1. Introduction
Efficient waste management is crucial for environmental sustainability and resource conservation, yet it remains a significant global challenge due to increasing urbanization and consumption rates. Automated waste classification systems have emerged as promising solutions, enabling precise sorting and recycling of materials. Conventional approaches primarily rely on convolutional neural networks (CNNs), which necessitate extensive datasets with annotated labels to achieve high accuracy. However, such supervised methods are impeded by labor-intensive and costly data annotation processes, which limit scalability and adaptability in practical, dynamic environments [
1].
Given the impracticality of manually annotating large volumes of waste images in real-world settings, it is essential to develop methods that reduce dependence on the data labeling process itself. Zero-shot learning (ZSL) provides a scalable alternative by enabling classification without task-specific retraining. ZSL has recently gained considerable attention as a powerful alternative to traditional supervised learning frameworks. Unlike supervised methods, ZSL allows models to identify and classify objects not seen during training by leveraging semantic relationships and external knowledge [
2]. This approach significantly reduces the dependency on large annotated datasets, thereby enhancing scalability and flexibility.
Efficient and scalable waste classification is a critical component of sustainable waste management and environmental stewardship. Traditional deep learning approaches, particularly those relying on supervised learning, have shown strong performance in image classification tasks but depend heavily on large volumes of labeled training data. In dynamic and evolving domains such as waste management—where new materials frequently appear and data labeling is labor-intensive—this dependence presents a significant bottleneck. Foundation models are trained on large amounts of images and text together, which helps them understand the meaning behind visual and language concepts. Because of this, they can recognize new or unseen categories without needing specific labeled examples, a capability known as ZSL.
Recent studies have shown that ZSL and open-vocabulary models can be effective tools for waste classification across a range of applications. Ranjbar et al. applied ZSL to construction and demolition plastic waste and showed that vision-language models could successfully identify materials they had not seen during training [
3]. Madhini and Supraja tested several ZSL methods—including Grounding DINO and OWL-ViT—for plastic waste detection, demonstrating strong performance without the need for retraining on task-specific data [
4]. Freitas et al. used a ZSL-based approach in combination with hyperspectral imaging to detect marine litter from airborne platforms, achieving high accuracy even for previously unseen waste types [
5]. Zhou et al. explored few-shot and zero-shot techniques for real-time municipal waste detection, highlighting their suitability for use on devices with limited computing resources [
6]. Together, these studies underscore the potential of ZSL approaches in diverse waste management scenarios, from industrial settings to real-time public infrastructure.
While recent work has applied ZSL to specific waste streams—such as construction plastics, plastic packaging, and marine litter—most studies are limited to narrow domains or specialized setups like aerial imaging and robotic sorting. Despite these promising developments, there remains a lack of comprehensive evaluation of ZSL models for general municipal solid waste (MSW). In particular, prior work rarely benchmarks ZSL methods against traditional supervised models using standard datasets such as TrashNet under consistent evaluation protocols. This gap makes it difficult to assess whether ZSL can serve as a practical and scalable alternative in realistic, mixed-waste classification scenarios. Given this context, the present study seeks to answer the following research question: Can ZSL models achieve competitive performance in the automated classification of solid waste compared to supervised methods, particularly when applied to benchmark datasets without task-specific retraining?
Foundation models are large-scale neural networks trained on diverse and massive datasets, often combining vision and language, which enables them to generalize across tasks and domains. This dual approach offers insight into the generalization capabilities of foundation models and their applicability to real-world classification problems without manual annotation. Building on this, in this study, we explore the application of ZSL to automated waste classification by employing the OWL-ViT (Open-World Object Detection with Vision Transformers) models [
7], a vision-language transformer designed for open-world object detection. We adapt this model for image-level classification by using carefully crafted textual prompts for each waste category. This allows the model to infer the correct class without any retraining on the TrashNet dataset—a widely used benchmark containing six MSW categories commonly found in household waste streams: cardboard, glass, metal, paper, plastic, and general trash [
8]. In addition to OWL-ViT, we evaluate OpenCLIP models (ViT-L/14-336, ViT-L/14, ViT-B/32, RN50), enabling a comparative analysis of multiple vision-language architectures in a zero-shot setting.
Our evaluation also includes a supervised learning baseline, incorporating models such as MobileNet V3-Small, ResNet18, ViT-B/16, and Swin V2-Tiny trained on the same dataset. This allows us to contrast zero-shot performance against fine-tuned models in terms of accuracy, inference speed, and computational efficiency. Notably, we analyze class-wise accuracy, highlighting both the competitiveness and limitations of zero-shot models, particularly in ambiguous categories such as trash, where semantic vagueness impacts performance. The insights gained underscore the transformative potential of ZSL in building adaptive, scalable, and annotation-free waste classification systems, paving the way for more intelligent and sustainable recycling solutions.
