A Survey of Deep Learning-Based Source Image Forensics


 and
and 
Abstract
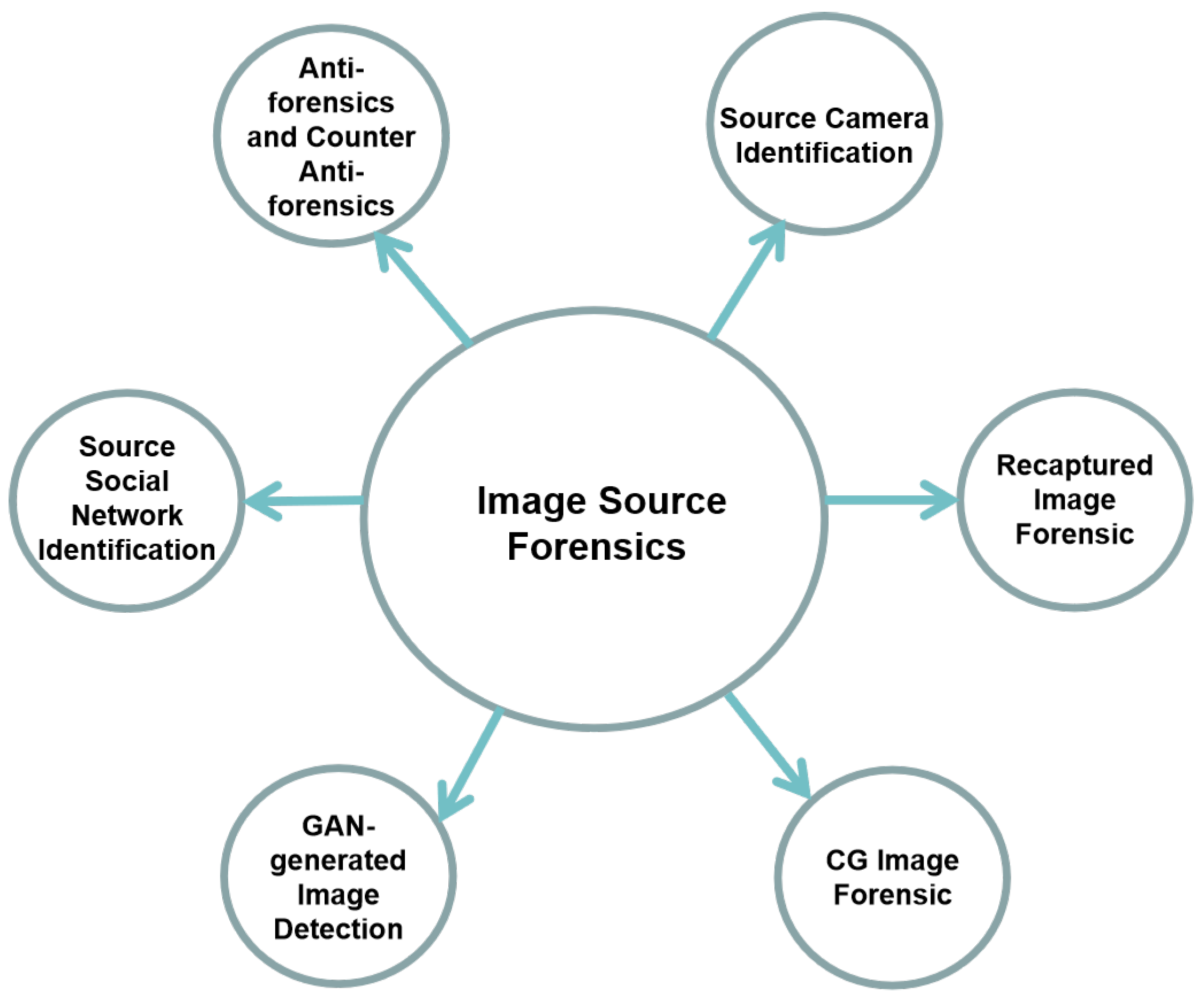
1. Introduction
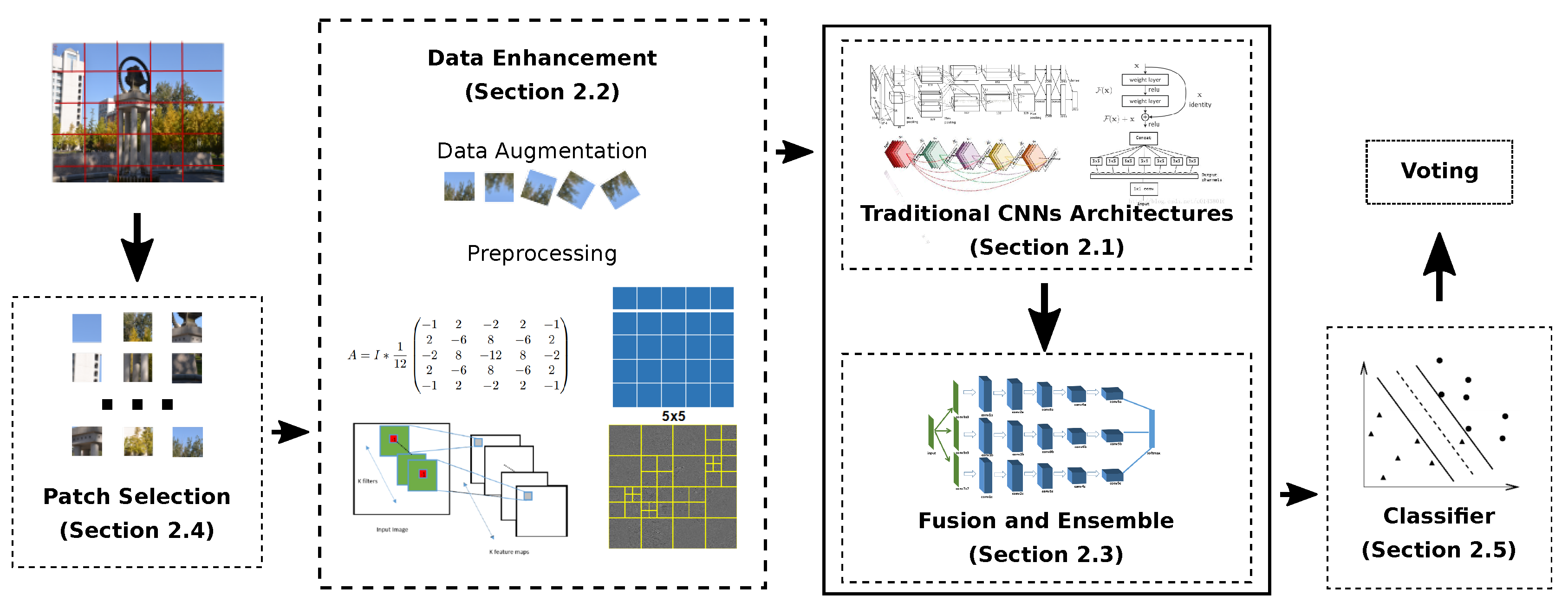
- adoption of traditional convolutional neural networks (T.CNN) for source camera identification tasks;
- improvement of performance by using data enhancement (D.A.), including data augmentation and data preprocessing;
- improvement of performance through fusion and ensemble (F./E.);
- improvement of performance by means of patch selection (P.S.);
- adoption of different classifiers (C.).
2. Source Camera Identification
2.1. Traditional Convolutional Neural Networks (T.CNN)
2.2. Data Enhancement (D.E.)
2.3. Fusion and Ensemble (F./E.)
2.4. Patch Selection (P.S.)
2.5. Classifier (C.)
2.6. Summary
3. Recaptured Image Forensic
4. Computer Graphics Image Forensic
5. GAN-Generated Image Detection
6. Source Social Networks Identification
7. Anti-Forensics and Counter Anti-Forensics
8. Evaluation Measures and Datasets
8.1. Source Camera Identification
8.2. Recaptured Image Forensic
8.3. CG Image Detection
8.4. GAN-Generated Image Detection
8.5. Social Network Identification
9. Discussion and Conclusions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhu, B.B.; Swanson, M.D.; Tewfik, A.H. When seeing isn’t believing [multimedia authentication technologies]. IEEE Signal Process. Mag. 2004, 21, 40–49. [Google Scholar] [CrossRef]
- Farid, H. Digital doctoring: How to tell the real from the fake. Significance 2006, 3, 162–166. [Google Scholar] [CrossRef]
- Cao, Y.J.; Jia, L.L.; Chen, Y.X.; Lin, N.; Yang, C.; Zhang, B.; Liu, Z.; Li, X.X.; Dai, H.H. Recent Advances of Generative Adversarial Networks in Computer Vision. IEEE Access 2019, 7, 14985–15006. [Google Scholar] [CrossRef]
- Beridze, I.; Butcher, J. When seeing is no longer believing. Nat. Mach. Intell. 2019, 1, 332–334. [Google Scholar] [CrossRef]
- Piva, A. An overview on image forensics. ISRN Signal Process. 2013, 2013. [Google Scholar] [CrossRef]
- Guan, H.; Kozak, M.; Robertson, E.; Lee, Y.; Yates, A.N.; Delgado, A.; Zhou, D.; Kheyrkhah, T.; Smith, J.; Fiscus, J. MFC Datasets: Large-Scale Benchmark Datasets for Media Forensic Challenge Evaluation. In Proceedings of the 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 63–72. [Google Scholar]
- IEEE. Signal Processing Society—Camera Model Identification; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy layer-wise training of deep networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2007; pp. 153–160. [Google Scholar]
- Ranzato, M.; Poultney, C.; Chopra, S.; LeCun, Y. Efficient learning of sparse representations with an energy-based model. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2007; pp. 1137–1144. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A Survey of the Recent Architectures of Deep Convolutional Neural Networks. arXiv 2019, arXiv:1901.06032. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Jie, H.; Li, S.; Albanie, S.; Gang, S.; Wu, E. Squeeze-and-Excitation Networks. arXiv 2017, arXiv:1709.01507. [Google Scholar]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a Similarity Metric Discriminatively, with Application to Face Verification. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05) - Volume 1 - Volume 01; IEEE Computer Society: Washington, DC, USA, 2005; CVPR ’05; pp. 539–546. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Bondi, L.; Baroffio, L.; Güera, D.; Bestagini, P.; Delp, E.J.; Tubaro, S. Camera identification with deep convolutional networks. arXiv 2016, arXiv:1603.01068. [Google Scholar]
- Freire-Obregón, D.; Narducci, F.; Barra, S.; Castrillón-Santana, M. Deep learning for source camera identification on mobile devices. Pattern Recognit. Lett. 2019, 126, 86–91. [Google Scholar] [CrossRef]
