
Improved Visual Localization via Graph Filtering


Abstract
1. Introduction
- We apply the theory and methods of Graph Signal Processing to the problem of visual localization. To the best of our knowledge, this is the first attempt to bring these two areas of research together.
- Through experiments on real-world datasets, we demonstrate the efficacy of the proposed method in improving localization accuracy with almost no computation overhead at inference.
- We demonstrate that this method can be applied to traditional image retrieval benchmarks and perform well on them.
2. Related Work
3. Proposed Method
3.1. Graph Signal Processing
3.2. Problem Setting
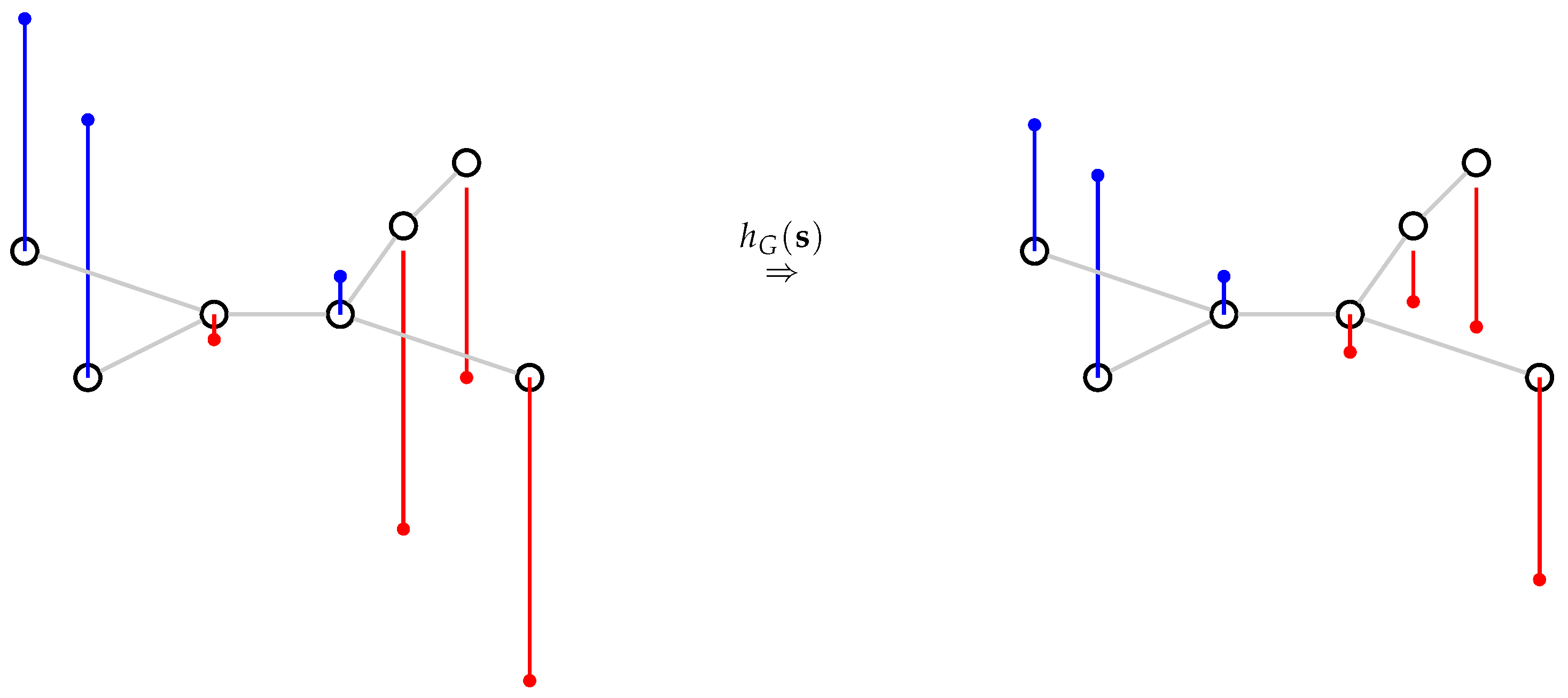
3.3. Graph Signals Low-Pass Filtering
3.4. Graph Definition
- Metric distance (dist): the distance measured by the GPS coordinates between vertices and ;
- Sequence (seq): the distance in time acquisition between two images (acquired as frames in videos);
- Latent similarity (latent_sim): the cosine similarity between latent representations.
