
ViTSTR-Transducer: Cross-Attention-Free Vision Transformer Transducer for Scene Text Recognition


Abstract
:1. Introduction
- 1.
- We propose a cross-attention-free STR framework called ViTSTR-Transducer. Thus, our proposed framework has a constant decoding time with respect to the size of visual feature maps.
- 2.
- The analysis of inference time and accuracy indicates that our ViTSTR-Transducer models offer considerably lower latency while maintaining competitive recognition accuracy, compared with the baseline attention-based models. Compared with the baseline context-free ViTSTR models, our ViTSTR-Transducer models achieve superior recognition accuracy.
- 3.
- Compared with the state-of-the-art (SOTA) attention-based methods, our ViTSTR-Transducer models achieve competitive recognition accuracy.
- 4.
- The ablation results on the encoder’s backbone show that a ViT-based backbone, via its self-attention layers, allows the rearrangement of feature order to align with that of a target sequence.
2. Related Work
2.1. Context-Free Methods
2.2. Context-Aware Methods
2.3. Enhanced Context-Aware Methods
2.4. Vision Transformer-Based Methods
3. Materials and Methods
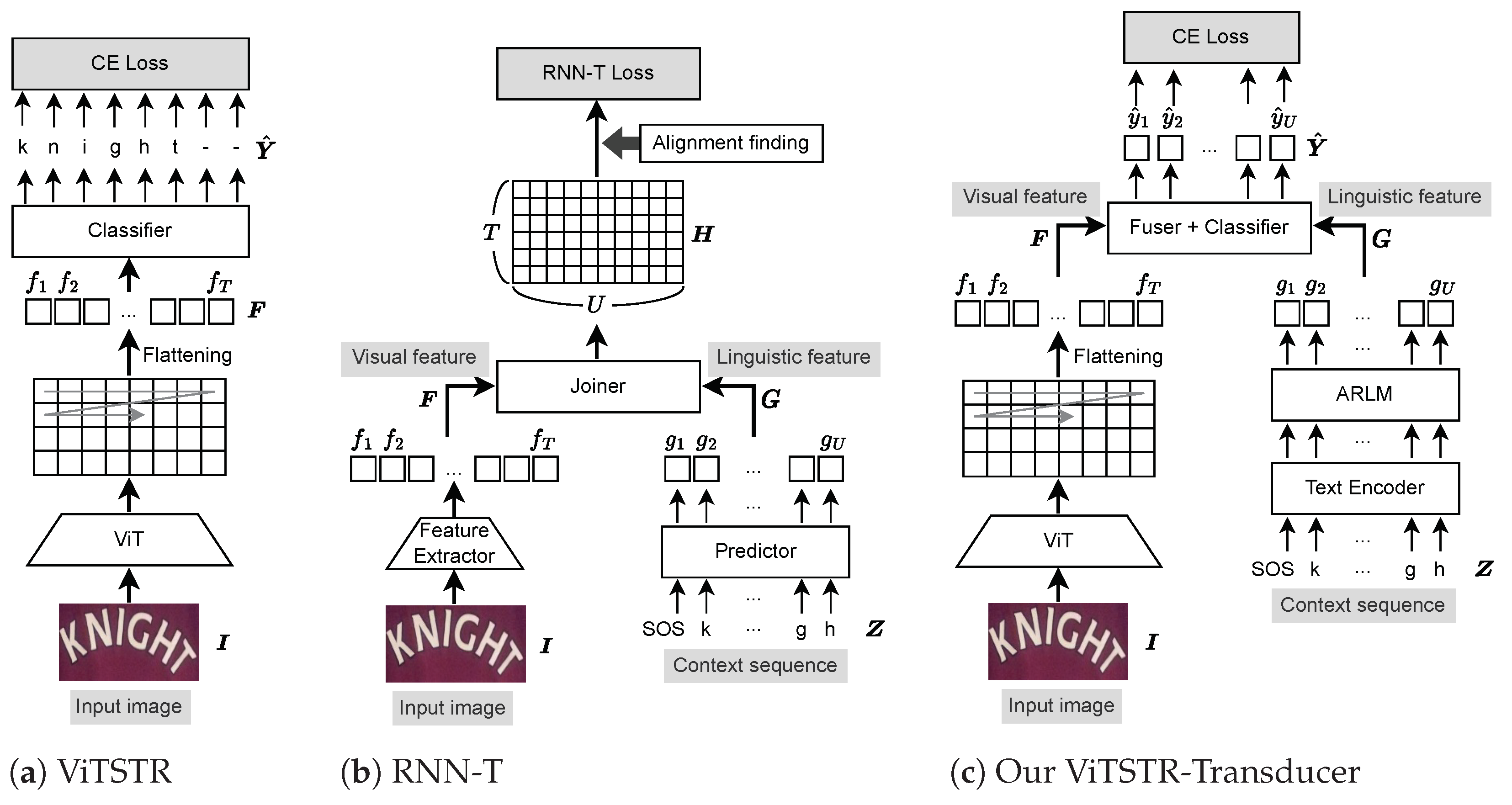
3.1. Proposed Method
3.1.1. ViTSTR
3.1.2. RNN-T
3.1.3. ViTSTR-Transducer
3.2. Datasets
3.2.1. Public Synthetic Datasets
3.2.2. Public Real Labeled Datasets
3.3. Experiments
3.3.1. Experiment Setup
3.3.2. Implementation Details
4. Results
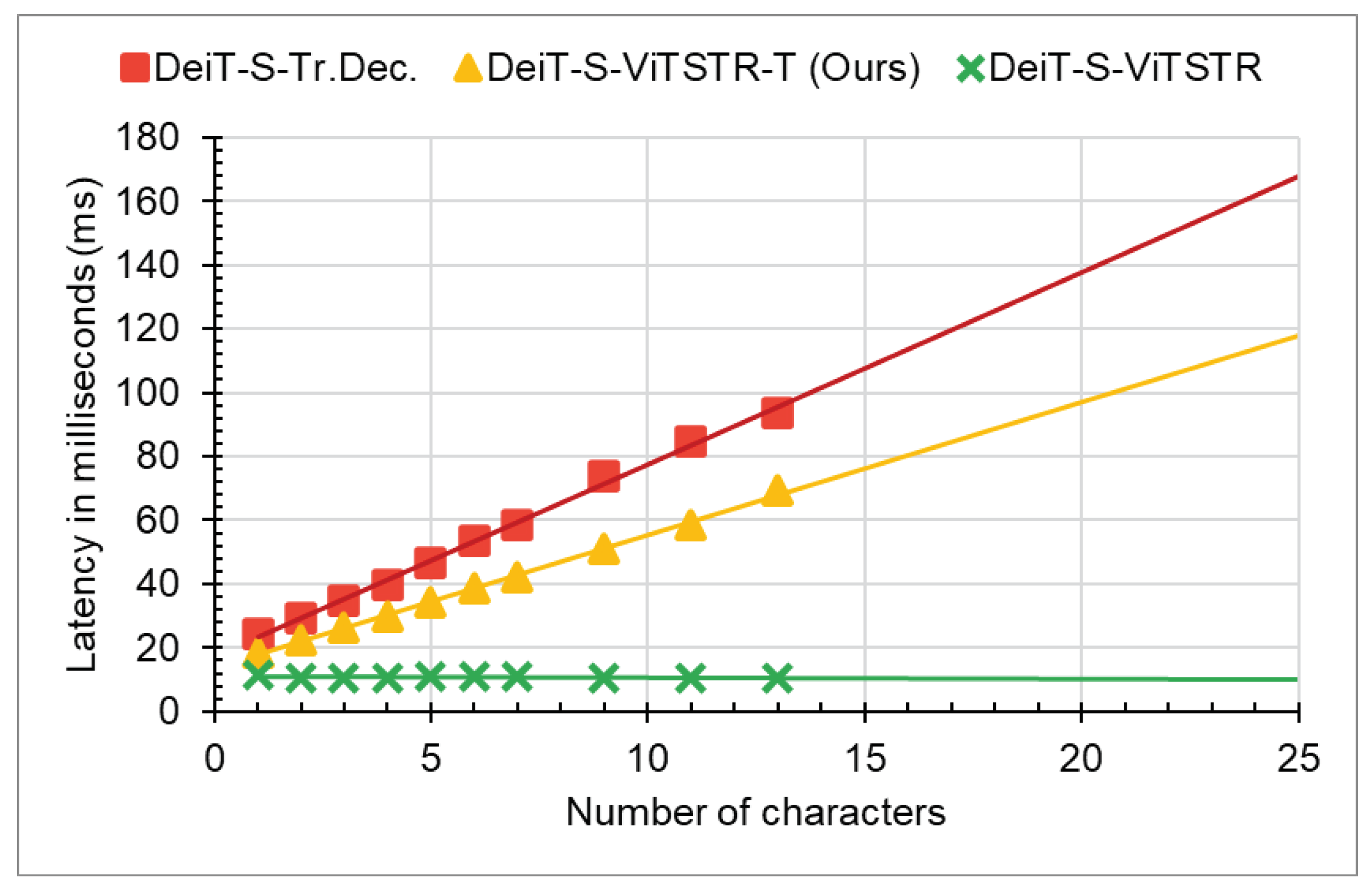
4.1. Recognition Accuracy and Efficiency Comparison with the Baseline Methods
4.2. Ablation Analyses of the Encoder and Decoder Complexities
4.3. Recognition Accuracy Comparison with the SOTA Methods