- Huang, N.; He, J.; Zhu, N.; Xuan, X.; Liu, G.; Chang, C. Identification of the source camera of images based on convolutional neural network. Digit. Investig. 2018, 26, 72–80. [Google Scholar] [CrossRef]
- Yao, H.; Qiao, T.; Xu, M.; Zheng, N. Robust multi-classifier for camera model identification based on convolution neural network. IEEE Access 2018, 6, 24973–24982. [Google Scholar] [CrossRef]
- Chen, Y.; Huang, Y.; Ding, X. Camera model identification with residual neural network. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 4337–4341. [Google Scholar]
- Ding, X.; Chen, Y.; Tang, Z.; Huang, Y. Camera Identification based on Domain Knowledge-driven Deep Multi-task Learning. IEEE Access 2019, 7, 25878–25890. [Google Scholar] [CrossRef]
- Marra, F.; Gragnaniello, D.; Verdoliva, L. On the vulnerability of deep learning to adversarial attacks for camera model identification. Signal Process. Image Commun. 2018, 65, 240–248. [Google Scholar] [CrossRef]
- Stamm, M.; Bestagini, P.; Marcenaro, L.; Campisi, P. Forensic Camera Model Identification: Highlights from the IEEE Signal Processing Cup 2018 Student Competition [SP Competitions]. IEEE Signal Process. Mag. 2018, 35, 168–174. [Google Scholar] [CrossRef]
- Kamal, U.; Rafi, A.M.; Hoque, R.; Das, S.; Abrar, A.; Hasan, M. Application of DenseNet in Camera Model Identification and Post-processing Detection. arXiv 2018, arXiv:1809.00576. [Google Scholar]
- Kuzin, A.; Fattakhov, A.; Kibardin, I.; Iglovikov, V.I.; Dautov, R. Camera Model Identification Using Convolutional Neural Networks. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 3107–3110. [Google Scholar]
- Ferreira, A.; Chen, H.; Li, B.; Huang, J. An Inception-Based Data-Driven Ensemble Approach to Camera Model Identification. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, 11–13 December 2018; pp. 1–7. [Google Scholar]
- Bayar, B.; Stamm, M.C. Towards open set camera model identification using a deep learning framework. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2007–2011. [Google Scholar]
- Mayer, O.; Stamm, M.C. Learned forensic source similarity for unknown camera models. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2012–2016. [Google Scholar]
- Bondi, L.; Baroffio, L.; Güera, D.; Bestagini, P.; Delp, E.J.; Tubaro, S. First steps toward camera model identification with convolutional neural networks. IEEE Signal Process. Lett. 2017, 24, 259–263. [Google Scholar] [CrossRef]
- Bondi, L.; Güera, D.; Baroffio, L.; Bestagini, P.; Delp, E.J.; Tubaro, S. A preliminary study on convolutional neural networks for camera model identification. Electron. Imaging 2017, 2017, 67–76. [Google Scholar] [CrossRef]
- Bayar, B.; Stamm, M.C. Augmented convolutional feature maps for robust cnn-based camera model identification. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 4098–4102. [Google Scholar]
- Tuama, A.; Comby, F.; Chaumont, M. Camera model identification with the use of deep convolutional neural networks. In Proceedings of the 2016 IEEE International workshop on information forensics and security (WIFS), Abu Dhabi, UAE, 4–7 December 2016; pp. 1–6. [Google Scholar]
- Zuo, Z. Camera Model Identification with Convolutional Neural Networks and Image Noise Pattern. 2018. Available online: http://hdl.handle.net/2142/100123 (accessed on 2 July 2018).
- Wang, B.; Yin, J.; Tan, S.; Li, Y.; Li, M. Source camera model identification based on convolutional neural networks with local binary patterns coding. Signal Process. Image Commun. 2018, 68, 162–168. [Google Scholar] [CrossRef]
- Yang, P.; Zhao, W.; Ni, R.; Zhao, Y. Source camera identification based on content-adaptive fusion network. arXiv 2017, arXiv:1703.04856. [Google Scholar] [CrossRef]
