Real-Time System for Driver Fatigue Detection Based on a Recurrent Neuronal Network


Abstract
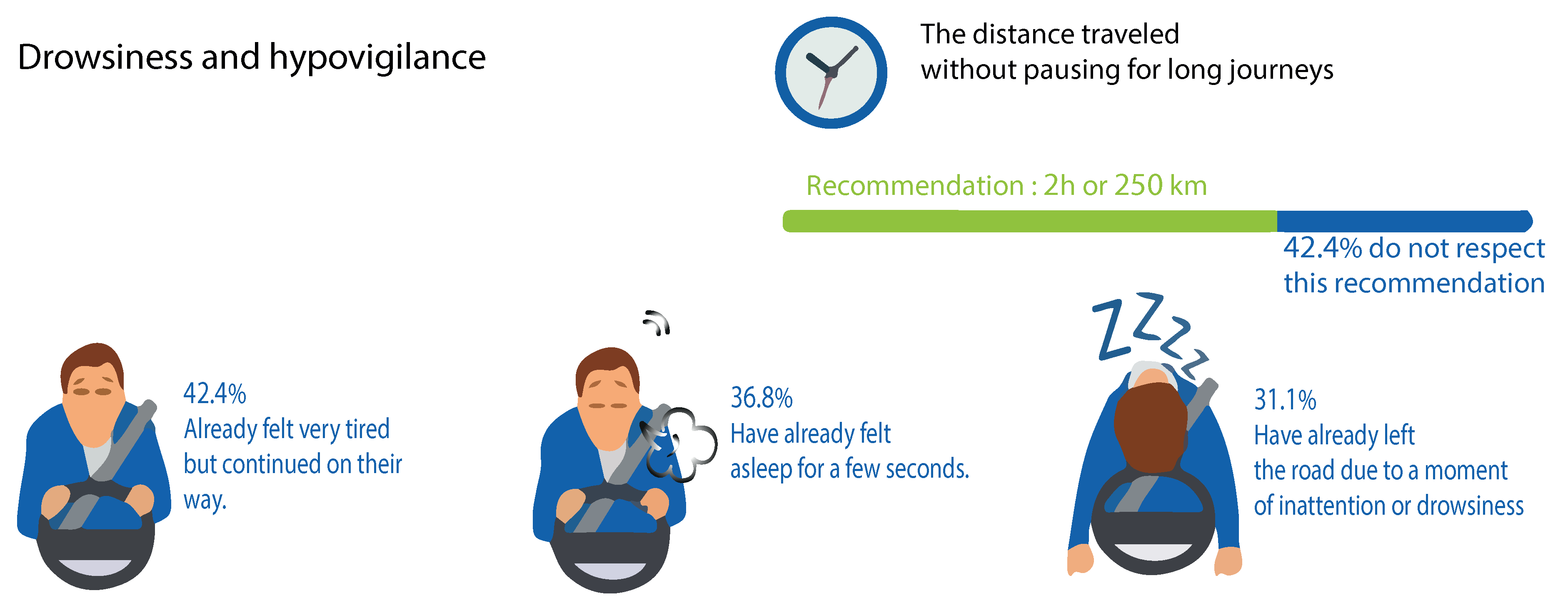
1. Introduction
2. Related Work
3. Background
3.1. Deep Learning
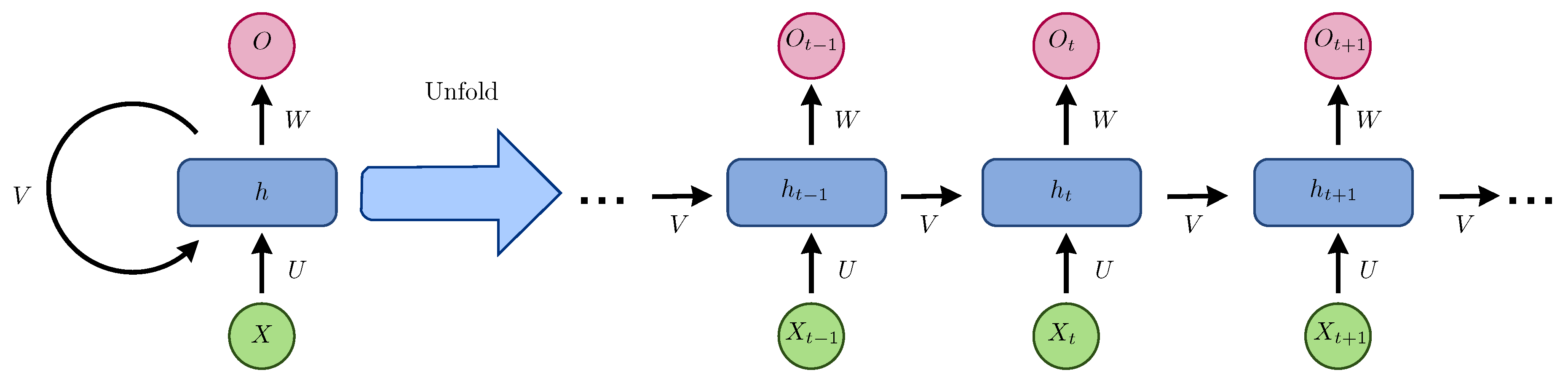
