
DataPLAN: A Web-Based Data Management Plan Generator for the Plant Sciences

 , , , , , and
, , , , , and
Abstract
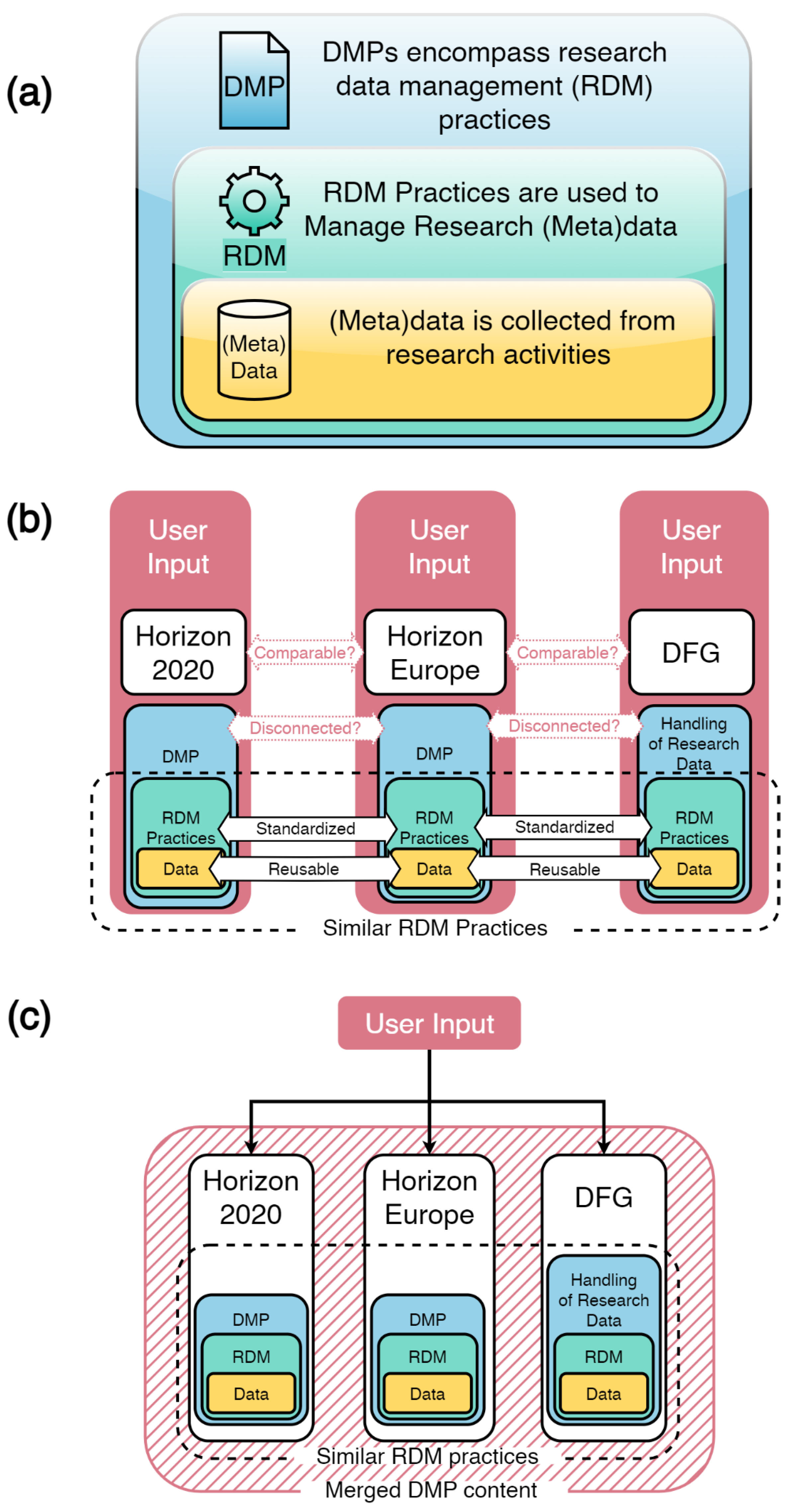
:1. Introduction
2. Materials and Methods
2.1. DMP Template and Questionnaire Design
2.2. Software Development
2.3. Testing
3. Results
3.1. DMP Content Generation and Modification Using DataPLAN
3.1.1. Incorporation of RDM Practices and Platforms for the Plant Sciences

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Genomics | Transcriptomics | Proteomics | Metabolomics | Plant Phenotyping | |
|---|---|---|---|---|---|
| Minimum information standard | MinSEQe [86] | MIAME [45] MinSEQe [86] | MIAPE [44] | MSI [84] | MIAPPE [43] |
| Endpoint repositories | ENA [87] EBI NCBI [88] DDBJ [89] SRA [90] GenBank [91] | GEO [88] SRA [90] | PRIDE ProteomeXchange [92] | Metabolights [93] | e!DAL-PGP [46] Gnpis [94] EURISCO [95] |
| RDM platform | DataPLANT [59] | ||||
3.1.2. Categories of Prewritten DMP Content
3.2. User Interface
3.2.1. Main Menu
3.2.2. Questionnaire (Right Panel)
3.2.3. Live Preview (Left Panel)
3.3. DataPLAN Workflow
3.3.1. Saving and Importing Data
3.3.2. Main Output (DMP-Related Documents)
3.3.3. Warnings
3.4. Testing and Validating DataPLAN According to FAIR Principles of Software
3.4.1. Findability of the Software
3.4.2. Accessibility of the Software
3.4.3. Interoperability of the Software
3.4.4. Reusability of the Software
4. Discussion
4.1. Comparison with Existing DMP Tools
| Name | Programming Language | Funding Body Templates | Customizable | Templates | Content Preview | Open Source |
|---|---|---|---|---|---|---|
| Data Stewardship Wizard (DSW) [18] | Haskell ELM | 3 | Yes, with programming | Yes | Yes [107] | No |
| DMP Canvas Generator [108] | JavaScript | 0 | No | No | No | No |
| DMPonline [19] | Ruby JavaScript | 18 | Yes, with programming | No | Yes [29] | No |
| DMP tools [2] | Ruby JavaScript | 19 | Yes, with programming | No | Yes [29] | No |
| DMProadmap | Ruby JavaScript | 19 | Yes, with programming | No | Yes [29] | No |
| RDMO [20] | Python (Django) and JavaScript (AngularJS) | 6 | Yes, with programming | No | Yes [30] | Yes |
| Research Data Manager (UQRDM) [21] | Not available | 0 | Not available | No | No | No |
| DataWiz [22] | JAVA | 0 | Not available | No | Yes [32] | No |
| ezDMP [27] | Not available | 0 | No | No | No | No |
| ARGOS [23] | JAVA and Typescript | 0 | Yes | No | Yes [29] | No |
| UWADMP [26] | Not available | 0 | NA | No | No | No |
| DMPTY [25] | JavaScript, HTML | 0 | No | Yes | No | No |
| easyDMP [24] | Python (Django) | 1 | No | No | No | No |
| DAMAP [39] | Typescript, Java | 1 | NA | NA | No | Yes |
| DataPLAN (the tool in this paper) | Frontend: JavaScript No backend | 3 | Yes, no need for programming | Yes | Yes | Yes |