In this study, the focus is on MSW—the everyday items discarded by households and businesses. This includes commonly recyclable materials such as plastic bottles, cardboard boxes, glass jars, and food containers. The TrashNet dataset used in our experiments reflects this domain. Classifying MSW presents a real-world challenge due to its visual variability, frequent introduction of novel packaging types, and the cost of manual sorting and annotation. These characteristics underscore the need for scalable and adaptable approaches, such as ZSL.
2. Related Work
Automated waste classification has been extensively studied in recent years due to its importance in achieving sustainable waste management and efficient recycling processes. Traditional supervised machine learning methods, particularly convolutional neural networks (CNNs), have dominated this field, achieving high accuracy rates. For instance, Yang and Thung [
8] introduced the TrashNet dataset and utilized CNN models to classify various waste materials. The dataset, consisting of six waste classes with images taken against a white background, posed challenges due to its limited size. In a recent study, Aral et al. focus on classifying recyclable materials using deep learning models applied to the TrashNet dataset [
9]. The authors evaluate several state-of-the-art convolutional neural networks, including DenseNet121, DenseNet169, MobileNet, Xception, and InceptionResNetV2, using fine-tuning and data augmentation strategies to improve performance. The experiments revealed that the DenseNet121 and DenseNet169 models achieved the highest test accuracy of 95%, demonstrating the effectiveness of fine-tuned CNNs for this task. These findings affirm that deep learning architectures—when properly tuned—can achieve high precision in automated waste classification systems using publicly available datasets like TrashNet. Subsequently, several studies have adopted similar datasets to refine CNN-based classification performance further, achieving accuracy levels up to 95% through architectures like DenseNet and MobileNet [
10,
11].
However, a significant limitation of supervised deep learning methods is the extensive requirement for manually labeled training data. This labeling process is labor-intensive, costly, and often impractical for real-world scenarios involving diverse and continuously evolving categories of waste [
12,
13]. To address these limitations, the machine learning community has shifted attention toward weakly supervised and ZSL paradigms, where models can generalize knowledge from existing categories to novel unseen classes without additional labeled data [
14,
15].
In a notable study on waste management, Srinilta and Kanharattanachai investigate the effectiveness of CNN-based models for MSW segregation in Thailand [
16]. Motivated by the country’s growing waste crisis, their research explores the use of transfer learning with four CNN architectures—VGG-16, ResNet-50, MobileNet V2, and DenseNet-121—to classify 9200 waste images into four standardized categories: general, compostable, recyclable, and hazardous. The authors introduce both direct waste-type classifiers and a novel derived approach, where waste-item predictions are mapped to their corresponding waste-type labels. Their results reveal that ResNet-50 achieved the highest classification accuracy of 94.86% using the derived method, outperforming all direct classifiers. This work highlights CNNs’ potential in automated waste segregation and underscores the value of item-level classification as a stepping stone toward more effective, real-world waste management solutions.
In recent work, Huang et al. propose a vision transformer (ViT)-based approach for automatic waste classification aimed at enhancing resource recycling efficiency through portable devices [
17]. Unlike conventional CNN-based methods that face limitations in capturing global contextual features, their ViT model leverages a self-attention mechanism to extract richer representations from waste images. The model was trained using the TrashNet dataset and achieved a classification accuracy of 96.98%, surpassing the performance of state-of-the-art CNN architectures such as DenseNet and ResNet. To address deployment challenges in resource-constrained environments like waste sorting stations, the authors implemented a cloud-based classification system accessed via mobile devices. This system enables real-time waste recognition without the need for high-performance local computation, making it highly practical for urban waste management applications. Their work demonstrates the potential of ViTs not only in boosting classification accuracy but also in improving system portability and deployment scalability for real-world recycling systems.
ZSL leverages semantic relationships or textual descriptions to recognize categories without directly observing examples from those classes during training. Vision-language models like CLIP [
18] and OWL-ViT [
7] have demonstrated remarkable zero-shot capabilities in open-vocabulary image recognition tasks by bridging textual and visual representations effectively. Recent applications in waste management contexts have shown the promise of these models for scalable and adaptable classification without needing exhaustive labeling efforts [
19].
Despite the evident advantages, ZSL methods also present challenges, such as prompt sensitivity and lower accuracy compared to fully supervised models, particularly for ambiguous or visually diverse categories [
2]. Research continues to focus on improving semantic embeddings, optimizing textual prompts, and integrating few-shot learning techniques to enhance accuracy and robustness in practical zero-shot applications [
20,
21].
3. Results
This section presents a comparative analysis of supervised and ZSL models applied to the TrashNet dataset. The models were evaluated on four key metrics: parameter size, inference speed (FPS), classification accuracy, and training time (where applicable).
