1. Introduction
The image restoration problem under Poisson noise corruption is a task that has been extensively addressed in the literature as it arises in many real-world applications, where the acquired image is obtained by counting the particles, e.g., photons, hitting the image domain [
1]. The typical image formation model under blur and Poisson noise corruption takes the form
where
models the blur operator, which we assume to be known;
and
are the observed
and unknown
images in column-major vectorized form (with
and
), respectively;
is a non-negative background emission, and where
, with
indicating the realization of a Poisson-distributed random variable of parameter (mean)
.
When tackling the recovery of
starting from
, one has also to consider the intrinsic constraint
which accounts for the pixel values being non-negative.
In a probabilistic perspective [
2], problem (
1) and (
2) can be addressed by modeling the unknown
as a random variable. In general, the information on the degradation process is encoded in the so-called
likelihood probability density function (pdf)
, while the prior beliefs on the unknown
are expressed by the
prior pdf
. In the Bayesian framework, one aims to recover the
posterior pdf, which is related to the likelihood and the prior term via the Bayes formula:
with
P denoting the probability mass function (pmf) that replaces the continuous pdf
p to account for the discrete nature of the data
.
According to the Maximum A Posteriori (MAP) estimation approach, the mode of
can be selected as a single-point representative of the posterior distribution, so that the original problem (
1) and (
2) turns into:
In light of the constraint expressed in (
2), the general form of the prior pdf reads
with
and
encoding other information possibly available on
. A typical choice for
is given by the Total Variation (TV) Gibbs prior—see [
3]—which reads
where
is a normalization constant,
is the prior parameter and
denotes the discrete gradient operator with
, two linear operators representing the finite difference discretizations of the first-order partial derivatives of the image
in the horizontal and vertical direction. The negative logarithm of the prior pdf
thus reads
with
denoting the indicator function of set
, which is equal to 0 if
, or
otherwise.
Concerning the likelihood pdf, first, we notice that the forward model (
1) can be usefully rewritten in component-wise (pixel-wise) form as follows:
with
,
, and where
denotes the
i-th row of matrix
. Upon the assumption of independence of the Poisson noise realizations at different pixels, we have:
where
, which denotes the probability for
to be the realization of a Poisson-distributed random variable with mean
, reads
with
denoting the set of non-negative real numbers. Hence, the associated negative log-pmf reads
By plugging (6) into (5), the negative log-likelihood takes the following form:
Finally, plugging (4) and (7) into (3), dropping out the constant term
in (4), readjusting the constant terms in (7) (by adding
to each term in the sum), and then dividing the cost function by the positive scalar
, we obtain the so-called TV-KL variational model:
where
, the TV semi-norm term [
4], is defined by
and the term
indicates the generalized Kullback–Leibler (KL) divergence between
and the observation
, which reads
Note that the adoption of the MAP strategy within a probabilistic framework yields a minimization problem, which is typically addressed in the context of variational methods for image restoration. The TV term and the KL divergence play the role of the regularization and data fidelity term, respectively. Moreover, the parameter , which has been defined starting from the prior parameter , is the so-called regularization parameter balancing the action of regularization and data fidelity terms.
The selection of a suitable value for the regularization parameter
is of crucial importance for obtaining high-quality results. This relation is highlighted by the explicit dependence in (8) of the solution
on the parameter
. Very often,
is chosen empirically by brute-force optimization with respect to some visual quality metrics. However, for Poisson data, a large amount of literature has been devoted to the analysis of the Discrepancy Principle (DP), which can be formulated in general terms as follows [
5]:
where the last equality and the scalar
in (10) are commonly referred to as the
discrepancy equation and the
discrepancy value, respectively, while the
discrepancy function is defined by
with function
F defined in (9) and
The DP in (10)–(12) formalizes a quite simple idea: choose the value of the regularization parameter in the TV-KL model (8) such that the value of the KL data fidelity term associated with the solution is equal to a prescribed discrepancy value . However, applying the DP in an effective manner in practice is not straightforward as several issues concerning the computational efficiency and, more importantly, the quality of the output solutions arise. We examine both of them more closely.
- (I1)
Computational efficiency. The solution function of model (8) does not admit a closed-form expression and iterative solvers must be used to compute the restored image associated with any . Hence, selecting by solving the scalar discrepancy equation defined in (10)–(12) as an efficient preliminary step and then computing the sought restored image by iteratively solving model (8) only once is not feasible.
- (I2)
Quality of solution(s). Even if an efficient algorithm is used for the computation, the obtained restored image may be of such low quality that it is of no practical use if the discrepancy value in (10) is not suitably chosen.
Issue (I1) concerning computational efficiency has been successfully addressed in [
6], where the authors propose to automatically update
along the iterations of the minimization algorithm used for solving the TV-KL model so as to satisfy (at convergence) a specific version of the general DP defined in (10)–(12).
Concerning (I2), we highlight that, in the theoretical hypothesis that the target image
is known, so that
is also known, one would select
such that the value of the KL fidelity term associated with the solution
is equal to the value of the KL fidelity term associated with
. This clearly does not guarantee that the obtained solution
coincides with the target image
. However, by constraining
to belong to the unique level set of the (convex) KL fidelity term containing
, this abstract strategy, which we refer to as the Theoretical DP (TDP), represents an oracle for the general DP in (10)–(12). The TDP is thus formulated as follows:
with function
F defined in (9). Clearly, the value
cannot be computed in practice as the original image
is not available. As in the case of the Morozov discrepancy principle for Gaussian noise, one could replace the scalar
with the expected value of the KL fidelity term in (9) regarded as a function of the
m-variate random variable
. We will refer to this version of the DP as Exact (or Expected value) DP (EDP). In the following formula
where
denotes the expected value of
regarded as a function of the Poisson-distributed random variable
. Nonetheless, unlike the Gaussian noise case, the discrepancy value is not a constant but is a function
of the regularization parameter
, and deriving its analytic expression is a very challenging task. A popular and widespread strategy, originally proposed in [
