1. Introduction
Cultural heritage bears witness to life and history, provides an identity to nations, and represents an irreplaceable source of inspiration. Its importance from cultural, historical, and economic points of view is invaluable; thus, its preservation and valorization are crucial topics for our society. Natural aging and deterioration due to external agents endanger artworks such as paintings, sculptures, and architecture, and therefore diagnostic tools are needed for monitoring and preservation.
Monitoring historical artistic heritage consists of the evaluation of possible modifications of some characteristics of the object under observation. When it comes to a artwork or, more generally, a mono- or polychromatic surface, color is one of those characteristics, as it is easily perceivable by the human eye, allows one to distinguish an artwork, and provides information on the nature and status of an artwork.
Color analysis on artworks is generally performed via specific instruments such as colorimeters and spectrophotometers, both of which use sophisticated technologies to accurately and precisely quantify and define color, working in a device-independent color space as Commission Internationale de l’Éclairage (CIE) L*a*b* [
1,
2] This allows for objective assessment of color changes in order to monitor the state of the painting over time and appropriately plan periodic protection or restoration actions. Color studies of artworks could also make use of Infrared (IR) and Ultraviolet (UV) data (by means of, e.g., infrared reflectography, UV–Visible spectrophotometry, UV reflectance, etc.) or X-ray fluorescence spectroscopy (XRF) [
3,
4].
However, several drawbacks may limit the efficacy of such devices/methodologies. First, colorimeters and spectrophotometers give, as with XRF, pointwise measurements; thus, color studies on large areas require several time-consuming repetitions. Furthermore, even though spectrophotometers are defined as non-invasive devices [
5], they must perfectly lean onto the artwork surface in order to exclude external light radiation, thus, risking ruining the painting. Finally, it is still rare nowadays that small laboratories are equipped with the abovementioned costly devices.
In order to address such issues, recent studies have proposed performing color monitoring through photographic documentation. Here, the necessary equipment is conceivably minimal and considerably cheaper, consisting of a professional digital camera and a photographic set with adequate lighting; then, the color data of each pixel of the selected area can be stored from a single photoshoot, limited only by illumination [
6]. However, uncorrected digital data are not directly comparable, in terms of quantitative reliability, to the standard provided by the more specific spectrophotometric instrumentation. In addition, a well-defined procedure consisting of camera calibration, arrangement of lights, and positioning of the artwork, although necessary, is not sufficient per se for a correct comparison of digital data with colorimetric data. Finally, another major problem when using a digital camera for measuring color is that consumer-level sensors (either CCD or CMOS type) are typically uncalibrated.
Therefore, camera characterization is needed, i.e., some specific digital image processing to transform raw color digital values into objective L*a*b* values equivalent to colorimetric measures.
A common approach to minimize the difference between digital and colorimetric determinations relies on the application of a correction based on a least-squares regression to the uncalibrated digital data. Linear [
7,
8], nonlinear, and mixed [
9] approaches have all been described in the literature. Regarding nonlinear regressions, one can mention polynomial regressions [
10,
11], neural networks (NNs) [
12,
13], and look-up tables [
14]. In addition, the problem of different color spaces based on the acquisition device must be addressed. Indeed, camera data usually refer to RGB or sRGB color spaces. Several approaches have been proposed [
15], such as linear or quadratic models, neural networks for L*a*b* regression starting from RGB values, and models requiring RGB data to be converted into XYZ values, which are then used to derive L*a*b* values, with and without a linearization of sRGB data via a gamma model. Gamma correction is also involved in the method [
16].
Further aiming at minimization of the correction error, other features to be preserved may be considered. For instance, characterization should be robust across different illuminants and reflectance types, and across noise [
17,
18,
19].
To achieve better results, the use of digital image processing techniques for camera characterization can also be combined with different disciplines. Indeed, a multidisciplinary approach allows one to deal with specific features related to the heterogeneity of the data under analysis. Therefore, in order to overcome the lack of homoscedasticity required to apply a single-step procedure, an innovative approach combining pattern recognition and image processing techniques with chemistry information is proposed here.
In the present study, 117 tiles from the database of diagnostic analyses of The Foundation Centre for Conservation and Restoration of Cultural Heritage “La Venaria Reale” (in collaboration with the National Institute of Metrological Research and Laboratorio Analisi Scientifiche of Regione Autonoma Valle d’Aosta) represent the basic dataset [
3,
20].
