
Machine Learning and Metaheuristics Approach for Individual Credit Risk Assessment: A Systematic Literature Review

 ,
,  , , , ,
, , , ,  , and
, and
Abstract
1. Introduction
- Ref. [2]—This article comprehensively reviews different machine learning models applied in credit risk assessment, focusing on their performance, interpretability, and application in various financial contexts. The study highlights the importance of data preprocessing, feature selection, and optimization techniques in improving model accuracy and reliability.
- Ref. [6]—The paper explores the use of federated learning in credit risk assessment, emphasizing its potential to enhance data privacy and security while maintaining high predictive performance. The authors discuss the challenges and benefits of implementing federated learning in financial institutions but do not specifically focus on feature selection methods.
- Ref. [3]—This comprehensive review covers various AI-based methods for credit risk assessment, evaluating their effectiveness in different scenarios. The authors compare traditional and advanced machine learning techniques, including neural networks and ensemble methods. While the review highlights feature selection and optimization techniques, it does not exclude non-AI methods.
- Ref. [5]—This review focuses on applying machine learning for credit risk prediction, identifying key trends and methodologies in the field. The review highlights the importance of using diverse datasets, feature selection, optimization techniques, and robust evaluation metrics to ensure model reliability and generalizability. However, it includes a variety of statistical methods alongside AI techniques, not exclusively focusing on AI.
- Ref. [4]—This study presents a longitudinal analysis of repayment behaviour in higher education, examining factors that influence loan default rates among students. The findings suggest that demographic and socio-economic variables significantly predict repayment behaviour. However, it does not explicitly focus on feature selection or optimization techniques.
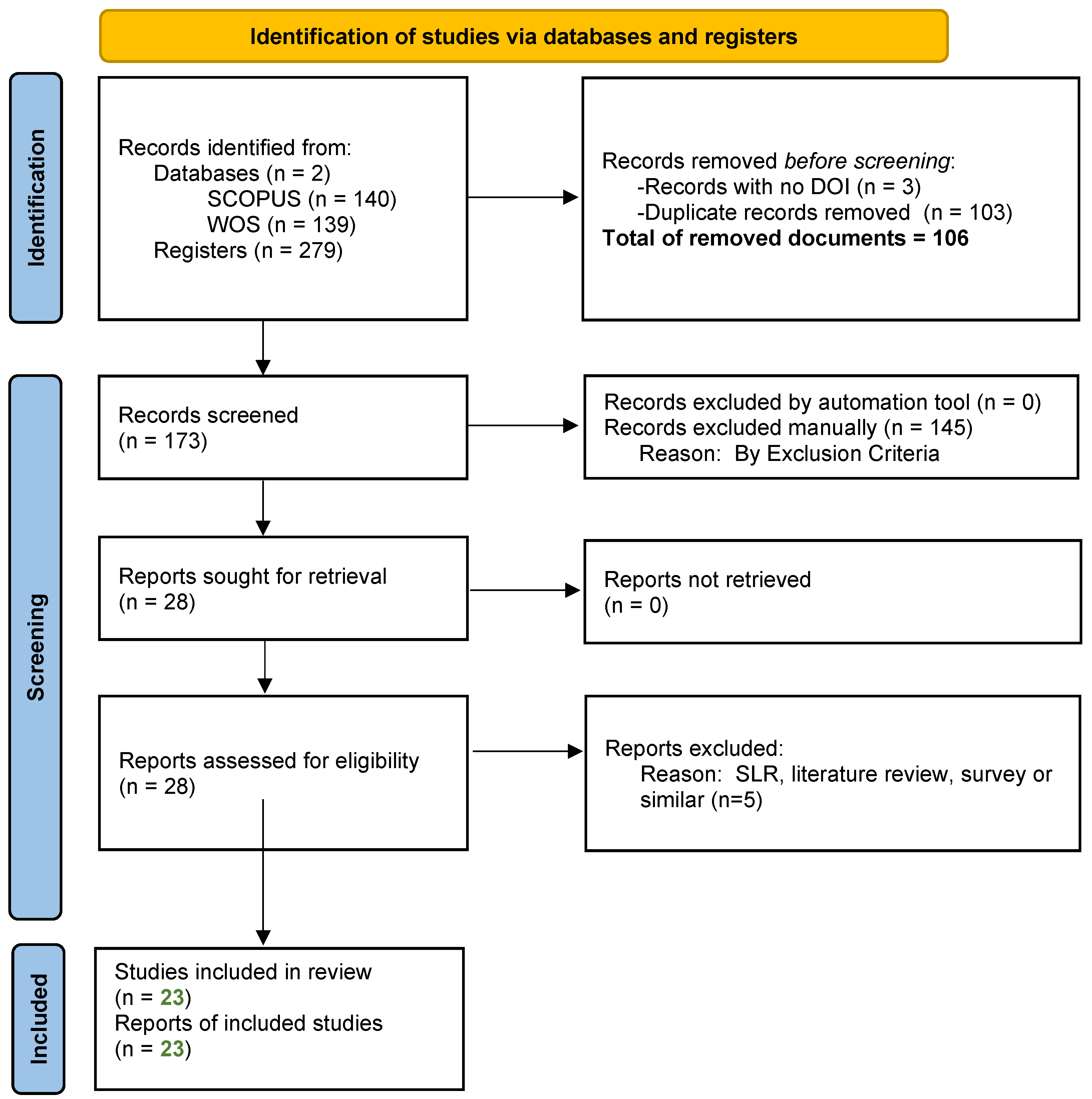
2. Methodology
