This section provides the necessary background and context for our research and is divided into four parts. First, we introduce the field of human action recognition and its common challenges. Second, we provide an overview of the approaches taken in the field. Third, we review the current research in this area. Finally, we explain how our work fits the existing literature.
2.2.1. Video-Based Human Action Recognition Field
Video-based human action recognition is an active field of research with ongoing developments. Its goal is to develop a model that can extract and understand the encoded message of human action, as
Section 2.1 introduced.
Despite our natural talent to understand human actions, a computer faces different challenges. These can be divided into five areas [
20]: action–class variability, sensor capabilities, environmental conditions, dataset restrictions, and computational constraints.
When discussing action–class variability, we have two types: intra-class variations, which refer to differences within specific action classes, and inter-class variations, which refer to the differences between various action classes [
6]. In order to improve the accuracy of computer vision applications, it is crucial for models to address inter- and intra-class variations effectively.
On the other hand, despite being the most commonly used sensor for video action recognition, RGB cameras present challenges such as a restricted field of view and limited perspective, making it difficult for them to detect human actions accurately. Moreover, environmental conditions and the quality of the sensor’s images can significantly affect the model’s classification performance [
6,
19].
A significant challenge to constructing a high-classification model is the amount and quality of data used. There are two main approaches; creating datasets from scratch can ensure fitting the application’s specifications, but this can be resource intensive [
21], and extracting data for some application domains can be difficult due to factors related to the nature of data, data privacy, or ethical considerations [
22]. On the other hand, utilizing existing datasets may not adequately represent all the variations of target actions or fulfill the data dimensionality requirements [
6]. Additionally, the degradation of publicly available datasets over time is a concern [
6].
Finally, providing adequate computational resources is challenging when constructing video models for human action recognition [
23]. On the one hand, most approaches use a supervised approach, which demands dealing with high-dimensional data and complex architectures [
10,
11,
24]. On the other hand, specific applications require a fast inference response [
9], and the model’s complexity may surpass the hardware’s processing capabilities [
6,
9].
2.2.2. Approach Evolution
Early approaches for human action recognition were based on handcrafted methodologies [
19,
25], which are known for their manual feature engineering.
Nevertheless, owing to their performance and ability to extract video features without human engineering, deep learning approaches have set a novel standard for human action recognition [
1,
26,
27].
However, applying deep learning methods to action recognition was not straightforward. Early approaches based on traditional CNNs do not outperform handcrafted methods since human actions are defined into spatial–temporal features and traditional neural networks. Therefore, exploring how to model temporal information became the research focus, and researchers arrived at a two-stream network with two separate networks to process the spatial and temporal information separately. The next step in video-based action recognition was the two-stream inflated 3D ConvNet (I3D) [
2] architecture. I3D [
2] demonstrates that 3D convolutional networks can be pretrained. From this point, multiple video architectures emerged, including R3D [
28] and R(2+1)D [
29].
Transferring knowledge from one model to another is a common way to reduce computational resource requirements [
7]. Two commonly used techniques in the literature are transfer learning and fine-tuning [
7,
8].
Transfer learning [
7] involves using the architecture and weights of a preexisting model to train a new model, which is particularly effective when the new task is similar to the original task on which the preexisting model was trained. On the other hand, adding trainable layers to an existing pretrained model and training only these layers on a new task is called fine-tuning [
8].
While transfer learning [
7] and fine-tuning [
8] can be beneficial for reducing computational resource requirements and speeding up the training process, they have some limitations. Due to their reliance on pretrained models’ architectural cues, these techniques can significantly limit the knowledge extracted from the model, making the training process highly specific to a particular task [
6,
9].
