
Synthesising Facial Macro- and Micro-Expressions Using Reference Guided Style Transfer


Abstract
:1. Introduction
- The first synthetic facial macro- and micro-expression style dataset using style transfer on pre-existing dataset.
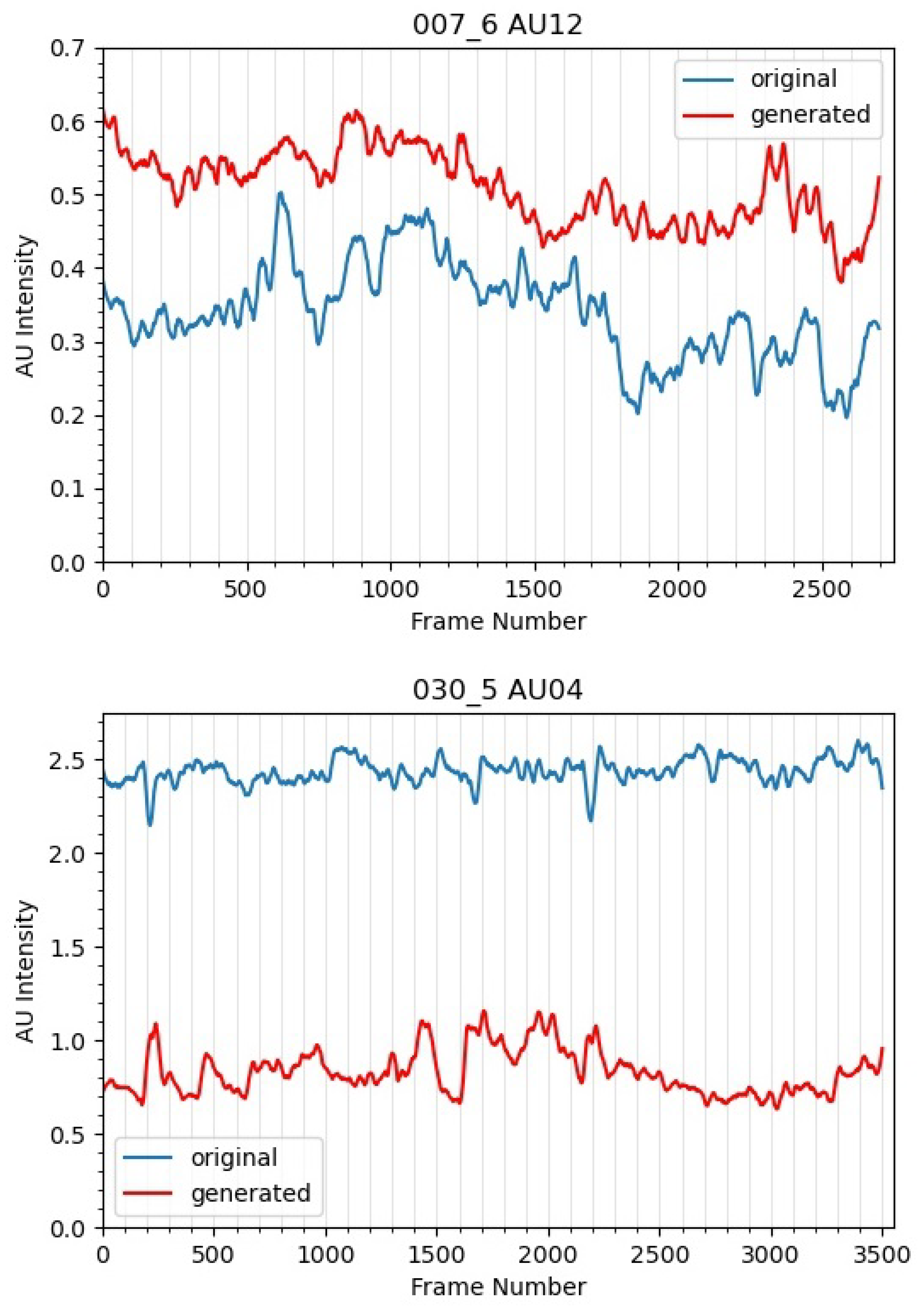
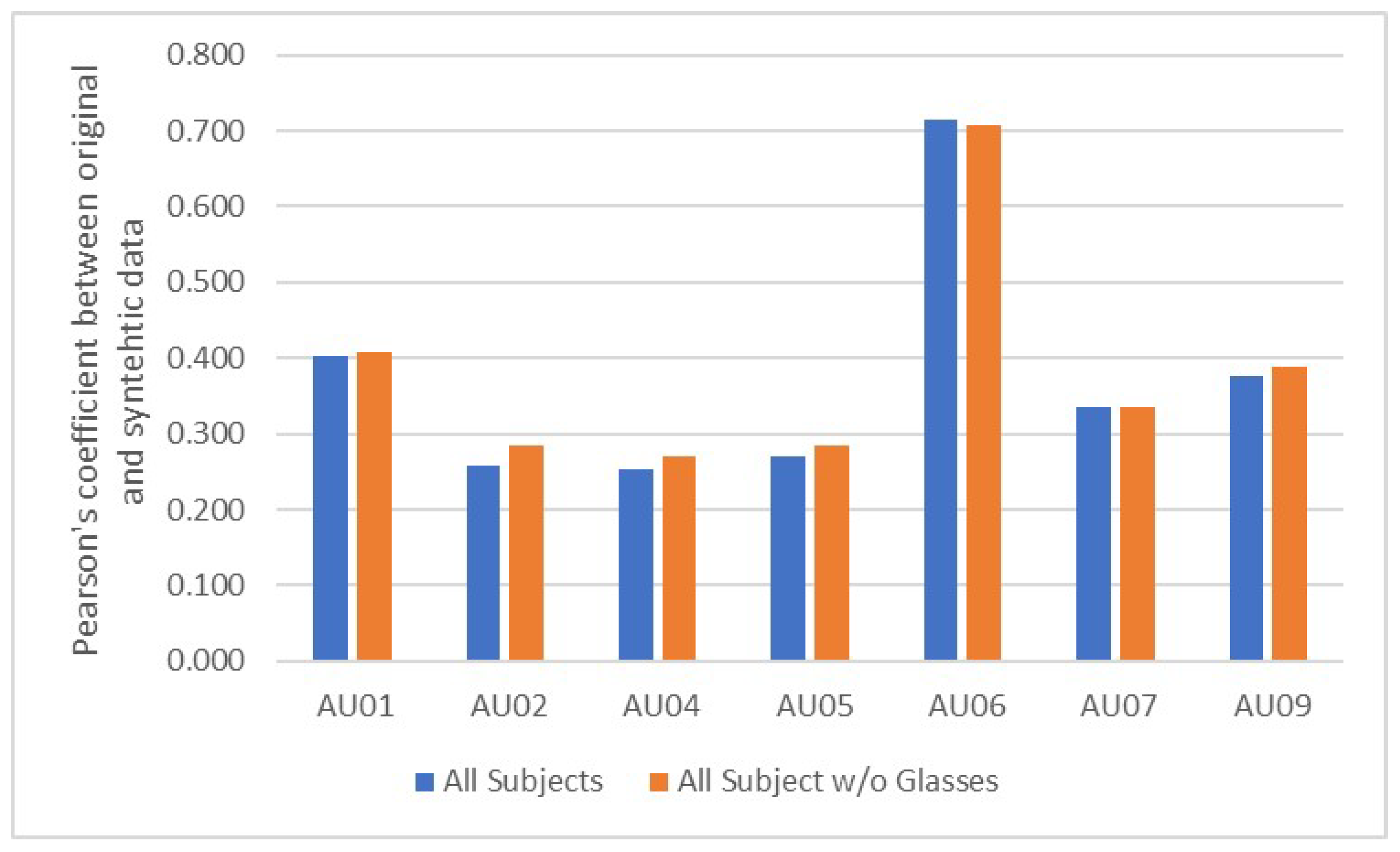