SCOPUS: (TITLE-ABS-KEY (“Credit risk assessment” OR “Repayment Behavior” OR “Loan repayment behavior” OR “Loan Payment” OR “Payment Behavior” OR “Debt repayment” OR “Borrower payment habits” OR “Loan default predictors”) AND TITLE-ABS-KEY (“Machine Learning” OR “Artificial intelligence” OR “Predictive Model” OR “Classification model” OR “Prediction”)) AND PUBYEAR > 2018 AND PUBYEAR < 2024 AND (LIMIT-TO (DOCTYPE “ar”)) AND (LIMIT-TO (LANGUAGE “English”))
WOS: (TS=(”Credit risk assessment” OR “Repayment Behavior” OR “Loan repayment behavior” OR “Loan Payment” OR “Payment Behavior” OR “Debt repayment” OR “Borrower payment habits” OR “Loan default predictors”) AND TS=(”Machine Learning” OR “Artificial intelligence” OR “Predictive Model” OR “Classification model” OR “Prediction”)) AND (PY==(”2023” OR “2022” OR “2021” OR “2020” OR “2019”) AND DT==(”ARTICLE”) AND LA==(”ENGLISH”)
3. Findings
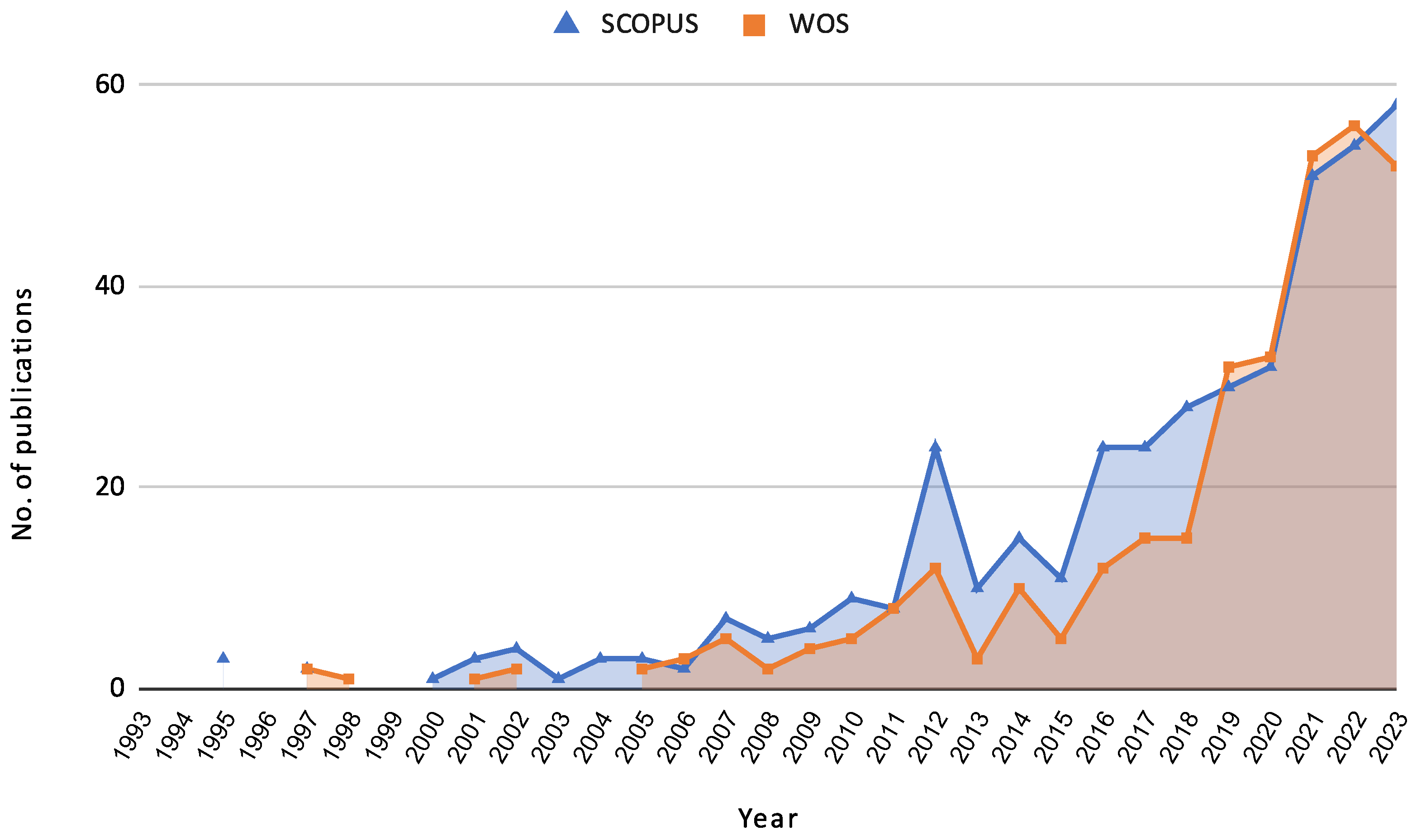
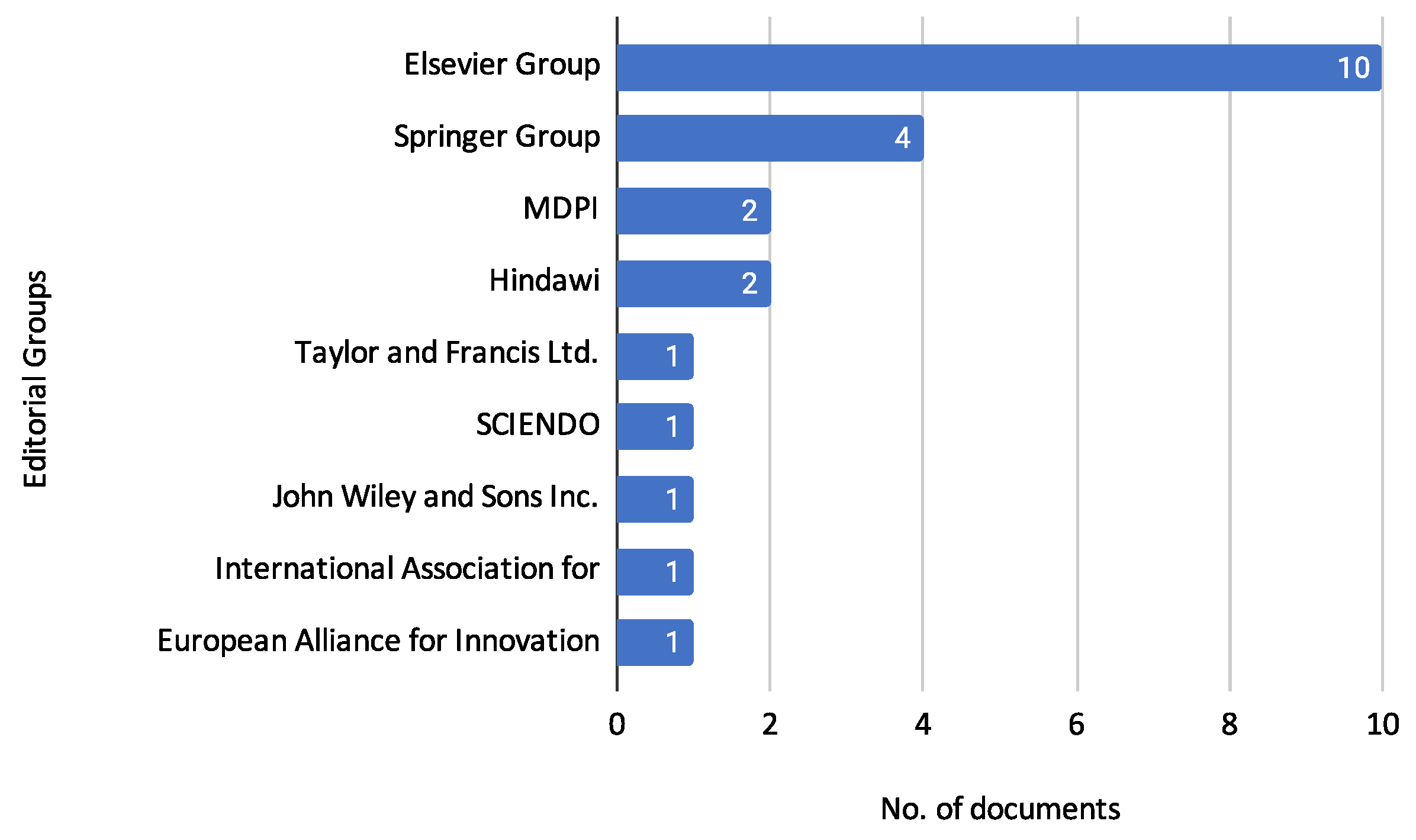
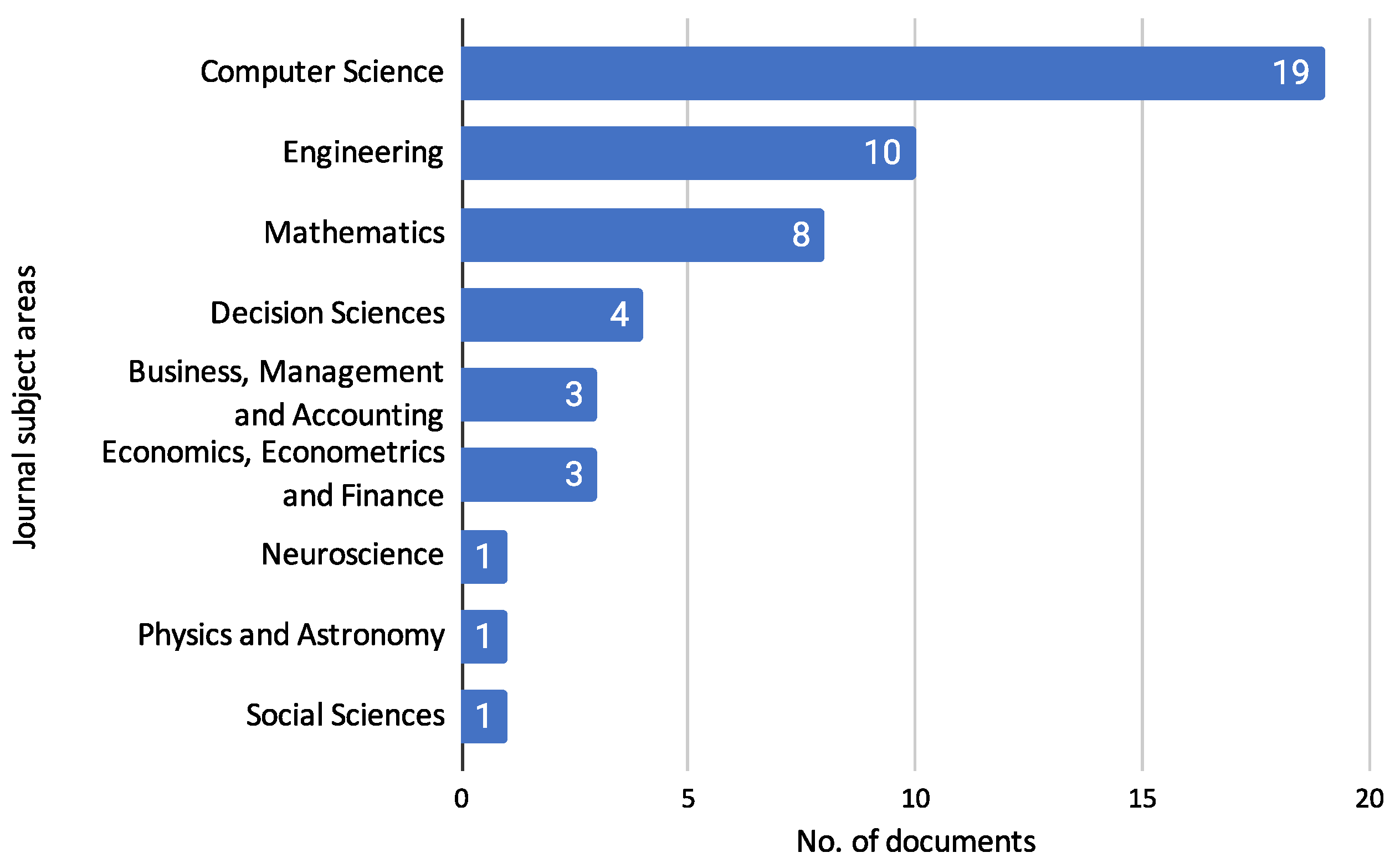
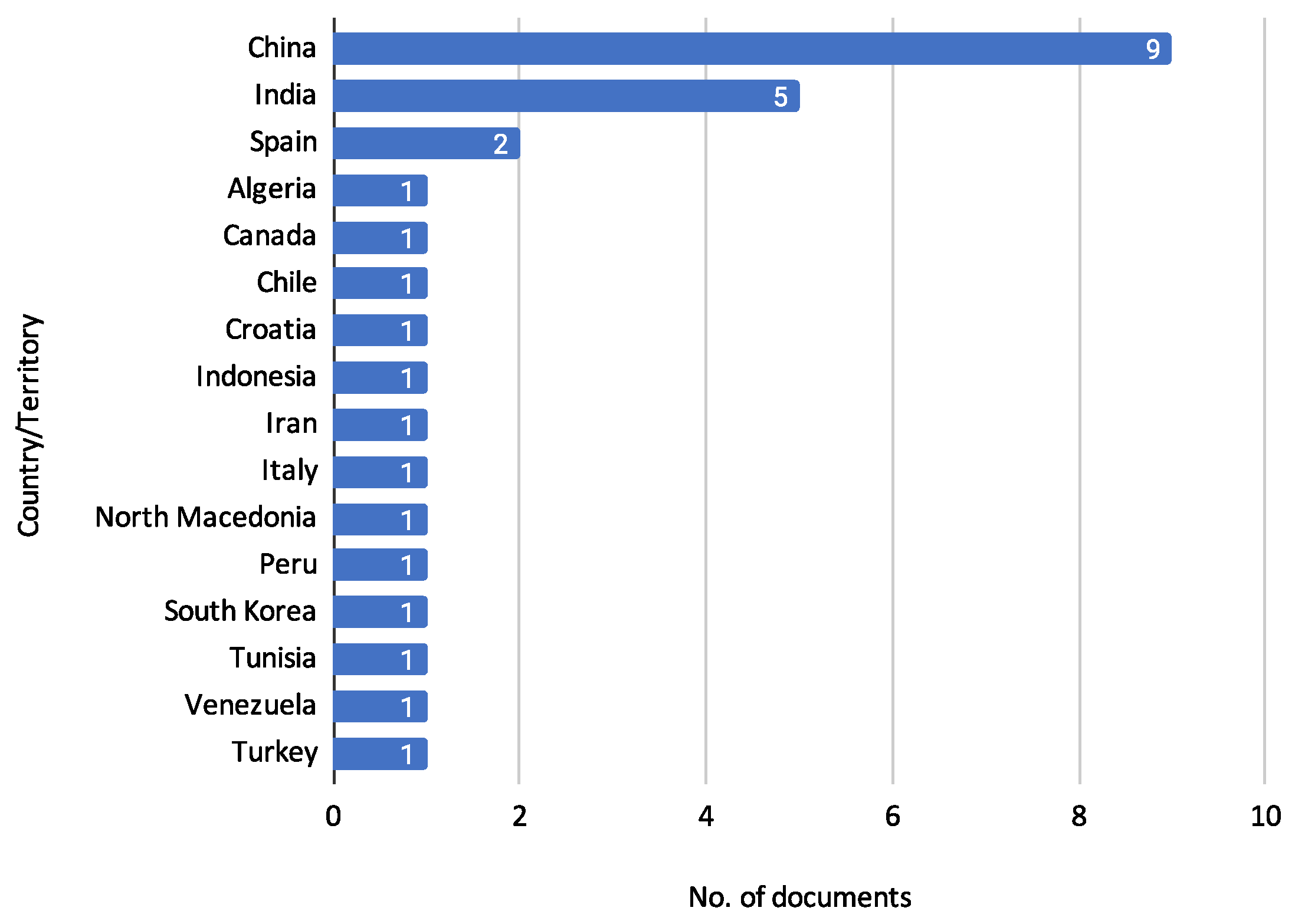
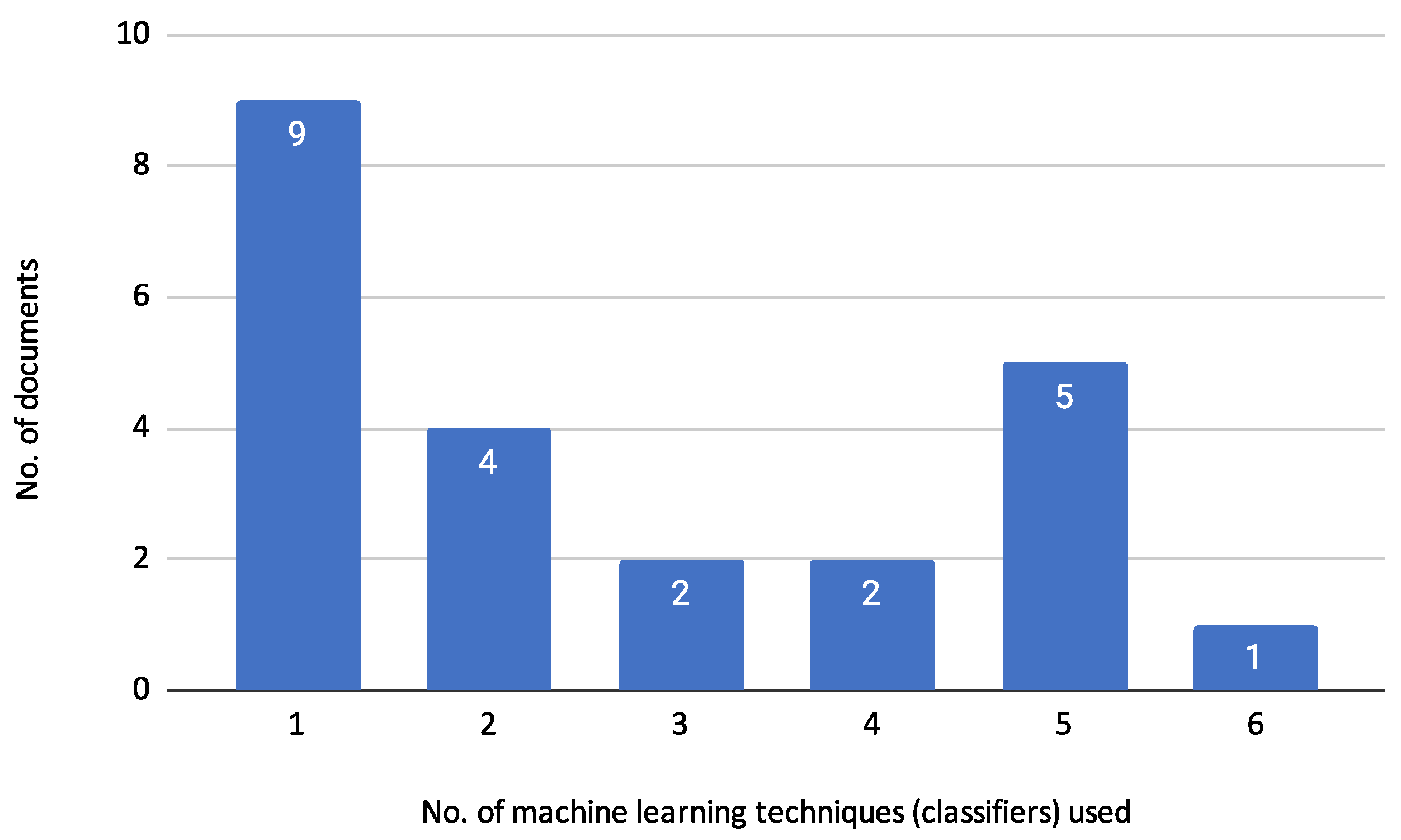
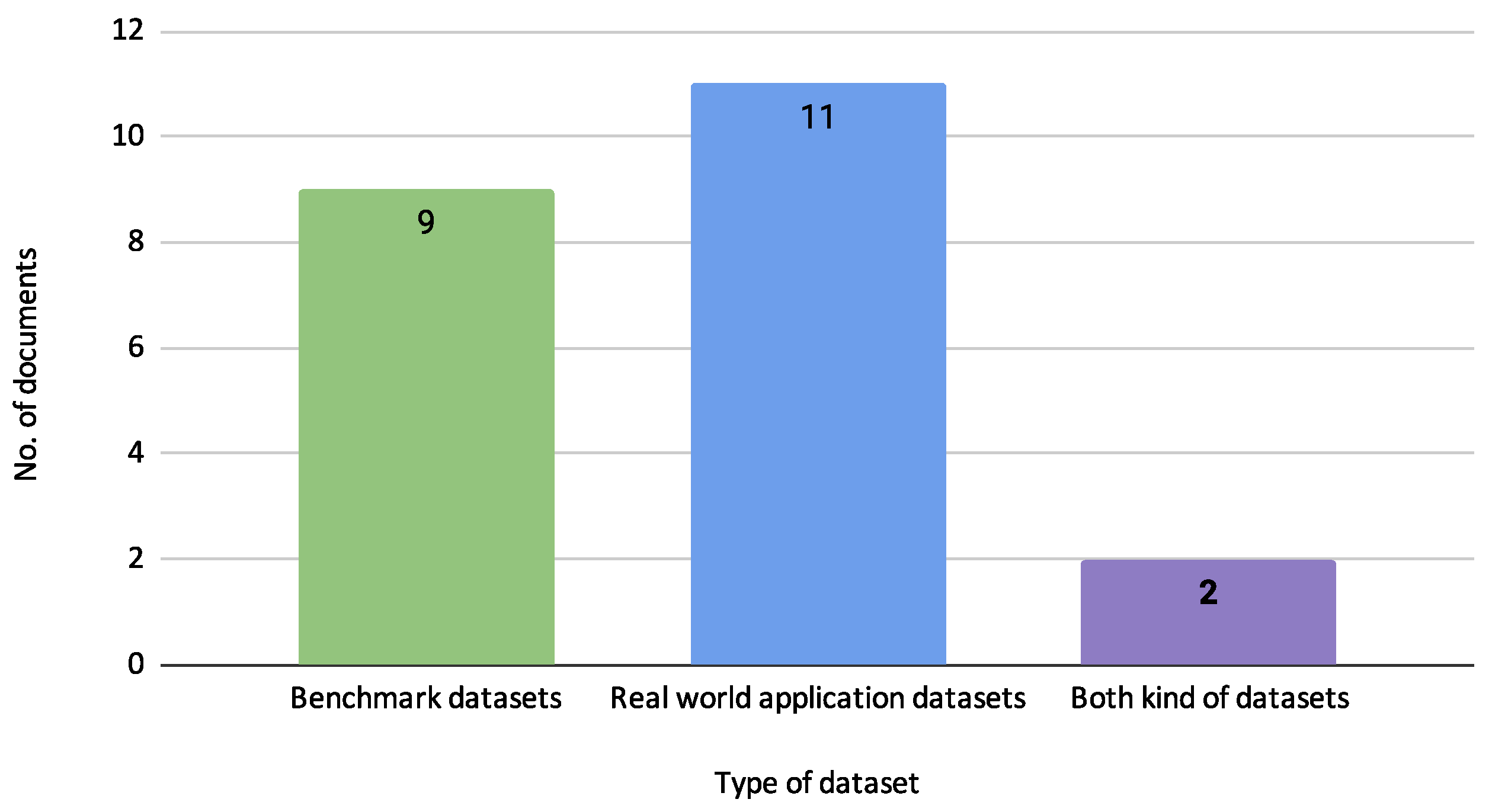
3.1. Characterization of Reviewed Documents
3.2. Machine Learning in Credit Assessment
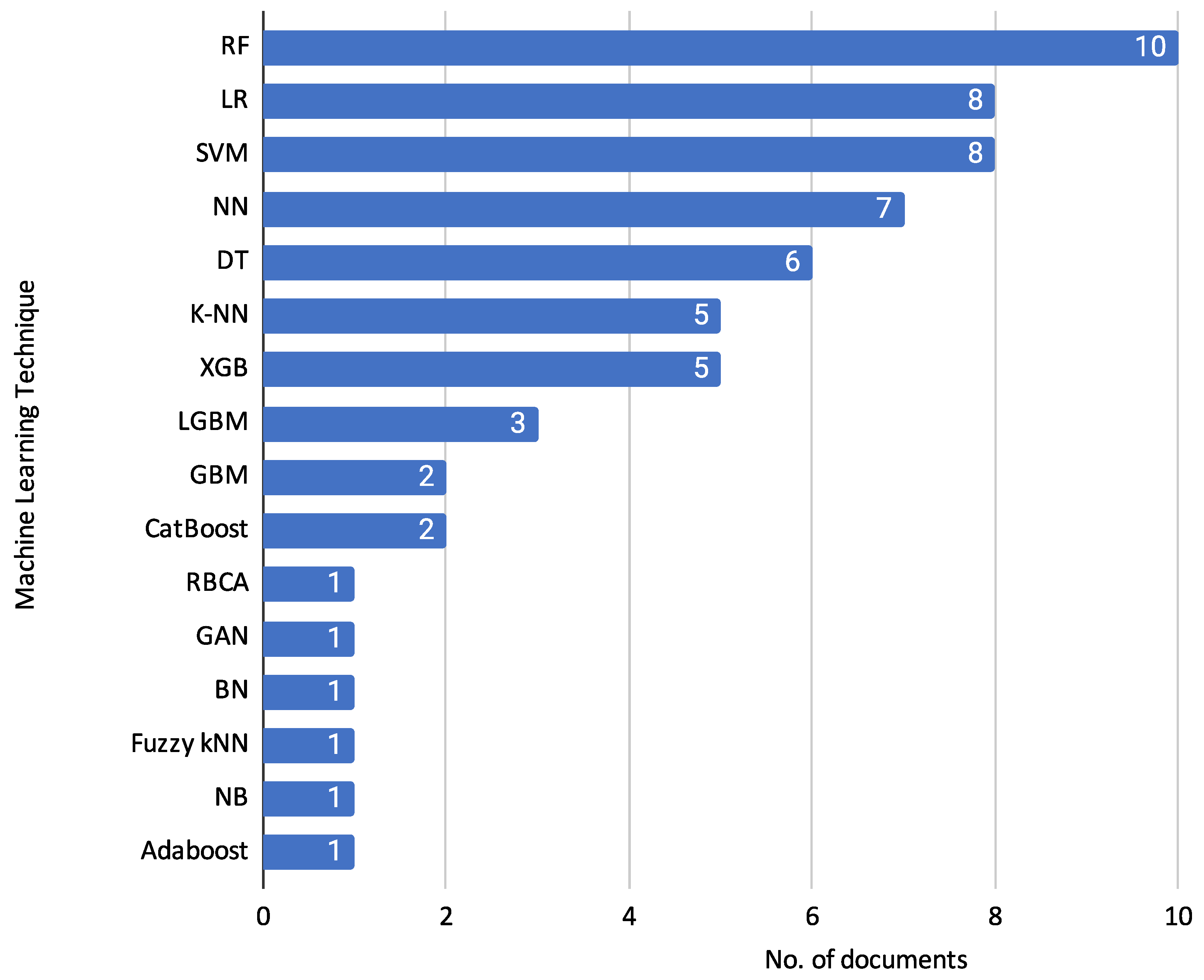
- Supervised Learning (SL): This category includes traditional algorithms such as Logistic Regression (LR), Decision Trees (DT), Random Forest (RF), Support Vector Machines (SVM), and Gradient Boosting Machines (GBM). These methods require labelled data to train models to predict the likelihood of default.
- Unsupervised Learning (UL): Techniques such as clustering and anomaly detection fall under this category. Methods like K-means and Principal Component Analysis (PCA) are used to identify patterns and outliers in the data without the need for labelled training samples.
- Reinforcement Learning (RL): RL involves training algorithms based on the reward feedback from their actions, optimizing long-term performance through trial and error.
3.2.1. Machine Learning Techniques
- Ref. [15] applied Recursive Feature Elimination with Random Forest (RFE-RF) for feature selection, utilizing logistic regression, random forest, and SVM to improve model performance.
