
Wineinformatics: Comparing and Combining SVM Models Built by Wine Reviews from Robert Parker and Wine Spectator for 95 + Point Wine Prediction

Abstract
:1. Introduction
2. Methods and Materials
2.1. Wine Reviews
2.2. 1855 Elite Bordeaux RP + WS Dataset
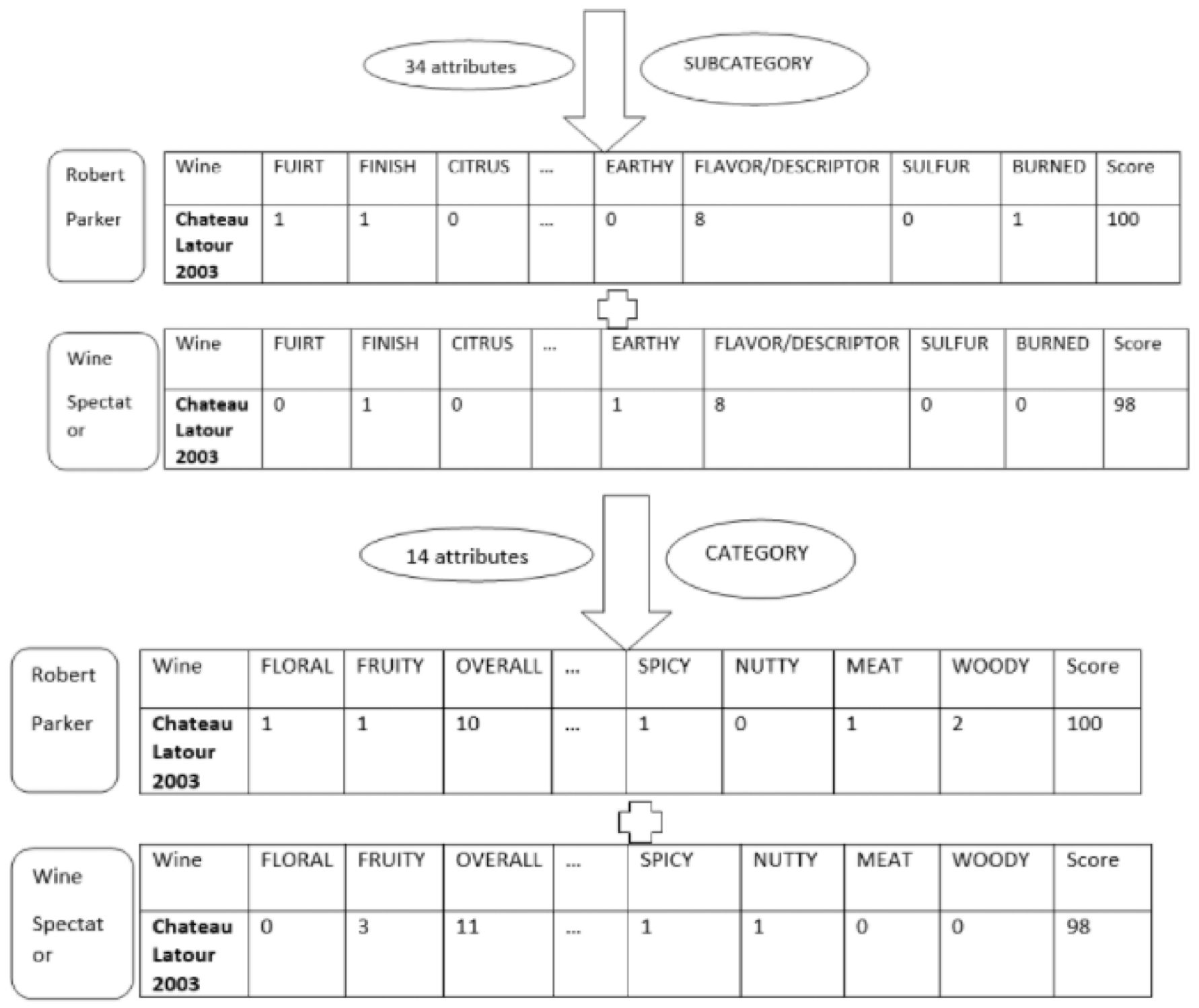
