1. Introduction
Condition monitoring (CM) is the process of monitoring one or more condition parameters in a system or machinery in order to identify some changes that are indicative of an incipient fault or, alternatively, imminent degradation of the equipment health (for more information see [
1,
2,
3,
4]). In the past, condition monitoring was applied simply through manual diagnostic actions. Nowadays, with the introduction of low-cost sensors and automated monitoring systems, online condition monitoring is rapidly growing. Condition monitoring strategies help select parameters from the sensors installed in the system in order to detect a change in the machine’s health condition [
5,
6,
7]. This procedure is the core of predictive maintenance policies. As a matter of fact, the use of CM provides all the necessary information to schedule maintenance activities promptly and prevent unexpected failures [
8,
9,
10,
11,
12]. Thus, cost reduction is guaranteed, maximizing the system uptime and optimizing the production efficiency. The added values of online rather than offline condition monitoring and manual data collection are listed below:
Workforce optimization: manual diagnostics requires time and resource allocation to analyze the collected data and assess the required maintenance targets.
Increased data storage: online monitoring guarantees continuous measurements for any piece of machinery, avoids mistakes in the registration of values and creates a trustworthy database.
Improved diagnostics: great accuracy in failure prediction is achievable thanks to the unique database for historical trends and baseline data.
Cost reduction: even if online diagnostics requires expensive software and application devices, the cost of manual diagnostics is considerably higher due to the personnel and time required, effectiveness of the implemented solutions, possibility of human errors, cost, and productivity impact of undiagnosed outage, etc.
Condition monitoring techniques are widely used on rotating equipment and other machinery (e.g., pumps, electric motors, and engines). The most popular methods used in modern industries to monitor the health state of such devices are vibration analysis, oil analysis, thermal analysis, power consumption analysis, and ultrasound analysis (see, for instance, but not only, [
13,
14,
15,
16,
17]). Effectiveness and efficiency of condition monitoring remarkably depend on the application field. It seems obvious that monitoring the health state of a complex system to anticipate the occurrence of failures avoiding unexpected productivity outage allows achieving high availability with lower costs. However, a cost–benefit analysis is required to evaluate the proper effectiveness of CM in each field. For instance, a modern study emphasizes that the repayment period of a condition monitoring system for remote maintenance of a power plant is one single maintenance mission, reaching an estimated economic benefit of approximately 45 million euros after 10 maintenance missions [
18].
This paper deals with the possible diagnostic solutions that could be implemented to improve the performances of safety instrumented systems (SIS) and thus guarantee adequate levels of the RAMS (reliability, availability, maintainability, and safety) parameters in the oil and gas industry.
Diagnostics and RAMS analysis are fundamental and critical aspects at oil and gas plants due to several different types of accidents and problems that have occurred over the years. Just to cite one of the major worldwide disasters in this field, Piper Alpha offshore disaster (1988, UK) resulted in 167 deaths and an approximate loss of
$3.4 billion [
19,
20]. Taking 2012 as an example, 88 fatalities occurred in 52 separate incidents worldwide at onshore and offshore oil and gas plants. In addition, in the same year, 1699 injuries were reported in at least one day of work, with 53,325 lost workdays in total and billions of dollars of production losses [
19]. Such examples allow to easily understand the crucial role that SIS and, more generally, functional safety play in the oil and gas industry in terms of human safety, productivity, environment safety and profits [
20].
Consequently, the aim of the paper was to design and develop a safety instrumented system taking into account online diagnostic solutions for the oil and gas field. The main contribution of the presented methodology is the ability to reach the optimal tradeoff between the procedure defined in the international standards and the market requirements using a diagnostic solution in order to maximize risk reduction and increase the safety performance. The design of a SIS is a critical and crucial task in oil and gas applications, as well as in any other application fields. Usually, the design is performed following the guidelines of adequate international standards. From this point of view, the major gap that needs to be addressed is a lack of clarity and exhaustive explanation of the procedures contained in the standards for every possible system architecture, with particular reference to diagnostics-oriented solutions. This paper allows filling this gap with a step-by-step application to a real case study for the oil and gas industry. Furthermore, the paper emphasizes the need in a proper and accurate estimation of the reliability performance (e.g., in terms of the failure rate classification) for every item that makes up the SIS.
This paper is structured as follows:
Section 2 presents the proposed diagnostic solutions to monitor the health state of the safety instrumented systems used in oil and gas applications.
