Figure 1.
Types of Security Vulnerabilities in Apache Tomcat.
Figure 1.
Types of Security Vulnerabilities in Apache Tomcat.
Figure 2.
Types of Security Vulnerabilities in Apache Struts-2-core.
Figure 2.
Types of Security Vulnerabilities in Apache Struts-2-core.
Figure 4.
Research Method.
Figure 4.
Research Method.
Figure 5.
Positive to negative instance differences in both datasets.
Figure 5.
Positive to negative instance differences in both datasets.
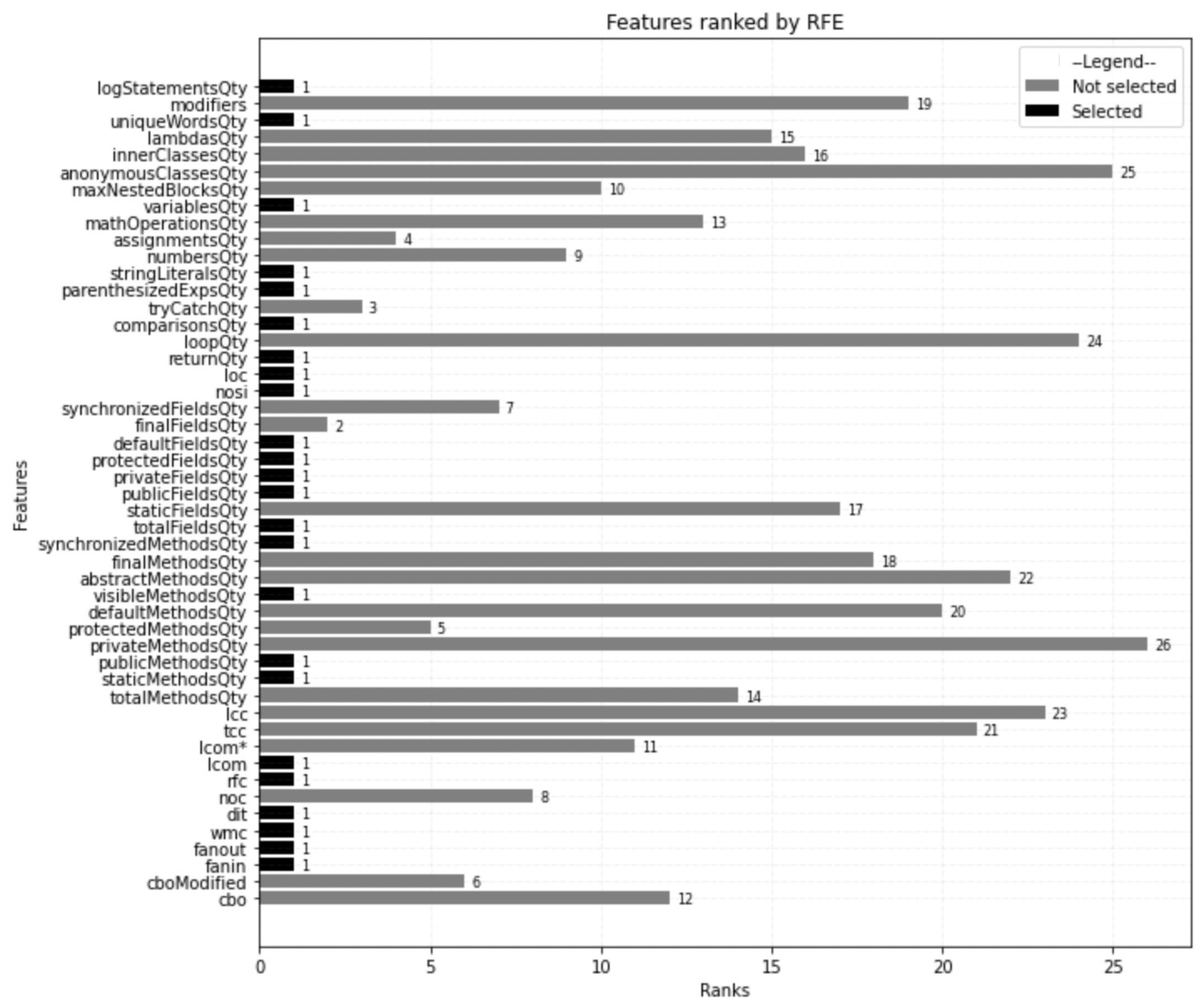
Figure 6.
Features ranked by Recursive Feature Elimination.
Figure 6.
Features ranked by Recursive Feature Elimination.
Figure 7.
Confusion matrix for all learners in predicting vulnerable status (Tomcat–RFE).
Figure 7.
Confusion matrix for all learners in predicting vulnerable status (Tomcat–RFE).
Figure 8.
Confusion matrix for all learners in predicting vulnerable status (Struts–RFE).
Figure 8.
Confusion matrix for all learners in predicting vulnerable status (Struts–RFE).
Figure 9.
Confusion matrix for all learners in predicting vulnerable status (Tomcat–SFS).
