2. Uninformed Information Fusion
Let us start by formalizing the problem considered in this paper. I adopt the broad paradigm of so-called data source identification and matching. In particular, I assume that the available data comprises a set of n sensed observations, , which correspond to different modalities sensing the same data source. Furthermore, I assume that there are functions (i.e., algorithms) which quantify how well a particular observation matches a specific data source. Without loss of generality I assume , where 0 indicates the best possible match, and the worst i.e., can be thought of a quasi-distance—’quasi-’ to emphasise that it is not required that meets the strict conditions required of a metric. Note that the aforestated setting describes observations in the most general sense, e.g., these may be feature vectors (such as rasterized appearance images or SIFT descriptors in computer vision), sets of vectors, and so on, and they do not need to be of the same type (for example, some may be vectors, others sequences) or dimensionalities.
As noted in the previous section, we are looking for a simple way of fusing different matching decisions
in a simple manner which is a reasonable baseline in an uninformed setting, that is, without exploiting any particular properties of different functions
or observations
. A common one pervasively used in the literature is weighted linear fusion, which can be expressed as follows:
where:
Here
is the fused matching score which is derived by simply combining different
, and (
2) ensures that the condition
is maintained for
as well, i.e., that it is the case that
.
The fusion approach described by (
1) can also be rewritten more simply as:
where:
Here the original weighted linear fusion of the contributing terms
in (
1) has been replaced by unweighted linear fusion of terms
which adjust the magnitudes of the fused scores directly. This can be achieved simply by considering the statistics of the distributions of different
and the corresponding prediction, and without any knowledge of what different features
represent or what form different
have, i.e., while maintaining the premise of uninformed fusion.
It can be readily seen that the described fusion approach fits the conditions specified in the proceeding section—namely, simplicity (both methodological and that of implementation) and broad applicability. Although simple, uninformed fusion demonstrates remarkably good performance across a wide span of different data types and domains, ranging from dementia screening [
9] to multimodal biometric identification [
2,
10].
where as before:
where, analogously to (
5), the adjusted fusion scores can be expressed as:
The formulation in (9) can be readily recognized as the quadratic mean, in engineering also commonly referred to as the root mean square (RMS), of the n terms .
Before proceeding with a formal analysis of the two fusion approaches, it is insightful to gain an intuitive understanding of the difference between them. Note that simple linear fusion described in (4) treats different scores as effectively interchangeable—a decrease in one score is exactly compensated by an increase in another score by the same amount. This is sensible when the scores correspond to the same measurement which is merely repeated. The described fusion can then be seen as a way of reducing measurement error, assuming that measurement is unbiased and that errors are identically and independently distributed [
11]. However this is a rather trivial case of fusion and in practice one is more commonly interested in fusion of different types of data modalities. Indeed, in practice it is often the explicit aim to try to use information sources which vary independently, and attempt to exploit best their complementary natures [
12]. In such instances different scores are best treated as describing a source in orthogonal directions, thereby giving rise to a feature vector
. The quadratic mean-based fusion of (9) can then be thought of as emerging from a normalized distance measure between such feature vectors in the corresponding ambient embedding space
.
Let us now consider the effects of the two fusion approaches in more detail. Firstly, note that scoring measures
and
are inevitably imperfect—neither can be expected to produce universally the perfect matching score of 0 when the query correctly matches a source and
∞ when it does not. Even the weaker requirement of universally smaller pseudo-distances for correct matches is unrealistic. Indeed, it is precisely this practical challenge that motivates multimodal fusion. Consequently, they are appropriately modelled as resulting from draws from random variables:
Let us examine the effects of the two fusion approaches in detail. Specifically, for clarity consider the fusion of two sources, say
i and
j, while observing that the derived results are readily applicable to the fusion of an arbitrary number of sources through the use of an inductive argument. Following (4) and (9), applying linear and quadratic mean-based fusion results in scores described respectively by random variables
and
, where:
and:
The former can be further expanded as:
and the latter:
Writing:
and using the standard definition of Pearson’s correlation coefficient
:
we can write:
Therefore: . In other words, following the fusion of the same scores the proposed quadratic mean-based fusion results in lower fused matching scores (quasi-distances described by the random variable ) than those obtained by employing linear fusion (described by the random variable ).
At first sight, the significance of the finding in (23) is not clear, given that it applies equally to the fusion of scores which result from matching and non-matching sources—quadratic mean-based fusion produces lower fusion scores in both cases. For the proposed fusion strategy to be advantageous it has to exhibit a differential effect and reduce matching scores more than non-matching ones. To see why there are indeed sound reasons to expect this to be the case, consider the intermediate result in (21). From this expression it can be readily seen that the reduction in the magnitude of the fused score effected by the proposed quadratic mean-based fusion in comparison with the linear baseline is dependent on Pearson’s correlation between random variables and which capture the stochastic properties of the original non-fused scores. Specifically, the greater the correlation between them the greater the corresponding reduction in the fused score becomes. The reason why this observation is key lies in the nature of the problem at hand: though imperfect, by their very design sensible matching functions which produce different and () should be expected preferentially and systematically to produce lower scores for correctly matching sources and higher scores for incorrectly matching sources. Therefore, while non-matching comparisons may result in some of the fused scores erroneously to be low, on average such errors should exhibit a lower degree of correlation than low scores across different modalities do for correct matches. In the next section I will demonstrate that this indeed is the case in practice.
3. Experimental Section
Having laid out the theoretical argument against simple weighted combination as the default baseline for uninformed fusion, in favour of the quadratic mean, in this section the two are compared empirically. In
Section 3.1 I begin by describing experiments on synthetic data, which allow the characteristics of the two approaches to be studied in a carefully controlled fashion, and then proceed with experiments on real, challenging data sets of vastly different types. In particular, the popular computer vision problem of image-based object recognition is used as a case study in
Section 3.2, arrhythmia prediction in
Section 3.3, and finally fatality prediction in road vehicle accidents in
Section 3.4.
3.1. Synthetic Data
I start my comparative analysis with a simple synthetic example involving the fusion of two information sources. The main goal of this experiment is twofold. Firstly it is to examine if empirical results obtained in controlled and well understood conditions are consistent with the theoretical prediction of superior performance of the proposed quadratic mean-based fusion in comparison with the common linear fusion-based approach. My second aim is to investigate if the differential advantage of the proposed method indeed varies in accordance to the degree to which the fused information sources are correlated.
In this experiment I adopt a generative model which comprises two modalities which are used to sense two information sources. The model thus generates a set of observations:
where
is the
i-th measurement using the
j-th modality (where
). For a given modality, i.e., for fixed
j, different
are independent and identically distributed samples. A measurement
is generated by a random draw from the ground truth distribution represented by the random variable
and corrupting it by a random draw from the noise distribution represented by the random variable
:
On the other hand, a measurement
is generated using in part a process independent of the measurement
and in part dependent on it. The former contribution is generated as per (25)–(27) while the latter is modelled using a weighted contribution of
. Formally:
Here
captures Pearson’s correlation described in
Section 2.
Lastly, the quasi-similarity functions
which quantify how well an observation matches a particular information source are computed as:
where
models the separation (dissimilarity) between the two information sources. Note that all
are already normalized to be in the range assumed in
Section 1, that is
.
3.1.1. Results, Analysis and Discussion
I compared the performance of the two fusion approaches discussed in
Section 2 by computing fused quasi-similarities between the generated data and the two information sources as per (31)–(34). Specifically, the linearly fused quasi-similarity of
and
was computed as:
and similarly of of
and
was computed as:
The proposed quadratic-mean-based fusions were computed as respectively:
and:
To evaluate and compare the two methods I examined the corresponding differential matching scores computed for the correct and incorrect information sources, that is:
for the linear fusion, and
for the proposed quadratic mean-based fusion. It can be readily seen that a positive differential score corresponds to the correct source attribution (and a more confident decision for greater magnitudes thereof), a negative one to incorrect attribution (and a more mistaken confidence for greater magnitudes thereof), and a vanishing score to uncertain attribution. To examine the effects of dissimilarity of information sources
, introduced in (33) and (34), the amount of noise captured by
in (26) and (29), and the correlation
between the sensing modalities, experiments were repeated for all combinations of the following values of the three parameters:
(logarithmically equidistant values between 0.05 and 3.00),
(logarithmically equidistant values between 0.10 and 5.00), and
(approximately linearly equidistant values between 0.00 and 1.00).