- Yang, P.; Ni, R.; Zhao, Y.; Zhao, W. Source camera identification based on content-adaptive fusion residual networks. Pattern Recognit. Lett. 2019, 119, 195–204. [Google Scholar] [CrossRef]
- Pevny, T.; Bas, P.; Fridrich, J. Steganalysis by subtractive pixel adjacency matrix. IEEE Trans. Inf. Forensics Secur. 2010, 5, 215–224. [Google Scholar] [CrossRef]
- Bayar, B.; Stamm, M.C. Constrained convolutional neural networks: A new approach towards general purpose image manipulation detection. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2691–2706. [Google Scholar] [CrossRef]
- Güera, D.; Zhu, F.; Yarlagadda, S.K.; Tubaro, S.; Bestagini, P.; Delp, E.J. Reliability map estimation for CNN-based camera model attribution. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 964–973. [Google Scholar]
- Tang, Y. Deep learning using linear support vector machines. arXiv 2013, arXiv:1306.0239. [Google Scholar]
- Chen, S.; Wang, Y. Convolutional Neural Network and Convex Optimization; Department of Electrical and Computer EngineeringUniversity of California San Diego: San Diego, CA, USA, 2014. [Google Scholar]
- Abdulnabi, A.H.; Wang, G.; Lu, J.; Jia, K. Multi-task CNN model for attribute prediction. IEEE Trans. Multimed. 2015, 17, 1949–1959. [Google Scholar] [CrossRef]
- Yang, P.; Ni, R.; Zhao, Y. Recapture image forensics based on Laplacian convolutional neural networks. In International Workshop on Digital Watermarking; Springer: Berlin, Germany, 2016; pp. 119–128. [Google Scholar]
- Choi, H.Y.; Jang, H.U.; Son, J.; Kim, D.; Lee, H.K. Content Recapture Detection Based on Convolutional Neural Networks. In International Conference on Information Science and Applications; Springer: Berlin, Germany, 2017; pp. 339–346. [Google Scholar]
- Li, H.; Wang, S.; Kot, A.C. Image recapture detection with convolutional and recurrent neural networks. Electron. Imaging 2017, 2017, 87–91. [Google Scholar] [CrossRef]
- Agarwal, S.; Fan, W.; Farid, H. A diverse large-scale dataset for evaluating rebroadcast attacks. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 1997–2001. [Google Scholar]
- Yu, I.J.; Kim, D.G.; Park, J.S.; Hou, J.U.; Choi, S.; Lee, H.K. Identifying photorealistic computer graphics using convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 4093–4097. [Google Scholar]
- He, P.; Jiang, X.; Sun, T.; Li, H. Computer Graphics Identification Combining Convolutional and Recurrent Neural Networks. IEEE Signal Process. Lett. 2018, 25, 1369–1373. [Google Scholar] [CrossRef]
- Yao, Y.; Hu, W.; Zhang, W.; Wu, T.; Shi, Y.Q. Distinguishing Computer-Generated Graphics from Natural Images Based on Sensor Pattern Noise and Deep Learning. Sensors 2018, 18, 1296. [Google Scholar] [CrossRef] [PubMed]
- Quan, W.; Wang, K.; Yan, D.M.; Zhang, X. Distinguishing between natural and computer-generated images using convolutional neural networks. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2772–2787. [Google Scholar] [CrossRef]
- Rahmouni, N.; Nozick, V.; Yamagishi, J.; Echizen, I. Distinguishing computer graphics from natural images using convolution neural networks. In Proceedings of the 2017 IEEE Workshop on Information Forensics and Security (WIFS), Rennes, France, 4–7 December 2017; pp. 1–6. [Google Scholar]
- Mo, H.; Chen, B.; Luo, W. Fake Faces Identification via Convolutional Neural Network. In Proceedings of the 6th ACM Workshop on Information Hiding and Multimedia Security, Innsbruck, Austria, 20–22 June 2018; pp. 43–47. [Google Scholar]
- Amerini, I.; Uricchio, T.; Caldelli, R. Tracing images back to their social network of origin: A cnn-based approach. In Proceedings of the 2017 IEEE Workshop on Information Forensics and Security (WIFS), Rennes, France, 4–7 December 2017; pp. 1–6. [Google Scholar]