Figure 9.
Confusion matrix for all learners in predicting vulnerable status (Tomcat–SFS).
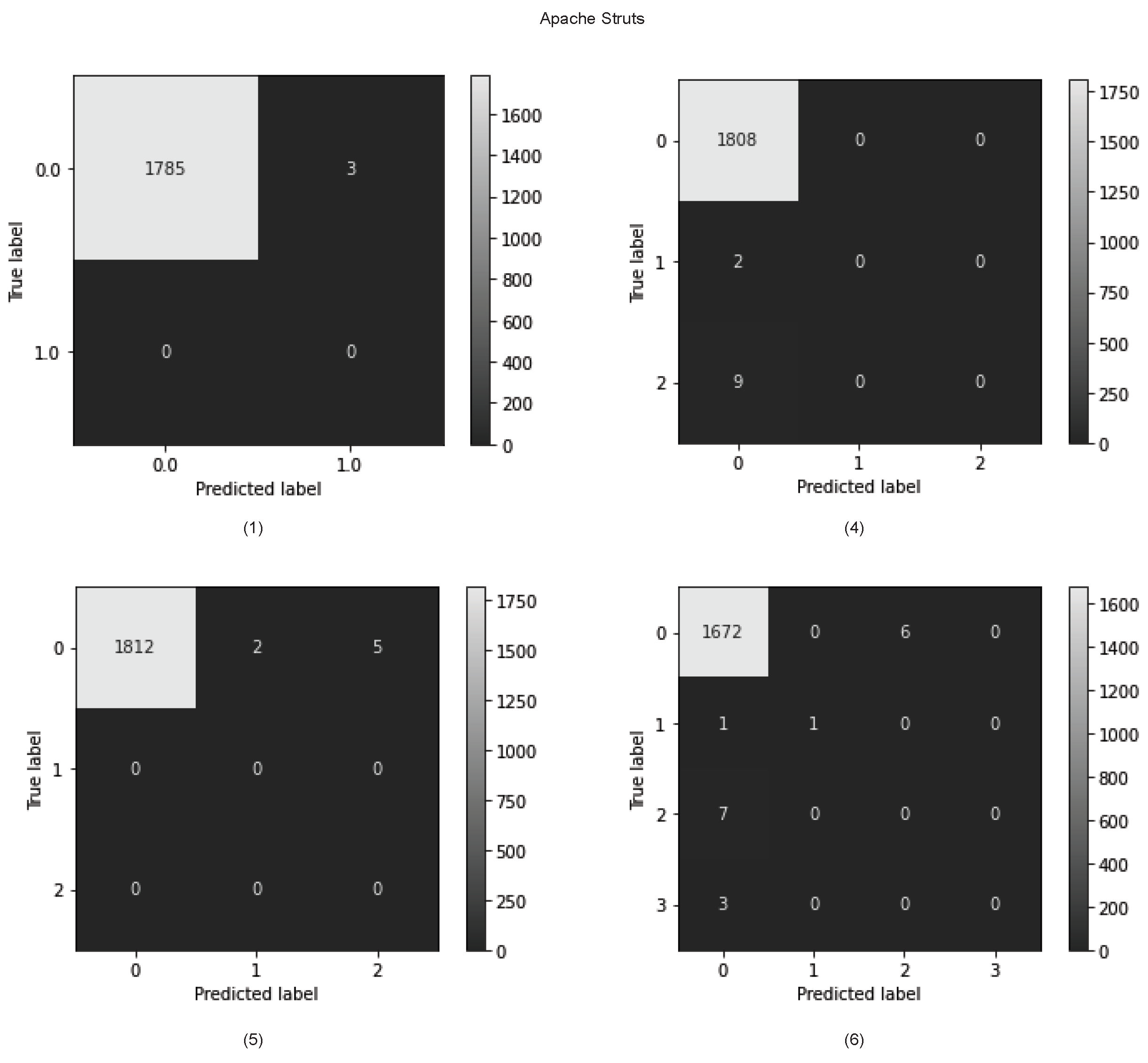
Figure 10.
Confusion matrix for all learners in predicting vulnerable status (Struts–SFS).
Figure 10.
Confusion matrix for all learners in predicting vulnerable status (Struts–SFS).
Figure 11.
Confusion matrix for all learners in predicting severity (Tomcat–SFS).
Figure 11.
Confusion matrix for all learners in predicting severity (Tomcat–SFS).
Figure 12.
Confusion matrix for all learners in predicting severity (Struts–SFS).
Figure 12.
Confusion matrix for all learners in predicting severity (Struts–SFS).
Figure 13.
Confusion matrix for all learners in predicting severity (Tomcat–RFE).
Figure 13.
Confusion matrix for all learners in predicting severity (Tomcat–RFE).
Figure 14.
Confusion matrix for all learners in predicting severity (Struts–RFE).
Figure 14.
Confusion matrix for all learners in predicting severity (Struts–RFE).
Figure 15.
AUC-ROC curve for all learners (Tomcat).
Figure 15.