I started my analysis on the coarsest level by examining the proportion of cases in which the proposed method was at least as successful as the alternative, that is, the proportion of cases in which
. Already at this stage the findings were decisively in favour of the proposed approach which
never did worse than linear fusion across all combinations of
and
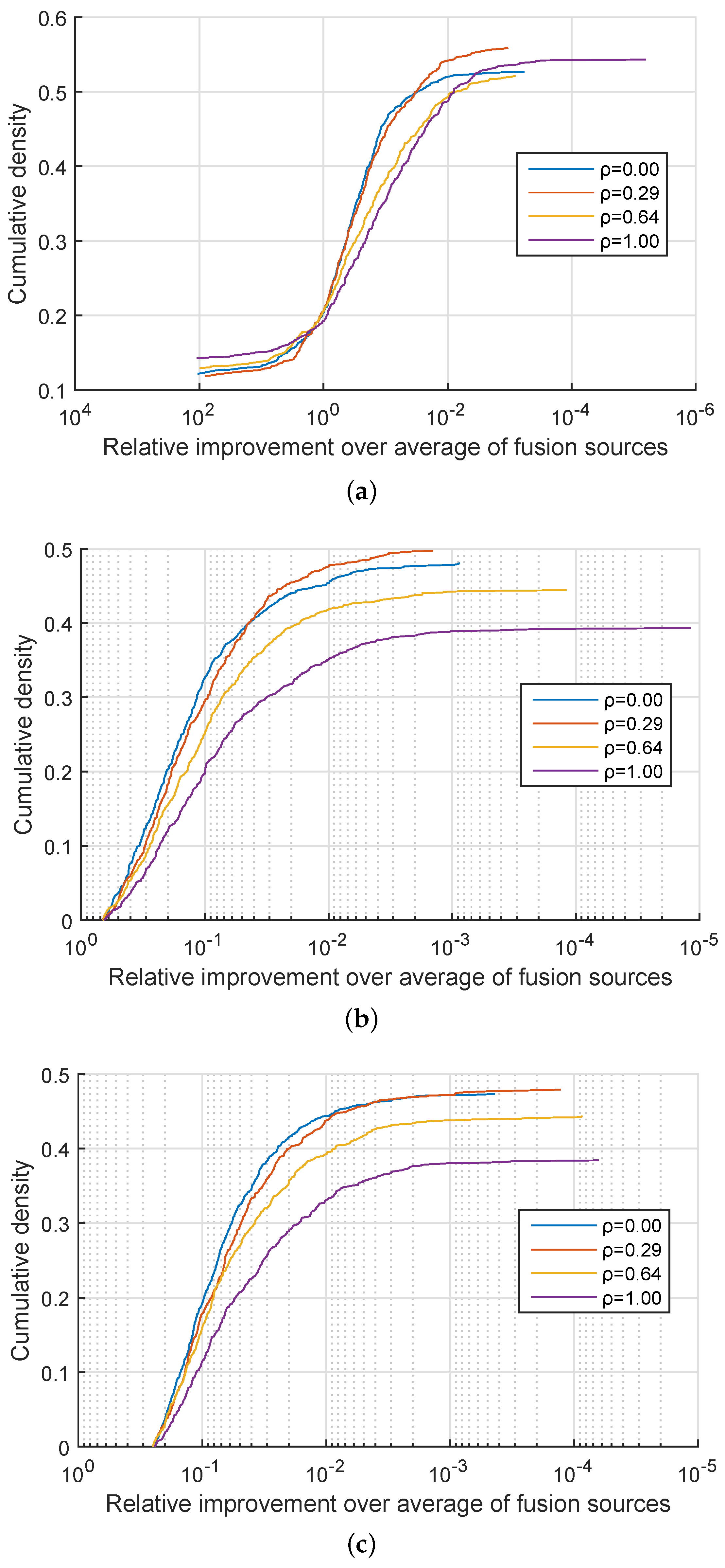
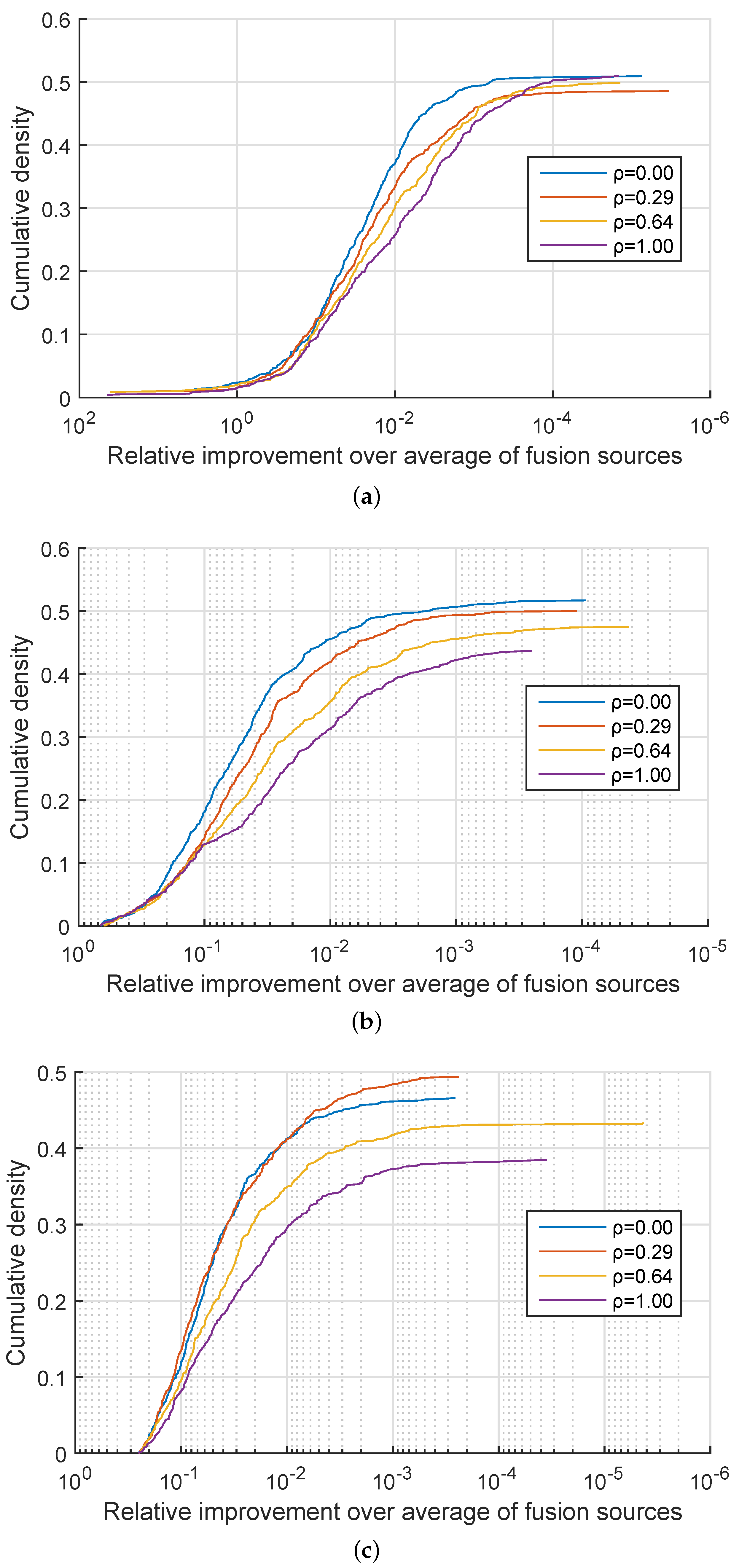
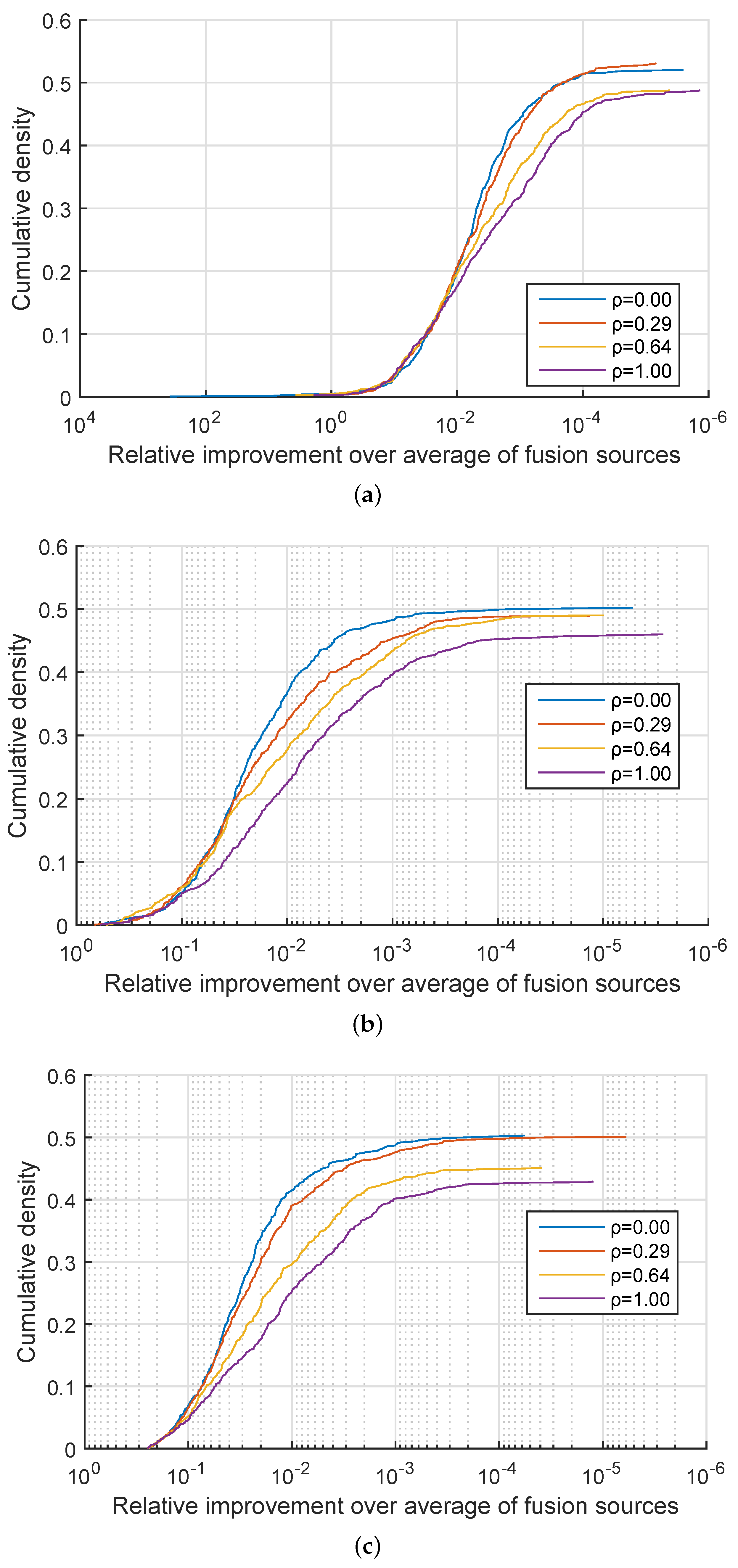
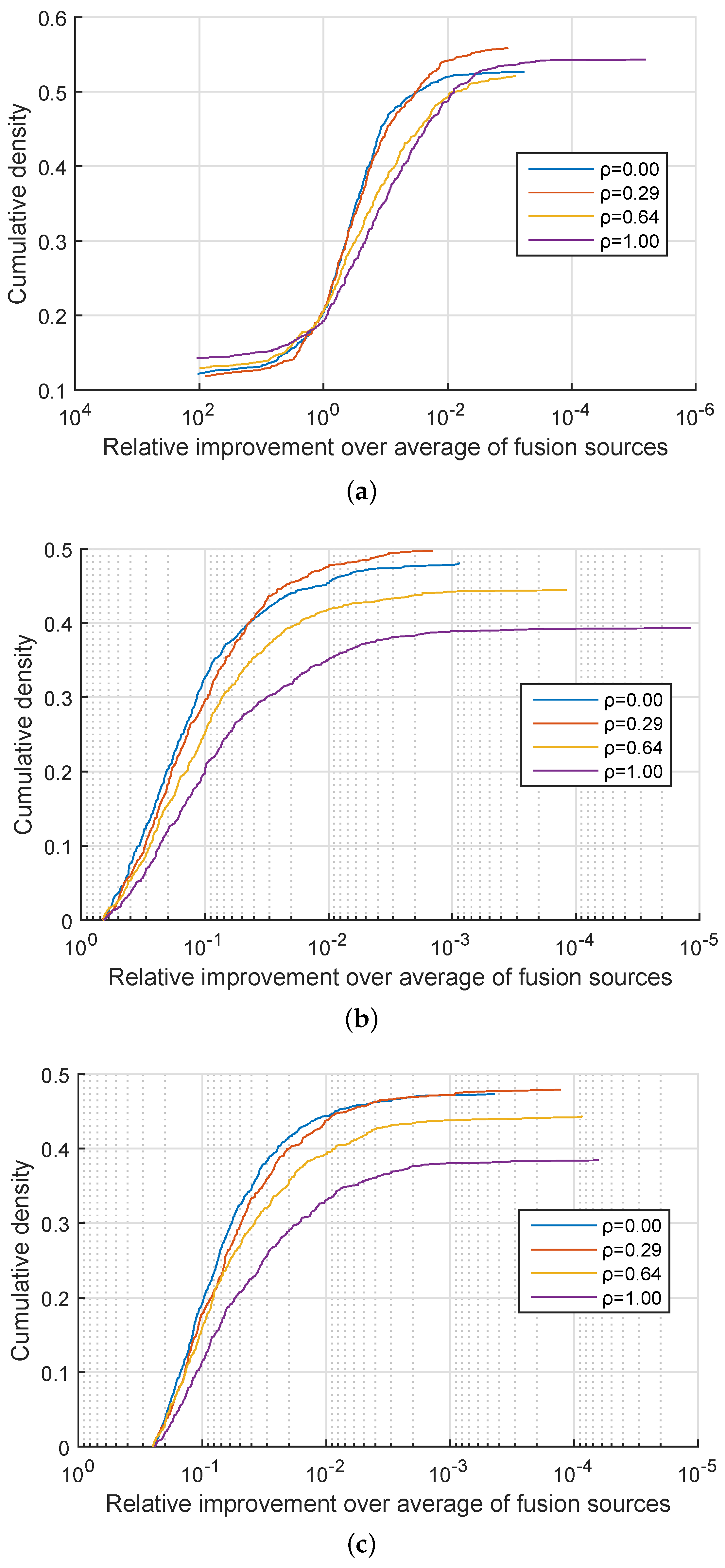
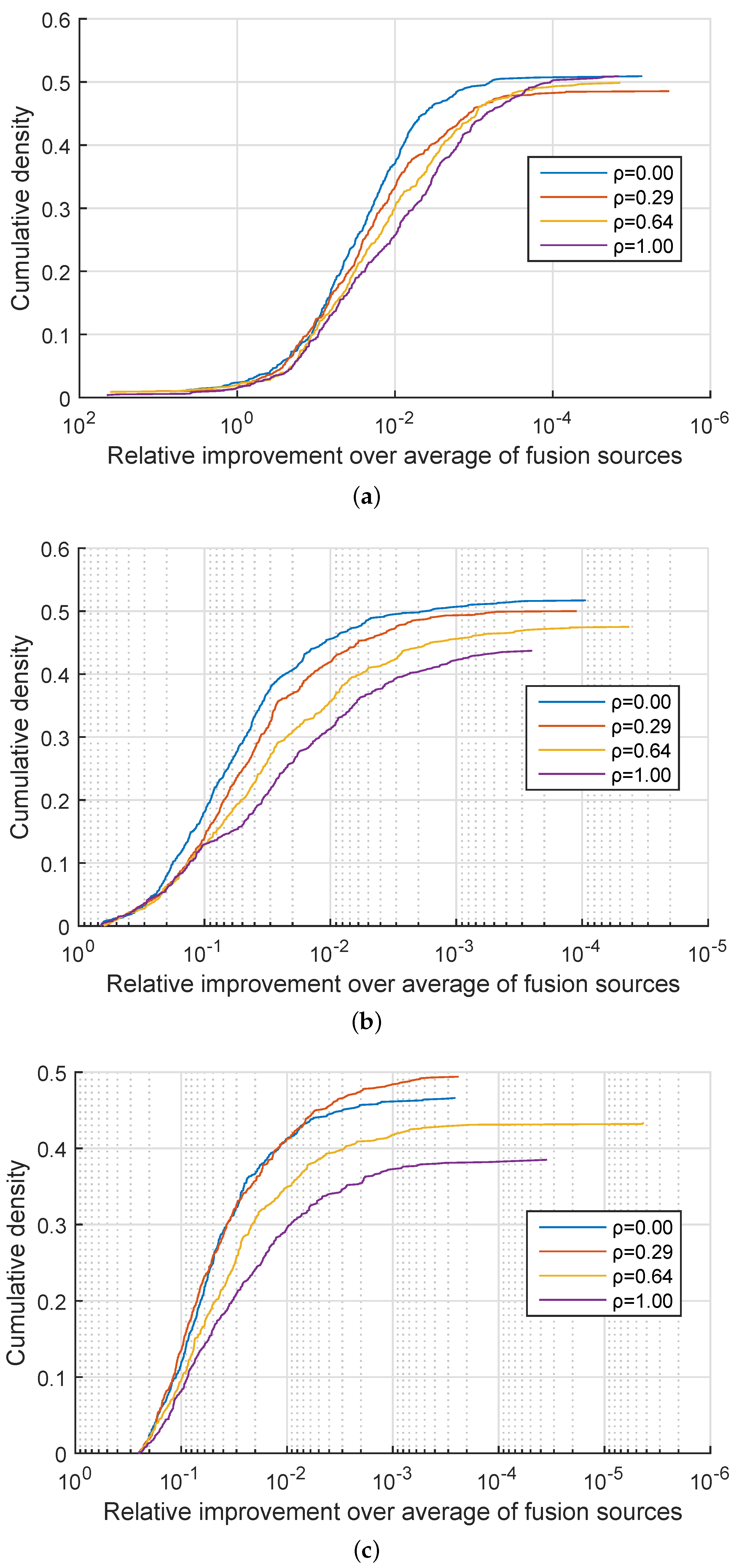
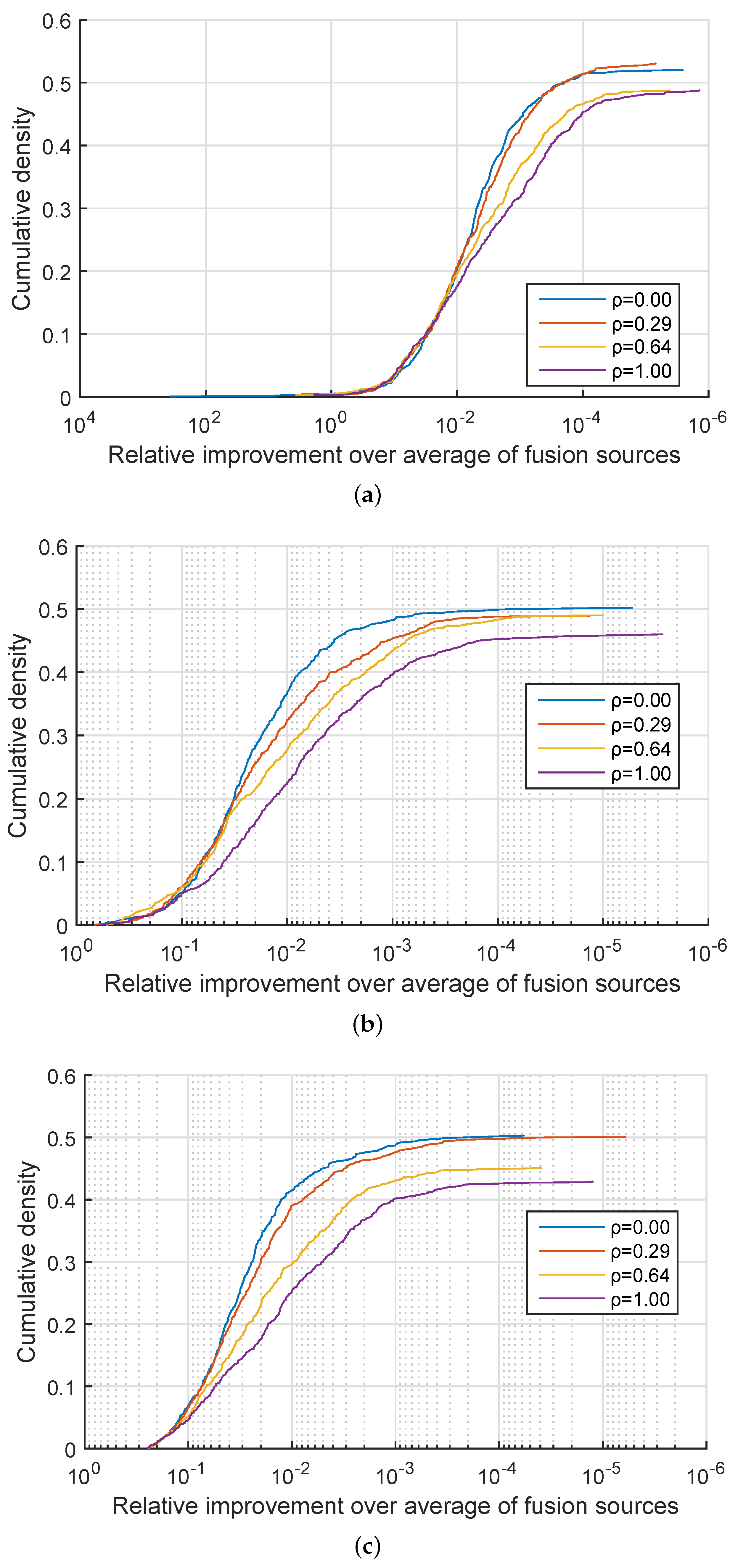
. In approximately 50% of the cases my method performed equally well as linear fusion and in the remaining 50% of the cases effected an improvement. A more detailed insight is offered by the plots in
Figure 1,
Figure 2 and
Figure 3 which show the cumulative density distribution of the relative improvement achieved by the proposed method, that is
when the source was correctly matched, across different experiments. For example from
