
An Optimized Hybrid Approach for Feature Selection Based on Chi-Square and Particle Swarm Optimization Algorithms


Abstract
1. Introduction
- I.
- An evolutionary algorithm takes advantage of processes such as reproduction, mutation, recombination, and selection, which are modelled after biological evolution. The fitness function identifies the quality of candidate solutions to the optimization problem, which act as members of a population. The original population changes after several iterations of the evolutionary algorithm, moving towards global optimization [13].
- II.
- Swarm intelligence: The foundation of swarm intelligence is self-organizing group behavior, which involves the intelligence that is generated by the collective contributions of numerous individuals. Since these connections, as seen in nature like in bees or ants, do not exist naturally in humans, technology uses swarm artificial intelligence (AI) to provide feedback to human members as demonstrated in [14,15]. Collective behavior shows that united systems do better than the majority of single individuals. Ad hoc data and sharing are dynamically generated by the group, and the basis of agreement is the dissemination of collective wisdom. Briefly stated, swarm intelligence relies on the “knowledge of the public”, and is desperately needed to address a myriad of questions [16].
2. Related Works
3. Background
3.1. Overview of PSO
| Algorithm 1. PSO pseudo code: |
| 1: initialize population of particles and velocities 2: while t < maximum number of iterations 3: calculate the fitness of all particles 4 updating position and fitness of particles 5: choose the particle of best fitness value and the Gbest of all particles 6: for each particle 7: calculate the velocity of particle by Equation (2) 8: update particle position by Equation (1) 9: end for 10: End while |
3.2. Overview of GWO
| Algorithm 2. GWO pseudo code: |
| 1: initialize grey wolf populations 2: initialize a, A and c values 3: calculate the fitness of each search agent 4: = The best search agent = The second best search agent = The Third best search agent 5: while t < maximum number of iterations 6: for each GWO search agent 7: update the position of current search agent by Equation (5) 8: end for 9: update A, c, w 10: calculate the fitness of all search agents 11: update 12: End while |
3.3. Overview of Chi-Square
4. Proposed Approach
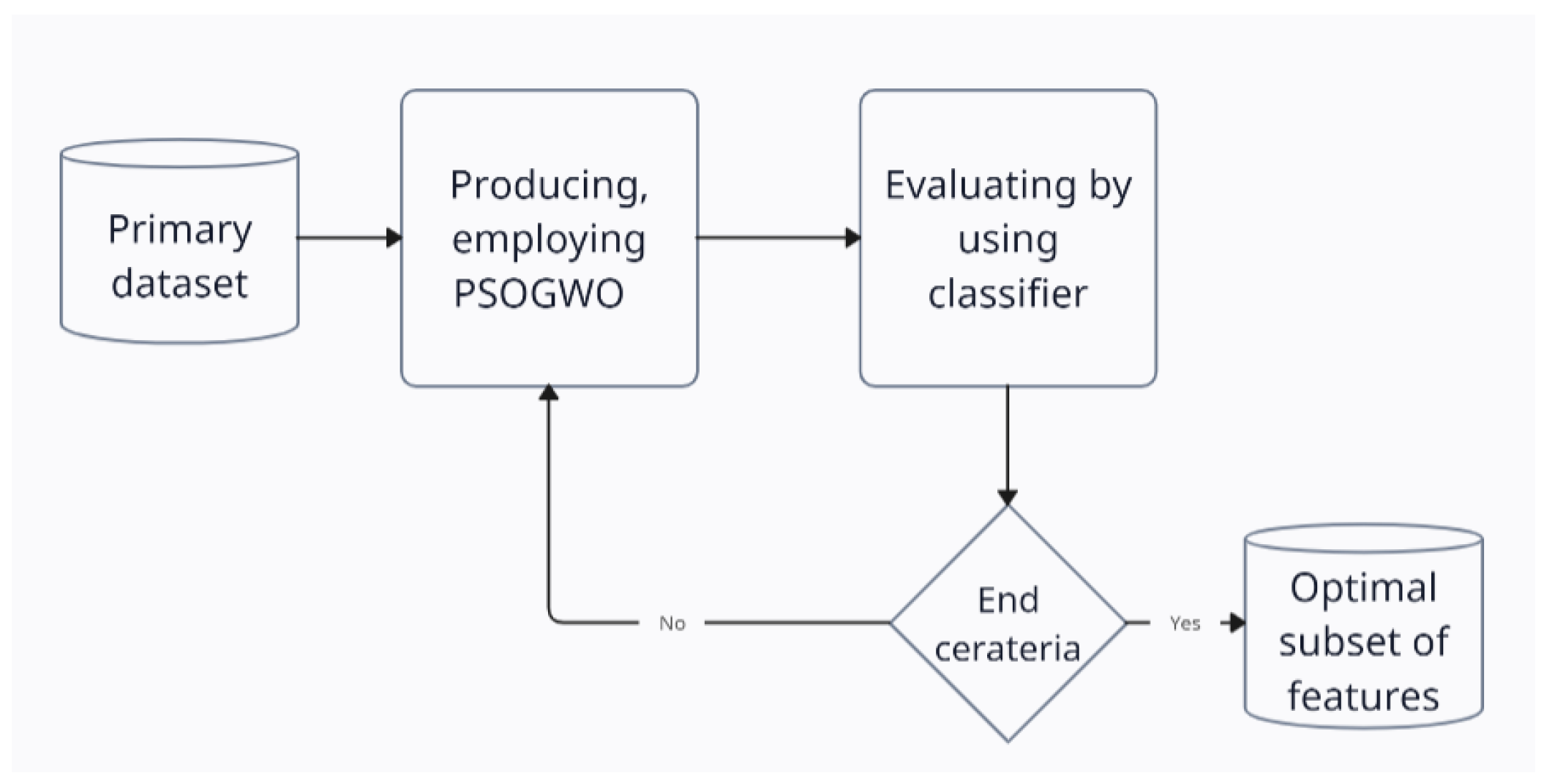
4.1. PSOGWO (Phase 1)
| Algorithm 3.Chi square-PSOGWO pseudocode: |
| 1: Initialization dataset #Phase 2 2: Rank features using Chi-square filter method 3: indicate the chosen features in the minimized dataset #Phase 1 4: initialize population of particles and velocities 5: initialize grey wolf populations 6: initialize w, a, A and c values 7: calculate the fitness of each search agent and particle 8: while t < maximum number of iterations 9: for each particle 10: update velocity by Equation (2) update position of particles by Equation (1) 11: end for 12: for each GWO search agent 13: update the position of current search agent by Equation (5) 14: end for 15: compare fitness of Gbest, Localbest and and update Gbest, by the best values respectively (Gbest, Localbest = 16: update A, c, w 17: End while |