5] for denoising purposes and extended in [
7] to the image restoration task, replaces the exact expected value function
with a constant approximation coming from truncating its Taylor series expansion. We will refer to this version of the DP as Approximate DP (ADP). It reads:
Despite its extensive use due to the good performance achieved in the mid- and high-count regimes, the (15) is known to return poor-quality results in the low-count Poisson regime [
8], i.e., when the number of photons hitting the image domain is small. In fact, in [
7], where the ADP was first extended to the image deblurring task, the authors state (in Remark 3) that the choice of the constant value
in (15) may not be “optimal” and suggest replacing it with
, where
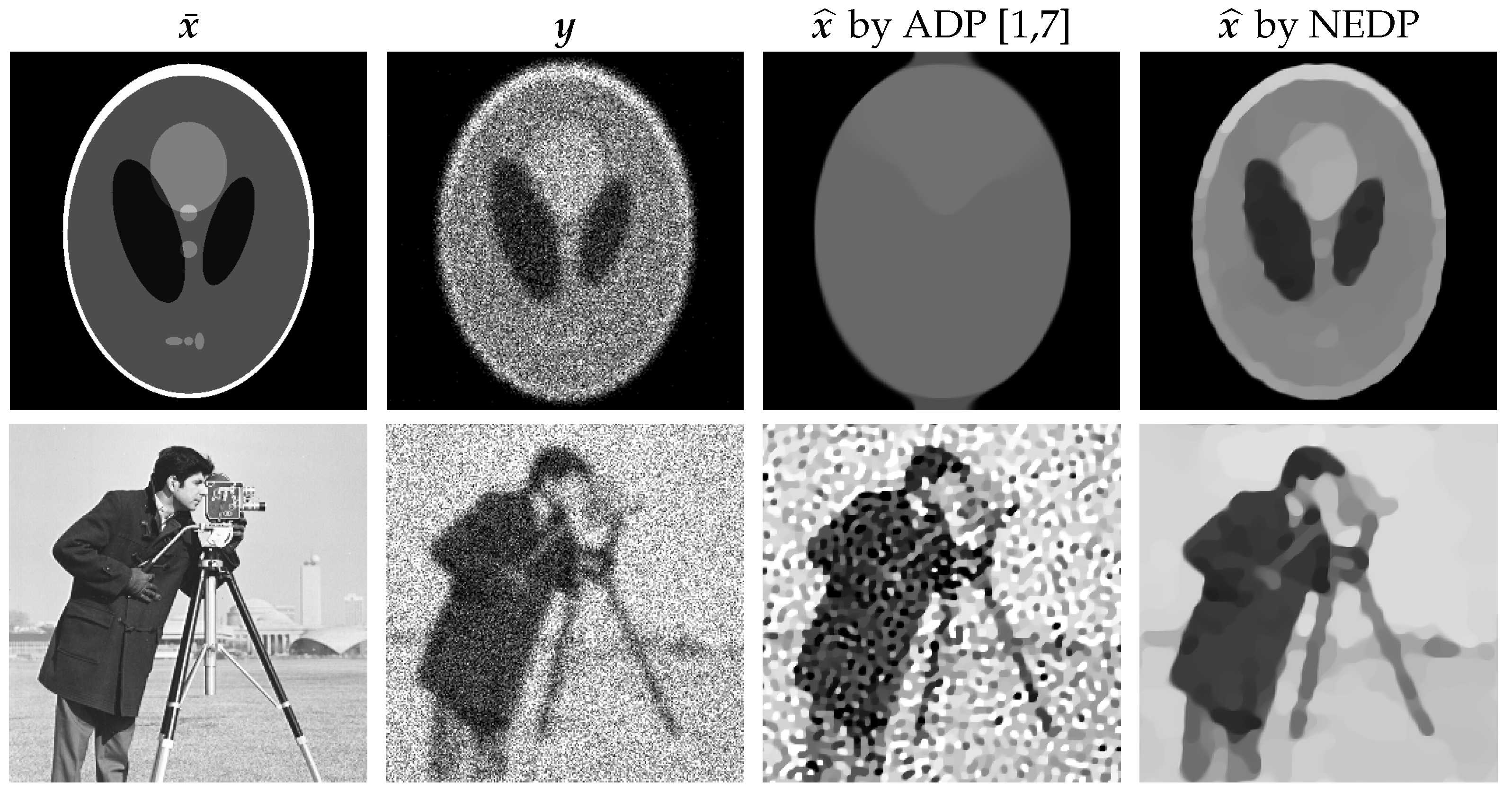
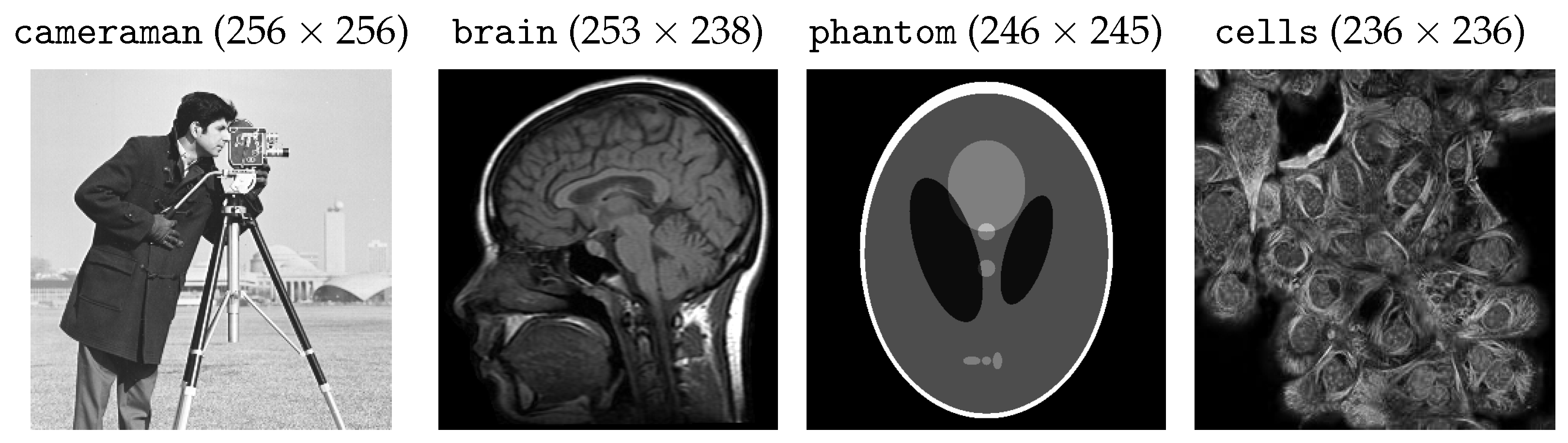
is a small positive or negative real number. As a preliminary, qualitative proof of the possible poor performance of (15) in the low-count regime, in the first column of
Figure 1, we show the two test images
phantom and
cameraman, which have been corrupted by blur and heavy Poisson noise (second column). The TV-KL image restoration model in (8), with regularization parameter
selected according to the (15), has been performed. The output restorations are displayed in the third column of
Figure 1. One can see that the rough approximation
used in the (15) can either return oversmoothed results, as in the case of
phantom, or undersmoothed restorations, as for
cameraman.
Since its proposal in [
5], the ADP has been (and still is) widely used for variational image restoration (see, e.g., [
9,
10]) and it can be regarded as the standard extension of the Morozov DP for Gaussian noise to the Poisson noise case. Then, some literature exists working on the ADP, e.g., by proposing, analyzing, and testing its usage in KL-constrained variational models [
11] or by analyzing it theoretically [
12]. However, to the best of the authors’ knowledge, the only attempt to improve the ADP by giving a face to the
adjustment to the approximate, constant discrepancy value
is the one in [
8]. The authors in [
8] correctly state that
must not be a constant, but a function
of the photon count level. However, they propose to take
as the sum of the second to tenth terms of the same Taylor expansion used in [
5]. As we will highlight later in the paper, such expansion converges only for
approaching
; hence, the choice in [
8] cannot aspire to improve the performance of ADP in low-count regimes.
Contribution
The goal of this paper is to provide novel insights about the EDP and the ADP in order to design a novel discrepancy principle capable of outperforming the classical ADP proposed in [
5]. In more detail, we will provide a qualitative study proving that the recovery of a closed-form expression for function
in (14) through its Taylor series expansion used in [
5,
8] is not only difficult to achieve but also theoretically unfeasible for low-count Poisson regimes. Moreover, we will explore in detail the properties of the ADP motivating the dichotomic behavior (i.e., oversmoothing/undersmoothing) arising upon its adoption in the low-count regime. Finally, based on a simple Monte Carlo simulation followed by weighted least-square fitting, we will derive a novel version of the general DP in (10)–(12) based on a nearly exact (NE) approximation of function
in (14), concisely referred to as NEDP. Our approach will successfully address issues (I1)–(I2). In particular, it will be demonstrated experimentally that NEDP can return high-quality results both for low-count and mid/high-count acquisitions. The good performance of NEDP is anticipated in the last column of
Figure 1, where we show the output restorations achieved by using the TV-KL model in (8) and (9) coupled with the novel
-selection strategy.
2. Limits of the Approximate DP
The discrepancy principle proposed by Zanella et al. in [
5] for Poisson image denoising and then extended to image restoration by Bertero et al. in [
7] relies on Lemma 1 in [
5], whose proof has been completed in [
5] (corrigendum), which we report below for completeness.
Lemma 1. Let be a Poisson random variable with expected value and consider the function of defined by Then, the following estimate of the expected value of holds true for large λ: Based on the estimate above, and implicitly assuming a sufficiently large
(i.e., a sufficiently high-count Poisson regime) such that the
term can be neglected, the exact DP outlined in (14) is replaced in [
5,
7] by the approximation given in (15) and recalled below:
However, the ADP performs poorly for low-count Poisson images. Our goal here is to highlight that the reason for this lies precisely in the constant approximation used in (15) and then propose a nearly exact DP based on a much less approximate estimate of the expected value function .
For this purpose, first, we carry out a preliminary Monte Carlo simulation aimed at highlighting the error associated with the approximation in (15). In particular, we consider a discrete set of
values
and, for each
, we generate pseudo-randomly a large number (
of realizations of the Poisson random variable
. Then, we compute the associated values of the function
defined in (16) and, finally, for each
, we obtain an estimate
of
by calculating the sample mean of these function values. The results of this simulation are shown in
Figure 2. In particular, in the left figure, we report the computed estimates
, whereas, in the right figure, we report the percentage errors (with respect to the estimates) associated with using the constant value
as in the (15). The percentage error approaches
for
tending to zero and is in the order of
for
; then, as expected, it decreases (quite slowly) to zero for
tending to
. The error is thus quite large for small
and this can explain the poor performance of the (15) in the low-count Poisson regime.
In order to obtain a more accurate approximation or even an exact analytical expression for the expected value function
, we now retrace in detail the proof of Lemma 1 given in [
5], and completed in [
5] (corrigendum), and check if the rough truncation carried out in [
5] can be avoided.
After noting that function
is
on its domain
and considering its Taylor expansion around 0, the Taylor theorem with the remainder in integral form allows one to write:
Replacing the expansion above with
in the expression of function
F defined in (16), we obtain
After noting that the only random quantity in (19) is
, the expected value reads
with coefficients
,
, and remainder function
given by
and where
denote the central moments of order
of the Poisson random variable
. It is well known (see [
13], p. 162) that these moments can be obtained by the recursive formula
After noting that, in (20), only moments
with
are present and that they are all divided by
, it is easy to verify that, by applying (22), one obtains the following general algebraic polynomial expression:
where
are all integer coefficients with
for any
and where the degrees
of polynomials
are given by
where
denotes the floor function. The first 8 polynomials,
,
, read
By replacing the expressions of
given in (23) into (20), one obtains the following general formula:
where the coefficients
of the rational polynomials
in (25) read
with
given in (21) and
defined in (23).