4.1.1. Technical Comparison
4.1.2. Content Comparison
4.2. Outlook
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ARC | annotated research context |
| DDBJ | DNA Data Bank of Japan |
| DFG | German Research Foundation (Deutsche Forschungsgemeinschaft) |
| DMP | data management plan |
| EBI | European Bioinformatics Institute |
| ENA | European Nucleotide Archive |
| EU | European Union |
| FAIR | findable, accessible, interoperable and reusable |
| GDPR | EU General Data Protection Regulation |
| GEO | Gene Expression Omnibus |
| MIAME | minimal information about a microarray experiment |
| MIAPE | minimum information about a proteomics experiment |
| MIAPPE | minimal information about plant phenotyping experiment |
| MinSEQe | minimum information about a high-throughput sequencing experiment |
| MSI | Metabolomics Standards Initiative |
| NCBI | National Center for Biotechnology Information |
| NFDI | National Research Data Infrastructure (of Germany) |
| PRIDE | Proteomics Identification Database |
| RDM | research data management |
| RNA-Seq | RNA sequencing |
| SRA | Sequence Read Archive |
References
- Jones, S.; Pergl, R.; Hooft, R.; Miksa, T.; Samors, R.; Ungvari, J.; Davis, R.I.; Lee, T. Data Management Planning: How Requirements and Solutions Are Beginning to Converge. Data Intell. 2020, 2, 208–219. [Google Scholar] [CrossRef]
- Sallans, A.; Donnelly, M. DMP Online and DMPTool: Different Strategies Towards a Shared Goal. Int. J. Digit. Curation 2012, 7, 123–129. [Google Scholar] [CrossRef]
- Miksa, T.; Simms, S.; Mietchen, D.; Jones, S. Ten Principles for Machine-Actionable Data Management Plans. PLoS Comput. Biol. 2019, 15, e1006750. [Google Scholar] [CrossRef] [PubMed]
- Stewart, A.J.; Farran, E.K.; Grange, J.A.; Macleod, M.; Munafò, M.; Newton, P.; Shanks, D.R.; UKRN Institutional Leads. Improving Research Quality: The View from the UK Reproducibility Network Institutional Leads for Research Improvement. BMC Res. Notes 2021, 14, 458. [Google Scholar] [CrossRef]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for Scientific Data Management and Stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef]
- Du, X.; Dastmalchi, F.; Ye, H.; Garrett, T.J.; Diller, M.A.; Liu, M.; Hogan, W.R.; Brochhausen, M.; Lemas, D.J. Evaluating LC-HRMS Metabolomics Data Processing Software Using FAIR Principles for Research Software. Metabolomics 2023, 19, 11. [Google Scholar] [CrossRef]
- Gajbe, S.B.; Tiwari, A.; Gopalji; Singh, R.K. Evaluation and Analysis of Data Management Plan Tools: A Parametric Approach. Inf. Process. Manag. 2021, 58, 102480. [Google Scholar] [CrossRef]
- Vieira, A. How to Comply with Horizon Europe Mandate for RDM. Available online: https://www.openaire.eu/how-to-comply-with-horizon-europe-mandate-for-rdm (accessed on 25 September 2023).
