Evaluation of the Effectiveness of a Gaze-Based Training Intervention on Latent Hazard Anticipation Skills for Young Drivers: A Driving Simulator Study


Abstract
:1. Introduction
2. Results
2.1. Eye Movements
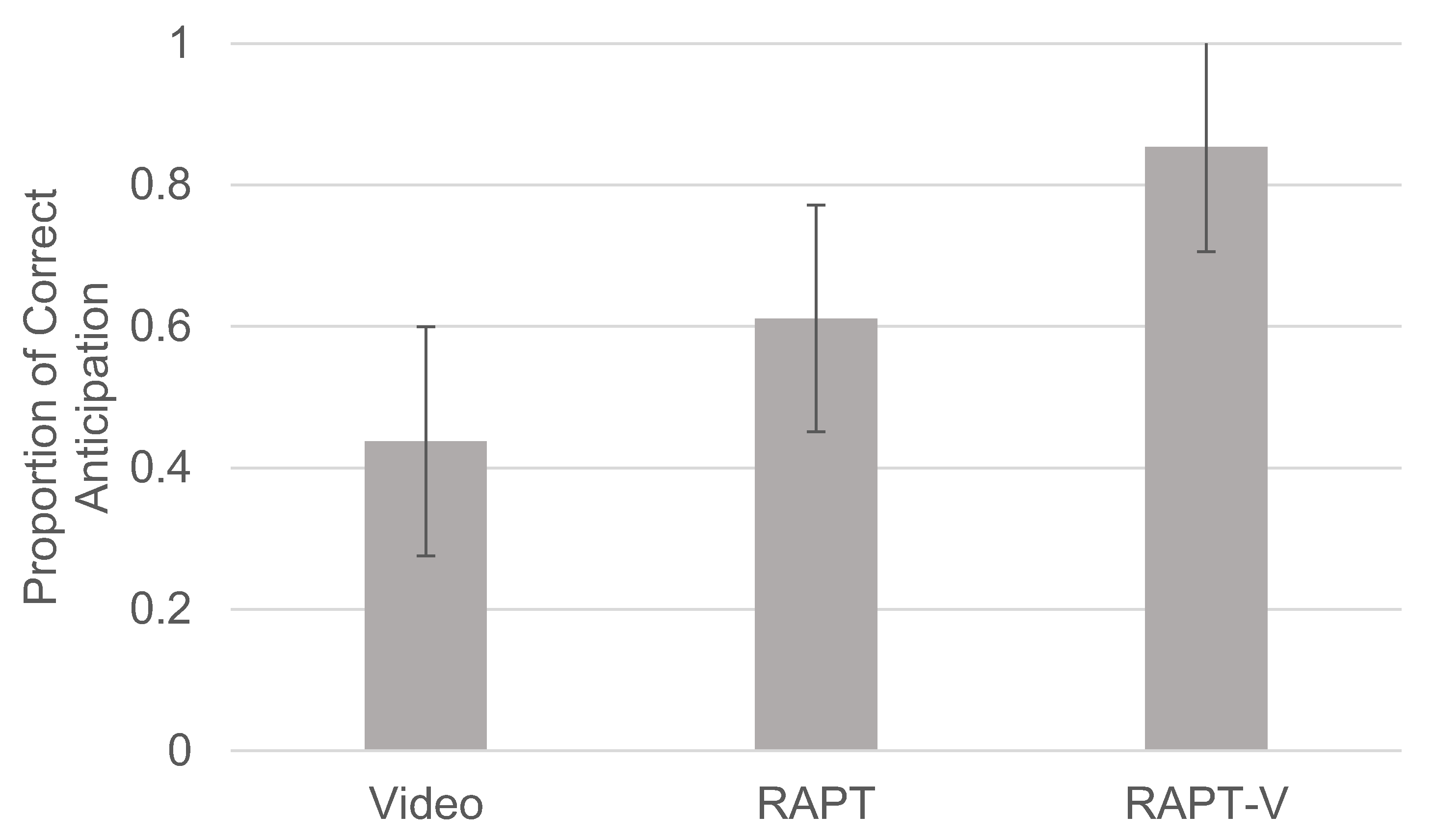
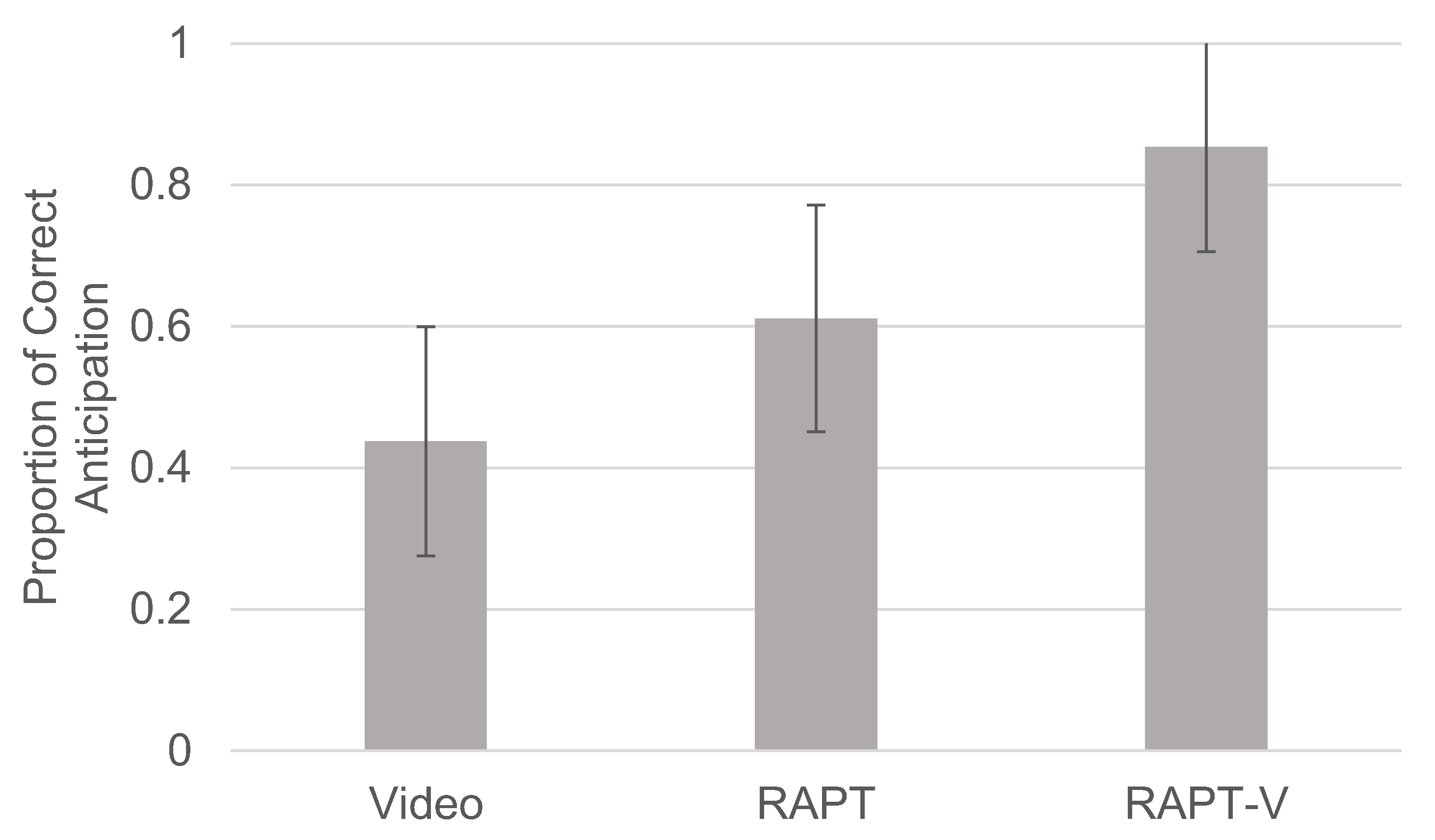
2.1.1. Hazard Anticipation
2.1.2. Mean Fixation Duration
2.1.3. Number of Fixations
2.1.4. Variance of Horizontal and Vertical Fixation Locations
2.2. Vehicle Control Behavior
Mean Travel Speed
3. Discussion
4. Materials and Methods
4.1. Participants
4.2. Apparatus
4.2.1. Driving Simulator
4.2.2. Eye Tracker
4.2.3. Simulator Scenarios
4.2.4. Training Program
4.2.5. Eye Movement Video
4.3. Procedure
4.4. Dependent Variables
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Insurance Institute for Highway Safety. Fatality Facts 2015: Teenagers; Insurance Institute for Highway Safety: Arlington, VA, USA, 2016. [Google Scholar]
- Fisher, D.L.; Caird, J.; Horrey, W.J.; Trick, L. Handbook of Teen and Novice Drivers: Research, Practice, Policy and Directions; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- McKnight, A.J.; McKnight, A.S. Young novice drivers: Careless or clueless. Accid. Anal. Prev. 2003, 35, 921–925. [Google Scholar] [CrossRef]
- Mcdonald, C.C.; Curry, A.E.; Kandadai, V.; Sommers, M.S.; Winston, F.K. Comparison of teen and adult driver crash scenarios in a nationally representative sample of serious crashes. Accid. Anal. Prev. 2014, 72, 302–308. [Google Scholar] [CrossRef] [PubMed]
- Mourant, R.R.; Rockwell, T.H. Strategies of visual search by novice and experienced drivers. Hum. Factors 1972, 14, 325–335. [Google Scholar] [CrossRef] [PubMed]
- Pradhan, A.K.; Pollatsek, A.; Knodler, M.; Fisher, D.L. Can younger drivers be trained to scan for information that will reduce their risk in roadway traffic scenarios that are hard to identify as hazardous. Ergonomics 2009, 52, 657–673. [Google Scholar] [CrossRef] [PubMed]
- Yamani, Y.; Samuel, S.; Knodler, M.A.; Fisher, D.L. Evaluation of the effectiveness of a multi-skill program for training younger drivers on higher cognitive skills. Appl. Ergon. 2016, 52, 135–141. [Google Scholar] [CrossRef] [PubMed]