Table 1 summarizes the performance across all evaluated models. For supervised learning models, accuracy is reported only on the test set (15% of the dataset), while for OpenCLIP and OWL-ViT zero-shot models, accuracy is calculated over the entire dataset, since these models were not trained or fine-tuned on TrashNet.
In addition to accuracy, we also report recall to better reflect performance on critical waste classes where detecting true positives is especially important. Notably, the best-performing supervised models—Swin V2-T and ViT-B/16—achieved recall scores above 92%, while the top zero-shot model (ViT-L/14-336) reached a recall of 69.18%.
Among the supervised models, Swin V2-T achieved the highest classification accuracy at 95.37%, followed closely by ViT-B/16 at 93.97%. Both models required substantial training time (approximately 20 min), reflecting the computational cost of fine-tuning large vision transformers. Notably, ResNet18, a smaller and more efficient model, attained a strong 91.53% accuracy with a training time of just over 4 min, offering a favorable balance between performance and efficiency. MobileNet-v3-small, the lightest model evaluated (1.52 M parameters), delivered 89.44% accuracy with the highest inference speed (121.47 FPS), making it suitable for real-time or resource-constrained applications.
The CLIP-based models, evaluated in a zero-shot setting (i.e., no additional training on TrashNet), demonstrated strong generalization capabilities. ViT-L/14-336 achieved the highest accuracy among the CLIP models at 76.30%, despite having no exposure to the dataset during training. It also had the largest parameter count (427.94 M) and an inference speed (2.83 FPS). ViT-L/14, ViT-B/32 and RN50 followed with 74.40%, 71.15% and 62.29% accuracy respectively, balancing performance with faster inference. These results highlight CLIP’s potential for tasks where labeled data is limited or unavailable, as it performs reasonably well purely based on textual prompts and prior knowledge from its pretraining corpus.
Although OWL-ViT models are primarily designed for object detection, we adapted them for image classification using class-specific prompts. The results for the OWL-ViT models, as shown in
Table 2, highlight the model’s strong sensitivity to the semantic richness of the input prompts. OWLv2 CLIP B/16 ST/FT ensemble models were evaluated using four progressively detailed token sets (Token1 to Token4). The accuracy steadily improves with the level of detail in the prompt: from 41.52% with Token1 (a minimal keyword) to 64.20% with Token4 (containing highly specific descriptions such as “newspaper” and “envelope”). This trend clearly indicates that prompts with more descriptive and contextually aligned tokens yield significantly better performance. The substantial accuracy gap between Token1 and Token4 (over 20%) underscores OWL-ViT’s heavy dependence on prompt quality—minor variations in phrasing can drastically influence the model’s zero-shot classification capability. This sensitivity emphasizes the importance of careful prompt engineering when deploying OWL-ViT for domain-specific tasks like waste classification on datasets such as TrashNet. These results show that while OWL-ViT can be effectively repurposed for classification, the computational cost is significantly higher than both CLIP and standard classifiers. However, the accuracy it delivers—without any training—underscores its utility in open-world scenarios.
3.1. Class-Wise Accuracy for Different Models
The class-wise accuracy scores reveal that zero-shot models (OpenCLIP and OWL-ViT) perform competitively across most categories, especially in classes with distinct visual features such as metal, glass, and plastic. Models like ViT-L/14 (OpenCLIP) and OWL-ViT CLIP B/16 ST/FT ensemble achieve accuracy levels above 60–80% in several categories, demonstrating strong generalization without any task-specific training. This highlights the effectiveness of natural language prompts and large-scale pretraining in enabling these models to recognize visual categories they have not explicitly seen before. The
Table 2 shows the class-wise accuracy in percentage for all the classes present in the TrashNet dataset. However, a consistent trend across all zero-shot models is the notably lower accuracy on the trash class, where OpenCLIP and OWL-ViT models drop to around 0–30% accuracy in some cases.
This suggests that the trash category, which likely contains more visual noise, diversity, and ambiguity, poses a greater challenge for prompt-based inference. Despite this, the performance of zero-shot models in the remaining categories is often within reach of supervised models, underscoring their potential as viable alternatives when labeled training data is limited or unavailable.
