Olympic Games Event Recognition via Transfer Learning with Photobombing Guided Data Augmentation



Abstract
1. Introduction
2. Related Work
3. Data Collection and Proposed Framework
3.1. Data Collection: Olympic Games Event Dataset (OGED)
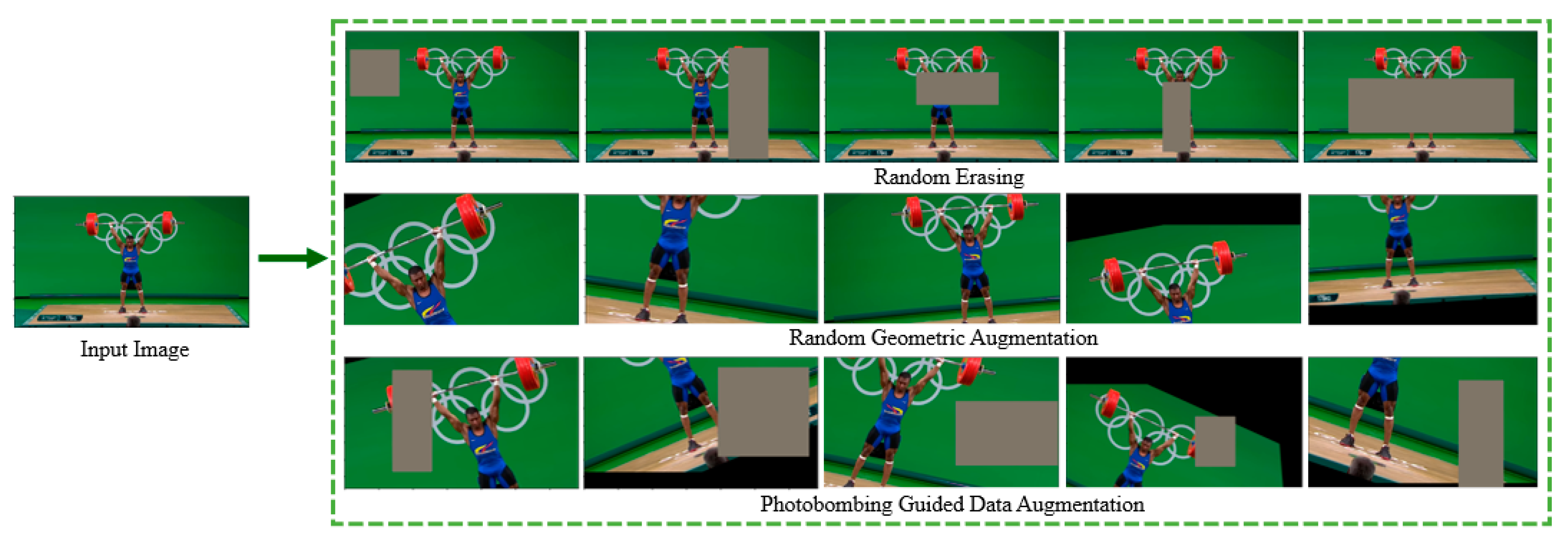
3.2. Photobombing Guided Data Augmentation
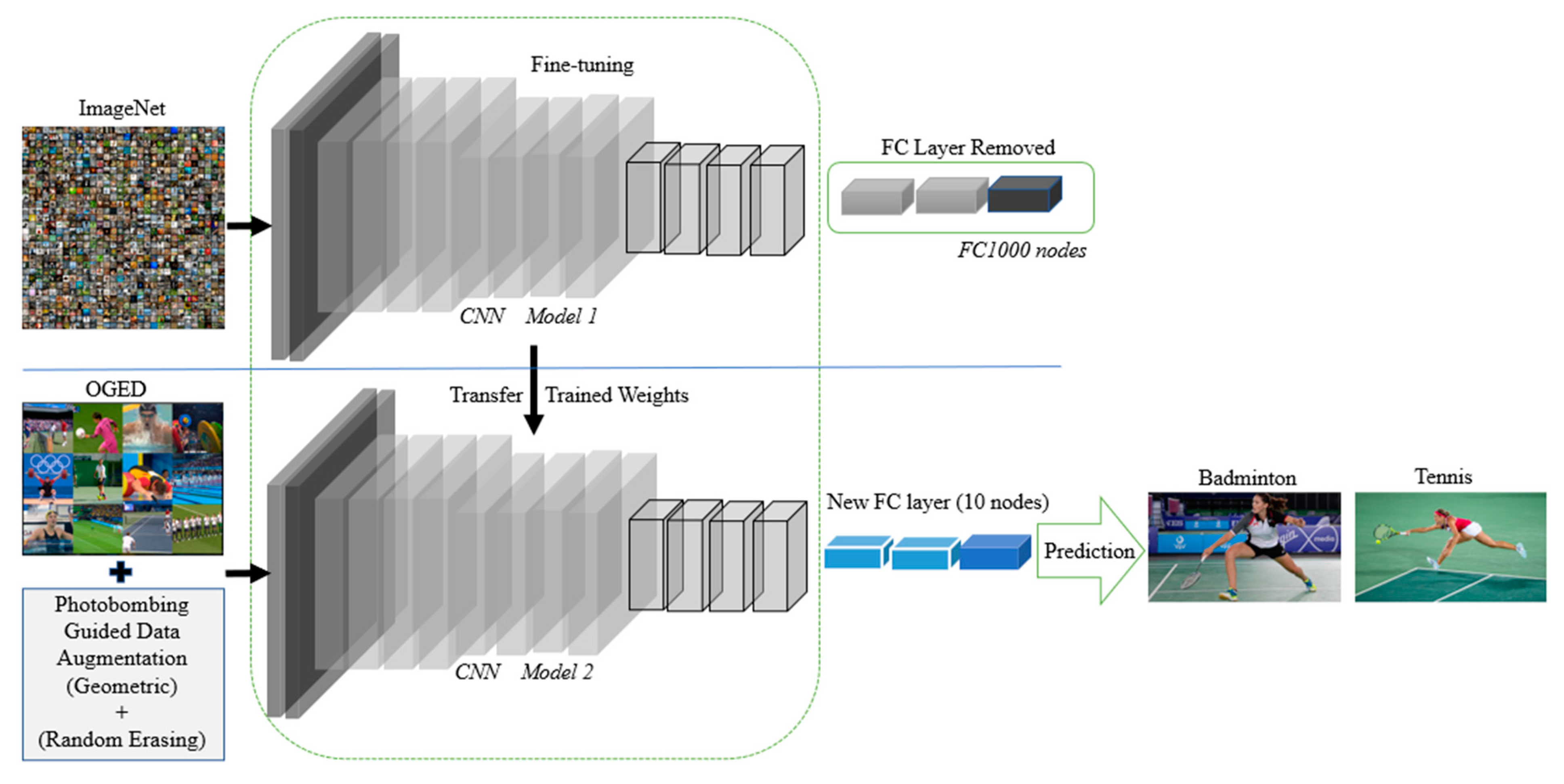
3.3. Transfer Learning Using Pre-Trained Models
4. Experimental Results
4.1. Experimental Settings
- Fine-tuning the network without data augmentation.
- Fine-tuning the network with geometric data augmentation technique where we perform rotation, translation, shearing, and horizontal flipping.
- Fine-tuning the network with randomly erased data augmentation technique [19].
- Fine-tuning the network with the proposed photobombing guided data augmentation.
