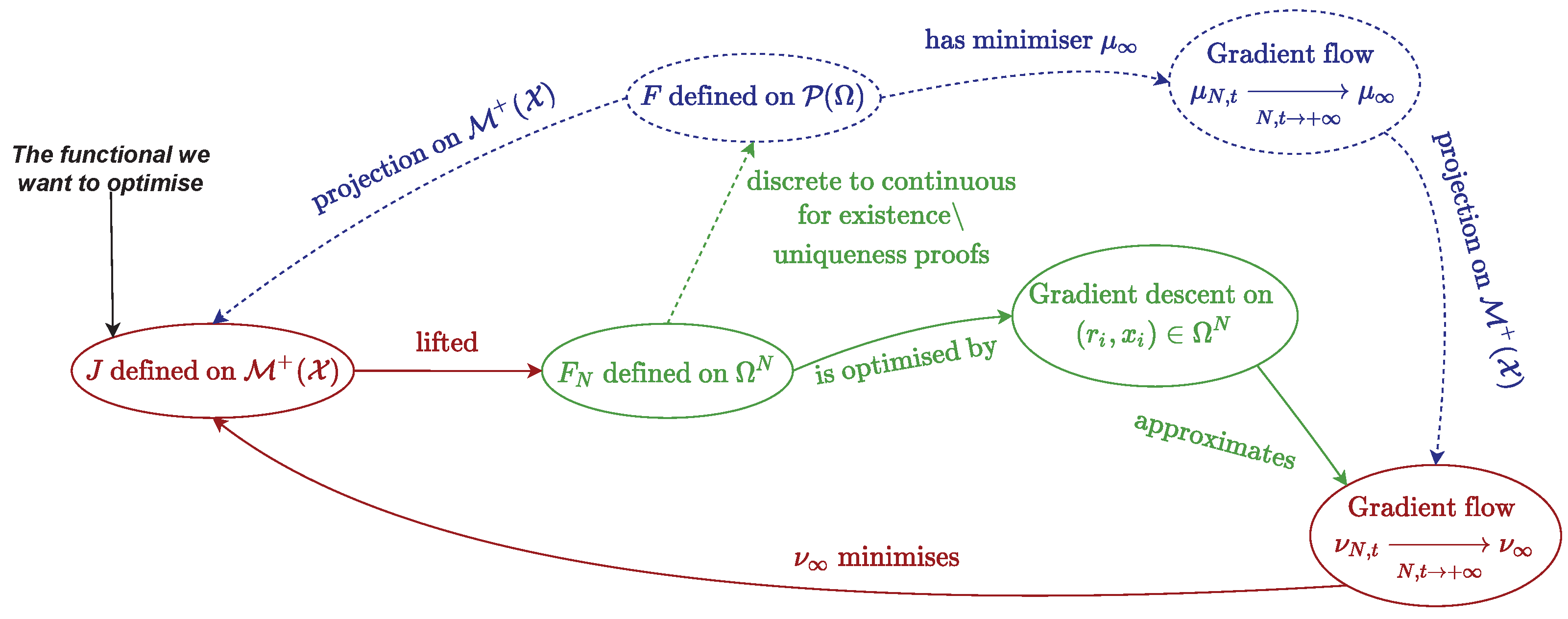
All the following results are proven for a domain
with no boundaries, e.g., the
d-dimensional torus
. The case described in the former sections—
is any compact of
—is included in this new setting, since any compact
can be periodised to yield a domain with no boundaries. The forward operator kernel
should also be differentiable in the Fréchet sense. The least squares term in BLASSO is denoted by the more general data term
, the functional
of the BLASSO will now be restricted to
and denoted
J; its Fréchet differential at point
is denoted
:
Sparse optimisation on measures through optimal transport [
3,
23] relies on the approximation of the ground-truth positive measure
by a ‘system of
particles’, i.e., an element of the space
. The point is then to estimate the ground-truth measure by a gradient-based optimisation on the objective function:
where
belongs to the lifted space
endowed with a metric. Hence, the hope is that the gradient descent on
converges to the amplitudes and the positions of the ground-truth measure, despite the non-convexity of functional (7). The author of [
23] proposes the definition of a suitable metric for the gradient of
, which enables separation of the variables in the gradient descent update. Let
be two parameters such that
and
and for any
, we define the Riemannian inner product of
called the
cone metric endowing
as defined by
,
:
3.3.1. Theoretical Results
The main idea of these papers [
3,
23] boils down to the following observation: the minimisation of function (7) is a peculiar case of a more general problem, formulated in terms of measure of the lifted space
. The space is more precisely
subset of
, namely the space of probabilities with finite second moments endowed with the 2-Wasserstein metric i.e., the optimal transport distance: see
Appendix B.5 for more details. Hence, the lift of the unknown
to