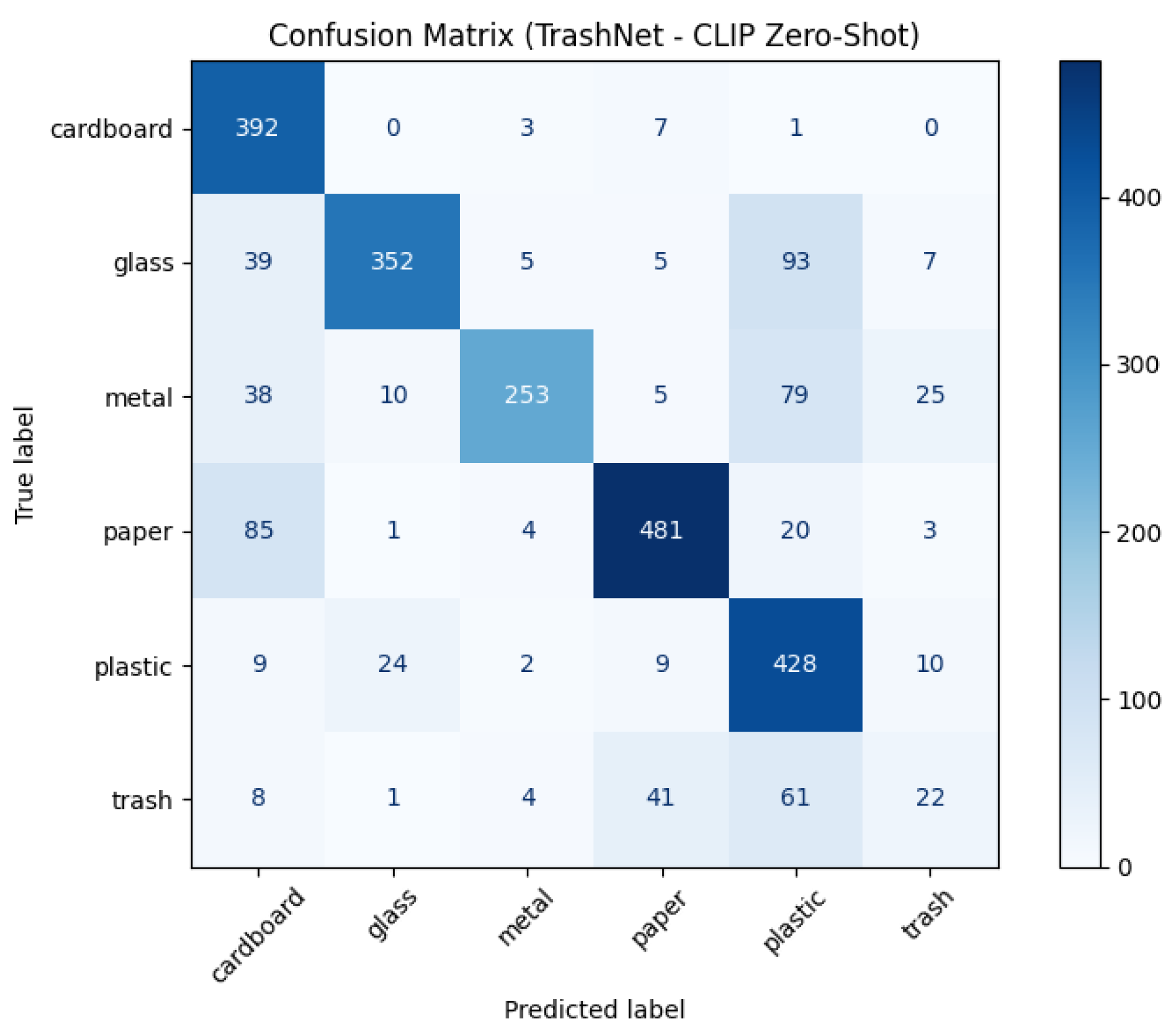
3.2. Confusion Matrix Analysis (OpenCLIP ViT-L/14-336)
As shown in the
Figure 1, the confusion matrix for the OpenCLIP ViT-L/14-336 model highlights both the strengths and limitations of zero-shot classification using vision-language models. Categories with distinctive visual features—such as plastic and paper—show strong diagonal dominance, indicating consistent and confident predictions. However, there is noticeable confusion between visually similar or semantically overlapping classes, such as glass being misclassified as plastic, and metal as plastic or glass. This suggests that, in the absence of task-specific training, the model relies heavily on generalized semantic associations, which may not always capture subtle material-specific visual cues. The most pronounced challenge is observed in the trash category, where predictions are widely dispersed across other classes, reflecting the class’s ambiguous nature and the model’s struggle to ground its prompt meaning accurately.
4. Discussion
This study demonstrates that foundation models offer a compelling alternative to traditional supervised approaches in the context of automated waste classification. By evaluating pre-trained vision-language models—specifically OpenCLIP and OWL-ViT—we show that meaningful classification performance can be achieved without any model retraining or access to labeled examples. These zero-shot models, particularly OWL-ViT v2 and OpenCLIP ViT-L/14-336, achieved competitive results across most waste categories, with OpenCLIP ViT-L/14-336 reaching up to 76.30% accuracy. This highlights the strength of prompt-based inference when supported by large-scale pretraining.
