
Empowering Deaf-Hearing Communication: Exploring Synergies between Predictive and Generative AI-Based Strategies towards (Portuguese) Sign Language Interpretation

 ,
, 
 ,
,  and
and 
Abstract
:1. Introduction
2. Related Work
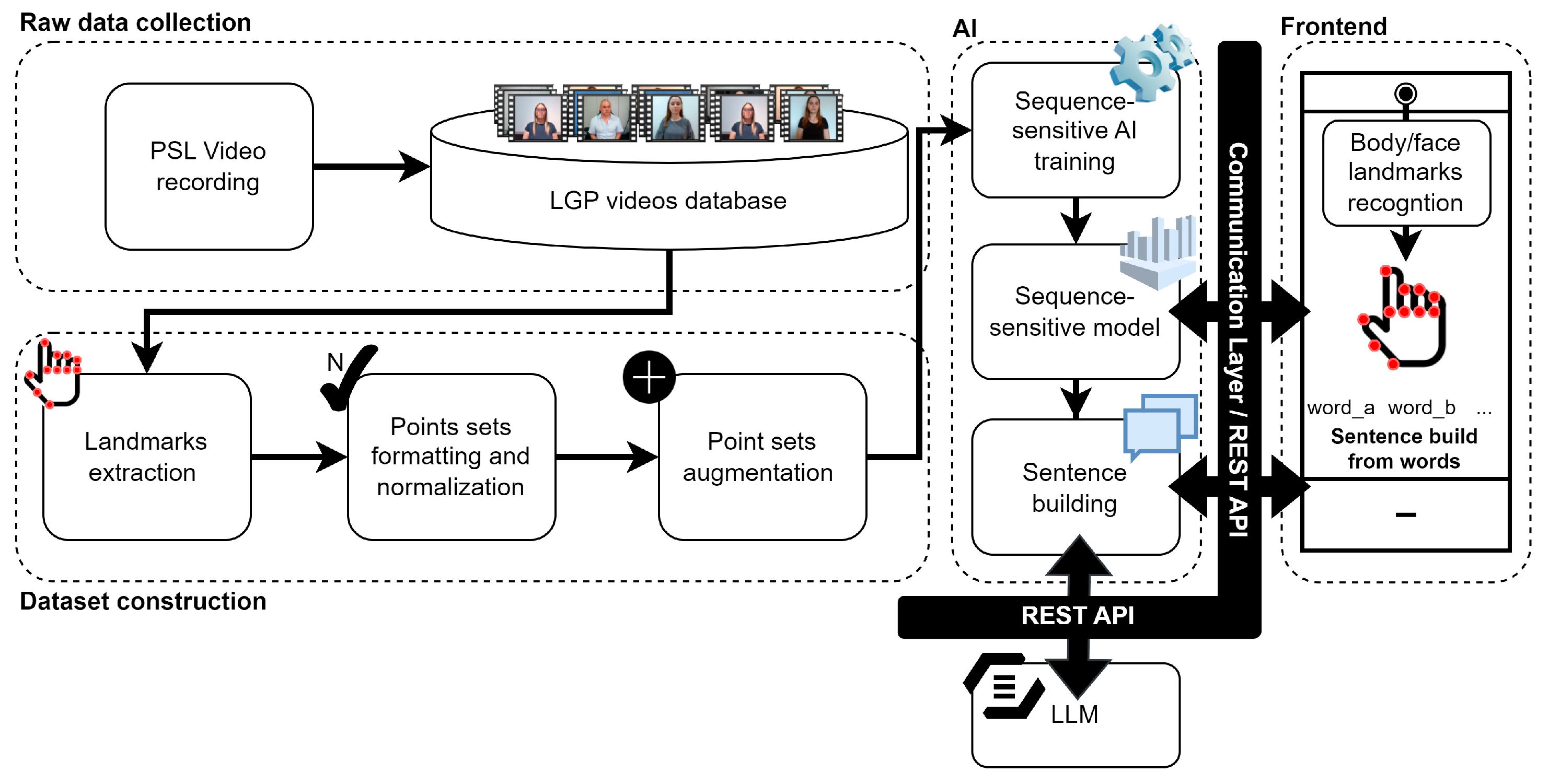
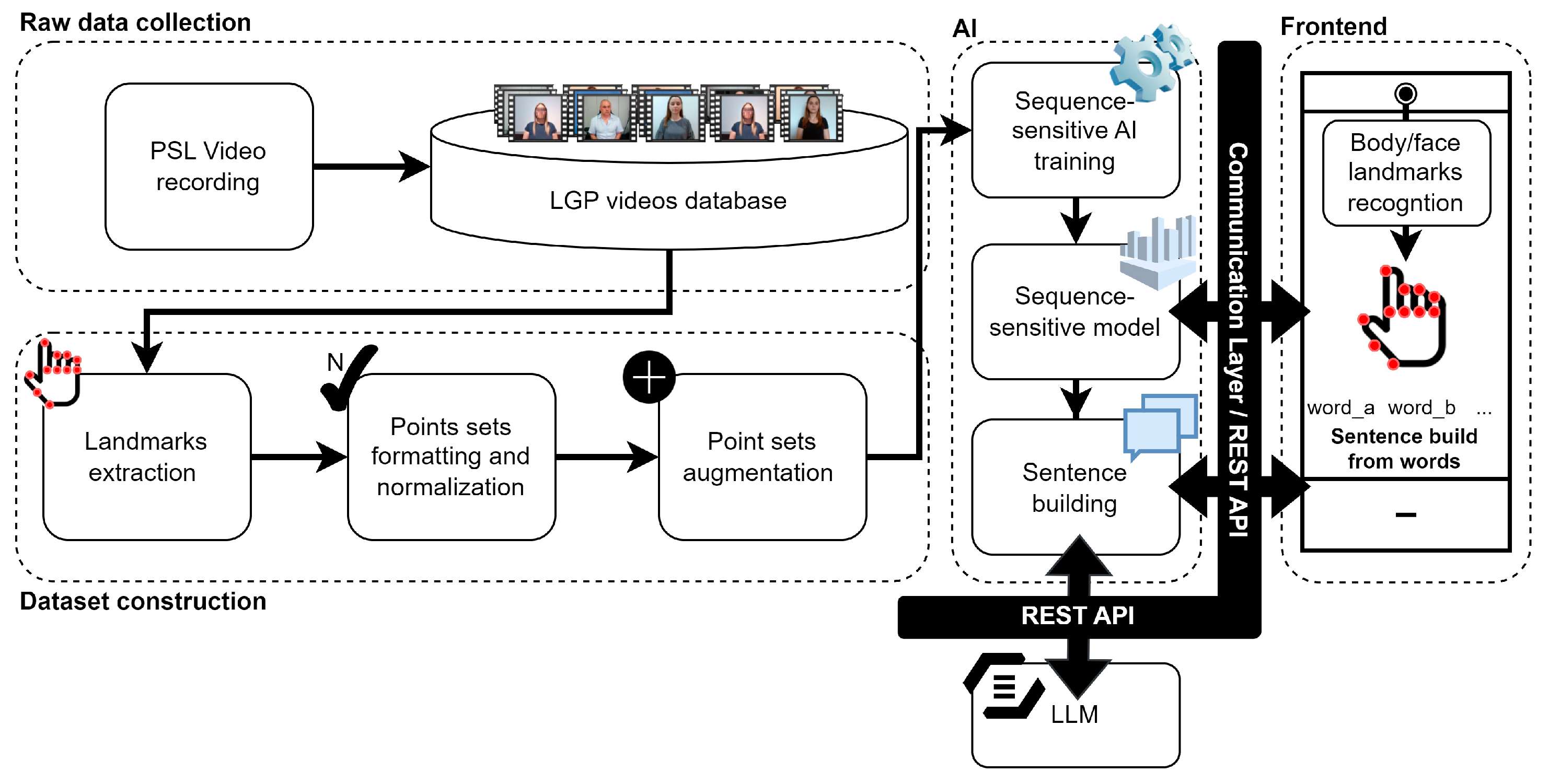
3. LGP-to-Text System Specification
3.1. Main Architecture
- Extraction of relevant features, namely anatomical landmarks points sets;
- Normalization of these points sets into a structure compatible with AI processing;
- Application of augmentations to both video frames and extracted point sets.
3.2. Acquisition Campaign and Steps for Structuring Data
- Contributors should position themselves at the center of the camera’s frame, ensuring roughly the same space at both lateral margins (left and right);
- Their background should be kept free of other people or visible elements that could resemble people, besides themselves;
- Gestures should be made calmly and slowly, allowing the camera to capture most of the motion details;
- The place chosen for acquiring the videos should be uniformly illuminated, avoiding excessive darkness while also preventing overexposure caused by strong and direct source lights;
- Videos should be labeled in agreement with the recorded signs.