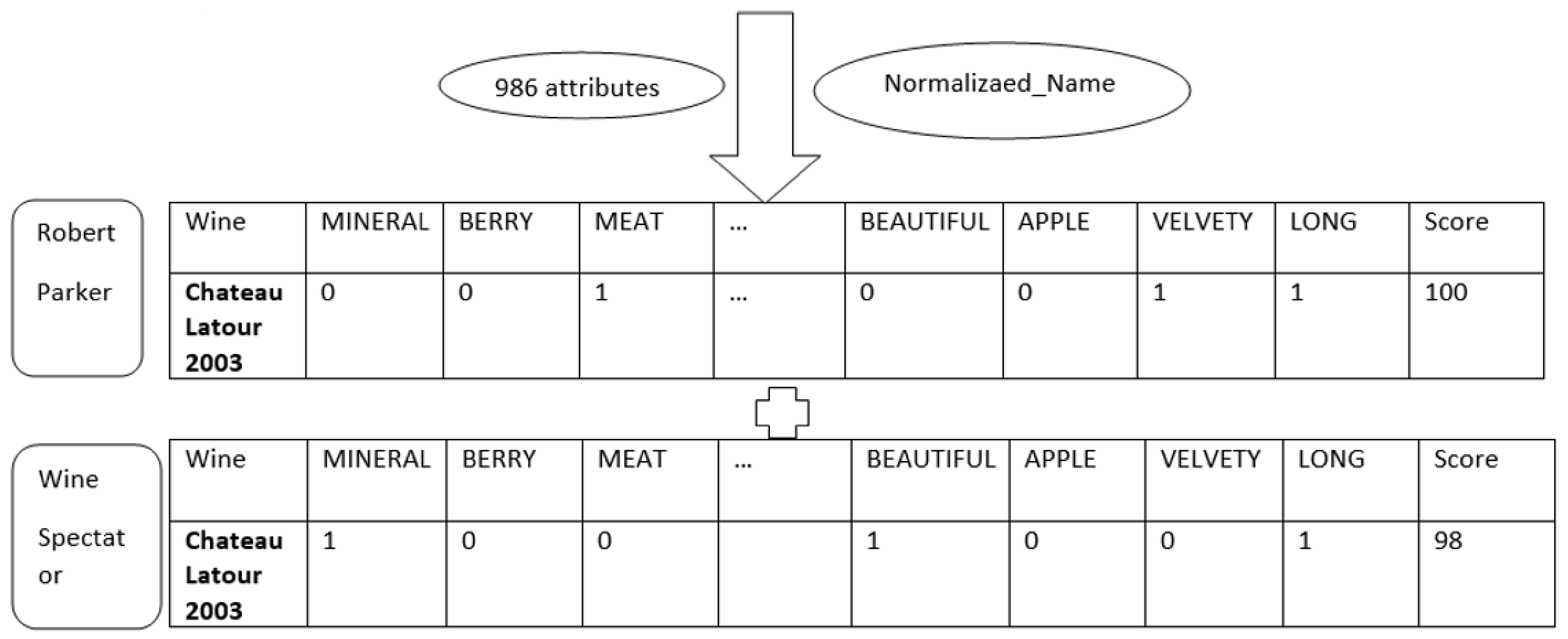
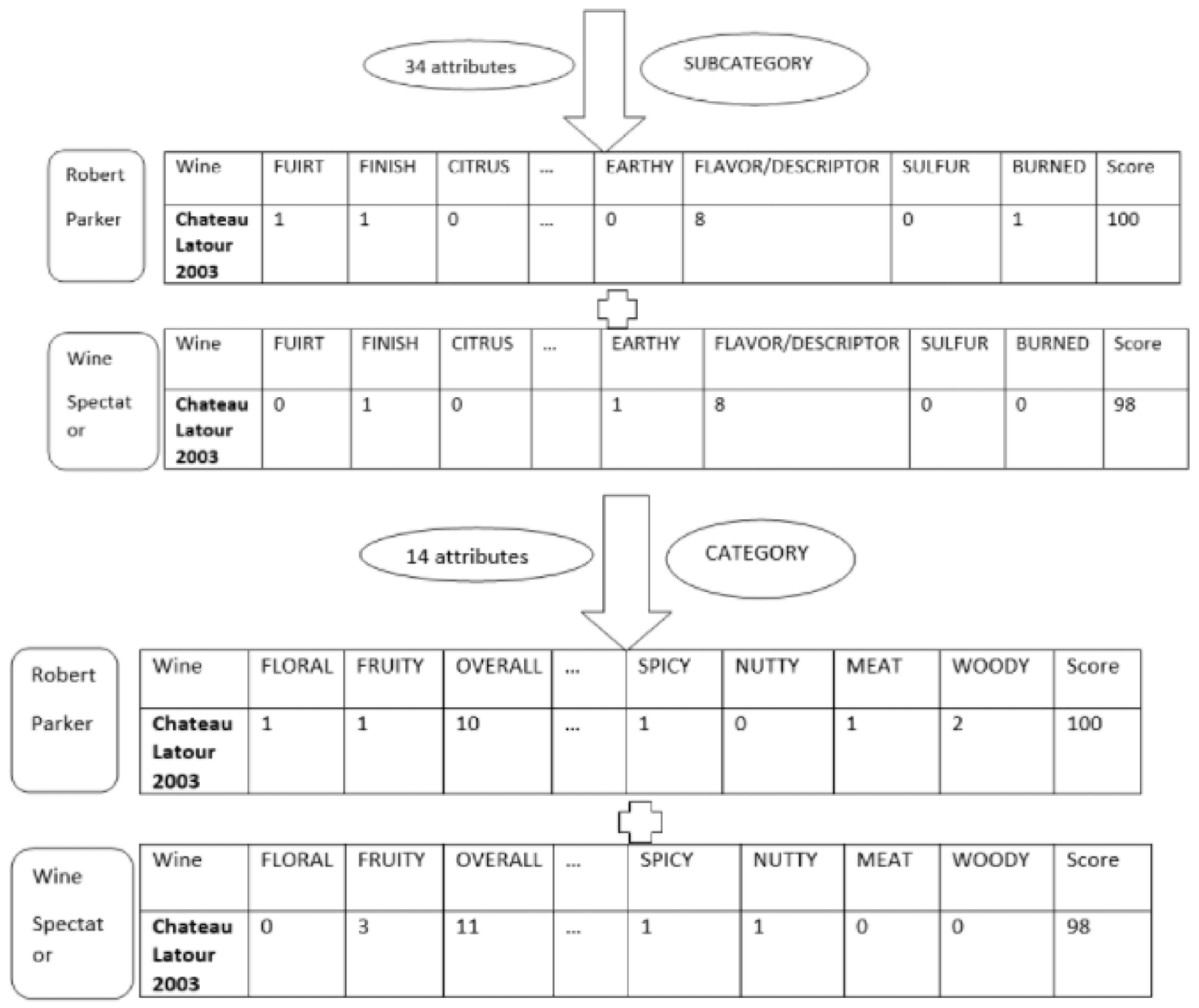
2.3. The Computational Wine Wheel
2.4. Supervised Learning Algorithm: SVM
2.5. Evaluation of the Classification Results
3. Results
3.1. CWW Conversion Rate
3.2. Prediction Results
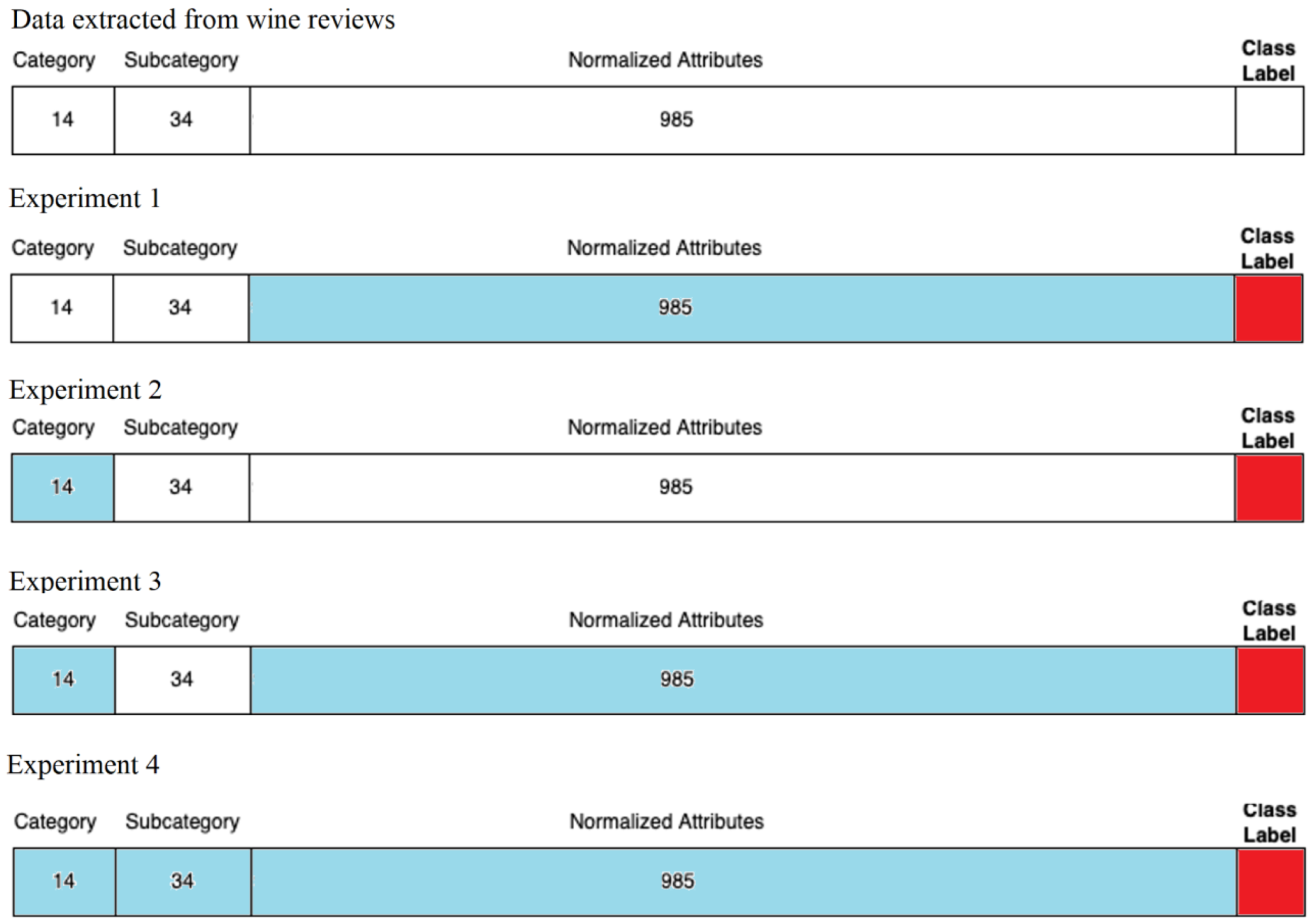