Figure 1 it can be seen that the matching score separation increased twofold (corresponding to the abscissa value of
) in approximately 20% of the cases for the three experiments with
, and in approximately 15% of the cases for the three experiments with
from
Figure 2, while in the three experiments with
the relative differential matching score increase of this degree was rare (
Figure 3). A comparison of the plots in the three figures further reveals that the dissimilarity between information sources has little effect on the average benefit of the proposed method. However the value of
did affect performances for different values of
. Specifically, across
Figure 1,
Figure 2 and
Figure 3 it can be seen that for small values of
, that is, for very similar information sources that we are seeking to discriminate between, the proposed fusion methodology offered approximately equal benefits over linear fusion for different values of
. In other words the redundancy of the two sensed modalities, or lack thereof, had little effect. In contrast, as the information sources become more separated (increasing
), the greater the effect of
becomes, with the proposed method offering the greatest advantage when the sensed modalities are complementary i.e., when
.
3.2. Object Recognition
In a controlled experiment using synthetic data and and well-understood information sources, I demonstrated both the superior performance of the proposed generic fusion approach over the common alternative in the form of linear fusion, as well as the consistency of its behaviour with theoretical expectations put forward previously. I next set out to examine whether the same advantages are observed when real-world data is used instead. After all, recall that the central aim of the present paper is to scrutinize the soundness of linear fusion as a generic baseline and argue in favour of the described quadratic mean-based fusion as an alternative with superior performance but paralleled quasi-universality and simplicity of implementation.