As proposed by the state-of-the-art literature, the methods of linear regression, polynomial regression, and NN [
8,
9,
19] were initially applied herein to the whole dataset, but the resulting performances unfortunately proved to be not satisfactory. It is worthwhile mentioning that a preliminary camera calibration using the X-Rite ColorChecker Passport Photo failed to provide satisfactory results [
9], as expected, due to the limited color content of such a color chart.
To understand the reason for such poor results, the work was adapted by conducting a closer investigation of the pigments’ characteristics and their corresponding statistical analysis in photographic images in order to overcome the significant lack of the homoscedasticity feature that is required for proper application of approaches in the literature, which work at a global level.
Consequently, from the perspective of optimizing the analysis, the original idea proposed herein is to apply state-of-the-art characterization methods to clusters of data rather than to the whole digital dataset, selected by means of two different criteria, i.e., the color and chemical properties of pigments. Regarding the latter, based on Kremer code, the main chemical element can be objectively defined for each pictorial layer analyzed.
To overcome the issue of a small amount of data and to find one-to-one correspondence between an image and colorimetric data, samples referring to the same tile are sorted by hue values, which provides coupled data and the use of supervised methods for precise and punctual color correction.
Thus, the application of several methods for camera characterization to numerous clusters of the base dataset is described hereinafter, in order to minimize the difference between digital and spectrophotometric quantitative color data, and therefore validate a handy diagnostic tool such as a digital camera for color determination. The best characterization approach results were achieved from a polynomial regression, while the predominant factor that affects the efficacy of the color correction could be found in the chemical composition, more precisely, in the nature of the central element. The best results were those splitting the data by chemical composition. In addition, the proposed method also proved to be effective with organic pigments, which could not be analyzed via standard approaches such as XRF; in fact, the latter has been employed to identify the presence of inorganic pigments, characterized by elements with an atomic number higher than 13. Instead, other non-invasive approaches for the study of organic pigments (usually referred to as “lakes”) include IR and Raman spectroscopy, but still require rather sophisticated instrumentation.
The considered approaches are briefly presented in
Section 2, along with the dataset. Additionally, details on how data were collected and split into clusters and how camera images were used are provided.
Although a complete color analysis of artworks is also based on IR and UV data, the scope of the present study is to investigate how deep an analysis performed with traditional photographic data can be.
2. Materials and Methods
2.1. Background
Sensors’ responses to light distribution are clearly defined in the literature [
21,
22]. For the sake of clarity, let
be the illuminant spectral power distribution falling on the surface patch (
is the wavelength), and let
be the reflectance function of the material the object is made from (or that its surface is painted with), so that the spectral power distribution
can be expressed as follows:
where
is the spectrum of the light that reaches the sensor and is associated with the corresponding pixels of the image.
Then, let
be the spectral filter function of the sensor, and define the sensor’s response to
as follows:
As mentioned in the Introduction, in the present study, camera and colorimeter sensors are involved. Hence, hereinafter, whenever refers to the camera, it will be referred to as , while the colorimeter, , will be referred to as (which will be the reference measurement). Specifically, based on the available data, is a three-dimensional vector , laying in the RGB color space. Similarly, the colorimeter response comes from the device-independent color space CIE L*a*b*, namely .
In order to perform an efficient correction on error-prone measurements of color changing, such as those deriving from commercial cameras, an optimal transformation
such that
must be found. In fact, the final value of such a correction is only an approximation of the real corresponding
value, namely
, due to the different nature of the considered color spaces, to noise, estimation, and computation errors, etc. Some constraints can be added to improve the precision of the correction and are discussed later in the paper. The general requirement for the function
is to be error-minimizing, i.e.:
where
N is the number of color triplets in the dataset,
is a color space transformation to ensure that
and
refer to the same color space, and
is the norm. In the present manuscript, the considered norms will be the root mean squared error (Euclidean distance) and ΔE
00 [
23]. In addition, a similarity measure will also be involved, i.e., Pearson’s correlation coefficient.
In the following, since is properly designed to correct to be more similar to , hence, both and are in the CIE L*a*b* color space, and is assumed to be the identity function.