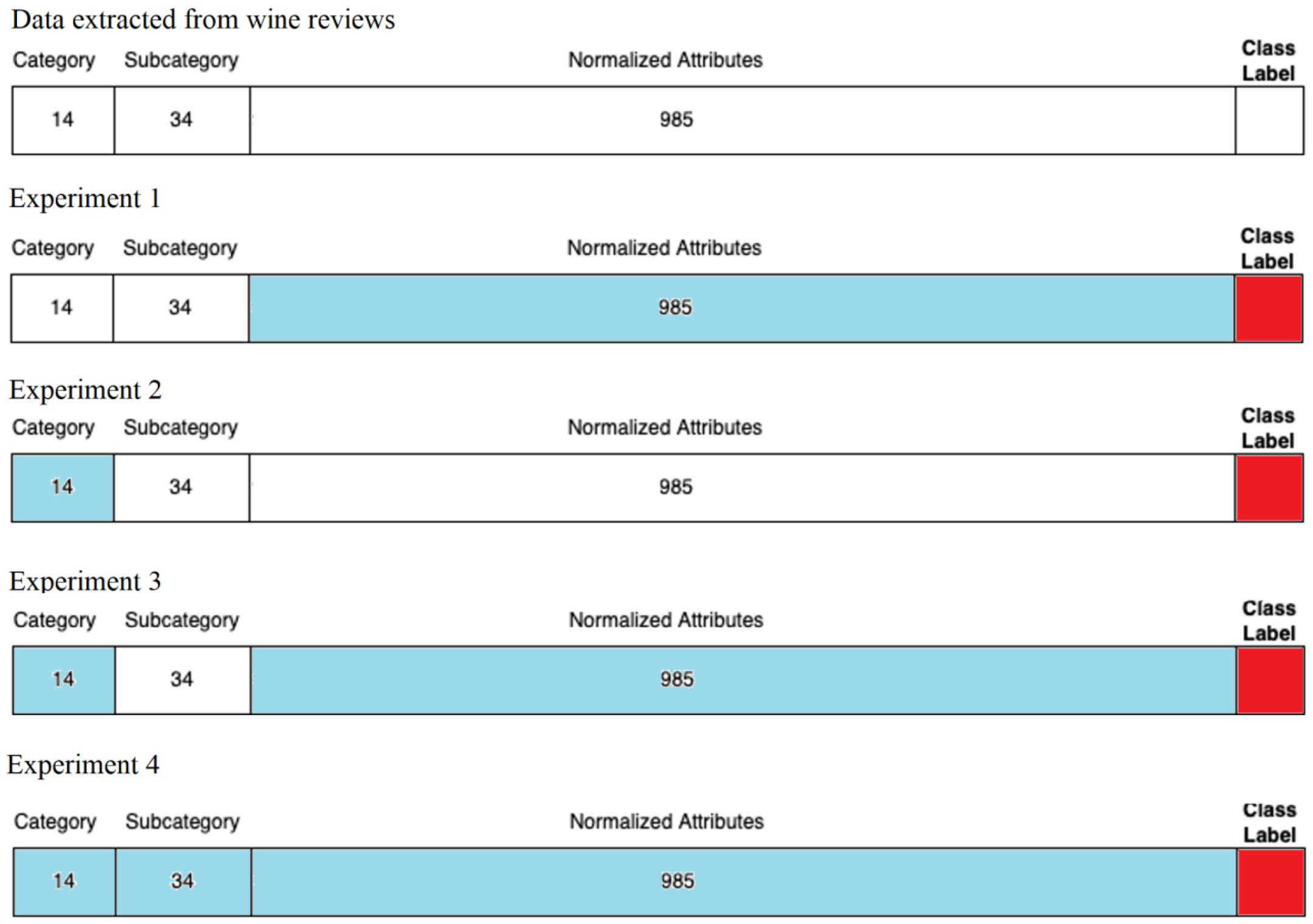
3.2.1. Experiments on Normalized Attributes
3.2.2. Experiments on Category Attributes
3.2.3. Experiments on Category + Normalized Attributes
3.2.4. Experiments on Category + Subcategory + Normalized Attributes
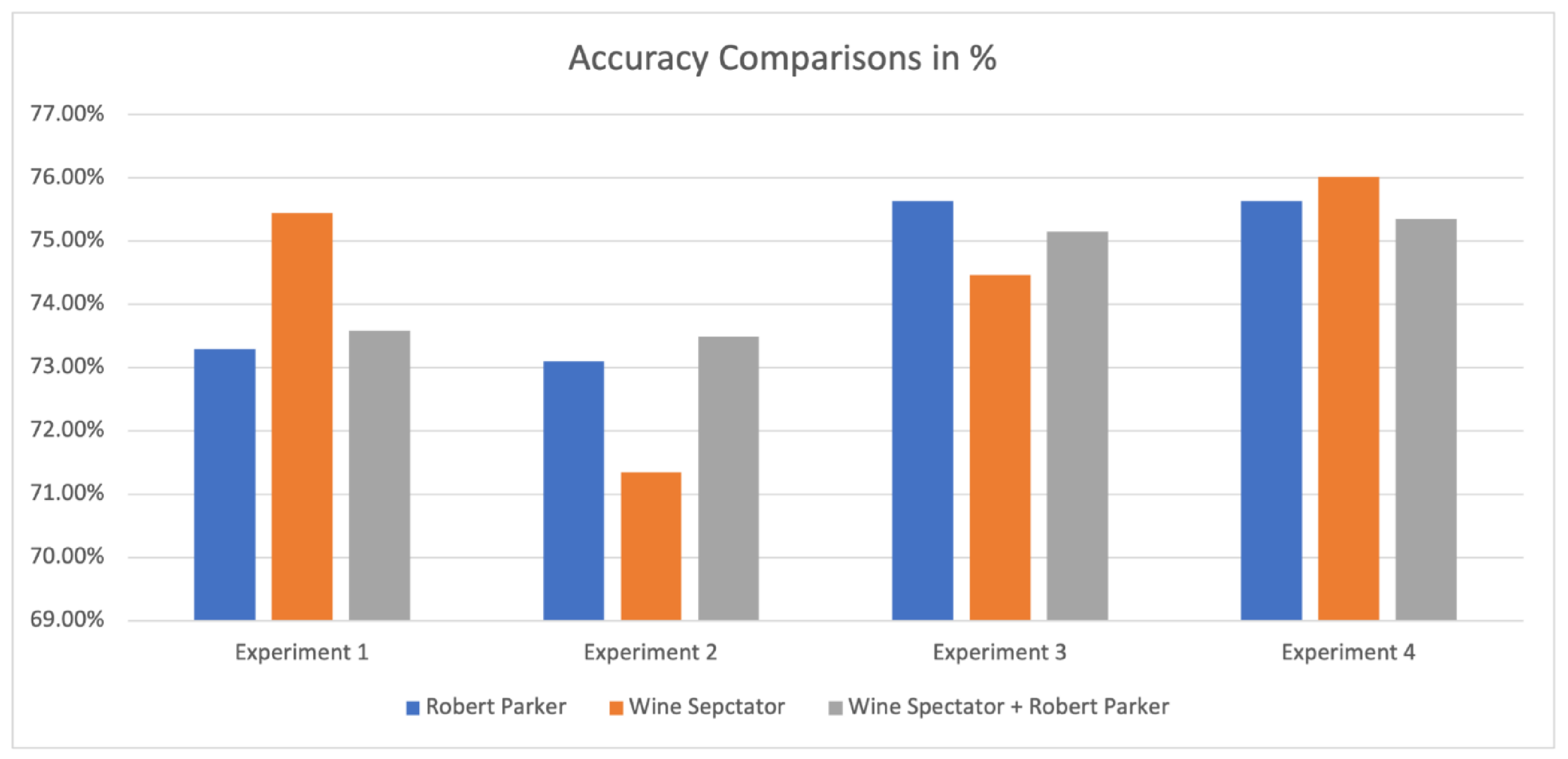