- Ref. [19] employed decision tree and logistic regression algorithms for evaluating credit status on P2P lending platforms, using the CfsSubsetEval evaluation strategy and BestFirst search strategy for feature selection.
- Ref. [25] utilized the Firefly Algorithm for feature selection in conjunction with KNN, Fuzzy KNN, Random Forest, Decision Tree, and SVM to enhance credit risk prediction accuracy.
- Ref. [14] combined Particle Swarm Optimization (PSO) with Structure Decision Tree Learning (SDTL) to improve financial credit risk assessment.
- Ref. [24] aimed to enhance interpretability in loan evaluation by extracting rules from a tree ensemble model using the NSGA-II algorithm.
- Ref. [20] employed boosting methods, including CatBoost, XGBoost, and LightGBM, to evaluate credit risk.
- Ref. [21] evaluated credit risk using decision tree and K-Nearest Neighbors (KNN) algorithms optimized through Bayesian optimization.
- Ref. [29] used heterogeneous ensemble learning to predict the default risk of national student loans, integrating algorithms like CatBoost, XGBoost, LightGBM, and Random Forest.
- Ref. [27] used the GBM Grid model to predict student payment behaviour at a private university, utilizing gradient boosting algorithms for classification.
- Ref. [31] employed various machine learning models, including SVM, logistic regression, random forest, Light Gradient Boosting (LGB), and eXtreme Gradient Boosting (XGB), for evaluating customer creditworthiness and monitoring credit repayments.
- Ref. [22] proposed the LGBBO-RuleMiner, a rule-based classification technique designed for predicting credit risk using a novel Biogeography Based Optimization (BBO) method.
- Ref. [12] combined Bolasso (Bootstrap-Lasso) with Random Forest, using the stability of Bolasso for feature selection and the classification power of Random Forest, along with SVM, Naïve Bayes, and K-Nearest Neighbors (K-NN).
- Ref. [9] employed a discrete Bayesian Network (BN) integrated with a latent variable for assessing credit risk by modelling the probability of loan default.
- Ref. [10] proposed a model that utilizes Gradient Boosting, a supervised learning method.