A critical limitation identified across zero-shot models is their reduced effectiveness in the “trash” category. This class typically features greater visual variability and semantic ambiguity, which cannot be easily captured by general text prompts. Consequently, zero-shot models struggled to associate the vague notion of “trash” with its many real-world visual forms, resulting in accuracy as low as 0–40%. Despite this, performance across more visually distinct categories like metal, and plastic approached or exceeded 70%, suggesting that zero-shot models are highly effective when the visual features of a class align well with its textual representation. These findings underscore the need for prompt optimization and potentially few-shot refinement in future research to better handle edge cases and ambiguous categories.
Despite its advantages, ZSL models inherently rely heavily on the quality and structure of textual prompts, making them particularly sensitive to semantic phrasing. Minor variations in wording can significantly influence classification outcomes, especially for classes with less distinctive or more abstract visual features. For example, the discrepancy in performance for the trash category suggests that existing prompts may not fully capture the diversity and ambiguity of general waste. This highlights the need for more systematic prompt engineering—including prompt paraphrasing, prompt ensembles, and the use of richer, context-aware language models—to improve robustness and consistency across categories.
Furthermore, while the OWL-ViT and OpenClip models excel in generalized recognition and offer strong zero-shot performance, its computational overhead and lower inference speed make it less practical for real-time or resource-constrained applications. This opens opportunities for hybrid frameworks that combine the adaptability of zero-shot models with the high precision and efficiency of supervised learning. From an industrial perspective, the results highlight the potential of ZSL models for scalable and flexible deployment in waste management systems. These models can be integrated into smart sorting stations, IoT-enabled waste bins, or recycling plants to classify newly emerging waste types without retraining. This eliminates the need for extensive labeled datasets, reducing annotation costs and enabling faster deployment in dynamic environments with evolving material compositions. Furthermore, combining zero-shot models with lightweight supervised systems offers a promising hybrid approach for real-time classification in resource-constrained settings. Additionally, this research builds upon our prior collaborative work with AMCS Group, Limerick (
https://www.amcsgroup.com/, accessed on 8 July 2025), a company with extensive domain expertise in commercialising waste management technologies. That collaboration, detailed in our earlier publication on contamination detection in cluttered waste scenes [
22], involved the deployment of computer vision models on camera-equipped waste collection trucks to identify recycling contamination at the source. This real-world experience grounds our understanding of industrial implementation challenges and commercial requirements. It also affirms the practical relevance and translational potential of the ZSL approaches presented in this paper.
For instance, supervised models could handle frequently occurring or visually complex categories, while zero-shot models could provide flexible coverage for rare or newly introduced classes. Integrating such strategies could lead to more scalable, interpretable, and real-world-ready waste classification systems. Future work could also explore incorporating active learning or few-shot fine-tuning mechanisms to iteratively refine zero-shot models using minimal human-labeled data, further bridging the gap between generalization and task-specific accuracy.
The results further underscore the critical role of prompt design in the performance of OWL-ViT models. Our experiments revealed that prompts with more semantically detailed and visually aligned descriptions (e.g., Token4) significantly outperformed simpler alternatives (e.g., Token1), with accuracy improvements exceeding 12% in some cases. This sensitivity to prompt structure indicates that OWL-ViT’s zero-shot capabilities are not only enabled by large-scale vision-language pretraining but are also highly dependent on the quality and specificity of textual input. Even minor changes in phrasing can lead to substantial performance differences, particularly in categories with high visual or semantic variability. Therefore, effective deployment of OWL-ViT in real-world classification tasks requires careful prompt engineering, ideally informed by both dataset analysis and domain knowledge.
While this study demonstrates the viability of ZSL for MSW classification, a broader comparative analysis with related work in diverse settings can deepen the theoretical grounding. For instance, Ranjbar et al. [
3] applied vision-language models such as CLIP, CoCa, and ALIGN to classify construction and demolition plastic waste, reporting 70.15% accuracy in zero-shot settings and up to 85.07% with few-shot multimodal fusion. Their results affirm the capacity of foundational models to generalize to unseen material types, echoing our finding where OpenCLIP ViT-L/14-336 achieved 76.30% accuracy on the TrashNet dataset without any fine-tuning. Similarly, Zhou et al. [
6] proposed a few-shot object detection pipeline that incorporates attention modules and achieved 31.16% mean average precision (mAP) [
23] with only 30 labeled instances per class across 12 waste categories. While their framework reduces the annotation burden, its relatively modest detection performance underscores the scalability advantage of the fully prompt-based zero-shot classification methods explored in our study. In contrast, Freitas et al. [
5] integrated hyperspectral imaging with generalized zero-shot learning (GZSL) to detect marine litter from aerial platforms, attaining over 56% precision on unknown classes and 98.71% overall accuracy. Although their approach benefits from the discriminative power of spectral data, it requires specialized sensors and domain-specific tuning. Our vision-language strategy, by comparison, leverages general-purpose models and RGB images, making it more accessible and adaptable to standard MSW settings.
