1. Introduction
Automation surprises (AS) in aviation continue to be a significant safety concern [
1,
2,
3] and the community’s search for effective strategies to mitigate them are ongoing. Guidance for such mitigation efforts comes not only from operational experiences, but from our understanding of the cognitive processes that govern human interaction with automation. This helps us better explain the kinds of breakdowns that can occur, and know what exactly it is that we need to prevent [
4,
5,
6,
7,
8]. So far, however, the literature has offered divergent directions because they are based on two fundamentally divergent assumptions about the nature of cognition and collaboration with automation—a difference that reaches back beyond the so-called ’cognitive revolutions’ of the 1950s and 1990s [
9,
10]. One sees cognition as individual information-processing, the other as collaborative and distributed across human and machine agents. They have produced different diagnoses, understandings, and definitions, and concomitantly different prescriptions for mitigating automation surprises. In this paper, we report the results of a field study that empirically compares and contrasts two models of automation surprises that have been proposed in the literature based on this divergent understanding: a normative model proposed by Parasuraman & Manzey [
11] and a sensemaking model described by Rankin, Woltjer, & Fields [
12]. The first model (fully labeled as ‘integrated model of complacency and automation bias’) focuses on suboptimal human performance (normative model); the second (‘crew–aircraft contextual control loop’) on the complexity of the context (sensemaking model). This difference is relevant for our understanding of the cognitive processes that govern the human interaction with automation and measures that are to be taken to reduce the frequency of automation-induced events. Before reporting method and results, we elaborate on the two different models.
1.1. Individual versus Distributed Cognition
The first research tradition on cognition in human factors fits within a larger metatheoretical perspective that takes the individual as its central focus. For human factors, this has meant that the processes worth studying take place within the boundaries of the individual (or her/his mind), as epitomized by the mentalist focus on information processing and various cognitive biases [
13,
14]. In this tradition, automation surprises are ultimately the result of mental proclivities that can be studied and defined as attached to an individual. One such tendency has been defined as “automation bias”, which is “resulting from people’s using the outcome of the decision aid as a heuristic replacement for vigilant information seeking and processing” ([
11] p. 391). Remedies rely on intervention at the level of the individual as well, particularly training. Some innovations in training are already being developed, such as the nurturing of flight path management skills using manual flight from the outset and then introducing increasing levels of autoflight systems to achieve the same flight path tasks on the Airbus A350 [
