
Deep Concatenated Residual Networks for Improving Quality of Halftoning-Based BTC Decoded Image





Abstract
1. Introduction
2. Related Works
2.1. H-BTC Image Compression
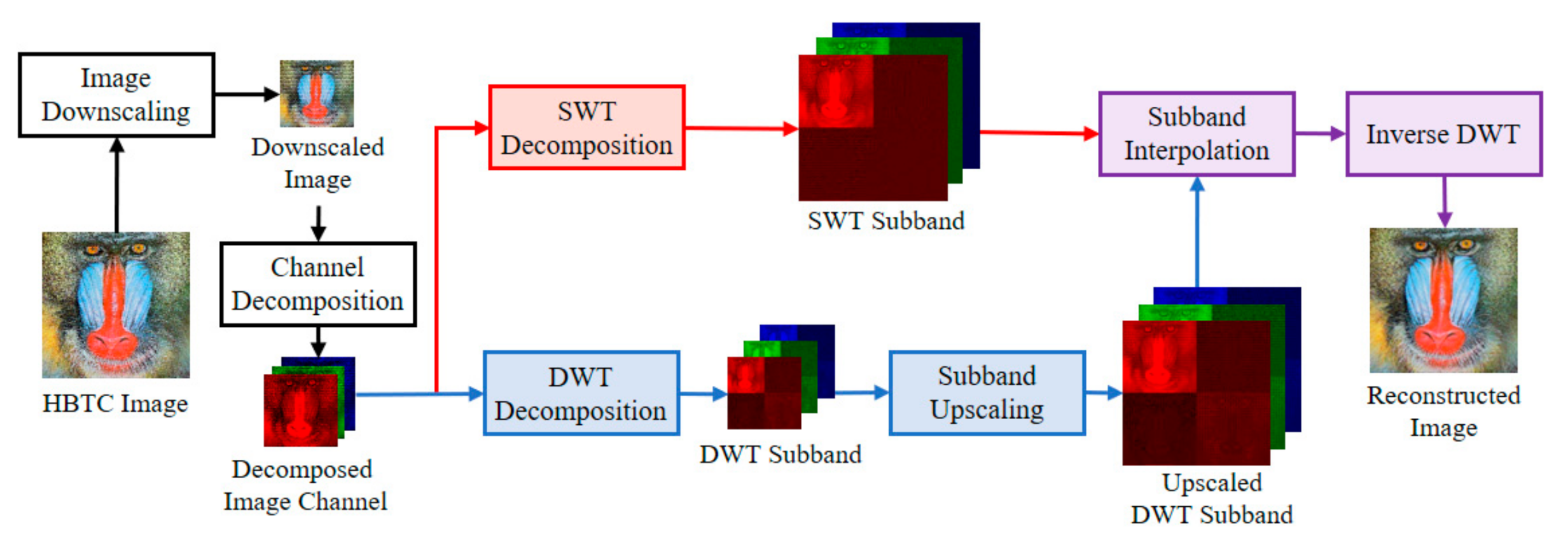
2.2. Wavelet-Based H-BTC Image Reconstruction
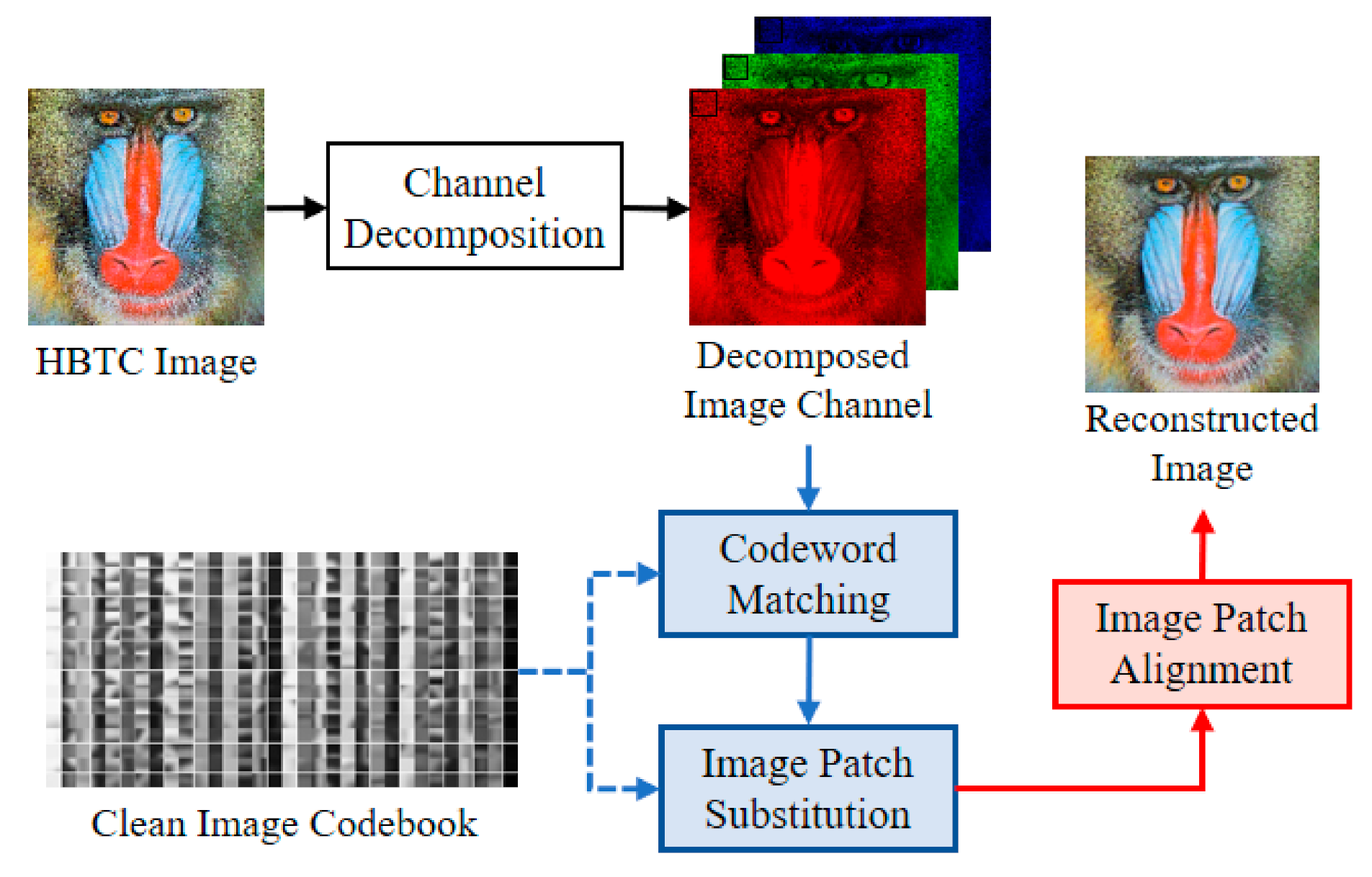
2.3. Fast Vector Quantization Based H-BTC Image Reconstruction
3. Deep Learning Based H-BTC Image Reconstruction
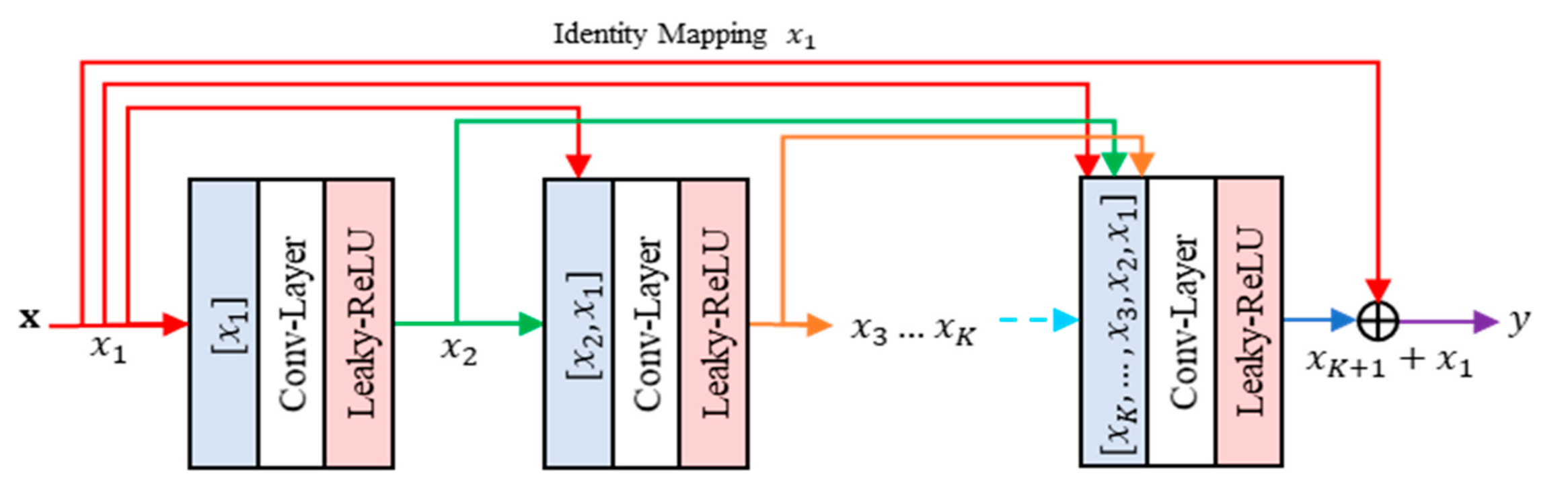
3.1. Residual Concatenated Networks
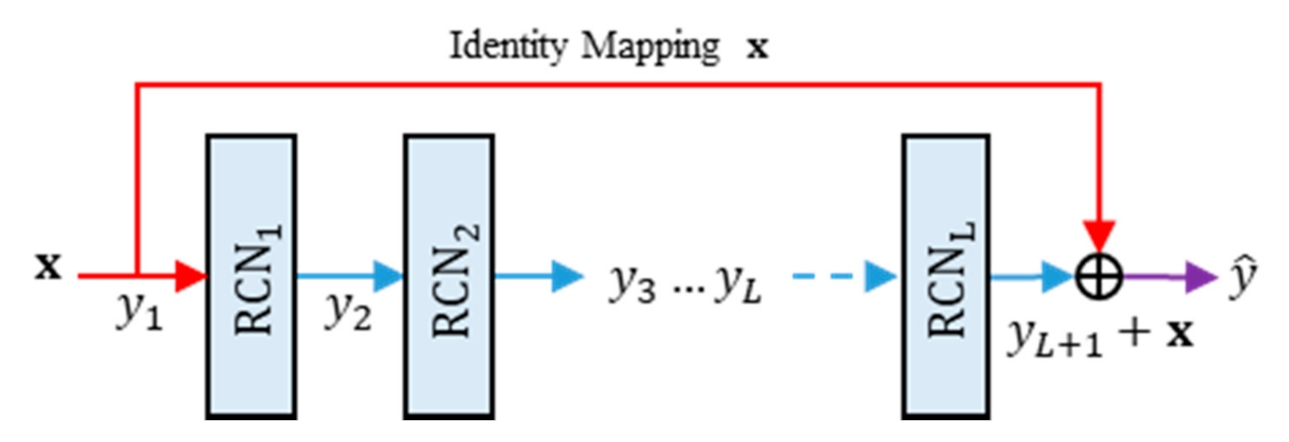
3.2. Residual Networks of Residual Concatenated Networks
3.3. Reconstruction Networks
- (1)
- Patch Extractor: This network part owns a single weight layer for performing image patch extraction and representation. Herein, an input image is divided into several overlapping patches. Suppose denotes the number of image channels. This network part acts as a convolution layer with 32 filters, each of size . It generates feature maps. These feature maps are further processed with nonlinearity mapping activation function, i.e., Leaky ReLU. At the end of the process, this network part yields feature maps of size , denoted as .
- (2)
- Feature Decomposer: This network part consists of multiple RRCN and downsampling operators. This network part decomposes and aggregates the extracted feature into multiple resolutions of feature maps. The downsampling operations are performed by a convolution layer with two-unit strides. The RRCN in this part employs the RCN modules with dilated convolution. Using this configuration strategy, the receptive field area of networks can be expanded without increasing the number of parameters. This scenario is also motivated by the well-known algorithme a’trous, i.e., an algorithm to perform SWT with dilated convolution [10]. The network part produces a feature map of the same size with . It also generates other maps, i.e., and , each of half size compared to . Other maps also yield and , each of quarter size in comparison to that of .