These comparative insights reveal that while performance outcomes vary by domain, data modality, and task type (detection, classification), zero-shot models consistently demonstrate robust generalization—particularly when labeled data is scarce or unavailable. Our use of OWL-ViT and OpenCLIP contributes to this evolving landscape by delivering competitive performance in a household MSW classification task without manual supervision or domain-specific engineering. These parallels reinforce the broader applicability of zero-shot vision-language models across diverse regional and industrial waste management contexts.
5. Materials and Methods
This study compares supervised learning and foundation models for multi-class image classification on the TrashNet dataset. The experiments were conducted using a range of pre-trained models from both paradigms: supervised models were fine-tuned on the dataset, while zero-shot models were evaluated without additional training.
5.1. Dataset Preparation
For this study, we utilized the TrashNet dataset [Stanford University, Stanford, CA, USA], a publicly available and widely adopted benchmark dataset designed specifically for waste classification tasks. The dataset comprises 2527 images evenly distributed among six waste categories: cardboard, glass, metal, paper, plastic, and trash. This balanced dataset enables robust evaluation without concerns of skewed class distributions affecting performance outcomes.
Figure 2 shows the sample images present in the TrashNet dataset.
For supervised learning, the dataset was split into three subsets: 70% for training, 15% for validation, 15% for testing. These splits were stratified and consistent across all supervised models. Images were preprocessed using standard transformations, including resizing, normalization with ImageNet mean and standard deviation.
In contrast, for ZSL approaches (OpenCLIP and OWL-ViT), the entire dataset was used directly for evaluation without any training or fine-tuning. Each image was classified independently using pre-trained models and prompt-based inference. All class labels were retained, and no data augmentation or resampling was applied beyond necessary preprocessing for the specific model input requirements. This setup ensures that supervised models learn from labeled examples, whereas zero-shot models are evaluated in a purely inference-driven manner to assess their generalization capabilities without any task-specific training.
5.2. Supervised Learning Setup
We evaluated four supervised models: MobileNetV3-Small, ResNet-18, ViT-B/16, and Swin V2-Tiny. These models were initialized with ImageNet pre-trained weights and fine-tuned on the training split of TrashNet.
Architecture: The final classification layer of each model was replaced with a new linear layer matching the number of TrashNet classes.
Training details: Models were trained with batch size 8, for up to 50 epochs using Adam optimizer with a learning rate of and CrossEntropyLoss as the loss function. Early stopping was implemented with a patience of 7 epochs based on validation accuracy.
Data augmentation: Training data underwent random resized cropping and horizontal flipping to improve generalization, while validation and test data were center cropped and resized.
Evaluation: The best-performing model (based on validation accuracy) was saved and later evaluated on the test set using standard evaluation metrics. Accuracy was chosen as the primary evaluation metric due to its effectiveness in summarizing overall model performance across all six balanced classes in the dataset. While other metrics such as recall may be more relevant for specific application contexts, this study focuses on accuracy as a first-order comparison across models.
5.3. Zero-Shot Learning with CLIP
To evaluate the ZSL capabilities of vision-language models, we used the OpenCLIP library [version 2.32.0, LAION (Large-scale AI Open Network), Hamburg, Germany] which is an open source implementation of OpenAI’s CLIP (Contrastive Language-Image Pre-training) and it supports a wide variety of CLIP architectures trained on large-scale datasets. For this study, four model variants were employed: ViT-L/14-336, ViT-L/14, ViT-B/32, RN50, openly available from OpenAI and are incorporated in OpenCLIP library. These models were pre-trained on contrastive image-text pairs and can perform classification without fine-tuning by leveraging aligned visual and textual embeddings.
Creating Text Descriptions for Each Class: First, we defined simple, natural-language descriptions for each of the six waste categories. For example, the class “metal” was described as “a photo of metal”, while “glass” was represented by “a photo of glass”. These descriptions act like prompts to help the model understand what each class refers to.
Preprocessing the Images: All images from the TrashNet dataset were passed through CLIP’s preprocessing pipeline to ensure they matched the input format expected by the model. This involved resizing the images and converting them into a format the model can interpret.
Generating Predictions: For each image, CLIP was asked to “compare” it to all six textual descriptions. The model computed how similar the image was to each of the text prompts. The class whose description was most similar to the image was selected as the predicted label. This approach requires no training on the dataset—it relies entirely on the model’s prior understanding of visual and textual concepts.