1]. There is consensus, however, that training and a focus on individual knowledge is a partial solution at best. As the Commercial Aviation Safety Team observed about flight management system and automation surprises:
“The errors are noteworthy, and it has not been possible to mitigate them completely through training (although training could be improved). This reflects that these are complex systems and that other mitigations are necessary”.
The realization that the problem of automation surprises might rather be defined, studied, and understood as the product of complex systems is found in what became known as cognitive systems engineering [
15,
16,
17], and in the study of distributed cognition, which has renewed the status of the environment as active, constituent participant in cognitive processes [
10,
11,
12,
13,
14,
15,
16,
17,
18]. This has formed the basis for the second model. The cognitive systems synthesis invokes a new unit of analysis: all of the devices that do or shape cognitive work should be grouped with human cognitive work as part of a single joint human–machine cognitive system. Automation surprises in this conception are not the result of either pilot error or a cockpit designer’s over-automation. Instead, they exhibit characteristics of a human–machine coordination breakdown—a kind of weakness in a distributed cognitive system [
19]. There is still a placeholder for individual cognition in this model too, under the label of mental model. When conceptualized in this way, automation surprises reveal the following pattern [
5,
20]:
Automated systems act on their own without immediately preceding directions, inputs, or commands from human(s);
There are gaps in users’ mental models of how the automation works;
Feedback about the activities and future behavior of the automation is weak.
An automation surprise can then be defined as the end result of a deviation between expectation and actual system behavior, that is only discovered after the crew notices strange or unexpected behavior and that may already have led to serious consequences by that time [
21]. The question raised by these differential diagnoses of automation surprises is this: which offers industry better pathways for prevention?
1.2. The Models
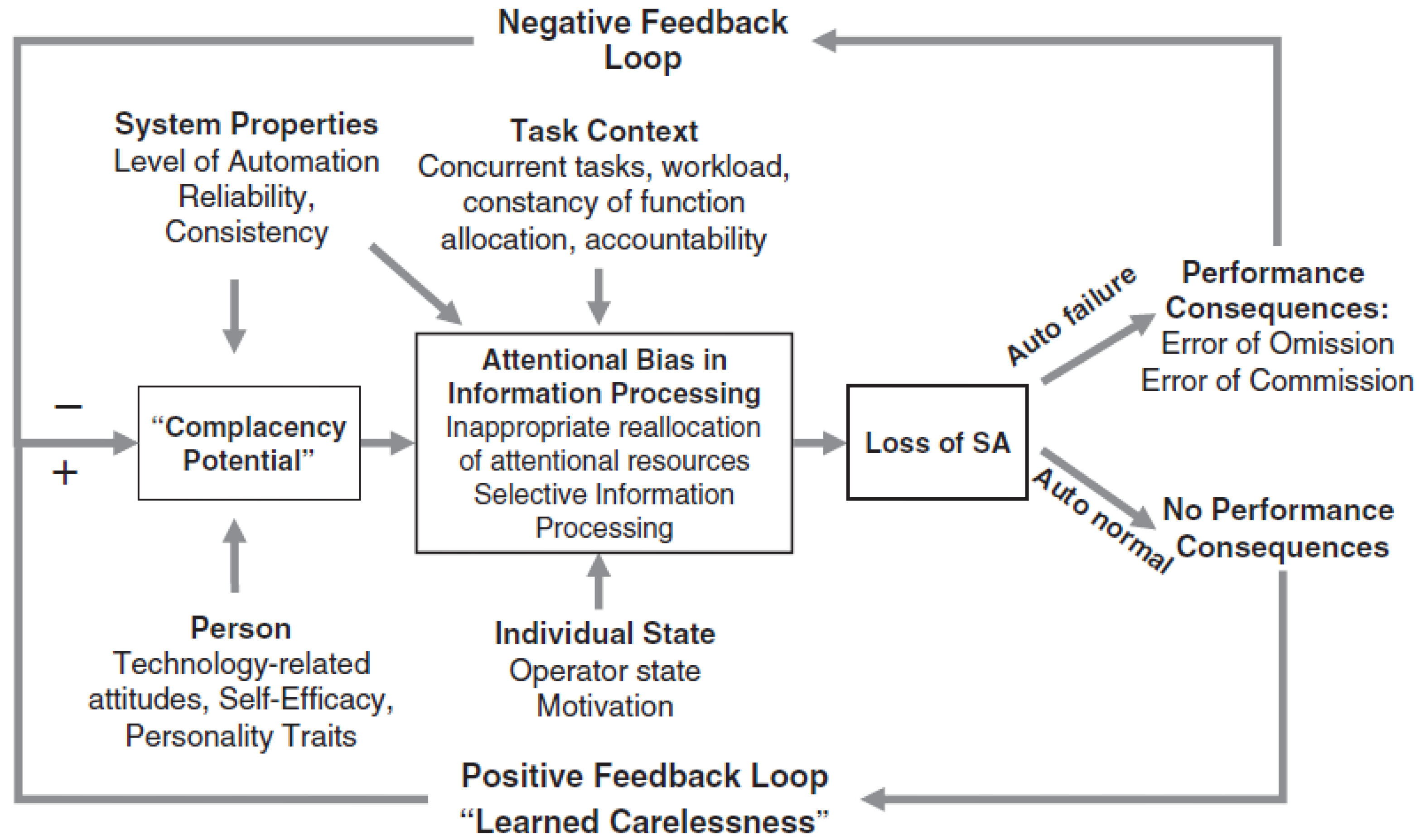
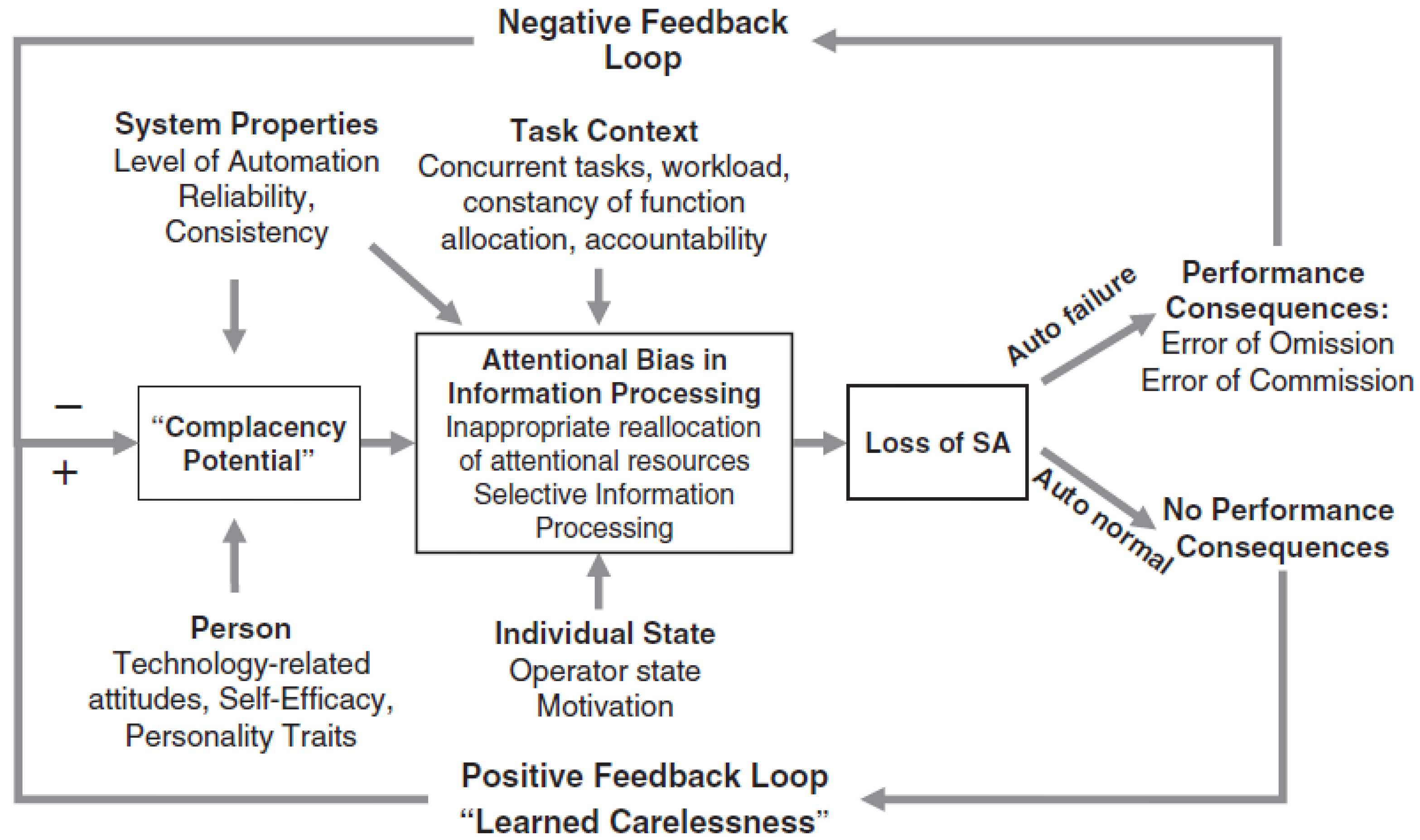
Parasuraman & Manzey suggest that automation surprise is a result of ‘complacency’ and ‘attentional bias’ which according to the authors is “induced by overtrust in the proper function of an automated system” [
11] (p. 404). Their ‘integrated model of complacency and automation bias’ shows ‘complacency bias’ leading to ‘attentional bias in information processing’ and then loss of situational awareness. A lack of contradictory feedback induces a cognitive process that resembles what has been referred to as “learned carelessness”. Even a single instance of contradictory feedback may lead to a considerable reduction in trust in the automated system [
11,
22]. The authors suggest that both conscious and unconscious responses of the human operator can induce these attentional effects. The integrated model of complacency and automation bias is represented in
Figure 1.