- Handling of Research Data. Available online: https://www.dfg.de/en/research_funding/principles_dfg_funding/research_data/ (accessed on 25 September 2023).
- NOT-OD-21-013: Final NIH Policy for Data Management and Sharing. Available online: https://grants.nih.gov/grants/guide/notice-files/NOT-OD-21-013.html (accessed on 25 September 2023).
- Preparing Your Data Management Plan. Available online: https://new.nsf.gov/funding/data-management-plan (accessed on 25 September 2023).
- Data Management Plan (DMP)—Guidelines for researchers. Available online: https://www.snf.ch/en/FAiWVH4WvpKvohw9/topic/research-policies (accessed on 25 September 2023).
- Monastersky, R. Publishing Frontiers: The Library Reboot. Nature 2013, 495, 430–432. [Google Scholar] [CrossRef]
- Tenopir, C.; Birch, B.; Allard, S. Academic Libraries and Research Data Services: Current Practices and Plans for the Future; Association of College and Research Libraries: Chicago, IL, USA, 2012. [Google Scholar]
- Sheikh, A.; Malik, A.; Adnan, R. Evolution of Research Data Management in Academic Libraries: A Review of the Literature. Inf. Dev. 2023. [Google Scholar] [CrossRef]
- Datenmanagementpläne. Available online: https://www.fu-berlin.de/sites/forschungsdatenmanagement/materialien/handreichungen/dmp/index.html (accessed on 25 September 2023).
- Muster Datenmanagementplan für einen DFG-Antrag. Available online: https://www.cms.hu-berlin.de/de/dl/dataman/muster-dmp-dfg/view (accessed on 25 September 2023).
- Pergl, R.; Hooft, R.; Suchánek, M.; Knaisl, V.; Slifka, J. “data Stewardship Wizard”: A Tool Bringing Together Researchers, Data Stewards, and Data Experts around Data Management Planning. Data Sci. J. 2019, 18, 59. [Google Scholar] [CrossRef]
- Getler, M.; Sisu, D.; Jones, S.; Miller, K. DMPonline Version 4.0: User-Led Innovation. Int. J. Digit. Curation 2014, 9, 193–219. [Google Scholar] [CrossRef]
- Engelhardt, C.; Enke, H.; Klar, J.; Ludwig, J.; Neuroth, H. Research Data Management Organiser. In Proceedings of the 19th Conference EGU General Assembly, EGU2017, Vienna, Austria, 23–28 April 2017; p. 15760. [Google Scholar]
- Research Data Manager (RDM). Available online: https://research.uq.edu.au/rmbt/uqrdm (accessed on 25 September 2023).
- Blask, K.; Bölter, R. DataWiz. Available online: https://datawiz.leibniz-psychology.org/DataWiz/ (accessed on 25 September 2023).
- Simpson, P.W. Argos; Month9books: Raleigh, NC, USA, 2016; ISBN 9780996890434. [Google Scholar]
- Sigma, U. EasyDMP. Available online: https://easydmp.sigma2.no/ (accessed on 25 September 2023).
- Trippel, T.; Zinn, C. DMPTY—A Wizard for Generating Data Management Plans. In Proceedings of the Selected Papers from the CLARIN Annual Conference 2015, Wroclaw, Poland, 14–16 October 2015; Linköping University Electronic Press: Linköping, Sweden, 2015; pp. 71–78. [Google Scholar]
- UWA Library Guides: Research Data Management Toolkit: Welcome. Available online: https://guides.library.uwa.edu.au/RDMtoolkit (accessed on 25 September 2023).
- Lehnert, K.; Ferrini, V.L.; Berman, H.; Gabanyi, M.; Stodden, V.; Morton, J.J. ezDMP: Data Management Planning Made Easy. In Proceedings of the AGU Fall Meeting, Washington DC, USA, 10–14 December 2018; Volume 2018, p. ED53C-01. [Google Scholar]
- Neuroth, H.; Engelhardt, C.; Klar, J.; Ludwig, J.; Enke, H. Aktives Forschungsdatenmanagement. ABI Tech. 2018, 38, 55–64. [Google Scholar] [CrossRef]
- Riley, B.; Rust, S.; Morrice, G.; Carrick, R. Roadmap: DCC/UC3 Collaboration for a Data Management Planning Tool. Available online: https://github.com/DMPRoadmap/roadmap (accessed on 25 September 2023).
- Klar, J.; Michaelis, O.; Wallace, D.; Schröder, M.; Fütterer, H.; Lanza, G.; Martínez Muñoz, D.; Pilori, D.; Harry, E. Rdmo: A Tool to Support the Planning, Implementation, and Organization of Research Data Management. Available online: https://github.com/rdmorganiser/rdmo (accessed on 25 September 2023).