4.2. Chi-Square PSOGWO (Phase 2)
5. Experiments and Results
5.1. Parameter Settings
5.2. General Data Settings
5.3. Experiment 1
5.3.1. Dataset Settings
5.3.2. Results and Discussion
5.4. Experiment 2
5.4.1. Dataset Settings
5.4.2. Result and Discussion
5.5. Experiment 3
5.5.1. Dataset Settings
5.5.2. Results and Discussion
6. Summary and Observations
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mahapatra, M.; Majhi, S.K.; Dhal, S.K. MRMR-SSA: A hybrid approach for optimal feature selection. Evol. Intell. 2022, 15, 2017–2036. [Google Scholar] [CrossRef]
- Di Mauro, M.; Galatro, G.; Fortino, G.; Liotta, A. Supervised feature selection techniques in network intrusion detection: A critical review. Eng. Appl. Artif. Intell. 2021, 101, 104216. [Google Scholar] [CrossRef]
- Liu, B.; Yu, H.; Zeng, X.; Zhang, D.; Gong, J.; Tian, L.; Qian, J.; Zhao, L.; Zhang, S.; Liu, R. Lung cancer detection via breath by electronic nose enhanced with a sparse group feature selection approach. Sens. Actuators B Chem. 2021, 339, 129896. [Google Scholar] [CrossRef]
- Zhao, H.; Liu, Z.; Yao, X.; Yang, Q. A machine learning-based sentiment analysis of online product reviews with a novel term weighting and feature selection approach. Inf. Process. Manag. 2021, 58, 102656. [Google Scholar] [CrossRef]
- Sen, S.; Saha, S.; Chatterjee, S.; Mirjalili, S.; Sarkar, R. A bi-stage feature selection approach for COVID-19 prediction using chest CT images. Appl. Intell. 2021, 51, 8985–9000. [Google Scholar] [CrossRef] [PubMed]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Othman, G.; Zeebaree, D.Q. The applications of discrete wavelet transform in image processing: A review. J. Soft Comput. Data Min. 2020, 1, 31–43. [Google Scholar]
- Omuya, E.O.; Okeyo, G.O.; Kimwele, M.W. Feature selection for classification using principal component analysis and information gain. Expert Syst. Appl. 2021, 174, 114765. [Google Scholar] [CrossRef]
- Bahassine, S.; Madani, A.; Al-Sarem, M.; Kissi, M. Feature selection using an improved Chi-square for Arabic text classification. J. King Saud Univ. -Comput. Inf. Sci. 2020, 32, 225–231. [Google Scholar] [CrossRef]
- Tubishat, M.; Idris, N.; Shuib, L.; Abushariah, M.A.; Mirjalili, S. Improved Salp Swarm Algorithm based on opposition based learning and novel local search algorithm for feature selection. Expert Syst. Appl. 2020, 145, 113122. [Google Scholar] [CrossRef]
- Adamu, A.; Abdullahi, M.; Junaidu, S.B.; Hassan, I.H. An hybrid particle swarm optimization with crow search algorithm for feature selection. Mach. Learn. Appl. 2021, 6, 100108. [Google Scholar] [CrossRef]
- BinSaeedan, W.; Alramlawi, S. CS-BPSO: Hybrid feature selection based on chi-square and binary PSO algorithm for Arabic email authorship analysis. Knowl.-Based Syst. 2021, 227, 107224. [Google Scholar] [CrossRef]
- Gong, D.; Xu, B.; Zhang, Y.; Guo, Y.; Yang, S. A similarity-based cooperative co-evolutionary algorithm for dynamic interval multiobjective optimization problems. IEEE Trans. Evol. Comput. 2019, 24, 142–156. [Google Scholar] [CrossRef]
