1. Introduction
Connected components labelling is an important step in many image analysis and image processing algorithms. It processes a binary input image, for example after segmentation, and provides as output a labelled image where each distinct group of connected pixels has a single unique label. There are many different labelling algorithms (see for example the recent review [
1]). Three main classes of algorithms are:
Contour tracing [
2,
3], where the image is scanned until an object pixel is encountered. The boundary is then traced and marked, enabling all pixels to be labelled with the same label when scanning resumes.
Label propagation algorithms [
4] where labels are propagated through multiple passes through the image.
Two pass algorithms, generally based on Rosenfeld and Pfaltz’s algorithm [
5]. The first pass propagates provisional labels to object pixels from adjacent pixels that have already been processed. Sets of equivalent labels are processed to derive a representative label for the connected component, usually using some form of union-find algorithm [
1,
6]. Finally, the image is relabelled in a second pass, changing the provisional label for each pixel to the representative label.
The different two-pass algorithms fall into three broad classes: those that process single pixels at a time (e.g., [
7,
8]), those that process a run of pixels at a time (e.g., [
9,
10]), and those that process a block of pixels at a time (1 × 2 block in [
11,
12], 1 × 3 block in [
13], and 2 × 2 block in [
14,
15]). There have been several FPGA implementations of connected components labelling (e.g., [
16,
17]), but the key disadvantage of these two-pass algorithms is the requirement to buffer the complete image between passes.
Connected component labelling is often followed by an analysis step, where a feature vector (usually based on the shape, but can also be based on statistics of the original image pixel values) is derived for each label. These feature vectors can then be used for subsequent classification, or even directly provide output data for some image analysis applications. When the labelling and feature vector measurement are combined as a single operation, it is termed connected components analysis (CCA).
Single pass CCA algorithms, introduced by Bailey and Johnston [
18,
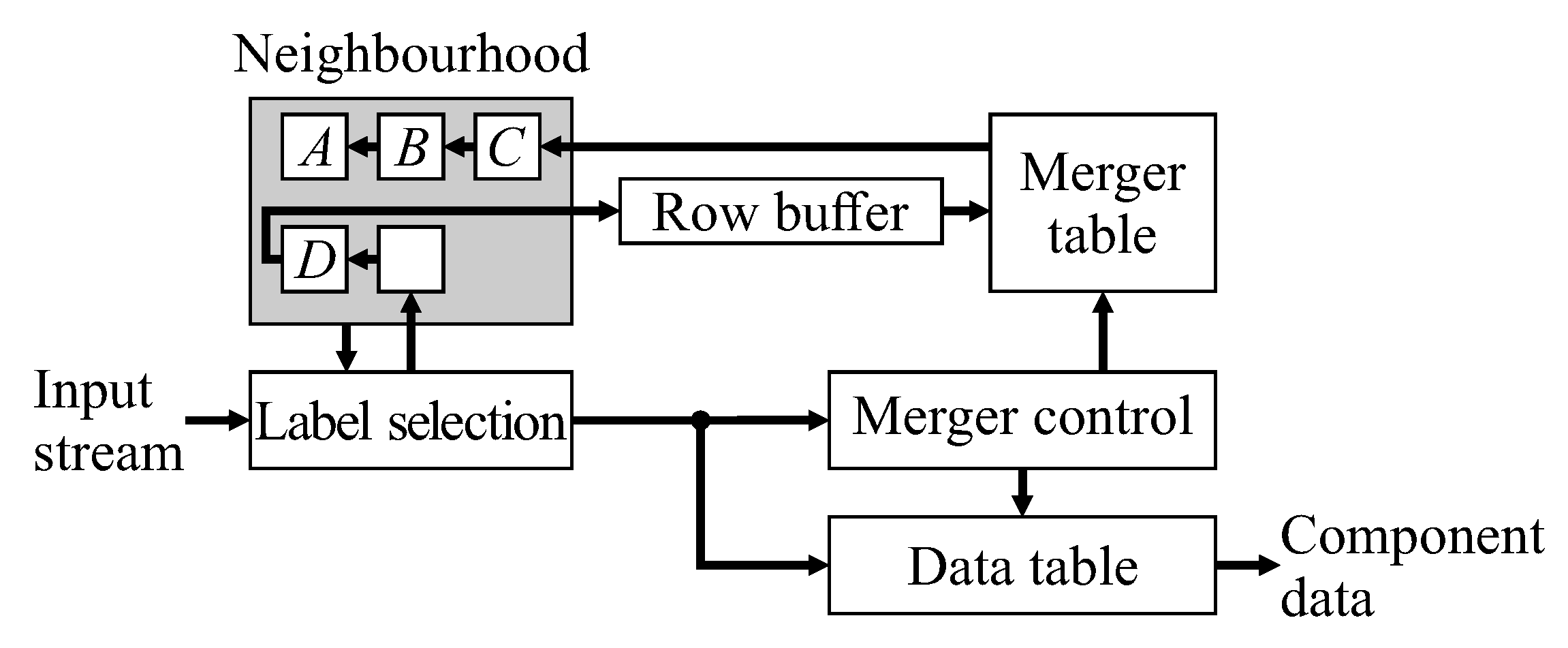
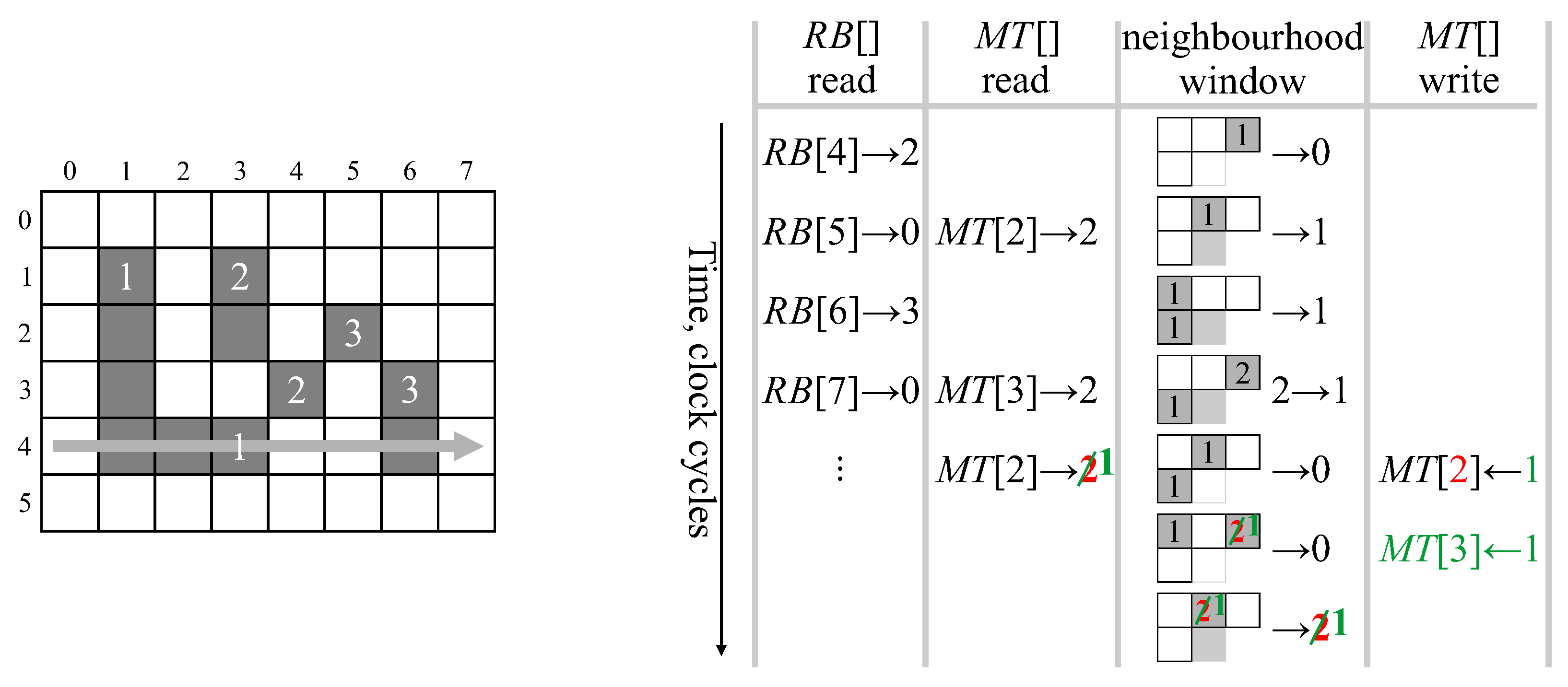
19], extract feature data for each component during the initial provisional labelling pass. The labelled image, as an intermediate data structure, is no longer required, so the second relabelling pass can be skipped, enabling the complete algorithm to operate in a single pass. This has led to efficient low-latency hardware architectures that are able to operate directly on a video stream. The basic architecture of
Figure 1 works as follows: For each pixel in the input stream, provisional labels are propagated from already processed pixels (represented by the neighbourhood window). Labels assigned in the current row are cached in a row buffer to provide the neighbourhood when processing the next row. When components merge, the associated labels are equivalent. One label is selected as the representative label (usually the label that was assigned the earliest), with the equivalence between the labels recorded in the merger table. Provisional labels saved in the row buffer may have been updated as a result of subsequent mergers and may no longer be current, so the output from the row buffer is looked up in the merger table to obtain the current representative label for the neighbourhood. For a single-pass operation, feature data is accumulated for each component on-the-fly within the data table. When components merge, the associated feature data is also merged. The component data is available after the component is completed, that is after no pixels extend from that component onto the current row.
The main limitation of the first single-pass algorithm [
18] was that the data was only available at the end of the frame. In the worst case, this required resources proportional to the area of the image, preventing the use of on-chip memory for all but small images, or a restricted subset of images with a limited number of components. This was solved by Ma et al. [
20], by recycling labels which requires identifying completed components, and freeing up the resources. Ma’s approach aggressively relabelled each component starting from the left of each row. It, therefore, required two lookups, one to resolve mergers, and one to translate labels from the previous row to the current row.
The next improvement in this class of CCA algorithms was developed by Klaiber et al. [
21]. This solved the problem of two lookups by introducing augmented labels. Labels are allocated from a pool of recycled labels, and are augmented with row number to enable correct precedence to be determined when merging.
