1. Introduction
Micro-expression (ME) is described as a brief facial expression which appears on a person’s face according to the emotions being observed. ME occurs when people deliberately try to conceal their emotions, or unconsciously repress their emotions [
1]. ME becomes more likely when there is more risk of revealing the emotions in a high-stake environment.
ME contains significant amount of information about the actual emotions of a person. These emotions maybe useful for applications including healthcare, security and interrogations [
2]. However, extracting this information is highly challenging due to the subtleness of facial muscles movements in ME. This is mainly because the features are needed to be more descriptive. Moreover, another challenge is the duration ranging from 1/25 to 1/5 of a second, which is one of the main characteristics of ME [
1].
In spite of these constrain, ME continues to attract the attention of researchers in the computer vision domain due to its vast potentials in security and interrogations, healthcare, and automatic recognition for real-time applications. In fact, current state-of-the-art methods are able to spot micro-level emotions with accuracies ranging between 65% and 80%. This in turn increases the viability of current ME techniques for real-world implementation. However, for ME system to perform in a real-time system, the following challenges need to be addressed:
Reliability of accuracy—A real-time ME system needs to be able to reliably spot micro-emotions from a person face. Existing ME techniques are however limited to certain datasets which curtails its reliability in multifarious settings.
Computational performance—Given that MEs usually last for a very short duration, it is imperative for a ME system to be able to process and classify a person’s emotion in real-time. Although existing approaches in ME recognition emphasizes on accuracy, the computational complexities of these approaches are not readily applicable for a real-time system.
Automatic onset-offset frames detection—Current state-of-the-art approaches in ME with high accuracies actually requires pre-defined spotting of the onset and offset frames. These constrain are not viable in real-time environment whereby the onset or offset frames cannot be pre-determined.
Generally, the process of recognising micro facial expression is divided into three parts, namely pre-processing, feature extraction and classification. Each part here plays an important role towards reliably classifying a person’s emotion. However, for automatic ME recognition, the features extracted should be more descriptive due to the subtleness of facial movement. Currently, the common feature extraction methods used for automatic ME recognition are Local Binary Pattern histogram from Three Orthogonal Planes (LBP-TOP) [
3], Histogram of Oriented Gradients (HOG) [
4] and Histograms of Oriented Optical Flow (HOOF) [
5].
LBP-TOP represents a popular feature extraction method which considers the co-occurrences statistics in three directions (i.e., XY, XT and YT) of a video sequence. Here,
X,
Y and
T represent the width, height and number of frames in a video stream, respectively [
6]. However, the
time complexity of LBP-TOP renders it computationally expensive as a real-time application. Attempts were made to accelerate the performance of LBP-TOP for ME recognition [
7,
8] with GPU computing platform. However, these methods recorded lower accuracies (i.e., 50%) and lacks clear indication on frame rate.
For the HOG feature extraction approach, the number of occurrences of gradient orientation in localized portions of an image (e.g., detection window, region of interest) is counted. The study in Reference [
9] implemented 3D gradient histogram descriptor (HOG 3D) that computes features at the speed of 3.3 ms per sample. However, this method manually selects relevant regions based on Facial Action Coding System (FACS) [
10] movement so that unwanted regions of the face are removed. Another study in Reference [
11] proposed a FACS based method that utilizes a template of 26 defined facial regions. This method applies 3D HOG to extract temporal features of each region, and then utilizes Chi-square distance to find subtle facial motion in the local regions. However, the approaches presented in References [
9,
11] of defining movement within the selected regions are computationally expensive and therefore not suitable for real-time application. Though, study in Reference [
12] attempted to improve the computation performance of HOG, but it was not tested for ME recognition.
On the other hand, Reference [
13] proposed a Bi-Weighted Oriented Optical Flow (BI-WOOF) feature descriptor that implements local and global weight of HOOF descriptor. The reported results in Reference [
13] demonstrates promising performance of ME recognition using only the onset-frame and the apex-frame in order to reduce the computational time. While Reference [
14] proposed a feature descriptor that are less sensitive to the change in pose, illumination, and so forth, to increase the reliability of ME recognition for practical application. Another study in Reference [
15] proposed an optical flow features from Apex frame Network to compute the optical strain features. Using a multi-database (i.e., SMIC, CASMEII and SAMM) setup with leave-one-subject-out cross-validation experimental protocol, these methods achieve ME recognition as high as 74.60%.
Although the aforementioned methods demonstrate notable improvements in ME accuracy, the high computational cost and requirements for pre-defined spotting of onset and offset frames renders these methods impractical as a real-time solution. Looking into macro-expression detection and recognition, References [
16,
17,
18] suggested that geometric features are more robust in spotting the changes in face components, in comparison to the appearance based features using LPB-TOP, HOG and HOOF. However, to the best of our knowledge, very few articles utilize the geometric features for ME recognition based on single-frame sample. Existing geometric-based feature extraction algorithms yield poor ME recognition accuracy. This is due to the fact that geometric approach require large number of features [
19]. However, since some of the existing ME datesets are FACS-coded. This suggests that the geometric features based on FACS could improve the recognition accuracy challenges. Therefore, this paper puts forward a geometric-based feature extraction technique using FACS for ME recognition with facial landmarks. The proposed method here addresses both the accuracy and computational cost for real-time ME. Crucially, the proposed technique processes ME recognition on frame-based samples, which substantially increases its feasibility in processing video of high frame rates. It computes features using facial landmarks extracted from the pre-processing stage of any input frame. This in turn substantially reduces the computational complexity in processing high frame rate video while at the same time improves the ME recognition accuracy further in comparison to the latest published article using the same validation technique [
15].