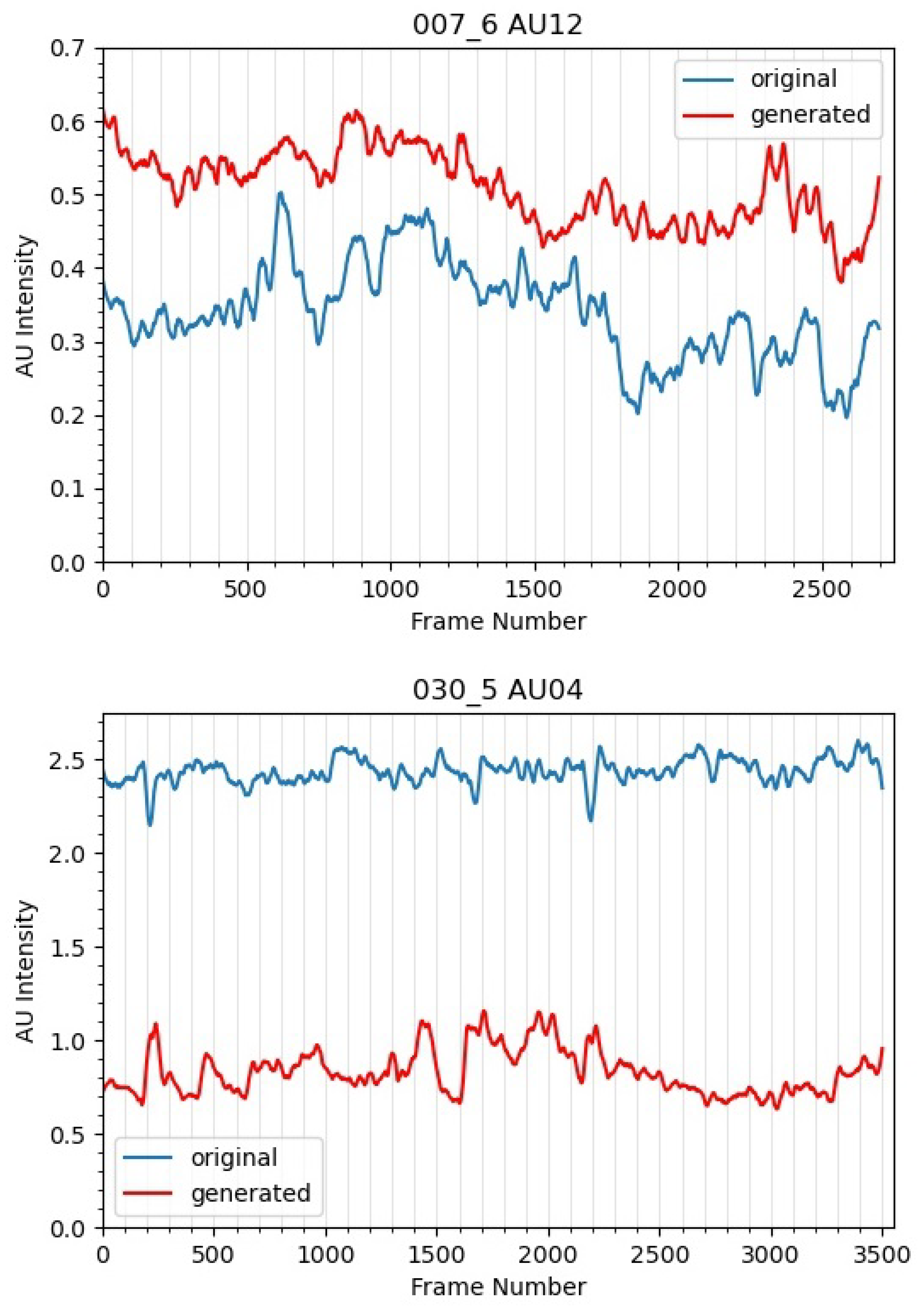
- We study the correlation of the original and synthetic data using AUs detected by OpenFace.