After noting that, from (24), it follows that
for any
, it is a matter of simple algebra to verify that (25) can be equivalently and more compactly rewritten as
with
computable coefficients. In particular, for
, we have
from which we note how, as the truncation order
N increases, the coefficients
stabilize at some values, which we denote by
. Unfortunately, we are not able to obtain an explicit analytical expression for the sequence of coefficients
(as we are not able to obtain explicit analytic expressions for the coefficients
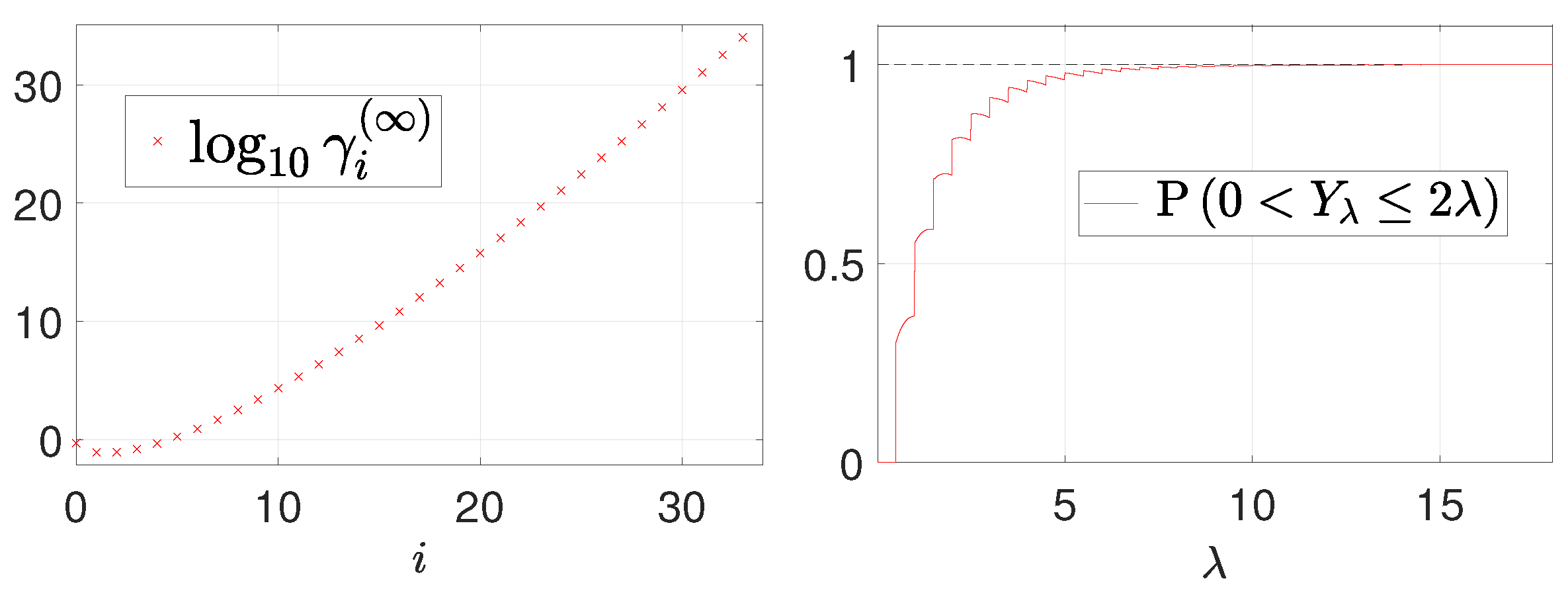
defining the central moments of a Poisson random variable). By means of the Matlab symbolic toolbox, we were able to compute the first 34 coefficients
,
, shown (in logarithmic scale) in
Figure 3 (left). Determining the subsequent coefficients becomes unfeasible due the huge computation time required. Hence, the following short discussion must be regarded as conjectural as it relies on the assumption that the behavior of coefficients
,
, can be smoothly extrapolated from the first 34 coefficients shown in
Figure 3 (left). These first 34 coefficients indicate that the coefficient sequence is positive and strictly increasing for
. This implies that making the truncation order
N tend to
, the (infinite) weighted geometric series in (26) is divergent for
. Even without analyzing the case
, we can state that an analytical form for function
in the low-count Poisson regime is very unlikely to be obtainable as the sum of the series in (26). In fact, there will be, very likely, at least one pixel such that
.
We believe that it is worth concluding this section by pointing out the theoretical reason for the non-convergence of the series in (26). Function
is analytical at
, but its Maclaurin series converges (pointwise to the function) only for
. Hence, as
N tends to
, the Taylor series expansion in (19) converges to the function
only for
. However,
in (20) represents a Poisson random variable with parameter
. Hence, for
N tending to
, the series in (20) converges to the function
only if the random variable
satisfies
From
Figure 3 (right), where we plot the probability in (28) as a function of
, one can notice that condition (28) for convergence of the series in (20) is fulfilled asymptotically for
approaching
but it is not satisfied at all for small
values.
3. A Nearly Exact DP Based on Monte Carlo Simulation
Since it is not possible to derive analytically the expression of function
in (17), the goal in this section is to compute a nearly exact estimate
of function
based on a simple Monte Carlo simulation approach analogous to that used at the beginning of
Section 2. Based on the expected shape of function
—see
Figure 2(left)—here, we consider a set of 1385 unevenly distributed
values
, namely
This set comes from the union of three subsets of equally spaced
values, namely from 0 to 6 with step
, from 6 to 66 with step
, and from 66 to 250 with step 1. For each
, we generate pseudo-randomly a very large number
of samples
,
, of the Poisson random variable
; then, we compute the associated values
,
, of the function
defined in (16) and, finally, we calculate the sample mean
and variance
of these function values. In formula,
Notation for the sample means come from them representing estimates of the sought theoretical means
,
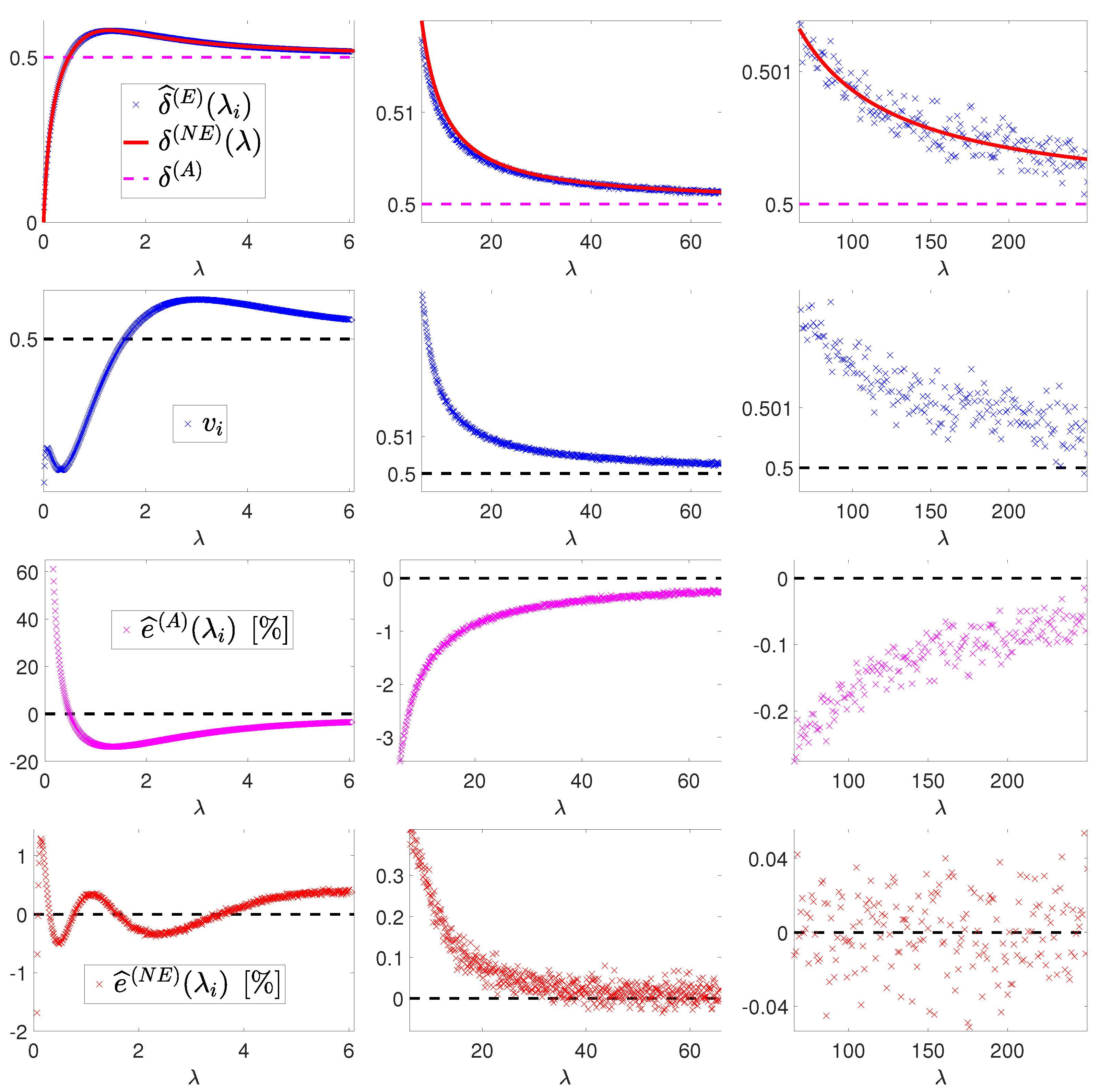
. The obtained values
and
are shown (blue crosses) in the first and second row of
Figure 4, respectively. It is well known that
and
represent unbiased estimators of the mean and standard deviation of the random variable
and that, according to the central limit theorem, for a very large number
S of samples (which is definitely our case), the sample mean
can be regarded as a realization of a Gaussian random variable with the theoretical mean
of the random variable
and the sample variance
divided by the number of samples
S. In formulas,
We now want to fit a parametric model
, with
the parameter vector, to the obtained Monte-Carlo-simulated data points
,
. First, in accordance with the trend of these data—see the blue crosses in the first row of
Figure 4—and recalling the expected asymptotic behavior of function
for
approaching
—see the discussion in
Section 2, particularly the first two terms of the expansion in (27)—we choose a model of the form
with function
exhibiting the following properties:
Then, with the aim of achieving a good trade-off between the model’s ability to accurately fit data and the computational efficiency of its evaluation, we choose the following rational form for function
:
Thanks to (30), fitting model
f in (31) with
as in (32) can be obtained via a Maximum Likelihood (ML) estimation of the parameter vector
. In fact, according to (30), the likelihood reads
and the ML estimate
of
can be computed as follows:
where we dropped constants (with respect to the optimization variable
) and defined
Problem (34) is a nonlinear (in particular, rational) weighted least-squares problem. The cost function is non-convex and local minimizers exist. We compute an estimate
of
by solving (34) via the iterative trust-region algorithm 1000 times starting from 1000 different initial guesses
randomly sampled from a uniform distribution with support
and then picking up the solution
yielding the minimum cost function value. The obtained parameter estimate is as follows:
We thus define the nearly exact estimate
of the theoretical expected value function
as the parametric function
defined in (31), (32) with parameter vector
equal to
given in (35). In formula,
In the first row of
Figure 4, we plot the constant approximate function
and the obtained nearly exact function
, whereas, in the third and fourth row of
Figure 4, we report the errors
and
, respectively. They are defined by
and represent the percentage errors associated with using the approximations
and
with respect to the very accurate Monte Carlo estimates
of the true underlying expected values
. One can notice that
is around 20 times smaller than
for
(first column of
Figure 4) and around 10 times less for
(second and third column
Figure 4). In particular, in the low-count Poisson regime (which we can roughly associate with
), the proposed nearly exact estimate of the theoretical expected value function
yields a percentage error in the order of
, whereas the constant approximation used in [
5,
7] leads to a percentage error in the order of
. Such a large error is the reason for the poor performance of the (15) in the low-count regime.