- (3)
- Feature Integrator: This network part has almost similar structure compared to that of the feature decomposer part. The main difference is only on the replacement of the downsampling operator with the upsampling operator. The typical interpolation algorithm, such as bilinear or bicubic, can be selected as an upsampling operator in this network part. The long skip connection in this network part connects the aggregated feature maps from the feature decomposer part and aggregated feature maps from this network part. This long skip connection aims to ease the network training. It can trivially mitigate the modeling of identity mapping in the networks [11]. Yet, the integration process is performed by pixel-wise addition between each channel of feature maps.
- (4)
- Feature Reconstruction and Output Layers: Both these layers contain a single weight layer. These two parts perform feature aggregation between the integrated feature maps of and . After the aggregation operation, we obtain the resulting feature maps denoted as . These feature maps are further processed by the output layer to yield the H-BTC reconstructed image, i.e., . This is regarded as the improved quality of the H-BTC decoded image with a reduced impulsive noise occurrence.
3.4. Loss Function
4. Experimental Results
4.1. Experimental Setup
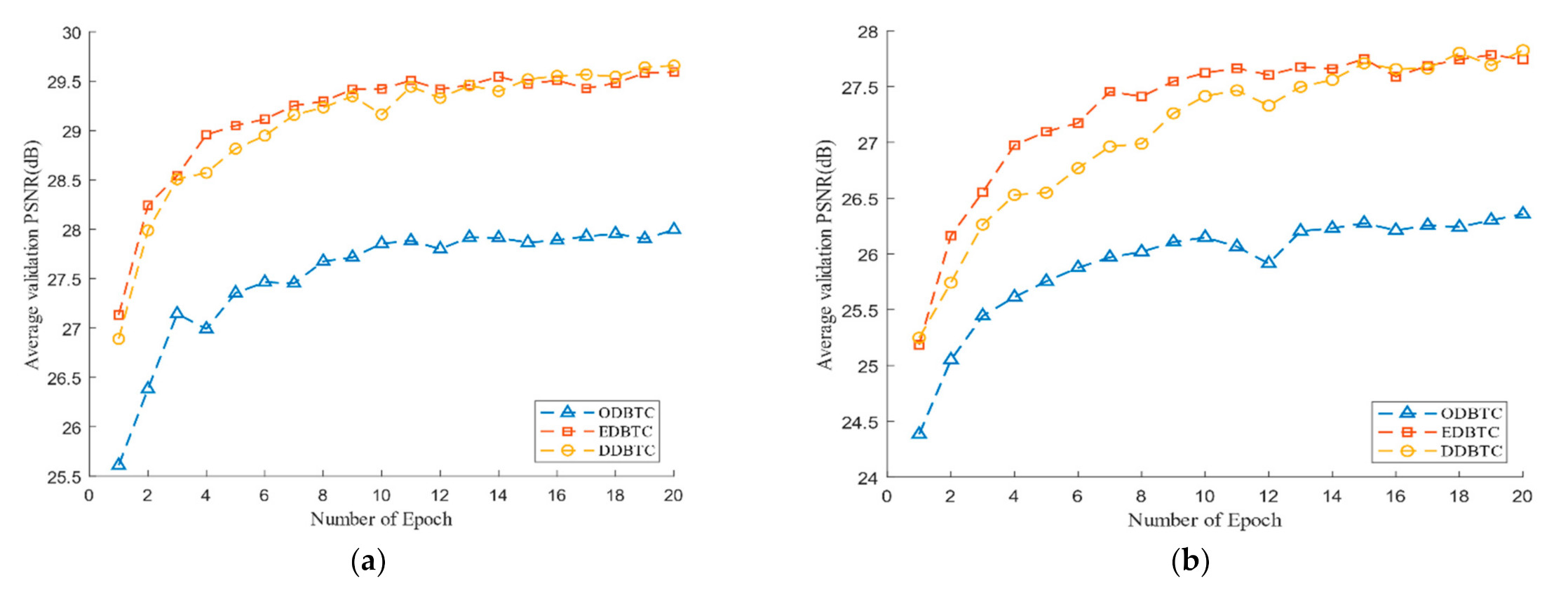
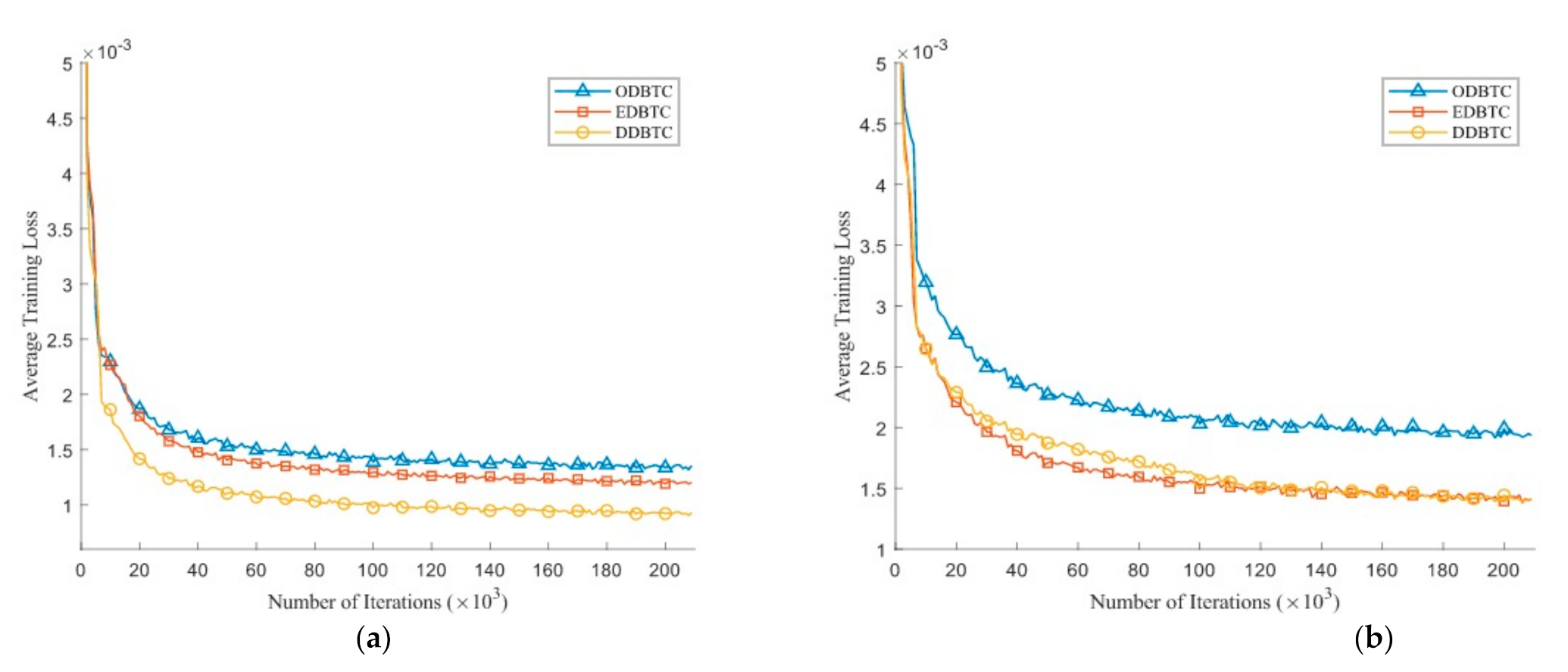
4.2. Networks Training and Model Initialization
4.3. Visual Investigation
4.4. Performance Comparisons
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Delp, E.; Mitchell, O. Image Compression Using Block Truncation Coding. IEEE Trans. Commun. 1979, 27, 1335–1342. [Google Scholar] [CrossRef]
- Guo, J.-M.; Wu, M.-F. Improved Block Truncation Coding Based on the Void-and-Cluster Dithering Approach. IEEE Trans. Image Process. 2009, 18, 211–213. [Google Scholar] [PubMed]