- EDITORIAL. Everyone Needs a Data-Management Plan. Nature 2018, 555, 286. [Google Scholar] [CrossRef]
- Leibniz-Institute for Psychology Information DataWiz: An Automated Assistant for the Management of Psychological Research Data. Available online: https://github.com/ZPID/DataWiz (accessed on 25 September 2023).
- Klar, J.; Engelhardt, C.; Neuroth, H.; Enke, H.; Ludwig, J. RDMO—Research Data Management Organiser. In Proceedings of the EGU General Assembly, Vienna, Austria, 23–28 April 2017; p. 15760. [Google Scholar]
- Miksa, T.; Oblasser, S.; Rauber, A. Automating Research Data Management Using Machine-Actionable Data Management Plans. ACM Trans. Manag. Inf. Syst. 2022, 13, 1–22. [Google Scholar] [CrossRef]
- DMPTool. Available online: https://dmptool.org/ (accessed on 25 September 2023).
- Fabry, C. Nouvelle version de DMP OPIDoR: Vers un DMP Machine Actionnable. Available online: https://zenodo.org/records/6760990 (accessed on 25 September 2023).
- ARGOS Dmp. Available online: https://gitlab.eudat.eu/dmp (accessed on 25 September 2023).
- EasyDMP—NIRD Data Planning. Available online: https://www.sigma2.no/data-planning (accessed on 25 September 2023).
- Blumesberger, S.; Gänsdorfer, N.; Ganguly, R.; Gergely, E.; Gruber, A.; Hasani-Mavriqi, I.; Kalová, T.; Ladurner, C.; Macher, T.; Miksa, T.; et al. FAIR Data Austria—Abstimmung der Implementierung von FAIR Tools und Services. Mitteilungen VÖB 2021, 74, 102–120. [Google Scholar] [CrossRef]
- Diepenbroek, M.; Glöckner, F.O.; Grobe, P.; Güntsch, A.; Huber, R.; König-Ries, B.; Kostadinov, I.; Nieschulze, J.; Seeger, B.; Tolksdorf, R.; et al. Towards an Integrated Biodiversity and Ecological Research Data Management and Archiving Platform: The German Federation for the Curation of Biological Data (GFBio). Informatik 2014, 1711–1721. [Google Scholar]
- Zheng, Y. Methodologies for Cross-Domain Data Fusion: An Overview. IEEE Trans. Big Data 2015, 1, 16–34. [Google Scholar] [CrossRef]
- Hannemann, J.; Poorter, H.; Usadel, B.; Bläsing, O.E.; Finck, A.; Tardieu, F.; Atkin, O.K.; Pons, T.; Stitt, M.; Gibon, Y. Xeml Lab: A Tool That Supports the Design of Experiments at a Graphical Interface and Generates Computer-Readable Metadata Files, Which Capture Information about Genotypes, Growth Conditions, Environmental Perturbations and Sampling Strategy. Plant Cell Environ. 2009, 32, 1185–1200. [Google Scholar] [CrossRef]
- Papoutsoglou, E.A.; Faria, D.; Arend, D.; Arnaud, E.; Athanasiadis, I.N.; Chaves, I.; Coppens, F.; Cornut, G.; Costa, B.V.; Ćwiek-Kupczyńska, H.; et al. Enabling Reusability of Plant Phenomic Datasets with MIAPPE 1.1. New Phytol. 2020, 227, 260–273. [Google Scholar] [CrossRef]
- Taylor, C.F. Minimum Reporting Requirements for Proteomics: A MIAPE Primer. Proteomics 2006, 6, 39–44. [Google Scholar] [CrossRef]
- Brazma, A.; Hingamp, P.; Quackenbush, J.; Sherlock, G.; Spellman, P.; Stoeckert, C.; Aach, J.; Ansorge, W.; Ball, C.A.; Causton, H.C.; et al. Minimum Information about a Microarray Experiment (MIAME)—Toward Standards for Microarray Data. Nat. Genet. 2001, 29, 365–371. [Google Scholar] [CrossRef]
- Arend, D.; Lange, M.; Chen, J.; Colmsee, C.; Flemming, S.; Hecht, D.; Scholz, U. e!DAL—A Framework to Store, Share and Publish Research Data. BMC Bioinform. 2014, 15, 214. [Google Scholar] [CrossRef] [PubMed]