enables the removal of the asymmetry for discrete measures between position
and amplitude
by lifting
to
. The lifted functional now writes down for parameter
:
where
for
and
is the TV-norm on the spatial component of the measure
. The functional is non-convex, its Fréchet differential is denoted
, and for
:
with
. Then, a discrete measure
of
can also be seen as an element of
from the standpoint of its components
. It allows the authors of [
3,
23] to perform a precise characterisation of the source recovery conditions, through the measures and the tools of optimal transport such as gradient flow (see below).
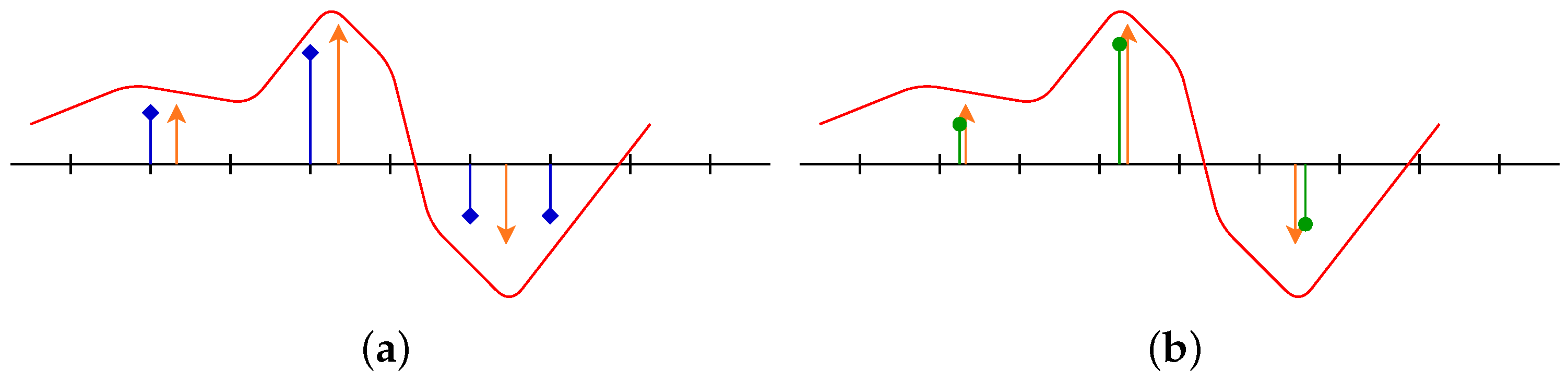
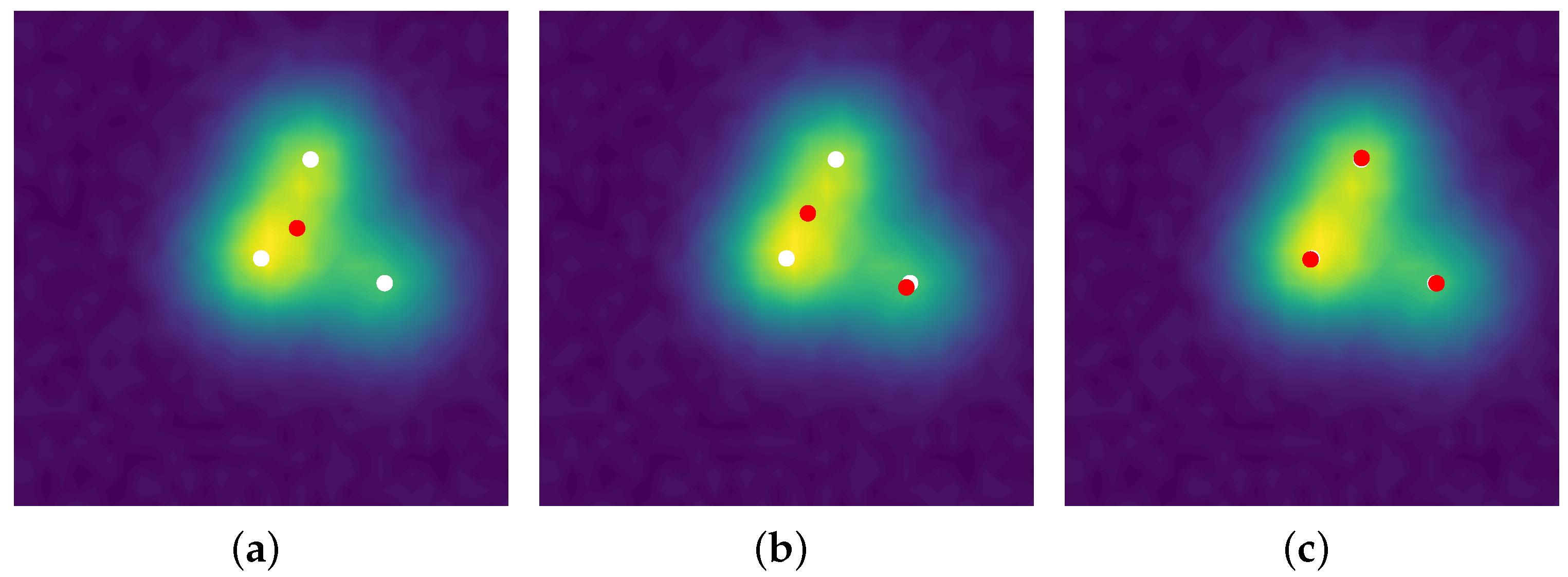
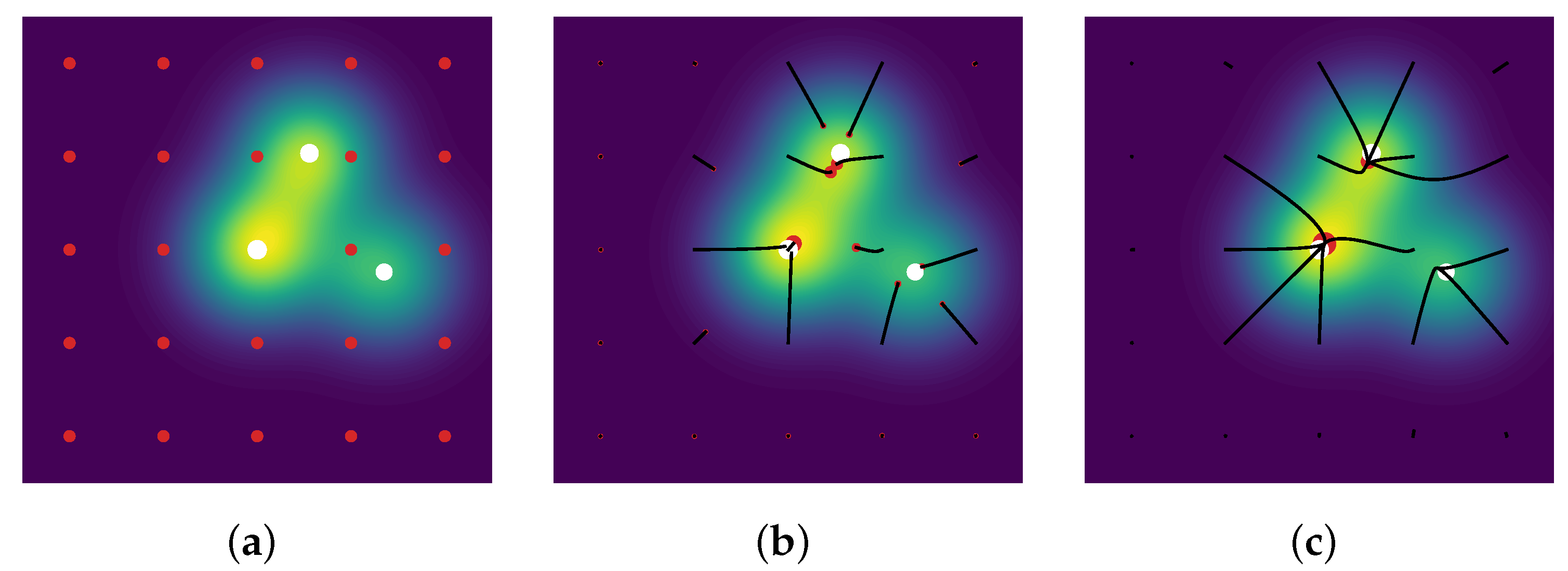
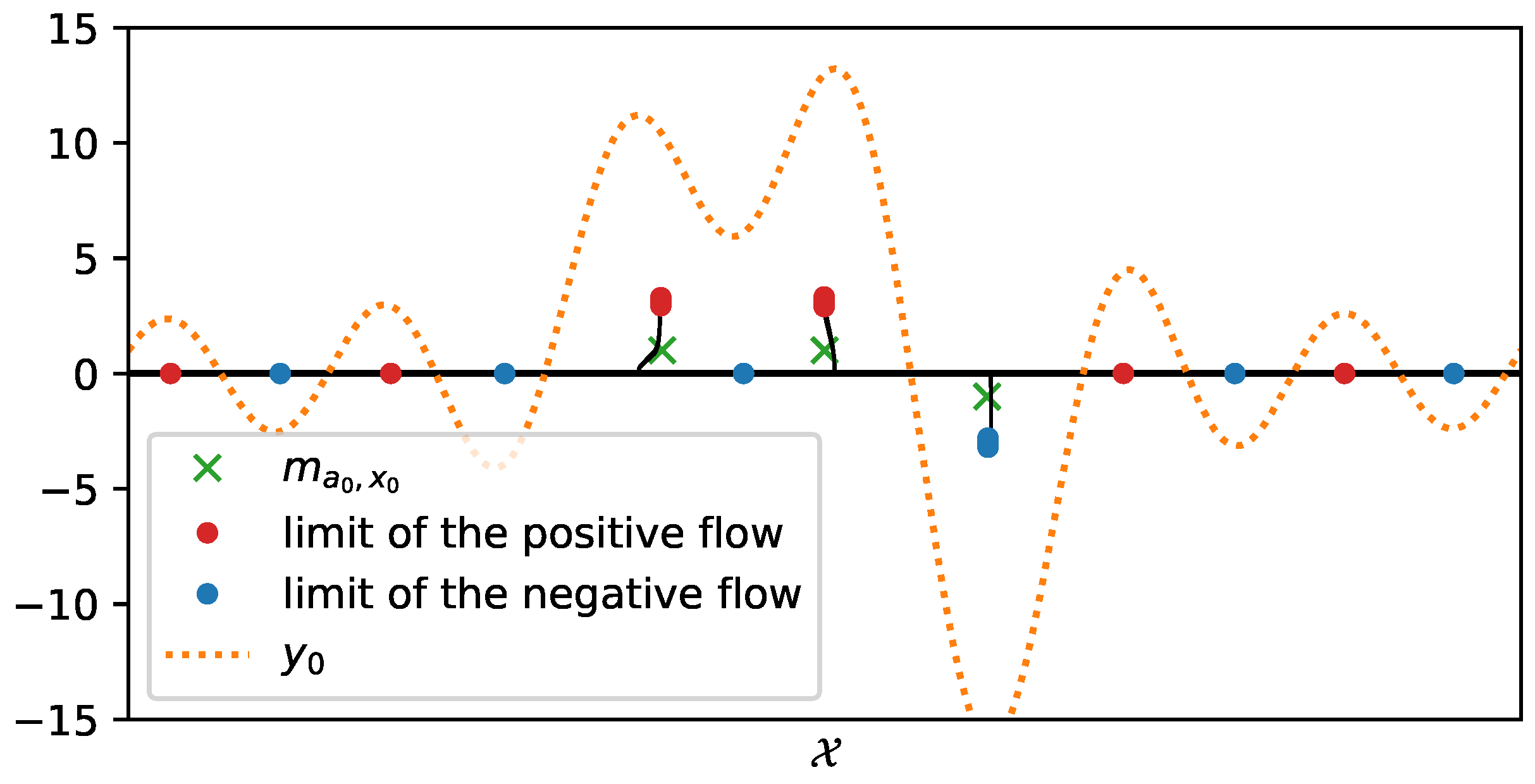
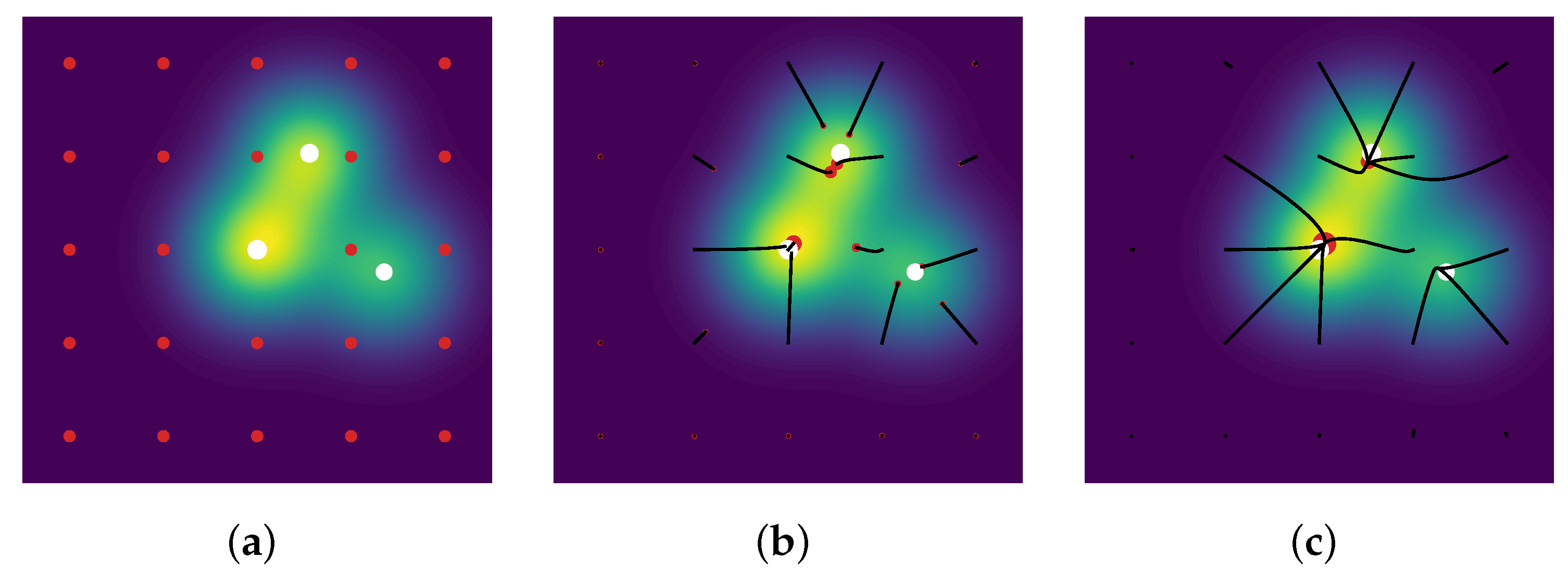
Then, one may run a gradient descent on the amplitudes and positions of the measure , in order to exploit the differentiability of the kernel . Note that the measure is over-parametrized, i.e., its number of -peaks is larger compared to the number of spikes of the ground-truth measure: thus, the particles, namely the -peaks of the space , are covering the domain for their spatial part.as an example, where is plotted in red dots.
Before giving the main results, we need to clarify the generalised notion of gradient descent to measure function called the
gradient flow [
35,
36] from optimal transport theory, the main ingredient in the particle gradient descent. Letting
be the objective function with certain regularity, a gradient flow describes the evolution of a curve
such that its starting point at
is
, evolving by choosing at any time
t in the direction that decreases the function
F the most [
36]:
The interest of gradient flow is its extension to spaces
X with no differentiable structure. In the differentiable case, one can consider the discretisation of the gradient flow i.e., the sequence defined for a step-size