3.4.1. Metric Distance
3.4.2. Sequence
3.4.3. Latent Similarity
4. Results
4.1. Visual Localization
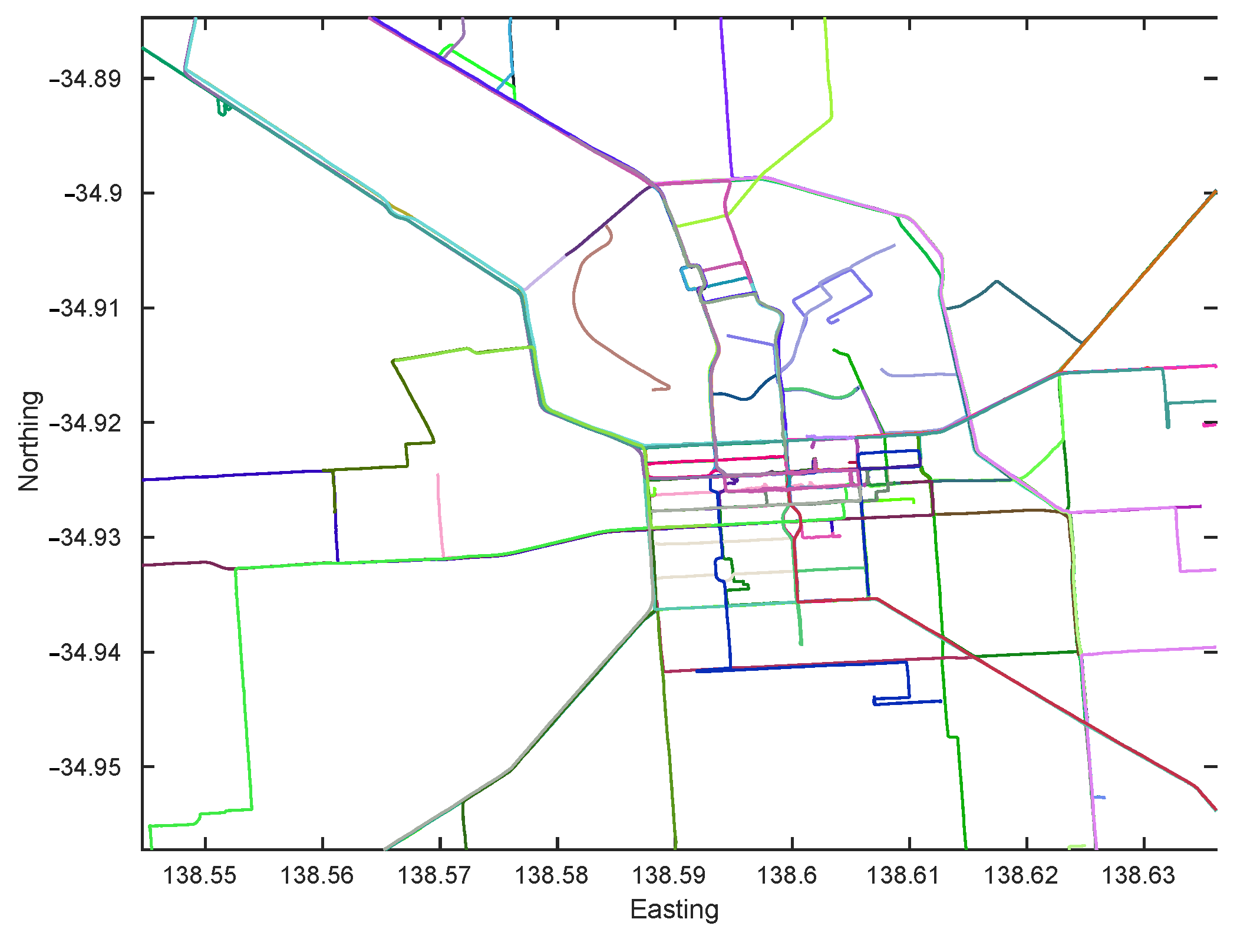
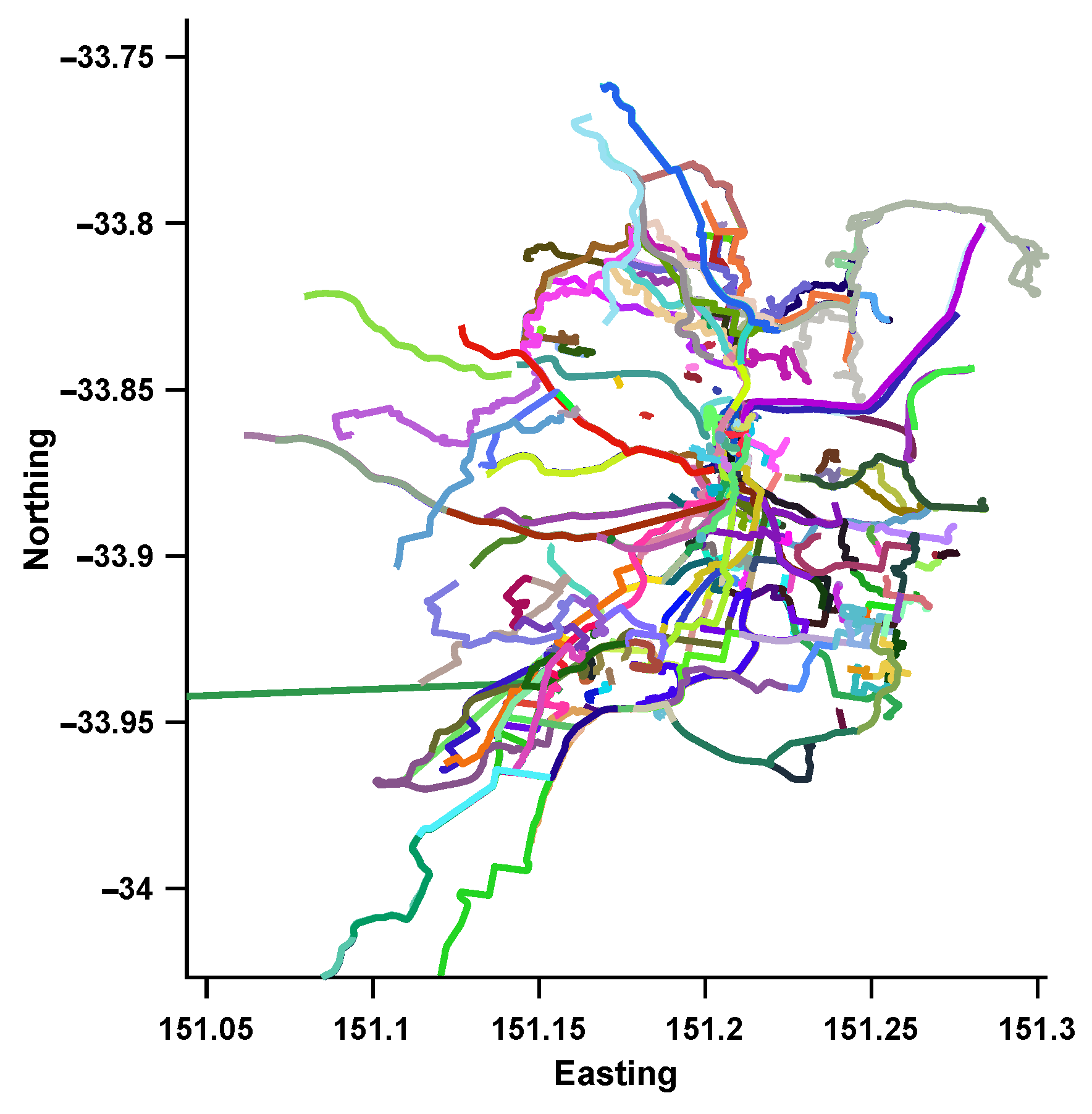
4.1.1. Dataset Generation
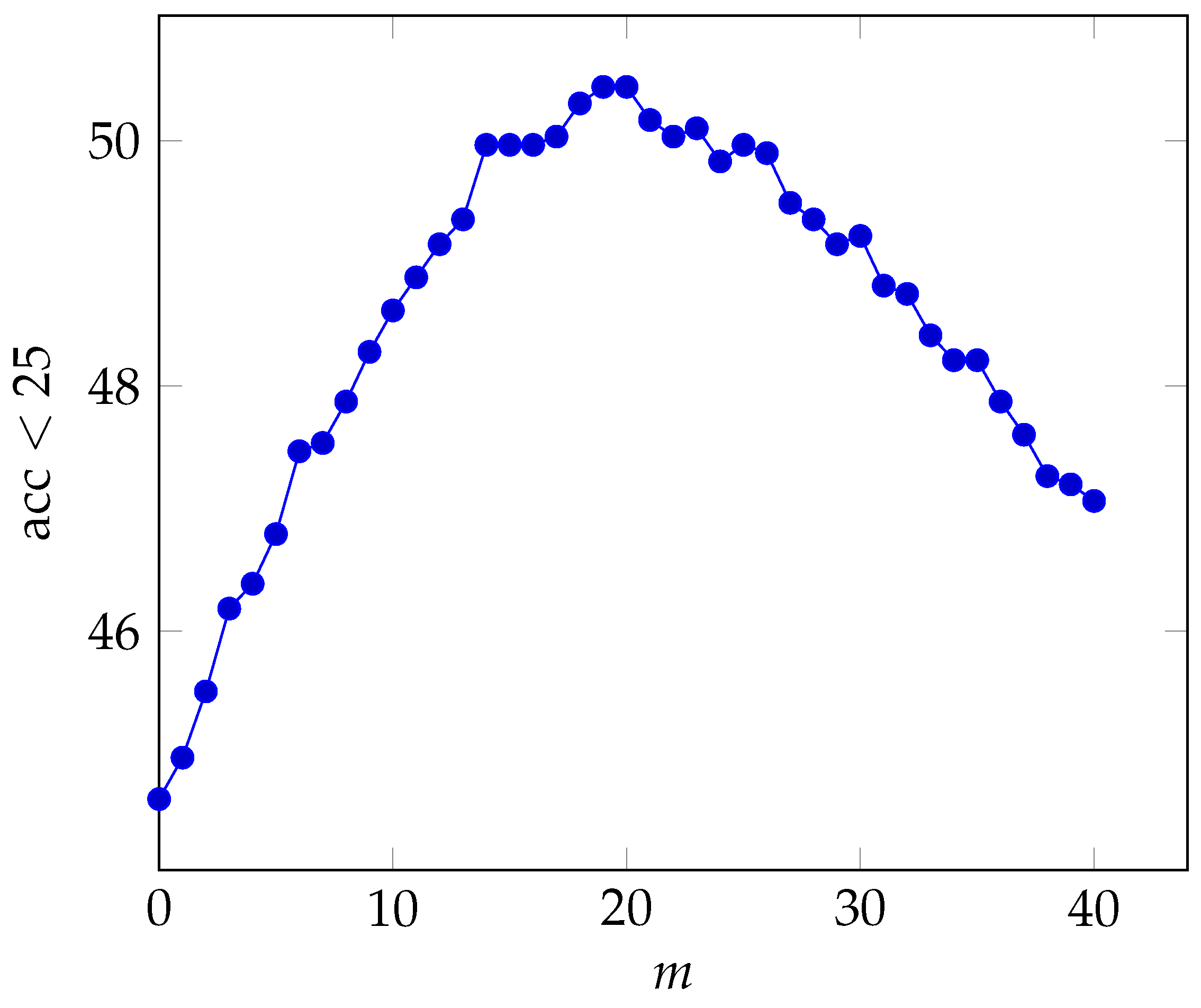
4.1.2. Parameter Definition
4.1.3. Application to VBL
- Features are extracted using [4];
- Graphs are generated for support, query or both using the previously described graph inference method;
- If graphs exist for a set, the features of the set are then filtered using the previously described methodology;
- Localization of a query image is then defined by the nearest example in the support database (either using features from step 1 or 3, depending on where graph filtering is applied).