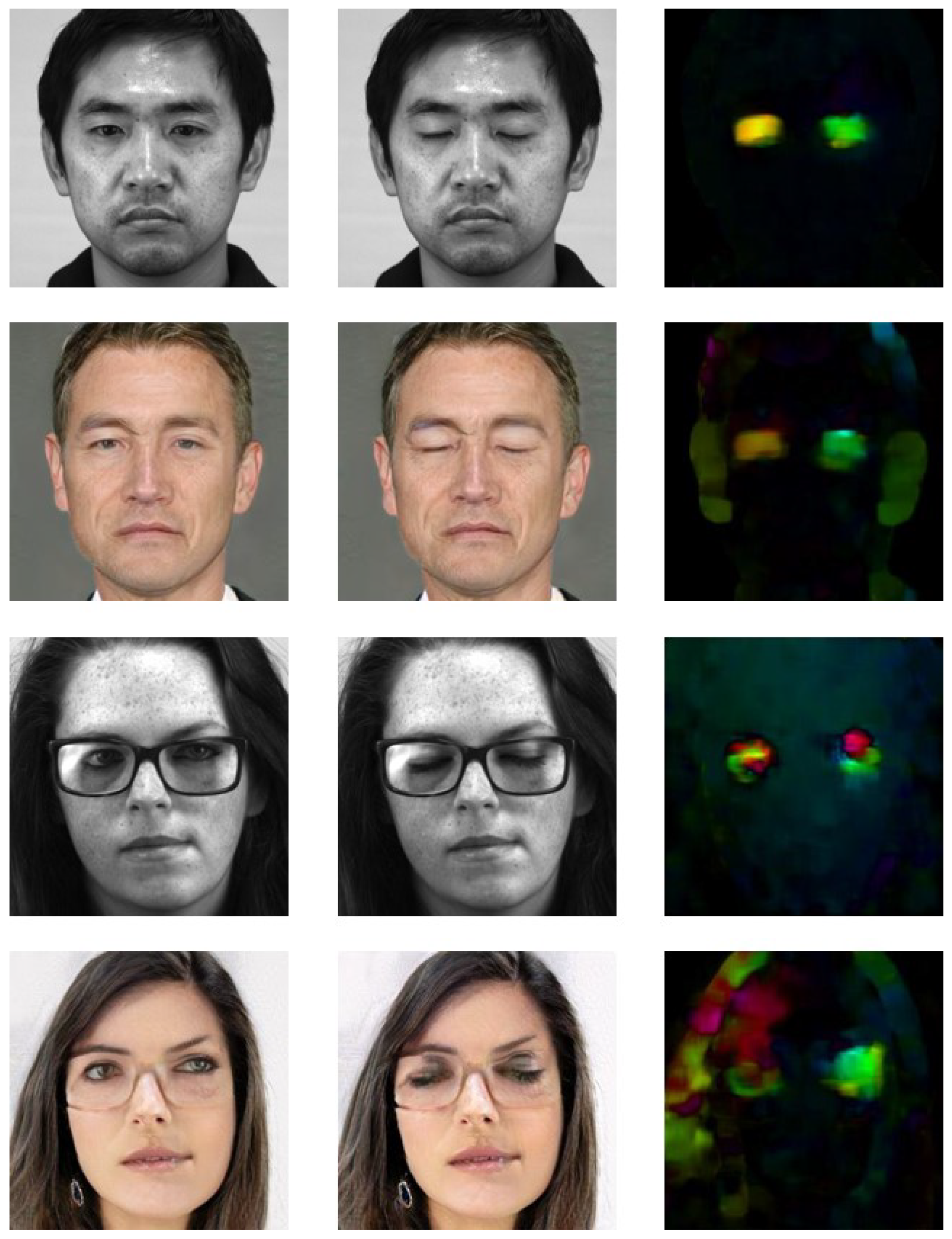
- We recommend to use optical flow for facial motion transfer analysis, to visualise the facial movements and its intensity.
- We share our synthetic dataset with the research community and present future challenges in spotting expressions (particularly micro-expressions) on long videos.
2. Related Work
3. Method
3.1. Datasets
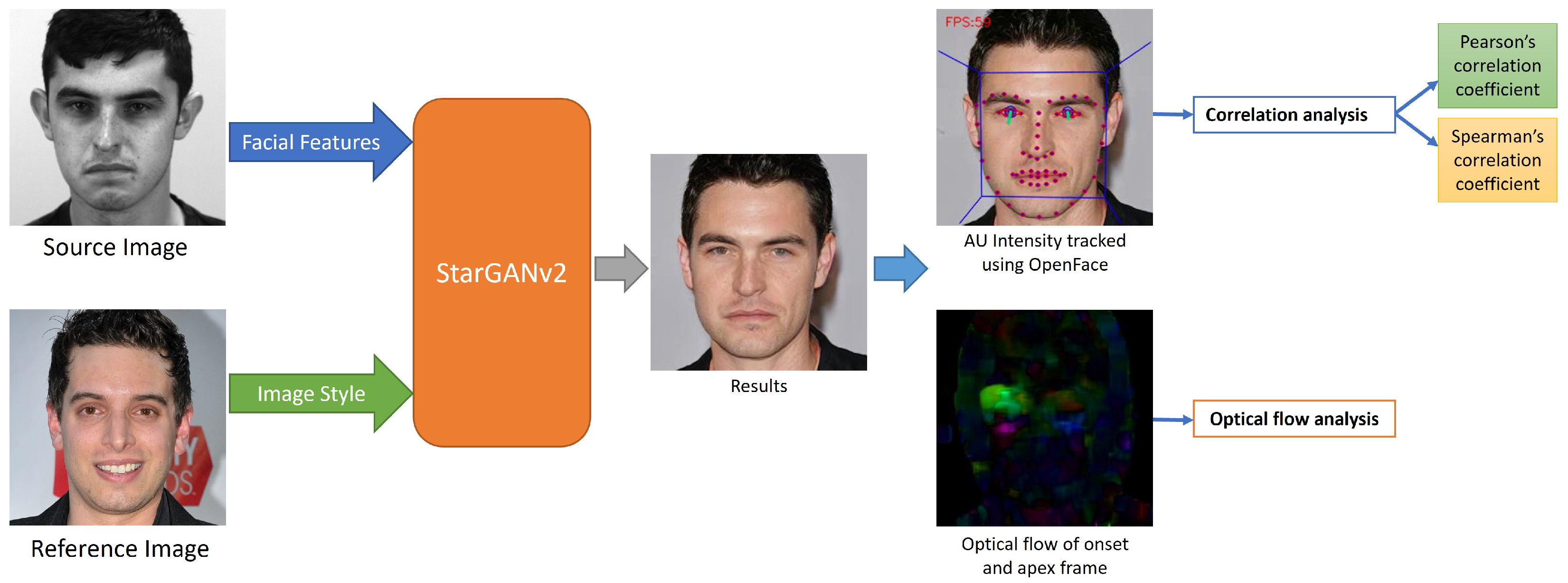
3.2. Style Transfer
4. Results and Discussion
4.1. Generated Data
4.2. Action Unit Analysis Using OpenFace
4.3. Optical Flow Analysis
4.4. Advantages
4.5. Limitations and Challenges
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yan, W.J.; Wu, Q.; Liang, J.; Chen, Y.H.; Fu, X. How fast are the leaked facial expressions: The duration of micro-expressions. J. Nonverbal Behav. 2013, 37, 217–230. [Google Scholar] [CrossRef]
- Ekman, P. Darwin, deception, and facial expression. Ann. N. Y. Acad. Sci. 2003, 1000, 205–221. [Google Scholar] [CrossRef] [Green Version]
- Ekman, P.; Yamey, G. Emotions revealed: Recognising facial expressions. Stud. BMJ 2004, 12, 140–142. [Google Scholar]
- Ekman, P. Facial expression and emotion. Am. Psychol. 1993, 48, 384. [Google Scholar] [CrossRef]
- Li, J.; Soladie, C.; Seguier, R.; Wang, S.J.; Yap, M.H. Spotting micro-expressions on long videos sequences. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–5. [Google Scholar]
- Li, J.; Wang, S.; Yap, M.H.; See, J.; Hong, X.; Li, X. MEGC2020-The Third Facial Micro-Expression Grand Challenge. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020)(FG), Buenos Aires, Argentina, 16–20 May 2020; pp. 234–237. [Google Scholar]
- See, J.; Yap, M.H.; Li, J.; Hong, X.; Wang, S.J. Megc 2019—The second facial micro-expressions grand challenge. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–5. [Google Scholar]
- Yap, C.H.; Kendrick, C.; Yap, M.H. SAMM Long Videos: A Spontaneous Facial Micro-and Macro-Expressions Dataset. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020) (FG), Buenos Aires, Argentina, 18–22 May 2020; IEEE Computer Society: Los Alamitos, CA, USA, 2020; pp. 194–199. [Google Scholar] [CrossRef]
- Qu, F.; Wang, S.J.; Yan, W.J.; Li, H.; Wu, S.; Fu, X. CAS (ME)ˆ 2: A Database for Spontaneous Macro-expression and Micro-expression Spotting and Recognition. IEEE Trans. Affect. Comput. 2017, 9, 424–436. [Google Scholar] [CrossRef]
- Ekman, R. What the Face Reveals: Basic and Applied Studies of Spontaneous Expression Using the Facial Action Coding System (FACS); Oxford University Press: Oxford, UK, 1997. [Google Scholar]