,
:
It is the implicit Euler scheme for the equation
, or the weaker
if
F is convex and non-smooth. The gradient flow is then the limit (under certain hypotheses) of the sequence
for
for a starting point
. Gradient flow can be extended to metric space: indeed, for a metric space
and a map
lower semi-continuous one can define the discretisation of gradient flow by the sequence
In the case of the metric space of probability measures i.e., the measures with unitary mass, the limit
of the scheme exists and converges to the unique gradient flow starting at
element of the metric space. A typical case is the space of probabilities with finite second moments
, endowed with 2-Wasserstein metric, i.e., the optimal transport distance (see
Appendix B.5): a gradient flow in this space
is a curve
called a
Wasserstein gradient flow starting at
, for all
, one has
, obeying the partial differential equation in the sense of distributions:
Recall that for all , derivatives ought to be understood in the distributional sense. This equation ensures the conservation of the mass, namely, at each time , one has . Hence, despite the lack of differentiability structure of which forbids straightforward application of a classical gradient-based algorithm, one can perform an optimisation on the space through gradient flow to reach a minimum of F by discretizing (11).
The interesting case of a gradient flow in is the flow starting at , uniquely defined by Equation (11), which writes down for all : , where and are continuous maps. This path is a Wasserstein gradient flow, and uses N Dirac measures over to optimise the objective function F in (9). When the number of particles N goes to infinity and if converges to some , the gradient flow converges to the unique Wasserstein gradient flow of F starting from , described by the time-dependent density valued in obeying the latter partial differential Equation (11).