- Wang, M.; Wu, C.; Wang, L.; Xiang, D.; Huang, X. A feature selection approach for hyperspectral image based on modified ant lion optimizer. Knowl.-Based Syst. 2019, 168, 39–48. [Google Scholar] [CrossRef]
- Hanbay, K. A new standard error based artificial bee colony algorithm and its applications in feature selection. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 4554–4567. [Google Scholar] [CrossRef]
- Chang, A.C. Intelligence-Based Medicine: Artificial Intelligence and Human Cognition in Clinical Medicine and Healthcare; Academic Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Papazoglou, G.; Biskas, P. Review and Comparison of Genetic Algorithm and Particle Swarm Optimization in the Optimal Power Flow Problem. Energies 2023, 16, 1152. [Google Scholar] [CrossRef]
- Cao, Y.; Liu, G.; Sun, J.; Bavirisetti, D.P.; Xiao, G. PSO-Stacking improved ensemble model for campus building energy consumption forecasting based on priority feature selection. J. Build. Eng. 2023, 72, 106589. [Google Scholar] [CrossRef]
- Abd Elaziz, M.; Al-qaness, M.A.; Dahou, A.; Ibrahim, R.A.; Abd El-Latif, A.A. Intrusion detection approach for cloud and IoT environments using deep learning and Capuchin Search Algorithm. Adv. Eng. Softw. 2023, 176, 103402. [Google Scholar] [CrossRef]
- Qin, J. Analysis of factors influencing the image perception of tourism scenic area planning and development based on big data. Appl. Math. Nonlinear Sci. 2023; ahead of print. [Google Scholar] [CrossRef]
- Yawale, N.M.; Sahu, N.; Khalsa, N.N. Design of a Hybrid GWO CNN Model for Identification of Synthetic Images via Transfer Learning Process. Int. J. Intell. Eng. Syst. 2023, 16, 292–301. [Google Scholar]
- Seyyedabbasi, A. Binary Sand Cat Swarm Optimization Algorithm for Wrapper Feature Selection on Biological Data. Biomimetics 2023, 8, 310. [Google Scholar] [CrossRef]
- Zivkovic, M.; Stoean, C.; Chhabra, A.; Budimirovic, N.; Petrovic, A.; Bacanin, N. Novel improved salp swarm algorithm: An application for feature selection. Sensors 2022, 22, 1711. [Google Scholar] [CrossRef] [PubMed]
- Zouache, D.; Abdelaziz, F.B. A cooperative swarm intelligence algorithm based on quantum-inspired and rough sets for feature selection. Comput. Ind. Eng. 2018, 115, 26–36. [Google Scholar] [CrossRef]
- Sheykhizadeh, S.; Naseri, A. An efficient swarm intelligence approach to feature selection based on invasive weed optimization: Application to multivariate calibration and classification using spectroscopic data. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2018, 194, 202–210. [Google Scholar] [CrossRef] [PubMed]
- Chen, K.; Zhou, F.-Y.; Yuan, X.-F. Hybrid particle swarm optimization with spiral-shaped mechanism for feature selection. Expert Syst. Appl. 2019, 128, 140–156. [Google Scholar] [CrossRef]
- Mostafa, R.R.; Ewees, A.A.; Ghoniem, R.M.; Abualigah, L.; Hashim, F.A. Boosting chameleon swarm algorithm with consumption AEO operator for global optimization and feature selection. Knowl.-Based Syst. 2022, 246, 108743. [Google Scholar] [CrossRef]
- El-Kenawy, E.-S.; Eid, M. Hybrid gray wolf and particle swarm optimization for feature selection. Int. J. Innov. Comput. Inf. Control 2020, 16, 831–844. [Google Scholar]