- Guo, J.-M. Improved block truncation coding using modified error diffusion. Electron. Lett. 2008, 44, 462. [Google Scholar] [CrossRef]
- Guo, J.-M.; Liu, Y.-F. Improved Block Truncation Coding using Optimized Dot Diffusion. IEEE Int. Symp. Circuits Syst. 2010, 23, 1269–1275. [Google Scholar]
- Prasetyo, H.; Riyono, D. Wavelet-based ODBTC image reconstruction. J. Telecommun. Electron. Comput. Eng. 2018, 10, 95–99. [Google Scholar]
- Prasetyo, H.; Riyono, D. Fast vector quantization for ODBTC image reconstruction. In Proceedings of the 2017 International Conference on Computer, Control, Informatics and its Applications, Jakarta, Indonesia, 23–26 October 2017; pp. 75–79. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 6–21 June 2013; p. 6. [Google Scholar]
- Zhang, K.; Sun, M.; Han, T.X.; Yuan, X.; Guo, L.; Liu, T. Residual Networks of Residual Networks: Multilevel Residual Networks. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 1303–1314. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V.; Funkhouser, T. Dilated Residual Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 636–644. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the Computer Vision—ECCV, Amsterdam, The Netherlands, 11–14 October 2016; pp. 630–645. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. arXiv 2015. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wicaksono, A.; Prasetyo, H.; Guo, J.-M. Residual Concatenated Network for ODBTC Image Restoration. In Proceedings of the 2019 International Symposium on Intelligent Signal Processing and Communication Systems, Taipei, Taiwan, 3–6 December 2019; pp. 1–2. [Google Scholar]
- Chen, J.; Zhang, G.; Xu, S.; Yu, H. A Blind CNN Denoising Model for Random-Valued Impulse Noise. IEEE Access 2019, 7, 124647–124661. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed]
