
DCTable: A Dilated CNN with Optimizing Anchors for Accurate Table Detection

 , ,
, ,  ,
,
Abstract
:1. Introduction
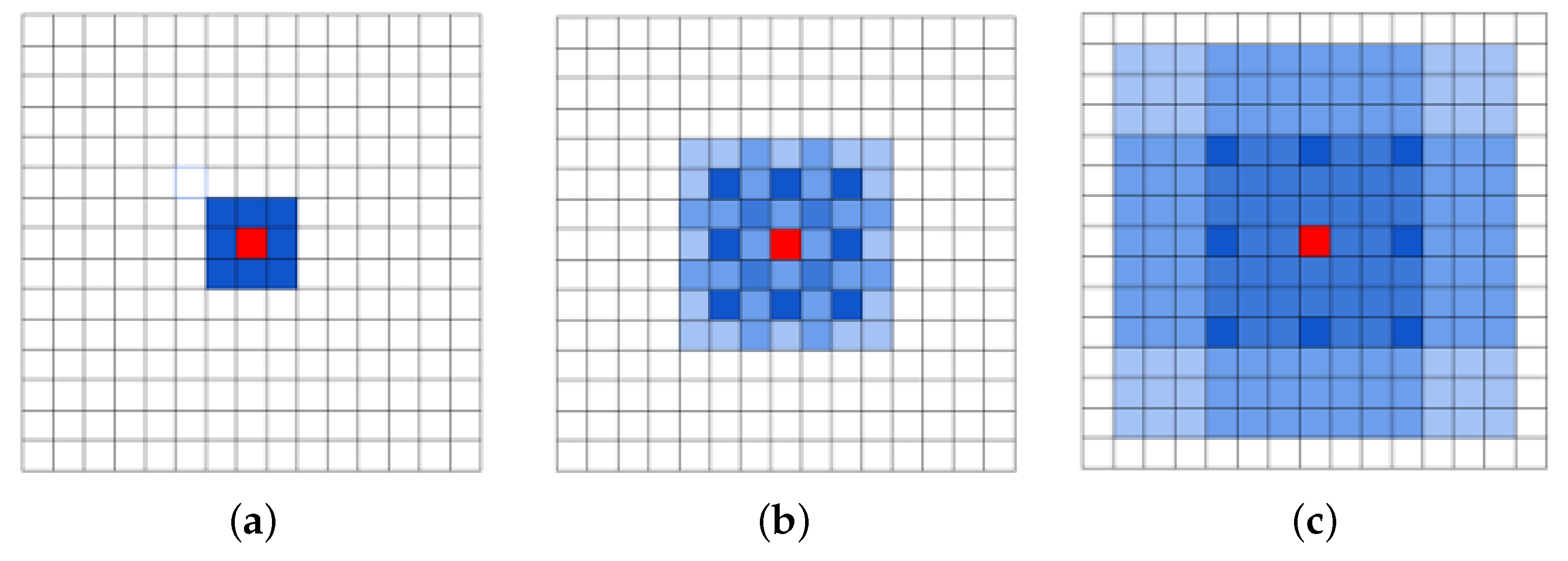
- We use a dilated VGG-16 network for the feature extraction where we remove the downsampling (in max-pooling and strided convolution). This leads to the expansion of the receptive fields of the conv_4 and