- Caldelli, R.; Amerini, I.; Li, C.T. PRNU-based Image Classification of Origin Social Network with CNN. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 1357–1361. [Google Scholar]
- Gloe, T.; Böhme, R. The Dresden Image Database for benchmarking digital image forensics. In Proceedings of the 2010 ACM Symposium on Applied Computing, Sierre, Switzerland, 22–26 March 2010; pp. 1584–1590. [Google Scholar]
- De Marsico, M.; Nappi, M.; Riccio, D.; Wechsler, H. Mobile iris challenge evaluation (MICHE)-I, biometric iris dataset and protocols. Pattern Recognit. Lett. 2015, 57, 17–23. [Google Scholar] [CrossRef]
- Shullani, D.; Fontani, M.; Iuliani, M.; Al Shaya, O.; Piva, A. VISION: A video and image dataset for source identification. EURASIP J. Inf. Secur. 2017, 2017, 15. [Google Scholar] [CrossRef]
- Cao, H.; Kot, A.C. Identification of recaptured photographs on LCD screens. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; pp. 1790–1793. [Google Scholar]
- Li, R.; Ni, R.; Zhao, Y. An effective detection method based on physical traits of recaptured images on LCD screens. In International Workshop on Digital Watermarking; Springer: Berlin, Germany, 2015; pp. 107–116. [Google Scholar]
- Gao, X.; Qiu, B.; Shen, J.; Ng, T.T.; Shi, Y.Q. A smart phone image database for single image recapture detection. In International Workshop on Digital Watermarking; Springer: Berlin, Germany, 2010; pp. 90–104. [Google Scholar]
- Thongkamwitoon, T.; Muammar, H.; Dragotti, P.L. An image recapture detection algorithm based on learning dictionaries of edge profiles. IEEE Trans. Inf. Forensics Secur. 2015, 10, 953–968. [Google Scholar] [CrossRef]
- Ng, T.T.; Chang, S.F.; Hsu, J.; Pepeljugoski, M. Columbia Photographic Images and Photorealistic Computer Graphics Dataset; ADVENT Technical Report Columbia University: New York, NY, USA, 2005; pp. 205–2004. [Google Scholar]
- He, M. Distinguish computer generated and digital images: A CNN solution. Concurrency Comput. Pract. Exp. 2018. [Google Scholar] [CrossRef]
- Tokuda, E.; Pedrini, H.; Rocha, A. Computer generated images vs. digital photographs: A synergetic feature and classifier combination approach. J. Vis. Commun. Image Represent. 2013, 24, 1276–1292. [Google Scholar] [CrossRef]
- Cui, Q.; McIntosh, S.; Sun, H. Identifying materials of photographic images and photorealistic computer generated graphics based on deep CNNs. Comput. Mater. Contin. 2018, 55, 229–241. [Google Scholar]
- Nguyen, H.H.; Tieu, T.; Nguyen-Son, H.Q.; Nozick, V.; Yamagishi, J.; Echizen, I. Modular convolutional neural network for discriminating between computer-generated images and photographic images. In Proceedings of the 13th International Conference on Availability, Reliability and Security, Hamburg, Germany, 27–30 August 2018; p. 1. [Google Scholar]
- De Rezende, E.R.; Ruppert, G.C.; Theóphilo, A.; Tokuda, E.K.; Carvalho, T. Exposing computer generated images by using deep convolutional neural networks. Signal Process. Image Commun. 2018, 66, 113–126. [Google Scholar] [CrossRef]
- Caldelli, R.; Becarelli, R.; Amerini, I. Image origin classification based on social network provenance. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1299–1308. [Google Scholar] [CrossRef]
- Giudice, O.; Paratore, A.; Moltisanti, M.; Battiato, S. A classification engine for image ballistics of social data. In International Conference on Image Analysis and Processing; Springer: Berlin, Germany, 2017; pp. 625–636. [Google Scholar]
- Ng, T.T.; Chang, S.F.; Hsu, J.; Xie, L.; Tsui, M.P. Physics-motivated features for distinguishing photographic images and computer graphics. In Proceedings of the 13th Annual ACM International Conference on Multimedia, Singapore City, Singapore, 6–11 November 2005; pp. 159–164. [Google Scholar]