Trein et al. [
22] took an alternative approach to single-pass CCA on FPGA, and run-length encoded the binary image first. Then, each run was processed in a single clock cycle, enabling acceleration when processing typical objects. In the worst case, however, the performance of run-based processing is the same as for pixel-based processing. Trein et al.’s method also suffers from the problem of chaining, although this was not identified in their paper.
The main issue with managing mergers on-the-fly is sequences of mergers requiring multiple look-ups to identify the representative label of their connected component. Those labels that require more than one lookup to lead to their representative label are referred to as
stale labels [
6]. This can occur after two or more mergers, where a single lookup in the merger table is insufficient to determine the representative label. Bailey and Johnston [
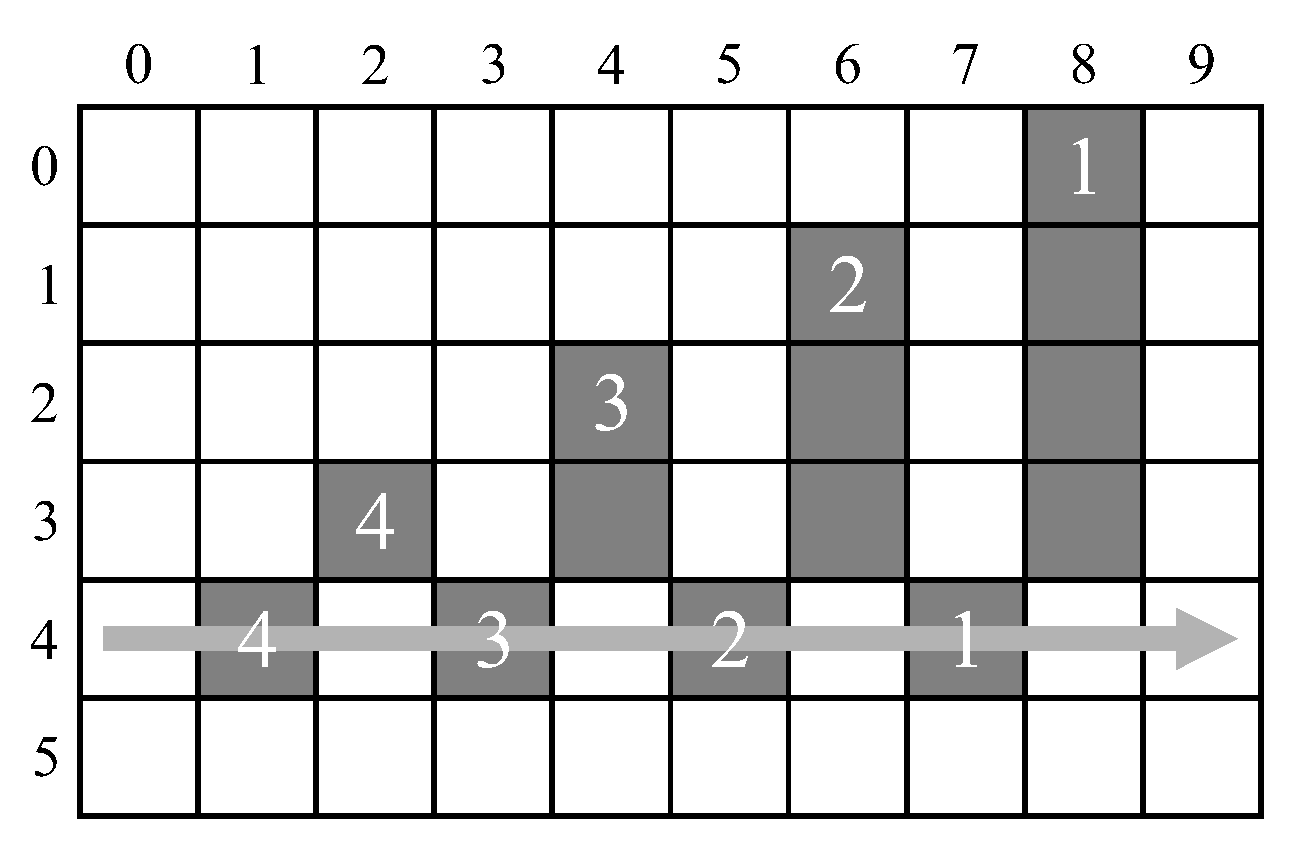
18] identified chains of mergers that occur when the rightmost branch of a sequence of mergers is selected as the representative label (as illustrated in
Figure 2). Before processing the next row, it is necessary to unlink such chains so that each old label directly points to the representative label. This unlinking is called path compression in union-find parlance.
The labels within such chains cannot occur later in the row because the label that was allocated the earliest was selected as the representative label. therefore, chain unlinking can be deferred until the end of each row [
18]. Since the representative label within such a chain is rightmost, potential chain links can be saved on a stack enabling them to be unlinked from right to left. A disadvantage of such unlinking is that it incurs overhead at the end of each row. Typically, this overhead is about 1% [
18], although in the worst case is 50% for a single row, or 20% for a whole image. A further complicating factor is that the overhead is image-dependent, and cannot be predicted in advance.
To overcome the chaining problem, Jeong et al. [
23] proposed to directly replace all old entries within the row buffer with the new representative label whenever a merger occurs. This removes the unlinking overhead, and also the need for the merger table. To accomplish this, the row buffer must instead be implemented as a shift register, with each stage having a comparator to detect the old label, and a multiplexer to replace it with the representative label. Since such a content addressable memory cannot easily be implemented using a block memory, the resulting logic requires considerable FPGA resources.
Zhao et al. [
24] also used aggressive relabelling, similar to Ma et al. [
20], but instead used pixels as the processing unit, and runs as the labelling unit. The goal of this approach is to eliminate unnecessary mergers, and avoid the overhead at the end of each row. While labelling a run at a time does significantly reduce the number of mergers required, it does not eliminate chains of mergers (the pattern is more complex than
Figure 2 of course). So although Zhao et al. claim to eliminate the end-of-row processing, without correctly resolving such chains, the results for some images will be incorrect.
Finally, Tang et al. [
25] optimise this approach of using runs as a labelling unit to actually eliminate the end of row processing. They assign a unique label to each run, and rather than relabel runs when they connect, the connectivity is maintained within a linked list structure for each image row. The head of the list maintains the feature vector, and whenever a run is added to the list, both the list and data are updated. Clever use of the pointers enables the pointers to be kept in order, and enable the data to be accessed with two lookups, completely avoiding the problems with chains. It also means that labels are automatically recycled, and completed components are detected with a latency of one image row. There are two limitations of this algorithm: (1) It only handles 4-connectivity, rather than 8-connectivity which is usually used; Tang et al. also propose a pre-filter to convert an 8-connected image into the required 4-connected image prior to CCA. However, the pre-filter also means that incorrect values are derived for some features (e.g., area) without additional processing, although that processing is straight forward. (2) The outermost border of the image must be set to the background before processing; Tang et al. suggest extending the image with background pixels prior to processing to guarantee this condition. However, this would reintroduce 2 clock cycles per row overhead.
The primary contributions of this paper are: a novel approach to eliminate the end-of-row overhead associated with unchaining; and a novel method to detect completed components as soon as they are completed, giving a reduction in latency. These are based on a zig-zag based scan pattern through the image, with the algorithm outlined in
Section 2. An FPGA architecture for realising zig-zag based CCA is described in detail in
Section 3. The algorithm and architecture are analysed in
Section 4 to show correct behaviour. Finally,
Section 5 compares the new algorithm with existing single-pass pixel-based approaches.
2. Proposed Approach
Unchaining within the traditional algorithms [
6,
18,
20,
21] is effectively accomplished by performing a reverse scan back through the labels merged in the current row at the end of each row. This approach comes at the cost of having to introduce additional overhead to store the sequences of mergers in a stack data structure and unchain them sequentially at the end of each image row.
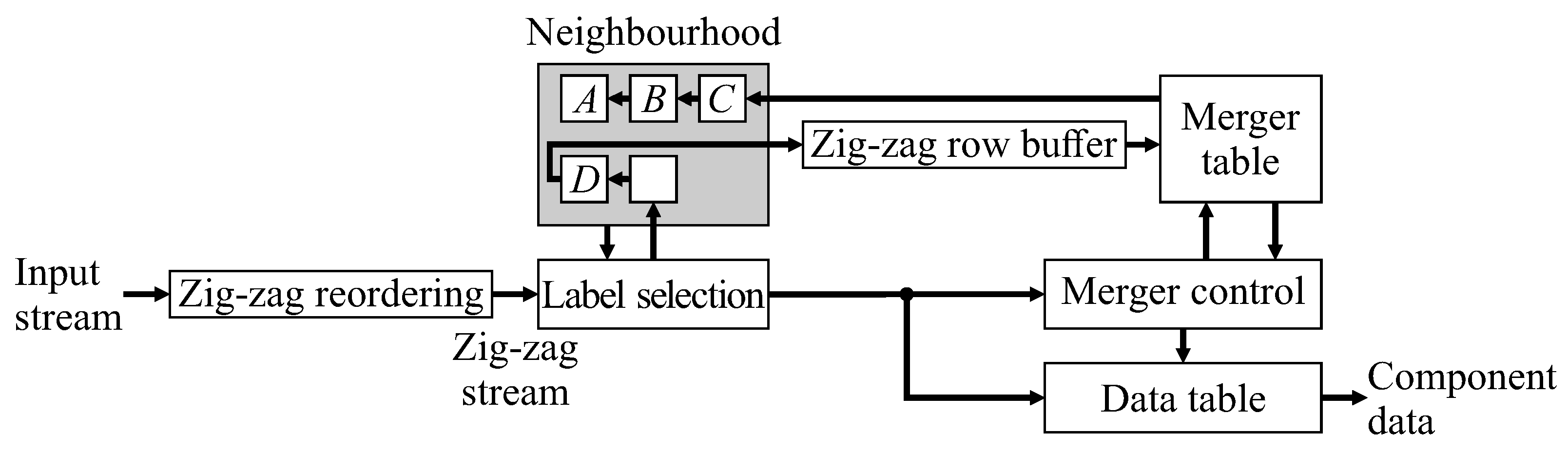
This paper proposes replacing the raster scan with a zig-zag scan, with every second row processed in the reverse direction. This enables chains of mergers to be resolved on-the-fly, as part of the merger table lookup and update process. The basic architecture of
Figure 1 needs to be modified for the zig-zag scan, giving the system architecture of
Figure 3. Although many of the blocks have the same name and function as those in
Figure 1, the detailed implementation of many of these is changed.