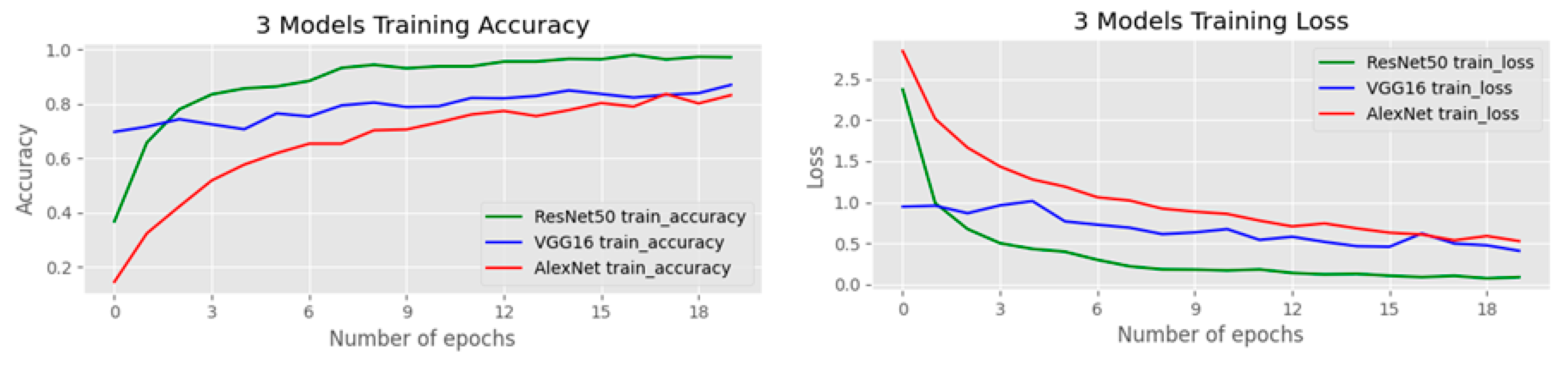
4.2. Performance of Pre-Trained Models with KNN
4.3. Experimental Results on OGED
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Shih, H.-C. A Survey of Content-Aware Video Analysis for Sports. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 1212–1231. [Google Scholar] [CrossRef]
- Stein, M.; Janetzko, H.; Lamprecht, A.; Breitkreutz, T.; Zimmermann, P.; Goldlucke, B.; Schreck, T.; Andrienko, G.; Grossniklaus, M.; Keim, D.A. Bring It to the Pitch: Combining Video and Movement Data to Enhance Team Sport Analysis. IEEE Trans. Vis. Comput. Graph. 2018, 24, 13–22. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 7–12 June 2017; Volume 39, pp. 640–651. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A Fast Learning Algorithm for Deep Belief Nets. Neural. Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Sargano, A.B.; Wang, X.; Angelov, P.; Habib, Z. Human Action Recognition Using Transfer Learning with Deep Represen-tations. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 463–469. [Google Scholar]
- Russo, M.A.; Kurnianggoro, L.; Jo, K.-H. Classification of sports videos with combination of deep learning models and transfer learning. In Proceedings of the 2019 International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’sBazar, Bangladesh, 7–9 February 2019; pp. 1–5. [Google Scholar]
- Nguyen, T.V.; Mirza, B. Dual-layer kernel extreme learning machine for action recognition. Neurocomputing 2017, 260, 123–130. [Google Scholar] [CrossRef]
- Nguyen, T.V.; Feng, J.; Nguyen, K. Denser Trajectories of Anchor Points for Action Recognition. In Proceedings of the 12th International Conference on Interaction Design and Children, New York, NY, USA, 24–27 June 2013; Association for Computing Machinery (ACM): New York, NY, USA, 2018; Volume 1, p. 1. [Google Scholar]
- Hong, Y.; Ling, C.; Ye, Z. End-to-end soccer video scene and event classification with deep transfer learning. In Proceedings of the 2018 International Conference on Intelligent Systems and Computer Vision (ISCV), Fez, Morocco, 2–4 April 2018; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA; pp. 1–4. [Google Scholar]
- Dixit, K.; Balakrishnan, A. Deep learning using cnns for ball-by-ball outcome classification in sports. In Report on the Course: Convolutional Neural Networks for Visual Recognition; Stanford University: Stanford, CA, USA, 2016. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Canziani, A.; Paszke, A.; Culurciello, E. An Analysis of Deep Neural Network Models for Practical Applications. arXiv 2017, arXiv:1605.07678. [Google Scholar]
- Maeda-Gutiérrez, V.; Galván-Tejada, C.E.; Zanella-Calzada, L.A.; Celaya-Padilla, J.M.; Galván-Tejada, J.I.; Gamboa-Rosales, H.; Luna-García, H.; Magallanes-Quintanar, R.; Guerrero-Mendez, C.; Olvera-Olvera, C. Comparison of Convolutional Neural Network Architectures for Classification of Tomato Plant Diseases. Appl. Sci. 2020, 10, 1245. [Google Scholar] [CrossRef]
- Dhankhar, P. ResNet-50 and VGG-16 for Recognizing Facial Emotions. Int. J. Innov. Eng. Technol. 2019, 13, 126–130. [Google Scholar]
- Tokyo 2020 Olympics. Available online: https://tokyo2020.org/en/sports/ (accessed on 22 November 2020).