AUC-ROC curve for all learners (Tomcat).
Figure 16.
AUC-ROC curve for all learners (Struts).
Figure 16.
AUC-ROC curve for all learners (Struts).
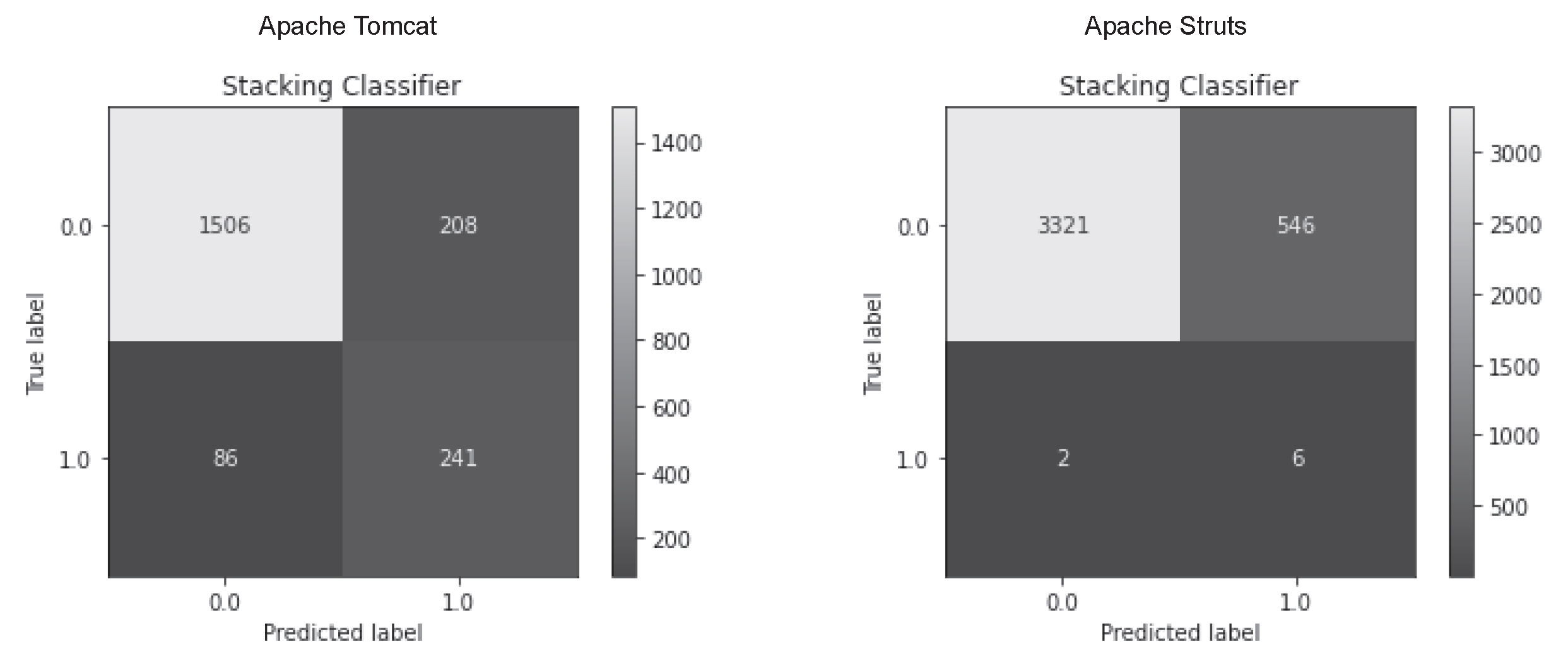
Figure 17.
Confusion matrix for Stacking classifier in predicting vulnerable status.
Figure 17.
Confusion matrix for Stacking classifier in predicting vulnerable status.
Figure 18.
Confusion matrix for Stacking classifier in predicting severity.
Figure 18.
Confusion matrix for Stacking classifier in predicting severity.
Figure 19.
AUC-ROC curve for Stacking classifier.
Figure 19.
AUC-ROC curve for Stacking classifier.
Figure 20.
Confusion matrix for cross-version experiments in predicting vulnerable status (Tomcat (1)–(3)).
Figure 20.
Confusion matrix for cross-version experiments in predicting vulnerable status (Tomcat (1)–(3)).