3.2. Recurrent Neural Networks (RRN)
4. Proposed Approach
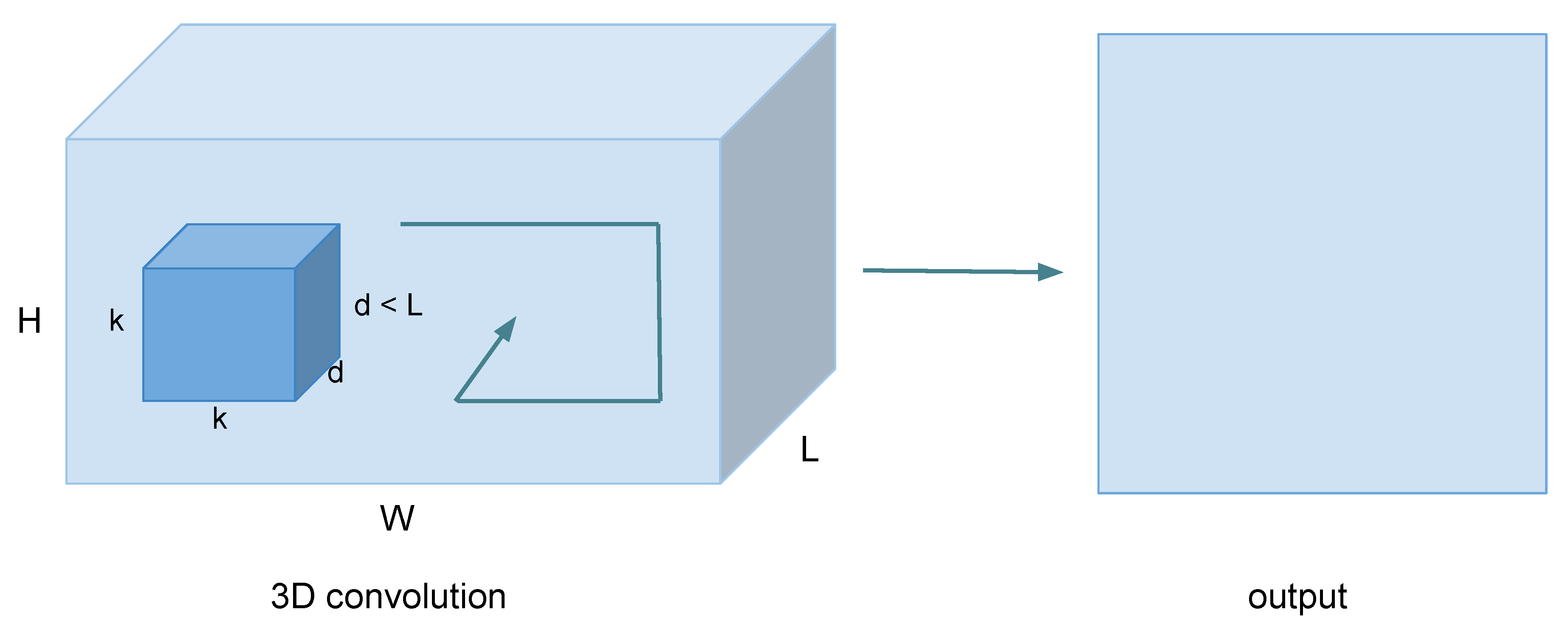
4.1. Learning Features with 3D Convolutional Networks
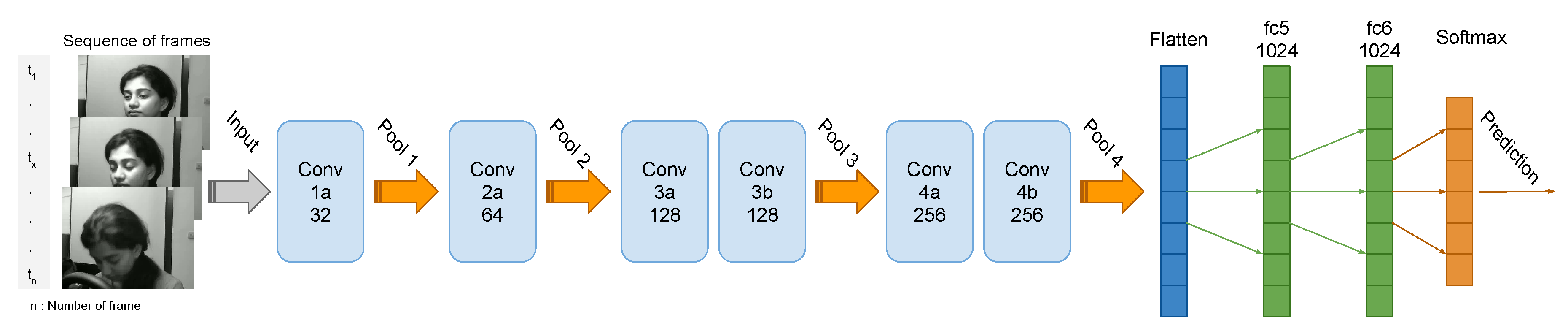
4.2. Multi-Layer Architectures