- Von Suchodoletz, D.; Mühlhaus, T.; Brillhaus, D.; Tschöpe, M.; Maus, O.; Grüning, B.; Garth, C.; Rodrigues, C.M. DataPLANT—Tools and Services to structure the Data Jungle for fundamental plant researchers. In E-Science-Tage 2021: Share Your Research Data; Vincent Heuveline, N.B., Ed.; heiBOOKS: Heidelberg, Germany, 2022; pp. 132–145. ISBN 9783948083540. [Google Scholar]
- Arsova, B.; Foster, K.J.; Shelden, M.C.; Bramley, H.; Watt, M. Dynamics in Plant Roots and Shoots Minimize Stress, Save Energy and Maintain Water and Nutrient Uptake. New Phytol. 2020, 225, 1111–1119. [Google Scholar] [CrossRef] [PubMed]
- Watt, M.; Fiorani, F.; Usadel, B.; Rascher, U.; Muller, O.; Schurr, U. Phenotyping: New Windows into the Plant for Breeders. Annu. Rev. Plant Biol. 2020, 71, 689–712. [Google Scholar] [CrossRef] [PubMed]
- Bar-On, Y.M.; Phillips, R.; Milo, R. The Biomass Distribution on Earth. Proc. Natl. Acad. Sci. USA 2018, 115, 6506–6511. [Google Scholar] [CrossRef]
- Lobet, G.; Pound, M.P.; Diener, J.; Pradal, C.; Draye, X.; Godin, C.; Javaux, M.; Leitner, D.; Meunier, F.; Nacry, P.; et al. Root system markup language: Toward a unified root architecture description language. Plant Physiol. 2015, 167, 617–627. [Google Scholar] [CrossRef]
- Zhu, X.G.; Long, S.P.; Ort, D.R. What Is the Maximum Efficiency with Which Photosynthesis Can Convert Solar Energy into Biomass? Curr. Opin. Biotechnol. 2008, 19, 153–159. [Google Scholar] [CrossRef]
- Bolger, M.; Schwacke, R.; Gundlach, H.; Schmutzer, T.; Chen, J.; Arend, D.; Oppermann, M.; Weise, S.; Lange, M.; Fiorani, F.; et al. From Plant Genomes to Phenotypes. J. Biotechnol. 2017, 261, 46–52. [Google Scholar] [CrossRef]
- Cantelli, G.; Bateman, A.; Brooksbank, C.; Petrov, A.I.; Malik-Sheriff, R.S.; Ide-Smith, M.; Hermjakob, H.; Flicek, P.; Apweiler, R.; Birney, E.; et al. The European Bioinformatics Institute (EMBL-EBI) in 2021. Nucleic Acids Res. 2022, 50, D11–D19. [Google Scholar] [CrossRef]
- Marks, R.A.; Amézquita, E.J.; Percival, S.; Rougon-Cardoso, A.; Chibici-Revneanu, C.; Tebele, S.M.; Farrant, J.M.; Chitwood, D.H.; VanBuren, R. A Critical Analysis of Plant Science Literature Reveals Ongoing Inequities. Proc. Natl. Acad. Sci. USA 2023, 120, e2217564120. [Google Scholar] [CrossRef]
- Arend, D.; Junker, A.; Scholz, U.; Schüler, D.; Wylie, J.; Lange, M. PGP Repository: A Plant Phenomics and Genomics Data Publication Infrastructure. Database 2016, 2016, baw033. [Google Scholar] [CrossRef]
- Arend, D.; Psaroudakis, D.; Memon, J.A.; Rey-Mazón, E.; Schüler, D.; Szymanski, J.J.; Scholz, U.; Junker, A.; Lange, M. From Data to Knowledge—Big Data Needs Stewardship, a Plant Phenomics Perspective. Plant J. 2022, 111, 335–347. [Google Scholar] [CrossRef] [PubMed]
- Agrahari, R.K.; Singh, P.; Koyama, H.; Panda, S.K. Plant-Microbe Interactions for Sustainable Agriculture in the Post-Genomic Era. Curr. Genom. 2020, 21, 168–178. [Google Scholar] [CrossRef] [PubMed]
- von Suchodoletz, D.; Mühlhaus, T.; Krüger, J.; Usadel, B.; Rodrigues, C.M. DataPLANT—Ein NFDI-Konsortium der Pflanzen-Grundlagenforschung. BFDM 2021, 2, 46–56. [Google Scholar]
- Specka, X.; Martini, D.; Weiland, C.; Arend, D.; Asseng, S.; Boehm, F.; Feike, T.; Fluck, J.; Gackstetter, D.; Gonzales-Mellado, A.; et al. FAIRagro: Ein Konsortium in Der Nationalen Forschungsdateninfrastruktur (NFDI) Für Forschungsdaten in Der Agrosystemforschung: Herausforderungen und Lösungsansätze für den Aufbau einer FAIRen Forschungsdateninfrastruktur. Informatik 2023, 46, 24–35. [Google Scholar] [CrossRef]
- Plant Sciences Community. Available online: https://elixir-europe.org/communities/plant-sciences (accessed on 25 September 2023).