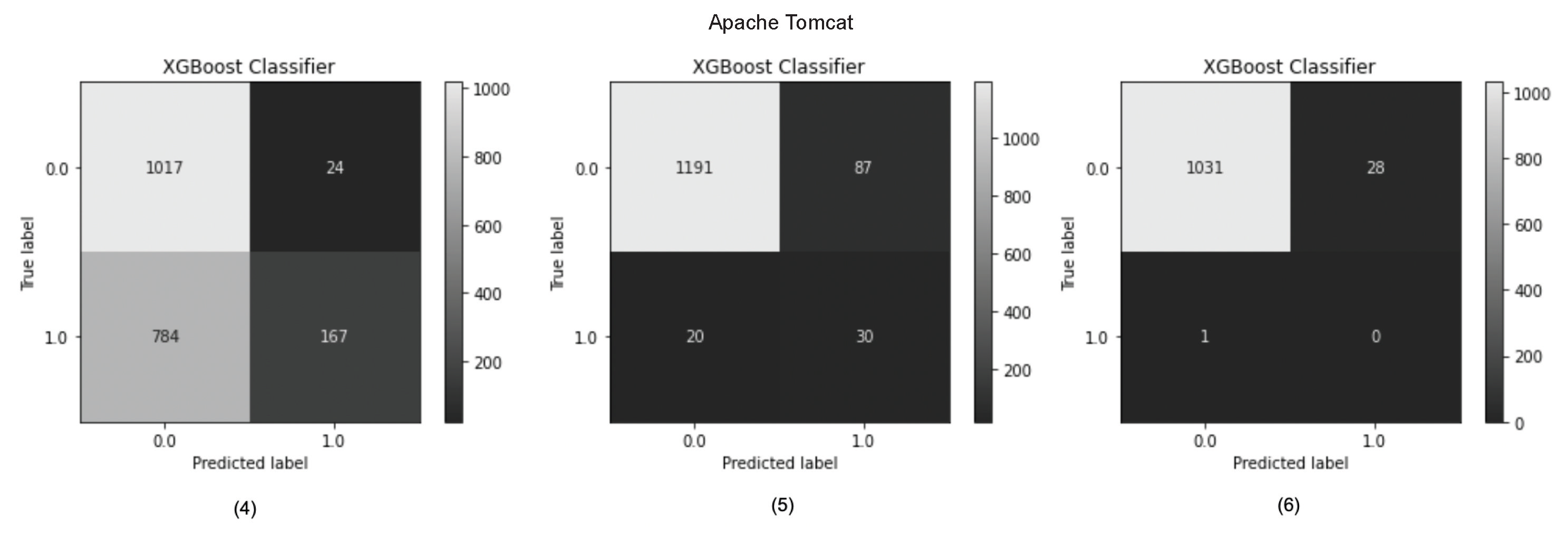
Figure 21.
Confusion matrix for cross-version experiments in predicting vulnerable status (Tomcat (4)–(6)).
Figure 21.
Confusion matrix for cross-version experiments in predicting vulnerable status (Tomcat (4)–(6)).
Figure 22.
Confusion matrix for cross-version experiments in predicting severity (Tomcat).
Figure 22.
Confusion matrix for cross-version experiments in predicting severity (Tomcat).
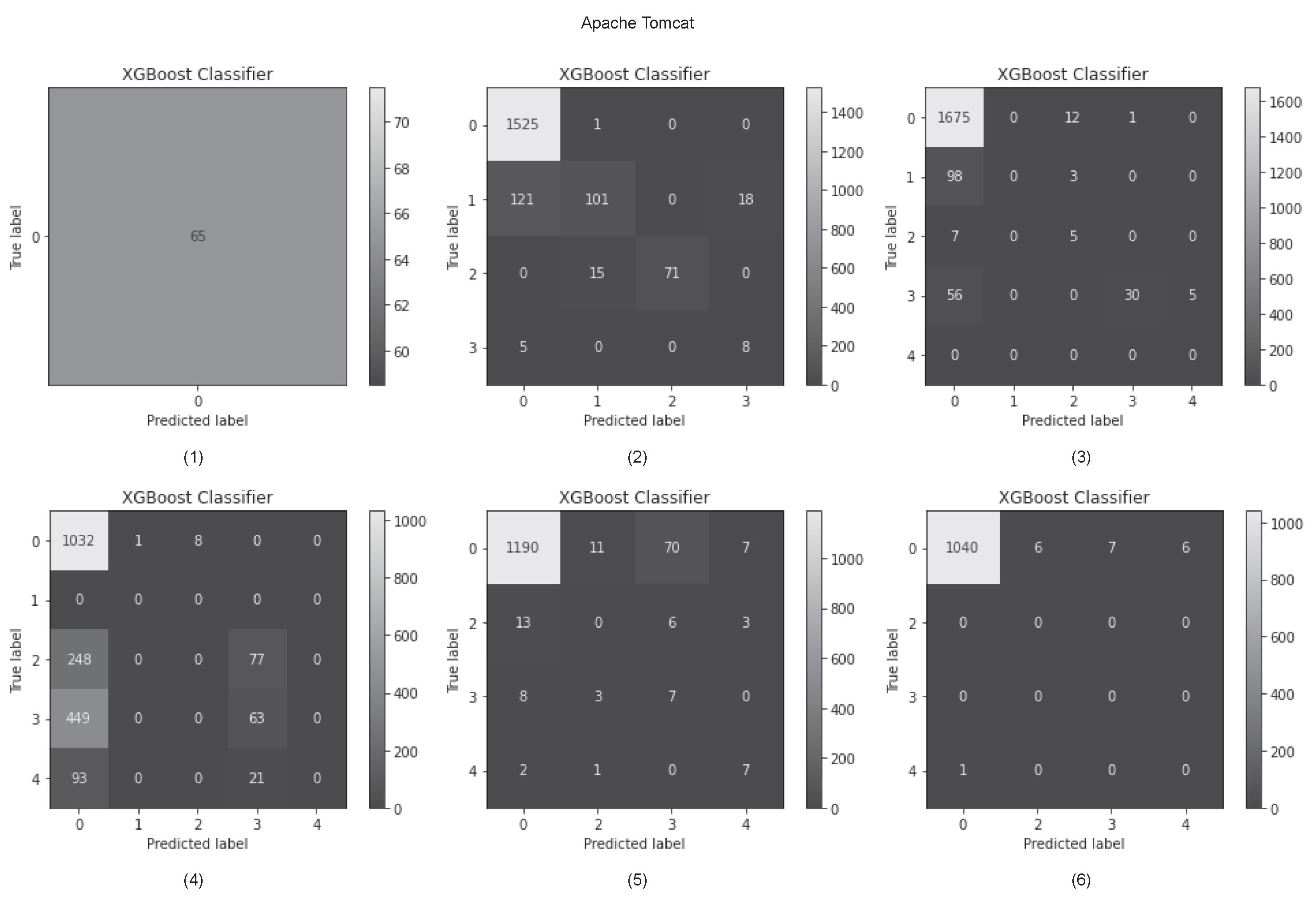
Figure 23.
