
Automatic Detection of Post-Operative Clips in Mammography Using a U-Net Convolutional Neural Network

 , , , ,
, , , ,
Abstract

1. Introduction
2. Materials and Methods
2.1. Training and Validation Dataset
2.2. Test Dataset
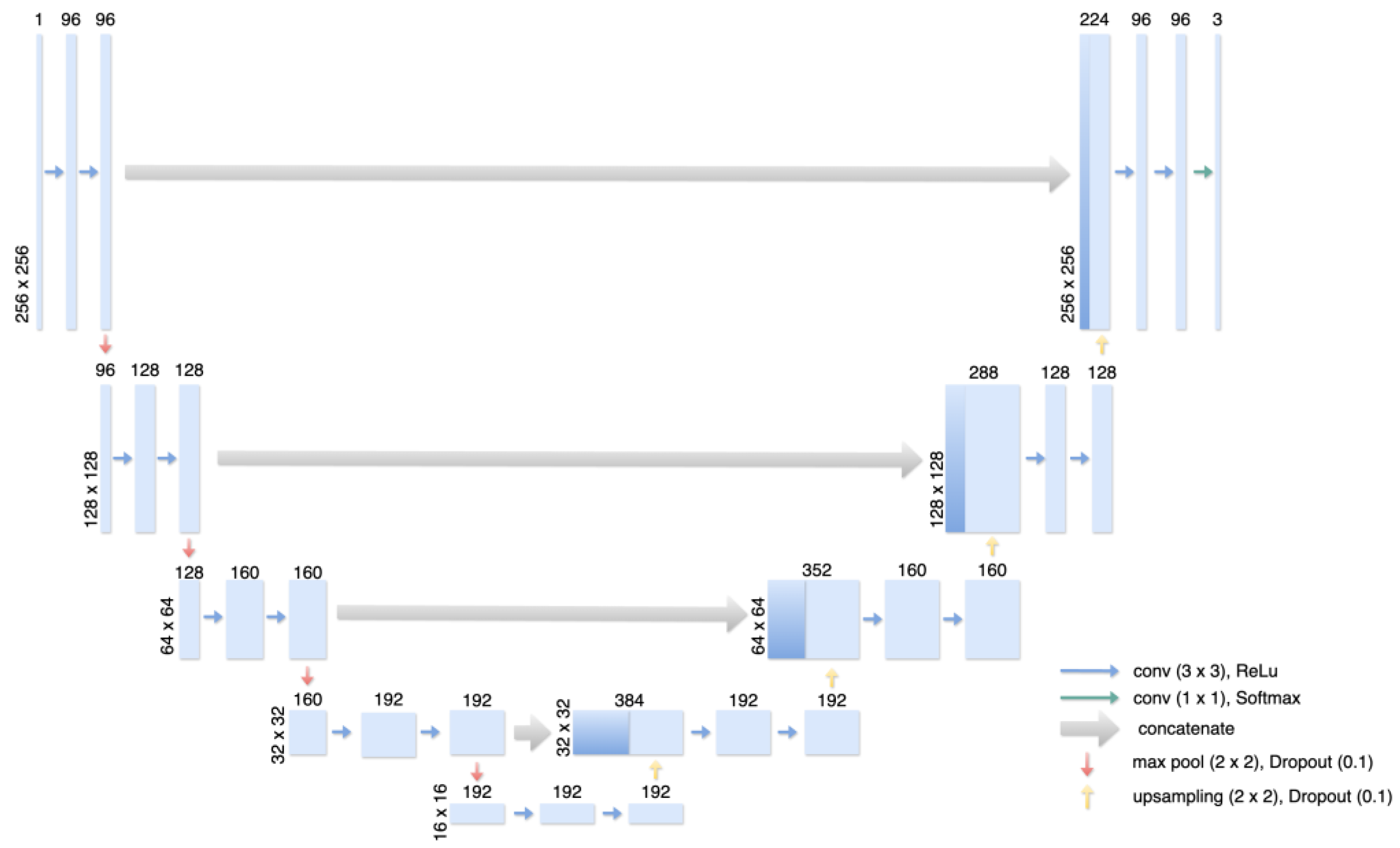
2.3. Training of the dCNN
2.4. Statistical Analysis
3. Results
3.1. Training and Validation
3.2. Clinical and Statistical Validation of the Test Dataset
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, J.; Chan, P.S.; Lok, V.; Chen, X.; Ding, H.; Jin, Y.; Yuan, J.; Lao, X.-Q.; Zheng, Z.-J.; Wong, M.C. Global incidence and mortality of breast cancer: A trend analysis. Aging 2021, 13, 5748–5803. [Google Scholar] [CrossRef] [PubMed]
- Ferlay, J.; Colombet, M.; Soerjomataram, I.; Parkin, D.M.; Piñeros, M.; Znaor, A.; Bray, F. Cancer statistics for the year 2020: An overview. Int. J. Cancer 2021, 149, 778–789. [Google Scholar] [CrossRef] [PubMed]
- Marmot, M.G.; Screening, T.I.U.P.O.B.C.; Altman, D.G.; Cameron, D.A.; Dewar, J.A.; Thompson, S.G.; Wilcox, M. The benefits and harms of breast cancer screening: An independent review. Br. J. Cancer 2013, 108, 2205–2240. [Google Scholar] [CrossRef] [PubMed]
- Eklund, G.W. The art of mammographic positioning. In Radiological Diagnosis of Breast Diseases; Thieme Medical Publishers: New York, NY, USA, 2000; pp. 75–88. [Google Scholar]
- Hofvind, S.; Vee, B.; Sørum, R.; Hauge, M.; Ertzaas, A.-K.O. Quality assurance of mammograms in the Norwegian Breast Cancer Screening Program. Eur. J. Radiogr. 2009, 1, 22–29. [Google Scholar] [CrossRef]
- National Health Service Breast Cancer Screening Program. National quality assurance coordinating group for radiography. In Quality Assurance Guidelines for Mammography Including Radiographic Quality Control; NHSBSP: Sheffield, MA, USA, 2006; Publication No. 63; ISBN 1 84463 028 5. [Google Scholar]
- Schmidt, G.; Findeklee, S.; Martinez, G.d.S.; Georgescu, M.-T.; Gerlinger, C.; Nemat, S.; Klamminger, G.G.; Nigdelis, M.P.; Solomayer, E.-F.; Hamoud, B.H. Accuracy of Breast Ultrasonography and Mammography in Comparison with Postoperative Histopathology in Breast Cancer Patients after Neoadjuvant Chemotherapy. Diagnostics 2023, 13, 2811. [Google Scholar] [CrossRef] [PubMed]
- van Breest Smallenburg, V.; Duijm, L.E.; Voogd, A.C.; Jansen, F.H.; Louwman, M.W. Mammographic changes resulting from benign breast surgery impair breast cancer detection at screening mammography. Eur. J. Cancer 2012, 48, 2097–2103. [Google Scholar] [CrossRef] [PubMed]