5. Experiments
5.1. The NTHU-DDD Dataset
5.2. Training
6. Results Analysis
6.1. Accuracy Results
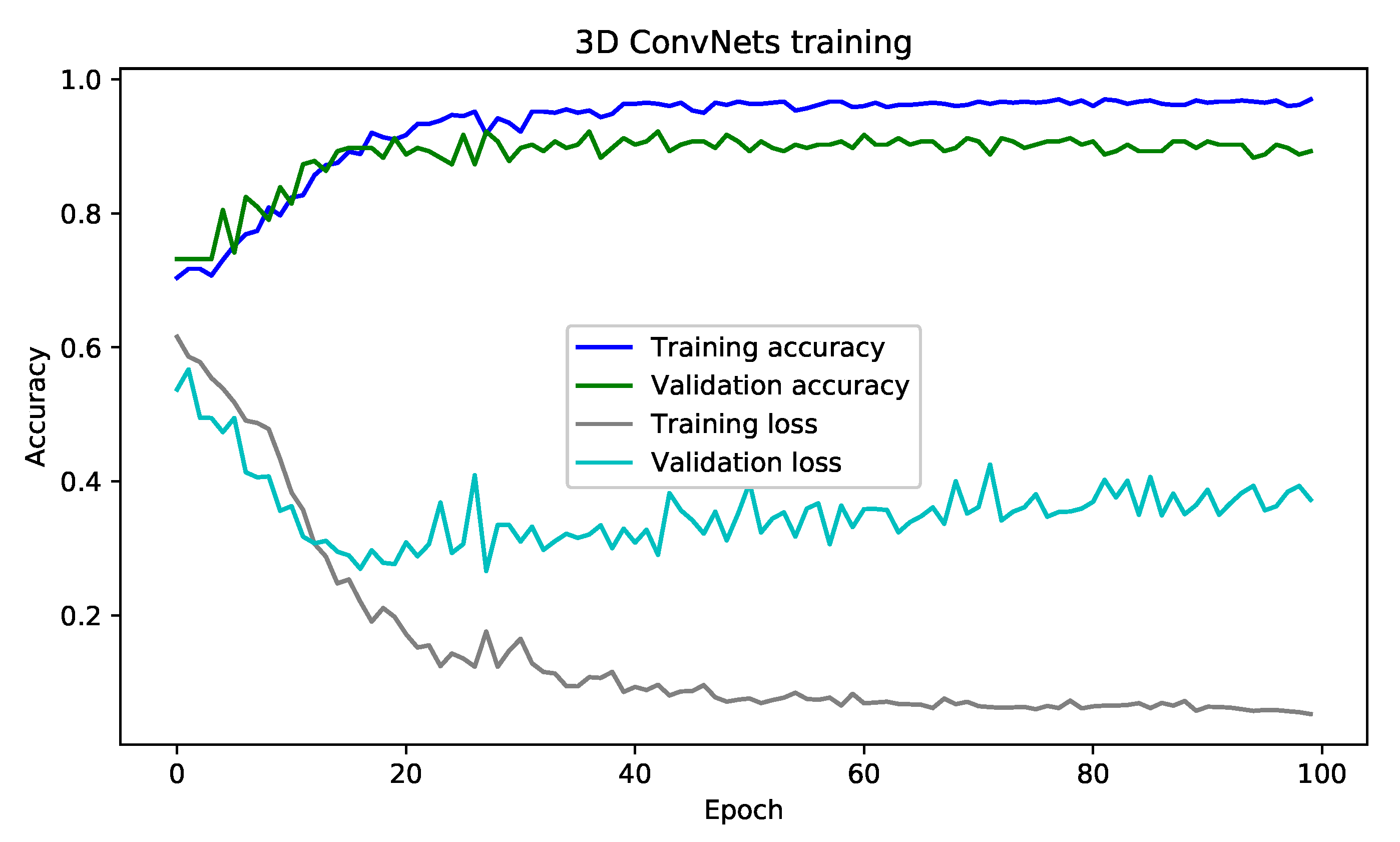
6.2. Evolution of the Training
6.3. Performance Measurement
6.4. Comparison with Other Methods