- Hamm, J.; Kohler, C.G.; Gur, R.C.; Verma, R. Automated facial action coding system for dynamic analysis of facial expressions in neuropsychiatric disorders. J. Neurosci. Methods 2011, 200, 237–256. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lewinski, P.; den Uyl, T.M.; Butler, C. Automated facial coding: Validation of basic emotions and FACS AUs in FaceReader. J. Neurosci. Psychol. Econ. 2014, 7, 227. [Google Scholar] [CrossRef] [Green Version]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Sucholutsky, I.; Schonlau, M. ‘Less Than One’-Shot Learning: Learning N Classes From M<N Samples. arXiv 2020, arXiv:2009.08449. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. A neural algorithm of artistic style. arXiv 2015, arXiv:1508.06576. [Google Scholar] [CrossRef]
- Li, C.; Wand, M. Combining markov random fields and convolutional neural networks for image synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2479–2486. [Google Scholar]
- Champandard, A.J. Semantic style transfer and turning two-bit doodles into fine artworks. arXiv 2016, arXiv:1603.01768. [Google Scholar]
- Shih, Y.; Paris, S.; Barnes, C.; Freeman, W.T.; Durand, F. Style transfer for headshot portraits. ACM Trans. Graph. 2014, 33, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Pumarola, A.; Agudo, A.; Martinez, A.M.; Sanfeliu, A.; Moreno-Noguer, F. Ganimation: Anatomically-aware facial animation from a single image. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–16 October 2018; pp. 818–833. [Google Scholar]
- Siarohin, A.; Lathuilière, S.; Tulyakov, S.; Ricci, E.; Sebe, N. First order motion model for image animation. arXiv 2020, arXiv:2003.00196. [Google Scholar]
- Vondrick, C.; Pirsiavash, H.; Torralba, A. Generating videos with scene dynamics. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Kyoto, Japan, 16–21 October 2016; pp. 613–621. [Google Scholar]
- Saito, M.; Matsumoto, E.; Saito, S. Temporal generative adversarial nets with singular value clipping. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2830–2839. [Google Scholar]
- Tulyakov, S.; Liu, M.Y.; Yang, X.; Kautz, J. Mocogan: Decomposing motion and content for video generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1526–1535. [Google Scholar]
- Xie, H.X.; Lo, L.; Shuai, H.H.; Cheng, W.H. AU-assisted Graph Attention Convolutional Network for Micro-Expression Recognition. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2871–2880. [Google Scholar]