- Fisher, D.L.; Narayanaan, V.; Pradhan, A.; Pollatsek, A. Using eye movements in driving simulators to evaluate effects of PC-based risk awareness training. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2004, 48, 2266–2270. [Google Scholar] [CrossRef]
- Gist, M.; Schwoerer, C.; Rosen, B. Effects of alternative training methods on self-efficacy and performance in computer software training. J. Appl. Psychol. 1989, 74, 884–891. [Google Scholar] [CrossRef]
- Unverricht, J.; Samuel, S.; Yamani, Y. Latent hazard anticipation in young drivers: A review and meta-analysis of training studies. Transp. Res. Rec. (In press).
- Thomas, F.D.; Rilea, S.L.; Blomberg, R.D.; Peck, R.C.; Korbelak, K.T. Evaluation of the Safety Benefits of the Risk Awareness and Perception Training Program for Novice Teen Drivers; Report No. DOT HS 812 235; National Highway Traffic Safety Administration: Washington, DC, USA, January 2016. [Google Scholar]
- Voyer, D.; Voyer, S.D.; Saint-Aubin, J. Sex differences in visual-spatial working memory: A meta-analysis. Psychon. Bull. Rev. 2016, 24, 307–334. [Google Scholar] [CrossRef] [PubMed]
- Chapman, P.; Underwood, G.; Roberts, K. Visual search patterns in trained and untrained novice drivers. Trans. Res. Part F 2002, 5, 157–167. [Google Scholar] [CrossRef]
- Pradhan, A.K.; Crundall, D. Hazard avoidance in young novice drivers: Definitions and a framework. In Handbook of Teen and Novice Drivers: Research, Practice, Policy, and Directions; Fisher, D.L., Caird, J.K., Horrey, W.J., Trick, L.M., Eds.; CRC Press: Boca Raton, FL, USA, 2016; pp. 61–74. [Google Scholar]
- Crundall, D.E.; Underwood, G. Effects of experience and processing demands on visual information acquisition in drivers. Ergonomics 1998, 41, 448–458. [Google Scholar] [CrossRef]
- Underwood, G. Visual attention and the transition from novice to advanced driver. Ergonomics 2007, 50, 1235–1249. [Google Scholar] [CrossRef] [PubMed]
- Litchfield, D.; Ball, L.; Donovan, T.; Manning, D.J.; Crawford, T. Viewing another person’s eye movements improves identification of pulmonary nodules in chest X-ray inspection. J. Exp. Psychol. Appl. 2010, 16, 251–262. [Google Scholar] [CrossRef] [PubMed]