The main contributions of this paper are:
FACS-based graph features using facial landmarks is proposed for real-time ME recognition. The proposed technique addresses both the accuracy and computational cost for real-time ME systems. The proposed technique computes features for ME recognition based on single-frame sample only, which substantially increases its feasibility of ME recognition with high speed camera.
Implementation of large-sample validation technique for single-frame geometric based features. Thus, multiple frames were selected from each video sequence and represented as samples of every corresponding class, which in turn increases the total number of samples of every class per dataset.
The rest of the paper is organized as follows:
Section 2 reviews the related work.
Section 3 formulates the proposed feature extraction algorithm based on FACS graph with facial landmark points, and
Section 4 describes the dataset restructuring for frame-based sample analysis.
Section 5 presents the experimental results and analyzes the performance for different spontaneous dataset and concludes this paper.
2. Related Work
Comprehensive review on automatic ME recognition and analysis challenges have recently been presented in Reference [
20], focusing on the clarification on how far the field has come, identifying new goals, and providing the results of the baseline algorithms. As reported in Reference [
20], feature extraction improvement is the main focus in the existing studies of ME detection and recognition. Studies in References [
3,
21,
22] suggest accuracy improvement is more significant by employing an additional pre-processing to enhance quality of data before feature extraction process [
23]. However, implementation of the existing pre-processing approaches, such as TIM [
3], emotion magnification [
21], and filtering [
22], introduces more computational cost challenges. Besides, to the best of our knowledge, there is no published article until date towards real-time implementation of these pre-processing methods for automatic ME spotting.
Hence, an acceleration of feature extraction has become necessary for real-time ME recognition in order to attain high throughput. In addition, from the feature perspective for ME recognition, there are three major approaches, namely—appearance-based approach, dynamic approach and geometry-based approach. Based on reported results in Reference [
24], both appearance-based and dynamic approaches are not feasible for real-time systems on low-level systems as they involve high cost computations. However, Reference [
7] proposed an appearance-based feature extraction method described as fast LBP-TOP using the concept of tensor unfolding to accelerate the implementation process from 3D-space to 2D-space. This method improves the computational time by 31.19 times on average when compared to the original LBP-TOP implemented in Reference [
7]. Moreover, Reference [
8] proposed another appearance-based feature extraction method by computing conventional LBP-TOP using many-core graphics processing unit (GPU) with CUDA parallel computing platform [
8]. The proposed algorithm in Reference [
8] increases the performance speedup up to 130× faster against the serial algorithm, with 1120 × 1360 video resolution. However, References [
7,
8] neither measure nor present the frame rate of their accelerated LBP-TOP algorithms, which make no conclusions for the feasibility of computing in real-time automatic ME recognition. Thus, in fairness conclusions of computational complexity as suggested by Reference [
17,
18], geometric-based approach is the best option towards realization of real-time ME recognition system as it involves low complexity computations of facial muscle movement. In addition, there is no requirements of onset-offset detection for geometric-based approach, which substantially increases its feasibility in processing video of high frame rate.
Geometry-based feature extraction approach deals with symmetrical features that gives the locations and shapes of facial components [
25]. The study in Reference [
26] presented graph-based features that locate and define points into regions of face in order to compute features, and then recognition of emotions is done by using corresponding feature vector. Moreover, Reference [
27] proposed a new face expression recognition method based on extracting discriminative features. The study in Reference [
14], the proposed method utilizes local statistical features from a region-of-interest and applied AU codes to detect ME. Action Units (AU) are the fundamental actions of individual muscles or groups of muscles, and FACS involves 44 AUs related to visually discernible facial muscle activation. Moreover, FACS defines AU intensities on a five-point ordinal scale (i.e., from lowest
A to strongest
E intensity. The main benefit of estimating AU strengths is that the qualified AUs would yield more information about the emotional involvement of a subject. Moreover, since humans can express their feelings in different ways under different situations, information conveyed by AU intensities can be exploited to adapt emotion recognition.
Table 1 summarizes the advantages and disadvantages of the aforementioned feature extraction approaches.