4.1.4. Results
4.1.5. Ablation Studies
4.2. Image Retrieval
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Piasco, N.; Sidibé, D.; Demonceaux, C.; Gouet-Brunet, V. A survey on Visual-Based Localization: On the benefit of heterogeneous data. Pattern Recognit. 2018, 74, 90–109. [Google Scholar] [CrossRef]
- Brahmbhatt, S.; Gu, J.; Kim, K.; Hays, J.; Kautz, J. Geometry-aware learning of maps for camera localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2616–2625. [Google Scholar]
- Kendall, A.; Grimes, M.; Cipolla, R. Posenet: A convolutional network for real-time 6-dof camera relocalization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2938–2946. [Google Scholar]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN architecture for weakly supervised place recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5297–5307. [Google Scholar]
- Doan, A.D.; Latif, Y.; Chin, T.J.; Liu, Y.; Do, T.T.; Reid, I. Scalable Place Recognition Under Appearance Change for Autonomous Driving. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Van Noord, N. pytorch-NetVlad. 2019. Available online: https://github.com/Nanne/pytorch-NetVlad (accessed on 29 January 2021).
- Shuman, D.; Narang, S.; Frossard, P.; Ortega, A.; Vandergheynst, P. The Emerging Field of Signal Processing on Graphs: Extending High-Dimensional Data Analysis to Networks and Other Irregular Domains. IEEE Signal Process. Mag. 2013, 3, 83–98. [Google Scholar] [CrossRef]
- Radenović, F.; Tolias, G.; Chum, O. Fine-Tuning CNN Image Retrieval with No Human Annotation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1655–1668. [Google Scholar] [CrossRef]
- Lowry, S.; Sünderhauf, N.; Newman, P.; Leonard, J.J.; Cox, D.; Corke, P.; Milford, M.J. Visual place recognition: A survey. IEEE Trans. Robot. 2015, 32, 1–19. [Google Scholar] [CrossRef]
- Liu, C.; Yu, G.; Volkovs, M.; Chang, C.; Rai, H.; Ma, J.; Gorti, S.K. Guided Similarity Separation for Image Retrieval. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2019; pp. 1554–1564. [Google Scholar]
- Torii, A.; Sivic, J.; Pajdla, T. Visual localization by linear combination of image descriptors. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 102–109. [Google Scholar]
- Cao, S.; Snavely, N. Graph-Based Discriminative Learning for Location Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Iscen, A.; Tolias, G.; Avrithis, Y.; Furon, T.; Chum, O. Efficient diffusion on region manifolds: Recovering small objects with compact cnn representations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2077–2086. [Google Scholar]
- Carlone, L.; Calafiore, G.C.; Tommolillo, C.; Dellaert, F. Planar pose graph optimization: Duality, optimal solutions, and verification. IEEE Trans. Robot. 2016, 32, 545–565. [Google Scholar] [CrossRef]
- Grelier, N.; Pasdeloup, B.; Vialatte, J.; Gripon, V. Neighborhood-preserving translations on graphs. In Proceedings of the 2016 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Washington, DC, USA, 7–9 December 2016; pp. 410–414. [Google Scholar]
- Henaff, M.; Bruna, J.; LeCun, Y. Deep Convolutional Networks on Graph-Structured Data. arXiv 2015, arXiv:1506.05163. [Google Scholar]
- Segarra, S.; Marques, A.G.; Ribeiro, A. Optimal Graph-Filter Design and Applications to Distributed Linear Network Operators. IEEE Trans. Signal Process. 2017, 65, 4117–4131. [Google Scholar] [CrossRef]
- Hammond, D.K.; Vandergheynst, P.; Gribonval, R. Wavelets on graphs via spectral graph theory. Appl. Comput. Harmon. Anal. 2011, 30, 129–150. [Google Scholar] [CrossRef]