The integrated model of complacency and automation bias is a normative model because the authors suggest that there is “some normative model of ‘optimal attention allocation’” by which the performance of the human operator can be evaluated [
11] (p. 405). This assessment enables the identification of “complacency potential”, “complacency”, “automation bias”, “learned carelessness”, and “lack of situational awareness”.
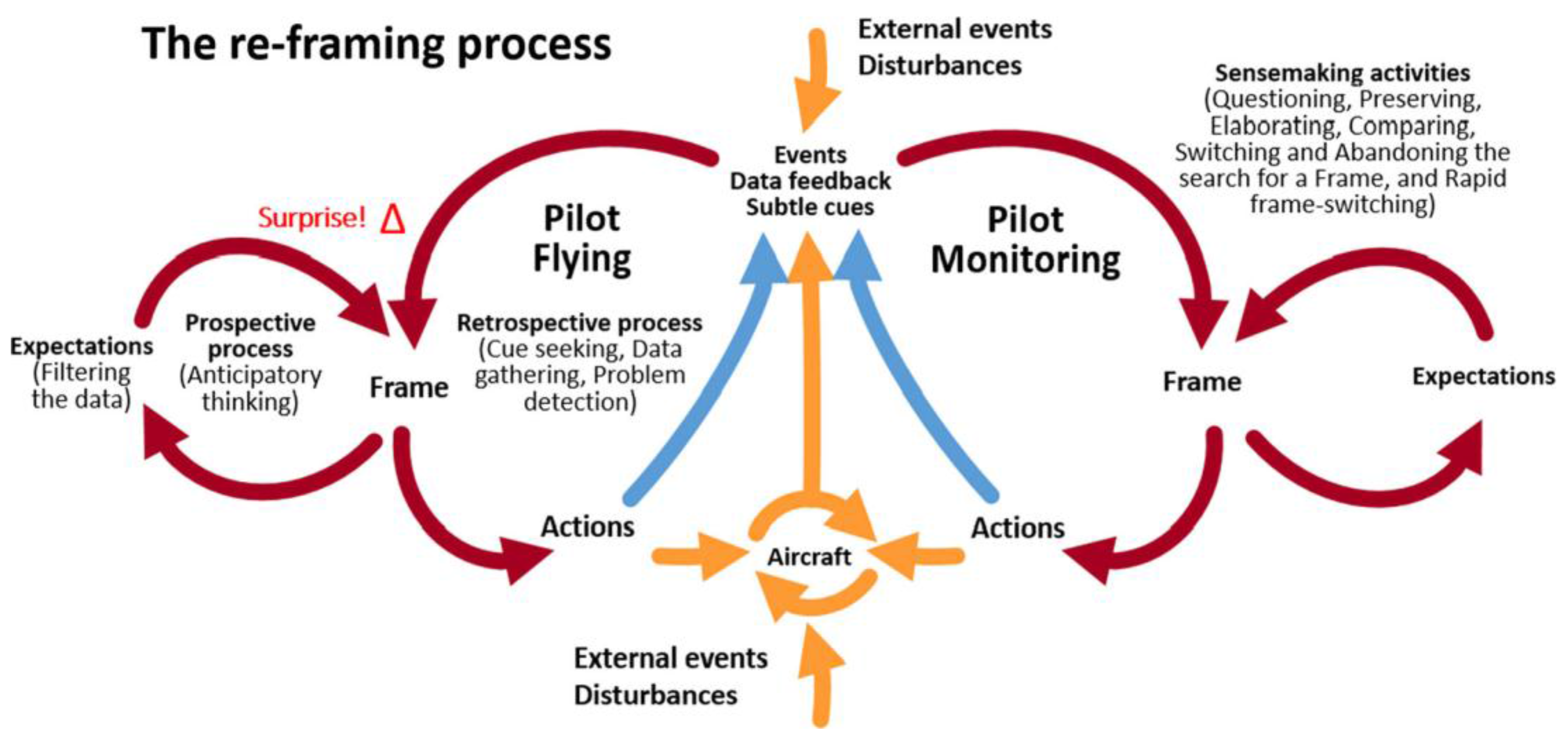
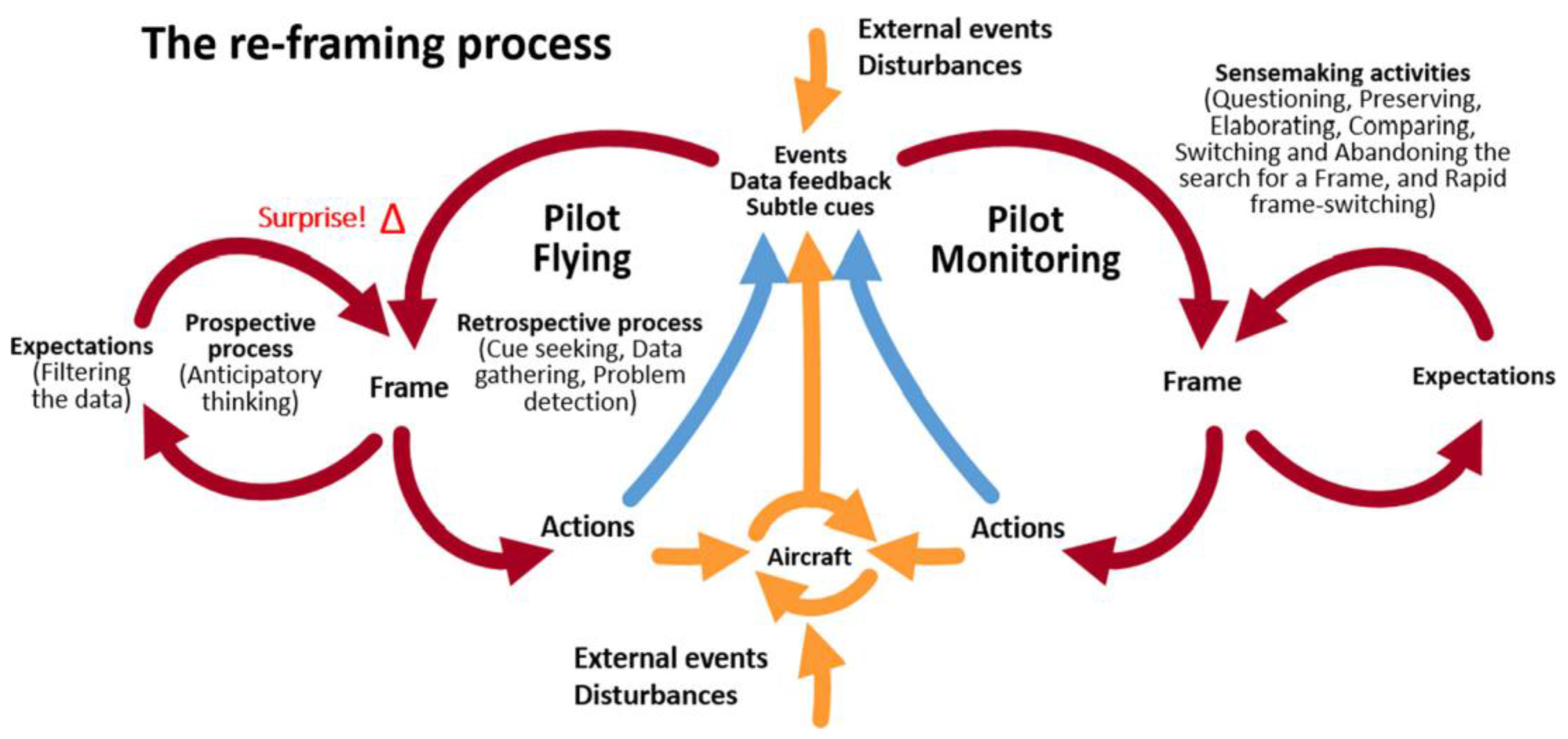
In contrast, and more recently, Rankin, Woltjer & Field [
12]—building on Hollnagel & Woods [
23] and Klein, Wiggins, & Dominguez [
24]—propose the “crew–aircraft contextual control loop” in which the element of surprise marks the cognitive realization that what is observed does not fit the current frame of thinking. Commencing with automation in aviation, they extend their model to include other operational issues between the crew and the aircraft. Other literature outside aviation supports their suggestion that cues are ignored due to a previously existing frame or mental model, until a sudden awareness occurs of the mismatch between what is observed and what is expected [
25,
26,
27,
28]. The crew–aircraft contextual control loop is represented in
Figure 2.
As Rankin, Woltjer, & Field indicate, the contextual loop is a sensemaking model in that it assumes:
“…perceiving and interpreting input from the environment after the fact (retrospective) [and] the continuous process of fitting what is observed with what is expected (anticipatory), an active process guided by our current understanding”.
The normative character of the “integrated model of complacency and automation bias” indicates that negative performance consequences due to automation failure are perceived as a result of “a conscious or unconscious response of the human operator”, i.e., human error. Numerous personal, situational, and automation-related factors play a role, but the main finding is that we need “to make users of automation more resilient to complacency and automation-bias effects” [
11] (p. 406). The “crew–aircraft contextual control loop” on the other hand suggests that we need to “adequately prepare pilots to cope with surprise, such as by using scenarios with ambiguous and potentially conflicting information”. Human operators are submerged in “ambiguities and trade-offs regarding manual control, procedure applicability, system knowledge, and training” and balancing different goals and strategies while trying to make sense of possibly conflicting inputs. Under these circumstances, we need to better “prepare crews for the unexpected” [
12].
Although the two models share many common factors affecting the prevalence of automation surprise (such as personality, fatigue, and automation design) [
29], they each predict different outcomes. Firstly, according to the integrated model even a single instance of contradictory feedback may lead to a considerable reduction in trust in the automated system [
11] (p. 405). In case of the contextual control loop, the trust in the automation is not necessarily reduced through contradictory feedback, but reframing occurs [