- Ref. [17] introduced the ABSMPNN model, which integrates Binarized Spiking Neural Networks (BSNN) with the Adaptive Marine Predators Algorithm (AMPA) for optimization, achieving high accuracy in credit risk evaluation with reduced computational time.
- Ref. [30] combined a Backpropagation (BP) neural network with a mutation genetic algorithm to improve the accuracy of credit risk assessment for commercial banks.
- Ref. [18] evaluated several machine learning models, including logistic regression, decision tree, random forest, SVM, and neural networks for credit risk assessment.
- Ref. [23] utilized logistic regression and neural network models within an automated ETL (Extraction, Transformation, Load) process to assess credit risk in compliance with Basel II standards, focusing on calculating Probability of Default (PD), Loss Given Default (LGD), and Exposure at Default (EAD).
- Ref. [28] integrated Wasserstein Generative Adversarial Networks (WGAN) with a hybrid feature selection approach combining Kernel Partial Least Square (KPLS) and Quantum Particle Swarm Optimization (QPSO), utilizing SVM, logistic regression, KNN, Adaboost, and Random Forest.
- Ref. [11] proposed the MIFCA model, which integrates multiple classifiers including decision tree, random forest, SVM, k-Nearest Neighbors (k-NN), BP Neural Network, and XGBoost to enhance the accuracy and robustness of credit risk assessment.
- Ref. [26] utilized deep neural networks to assess behavioural credit ratings, logistic regression, SVM, random forest, and XGBoost to meet Basel regulatory framework requirements.
- The Interpretable Selective Learning Framework proposed by [16] utilizes both logistic regression and neural networks. The framework enhances interpretability by selectively using the simpler logistic regression model where it is sufficient and the more complex neural network model where necessary.
3.2.2. Credit Risk Assessment in Practice
- Ref. [17] Used in the banking sector to improve the accuracy and efficiency of identifying customer credit quality.
- Ref. [23] Focuses on automated credit risk assessment to enhance operational efficiency and compliance with regulatory standards in the financial sector.
- Ref. [15] Aims to optimize predictive accuracy and stability of credit scoring models.
- Ref. [12] Enhances the stability and accuracy of predictions regarding loan defaults.
- Ref. [13] Improves the accuracy and efficiency of credit risk assessment models by effectively handling missing data.
- Ref. [11] Enhances the accuracy and efficiency of personal credit risk predictions in the banking sector.
- Ref. [10] Integrates credit history, repayment behaviour, and social network data to improve creditworthiness assessment.
- Ref. [16] Aims to improve the interpretability and accuracy of credit risk predictions.
- Ref. [25] Focused on improving the accuracy and interpretability of credit card risk prediction.
- Ref. [14] Enhances prediction models for credit risk management in digital banking.
- Ref. [31] Designed to enhance transparency, fairness, and effectiveness of credit scoring systems in the financial domain.
- Ref. [26] Predicts the future performance of credit portfolios, focusing on behavioural patterns indicating a risk of default.
- Ref. [18] Uses data from the Central Bank Credit Registry to enhance predictive models for credit risk assessment.
- Ref. [9] Models payment default of loan subscribers using a Bayesian network with a latent variable.
- Ref. [24] Loan Evaluation with Tree Ensemble Models: Improves the interpretability of loan evaluation models while maintaining predictive performance.
- Ref. [30] Focuses on the credit risk assessment of commercial banks to improve decision-making processes.
- Ref. [28] focuses on improving credit risk assessment models by addressing challenges related to high-dimensional data and small sample sizes in emerging financial sectors.
- Ref. [20] Uses boosting methods for credit risk assessment, exploring the effectiveness of these methods on high-dimensional, weakly correlated, and sparse datasets.
- Ref. [22] Applied in financial institutions to improve decision-making processes regarding loan approvals.
- Ref. [19] Risk Evaluation and Management: Assesses credit risk on P2P lending platforms to improve risk evaluation and management.
- Ref. [21] Borrower Classification: Classifies borrowers to identify potential defaulters in P2P lending, enhancing the reliability of credit assessments.
3.3. Feature Selection Methods
- Filter Methods: Filter methods evaluate the relevance of features by examining their statistical properties concerning the target variable. These methods are independent of any machine learning algorithm. Common filter methods include, Mutual Information: Measures the mutual dependence between features and the target variable; Chi-Squared Test: Assesses the association between categorical features and the target variable; Correlation Coefficient: Examines the linear relationship between numerical features and the target variable.
- Wrapper Methods: Wrapper methods evaluate feature subsets based on their performance with a specific machine learning algorithm. These methods involve training and evaluating a model for each subset of features. Common wrapper methods include, Recursive Feature Elimination (RFE): Iteratively removes the minor essential features based on model performance until the optimal feature subset is obtained; Forward Selection: Starts with an empty feature set and adds features one by one based on their contribution to model performance; Backward Elimination: Starts with all features and removes them one by one based on their lack of contribution to model performance.
- Embedded Methods: Embedded methods perform feature selection during the model training process. These methods are specific to particular algorithms and integrate feature selection as part of the model building. Standard embedded methods include Least Absolute Shrinkage and Selection Operator (LASSO): A linear model that performs L1 regularization, which can shrink some coefficients to zero, effectively selecting a subset of features; Tree-based Methods: Decision trees and ensemble methods like Random Forest and Gradient Boosting inherently perform feature selection by selecting essential features during the tree-building process; Elastic Net: Combines L1 and L2 regularization to choose a subset of features while maintaining some of their effects.
3.4. Optimization Techniques (Metaheuristics)
- Biogeography Based Optimization (BBO): Biogeography Based Optimization (BBO) is inspired by the science of biogeography, which studies the distribution of species across different habitats over time [46]. In BBO, each potential solution to an optimization problem is considered a habitat with a habitat suitability index (HSI) representing its fitness. Habitats with high HSI share their characteristics with habitats with lower HSI, analogous to species migration in natural ecosystems. This exchange of features helps explore the search space and find optimal solutions.
- Adaptive Marine Predators Algorithm (AMPA): The Adaptive Marine Predators Algorithm (AMPA) mimics the adaptive foraging behaviour of marine predators [47]. This algorithm adapts the strategies of pursuit, encircling, and attacking prey based on the dynamic environment of the prey-predator interaction, enhancing its exploration and exploitation capabilities.
- Variable Color Harmony Algorithm (VCHA): The Variable Color Harmony Algorithm (VCHA) is inspired by the improvisation process of musicians when harmonizing different colours [48]. This algorithm adjusts its parameters dynamically to balance exploring new solutions and exploiting known reasonable solutions, optimizing complex functions effectively.
- Quantum Particle Swarm Optimization (QPSO): Quantum Particle Swarm Optimization (QPSO) is an advanced version of Particle Swarm Optimization (PSO) that incorporates principles of quantum mechanics [49]. In QPSO, particles have quantum behaviour, allowing them to explore the search space more effectively. The position of each particle is updated based on a probability distribution rather than a deterministic rule, which helps avoid local optima and find global solutions.
- Firefly Algorithm (FFA): The Firefly Algorithm (FFA) is inspired by the flashing behaviour of fireflies [50]. In this algorithm, the brightness of each firefly is associated with its fitness, and fireflies are attracted to brighter ones. The attractiveness decreases with distance, leading fireflies towards more glowing and optimal solutions. This behaviour enables effective exploration and exploitation of the search space.
- Particle Swarm Optimization (PSO): Particle Swarm Optimization (PSO) is a population-based optimization technique inspired by the social behaviour of birds flocking or fish schooling [51]. In PSO, each particle represents a potential solution and adjusts its position in the search space based on its own experience and the experience of neighbouring particles. The particles move towards better solutions over iterations, balancing exploration and exploitation to find the global optimum.
- Non-dominated Sorting Genetic Algorithm II (NSGA-II): NSGA-II is an advanced evolutionary algorithm specifically designed for solving multi-objective optimization problems [52]. It uses a fast, non-dominated sorting approach to classify solutions into different fronts based on Pareto dominance. Additionally, NSGA-II employs a crowding distance mechanism to ensure diversity among the solutions and a binary tournament selection based on the rank and crowding distance. This algorithm effectively balances convergence towards the Pareto front and diversity among the solutions, making it widely used in various optimization tasks where multiple conflicting objectives must be optimized simultaneously.
- Genetic Algorithm (GA): Genetic Algorithm (GA) is a popular metaheuristic inspired by the principles of natural selection and genetics [53]. It works by evolving a population of potential solutions over successive generations. Each individual in the population represents a candidate solution encoded as a chromosome. The algorithm uses selection, crossover (recombination), and mutation operators to generate new offspring. Selection chooses the fittest individuals to reproduce, crossover combines parts of two parents to create offspring, and mutation introduces random changes to maintain genetic diversity. GAs are highly effective for solving complex optimization problems because they can explore an ample search space and avoid local optima.
3.5. Datasets and Variables
3.5.1. Analysis of Commonly Used Datasets
- Thomas dataset: The Thomas dataset [1] includes various attributes commonly used in credit scoring models. This dataset is used to analyze credit risk and develop credit scoring models. Ref. [25] utilized this dataset to explore advanced credit scoring techniques and assess model performance under various conditions.
- Statlog (German Credit Data): The Statlog (German Credit Data) [54] dataset is used to classify loan applicants as either good or bad credit risks based on various personal and financial attributes. This dataset has been extensively used in multiple studies, including [12,15,22,24,25], to test and validate different credit scoring models and machine learning algorithms.
- Statlog (Australian Credit Approval): The Statlog (Australian Credit Approval) dataset [55] is used for credit scoring, facilitating quick decision-making and reducing risks associated with loan collections. It has been employed in various research works, such as [22,24], to evaluate the effectiveness of credit approval models.
- Lending Club Loan Data—This dataset contains consumer loans from 2007 to 2018 from the Lending Club. It was used in [23].
- Lending Club Dataset—Includes records from loans issued by Lending Club between 2007 and 2011. Referenced in [12].
- Credit Risk Assessment Data—Private data of credit risk assessment provided by a local bank in China. Utilized in [13].
- LendingClub (LC)—The dataset includes comprehensive loan data from Lending Club from 2018. It is used to evaluate the credit risk of borrowers on the P2P lending platform, as seen in [19].
- Commercial Bank Credit Records—Contains personal loan application records used for credit risk assessment. Referenced in [11].
- Business Credit Score Dataset—Comprises financial and social interaction data of companies from their first loan and observed over 12 months. Used in [10].
- Personal Credit Score—Comprises financial and social interaction data of individuals from their first loan and observed over 12 months. Referenced in [10].
- General Data Protection Regulation (GDPR)—Reflects monthly credit statuses for certain clients until the planned completion of their loans. Referenced in [14].
- Advanced Analytics of Credit Registry Dataset—This dataset includes properties, dependencies, trends, and advanced analytics features for in-depth data analysis. Referenced in [14].
- WIND Dataset—Covers personal credit data and is used for PSO-SDTL model analysis. Referenced in [14].
- Croatian Bank Credit Risk Dataset 2009–2013—The dataset tracks loan information annually and predicts default events within a year following each annual snapshot. Utilized in [26].
- Croatian Bank Credit Risk Dataset 2004–2018—Similar to the 2009-2013 dataset, it tracks annual loan information to predict default events. Referenced in [26].
- North Macedonia Credit Registry Data—Central to all credit activities in the country, capturing monthly credit and credit card status for various clients, aggregated from all commercial banks. Referenced in [18].
- Tunisian Bank Loan Data—Describes loan contracts granted by several Tunisian banks from 1990-2012. Referenced in [9].
- Lending Club (LC) Dataset 2017–2018—Includes records of loans to evaluate the performance of machine learning models in predicting loan defaults. Utilized in [24].
- Bank Credit Risk Data—Contains financial and non-financial information used to assess the credit risk of loan enterprises. Referenced in [30].
- National Student Loans Dataset—Data collected on students who had applied for national student loans, including personal honours, GPA by semester, and loan information, tracked until May 2022. Referenced in [29].
- Student Payment Behavior Dataset—Students have been considered participants for predicting payment behaviour in students of a private university in Peru in 2022. Utilized in [27].