In general, methods in the literature are applied to the entire dataset. However, it appeared that no conditions for a single correction were present because of the non-homoscedasticity of the data. Hence, the methods were applied to clusters of tiles that could be determined according to some criterion. Here, this multi-cluster approach is based on either the chemical element or color, which is the major novelty of this study.
In this paper, the dependance of the color on the predominant chemical composition as well as on its chromaticity is investigated. More specifically, let
be the i-th cluster of color, based on either the chemical properties or the chromaticity. The purpose is to find many functions
, one for each cluster, which, of course, depends on the cluster that the input color belongs to:
2.2. Instrumentation
According to the CIE standard definition [
24], reference measurements were made using a Konica Minolta CM2600d spectrophotometer (Konica Minolta, Ramsey, NJ, USA) [
25] with the following setup: standard observer at 10°, illuminant D65, and acquisition SCI. Five measurements were acquired for each pictorial layer.
Photographic image data were acquired with a Lumix DMC-FZ200 camera (Panasonic, Osaka, Japan). The following image acquisition setup was used: The camera was placed vertically at 46.5 cm from the samples. The angle between the axis of the lens and the sources of illumination was approximately 45°. Illumination was achieved with two Natural Daylight 23 W fluorescent lights (OSRAM, Munich, Germany), color temperature 6500 K, reproducing the standard D65 illuminant. The photos were shot in a dark room. The settings of the camera are summarized in
Table 1.
2.3. Dataset
As previously mentioned, the dataset of the present study consisted of 117 tiles from the database of diagnostic analyses of La Venaria Reale [
20]. A picture for each tile was taken to enable analysis.
Figure 1a shows an example of a photographic picture of the tables from Venaria.
In the table, each pigment (
Figure 1b) is presented in a mixture with two binders: polyvinyl acetate (PVAc) (column on the left) and linseed oil (column on the right). Then, the painted surface is divided into 3 rows. The first two present 2 different finishings: terpene resin (stripe on the top) and acrylic resin (middle stripe), while the third one is unprotected. For the present study, only the unprotected and the linseed oil sectors were taken into consideration (the red box in
Figure 1b), because the linseed oil technique is the one most used by painters since the 15th century. The central portion of the camera acquisition was considered in order to avoid specularity and saturation problems.
Figure 2 shows some of the selected parts of tiles involved in the study.
To address the local color inhomogeneity of tiles, the characterization was performed by taking into consideration five measurements via the colorimeter and five RGB triplets extracted from the pictures in order to create paired couples and to develop a robust supervised color correction.
Specifically, pixels from each tile were sorted by hue (in ascending order). Then, five triplets were extracted, namely the first one (i.e., the one with minimal hue), the last one (i.e., the one with maximal hue), and the ones corresponding to the 25th, 50th, and 75th percentiles. This was done to obtain as many samples as possible for the reference dataset.
2.4. Linear Regression
The method consists of estimating the L*, a*, and b* values separately via linear regression. In particular, let
,
, and
be the regression coefficients for L*, a*, and b*, respectively, so that the estimated values are
,
, and
, where
,
, and
are the colorimeter values. To find the best characterization of the camera data with
and
, the constraints
,
, and
are added, yielding the following:
2.5. Polynomial Regression
The polynomial regression approach consists of mapping a polynomial expansion of the device RGB values to estimated L*a*b*. In the following, the polynomial
was used:
The corrected L*a*b* triplet
is obtained via the following equation:
where
is the
tranformation matrix, which is derived via a pseudo-inversion procedure as in [
11].
2.6. Hue-Plane-Preserving Camera Characterization—Weighted Constrained Matrixing Method
The Hue-Plane-Preserving Camera Characterization—Weighted Constrained Matrixing (HPPCC-WCM) method [
19] is aimed at ensuring that the characterization preserves the hue plane and minimizes error. Starting from the camera data, the transformation matrix is defined in function of the device hue angle
and of the parameter
referring to the order of the transformation, as follows:
where
is the number of training coupled colorimeter–camera data (
),
is the transforming matrix
,
, with
being the
i-th training color hue angle, and
.