We thus propose the following nearly exact DP (NEDP):
with function
and parameter vector
given in (32) and (35), respectively.
4. Numerical Solution via ADMM
In the following, we detail how to tackle the minimization problem in (8) and (9) when the regularization parameter is automatically selected according to one of the considered versions of the DP, namely the TDP in (13), the ADP in (15), and the NEDP in (37).
In principle, one could set a fine grid of -values and compute the solution corresponding to each . Then, among the recorded solutions, one could select the one such that the TDP, the ADP, or the NEDP is satisfied. However, this algorithmic scheme, to which we refer as the a posteriori optimization procedure, turns out to be particularly costly.
In [
6,
14], the authors propose to update the regularization parameter according to the ADP along the iterations of the popular Alternating Direction Method of Multipliers (ADMM) [
15,
16]. Here, we detail the steps of the proposed algorithmic procedure, which can be employed for applying not only the ADP but also the TDP and the NEDP. Finally, we remark that the case of the TDP is only addressed for explanatory purposes and it cannot be performed in practice as
is not available.
After introducing the auxiliary variables
,
,
, problem (8) and (9) can be equivalently written as follows:
where, with a little abuse of notation, we define
, for every
.
To solve problem (38), we introduce the augmented Lagrangian function,
where
,
,
are the vectors of Lagrange multipliers associated with the linear constraints in (38), while
are the ADMM penalty parameters.
By setting
,
,
, and
, we observe that solving (38) amounts to seeking solutions of the saddle-point problem:
Upon suitable initialization, and for any
, the
k-th iteration of the ADMM algorithm applied to the solution of (40) with the augmented Lagrangian function
defined in (39) reads
In the following subsections, we discuss the solution of subproblems (41)–(44) for the four primal variables , , , . Since the solution of the subproblem for variable is the most complicated and requires the application of the DP, it is presented last.
4.1. Solving Subproblem for g
The subproblem for
in (42) reads
Solving (48) is equivalent to solving the
n independent two-dimensional minimization problems
which yields the unique solution
4.2. Solving Subproblem for z
The subproblem for
in (43) reads
Hence, the solution
is given by the unique Euclidean projection of vector
defined in (50) onto the (convex) nonnegative orthant and admits the simple closed-form expression
4.3. Solving Subproblem for
After dropping the constant terms, the
-subproblem in (44) reads:
By imposing a first-order optimality condition on the quadratic cost function in (52), after simple algebraic manipulations, we obtain the following linear system of equations:
which is solvable since the coefficient matrix is symmetric positive definite and hence nonsingular. When assuming periodic boundary conditions for
, the blur matrix
is square, i.e.,
, and, more importantly,
,
and—trivially—
are block circulant matrices with circulant blocks. Hence, the linear system (53) can be solved efficiently by one application of the direct 2D Fast Fourier Transform (FFT) and one application of the inverse 2D FFT, each at a cost of
.
4.4. Solving Subproblem for and Applying the DP
The subproblem for
in (41) reads
After manipulating algebraically the last two terms of the cost function in (54), dropping constant terms, and then dividing by the positive scalar
, problem (54) can be equivalently rewritten as follows:
In (55), we introduced the explicit dependence of the solution
on the parameter
, which is the basis of the application of the DP. Notice that the ADMM penalty parameter
is fixed; hence,
plays the role of the regularization parameter
in the DP applied to this subproblem. Problem (55) can be further simplified after noting that it can be equivalently rewritten in component-wise (pixel-wise) form as follows:
It is easy to prove that, for any
and independently of the constants
and
, all the minimization problems in (56) admit a unique solution given by
We now want to apply one among the DP versions—namely, (13), (15), and the proposed (37)—outlined in
Section 1 and
Section 3 for selecting a value of the free parameter
in (57). In particular, we select
such that
satisfies the discrepancy equation, which, in accordance with the general definition given in (10)–(12), takes here the form
where the discrepancy function reads
with function
F defined in (9), and where the discrepancy value
, according to the definitions given in (13), (15) and (37), takes one of the following values/forms:
with rational polynomial function
defined in (32) and parameter vector
given in (35). We notice that
and
are two positive scalars that can be computed once for all and do not change their values during the ADMM iterations, whereas
is a function of
, which almost certainly changes its shape along the ADMM iterations (due to function
in (57) changing its shape when vector
in (55) changes).
Summing up, the complete procedure for the DP-based update of the parameter
and, then, of the variable
reads as follows:
Concerning the ADP, in [
6], the authors have proven that along the ADMM iterations, the function
is convex and decreasing so that the existence and the uniqueness of the solution of the discrepancy equation in (58) with
is guaranteed. The same result can be immediately extended to the case of the TDP. When considering the NEDP, the functional form of
is such that the above result cannot be straightforwardly applied. However, the following proposition on the existence of a solution for the discrepancy equation (58) with
holds true.
Proposition 1. Consider the discrepancy equation in (58)–(60) with and with vector and function defined as in (55) and (57), respectively, and let Then, the discrepancy equation admits a solution if the following condition is fulfilled:where function is defined bywith function F, function ϵ, and parameter vector given in (9), (32), and (35), respectively. Proof. Since functions F in (9), in (32), and in (57) are all continuous, then the function G defined in (58)–(60) with is continuous in the variable on its entire domain , for any and any .
Then, it is easy to prove that function
in (57) satisfies
with vector
defined in (64).
It thus follows from (67) and from the definition of functions
in (59) and
in (60) that
and that
where function
in (68) is defined in (65), cancelling the first summation in (69) comes from
for any
(see the definition of function
F in (9), where
for
) and (70) comes from the definition of function
f in (36).
From (70) and the continuity of function , we can conclude that, for any , the discrepancy equation admits a solution if . It thus follows from (68) that the sufficient condition in (64)–(66) holds true. □
In Algorithm 1, we outline the general ADMM-based scheme used for solving image restoration variational models of the TV-KL form in (8) and (9) with automatic update/selection of the regularization parameter according to one of the considered versions of the DP. We refer to the general scheme as DP-ADMM, whereas the specific schemes using one among the DP versions TDP, ADP, and NEDP will be named TDP-ADMM, ADP-ADMM, and NEDP-ADMM, respectively. Notice that the -update at step 3 can be performed by means of a derivative-free approach, such as bisection or the secant method.
| Algorithm 1: General DP-ADMM approach for image restoration variational models of the TV-KL form in (8) and (9) and automatic selection of via DP. |
| inputs: observed degraded image , emission background , blur and regularization operators , |
| output: estimated restored image |
| 1. initialise: set |
| 2. for k = 0, 1, 2, until convergence do: |
| 3. compute | by (61) and (62) |
| 4. compute | by (63) |
| 5. compute | by (49) |
| 6. compute | by (51) |
| 7. compute | by (53) |
| 8. compute | by (45)–(47) |
| 9. end for |
| 10. |
5. Numerical Results
In this section, we evaluate the performance of the proposed NEDP in (37) for the automatic selection of the regularization parameter in image restoration variational models of the TV-KL form in (8) and (9).
Our approach is compared with the TDP and the ADP in (13) and (15), respectively. For each criterion, we perform the ADMM-based scheme outlined in Algorithm 1. As recalled in
Section 4, the
-selection problem along the ADMM iterations always admits a unique solution under the adoption of the ADP and TDP. Concerning the NEDP-ADMM, at the generic iteration
k of Algorithm 1, the regularization parameter
is updated provided that the condition stated in Proposition 1 is satisfied. If this is not the case, the parameter update is not performed and
.
The numerical tests have been designed with the following twofold aim:
- (i)
to prove that the proposed NEDP criterion is capable of selecting optimal values returning high-quality restoration results and, in particular, that it outperforms the classical ADP criterion in the low-count Poisson regime;
- (ii)
to prove that the proposed NEDP-ADMM scheme outlined in Algorithm 1 is capable of automatically selecting such optimal values in a robust (and efficient) manner.
More specifically, the latter point will be proven by showing that the iterated and the a posteriori version of our approach behave similarly in terms of -selection.
The -values selected by the TDP, the ADP, and the NEDP applied a posteriori will be denoted by , respectively, while the output -value of the ADP-ADMM and of the NEDP-ADMM scheme will be denoted by and , respectively.
The quality of the restorations
with respect to the original uncorrupted image
will be assessed by means of two scalar measures, namely the Structural Similarity Index (SSIM) [
17] and the Improved-Signal-to-Noise Ratio (ISNR), defined by
For all tests, the iterations of the ADMM-based scheme in Algorithm 1 are stopped as soon as
and the ADMM penalty parameters
are set manually so as to achieve fast convergence. More precisely, in each test, the same triplet
of ADMM penalty parameters is used for the three compared discrepancy principles TDP, ADP, and NEDP, with
.
We consider the four test images, each with pixel values between 0 and 1, shown in
Figure 5. The acquisition process (
1) has been simulated as follows. First, the original image is multiplied by a factor
representing the maximum emitted photon count, i.e., the maximum expected value of the number of photons emitted by the scene and hitting the image domain. Clearly, the lower
, the lower the SNR of the observed noisy image and the more difficult the image restoration problem. For each image, several values
ranging from 3 to 1000 have been considered. Then, the resulting images have been corrupted by space-invariant Gaussian blur, with a blur kernel generated by the Matlab routine
fspecial, which is characterized by two parameters, namely the
band parameter, representing the side length (in pixels) of the square support of the kernel, and
sigma, which is the standard deviation (in pixels) of the isotropic bivariate Gaussian distribution defining the kernel in the continuous setting. We consider two different blur levels characterized by the parameters
band = 5,
sigma = 1 and
band = 13,
sigma = 3. The blurred noiseless image
is then generated by adding to the blurred image a constant emission background
of value
. The observed image
is finally obtained by pseudo-randomly generating an
m-variate independent Poisson realization with mean vector
.