- Peng, F.; Zhou, D.L.; Long, M.; Sun, X.M. Discrimination of natural images and computer generated graphics based on multi-fractal and regression analysis. AEU-Int. J. Electron. Commun. 2017, 71, 72–81. [Google Scholar] [CrossRef]
- Tolosana, R.; Vera-Rodriguez, R.; Fierrez, J.; Morales, A.; Ortega-Garcia, J. DeepFakes and Beyond: A Survey of Face Manipulation and Fake Detection. arXiv 2020, arXiv:2001.00179. [Google Scholar]
- Verdoliva, L. Media Forensics and DeepFakes: Sn overview. arXiv 2020, arXiv:2001.06564. [Google Scholar]
- Nguyen, T.T.; Nguyen, C.M.; Nguyen, D.T.; Nguyen, D.T.; Nahavandi, S. Deep Learning for Deepfakes Creation and Detection. arXiv 2019, arXiv:1909.11573. [Google Scholar]
- Marra, F.; Gragnaniello, D.; Cozzolino, D.; Verdoliva, L. Detection of GAN-generated fake images over social networks. In Proceedings of the 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; pp. 384–389. [Google Scholar]
- Fridrich, J.; Kodovsky, J. Rich models for steganalysis of digital images. IEEE Trans. Inf. Forensics Secur. 2012, 7, 868–882. [Google Scholar] [CrossRef]
- Cozzolino, D.; Poggi, G.; Verdoliva, L. Recasting residual-based local descriptors as convolutional neural networks: An application to image forgery detection. In Proceedings of the 5th ACM Workshop on Information Hiding and Multimedia Security, Paris, France, 3–5 July 2017; pp. 159–164. [Google Scholar]
- Bayar, B.; Stamm, M.C. A deep learning approach to universal image manipulation detection using a new convolutional layer. In Proceedings of the 4th ACM Workshop on Information Hiding and Multimedia Security, Vigo, Spain, 20–22 June 2016; pp. 5–10. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Haodong, L.; Han, C.; Bin, L.; Shunquan, T. Can Forensic Detectors Identify GAN Generated Images? In Proceedings of the APSIPA Annual Summit and Conference 2018, Honolulu, HI, USA, 12–15 November 2018; pp. 722–727. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. In Proceedings of the 4th International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein Generative Adversarial Networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Li, H.; Li, B.; Tan, S.; Huang, J. Detection of deep network generated images using disparities in color components. arXiv 2018, arXiv:1808.07276. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE international conference on computer vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Huang, G.B.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments. In Proceedings of the Workshop on faces in‘Real-Life’Images: Detection, Alignment, and Recognition, Marseille, France, 17–18 October 2008. [Google Scholar]
- Hou, X.; Shen, L.; Ke, S.; Qiu, G. Deep Feature Consistent Variational Autoencoder. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2016. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved Training of wasserstein GANs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Boulkenafet, Z.; Jukka, K.; Abdenour, H. Face spoofing detection using colour texture analysis. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1818–1830. [Google Scholar] [CrossRef]
- McCloskey, S.; Albright, M. Detecting GAN-generated Imagery using Color Cues. arXiv 2018, arXiv:1812.08247. [Google Scholar]
- Chen, C.; McCloskey, S.; Yu, J. Focus Manipulation Detection via Photometric Histogram Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1674–1682. [Google Scholar]
- Marra, F.; Gragnaniello, D.; Verdoliva, L.; Poggi, G. Do GANs leave artificial fingerprints? arXiv 2018, arXiv:1812.11842. [Google Scholar]
- Wang, Q.; Zhang, R. Double JPEG compression forensics based on a convolutional neural network. EURASIP J. Inf. Secur. 2016, 2016, 23. [Google Scholar] [CrossRef]