To sum up, the color correction here proposed is as follows:
2.7. Data Grouping
To avoid the application of each method in a global way, the dataset under analysis was clustered according to two different criteria, i.e., according to chromatic appearance and the chemical composition, with reference to the central metal atom.
Table A1 in
Appendix A shows the available pigments and relevant features (pigment name and color, chemical composition, chemical cluster, and chromatic cluster). Regarding the chromatic appearance, five classes were subjectively identified. Conversely, regarding the chemical composition, Kremer code [
26] was objectively considered. The clusters and relevant numbers of tiles are summarized in
Table 2.
Some considerations regarding this clustering are made in the following.
In general, three phases drove the choice of the different chemical clusters. Firstly, three major classes were considered referring to the elements most spread in the dataset: iron, lead, and copper (Phase 1).
Then, by looking at the copper class, it was found that some tiles were organic lakes, generating the idea that this clustering method could also be effectively applied to organic dyestuff. Accordingly, the clusters “copper (organic)” and “organic” (collecting all the lakes in the dataset) were considered (Phase 2).
Finally, a mixed class was also considered, characterized by the presence of either iron, manganese, or cobalt, i.e., vicinal transition metals with very similar electronic properties (Phase 3).
Regarding the chromatic clusters, the gray cluster collects pigments with similar R, G, and B values (thus also including black and white pigments).
In
Table A1, one can notice that the color grouping of some pigments differs from the chromatic class to which they belong, according to the closest color perception. For example, tile number 57, despite being visually brown/violet, also has shades of red given by its chemical description provided by Kremer, which identifies it as a red pigment.
2.8. Proposed Method
The proposed approach involves a combination of the aforementioned procedures. The data grouping procedure splits the dataset into clusters, which are homogeneous in terms of either color or chemical properties. The color correction methods are independently applied to each cluster. Recall that colorimetric and camera data are precisely coupled by hue, as specified in
Section 2.3. Altogether, this leads to an adaptive color correction method.
4. Discussion
First, the obtained results are discussed in terms of the values of the metric considered. Then, the importance of the preliminary cluster analysis is highlighted, with observations mainly relevant to the two clustering procedures. To conclude, possible applications of the proposed pipeline are disclosed, along with the limitations of the present research and foreseeable future developments.
4.1. Discussing the Considered Indexes’ Values
Table 3, referring to the application of the methods to the whole dataset, shows a strong agreement among the traditional metrics of correlation, the RMS on the L*, a*, and b* parameters, and the color distance
.
In general, for both the whole dataset and the different selected clusters, the characterization method that produced the best color correction was polynomial regression, which was always able to improve similarity with colorimetric data as compared with uncalibrated data. Linear regression dramatically worsened the result as compared with the original data, as did the HPPCC-WCM method on most of the indexes. However, even though polynomial regression always showed improvements, according to the ΔE00 distance, the HPPCC-WCM method outperformed the others since both the method and the metric rely on the more recent CIE standards, facing some drawbacks of the traditional standards.
Table 4,
Table 5,
Table 6 and
Table 7 confirm the best performances of polynomial regression, which improved uncalibrated data on all clusters, even in the challenging case of copper (organic), where the acquired colorimetric and photographic L parameters showed a strong misalignment.
Table 8 gives further evidence that the ΔE
00 metric can solve some problems of traditional colorimetry as, except for the lead cluster, it gives better improvements. Additional results reported in
Table 11 show that the blue, green, and, to a lesser extent, the gray clusters might benefit from hue preservation and the new metric, as declared in the new standard scope.
The Pearson coefficients were already high for the whole dataset; hence, the improvement obtained by clustering was less relevant for this index. Conversely, by taking into consideration RMS, ΔE
00, and Δ, the improvement when passing from the global correction to the cluster-based correction was significant, as they both decreased when focusing on chemical and chromatic clusters. In fact, the expression of the prediction error in terms of color units is only intended to evaluate the human perception of the correction; indeed, recall that if the error is approximately less than 2.2 color units, then, the difference is considered to be imperceptible to the human eye. It is worthwhile noting the improvement in this index, which decreased from a mean value across classes of 27.56 (
Table 12, “uncalibrated”) to 13.95 with respect to the chemical clusters (
Table 12, “polynomial regression”), and from a mean value across classes of 24.14 (
Table 13, “uncalibrated”) to 13.26 with respect to the chromatic clusters (
Table 13, “polynomial regression”). In such a case, clustering based on the chemical components is the most effective procedure, i.e., the one producing the lowest error. It is expected that more sophisticated algorithms, which could be investigated in future developments of the present study, would lead to an even lower color unit error.