Confusion matrix for cross-version experiments in predicting vulnerable status (Struts (1)–(4)).
Figure 23.
Confusion matrix for cross-version experiments in predicting vulnerable status (Struts (1)–(4)).
Figure 24.
Confusion matrix for cross-version experiments in predicting vulnerable status (Struts (5)–(8)).
Figure 24.
Confusion matrix for cross-version experiments in predicting vulnerable status (Struts (5)–(8)).
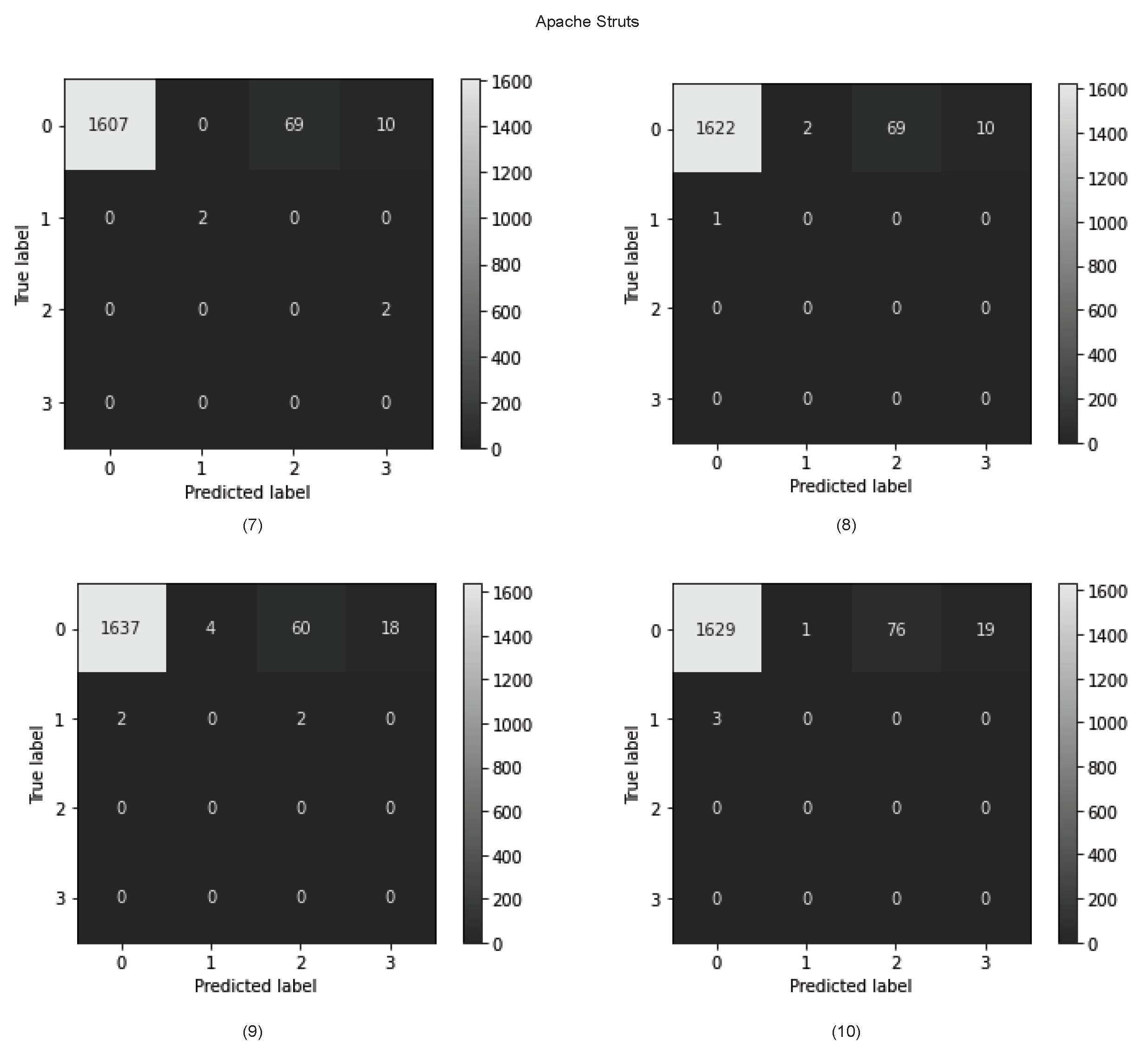
Figure 25.
