Transcription of Spanish Historical Handwritten Documents with Deep Neural Networks

 , ,
, , 
Abstract
1. Introduction
2. The Rodrigo Dataset
3. Handwritten Text Recognition Systems
3.1. Proposal
Agora cuenta la historiawould be transformed into the following character sequence:
A g o r a~<SPACE> c u e n t a~<SPACE> l a~<SPACE> h i s t o r i aor into the following sequence following the hyphenation rules for Spanish:
Ago ra <SPACE> cuen ta <SPACE> la <SPACE> his to ria
vio e recognoscio el Astragamiento que perdiera de su gente
vno & rea gustio el Astragar mando que perdona de lugar
which represents a Character Error Rate (CER) equal to
with respect to the reference text-line transcription. However, using a sub-word based approach, the following best hypothesis is obtained:
vio <SPACE> & <SPACE> re ca ges cio <SPACE> el <SPACE> As tra ga mien to
<SPACE> que <SPACE> per do na <SPACE> de <SPACE> lu gar <SPACE>
which is transformed into the improved hypothesis (CER =
):
vio & recagescio el Astragamiento que perdona de lugar
v i o <SPACE> & <SPACE> r e c e g e s c i o <SPACE> e l <SPACE> A s t r a~g a~m i e n t o
<SPACE> q u e <SPACE> p e r d i e r a~<SPACE> d e l <SPACE> s e g u n d o
which results in the next final best hypothesis (CER =
):
vio & recegescio el Astragamiento que perdiera del segundo
3.2. Handcrafted Features
3.3. Lexicon and Language Models
3.4. Optical Models
3.4.1. Hidden Markov Models
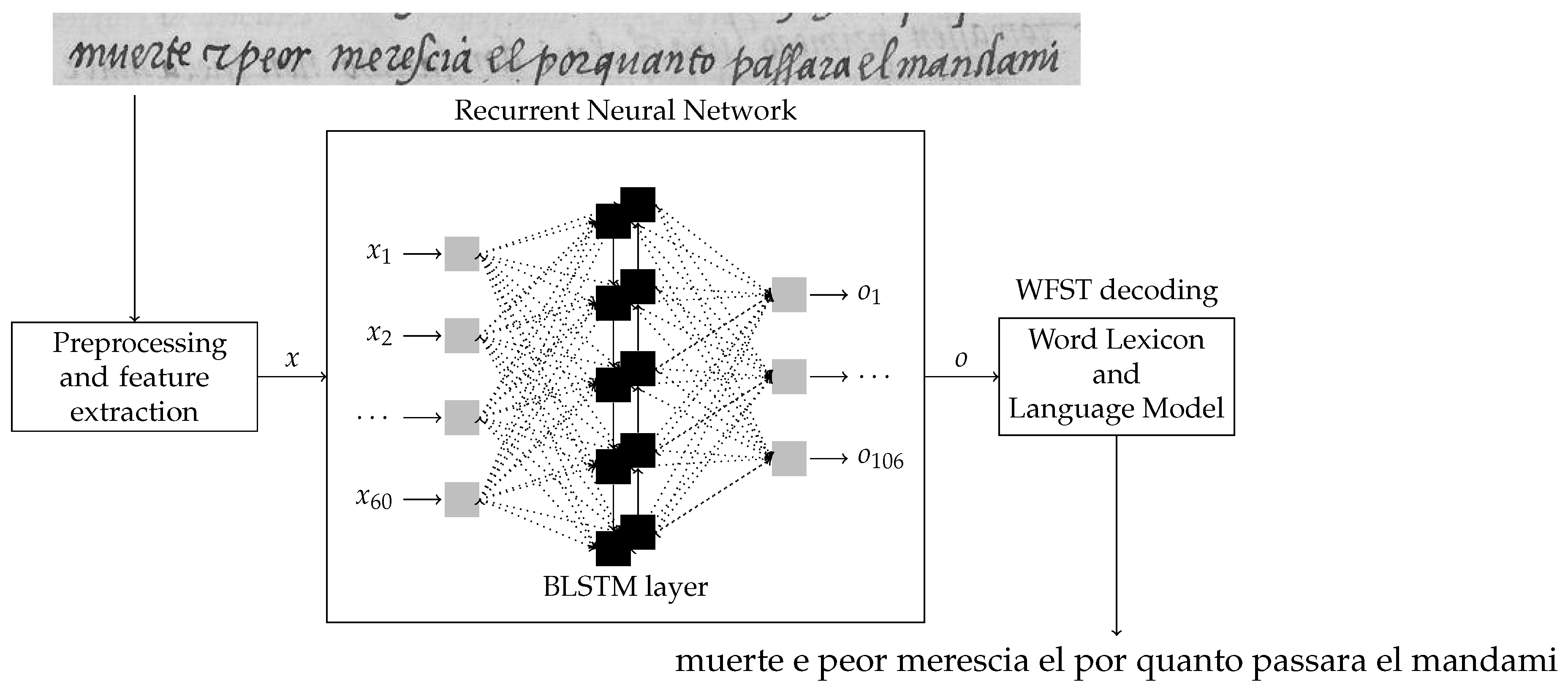
3.4.2. Deep Models Based on BLSTMs
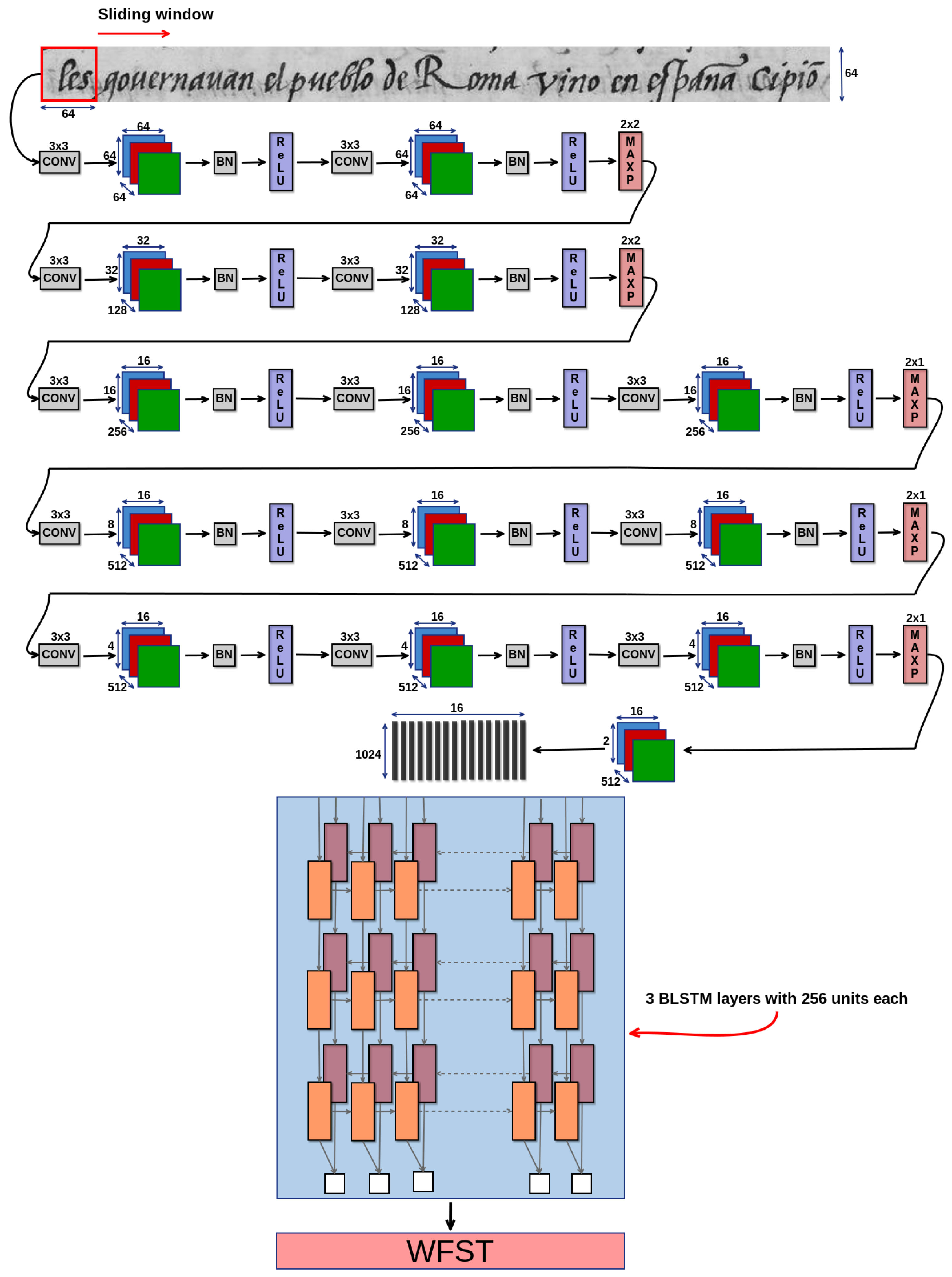
3.4.3. Deep Models Based on Convolutional Recurrent Neural Networks