3.5.2. Summary of Variables Commonly Used
Demographic Information
- Age: The age of the borrower (e.g., Lending Club dataset, Statlog (German Credit Data)).
- Gender: The gender of the borrower (e.g., Default of Credit Card Clients).
- Marital status: Whether the borrower is single, married, or divorced (e.g., Default of Credit Card Clients).
- Personal status and sex: Combined information on sex and marital status (e.g., Statlog (German Credit Data)).
Financial Information
- Annual Income: The annual income reported by the borrower (e.g., Lending Club dataset, Kaggle’s Bank Loan Status dataset).
- Monthly debt: The amount of debt the borrower is paying monthly (e.g., Kaggle’s Bank Loan Status dataset).
- Savings account/bonds: The savings the borrower holds (e.g., Statlog (German Credit Data)).
Loan Information
- Loan amount: The total loan amount applied for (e.g., Lending Club dataset, Statlog (German Credit Data)).
- Term: The loan duration in months (e.g., Lending Club dataset, Kaggle’s Bank Loan Status dataset).
- Purpose: The reason for which the loan is taken (e.g., Lending Club dataset, Statlog (German Credit Data)).
Credit History
- Credit history: The history of compliance with previous or concurrent credit contracts (e.g., Statlog (German Credit Data), Default of Credit Card Clients).
- Number of open accounts: The number of open credit lines in the borrower’s credit file (e.g., Lending Club dataset).
- Delinquencies: The number of delinquent accounts in the borrower’s credit file (e.g., Lending Club dataset, Default of Credit Card Clients).
Employment Information
- Employment length: The duration of the borrower’s current employment (e.g., Lending Club dataset, Default of Credit Card Clients).
- Job: The type of job the borrower holds (e.g., Statlog (German Credit Data), Tunisian Bank Loan Data).
Educational Information
- Education level: The highest level of education the borrower completes (e.g., Default of Credit Card Clients).
- GPA: The borrower’s grade point average (e.g., loan default risk for college students dataset).
Loan Default Behavior
- Default: Whether the borrower has defaulted on a loan (e.g., Default of Credit Card Clients, Tunisian Bank Loan Data).
- Loan status: The current status of the loan (e.g., Lending Club dataset, Kaggle’s Bank Loan Status dataset).
3.5.3. Relevant Variables and Their Impact on Prediction
- Statlog (Australian Credit Approval) and Statlog (German Credit Data): While the reviewed articles did not determine the specific importance of variables for these datasets, they remain pivotal for benchmarking credit scoring models due to their comprehensive feature sets.
- Credit Risk Dataset: The dataset includes several personal and loan-specific variables, though the articles did not specifically rank their importance. These variables are a person’s age, yearly income, homeownership, employment length (in years), loan purpose, loan rating, amount of loan, interest rate, loan status (0 for reject, 1 for approve), percentage revenue, ancient default, and credit history length. These features collectively contribute to the comprehensive credit risk assessment, providing critical insights into the borrower’s financial stability and creditworthiness.
- Lending Club Loan Data: This dataset includes various financial and demographic variables, but the reviewed articles did not detail their specific predictive impact.
- Give Me Some Credit Dataset: The following variables were identified as having significant predictive impact: Number of times the borrower has been 90 days or more past due (importance: 1); Number of times borrower has been 60–89 days past due but no worse in the last two years (importance: 2); Number of times borrower has been 30–59 days past due but no worse in the previous two years (importance: 3); Number of open loans (importance: 4) and Monthly debt payments, alimony, and living costs divided by monthly gross income (importance: 5).
- Loan Default Risk for College Students: In this dataset, the following variables were reported to have significant predictive importance: Total amount of scholarship (importance: 1); 5th semester GPA (importance: 2); Score obtained in the college entrance examination (importance: 3); Examinee category (importance: 4) and 4th semester GPA (importance: 5).
- North Macedonia Credit Registry Data: This dataset is notable for its detailed financial records, with the following variables identified as particularly impactful: Days delayed (importance: 1); Successfully paid loans (importance: 2); Loan duration in years (importance: 3); Actual year loan (importance: 4) and Interest rate (importance: 5).
- Tunisian Bank Loan Data: For this dataset, the following variables were highlighted for their impact: Amount of credit (importance: 1) and related to Credit type (importance: 2); Credit duration (importance: 3) and related to Job of households (importance: 4). The relatedness of these variables indicates that while each variable has its importance score, their predictive power is also influenced by their connections to other variables. These connections highlight that the impact of one variable can propagate through its links with different variables, amplifying or modifying its effect on the prediction of loan defaults. The relationship is illustrated by a network graph by [9], which shows how the variables interact and contribute collectively to the prediction model.
- Thomas Dataset: The Thomas dataset, used for advanced credit scoring techniques, includes several important variables, although specific rankings were not provided.
3.5.4. Challenges Associated with Data Scarcity and Imputation
3.5.5. Relevance to Individual Credit Risk Assessment
3.5.6. Limited Study on Dataset Used
3.6. Evaluation Metrics
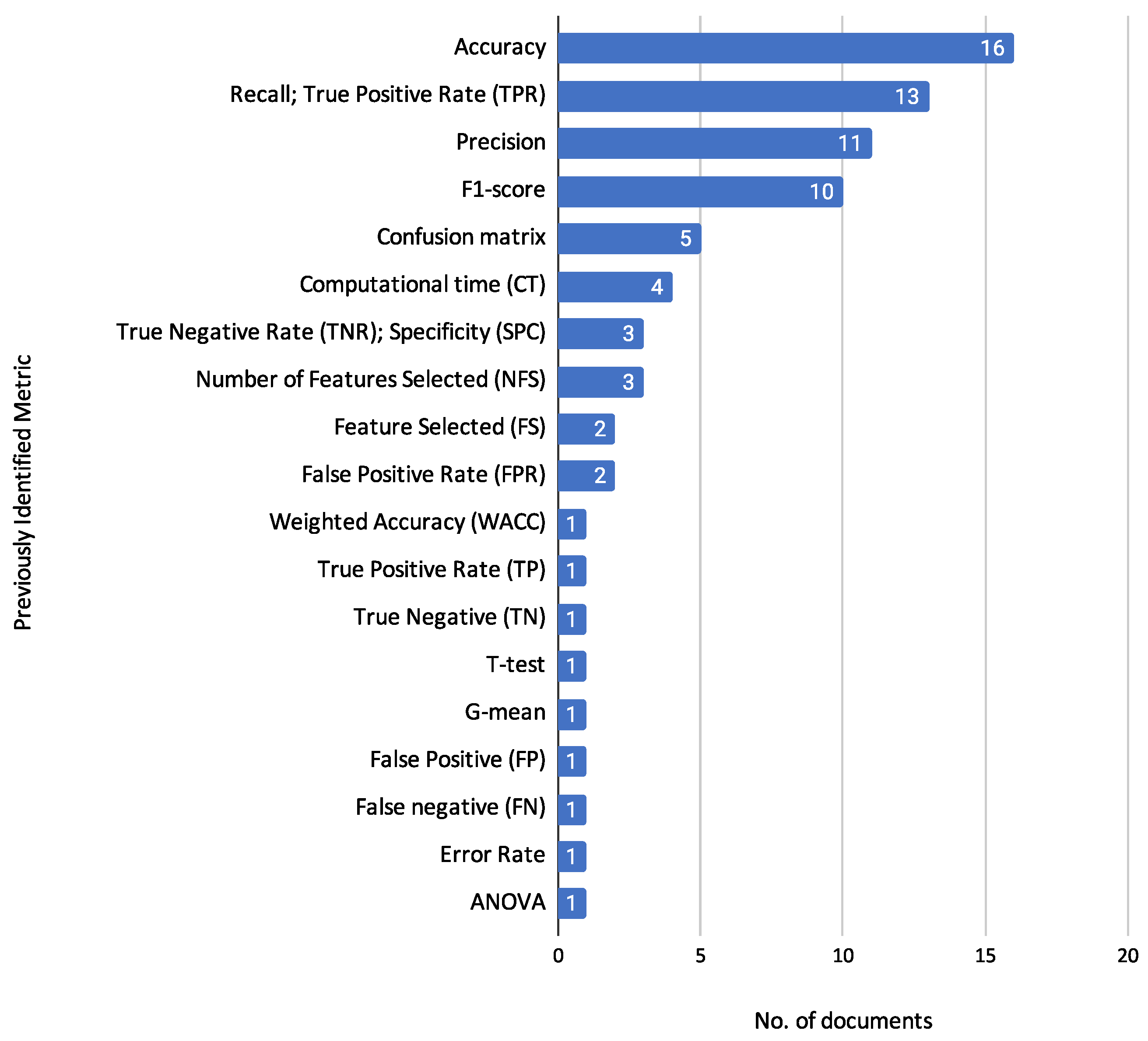
3.6.1. Previously Identified Metrics
Performance Metrics:
- Confusion Matrix: Used in studies [11,16,17,21,23], it provides a comprehensive view of the performance of an algorithm by displaying true positives, false positives, true negatives, and false negatives. The confusion matrix is a relevant tool for evaluating the performance of a classification model, providing a detailed breakdown of the model predictions compared to the actual outcomes. Table 7 shows a confusion matrix structure:Where:
- –
- TP (True Positives): The number of positive instances correctly classified as positive.
- –
- FN (False Negatives): The number of positive instances incorrectly classified as negative.
- –
- FP (False Positives): The number of negative instances incorrectly classified as positive.
- –
- TN (True Negatives): The number of negative instances correctly classified as negative.
In [31], TP, TN, FP, and FN were used to compare the performance of different algorithms. - Accuracy: Reported in multiple studies [9,11,12,14,15,17,18,19,20,21,22,23,25,29,30,31], it measures the proportion of correctly classified instances. Accuracy has the following formulation:In [28], a variation called Weighted Accuracy (WACC) is presented, which is useful for imbalanced datasets. WACC is calculated based on the accuracy of different classes weighted by the class proportions. WACC is defined as:where is the weight of class i and is the accuracy of class i.
- Error Rate: Reported in [16], it measures the proportion of incorrectly classified observations. The error rate is calculated as:
- G-Mean: Found in [28], it is the geometric mean of sensitivity and specificity. G-Mean is calculated as:
Metaheuristics Metrics:
- Computational Time (CT): Reported in studies [12,15,17,28,30], CT measures the time taken by an algorithm or model to train, reach a solution, or make a prediction. This metric is crucial for evaluating the efficiency of an algorithm, especially in large-scale or real-time applications, where shorter computational times are often desired.
Feature Metrics:
- Feature selected (FS): Mentioned in [12,25], FS corresponds to the identification of the selected characteristics. This metric indicates which specific features are chosen from the original set for model building. The notation for FS can be represented as:where is the subset of selected features and are the individual features in the subset.