First, a zig-zag reordering buffer is required in the input, to present the pixel stream in zig-zag order to the CCA unit. The row buffer also has to be modified to buffer data in zig-zag form. (Note that if the image is streamed from memory, this is unnecessary, as the pixels can directly be read from memory in zig-zag order.) Label selection is unchanged, as is the data table processing (apart from a novel extension to enable completed components to be detected earlier). The key changes are in the merger table processing for forming the neighbourhood, and merger control blocks. Zig-zag CCA is represented algorithmically in Algorithm 1. The nested for loops perform a zig-zag scan through the binary input image, with key steps as sub-algorithms described in the following sections.
2.1. Definitions
We first offer some definitions. The already processed pixels in the neighbourhood of the current pixel,
X, are denoted
A,
B,
C, and
D as indicated in
Figure 4. The labels associated with the neighbourhood pixels are designated
through
. Background pixels are assigned label 0. A logic test of
evaluates to true if pixel
p is an object pixel and false if it is part of the background.
| Algorithm 1 Zig-zag CCA algorithm |
Input: Binary image I of width W and height H
Output: A feature vector for each connected component in I- 1:
- 2:
fortodo - 3:
for to when y is even else downto 0 do ▹ Zig-zag scan - 4:
if then - 5:
ReverseNeighbourhood ▹ Algorithm 3 - 6:
- 7:
else - 8:
UpdateNeighbourhood ▹ Algorithm 2 - 9:
end if - 10:
UpdateDataStructures ▹ Algorithm 4 - 11:
end for - 12:
- 13:
end for
|
For the new scan order, it is convenient to define a precedence operator, ≺, based on the order in which pixels are encountered during processing. Given two pixels,
and
, then
Precedence is used to select which label is the representative label during merger operations, and to determine when a connected component is completed.
Three auxiliary data structures are required for connected components analysis:
The row buffer, , saves the provisional labels assigned in the current row for providing the neighbourhood when processing the next row. Although the row buffer needs to manage pixels processed in a zig-zag scanned order, it is indexed within the following algorithms by logical pixel position.
The merger table, , indexed by label. This is to provide the current representative label for a component, given a provisional label. However, as a result of chains, more than one lookup in may be required.
The data table, , also indexed by label. This is to accumulate the feature vector extracted from each component. is the initial feature vector to be accumulated from the current pixel, and ∘ is the binary operator which combines two feature vectors.
Additional variables and arrays will be defined as required in the following algorithms.
2.2. Update Neighbourhood
Since the input pixels are streamed, moving from one pixel position to the next involves shifting pixels along within the neighbourhood window. Algorithm 2 indicates how the neighbourhood is updated during normal processing. A merger can only occur between pixels
A and
C, or
D and
C [
26], and if both
A and
D are object pixels then they will already have the same label (from processing the previous window position). Therefore, the neighbourhood can be optimised with
being the label
or
as required. The use of a superscript −, as in
, indicates the label
at the end of the previous iteration.
| Algorithm 2UpdateNeighbourhood |
- 1:
ifthen ▹ Select based on whether A (previous B) is an object pixel - 2:
▹ Next value of - 3:
else - 4:
▹ Next value of - 5:
end if - 6:
- 7:
▹ Look up position C in the row buffer - 8:
ifthen ▹ An object pixel is coming into neighbourhood - 9:
if then ▹ It is the first object pixel after a background pixel - 10:
▹ First lookup in merger table - 11:
if then ▹ Label was representative label - 12:
- 13:
else - 14:
▹ Second lookup in merger table to get representative label - 15:
if then ▹ Label change on second lookup indicates a chain - 16:
▹ Update merger table to unlink the chain - 17:
end if - 18:
end if - 19:
else ▹ Part of a run of consecutive pixels - 20:
▹ Repeat latest label - 21:
if then ▹ Label has changed, indicating a chain of mergers - 22:
▹ Update merger table to unlink the chain - 23:
end if - 24:
end if - 25:
else - 26:
▹ Lookup of background is unnecessary - 27:
end if
|
As the neighbourhood window pixels are shifted along, the new value for position C is obtained from the row buffer (line 7). If this is a background pixel, it is simply assigned label 0 (line 26). Note that if C is outside the image, for example when processing row 0 or when X is the last pixel in processing a row, then the background label (0) is used.
The row buffer provides the provisional labels assigned when processing the previous row. Although this label was the representative label for the component when it was written into the row buffer, subsequent mergers may mean that the label read from the row buffer is no longer the current representative label. It is necessary to look up the label in the merger table to obtain the current label (line 10). In a run of consecutive object pixels, all will belong to the same object, and will have the same label. The last label assigned to the run in the previous row will be the first read from the row buffer (as a result of the zig-zag scan), so only this label (see line 9) needs to be looked up in .
As a result of chains of mergers, a single lookup is not sufficient in the general case. Provided that the merger table is updated appropriately, two lookups may be required to give the current representative label. If the first lookup returns the same label (line 11), then that label has been unchanged (and is the representative label). However, if the first lookup returns a different label, then the provisional label may be stale and a second lookup is necessary (line 14). If the second lookup does not change the label, then this indicates that the single lookup was sufficient. If the second lookup returns a label that is different again, then this is part of a chain, and the value returned will be the current representative label.
To avoid having to lookup more than twice, it is necessary to update the merger table so that subsequent lookups of the original label produce the correct representative (line 16). This merger table update compresses the path, and performs the unchaining on-the-fly.
Within a run of consecutive object pixels, the representative label does not change. The latest label (after any merger at the previous window location, see line 20) is simply reused for C. If the row buffer output changes within a run of consecutive object pixels, this indicates that a merger occurred when processing the previous row and the provisional label from is out-of-date. This chain is unlinked, compressing the path by updating for the new label (line 22).
At the end of each row, it is necessary to reinitialise the window for the next row. As the window moves down, the pixels in the current row become pixels in the previous row. It is also necessary to flip the window to reflect the reversal of the scan direction. Algorithm 3 gives the steps required. Note that this is in place of Algorithm 2 for the first pixel of the next row.
| Algorithm 3ReverseNeighbourhood |
- 1:
▹This is now off the edge of the image - 2:
▹Moving down makes current row into previous row - 3:
|
2.3. Update Data Structures
Updating the data structures involves the following: assigning a provisional label to the incoming pixel based on the neighbourhood context; updating the merger table when a new label is assigned, or when a merger occurs; updating the feature vectors within the data table, and detecting when a connected component is completed. These are detailed in Algorithm 4.
A merger can only occur when
B is a background pixel and
is different from
[
26]. This condition corresponds to the block beginning line 3. The earliest assigned of
or
is selected as the representative label, and the other label is no longer used. The feature vectors associated with the two labels are merged, with the feature vector of the current pixel merged with the combination.
A new label is assigned to when , and are background (line 15). New labels are assigned from the labelling recycling first-in-first-out (FIFO) buffer. Consequently, the label numbers are not in numerical sequence, so to determine precedence under merger conditions it is necessary to augment the labels with the row number (line 17). The feature vector for the new component is initialised with the feature vector of the current pixel, .
If there is exactly one label in , or , it is assigned to and its feature vector in the data table at is merged with the feature vector of the current pixel , as shown in lines 26 and 30.
A connected component is finished when it is not extended into the current image row. To detect this, an active tag,
, field is introduced within the data table,
. For each label,
stores the 2D coordinates on the following image row beyond which no further pixels could be added to the component. When the scan passes this point on the following row (line 34), it is determined that the component is completed, enabling the feature vector to be output and the label recycled. The initial feature vector for the active tag is
| Algorithm 4UpdateDataStructures |
- 1:
ifthen ▹Object pixel - 2:
if then - 3:
if then ▹ Merger operation - 4:
if then ▹ Propagating merger - 5:
▹ Assign representative label - 6:
- 7:
▹ Update neighbourhood label - 8:
else - 9:
▹ Assign representative label - 10:
- 11:
end if - 12:
▹ Record merger in table - 13:
▹ Merge data (and active tags) - 14:
▹ Recycle the old label - 15:
else if then ▹ New label operation - 16:
() ▹ From a recycle queue - 17:
▹ Augment label with row number - 18:
▹ Initialise merger table - 19:
▹ Start feature vector - 20:
else - 21:
if then ▹ Copy - 22:
- 23:
else ▹ Copy - 24:
- 25:
end if - 26:
▹ Add current pixel to data table - 27:
end if - 28:
else ▹ Copy - 29:
- 30:
▹ Add current pixel to data table - 31:
end if - 32:
else - 33:
▹ Background pixel - 34:
if then ▹ Check completed object - 35:
Output: - 36:
▹ Recycle the label - 37:
end if - 38:
end if - 39:
▹ Save label in row buffer for next row
|
For a label copy operation and a label merger operation, the active tag is updated along with the rest of the feature vector. The combination operator ∘ for two active tags is realised by applying precedence as defined in Equation (
1) to select the later of the two active tags.
For an efficient hardware implementation, it is sufficient to store only the least-significant bit of y for each active tag entry.
Figure 5 illustrates the update of active tags and detection of completed connected components. At the start of processing row 4, there 3 components with active tags as listed. Since row 4 is even (scanning left to right), the active tags are on the right hand end of the respective components. At
, component 3 is extended and the active tag updated to
—the last possible scan position that could extend the current component 3. Similarly, at
component 2 is extended. At
, components 1 and 2 merge with label 1 being retained as the representative label. Label 2 is recycled, and the active tags of labels 1 and 2 are combined. Further extensions of label 1 do not affect the active tag because the corresponding pixel active tags occur earlier in the scan sequence. When scanning back on row 5, label 1 is not extended, so when pixel
is a background pixel, the component labelled 1 is detected as completed, the feature vector output, and the label recycled. Similarly, at
component labelled 3 is detected as completed.