Section 3 illustrates the phases required to carry out a proper and accurate diagnostics-oriented design of a SIS. Finally,
Section 4 presents the results of an actual application in which a safety instrumented system for the oil and gas industry is designed taking into account the diagnostics-oriented approach. The results emphasize how the implementation of an accurate diagnostic solution can help to reach the safety integrity level (SIL) determined during the specification phase.
3. Methodology: A Diagnostics-Oriented Design for Safety Instrumented Systems
In several manufacturing processes (e.g., chemical and oil and gas applications), the industrial operation involves an intrinsic risk to the operator, property, and environment. In order to prevent and control dangerous failures, the functional safety consists of designing, building, operating, and maintaining an appropriate system called a safety instrumented system (SIS). A preliminary risk analysis is mandatory to obtain the required SIS performance [
37,
38,
39].
Process plant, machinery, and equipment may present risks to the operator and environment from hazardous situations (e.g., machinery traps, explosions, fires, and radiation overdose) in case of malfunction such as failures of electrical, electronic, and/or programmable electronic (E/E/PE) devices. Failures can arise from either physical faults in the device (e.g., causing random hardware failures) [
40], systematic faults (for example, human errors made in the specification and design of a system causing a systematic failure under some particular combination of inputs [
41]), or some environmental conditions [
42]. The risk for industrial equipment is associated with an initiating event that leads the system into a degraded state in which the integrity of the system itself is more or less severely impacted [
43].
To mitigate the risk, the solution is to reduce its frequency of occurrence or its severity.
Table 1 shows the risk matrix in terms of severity and frequency of occurrence in compliance with IEC 61508:2010 [
44]. The latter is an international standard that provides the specifications and guidelines to properly design a SIS for functional safety of industrial applications based on E/E/PE [
45,
46].
Safety instrumented systems (SISs) are explicitly designed to protect people, equipment, and environment by reducing the occurrence and/or the impact severity of dangerous events.
Figure 4 illustrates a generic SIS which is typically constituted by a chain of three main items [
47,
48]:
Sensor(s) stage: it monitors the physical quantity and provides a corresponding electrical output. Field sensors are used to collect information and determine an incipient danger: these sensors evaluate process parameters such as pressure, temperature, acceleration, flow, etc. Some manufacturing companies design sensors dedicated for use in safety systems.
Logic solver(s) stage: it accepts the data collected by the sensor(s) and elaborates them in order to determine if the process (or the whole plant) is in a safe state and working properly. Generically, it is an electronic controller properly programmed to elaborate the sensors’ information.
Final element(s) stage: it is an actuator and it is used to implement the output of the electronic controller. It is the last item of the loop and, in oil and gas applications, it generally is a pneumatic valve.
SIS are specifically developed to reduce the risk associated with hazardous events, such as human errors and hardware/software faults. It is important to emphasize that SIS are fully automated systems able to detect a hazardous condition and respond adequately to mitigate the risk without the need of a human–machine interface and/or a human intervention. This is essential to remove the probability of a human error, which grows critically in the presence of dangerous scenarios (see, for instance, [
49,
50,
51]).
In order to assure a proper safety integrity level (SIL), each safety instrumented system implement one or more safety instrumented functions (SIF). SIFs monitor dangerous processes and avoid unacceptable or dangerous conditions for people, plant, and environment. International standard IEC 61508 indicates the procedure to determine the SIL using the risk reduction factor parameter (RRF) of the equipment under control (EUC). The safety level classification is divided into four integer values: from SIL 0 associated with the lowest-risk reduction to SIL 4 associated with the highest-risk reduction. The inverse value of the RRF is the probability of failure on demand (PFD) that is the average probability of a system failing to respond to a demand in a specified time interval, usually called the proof test interval. International standard IEC 61508:2010 [
44] considers three different modes of operation for a generic SIF:
Low-demand mode: the safety function is only performed not more than once per year. It is associated with the PFD target to be achieved.
High-demand mode: the safety function is always performed on demand, more than once per year. It is associated with the probability of failure per hour (PFH).
Continuous mode: the safety function is part of normal operation. Like the high-demand mode, it is associated with the PFH.