Confusion matrix for cross-version experiments in predicting vulnerable status (Struts (9)–(10)).
Figure 25.
Confusion matrix for cross-version experiments in predicting vulnerable status (Struts (9)–(10)).
Figure 26.
Confusion matrix for cross-version experiments in predicting severity (Struts (1), (4)–(6)).
Figure 26.
Confusion matrix for cross-version experiments in predicting severity (Struts (1), (4)–(6)).
Figure 27.
Confusion matrix for cross-version experiments in predicting severity (Struts (7)–(10)).
Figure 27.
Confusion matrix for cross-version experiments in predicting severity (Struts (7)–(10)).
Figure 28.
AUC-ROC curve for Vulnerable (Tomcat).
Figure 28.
AUC-ROC curve for Vulnerable (Tomcat).
Figure 29.
AUC-ROC curve for Severity (Tomcat).
Figure 29.
AUC-ROC curve for Severity (Tomcat).
Figure 30.
AUC-ROC curve for Title (Tomcat).
Figure 30.
AUC-ROC curve for Title (Tomcat).
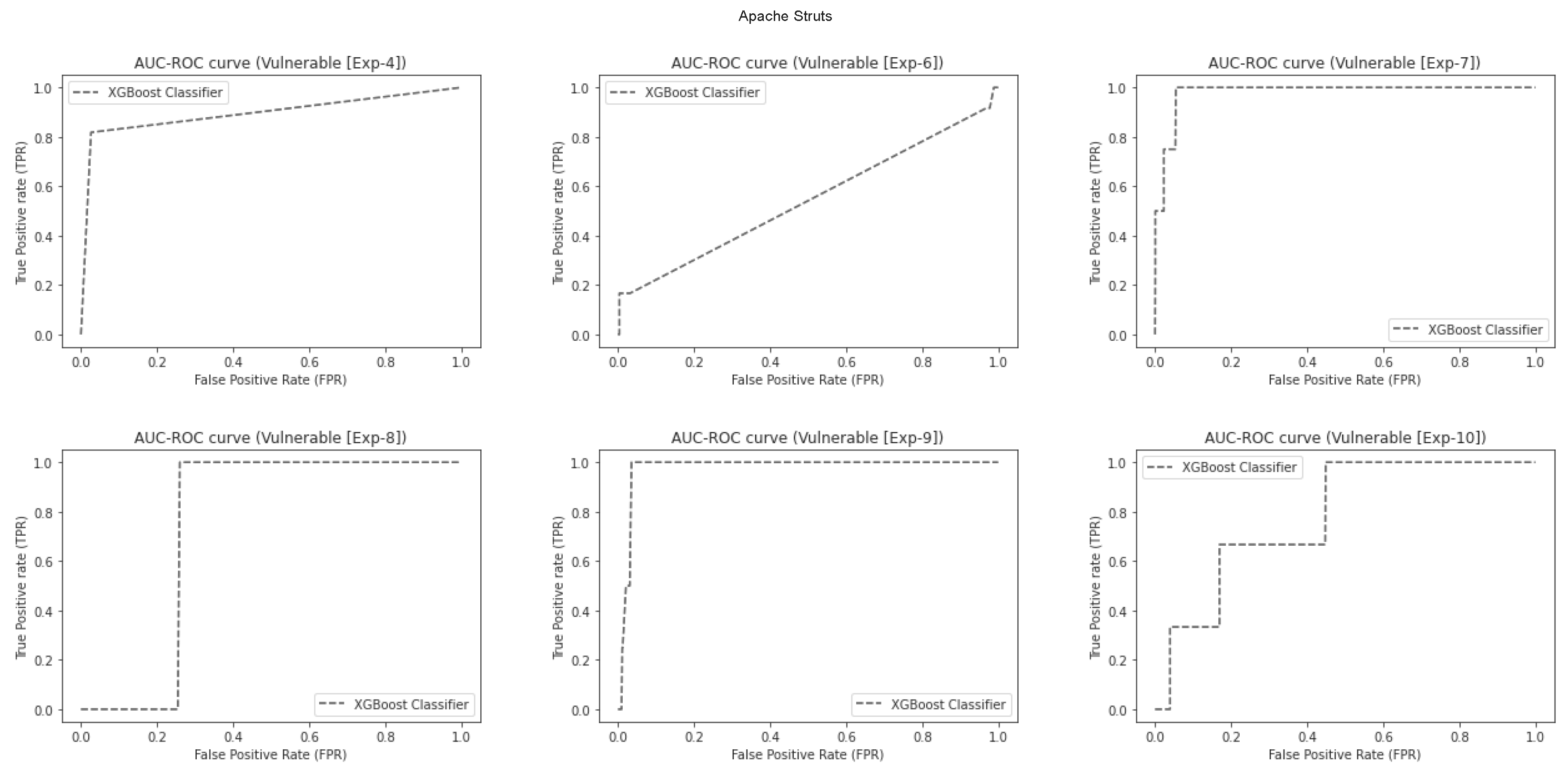
Figure 31.