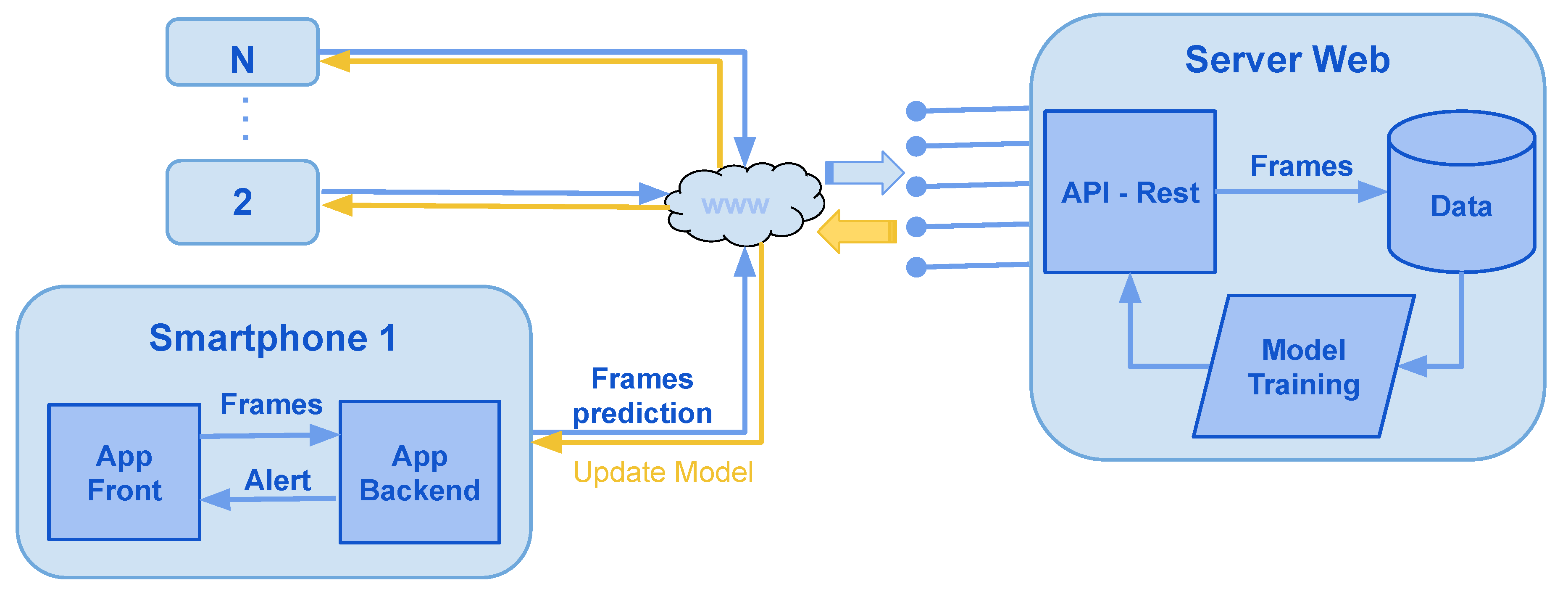
7. Proposed System
- Mobile application: Kivy and Tensorflow (Python3)
- Web server: Flask and Tensorflow (Python3).
- Database: Postgresql (sql).
- Storage: File system or cloud.