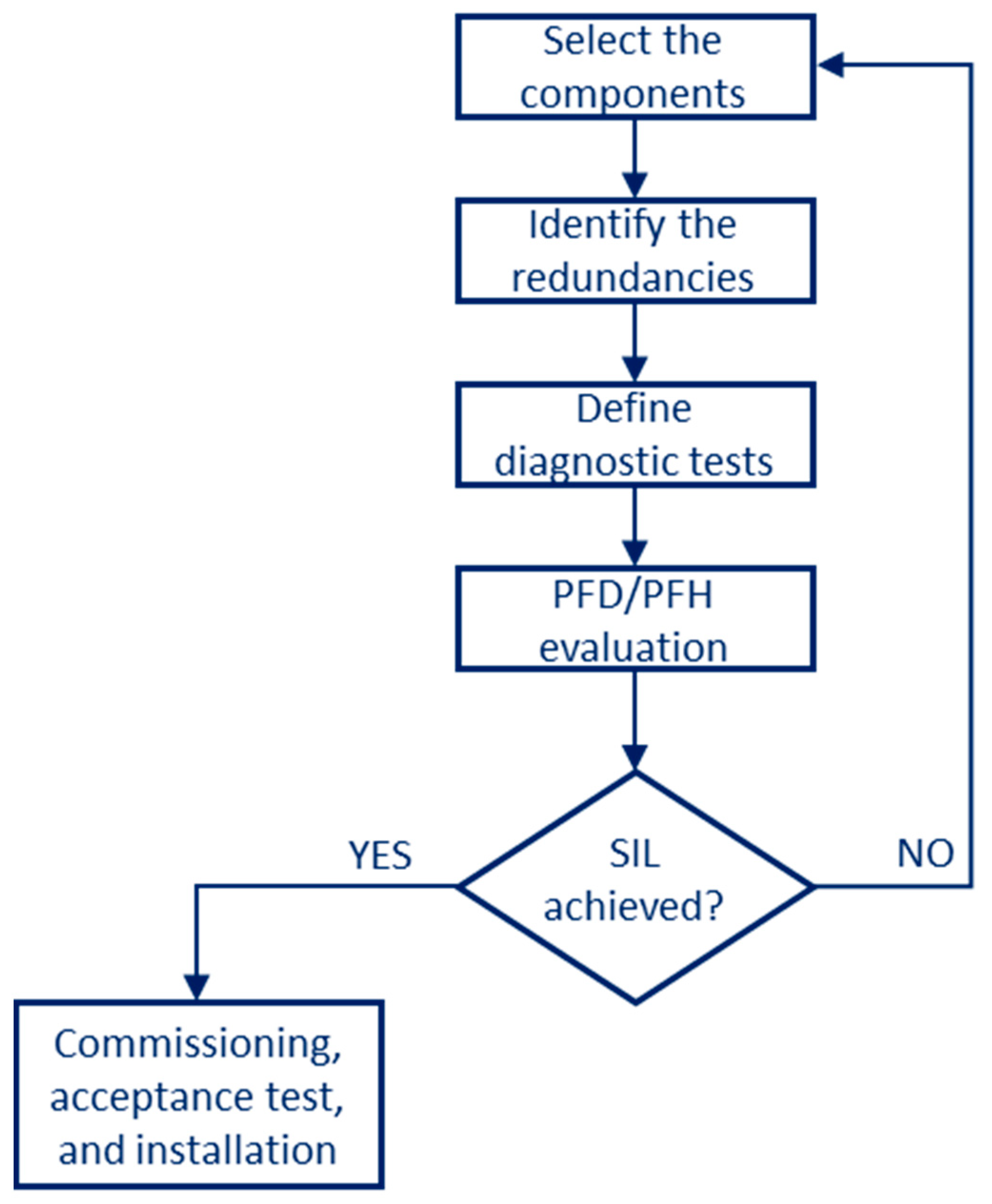
In compliance with IEC 61508:2010 [
44], the SIS design is divided in several steps as illustrated in
Figure 5.
The first step consists of the selection of the items making up the safety system. In order to obtain the failure rate of an element, a preliminary FMEDA (failure modes, effects, and diagnostic analysis) must be developed. After that, according to IEC61508, diagnostic coverage (DC) and safe failure fraction (SFF) are defined as follows:
In the equations above, the failure rate of the device is divided into four different components [
52,
53]:
Safe undetected failures ;
Safe detected failures ;
Dangerous detected failures ;
Dangerous undetected failures .
In other words, DC is the ratio of the probability of detected failures to the probability of all the dangerous failures and is a measure of system ability to detect failures [
54,
55]. Instead, SFF indicates the probability of the system failing in a safe state so it shows the percentage of possible failures that are self-identified by the device or are safe and have no effect [
56,
57].