AUC-ROC curve for Vulnerable (Struts).
Figure 31.
AUC-ROC curve for Vulnerable (Struts).
Figure 32.
AUC-ROC curve for Severity (Struts).
Figure 32.
AUC-ROC curve for Severity (Struts).
Figure 33.
AUC-ROC curve for Title (Struts).
Figure 33.
AUC-ROC curve for Title (Struts).
Figure 34.
Confusion matrix for cross-project experiments in predicting vulnerable status; (1) Train on Tomcat, test on Struts; (2) Train on Struts, test on Tomcat.
Figure 34.
Confusion matrix for cross-project experiments in predicting vulnerable status; (1) Train on Tomcat, test on Struts; (2) Train on Struts, test on Tomcat.
Figure 35.
Confusion matrix for cross-project experiments in predicting severity; (1) Train on Tomcat, test on Struts; (2) Train on Struts, test on Tomcat.
Figure 35.
Confusion matrix for cross-project experiments in predicting severity; (1) Train on Tomcat, test on Struts; (2) Train on Struts, test on Tomcat.
Figure 36.
AUC-ROC curve for RQ4.
Figure 36.
AUC-ROC curve for RQ4.
Table 1.
List of static source code metrics [
12].
Table 1.
List of static source code metrics [
12].
| Metrics | Definitions |
|---|
| anonymousClassesQty | Number of anonymous classes in a class. |
| assignmentsQty | How often each variable was used inside each class. |
| CBO | Coupling Between Objects. The number of dependencies in a class. |
| comparisonsQty | Represent the comparison operators in a class. |
| defaultFieldsQty | Number of fields of default types. |
| DIT | Depth of Inheritance Tree. Number of fathers in a class. |
| fieldQty | How often each local field was used inside each class. |
| finalFieldsQty | Number of fields of final types. |
| HasJavadoc | Whether the source code has JavaDoc or not. |
| innerClassesQty | Number of inner classes in a class. |
| lambdsQty | Number of lambda expressions in a class. |
| LCC | Loose Class Cohesion. Same as TCC but also includes the number of indirect connections between visible classes for the cohesion calculation. |
| LCOM | Lack of Cohesion of Methods Count of the number of method pairs whose similarity is 0. |
| LOC | Lines of Code. Total lines of code in a class. |
| logStatementsQty | Count of log statements in a class. |
| loopQty | Represent the number of loops in a class. |
| mathOperationsQty | Represent the number of arithmetic symbols in a class. |
| maxNestedBlocksQty | Max Nested Blocks. The highest number of blocks nested within each other. |
| Method Invocations | Number of directly invoked methods, variations are local invocations and indirect local invocations. |
| NoSI | Number of Static Invocations. The number of invocations to static methods but is limited to JDT
resolved methods. |
| numbersQty | Represent the number of numeric literals in a class. |
| paranthesizedExpsQty | Represent the number of parenthesized expressions in a class. |
| privateMethodsQty | Whether a class is private |
| protectedFieldsQty | Number of fields of protected types. |
| protectedMethodsQty | Whether a class is protected. |
| returnQty | Represent the number of return statements in a class. |
| RFC | Response for a Class. The number of unique method invocations in a class but fails with
overloaded methods. |
| stringLiteralsQty | Represent the number of string literals in a class. |
| synchronizedMethodsQty | Number of synchronized methods in a class. |
| TCC | Tight Class Cohesion. The cohesion of a class and results are delivered between 0 and 1. |
| totalFieldsQty | Number of total fields. |
| totalMethodsQty | Number of Methods. The number of methods of various return types and scopes. |
| tryCatchQty | Represent the try and catch statements used in a class. |
| uniqueWordsQty | Count of unique words in a class. |
| variablesQty | Represent the number of variables in a class. |
| visibleMethodsQty | Number of Visible Methods. The number of non-private methods. |
| WMC | Weight Method Class. Also known as McCabe’s complexity, it counts the number of branch instructions in a class. |
Table 2.
Features selected by SFS and RFE on both the datasets.
Table 2.