12] (p. 635). Secondly, in the integrated model the complacency potential increases over time as long as contradictory feedback is lacking [
11] (p. 405). This suggests that alerting systems or a second crew member will be instrumental in alleviating the mismatch between what is observed and what is expected. In contrast, re-framing in the contextual control loop may occur at any time within the individual [
12] (p. 639) when the discrepancy between stimuli and expectations becomes large, and is not dependent upon specific alarms or warnings by fellow crew-members. Thirdly, the integrated model implies that the cause of automation surprise is attributed to too much trust in automation and a lack of situational awareness [
11] (p. 406), whereas in the case of the contextual control loop, the predominant cause is expected to be lack of knowledge about the automation in relation to the current operational context [
12] (p. 635). Note that a number of recent studies that have identified the “looking-but-not-seeing” phenomenon as a precursor for automation surprise [
30,
31,
32,
33,
34] do not invalidate the integrated model. Although Parasuraman & Manzey do not make this explicit, their model can accommodate this phenomenon as a special case of “attentional bias”. This phenomenon is explicitly possible in the contextual control loop.
The objective of this study is to find evidence to support either the integrated model [
11] or evidence for the contextual control loop [
12]. Previously, a field survey was created to determine the prevalence of AS as it is experienced in routine airline operations, to establish the severity of the consequences of AS and test some of the factors that were expected to contribute to the prevalence of AS [
35]. Parts of this survey are used to empirically compare and contrast the two models of automation surprise.
2. Method
A questionnaire was developed with the objective to ascertain the prevalence of automation surprise in the field and contrast this with laboratory studies on automation surprise. The questionnaire contained 20 questions of which 14 were multiple choice, 4 were open questions, and 2 that were based on 6-point Likert scales. There were three parts to the questionnaire: (1) respondent demographics and flight experience, (2) specific details about the last automation surprise-experience that can be recalled and (3) experiences with automation surprise in general. The potential participants were recruited by a mailing through the Dutch Airline Pilots Association (VNV), several pilots’ websites and at the time of the pilots’ briefing for a flight. Respondents were directed to a website which hosted the questionnaire or filled out the questionnaire on paper. The questionnaire was anonymous and it was assured that data would remain confidential. Two language versions were available (English and Dutch), which were cross-checked by a bilingual Dutch/English speaker. Further details of the method can be found in De Boer & Hurts [
35].