In order to assess DC and SFF, the analyst has to include all the electrical, electronic, electromechanical, and mechanical items necessary to allow the system to process the required safety functions. Similarly, it is mandatory to consider all of the possible dangerous failure modes that could lead to an unsafe state, prevent a safe response on demand, or compromise the system safety integrity. Within the dangerous failures, it is necessary to estimate for each component the fraction of failures that are detected by the diagnostic tests: these tests (e.g., comparison checks in redundant architectures, additional built-in test routines, and continuous condition monitoring) are a huge contribution to the diagnostic coverage.
Architectural constraints (second step of the flowchart in
Figure 5) on hardware safety integrity are a set of architectural requirements that influence the SIL assessment for each subsystem. These constraints are associated with three parameters: hardware fault tolerance, safe failure fraction, and “A/B type” classification [
39,
44]. Hardware fault tolerance (HFT) is the maximum number of hardware faults that will not lead to a dangerous failure. HFT of “n” means that “n + 1” faults cause a loss of a SIF. This type of fault tolerance can be increased by means of system architecture: the limit of each configuration is the number of working devices required to perform the safety function. As for all redundant architectures, common-cause failures (CCF) can nullify the redundancy. There are three different stages of hardware fault tolerance:
HFT = 0: In a single channel architecture (1oo1), only in case of no failure the safety function can be performed.
HFT = 1: In a dual redundancy (1oo2 or 2oo3), even in case of one failure in the sensing elements or logic solvers the safety function can still be performed.
HFT = 2: In a triple redundancy (1oo3), up to two failures can be tolerated in order to perform the safety function.
The subsystems are classified as follows: type A units have consolidated design and the behavior in case of errors is well-known, while type B items have unknown behavior in case of failure [
58]. The procedure that allows determining the optimal redundancy is called Route 1H and is shown in
Table 2 in case of type A and type B units, respectively.
The following step requires obtaining the average probability of failure on demand varying the possible diagnostic test for each possible redundancy. There are two main categories of tests: proof tests and diagnostic tests. A proof test is a periodic test performed to detect dangerous hidden failures in a SIS [
59]. In other words, a proof test is a form of a stress test with the aim of demonstrating the fitness of equipment.
Usually, it is performed on a single unit, and the structure is subjected to loads above that expected in actual use, demonstrating the safety and design margin. Anyway, a proof test is nominally a nondestructive test if both design margins and test levels are well-chosen. The frequency of conducting these tests influences the component’s average probability of failure on demand (
). As a matter of fact, a higher test frequency means a lower
and a higher RRF. The PFD increases over time but returns to its original level when a proof test is performed to prove that everything works as expected. Running the same proof test twice as often lowers the average PFD. This strategy allows design engineers to meet higher SIL requirements using the same equipment or, alternatively, choosing cheaper items to achieve the same SIL target. A diagnostic test, instead, is performed periodically to detect some of the dangerous faults that prevent the SIS from responding to a demand. Some SIS may conduct self-diagnostic testing during operation in order to detect some dangerous failures immediately when they occur (essentially, a diagnostic test is a partial proof test). In order to double the full proof test interval and maintain the same average PFD, a possible approach is to run partial tests frequently [
59,
60]. This concept is clearly illustrated in
Figure 6a, where the PFD trend in time considers only proof test procedures. On the contrary,
Figure 6b shows the results of combining full proof tests and partial stroke tests (i.e., diagnostic tests).
Finally, when assessing the probability of failure on demand (PFD) of a designed SIS by means of DC and SFF, it is important to take into account uncertainties of failure rate data. The risk analysis of industrial systems and the design of a SIS are phases characterized by a remarkable level of uncertainty due to incomplete and vague information and/or insufficient knowledge and experience of the team. Some approaches available in the literature tried to deal with this problem introducing fuzzy logic, Monte Carlo simulations, sensitivity analysis, etc. (for more information, see, for instance, [
58,
61,
62,
63]).
4. Case Study: Application in the Oil and Gas Industry
This section deals with the design of a SIS for oil and gas applications in the low-demand mode of operation with the 1-year proof test interval ( = 1 year = 8760 h). The objective of the design is to achieve the SIL 3 target because of the criticality and dangerousness of the field of application. The monitored parameter to keep the plant under control is temperature; the collected data are elaborated by a PLC and the outcomes are implemented by a pressure valve. The controller communicates with the other equipment of the SIS by using the 4–20 mA HART® communication protocol and is able to detect under- and over-range currents, so both fail-low and fail-high conditions are detectable.