- Alrefai, N.; Ibrahim, O. Optimized feature selection method using particle swarm intelligence with ensemble learning for cancer classification based on microarray datasets. Neural Comput. Appl. 2022, 34, 13513–13528. [Google Scholar] [CrossRef]
- Ibrahim, R.A.; Ewees, A.A.; Oliva, D.; Abd Elaziz, M.; Lu, S. Improved salp swarm algorithm based on particle swarm optimization for feature selection. J. Ambient Intell. Humaniz. Comput. 2019, 10, 3155–3169. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Thakkar, A.; Lohiya, R. Attack classification using feature selection techniques: A comparative study. J. Ambient Intell. Humaniz. Comput. 2021, 12, 1249–1266. [Google Scholar] [CrossRef]
- Guha, R.; Chatterjee, B.; Khalid Hassan, S.; Ahmed, S.; Bhattacharyya, T.; Sarkar, R. Py_fs: A python package for feature selection using meta-heuristic optimization algorithms. In Computational Intelligence in Pattern Recognition: Proceedings of CIPR 2021; Springer: Singapore, 2022; pp. 495–504. [Google Scholar]
- Gad, A.G. Particle swarm optimization algorithm and its applications: A systematic review. Arch. Comput. Methods Eng. 2022, 29, 2531–2561. [Google Scholar] [CrossRef]
- Deepa, B.; Ramesh, K. Epileptic seizure detection using deep learning through min max scaler normalization. Int. J. Health Sci 2022, 6, 10981–10996. [Google Scholar] [CrossRef]
- Available online: https://archive.ics.uci.edu/ml/datasets.php (accessed on 1 May 2022).
- Available online: https://www.kaggle.com/ (accessed on 1 April 2022).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter settings | |
| Number of search agents | 30 |
| Maximum number of iterations | 100 |
| Number of runs for a single case | 10 |
| 0.5 | |
| GWO | r1, r2 are random vectors in [0, 1] components of 2 and linearly decrease to 0 over the course of iterations |
| PSO | w starts from 1.0 and decreases by iterations of 1.0—(iter_no/max_iter) r1, r2 are random vectors in [0, 1] c1, c2 = 1 |
| Chi-square | The standard parameters for original chi-square algorithm were used Selection method = numTopFeatures Top features = Experts’ handpick |
| No. of Features | Category | No. of Records | Category |
|---|---|---|---|
| [0, 18] | Lower (L) | [0, 300] | Lower (L) |
| [19, 46] | Medium (M) | [301, 500] | Medium (M) |
| [50, ∞] | Higher (H) | [501, ∞] | Higher (H) |
| NO. | Dataset | Features | Records | Class Variables |
|---|---|---|---|---|
| 1. | Ionosphere | 34 | 351 | 2 |
| 2. | Hepatitis | 19 | 155 | 2 |
| 3. | Heart | 13 | 270 | 2 |
| 4. | Breast cancer | 9 | 683 | 2 |
| 5. | Sonar | 60 | 208 | 2 |
| 6. | Lymphography | 19 | 148 | 4 |
| 7. | Waveform | 21 | 5000 | 3 |
| No. | Dataset | SSA | SSAPSO | GA | BAT | PSO | PSOGWO | Notes | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Feature | Records | Classes | ||||||||
| 1. | Ionosphere | 93.9 | 95.1 | 91.6 | 90.4 | 94.9 | 95.3 | M | M | 2 |
| 2. | Hepatitis | 71.7 | 74.8 | 64.3 | 62.9 | 72.1 | 85.3 | M | L | 2 |
| 3. | Waveform | 78.49 | 79.13 | 78.38 | 79.29 | 79.47 | 87.3 | M | H | 3 |
| 4. | Heart | 82.3 | 84.7 | 79.0 | 76.1 | 83.1 | 83.3 | L | L | 2 |
| 5. | Breast cancer | 96.3 | 97.8 | 97.5 | 97.2 | 97.6 | 74.3 | L | H | 2 |
| 6. | Sonar | 94.43 | 96.20 | 96.70 | 95.27 | 96.94 | 87.4 | H | L | 2 |