For these non-convex gradient flows, the authors of [
3] give a consistent result for gradient based optimisation methods: under a certain hypothesis, the gradient flow
converges to global
minima in the over-parametrization limit i.e., for
. It relies on two important assumptions that prevent the optimisation from being blocked in non-optimal points:
We can then introduce the fundamental result for the many particle limits [
3], the mean-field limits of gradient flows
, despite the lack of convexity of these gradient flows:
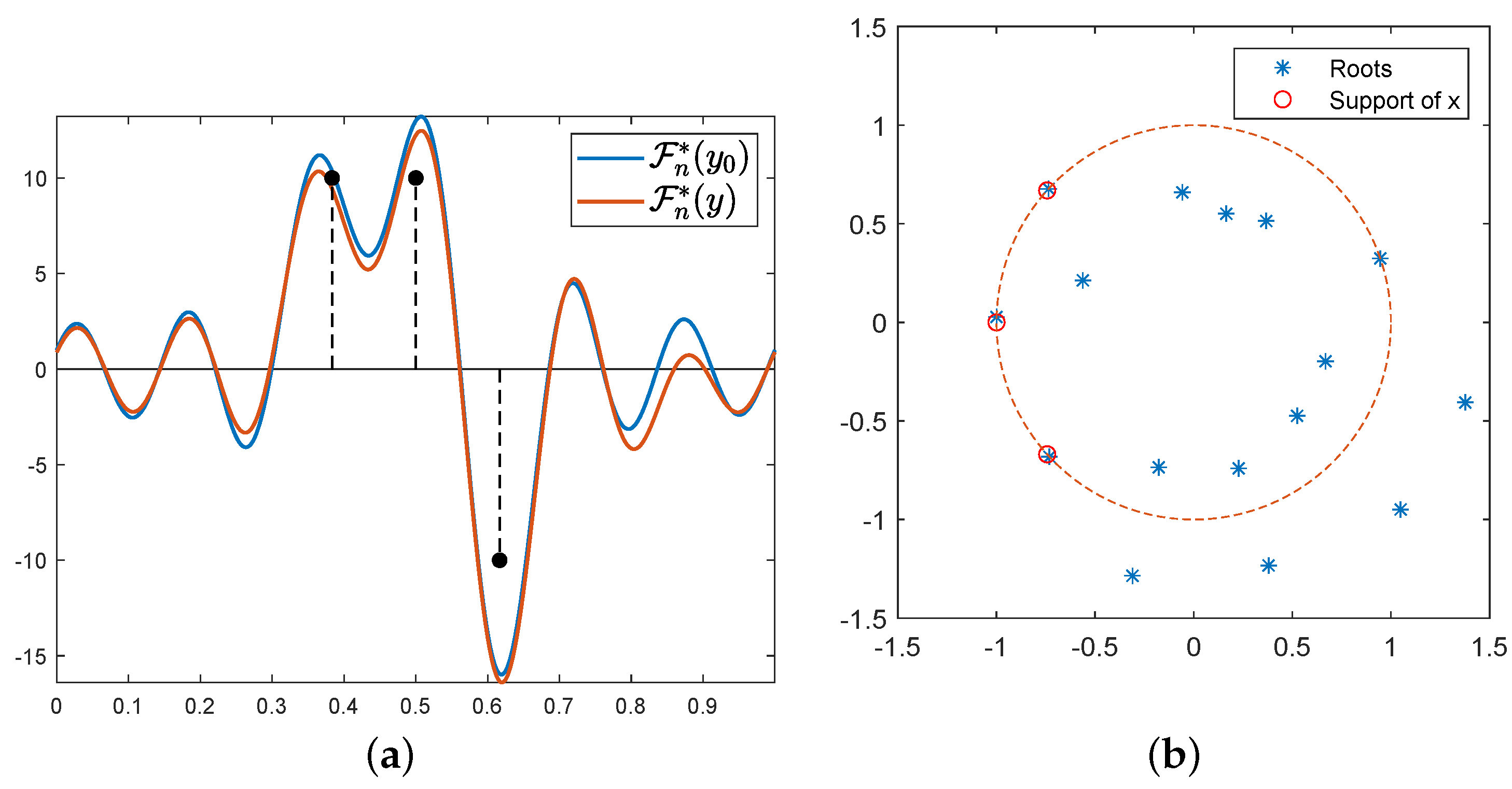
Theorem 2 (Global convergence—informal).If the initialisation is such that support separates (The support of a measure m is the complement of the largest open set on which m vanishes. In an ambient space , we say that a set C separates the sets A and B if any continuous path in with endpoints in A and B intersects C.) from then the gradient flow weakly-* (see Appendix B.1) converges in to a global minimum
of F, and we also have: Limits can be interchanged; the interested reader might take a look at [
3] for precise statements and exact hypothesis (boundary conditions, ‘Sard-type’ regularity e.g.,
is
d-times continuously differentiable, etc).
Since we have a convergence result, we can then investigate the numerical implementation. This optimisation problem is tractable thanks to the Conic Particle Gradient Descent algorithm [
23] denoted CPGD: the proposed framework involves a slightly different gradient flow
defined through a projection of
onto
. This new gradient flow
is defined for a specific metric in
, which is now a trade-off between Wasserstein and Fisher–Rao (also called Hellinger metric.) metric [
23], it is then called a
Wasserstein–Fisher–Rao gradient flow. Then, the Wasserstein–Fisher–Rao gradient flow starting at
in
writes down
in
, rather than the Wasserstein flow
starting at
in
. The partial differential equation of a Wasserstein–Fisher–Rao flow writes down:
for the two parameters
arising from the cone metric,
tunes the Fisher–Rao metric weight, while
tunes the Wasserstein metric one. All statements on convergence could be made alternatively on
or
, and we have indeed the same theorem:
Theorem 3 (Global convergence—informal).If has full support (its support is the whole set ) and converges for , then the limit is a global minimum
of J. If in the weak-* sense, then: Summary (3rd algorithm theoretical aspects): we introduced the proposed solution of [3,23], namely approximating the source measure by a discrete non-convex objective function of amplitudes and positions. The analytical study of the discrete function is an uphill problem and could be tackled thanks to the recast of the problem in the space of measures. Then, we exhibited the theoretical framework on gradient flows, understood in the sense of generalisation of gradient descent in the space of measures. Eventually, we presented the convergence results of the gradient flow denoted towards the minimum of the BLASSO, thus enabling results for the convergence. Gradient descent on the discrete objective approximates well the gradient flow dynamic and can then benefit from the convergence results exhibited before. We now discuss the numerical results of the particle gradient descent. The reader is advised to take a look at
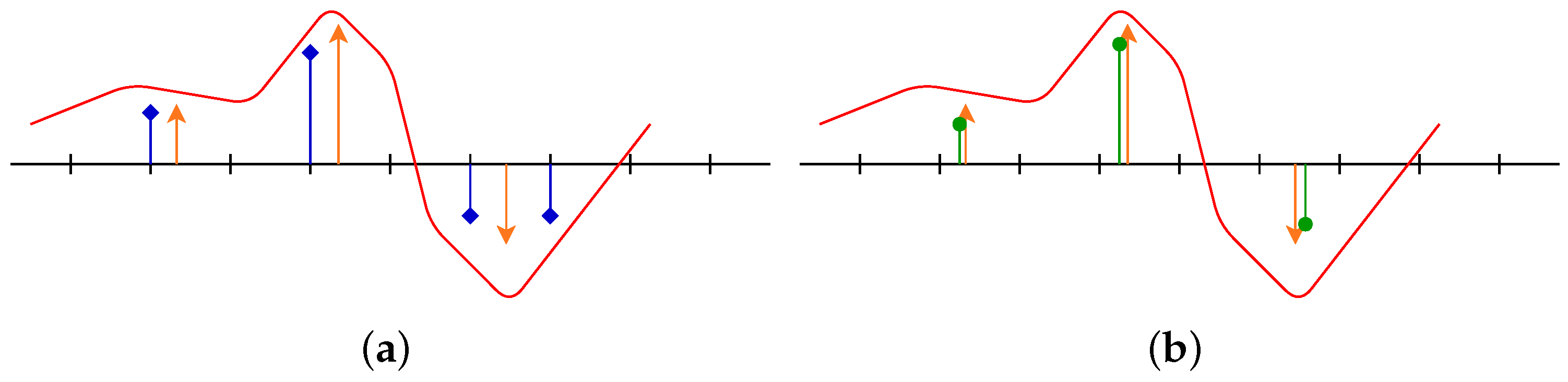
Figure 6, more precisely at red and green ellipses, to get a grasp on the numerical part.
3.3.2. Numerical Results
We recall that a gradient flow
starting at
can be seen as a (time continuous) generalisation of gradient descent in the space of measures, allowing precise theoretical statements on the recovery conditions. To approach this gradient flow, we use the Conic Particle Gradient Descent algorithm [
23] denoted CPGD: the point is to discretise the evolution of the gradient flow
through a numerical scheme on (12). This consists of a gradient descent on the amplitudes
r and positions
x through the gradient of the functional
in Equation (8), a strategy which approximates well the dynamic of the gradient flow [
23].
This choice of gradient with the cone metric enables multiplicative updates in
r and additive in
x, the two updates being independent of each other. Then, the algorithm consists of a gradient descent with the definition of
and
according to [
2,
23]:
thanks to a gradient in Equation (8), for the mirror retraction (The notion of
retraction compatible with cone structure is central: in the Riemann context, a retraction is a continuous mapping that maps a tangent vector to a point on the manifold. Formally, one could see it as a way to enforce the gradient evaluation to be mapped on the manifold. See [
23] for other choices of compatible retractions and more insights on these notions.) and
. The structure of the CPGD is presented in Algorithm 4. Note that the multiplicative updates in
r yields an exponential of the certificate, and that the updates of the quantities
are separated.