conv_5, thus obtaining more discriminative features and preventing both confused and missed detections.
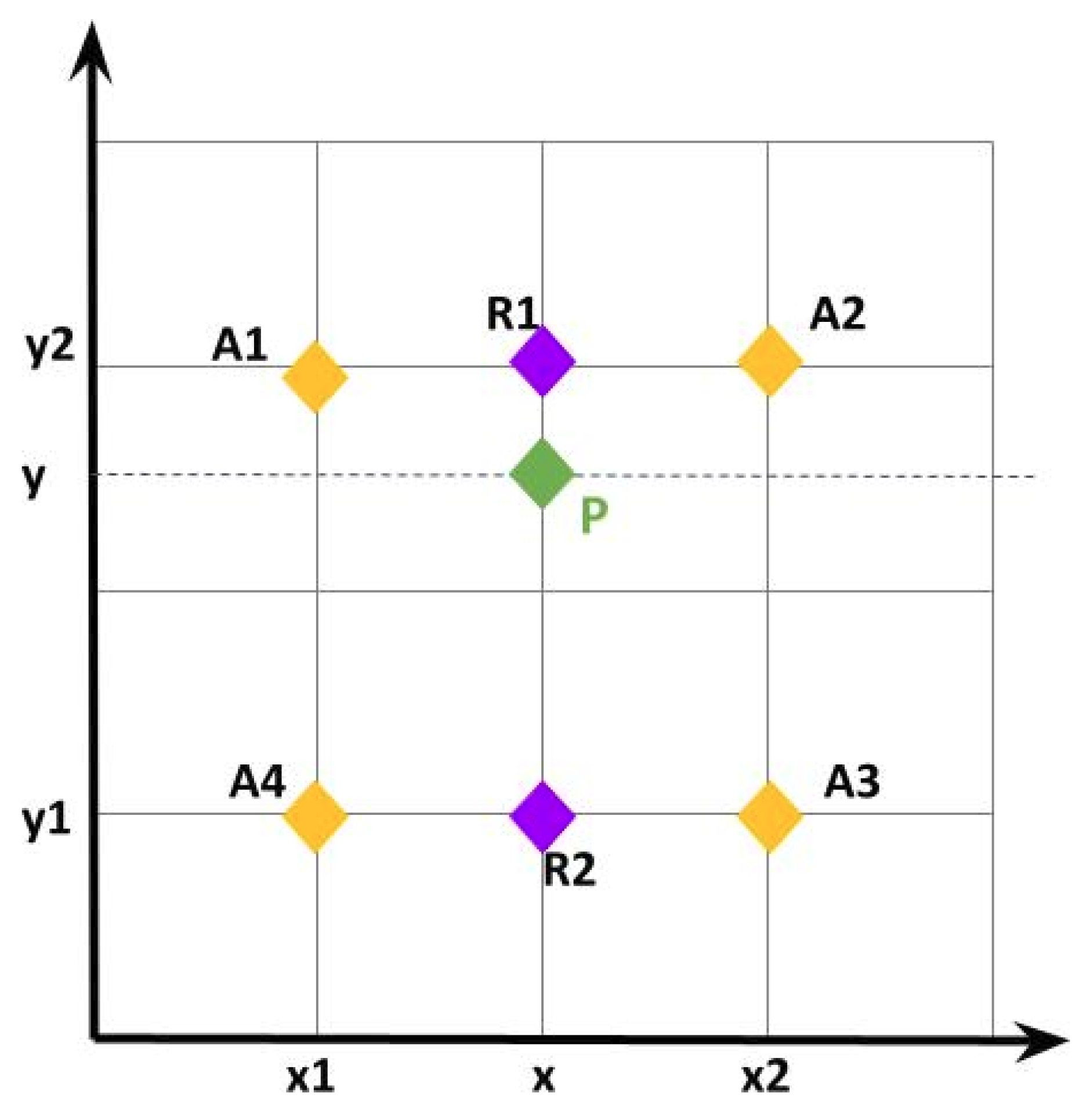
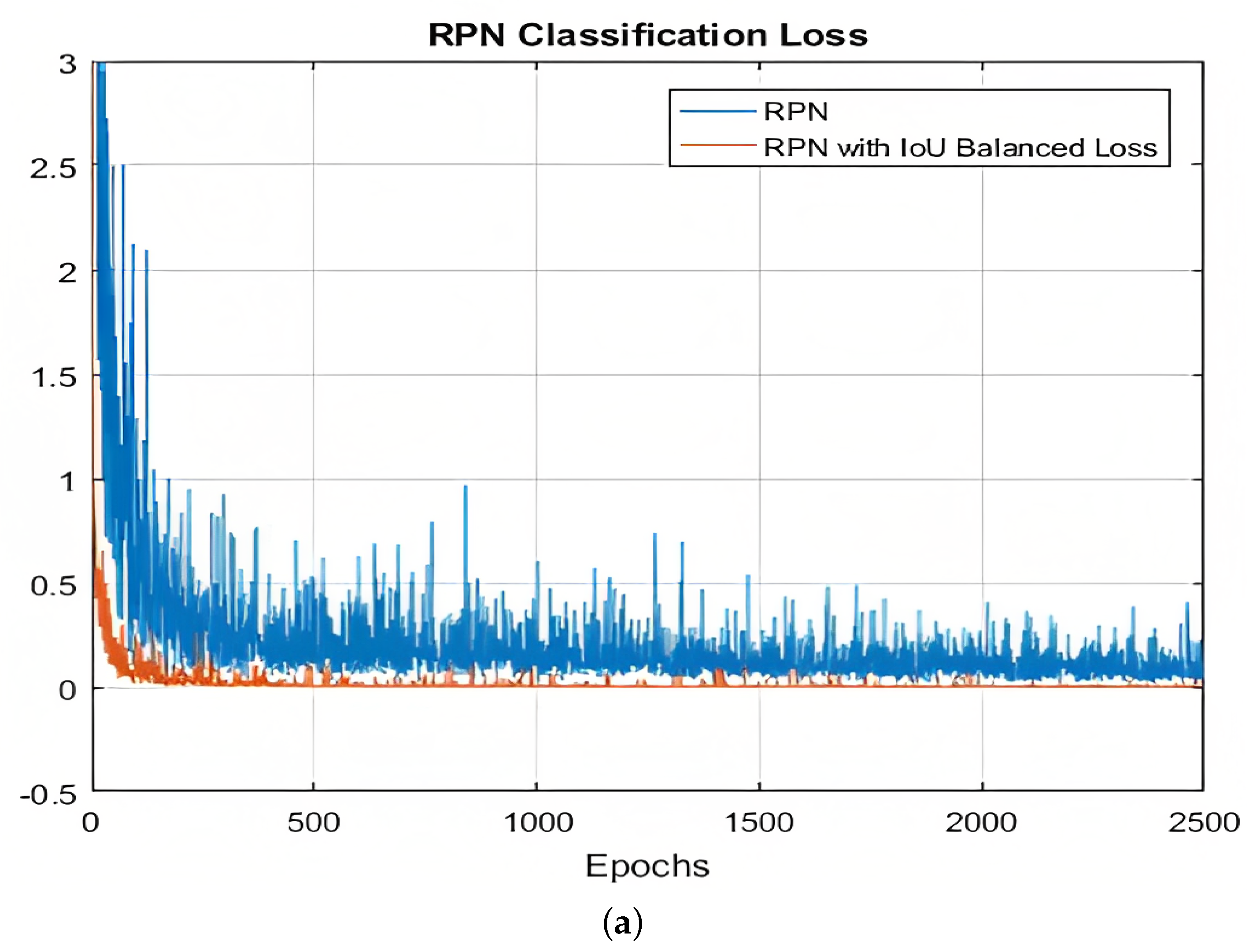
- We leverage the great potential of weighted IoU in the correlated IoU balanced-loss functions [15] to improve the localization accuracy of the RPN and alleviate the confusion problem.