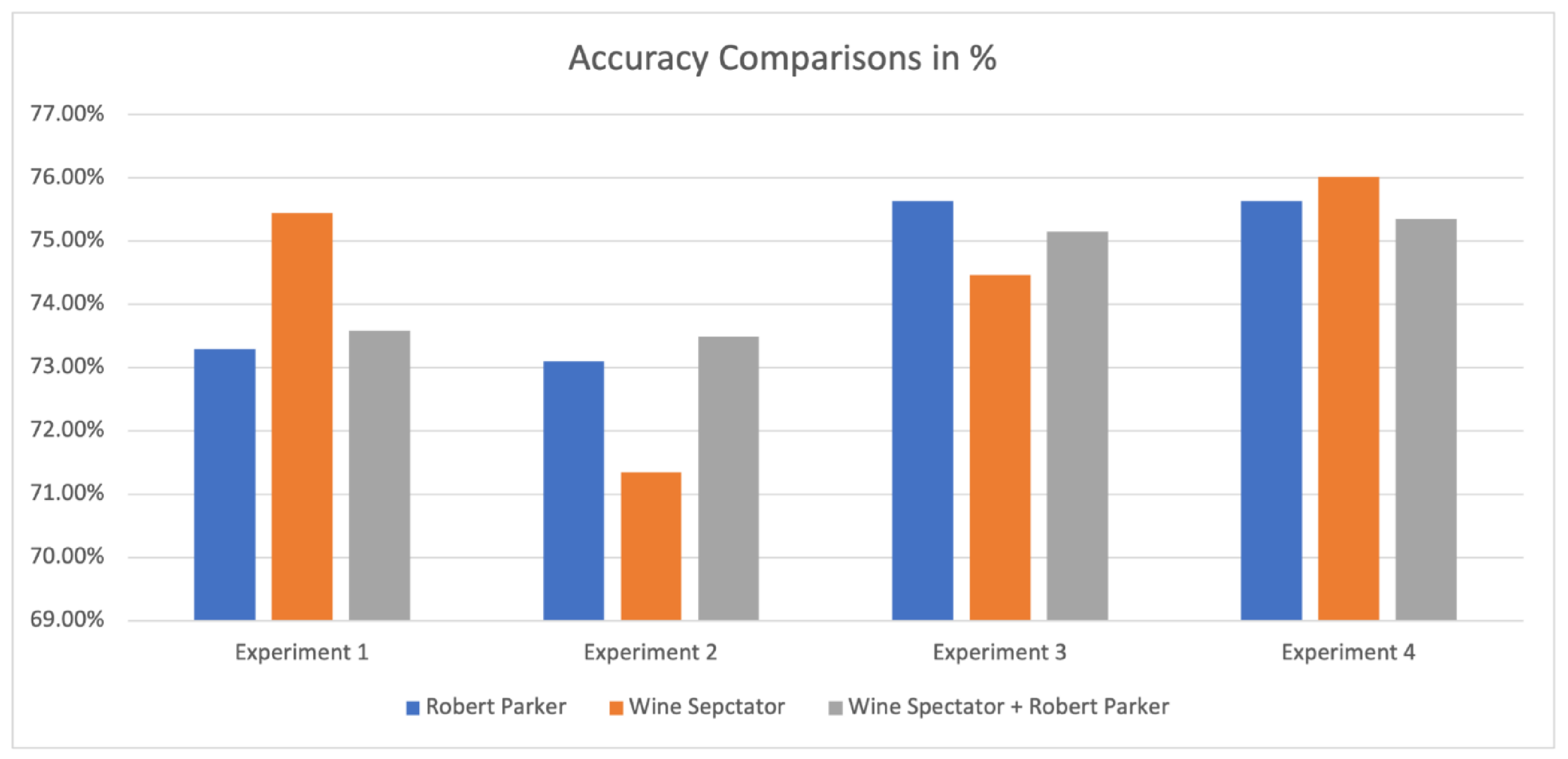
3.2.5. Comparison of All Experiments
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Roca, P. State of the Vitiviniculture World in 2020; International Organization of Vine and Wine: Paris, France, 2021. [Google Scholar]
- Nandagopal, G.; Nair, P.S. Production of Wine from Ginger and Indian Gooseberry and A Comparative Study of Them over Commercial Wine. Am. J. Eng. Res. 2013, 3, 19–38. [Google Scholar]
- Chambers, P.J.; Pretorius, I.S. Fermenting knowledge: The history of winemaking, science and yeast research. EMBO Rep. 2010, 11, 914–920. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schuring, R. RoboSomm Chapter 3: Wine Embeddings and a Wine Recommender. Available online: https://towardsdatascience.com/robosomm-chapter-3-wine-embeddings-and-a-wine-recommender-9fc678f1041e (accessed on 12 November 2020).