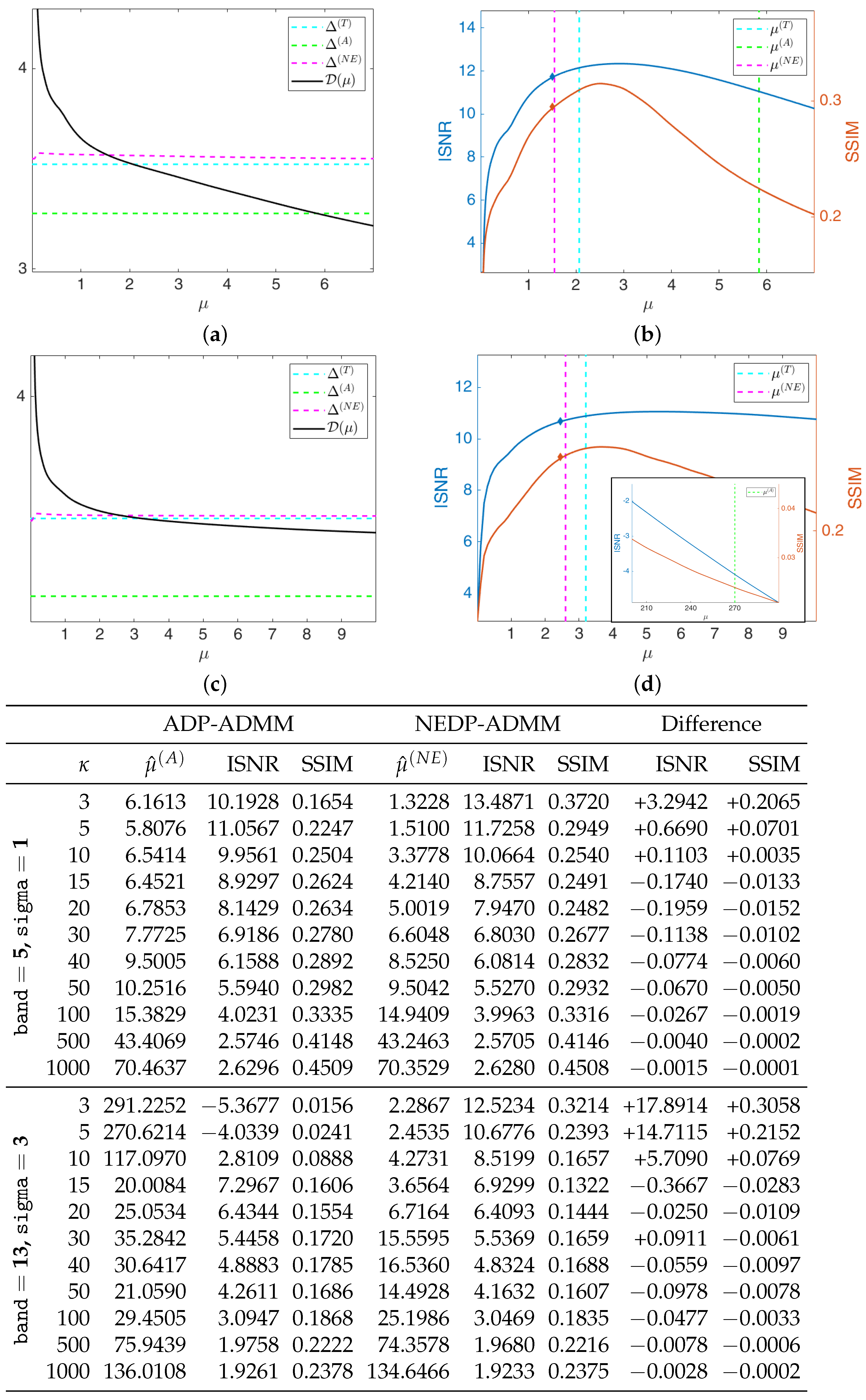
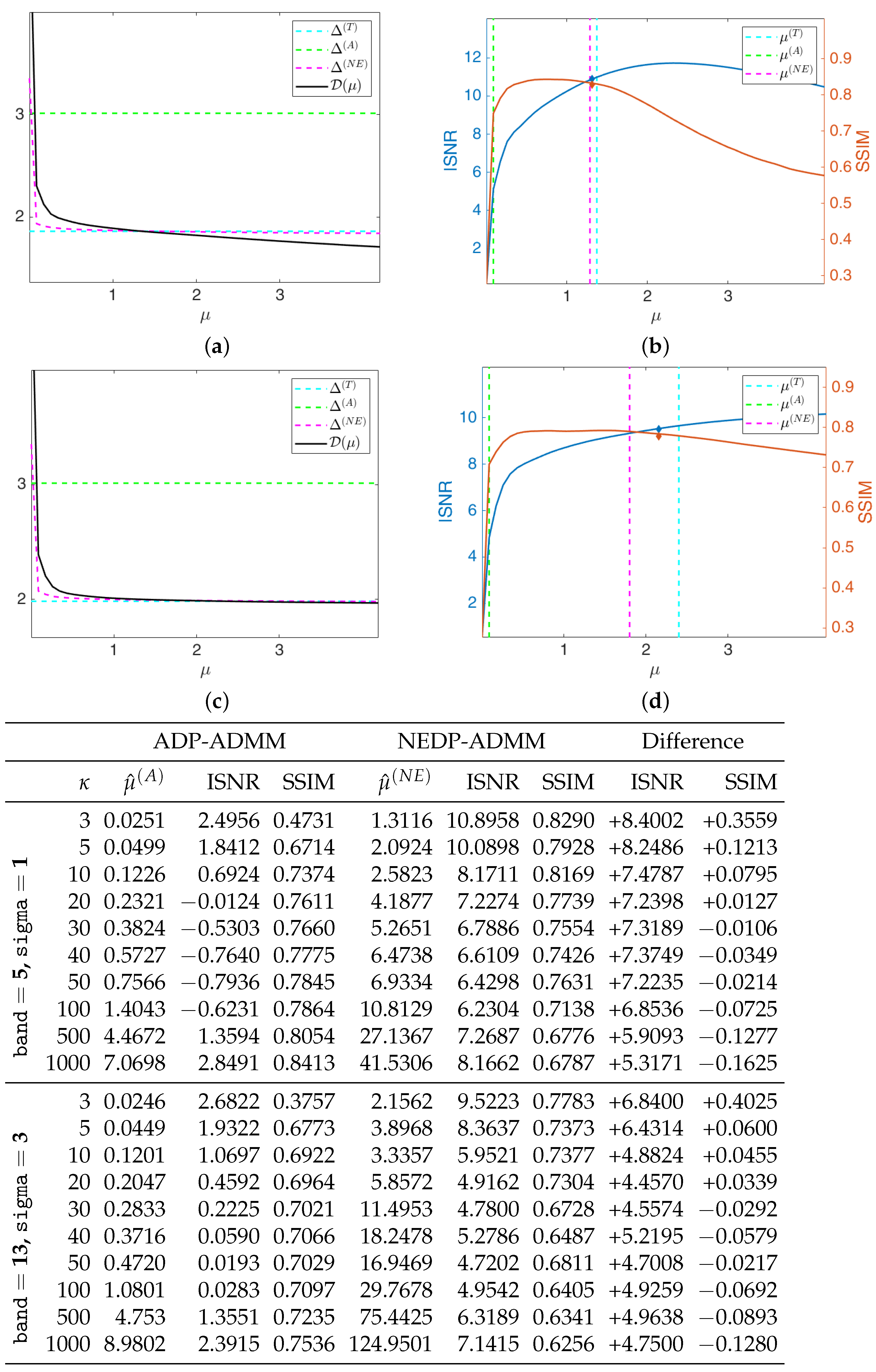
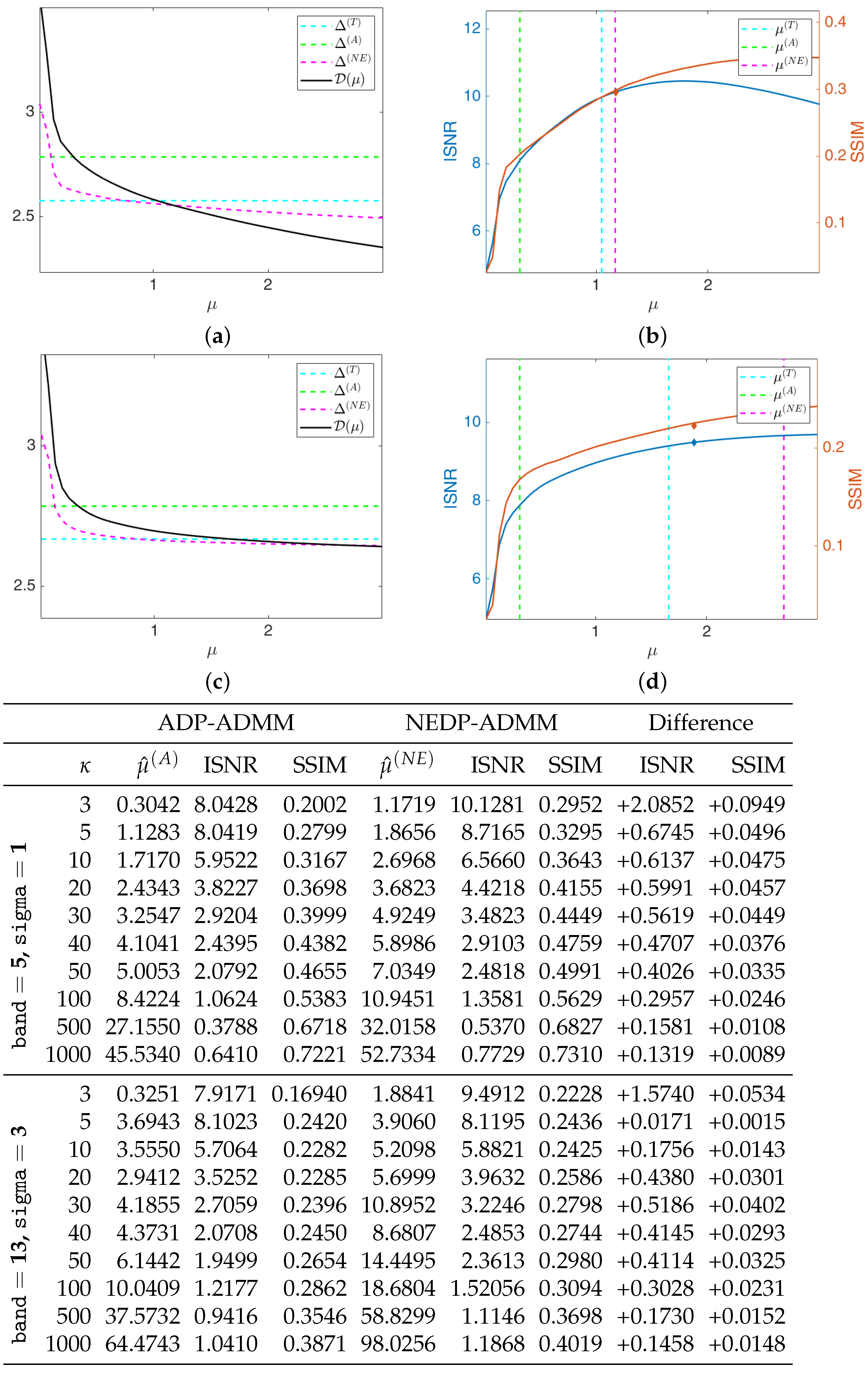
The black solid curves plotted in
Figure 6a,c represent the function
as defined in (11) and (12) for the first test image
cameraman and
, for the less severe (first row) and more severe (second row) blur level. They have been computed by solving the TV-KL model in (8) for a fine grid of different
-values, and then calculating
for each
. The horizontal dashed cyan and green lines represent the constant discrepancy values
and
used in (13) and (15), respectively, while the dashed magenta curve represents the discrepancy value function
defined in (37). We remark that
has been obtained in the same way as
, i.e., by computing the expression in (37) for each
of the selected fine grid. One can clearly observe that the intersection points between the curve
and the function
and between the line representing
and
are very close, and both at a significant distance from the intersection point detected by
.