My first case-study involves computer-based object recognition. This is an important problem in the spheres of computer vision and pattern recognition, and which has potential for use in a wide spectrum of practical applications. Examples range from motorway toll booths that automatically verify that the car type and its licence plate match the registration database, to online querying and searching for an object of interest that was captured using a mobile phone camera. Object recognition has attracted much research attention [
13,
14,
15,
16] and this interest has particularly intensified in recent years after significant advances towards practically viable systems have been made [
15,
16,
17].
Here I consider the fusion of texture-based and shape-based object descriptors. The former group has dominated research efforts to date [
17] and has been highly successful in the matching of textured objects. However, it fails when applied on untextured objects (sometimes referred to as ’smooth’) [
15] Considering that their texture is not informative, characteristic discriminative information of smooth objects must be extracted from shape instead. Following the method described in [
18] I extract and process the representations of the two modalities (texture and shape) independently. An object’s texture is captured using a histogram computed over a vocabulary of textural words, learnt by clustering local texture descriptors extracted from the training data set. Similarly, a histogram over a vocabulary of elementary shapes, learnt by clustering local shape descriptors, is used to capture the object’s shape. I adopt the standard SIFT descriptor as the basic building block of the texture representation and an analogous descriptor of local shape for the characterization of shape [
19]. In both cases descriptors are matched using the Euclidean distance.
3.2.1. Results, Analysis and Discussion
As in the preceding section in which synthetic data was used, fused quasi-similarities between the observed data and the two information sources were computed as per (31)–(34), and their performance assessed by analysing the corresponding differential matching scores computed for the correct and incorrect information sources as detailed previously and summarized by (
39) and (
40).
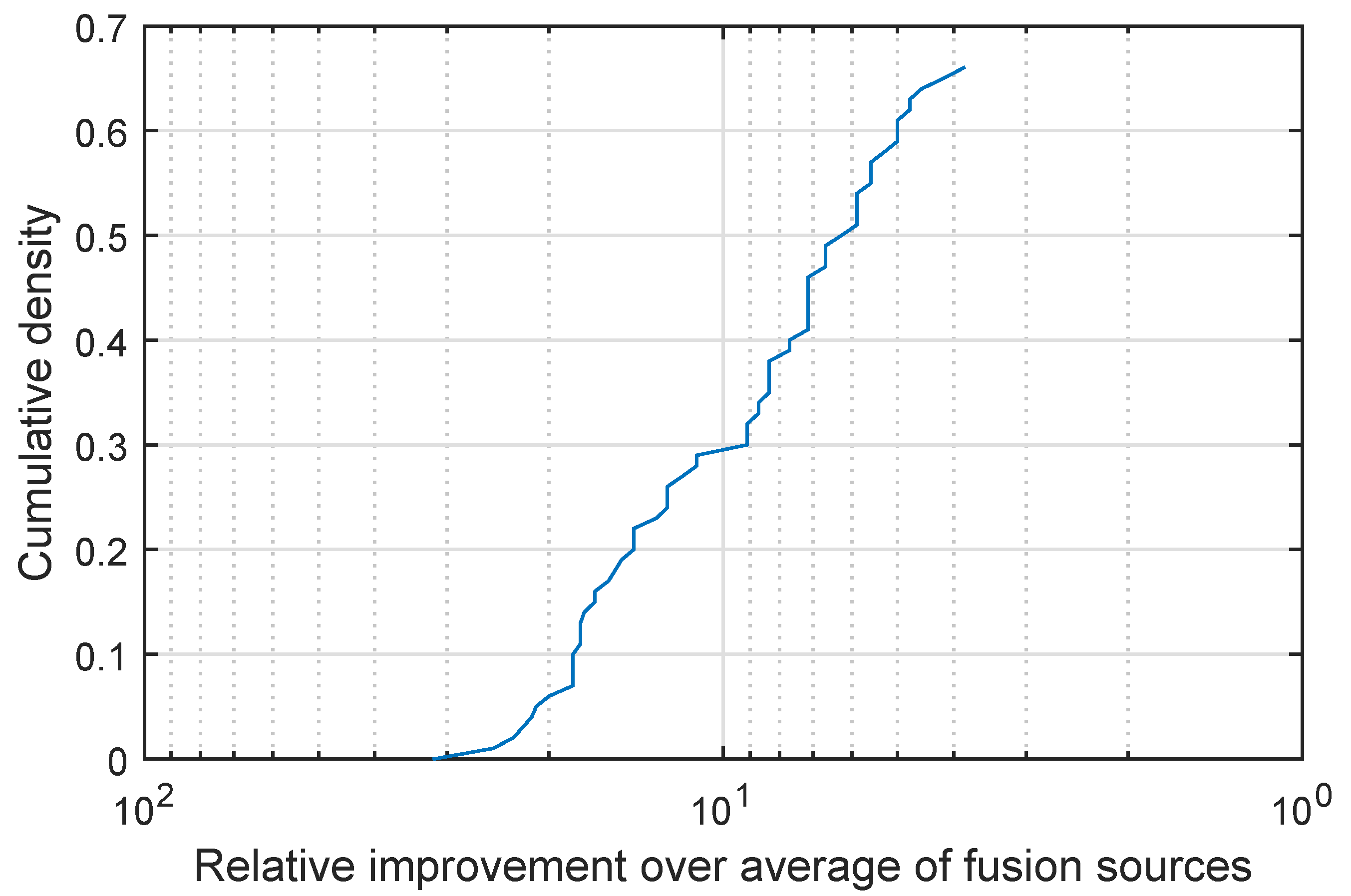
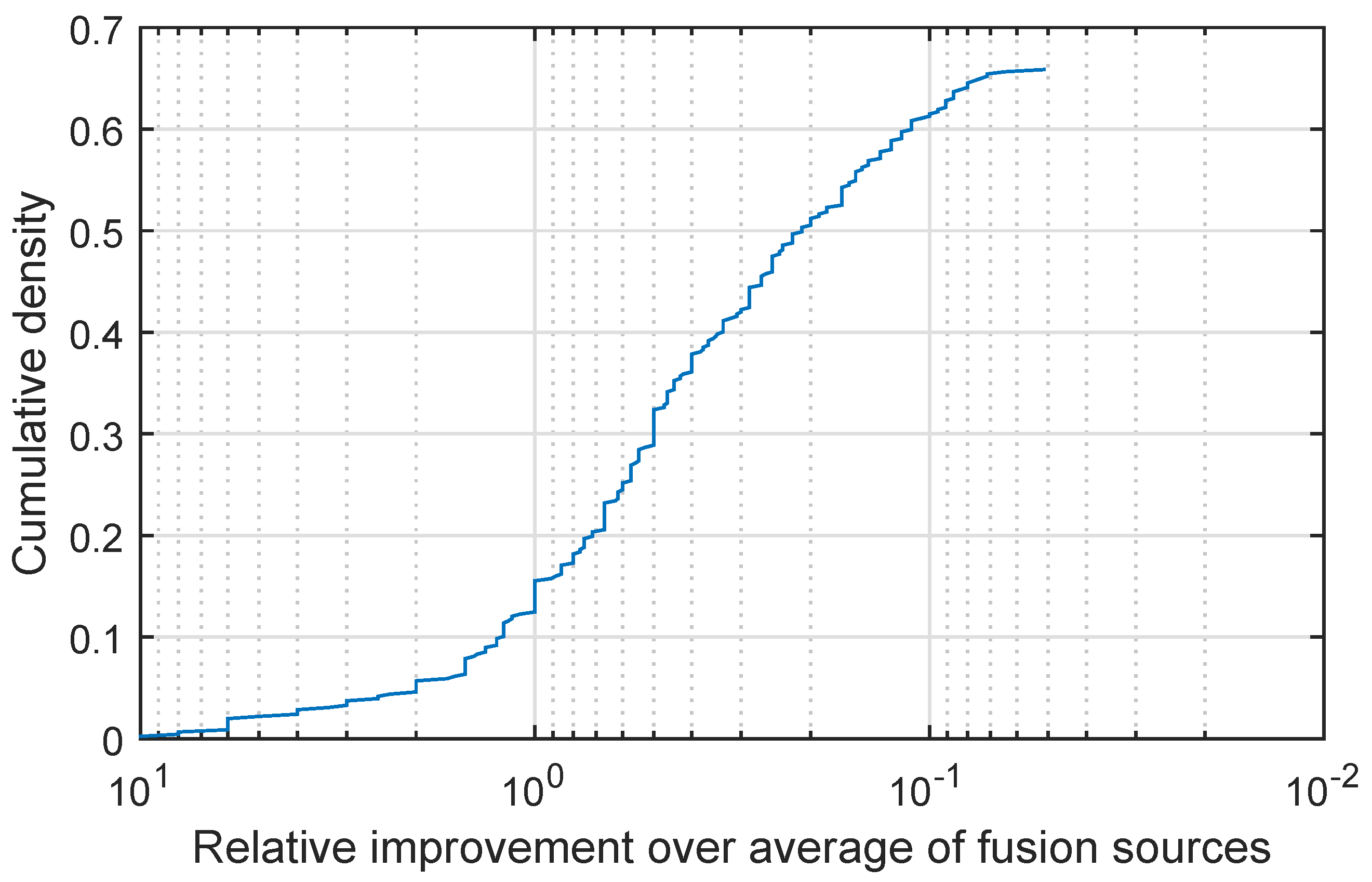
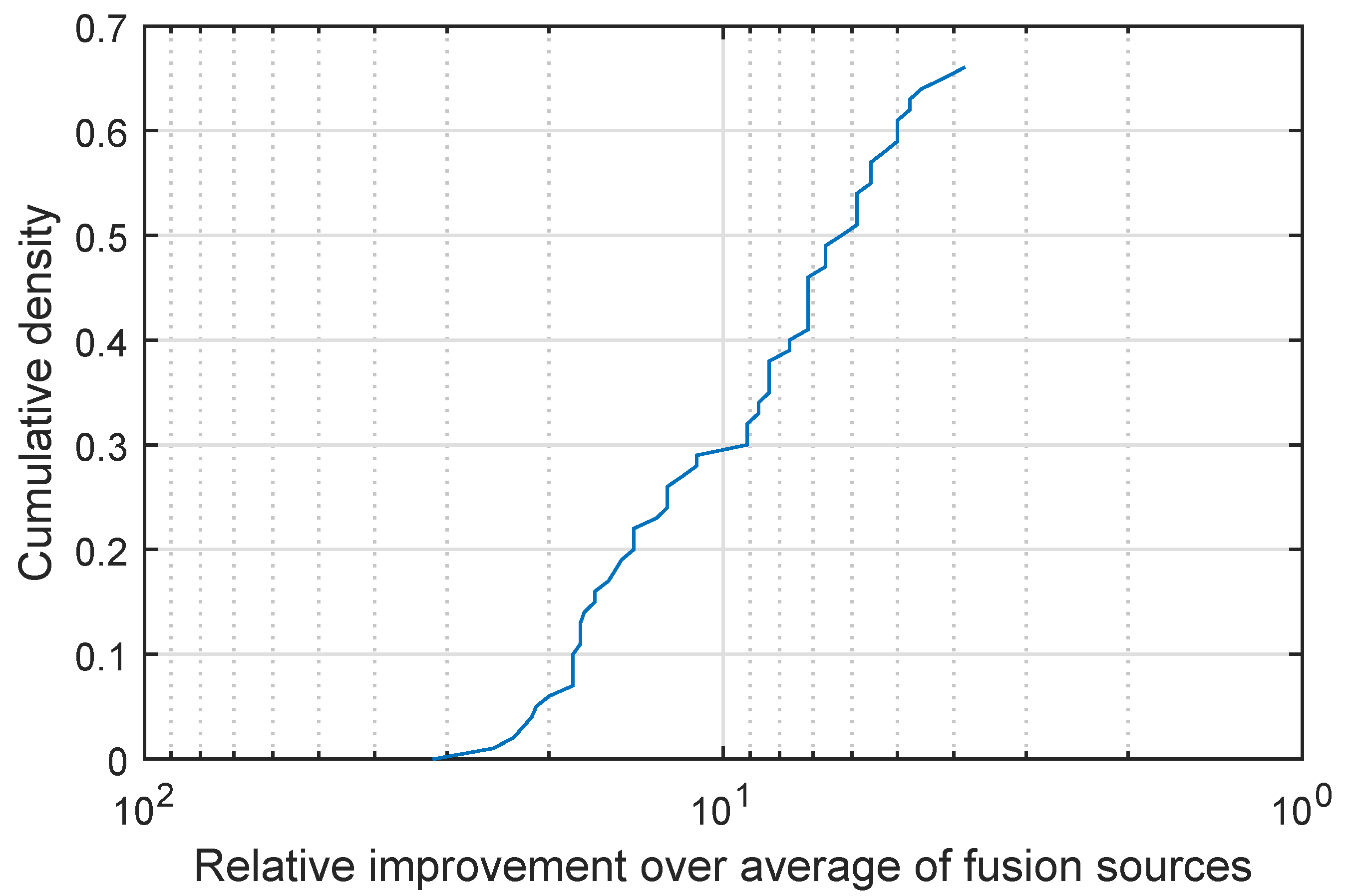
I display my findings in
Figure 4 which shows a plot of the cumulative density distribution of the relative improvement achieved by the proposed method (as before please note that the abscissa scale is logarithmic and that it is increasing in the leftward direction). Firstly let us make the highly encouraging observation that the same qualitative behaviour of this characteristic plot is exhibited on this real-world data set as on the synthetic data of the previous experiment. Remarkably, in all cases the proposed