- Güera, D.; Wang, Y.; Bondi, L.; Bestagini, P.; Tubaro, S.; Delp, E.J. A counter-forensic method for cnn-based camera model identification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1840–1847. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Papernot, N.; Mcdaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The Limitations of Deep Learning in Adversarial Settings. In Proceedings of the IEEE European Symposium on Security & Privacy, Saarbrucken, Germany, 21–24 March 2016. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Zhao, W.; Yang, P.; Ni, R.; Zhao, Y.; Wu, H. Security Consideration for Deep Learning-Based Image Forensics. IEICE Trans. Inf. Syst. 2018, 101, 3263–3266. [Google Scholar] [CrossRef]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial Machine Learning at Scale. arXiv 2016, arXiv:1611.01236. [Google Scholar]
- Fan, W.; Agarwal, S.; Farid, H. Rebroadcast Attacks: Defenses, Reattacks, and Redefenses. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 942–946. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Chen, C.; Zhao, X.; Stamm, M.C. Mislgan: An Anti-Forensic Camera Model Falsification Framework Using A Generative Adversarial Network. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 535–539. [Google Scholar]
- Zhao, W.; Yang, P.; Ni, R.; Zhao, Y.; Li, W. Cycle GAN-Based Attack on Recaptured Images to Fool both Human and Machine. In International Workshop on Digital Watermarking; Springer: Berlin, Germany, 2018; pp. 83–92. [Google Scholar]
- Barni, M.; Stamm, M.C.; Tondi, B. Adversarial Multimedia Forensics: Overview and Challenges Ahead. In Proceedings of the 26th European Signal Processing Conference (EUSIPCO), IEEE, Rome, Italy, 3–7 September 2018; pp. 962–966. [Google Scholar]
- Akhtar, N.; Mian, A. Threat of adversarial attacks on deep learning in computer vision: A survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- Kurakin, A.; Goodfellow, I.; Bengio, S.; Dong, Y.; Liao, F.; Liang, M.; Pang, T.; Zhu, J.; Hu, X.; Xie, C.; et al. Adversarial attacks and defences competition. In The NIPS’17 Competition: Building Intelligent Systems; Springer: Berlin, Germany, 2018; pp. 195–231. [Google Scholar]
- Carrara, F.; Falchi, F.; Caldelli, R.; Amato, G.; Fumarola, R.; Becarelli, R. Detecting adversarial example attacks to deep neural networks. In Proceedings of the 15th International Workshop on Content-Based Multimedia Indexing, ACM, Florence, Italy, 19–21 June 2017; p. 38. [Google Scholar]
- Carrara, F.; Falchi, F.; Caldelli, R.; Amato, G.; Becarelli, R. Adversarial image detection in deep neural networks. Multimed. Tools Appl. 2019, 78, 2815–2835. [Google Scholar] [CrossRef]
- Schöttle, P.; Schlögl, A.; Pasquini, C.; Böhme, R. Detecting Adversarial Examples – a Lesson from Multimedia Security. In Proceedings of the 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 947–951. [Google Scholar]
- Carlini, N.; Wagner, D. Adversarial examples are not easily detected: Bypassing ten detection methods. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, ACM, Dallas, TX, USA, 30 October–3 November 2017; pp. 3–14. [Google Scholar]
- Papernot, N.; Faghri, F.; Carlini, N.; Goodfellow, I.; Feinman, R.; Kurakin, A.; Xie, C.; Sharma, Y.; Brown, T.; Roy, A.; et al. Technical Report on the CleverHans v2.1.0 Adversarial Examples Library. arXiv 2018, arXiv:1610.00768. [Google Scholar]



{kind=link}
{kind=link}
| Architecture | Input Size | Preprocessing | Convolutional Part | Fully Connected Part | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| N Layers | Activation | Pooling | BN | GAP | N Layers | Activation | Dropout | |||
| A1 [23] | 48 × 48 × 3 | - | 3 | ReLU | Max | - | - | 1 | ReLU | ✓ |
| A2 [24] | 32 × 32 × 3 | - | 2 | L-ReLU | Max | - | - | 2 | L-ReLU | ✓ |