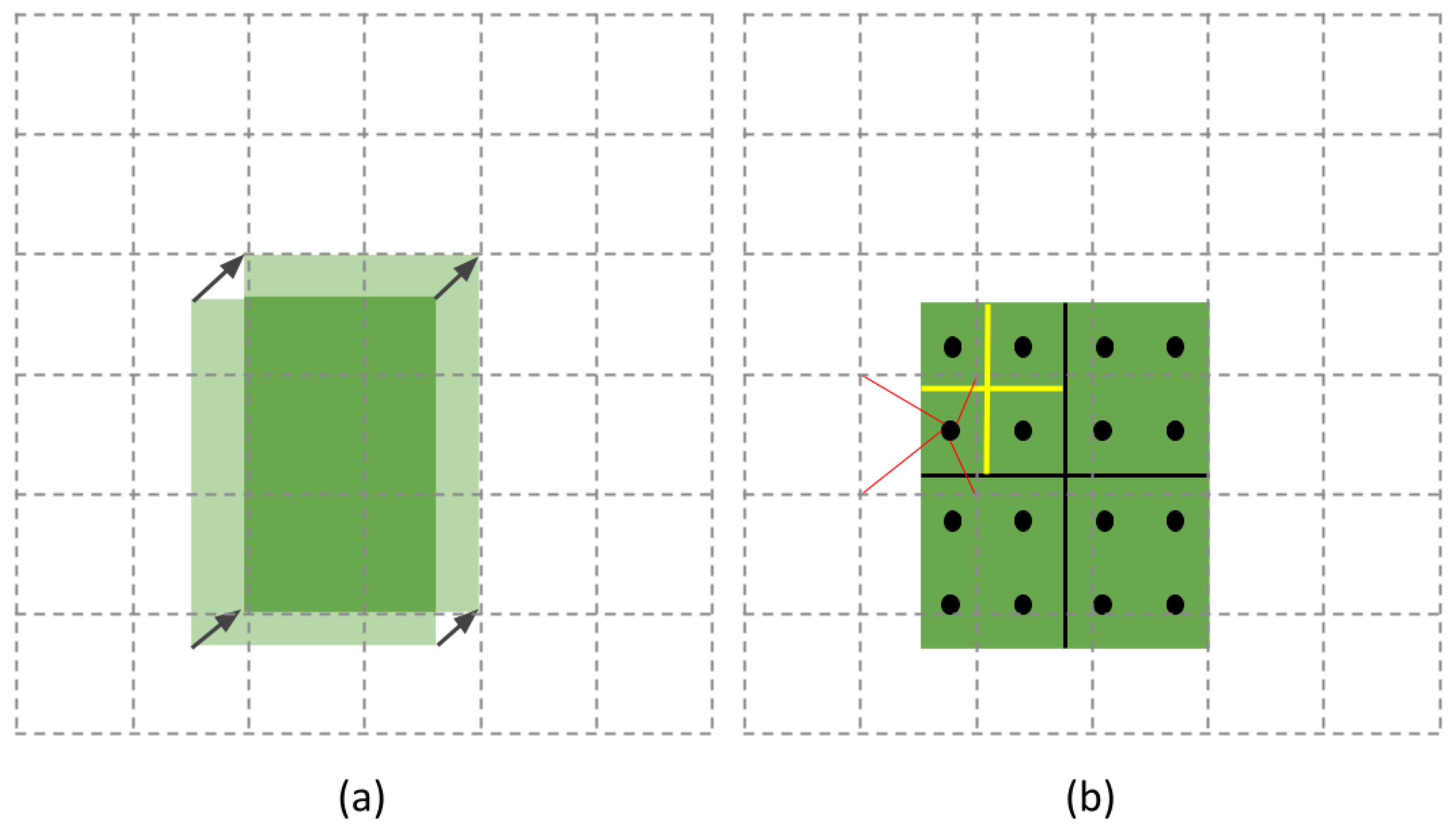
- We introduce the bilinear interpolation in the Faster R-CNN in order to ensure a mapping based on exact spatial locations and correctly align the extracted features with the input by replacing the typical RoI pooling with the RoIAlign layer.
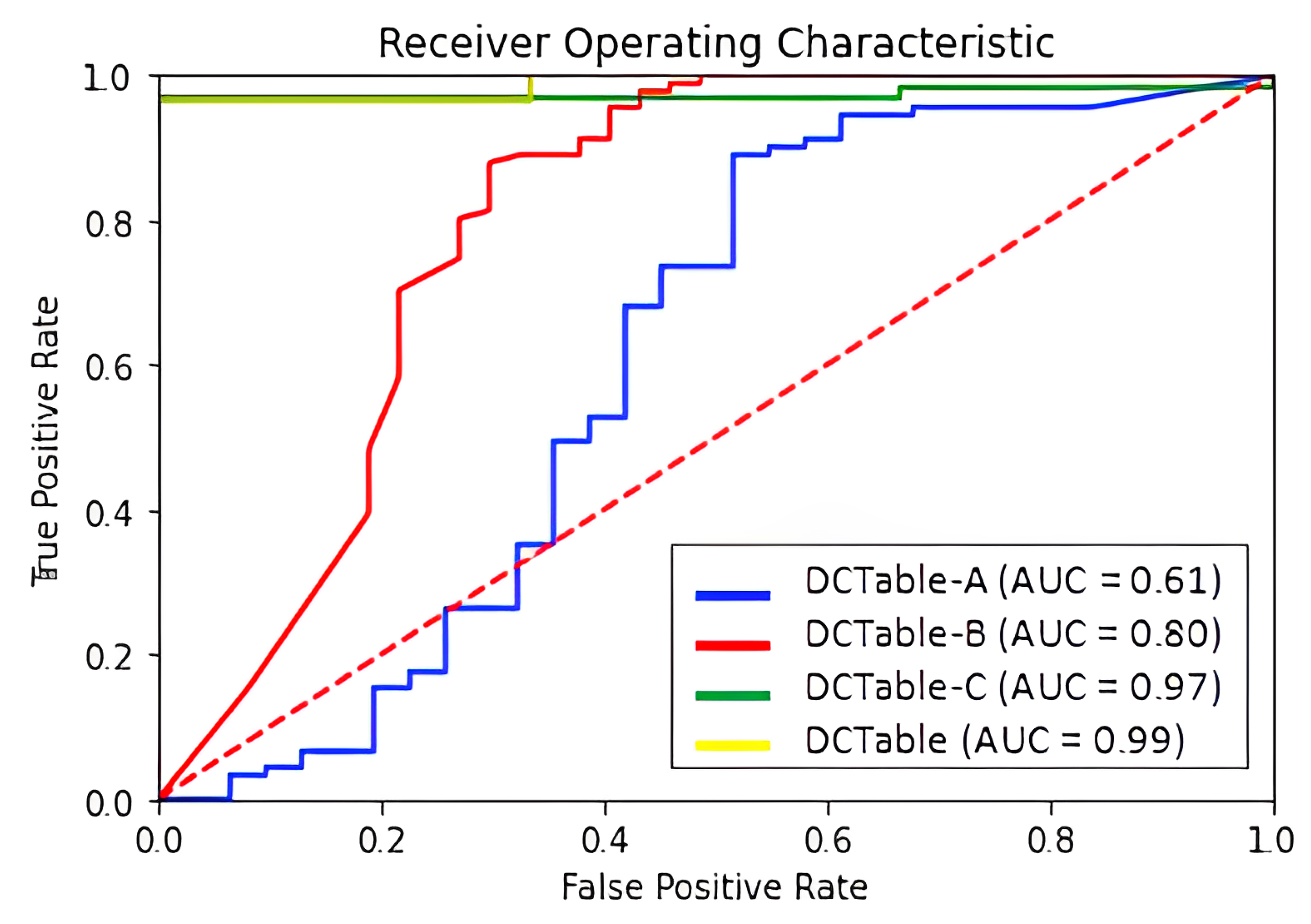
- We evaluate the enhanced approach on four datasets using not only a Precision-Recall space, but also the ROC space to show how much our approach improves localization.
2. Related Works
2.1. Heuristics-Based Table Detection
2.2. Learning-Based Table Detection
3. Method
3.1. Feature Extractor with Dilated Convolutions