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- World Health Organization. Global Status Report on Road Safety 2015; World Health Organization: Geneva, Switzerland, 2015. [Google Scholar]
- El Ftouh, M.; Derradji, A.; Jniene, A.; Fihry, M.T.E.F. Étude de la prévalence et les facteurs de risque de la somnolence au volant dans une population marocaine. Médecine Du Sommeil 2013, 10, 141–145. [Google Scholar] [CrossRef]
- Ed-doughmi, Y.; Idrissi, N. Driver Fatigue Detection using Recurrent Neural Networks. In Proceedings of the 2nd International Conference on Networking, Information Systems & Security, Rabat, Morocco, 27–28 March 2019; ACM: New York, NY, USA, 2019; p. 44. [Google Scholar]
- Shih, T.H.; Hsu, C.T. MSTN: Multistage spatial-temporal network for driver drowsiness detection. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 146–153. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Huynh, X.P.; Park, S.M.; Kim, Y.G. Detection of driver drowsiness using 3D deep neural network and semi-supervised gradient boosting machine. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 134–145. [Google Scholar]
- Computer Vision Lab, National Tsuing Hua University. Driver Drowsiness Detection Dataset. 2016. Available online: http://cv.cs.nthu.edu.tw/php/callforpaper/datasets/DDD/ (accessed on 1 March 2020).
- Weng, C.H.; Lai, Y.H.; Lai, S.H. Driver Drowsiness Detection via a Hierarchical Temporal Deep Belief Network. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 117–133. [Google Scholar]
- Summala, H. Towards understanding motivational and emotional factors in driver behaviour: Comfort through satisficing. In Modelling Driver Behaviour in Automotive Environments; Springer: Berlin/Heidelberg, Germany, 2007; pp. 189–207. [Google Scholar]
- Koilias, A.; Mousas, C.; Rekabdar, B. The Effects of Driving Habits on Virtual Reality Car Passenger Anxiety. In Proceedings of the International Conference on Virtual Reality and Augmented Reality, Tallinn, Estonia, 23–25 October 2019; pp. 263–281. [Google Scholar]
- Borghini, G.; Astolfi, L.; Vecchiato, G.; Mattia, D.; Babiloni, F. Measuring neurophysiological signals in aircraft pilots and car drivers for the assessment of mental workload, fatigue and drowsiness. Neurosci. Biobehav. Rev. 2014, 44, 58–75. [Google Scholar] [CrossRef] [PubMed]
- Mu, Z.; Hu, J.; Min, J. Driver fatigue detection system using electroencephalography signals based on combined entropy features. Appl. Sci. 2017, 7, 150. [Google Scholar] [CrossRef]
- Zhang, X.; Li, J.; Liu, Y.; Zhang, Z.; Wang, Z.; Luo, D.; Zhou, X.; Zhu, M.; Salman, W.; Hu, G.; et al. Design of a fatigue detection system for high-speed trains based on driver vigilance using a wireless wearable EEG. Sensors 2017, 17, 486. [Google Scholar] [CrossRef]
- Chaudhuri, A.; Routray, A. Driver Fatigue Detection Through Chaotic Entropy Analysis of Cortical Sources Obtained From Scalp EEG Signals. IEEE Trans. Intell. Transp. Syst. 2019. [Google Scholar] [CrossRef]
- Massoz, Q.; Verly, J.; Van Droogenbroeck, M. Multi-Timescale Drowsiness Characterization Based on a Video of a Driver’s Face. Sensors 2018, 18, 2801. [Google Scholar] [CrossRef]
- Mandal, B.; Li, L.; Wang, G.S.; Lin, J. Towards detection of bus driver fatigue based on robust visual analysis of eye state. IEEE Trans. Intell. Transp. Syst. 2017, 18, 545–557. [Google Scholar] [CrossRef]
- Al-Rahayfeh, A.; Faezipour, M. Eye tracking and head movement detection: A state-of-art survey. IEEE J. Transl. Eng. Health Med. 2013, 1, 2100212. [Google Scholar] [CrossRef]
- Kurylyak, Y.; Lamonaca, F.; Mirabelli, G. Detection of the eye blinks for human’s fatigue monitoring. In Proceedings of the Medical Measurements and Applications Proceedings (MeMeA), Budapest, Hungary, 18–19 May 2012; pp. 1–4. [Google Scholar]