- Yan, W.J.; Li, X.; Wang, S.J.; Zhao, G.; Liu, Y.J.; Chen, Y.H.; Fu, X. CASME II: An improved spontaneous micro-expression database and the baseline evaluation. PLoS ONE 2014, 9, e86041. [Google Scholar] [CrossRef] [PubMed]
- Davison, A.K.; Lansley, C.; Costen, N.; Tan, K.; Yap, M.H. SAMM: A Spontaneous Micro-Facial Movement Dataset. IEEE Trans. Affect. Comput. 2018, 9, 116–129. [Google Scholar] [CrossRef] [Green Version]
- Choi, Y.; Uh, Y.; Yoo, J.; Ha, J.W. Stargan v2: Diverse image synthesis for multiple domains. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 8188–8197. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4401–4410. [Google Scholar]
- Baltrusaitis, T.; Zadeh, A.; Lim, Y.C.; Morency, L.P. Openface 2.0: Facial behavior analysis toolkit. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 59–66. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Zadeh, A.; Chong Lim, Y.; Baltrusaitis, T.; Morency, L.P. Convolutional experts constrained local model for 3d facial landmark detection. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2519–2528. [Google Scholar]
- Savitzky, A.; Golay, M.J. Smoothing and differentiation of data by simplified least squares procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Freedman, D.; Pisani, R.; Purves, R. Statistics (International Student Edition), 4th ed.; Pisani, R.P., Ed.; WW Norton & Company: New York, NY, USA, 2007. [Google Scholar]
- Fisher, R.A. On the ‘probable error’ of a coefficient of correlation deduced from a small sample. Metron 1921, 1, 1–32. [Google Scholar]
- Mavadati, S.M.; Mahoor, M.H.; Bartlett, K.; Trinh, P.; Cohn, J.F. Disfa: A spontaneous facial action intensity database. IEEE Trans. Affect. Comput. 2013, 4, 151–160. [Google Scholar] [CrossRef]
- Farnebäck, G. Two-frame motion estimation based on polynomial expansion. In Scandinavian Conference on Image Analysis; Springer: Berlin/Heidelberg, Germany, 2003; pp. 363–370. [Google Scholar]
- Oh, Y.H.; See, J.; Le Ngo, A.C.; Phan, R.C.W.; Baskaran, V.M. A survey of automatic facial micro-expression analysis: Databases, methods, and challenges. Front. Psychol. 2018, 9, 1128. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Klare, B.F.; Burge, M.J.; Klontz, J.C.; Bruegge, R.W.V.; Jain, A.K. Face recognition performance: Role of demographic information. IEEE Trans. Inf. Forensics Secur. 2012, 7, 1789–1801. [Google Scholar] [CrossRef] [Green Version]
- Buolamwini, J.; Gebru, T. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Proceedings of the Conference on Fairness, Accountability and Transparency, PMLR, New York, NY, USA, 23–24 February 2018; pp. 77–91. [Google Scholar]