3. Architecture
Within this section, the hardware architecture to realise this algorithm is described. The input pixel stream is continuous, with one 1-bit binary pixel per clock cycle. Since there are no blanking periods, a streaming protocol based on AXI4-Stream [
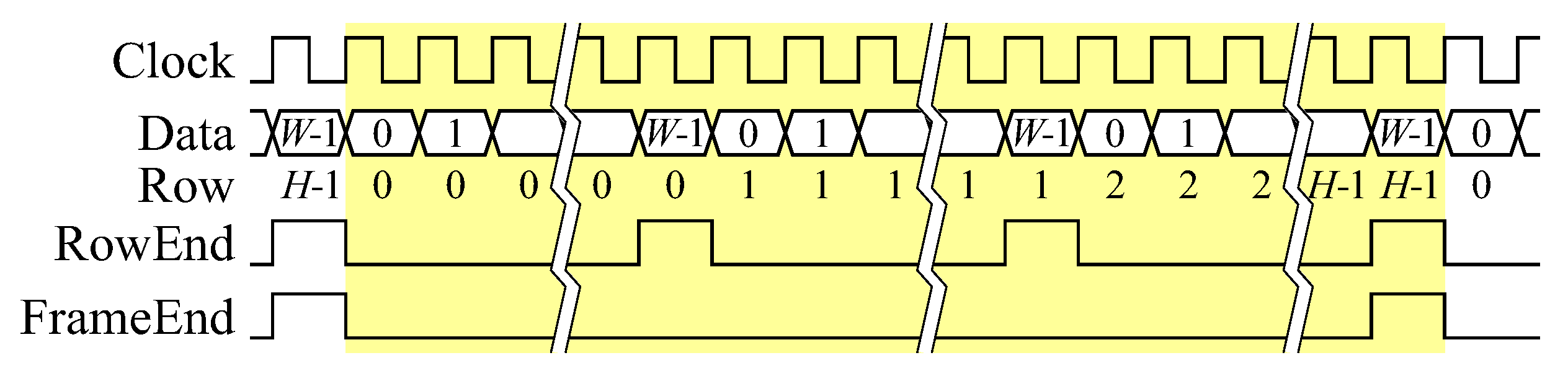
27] (advanced extensible interface) is used throughout the design. The modified protocol shown in
Figure 6 has two control bits, one indicating the last pixel in every row, and one indicating the last pixel in every frame.
3.1. Zig-Zag Scan
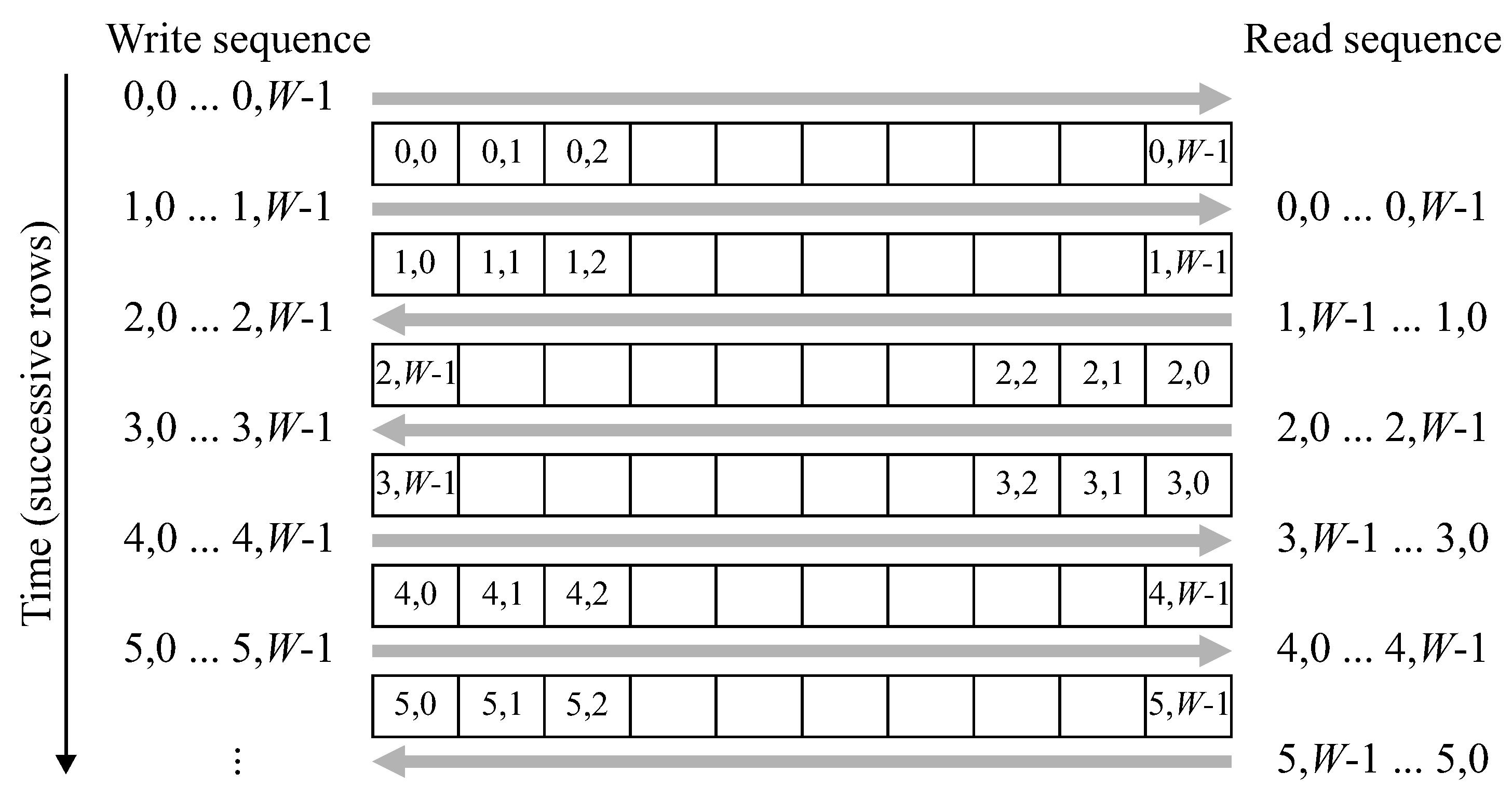
The raster scanned input stream must be converted to a zig-zag ordered stream, where the odd numbered rows are presented in reverse order. Although this could easily be achieved with double buffering (reading the previous row from one buffer while writing the current row into a separate buffer) it can also be accomplished with a single row buffer with the access pattern shown in
Figure 7.
After row 0 is initially written into the buffer, reading and writing are performed at the same address, with the raster based input stream being written into the same location that the zig-zag stream is read from. This requires switching the address sequence direction every second row. Converting the raster scan to a zig-zag scan introduces a latency of one row and one pixel.
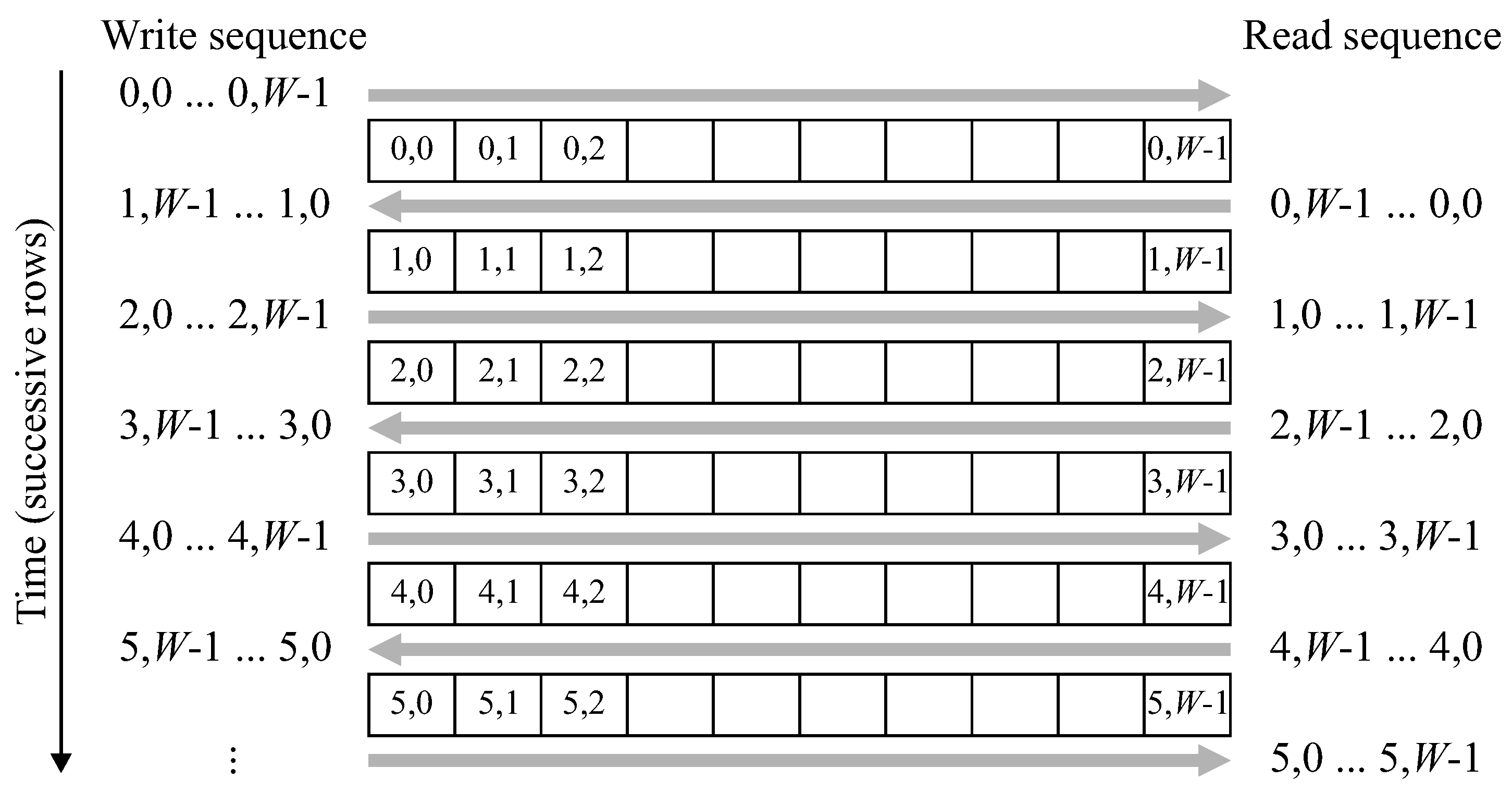
The row buffer must also be modified to operate with a zig-zag scan pattern. Since successive rows are processed in the opposite order, the labels for each row must be read out in the reverse order that they were written. Data coming in for the new row overwrites the old data (already read out) in the buffer. As demonstrated in
Figure 8, this can be accomplished by reversing the scan direction each row, effectively storing each label at the row buffer memory address corresponding to its
x position.