4.2. The Significance of the Clustering Procedure
Splitting the dataset into clusters led to a better color correction for both splitting criteria (chromatism or chemical composition). The efficacy of clustering can be appreciated by comparing the value of, for example, the Δ index for the whole dataset (
Table 3, 16.60 after polynomial regression characterization, with a 32% decrease with respect to the value for the uncalibrated data) with the values for the single clusters in
Table 12 and
Table 13, for example, for the “lead” cluster, the value is 9.67, with a 54% decrease after characterization. Therefore, one can infer that the clustering procedure effectively addresses the homoscedasticity of the data. Indeed, the major contribution of the present study is the efficiency of the coupling between clustering and application of some state-of-the-art color correction methods. In addition, it is worth stressing that, although one might expect better results and a more effective color correction from chromatic clusters, the best correction was provided by chemical clusters. This is likely due to the objectivity of the chemical component criterion for defining clusters, while chromatic properties are more dependent on human perception, thus, leading to less homogeneous classes.
To stress once more the novelty of the present study, to the best of our knowledge, such an approach as well as the results relevant to the different clustering criteria are unprecedented.
4.3. Chromatic Clusters
As outlined above, clustering by chromatism seems less effective for color correction purposes. The perceived colors driving the selection of the chromatic clustering depend, to some extent, on the observer, and therefore are subjective. In addition, several color shades are present, which may lead to heterogeneous classes. Of course, having more samples for each tile would allow one to split the data into more classes, each being characterized by a closer chromatic similarity; as a result, the training phase would benefit, thus, conceivably leading to better color correction.
The correction provided by the polynomial regression method on the coordinates of the Lab color space suggests some additional considerations, recalling that “L” represents the perceptual lightness, while “a” and “b” refer to the four colors in the opposite component model of human vision, i.e., red, green, blue, and yellow.
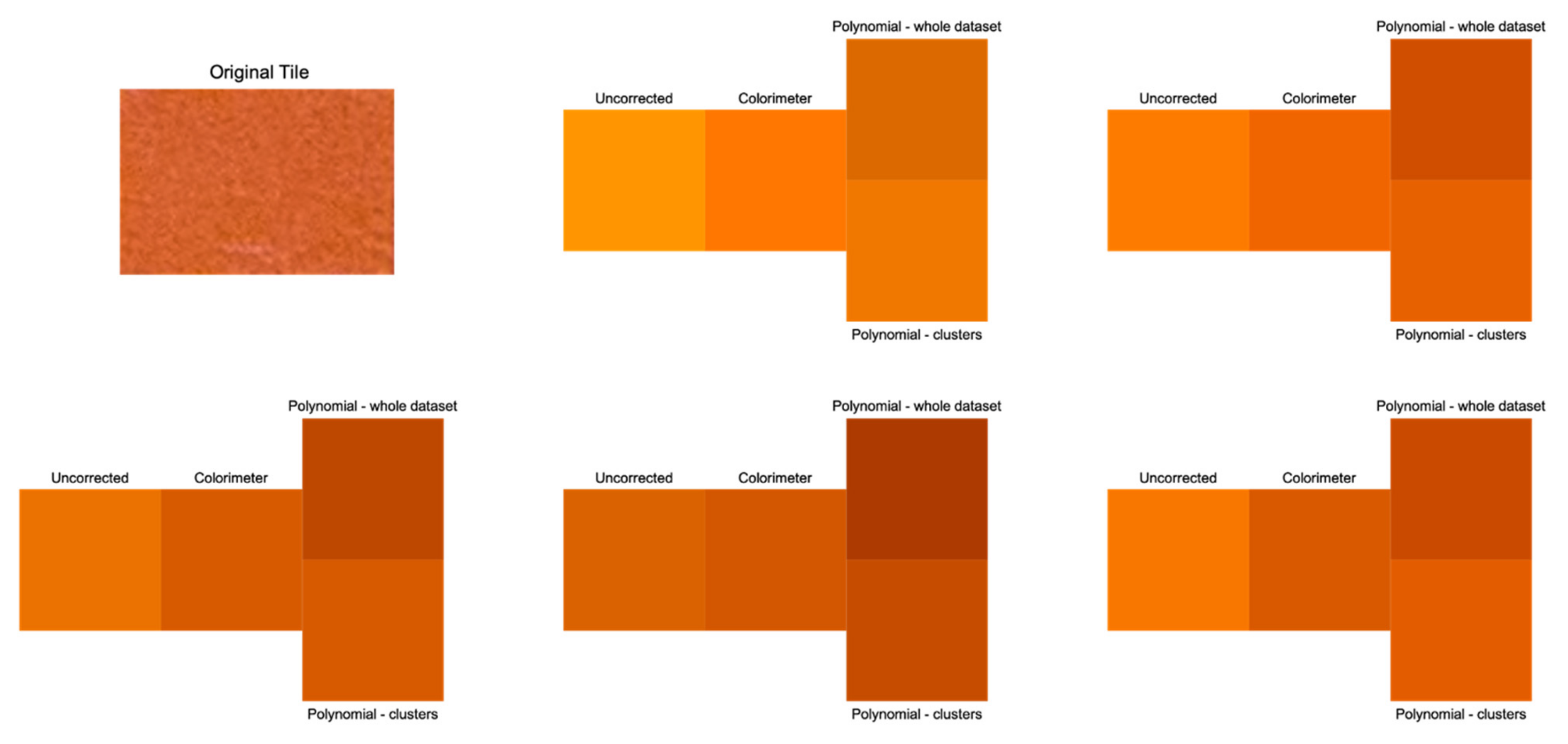
The most improved coordinate was L, meaning that this procedure addresses the problems in terms of the lightness sensitivity of photographic data. Without correction, the error is so high that the observer perceives a consistently different color with respect to the colorimetric data (see
Figure 3).