Pilots were prompted to describe a recent case of automation surprise, using a pragmatic description that paraphrases the definition by Sarter, Woods, & Billings [
7], Wiener [
4], and Woods & Sarter [
5]: “For this research, we are specifically interested in the last time you experienced automation surprise. The following questions […] are aimed at the last time you exclaimed something like: ‘What is it doing now?’ or ‘How did it get into this mode?’.” In our endeavor to empirically compare and contrast the two models of automation surprise, we used four questions from the complete survey as markers. First of all, the change in trustworthiness of the automation following the most recent automation surprise experience was determined on a 6-point Likert scale (1 = trust in automation did not change; 6 = much less trust in automation) in response to the question: ”Automation surprises can cause the automation to be perceived as less trustworthy. As a result of your last automation surprise, did your trust in the system change?” More change in trust credits the integrated model of complacency and automation bias. Secondly, we identified whether an alerting systems or a second crew member was instrumental in alleviating the mismatch between what is observed and what is expected by asking: “How was this last automation surprise discovered?” Four mutually exclusive responses were possible: the respondent him/herself, a colleague pointed it out, by an Alerting System or ATC discovered it. Discovery by the respondent credits the crew–aircraft contextual control loop. Thirdly, we investigated whether too much trust in automation and a lack of situational awareness were considered relevant for AS, or whether lack of knowledge about the automation in relation to the current operational context played a more prominent role. We asked the respondents about the causes of automation surprise: “Below is a list of causes for Automation Surprises. Please state which ones are applicable to your last automation surprise. Multiple options are possible.” We also asked the respondents “…to indicate how often [the same] factors are involved in automation surprise in general” on a 6-point Likert scale (1 = never; 6 = very often). We included nine possible pre-printed responses and a field for “other”. Too much trust in automation and a lack of situational awareness credits the integrated model, whereas lack of system knowledge credits the contextual control loop.
3. Results
During the study period, 200 questionnaires were filled in and returned. The respondents were predominantly male (96%), 54% was in the rank of captain, and 42% was in the rank of first officer (the balance is in the rank of second officer). With regard to aircraft type currently operated, respondents mentioned (in order of frequency): Boeing 737NG, Airbus A330, Boeing 777, Embraer 170/190, and Fokker 70/100 as the aircraft types flown most frequently. The age of the respondents ranged from 23 to 58 years (median 38 years). The flying experience varied from 750 to 27,500 h (median 7500 h). The median number of flights executed per month was 28, with a range from 3 to 43 flights per month. The sample is considered representative for the Dutch commercial pilot community.
Through descriptions of the event, we were able to validate that the introductory question had appropriately triggered a memory of automation surprise. For instance, one narrative was: “When a new approach is programmed in the FMS and you’re already on the approach, the plane can fly back to the IAF again if in LNAV. It is clear why it happens, but a fraction of a second you are still surprised” [
35]. As reported in De Boer and Hurts [
35], the prevalence of automation surprise is estimated at about three times per year per pilot. In 90% of the AS events, an undesired aircraft state was not induced, and only in one case of AS (0.5%) was consequential damage to the aircraft reported. Based on the severity and prevalence of AS, each pilot is expected to experience a reportable AS event about once every three years.
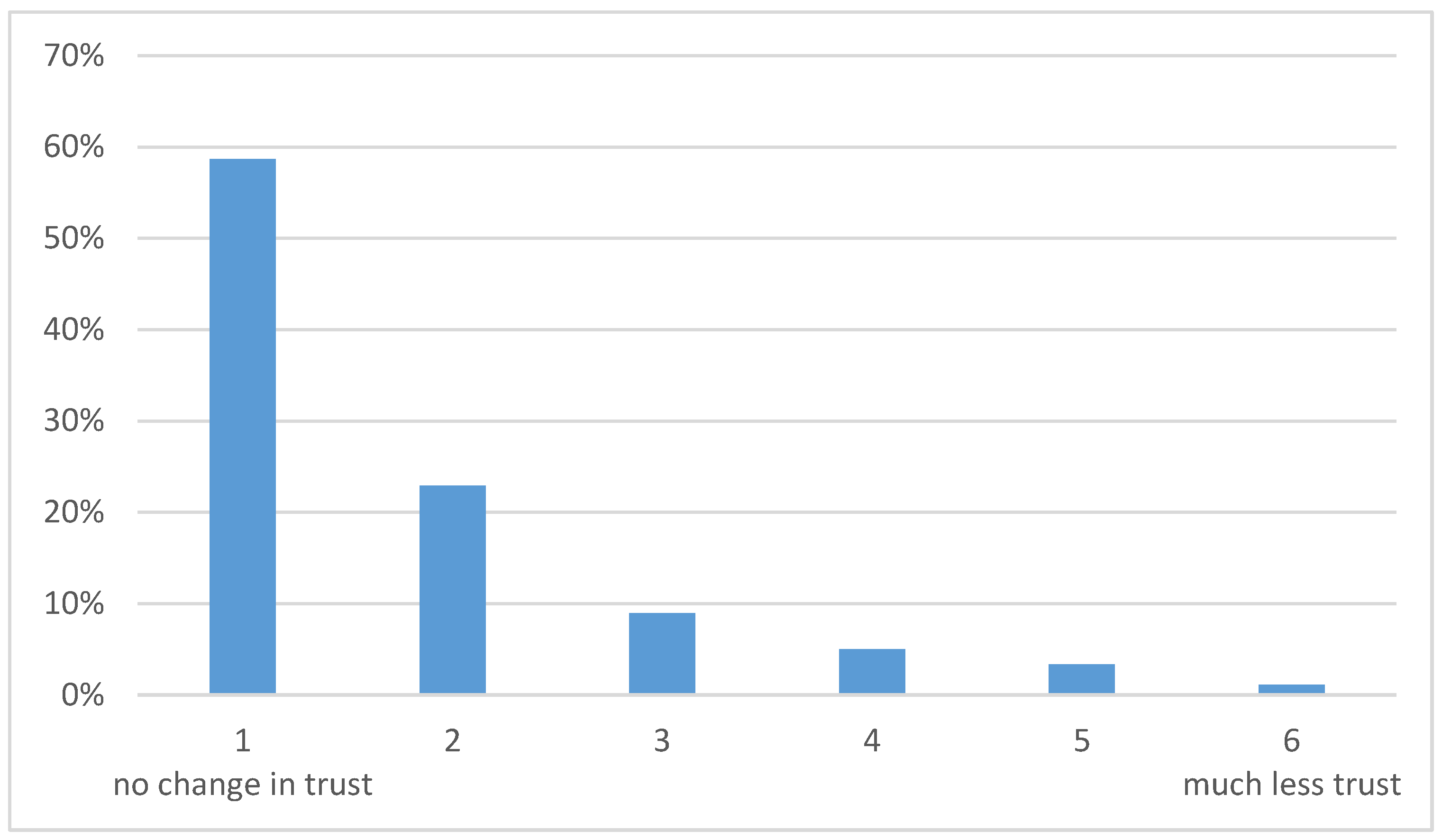
Out of the 180 respondents that had reported an AS event 106 of these (59%) reported that their trust had not changed following the AS event, as shown in
Figure 3. Only 17 respondents (9%) reported a reduction in trust of score 4 or higher (i.e., over the halfway mark). The distribution of responses across the various rating categories was not due to chance (
Χ2(5) = 252,
p < 0.001) but rather a statistically significant finding in support of the contextual control loop. The contextual control loop predicted that the trust in the automation is not necessarily reduced through contradictory feedback as was the case in 59% of the response. The integrated model on the other hand predicted that even a single instance of contradictory feedback leads to a considerable reduction in trust in the automated system but this is not consistent with our findings.