5. Limitations and Future Work
- In this study, ViT-based backbones have been proven to produce the visual features, , that align with the linguistic features, . However, further experiments are required to confirm whether this assumption is valid for a pure convolutional backbone or a hybrid convolutional transformer backbone.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, X.; Jin, L.; Zhu, Y.; Luo, C.; Wang, T. Text recognition in the wild. ACM Comput. Surv. 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Wang, J.; Hu, X. Gated Recurrent Convolution Neural Network for OCR. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 334–343. [Google Scholar]
- Borisyuk, F.; Gordo, A.; Sivakumar, V. Rosetta: Large scale system for text detection and recognition in images. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018. [Google Scholar]
- Shi, B.; Wang, X.; Lyu, P.; Yao, C.; Bai, X. Robust scene text recognition with automatic rectification. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2298–2304. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.; Osindero, S. Recursive recurrent nets with attention modeling for OCR in the wild. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Lee, J.; Park, S.; Baek, J.; Oh, S.; Kim, S.; Lee, H. On recognizing texts of arbitrary shapes with 2D self-attention. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Li, H.; Wang, P.; Shen, C.; Zhang, G. Show, attend and read: A simple and strong baseline for irregular text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8610–8617. [Google Scholar]
- Shi, B.; Yang, M.; Wang, X.; Lyu, P.; Yao, C.; Bai, X. Aster: An attentional scene text recognizer with flexible rectification. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2035–2048. [Google Scholar] [CrossRef] [PubMed]
- Bautista, D.; Atienza, R. Scene text recognition with permuted autoregressive sequence models. In Computer Vision—ECCV 2022, Proceedings of the 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Lecture Notes In Computer Science; Springer: Cham, Switzerland, 2022; pp. 178–196. [Google Scholar]
- Fang, S.; Xie, H.; Wang, Y.; Mao, Z.; Zhang, Y. Read like humans: Autonomous, bidirectional and iterative language modeling for scene text recognition. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Qiao, Z.; Zhou, Y.; Yang, D.; Zhou, Y.; Wang, W. Seed: Semantics enhanced encoder–decoder framework for scene text recognition. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Wang, Y.; Xie, H.; Fang, S.; Wang, J.; Zhu, S.; Zhang, Y. From Two to One: A New Scene Text Recognizer with Visual Language Modeling Network. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar] [CrossRef]
- Yu, D.; Li, X.; Zhang, C.; Liu, T.; Han, J.; Liu, J.; Ding, E. Towards accurate scene text recognition with Semantic Reasoning Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Graves, A. Sequence transduction with recurrent neural networks. arXiv 2012, arXiv:1211.3711. [Google Scholar]
- Graves, A.; Mohamed, A.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech Furthermore, Signal Processing, Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar]
- Lugosch, L. Sequence-to-Sequence Learning with Transducers. November 2020. Available online: https://lorenlugosch.github.io/posts/2020/11/transducer/ (accessed on 1 April 2023).