To date, the achievement of ME recognition accuracy using spontaneous ME datasets ranges from 40% to 88% using different validation approaches including leave one subject out cross validation, leave one video out cross validation and k-fold cross validation. For methods tested using all classes, the highest accuracy is 88.28% with F1-score of 0.87 with OFF-ApexNet method from Reference [
15] over CASMEII dataset. As reported in Reference [
28], the uneven distribution samples among classes create more challenges that impacts recognition rate. The trend of ME recognition is also changing from low-level hand-crafted feature to high-level approaches. However, the development of high-level approach is restricted by small dataset sizes. Hence, augmentation of data or transfer learning is done to provide higher number of samples. The study in Reference [
29] present deep learning model named spatio-temporal recurrent convolutional networks (STRCN), and the reported ME recognition accuracy is 80.3% with F1-score rate of 0.75 on CASMEII dataset. Moreover, another study in Reference [
30] presents a shallow triple stream 3D CNN (STSTNet) that is computationally light whilst capable of extracting discriminative high level features and details of MEs. The reported results active up to 76.05% of recognition accuracy with 0.74 F1-score rate on a combined dataset created from SMIC, CASMEII and SAMM datasets.
While the aforementioned studies lay a solid groundwork in ME recognition accuracy, the computation performance based on speed per frame remains unreported. Moreover, with the current advancement of technology for real-time machine learning based systems for automatic ME recognition, it is necessary to have a reliable feature extraction algorithm for real-time implementation of ME recognition systems. Looking into the FACS-based features, where a trained coder views facial geometric movements and expressions in video sequences, and then observe each muscle movements as AU. FACS is described as efficient, objective and comprehensive technique to present facial expression without any downside [
31], and it is widely accepted by many researchers in the field of psychology and physics. FACS devised 46 AUs, where the expressions to represent human emotional states are produced by the movements of AUs or their combination based on these system. Thus, identifying AUs based on facial muscles movement for ME recognition could address the computational challenges for real-time application. In this regard, this paper puts forward a FACS-based graph features using facial landmarks for real-time ME recognition systems. Crucially, the proposed feature extraction algorithm improves the recognition accuracy as well as the computation complexity. The following section presents the formulation and implementation of the proposed algorithm.
3. Proposed Algorithm
This section presents the proposed facial feature extraction algorithms for ME recognition.
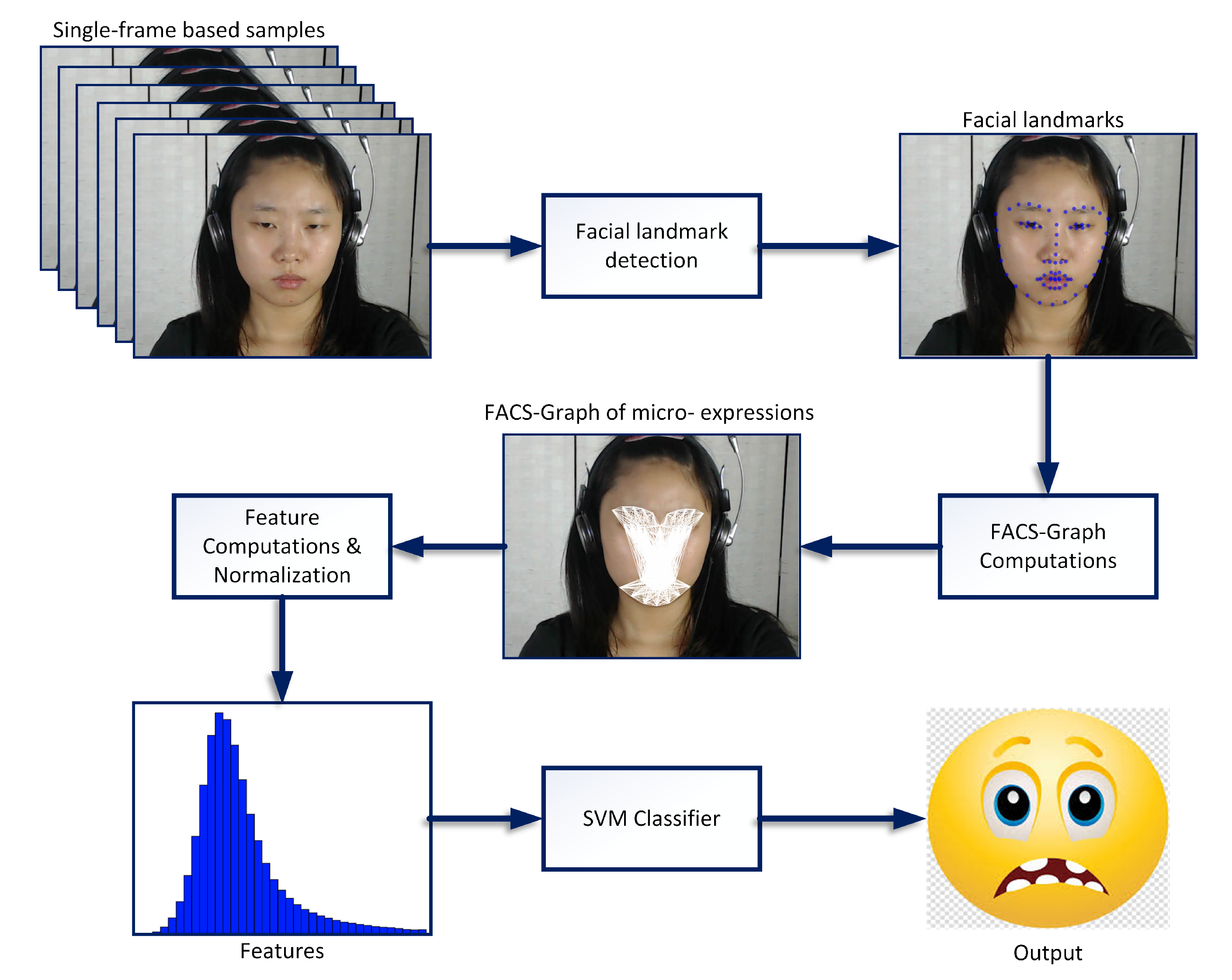
Figure 1 shows the flow of processes for real-time ME detection and classification using the proposed feature extraction.