Automation surprises were predominantly discovered by the respondents themselves. Of the 176 respondents that had reported an AS event and responded to this question, 89% reported that he or she noticed it themselves. 7% were warned by an alerting system, and 5% were notified by the fellow pilot. Air traffic control did not contribute to the discovery of an AS event in our sample. The distribution of respondents across the rating categories was not random (Χ2 (3) = 370, p < 0.001). This finding supports the contextual control loop model which suggests that re-framing may occur as a function of time within the individual when the discrepancy between stimuli and expectations becomes large, and is not dependent upon specific alarms or warnings by fellow crew-members. The integrated model suggests that alerting systems or a second crew member will be instrumental in alleviating the mismatch between what is observed and what is expected, because the complacency potential increases over time as long as contradictory feedback is lacking.
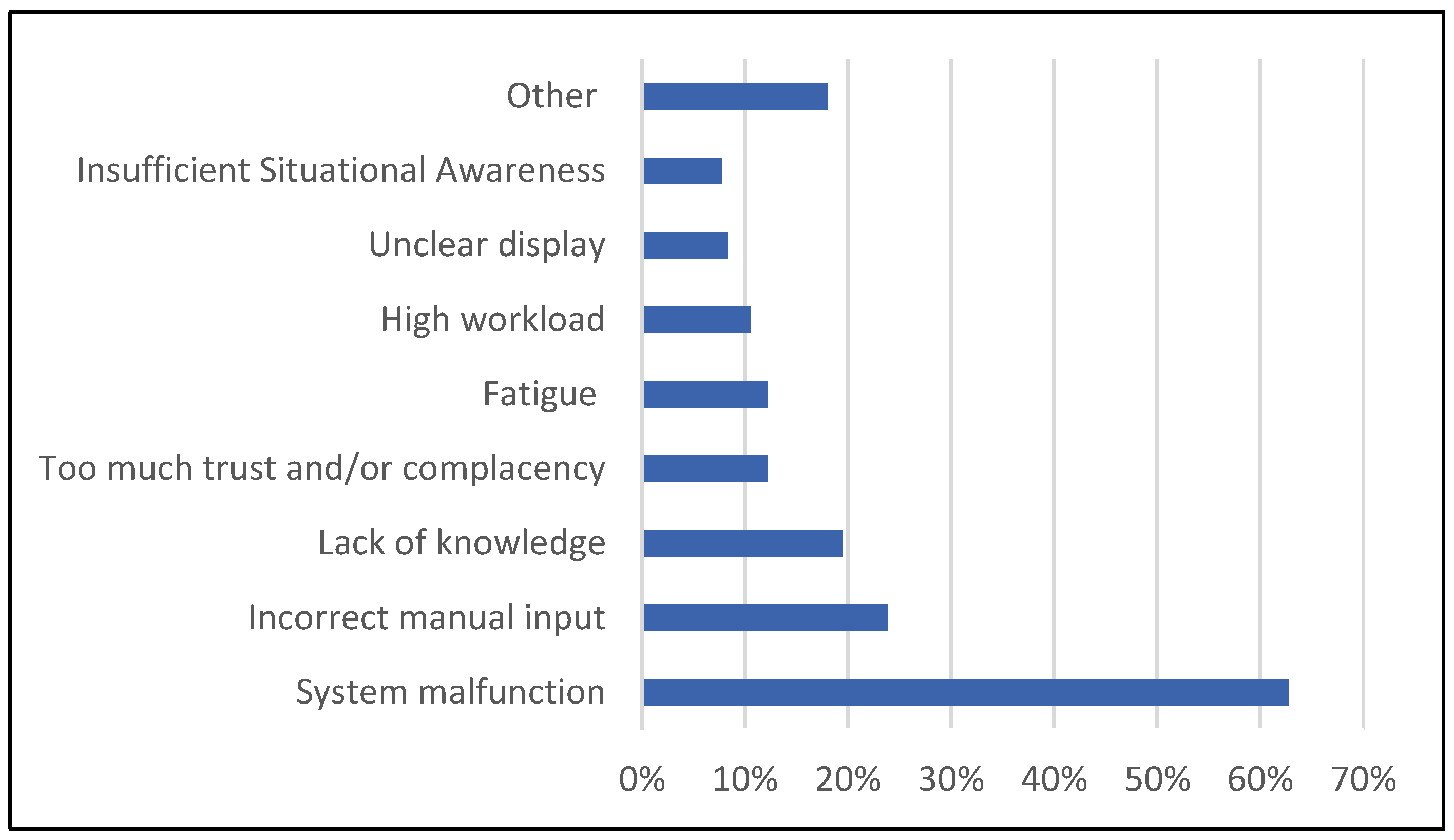
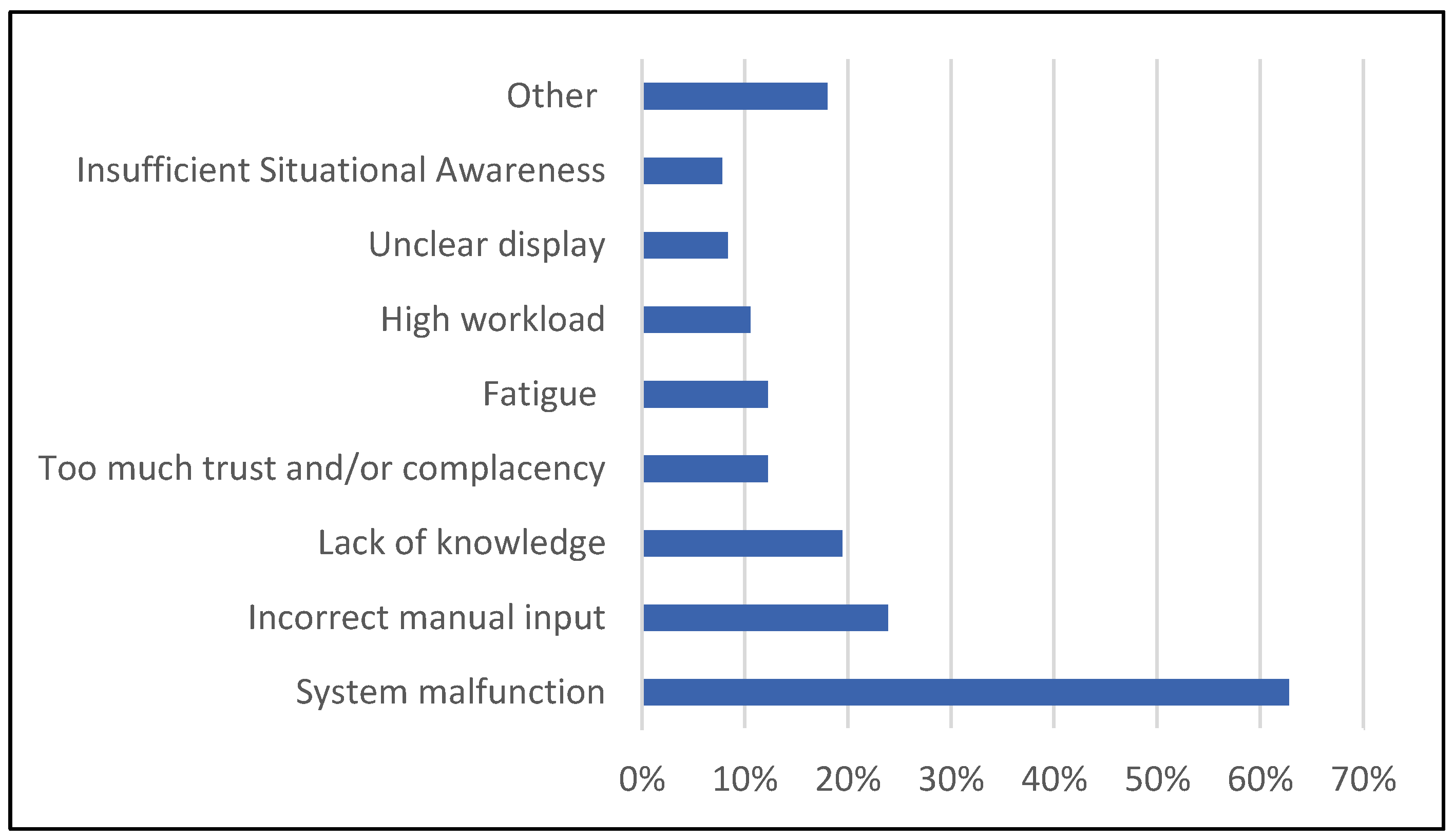
In answer to what the cause was of the last AS event that was experienced (multiple answers permitted), a total of 315 reasons were given for the 180 AS events that were reported. AS shown in
Figure 4, in nearly two-thirds of the AS events (63%) one of the relevant causes was claimed to be system malfunction. We interpret this as a lack of understanding of the system, because of the high reliability of aviation systems, the tight coupling of the modules of cockpit automation, the interface design choices, and the use of automation in aviation that is above the critical boundary of action selection found by Onnasch, Wickens, Li and Manzey [