3.3. Strategy for Data Preparation: From Augmentation to Dataset Arrangement
| Algorithm 1: Pseudo-code responsible for skeletal landmarks-based key points RRS |
| Input: landmarks_groups: a dictionary containing groups of key points (x,y) lists. radius_range_norm: a range of radii for performing RRS (default [0.01, 0.05]) |
| Output: landmarks_rrs: a dictionary containing groups of key points induced with RRS variation |
Begin
|
| End |
| Notes: (1) landmarks_groups contains groups of key points that are normalized from 0..1; (2) the radius_range_norm must take into account the previous assumption, and adequate the perturbation range accordingly; (3) trimming the landmarks will prevent out (normalized) values to be out of range; |
| Algorithm 2: Pseudo-code responsible for skeletal landmarks-based key points SBI |
| Input: landmarks_groups: a dictionary containing groups of key points (x,y) lists. n_points: limit of points to interpolate for each coordinate set. groups_per_point: limit of groups to split the key points augmented. |
| Output: landmarks_sbi: a dictionary representing the interpolated and normalized sequence of key points and coordinates. |
Begin
|
| End |
| Notes: (1) landmarks_groups contains groups of key points that are normalized from 0..1; (2) interpolate_spline_normalized is a recursive function that performs spline interpolation in a sequence of x,y points until a given limit (in this case, n_points × groups_per_point); |
- is the cubic spline function in the interval [, ].
- , , , and are coefficients specific to the i-th interval.
- is the starting point of the interval.
- is the input value within the interval.
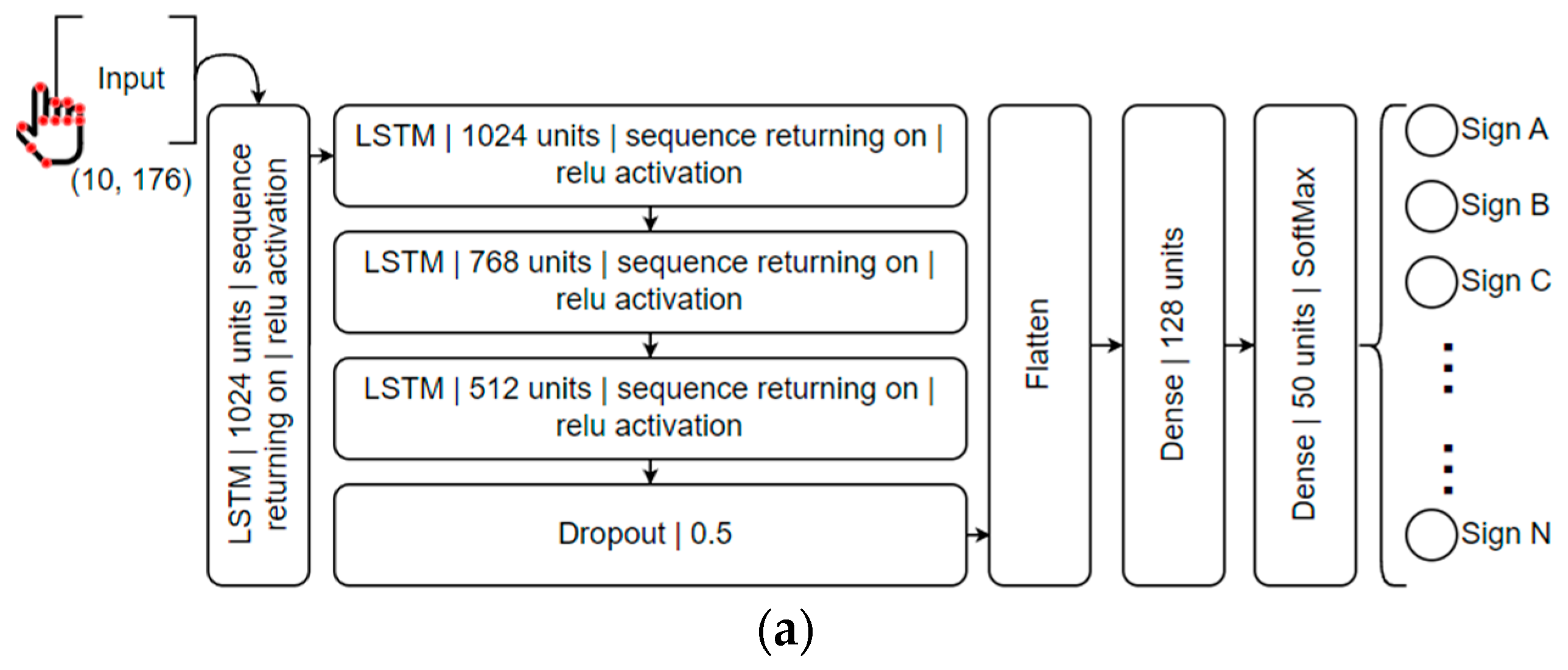
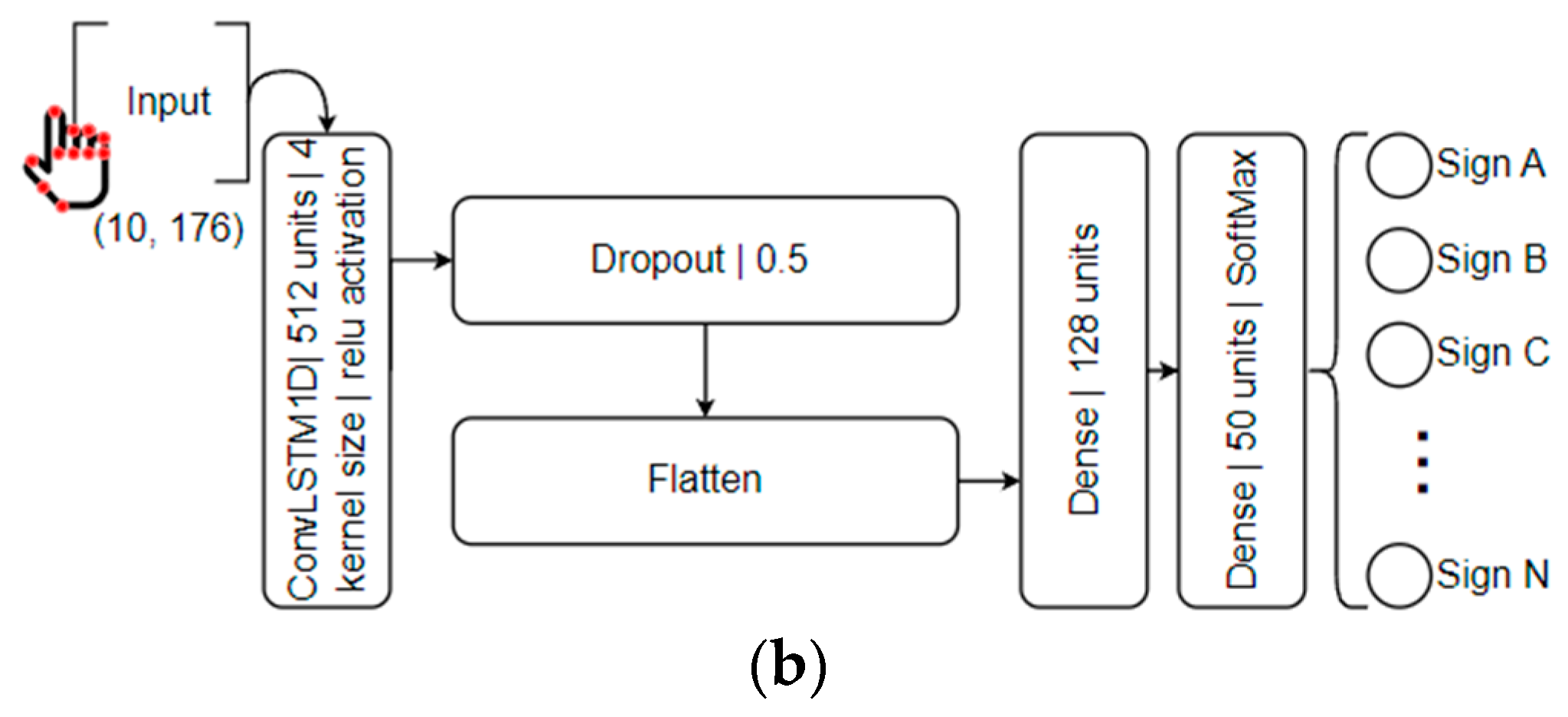