Regarding the coordinates “a” and “b”, it is interesting to consider the chromatic class of gray. The values in this class are supposed to be similar, and so the difference between colorimeter and photographic data should also be similar. However, by looking at the RMS index (
Table 10), we found that the difference between colorimeter and photographic data was much higher for “b” than for “a”. Conversely, once the values were corrected with polynomial regression, the errors were similar, thus, suggesting that the procedure is useful to address some imbalance for the gray class.
4.4. Chemical Clusters
The criterion based on chemical composition is more univocal, an aspect that surely contributes, in general, to the results being more similar as well as rewarding across the considered classes.
In particular, the RMS index mirrors a gratifying, effective color correction for the main elemental clusters (lead, iron, and copper, see
Table 6) after polynomial regression characterization.
Regarding the additional elemental classes reported in
Table 2, particular attention must be paid to the copper-based samples. In fact, the “copper” cluster of
Table 2 (16 samples) also included nine organic samples, where copper was the metal cation of an organic salt, which made up the selected subcluster defined as “copper (organic)”. In terms of the RMS index, both the “copper” cluster and the subcluster performed extremely well (
Table 6 and
Table 7, respectively) as far as the “L” component was concerned, while the components “a” and “b” did not seem to be significantly corrected for the subcluster by the characterization method of choice. Nonetheless, we paid attention to the consistent number of tiles containing organic pictorial matter (either organic dyes or metal salts of organic acids); satisfactorily enough, the rather crowded (34 samples of lakes) “organic dyes and salts” cluster responded positively to the polynomial regression characterization (as compared with the values of the RMS index in
Table 7 or of the ∆ index in
Table 12) or to the HPPCC-WCM treatment (as compared with the value of the ∆E
00 index in
Table 8).
The performance provided by the cluster of lakes represents, in our opinion, a further original and very interesting aspect of the camera characterization procedure herein. This is because the identification and study of organic matter on pictorial artworks cannot be achieved by means of XRF, a non-invasive technique that is widely applied in the presence of pigments containing heavy metals, but which fails to detect organic dyestuff because C, N, and O atoms are too light. Instead, the current approach based on the correction of digital data grouped in elemental clusters does not depend on the atomic weight, and thus opens very appealing perspectives as to the analysis of lakes. Developments and applications to study cases are necessary to sustain this hypothesis.