The real-time system utilizes a high speed camera to capture video frames, then Facial Detection algorithm is applied to identify the presence of face for micro-emotion analysis within the processing frame. For every successful detected face, 68 landmark points will be identified for the subject’s facial components. Subsequently, the proposed technique utilizes these landmark points to compute FACS-based graph for different emotions, and then the distance and gradient of segments from the computed graphs are presented as features. These features are normalized and then presented to the Classifier for ME detection and recognition.
The authors of Reference [
32] demonstrated that the geometric variation of these features can be utilized to identify different facial emotions. However, the challenge of this technique is to correctly identify the effective region that represents each facial emotion for recognition. Thus, this paper presents a new method that utilizes facial landmark based graph to compute features. This paper analyse the geometric features using two methods, namely: (i) Full-face graph and (ii) the proposed FACS-based graph. For both methods, the dlib [
33] facial landmark detection tool were utilized for facial landmark detection. This tool utilizes histogram of oriented gradients (HOG) face detector to provide a 68-point model that represents a face shape, eyebrow, eyes, nose and mouth. The dlib facial landmark detection is able to achieve high speed performance and accurate in comparison to other facial detection methods [
34].
Algorithm 1 presents the first method, that is, feature computation using the Full-face facial graph. This algorithm computes a total of 2278 one-to-all segments generated from the 68-points facial landmarks for every sample (i.e., single frame samples). Here,
represents the facial landmark points as input data, where
n represents the index for the
x and
y coordinates of a landmark point. Then,
represents the computed features as output data (i.e., the results), where
k represents the number of computed elements. As shown in Algorithm 1, two feature elements are computed from every segment, where the first element is the distance between the two points computed using Euclidean algorithm and the second element is the gradient of the two points computed using slope equation. Thus, the total number of feature elements computed from the 2278 segments is 4556.
| Algorithm 1: Feature computation with full-face graph. |
 |
On the other hand, Equations (
1)–(
3) express the FACS-based graph computation using the facial landmarks. Firstly, Equation (
1) groups the AU codes based on FACS by computing the landmark coordinates of every connecting points of facial components defined within the AU region, where
represent the first connecting point and
represent the second connecting point. Then, Equation (
2) combines the AUs codes defined from Equation (
1) to generate graphs for every emotion (denoted as
), where
R represents the number of AUs for per emotion. While, Equation (
3) groups the generated graphs of all the seven emotions computed using Equation (
2) to form the combined graph (denoted as
), where
K represents the total number of emotions considered in this work. Equation (
4) deletes the repeated segments within the combined graph (i.e.,
) in order to produce the final FACS-based graph (denoted as
). Total number of segments computed from Equation (
3) is 3083. Then, after removing the repeated segments using Equation (
4), the new total number of segments is reduced to 1178.
Algorithm 2 describes how the features are computed using the FACS-based graph. Similarly, Algorithm 2 computes two feature elements for every segment, and this process is repeated for all the segments of the FACS-based graph to compute the complete 2356 (i.e., 1178 × 2) features.
| Algorithm 2: Feature computation with FACS-based graph. |
 |
As observed here, the total features computed with Algorithm 2 are lesser in comparison with the features computed in Algorithm 1. Note that the features are computed in the same manner in methods after the graph formation using Equation (
1)–(
4) (as described in
Figure 1). To further elaborate the proposed FACS-based graph features,
Table 2 lists the facial region grouping for AUs defined based on landmarks using FACS codes.
As shown
Table 2, the first column lists the emotions classes (denoted as
), second column lists the number of AUs for each emotion, while the third column lists the AU codes based on FACS, and then the fourth column lists the grouping of facial components landmarks per AU. Here, the 68 points facial landmarks is divided into seven facial units namely; lower-jaw, left-eyebrow, left-eye, right-eyebrow, right-eye, nose and mouth, which are defined as LJ, LEB, LE, REB, RE, N and M respectively. Furthermore, the grouping of facial components landmarks consist of one part for
and two parts for
. For the grouping with one part, the sets of landmarks from the facial components within the AU region are combined to form a single set, then using Equation (
1), the segments are computed to form a graph of AU. While, for grouping with two parts, segments are computed in similar way as described for grouping with one part, and then the two groups of segments are combined (shown in
Table 2, column four using ∪) to form a graph of AU.