Statistical Test Metrics:
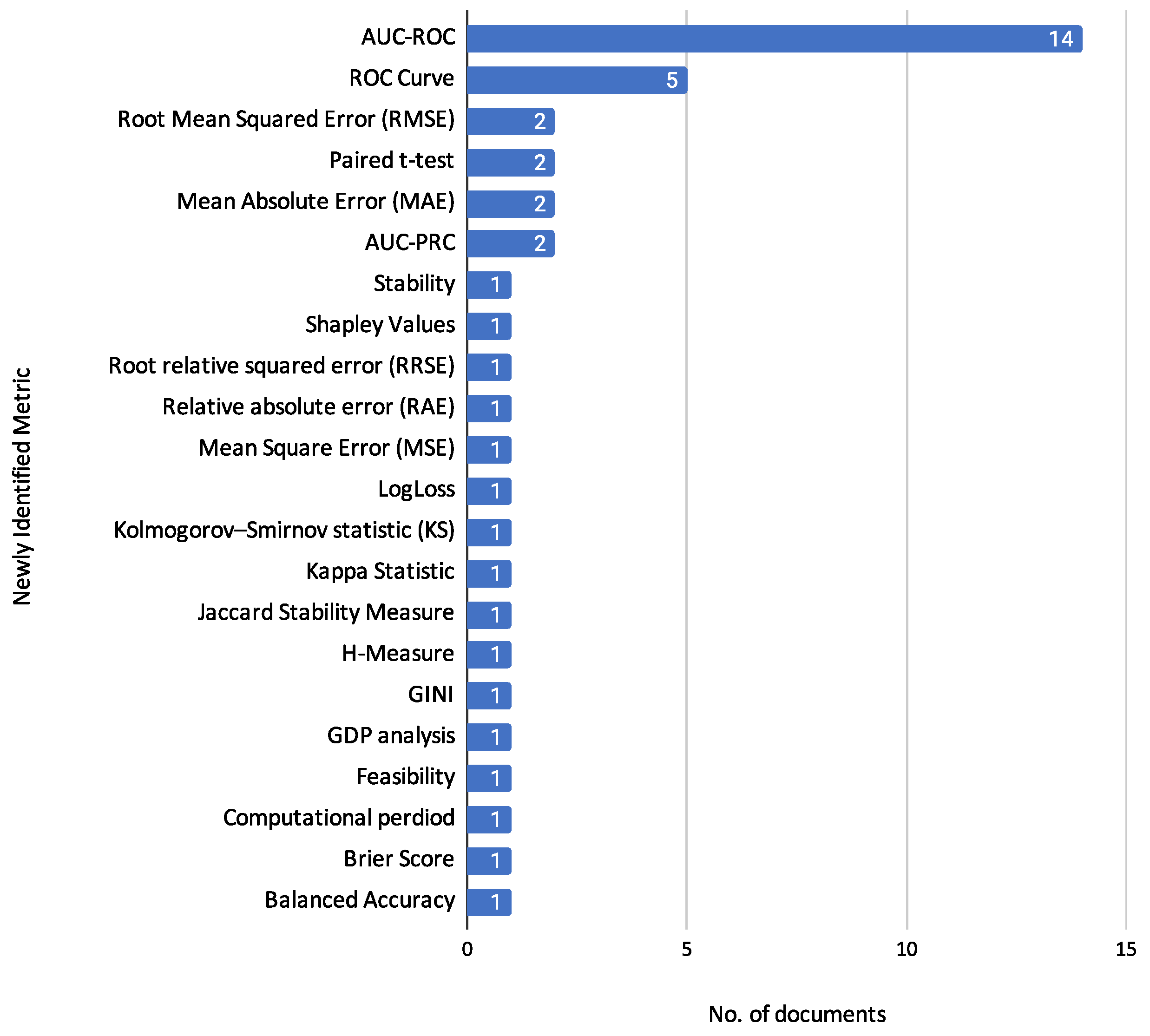
3.6.2. Newly Identified Metrics
Performance Metrics:
- Receiver Operating Characteristic Curve (ROC Curve): Used in [16,17,18,23,29]. The ROC curve is a graphical plot that illustrates the performance of a binary classifier system as its discrimination threshold is varied. As is illustrated in [69], the ROC curve is constructed by plotting pairs of False Positive Rate (FPR, defined in Equation (6)) and True Positive Rate (TPR, defined in Equation (4)) for all possible cut-off values c. Formally, it is represented as:
- Area Under the Receiver Operating Characteristic Curve (AUC-ROC): Seen in studies [10,12,16,17,20,21,22,23,24,26,27,28,29,31], it evaluates the ability of the model to discriminate between classes. A mathematical definition is provided by [69], where AUC is defined as:where is the function describing the ROC curve, and t represents the threshold. The AUC value ranges from 0 to 1, with higher values indicating better model performance.
- Area Under the Precision-Recall Curve (AUC-PRC): Reported in [22,27], it evaluates the trade-off between precision and recall for different threshold values. We present the following formulation for the AUC-PRC, calculated as the area under the precision-recall curve:where is the precision-recall curve as a function of the threshold t.
- Kolmogorov–Smirnov Statistic (KS): Used in [10] to evaluate the performance of the model. It is a non-parametric test that quantifies the difference between the distribution of predictions for different classes [70]. The KS statistic is defined as:where and are the empirical cumulative distribution functions of the predicted scores for the positive and negative classes, respectively. A higher KS value indicates better model discrimination between the classes.
- Kappa Statistic: As reported in [22], the Kappa statistic measures the agreement between predicted and observed categorizations. It is calculated as:where is the observed agreement and is the expected agreement. These are calculated as , where NRA is the Number of times both raters agree, and TNI is the Total number of instances. The expected agreement is , where k is the number of categories, is the proportion of instances assigned to the i-th category by the first rater, and is the proportion assigned by the second rater.
- GINI: Found in [27], it measures the inequality among values of a frequency distribution. This metric evaluates the performance of credit risk assessment models in distinguishing between different credit risk levels. The GINI coefficient summarizes the dispersion or inequality commonly used in economic studies. A higher GINI coefficient indicates better classification ability of the model. The article did not provide a specific mathematical formulation.
- GDP analysis: Found in [14], it is used to evaluate the economic impact of the proposed credit risk assessment models. By analyzing GDP, the study assesses the effectiveness of these models in improving financial stability and economic performance. It is important to note that no mathematical description of the GDP analysis metric is provided in the article.
- Mean Square Error (MSE): Mentioned in [14], MSE evaluates the performance of credit risk assessment models by measuring the average squared difference between the estimated and actual values. Lower MSE values indicate better model performance. The mathematical formulation of MSE is as follows:where n is the number of observations, represents the actual values, and represents the predicted values.
- Root Relative Squared Error (RRSE): Mentioned in [22], RRSE measures the square root of the sum of the squared differences between predicted and actual values, normalized by the sum of the squared differences between the actual values and their mean. It offers a relative measure of the model prediction error. The formulation is:where: n is the number of observations, represents the actual values, represents the predicted values and represents the mean of the actual values.
- Relative absolute error (RAE): Reported in [22], RAE provides a relative measure of the average absolute error by comparing the sum of the absolute differences between predicted and actual values to the sum of the absolute differences between the actual values and their mean. The formulation is:where: n is the number of observations, represents the actual values, represents the predicted values and represents the mean of the actual values.
- Log Loss: Mentioned in [27], Log Loss measures the performance of a classification model where the prediction is a probability value between 0 and 1. It penalizes false classifications and provides a better sense of the model’s uncertainty in its predictions.where is the predicted probability of the positive class, is the actual class label (0 or 1), and n is the number of observations.
- Brier Score: Found in [26], it measures the accuracy of probabilistic predictions. Brier score has the following formulation:where is the label of the i-th example, denotes the probability of the i-th example classified into the positive class, and N is the total number of examples.
Metaheuristics Metrics:
- Stability: Mentioned in [15], it assesses the stability of a feature selection algorithm against sampling fluctuations. The measure used is pairwise similarity (Jaccard Index) across all feature selection subsets .where: M is the number of feature selection subsets, is the similarity measure (Jaccard Index) between feature selection subsets and formulated as . Because the scaled measure ranges between 0 and 1, it is possible to compare the stability of classifiers of various types.
- Jaccard Stability Measure: Described in [12], this metric compares the stability of feature selection algorithms. Jaccard stability measure is an intersection-based metric that finds the average similarity between different feature sets. The value of JSM ranges from 0 to 1, where a value near 1 is desirable as it means that the feature set selected does not change significantly and, hence, is more stable concerning small variations in the dataset. Formally, the Jaccard stability measure is calculated as:where Q is the number of sub-samples of training data, . and denote the feature sets, denotes the number of common features.
- Computational period: Reported in [17], this metric represents the time taken to classify a loan as approved or rejected. It is expressed as follows:where represents the count of loans, is Cycles Per Instructions, and denotes the computational period.
- Feasibility: Reported in [14], this metric evaluates the practicality of implementing an algorithm in real-world scenarios. It is important to note that no mathematical description of the Feasibility metric is provided in the article.
Feature Metrics:
Statistical Test Metrics:
- Welch’s t-test: Used in [15], it compares the means of two independent groups while accounting for unequal variances and sample sizes, offering a more robust alternative to the standard t-test in heterogeneous data scenarios.
3.7. Reported Algorithm Performance by Benchmark Dataset
- Ref. [16] propose a two-stage selective learning framework, combining logistic regression for easy instances and a neural network for hard cases. However, they do not provide a unified performance metric that captures the behavior of the complete system; hence, no global value is included in the table.
- Similarly, ref. [24] introduce a two-stage rule extraction method, but only report performance metrics separately for the local rule extraction stage (see Table 6 in their paper) and the global optimization stage (see Table 7 in the same paper), without an aggregate evaluation of the integrated model.
- Ref. [20] report results for multiple classifiers and include both global (i.e., dataset-level) metrics and class-specific metrics. Specifically, accuracy and AUC are reported as overall summary measures, while precision, recall, and F1-score are provided separately for each class. As a result, only accuracy and AUC are included in the benchmark table, as the remaining metrics cannot be directly compared due to the lack of aggregated or averaged values.
3.8. Summary of Findings
4. Conclusions
- Machine Learning Techniques: A wide array of supervised learning algorithms such as Logistic Regression, Decision Trees, Random Forest, Support Vector Machines, and Gradient Boosting Machines are predominantly used. Unsupervised learning, reinforcement learning, and deep learning models also contribute significantly to improving predictive accuracy.
- Feature Selection Methods: Effective feature selection methods, categorized into filter, wrapper, and embedded approaches, are critical for enhancing model performance. Techniques like mutual information, chi-squared tests, Recursive Feature Elimination, LASSO, and tree-based methods are widely utilized.
- Applications in Various Financial Contexts: Machine learning and optimization techniques are applied in traditional banking, peer-to-peer lending, and educational institutions, each with unique challenges and benefits. These applications improve the accuracy and efficiency of credit risk assessments and support financial planning and risk management.
- Datasets and Variables: Public and proprietary datasets, including the Statlog (German Credit Data), Lending Club Loan Data, and Default of Credit Card Clients, are commonly used. Key variables include demographic information, financial status, loan specifics, credit history, employment details, and educational background.
- Evaluation Metrics: A comprehensive set of metrics, such as accuracy, precision, recall, F1-score, AUC, MAE, and RMSE, are used to evaluate model performance. These metrics ensure a thorough model accuracy, efficiency, and practicality assessment.