fusion strategy did at least as well as the simple weighted fusion. In approximately 66% of the cases the proposed quadratic fusion exhibited superior performance, performing on par in the remaining 34% of the cases. A further examination of the plot reveals an even stronger case for the proposed method—not only does it outperform simple weighted fusion in 66% of the cases but it does so with a great margin. For example in 30% of the cases the inter-class separation is increased 10-fold (i.e., by an order of magnitude).
3.3. Arrhythmia Prediction
My second real-world case-study concerns automatic arrhythmia prediction from demographic data and physiological measurements. This is a challenging task of enormous importance in the provision of timely and informed healthcare provision to the population at risk of cardiac complications. This primarily includes individuals with preexisting cardiac problems or congenital factors, which are further modulated by various environmental factors such as high physical exertion [
20] or the use of certain classes of drugs.
A normally functioning human heart maintains a remarkably well controlled heartbeat rhythm. Arrhythmias are abnormalities of this rhythm and are caused by physiological factors pertaining to electrical impulse generation or propagation. Arrhythmia types can be grouped under the umbrellas of three broad categories: tachycardias (overly high heartbeat rate), bradycardias (overly low heartbeat rate), and arrhythmias with an irregular heartbeat rate. While most arrhythmias are transient in nature and do not pose a serious health risk, some arrhythmias (particularly in high risk populations) can have serious consequences such as stroke, cardiac arrest, or heart failure and death [
21].
Arrhythmias can be diagnosed using nonspecific means, e.g., using a stethoscope or a tactile detection of pulse, or specific methods and in particular the electrocardiogram (ECG). Moreover, the rich information provided by the latter can be used to predict and detect the onset of arrhythmias by analysing electric impulse patterns [
22]. In the present study I evaluate the proposed fusion methodology in the context of this prediction.
I used the dataset collected by Guvenir et al. [
22] which is freely available online and can be downloaded [
23]. The dataset comprises a rich set of demographic and antropometric variables, such as each person’s age, sex, height, and bodyweight, as well as a variety of features extracted from the person’s ECG, including the heart rate and a series of characteristics of the corresponding signal deflections (the duration of the QRS interval, amplitudes of Q, R, and S waves etc.); please refer to the original publication for full detail [
22]. The target variable for the purpose of the present experiment can be considered to be binary valued, taking on the value 0 when arrhythmia is not present and 1 when it is; please see
Table 1.