Table 3 tabulates the list of AUs and descriptions for facial muscle movement according to Reference [
10]. As shown in
Table 3, the first column lists the class of emotions, while the second column lists the marked-samples with arrows showing the direction of face muscle movement for each class of emotion, then the third column lists the combination of AUs to represent each class of emotion, and the last column lists the FACS name for all AUs for the corresponding class of emotions.
To further describe the FACS-based graphs for each emotion,
Figure 2 present a sample image (mid-frame of subject 1 from CAS(ME)
dataset), where
Figure 2a maps the 68 landmarks on the targeted facial components. While,
Figure 2b–h maps the proposed FACS-based graph generated for different emotions. For further illustration,
Figure 3 compares Algorithm 1 and the proposed FACS-based graph. Specifically,
Figure 3a shows the FACS-based graph that combines all the 7 emotions graphs (i.e., graphs in
Figure 2b–h) into one graph of all the 7 emotions, while
Figure 3b shows the Full-face method. Here, each segment indicates a process of distance and gradient computation. Therefore, this suggests that the FACS-based features (i.e.,
Figure 3a) have fewer computational processes compared to the Full-face features.
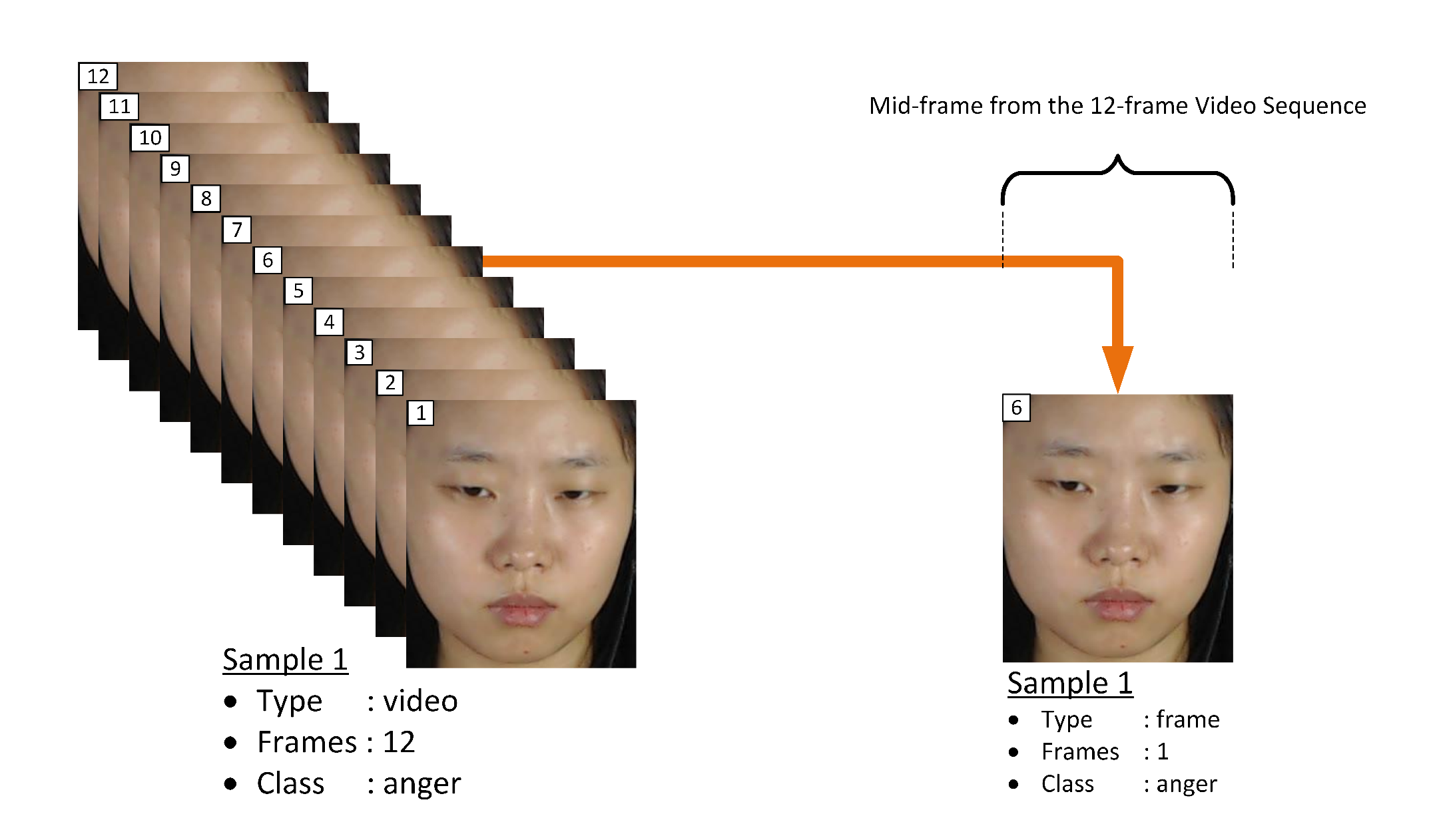
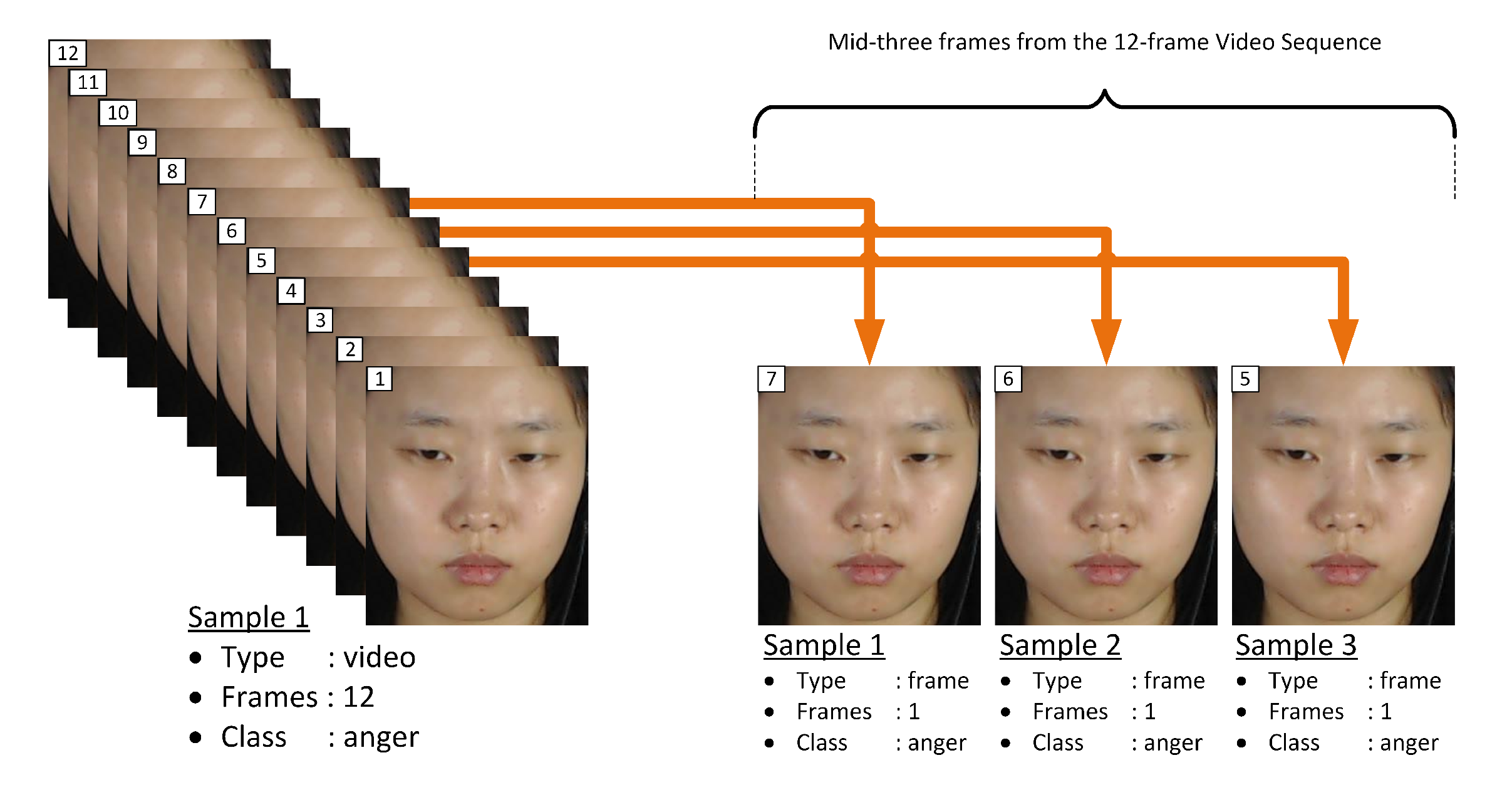
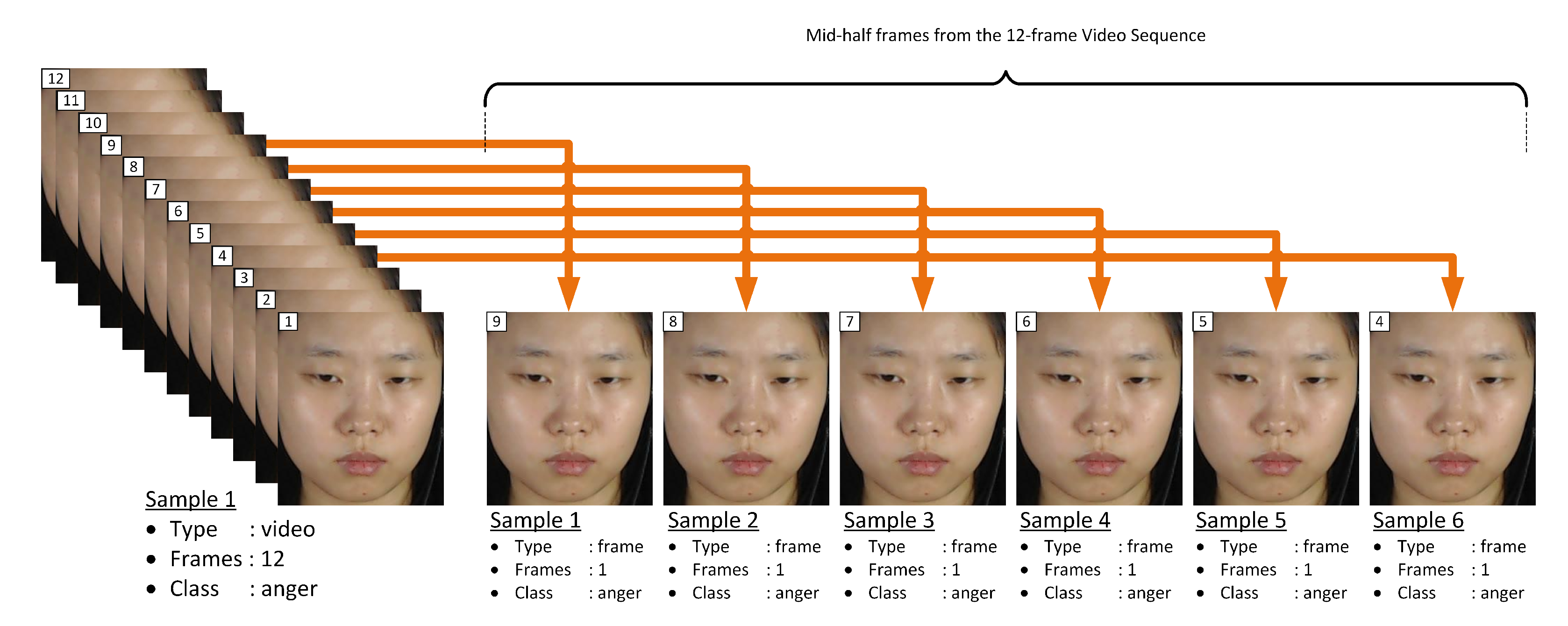
To further justify our motive of the proposed single frame-based analysis for fast computation and better accuracy, this paper analyzes the performance of the single frame-based approach under three different setups. For each setup, set(s) of samples are extracted using the corresponding Equation from (