- Sadasivan, S.; Greenstein, J.S.; Gramopadhye, A.K.; Duchowski, A.T. Use of eye movements as feedforward training for a synthetic aircraft inspection task. In Proceedings of the SIGCHI conference on Human factors in computing systems, Portland, OR, USA, 2–7 April 2005; pp. 141–149. [Google Scholar]
- Brennan, S.E.; Chen, X.; Dickinson, C.A.; Neider, M.B.; Zelinsky, G.J. Coordinating cognition: The costs and benefits of shared gaze during collaborative search. Cognition 2008, 106, 1465–1477. [Google Scholar] [CrossRef] [PubMed]
- Yamani, Y.; Neider, M.B.; Kramer, A.F.; McCarley, J.S. Characterizing the efficiency of collaborative visual search with systems factorial technology. Arch. Sci. Psychol. 2017, 5, 1–9. [Google Scholar] [CrossRef]
- Konstantopoulos, P.; Chapman, P.; Crundall, D. Driver’s visual attention as a function of driving experience and visibility. Using a driving simulator to explore drivers’ eye movements in day, night and rain driving. Accid. Anal. Prev. 2010, 42, 827–834. [Google Scholar] [CrossRef] [PubMed]
- Mackenzie, A.; Harris, J.J. Using experts’ eye movements to influence scanning behavior in novice drivers. J. Vis. 2015, 15, e367. [Google Scholar] [CrossRef]
- Rouder, J.N.; Morey, R.D. Default Bayes factors for model selection in regression. Multivar. Behav. Res. 2012, 47, 877–903. [Google Scholar] [CrossRef] [PubMed]
- Jeffreys, H. Theory of Probability, 3rd ed.; Oxford University Press: Oxford, UK, 1961. [Google Scholar]
- Samuel, S.; Fisher, D.L. Evaluation of the Minimum Forward Roadway Glance Duration. Trans. Res. Rec. J. Trans. Res. Board 2015, 2518, 9–17. [Google Scholar] [CrossRef]
- Engbert, R.; Kliegl, R. Microsaccades uncover the orientation of covert attention. Vis. Res. 2003, 43, 1035–1045. [Google Scholar] [CrossRef]

{kind=link}
| Truck Crosswalk Scenario Subject vehicle (V) approaches a crosswalk and the driver should monitor the area behind the truck for hidden hazards (e.g., pedestrians). |  | 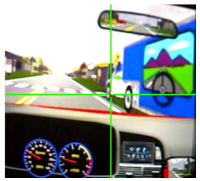 |
| Hedge Scenario Subject vehicle approaches a stop sign-controlled intersection. After a full stop, the driver should look for a hidden hazard that might be occluded by hedges on the right side of the travel lane. |  |  |