3.5. Decoding with Deep Optical Models
3.6. Evaluation Metrics
4. Experimental Results
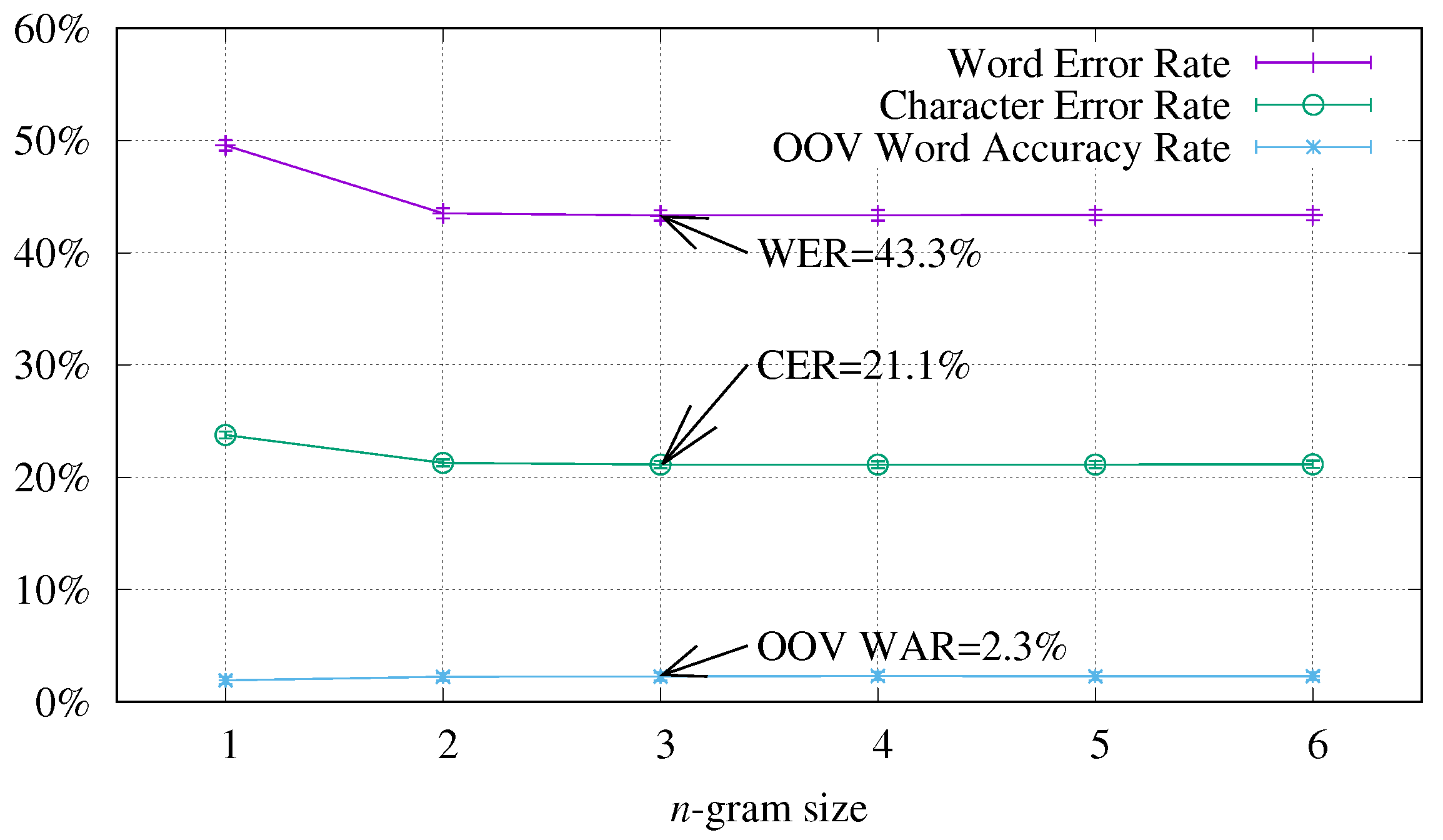
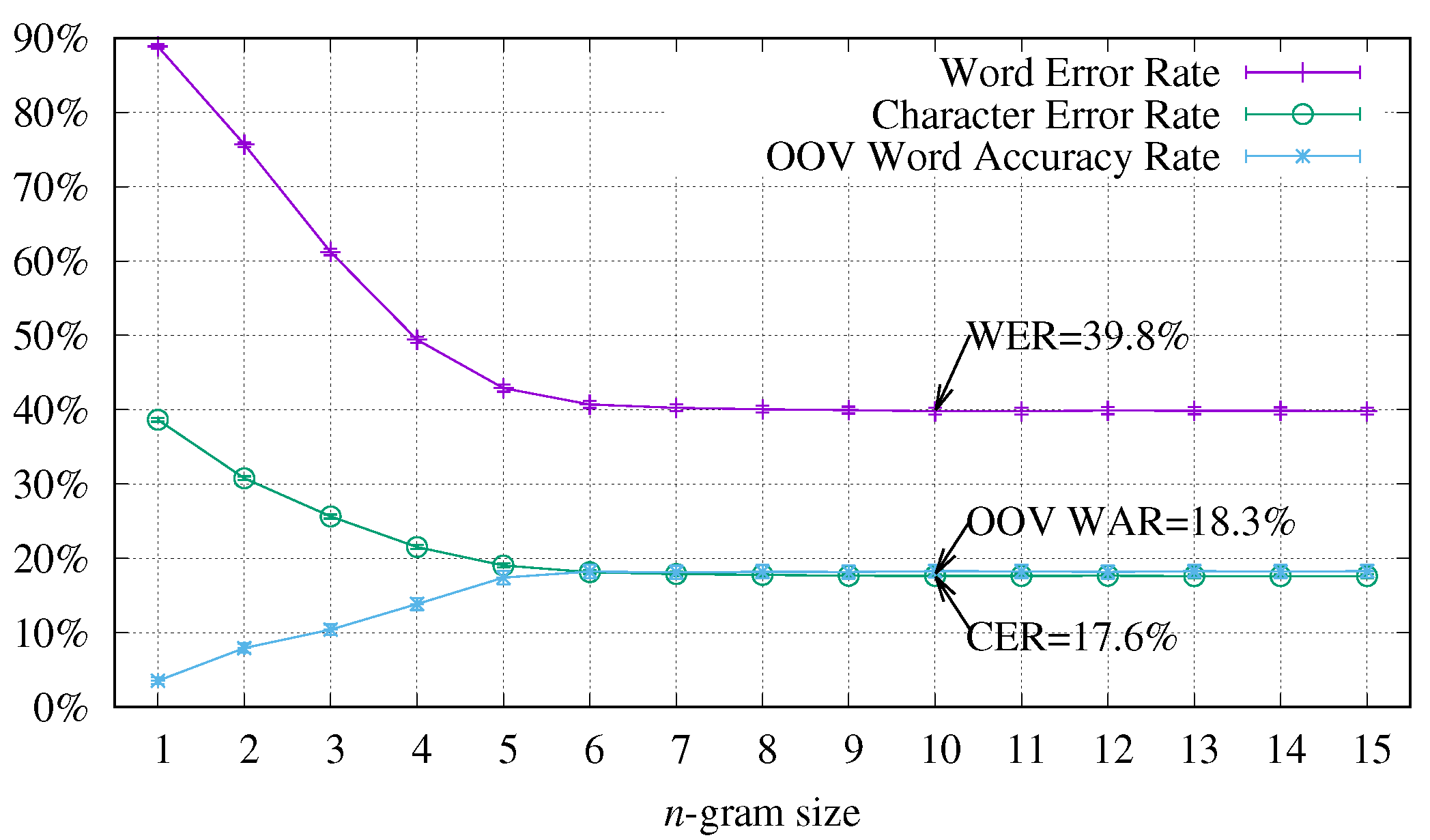
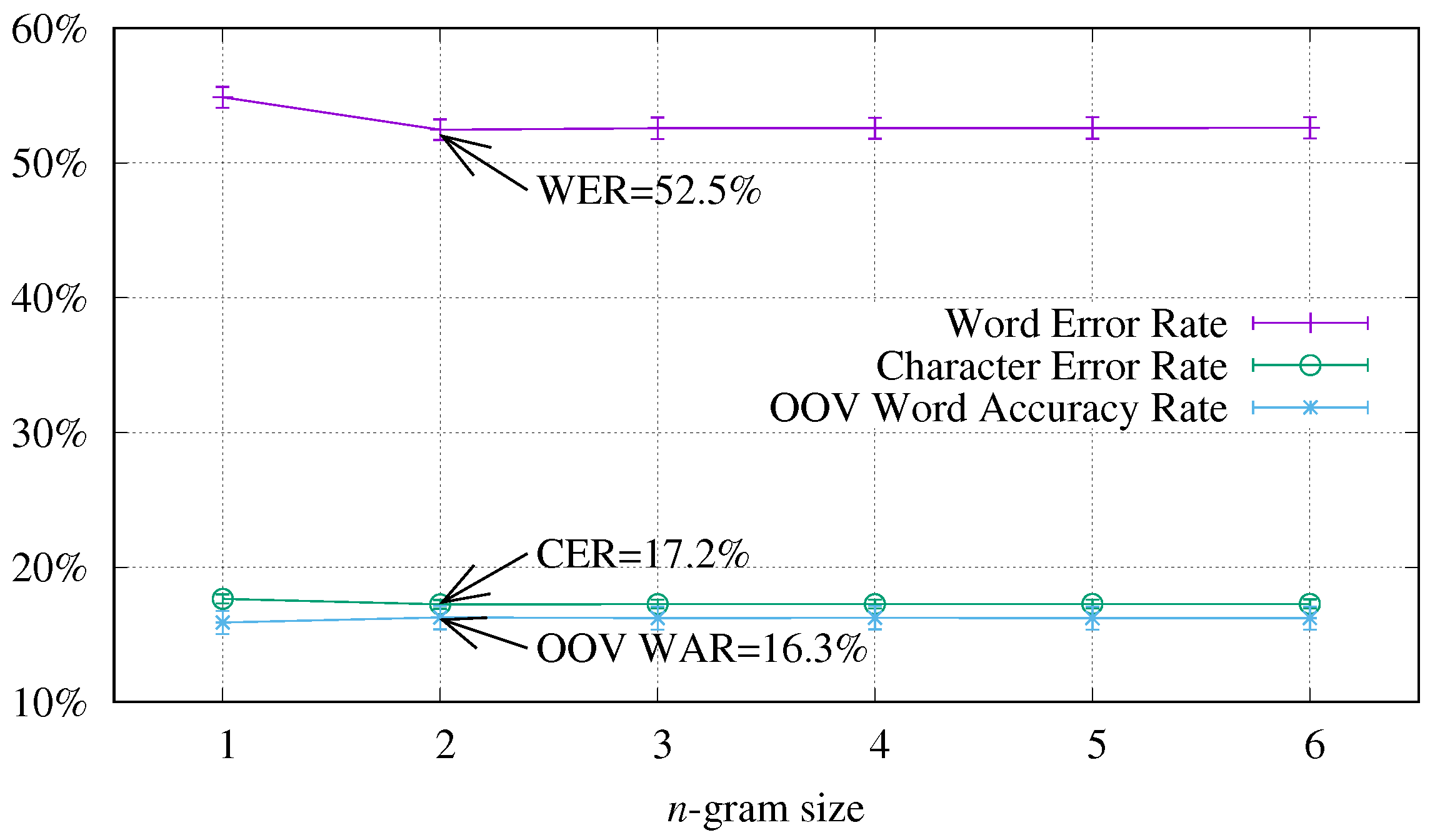
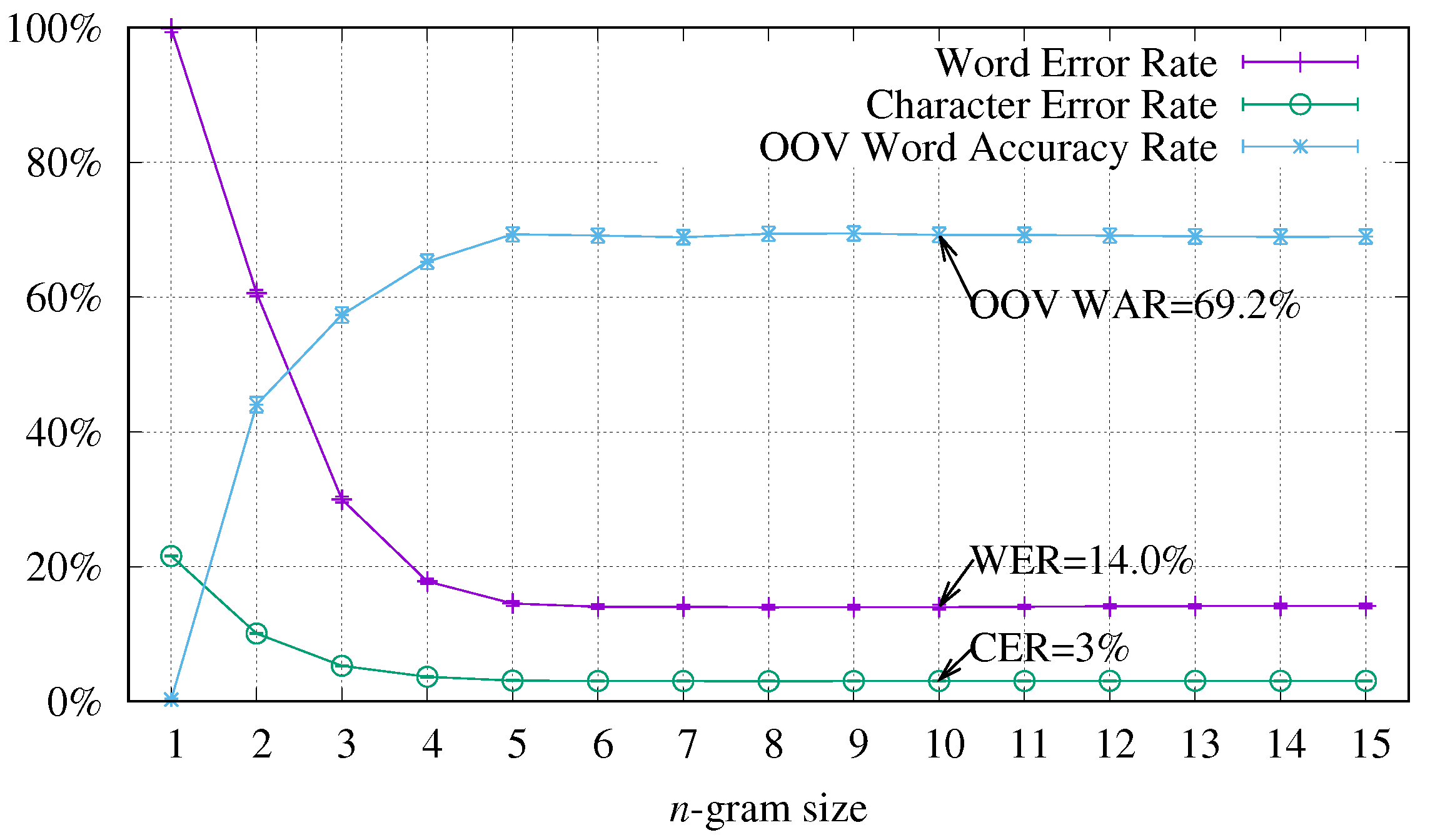
4.1. Study of the Context Size Influence
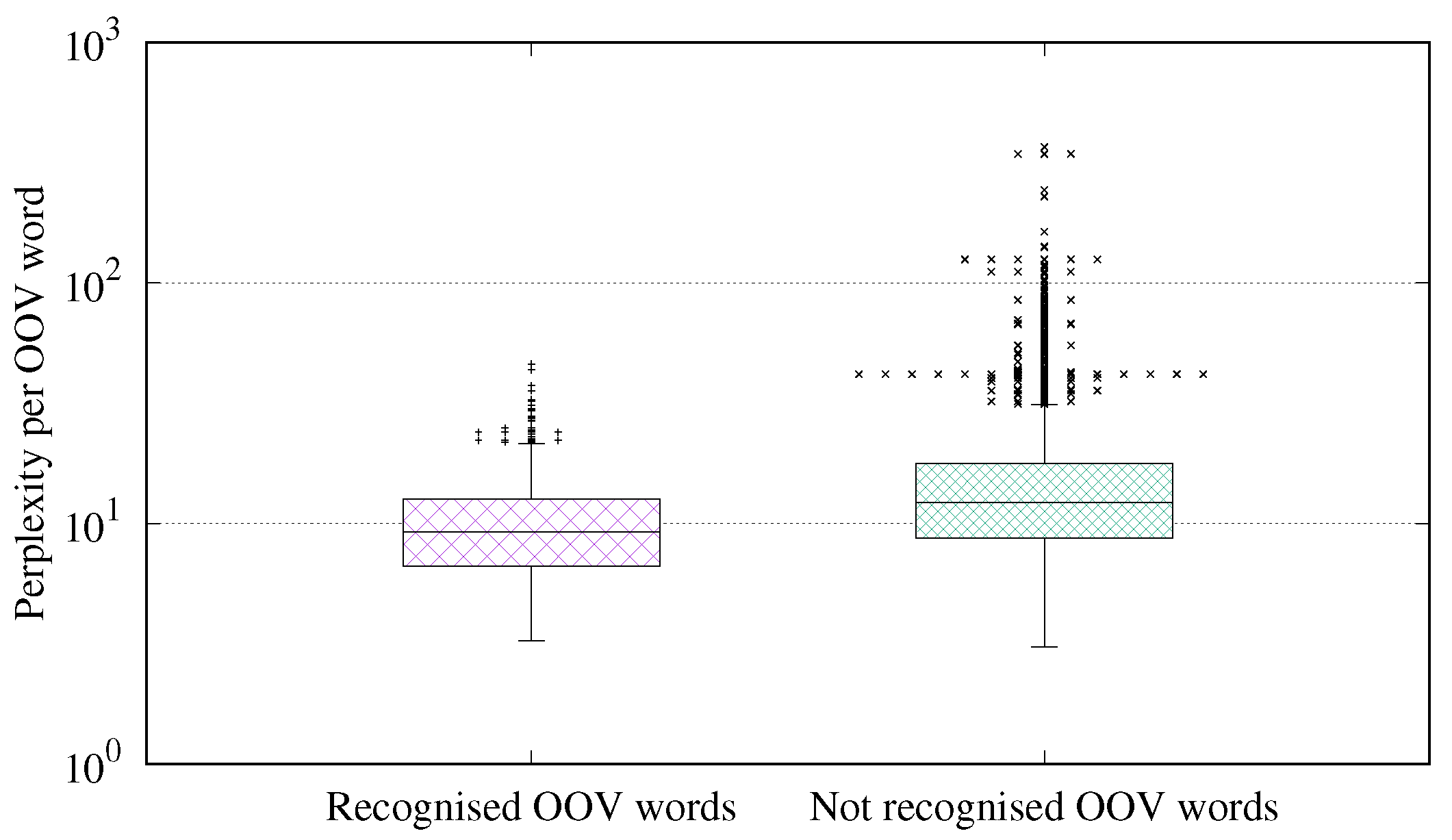
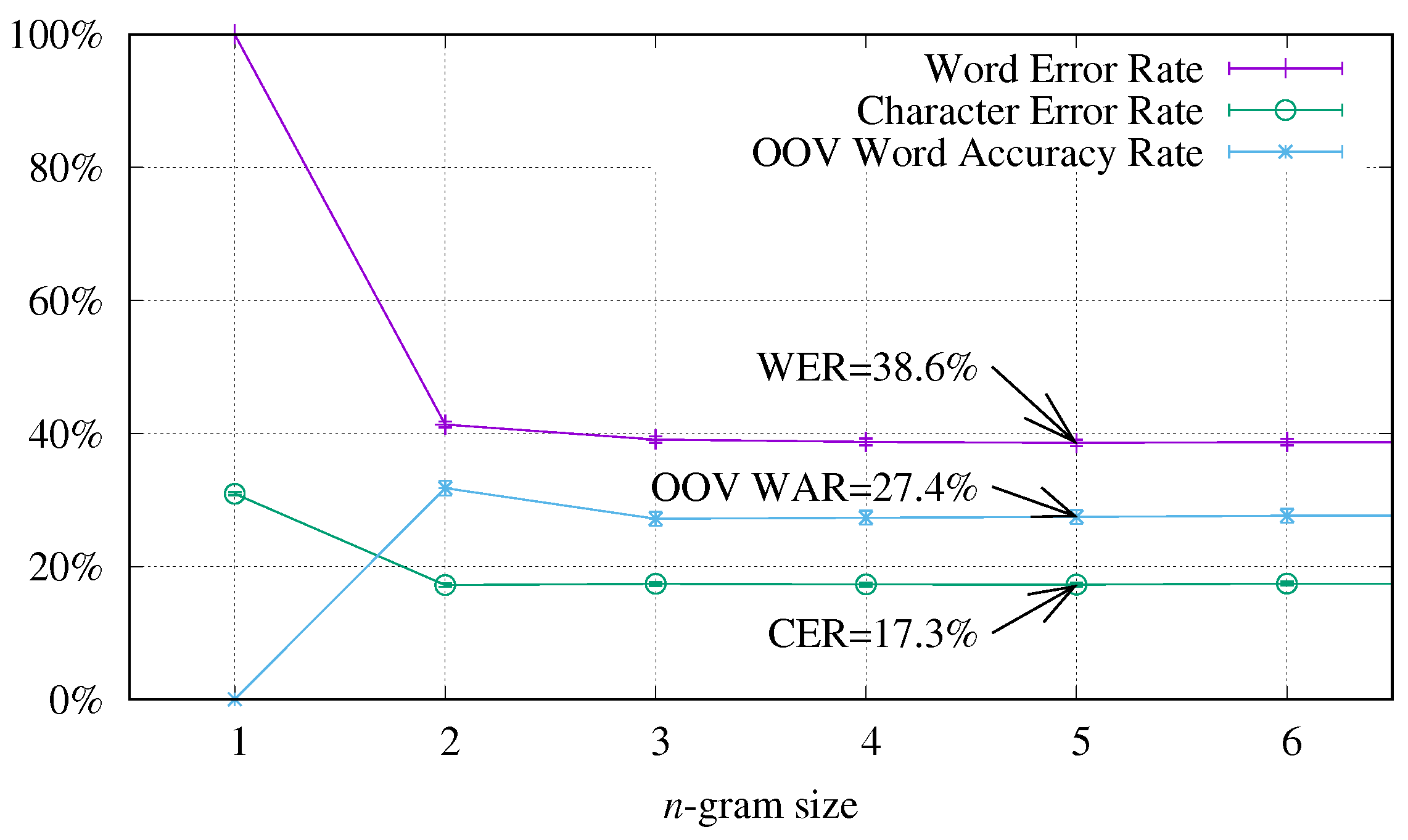
4.2. Study of the Relation between the Structure of the OOV Words and the Training Words
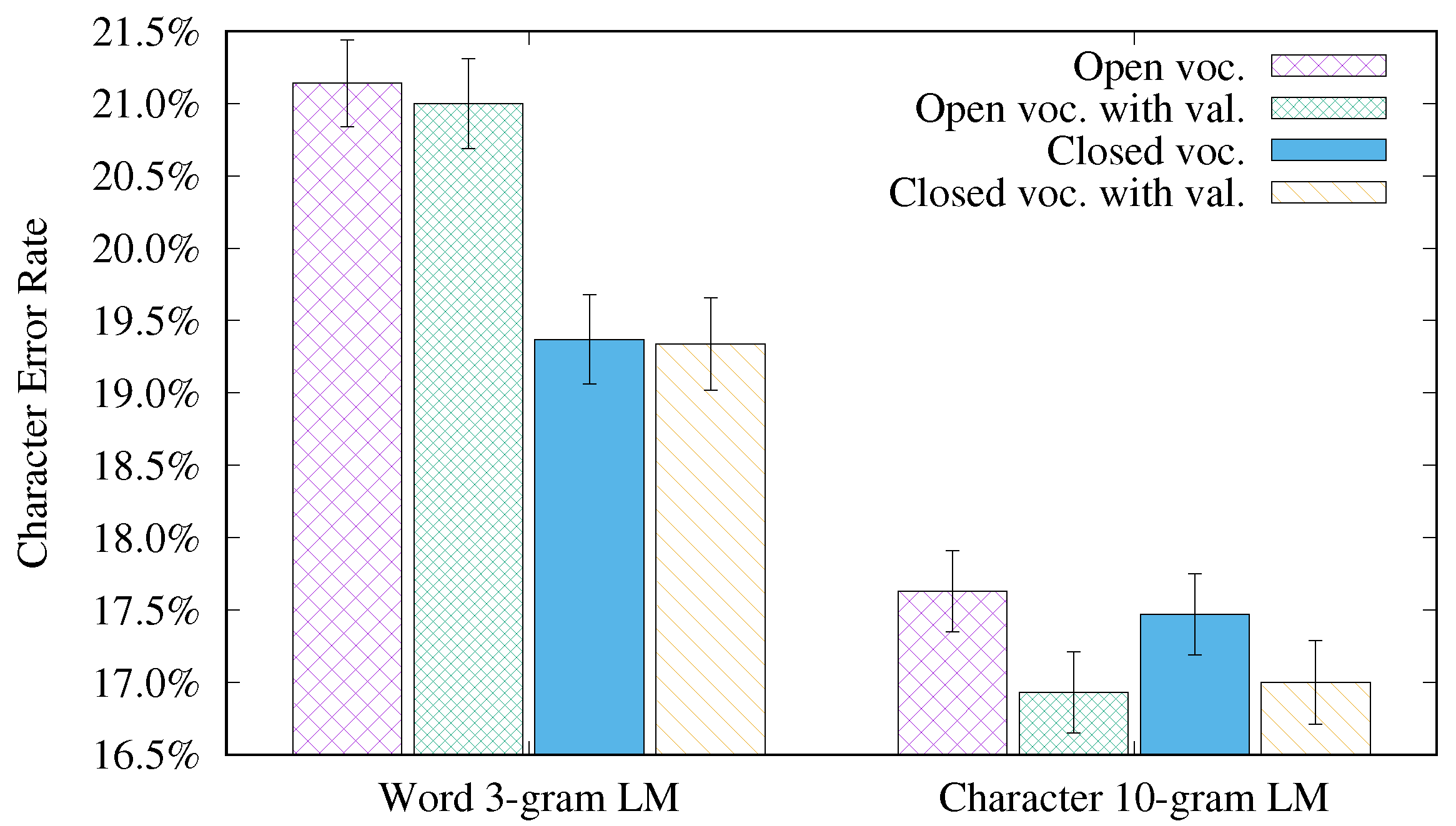