3.2. IoU-Balanced Loss for Optimizing Anchors
3.3. RoIAlign in DCTable
4. Datasets
4.1. ICDAR-POD2017
4.2. ICDAR-2019
4.3. Marmot
4.4. RVL-CDIP
5. Evaluation Metrics
5.1. Precision-Recall Space
5.2. ROC Space
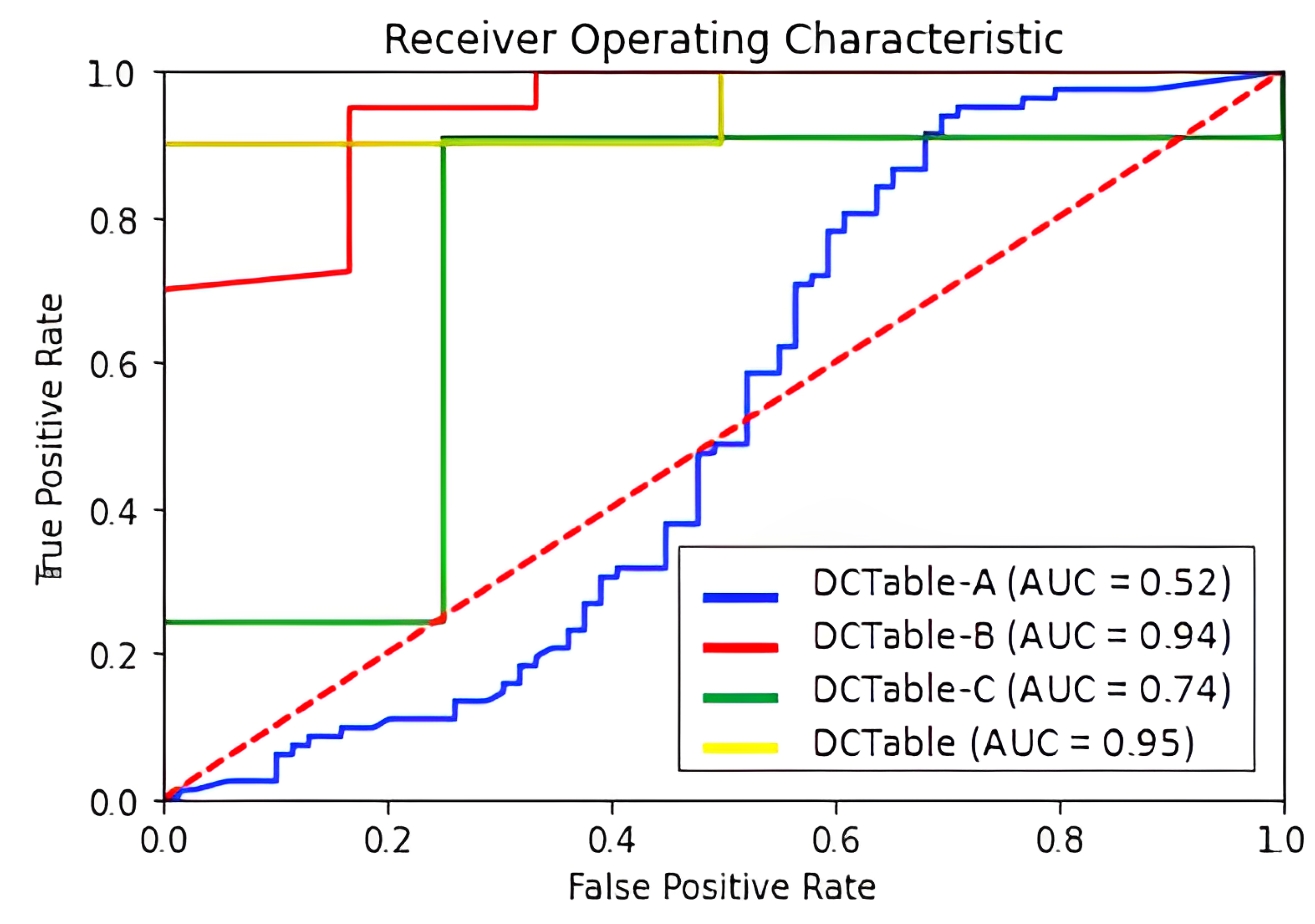
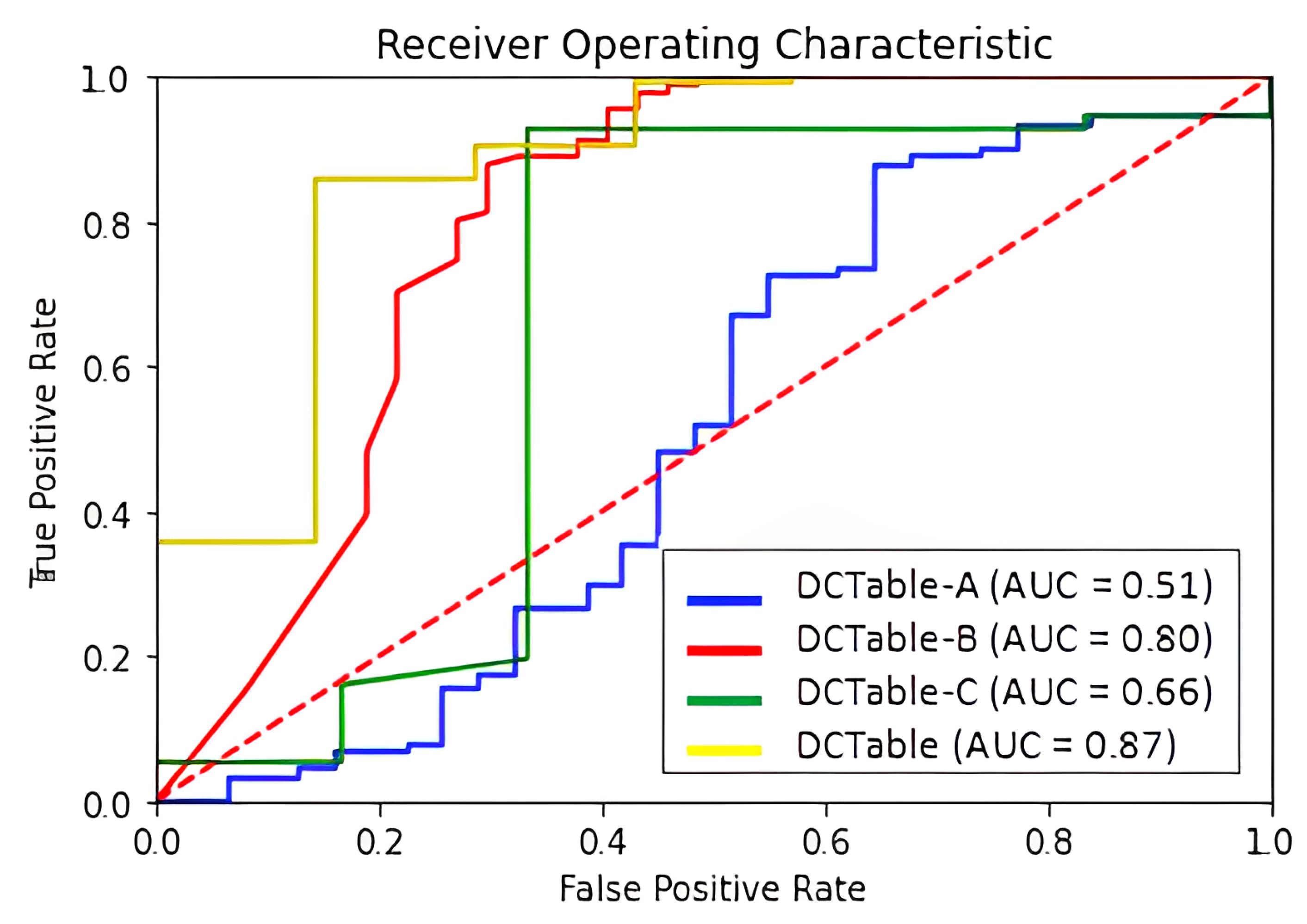
6. Results and Discussion
- DCTable-B: a Faster R-CNN based on a dilated VGG-16. We replaced conventional convolutions of the conv_4 and conv_5 with dilated ones where the used dilation rates are and , respectively. The output region proposals are fed into the RoIALign layer. The RPN is trained using the typical loss function as defined in the original paper [7].
- DCTable-C: we replaced the typical loss function in the RPN in DCTable-A with the IoU-balanced loss function.
- DCTable: we replace the loss functions of the RPN in DCTable-B with the IoU-balanced loss function.
Effectiveness of IoU-Balanced Loss
6.1. Test Performance on ICDAR2017
6.2. Test Performance on ICDAR 2019
6.3. Test Performance on Marmot
6.4. Test Performance on RVL-CDIP
6.5. Test Performance with Leave-One-Out Scheme of DCTable
- Scheme 1: DCTable is trained on a combining set composed of ICDAR 2019, Marmot and RVL CDIP and tested on ICDAR 2017.