In
Figure 6b,d, we show the INSR and SSIM values achieved for different
-values with
. The vertical cyan, green, and magenta lines correspond to the
-values detected by the intersection of
and
,
,
, respectively. As a reflection of the behavior of the discrepancy function and of the three curves, the ISNR/SSIM corresponding to
and
are very close to each other and almost reach the maximum of the two curves. We also highlight that, when considering the more severe blur case, the ADP selects a very large
-value, which returns very low ISNR and SSIM values—see the thumbnail image in the right-hand corner of
Figure 6d.
We are also interested in verifying that the proposed NEDP-ADMM scheme outlined in Algorithm 1 succeeds in automatically selecting such optimal
in a robust and efficient way: the blue and red markers in
Figure 6b,d represent the final ISNR and SSIM values, respectively, of the image restored via NEDP-ADMM. Clearly, the markers are plotted in correspondence of
, which is, as we recall, the output
-value of the iterative scheme NEDP-ADMM; one can clearly observe that
is very close to the optimal
detected
a posteriori by the NEDP.
As a further analysis, at the bottom of
Figure 6, we report the output
-values, the ISNR and the SSIM values for the two blur levels, and the 11
-values considered to be obtained by the ADP-ADMM (first column) and the NEDP-ADMM (second column). To facilitate the comparison, we also report in blue/red the increments/decrements of the ISNR and SSIM achieved by our method with respect to the approximate criterion. Notice that the NEDP outperforms the ADP both in terms of ISNR and SSIM for the low-count acquisitions. However, when the
increases, the two methods behave very similarly, with the ISNR and SSIM values obtained by the ADP-ADMM being slightly larger than those obtained by the NEDP-ADMM. In accordance with this analysis, the output
and
are significantly different in low-count regimes, similar in mid-count regimes, and particularly close in high-count regimes. Notice that this behavior can be easily explained in light of the analysis carried out in
Section 2, where we have shown that the approximation provided by
becomes more and more accurate as the number of pixels with large values increases.
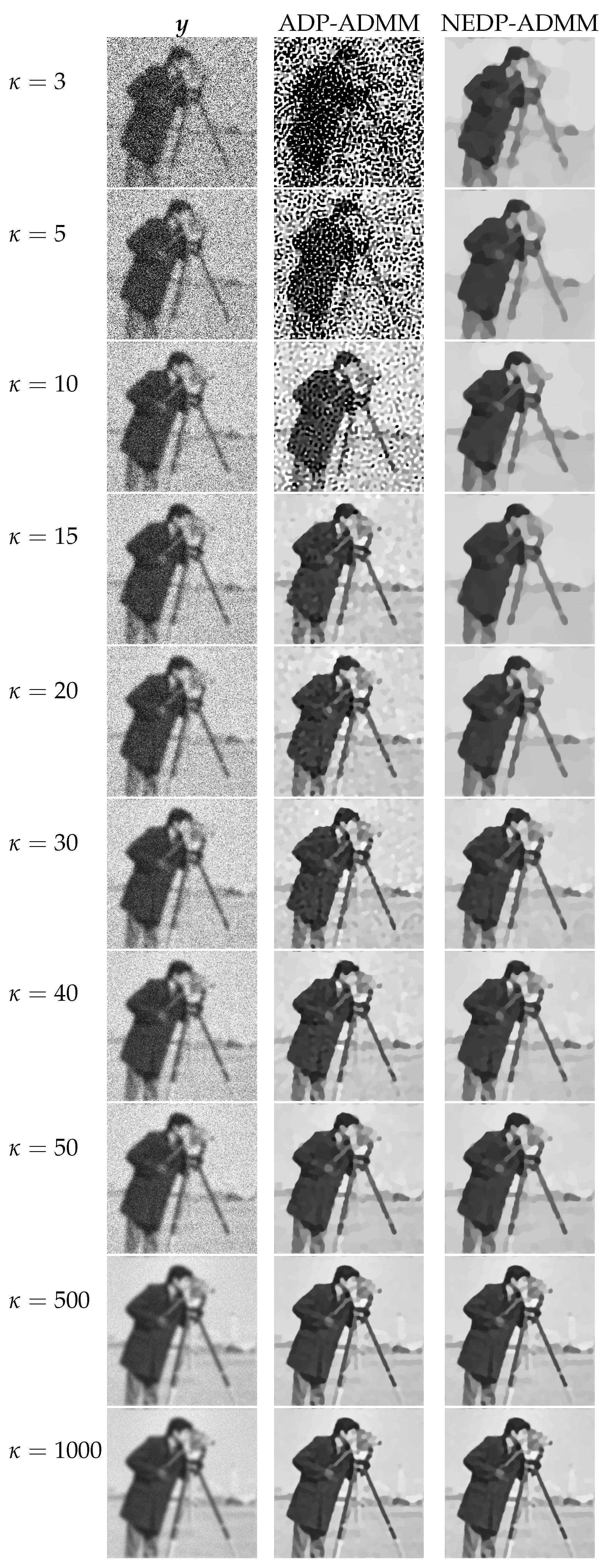
For a visual comparison, in
Figure 7 and
Figure 8, we show the observed images (left column), the restorations via ADP-ADMM (middle column) and via NEDP-ADMM (right column) for the less and more severe blur level, respectively, and when different photon count regimes, ranging from very low to very high, are considered. As already observed from the ISNR and SSIM values reported at the bottom of
Figure 6, we notice that for low-count acquisitions, the
-value selected by the ADP does not allow for a proper regularization, so that NEDP-ADMM clearly outperforms the competitor. However, starting from
—for the first blur level—and from
—for the second blur level—the two approaches return similar output images.