The average probability of failure on demand of a safety function for the E/E/PE safety-related system is determined by calculating and combining the average probability of failure on demand for all the subsystems which together implement the safety function; therefore, the average PFD can be expressed as follows:
where the subscript SE stands for sensing element, LS is the acronym of logic solver, while FE represents the final element. The sensor stage is composed of a Rosemount
® 3144P HART
® Temperature Indicator Transmitter (TIT), a temperature monitoring device widely used at oil and gas plants. This equipment is a temperature sensor assembly made of two main parts:
A temperature-sensing device, such as an RTD (i.e., a resistance temperature detector) or a thermocouple.
A dedicated transmitter to communicate with the logic solver with the 4–20 mA HART® Communication Protocol.
The TIT used is equipped with an RTD as the sensing device with the failsafe state set as fail-low; that means it is programmed to focus on low outcomes when detecting a failure: this condition is called an under-range failsafe state. The failure rates (expressed in failures in time (FIT), i.e., failures over 1 billion hours), the DC, and the SFF achieved with Equations (1) and (2) for the 3144P TIT are reported in
Table 3.
The failure rates of the sensors selected for the SIS under analysis play a fundamental role in the achievement of the specific requirements. More in detail, the higher the SIL requirement, the lower the probability of failure of the SIS must be, leading to a lower threshold of the acceptable failure rate.
Considering the SIL 3 objective for the developed SIS, the optimal redundancy for this sensor (type B element) is determined by using the procedure illustrated in
Table 2 and the SFF value obtained in
Table 3. Considering the abovementioned data, the optimal hardware fault tolerance for the temperature sensor under analysis is HFT = 1. Following the information reported on the 3144P TIT datasheet, the best architecture with HFT = 1 is the 2-out-of-3 (2oo3), which is made by three identical blocks connected in a parallel configuration. The three outputs are subject to a major voting mechanism: the SIF is required when at least two blocks demand it and the system state is not changed if only one channel gives a different result which disagrees with the other two channels. The employment of a redundant architecture provides some benefits in terms of system reliability and risk related to hazardous fault. The main drawback of redundancy is the issue of common-cause failures. Standard IEC 61508 [
44] illustrates a procedure to evaluate two parameters
and
that consider the effect of common-cause failures. In particular, for the considered sensor, the results are as follows:
and
. In compliance with IEC61508, considering the mean time to repair and the mean restoration time MTTR = MRT = 8 h, the average PFD for the sensor stage in the 2oo3 TIT architecture is as follows:
where the channel equivalent mean downtime
and the system equivalent downtime
are determined using the following equations:
Considering Equations (4)–(6) and substituting the values above, the probability of failure on demand of the sensing element
is:
A Moore Industries® Safety Trip Alarm (STA) logic solver is used as the second block of the SIS chain. This controller is used to:
Provide emergency shutdown.
Warn of unwanted process conditions.
Provide on/off control in both SIS and traditional alarm trip applications.
The failure rates, the DC, and the SFF achieved with Equations (1) and (2) for the STA logic solver under analysis are reported in
Table 4.
According to SIL 3 objective for the SIS, the optimal redundancy for this sensor (type B element) is HFT = 1. In compliance with the sensor stage, the configuration that best fits this condition is the 2oo3, so that each TIT is connected with one STA. Redundancy in the logic solver leads to common-cause failures and the parameters to evaluate them are
and
. Considering MTTR = MRT = 8 h and taking into account the 2oo3 architecture, the PFD of the logic solver is as follows:
A redundant control system (RCS) by ASCO® is the final element selected for this application. It is an electromechanical and pneumatic system consisting of two solenoid valves and one pneumatic valve (bypass valve). In order to screen the pressures at dangerous points of the RCS, the actuator is provided by three pressure switches on each valve for diagnostic purposes. The switch contacts are closed in the presence of pressure because they are normally open.
According to the international standard IEC 6150 [
44], the RCS is utilized as the final element of the SIS together with a controlled block valve (BV). In particular, in this design, the RCS is considered in series with an X Series Ball Valve with the floating ball design. The objective is to move toward the safe state in brief time. The safe state is obtained with de-energized signals so at least one of the two solenoid valves has to be energized to prevent the block valve from moving to the safe state. The failure rates for the RCS are reported in
Table 5.
The safe failure fraction of the final element can be calculated using Equation (2) and the failure rate data included in
Table 5. The obtained value is SFF = 99.38%. Consequently, through
Table 2 for type A element, the required redundancy to achieve the SIL 3 target is HFT = 0.