I consider two baseline classifiers. The first of these takes height, bodyweight, and the duration of the QRS interval as input variables (i.e., independent variables). The second one makes the prediction based on what are effectively integrals of Q, R, and S deflections (i.e., referred to as QRSA in the dataset description; please see the original reference for detail [
22]), and the Q, R, S, and T deflections (i.e., referred to as QRSTA in the dataset description. Each classifier is built upon a generalized linear model (GLM) [
24]. Recall that in a GLM the mean
of the target, outcome variable
Y is related to a linear predictor based on the independent variables through a link function
:
The variance
of
Y is modelled as a function
of this mean:
In my experiment, the continuous output of a GLM is used to detect the presence of arrhythmia using what is effectively the nearest neighbour criterion: if the output is closer to 0 the prediction is taken to be negative, and if it is closer to 1 positive. The dataset contains 452 diagnosis cases of which 100 were used for training the classifiers; the remaining 352 were used for testing.
3.3.1. Results, Analysis and Discussion
As in the previous experiments, fused quasi-similarities between the observed data and the two information sources were computed as per (31)–(34), and their performance assessed by analysing the corresponding differential matching scores computed for the correct and incorrect information sources as detailed previously and summarized by (
39) and (
40).
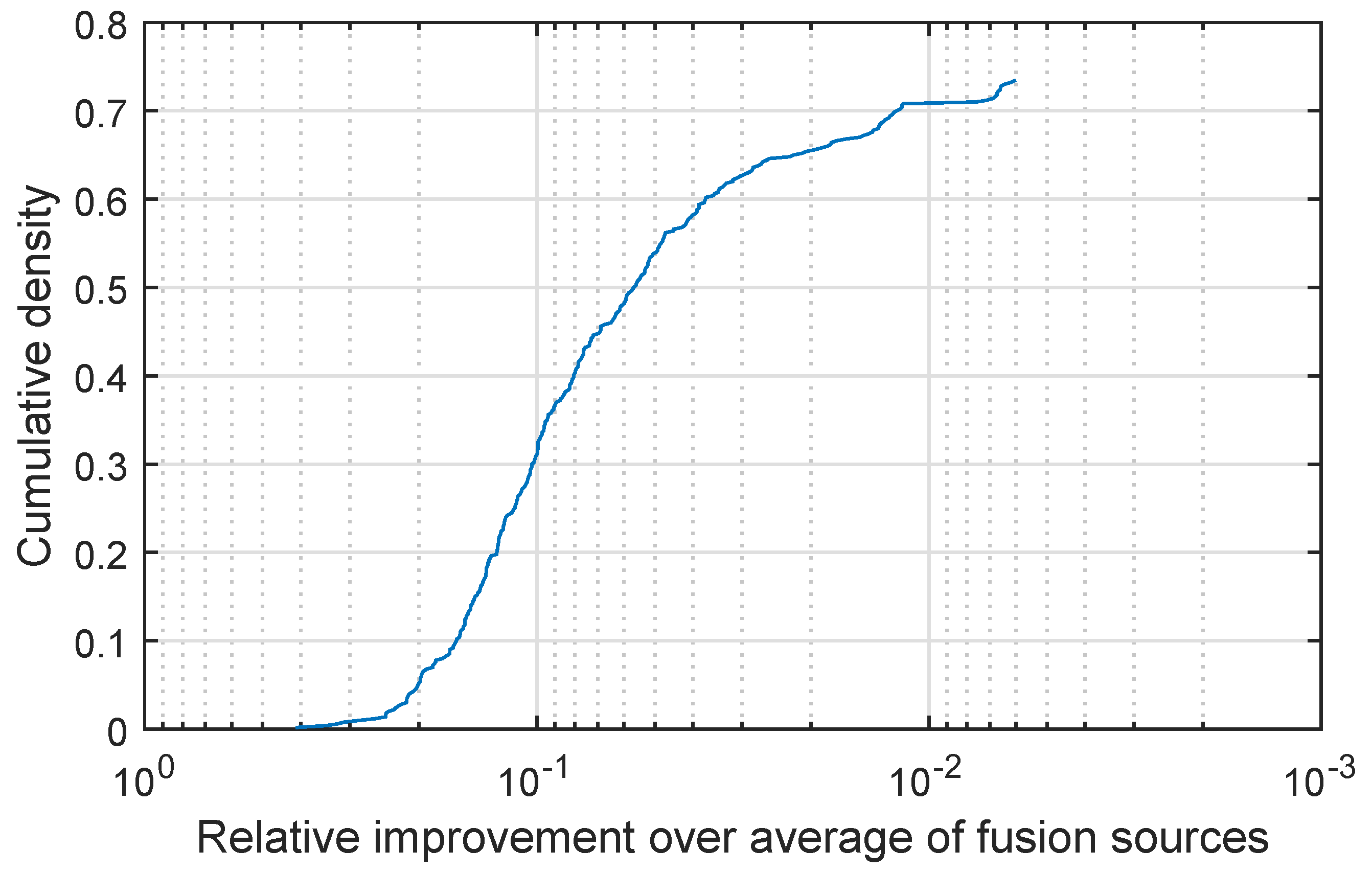
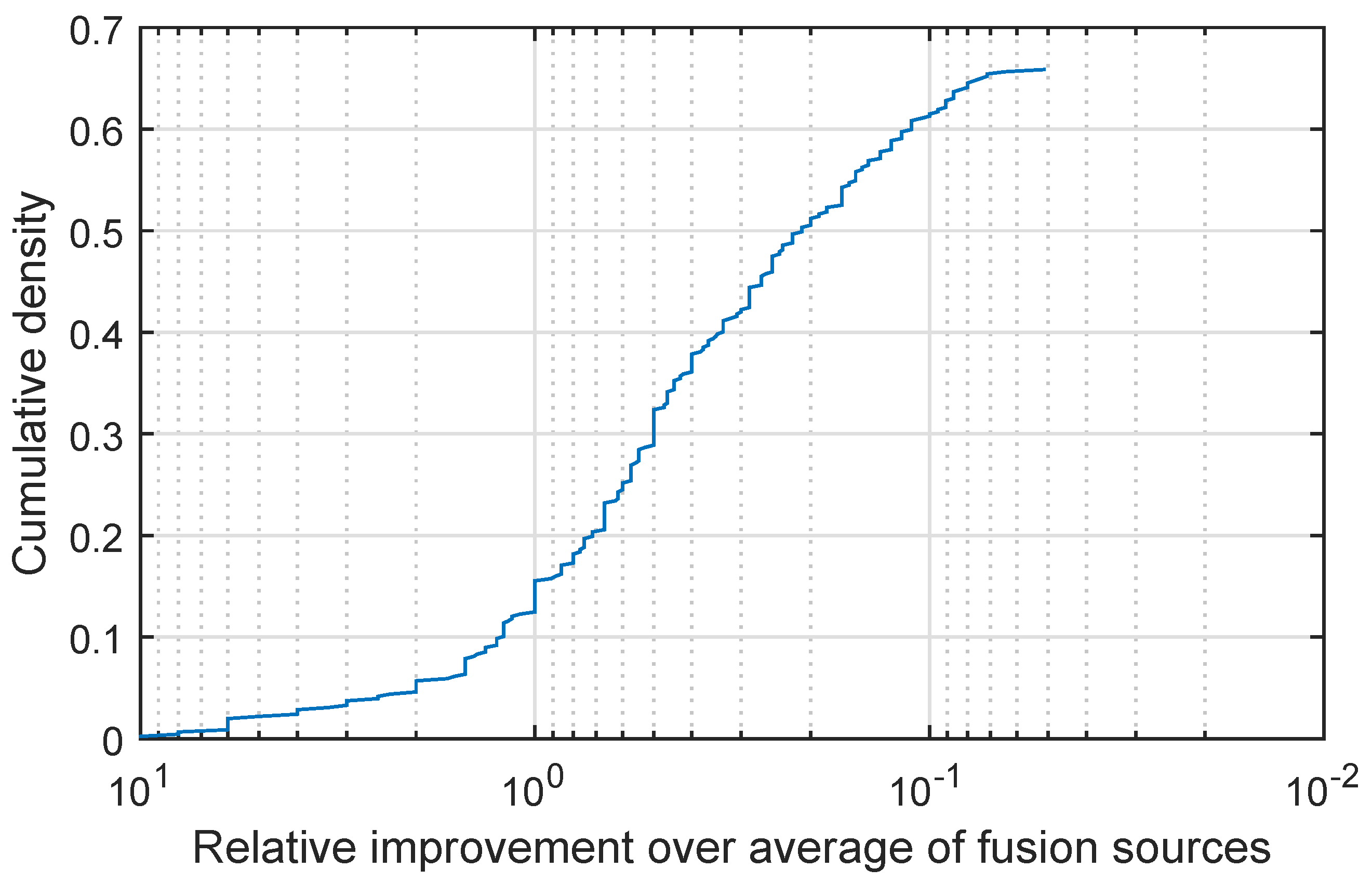
I display my findings in
Figure 5, which shows a plot of the cumulative density distribution of the relative improvement achieved by the proposed method (as before please note that the abscissa scale is logarithmic and that it is increasing in the leftward direction). We can again start with the observation which can be made by comparing the characteristics of the plot in
Figure 5 with those of the plots in
Figure 4 and
Figure 1,
Figure 2 and
Figure 3 and observing that again the same qualitative behaviour is exhibited on this data too. In all cases the proposed fusion strategy did at least as well as the simple weighted fusion, with approximately 65% of the cases resulting in superior performance of the proposed quadratic fusion and the remaining 35% in on a par performance. As in the previous experiments when my method outperforms simple weighted fusion it does so with a significant margin with an over doubled separation increase in approximately 16% of the cases. Moreover I found that while simple weighted fusion failed to improve the prediction of the better performing baseline classifier in 15% of the cases, the same was the case with the proposed method in fewer than 7.8% of the cases.