- Lienhart, R.; Maydt, J. An extended set of haar-like features for rapid object detection. In Proceedings of the 2002 International Conference on Image Processing, New York, NY, USA, 22–25 September 2002; Volume 1, p. I. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the Thirteenth International Conference on International Conference on Machine LearningJuly 1996 (ICML’96), Bari, Italy, 3–6 July 1996; Volume 96, pp. 148–156. [Google Scholar]
- Alioua, N.; Amine, A.; Rogozan, A.; Bensrhair, A.; Rziza, M. Driver head pose estimation using efficient descriptor fusion. EURASIP J. Image Video Process. 2016, 2016, 2. [Google Scholar] [CrossRef]
- Burges, C.J. A tutorial on support vector machines for pattern recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Dong, N.; Li, Y.; Gao, Z.; Ip, W.H.; Yung, K.L. A WPCA-Based Method for Detecting Fatigue Driving From EEG-Based Internet of Vehicles System. IEEE Access 2019, 7, 124702–124711. [Google Scholar] [CrossRef]
- Yang, Y.; Gao, Z.; Li, Y.; Cai, Q.; Marwan, N.; Kurths, J. A Complex Network-Based Broad Learning System for Detecting Driver Fatigue From EEG Signals. IEEE Trans. Syst. Man Cybern. Syst. 2019. [Google Scholar] [CrossRef]
- Han, C.; Sun, X.; Yang, Y.; Che, Y.; Qin, Y. Brain Complex Network Characteristic Analysis of Fatigue during Simulated Driving Based on Electroencephalogram Signals. Entropy 2019, 21, 353. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, Z.; Zhou, Q.; Chen, X. Wavelet Packet Entropy Analysis of Resting State Electroencephalogram in Sleep Deprived Mental Fatigue State. In Proceedings of the International Conference on Human-Computer Interaction, Orlando, FL, USA, 26–31 July 2019; pp. 484–494. [Google Scholar]
- Haggag, O. Automated Drowsiness Detection while Driving using Depth Camera. In Proceedings of the Umeå’s 23rd Student Conference in Computing Science, USCCS 2019, Umeå University, Umeå, Swedish, February 2019; p. 11. [Google Scholar]
- Liu, T. Using Kinect to Capture the Joint Angles of Static Driving Posture. In Advances in Physical Ergonomics & Human Factors: Proceedings of the AHFE 2018 International Conference on Physical Ergonomics & Human Factors, Orlando, FL, USA, 24–25 July 2018; Loews Sapphire Falls Resort at Universal Studios; Springer: Berlin/Heidelberg, Germany, 2018; Volume 789, p. 297. [Google Scholar]
- Liu, F.; Li, X.; Lv, T.; Xu, F. A Review of Driver Fatigue Detection: Progress and Prospect. In Proceedings of the 2019 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 11–13 January 2019; pp. 1–6. [Google Scholar]
- Rev., M.T. Dueling Neural Networks. 2018. Available online: https://www.technologyreview.com/lists/technologies/2018/ (accessed on 3 March 2018).
- Liu, W.; Qian, J.; Yao, Z.; Jiao, X.; Pan, J. Convolutional Two-Stream Network Using Multi-Facial Feature Fusion for Driver Fatigue Detection. Future Internet 2019, 11, 115. [Google Scholar] [CrossRef]
- Xiao, Z.; Hu, Z.; Geng, L.; Zhang, F.; Wu, J.; Li, Y. Fatigue driving recognition network: Fatigue driving recognition via convolutional neural network and long short-term memory units. IET Intell. Transp. Syst. 2019, 13, 1410–1416. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Wang, X.; Xu, C. Driver drowsiness detection based on non-intrusive metrics considering individual specifics. Accid. Anal. Prev. 2016, 95, 350–357. [Google Scholar] [CrossRef]
- Liang, Y.; Horrey, W.J.; Howard, M.E.; Lee, M.L.; Anderson, C.; Shreeve, M.S.; O’Brien, C.S.; Czeisler, C.A. Prediction of drowsiness events in night shift workers during morning driving. Accid. Anal. Prev. 2017, 126, 105–114. [Google Scholar] [CrossRef]
- François, C.; Hoyoux, T.; Langohr, T.; Wertz, J.; Verly, J.G. Tests of a new drowsiness characterization and monitoring system based on ocular parameters. Int. J. Environ. Res. Public Health 2016, 13, 174. [Google Scholar] [CrossRef]