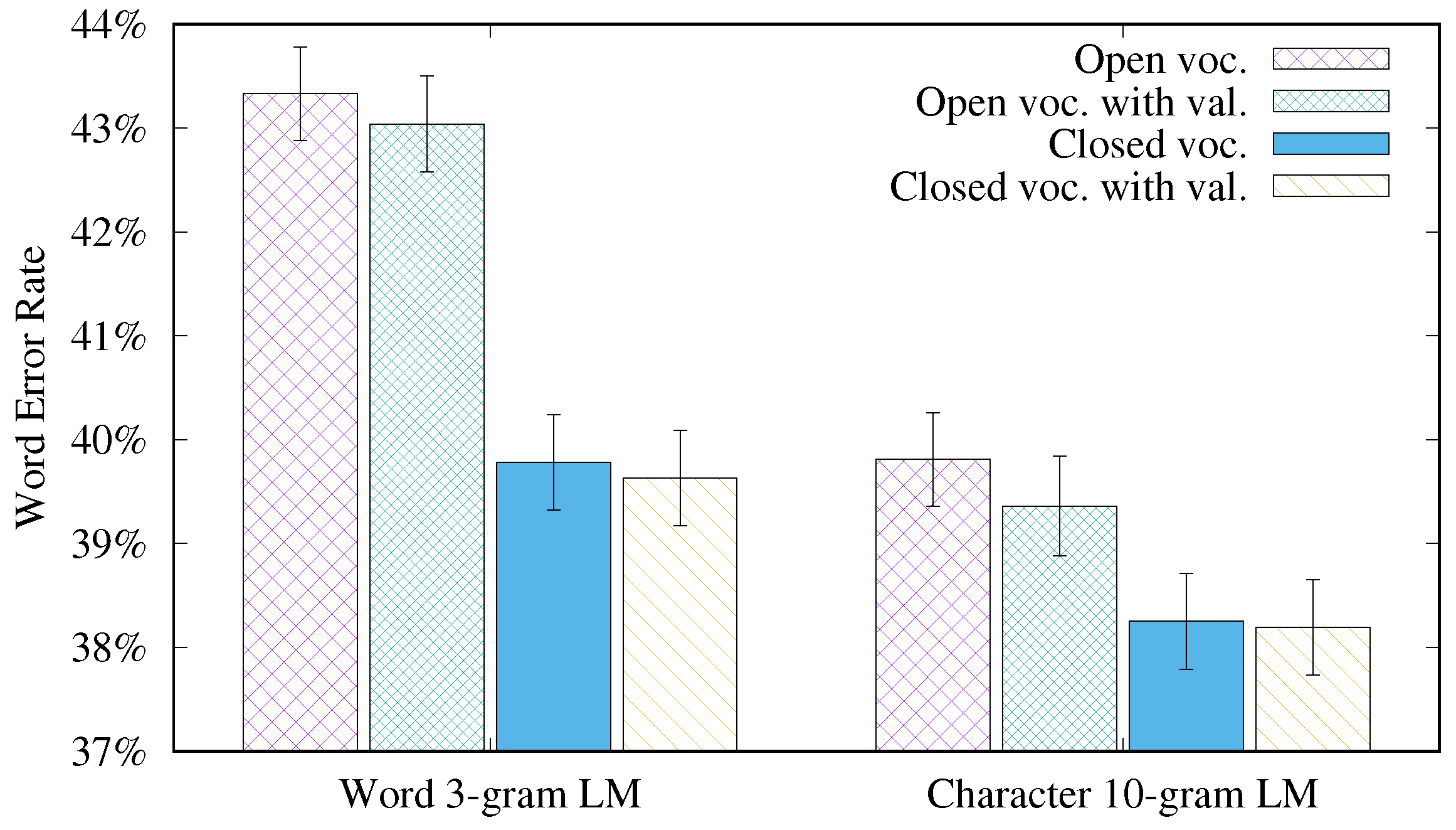
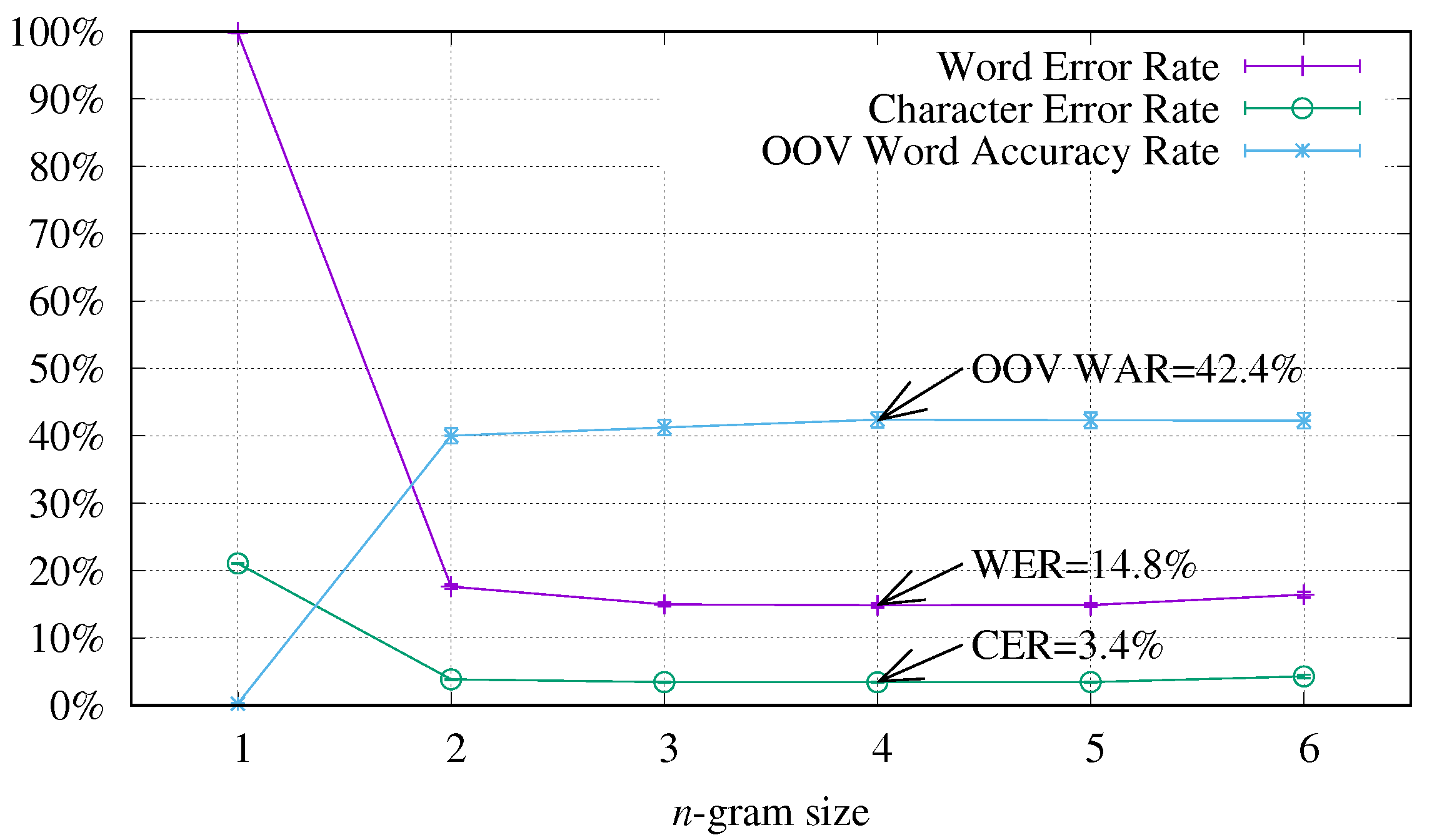
4.3. Study of the Effect of Closing the Vocabulary and Adding the Transcription of the Validation Set for Training the LM
4.4. Study of the Context Size Influence Using Deep Optical Models
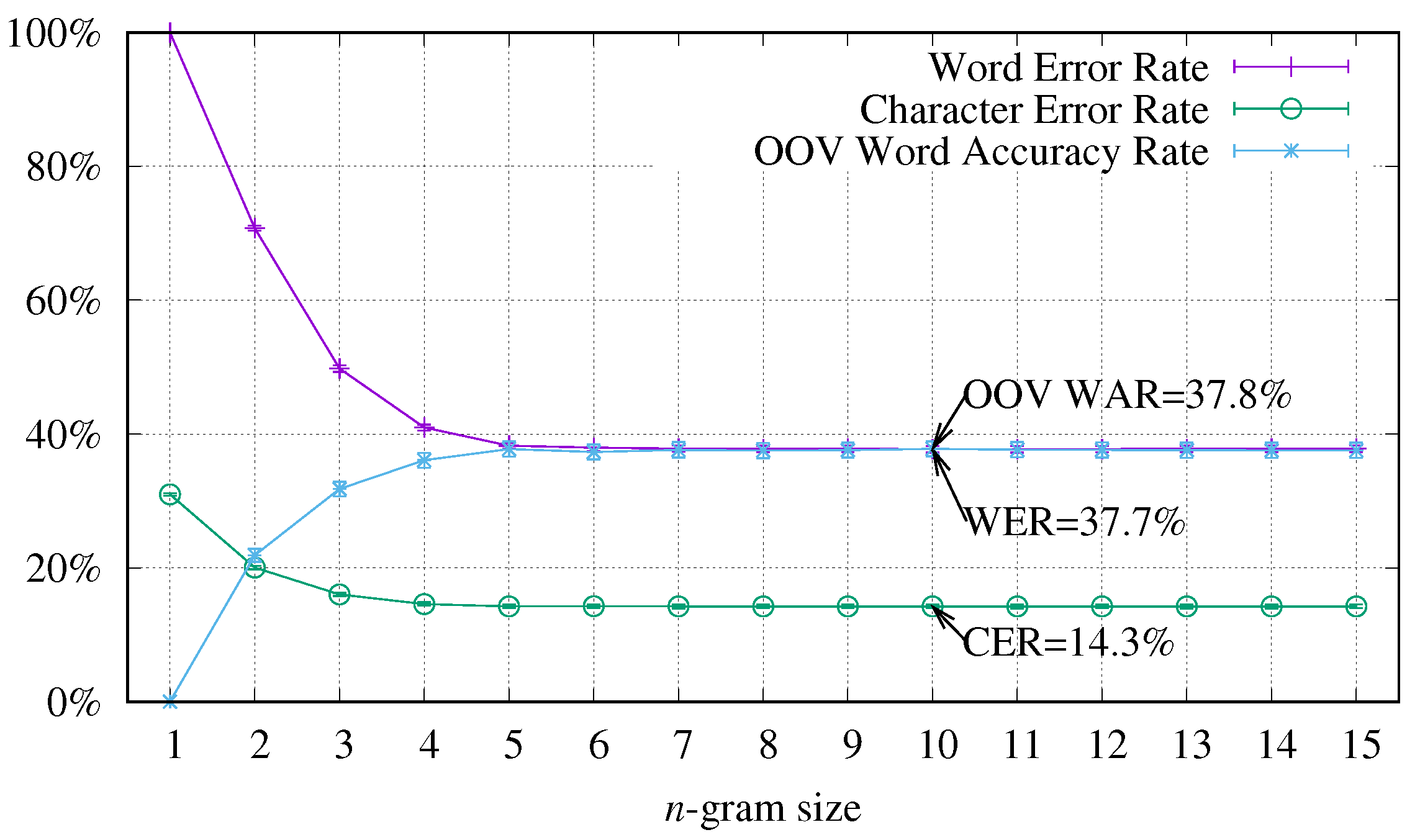
4.4.1. Results for Deep Models Based on Recurrent Neural Networks with BLSTMs
4.4.2. Results for Deep Models Based on Convolutional Recurrent Neural Networks
5. Conclusions
- comparing several types of HTR systems (HMM-based, RNN-based).
- proposing a state-of-the-art HTR system for the transcription of ancient Spanish documents whose optical part is based on very deep nets (CRNNs).
- proposing to associate the optical HTR system with a dictionary and a language model based on sub-lexical units. These units are shown to be efficient in order to cope with OOV words.
- reaching with such optical and LM HTR components the best overall recognition results on a publicly available Spanish historical dataset of document images.