- Scheme 2: DCTable is trained on a combining set composed of ICDAR 2017, Marmot and RVL CDIP and tested on ICDAR 2019.
- Scheme 3: DCTable is trained on a combining set composed of ICDAR 2017, ICDAR 2019 and RVL CDIP and tested on Marmot.
- Scheme 4: DCTable is trained on a combining set composed of ICDAR 2017, ICDAR 2019 and Marmot and tested on RVL CDIP.
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Marinai, S. Introduction to Document Analysis and Recognition. In Studies in Computational Intelligence; Springer: New York, NY, USA, 2008; pp. 1–20. [Google Scholar] [CrossRef] [Green Version]
- Faisal, S.; Smith, R. Table detection in heterogeneous documents. In Proceedings of the 9th IAPR International Workshop on Document Analysis Systems, Boston, MA, USA, 9–11 June 2010; pp. 65–72. [Google Scholar] [CrossRef] [Green Version]
- Hashmi, K.A.; Liwicki, M.; Stricker, D.; Afzal, M.A.; Afzal, M.A.; Afzal, M.Z. Current Status and Performance Analysis of Table Recognition in Document Images with Deep Neural Networks. IEEE Access 2021, 9, 87663–87685. [Google Scholar] [CrossRef]
- Bhowmik, S.; Sarkar, R.; Nasipuri, M.; Doermann, D. Text and non-text separation in offline document images: A survey. Int. J. Doc. Anal. Recognit. 2018, 21, 1–20. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gilani, A.; Qasim, S.R.; Malik, I.; Shafait, F. Table detection using deep learning. In Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 771–776. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar] [CrossRef]
- Huang, Y.; Yan, Q.; Li, Y.; Chen, Y.; Wang, X.; Gao, L.; Tang, Z. A yolo-based table detection method. In Proceeding of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, NSW, Australia, 20–25 September 2019; pp. 813–818. [Google Scholar] [CrossRef]
- Riba, P.; Dutta, A.; Goldmann, L.; Fornés, A.; Ramos, O.; Lladós, J. Table detection in invoice documents by graph neural networks. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, NSW, Australia, 20–25 September 2019; pp. 122–127. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef] [Green Version]
- Wu, S.; Yang, J.; Wang, X.; Li, X. IoU-balanced loss functions for single-stage object detection. Pattern Recognit. Lett. 2022, 156, 96–103. [Google Scholar] [CrossRef]
- Kieninger. T. Table structure recognition based on robust block segmentation. Doc. Recognit. 1998, 3305, 22–32. [Google Scholar] [CrossRef]
- Cesarini, F.; Marinai, S.; Sarti, L.; Soda, G. Trainable table location in document images. In Proceedings of the 2002 International Conference on Pattern Recognition, Quebec City, QC, Canada, 11–15 August 2002; IEEE: New York, NY, USA, 2002; pp. 236–240. [Google Scholar] [CrossRef]
- e Silva, A.C. Learning rich hidden markov models in document analysis: Table location. In Proceedings of the 2009 International Conference on Document Analysis and Recognition, Washington, DC, USA, 26–29 July 2009; pp. 843–847. [Google Scholar] [CrossRef]
- Kasar, T.; Barlas, P.; Adam, S.; Chatelain, C.; Paquet, T. Learning to detect tables in scanned document images using line information. In Proceedings of the 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1185–1189. [Google Scholar] [CrossRef] [Green Version]
- Jahan, M.A.C.A.; Ragel, R.G. Locating tables in scanned documents for reconstructing and republishing. In Proceedings of the 7th International Conference on Information and Automation for Sustainability, Colombo, Sri Lanka, 22–24 December 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Tran, D.N.; Tran, T.A.; Oh, A.; Kim, S.H.; Na, I.S. Table detection from document image using vertical arrangement of text blocks. Int. J. Contents 2015, 11, 77–85. [Google Scholar] [CrossRef] [Green Version]
- Saman, A.; Faisal, S. Table detection in document images using foreground and background features. In Proceedings of the 2018 Digital Image Computing: Techniques and Applications (DICTA), Canberra, ACT, Australia, 10–13 December 2018; pp. 1–8. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 International Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Gao, L.; Yi, X.; Jiang, Z.; Hao, L.; Tang, Z. ICDAR 2017 competition on page object detection. In Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2019. [Google Scholar] [CrossRef]
- Zhu, N.S.Y.; Hu, X. Faster R-CNN based table detection combining corner locating. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, NSW, Australia, 20–25 September 2019; IEEE: New York, NY, USA, 2019; pp. 1314–1319. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Schreiber, S.; Agne, S.; Wolf, I.; Dengel, A.; Ahmed, S. DeepDeSRT: Deep learning for detection and structure recognition of tables in document images. In Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; IEEE: New York, NY, USA, 2017; pp. 1162–1167. [Google Scholar] [CrossRef]