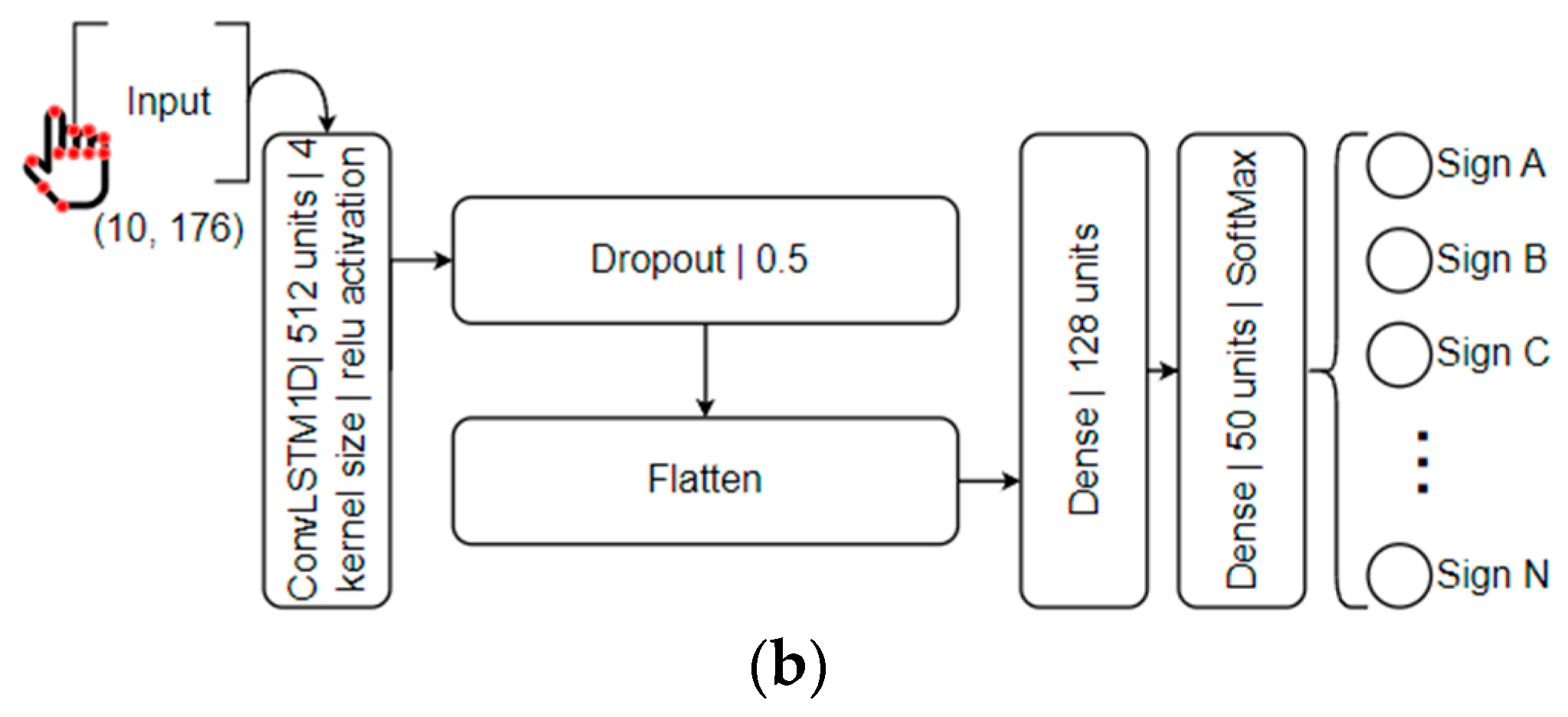
3.4. ML Powered by LSTMs for LGP Recognition
3.5. Tokenization Strategy—A Conditioning Interaction-Based Approach
3.6. LLM-Based Sentence Construction
4. LGP-To-Text System Implementation
4.1. Web-Based Tool for Raw Data Collection
4.2. Data Engineering toward the Construction of ML-Compliant Datasets
4.2.1. Step 1: Splitting Data into Train/Validation and Test Subsets
4.2.2. Step 2: Video-Based Data Augmentation
4.2.3. Step 3: Landmark-Based Sequence Points Extraction with Lateral Dominance Balance
- Pose landmarks: including right eye, left eye, right shoulder, left shoulder, right elbow, and left elbow;
- Left/right hand landmarks: encompassing various parts, such as the wrist, thumb carpometacarpal joint, thumb metacarpophalangeal joint, thumb interphalangeal joint, thumb tip, index finger metacarpophalangeal joint, index finger proximal interphalangeal joint, index finger distal interphalangeal joint, index finger tip, and corresponding components for the middle, ring and pinky fingers;
- Face landmarks: covering a total of 66 points situated around the upper and lower lips.
4.2.4. Step 4: Point-Based Data Augmentation, Normalization, and Dataset Consolidation
4.3. LSTM Models Training and Deployment
- Early stopping: it halts the training process after a specified number of consecutive epochs without significant learning improvements. In this work, the threshold—also known as patience—was set to 30 epochs, the loss associated with validation data was monitored, and a minimum fluctuation of 1 × 10−4 was required to consider further learning.