- Leonelli, S.; Davey, R.P.; Arnaud, E.; Parry, G.; Bastow, R. Data Management and Best Practice for Plant Science. Nat. Plants 2017, 3, 17086. [Google Scholar] [CrossRef]
- Krantz, M.; Zimmer, D.; Adler, S.O.; Kitashova, A.; Klipp, E.; Mühlhaus, T.; Nägele, T. Data Management and Modeling in Plant Biology. Front. Plant Sci. 2021, 12, 717958. [Google Scholar] [CrossRef]
- Sansone, S.-A.; Rocca-Serra, P.; Brandizi, M.; Brazma, A.; Field, D.; Fostel, J.; Garrow, A.G.; Gilbert, J.; Goodsaid, F.; Hardy, N.; et al. The First RSBI (ISA-TAB) Workshop: “Can a Simple Format Work for Complex Studies? OMICS 2008, 12, 143–149. [Google Scholar] [CrossRef]
- Rocca-Serra, P.; Brandizi, M.; Maguire, E.; Sklyar, N.; Taylor, C.; Begley, K.; Field, D.; Harris, S.; Hide, W.; Hofmann, O.; et al. ISA Software Suite: Supporting Standards—Compliant Experimental Annotation and Enabling Curation at the Community Level. Bioinformatics 2010, 26, 2354–2356. [Google Scholar] [CrossRef]
- Amstutz, P.; Crusoe, M.R.; Tijanić, N.; Chapman, B.; Chilton, J.; Heuer, M.; Kartashov, A.; Leehr, D.; Ménager, H.; Nedeljkovich, M.; et al. Common Workflow Language, v1.0. Available online: https://research.manchester.ac.uk/files/57032695/cwl_1.0_tool.pdf. (accessed on 25 September 2023).
- Mason, P.G.; Barratt, B.I.P.; Mc Kay, F.; Klapwijk, J.N.; Silvestri, L.C.; Hill, M.; Hinz, H.L.; Sheppard, A.; Brodeur, J.; Vitorino, M.D.; et al. Impact of Access and Benefit Sharing Implementation on Biological Control Genetic Resources. Biocontrol 2023, 68, 235–251. [Google Scholar] [CrossRef]
- GFBio e.V FAR-DSI: Feasibility Assessment of Regulation for Digital Sequence Information. Available online: https://www.gfbio.org/gfbio_ev/far-dsi-project/ (accessed on 25 September 2023).
- European Commission Data Management—H2020 Online Manual. Available online: https://ec.europa.eu/research/participants/docs/h2020-funding-guide/cross-cutting-issues/open-access-data-management/data-management_en.htm (accessed on 25 September 2023).
- Garfolo, B.T. JavaScript. In Encyclopedia of Information Systems; Elsevier: Amsterdam, The Netherlands, 2003; pp. 715–735. ISBN 9780122272400. [Google Scholar]
- Otto, M.; Thornton, J. Bootstrap. Available online: https://getbootstrap.com/ (accessed on 25 September 2023).
- Yaras bs5-Intro-Tour: Extension for Bootstrap 5 Which Allows to Build Intro Tours. Available online: https://github.com/yaras6/bs5-intro-tour (accessed on 25 September 2023).
- Davies, J. d3-Cloud: Create Word Clouds in JavaScript. Available online: https://github.com/jasondavies/d3-cloud (accessed on 25 September 2023).
- Grey, E. FileSaver.js: An HTML5 saveAs() FileSaver Implementation. Available online: https://github.com/eligrey/FileSaver.js (accessed on 25 September 2023).
- Split.js. Available online: https://split.js.org/ (accessed on 25 September 2023).
- Performance: Measure() Method. Available online: https://developer.mozilla.org/en-US/docs/Web/API/Performance/measure (accessed on 25 September 2023).
- Lighthouse Overview. Available online: https://developer.chrome.com/docs/lighthouse/overview/ (accessed on 25 September 2023).
- von Suchodoletz, D.; Krüger, J.; Mühlhaus, T.; Usadel, B.; Gauza, H.; Rodrigues, C.M. Data Stewards as Ambassadors between the NFDI and the Community; Universitätsbibliothek: Heidelberg, Germany, 2021. [Google Scholar]
- Mühlhaus, T.; Garth, C.; Brilhaus, D.; Von Suchodoletz, D. ARC-Specification. Available online: https://github.com/nfdi4plants/ARC-specification (accessed on 25 September 2023).
- Frey, K. Swate: Excel Add-in for Annotation of Experimental Data and Computational Workflows. Available online: https://github.com/nfdi4plants/Swate (accessed on 25 September 2023).
- Weil, L.; Maus, O. ARCCommander: Tool to Manage Your ARCs. Available online: https://github.com/nfdi4plants/arcCommander (accessed on 25 September 2023).
- Weil, H.L.; Schneider, K.; Tschöpe, M.; Bauer, J.; Maus, O.; Frey, K.; Brilhaus, D.; Martins Rodrigues, C.; Doniparthi, G.; Wetzels, F.; et al. PLANTdataHUB: A Collaborative Platform for Continuous FAIR Data Sharing in Plant Research. Plant J. 2023. [Google Scholar] [CrossRef] [PubMed]
- Rustici, G.; Williams, E.; Barzine, M.; Brazma, A.; Bumgarner, R.; Chierici, M.; Furlanello, C.; Greger, L.; Jurman, G.; Miller, M.; et al. Transcriptomics Data Availability and Reusability in the Transition from Microarray to next-Generation Sequencing. Available online: https://www.biorxiv.org/content/biorxiv/early/2021/01/03/2020.12.31.425022 (accessed on 25 September 2023).