- Mao, X.-J.; Shen, C.; Yang, Y.-B. Image Restoration Using Very Deep Convolutional Encoder-Decoder Networks with Symmetric Skip Connections. In Advances in Neural Information Processing Systems; Curran Associates: New York, NY, USA, 2017. [Google Scholar]
- Plötz, T.; Roth, S. Neural Nearest Neighbors Networks. In Advances in Neural Information Processing Systems; Curran Associates: New York, NY, USA, 2017; pp. 1089–1098. [Google Scholar]
- Liu, B.D.; Wen, Y.; Fan, C.; Loy, C.; Huang, T.S. Non-local Recurrent Network for Image Restoration. In Proceedings of the 32nd Conference on Neural Information Processing Systems, Montreal, QC, Canada, 2–8 December 2018; pp. 1673–1682. [Google Scholar]
- Valsesia, D.; Fracastoro, G.; Magli, E. Deep Graph-Convolutional Image Denoising. IEEE Trans. Image Process. 2020, 29, 8226–8237. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation; Springer: Berlin, Germany, 2015; pp. 234–241. [Google Scholar]
- Hsia, C.-H.; Guo, J.-M.; Chiang, J.-S. Improved low-complexity algorithm for 2-D integer lifting-based discrete wavelet transform using symmetric mask-based scheme. Trans. Circuits Syst. Video Technol. 2009, 19, 1201–1208. [Google Scholar]
- Hsia, C.-H.; Chiang, J.-S. Memory-Efficient Hardware Architecture of 2-D Dual-Mode Lifting-Based Discrete Wavelet Transform for JPEG2000. Trans. Circuits Syst. Video Technol. 2013, 23, 671–683. [Google Scholar] [CrossRef]
- Lu, Z.-M.; Pei, H. Equal-average equal-variance nearest neighbor search algorithm based on hadamard transform. IEEE Int. Conf. Mach. Learn. Cybern. 2003, 5, 2976–2978. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Agustsson, E.; Timofte, R. NTIRE 2017 Challenge on Single Image Super-Resolution: Dataset and Study. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1122–1131. [Google Scholar]
- Huang, J.-B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- True Color Kodak Images. Available online: http://r0k.us/graphics/kodak/ (accessed on 24 October 2019).