- Model checkpoint: this callback saves models after each training epoch, with a designated format name, allowing for easy tracking of model progressed. Again, the variable to monitor the learning status is the loss associated with validation. It also includes a flag to save models that exhibited improved learning.
- Graphical monitor—TensorBoard (TensorBoard|TensorFlow, available in https://www.tensorflow.org/tensorboard, accessed on 14 September 2023): this tool logs essential training progress, including training accuracy, training loss, validation accuracy, and validation loss, among other metrics. It provides valuable insights and can be accessed through a web-based application.
- Processor: 11th Gen Intel® Core™ i7-11800H @ 2.30GHz (Intel Co., Santa Clara, CA, USA);
- Random Access Memory (RAM): 32GB @ 2933MHz SODIMM (Corsair Gaming, Inc., Milpitas, CA, USA);
- Graphic Card: Nvidia® GeForce RTX 3080 (laptop edition), 16.0GB GDDR6 RAM (Nvidia Co., Santa Clara, CA, USA);
- Storage: 1TB, 3500MB/R, 3300MB/W (Samsung Electronics Co., Ltd., Suwon, Republic of Korea);
- Operative System: Windows 10 Home 64 Bit (Microsoft Co., Redmond, WA, USA).
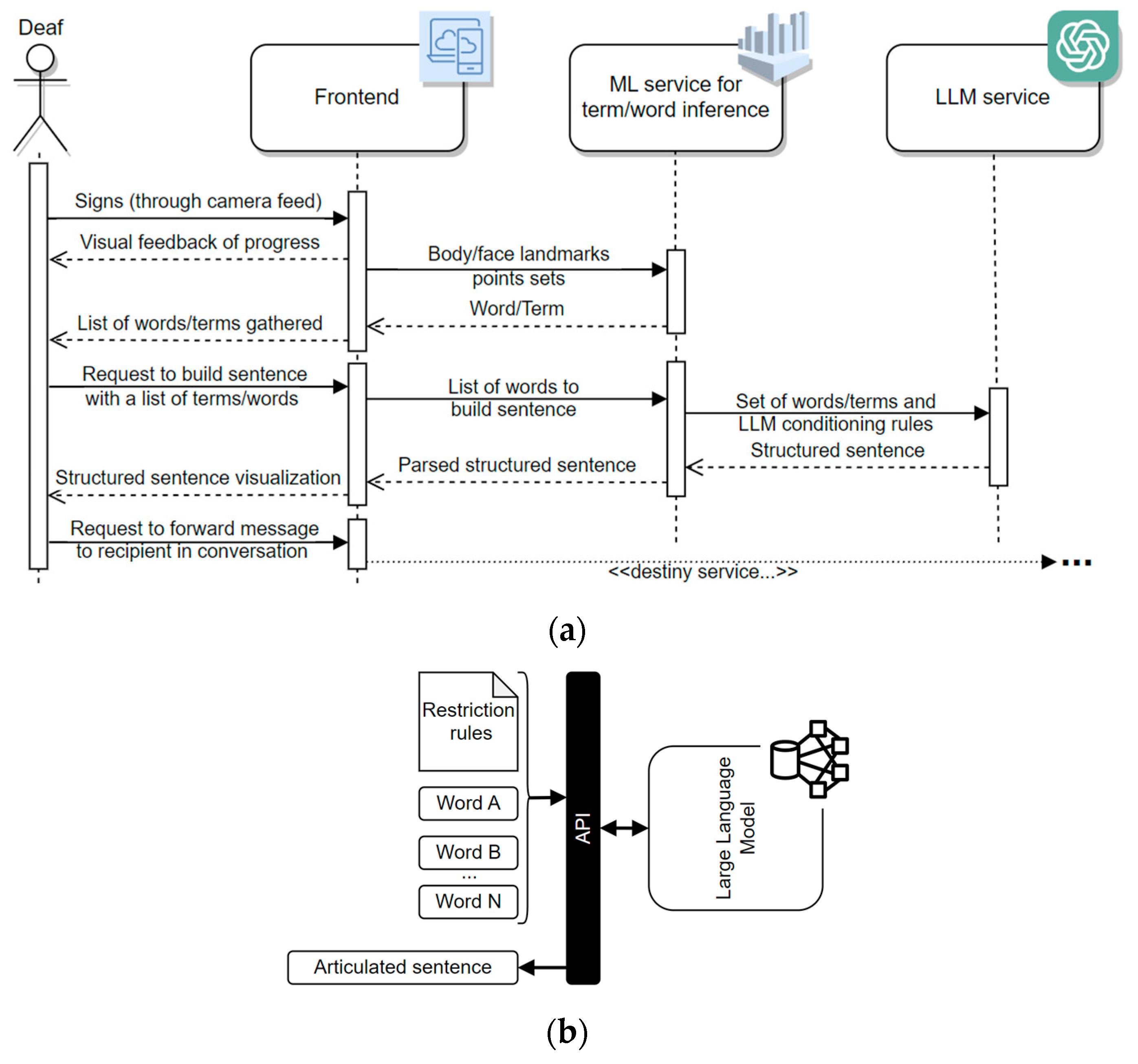
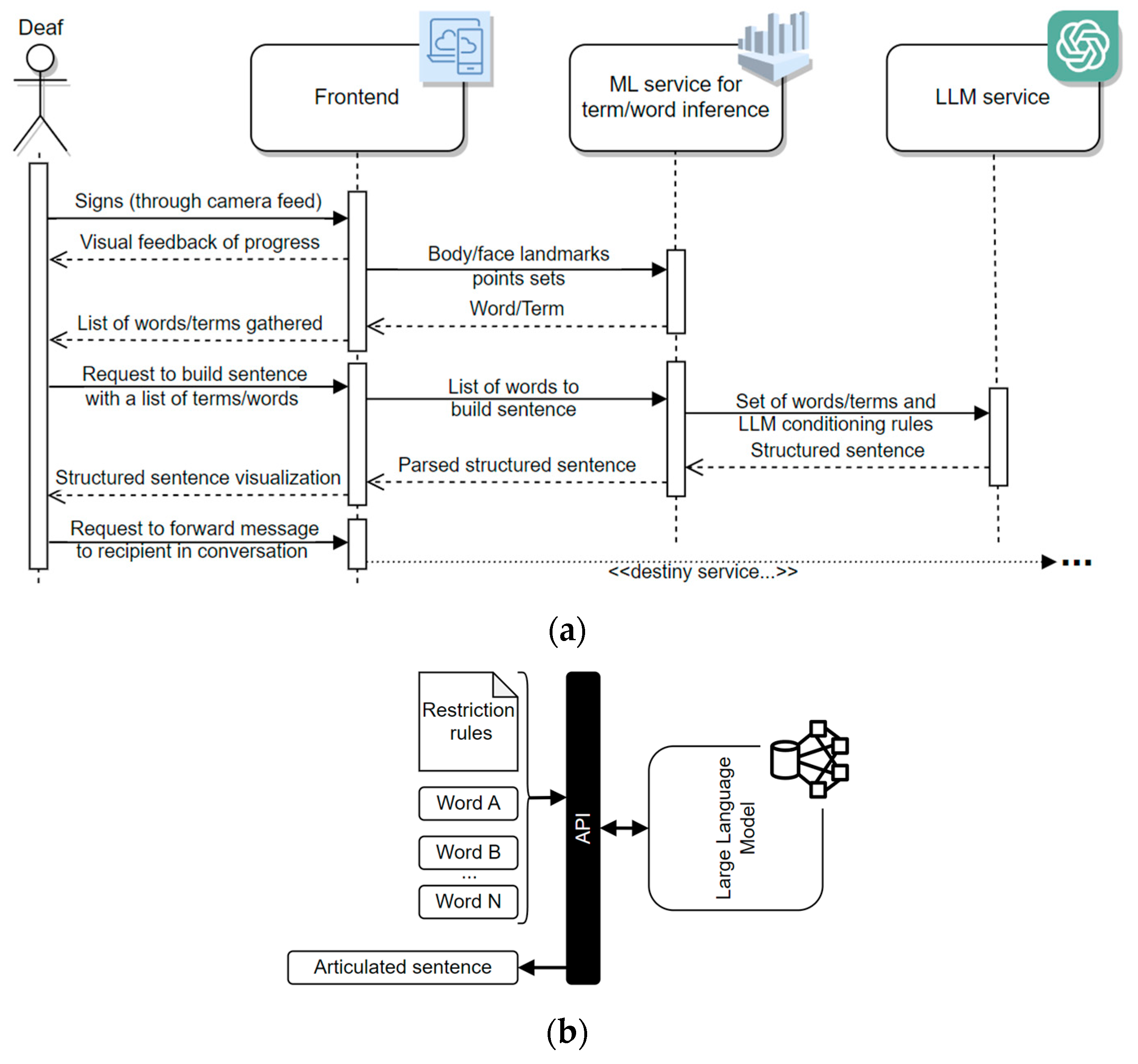
4.4. Sentence Construction Powered by Chat-GPT
- Dynamic rules: “To generate a concise sentence considering the following words/terms and punctuation from the given set Stokens”, where Stokens represents a sequence of words/terms, optionally ended by a punctuation mark, more specifically, a “.” or a “?”.
- Static rules: (a) “To ignore repeated words/terms”; (b) “To restrain, as much as possible, to the tokens that there are in the given set, avoiding to add more”; (c) “To consider the present indicative by default;” (d) “If a personal pronoun is not indicated, to conjugate the verbs in the first person singular”; (e) “To perform only minimal transformations to the words¨, with the goal of ensuring grammatical correctness”; (f) “To perform spelling corrections, whenever necessary”; (g) “To correct gender and number agreement inconsistencies”; and, finally h) “To interpret numbers as quantifiers”.