2.2.3. Current Research
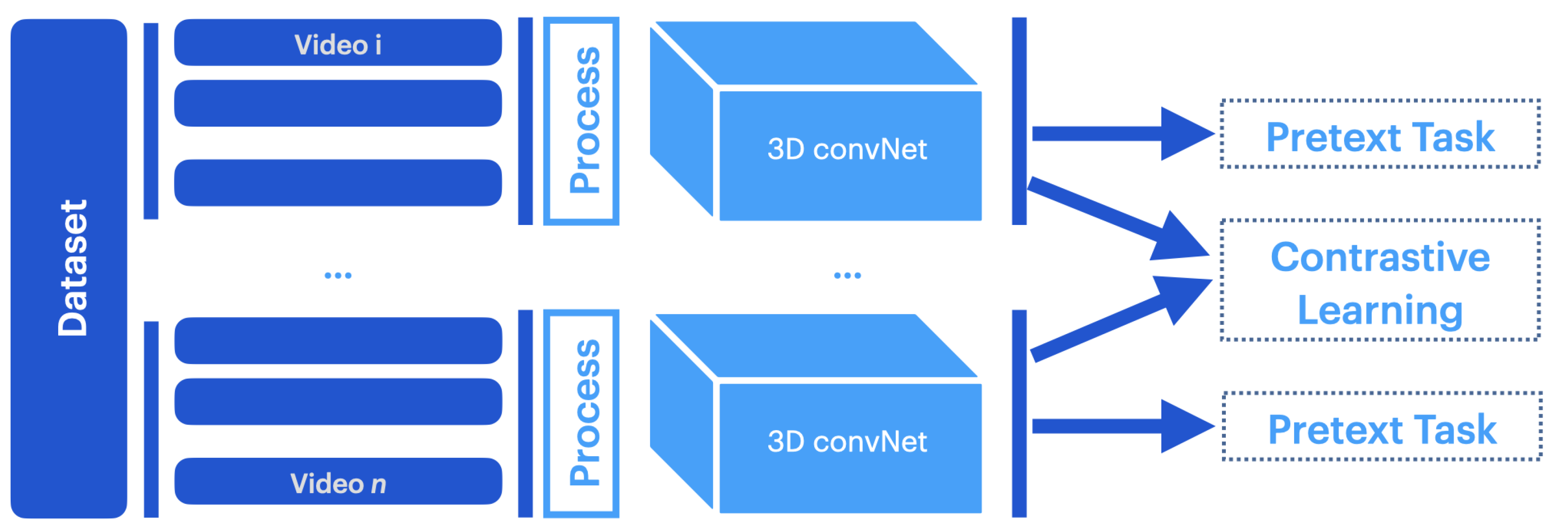
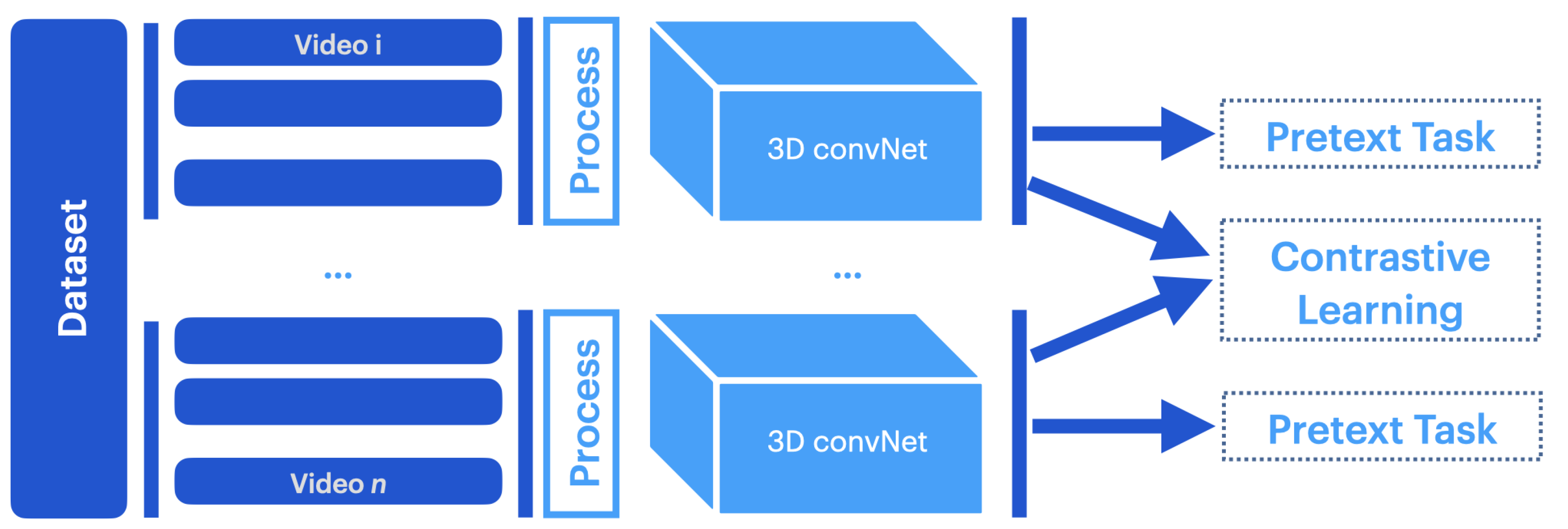
Current research in video-based learning can be divided into six directions: new architectures, novel learning paradigms, pretraining and knowledge transfer, exploring video modalities, and cross and multimodal learning.