3.4. Car Accident Fatality Prediction
My fourth and final experiment concerns the inference of risk factors for car accident fatalities. In particular in this experiment I was interested in discovering what aspects of the context of an accident predict best if a fatality will occur. For this purpose I used the official statistics released by the government of the USA through the Fatality Analysis Reporting System (FARS) for the year 2011. These are freely publicly available and dataset can be downloaded [
25]. The dataset comprises a number of person specific variables, such as age, sex, race, blood alcohol level, and drug use status, as well as a variety of variables pertaining to the context of the accident, including the type of the road and the state where the accident took place, and the weather conditions at the time (please see [
25] for full description). The target variable for the purpose of the present experiment can be considered to be binary valued, taking on the value 1 when there has been a fatality and 0 otherwise; please see
Table 2.
As in the previous experiment, I consider two baseline classifiers, each built upon a generalized linear model. The first of these takes the person’s age and blood alcohol level as input variables (i.e., independent variables). The second one makes the prediction based on atmospheric conditions and the road type. Following the same framework as described in the previous section, the continuous output of a GLM is used to predict the occurrence of a fatality using what is effectively the nearest neighbour criterion: if the output is closer to 0 the prediction is taken to be negative, and if it is closer to 1 positive. The dataset contains 5000 accidents of which 1000 randomly selected cases were used for training the baseline classifiers with the remainder employed for performance evaluation.
3.4.1. Results, Analysis and Discussion
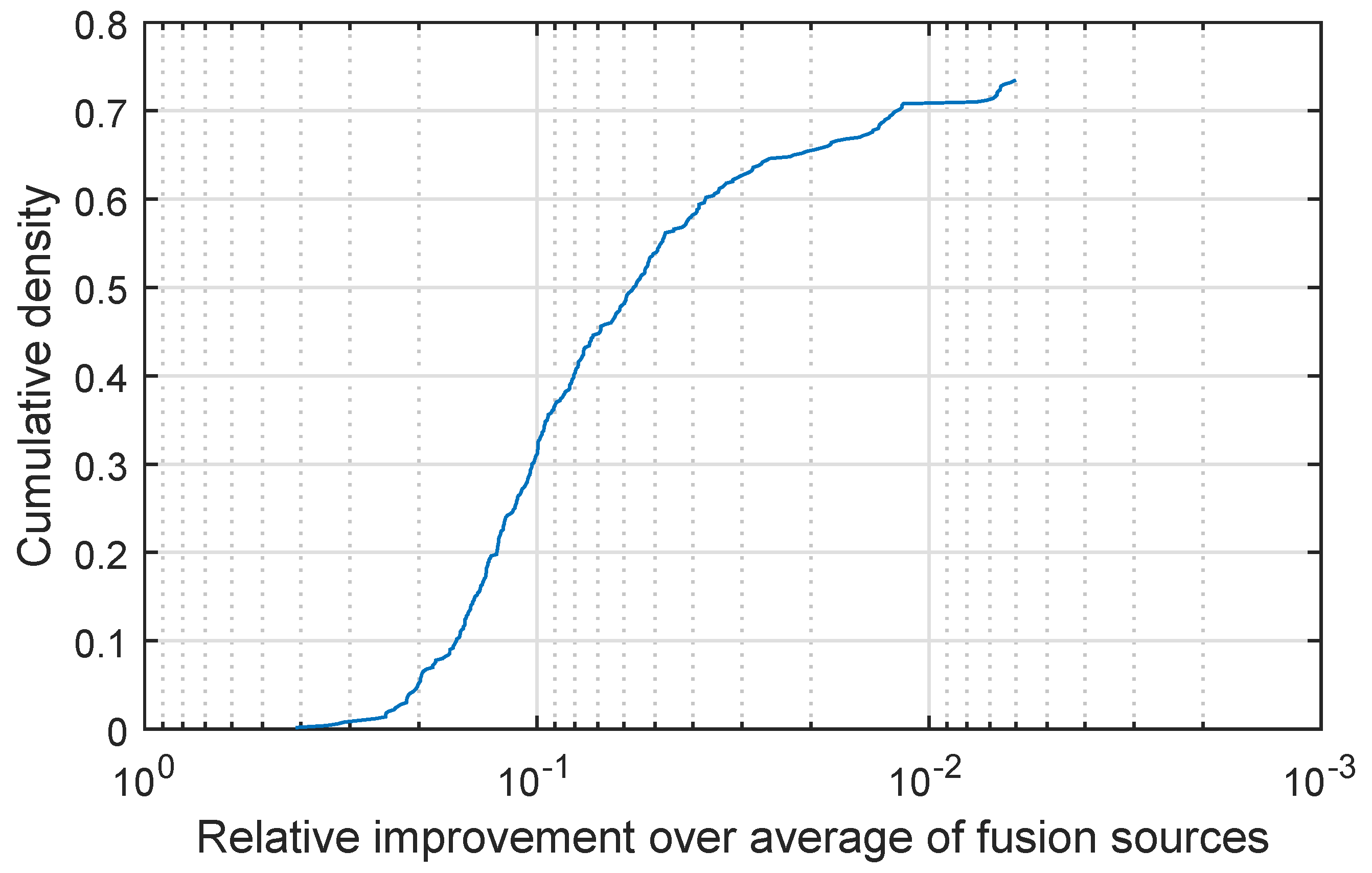
I followed the same evaluation methodology as in the preceding experiments. In the same vein I display my findings in
Figure 6 which shows a plot of the cumulative density distribution of the relative improvement achieved by the proposed method (as before please note that the abscissa scale is logarithmic and that it is increasing in the leftward direction). Yet again, in agreement with the results obtained in all experiments I conducted, we can observe the same functional characteristics in the plot of
Figure 6 and of those in
Figure 1,
Figure 2,
Figure 3,
Figure 4 and
Figure 5. In further agreement with the previous experiments is my finding that in all instances of car accidents used for evaluation, the proposed fusion strategy did at least as well as the simple weighted fusion in terms of its predictive ability. With regard to this point, it is interesting to note that notwithstanding the remarkable qualitative similarity of the CDFs corresponding to different experiments, there are some quantitative differences. For example, note that in the present experiment approximately 73% of the cases resulted in superior performance of the proposed quadratic fusion and the remaining 27% in on a par performance. The proportion of evaluation instances yielding superior performance is thus higher than e.g., in the object recognition experiment described in
Section 3.2. However, the resulting benefit is smaller. For example, while in the object recognition experiment about 30% of the evaluation cases result in at least 10-fold class separation increase, in the present experiment in no case is the benefit as large. This is most likely a consequence of the inherent information content in the data itself, rather than of some algorithmic aspect of the proposed method. In other words, the lesser advantage (though still consistent and observed in an overwhelming number of cases) of using the proposed method stems from greater redundancy across the fused information sources.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}