8]. Other frequently reported causes include wrong manual input (24%) and lack of knowledge concerning aircraft systems (19%). Too much trust in the proper operation of systems and/or complacency was only mentioned in 38 cases (12%) and lack of situational awareness 25 times (8%).
We also asked how often specific factors are involved in AS in general (6-point Likert scale, average response across all factors 2.9). There were relatively high average scores for wrong manual input (3.4) and lack of knowledge concerning aircraft systems (3.1). Too much trust in the proper operation of automated systems scored equal to average (2.9) and lack of situational awareness scored lower than average (2.6). Both the results about the last AS event and about AS in general lend credibility to the contextual control loop, because this model suggests that a lack of knowledge about the automation in the context of the operation will be the predominant cause of AS. In contrast, the integrated model implies that the cause of automation surprise is attributed to too much trust in automation and a lack of situational awareness, which scored lower in both questions on the cause of AS in our survey.
4. Discussion
We have reported the results of a field survey that was administered to a representative sample of 200 airline pilots [
35]. The data was used to empirically evaluate the integrated model of complacency and automation bias [
11] and the crew–aircraft contextual control loop [
12]. To differentiate between these two models, we identified three indicators: (1) a reduction in trust in the automated system following an automation surprise; (2) the way that the automation surprise was discovered; and (3) to which cause the automation surprise was attributed.