4.5. Web-Based Central Service Layer
- config—provides an external service consumer with the current prediction configurations, offering information about the available vocabulary sets and LGP models to use, as well as the expected landmarks to monitor, assuming MediaPipe data formats;
- vocab_selector—allows the switching between existing vocabulary and model combinations (compliant with the data provided by config endpoint);
- mp_estimator—returns word/expression predictions upon a provided list of coordinates sent by an external service consumer;
- sentence_GPT—when provided with a list of words from an external service consumer, this endpoint generates a prompt for ChatGPT API, yielding a simple but semantically and grammatically consistent sentence integrating the referred list of words.
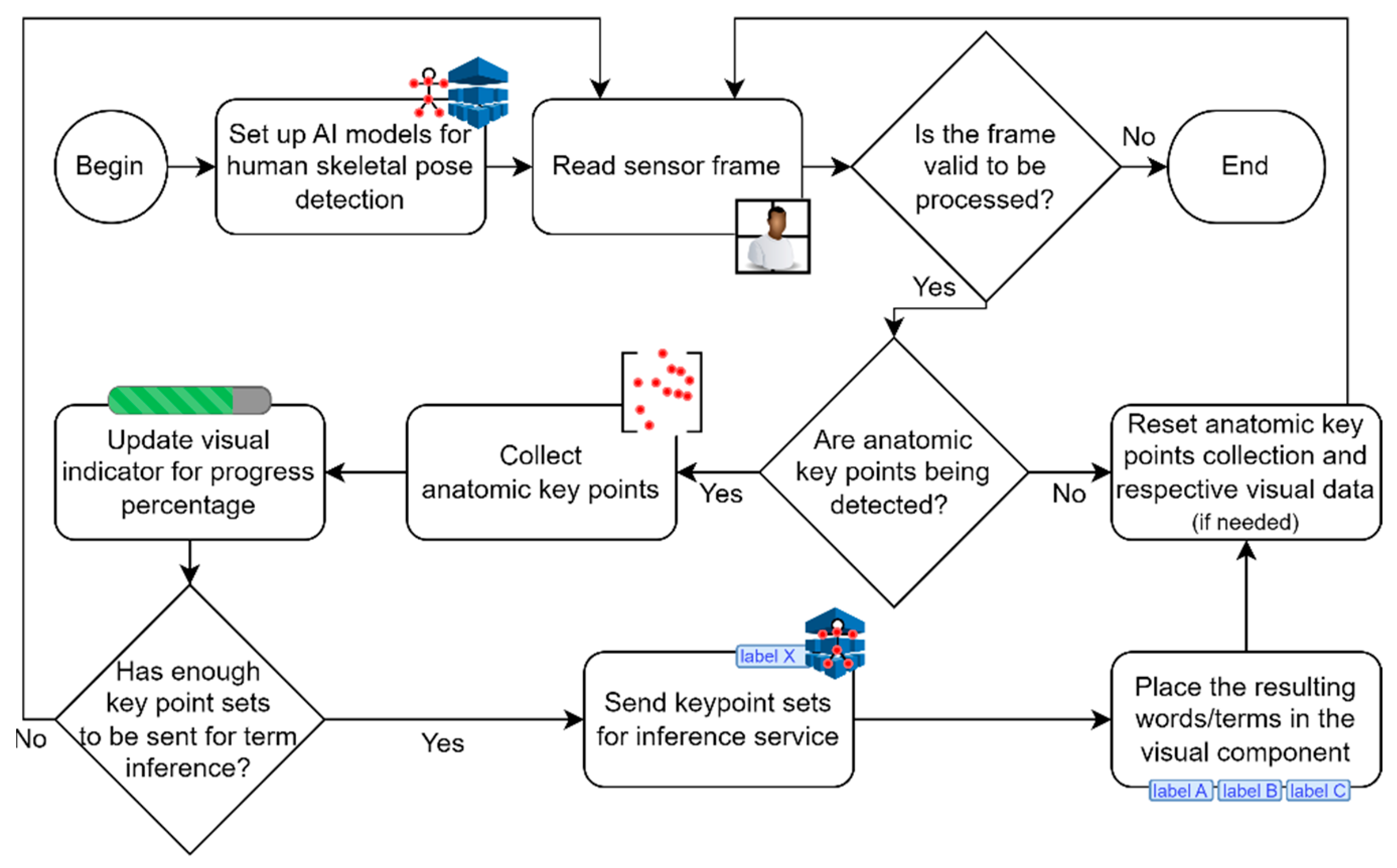
4.6. Deaf-Side Frontend Experimental Tool
5. Tests and Results
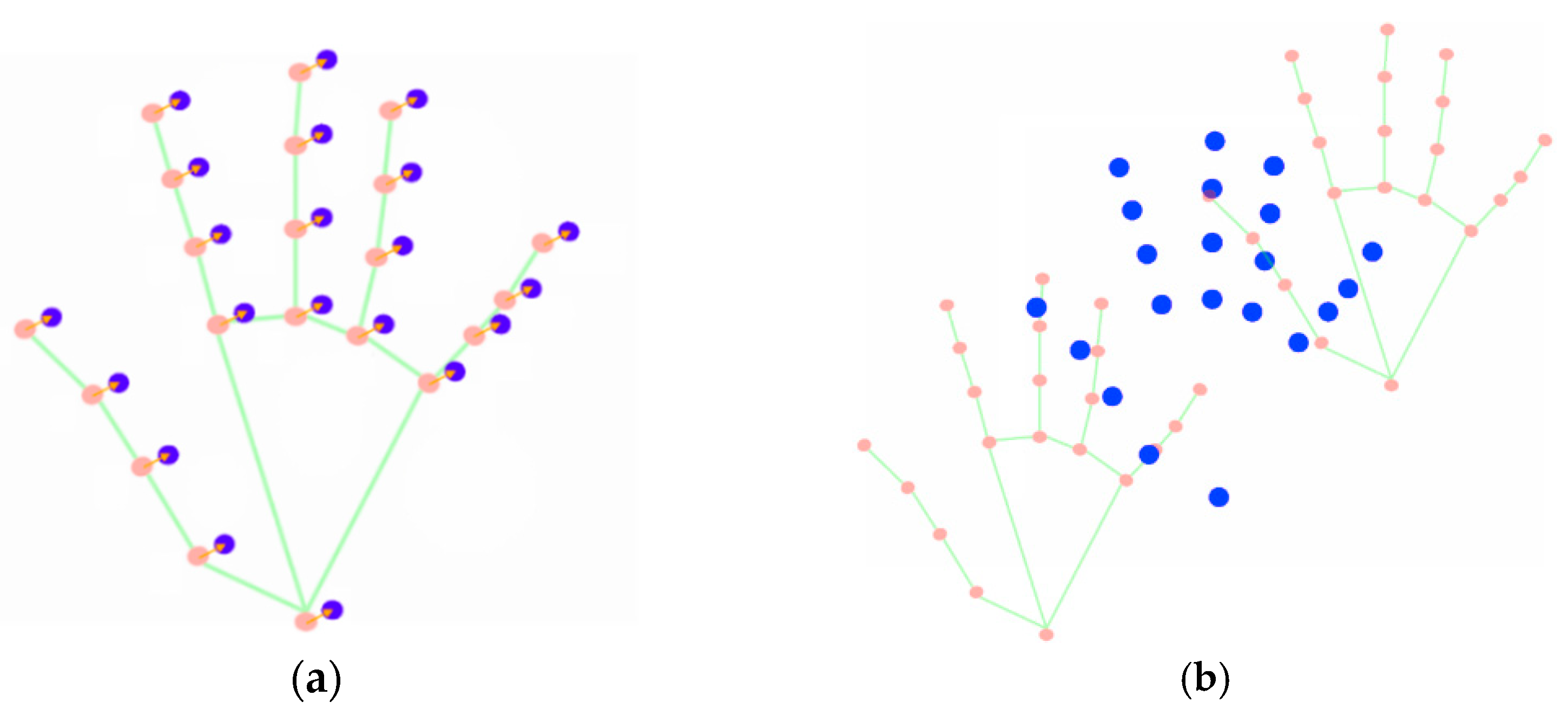
5.1. Landmark-Based Points Extraction
5.2. LGP Models Parameters
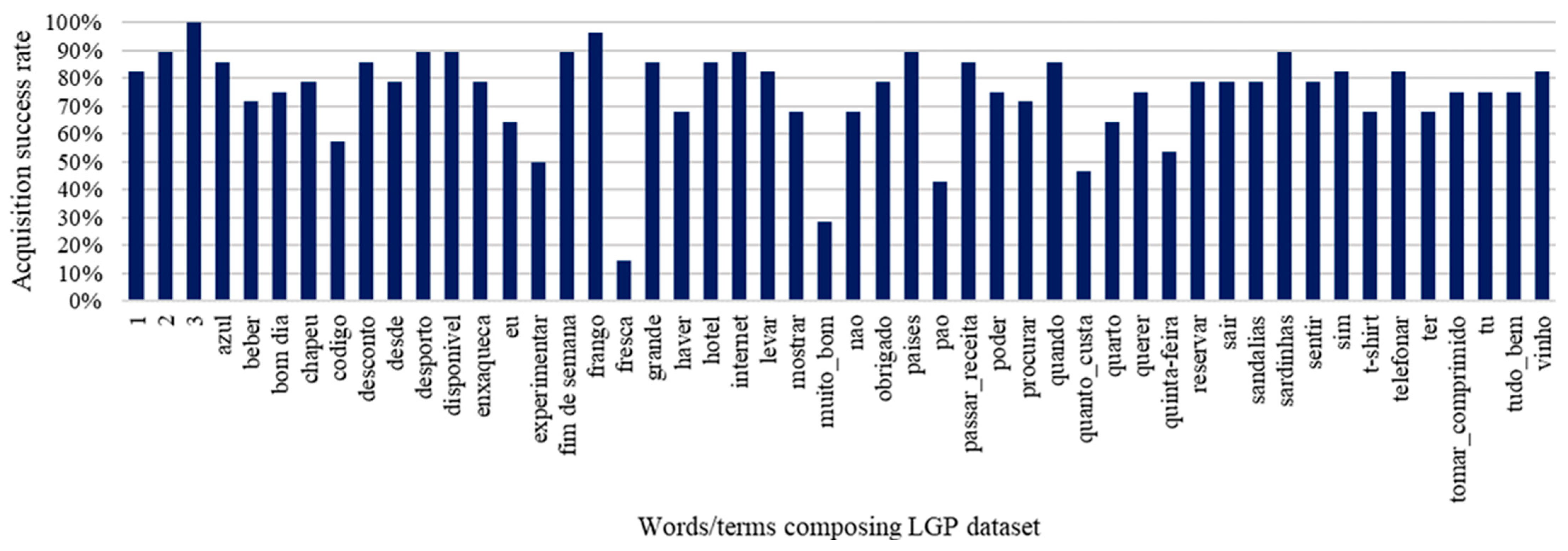
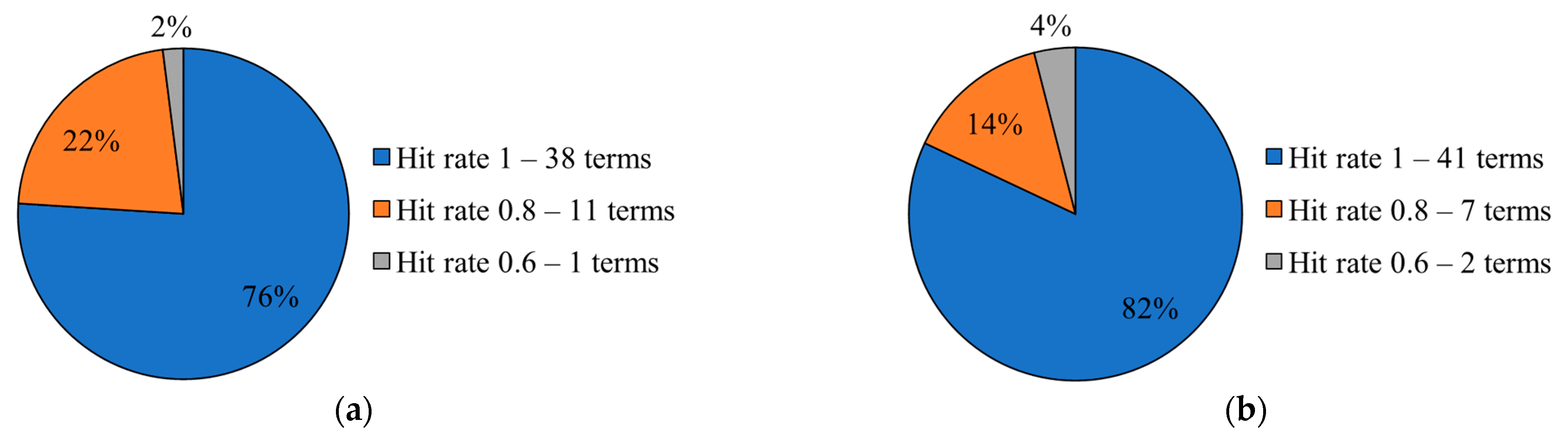
5.3. LGP Terms Inference Accuracy
- is the limit for data augmentation, per class;
- represents the number of elements, per class (in unbalanced data, the class with the higher number of examples is the reference);
- stands for the number of dataset augmentation transformers, besides the use of original data;
- is the number of passages specified for applying dataset augmentation transformers.