- Ménoret, M.; Farrugia, N.; Pasdeloup, B.; Gripon, V. Evaluating graph signal processing for neuroimaging through classification and dimensionality reduction. In Proceedings of the 2017 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Montreal, QC, Canada, 14–16 November 2017; pp. 618–622. [Google Scholar]
- Bontonou, M.; Lassance, C.; Hacene, G.B.; Gripon, V.; Tang, J.; Tang, J. Introducing Graph Smoothness Loss for Training Deep Learning Architectures. In Proceedings of the 2019 IEEE Data Science Workshop (DSW), Minneapolis, MI, USA, 2–5 June 2019; pp. 160–164. [Google Scholar]
- Anirudh, R.; Thiagarajan, J.J.; Sridhar, R.; Bremer, T. Influential Sample Selection: A Graph Signal Processing Approach. arXiv 2017, arXiv:1711.05407. [Google Scholar]
- Taubin, G. Geometric Signal Processing on Polygonal Meshes; STAR—State of The Art Report; The Eurographics Association: Munich, Germany, 2000. [Google Scholar]
- Radenović, F.; Iscen, A.; Tolias, G.; Avrithis, Y.; Chum, O. Revisiting oxford and paris: Large-scale image retrieval benchmarking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5706–5715. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| City | Adelaide | |
|---|---|---|
| # Sequences | # Images | |
| Support Database | 44 | 24,263 |
| Validation Query | 4 | 2141 |
| Test Query | 5 | 1481 |
| Sydney | ||
| # Sequences | # Images | |
| Support Database | 284 | 117,860 |
| Easy Query | 5 | 1915 |
| Hard Query | 5 | 2285 |
| Measure | None | GF Database | GF Query | GF D + Q |
|---|---|---|---|---|
| Validation | ||||
| acc < 25 m | 66.84% | 76.09% | 69.92% | 79.22% |
| median distance | 8.76 m | 6.90 m | 13.04 m | 8.86 m |
| Test | ||||
| acc < 25 m | 44.63% | 50.44% | 46.32% | 52.06% |
| median distance | 110.66 m | 24.30 m | 41.84 m | 22.66 m |
| Measure | None | GF Database | GF Query | GF D + Q |
|---|---|---|---|---|
| Easy | ||||
| acc < 25 m | 49.45% | 55.28% | 55.46% | 63.75% |
| median distance | 28.25 m | 14.12 m | 18.77 m | 11.93 m |
| Hard | ||||
| acc < 25 m | 13.87% | 17.33% | 16.54% | 24.86% |
| median distance | 4000 m | 3253 m | 3180 m | 1700 m |
| Median Distance | acc < 25 m | |||
|---|---|---|---|---|
| 110.66 m | 44.63% | |||
| X | 29.26 m | 49.42% | ||
| X | 39.11 m | 47.47% | ||
| X | X | 28.41 m | 49.56% | |
| X | X | 24.35 m | 50.17% | |
| X | X | 37.34 m | 47.74% | |
| X | X | X | 24.30 m | 50.44% |
| rOxford | rParis | ||||
|---|---|---|---|---|---|
| Features | Ranking | Medium | Hard | Medium | Hard |
| [8] | 64.7 | 38.5 | 77.2 | 56.3 | |
| [8] | [13] | 69.8 | 40.5 | 88.9 | 78.5 |
| [8] + Our filter | 70.58 | 47.67 | 87.77 | 76.04 | |
| [8] + Our filter | [13] | 71.41 | 51.27 | 91.54 | 81.85 |
| [8] + [10] | [10] | 77.8 | 57.5 | 92.4 | 83.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lassance, C.; Latif, Y.; Garg, R.; Gripon, V.; Reid, I. Improved Visual Localization via Graph Filtering. J. Imaging 2021, 7, 20. https://doi.org/10.3390/jimaging7020020
Lassance C, Latif Y, Garg R, Gripon V, Reid I. Improved Visual Localization via Graph Filtering. Journal of Imaging. 2021; 7(2):20. https://doi.org/10.3390/jimaging7020020
Chicago/Turabian StyleLassance, Carlos, Yasir Latif, Ravi Garg, Vincent Gripon, and Ian Reid. 2021. "Improved Visual Localization via Graph Filtering" Journal of Imaging 7, no. 2: 20. https://doi.org/10.3390/jimaging7020020
APA StyleLassance, C., Latif, Y., Garg, R., Gripon, V., & Reid, I. (2021). Improved Visual Localization via Graph Filtering. Journal of Imaging, 7(2), 20. https://doi.org/10.3390/jimaging7020020