3.2. Merger Table Processing
The label read from the row buffer may no longer be the current representative label as a result of mergers. For the look up operations performed in lines 7, 10, and 14 of Algorithm 2 it is necessary to look up the label in the merger table up to two times to obtain the current label. This is similar to the double lookup algorithm proposed in [
6].
Although some labels may require two lookups, a single read port of a dual-port on-chip memory is sufficient for the merger table because it is unnecessary to look up every label from the row buffer. Labels of background pixels do not need to be looked up—all background pixels are simply labelled 0. In a sequence of consecutive object pixels, it is only necessary to look up the label of the first pixel in the sequence. An object pixel will either be followed by another object pixel or by a background pixel, neither of which need to be looked up, giving sufficient bandwidth for the two lookups.
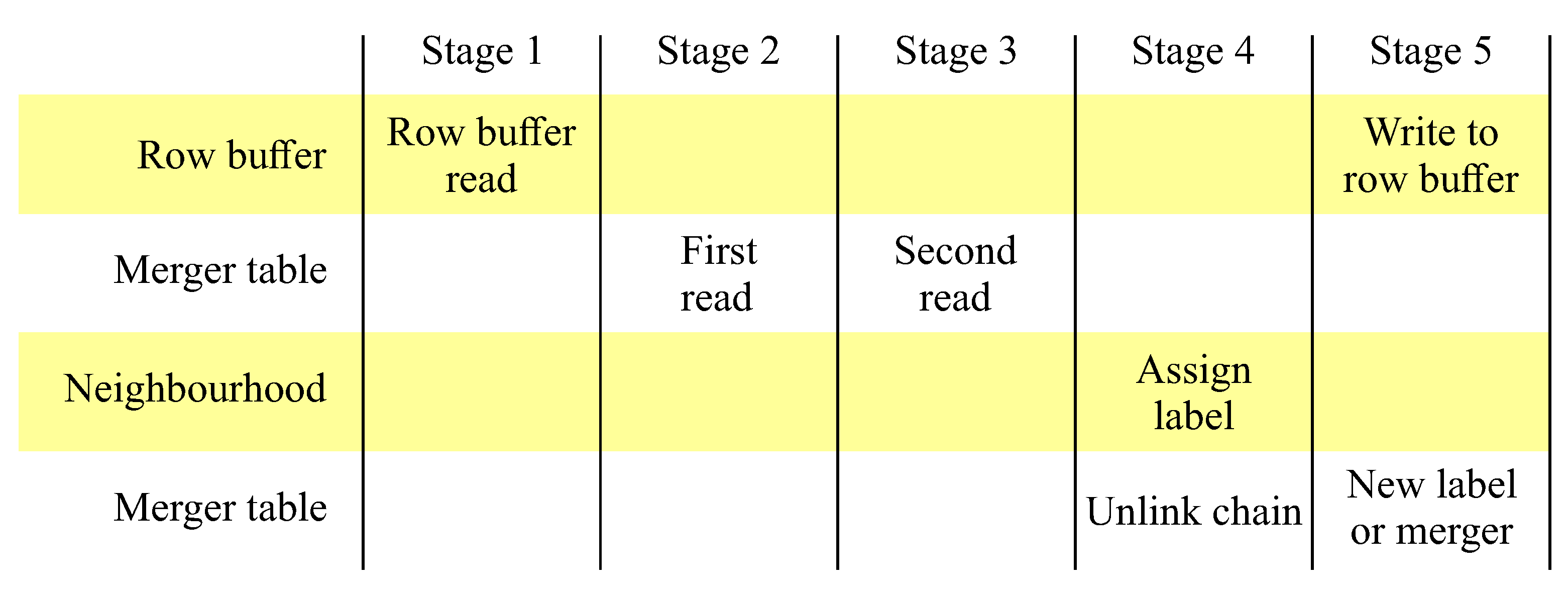
Since each memory access requires 1 clock cycle (for synchronous memories such as the random access memory (RAM) blocks on most current FPGAs), it is necessary to pipeline the processing over 5 clock cycles as shown in
Figure 9. The memory accesses are scheduled in advance so that the labels are available in the neighbourhood for assigning a label to the current pixel in stage 4.
As a result of pipelining, the write to the row buffer is delayed from the read by four clock cycles. This necessitates using a dual-port memory for the row buffer. The merger table is also dual-port, with the read port used for determining the representative label in stages 2 and 3 of the pipeline. The write port for the merger table is used for initialising the merger table when a new label is assigned (line 15), and for updating the merger table during merger operations (line 3). Both new label and merger operations occur in stage 5 of the pipeline. Unchaining of stale labels is also performed as the stale labels are encountered during the neighbourhood update (Algorithm 2) in stage 4 of the pipeline. The detailed architecture for implementing this is shown in
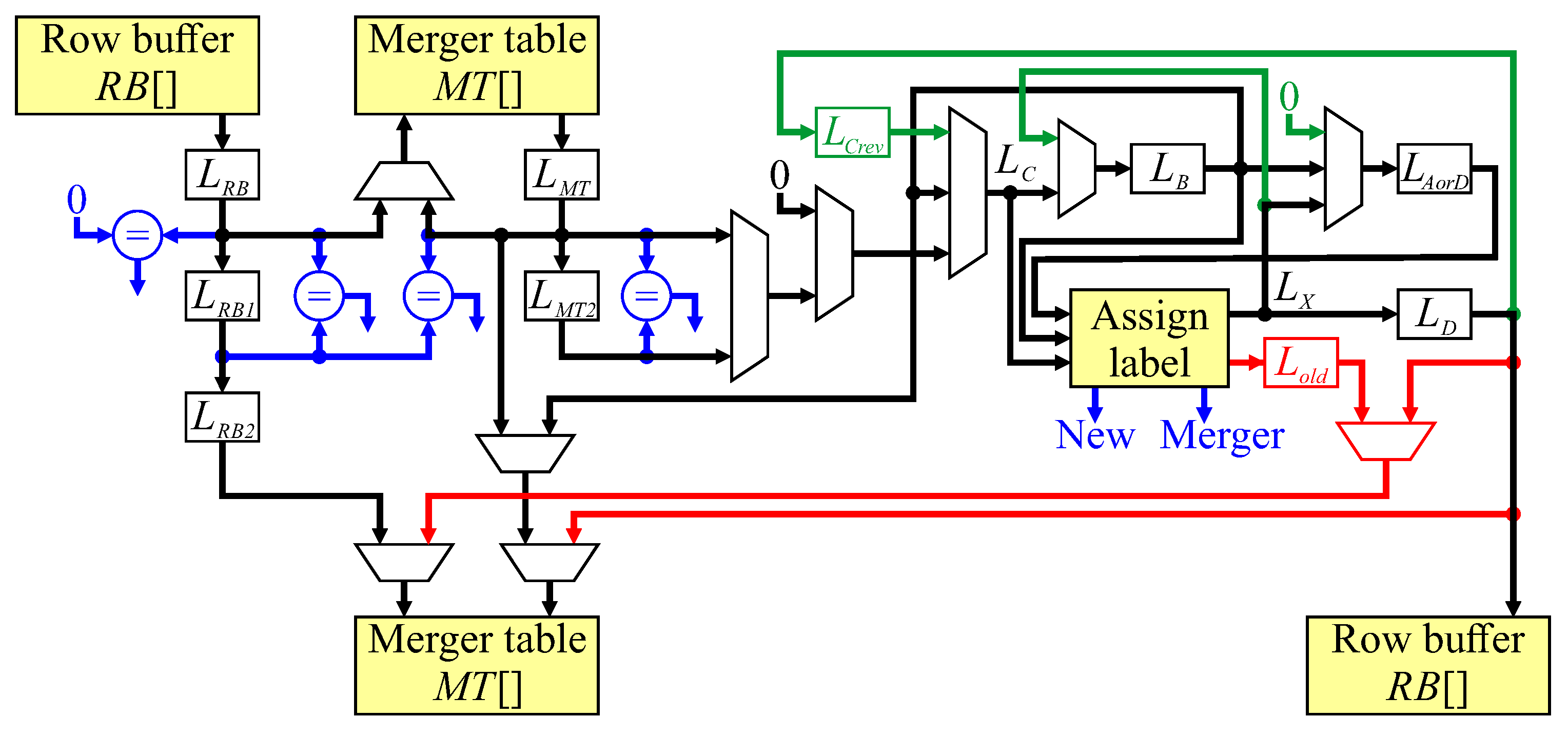
Figure 10.
With synchronous memory, each read from an on-chip memory block is stored into a register; these are
and
for the row buffer and merger table respectively. The address for the merger table read comes either from
for the first read, or
for the second. Register
is a pipeline register to hold the data if only a single read is required, with a multiplexer selecting the output of
or
as the representative label. The conditional statements in Algorithm 2 are shown in blue in
Figure 10, and are used to provide control signals for selecting appropriate multiplexer inputs.
In terms of forming the neighbourhood, is not directly registered, but is the output of multiplexers selecting the appropriate source register for . and are registers. The current label output, is not registered, but is the output of the combinatorial logic which assigns a label to the current input pixel. This output is registered as , available in the following clock cycle for window reversal at the end of each row, and for updating the merger table in pipeline stage 5 (if required). For row reversal, is assigned (Algorithm 3); however, since is not a register, it is necessary to insert a pipeline register, .
Unchaining updates the merger table in pipeline stage 4. The data from line 16 is naturally available in that stage, but line 22 is detected at stage 2. It is necessary to delay both the address and data until stage 4. The address is delayed by pipeline registers and , with the data coming from , which at that stage in a run of consecutive pixels, is the feedback path from (line 20). For updating the merger table as a result of label assignment, for a new label, both the address and data come from (line 18). In the case of a merger, registers the old label, and is used for the address for the merger table update.