Evaluating Performance: We compared the model’s predictions against the actual class labels provided by the dataset.
5.4. Zero-Shot Object Classification with OWL-ViT
We also explored ZSL using OWL-ViT [version June 2023, Google Research, Mountain View, CA, USA], a model designed primarily for object detection. Unlike traditional image classifiers, OWL-ViT is built to find and identify objects within an image using natural language prompts. However, in this study, we adapted OWL-ViT for a classification task to determine how well it can distinguish between different categories of waste without any additional training.
We used two OWL-ViT models: owlv2-base-patch16-ensemble and owlvit-base-patch32, both pre-trained on diverse image–text data.
Designing Prompts for Each Waste Category: Because OWL-ViT works with text-based object queries, we created a small set of descriptive prompts for each class. For instance, we designed a structured hierarchy of text-based prompts (tokens) with increasing semantic detail to guide OWL-ViT in ZSL for the TrashNet dataset as shown in the
Table 3. For each of the six categories, we defined four levels of tokens, from general to highly detailed. Token1 includes only the class label (e.g., “plastic”), while Token2 adds basic context such as “a photo of plastic.” Token3 introduces moderate detail by incorporating object-level descriptors commonly seen in the dataset, such as “a plastic bottle” or “a metal can.” Token4 provides the highest level of specificity, carefully tailored after analyzing the TrashNet images, with examples like “milk gallon jug,” “crumpled chip bag,” and “crushed aluminum soda can.” These highly detailed prompts are crafted to maximize visual–textual alignment by reflecting the actual appearance and variety of items within the TrashNet dataset, enhancing OWL-ViT’s ability to identify categories without prior training.
Feeding Images and Prompts into the Model: Each image from the TrashNet dataset was passed to the OWL-ViT model along with the set of prompts. The model attempted to detect any regions in the image that matched the meaning of each prompt.
Adapting Detection to Classification: Although OWL-ViT is built to draw bounding boxes around objects, our goal was classification. So instead of focusing on where in the image an object was, we looked at what the model detected. For every image, we collected all predictions made across prompts and selected the one with the highest confidence score. The class label associated with that top detection was considered the predicted category for the entire image. In this way, we repurposed OWL-ViT’s detection ability to perform image-level classification.
Recording and Evaluating Results: For each image, the predicted class was compared to the true label. We measured both overall accuracy and per-class accuracy to understand performance across different categories.
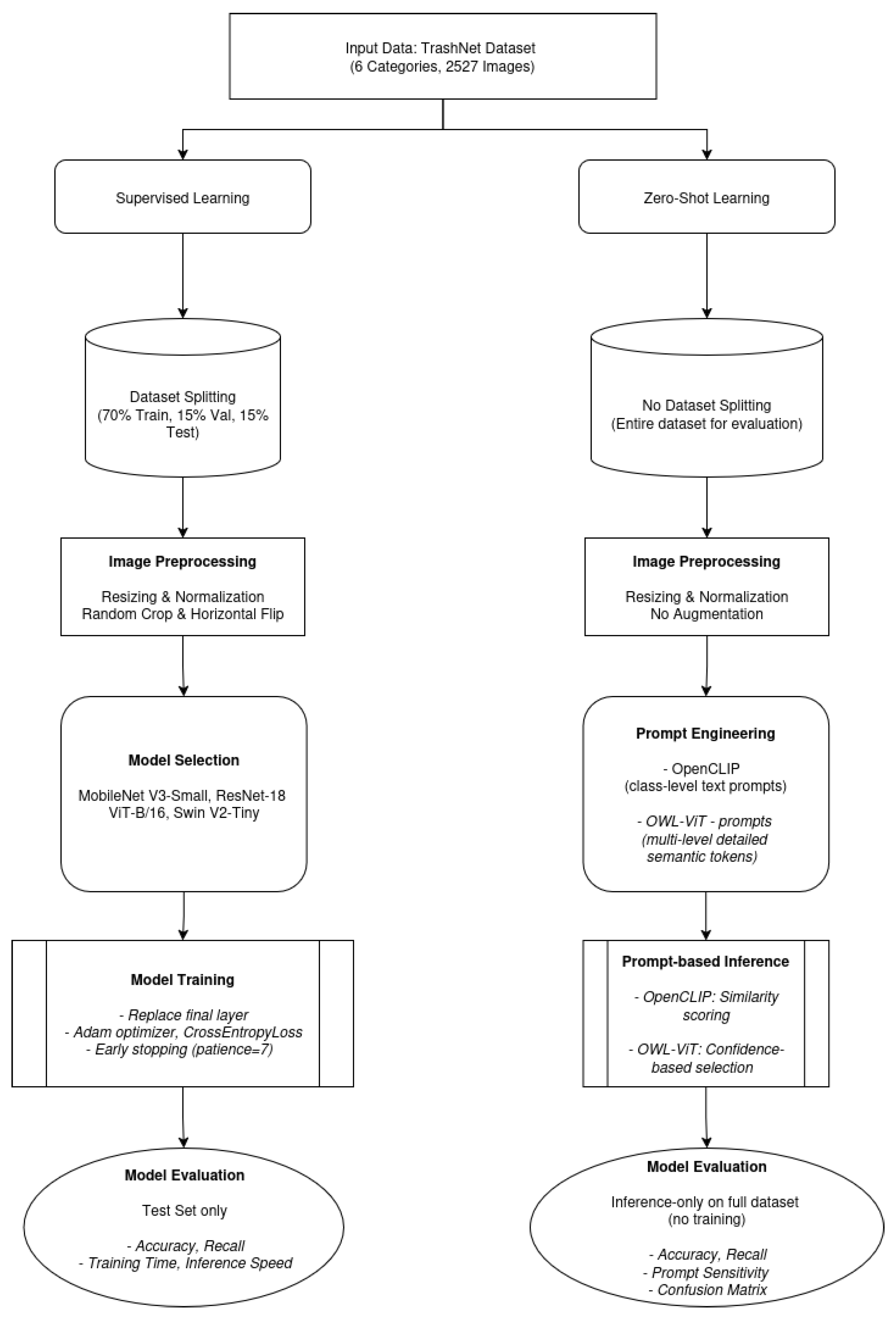
To enhance clarity and reproducibility,
Figure 3 presents a visual summary of the dual-path experimental framework used in this study. This flowchart compares the supervised and ZSL pipelines, highlighting each step from dataset handling to final evaluation. The supervised learning track includes data splitting, model fine-tuning with augmentations, and evaluation on a held-out test set. In contrast, the zero-shot track bypasses training and instead leverages prompt-based inference over the full dataset using pretrained vision-language models. This parallel comparison framework underpins the performance analysis presented in the following section.