- Ebrahim, P.; Abdellaoui, A.; Stolzmann, W.; Yang, B. Eyelid-based driver state classification under simulated and real driving conditions. In Proceedings of the 2014 IEEE International Conference on Systems, Man and Cybernetics (SMC), San Diego, CA, USA, 5–8 October 2014; pp. 3190–3196. [Google Scholar]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Sermanet, P.; Kavukcuoglu, K.; Chintala, S.; LeCun, Y. Pedestrian detection with unsupervised multi-stage feature learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 July 2013; pp. 3626–3633. [Google Scholar]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Jordan, M.I. Serial order: A parallel distributed processing approach. In Advances in Psychology; Elsevier: Amsterdam, The Netherlands, 1997; Volume 121, pp. 471–495. [Google Scholar]
- Rekabdar, B.; Mousas, C.; Gupta, B. Generative adversarial network with policy gradient for text summarization. In Proceedings of the 2019 IEEE 13th International Conference on Semantic Computing (ICSC), Newport Beach, FL, USA, 30 January–1 February 2019; pp. 204–207. [Google Scholar]
- Abdel-Hamid, O.; Mohamed, A.R.; Jiang, H.; Penn, G. Applying convolutional neural networks concepts to hybrid NN-HMM model for speech recognition. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 4277–4280. [Google Scholar]
- Chéron, G.; Laptev, I.; Schmid, C. P-cnn: Pose-based cnn features for action recognition. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 3218–3226. [Google Scholar]
- Zhou, Y.; Li, Z.; Xiao, S.; He, C.; Huang, Z.; Li, H. Auto-conditioned recurrent networks for extended complex human motion synthesis. arXiv 2017, arXiv:1707.05363. [Google Scholar]
- Saito, S.; Wei, L.; Hu, L.; Nagano, K.; Li, H. Photorealistic facial texture inference using deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5144–5153. [Google Scholar]
- Sela, M.; Richardson, E.; Kimmel, R. Unrestricted facial geometry reconstruction using image-to-image translation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1576–1585. [Google Scholar]
- Rekabdar, B.; Mousas, C. Dilated Convolutional Neural Network for Predicting Driver’s Activity. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3245–3250. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 4489–4497. [Google Scholar]
- Mustafa, M.K.; Allen, T.; Appiah, K. A comparative review of dynamic neural networks and hidden Markov model methods for mobile on-device speech recognition. Neural Comput. Appl. 2019, 31, 891–899. [Google Scholar] [CrossRef]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Li, F.-F. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef]
- Sun, L.; Jia, K.; Yeung, D.Y.; Shi, B.E. Human action recognition using factorized spatio-temporal convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 4597–4605. [Google Scholar]
- Ma, Z.; Chang, D.; Li, X. Channel Max Pooling Layer for Fine-Grained Vehicle Classification. arXiv 2019, arXiv:1902.11107. [Google Scholar]
- Giusti, A.; Cireşan, D.C.; Masci, J.; Gambardella, L.M.; Schmidhuber, J. Fast image scanning with deep max-pooling convolutional neural networks. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, VIC, Australia, 15–18 September 2013; pp. 4034–4038. [Google Scholar]
- Jin, J.; Dundar, A.; Culurciello, E. Flattened convolutional neural networks for feedforward acceleration. arXiv 2014, arXiv:1412.5474. [Google Scholar]
- Reverdy, P.; Leonard, N.E. Parameter estimation in softmax decision-making models with linear objective functions. IEEE Trans. Autom. Sci. Eng. 2016, 13, 54–67. [Google Scholar] [CrossRef]
- Martins, A.; Astudillo, R. From softmax to sparsemax: A sparse model of attention and multi-label classification. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1614–1623. [Google Scholar]
- Gulli, A.; Pal, S. Deep Learning with Keras; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the OSDI, Savannah, GA, USA, 2–4 November 2016; Volume 16, pp. 265–283. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 5–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Bhagyesh Vikani, F.S. CNN Visualization. 2017. Available online: https://github.com/InFoCusp/tf_cnnvis/ (accessed on 1 April 2018).