- Cortez, P.; Cerdeira, A.; Almeida, F.; Matos, T.; Reis, J.L. Modeling wine preferences by data mining from physicochemical properties. Decis. Support Syst. 2009, 47, 547–553. [Google Scholar] [CrossRef] [Green Version]
- Er, Y.; Atasoy, A. The Classification of White Wine and Red Wine According to Their Physicochemical Qualities. Int. J. Intell. Syst. Appl. Eng. 2016, 4, 23–26. [Google Scholar] [CrossRef]
- Quandt, R.E. A note on a test for the sum of ranksums. J. Wine Econ. 2007, 2, 98–102. [Google Scholar] [CrossRef] [Green Version]
- Ashton, R.H. Improving experts’ wine quality judgments: Two heads are better than one. J. Wine Econ. 2011, 6, 135–159. [Google Scholar] [CrossRef]
- Ashton, R.H. Reliability and consensus of experienced wine judges: Expertise within and between? J. Wine Econ. 2012, 7, 70–87. [Google Scholar] [CrossRef]
- Bodington, J.C. Evaluating wine-tasting results and randomness with a mixture of rank preference models. J. Wine Econ. 2015, 10, 31–46. [Google Scholar] [CrossRef]
- Chen, B.; Velchev, V.; Palmer, J.; Atkison, T. Wineinformatics: A Quantitative Analysis of Wine Reviewers. Fermentation 2018, 4, 82. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.; Rhodes, C.; Crawford, A.; Hambuchen, L. Wineinformatics: Applying data mining on wine sensory reviews processed by the computational wine wheel. In Proceedings of the 2014 IEEE International Conference on Data Mining Workshop, Shenzhen, China, 14 December 2014; pp. 142–149. [Google Scholar]
- Chen, B.; Rhodes, C.; Yu, A.; Velchev, V. The Computational Wine Wheel 2.0 and the TriMax Triclustering in Wineinformatics. In Industrial Conference on Data Mining; Springer: Cham, Switzerland, 2016; pp. 223–238. [Google Scholar]
- McCune, J.; Riley, A.; Chen, B. Clustering in Wineinformatics with Attribute Selection to Increase Uniqueness of Clusters. Fermentation 2021, 7, 27. [Google Scholar] [CrossRef]
- Kwabla, W.; Coulibaly, F.; Zhenis, Y.; Chen, B. Wineinformatics: Can Wine Reviews in Bordeaux Reveal Wine Aging Capability? Fermentation 2021, 7, 236. [Google Scholar] [CrossRef]
- Dong, Z.; Atkison, T.; Chen, B. Wineinformatics: Using the Full Power of the Computational Wine Wheel to Understand 21st Century Bordeaux Wines from the Reviews. Beverages 2021, 7, 3. [Google Scholar] [CrossRef]
- Hommerberg, C. Persuasiveness in the Discourse of Wine: The Rhetoric of Robert Parker. Ph.D. Thesis, Linnaeus University Press, Kalmar, Sweden, 2011. [Google Scholar]
- Wine Spectator. Available online: https://www.winespectator.com (accessed on 1 December 2021).
- Valentin, D.V. Wineinformatics: A Quantitative Analysis of Wine Reviewers. Master’s Thesis, University of Central Arkansas, Conway, AR, USA, 2017. [Google Scholar]
- Chen, B. Wineinformatics: 21st Century Bordeaux Wines Dataset. IEEE Dataport. Available online: https://ieee-dataport.org/open-access/wineinformatics-21st-century-bordeaux-wines-dataset (accessed on 28 March 2022).
- Robert Parker’s 100-Point Wines. Available online: Wine-Searcher.com (accessed on 1 December 2021).
- Marter, G. Robert Parker’s Wine Advocate and the Consequential Pricing of Provençal Wines. Bachelor’s Thesis, Scripps College, Claremont, CA, USA, 2017; p. 973. [Google Scholar]
- 100-Point Wines|Wine Spectator. Available online: https://www.winespectator.com/articles/scoring-scale (accessed on 1 December 2021).
- Dong, Z.; Guo, X.; Rajana, S.; Chen, B. Understanding 21st Century Bordeaux Wines from Wine Reviews Using Naïve Bayes Classifier. Beverages 2020, 6, 5. [Google Scholar] [CrossRef] [Green Version]
- Patten, T.; Jacobs, P. Natural-language processing. IEEE Expert 1994, 9, 35. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Liu, Z. A method of SVM with Normalization in Intrusion Detection. Procedia Environ. Sci. 2011, 11, 256–262. [Google Scholar] [CrossRef] [Green Version]
- Patro, S.G.K.; Sahu, K.K. Normalization: A Preprocessing Stage. arXiv 2015, arXiv:1503.06462. [Google Scholar] [CrossRef]
- Suykens, K.J.A.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- RayI, S. SVM: Support Vector Machine Algorithm in Machine Learning. 23 November 2020. Available online: https://www.analyticsvidhya.com/blog/2017/09/understaing-support-vector-machine-example-code/ (accessed on 28 November 2020).