- Soulami, K.B.; Kaabouch, N.; Saidi, M.N.; Tamtaoui, A. Breast cancer: One-stage automated detection, segmentation, and classification of digital mammograms using UNet model based-semantic segmentation. Biomed. Signal Process. Control. 2021, 66, 102481. [Google Scholar] [CrossRef]
- Ciritsis, A.; Rossi, C.; De Martini, I.V.; Eberhard, M.; Marcon, M.; Becker, A.S.; Berger, N.; Boss, A. Determination of mammographic breast density using a deep convolutional neural network. Br. J. Radiol. 2018, 92, 20180691. [Google Scholar] [CrossRef] [PubMed]
- Ciritsis, A.; Rossi, C.; Eberhard, M.; Marcon, M.; Becker, A.S.; Boss, A. Automatic classification of ultrasound breast lesions using a deep convolutional neural network mimicking human decision-making. Eur. Radiol. 2019, 29, 5458–5468. [Google Scholar] [CrossRef] [PubMed]
- Meraj, T.; Alosaimi, W.; Alouffi, B.; Rauf, H.T.; Kumar, S.A.; Damaševičius, R.; Alyami, H. A quantization assisted U-Net study with ICA and deep features fusion for breast cancer identification using ultrasonic data. PeerJ Comput. Sci. 2021, 7, e805. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Landis, J.R.; Koch, G.G. The Measurement of Observer Agreement for Categorical Data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [PubMed]
- Sujlana, P.S.; Mahesh, M.; Vedantham, S.; Harvey, S.C.; Mullen, L.A.; Woods, R.W. Digital breast tomosynthesis: Image acquisition principles and artifacts. Clin. Imaging 2018, 55, 188–195. [Google Scholar] [CrossRef] [PubMed]
- Patel, U.; Haffty, B.; Azu, M.; Kearney, T.; Yue, N.; Goyal, S. Placement and Visualization of Surgical Clips in the Lumpectomy Cavity of Patients with Stage 0, I, and II Breast Cancer Treated with Breast Conserving Surgery and Radiation Therapy (BCS+RT). Int. J. Radiat. Oncol. 2010, 78, S251–S252. [Google Scholar] [CrossRef]
- Topolnjak, R.; de Ruiter, P.; Remeijer, P.; van Vliet-Vroegindeweij, C.; Rasch, C.; Sonke, J.J. Image-guided radiotherapy for breast cancer patients: Surgical clips as surrogate for breast excision cavity. Int. J. Radiat. Oncol. Biol. Phys. 2011, 81, e187–e195. [Google Scholar] [CrossRef] [PubMed]
- Ouf, T.I.; El-Din Osman, A.G.; Mahmoud Mohammed, R.F.H. The role of surgical clips in Breast Conserving Therapy: Systematic review of the Literature. QJM Int. J. Med. 2021, 114, 142. [Google Scholar] [CrossRef]
- Corso, G.; Maisonneuve, P.; Massari, G.; Invento, A.; Pravettoni, G.; De Scalzi, A.; Intra, M.; Galimberti, V.; Morigi, C.; Lauretta, M.; et al. Validation of a Novel Nomogram for Prediction of Local Relapse after Surgery for Invasive Breast Carcinoma. Ann. Surg. Oncol. 2020, 27, 1864–1874. [Google Scholar] [CrossRef] [PubMed]