- Atienza, R. Vision transformer for fast and efficient scene text recognition. In Proceedings of the Document Analysis and Recognition—ICDAR 2021: 16th International Conference, Lausanne, Switzerland, 5–10 September 2021; pp. 319–334. [Google Scholar]
- Bhunia, A.; Sain, A.; Kumar, A.; Ghose, S.; Nath Chowdhury, P.; Song, Y. Joint Visual Semantic Reasoning: Multi-Stage decoder for text recognition. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Liu, W.; Chen, C.; Wong, K.; Su, Z.; Han, J. Star-net: A spatial attention residue network for scene text recognition. In Proceedings of the British Machine Vision Conference 2016, York, UK, 19–22 September 2016. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist Temporal Classification. In Proceedings of the 23rd International Conference on Machine Learning—ICML ’06, Pittsburgh, PA, USA, 25–29 June 2006. [Google Scholar]
- Hannun, A. Sequence Modeling with CTC. Distill 2017, 2, e8. Available online: https://distill.pub/2017/ctc (accessed on 1 April 2023). [CrossRef]
- Jurafsky, D.; Martin, J. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition; Pearson: London, UK, 2009. [Google Scholar]
- Diaz, D.; Qin, S.; Ingle, R.; Fujii, Y.; Bissacco, A. Rethinking Text Line Recognition Models. arXiv 2021, arXiv:104.07787. [Google Scholar]
- Baek, J.; Kim, G.; Lee, J.; Park, S.; Han, D.; Yun, S.; Oh, S.; Lee, H. What is wrong with scene text recognition model comparisons? Dataset and model analysis. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Ngo, T.; Nguyen, H.; Ly, N.; Nakagawa, M. Recurrent neural network transducer for Japanese and Chinese offline handwritten text recognition. In Proceedings of the Document Analysis and Recognition—ICDAR 2021 Workshops, Lausanne, Switzerland, 5–10 September 2021; pp. 364–376. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Touvron, H.; Cord, M.; Sablayrolles, A.; Synnaeve, G.; J’egou, H. Going deeper with Image Transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 32–42. [Google Scholar]
- Touvron, H.; Cord, M.; Jegou, H. DeiT III: Revenge of the ViT. arXiv 2022, arXiv:2204.07118. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Chen, M.; Wu, K.; Ni, B.; Peng, H.; Liu, B.; Fu, J.; Chao, H.; Ling, H. Searching the Search Space of Vision Transformer. In Proceedings of the Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, Virtual, 6–14 December 2021; pp. 8714–8726. Available online: https://proceedings.neurips.cc/paper/2021/hash/48e95c45c8217961bf6cd7696d80d238-Abstract.html (accessed on 1 April 2023).