Due to the growing popularity of transformers in natural language processing, their application to human action recognition has emerged [
30]. Conversely, deep learning methods rely extensively on labeled datasets; therefore, there is a need for a more efficient and less resource-intensive learning paradigm [
10,
24,
31,
32,
33]. Some of the novel learning paradigms include semi-supervised learning [
31], weakly supervised learning [
32], and self-supervised learning (SSL) [
24,
33].
Self-supervised learning leverages unlabeled data by generating a supervision signal without manual annotation, as inspired by our natural learning processes [
33]; one promising approach in image-based tasks is few-shot learning. It allows for learning with limited data, reduces computational demands, and generalizes to new action classes [
21,
34,
35,
36,
37].
Transfer learning [
7] and fine-tuning [
8] have been demonstrated to be beneficial for improving the performance and convergence of a model. Novel approaches have emerged, including knowledge distillation (KD) [
10,
11,
12]. KD is a widely used technique for creating a smaller version of a pretrained model that meets specific application needs. However, recently, it has been explored for its potential as a knowledge transfer technique for image tasks [
10]. However, applying knowledge distillation for knowledge transfer for video-based human action recognition remains unexplored.
Another significant factor is related to video modalities; most works use the RGB modality, but the application of other modalities could improve the features extracted in specific scenarios [
30]. In general, video modalities can be divided into visual and non-visual modalities [
30]. Potential visual modalities includes RGB [
38], Skelethon [
39,
40,
41,
42], depth [
43], infrared [
44], and thermal [
45]. On the other hand, emerging nonvisual modalities include audio [
46], acceleration [
47], radar [
48], and WiFi [
49].
Our interaction with the world is multimodal; therefore, developing models that can leverage the strength of each modality may improve performance, robustness, and privacy. Two common ways to use different modalities are multi-modal [
33,
50] and cross-modal [
51].
2.2.4. How Our Work Fits in the Literature
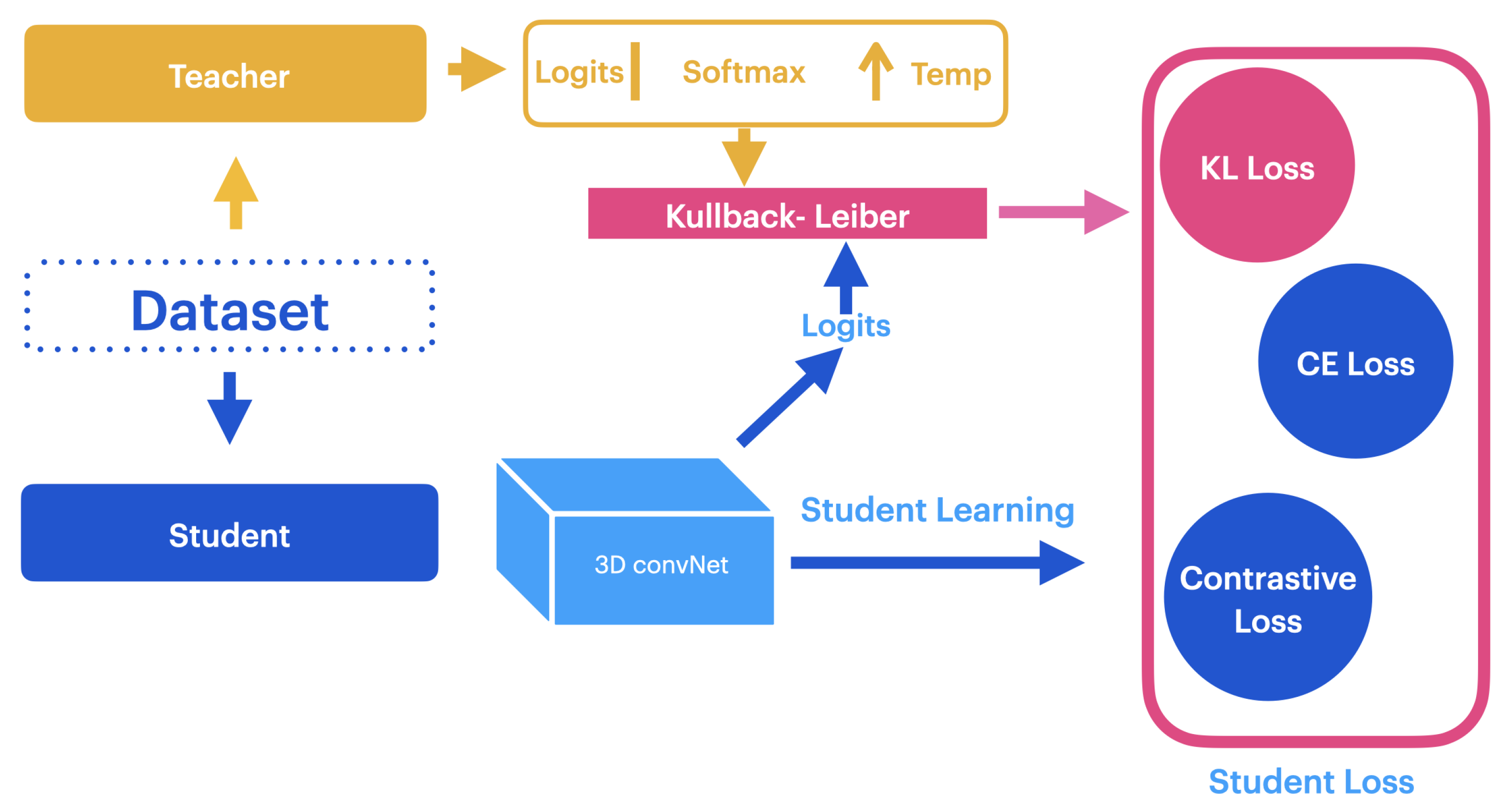
We set five current research paths: new architectures, novel learning paradigms, pretraining and knowledge transfer, exploring video modalities, and cross and multimodal learning. Our work fits in with the knowledge transfer research path since our primary focus is to explore novel knowledge transfer methods that do not depend on architectural cues, which is helpful for ensuring the transferability of knowledge for emerging novel architectures. Additionally, our work is done in a self-supervised environment and focuses on testing in low-data settings, which is also considered a current research path. Further, we believe that a potential future direction of our work will be in cross-modality learning scenarios, which is challenging because of the disjunctive feature space of the modalities.
Regarding similar works, current research in knowledge distillation has primarily focused on transferring knowledge in the domain of language models [
13,
14] and image classification tasks [
10,
15,
16,
17]. Yet there have been fewer works in other fields, such as object detection [
52] and segmentation [
53], domain generalization [
54], and video classification. Our work contributes to exploring knowledge distillation in the video-based action recognition field [