- Li, M.; Cui, L.; Huang, S.; Wei, F.; Zhou, M.; Li, Z. Tablebank: Table benchmark for image-based table detection and recognition. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 1918–1925. [Google Scholar]
- Casado-García, Á.; Domínguez, C.; Heras, J.; Mata, E.; Pascual, V. The benefits of close-domain fine-tuning for table detection in document images. In International Workshop on Document Analysis Systems; Springer: Cham, Switzerland, 2020; pp. 199–215. [Google Scholar] [CrossRef]
- Siddiqui, S.A.; Malik, M.I.; Agne, S.; Dengel, A.; Ahmed, S. DeCNT: Deep deformable cnn for table detection. IEEE Access 2018, 74151–74161. [Google Scholar] [CrossRef]
- Agarwal, M.; Mondal, A.; Jawahar, C.V. CDeC-NET: Composite deformable cascade network for table detection in document images. In Proceedings of the 2021 International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, Y.; Wang, Y.; Wang, S.; Liang, T.; Zhao, Q.; Tang, Z.; Ling, H. CBNet: A novel composite backbone network architecture for object detection. Proc. Int. Conf. Artif. Intell. 2020, 34, 11653–11660. [Google Scholar] [CrossRef]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W.; et al. Hybrid task cascade for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4969–4978. [Google Scholar] [CrossRef] [Green Version]
- Nazir, D.; Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. HybridTabNet: Towards Better Table Detection in Scanned Document Images. Appl. Sci. 2021, 11, 8396. [Google Scholar] [CrossRef]
- Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. CasTabDetectoRS: Cascade Network for Table Detection in Document Images with Recursive Feature Pyramid and Switchable Atrous Convolution. J. Imaging 2021, 7, 214. [Google Scholar] [CrossRef] [PubMed]
- Qiao, S.; Chen, L.C.; Yuille, A. DetectoRS: Detecting objects with recursive feature pyramid and switchable atrous convolution. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10208–10219. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, S.; Deng, W. Very deep convolutional neural network based image classification using small training sample size. In Proceedings of the 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 730–734. [Google Scholar] [CrossRef]
- Isaak, K.; Pino, C.; Palazzo, S.; Rundo, F.; Giordano, D.; Messina, P.; Spampinato, C. A saliency-based convolutional neural network for table and chart detection in digitized documents. In Proceedings of the 2019 International Conference on Image Analysis and Processing, Trento, Italy, 9–13 September 2019; pp. 292–302. [Google Scholar] [CrossRef] [Green Version]
- Fisher, Y.; Koltun, V. Multi-scale context aggregation by dilated convolutions. In Proceedings of the 15th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 6–9 December 2020; pp. 240–245. [Google Scholar] [CrossRef]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the 2018 IEEE winter conference on applications of computer vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar] [CrossRef] [Green Version]
- Fisher, Y.; Vladlen, K.; Thomas, F. Dilated residual networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 472–480. [Google Scholar] [CrossRef] [Green Version]
- Zhu, L.; Xie, Z.; Liu, L.; Tao, B.; Tao, W. Iou-uniform R-CNN: Breaking through the limitations of RPN. Pattern Recognit. 2021, 112, 107816. [Google Scholar] [CrossRef]
- Max, J.; Simonyan, K.; Zisserman, A. Spatial transformer networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2017–2025. [Google Scholar] [CrossRef]
- Gao, L.; Huang, Y.; Déjean, H.; Meunier, J.; Yan, Q.; Fang, Y.; Kleber, F.; Lang, E. ICDAR 2019 competition on table detection and recognition (cTDaR). In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, NSW, Australia, 20–25 September 2019; pp. 1510–1515. [Google Scholar] [CrossRef]
- Fang, J.; Tao, X.; Tang, Z.; Qiu, R.; Liu, Y. Dataset, ground-truth and performance metrics for table detection evaluation. In Proceedings of the 10th IAPR International Workshop on Document Analysis Systems, Gold Coast, QLD, Australia, 27–29 March 2012; pp. 445–449. [Google Scholar] [CrossRef]
- Chris, T.; Martinez, T. Analysis of convolutional neural networks for document image classification. In Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 388–393. [Google Scholar] [CrossRef] [Green Version]
- Jesse, D.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 6000–6010. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | IoU | P | R | F1-Score |