- Moreira, C.; Svoboda, K.; Poulos, A.; Taylor, R.; Page, A.; Rickard, M. Comparison of the validity and reliability of two image classification systems for the assessment of mammogram quality. J. Med. Screen. 2005, 12, 38–42. [Google Scholar] [CrossRef] [PubMed]
- Harris, E.E.; Small, W., Jr. Intraoperative radiotherapy for breast cancer. Front. Oncol. 2017, 7, 317. [Google Scholar] [CrossRef] [PubMed]
- Gnant, M. Breast surgery after neoadjuvant therapy. Curr. Opin. Oncol. 2022, 34, 643–646. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy of Detected Clips | Accuracy of Detected Calcifications | Classification Accuracy of Detected Clips and Calcifications | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| dCNN/Reader 1 | 88.1% | 83.74% | 89.5% | |||||||||
| dCNN/Reader 2 | 87% | 80.4% | 91.4% | |||||||||
| Reader 1/Reader 2 | 91.7% | 84.3% | 94.3% | |||||||||
| TP | TN | FP | FN | TP | TN | FP | FN | TP (Clips) | TN (Calcifications) | FP (Calcification detected as Clip) | FN (Clip detected as Calcification) | |
| dCNN/Reader 1 | 38 | 132 | 17 | 6 | 132 | 38 | 5 | 28 | 38 | 132 | 18 | 2 |
| dCNN/Reader 2 | 37 | 123 | 20 | 4 | 123 | 37 | 22 | 17 | 37 | 123 | 14 | 1 |
| Reader 1/Reader 2 | 37 | 129 | 9 | 6 | 129 | 37 | 3 | 28 | 37 | 129 | 8 | 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schnitzler, T.; Ruppert, C.; Hejduk, P.; Borkowski, K.; Kajüter, J.; Rossi, C.; Ciritsis, A.; Landsmann, A.; Zaytoun, H.; Boss, A.; et al. Automatic Detection of Post-Operative Clips in Mammography Using a U-Net Convolutional Neural Network. J. Imaging 2024, 10, 147. https://doi.org/10.3390/jimaging10060147
Schnitzler T, Ruppert C, Hejduk P, Borkowski K, Kajüter J, Rossi C, Ciritsis A, Landsmann A, Zaytoun H, Boss A, et al. Automatic Detection of Post-Operative Clips in Mammography Using a U-Net Convolutional Neural Network. Journal of Imaging. 2024; 10(6):147. https://doi.org/10.3390/jimaging10060147
Chicago/Turabian StyleSchnitzler, Tician, Carlotta Ruppert, Patryk Hejduk, Karol Borkowski, Jonas Kajüter, Cristina Rossi, Alexander Ciritsis, Anna Landsmann, Hasan Zaytoun, Andreas Boss, and et al. 2024. "Automatic Detection of Post-Operative Clips in Mammography Using a U-Net Convolutional Neural Network" Journal of Imaging 10, no. 6: 147. https://doi.org/10.3390/jimaging10060147
APA StyleSchnitzler, T., Ruppert, C., Hejduk, P., Borkowski, K., Kajüter, J., Rossi, C., Ciritsis, A., Landsmann, A., Zaytoun, H., Boss, A., Schindera, S., & Burn, F. (2024). Automatic Detection of Post-Operative Clips in Mammography Using a U-Net Convolutional Neural Network. Journal of Imaging, 10(6), 147. https://doi.org/10.3390/jimaging10060147