- Fiehn, O.; Sumner, L.W.; Rhee, S.Y.; Ward, J.; Dickerson, J.; Lange, B.M.; Lane, G.; Roessner, U.; Last, R.; Nikolau, B. Minimum Reporting Standards for Plant Biology Context Information in Metabolomic Studies. Metabolomics 2007, 3, 195–201. [Google Scholar] [CrossRef]
- Dumschott, K.; Brilhaus, D.; Tschöpe, M. nfdi4plants_ontology: A Intermediate Ontology for Plants Used by DataPLANT to Fill the Ontology Gap. Available online: https://github.com/nfdi4plants/nfdi4plants_ontology (accessed on 25 September 2023).
- Brazma, A.; Ball, C.; Bumgarner, R.; Furlanello, C.; Miller, M.; Quackenbush, J.; Reich, M.; Rustici, G.; Stoeckert, C.; Trutane, S.C.; et al. MINSEQE: Minimum Information about a High-throughput Nucleotide SeQuencing Experiment—A Proposal for Standards in Functional Genomic Data Reporting. Available online: https://zenodo.org/record/5706412 (accessed on 25 September 2023).
- Li, W.; Cowley, A.; Uludag, M.; Gur, T.; McWilliam, H.; Squizzato, S.; Park, Y.M.; Buso, N.; Lopez, R. The EMBL-EBI Bioinformatics Web and Programmatic Tools Framework. Nucleic Acids Res. 2015, 43, W580–W584. [Google Scholar] [CrossRef] [PubMed]
- Barrett, T.; Wilhite, S.E.; Ledoux, P.; Evangelista, C.; Kim, I.F.; Tomashevsky, M.; Marshall, K.A.; Phillippy, K.H.; Sherman, P.M.; Holko, M.; et al. NCBI GEO: Archive for Functional Genomics Data Sets—Update. Nucleic Acids Res. 2012, 41, D991–D995. [Google Scholar] [CrossRef]
- Miyazaki, S.; Sugawara, H.; Ikeo, K.; Gojobori, T.; Tateno, Y. DDBJ in the Stream of Various Biological Data. Nucleic Acids Res. 2004, 32, D31–D34. [Google Scholar] [CrossRef]
- Kodama, Y.; Shumway, M.; Leinonen, R.; International Nucleotide Sequence Database Collaboration. The Sequence Read Archive: Explosive Growth of Sequencing Data. Nucleic Acids Res. 2012, 40, D54–D56. [Google Scholar] [CrossRef]
- Benson, D.A.; Cavanaugh, M.; Clark, K.; Karsch-Mizrachi, I.; Lipman, D.J.; Ostell, J.; Sayers, E.W. GenBank. Nucleic Acids Res. 2013, 41, D36–D42. [Google Scholar] [CrossRef]
- Hermjakob, H.; Apweiler, R. The Proteomics Identifications Database (PRIDE) and the ProteomExchange Consortium: Making Proteomics Data Accessible. Expert Rev. Proteom. 2006, 3, 1–3. [Google Scholar] [CrossRef]
- Steinbeck, C.; Conesa, P.; Haug, K.; Mahendraker, T.; Williams, M.; Maguire, E.; Rocca-Serra, P.; Sansone, S.-A.; Salek, R.M.; Griffin, J.L. MetaboLights: Towards a New COSMOS of Metabolomics Data Management. Metabolomics 2012, 8, 757–760. [Google Scholar] [CrossRef]
- GnpIS. Available online: https://urgi.versailles.inra.fr/gnpis (accessed on 25 September 2023).
- Weise, S.; Oppermann, M.; Maggioni, L.; van Hintum, T.; Knüpffer, H. EURISCO: The European Search Catalogue for Plant Genetic Resources. Nucleic Acids Res. 2017, 45, D1003–D1008. [Google Scholar] [CrossRef]
- RDA DMP Common Standard for Machine-Actionable Data Management Plans. Available online: https://zenodo.org/records/4036060 (accessed on 25 September 2023).
- Sherman, B.; Henry, R.J. The Nagoya Protocol and Historical Collections of Plants. Nat. Plants 2020, 6, 430–432. [Google Scholar] [CrossRef] [PubMed]
- Voigt, P.; von dem Bussche, A. The EU General Data Protection Regulation (GDPR); Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar]
- Barker, M.; Chue Hong, N.P.; Katz, D.S.; Lamprecht, A.-L.; Martinez-Ortiz, C.; Psomopoulos, F.; Harrow, J.; Castro, L.J.; Gruenpeter, M.; Martinez, P.A.; et al. Introducing the FAIR Principles for Research Software. Sci. Data 2022, 9, 622. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X. Dataplan: DataPLAN Is the Data Management Plan (DMP) Generator Developed in DataPLANT. Available online: https://github.com/nfdi4plants/dataplan (accessed on 25 September 2023).