5) to (
7). More details of these Equations are presented in
Section 4.
5. Results and Discussion
To evaluate the proposed feature extraction algorithm tested on the single frame-based samples generated in this work, accuracy and F1-score are measured for four different datasets (i.e., SMIC, CASMEII, CAS(ME) and SAMM). Here, the accuracy refers to how good the predictions are on average, that is, “the number of emotion samples correctly predicted” by “the total number of testing samples”. On the other hand, the F1-score is the harmonic mean of precision and recall, where recall is the ratio of “the total amount of positive instances that were actually predicted”, while precision is the ratio of “positive instances among the predicted instances”. In addition, the validation technique used is leave-one-subject out cross validation (LOSOCV) in order to fit well with the frame-based samples.
Table 6 tabulates the results in terms of accuracy and F1-score. From these tables, Exp. I refers to the evaluation of the proposed algorithm with only the the middle frame from each video sequence to create single frame-based samples. While, Exp. II and III refers to the evaluation for mid-three and mid-half frames from the video sequence, respectively. From each experiment, features by Full-face graph and the proposed FACS-based graph are analyzed.
As shown in
Table 6, Exp. I, with Full-face graph features, SMIC yields the lowest accuracy and F1-score (i.e., 63.54% and 0.58) and SAMM yields the highest accuracy and F1-score (i.e., 80.28% and 0.80). On the other hand, for FACS-based graph features, SMIC also yields the lowest