- Garcia, R.V.; Wandzik, L.; Grabner, L.; Krueger, J. The harms of demographic bias in deep face recognition research. In Proceedings of the 2019 International Conference on Biometrics (ICB), Crete, Greece, 4–7 June 2019; pp. 1–6. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action Unit | SAMM-LV vs. SAMM-SYNTH | Benchmark |
|---|---|---|
| AU1 | 0.40 | 0.64 |
| AU2 | 0.26 | 0.50 |
| AU4 | 0.25 | 0.70 |
| AU5 | 0.27 | 0.67 |
| AU6 | 0.72 | 0.59 |
| AU7 | 0.33 | - |
| AU9 | 0.38 | 0.54 |
| AU10 | 0.28 | - |
| AU12 | 0.74 | 0.85 |
| AU14 | 0.42 | - |
| AU15 | 0.26 | 0.39 |
| AU17 | 0.15 | 0.49 |
| AU20 | 0.28 | 0.22 |
| AU23 | 0.40 | - |
| AU25 | 0.26 | 0.85 |
| AU26 | 0.20 | 0.67 |
| AU45 | 0.92 | - |
| Participant | Pearson | Spearman |
|---|---|---|
| 006 | 0.58 | 0.44 |
| 007 | 0.38 | 0.32 |
| 008 | 0.33 | 0.11 |
| 009 | 0.22 | 0.13 |
| 010 | 0.38 | 0.27 |
| 011 | 0.57 | 0.44 |
| 012 | 0.59 | 0.38 |
| 013 | 0.25 | 0.17 |
| 014 | 0.49 | 0.32 |
| 015 | 0.60 | 0.41 |
| 016 | 0.19 | 0.14 |
| 017 | 0.13 | 0.13 |
| 018 | 0.51 | 0.40 |
| 019 | 0.40 | 0.25 |
| 020 | 0.61 | 0.47 |
| 021 | 0.20 | 0.15 |
| 022 | 0.41 | 0.28 |
| 023 | 0.44 | 0.37 |
| 024 | 0.04 | 0.05 |
| 025 | 0.51 | 0.39 |
| 026 | 0.55 | 0.27 |
| 028 | 0.56 | 0.27 |
| 030 | 0.27 | 0.14 |
| 031 | 0.16 | 0.17 |
| 032 | 0.22 | 0.15 |
| 033 | 0.51 | 0.35 |
| 034 | 0.36 | 0.21 |
| 035 | 0.33 | 0.25 |
| 036 | 0.39 | 0.31 |
| 037 | 0.19 | 0.16 |
| Mean | 0.39 | 0.27 |
| Standard Deviation | 0.19 | 0.12 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yap, C.H.; Cunningham, R.; Davison, A.K.; Yap, M.H. Synthesising Facial Macro- and Micro-Expressions Using Reference Guided Style Transfer. J. Imaging 2021, 7, 142. https://doi.org/10.3390/jimaging7080142
Yap CH, Cunningham R, Davison AK, Yap MH. Synthesising Facial Macro- and Micro-Expressions Using Reference Guided Style Transfer. Journal of Imaging. 2021; 7(8):142. https://doi.org/10.3390/jimaging7080142
Chicago/Turabian StyleYap, Chuin Hong, Ryan Cunningham, Adrian K. Davison, and Moi Hoon Yap. 2021. "Synthesising Facial Macro- and Micro-Expressions Using Reference Guided Style Transfer" Journal of Imaging 7, no. 8: 142. https://doi.org/10.3390/jimaging7080142
APA StyleYap, C. H., Cunningham, R., Davison, A. K., & Yap, M. H. (2021). Synthesising Facial Macro- and Micro-Expressions Using Reference Guided Style Transfer. Journal of Imaging, 7(8), 142. https://doi.org/10.3390/jimaging7080142