- CN = 28 signs × 2 (from HF) × 2 (from SO) = 168;
- DE = 1, even for the dataset involving inline RRS/SBI augmentation, wherein both RRS and SBI are carried out combined in the same operational flow for data transformation;
- NP = 5, regarding the number of passages to apply DE.
5.4. Tests to Chat-GPT Restriction Rules for Conditioned Sentence Generation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Context | LGP Gloss | Expected Sentence | ChatGPT Sentence | Semantic Similarity |
|---|---|---|---|---|
| Commerce | FRANGO QUERER | Quero frango. | Eu quero frango. | 0.79 |
| QUANTO.CUSTA? | Quanto custa? | Quanto custa? | 1.00 | |
| PÃO TRÊS LEVAR | Levo três pães | Levo três pães. | 1.00 | |
| SARDINHAS HAVER? | Há sardinhas? | Há sardinhas? | 1.00 | |
| SARDINHA DOIS QUERER | Quero dois sardinhas? | Eu quero dois sardinhas. | 0.67 | |
| T-SHIRT DESPORTO HAVER? | Há t-shirts de desporto? | Há uma T-shirt de desporto? | 0.75 | |
| AZUL GRANDE TER? | Tu tens azuis, grandes (tamanho)? | Tu terás um grande azul? | 0.37 | |
| Tourism | QUARTO DISPONÍVEL QUINTA.FEIRA TU TER? | Tu tens quarto disponível para quinta-feira? | Tu terás um quarto disponível na quinta-feira? | 0.59 |
| RESERVAR QUERER | Quero reservar. | Quero reservar. | 1.00 | |
| HOTEL INTERNET TER? | O hotel tem Internet? | Ter internet no hotel? | 0.74 | |
| CÓDIGO TU TER? | Tu tens o código? | Tu tens código? | 0.91 | |
| FIM.DE.SEMANA TU DISPONÍVEL? | Tu estás disponível no fim de semana? | Tu tens disponível o fim de semana? | 0.80 | |
| PAÍS (TAMBÉM) HOTEL TU PROCURAR | Procuras país e hotel? | Tu procuras hotel no país? | 0.62 | |
| SAIR QUANDO? | Quando é para sair? | Quando saio? | 0.70 | |
| T-SHIRT CHAPÉU SANDÁLIAS TU LEVAR | Tu leva chapéu, t-shirt e sandálias. | Eu levo a T-shirt, o chapéu e as sandálias. | 0.59 | |
| VINHO SARDINHAS FRESCAS EXPERIMENTAR QUERER | Quero experimentar vinho e sardinhas frescas. | Quero experimentar vinho e sardinhas frescas. | 1.00 | |
| Heath care | ENXAQUECA SENTIR QUINTA-FEIRA DESDE | Sinto enxaqueca desde quinta-feira. | Sinto enxaqueca desde quinta-feira. | 1.00 |
| TU PASSAR.RECEITA? | Tu passas receita (médica)? | Tu passas a receita? | 0.91 | |
| VINHO BEBER PODER? | Posso beber vinho? | Posso beber vinho? | 1.00 | |
| Average Similarity: | 0.81 | |||
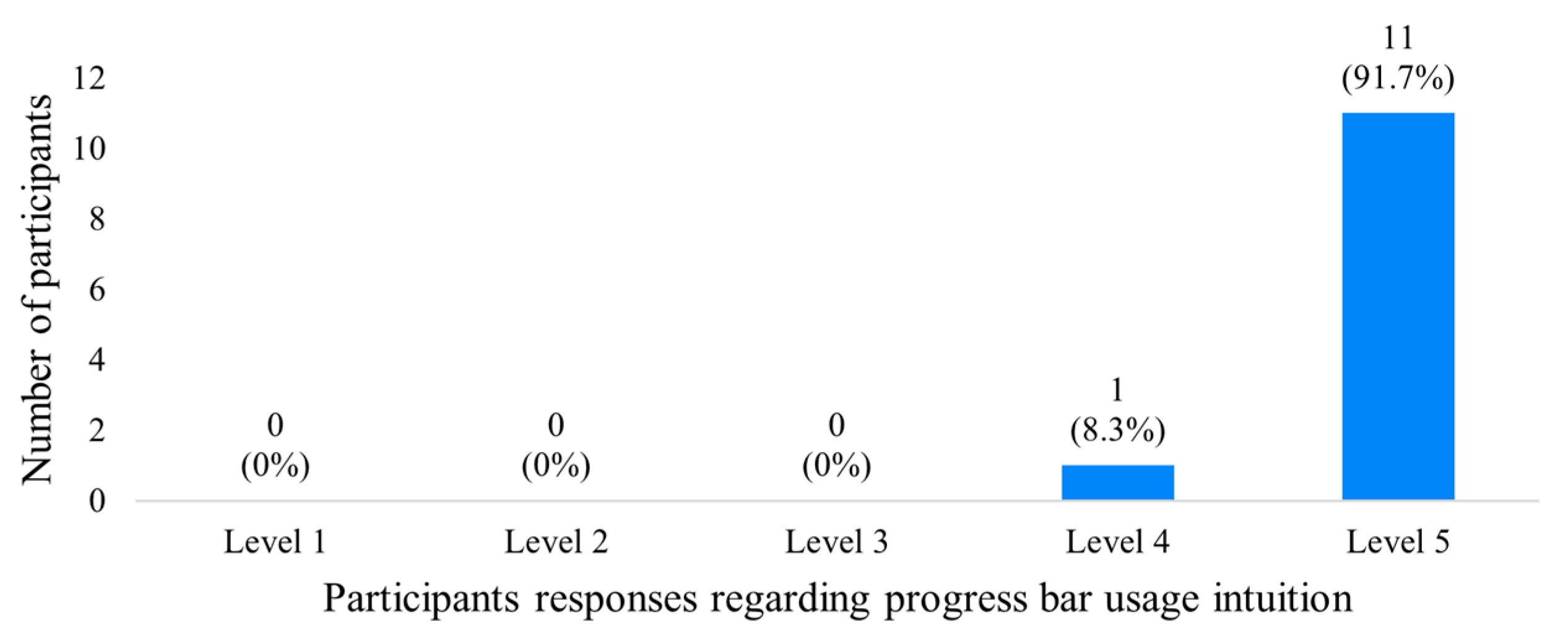
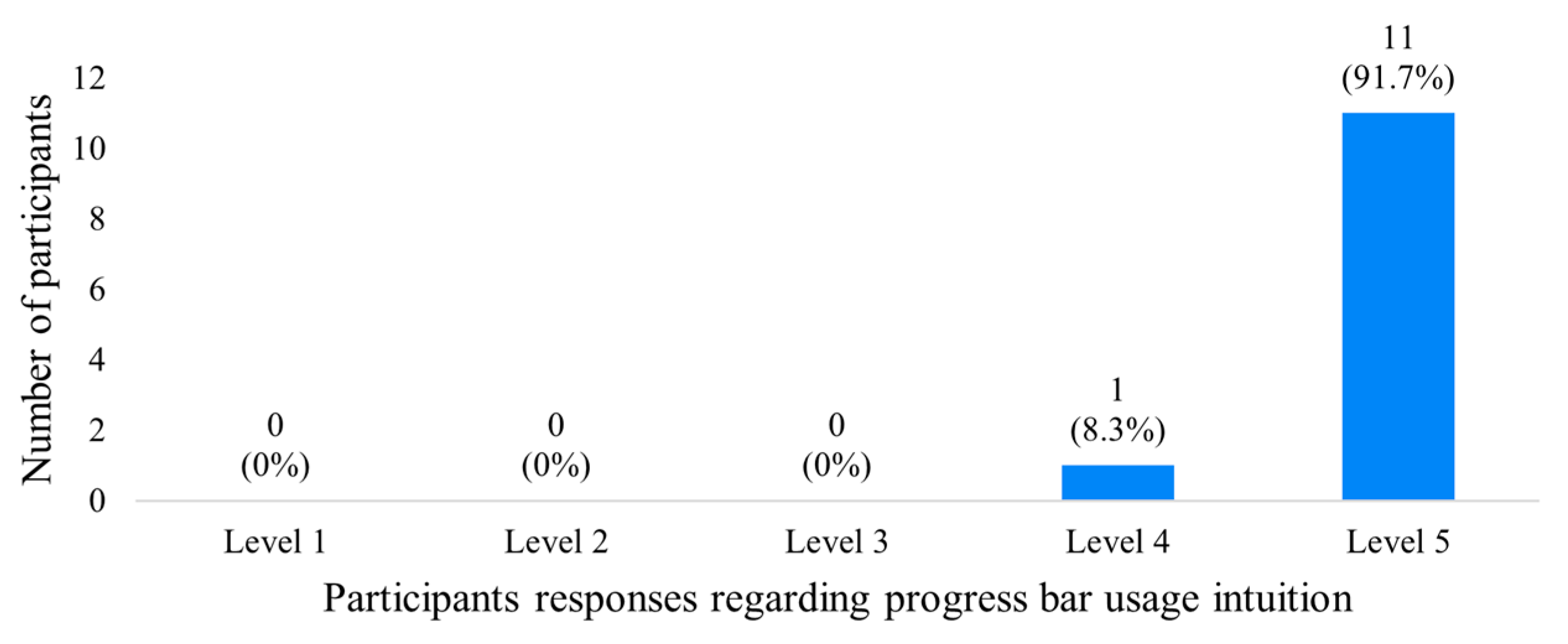
5.5. Tests with an End-User
- Total of synchronization errors: 1 (0.08 of mean);
- Total of inference errors: 14 (1.27 of mean).