accuracy and F1-score (i.e., 70.25% and 0.69), and SAMM yields the highest accuracy and F1-score (i.e., 87.33% and 0.87). In the case of Experiment II which considers Full-face graph features, SMIC yields the lowest accuracy and F1-score (i.e., 66.90% and 0.65) while SAMM yields the highest accuracy and F1-score (i.e., 74.00% and 0.70). Similarly, for FACS-based graph features, SMIC yields the lowest accuracy and F1-score (i.e., 76.67% and 0.75), while SAMM yields the highest accuracy and F1-score (85.85% and 0.84). Finally, for the case of Experiment III which considers Full-face graph features, also SMIC yields the lowest accuracy and F1-score (i.e., 62.34% and 0.60), while SAMM yields the highest accuracy and F1-score (i.e., 78.40% and 0.75). Similarly, for FACS-based graph features, SMIC yields the lowest accuracy and F1-score (i.e., 64.64% and 0.53) while SAMM yields the highest accuracy and F1-score (i.e., 81.43% and 0.81).
From these results, Experiment I outperformed Experiment II and III using the proposed FACS-based graph features analysis on SAMM with the highest accuracy and F1-score of 87.48% and 0.87, respectively. Similarly, Experiment I outperformed Experiment II and III using the Full-face graph features analysis on SAMM with the highest accuracy and F1-score of 80.28% and 0.80, respectively. As observed here, Experiment I achieved the highest accuracy due to two reasons; firstly, the size of samples per subject for each dataset is smaller and secondly, the selected frame (i.e., the presentation of mid-frame as the input frame from each video sequence) is more precise in comparison with other datasets (i.e., SMIC, CASMEII and CAS(ME)).