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random Erasing Data Augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 13001–13008. [Google Scholar]
- Photobombing Definition. Available online: https://www.oxfordlearnersdictionaries.com/us/definition/english/photobombing (accessed on 22 November 2020).
- Cao, X.; Wang, Z.; Yan, P.; Li, X. Transfer learning for pedestrian detection. Neurocomputing 2013, 100, 51–57. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision; Springer: Berlin, Germany, 2014. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Romanan, D.; Zitnick, C.L.; Dollar, P. Mi-crosoft COCO: Common Objects in Context. In European Conference on Computer Vision; Springer: Cham, Germany, 2014; pp. 740–755. [Google Scholar]
- Chung, Q.M.; Le, T.D.; Dang, T.V.; Vo, N.D.; Nguyen, T.V.; Nguyen, K. Data Augmentation Analysis in Vehicle Detection from Aerial Videos. In Proceedings of the 2020 RIVF International Conference on Computing and Communication Technologies (RIVF), Ho Chi Minh, Vietnam, 14–15 October 2020; pp. 1–3. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Augmentation Method | AlexNet [4] | VGG-16 [5] | ResNet-50 [6] |
|---|---|---|---|
| Pre-trained Model—KNN (N = 1) | 48% | 56% | 71% |
| Pre-trained Model—KNN (N = 3) | 54% | 60% | 66% |
| Pre-trained Model—KNN (N = 5) | 53% | 62% | 72% |
| Pre-trained Model—KNN (N = 10) | 50% | 66% | 73% |
| Transfer Learning—without any data augmentation | 73% | 79% | 82% |
| Transfer Learning—with geometric data augmentation | 83% | 84% | 87% |
| Transfer Learning—with randomly erased data augmentation [19] | 76% | 82% | 89% |
| Transfer Learning—with photobombing guided data augmentation | 84% | 85% | 90% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohamad, Y.I.; Baraheem, S.S.; Nguyen, T.V. Olympic Games Event Recognition via Transfer Learning with Photobombing Guided Data Augmentation. J. Imaging 2021, 7, 12. https://doi.org/10.3390/jimaging7020012
Mohamad YI, Baraheem SS, Nguyen TV. Olympic Games Event Recognition via Transfer Learning with Photobombing Guided Data Augmentation. Journal of Imaging. 2021; 7(2):12. https://doi.org/10.3390/jimaging7020012
Chicago/Turabian StyleMohamad, Yousef I., Samah S. Baraheem, and Tam V. Nguyen. 2021. "Olympic Games Event Recognition via Transfer Learning with Photobombing Guided Data Augmentation" Journal of Imaging 7, no. 2: 12. https://doi.org/10.3390/jimaging7020012
APA StyleMohamad, Y. I., Baraheem, S. S., & Nguyen, T. V. (2021). Olympic Games Event Recognition via Transfer Learning with Photobombing Guided Data Augmentation. Journal of Imaging, 7(2), 12. https://doi.org/10.3390/jimaging7020012