6. Conclusions
This study set out to evaluate whether ZSL can serve as a viable alternative to traditional supervised models for MSW classification, particularly in the absence of labeled training data. Through extensive experimentation on the TrashNet dataset using vision-language models like OpenCLIP and OWL-ViT, we have shown that zero-shot models can achieve competitive accuracy up to 76.30%, without any task-specific retraining. These findings affirmatively answer the central research question and demonstrate the potential of zero-shot methods to deliver scalable, annotation-free classification suitable for real-world waste management environments.
Our work contributes to a growing body of research that demonstrates the generalization capabilities of foundation models across specialized domains. Specifically, we validate the application of ZSL to MSW classification, offering empirical support that vision-language models can perform well in data-scarce scenarios. From a practical standpoint, the study offers a deployable alternative to supervised pipelines—eliminating the need for ongoing labeling and retraining as new waste types emerge. The comparative analysis across models also shows clear trade-offs between accuracy, inference speed, and model complexity, guiding real-world implementation strategies.
The main innovation of this research lies in the novel adaptation of prompt-based vision-language models—originally built for broad open-vocabulary tasks—to the nuanced and visually diverse problem of municipal waste classification. Our approach uniquely repurposes OWL-ViT for image-level classification and introduces a hierarchical prompt design strategy, showing how prompt specificity can substantially influence model effectiveness. Unlike prior studies limited to narrow waste domains or requiring few-shot supervision, our zero-shot setup achieves robust classification across multiple household categories, positioning it as a promising foundation for scalable and intelligent recycling systems.
In this work, we explored the viability of ZSL for sustainable waste classification using vision-language transformers, with a focus on OWL-ViT and OpenCLIP models. Through a comprehensive comparison with conventional supervised models such as ViT-B/16 and MobileNetV3-Small, we show that while supervised models still yield the highest accuracy when trained on labeled data, zero-shot approaches deliver strong performance with no training, significantly reducing the need for annotation. Furthermore, our findings suggest that future efforts in designing more semantically rich and context-aware prompts for OWL-ViT could further enhance its performance, underscoring the importance of prompt engineering as a key lever in maximizing the capabilities of zero-shot models.
Our results confirm that zero-shot models can generalize well across several waste categories, offering a scalable and adaptable solution for real-world recycling systems—especially where new waste types emerge or labeled datasets are unavailable. Future work should explore adaptive prompting techniques, semantic enrichment of class labels, and hybrid architectures that combine zero-shot flexibility with the precision of supervised learning to improve overall system robustness. Ultimately, this study highlights the growing potential of ZSL to transform waste management into a more intelligent, efficient, and sustainable process.


 ,
, 


{kind=link}
{kind=link}
{kind=link}