- Liu, H.; Wang, B.; Bao, Z.; Xue, M.; Kang, S.; Jiang, D.; Liu, Y.; Ren, B. Perceiving stroke-semantic context: Hierarchical contrastive learning for robust scene text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 1702–1710. [Google Scholar]
- Yang, M.; Liao, M.; Lu, P.; Wang, J.; Zhu, S.; Luo, H.; Tian, Q.; Bai, X. Reading and writing: Discriminative and generative modeling for self-supervised text recognition. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Synthetic Data and Artificial Neural Networks for Natural Scene Text Recognition. arXiv 2014, arXiv:1406.2227. [Google Scholar]
- Gupta, A.; Vedaldi, A.; Zisserman, A. Synthetic data for text localisation in natural images. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Veit, A.; Matera, T.; Neumann, L.; Matas, J.; Belongie, S. COCO-Text: Dataset and Benchmark for Text Detection and Recognition in Natural Images. arXiv 2016, arXiv:1601.07140. [Google Scholar]
- Shi, B.; Yao, C.; Liao, M.; Yang, M.; Xu, P.; Cui, L.; Belongie, S.; Lu, S.; Bai, X. ICDAR2017 competition on reading Chinese text in the wild (RCTW-17). In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017. [Google Scholar]
- Zhang, Y.; Gueguen, L.; Zharkov, I.; Zhang, P.; Seifert, K.; Kadlec, B. Uber-Text: A Large-Scale Dataset for Optical Character Recognition from Street-Level Imagery. In Proceedings of the SUNw: Scene Understanding Workshop—CVPR 2017, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chng, C.; Ding, E.; Liu, J.; Karatzas, D.; Chan, C.; Jin, L.; Liu, Y.; Sun, Y.; Ng, C.; Luo, C.; et al. ICDAR2019 robust reading challenge on arbitrary-shaped text—RRC-art. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019. [Google Scholar]
- Sun, Y.; Karatzas, D.; Chan, C.; Jin, L.; Ni, Z.; Chng, C.; Liu, Y.; Luo, C.; Ng, C.; Han, J.; et al. ICDAR 2019 competition on large-scale street view text with partial labeling—RRC-LSVT. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019. [Google Scholar]
- Zhang, R.; Yang, M.; Bai, X.; Shi, B.; Karatzas, D.; Lu, S.; Jawahar, C.; Zhou, Y.; Jiang, Q.; Song, Q.; et al. ICDAR 2019 robust reading challenge on reading Chinese text on Signboard. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019. [Google Scholar]
- Krylov, I.; Nosov, S.; Sovrasov, V. Open Images V5 Text Annotation and Yet Another Mask Text Spotter. In Proceedings of the Asian Conference On Machine Learning, ACML 2021, Virtual, 17–19 November 2021; Volume 157, pp. 379–389. [Google Scholar]