| A3 [25] | 36 × 36 × 3 | - | 3 | ReLU | Avg | ✓ | - | 1 | ReLU | ✓ |
| A4 [26] | 64 × 64 × 3 | - | 13 | ReLU | Max | - | - | 2 | ? | ✓ |
| A5 [27] | 256 × 256 × 3 | - | 1 Conv, 12 Residual | ReLU | - | - | ✓ | - | - | - |
| A6 [36] | 64 × 64 × 3 | - | 4 | ? | Max | - | - | 1 | ReLU | - |
| A7 [37] | 64 × 64 × 3 | - | 10 | ? | Max | - | - | 1 | ReLU | - |
| A8 [38] | 256 × 256 × 2 | IC + CC | 4 | TanH | Max, Avg | ✓ | - | 2 | TanH | - |
| A9 [39] | 256 × 256 | HP | 3 | ReLU | Max | - | - | 2 | ReLU | ✓ |
| A10 [41] | 256 × 256 × 3 | LBP | 3 | ReLU | Max | ✓ | - | 2 | ReLU | ✓ |
| A11 [42] | 64 × 64 × 3 | - | 6 | ReLU | Avg | ✓ | ✓ | - | - | - |
| A12 [43] | 64 × 64 × 3 | - | 1 Conv, 3 Residual | ReLU | Avg | - | ✓ | - | - | - |
| Architecture | Input size | Preprocessing | Convolutional part | Fully connected part | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| N Layers | Activation | Pooling | BN | GAP / Stats | N Layers | Activation | Dropout | ||||
| RF | B1 [50] | N × N × 3 | Lap | 5 | ReLU | Avg | ✓ | GAP | - | - | - |
| B2 [53] | 64 × 64 × 1 | GR | 6 | L-ReLU | - | ✓ | - | 1 | L-ReLU | - | |
| B3 [52] | 32 × 32 × 3 | Conv | 2 | ReLU | Avg | ✓ | - | 1 | ? | - | |
| B4 [51] | 64 × 64 × 3 | - | 6 | ReLU | Max | - | - | 2 | ReLU | ✓ | |
| CGI | C1 [54] | 32 × 32 × 3 | - | 6 | ReLU | - | - | - | 2 | ReLU + BN | - |
| C2 [55] | 96 × 96 | Col + Tex | 4 | ReLU | Avg | ✓ | - | 1 | ? | ✓ | |
| C3 [56] | 650 × 650 | Filters | 5 | ReLU | Avg | ✓ | GAP | - | - | - | |
| C4 [57] | NxN | Conv | 3 | ReLU | Max | ✓ | - | 1 | ReLU | ✓ | |
| C5 [58] | 100 × 100 × 1 | - | 2 | - | - | - | Stats | 1 | ReLU | ✓ | |
| GAN | D1 [59] | N × N × 3 | Lap | 3 | L-ReLU | Max | - | - | 2 | L-ReLU | - |
| SSN | E1 [60] | 64 × 64 | DCT-His | 2 | ReLU | Max | - | - | 1 | ReLU | ✓ |
| E2 [61] | 64 × 64 | PRNU | 4 | ReLU | Max | - | - | 1 | ReLU | ✓ | |
| Arch. | Input Size | D.A. | F./E. | P.S. | C. | Train: Test | Dataset | Perf. (Patch) | Perf. (Voting) | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | Sensor | Model | Sensor | |||||||||
| [23] | A1 | 48 × 48 × 3 | - | - | - | Softmax | 7:3 | Dresden [62] | 72.9% (27) | 29.8% (74) | 94.1% (27) | - |
| [24] | A2 | 32 × 32 × 3 | - | - | - | Softmax | MICHE-I [63] | 98.1% (3) | 91.1% (5) | - | - | |
| [25] | A3 | 36 × 36 × 3 | - | - | - | SVM | 8:2 | Dresden [62] | - | - | - | 99.9% (10) |
| [26] | A4 | 64 × 64 × 3 | - | - | ✓ | Softmax | 3:2 | Dresden [62] | 93% (25) | - | >98% (25) | - |
| [27] | A5 | 256 × 256 × 3 | - | - | - | Softmax | 7:3 | Dresden [62] | 94.7% (27) | 45.8% (74) | - | - |
| [29] | A6 | 64 × 64 × 3 | - | - | - | Softmax | 8:2 | VISION [64] | - | 80.77% (35) | - | 97.47% (35) |
| DenseNet-40 | 32 × 32 × 3 | - | 87.96% (35) | - | 95.06% (35) | |||||||
| DenseNet-121 | 224 × 224 × 3 | - | 93.88% (35) | - | 99.10% (35) | |||||||
| XceptionNet | 299 × 299 × 3 | - | 95.15% (35) | - | 99.31% (35) | |||||||
| [31] | DenseNet-201 + SE-Block | 256 × 256 × 1 | ✓ | ✓ | ✓ | SE-block | 3.2:1 | SPC2018 [7] | 98.37% (10, weighted) | - | - | - |
| [36] | A6 | 64 × 64 × 3 | - | - | ✓ | SVM | Dresden [62] | 93% (18) | - | >95 % (18) | - | |
| [37] | A7 | 64 × 64 × 3 | - | - | ✓ | Softmax | Dresden [62] | 94.93% (18) | - | - | - | |
| [38] | A8 | 256 × 256 × 2 | ✓ | ✓ | - | ET | 4:1 | Dresden [62] | 98.58% (26) | - | - | - |
| [39] | A9 | 256 × 256 | - | - | - | Softmax | 8:2 | Dresden [62] | 98.99% (12) 98.01% (14) | - | - | - |
| [41] | A10 | 256 × 256 × 3 | ✓ | - | - | Softmax | 8:2 | Dresden [62] | 98.78% (12) 97.41% (14) | - | - | - |
| [43] | A12 | 64 × 64 × 3 | ✓ | ✓ | ✓ | Softmax | 4:1 | Dresden [62] | - | 97.03% (9) | - | - |
| [32] | DenseNet-161 | 480 × 480 × 3 | ✓ | - | - | Softmax | SPC2018 [7] | 98% (10, weighted) | - | - | - | |