- Yu, Y.; Feng, Y. Modified Cross-Validation for Penalized High-Dimensional Linear Regression Models. J. Comput. Graph. Stat. 2014, 23, 1009–1027. [Google Scholar] [CrossRef] [Green Version]
- Picard, R.R.; Cook, R.D. Cross-Validation of Regression Models. J. Am. Stat. Assoc. 1984, 79, 575–583. [Google Scholar] [CrossRef]
- Palmer, J. Multi-Target Classification and Regression in Wineinformatics; University of Central Arkansas: Conway, AR, USA, 2018. [Google Scholar]
- Yang, C.; Yuan, K.; Zhu, Q.; Yu, W.; Li, Z. Multi-expert learning of adaptive legged locomotion. Sci. Robot. 2020, 5, eabb2174. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Confusion Matrix | Predicted: 95 + | Predicted: 94 − |
|---|---|---|
| Actual: 95 + | TP | FN |
| Actual: 94 − | FP | TN |
| Hand-Extracted Attributes | Program-Extracted Attributes | Common Attributes |
|---|---|---|
| powerful, blackcurrant, black raspberries, blueberry, pie, melted chocolate, aniseed, camphor, kirsch, subtle, floral, full-bodied, concentrated, bold, seductive, fine-grained, silt-like tannins, jam-packed, tightly wound, fruit, layers, finishing, wonderful, mineral, sparks, magic, | powerful, black raspberries, blueberry, pie, melted chocolate, kirsch, subtle, floral, full-bodied, concentrated, bold, seductive, jam-packed, tightly wound, fruit, layers, finishing, wonderful, mineral, sparks, purple color, tannins, explodes, | powerful, black raspberries, blueberry, pie, melted chocolate, kirsch, subtle, floral, full-bodied, concentrated, bold, seductive, jam-packed, tightly wound, fruit, layers, finishing, wonderful, mineral, sparks, |
| Total count: 26 | Total count: 23 | Total count: 20 |
| Normalized Attributes | Robert Parker (513 Wines) | Wine Spectator (513 Wines) | Robert Parker and Wine Spectator (513 + 513 = 1026 Wines) |
|---|---|---|---|
| Accuracy | 73.29% | 75.44% | 73.59% |
| Sensitivity | 49.75% | 54.1% | 53.42% |
| Specificity | 73.74% | 77.42% | 75.72% |
| Precision | 72.06% | 70.21% | 68.35% |
| Categories | Robert Parker (513 Wines) | Wine Spectator (513 Wines) | Robert Parker and Wine Spectator (513 + 513 = 1026 Wines) |
|---|---|---|---|
| Accuracy | 73.1% | 71.35% | 73.49% |
| Sensitivity | 40.61% | 34.43% | 41.32% |
| Specificity | 71.6% | 71.63% | 72.8% |
| Precision | 79.21% | 70% | 76.21% |
| Normalized Attributes Categories | Robert Parker (513 Wines) | Wine Spectator (513 Wines) | Robert Parker and Wine Spectator (513 + 513 = 1026 Wines) |
|---|---|---|---|
| Accuracy | 75.63% | 74.46% | 75.15% |
| Sensitivity | 52.79% | 50.27% | 55% |
| Specificity | 75.33% | 76.12% | 76.67% |
| Precision | 76.47% | 69.7% | 71.33% |
| Normalized Attributes. Categories and Subcategories | Robert Parker (513 Wines) | Wine Spectator (513 Wines) | Robert Parker and Wine Spectator (513 + 513 = 1026 Wines) |
|---|---|---|---|
| Accuracy | 75.63% | 76.02% | 75.35% |
| Sensitivity | 59.76% | 51.91% | 55% |
| Specificity | 74.81% | 77.02% | 76.73% |
| Precision | 78.12% | 73.08% | 71.82% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, Q.; Whiting, B.; Chen, B. Wineinformatics: Comparing and Combining SVM Models Built by Wine Reviews from Robert Parker and Wine Spectator for 95 + Point Wine Prediction. Fermentation 2022, 8, 164. https://doi.org/10.3390/fermentation8040164
Tian Q, Whiting B, Chen B. Wineinformatics: Comparing and Combining SVM Models Built by Wine Reviews from Robert Parker and Wine Spectator for 95 + Point Wine Prediction. Fermentation. 2022; 8(4):164. https://doi.org/10.3390/fermentation8040164
Chicago/Turabian StyleTian, Qiuyun, Brittany Whiting, and Bernard Chen. 2022. "Wineinformatics: Comparing and Combining SVM Models Built by Wine Reviews from Robert Parker and Wine Spectator for 95 + Point Wine Prediction" Fermentation 8, no. 4: 164. https://doi.org/10.3390/fermentation8040164
APA StyleTian, Q., Whiting, B., & Chen, B. (2022). Wineinformatics: Comparing and Combining SVM Models Built by Wine Reviews from Robert Parker and Wine Spectator for 95 + Point Wine Prediction. Fermentation, 8(4), 164. https://doi.org/10.3390/fermentation8040164