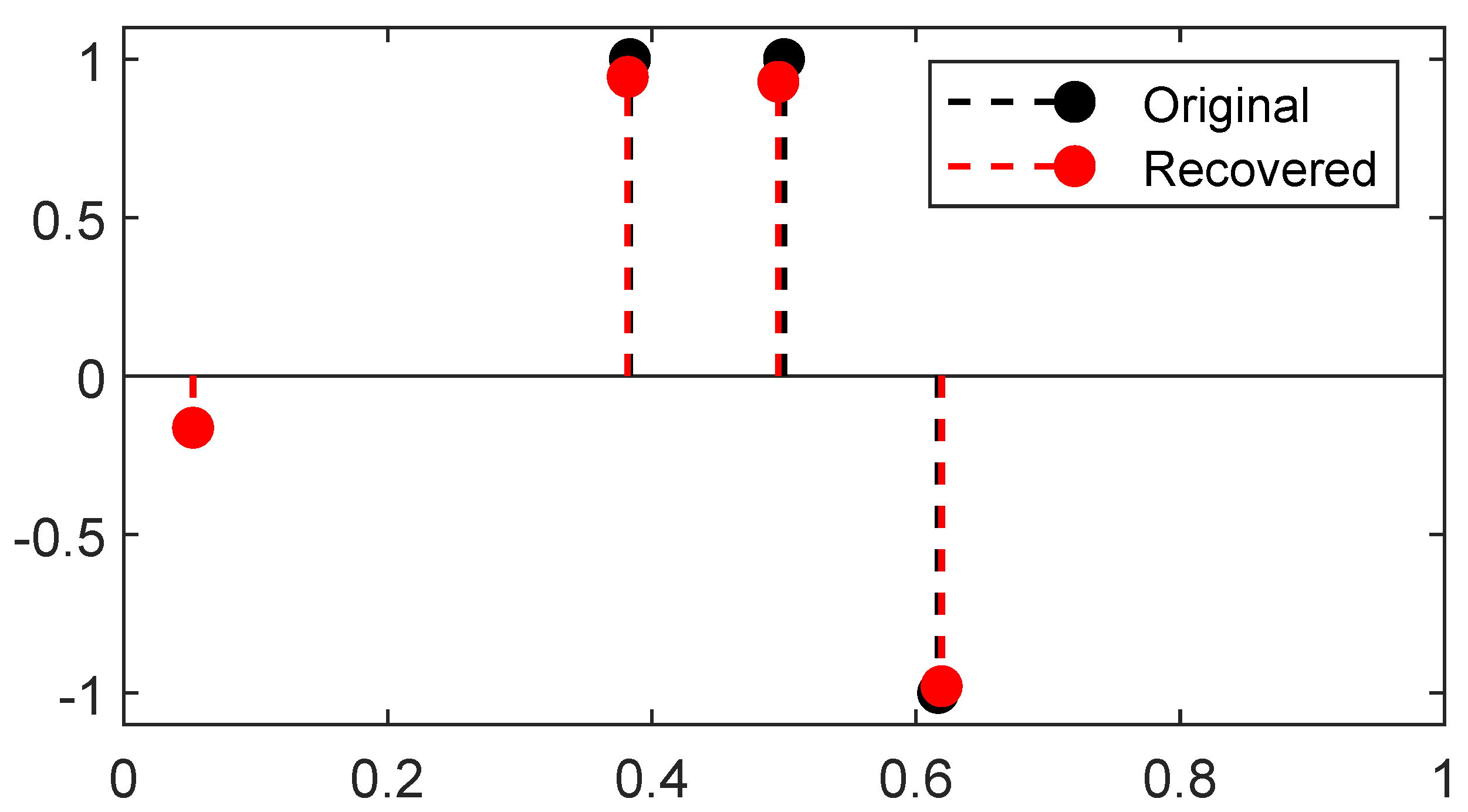
This algorithm has rather easy and cheap iterations: to reach an accuracy of
—i.e., a distance such as the
∞-Wasserstein distance between the source measure
and the reconstructed measure
is below
—the CPGD yields a typical complexity cost of
rather than
for convex program ([
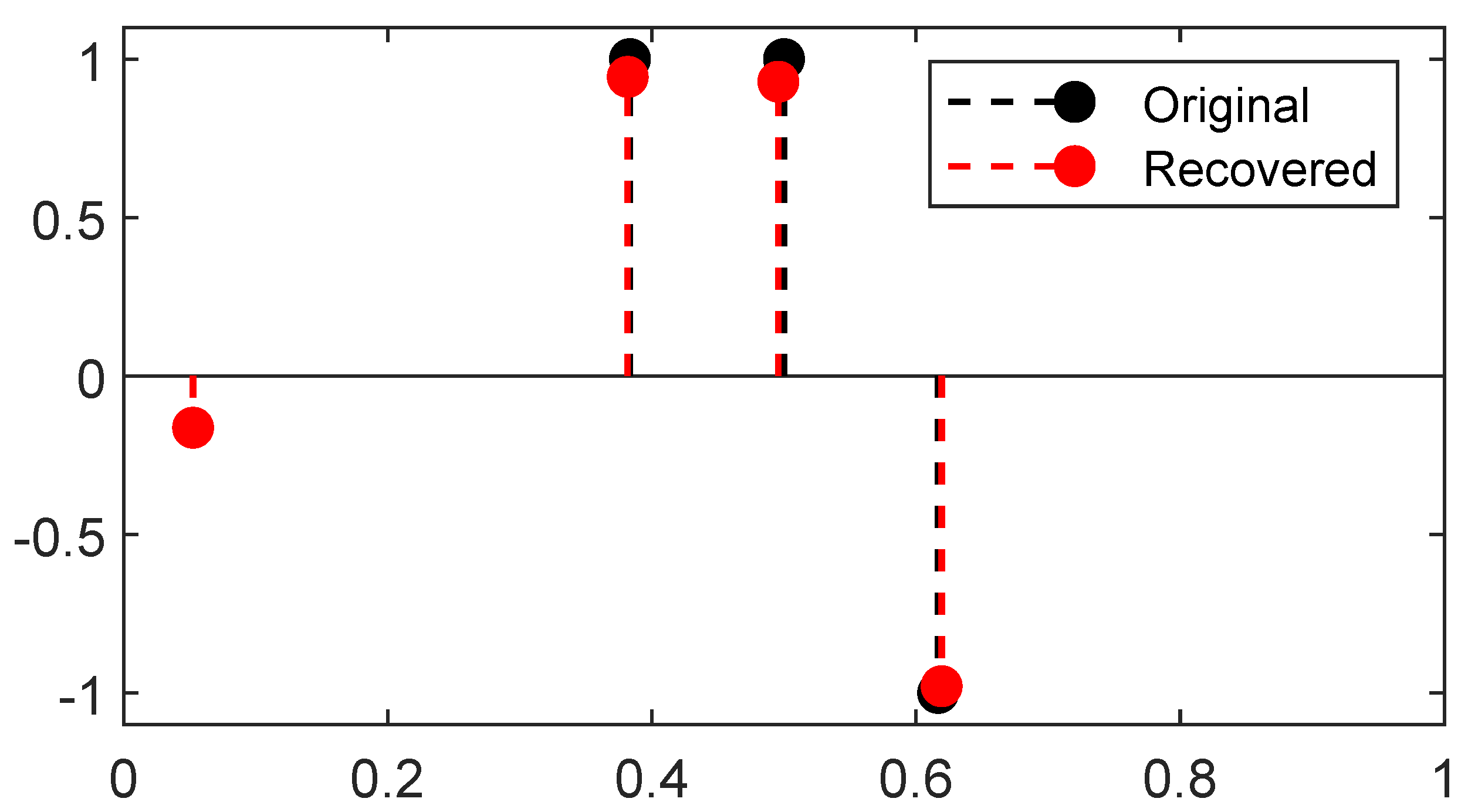
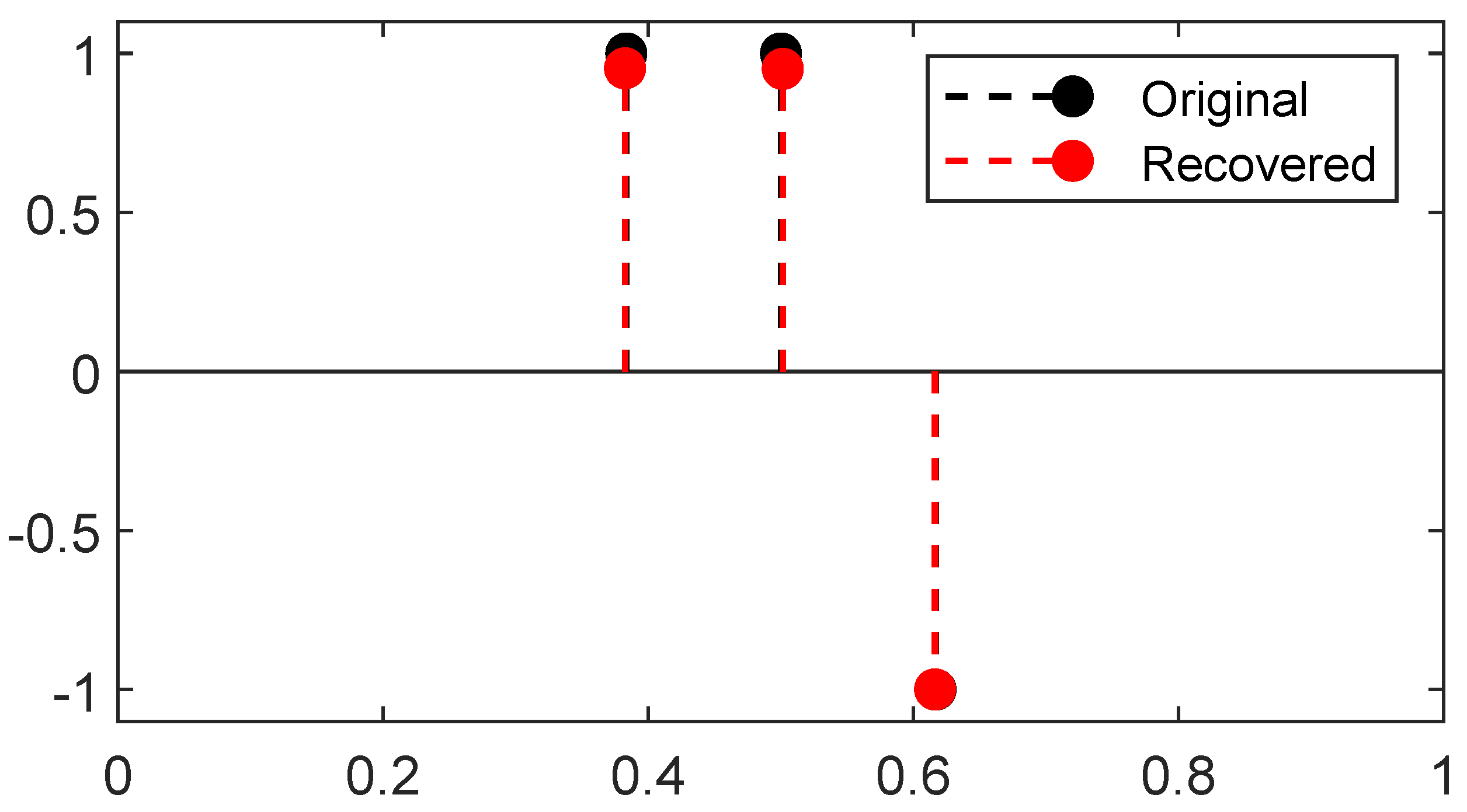
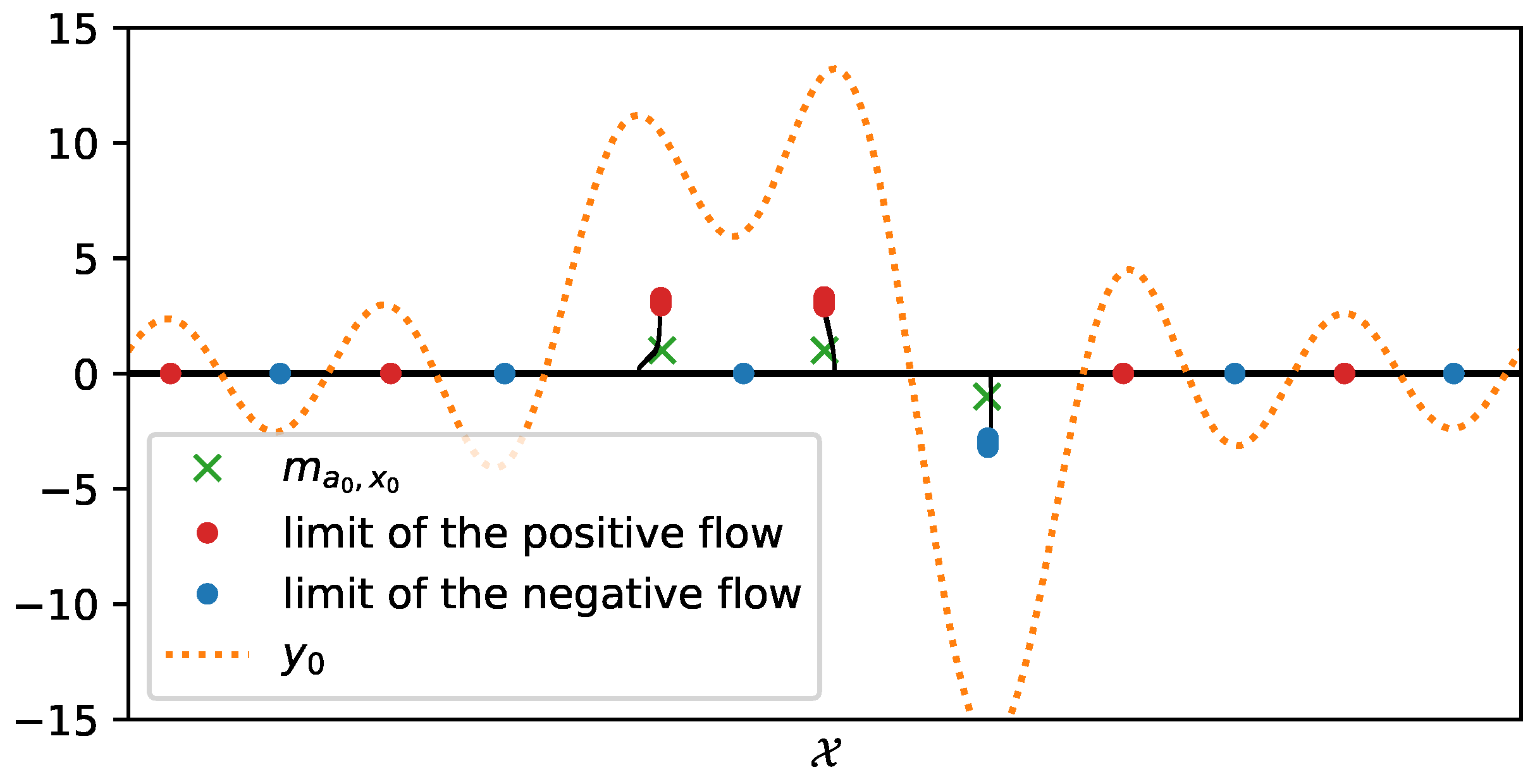
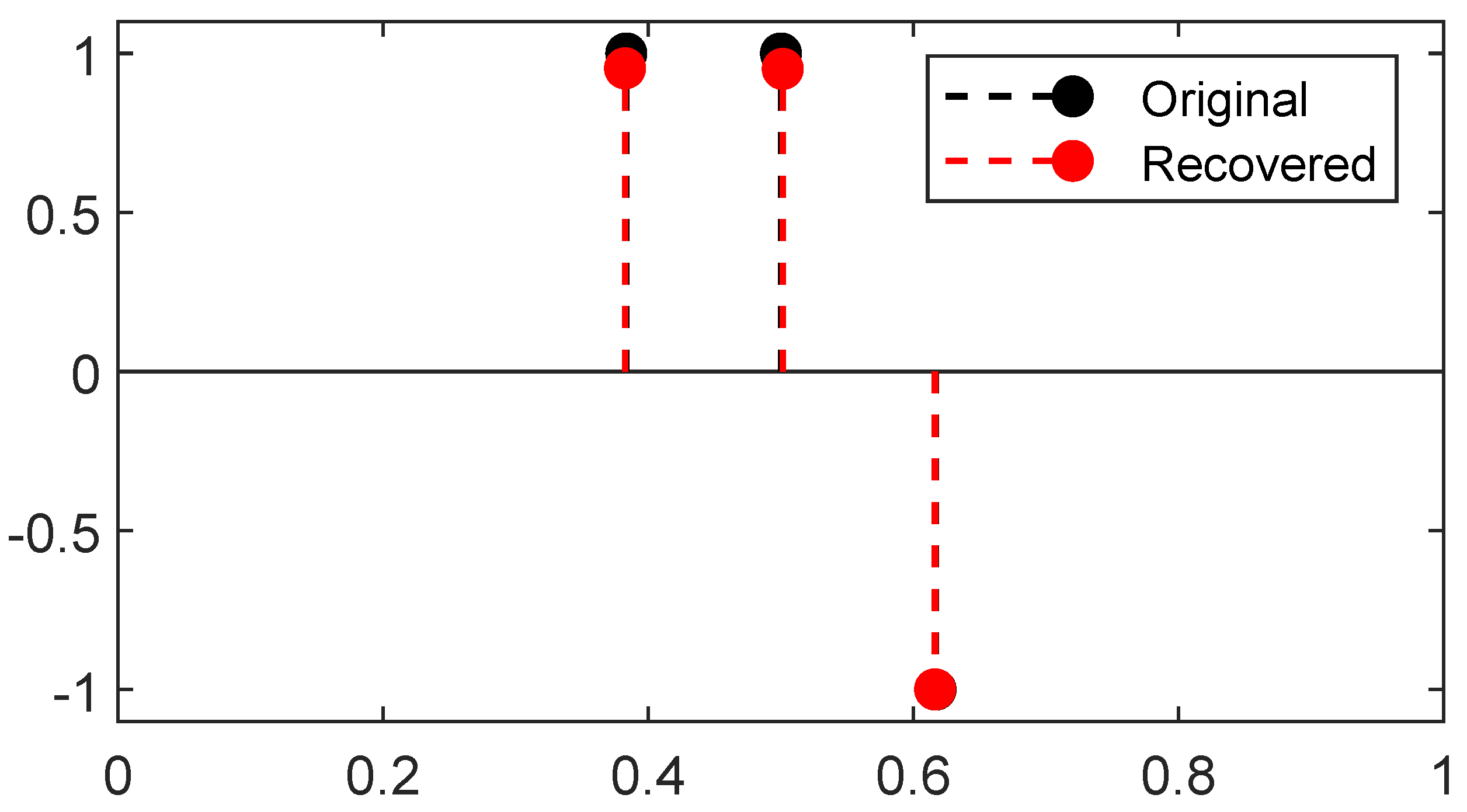
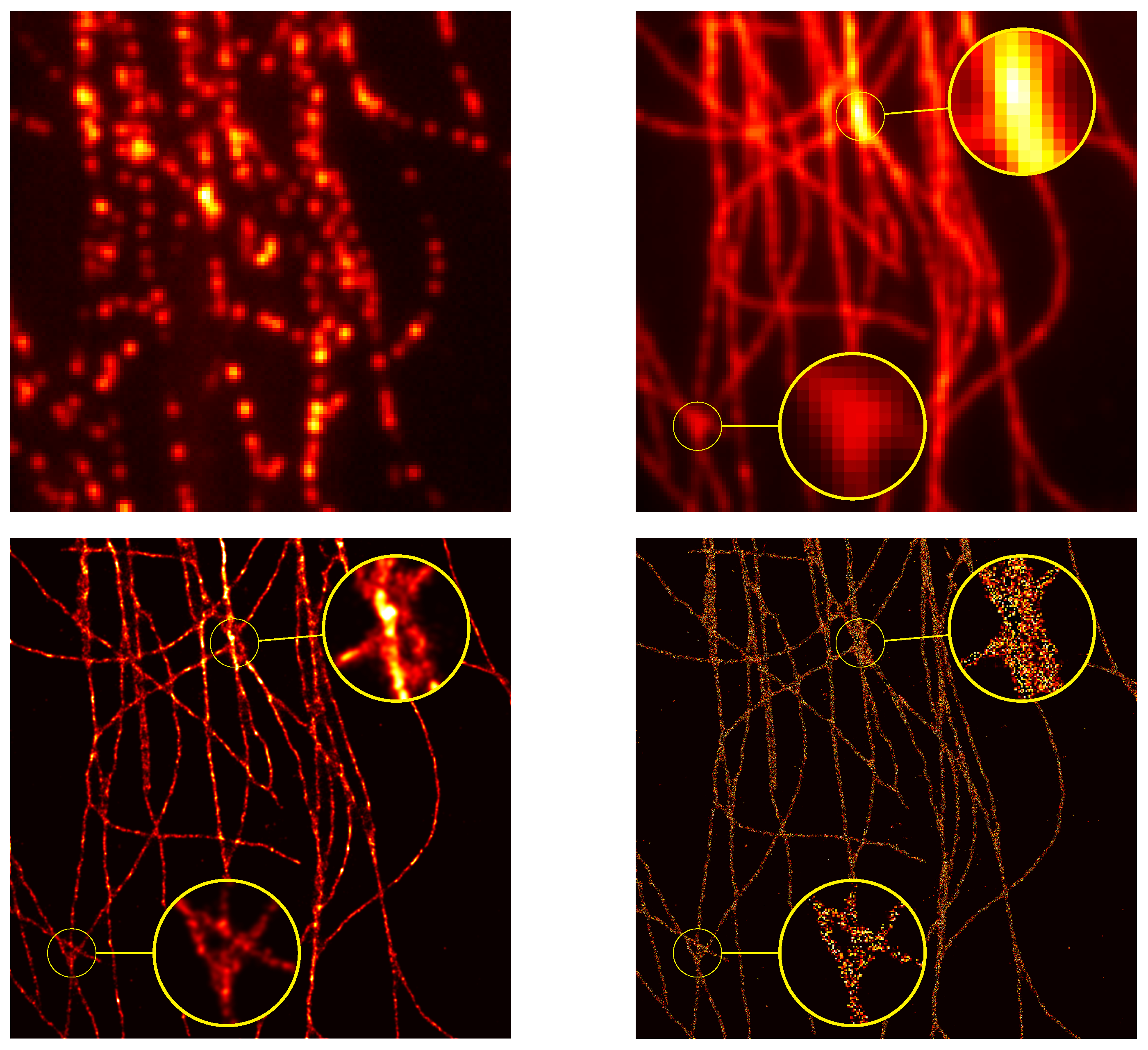