5.6. Integrated Frontend Layer Functional Testing
6. Discussion
- In [6], only 10 classes were regarded in the study—a categorical complexity 80% lesser than the proposed LGP dataset;
- In [7], the reference dataset was LSA64, having 3200 usable examples distributed among 64 classes—28% more classes than those composing the proposed LGP dataset, but, also, around twice of the exemplifying videos, from which 90% was assigned for training subset;
- Finally, in [8], the Persian dataset composed of 100 examples per 100 signs was used–twice of the classes composing the proposed LGP dataset, but 8 times more exemplifying videos, as well.
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Escudeiro, P.; Escudeiro, N.; Reis, R.; Lopes, J.; Norberto, M.; Baltasar, A.B.; Barbosa, M.; Bidarra, J. Virtual Sign—A Real Time Bidirectional Translator of Portuguese Sign Language. Procedia Comput. Sci. 2015, 67, 252–262. [Google Scholar] [CrossRef]
- Mayea, C.; Garcia, D.; Guevara Lopez, M.A.; Peres, E.; Magalhães, L.; Adão, T. Building Portuguese Sign Language Datasets for Computational Learning Purposes. In Proceedings of the 2022 International Conference on Graphics and Interaction (ICGI), Aveiro, Portugal, 3–4 November 2022. [Google Scholar]
- Podder, K.K.; Chowdhury, M.E.H.; Tahir, A.M.; Mahbub, Z.B.; Khandakar, A.; Hossain, M.S.; Kadir, M.A. Bangla Sign Language (BdSL) Alphabets and Numerals Classification Using a Deep Learning Model. Sensors 2022, 22, 574. [Google Scholar] [CrossRef] [PubMed]
- Abraham, E.; Nayak, A.; Iqbal, A. Real-Time Translation of Indian Sign Language Using LSTM. In Proceedings of the 2019 Global Conference for Advancement in Technology (GCAT), Bangaluru, India, 18–20 October 2019; pp. 1–5. [Google Scholar]
- Gangrade, J.; Bharti, J. Vision-Based Hand Gesture Recognition for Indian Sign Language Using Convolution Neural Network. IETE J. Res. 2023, 69, 723–732. [Google Scholar] [CrossRef]
- Zhu, G.; Zhang, L.; Shen, P.; Song, J. Multimodal Gesture Recognition Using 3-D Convolution and Convolutional LSTM. IEEE Access 2017, 5, 4517–4524. [Google Scholar] [CrossRef]
- Bohacek, M.; Hruz, M. Sign Pose-Based Transformer for Word-Level Sign Language Recognition. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW), Waikoloa, HI, USA, 4–8 January 2022; IEEE: Waikoloa, HI, USA, 2022; pp. 182–191. [Google Scholar]
- Rastgoo, R.; Kiani, K.; Escalera, S. Real-Time Isolated Hand Sign Language Recognition Using Deep Networks and SVD. J. Ambient. Intell. Hum. Comput. 2022, 13, 591–611. [Google Scholar] [CrossRef]
- Xiao, Q.; Chang, X.; Zhang, X.; Liu, X. Multi-Information Spatial–Temporal LSTM Fusion Continuous Sign Language Neural Machine Translation. IEEE Access 2020, 8, 216718–216728. [Google Scholar] [CrossRef]
- SLAIT—Real-Time Sign Language Translator with AI. Available online: https://slait.ai (accessed on 3 August 2023).
- Li, D.; Opazo, C.R.; Yu, X.; Li, H. Word-Level Deep Sign Language Recognition from Video: A New Large-Scale Dataset and Methods Comparison. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Ronchetti, F.; Quiroga, F.; Estrebou, C.; Lanzarini, L.; Rosete, A. LSA64: An Argentinian Sign Language Dataset. In Proceedings of the XXII Congreso Argentino de Ciencias de la Computación (CACIC), San Luis, Argentina, 3–7 October 2016. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- OpenAI. GPT-4 Technical Report. 2023. Available online: https://cdn.openai.com/papers/gpt-4.pdf (accessed on 11 August 2023).
- Singh, A.; Wadhawan, A.; Rakhra, M.; Mittal, U.; Ahdal, A.A.; Jha, S.K. Indian Sign Language Recognition System for Dynamic Signs. In Proceedings of the 2022 10th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 13–14 October 2022; pp. 1–6. [Google Scholar]
- Sridhar, A.; Ganesan, R.G.; Kumar, P.; Khapra, M. INCLUDE: A Large Scale Dataset for Indian Sign Language Recognition. In Proceedings of the 28th ACM International Conference on Multimedia, Association for Computing Machinery, New York, NY, USA, 12 October 2020; pp. 1366–1375. [Google Scholar]
- Koller, O.; Forster, J.; Ney, H. Continuous Sign Language Recognition: Towards Large Vocabulary Statistical Recognition Systems Handling Multiple Signers. Comput. Vis. Image Underst. 2015, 141, 108–125. [Google Scholar] [CrossRef]
- Duarte, A.; Palaskar, S.; Ventura, L.; Ghadiyaram, D.; DeHaan, K.; Metze, F.; Torres, J.; Giro-i-Nieto, X. How2Sign: A Large-Scale Multimodal Dataset for Continuous American Sign Language. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Cerna, L.R.; Cardenas, E.E.; Miranda, D.G.; Menotti, D.; Camara-Chavez, G. A Multimodal LIBRAS-UFOP Brazilian Sign Language Dataset of Minimal Pairs Using a Microsoft Kinect Sensor. Expert Syst. Appl. 2021, 167, 114179. [Google Scholar] [CrossRef]
- Brashear, H.; Henderson, V.; Park, K.-H.; Hamilton, H.; Lee, S.; Starner, T. American Sign Language Recognition in Game Development for Deaf Children. In Proceedings of the 8th International ACM SIGACCESS Conference on Computers and Accessibility, Association for Computing Machinery, New York, NY, USA, 23 October 2006; pp. 79–86. [Google Scholar]
- Blevins, T.; Gonen, H.; Zettlemoyer, L. Prompting Language Models for Linguistic Structure. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023. [Google Scholar]
- Chang, E.Y. Prompting Large Language Models with the Socratic Method. In Proceedings of the 2023 IEEE 13th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 8–11 March 2023. [Google Scholar]
- Zhang, B.; Haddow, B.; Birch, A. Prompting Large Language Model for Machine Translation: A Case Study. arXiv 2023, arXiv:2301.07069. [Google Scholar]
- Wei, J.; Kim, S.; Jung, H.; Kim, Y.-H. Leveraging Large Language Models to Power Chatbots for Collecting User Self-Reported Data. arXiv 2023, arXiv:2301.05843. [Google Scholar]
- Infopédia Infopedia.pt—Dicionários Porto Editora. Available online: https://www.infopedia.pt/dicionarios/lingua-gestual (accessed on 7 August 2023).
- Chowdhary, K.R. Natural Language Processing. In Fundamentals of Artificial Intelligence; Chowdhary, K.R., Ed.; Springer: New Delhi, India, 2020; pp. 603–649. ISBN 978-81-322-3972-7. [Google Scholar]
- Alves, V.; Ribeiro, J.; Romero, L.; Faria, P.M.; Costa, Â.; Ferreira, V. A Gloss Based Translation From European Portuguese to Portuguese Sign Language. In Proceedings of the 2023 30th International Conference on Systems, Signals and Image Processing (IWSSIP), Ohrid, North Macedonia, 27–29 June 2023; pp. 1–4. [Google Scholar]
- Introducing ChatGPT. Available online: https://openai.com/blog/chatgpt (accessed on 11 August 2023).