- Srivastava, N.; Mansimov, E.; Salakhudinov, R. Unsupervised learning of video representations using lstms. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 843–852. [Google Scholar]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Kumar, P.J. Multilayer Perceptron Neural Network Based Immersive VR System for Cognitive Computer Gaming. In Progress in Advanced Computing and Intelligent Engineering; Springer: Berlin/Heidelberg, Germany, 2018; pp. 91–102. [Google Scholar]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]
- Mbouna, R.O.; Kong, S.G.; Chun, M.G. Visual analysis of eye state and head pose for driver alertness monitoring. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1462–1469. [Google Scholar] [CrossRef]
- Omidyeganeh, M.; Shirmohammadi, S.; Abtahi, S.; Khurshid, A.; Farhan, M.; Scharcanski, J.; Hariri, B.; Laroche, D.; Martel, L. Yawning detection using embedded smart cameras. IEEE Trans. Instrum. Meas. 2016, 65, 570–582. [Google Scholar] [CrossRef]
- Chiou, C.Y.; Wang, W.C.; Lu, S.C.; Huang, C.R.; Chung, P.C.; Lai, Y.Y. Driver monitoring using sparse representation with part-based temporal face descriptors. IEEE Trans. Intell. Transp. Syst. 2019, 21, 346–361. [Google Scholar] [CrossRef]
- Kartsch, V.J.; Benatti, S.; Schiavone, P.D.; Rossi, D.; Benini, L. A sensor fusion approach for drowsiness detection in wearable ultra-low-power systems. Inf. Fusion 2018, 43, 66–76. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Sequence | Accuracy % | Validate % | Test % |
|---|---|---|---|---|
| Proposed method | 20 | 97.00 | 92.19 | 78.05 |
| 30 | 97.30 | 90.19 | 73.17 | |
| 40 | 97.12 | 90.40 | 82.00 | |
| LSTMs [66] | 20 | 92.51 | 90.07 | 80.36 |
| 30 | 92.58 | 90.06 | 78.04 | |
| 40 | 92.71 | 90.01 | 80.36 | |
| LRCN [67] | 20 | 91.18 | 82.44 | 78.04 |
| 30 | 90.72 | 81.86 | 78.04 | |
| 40 | 90.84 | 80.80 | 78.04 | |
| HTDBN [8] | 40 | 83.04 | 82.65 | 80.44 |
| 30 | 83.26 | 81.25 | 78.47 | |
| 40 | 83.04 | 82.65 | 80.44 | |
| DBN+SVM [39,68] | 20 | 80.65 | 80.41 | 76.51 |
| 30 | 80.01 | 78.58 | 75.21 | |
| 40 | 81.12 | 80.75 | 76.73 | |
| MLP [69] | 20 | 71.71 | 73.17 | 60.97 |
| 30 | 71.33 | 73.04 | 60.97 | |
| 40 | 71.18 | 72.22 | 60.97 |
| Model | Sequence | Precision % | Recall % | F1 Score % |
|---|---|---|---|---|
| Proposed method | 20 | 74 | 100 | 85 |
| 30 | 72 | 92 | 81 | |
| 40 | 72 | 92 | 81 | |
| LSTMs [66] | 20 | 100 | 62 | 77 |
| 30 | 100 | 44 | 61 | |
| 40 | 100 | 62 | 77 | |
| LRCN [67] | 20 | 75 | 96 | 80 |
| 30 | 80 | 96 | 82 | |
| 40 | 75 | 96 | 80 | |
| HTDBN [8] | 20 | 71 | 94 | 79 |
| 30 | 68 | 94 | 77 | |
| 40 | 71 | 94 | 79 | |
| DBN+SVM [39,68] | 20 | 60 | 84 | 64 |
| 30 | 58 | 84 | 64 | |
| 40 | 60 | 84 | 61 | |
| MLP [69] | 20 | 61 | 100 | 76 |
| 30 | 61 | 100 | 76 | |
| 40 | 61 | 100 | 76 |
| Method | Accuracy % | F1 Scrore % |
|---|---|---|
| Driver Alertness Monitoring [71] | 77.40 | 43.3 |
| Embedded Smart Cameras [72] | 81.40 | 43.7 |
| HTDBN [8] | 84.82 | 79.0 |
| Proposed method | 92.19 | 85.0 |
| Multi-timescale CNN [15] | 94.22 | - |
| HDMS [73] | 96.10 | 81.8 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ed-Doughmi, Y.; Idrissi, N.; Hbali, Y. Real-Time System for Driver Fatigue Detection Based on a Recurrent Neuronal Network. J. Imaging 2020, 6, 8. https://doi.org/10.3390/jimaging6030008
Ed-Doughmi Y, Idrissi N, Hbali Y. Real-Time System for Driver Fatigue Detection Based on a Recurrent Neuronal Network. Journal of Imaging. 2020; 6(3):8. https://doi.org/10.3390/jimaging6030008
Chicago/Turabian StyleEd-Doughmi, Younes, Najlae Idrissi, and Youssef Hbali. 2020. "Real-Time System for Driver Fatigue Detection Based on a Recurrent Neuronal Network" Journal of Imaging 6, no. 3: 8. https://doi.org/10.3390/jimaging6030008
APA StyleEd-Doughmi, Y., Idrissi, N., & Hbali, Y. (2020). Real-Time System for Driver Fatigue Detection Based on a Recurrent Neuronal Network. Journal of Imaging, 6(3), 8. https://doi.org/10.3390/jimaging6030008