Acknowledgments
Author Contributions
Conflicts of Interest
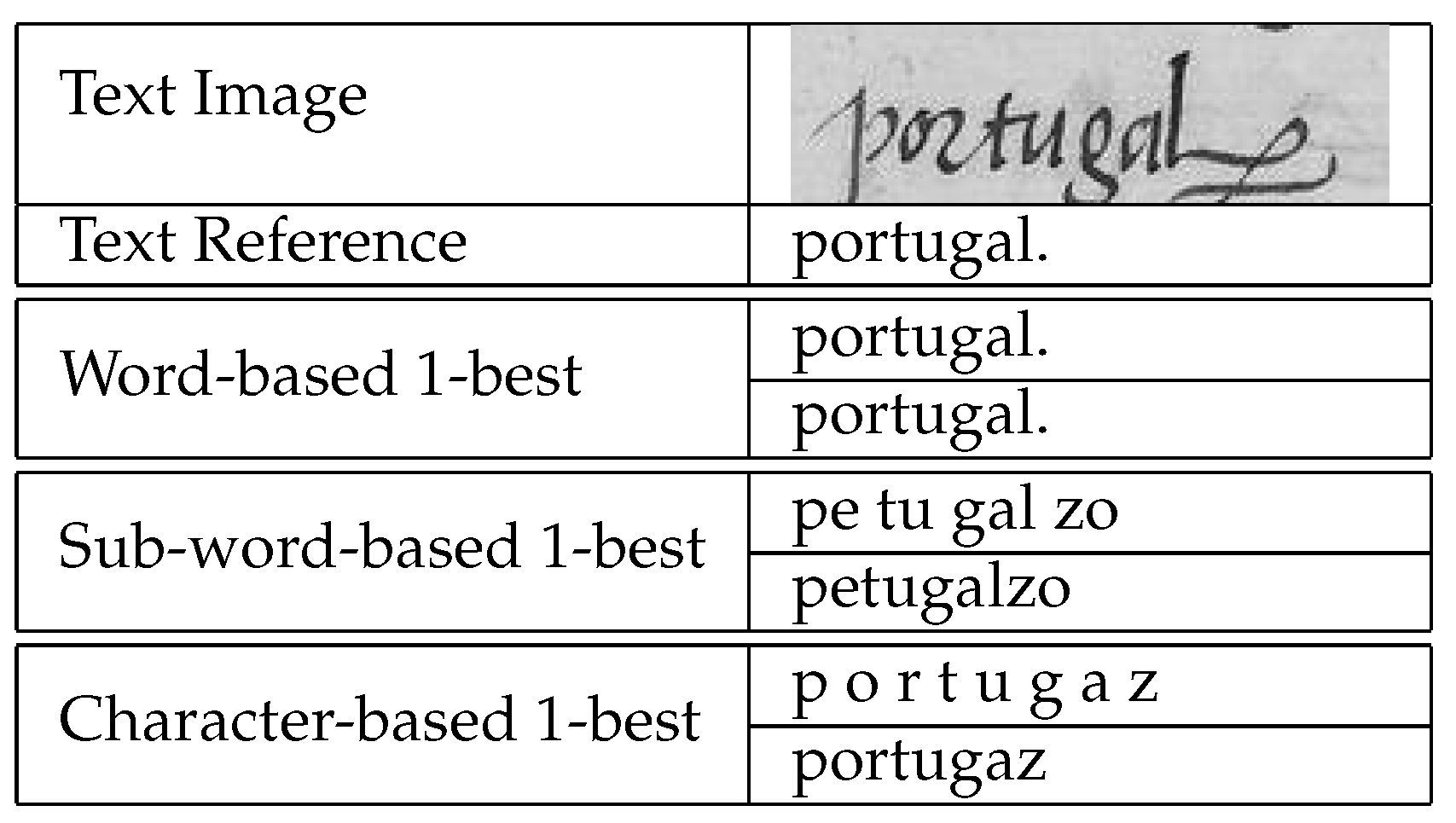
Appendix A. Some Recognition Examples



References
- España-Boquera, S.; Castro-Bleda, M.J.; Gorbe-Moya, J.; Zamora-Martinez, F. Improving Offline Handwritten Text Recognition with Hybrid HMM/ANN Models. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 767–779. [Google Scholar] [CrossRef] [PubMed]
- Al-Hajj-Mohamad, R.; Likforman-Sulem, L.; Mokbel, C. Combining Slanted-Frame Classifiers for Improved HMM-Based Arabic Handwriting Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 1165–1177. [Google Scholar] [CrossRef] [PubMed]
- Vinciarelli, A. A survey on off-line cursive word recognition. Pattern Recognit. 2002, 35, 1433–1446. [Google Scholar] [CrossRef]
- Bianne-Bernard, A.L.; Menasri, F.; El-Hajj, R.; Mokbel, C.; Kermorvant, C.; Likforman-Sulem, L. Dynamic and Contextual Information in HMM modeling for Handwritten Word Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 99, 2066–2080. [Google Scholar] [CrossRef] [PubMed]
- Graves, A. Supervised Sequence Labelling with Recurrent Neural Networks. Ph.D. Thesis, Technische Universität München, Munich, Germany, 2008. [Google Scholar]
- Xie, Z.; Sun, Z.; Jin, L.; Feng, Z.; Zhang, S. Fully convolutional recurrent network for handwritten Chinese text recognition. In Proceedings of the 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 4011–4016. [Google Scholar]
- Bluche, T.; Messina, R. Gated Convolutional Recurrent Neural Networks for Multilingual Handwriting Recognition. In Proceedings of the 13th International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 13–15 November 2017. [Google Scholar]
- Sudholt, S.; Fink, G.A. PHOCNet: A deep convolutional neural network for word spotting in handwritten documents. In Proceedings of the 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; pp. 277–282. [Google Scholar]
- Brakensiek, A.; Rottland, J.; Kosmala, A.; Rigoll, G. Off-line handwriting recognition using various hybrid modeling techniques and character n-grams. In Proceedings of the 7th International Workshop on Frontiers in Handwritten Recognition, Amsterdam, The Netherlands, 11–13 September 2000; pp. 343–352. [Google Scholar]
- Fischer, A.; Frinken, V.; Bunke, H.; Suen, C.Y. Improving hmm-based keyword spotting with character language models. In Proceedings of the 12th International Conference on Document Analysis and Recognition (ICDAR), Washington, DC, USA, 25–28 August 2013; pp. 506–510. [Google Scholar]
- Santoro, A.; Parziale, A.; Marcelli, A. A Human in the Loop Approach to Historical Handwritten Documents Transcription. In Proceedings of the 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; pp. 222–227. [Google Scholar]
- Stefano, C.D.; Marcelli, A.; Parziale, A.; Senatore, R. Reading Cursive Handwriting. In Proceedings of the 12th International Conference on Frontiers in Handwriting Recognition, Kolkata, India, 16–18 November 2010; pp. 95–100. [Google Scholar]
- Oprean, C.; Likforman-Sulem, L.; Popescu, A.; Mokbel, C. Handwritten word recognition using Web resources and recurrent neural networks. Int. J. Doc. Anal. Recognit. (IJDAR) 2015, 18, 287–301. [Google Scholar] [CrossRef]
- Frinken, V.; Fischer, A.; Martínez-Hinarejos, C.D. Handwriting recognition in historical documents using very large vocabularies. In Proceedings of the 2nd International Workshop on Historical Document Imaging and Processing, Washington, DC, USA, 24 August 2013; pp. 67–72. [Google Scholar]
- Swaileh, W.; Paquet, T. Handwriting Recognition with Multi-gram language models. In Proceedings of the 14h International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 10–15 November 2017. [Google Scholar]
- Kozielski, M.; Rybach, D.; Hahn, S.; Schlüter, R.; Ney, H. Open vocabulary handwriting recognition using combined word-level and character-level language models. In Proceedings of the 2013 International Conference on Acoustics, Speech and Signal Processing (ICASSP ’13), Vancouver, BC, Canada, 26–31 May 2013; pp. 8257–8261. [Google Scholar]
- Messina, R.; Kermorvant, C. Over-generative finite state transducer n-gram for out-of-vocabulary word recognition. In Proceedings of the 11th IAPR International Workshop on Document Analysis Systems (DAS), Tours, France, 7–10 April 2014; pp. 212–216. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2298–2304. [Google Scholar] [CrossRef] [PubMed]
- Serrano, N.; Castro, F.; Juan, A. The RODRIGO Database. In Proceedings of the 7th International Conference on Language Resources and Evaluation (LREC), Valletta, Malta, 17–23 May 2010; pp. 2709–2712. [Google Scholar]
- Pattern Recognition and Human Language Technology (PRHLT) Research Center. 2018. Available online: https://www.prhlt.upv.es (accessed on 5 January 2018).