23] Theorem 4.2). A reconstruction from the latter 1D Fourier measurements is plotted in
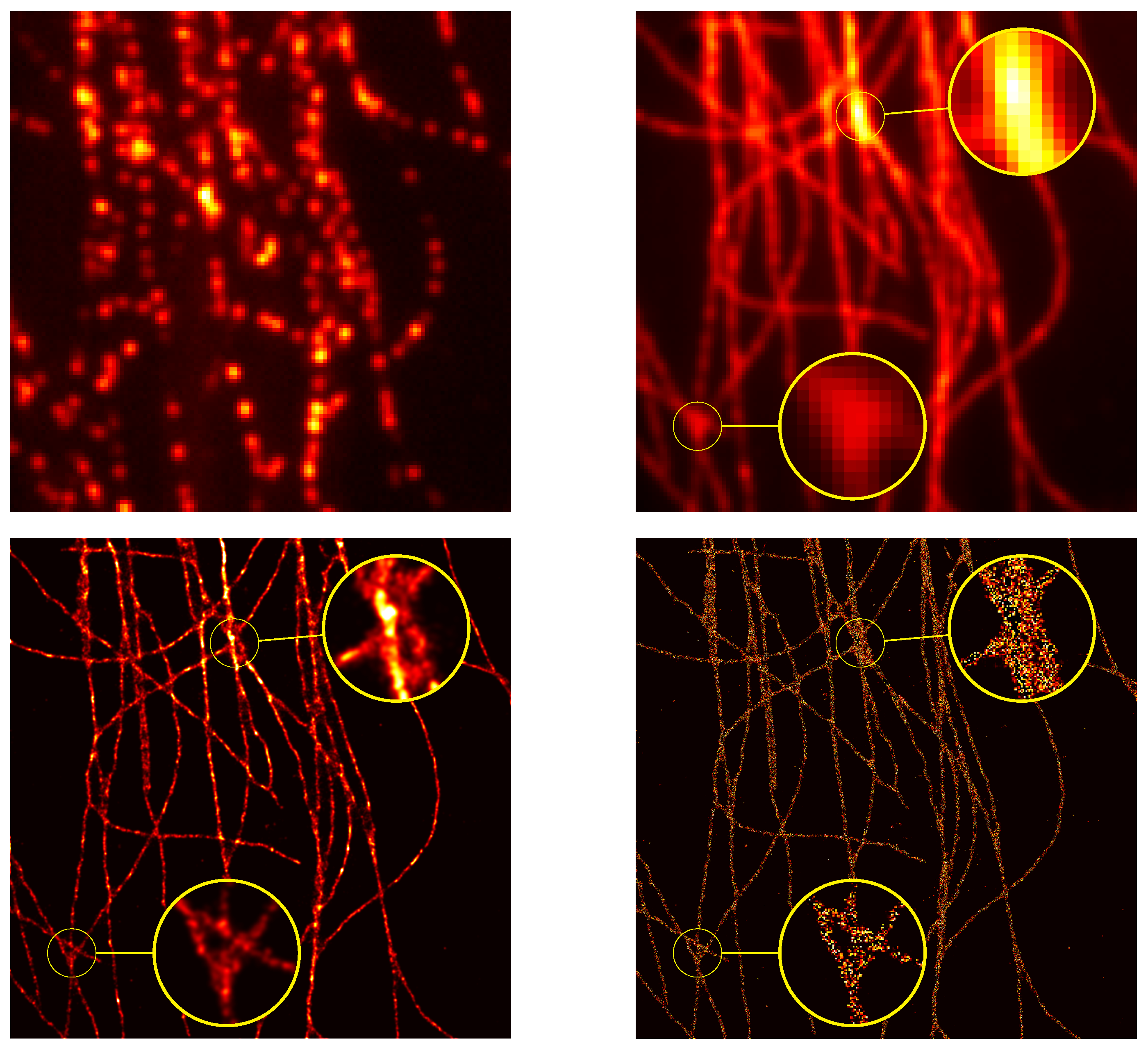
Figure 7, the reconstruction is obtained through two gradient flows, the former on the positive measures to recover the positive
-peaks of the ground-truth and the latter on the negative measures to recover the negative one: the merging of the two results gives the reconstructed
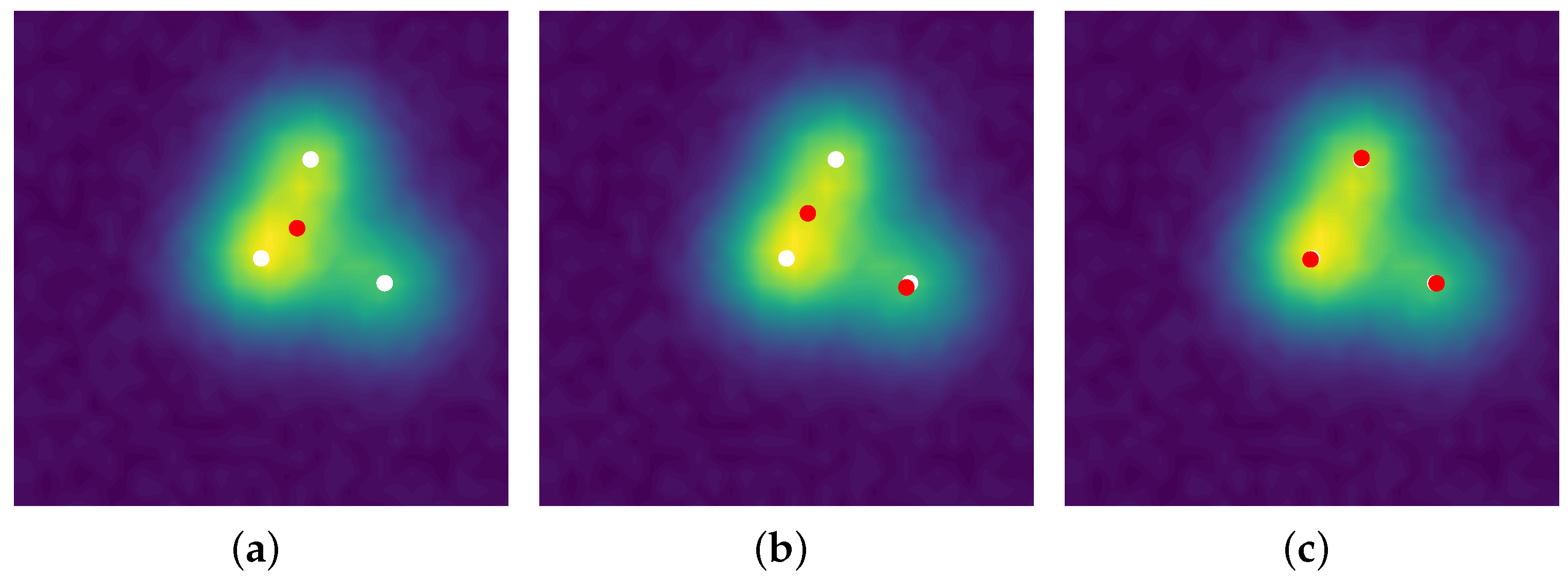
-peaks. The noiseless reconstruction (See our GitHub repository for our implementation:
https://github.com/XeBasTeX, accessed on 30 November 2021) for 2D Gaussian convolution with the same setting as the Frank–Wolfe section is plotted in
Figure 8. One can see that the spikes are well-recovered as some non-zero red and blue particles cluster around the three
-peaks.
| Algorithm 4. Conic particle gradient descent algorithm. |
![Jimaging 07 00266 i003]() |
Summary (3rd algorithm numerical aspects): the gradient flow is computable by the Conic Particle Gradient Descent algorithm, consisting in an estimation through a gradient (w.r.t. cone metric) descent on both amplitudes and positions of an over-parametrised measure, namely a measure with a fixed number of -peaks exceeding the source’s one. The iterations are cheaper than the SFW presented before, but the CPGD lacks guarantees in a low-noise regime.
To sum up all the pros and cons of these algorithms, we give
Table 1 for a quick digest. Since the CPGD lacks guarantees on the global optimality of its output, the following section will use the conditional gradient and more precisely the
Sliding Frank-Wolfe in order to tackle the SMLM super-resolution problem.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}