A first hypothesis about the reason why elemental clustering is a good approach is suggested by the results of the analysis on the mixed “iron, manganese, and cobalt” cluster. In fact, these three elements are transition metals adjacent in the periodic table, whose electronic configuration differs only for the number of electrons at the internal level, with the external one being identical for all three. The good results obtained for such a mixed class may mean that the proposed approach is sensitive to the outermost electronic level. Of course, more experimental trials are needed to validate the hypothesis, particularly by selecting other mixed clusters responding to the same characteristics.
4.5. A Possible Usage of the System for the Programming of Restoration Actions
A main concern about cultural heritage is the preservation of artwork for future generations. Of course, artworks, whatever the typology, inevitably tend to change or degrade with time due to several different causes, and restoration campaigns must be conducted whenever necessary. As far as pictorial artworks are concerned, color is surely the main sentinel to be observed in order to decide what actions to take. A handy and low-cost tool such as a digital camera would be optimal for frequent periodic control on artworks, as well as on large surfaces. In this way, time-dependent data describing the state of the paintings could be easily collected and analyzed preliminarily to further deepen more sophisticated analyses, if necessary, prior to a restoration action.
To this end, repeated periodical collections of data are necessary to verify the feasibility of selecting a parameter as a valid index of color deterioration. While elemental clustering has proven optimal for the identification of color, it could be foreseen that chromatic clustering would be best to handle the fading/deterioration of color with time. Of course, at the present time, this is only a conjecture to be verified in the future as a compulsory development of the present study.
4.6. Limitations and Future Developments
First, the amount of available data needs to be increased, as it is supposed that it would lead to better correction, at least on statistical grounds.
Of course, the present study cannot be limited to “theory”; in addition to the desirable significance of the method outlined in the previous paragraph, a main interest would be the application of the training to real cases in order to perform identification and study of the pictorial layers of an unknown composition. Thus, once the chemical clusters have been characterized, one can consider an “unknown” painting and focus on a particular area. If such an area fits a particular cluster, i.e., proper color correction is obtained by considering the parameters for that class, then it would mean that the relevant chemical elements are present in the considered area.
A continuing collaboration with the laboratories of “La Venaria Reale” and contacts with museums or galleries would surely satisfy both the outlined forms of progress and enable the development of a novel machine-learning-based approach, which is presently hampered by the limited size of the available dataset.
5. Conclusions
A dataset of digital camera photographs and of colorimetric measurements on 117 tiles from the database of diagnostic analyses of The Foundation Centre for Conservation and Restoration of Cultural Heritage “La Venaria Reale” was collected and analyzed with the aim of minimizing the difference between digital and spectrophotometric quantitative color data, from the perspective of validating a handy diagnostic tool such as a digital camera for quantitative color determination.
To address the homoscedasticity of the data acquired, the current study proposed a supervised approach to camera characterization and color correction based on clustered data. To this end, within the dataset, samples were grouped into clusters based on either the chromatic or the chemical properties of the pigments.
Among the different approaches studied in the present study, a polynomial regression obtained the best results with both of the proposed clustering criteria. Thus, while the correlation between characterized photographic data and colorimetric data remains high when considering both the entire dataset and the single clusters, in the latter case, notable improvements can be seen in the three parameters considered to test the efficacy of the characterization (i.e., RMS, ΔE00, and Δ). The central thesis that the piecewise method improves prediction accuracy was supported by numerical evaluations, even though, in absolute terms, the results were short of an error low enough to be imperceptible to a human expert.
In future studies, the aim could be to extend the dataset, for example, by developing the collaboration with La Venaria Reale. Of course, increasing the dataset would allow one to define new or more densely populated clusters, and therefore study the chemical and chromatic properties of the pigments in more detail, hopefully confirming the hypotheses above. A larger dataset may substantially improve the error, and therefore achieve imperceptible differences between the acquired data and the corrected data.
Furthermore, different approaches could be investigated, no longer based on the mean value of the colorimetric data, but rather looking for other significant parameters to perform the analysis. Additionally, further applications of the proposed approach are being investigated, such as applying it for characterizing the chemical composition of unknown artworks by leveraging the photographic data.


 ,
, 


{kind=link}
{kind=link}
{kind=link}