4.1. Practical Recommendations
4.2. Future Research Directions
4.3. Limitations
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Thomas, L.; Crook, J.; Edelman, D. Credit Scoring and Its Applications; SIAM: Philadelphia, PA, USA, 2017. [Google Scholar]
- Bhattacharya, A.; Biswas, S.K.; Mandal, A. Credit risk evaluation: A comprehensive study. Multimed. Tools Appl. 2023, 82, 18217–18267. [Google Scholar] [CrossRef]
- Amarnadh, V.; Moparthi, N.R. Comprehensive review of different artificial intelligence-based methods for credit risk assessment in data science. Intell. Decis. Technol. 2023, 17, 1265–1282. [Google Scholar] [CrossRef]
- Çallı, B.A.; Coşkun, E. A longitudinal systematic review of credit risk assessment and credit default predictors. Sage Open 2021, 11, 21582440211061333. [Google Scholar] [CrossRef]
- Noriega, J.P.; Rivera, L.A.; Herrera, J.A. Machine Learning for Credit Risk Prediction: A Systematic Literature Review. Data 2023, 8, 169. [Google Scholar] [CrossRef]
- Oualid, A.; Maleh, Y.; Moumoun, L. Federated learning techniques applied to credit risk management: A systematic literature review. EDPACS 2023, 68, 42–56. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ 2021, 372, n71. [Google Scholar] [CrossRef] [PubMed]
- Kitchenham, B. Procedures for Performing Systematic Reviews; Joint Technical Report TR/SE-0401; Department of Computer Science, Keele University: Keele, UK, Technical Report 0400011T.1; National ICT Australia Ltd.: Sydney, NSW, Australia, 2004. [Google Scholar]
- Masmoudi, K.; Abid, L.; Masmoudi, A. Credit risk modeling using Bayesian network with a latent variable. Expert Syst. Appl. 2019, 127, 157–166. [Google Scholar] [CrossRef]
- Muñoz-Cancino, R.; Bravo, C.; Ríos, S.A.; Graña, M. On the dynamics of credit history and social interaction features, and their impact on creditworthiness assessment performance. Expert Syst. Appl. 2023, 218, 119599. [Google Scholar] [CrossRef]
- Wang, T.; Liu, R.; Qi, G. Multi-classification assessment of bank personal credit risk based on multi-source information fusion. Expert Syst. Appl. 2022, 191, 116236. [Google Scholar] [CrossRef]
- Arora, N.; Kaur, P.D. A Bolasso based consistent feature selection enabled random forest classification algorithm: An application to credit risk assessment. Appl. Soft Comput. 2020, 86, 105936. [Google Scholar] [CrossRef]
- Zhao, F.; Lu, Y.; Li, X.; Wang, L.; Song, Y.; Fan, D.; Zhang, C.; Chen, X. Multiple imputation method of missing credit risk assessment data based on generative adversarial networks. Appl. Soft Comput. 2022, 126, 109273. [Google Scholar] [CrossRef]
- Tian, J.; Li, L. Digital universal financial credit risk analysis using particle swarm optimization algorithm with structure decision tree learning-based evaluation model. Wirel. Commun. Mob. Comput. 2022, 2022, 4060256. [Google Scholar] [CrossRef]
- Atif, D.; Salmi, M. The Most Effective Strategy for Incorporating Feature Selection into Credit Risk Assessment. SN Comput. Sci. 2022, 4, 96. [Google Scholar] [CrossRef]
- Chen, D.; Ye, J.; Ye, W. Interpretable selective learning in credit risk. Res. Int. Bus. Financ. 2023, 65, 101940. [Google Scholar] [CrossRef]
- Amarnadh, V.; Moparthi, N.R. Prediction and assessment of credit risk using an adaptive Binarized spiking marine predators’ neural network in financial sector. Multimed. Tools Appl. 2023, 83, 1–37. [Google Scholar] [CrossRef]
- Doko, F.; Kalajdziski, S.; Mishkovski, I. Credit risk model based on central bank credit registry data. J. Risk Financ. Manag. 2021, 14, 138. [Google Scholar] [CrossRef]
- Cai, S.; Zhang, J. Exploration of credit risk of P2P platform based on data mining technology. J. Comput. Appl. Math. 2020, 372, 112718. [Google Scholar] [CrossRef]
- Coşkun, S.; Turanli, M. Credit risk analysis using boosting methods. J. Appl. Math. Stat. Informatics 2023, 19, 5–18. [Google Scholar] [CrossRef]
- Pandey, P.; Bandhu, K.C. A credit risk assessment on borrowers classification using optimized decision tree and KNN with bayesian optimization. Int. J. Inf. Technol. 2022, 14, 3679–3689. [Google Scholar] [CrossRef]
- Giri, P.K.; De, S.S.; Dehuri, S.; Cho, S.B. Biogeography based optimization for mining rules to assess credit risk. Intell. Syst. Account. Financ. Manag. 2021, 28, 35–51. [Google Scholar] [CrossRef]
- Biswas, N.; Mondal, A.S.; Kusumastuti, A.; Saha, S.; Mondal, K.C. Automated credit assessment framework using ETL process and machine learning. Innov. Syst. Softw. Eng. 2022, 21, 257–270. [Google Scholar] [CrossRef] [PubMed]
- Dong, L.a.; Ye, X.; Yang, G. Two-stage rule extraction method based on tree ensemble model for interpretable loan evaluation. Inf. Sci. 2021, 573, 46–64. [Google Scholar] [CrossRef]
- Hassani, Z.; Meybodi, M.A.; Hajihashemi, V. Credit risk assessment using learning algorithms for feature selection. Fuzzy Inf. Eng. 2020, 12, 529–544. [Google Scholar] [CrossRef]
- Merćep, A.; Mrčela, L.; Birov, M.; Kostanjčar, Z. Deep neural networks for behavioral credit rating. Entropy 2020, 23, 27. [Google Scholar] [CrossRef] [PubMed]
- Villarreal-Torres, H.; Ángeles-Morales, J.; Marín-Rodriguez, W.; Andrade-Girón, D.; Carreño-Cisneros, E.; Cano-Mejía, J.; Mejía-Murillo, C.; Boscán-Carroz, M.C.; Flores-Reyes, G.; Cruz-Cruz, O. Development of a Classification Model for Predicting Student Payment Behavior Using Artificial Intelligence and Data Science Techniques. EAI Endorsed Trans. Scalable Inf. Syst. 2023, 10. [Google Scholar] [CrossRef]
- Zhang, X.; Yu, L.; Yin, H.; Lai, K.K. Integrating data augmentation and hybrid feature selection for small sample credit risk assessment with high dimensionality. Comput. Oper. Res. 2022, 146, 105937. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, Y.; Liang, M.; Yuan, R.; Feng, J.; Wu, J. National student loans default risk prediction: A heterogeneous ensemble learning approach and the SHAP method. Comput. Educ. Artif. Intell. 2023, 5, 100166. [Google Scholar] [CrossRef]
- Wang, X. Analysis of bank credit risk evaluation model based on BP neural network. Comput. Intell. Neurosci. 2022, 2022, 2724842. [Google Scholar] [CrossRef] [PubMed]
- Cornacchia, G.; Anelli, V.W.; Narducci, F.; Ragone, A.; Di Sciascio, E. A general architecture for a trustworthy creditworthiness-assessment platform in the financial domain. Ann. Emerg. Technol. Comput. (AETiC) 2023, 7, 56–64. [Google Scholar] [CrossRef]
- Mukhamediev, R.I.; Popova, Y.; Kuchin, Y.; Zaitseva, E.; Kalimoldayev, A.; Symagulov, A.; Levashenko, V.; Abdoldina, F.; Gopejenko, V.; Yakunin, K.; et al. Review of artificial intelligence and machine learning technologies: Classification, restrictions, opportunities and challenges. Mathematics 2022, 10, 2552. [Google Scholar] [CrossRef]
- Agrawal, P.; Abutarboush, H.F.; Ganesh, T.; Mohamed, A.W. Metaheuristic Algorithms on Feature Selection: A Survey of One Decade of Research (2009-2019). IEEE Access 2021, 9, 26766–26791. [Google Scholar] [CrossRef]
- Nssibi, M.; Manita, G.; Korbaa, O. Advances in nature-inspired metaheuristic optimization for feature selection problem: A comprehensive survey. Comput. Sci. Rev. 2023, 49, 100559. [Google Scholar] [CrossRef]
- Kurman, S.; Kisan, S. An in-depth and contrasting survey of meta-heuristic approaches with classical feature selection techniques specific to cervical cancer. Knowl. Inf. Syst. 2023, 65, 1881–1934. [Google Scholar] [CrossRef]
- Pham, T.H.; Raahemi, B. Bio-Inspired Feature Selection Algorithms With Their Applications: A Systematic Literature Review. IEEE Access 2023, 11, 43733–43758. [Google Scholar] [CrossRef]
- Sadeghian, Z.; Akbari, E.; Nematzadeh, H.; Motameni, H. A review of feature selection methods based on meta-heuristic algorithms. J. Exp. Theor. Artif. Intell. 2023, 37, 1–51. [Google Scholar] [CrossRef]
- Arun Kumar, R.; Vijay Franklin, J.; Koppula, N. A Comprehensive Survey on Metaheuristic Algorithm for Feature Selection Techniques. Mater. Today Proc. 2022, 64, 435–441, Presented at the International Conference on Advanced Materials for Innovation and Sustainability. [Google Scholar] [CrossRef]
- Akinola, O.O.; Ezugwu, A.E.; Agushaka, J.O.; Zitar, R.A.; Abualigah, L. Multiclass feature selection with metaheuristic optimization algorithms: A review. Neural Comput. Appl. 2022, 34, 19751–19790. [Google Scholar] [CrossRef] [PubMed]
- Dokeroglu, T.; Deniz, A.; Kiziloz, H.E. A comprehensive survey on recent metaheuristics for feature selection. Neurocomputing 2022, 494, 269–296. [Google Scholar] [CrossRef]
- Abu Khurma, R.; Aljarah, I.; Sharieh, A.; Abd Elaziz, M.; Damaševičius, R.; Krilavičius, T. A Review of the Modification Strategies of the Nature Inspired Algorithms for Feature Selection Problem. Mathematics 2022, 10, 464. [Google Scholar] [CrossRef]
- Yab, L.Y.; Wahid, N.; Hamid, R.A. A Meta-Analysis Survey on the Usage of Meta-Heuristic Algorithms for Feature Selection on High-Dimensional Datasets. IEEE Access 2022, 10, 122832–122856. [Google Scholar] [CrossRef]
- Abiodun, E.O.; Alabdulatif, A.; Abiodun, O.I.; Alawida, M.; Alabdulatif, A.; Alkhawaldeh, R.S. A systematic review of emerging feature selection optimization methods for optimal text classification: The present state and prospective opportunities. Neural Comput. Appl. 2021, 33, 15091–15118. [Google Scholar] [CrossRef]
- Al-Tashi, Q.; Abdulkadir, S.J.; Rais, H.M.; Mirjalili, S.; Alhussian, H. Approaches to Multi-Objective Feature Selection: A Systematic Literature Review. IEEE Access 2020, 8, 125076–125096. [Google Scholar] [CrossRef]
- Song, H.; Triguero, I.; Özcan, E. A review on the self and dual interactions between machine learning and optimisation. Prog. Artif. Intell. 2019, 8, 143–165. [Google Scholar] [CrossRef]
- Simon, D. Biogeography-based optimization. IEEE Trans. Evol. Comput. 2008, 12, 702–713. [Google Scholar] [CrossRef]
- Yu, G.; Meng, Z.; Ma, H.; Liu, L. An adaptive Marine Predators Algorithm for optimizing a hybrid PV/DG/Battery System for a remote area in China. Energy Rep. 2021, 7, 398–412. [Google Scholar] [CrossRef]
- Zaeimi, M.; Ghoddosian, A. Color harmony algorithm: An art-inspired metaheuristic for mathematical function optimization. Soft Comput. 2020, 24, 12027–12066. [Google Scholar] [CrossRef]
- Mikki, S.M.; Kishk, A.A. Quantum particle swarm optimization for electromagnetics. IEEE Trans. Antennas Propag. 2006, 54, 2764–2775. [Google Scholar] [CrossRef]
- Yang, X.S. Nature-Inspired Metaheuristic Algorithms; Luniver Press: Frome, UK, 2010. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Hofmann, H. Statlog (German Credit Data); UCI Machine Learning Repository: Irvine, CA, USA, 1994; Available online: https://archive.ics.uci.edu/dataset/144/statlog+german+credit+data (accessed on 12 May 2025).
- Quinlan, R. Statlog (Australian Credit Approval); UCI Machine Learning Repository: Irvine, CA, USA, 2019; Available online: https://archive.ics.uci.edu/dataset/143/statlog+australian+credit+approval (accessed on 12 May 2025).
- South German Credit; UCI Machine Learning Repository: Irvine, CA, USA, 2019; Available online: https://archive.ics.uci.edu/dataset/522/south+german+credit (accessed on 12 May 2025).
- Arnaud de Servigny, W.C. Loan Default Prediction—Imperial College London. 2014. Available online: https://www.kaggle.com/competitions/loan-default-prediction (accessed on 5 June 2024).
- Begiev, Z. My Dataset. 2018. Available online: https://www.kaggle.com/datasets/zaurbegiev/my-dataset (accessed on 5 June 2024).
- Home Credit Group. Home Credit Default Risk. 2018. Available online: https://www.kaggle.com/competitions/home-credit-default-risk (accessed on 5 June 2024).
- Credit Fusion, W.C. Give Me Some Credit. 2011. Available online: https://www.kaggle.com/datasets/brycecf/give-me-some-credit-dataset (accessed on 5 June 2024).
- Yeh, I.C. Default of Credit Card Clients; UCI Machine Learning Repository: Irvine, CA, USA, 2016; Available online: https://archive.ics.uci.edu/dataset/350/default+of+credit+card+clients (accessed on 12 May 2025).