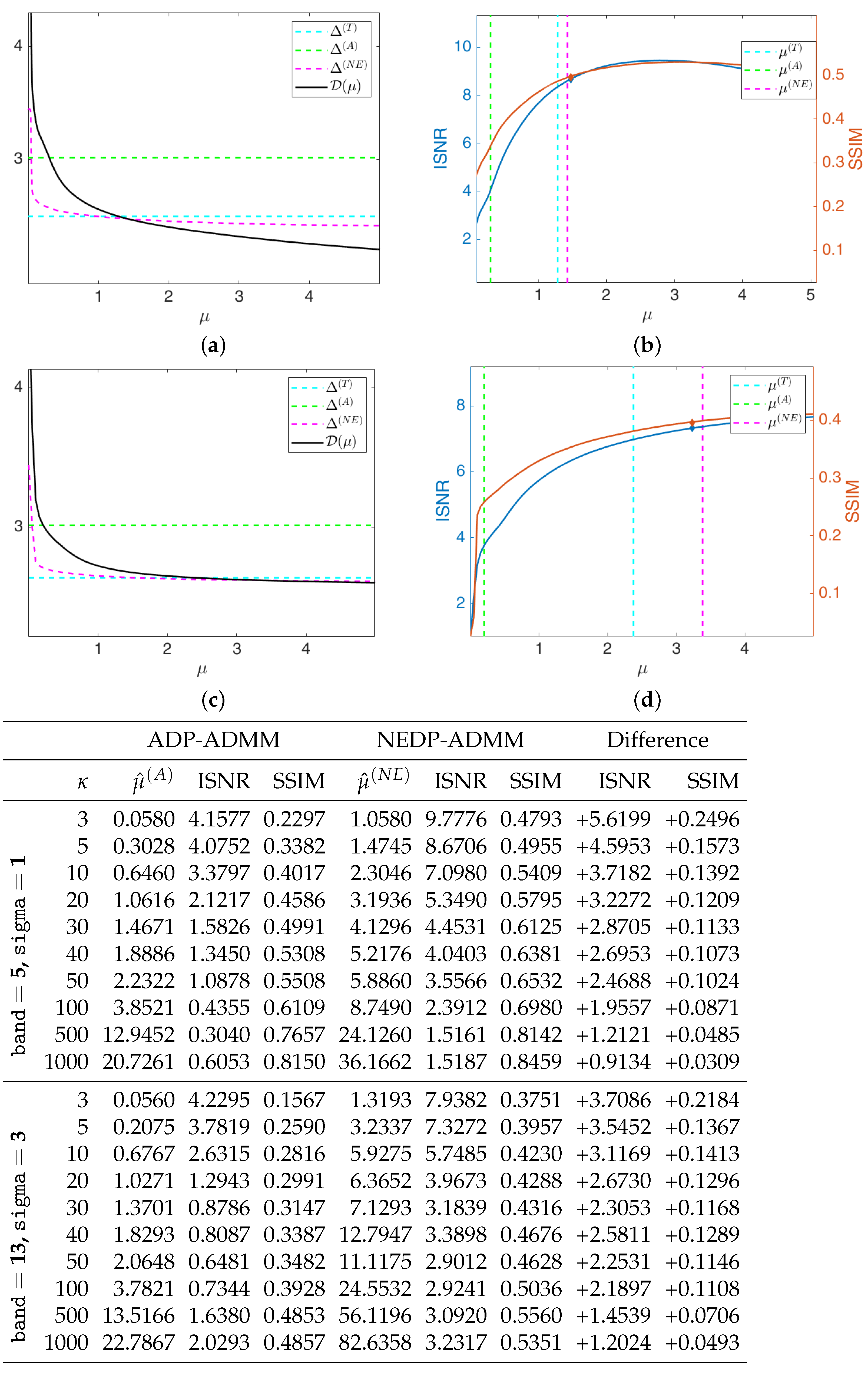
For the second test image,
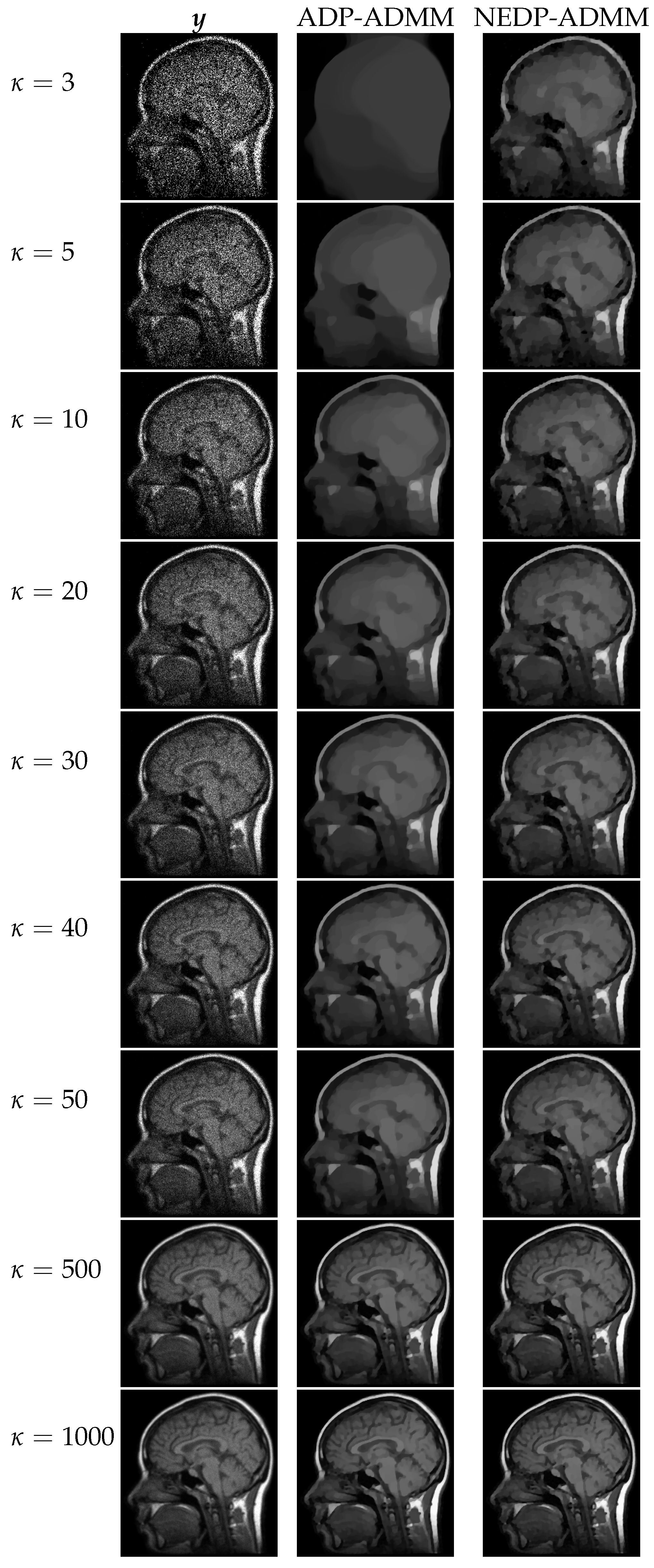
brain, we report in
Figure 9 the behavior of the discrepancy function
and of the ISNR/SSIM curves obtained by applying the TDP, the ADP, and the NEDP, for
and for the two considered blur levels. In addition, in this case, the NEDP and the TDP behave similarly and they almost achieve the maximum of the ISNR and of the SSIM curves. In contrast,
appears to be largely underestimated with respect to the optimal
—which can be intended as the one maximizing either the ISNR or the SSIM. As for the first test image, the blue and red markers, indicating the output ISNR and SSIM, respectively, of the iterated version of our approach, are very close to the ones achieved by applying the NEDP
a posteriori, suggesting that also
and
are very close.
From the table reported at the bottom of
Figure 9, we observe that the proposed
-selection criterion, for every
, returns restored images outperforming the ones achieved via the ADP both in terms of ISNR and SSIM. The poor behavior of the ADP can be related to the nature of the processed image, which, either for the low-count or high-count acquisitions, presents few pixels with large values so that the approximation in (15) is particularly inaccurate. As a signal of this, note that the output
is always smaller—or significantly smaller—than
.
The restored images in
Figure 10 and
Figure 11 reflect the values recorded in the table as, for the two considered blur levels, the output of the NEDP-ADDM appears to be remarkably sharper than the final restoration by ADP-ADMM, especially in low- and mid-count regimes.
In
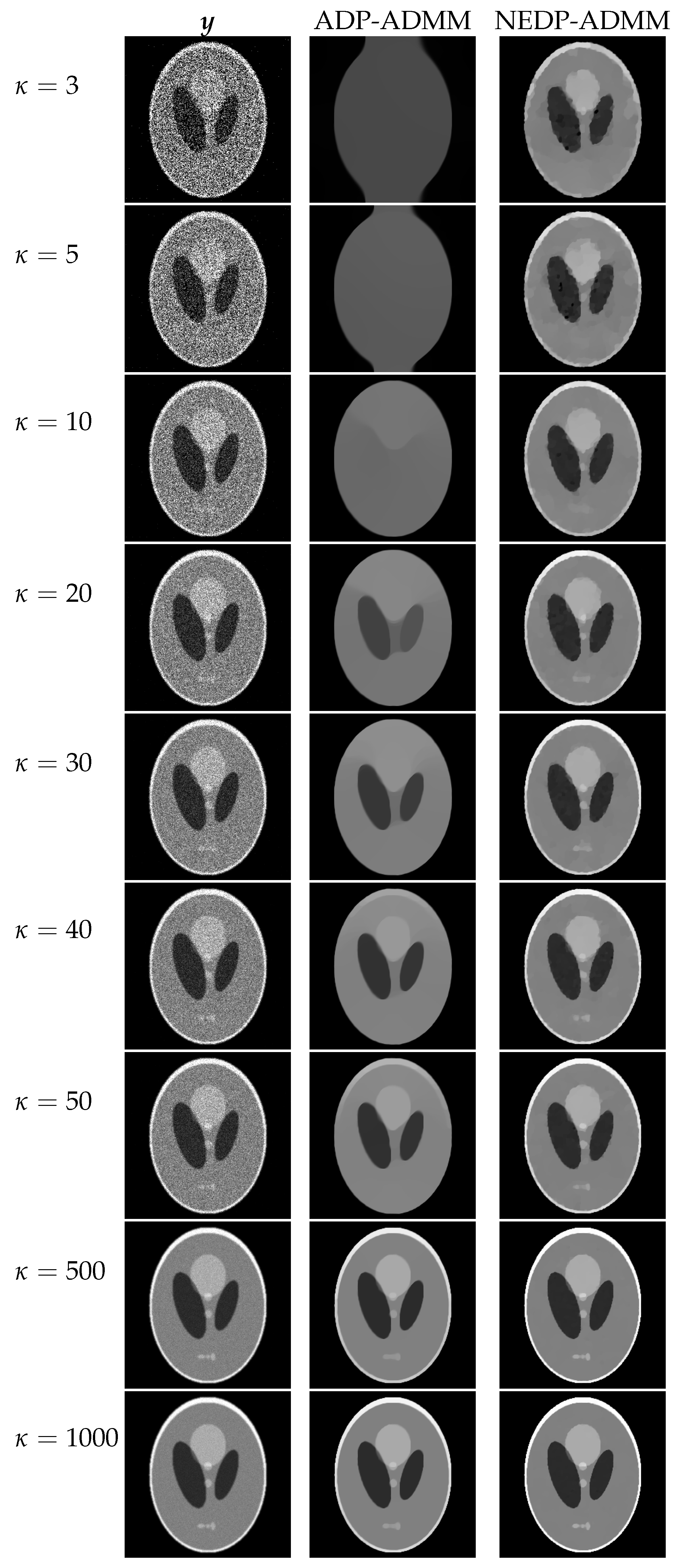
Figure 12, for the test image
phantom, we report the curve of the discrepancy function
obtained
a posteriori, as well as the curves of the ISNR and of the SSIM for
and the two blur levels considered. As for the test image
brain, in this case, the ADP also selects a
-value that is far from the optimal one, either if measured in terms of ISNR or SSIM. On the other hand,
and
are very close and, in particular, one can notice that the output of the NEDP-ADMM represents the optimal compromise in terms of ISNR and SSIM. Notice also that, when considering the larger blur level, the output value
of the NEDP-ADMM, detected by the red and blue markers, is larger than the one selected by the
a posteriori version of the NEDP. However, the difference in terms of ISNR and SSIM is not particularly significant. This behavior is due to the use of different penalty parameters
in the ADMM for the
a posteriori and the iterated version of our approach. In fact, when considering a large blur level, the convergence of the ADMM is particularly slow and can be achieved upon suitable selection of the penalty parameters, whose values may not coincide in the two scenarios addressed.