|---|---|---|---|---|
| DCTable-A | 0.6 | 0.891 | 0.937 | 0.913 |
| 0.8 | 0.946 | 0.909 | 0.927 | |
| DCTable-B | 0.6 | 0.919 | 1 | 0.958 |
| 0.8 | 0.937 | 1 | 0.967 | |
| DCTable-C | 0.6 | 0.911 | 0.911 | 0.911 |
| 0.8 | 0.953 | 0.911 | 0.932 | |
| DCTable | 0.6 | 0.952 | 1 | 0.976 |
| 0.8 | 0.975 | 0.975 | 0.975 | |
| HustVision [24] | 0.6 | 0.071 | 0.959 | 0.132 |
| FastDetectors [24] | 0.903 | 0.940 | 0.921 | |
| NLPR-PA L [24] | 0.968 | 0.953 | 0.960 | |
| DeCNT [30] | 0.965 | 0.971 | 0.968 | |
| CDeC-Net [31] | 0.977 | 0.931 | 0.954 | |
| HybridTabNet [35] | 0.882 | 0.997 | 0.936 | |
| CasTabDetectoRS [36] | 0.972 | 0.941 | 0.956 | |
| HustVision [24] | 0.8 | 0.062 | 0.836 | 0.115 |
| FastDetectors [24] | 0.879 | 0.915 | 0.896 | |
| NLPR-PAL [24] | 0.958 | 0.943 | 0.951 | |
| DeCNT [30] | 0.946 | 0.952 | 0.949 | |
| CDeC-Net [31] | 0.970 | 0.924 | 0.947 | |
| HybridTabNet [35] | 0.887 | 0.994 | 0.933 | |
| CasTabDetectoRS [36] | 0.962 | 0.932 | 0.947 | |
| (Sun et al., 2019) [25] | 0.832 | 0.943 | 0.956 | 0.949 |
| Models | IoU | P | R | F1-Score |
|---|---|---|---|---|
| DCTable-A | 0.6 | 0.834 | 0.899 | 0.865 |
| 0.8 | 0.866 | 0.887 | 0.876 | |
| 0.9 | 0.890 | 0.866 | 0.878 | |
| DCTable-B | 0.6 | 0.828 | 0.929 | 0.875 |
| 0.8 | 0.855 | 0.929 | 0.890 | |
| 0.9 | 0.869 | 0.926 | 0.896 | |
| DCTable-C | 0.6 | 0.866 | 0.869 | 0.868 |
| 0.8 | 0.896 | 0.851 | 0.873 | |
| 0.9 | 0.908 | 0.827 | 0.866 | |
| DCTable | 0.6 | 0.971 | 1 | 0.985 |
| 0.8 | 0.983 | 0.996 | 0.989 | |
| 0.9 | 0.983 | 0.991 | 0.987 | |
| TableRadar [46] | 0.8 | 0.950 | 0.940 | 0.945 |
| NLPR-PAL [24] | 0.930 | 0.930 | 0.930 | |
| Lenovo Ocean [46] | 0.880 | 0.860 | 0.870 | |
| CDeC-Net [31] | 0.953 | 0.934 | 0.944 | |
| HybridTabNet [35] | 0.920 | 0.933 | 0.928 | |
| CasTabDetectoRS [36] | 0.964 | 0.988 | 0.976 | |
| TableRadar [46] | 0.9 | 0.900 | 0.890 | 0.895 |
| NLPR-PAL [24] | 0.860 | 0.860 | 0.860 | |
| Lenovo Ocean [46] | 0.820 | 0.810 | 0.815 | |
| CDeC-Net [31] | 0.922 | 0.904 | 0.913 | |
| HybridTabNet [35] | 0.895 | 0.905 | 0.902 | |
| CasTabDetectoRS [36] | 0.928 | 0.951 | 0.939 |
| Models | IoU | P | R | F1-Score |
|---|---|---|---|---|
| DCTable-A | 0.5 | 0.708 | 0.966 | 0.817 |
| 0.9 | 0.776 | 0.941 | 0.850 | |
| DCTable-B | 0.5 | 0.705 | 1 | 0.827 |
| 0.9 | 0.778 | 0.901 | 0.891 | |
| DCTable-C | 0.5 | 0.898 | 0.946 | 0.922 |
| 0.9 | 0.945 | 0.929 | 0.937 | |
| DCTable | 0.5 | 0.933 | 1 | 0.966 |
| 0.9 | 0.969 | 0.971 | 0.969 | |
| DeCNT [30] | 0.5 | 0.946 | 0.849 | 0.895 |
| CDeC-Net [31] | 0.975 | 0.930 | 0.952 | |
| HybridTabNet [35] | 0.962 | 0.961 | 0.956 | |
| CasTabDetectoRS [36] | 0.952 | 0.965 | 0.958 | |
| CDeC-Net [31] | 0.9 | 0.774 | 0.765 | 0.769 |
| HybridTabNet [35] | 0.900 | 0.903 | 0.901 | |
| CasTabDetectoRS [36] | 0.906 | 0.901 | 0.904 |
| Models | IoU | P | R | F1-Score |
|---|---|---|---|---|
| DCTable-A | 0.5 | 0.607 | 0.774 | 0.680 |
| 0.8 | 0.635 | 0.734 | 0.681 | |
| DCTable-B | 0.5 | 0.905 | 1 | 0.950 |
| 0.8 | 0.948 | 1 | 0.974 | |
| DCTable-C | 0.5 | 0.926 | 0.984 | 0.955 |
| 0.8 | 0.955 | 0.984 | 0.969 | |
| DCTable | 0.5 | 0.948 | 1 | 0.973 |
| 0.8 | 0.964 | 1 | 0.982 |
| Scheme | Test Datasets | IoU | P | R | F1-Score |
|---|---|---|---|---|---|
| Scheme 1 | ICDAR 2017 | 0.6 | 0.978 | 0.953 | 0.965 |
| 0.8 | 0.981 | 0.995 | 0.987 | ||
| Scheme 2 | ICDAR 2019 | 0.6 | 0.961 | 0.959 | 0.959 |
| 0.8 | 0.953 | 0.937 | 0.944 | ||
| 0.9 | 0.921 | 0.950 | 0.935 | ||
| Scheme 3 | Marmot | 0.5 | 0.854 | 0.884 | 0.868 |
| 0.9 | 0.913 | 0.9 | 0.906 | ||
| Scheme 4 | RVL-CDIP | 0.5 | 0.72 | 0.79 | 0.75 |
| 0.8 | 0.68 | 0.73 | 0.70 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kazdar, T.; Mseddi, W.S.; Akhloufi, M.A.; Agrebi, A.; Jmal, M.; Attia, R. DCTable: A Dilated CNN with Optimizing Anchors for Accurate Table Detection. J. Imaging 2023, 9, 62. https://doi.org/10.3390/jimaging9030062
Kazdar T, Mseddi WS, Akhloufi MA, Agrebi A, Jmal M, Attia R. DCTable: A Dilated CNN with Optimizing Anchors for Accurate Table Detection. Journal of Imaging. 2023; 9(3):62. https://doi.org/10.3390/jimaging9030062
Chicago/Turabian StyleKazdar, Takwa, Wided Souidene Mseddi, Moulay A. Akhloufi, Ala Agrebi, Marwa Jmal, and Rabah Attia. 2023. "DCTable: A Dilated CNN with Optimizing Anchors for Accurate Table Detection" Journal of Imaging 9, no. 3: 62. https://doi.org/10.3390/jimaging9030062
APA StyleKazdar, T., Mseddi, W. S., Akhloufi, M. A., Agrebi, A., Jmal, M., & Attia, R. (2023). DCTable: A Dilated CNN with Optimizing Anchors for Accurate Table Detection. Journal of Imaging, 9(3), 62. https://doi.org/10.3390/jimaging9030062