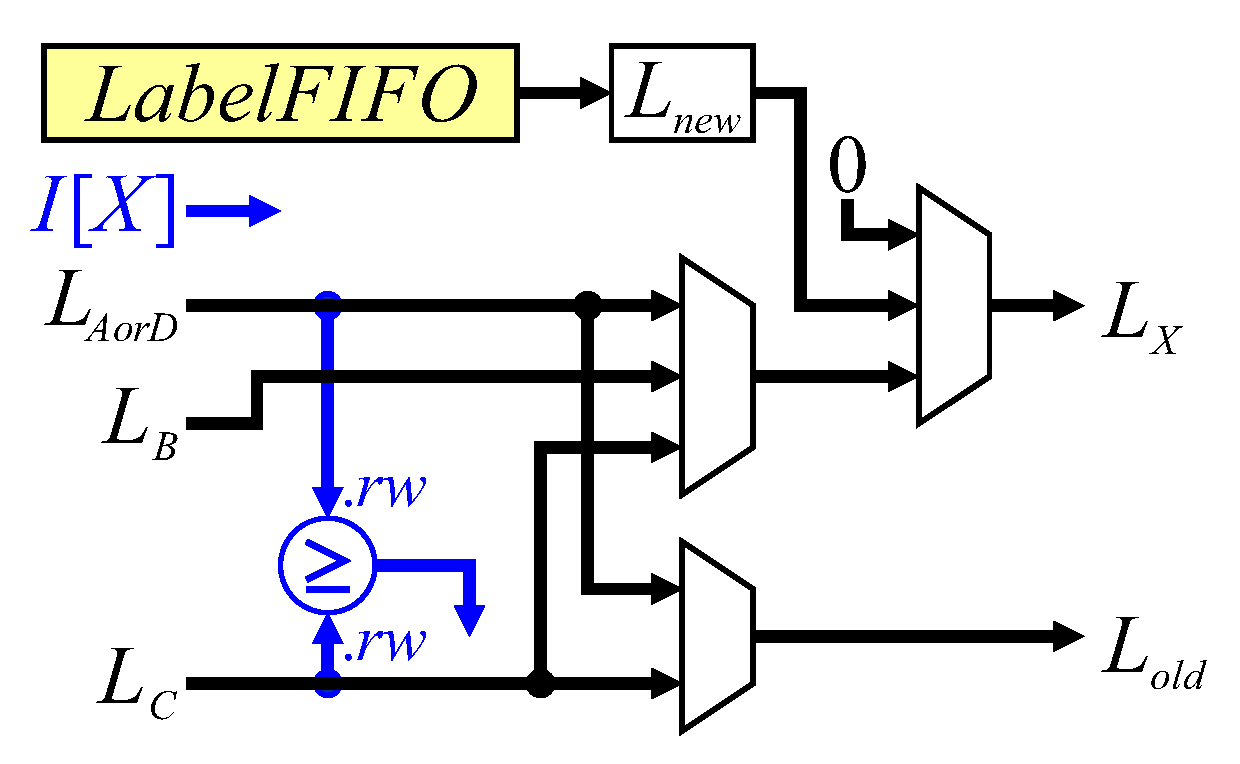
The dataflow for label assignment is shown in
Figure 11. The binary input pixel is used to directly provide a control signal. The first multiplexer selects the label to propagate from the neighbourhood, with the second multiplexer selecting the background label (0), or a new label from the
LabelFIFO (lines 16, 22, 29, 24 and 33). To reduce the logic requirements, the test for a background pixel on the row buffer output is simply pipelined through a series of registers to indicate whether
,
or
are object or background pixels.
3.3. Data Table
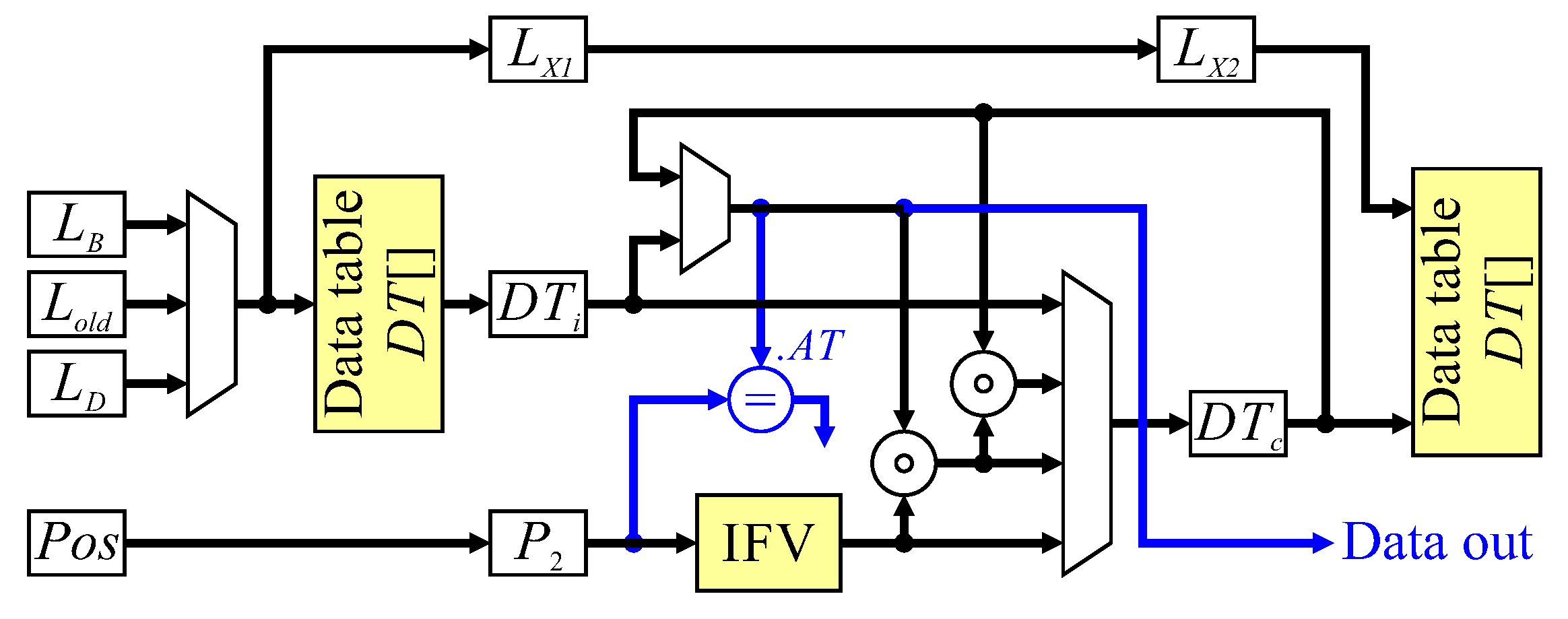
The final key section of the architecture is that which manipulates the data table.
Figure 12 shows the data flow for the update and completed object detection. The inputs come from neighbourhood processing, after registering to pipeline the processing. The current pixel label,
therefore, comes from the
register, and
in the case of mergers comes from the corresponding register in
Figure 10. Data table processing is pipelined over three clock cycles, with the first cycle reading existing data from the data table when required, the second clock cycle is used to calculate the new feature vector, with the result being written to the data table (where necessary) in the third cycle. The neighbourhood position must also be registered twice before deriving the initial feature value (
) to maintain synchronisation. Control signals come from label assignment, whether it is a propagating label, a new label, a merger, or background pixel. Each of these cases will be described in turn.
For a propagating label, the neighbourhood had only a single label, which is copied to the current object pixel. If the previous pixel was a background pixel, then it is necessary to read the existing feature vector from the data table first. Otherwise, the feature vector will be available in the data table cache () from processing the previous pixel. The initial feature vector, , derived from the neighbourhood position is combined with the existing data, and the result stored in the data table cache, . The resulting feature vector is written back to the data table only when a background pixel is reached.
A new label operation has no existing data to load; the data table cache, , is simply initialised with the initial feature vector, , in the second clock cycle.
A merger is a little more complex, because it may require two entries to be read from the data table. If the previous pixel was an object pixel, then the feature vector associated with will be available in . However, if the previous pixel was a background pixel, then data will not be cached for . To overcome this problem, when the current pixel is a background pixel, is looked up in the data table. If is the label of an object pixel, then on the next clock cycle, it becomes and will be available in the cache. A merger will trigger the loading of , so that it can be combined with and . During the second clock cycle, is invalidated, enabling the label to be recycled. On the third clock cycle, the merged feature vector is written back to the data table.
Preloading the data table cache also facilitates detection of completed objects. From Algorithm 4 line 34, when the active tag (
) of a completed object is the current pixel position, the last pixel will be in neighbourhood position
A. At least the last three pixels (including the current pixel) will also have been background pixels otherwise they would have extended the object. Therefore, looking up
when the current pixel is a background pixel gives the feature vector (containing
) in the following clock cycle, enabling completed object detection (shown in blue in
Figure 12). When the completed object is output, the data table entry is available for reuse by recycling the label.
4. Analysis
As a result of pipelining the computations, there are potentially data hazards, particularly in the use of memory for tables (the row buffer, merger table and data table), resulting from when data is expected to be in the table, but has not yet been written.