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Guo, J.-M.; Prasetyo, H.; Farfoura, M.E.; Lee, H. Vehicle Verification Using Features from Curvelet Transform and Generalized Gaussian Distribution Modeling. IEEE Trans. Intell. Transp. Syst. 2015, 16, 1989–1998. [Google Scholar] [CrossRef]
- Prasetyo, H.; Guo, J.-M. A Note on Multiple Secret Sharing Using Chinese Remainder Theorem and Exclusive-OR. IEEE Access 2019, 7, 37473–37497. [Google Scholar] [CrossRef]
- Prasetyo, H.; Hsia, C.-H. Improved multiple secret sharing using generalized chaotic image scrambling. Multimed. Tools Appl. 2019, 78, 29089–29120. [Google Scholar] [CrossRef]
- Prasetyo, H.; Hsia, C.-H. Lossless progressive secret sharing for grayscale and color images. Multimed. Tools Appl. 2019, 78, 24837–24862. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ODBTC | |||||||
| Datasets | Block Size | Decoded | Wavelet [5] | Fast VQ [6] | Residual Network [15,16] | Symmetric Skip CNN [17] | Proposed |
| SIPI | 19.73 | 25.12 | 27.34 | 28.11 | 29.31 | 29.90 | |
| 16.58 | 23.57 | 25.06 | 26.90 | 27.22 | 27.53 | ||
| Kodak | 19.25 | 24.55 | 27.48 | 28.91 | 29.45 | 30.58 | |
| 16.16 | 23.74 | 25.68 | 27.89 | 28.67 | 29.00 | ||
| BSD100 | 17.94 | 23.80 | 26.55 | 28.09 | 28.33 | 28.79 | |
| 15.06 | 23.14 | 24.97 | 26.88 | 26.98 | 27.51 | ||
| Urban100 | 16.15 | 20.89 | 23.93 | 27.34 | 27.77 | 28.26 | |
| 13.48 | 20.30 | 22.27 | 25.89 | 26.31 | 26.80 | ||
| EDBTC | |||||||
| Datasets | Block size | Decoded | Wavelet [5] | Fast VQ [6] | Residual Network [15,16] | Symmetric Skip CNN [17] | Proposed |
| SIPI | 19.80 | 25.12 | 27.44 | 29.39 | 29.77 | 30.78 | |
| 16.40 | 23.52 | 24.94 | 27.71 | 28.03 | 28.46 | ||
| Kodak | 19.28 | 24.61 | 27.83 | 30.44 | 31.78 | 32.03 | |
| 15.98 | 23.80 | 25.64 | 29.33 | 29.78 | 30.40 | ||
| BSD100 | 17.95 | 23.85 | 26.91 | 28.98 | 29.78 | 30.41 | |
| 14.88 | 23.22 | 24.94 | 28.45 | 29.00 | 29.11 | ||
| Urban100 | 16.21 | 20.90 | 24.17 | 28.65 | 28.91 | 29.20 | |
| 13.35 | 20.33 | 22.22 | 26.01 | 26.77 | 27.61 | ||
| DDBTC | |||||||
| Datasets | Block size | Decoded | Wavelet [5] | Fast VQ [6] | Residual Network [15,16] | Symmetric Skip CNN [17] | Proposed |
| SIPI | 2.037 | 25.00 | 27.68 | 28.89 | 29.78 | 30.79 | |
| 16.89 | 23.42 | 25.25 | 27.63 | 28.01 | 28.13 | ||
| Kodak | 20.02 | 24.48 | 28.31 | 30.33 | 31.78 | 32.26 | |
| 16.53 | 23.68 | 26.04 | 29.11 | 30.37 | 30.48 | ||
| BSD100 | 18.75 | 23.72 | 27.50 | 28.88 | 29.79 | 30.74 | |
| 15.47 | 23.10 | 25.40 | 28.01 | 28.99 | 29.19 | ||
| Urban100 | 17.04 | 20.83 | 24.71 | 28.64 | 28.91 | 29.54 | |
| 13.96 | 20.24 | 22.63 | 27.12 | 27.78 | 27.90 | ||
| ODBTC | |||||||
| Datasets | Block Size | Decoded | Wavelet [5] | Fast VQ [6] | Residual Network [15,16] | Symmetric Skip CNN [17] | Proposed |