- Berka, P. PKDD’99 Discovery Challenge Website. 1999. Available online: https://sorry.vse.cz/~berka/challenge/pkdd1999/chall.htm (accessed on 5 June 2024).
- Laotse. Credit Risk Dataset. 2024. Available online: https://www.kaggle.com/datasets/laotse/credit-risk-dataset (accessed on 5 June 2024).
- Becker, D. AER Credit Card Data. 2024. Available online: https://www.kaggle.com/datasets/dansbecker/aer-credit-card-data (accessed on 5 June 2024).
- China UnionPay Co., Ltd. China UnionPay Credit Dataset. 2019. Available online: https://open.chinaums.com/saas-web/ (accessed on 5 June 2024).
- Yoon, J.; Jordon, J.; Schaar, M. Gain: Missing data imputation using generative adversarial nets. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 5689–5698. [Google Scholar]
- Barrera-García, J.; Cisternas-Caneo, F.; Crawford, B.; Gómez Sánchez, M.; Soto, R. Feature Selection Problem and Metaheuristics: A Systematic Literature Review about Its Formulation, Evaluation and Applications. Biomimetics 2023, 9, 9. [Google Scholar] [CrossRef]
- Brodersen, K.H.; Ong, C.S.; Stephan, K.E.; Buhmann, J.M. The balanced accuracy and its posterior distribution. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 3121–3124. [Google Scholar]
- Calì, C.; Longobardi, M. Some mathematical properties of the ROC curve and their applications. Ric. Mat. 2015, 64, 391–402. [Google Scholar] [CrossRef]
- Hodges, J., Jr. The significance probability of the Smirnov two-sample test. Ark. Mat. 1958, 3, 469–486. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NeurIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; Volume 30, pp. 4768–4777. [Google Scholar]
- Hand, D.J. Measuring classifier performance: A coherent alternative to the area under the ROC curve. Mach. Learn. 2009, 77, 103–123. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Review | ICRA | ML | FS | OT | D&V | EM | EN-PPA | EN-AIT |
|---|---|---|---|---|---|---|---|---|
| [2] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| [6] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| [3] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| [5] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| [4] | ✓ | ✓ | ✓ | ✓ | ||||
| Our work | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| ID | Question | Purpose |
|---|---|---|
| RQ1 | What machine learning techniques are employed in individual credit risk assessment, and how are they applied in this context? | Identify and categorize machine learning algorithms for individual credit risk assessment and investigate their applications. |
| RQ2 | Which feature selection methods are used in credit risk assessment models for individuals? | Explore techniques for selecting relevant features in individual credit risk assessment models. |
| RQ3 | How are optimization techniques applied in the context of individual credit risk assessment? | Investigate the applications of optimization techniques specifically for individual credit risk assessment. |
| RQ4 | What datasets and variables are commonly used in individual credit risk assessment studies? | Identify the typical data sources and key variables used specifically in individual credit risk assessment studies. |
| RQ5 | What evaluation metrics are used to assess the performance of credit risk assessment models for individuals? | Examine the criteria used for evaluating the effectiveness of individual credit risk assessment models. |
| Journal Title | Documents |
|---|---|
| Expert Systems with Applications | [9,10,11] |
| Applied Soft Computing | [12,13] |
| Wireless Communications and Mobile Computing | [14] |
| SN Computer Science | [15] |
| Research in International Business and Finance | [16] |
| Multimedia Tools and Applications | [17] |
| Journal of Risk and Financial Management | [18] |
| Journal of Computational and Applied Mathematics | [19] |
| Journal of Applied Mathematics Statistics and Informatics | [20] |
| International Journal of Information Technology (Singapore) | [21] |
| Intelligent Systems in Accounting, Finance and Management | [22] |
| Innovations in Systems and Software Engineering | [23] |
| Information Sciences | [24] |
| Fuzzy Information and Engineering | [25] |
| Entropy | [26] |
| EAI Endorsed Transactions on Scalable Information Systems | [27] |
| Computers and Operations Research | [28] |
| Computers and Education: Artificial Intelligence | [29] |
| Computational Intelligence and Neuroscience | [30] |
| Annals of Emerging Technologies in Computing | [31] |
| Document | Cited by | Document | Cited by |
|---|---|---|---|
| [12] | 113 | [16] | 4 |
| [9] | 54 | [15] | 4 |
| [19] | 27 | [27] | 3 |
| [11] | 26 | [14] | 3 |
| [13] | 19 | [10] | 3 |
| [28] | 16 | [23] | 3 |
| [24] | 15 | [30] | 2 |
| [22] | 14 | [29] | 1 |
| [18] | 11 | [31] | 1 |
| [21] | 10 | [20] | 1 |
| [26] | 7 | [17] | 0 |
| [25] | 5 |
| Dataset Name | Source | Intances | Features | Labels |
|---|---|---|---|---|
| Statlog (Australian Credit Approval) | UCI | 690 | 14 | 2 |
| Statlog (German Credit Data) | UCI | 1000 | 20 | 2 |
| Default of Credit Card Clients | UCI | 30,000 | 23 | 2 |
| South German Credit Dataset | UCI | 1000 | 21 | 2 |
| Credit risk dataset | Kaggle | 239 | 11 | 2 |
| Kaggle’s Bank Loan Status dataset | Kaggle | 12,535 | 19 | 2 |
| Loan default prediction dataset | Kaggle | 105,471 | 769 | 2 |
| Give me some credit dataset | Kaggle | 120,969 | 10 | 2 |
| Credit card econometrics | Kaggle | 1320 | 12 | 2 |
| Kaggle Home Credit Default Risk | Kaggle | 307,511 | 122 | 2 |
| Czech Financial Dataset | Financial PKDD’99 Discovery Challenge | 682 | 55 | 2 |
| Thomas dataset | Credit Scoring and Its Applications, Book | 1225 | 14 | 2 |
| China UnionPay credit dataset | China UnionPay | 11,017 | 199 | 2 |
| Dataset Name | Source | Intances | Features | Labels |
|---|---|---|---|---|
| Lending Club loan data | Lendig club | n.a. | n.a. | n.a. |
| Lending club dataset | Lendig lub | 42,538 | 143 | 2 |
| Credit risk assessment data | Anonymous local bank in China. | 10,744 | 10 | n.a. |
| LendingClub (LC) | Lendig club | 500,000 | 120 | n.a. |
| Commercial Bank Credit Records | Anonymous commercial bank in China | 27,520 | 27 | 5 |
| Business credit score dataset | Data from a Latin American bank | 20,835 | 585 | 2 |
| Personal credit score | Data from a Latin American bank | 76,209 | 936 | 2 |
| General Data Protection Regulation (GDPR) | Commercial banks and savings institutions | 1,000,000 | n.a. | n.a. |
| Advanced Analytics of Credit Registry Dataset | undetermined | n.a. | n.a. | n.a. |
| WIND Dataset | Commercial bank’s personal credit database | n.a. | n.a. | n.a. |
| Croatian Bank Credit Risk Dataset 2009–2013 | Large Croatian Bank | 870,710 | 109 | 2 |
| Croatian Bank Credit Risk Dataset 2004–2018 | Large Croatian Bank | 782,875 | 108 | 2 |
| North Macedonia Credit Registry Data | Central Bank of the Republic of North Macedonia | 1,000,000,000 | 52 | 5 |
| Tunisian Bank Loan Data | Data from several Tunisian banks | n.a. | 9 | 2 |
| Lending Club (LC) dataset 2017–2018 | Lendig club | 477,131 | 16 | 2 |
| Bank credit risk data | Comercial Banks | 360 | n.a. | n.a. |
| National Student Loans Dataset | University in Beijing, China | 18,000 | 20 | 2 |
| Student Payment Behavior Dataset | Private university in Peru | 8495 | 13 | 2 |
| Confusion Matrix | Actual Positive (P) | Actual Negative (N) |
|---|---|---|
| Predicted Positive (P) | TP | FN |
| Predicted Negative (N) | FP | TN |
| Dataset | Article | Algorithm Proposed | Accuracy | Recall | Precision | F1-Score | AUC-ROC | AUC-PRC |
|---|---|---|---|---|---|---|---|---|
| Statlog (German Credit Data) [54] | [12] | BS-RF | 0.8400 | 0.7130 | ||||
| [15] | RFE-RF | 0.7710 | 0.9061 | 0.7987 | 0.8490 | |||
| [24] | Two-Stage Rule Extraction Method | * | * | * | ||||
| [22] | LGBBO-RuleMiner | 0.8930 | 0.7640 | 0.7510 | 0.7440 | 0.7910 | 0.8100 | |
| [25] | HFA-FKNN | 0.8714 | 0.8805 | 0.8918 | 0.8861 | |||
| Statlog (Australian Credit Approval) [55] | [24] | Two-Stage Rule Extraction Method | * | * | * | |||
| [22] | LGBBO-RuleMiner | 0.8700 | 0.8700 | 0.8690 | 0.8690 | 0.9270 | 0.9180 | |
| Default of Credit Card Clients [61] | [16] | Two-stage Selective Learning Framework | * | |||||
| [21] | Optimized Decision Tree | 0.8220 | 0.6900 | 0.3500 | 0.4125 | 0.7000 | ||
| South German Credit Dataset [56] | [25] | HFA-RF | 0.8621 | 0.8677 | 0.8700 | 0.8631 | ||
| Thomas Dataset [1] | [25] | HFA-RF | 0.8304 | 0.8269 | 0.8371 | 0.8314 | ||
| Kaggle’s Bank Loan Status dataset [58] | [12] | BS-RF | 0.7310 | 0.7310 | ||||
| Credit Card Econometrics [64] | [25] | HFA-RF | 0.9902 | 1.0000 | 0.9805 | 0.9901 | ||
| China UnionPay Credit Dataset [65] | [28] | WGAN + KPLS-QPSO-HFS | 0.6202 | 0.6309 | ||||
| Give Me Some Credit Dataset [60] | [16] | Two-stage Selective Learning Framework | * | |||||
| Kaggle Home Credit Default Risk [59] | [20] | XGBoost (Tuned) | 0.7600 | * | * | * | 0.7391 | |
| Credit risk dataset [63] | [17] | ABSMPNN | 0.9890 | 0.9910 | 0.9904 | 0.9865 | 0.9800 | |
| Loan default prediction dataset [57] | [28] | WGAN + KPLS-QPSO-HFS | 0.5971 | 0.6375 | ||||
| Czech Financial Dataset [62] | [31] | CSM–EWD-SVM | 0.8670 | 0.9960 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Paz, Á.; Crawford, B.; Monfroy, E.; Barrera-García, J.; Peña Fritz, Á.; Soto, R.; Cisternas-Caneo, F.; Yáñez, A. Machine Learning and Metaheuristics Approach for Individual Credit Risk Assessment: A Systematic Literature Review. Biomimetics 2025, 10, 326. https://doi.org/10.3390/biomimetics10050326
Paz Á, Crawford B, Monfroy E, Barrera-García J, Peña Fritz Á, Soto R, Cisternas-Caneo F, Yáñez A. Machine Learning and Metaheuristics Approach for Individual Credit Risk Assessment: A Systematic Literature Review. Biomimetics. 2025; 10(5):326. https://doi.org/10.3390/biomimetics10050326
Chicago/Turabian StylePaz, Álex, Broderick Crawford, Eric Monfroy, José Barrera-García, Álvaro Peña Fritz, Ricardo Soto, Felipe Cisternas-Caneo, and Andrés Yáñez. 2025. "Machine Learning and Metaheuristics Approach for Individual Credit Risk Assessment: A Systematic Literature Review" Biomimetics 10, no. 5: 326. https://doi.org/10.3390/biomimetics10050326
APA StylePaz, Á., Crawford, B., Monfroy, E., Barrera-García, J., Peña Fritz, Á., Soto, R., Cisternas-Caneo, F., & Yáñez, A. (2025). Machine Learning and Metaheuristics Approach for Individual Credit Risk Assessment: A Systematic Literature Review. Biomimetics, 10(5), 326. https://doi.org/10.3390/biomimetics10050326