The mismatch observed in
Figure 12 between the curves of the ISNR and of the SSIM is reflected in the values reported in the bottom part of the figure, whence we can conclude that the NEDP-ADMM outperforms the ADP-ADMM in terms of ISNR for each
-value, while the ADP-ADMM returns slightly better results in terms of SSIM for high-count acquisitions. As for the test image
brain, in this case, the output
also appears to be significantly small. Once again, this behavior can be related to the considered image, which is mostly characterized by pixels with very small values.
From the restorations shown in
Figure 13 and
Figure 14, one can also notice that the slight improvement in terms of SSIM does not correspond to any significant visual improvements. In fact, along the whole range of considered photon counts
, the NEDP-ADMM is capable of returning sharper restorations. This reflects the tendency of ADP-ADMM applied on the current test image in selecting not sufficiently large
-values, so that, in the TV-KL, the regularization term takes over. We also remark that for the current test image, the SSIM value does not seem to be particularly meaningful.
For the fourth and final test image,
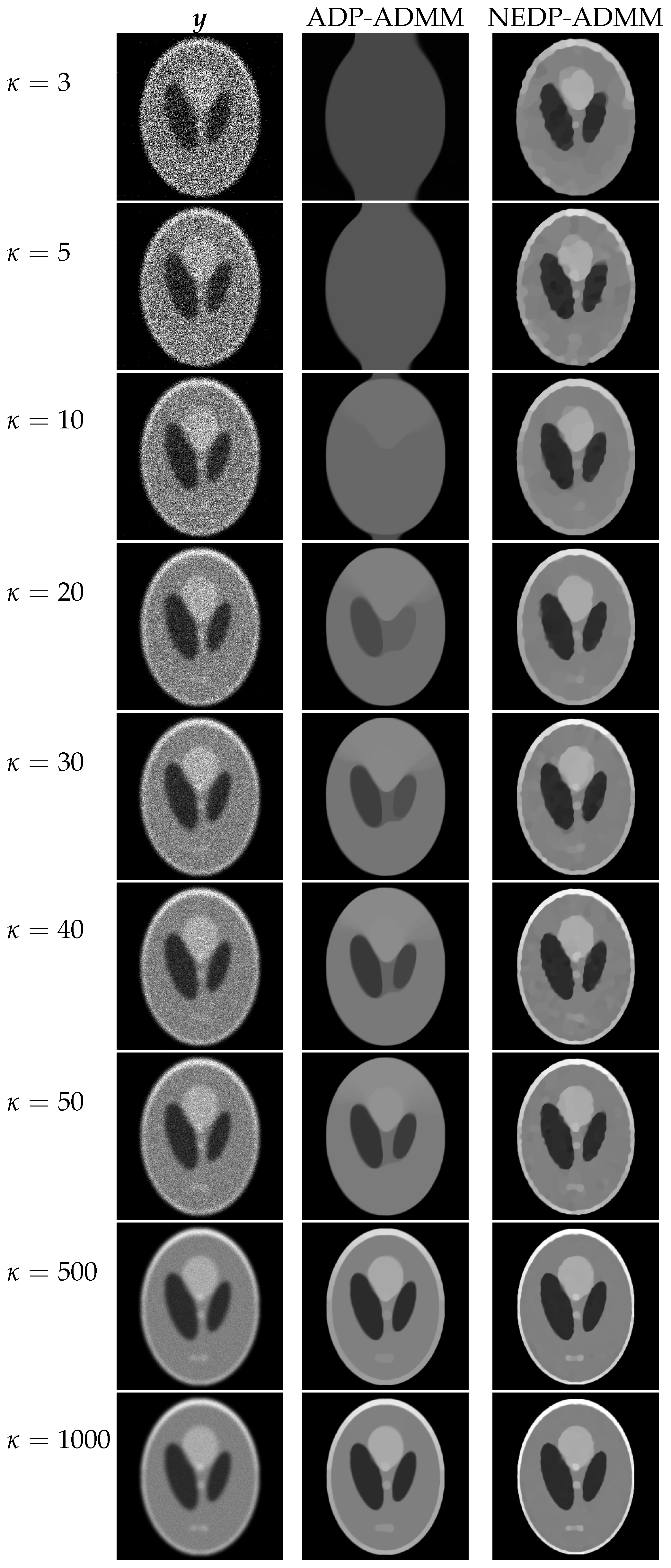
cells, we show in
Figure 15 the behavior of the discrepancy function
, as well as of the ISNR and SSIM values in the
a posteriori framework for the two blur levels and
. Note that, in the
a posteriori setting, for both blur levels, the NEDP achieves higher ISNR and SSIM values when compared to the ADP. However, we observe that when considering the larger blur level, the output
of the NEDP-ADMM is smaller than
; this behavior can be ascribed, once again, to the ADMM convergence issues and the different values selected for the penalty parameters.
From the values reported in the bottom part of
Figure 15, we notice that the NEDP-ADMM outperforms the ADP-ADMM in every photon count regime. Clearly, the closer
and
, the smaller the difference in terms of ISNR and SSIM.
The restorations computed by the ADP-ADMM and the NEDP-ADMM are shown in
Figure 16 for the smaller blur level and in
Figure 17 for the larger one. The obtained results confirm the values reported in the bottom of
Figure 15. Moreover, also from a visual viewpoint, the difference between the two performances increases when going from high- to low-count regimes.



{kind=link}
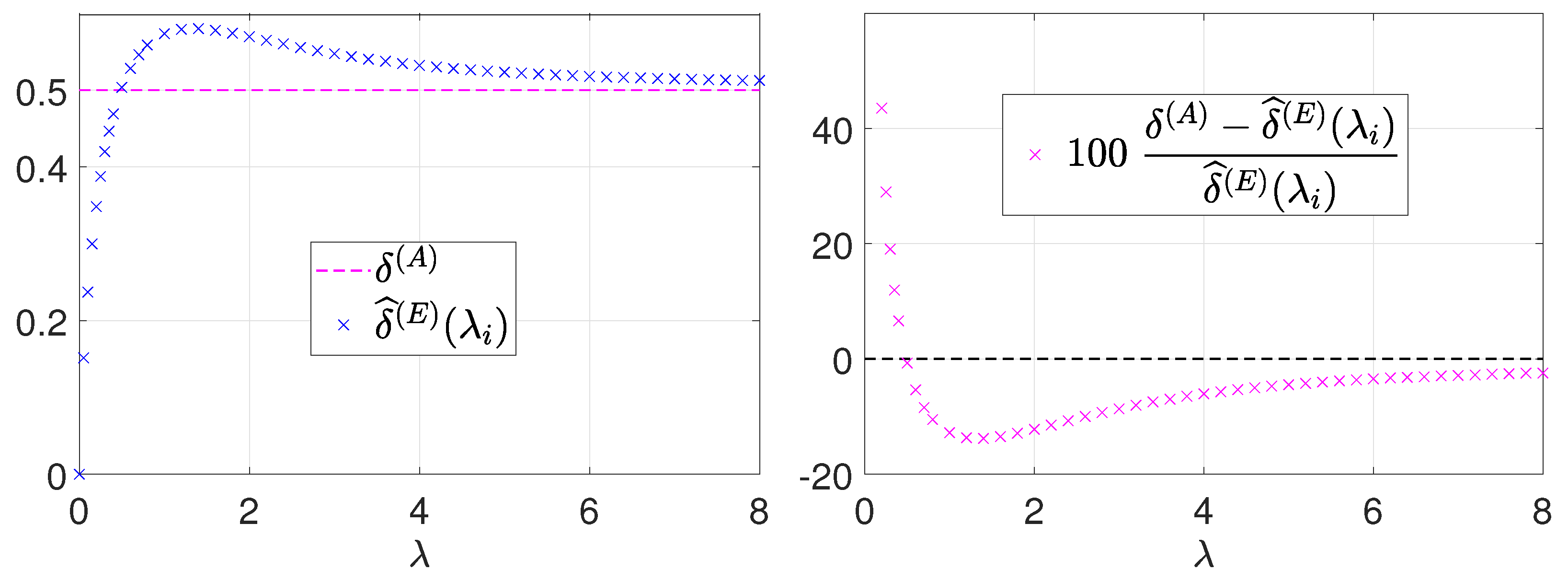{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
