The data we found were a good fit with the contextual control loop on all three points. (1) Despite experiencing an automation surprise, more than half of the respondents did not report a reduction in their trust of the automation. Only a small minority reported a strong reduction in trust. This is inconsistent with the integrated model, which suggests that even a single instance of contradictory feedback may lead to a considerable reduction in trust in the automated system [
11]. (2) The integrated model predicts that the “complacency potential” increases over time as long as contradictory feedback is lacking [
11] (p. 405). This suggests that alerting systems or a second crew member will be instrumental in alleviating the mismatch between what is observed and what is expected rather than the operator him/herself. However, our data shows that the discovery of the last automation surprise was predominantly (89%) by the respondent him/herself. This finding supports the contextual control loop model which suggests that re-framing may occur as a function of time without an external trigger [
12]. (3) The integrated model implies that the cause of automation surprise is attributed to too much trust in automation (or complacency) and a lack of situational awareness [
11] (p. 406). However, the data indicate that a lack of understanding of the system, manual input issues, and buggy knowledge concerning aircraft systems were the predominant causes of automation surprise—as predicted by the contextual control loop [
12].
Parasuraman and colleagues have documented some of the problems associated with measuring “trust”, and the discrepancy that typically occurs between objective versus subjective measures of trust. No strong link, for example, has yet been established between low sampling rates (or poor automation monitoring) and high self-reported trust in automation [
11]. As a result, previous studies have typically measured trust subjectively. The study reported here is consistent with that, so as to be as fair as possible in our empirical evaluation. This of course means that an alternative, but slightly far-fetched, explanation could be that the way that the automation surprise is discovered is by a higher memory retention for positive events (though the literature is ambiguous on this), or by cognitive dissonance (or another self-centered outcome perception bias). Experiencing automation surprise might challenge one’s self-esteem, which is restored if the event is perceived to be resolved by the self. Similarly, a low reduction in trust that was identified might be a result of the self-reporting nature of this study. As in many surveys, we acknowledge that the external validity and reliability of the collected data may be limited due to the self-report nature of the survey, and the post-hoc nature of having to rate “trust” in the wake of an event. As part of this, we also recognize that the voluntary participation may also have biased the results, particularly on the prevalence of automation surprises.
Nonetheless, the fit between our data and the crew–aircraft contextual control loop suggests that the complexity of the context needs to be addressed to resolve issues in human-automation interaction. This will likely produce better safety outcomes than a focus on suboptimal human performance, at least within routine airline operations. This finding is consistent with a school of safety thinking that has colloquially been dubbed the “New View” on human error [
9,
21,
36], which suggests that human errors are a symptom of system vulnerability. This “New View” postulates that terms like “complacency potential”, “complacency”, “automation bias”, “learned carelessness”, and “lack of situational awareness” do not serve our understanding of human-automation interaction, but instead are constructs that have no explanatory power and ultimately only blame the operator [
37]. The sensemaking approach suggested by Rankin, Woltjer, & Field [
12] that has been applied successfully in other domains [
24] seems to have more promising explanatory power.
Support for the need to take a sensemaking (rather than a normative) approach can further be found in our study, where a surprisingly high number of respondents (63%) indicated that a system malfunction was one of the causes of the most recent automation surprise event. This may be the result of the ambiguous nature of a “system malfunction”. The term can be used to denote (1) that there is a discrepancy between what the designer intended and what the crew thinks it should be doing—therefore not an actual malfunction but a “buggy” mental model; or (2) that the system is functioning correctly (i.e., logically) but not doing what the designer intended (i.e., poor execution of the design); or (3) that the system is not functioning correctly (i.e., “broken”). We propose that due to the high certification requirements in aviation that design errors (2) and malfunctions (3) will be less likely and the former (i.e., (1), the “buggy” mental model) will be predominant. This is supported by the relatively high score in our survey for “lack of knowledge concerning aircraft systems” and the higher prevalence of automation surprise events associated with higher degrees of automation, in which an appropriate mental model is more difficult to achieve. The high number of reports of “system malfunction” in our survey therefore lends further support to the need to understand how pilots make sense of the automation.
Rankin, Woltjer, Field & Wood [
38] describe automation surprise as arising “when Expectations do not match the interpretation of Events and Feedback. The surprise may result in a quick modification of the current Understanding […] or in a fundamental surprise which may result in a longer process of questioning the frame, elaborating the frame, and reframing the data, which in everyday language may be called confusion and problem solving.” This may be considered as a special (automation related) case of a generic process that has been previously described by several authors. Kahneman [
26] suggests two separate cognitive processes (system 1 and system 2). System 1 executes routine tasks without much cognitive effort, but if a mismatch between expectation and reality is perceived, this may initiate slower, more effortful, conscious cognitive processes (system 2). De Boer [
25] building on Schön [
28] and Johnson-Laird [
27] similarly suggests that a change in cognition is triggered by a surprise when expectation and reality do not match, leading to reflection on the current approach.
5. Conclusions
In this paper, we have reported the outcome of a field study to empirically validate two divergent models of human–automation interaction that have been proposed in the literature: the integrated model of complacency and automation bias (a normative model), and the crew–aircraft contextual control loop (a sensemaking model). These models make fundamentally different assumptions about the nature of human cognition—particularly whether all relevant processes occur within an individual (e.g., in the form of biases or motivational shortcomings such as complacency) or whether the pertinent cognitive processes are situated in a work environment and distributed across both human and machine partners. Support for the distributed cognitive, or sensemaking, model was found in a lack of reduction in trust in the automated system following an automation surprise, in the discovery of the automation surprise by the respondent him/herself and in the attribution of the cause of the automation surprise to a lack of knowledge about the automation. What are the implications for improving safety, in this case? The sensemaking model suggests that our understanding of the interaction between humans and automation can be improved by taking into account systemic factors and the complexity of the operational context, rather than focusing on suboptimal human performance. Automation surprise seems to be a manifestation of the system complexity and interface design choices in aviation today, and rarely the result of individual under-performance. Further research into individual automation surprise experiences can substantiate whether a “buggy” mental model was underlying the events, and if so whether redesign of the automation to facilitate the generation of an appropriate mental model, supported by sufficient training and the build-up of experience, is warranted.


{kind=link}
{kind=link}
{kind=link}
{kind=link}