- Singh, A.; Pang, G.; Toh, M.; Huang, J.; Galuba, W.; Hassner, T. TextOCR: Towards large-scale end-to-end reasoning for arbitrary-shaped scene text. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Wang, K.; Babenko, B.; Belongie, S. End-to-end scene text recognition. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Mishra, A.; Alahari, K.; Jawahar, C. Scene text recognition using higher order language priors. In Proceedings of the British Machine Vision Conference 2012, Surrey, UK, 3–7 September 2012. [Google Scholar]
- Karatzas, D.; Shafait, F.; Uchida, S.; Iwamura, M.; Bigorda, L.; Mestre, S.; Mas, J.; Mota, D.; Almazan, J.; Heras, L.; et al. ICDAR 2013 robust reading competition. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013. [Google Scholar]
- Karatzas, D.; Gomez-Bigorda, L.; Nicolaou, A.; Ghosh, S.; Bagdanov, A.; Iwamura, M.; Matas, J.; Neumann, L.; Chandrasekhar, V.; Lu, S.; et al. ICDAR 2015 competition on robust reading. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015. [Google Scholar]
- Phan, T.; Shivakumara, P.; Tian, S.; Tan, C. Recognizing text with perspective distortion in natural scenes. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Risnumawan, A.; Shivakumara, P.; Chan, C.; Tan, C. A robust arbitrary text detection system for natural scene images. Expert Syst. Appl. 2014, 41, 8027–8048. [Google Scholar] [CrossRef]
- Liu, N.; Schwartz, R.; Smith, N. Inoculation by fine-tuning: A method for analyzing challenge datasets. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Jiang, Q.; Wang, J.; Peng, D.; Liu, C.; Jin, L. Revisiting Scene Text Recognition: A Data Perspective. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 20543–20554. [Google Scholar]
- Sheng, F.; Chen, Z.; Xu, B. NRTR: A no-recurrence sequence-to-sequence model for scene text recognition. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019. [Google Scholar]
- Cui, M.; Wang, W.; Zhang, J.; Wang, L. Representation and correlation enhanced encoder–decoder framework for scene text recognition. In Proceedings of the Document Analysis and Recognition—ICDAR 2021, Lausanne, Switzerland, 5–10 September 2021; pp. 156–170. [Google Scholar]
- Baek, J.; Matsui, Y.; Aizawa, K. What if we only use real datasets for scene text recognition? Toward scene text recognition with fewer labels. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| ViT Model | Params | FLOPs | Input Size | Model Dim, D | Feature Maps |
|---|---|---|---|---|---|
| DeiT-Small | 28.5 M | 3.2 B | 32 × 128 | 384 | 8 × 16 |
| Parameters | Value |
|---|---|
| Model dimension | 384 |
| Decoder Stacks | 3 |
| Attention heads | 8 |
| Dropout | 0.1 |
| Feed-forward dimension | 1536 |
| Model | Params | Encoder | Decoder |
|---|---|---|---|
| DeiT-S-ViTSTR [18] | 21.4 M | 2.91 | 0.00 |
| DeiT-S-Tr.Dec. [7,34] | 28.5 M | 2.91 | 5.25 |