55].
Knowledge distillation has been adopted for language models as a response to the trend of building larger pretrained models efficiently. Qin et al. [
13] propose a knowledge inheritance (KI) framework that combines self-learning and teacher-guided learning to train large-scale language models using previously pretrained models. Its core idea relies on the inclusion of auxiliary supervision with a dynamically balancing weight to reduce the influence of the teacher model in the late stage of the training. Similarly, Chen et al. [
14] propose bert2BERT: a pretrained framework with the core idea of using smaller teachers to create a larger student model.
Knowledge distillation has also been explored for image classification tasks. Xu et al. [
10] present SSKD, which combines self-supervision and knowledge distillation to enable a model-agnostic approach that outperforms the state-of-the-art models on the CIFAR100 dataset. Park et al. [
15] aim to understand what makes a teacher model friendly to a student to increase classification performance. Rajasegaran et al. [
16] explore a two-stage learning process to extract better model representations that enable good performance for few-shot learning tasks. Yang et al. [
56] explore using hierarchical self-supervised knowledge distillation that adds auxiliary classifiers to intermediate feature maps with the goal of generating diverse self-supervised knowledge that can be transferred to the student model. Xu et al. [
17] suggest collaborative knowledge distillation between the teacher model and a self-distillation process. Wen et al. [
57] introduce the concepts of knowledge adjustments and dynamic temperature distillation to penalize inadequate supervision and, therefore, improve student learning. Finally, self-supervised teaching assistants (SSTA) [
58] focus on improving visual transformers using two teacher heads, either supervised or self-supervised, along with a selection method to mimic the attention distribution.
Further research is required in other domains, but the success of knowledge distillation in language and image classification tasks shows potential usefulness in other fields. The MobileVos framework [
53] aims to achieve real-time object segmentation on resource-constrained devices by combining KD and contrastive learning. Zhang et al. [
52] focus on object detection using KD to address two fundamental problems: the imbalance between foreground and background pixels and the lack of consideration of the pixel’s relations. Domain generalization is explored by Huang et al. [
54], where the student is encouraged to learn image representations using the teacher’s learned text representations. Finally, Dadashzadeh et al. [
55] introduced auxSDX, which adds an auxiliary distillation pretraining phase for video representations. Our work is fundamentally different from auxSDX [
55] since its core contributions rely on the introduction of a novel self-supervised pretext task that uses the distilled knowledge from the teacher. In contrast, despite also working on a self-supervised methodology, we explore a more general and flexible way to include the guidance of the teacher model by focusing on using the logits to understand how the probability distributions differ between the models. Another difference is that in Dadashzadeh et al.’s [
55] work, the teacher and student models share the same architectural settings, which differs from our flexibility goal.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}