| 7. | Lymphography | 94.43 | 90.20 | 96.70 | 95.27 | 97.6 | 88.2 | M | L | 4 |
| NO. | Dataset | Records | Features | Class Variables | Filter Selection |
|---|---|---|---|---|---|
| 1. | Abalone | 4177 | 8 | 3 | 6 |
| 2. | Breast cancer | 569 | 30 | 2 | 15 |
| 3. | Banknote authentication | 1372 | 5 | 2 | 4 |
| 4. | Car evaluation | 1727 | 6 | 4 | 5 |
| 5. | Heart disease | 303 | 13 | 2 | 9 |
| 6. | Habitats | 142 | 19 | 2 | 10 |
| 7. | Iris | 150 | 4 | 3 | 3 |
| 8. | Lymphography | 148 | 18 | 4 | 10 |
| 9. | Wine | 178 | 13 | 3 | 10 |
| NO. | Dataset | MRMR-SSA | MRMR-GA | MRMR-ALO | MRMR-ACO | MRMR-PSO | Chi2-PSOGWO | Notes | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Features | Records | Class Attributes | ||||||||
| 1 | Abalone | 78.87 | 77.73 | 54.33 | 76.57 | 56.38 | 53.54 | L | H | 3 |
| 2. | Breast cancer | 93.69 | 89.08 | 92.72 | 93.89 | 91.83 | 97.24 | M | H | 2 |
| 3. | Banknote authentication | 95.63 | 88.17 | 94.42 | 96.12 | 94.42 | 87.10 | L | H | 2 |
| 4. | Car evaluation | 73.87 | 73.33 | 70.22 | 74.82 | 70.71 | 61.01 | L | H | 4 |
| 5. | Heart disease | 82.98 | 80.67 | 84.44 | 82.98 | 81.02 | 95.961 | L | M | 2 |
| 6. | Habitats | 88.53 | 80.09 | 84.68 | 89.71 | 88.98 | 92.5 | M | L | 2 |
| 7. | Iris | 94.42 | 94.42 | 96.84 | 87.73 | 96.60 | 95 | L | L | 3 |
| 8. | Lymphography | 86.89 | 83.33 | 80.00 | 82.22 | 84.95 | 81.33 | M | L | 4 |
| 9. | Wine | 95.63 | 95.72 | 86.89 | 92.72 | 92.72 | 99.44 | L | L | 3 |
| Datasets | PSO | PSOGWO | Chi2-PSOGWO | Features | Records | Classes |
|---|---|---|---|---|---|---|
| Breast cancer | 97.6 | 74.3 | 75.3 | L | L | 2 |
| Sonar | 96.94 | 87.4 | 67.7 | L | H | 2 |
| Ionosphere | 94.9 | 95.3 | 94.7 | M | M | 2 |
| Hepatitis | 72.1 | 85.3 | 81.3 | M | M | 2 |
| Heart | 83.1 | 83.3 | 82 | M | L | 2 |
| Waveform | 79.47 | 87.3 | 81.72 | M | H | 3 |
| Lymphography | 87.425 | 88.2 | 84 | M | L | 4 |
| Datasets | PSOGWO | Chi2-PSOGWO | Features | Records | Classes |
|---|---|---|---|---|---|
| Ionosphere | 649.55 | 412.97 | M | M | 2 |
| Hepatitis | 65.5 | 20.8 | M | M | 2 |
| Heart | 12.77 | 9.2 | M | L | 2 |
| Breast cancer | 16.9 | 19.7 | L | L | 2 |
| Sonar | 17.11 | 16.7 | L | H | 2 |
| Lymphography | 55.946 | 14.49 | M | L | 4 |
| Waveform | 649.55 | 412.965 | M | H | 3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdo, A.; Mostafa, R.; Abdel-Hamid, L. An Optimized Hybrid Approach for Feature Selection Based on Chi-Square and Particle Swarm Optimization Algorithms. Data 2024, 9, 20. https://doi.org/10.3390/data9020020
Abdo A, Mostafa R, Abdel-Hamid L. An Optimized Hybrid Approach for Feature Selection Based on Chi-Square and Particle Swarm Optimization Algorithms. Data. 2024; 9(2):20. https://doi.org/10.3390/data9020020
Chicago/Turabian StyleAbdo, Amani, Rasha Mostafa, and Laila Abdel-Hamid. 2024. "An Optimized Hybrid Approach for Feature Selection Based on Chi-Square and Particle Swarm Optimization Algorithms" Data 9, no. 2: 20. https://doi.org/10.3390/data9020020
APA StyleAbdo, A., Mostafa, R., & Abdel-Hamid, L. (2024). An Optimized Hybrid Approach for Feature Selection Based on Chi-Square and Particle Swarm Optimization Algorithms. Data, 9(2), 20. https://doi.org/10.3390/data9020020