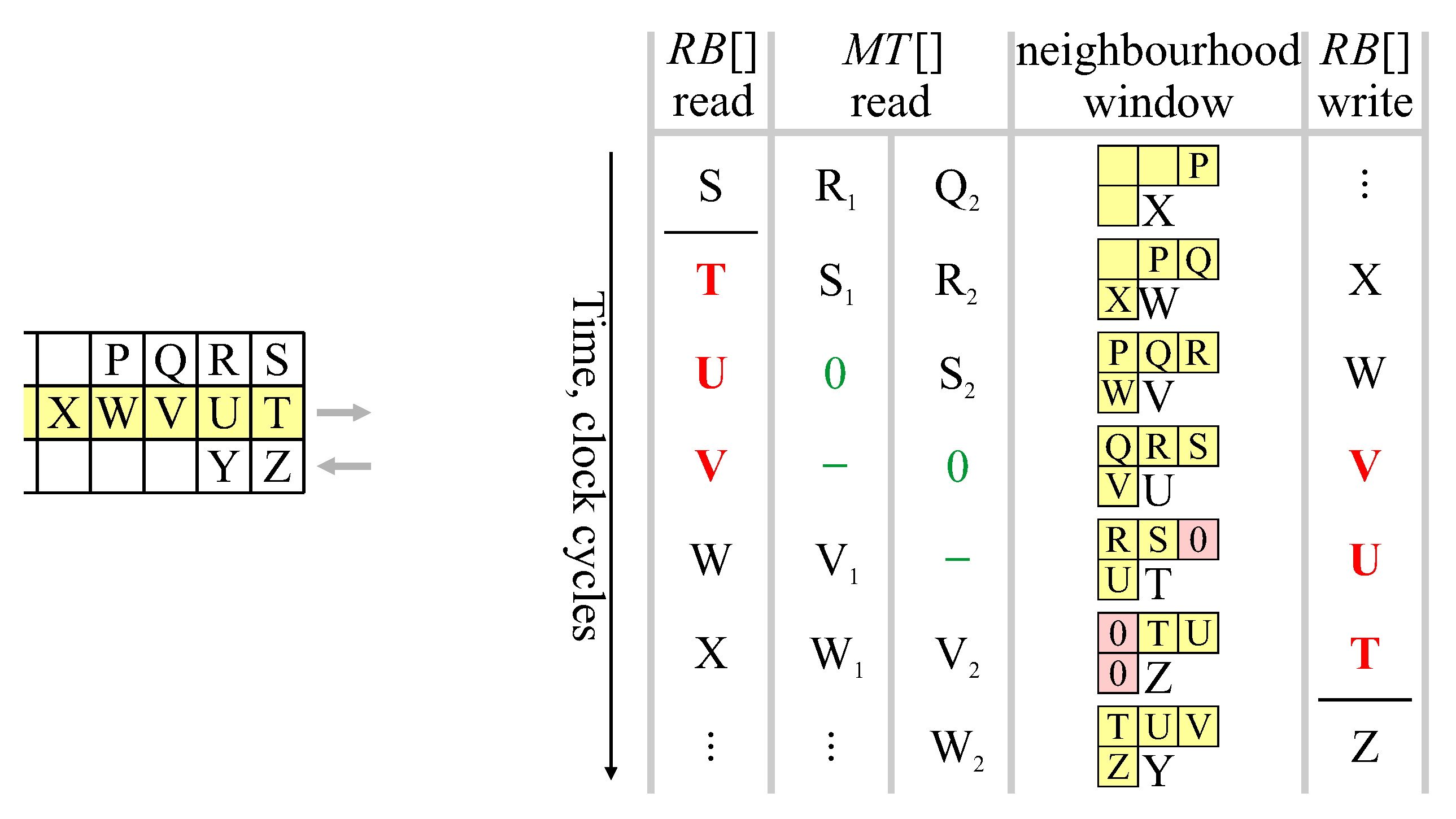
4.1. Row Buffer
For the row buffer, this can only occur at the end of the row, when the readout direction changes. The data hazards are demonstrated in
Figure 13.
The last pixel of the previous row,
S, is read from the row buffer when the neighbourhood window is at position
X (as a result of pipelining). In the following clock cycles, reads from the row buffer begin their backward scan of the next row. However, pixel positions
T,
U, and
V have not yet been written to the row buffer (or even assigned labels in the case of
T and
U). At the end of the row, lookup of positions
T and
U in the row buffer is actually unnecessary, because their values come directly from the neighbourhood when the window moves to the next row (Algorithm 3). Rather than read position
T, it can simply be treated as a background pixel (label 0). This ensures that when the neighbourhood is at location
T, neighbourhood position
C (which is off the edge of the image) is correctly assigned a 0 (shaded pink in
Figure 13). Similarly, position
U is copied directly from the previous neighbourhood when the neighbourhood reverses direction. The row buffer output for
U, too, can simply be treated as a background pixel. Finally, position
V is read in the same clock cycle as it is written. This requires that the row buffer support a write-before-read semantic, or bypass logic be added to forward the value being written to the output.
4.2. Path Compression
Since both path compression and label assignment have write access to the merger table, it is necessary to check that these will not clash by attempting to write simultaneously. The possible scenarios are illustrated in
Figure 14.
A new label and merger both update the merger table in pipeline stage 5. This is the clock cycle immediately following the label assignments, as illustrated in scenarios ① and ② respectively. Unchaining is performed in pipeline stage 4, corresponding to the clock cycle when the pixel appears in the neighbourhood window. This is illustrated in scenario ③ after two lookups, and scenarios ④ and ⑤ for a changed label within a consecutive run of pixels.
There cannot be a conflict between a change within a run, and a new label, because the change would require at least one pixel within the neighbourhood, preventing a new label assignment. Similarly, there can also be no conflict between a merger and a two lookup stale label because the merger would require
to be non-zero, so the following pixel cannot be the first in a run. However, there can be conflicts between a new label and a two lookup stale label (scenario ⑥ in
Figure 14b), and also between a merger and changed label in a run (scenario ⑦).
Where there is a conflict, the update resulting from the new label or merger should be deferred, with the stale label update taking priority. If the new label is followed by a merger (as in
Figure 14b) then only the merger needs to be saved. This requires adding an additional storage register and multiplexer to the data path, and appropriate control logic. The maximum delay is two clock cycles, corresponding to ⑧, because changed labels in a run can occur at most every second pixel.
4.3. Merger Table
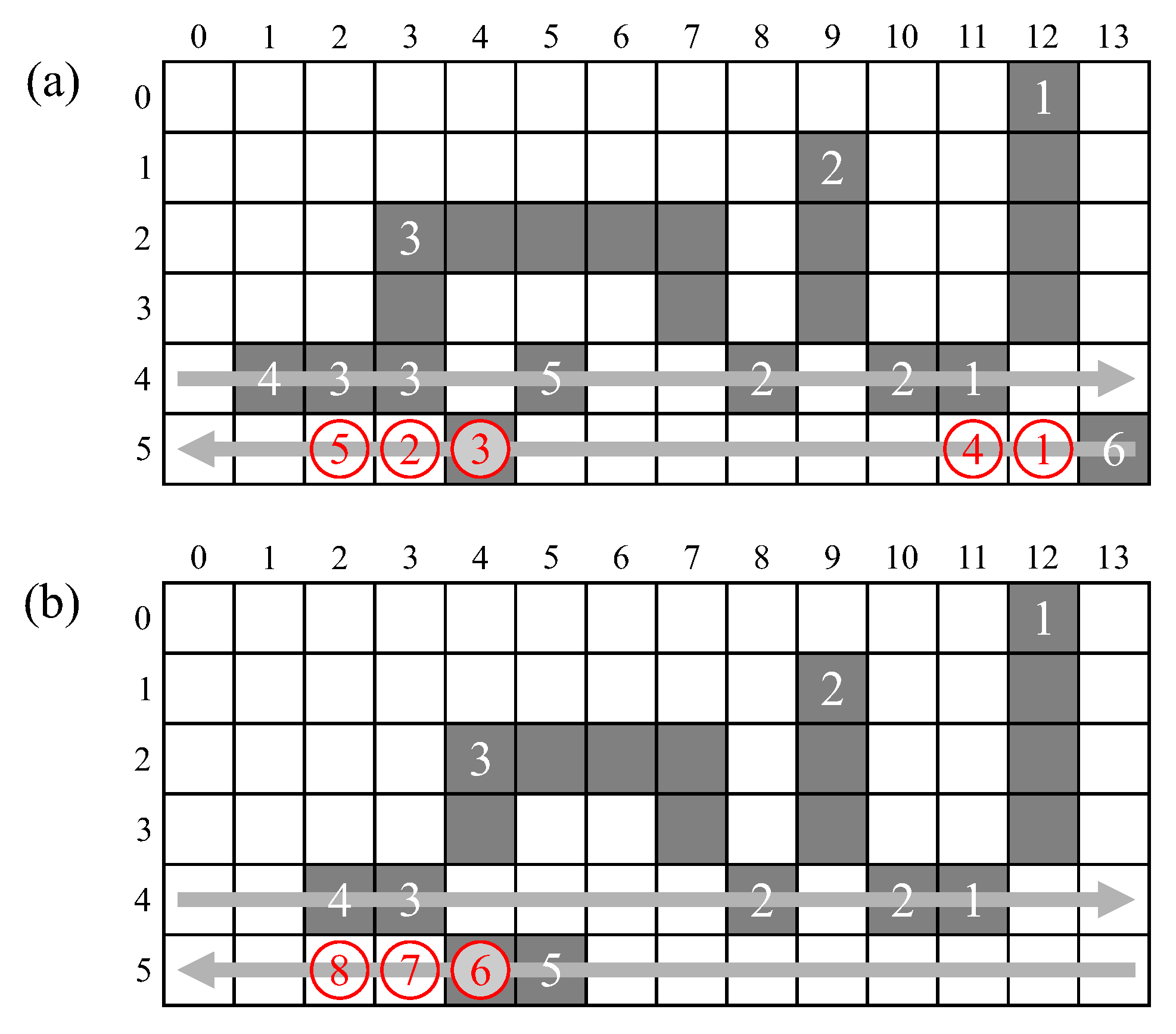
Potential data hazards can occur with the merger table, when data is read from the table before it is updated either as a result of merger or during the path compression.
A merger hazard is shown in
Figure 15 for label 3. When scanning row 4, label 2 is read from
, and is determined to be a representative label after a single lookup,
. Two clock cycles later, when the neighbourhood window is centred on pixel
, component segments associated with labels 1 and 2 merge, with
in the following cycle. Meanwhile, label 3 is read from
, and requires two lookups in
. The second lookup occurs in the same clock cycle that the merger is being written to
, so the second lookup would actually return the old label (2), shown in red in
Figure 15, and is not recognised as a stale label. A consequence of this is that pixel
would incorrectly be assigned label 2 rather than 1. To avoid this problem, the memory used for the merger table must also support the write-before-read semantic, or data forwarding be used to correctly return label (1) from the second lookup. Label 3 is then recognised as stale, and the merger table updated with
as shown in green.
Delaying the merger table update after a merger (as described in the previous section) does not introduce any additional hazards because the run of pixels which induces the delay would also delay the start of the following run.