- Cer, D.; Yang, Y.; Kong, S.; Hua, N.; Limtiaco, N.; John, R.S.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal Sentence Encoder. arXiv 2018, arXiv:1803.11175. [Google Scholar]






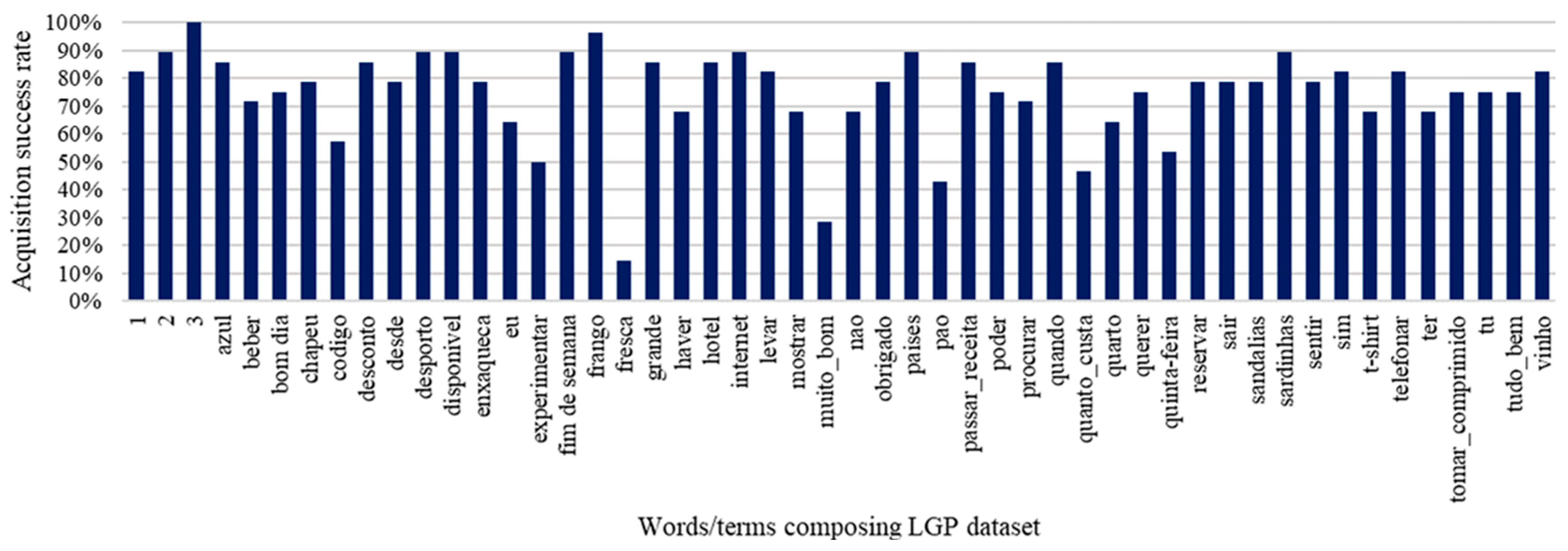
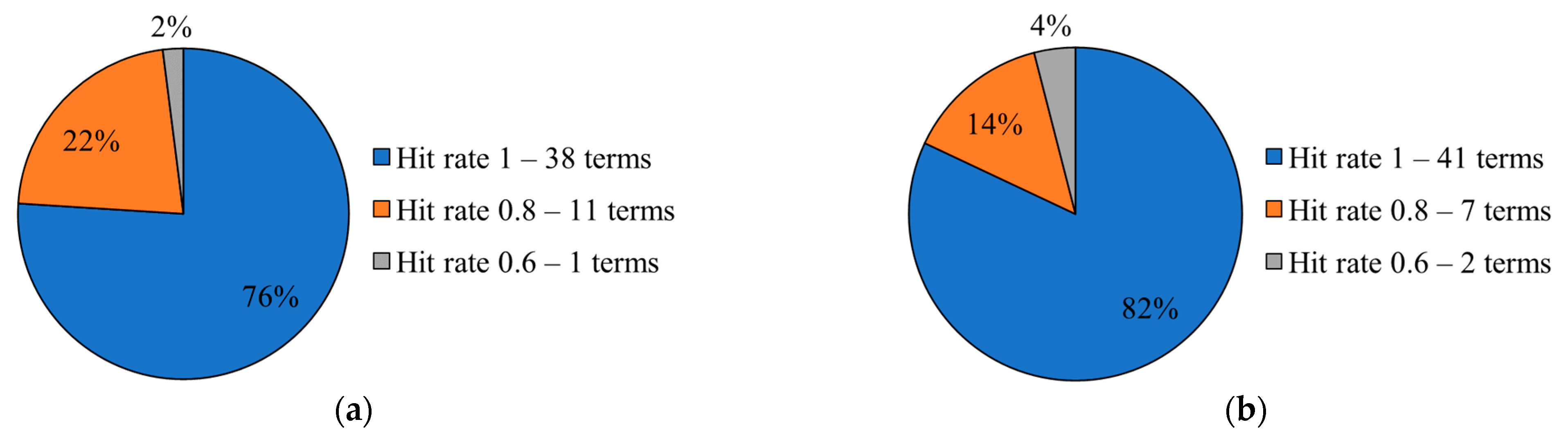

| Portuguese | English (Terms 1–25) | Portuguese | English (Terms 26–50) |
|---|---|---|---|
| 1/um | one | não | No |
| 2/dois | two | obrigado | thank you |
| 3/três | three | países | countries |
| azul | blue | pao | Bread |
| beber | to drink | passar (receita) | to prescribe |
| bom dia | good morning | poder | to be able to |
| chapéu | hat | procurar | to search |
| código | code | quando | when |
| desconto | discount | quanto custa | how much does it cost |
| desde | since | quarto | room |
| desporto | sports | querer | to want |
| disponível | available | quinta-feira | Thursday |
| enxaqueca | migraine | reservar | to reserve |
| eu | I | sair | to leave |
| experimentar | to try | sandálias | sandals |
| fim de semana | weekend | sardinhas | sardines |
| frango | chicken | sentir | to feel |
| fresca | fresh | sim | yes |
| grande | large | t-shirt | t-shirt |
| haver | to have | telefonar | to call |
| hotel | hotel | ter | to have |
| internet | internet | tomar (comprimido) | to take (a pill) |
| levar | to take | tu | you (informal) |
| mostrar | to show | tudo bem | okay |
| muito bom | very good | vinho | wine |
| Total of Examples | Data per Sign | ||||
|---|---|---|---|---|---|
| Videos | Testing Videos | Train/Validation Videos | Train Percentage | Validation Percentage | |
| 1650 | 33 | 5 | 28 | ~65% | ~35% |
| Transformation State | Frames Aspect |
|---|---|
| Original |  |
| Shear −16° |  |
| Shear 16° |  |
| Transformation State | Frames Aspect |
|---|---|
| Original |  |
| Horizontal flip |  |
| Model | Total Parameters | Trainable Parameters | Non-Trainable Parameters |
|---|---|---|---|
| SimpleLSTM | 13.221.554 | 13.221.554 | 0 |
| ConvLSTM | 15.548.850 | 15.548.850 |
| Model | Augmentation Conditions | Augmentation Limit | Accuracy | Loss | Final Epoch |
|---|---|---|---|---|---|
| SimpleLSTM | Horizontal flips (HF), not augmented (NA), not balanced. | N/A | 80% | 1.23 | 155 |
| HF + shear operations (SO), not augmented, not balanced. | N/A | 87% | 0.98 | 100 | |
| HF + SO + RRS augmentation, balanced. | 1008 | 94.8% | 0.47 | 110 | |
| HF + SO + SBI augmentation, balanced. | 1008 | 92% | 0.72 | 100 | |
| HF + SO + inline RRS/SBI augmentation, balanced. | 1008 | 93.8% | 0.444 | 75 |
| Model | Augmentation Conditions | Augmentation Limit | Accuracy | Loss | Final Epoch |
|---|---|---|---|---|---|
| ConvLSTM | HF + SO + RRS augmentation, balanced. | 1008 | 95.6% | 0.647 | 85 |
| HF+ SO + inline RRS/SBI augmentation, balanced. | 1008 | 94.4% | 0.455 | 150 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adão, T.; Oliveira, J.; Shahrabadi, S.; Jesus, H.; Fernandes, M.; Costa, Â.; Ferreira, V.; Gonçalves, M.F.; Lopéz, M.A.G.; Peres, E.; et al. Empowering Deaf-Hearing Communication: Exploring Synergies between Predictive and Generative AI-Based Strategies towards (Portuguese) Sign Language Interpretation. J. Imaging 2023, 9, 235. https://doi.org/10.3390/jimaging9110235
Adão T, Oliveira J, Shahrabadi S, Jesus H, Fernandes M, Costa Â, Ferreira V, Gonçalves MF, Lopéz MAG, Peres E, et al. Empowering Deaf-Hearing Communication: Exploring Synergies between Predictive and Generative AI-Based Strategies towards (Portuguese) Sign Language Interpretation. Journal of Imaging. 2023; 9(11):235. https://doi.org/10.3390/jimaging9110235
Chicago/Turabian StyleAdão, Telmo, João Oliveira, Somayeh Shahrabadi, Hugo Jesus, Marco Fernandes, Ângelo Costa, Vânia Ferreira, Martinho Fradeira Gonçalves, Miguel A. Guevara Lopéz, Emanuel Peres, and et al. 2023. "Empowering Deaf-Hearing Communication: Exploring Synergies between Predictive and Generative AI-Based Strategies towards (Portuguese) Sign Language Interpretation" Journal of Imaging 9, no. 11: 235. https://doi.org/10.3390/jimaging9110235
APA StyleAdão, T., Oliveira, J., Shahrabadi, S., Jesus, H., Fernandes, M., Costa, Â., Ferreira, V., Gonçalves, M. F., Lopéz, M. A. G., Peres, E., & Magalhães, L. G. (2023). Empowering Deaf-Hearing Communication: Exploring Synergies between Predictive and Generative AI-Based Strategies towards (Portuguese) Sign Language Interpretation. Journal of Imaging, 9(11), 235. https://doi.org/10.3390/jimaging9110235