Gaussian Mixture Model-Based Unsupervised Dendritic Artificial Visual System for Motion Direction Detection. Biomimetics. 2025; 10(5):332. https://doi.org/10.3390/biomimetics10050332
Chicago/Turabian StyleQiu, Zhiyu, Yuxiao Hua, Tianqi Chen, Yuki Todo, Zheng Tang, Delai Qiu, and Chunping Chu. 2025. "A Gaussian Mixture Model-Based Unsupervised Dendritic Artificial Visual System for Motion Direction Detection" Biomimetics 10, no. 5: 332. https://doi.org/10.3390/biomimetics10050332
APA StyleQiu, Z., Hua, Y., Chen, T., Todo, Y., Tang, Z., Qiu, D., & Chu, C. (2025). A Gaussian Mixture Model-Based Unsupervised Dendritic Artificial Visual System for Motion Direction Detection. Biomimetics, 10(5), 332. https://doi.org/10.3390/biomimetics10050332