- D’Anna, F.; Faria, D. Your Tasks: Data Management Plan. Available online: https://rdmkit.elixir-europe.org/data_management_plan (accessed on 25 September 2023).
- Ison, J.; Ienasescu, H.; Chmura, P.; Rydza, E.; Ménager, H.; Kalaš, M.; Schwämmle, V.; Grüning, B.; Beard, N.; Lopez, R.; et al. The Bio.tools Registry of Software Tools and Data Resources for the Life Sciences. Genom. Biol. 2019, 20, 164. [Google Scholar] [CrossRef] [PubMed]
- Hasselbring, W.; Carr, L.; Hettrick, S.; Packer, H.; Tiropanis, T. From FAIR Research Data toward FAIR and Open Research Software. It-Inf. Technol. 2020, 62, 39–47. [Google Scholar] [CrossRef]
- Becker, C.; Hundt, C.; Engelhardt, C.; Sperling, J.; Kurzweil, M.; Müller-Pfefferkorn, R. Data Management Plan Tools: Overview and Evaluation. Proc. Conf. Res. Data Infrastruct. 2023, 1, CoRDI2023-96. [Google Scholar] [CrossRef]
- Donnelly, M.; Jones, S.; Pattenden-Fail, J.W. DMP Online: The Digital Curation Centre’s Web-Based Tool for Creating, Maintaining and Exporting Data Management Plans. Int. J. Digit. Curation 2010, 5, 187–193. [Google Scholar] [CrossRef]
- Rice, R.; Fergusson, D. LEARN Toolkit of Best Practice for Research Data Management; Research Data Management at the University of Edinburgh: How is it done, what does it costs? CS17; UCL: London, UK, 2017; pp. 89–93. [Google Scholar]
- Suchánek, M.; Knaisl, V.; Pergl, R. Ds-Wizard: DSW Common Repository. Available online: https://github.com/ds-wizard/ds-wizard (accessed on 25 September 2023).
- SIB Swiss Institute of Bioinformatics/Vital-IT DMP Canvas Generator. Available online: https://dmp.vital-it.ch/#/login (accessed on 25 September 2023).
- Morgera, E.; Tsioumani, E.; Buck, M. Unraveling the Nagoya Protocol: A Commentary on the Nagoya Protocol on Access and Benefit-Sharing to the Convention on Biological Diversity; Martinus Nijhoff Publishers: Leiden, The Netherlands, 2014; ISBN 9789004217188. [Google Scholar]
- Rourke, M.; Eccleston-Turner, M. The Pandemic Influenza Preparedness Framework as a “specialized International Access and Benefit-Sharing Instrument” under the Nagoya Protocol. N. Ir. Legal Q. 2021, 72, 411–447. [Google Scholar] [CrossRef]
- Rothe, R.; Lindstädt, B. RDMO4Life im Projekt EmiMin—Die Anpassung von Datenmanagementplänen an lebenswissenschaftliche Fachspezifika. Available online: https://opus4.kobv.de/opus4-bib-info/frontdoor/index/index/docId/16229 (accessed on 25 September 2023).
- GFBio e.V GFBio Data Management Plan Tool. Available online: https://www.gfbio.org/plan/ (accessed on 25 September 2023).
- Cardoso, J.; Castro, L.J.; Ekaputra, F.J.; Jacquemot, M.C.; Suchánek, M.; Miksa, T.; Borbinha, J. DCSO: Towards an Ontology for Machine-Actionable Data Management Plans. J. Biomed. Semant. 2022, 13, 21. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, X.-R.; Beier, S.; Brilhaus, D.; Martins Rodrigues, C.; Mühlhaus, T.; von Suchodoletz, D.; Twyman, R.M.; Usadel, B.; Kranz, A. DataPLAN: A Web-Based Data Management Plan Generator for the Plant Sciences. Data 2023, 8, 159. https://doi.org/10.3390/data8110159
Zhou X-R, Beier S, Brilhaus D, Martins Rodrigues C, Mühlhaus T, von Suchodoletz D, Twyman RM, Usadel B, Kranz A. DataPLAN: A Web-Based Data Management Plan Generator for the Plant Sciences. Data. 2023; 8(11):159. https://doi.org/10.3390/data8110159
Chicago/Turabian StyleZhou, Xiao-Ran, Sebastian Beier, Dominik Brilhaus, Cristina Martins Rodrigues, Timo Mühlhaus, Dirk von Suchodoletz, Richard M. Twyman, Björn Usadel, and Angela Kranz. 2023. "DataPLAN: A Web-Based Data Management Plan Generator for the Plant Sciences" Data 8, no. 11: 159. https://doi.org/10.3390/data8110159
APA StyleZhou, X.-R., Beier, S., Brilhaus, D., Martins Rodrigues, C., Mühlhaus, T., von Suchodoletz, D., Twyman, R. M., Usadel, B., & Kranz, A. (2023). DataPLAN: A Web-Based Data Management Plan Generator for the Plant Sciences. Data, 8(11), 159. https://doi.org/10.3390/data8110159