To further evaluate the performance of the proposed graph algorithm,
Table 7 and
Table 8 record the accuracy and F1-score of the conventional methods considered for comparison against the proposed method. As shown in
Table 7 and
Table 8, studies from References [
13,
40,
41,
42,
43], registered the highest accuracies of 64.02%, 62.90%, 68.29%, 54.88% and 54.00% with F1-score of 0.64, 0.62, 0.67, 0.53 and 0.52 over SMIC dataset. While, the studies in References [
15,
24,
29] registered the highest accuracies of 76.60%, 80.30% and 88.28% with F1-score of 0.60, 0.75 and 0.87 over CASMEII dataset. On the other hand, the proposed algorithm with Full-face graph registered the highest accuracies of 66.54%, 73.45%, 74.41% and 80.28% with F1-score of 0.65, 0.70, 0.80 and 0.87 over SMIC, CASMEII, CAS(ME)
and SAMM datasets, respectively. While the proposed algorithm with FACS-based graph registered the highest accuracies of 76.67%, 75.04%, 81.85% and 87.33% with F1-score of 0.75, 0.74, 0.80 and 0.87 over SMIC, CASMEII, CAS(ME)
and SAMM datasets, respectively.
To sum up, the results presented in
Table 7 and
Table 8 suggest that the proposed FACS-based graph features outperformed the current state-of-the-art algorithms with accuracy and F1-score of 76.67% and 0.75 over SMIC, 81.85% and 0.80 over CAS(ME)
and 87.33% and 0.87 over SAMM, respectively. However, the reported results from Reference [
15] on CASMEII outperformed the proposed algorithm with accuracy and F1-score of 88.28% and 0.87, respectively. This suggests that the CASMEII datasets did not work well with the proposed algorithm, which could be due to the performance limitation of the landmarks detection tool used in our experiments (i.e., dlib tool).
In addition to the accuracy and F1-score, the computational time of the proposed feature extraction algorithm was investigated. The processing time of the proposed algorithm is analyzed on Xeon Processor E5-2650 v4 @ 2.4Ghz with 24 logical processors. The computation time taken to extract the features using one-to-all is approximately 3.1 ms. For the proposed feature extraction algorithm based on FACS, it takes approximately 2 ms to compute features per sample. Based on this analysis, the computational performance of the proposed feature extraction algorithm using either one-to-all or FACS-based significantly reduced the processing time of feature computation. This suggests that the proposed feature extraction algorithm is potential for real-time ME recognition with high speed camera integrated with fast facial landmark detection and accelerated SVM classification.
Table 9 lists the performances of computation time from References [
7,
8,
44] towards the implementation of real-time ME recognition. Knowing that the reported processing time from each article was based on the machine used for analysis, and therefore, no conclusions on the processing time differences. As shown in
Table 9, the first implementation of fast feature extraction algorithm by Reference [
7] using tensor unfolding with GPU achieves up to 31.9× faster than the un-optimised LBP-TOP on CPU. The processing time for feature computation per sample with 50 × 50 is 107.39 ms. Similarly, Reference [
8] implemented a GPU based LBP-TOP on CUDA programming platform and achieved an impressive performance of 2.98 ms for feature computation per sample with 140 × 170. On the other hand, Reference [
44] proposed method that computes the difference of onset and apex-frames as features. As reported by the authors, this method achieves 9 ms of processing time per frame for 640 × 480.
While acknowledging the differences in computing resources may have potentially contributed to the superiority of our method in computation time, the benchmark algorithms require several pre-process stages including face detection from the original raw video sequence, face alignment, face cropping and onset-offset detection. These pre-processings introduce more challenges of computational time, which limits the performance of the accelerated feature extraction. In addition, these challenges have not been addressed by any research so far, which makes these algorithms more crucial for real-life applications.
On the other hand, in the proposed method, the computed features using all landmark points requires 3.1 ms. In addition, the computed features by using selected landmark points based on FACS requires 2 ms. On the contrary, based on the benchmark studies, the proposed algorithms requires facial landmark detection as the only pre-processing stage. Then, by using the facial landmark points obtained from the processing stage, as described in
Section 3.
Thus, in comparison to the benchmark studies, the proposed FACS-based graph features achieve well above the required speed of 200 fps for real-time ME recognition, leaving 1.2 ms to compute the facial landmark detection and classification, while 0.8 ms to compute the face detection and classification for Full-face graph features. However, the performance of the proposed method is limited due to two major reasons, namely; (i) the definition of AUs are based on the FACS system presented in Reference [
10], which is described as not perfect to give an objective stance and emotion mapping [
24] and (ii) the instability of dlib facial landmark detection due to the factors including image lighting, subject pose and unintentional partial occlusion of subject face (such as wearing eyeglass or having long hair).

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