| DeiT-S-ViTSTR-T (Ours) | 27.0 M | 2.91 | 1.95 |
| (a) Methods trained on synthetic training data (S). | |||||||
| Method | IIIT | SVT | IC13 | IC15 | SVTP | CUTE | Total |
| DeiT-S-ViTSTR [18] | 92.2 | 90.0 | 93.8 | 79.7 | 82.2 | 82.9 | 87.9 |
| DeiT-S-Tr.Dec. [7,34] | 94.4 | 92.3 | 95.5 | 84.5 | 87.1 | 88.9 | 91.1 |
| DeiT-S-ViTSTR-T (Ours) | 92.7 | 92.1 | 95.5 | 82.3 | 85.7 | 84.0 | 89.5 |
| (b) Methods trained on real labeled training data (R). | |||||||
| Method | IIIT | SVT | IC13 | IC15 | SVTP | CUTE | Total |
| DeiT-S-ViTSTR [18] | 97.8 | 94.9 | 97.6 | 88.8 | 89.3 | 94.1 | 94.4 |
| DeiT-S-Tr.Dec. [7,34] | 98.6 | 97.1 | 97.9 | 90.6 | 93.6 | 97.9 | 95.9 |
| DeiT-S-ViTSTR-T (Ours) | 98.2 | 97.4 | 97.7 | 89.6 | 92.4 | 95.8 | 95.3 |
| (a) Methods trained on synthetic training data (S). | |||||||
| Method | IIIT | SVT | IC13 | IC15 | SVTP | CUTE | Total |
| DeiT-T-ViTSTR [18] | 90.2 | 88.3 | 90.4 | 75.9 | 78.4 | 79.4 | 85.1 |
| DeiT-T-Tr.Dec. [7,34] | 92.6 | 90.9 | 94.6 | 81.3 | 84.3 | 82.9 | 88.9 |
| DeiT-T-ViTSTR-T | 92.2 | 89.6 | 94.0 | 80.5 | 82.9 | 82.6 | 88.2 |
| DeiT-M-ViTSTR [18] | 93.8 | 90.7 | 94.4 | 81.8 | 84.7 | 85.4 | 89.5 |
| DeiT-M-Tr.Dec. [7,34] | 94.9 | 92.7 | 96.0 | 84.8 | 88.2 | 88.2 | 91.5 |
| DeiT-M-ViTSTR-T | 93.9 | 93.5 | 95.4 | 83.5 | 87.6 | 87.5 | 90.7 |
| DeiT-S-DEC1-ViTSTR-T | 93.2 | 91.5 | 95.4 | 82.4 | 86.2 | 84.7 | 89.7 |
| DeiT-S-DEC5-ViTSTR-T | 93.2 | 91.8 | 95.5 | 82.8 | 87.3 | 84.0 | 90.0 |
| DeiT-S-ViTSTR-T (Ours) | 92.7 | 92.1 | 95.5 | 82.3 | 85.7 | 84.0 | 89.5 |
| (b) Methods trained on real labeled training data (R). | |||||||
| Method | IIIT | SVT | IC13 | IC15 | SVTP | CUTE | Total |
| DeiT-T-ViTSTR [18] | 96.2 | 93.5 | 96.3 | 86.7 | 86.4 | 92.3 | 92.6 |
| DeiT-T-Tr.Dec. [7,34] | 97.7 | 95.7 | 97.3 | 88.8 | 91.3 | 95.5 | 94.7 |
| DeiT-T-ViTSTR-T | 97.4 | 95.8 | 97.5 | 88.7 | 90.5 | 96.2 | 94.5 |
| DeiT-M-ViTSTR [18] | 98.2 | 96.9 | 97.8 | 89.0 | 92.9 | 97.6 | 95.3 |
| DeiT-M-Tr.Dec. [7,34] | 98.6 | 97.5 | 98.6 | 91.0 | 94.0 | 96.9 | 96.2 |
| DeiT-M-ViTSTR-T | 98.3 | 97.4 | 97.9 | 90.8 | 93.5 | 97.9 | 95.9 |
| DeiT-S-DEC1-ViTSTR-T | 98.1 | 96.8 | 97.9 | 89.8 | 93.5 | 96.2 | 95.4 |
| DeiT-S-DEC5-ViTSTR-T | 97.8 | 96.6 | 98.3 | 90.1 | 92.9 | 97.2 | 95.4 |
| DeiT-S-ViTSTR-T (Ours) | 98.2 | 97.4 | 97.7 | 89.6 | 92.4 | 95.8 | 95.3 |
| Method | Params | Time (ms) |
|---|---|---|
| DeiT-T-ViTSTR [18] | 5.4 M | 10.2 |
| DeiT-T-Tr.Dec. [7,34] | 7.2 M | 151.3 |
| DeiT-T-ViTSTR-T | 6.9 M | 110.9 |
| DeiT-M-ViTSTR [18] | 40.0 M | 11.3 |
| DeiT-M-Tr.Dec. [7,34] | 50.6 M | 160.7 |
| DeiT-M-ViTSTR-T | 48.0 M | 112.0 |
| DeiT-S-DEC1-ViTSTR-T | 23.5 M | 63.3 |