| Adjacent Truck Intersection Scenario. The driver travels straight in the right lane on a two-lane road and should look for a hidden hazard (e.g., cross traffic; V’) across the intersection in the opposing lane that might be occluded by a left-turning truck (T) in the adjacent left lane. | 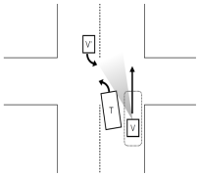 |  |
| Multiple-lane Intersection Scenario. While crossing a signal-controlled intersection, the driver should look for a hidden hazard (e.g., cross traffic; V’) that might be occluded by a bus approaching from the right, traveling in the left lane of the two travel lanes. | 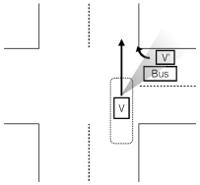 |  |
| RAPT | VIDEO | RAPT-V | |
|---|---|---|---|
| Gender | 5M, 7F | 6M, 6F | 5M, 7F |
| Age | 19.58 (1.24) | 19.41 (1.08) | 19.08 (1.08) |
| Years Licensed | 3.59 (1.25) | 2.95 (0.95) | 2.06 (0.94) |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yamani, Y.; Bıçaksız, P.; Palmer, D.B.; Hatfield, N.; Samuel, S. Evaluation of the Effectiveness of a Gaze-Based Training Intervention on Latent Hazard Anticipation Skills for Young Drivers: A Driving Simulator Study. Safety 2018, 4, 18. https://doi.org/10.3390/safety4020018
Yamani Y, Bıçaksız P, Palmer DB, Hatfield N, Samuel S. Evaluation of the Effectiveness of a Gaze-Based Training Intervention on Latent Hazard Anticipation Skills for Young Drivers: A Driving Simulator Study. Safety. 2018; 4(2):18. https://doi.org/10.3390/safety4020018
Chicago/Turabian StyleYamani, Yusuke, Pınar Bıçaksız, Dakota B. Palmer, Nathan Hatfield, and Siby Samuel. 2018. "Evaluation of the Effectiveness of a Gaze-Based Training Intervention on Latent Hazard Anticipation Skills for Young Drivers: A Driving Simulator Study" Safety 4, no. 2: 18. https://doi.org/10.3390/safety4020018
APA StyleYamani, Y., Bıçaksız, P., Palmer, D. B., Hatfield, N., & Samuel, S. (2018). Evaluation of the Effectiveness of a Gaze-Based Training Intervention on Latent Hazard Anticipation Skills for Young Drivers: A Driving Simulator Study. Safety, 4(2), 18. https://doi.org/10.3390/safety4020018