| [42] | A11 | 64 × 64 × 3 | ✓ | ✓ | - | Softmax | 4:1 | Dresden [62] | - | 94.14% (9) | - | - |
| [33] | Inception-Xception | 299 × 299 | - | ✓ | ✓ | Softmax | SPC2018 [7] | 93.29% (10, weighted) | - | - | - | |
| [28] | ResNet-modified | 48 × 48 × 3 | ✓ | - | - | Softmax | Dresden [62] | - | - | 79.71% (27) | 53.4% (74) | |
| Arch. | Input Size | D.A. | F./E. | P.S. | C. | Train: Test | Dataset | Perf. (Patch) | Perf. (Voting) | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| RF | [50] | B1 | N × N × 3 | ✓ | - | - | Softmax | 1:1 | NTU-Rose [65] LCD_R [66] | 99.74% (512) 99.30% (256) 98.48% (128) 95.23% (64) | |
| [53] | B2 | 64 × 64 × 1 | ✓ | ✓ | - | Softmax | 8:2 | LS-D [53] | 99.90% | ||
| [52] | B3 | 32 × 32 × 3 | ✓ | - | - | Softmax | 1:1 | ASTAR [67] | 86.78% | 93.29% (64) | |
| NTU-Rose [65] | 96.93% | 98.67% (64) | |||||||||
| ICL [68] | 97.79% | 99.54% (64) | |||||||||
| [51] | B4 | 64 × 64 × 3 | - | - | - | Softmax | 1:1 | ICL [68] | 85.73% | 96.60% | |
| CGI | [54] | C1 | 32 × 32 × 3 | - | - | - | Softmax | 3:1 | Columbia [69] | 98% | |
| [70] | ResNet50 | 224 × 224 | - | - | - | Softmax | 5-f CV | DSTok [71] | 96.1% | ||
| [55] | C2 | 96 × 96 | ✓ | ✓ | - | Softmax | 13:4 | 3Dlink [55] | 90.79% | 94.87% (192) | |
| [56] | C3 | 650 × 650 | ✓ | - | - | Softmax | 9:8 | WIFS [58] | 99.95% | 100% | |
| [72] | ResNet50 | ? | ✓ | - | - | Softmax | 7:1 | Columbia [69] | 98% | ||
| [57] | C4 | 233 × 233 | ✓ | - | ✓ | Softmax | 3:1 | Columbia [69] | 85.15% | 93.20% | |
| [58] | C5 | 100 × 100 × 1 | - | ✓ | - | MLP | 8:2 | WIFS [58] | 84.80% | 93.20% | |
| [73] | VGG19 | - | ✓ | ✓ | MLP | 5:2 | WIFS [58] | 96.55% | 99.89% | ||
| [74] | ResNet50 | 224 × 224 × 3 | - | - | - | SVM | DSTok [71] | 94% | |||
| SSN | [60] | E1 | 64 × 64 | ✓ | - | - | Softmax | 9:1 | UCID [75] | 98.41% | 95% (Avg.) |
| PUBLIC [75] | 87.60% | ||||||||||
| IPLAB [76] | 90.89% | ||||||||||
| [61] | E2 | 64 × 64 | ✓ | - | - | Softmax | 9:1 | UCID [75] | 79.49% | 90.83% | |
| VISION [64] | 98.50% | ||||||||||
| IPLAB [76] | 83.85% |
| GAN | Dataset | Method | Performance | |
|---|---|---|---|---|
| [82] | Cycle-GAN [87] | Cycle-GAN Data [87] | Cycle-GAN Discriminator [87] | 83.58% |
| Fridrich and Kodovsky [83] | 94.40% | |||
| Cozzolino et al. [84] | 95.07% | |||
| Bayar and Stamm [85] | 84.86% | |||
| Rahmouni et al. [58] | 85.71% | |||
| DenseNet [18] | 89.19% | |||
| InceptionNet V3 [86] | 89.09% | |||
| XceptionNet [19] | 94.49% | |||
| [88] | DC-GAN W-GAN | CelebA [92] | DCGAN Discriminator | 95.51% |
| VGG+FLD | >90 % (DC-GAN) >94% (W-GAN) | |||
| [91] | DFC-VAE DCGAN WGAN-GP PGGAN | CelebAHQ [93] CelebA [92] LFW [94] | Co-Color | 100% |
| [59] | PG-GAN | CelebAHQ [93] | Lap-CNN | 96.3% |
| [98] | GAN | MFS2018 [6] | RG-INHNet | 0.56 (AUC) |
| Saturation Features | 0.7 (AUC) | |||
| [100] | Cycle-GAN Pro-GAN Star-GAN | MFS2018 [6] | PRNU-based method | 0.999 (AUC) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, P.; Baracchi, D.; Ni, R.; Zhao, Y.; Argenti, F.; Piva, A. A Survey of Deep Learning-Based Source Image Forensics. J. Imaging 2020, 6, 9. https://doi.org/10.3390/jimaging6030009
Yang P, Baracchi D, Ni R, Zhao Y, Argenti F, Piva A. A Survey of Deep Learning-Based Source Image Forensics. Journal of Imaging. 2020; 6(3):9. https://doi.org/10.3390/jimaging6030009
Chicago/Turabian StyleYang, Pengpeng, Daniele Baracchi, Rongrong Ni, Yao Zhao, Fabrizio Argenti, and Alessandro Piva. 2020. "A Survey of Deep Learning-Based Source Image Forensics" Journal of Imaging 6, no. 3: 9. https://doi.org/10.3390/jimaging6030009
APA StyleYang, P., Baracchi, D., Ni, R., Zhao, Y., Argenti, F., & Piva, A. (2020). A Survey of Deep Learning-Based Source Image Forensics. Journal of Imaging, 6(3), 9. https://doi.org/10.3390/jimaging6030009