| DeiT-S-DEC5-ViTSTR-T | 30.6 M | 164.1 |
| DeiT-S-ViTSTR-T (Ours) | 27.0 M | 118.0 |
| (a) Methods trained on synthetic training data. | |||||||
| Method | IIIT | SVT | IC13 | IC15 | SVTP | CUTE | Total |
| ASTER [9] | 93.4 | 93.6 | 91.8 | 76.1 | 78.5 | 79.5 | 87.1 |
| NRTR [53] | 93.7 | 90.2 | 93.6 | 74.5 | 78.3 | 86.1 | 87.0 |
| SAR [8] | 91.3 | 84.7 | 91.2 | 70.7 | 76.9 | 83.0 | 84.1 |
| SEED [12] | 93.8 | 89.6 | 92.8 | 80.0 | 81.4 | 83.6 | 88.4 |
| SRN [14] | 94.8 | 91.5 | 95.5 | 82.7 | 85.1 | 87.8 | 90.5 |
| SATRN [7] | 94.7 | 92.1 | 94.2 | 82.1 | 86.4 | 87.6 | 90.3 |
| RCEED [54] | 94.9 | 91.8 | 94.7 | 82.2 | 83.6 | 91.7 | 90.4 |
| PerSec-ViT [33] | 88.1 | 86.8 | 94.2 | 73.6 | 77.7 | 72.7 | 83.8 |
| DeiT-T-ViTSTR-T (Ours) | 92.2 | 89.6 | 94.0 | 80.5 | 82.9 | 82.6 | 88.2 |
| DeiT-M-ViTSTR-T (Ours) | 93.9 | 93.5 | 95.4 | 83.5 | 87.6 | 87.5 | 90.7 |
| DeiT-S-ViTSTR-T (Ours) | 92.7 | 92.1 | 95.5 | 82.3 | 85.7 | 84.0 | 89.5 |
| (b) Methods trained on real labeled training data. | |||||||
| Method | IIIT | SVT | IC13 | IC15 | SVTP | CUTE | Total |
| TRBA [55] | 94.8 | 91.3 | 94.0 | 80.6 | 82.7 | 88.1 | 89.6 |
| DiG-ViT-tiny [34] | 96.4 | 94.4 | 96.2 | 87.4 | 90.2 | 94.1 | 93.4 |
| DiG-ViT-small [34] | 97.7 | 96.1 | 97.3 | 88.6 | 91.6 | 96.2 | 94.7 |
| DiG-ViT-base [34] | 97.6 | 96.5 | 97.6 | 88.9 | 92.9 | 96.5 | 94.9 |
| TRBA [10] | 98.6 | 97.0 | 97.6 | 89.8 | 93.7 | 97.7 | 95.7 |
| MAERec (pre-training) [52] | 98.0 | 96.8 | 97.6 | 87.1 | 93.2 | 97.9 | 95.1 |
| DeiT-T-ViTSTR-T (Ours) | 97.4 | 95.8 | 97.5 | 88.7 | 90.5 | 96.2 | 94.5 |
| DeiT-M-ViTSTR-T (Ours) | 98.3 | 97.4 | 97.9 | 90.8 | 93.5 | 97.9 | 95.9 |
| DeiT-S-ViTSTR-T (Ours) | 98.2 | 97.4 | 97.7 | 89.6 | 92.4 | 95.8 | 95.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Buoy, R.; Iwamura, M.; Srun, S.; Kise, K. ViTSTR-Transducer: Cross-Attention-Free Vision Transformer Transducer for Scene Text Recognition. J. Imaging 2023, 9, 276. https://doi.org/10.3390/jimaging9120276
Buoy R, Iwamura M, Srun S, Kise K. ViTSTR-Transducer: Cross-Attention-Free Vision Transformer Transducer for Scene Text Recognition. Journal of Imaging. 2023; 9(12):276. https://doi.org/10.3390/jimaging9120276
Chicago/Turabian StyleBuoy, Rina, Masakazu Iwamura, Sovila Srun, and Koichi Kise. 2023. "ViTSTR-Transducer: Cross-Attention-Free Vision Transformer Transducer for Scene Text Recognition" Journal of Imaging 9, no. 12: 276. https://doi.org/10.3390/jimaging9120276
APA StyleBuoy, R., Iwamura, M., Srun, S., & Kise, K. (2023). ViTSTR-Transducer: Cross-Attention-Free Vision Transformer Transducer for Scene Text Recognition. Journal of Imaging, 9(12), 276. https://doi.org/10.3390/jimaging9120276