In particular, the selected configuration is a single RCS element in a specific safety mode of operation called where only one solenoid valve is online in the standard work condition. The logic solver can detect every spurious trip of this operative valve by using the relative pressure switch outcome. In order to preserve air supply to the ball valve, the control unit energizes the other solenoid valve when a spurious trip is revealed.
Using a Markov diagram, it is possible to model the behavior of the component in various states using a memoryless process in which the next state of the item is only dependent on the transition values and the current state of the system [
64,
65]. Considering MTTR = 24 h and taking into account the Markov diagram suggested by the standard IEC 61508:2010 [
44], then the average probability of failures on demand for RCS is:
In order to monitor the dangerous failures of the utilized block valve (undetected by the standard diagnostics), a partial valve stroke test (PVST) is provided. The latter is a delicate procedure in particular in high energy and high flow applications where it could generate a response (and instabilities) in the process control system or in the safety instrumented system leading to a spurious trip.
The average PFD assessment follows a different procedure when a PVST is applied. Considering the failure rates in
Table 6 and MTTR = 96 h, according to the international standard IEC 61508 and using Markov diagrams, the average PFD of the block valve is:
Thus, the average PFD of the final element stage assembly by the RCS and the block valve is as follows:
The average probability of failure on demand
associated to a single safety function SIF of the developed SIS is obtained by summing the single PFD of all the subsystems (sensor stage, logic solver stage, final element stage) involved in the SIF. According to Equation (3), the probability of failure on demand of the whole system is as follows:
A summary of the developed SIS is included in
Table 7, focusing on the product detail of each specific component selected in this work.
In compliance with the translation table between the SIL target and the average PFD described in IEC 61508 [
44], for the SIS under test, the SIL 3 objective is reached because the average probability of failure on demand of the whole SIS belongs to the range of SIL3 attribution, as highlighted in
Table 8.
Figure 7 shows a pie chart of each contribution of the whole probability of failure on demand, highlighting that the greatest share refers to the final element, about 18% to the whole RCS system, and 72% to the block valve with a consequent whole percentage of 90%. The sensor and the logic solver are characterized by a small value of PFD, therefore, each one gives a 5% contribution to the whole PFD.
According to the literature (see, for instance, [
37,
38,
44,
47]), a realistic partition of the average system PFD widely accepted is 35% to the sensor stage, 15% to the logic solver stage, and 50% to the final element stage. In this application, the actuator is composed of a chain of two complex valves in the 1oo1 architecture, thus this configuration leads to associate 90% of the whole PFD to the final stage.
Figure 8 shows the average PFD assessed to the sensor stage (blue columns), to the logic solver stage (red columns), and to the final element stage (orange columns) considering a 1-year, 2-year, and 3-year proof test interval.
The figure highlights that at a higher value of PFD calculated with a 1-year proof test interval, the proof test interval increase corresponds with greater PFD increases. Instead, the PFD assessed to the least critical subsystem (a sensor and a logic solver) is characterized by a little increase when the proof test interval increases.
5. Conclusions
This paper deals with a diagnostics-oriented approach for the design of safety instrumented systems at oil and gas plants.
After an accurate review of diagnostic strategies to successfully implement condition monitoring at industrial plants, the design of an actual SIS is presented paying great attention to the role of diagnostics. The considered SIS is used in the oil and gas application, and it is composed of a sensor stage in the 2oo3 configuration, three logic solvers (one for each sensor) capable to elaborate data and activate the safety function, and a final element composed of an RCS system and a block valve in the series configuration. The paper emphasizes the need in a limit alarm trip, on-board diagnostics, and logic solver diagnostics to achieve low probability of failure on demand and ensure high SIL levels.
Redundant architectures improve system reliability and availability, decreasing the probability of dangerous failures. However, additional components require taking into account properly all common-cause failures during the design phase. The proposed diagnostics-oriented solution for safety improvements follows these steps: improve common cause strength, use diversity, use online condition monitoring and diagnostics, and add redundancy. Clearly, each choice is a tradeoff between safety and costs: to take these decisions, designers should select the best safety improvement, taking into account not only data provided by suppliers (usually validated in a laboratory environment), but considering real-world installed safety (which is always much worse). Only by quantifying installed safety designers can evaluate the real-world safety and cost impact of specific technology. The case study highlights these steps emphasizing the critical role of valves and redundant control systems accounting for 90% of the probability of failure on demand. This research is intended to be used as a guidance for the further design of safety instrumented systems in the oil and gas industry. Further study should focus on how to improve diagnostic, prognostic, and health monitoring and valves and actuators for oil and gas safety-related systems in order to reduce the probability of failure on demand of these critical items.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}