In a chain of successive mergers, such as in
Figure 2, the previous merger is unlinked or compressed during the first merger table lookup, enabling the second lookup to provide the representative label. There are no data hazards associated with this process.
4.4. Data Table
Hazards within the data table can occur because the updated feature vector is written two clocks after the feature vector is read from the table. Alternating background and object pixels, with the object pixels belonging to the same connected component, can, therefore, cause a problem since the same label is being read from and written to in the same clock cycle. This can be solved if the memory supports read-before-write, or by adding bypass detection logic (the feedback data path from to is already present).
The other issue with the data table is detecting components which complete on the last pixel of a row, and on the row of the image. Equation (
2) can be extended to include
Thus, an object on the last line will be detected as complete in the clock cycle following the last pixel for that object.
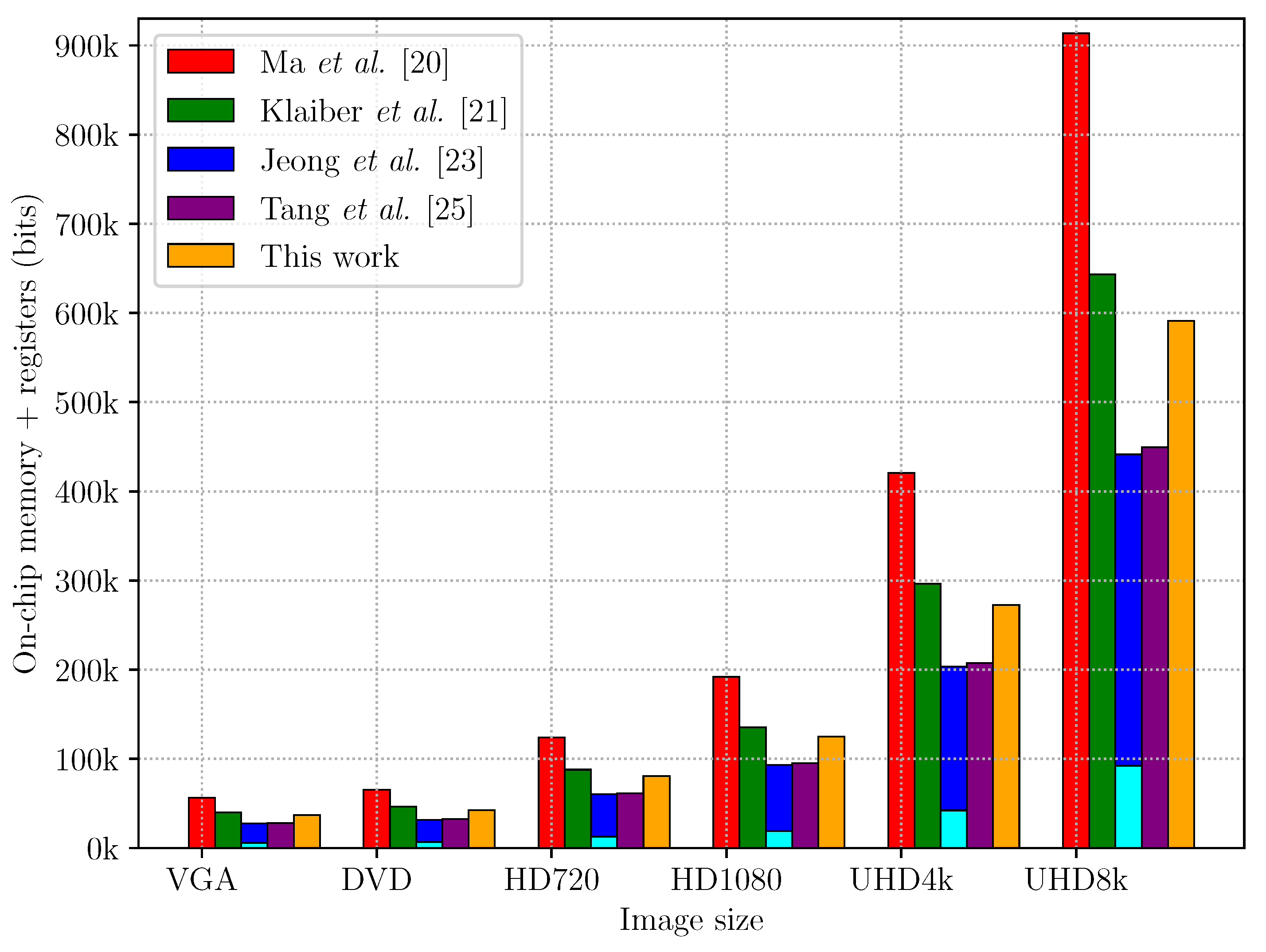
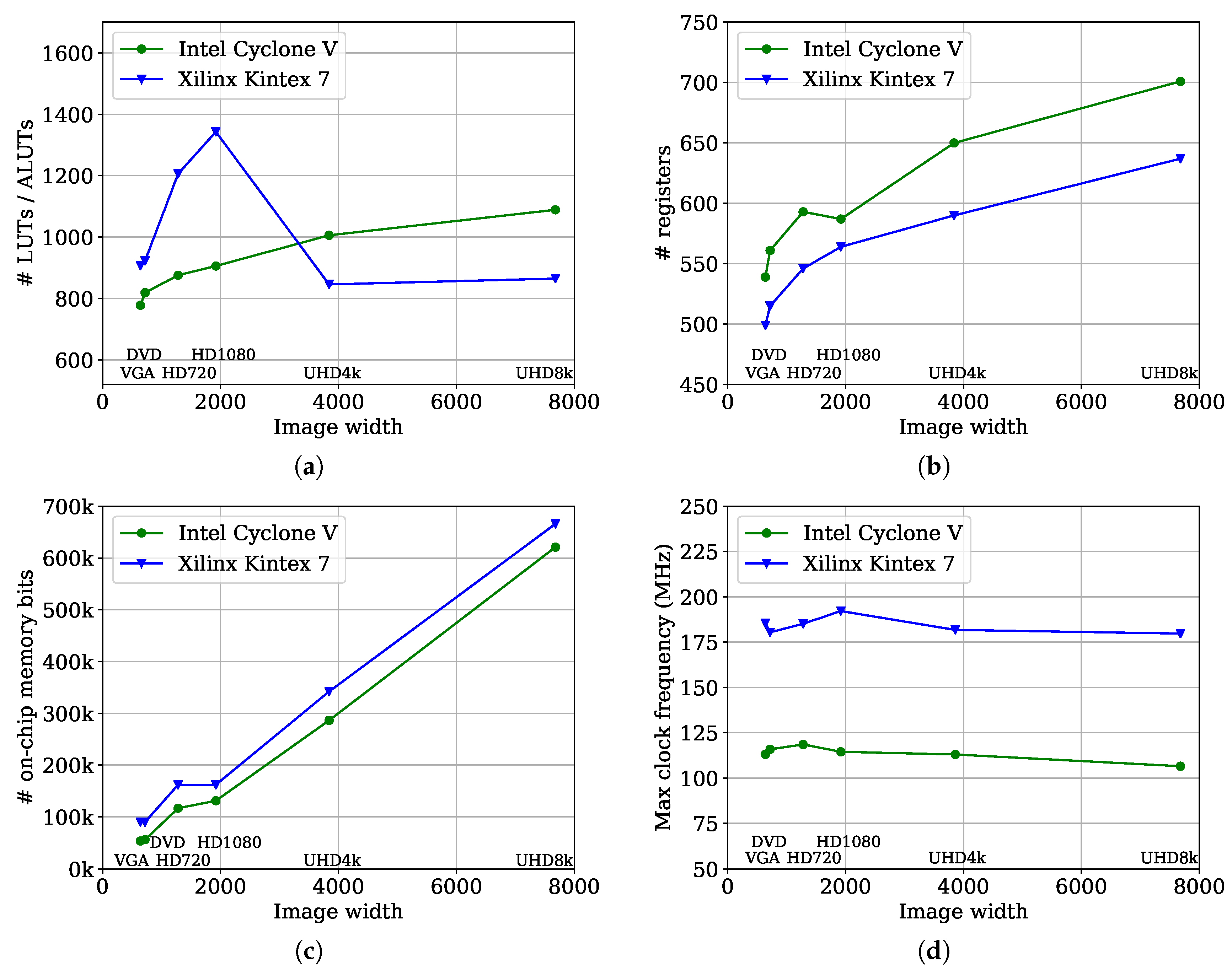
6. Summary and Conclusions
Pixel based hardware CCA architectures are designed to process streamed images at one pixel per clock cycle. However, with synchronous memories within modern FPGAs, this limits the designs to one memory access per clock cycle, which can create issues with stale labels resulting from chains of mergers. Current approaches manage this by resolving stale labels at the end of each image row, although this introduces a variable, image dependent, delay.
Jeong et al. [
23] solved this by replacing the memory with a multiplexed shift register, enabling all instances of old labels to be replaced immediately. However, the movement away from a memory structure comes at a cost of considerably increased logic resources and registers and a lower maximum clock frequency.
Tang et al. [
25] took a different approach, and rather than relabel the pixels which have already been seen, manages merger resolution through manipulation of pointers within a linked list structure. This eliminates the overheads associated with chains, and provides an efficient mechanism for detecting completed components and recycling labels. Although it claims to have no overheads, it does require the border pixels within the image to be background. This would require padding the image before processing, and results in two clock cycles overhead for each row.
In this paper, we have demonstrated an alternative approach to resolve stale labels on-the-fly by using a zig-zag scan. This allows continuous streamed images to be processed with no data dependent overheads, while retaining the use of memory for buffering the previous row.
The cost of this approach is slightly increased control logic over prior memory based approaches. This is to handle the zig-zag scan, and to manage multiple lookups within the merger table. The memory requirements are reduced because fewer auxiliary data structures are required. The presented design also allows a slightly higher clock frequency than prior state-of-the-art designs, in addition to the improved throughput. The use of memory rather than a multiplexed shift register makes it significantly faster than the architecture of [
23].
Conversion from a raster scan to a zig-zag scan does increase the latency (in terms of the number of clock cycles). This has been mitigated to some extent by a new algorithm that detects when objects are completed at the earliest possible time. Overall, the proposed changes give an improvement over current state-of-the-art methods.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}