| SIPI | 0.7188 | 0.8632 | 0.9132 | 0.9391 | 0.9399 | 0.9462 | |
| 0.5677 | 0.8118 | 0.8575 | 0.8911 | 0.9102 | 0.9186 | ||
| Kodak | 0.6425 | 0.8026 | 0.8921 | 0.9220 | 0.9378 | 0.9414 | |
| 0.4820 | 0.7624 | 0.8299 | 0.8998 | 0.9002 | 0.9155 | ||
| BSD100 | 0.5967 | 0.7778 | 0.8698 | 0.8978 | 0.9100 | 0.9193 | |
| 0.4373 | 0.7333 | 0.8008 | 0.8698 | 0.8709 | 0.8891 | ||
| Urban100 | 0.5940 | 0.7124 | 0.8266 | 0.9301 | 0.9299 | 0.9315 | |
| 0.4466 | 0.6605 | 0.7443 | 0.8760 | 0.8923 | 0.9006 | ||
| EDBTC | |||||||
| Datasets | Block size | Decoded | Wavelet [5] | Fast VQ [6] | Residual Network [15,16] | Symmetric Skip CNN [17] | Proposed |
| SIPI | 0.7242 | 0.8639 | 0.9153 | 0.9312 | 0.9457 | 0.9551 | |
| 0.5669 | 0.8138 | 0.8539 | 0.8991 | 0.9129 | 0.9291 | ||
| Kodak | 0.6512 | 0.8055 | 0.9005 | 0.9413 | 0.9550 | 0.9569 | |
| 0.4818 | 0.7705 | 0.8322 | 0.9221 | 0.9331 | 0.9349 | ||
| BSD100 | 0.6034 | 0.7781 | 0.8802 | 0.9378 | 0.9399 | 0.9415 | |
| 0.4374 | 0.7436 | 0.8044 | 0.9000 | 0.9167 | 0.9173 | ||
| Urban100 | 0.6048 | 0.7145 | 0.8348 | 0.9232 | 0.9389 | 0.9433 | |
| 0.4538 | 0.6686 | 0.7455 | 0.8975 | 0.9099 | 0.9124 | ||
| DDBTC | |||||||
| Datasets | Block size | Decoded | Wavelet [5] | Fast VQ [6] | Residual Network [15,16] | Symmetric Skip CNN [17] | Proposed |
| SIPI | 0.7530 | 0.8619 | 0.9216 | 0.9391 | 0.9478 | 0.9552 | |
| 0.5932 | 0.8101 | 0.8626 | 0.9090 | 0.9199 | 0.9287 | ||
| Kodak | 0.6940 | 0.8016 | 0.9129 | 0.9378 | 0.9457 | 0.9594 | |
| 0.5191 | 0.7622 | 0.8427 | 0.9229 | 0.9301 | 0.9385 | ||
| BSD100 | 0.6551 | 0.7741 | 0.8966 | 0.9331 | 0.9441 | 0.9474 | |
| 0.4797 | 0.7345 | 0.8162 | 0.9032 | 0.9210 | 0.9220 | ||
| Urban100 | 0.6543 | 0.7140 | 0.8541 | 0.9234 | 0.9299 | 0.9481 | |
| 0.4906 | 0.6612 | 0.7607 | 0.9163 | 0.9200 | 0.9210 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prasetyo, H.; Wicaksono Hari Prayuda, A.; Hsia, C.-H.; Guo, J.-M. Deep Concatenated Residual Networks for Improving Quality of Halftoning-Based BTC Decoded Image. J. Imaging 2021, 7, 13. https://doi.org/10.3390/jimaging7020013
Prasetyo H, Wicaksono Hari Prayuda A, Hsia C-H, Guo J-M. Deep Concatenated Residual Networks for Improving Quality of Halftoning-Based BTC Decoded Image. Journal of Imaging. 2021; 7(2):13. https://doi.org/10.3390/jimaging7020013
Chicago/Turabian StylePrasetyo, Heri, Alim Wicaksono Hari Prayuda, Chih-Hsien Hsia, and Jing-Ming Guo. 2021. "Deep Concatenated Residual Networks for Improving Quality of Halftoning-Based BTC Decoded Image" Journal of Imaging 7, no. 2: 13. https://doi.org/10.3390/jimaging7020013
APA StylePrasetyo, H., Wicaksono Hari Prayuda, A., Hsia, C.-H., & Guo, J.-M. (2021). Deep Concatenated Residual Networks for Improving Quality of Halftoning-Based BTC Decoded Image. Journal of Imaging, 7(2), 13. https://doi.org/10.3390/jimaging7020013