- Fischer, A. Handwriting Recognition in Historical Documents. Ph.D. Thesis, University of Bern, Bern, Switzerland, 2012. [Google Scholar]
- Michel, J.B.; Shen, Y.K.; Aiden, A.P.; Veres, A.; Gray, M.K.; Brockman, W.; Team, T.G.B.; Pickett, J.P.; Hoiberg, D.; Clancy, D.; et al. Quantitative analysis of culture using millions of digitized books. Science 2010, 331, 176–182. [Google Scholar] [CrossRef] [PubMed]
- Pastor, M.; Toselli, A.H.; Vidal, E. Projection profile based algorithm for slant removal. In Lecture Notes in Computer Science, Proceedings of the International Conference on Image Analysis and Recognition (ICIAR’04), Porto, Portugal, 29 September–1 October 2004; Springer: Berlin, Germany, 2004; Volume 3212, pp. 183–190. [Google Scholar]
- Toselli, A.H.; Juan, A.; González, J.; Salvador, I.; Vidal, E.; Casacuberta, F.; Keysers, D.; Ney, H. Integrated Handwriting Recognition and Interpretation using Finite-State Models. Int. J. Pattern Recognit. Artif. Intell. 2004, 18, 519–539. [Google Scholar] [CrossRef]
- Testhyphens – Testing hyphenation patterns. 2018. Available online: https://www.ctan.org/tex-archive/macros/latex/contrib/testhyphens (accessed on 5 January 2018).
- Kneser, R.; Ney, H. Improved backing-off for M-gram language modeling. In Proceedings of the 1995 International Conference on Acoustics, Speech, and Signal Processing (ICASSP’95), Detroit, MI, USA, 9–12 May 1995; Volume 1, pp. 181–184. [Google Scholar]
- Stolcke, A. SRILM—An extensible language modeling toolkit. In Proceedings of the 3rd Interspeech, Denver, CO, USA, 16–20 September 2002; pp. 901–904. [Google Scholar]
- Young, S.; Evermann, G.; Gales, M.; Hain, T.; Kershaw, D.; Liu, X.; Moore, G.; Odell, J.; Ollason, D.; Povey, D.; et al. The HTK Book (for HTK Version 3.4); Cambridge University Engineering Department: Cambridge, UK, 2006. [Google Scholar]
- Luján-Mares, M.; Tamarit, V.; Alabau, V.; Martínez-Hinarejos, C.D.; Pastor, M.; Sanchis, A.; Toselli, A.H. iATROS: A Speech and Handwriting Recognition System. V Jornadas en Tecnologías del Habla. 2008, pp. 75–78. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.329.6708&rep=rep1&type=pdf (accessed on 5 January 2018).
- Hermansky, H.; Ellis, D.P.W.; Sharma, S. Tandem connectionist feature extraction for conventional HMM systems. In Proceedings of the 2000 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP’00), Istanbul, Turkey, 5–9 June 2000; Volume 3, pp. 1635–1638. [Google Scholar]
- Graves, A. RNNLIB: A Recurrent Neural Network Library for Sequence Learning Problems. 2016. Available online: http://sourceforge.net/projects/rnnl/ (accessed on 5 January 2018).
- Chammas, E. Structuring Hidden Information in Markov Modeling with Application to Handwriting Recognition. Ph.D. Thesis, Telecom ParisTech, Paris, France, 2017. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G. Recent advances in convolutional neural networks. arXiv, 2015; arXiv:1512.07108. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: labeling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd international conference on Machine learning ACM, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Zeyer, A.; Schlüter, R.; Ney, H. Towards Online-Recognition with Deep Bidirectional LSTM Acoustic Models. In Proceedings of the 2016 INTERSPEECH, San Francisco, CA, USA, 8–12 September 2016; pp. 3424–3428. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Qian, N. On the momentum term in gradient descent learning algorithms. Neural Netw. 1999, 12, 145–151. [Google Scholar] [CrossRef]
- Zeiler, M.D. ADADELTA: an adaptive learning rate method. arXiv, 2012; arXiv:1212.5701. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Miao, Y.; Gowayyed, M.; Metze, F. EESEN: End-to-end speech recognition using deep RNN models and WFST-based decoding. In Proceedings of the 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Scottsdale, AZ, USA, 13–17 December 2015; pp. 167–174. [Google Scholar]
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar]
- Knezevic, A. Overlapping Confidence Intervals and Statistical Significance; StatNews; Cornell University Statistical Consulting Unit: Ithaca, NY, USA, 2008; Volume 73. [Google Scholar]
- Bisani, M.; Ney, H. Bootstrap estimates for confidence intervals in ASR performance evaluation. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing ICASSP’04, Montreal, QC, Canada, 17–21 May 2004; Volume 1, pp. 409–412. [Google Scholar]
- Brown, P.F.; Della Pietra, V.J.; Mercer, R.L.; Della Pietra, S.A.; Lai, J.C. An Estimate of an Upper Bound for the Entropy of English. Comput. Linguist. 1992, 18, 31–40. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
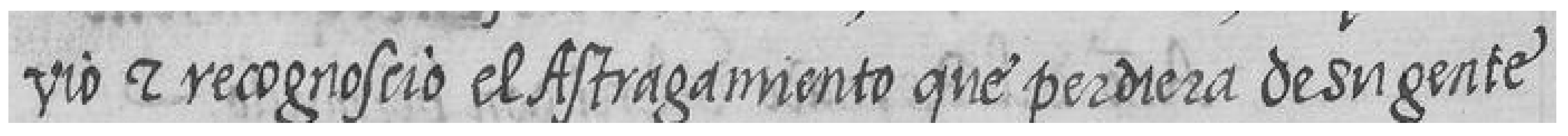{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Partition | Lines | Words Total/Diff./OOV (over.) | Sub-Words Total/Diff./OOV (over.) | Characters Total/Diff./OOV (over.) |
|---|---|---|---|---|
| Training | 9000 | 98,232/12,650/- | 148,070/3045/- | 493,126/105/- |
| Validation | 1000 | 10,899/3016/850 | 14,907/1074/7 | 54,936/82/1 |
| Test | 5010 | 55,195/7453/4918 (203) | 73,660/1418/55 (11) | 272,132/91/14 (1) |
| Measure | Word 3-gram | Sub-Word 4-gram | Character 10-gram |
|---|---|---|---|
| WER | |||
| CER | |||
| OOV WAR |
| Distribution | Q1 | Q2 | Q3 | IQR | Min. | Max. | SD |
|---|---|---|---|---|---|---|---|
| Recognized | 6.64 | 9.22 | 12.57 | 5.94 | 3.26 | 46.05 | 5.37 |
| Unrecognized | 8.70 | 12.21 | 17.75 | 9.05 | 3.06 | 367.07 | 16.25 |
| Measure | Word 2-gram | Sub-Word 5-gram | Character 10-gram |
|---|---|---|---|
| WER | |||
| CER | |||
| OOV WAR |
| Measure | Word 3-gram | Sub-Word 4-gram | Character 10-gram |
|---|---|---|---|
| WER | |||
| CER | |||
| OOV WAR |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Granell, E.; Chammas, E.; Likforman-Sulem, L.; Martínez-Hinarejos, C.-D.; Mokbel, C.; Cîrstea, B.-I. Transcription of Spanish Historical Handwritten Documents with Deep Neural Networks. J. Imaging 2018, 4, 15. https://doi.org/10.3390/jimaging4010015
Granell E, Chammas E, Likforman-Sulem L, Martínez-Hinarejos C-D, Mokbel C, Cîrstea B-I. Transcription of Spanish Historical Handwritten Documents with Deep Neural Networks. Journal of Imaging. 2018; 4(1):15. https://doi.org/10.3390/jimaging4010015
Chicago/Turabian StyleGranell, Emilio, Edgard Chammas, Laurence Likforman-Sulem, Carlos-D. Martínez-Hinarejos, Chafic Mokbel, and Bogdan-Ionuţ Cîrstea. 2018. "Transcription of Spanish Historical Handwritten Documents with Deep Neural Networks" Journal of Imaging 4, no. 1: 15. https://doi.org/10.3390/jimaging4010015
APA StyleGranell, E., Chammas, E., Likforman-Sulem, L., Martínez-Hinarejos, C.-D., Mokbel, C., & Cîrstea, B.-I. (2018). Transcription of Spanish Historical Handwritten Documents with Deep Neural Networks. Journal of Imaging, 4(1), 15. https://doi.org/10.3390/jimaging4010015