Features selected by SFS and RFE on both the datasets.
| Apache Tomcat | | Apache Struts2-Core | |
|---|
| SFS | RFE | SFS | RFE |
| LCOM | CBO | CBO | visibleMethodsQty |
| TCC | WMC | FanIn | abstractMethodsQty |
| LCC | RFC | NOC | finalMethodsQty |
| staticMethodsQty | LCOM | LCOM | synchronizedMethodsQty |
| privateMethodsQty | TCC | TCC | totalFieldsQty |
| protectedMethodsQty | LCC | LCC | staticFieldsQty |
| defaultMethodsQty | privateMethodsQty | totalMethodsQty | publicFieldsQty |
| visibleMethodsQty | staticFieldsQty | staticMethodsQty | finalFieldsQty |
| abstractMethodsQty | publicFieldsQty | privateMethodsQty | synchronizedFieldsQty |
| finalMethodsQty | privateFieldsQty | defaultMethodsQty | NoSI |
| synchronizedMethodsQty | protectedFieldsQty | abstractMethodsQty | LOC |
| staticFieldsQty | defaultFieldsQty | finalMethodsQty | returnQty |
| publicFieldsQty | finalFieldsQty | synchronizedMethodsQty | parenthesizedExpsQty |
| protectedFieldsQty | NoSI | privateFieldsQty | stringLiteralsQty |
| defaultFieldsQty | LOC | protectedFieldsQty | numbersQty |
| finalFieldsQty | comparisonsQty | defaultFieldsQty | assignmentsQty |
| synchronizedFieldsQty | parenthesizedExpsQty | synchronizedFieldsQty | mathOperationsQty |
| loopQty | stringLiteralsQty | loopQty | variablesQty |
| anonymousClassesQty | numbersQty | parenthesizedExpsQty | maxNestedBlocksQty |
| innerClassesQty | variablesQty | anonymousClassesQty | anonymousClassesQty |
| lambdasQty | uniqueWordsQty | innerClassesQty | innerClassesQty |
| modifiers | modifiers | lambdasQty | lambdasQty |
| | | modifiers | uniqueWordsQty |
| | | logStatementsQty | modifiers |
Table 3.
Performance metrics for predicting vulnerable status (0 or 1).
Table 3.
Performance metrics for predicting vulnerable status (0 or 1).
| Tomcat | | SFS | | | RFE | |
|---|
| | Accuracy in % | Precision in % | Recall in % | Accuracy in % | Precision in % | Recall in % |
| DT | 73.7 | 37.4 | 88.1 | 74.5 | 40.6 | 85.4 |
| LR | 85.7 | 55.6 | 74.1 | 83.5 | 53.5 | 72.5 |
| NB | 86.1 | 57.9 | 58.1 | 83.3 | 53.7 | 61.2 |
| XGB | 97.5 | 89.5 | 96.1 | 98.1 | 92 | 97.8 |
| Struts | | | | | | |
| DT | 78.1 | 0.9 | 72.7 | 81.7 | 0.5 | 57.1 |
| LR | 86.6 | 1.5 | 72.7 | 87.8 | 0.6 | 42.8 |
| NB | 59 | 0.5 | 81.8 | 89.6 | 0.2 | 14.2 |
| XGB | 99.5 | 26.6 | 36.3 | 99.6 | 28.5 | 28.5 |
Table 4.
Performance in predicting the severity of the vulnerability.
Table 4.
Performance in predicting the severity of the vulnerability.
| Tomcat | | SFS | | | RFE | |
|---|
| | Accuracy in % | Precision in % | Recall in % | Accuracy in % | Precision in % | Recall in % |
| DT | 71.8 | 45.3 | 55.6 | 59.9 | 45.5 | 64 |
| LR | 65.4 | 38.4 | 67.2 | 69.2 | 36.9 | 60.9 |
| NB | 30.6 | 33.4 | 47.7 | 36.7 | 39.1 | 50.3 |
| XGB | 93.9 | 75.9 | 88.3 | 93.8 | 74.9 | 85.6 |
| Struts | | | | | | |
| DT | 74.8 | 25.6 | 90.1 | 79 | 25.3 | 69.7 |
| LR | 75.8 | 25.6 | 90.3 | 84.9 | 25.4 | 54.5 |
| NB | 14.2 | 25.3 | 71.3 | 85.9 | 25.5 | 38.1 |
| XGB | 99.6 | 57.7 | 67.7 | 99.6 | 53 | 41.6 |
Table 5.
Performance in predicting the title (type) of the vulnerability.
Table 5.
Performance in predicting the title (type) of the vulnerability.
| Tomcat | | SFS | | | RFE | |
|---|
| | Accuracy in % | Precision in % | Recall in % | Accuracy in % | Precision in % | Recall in % |
| DT | 2.4 | 0.01 | 4 | 2.69 | 1.1 | 9.5 |
| LR | 42.2 | 23.4 | 58.2 | 56.3 | 24.1 | 64.3 |
| NB | 16 | 26.7 | 46.2 | 13.8 | 25.2 | 48 |
| XGB | 94 | 58.5 | 73.5 | 93.4 | 55.5 | 69.1 |
| Struts | | | | | | |
| DT | 77.9 | 11.6 | 30.8 | 62.8 | 12.9 | 45.3 |
| LR | 86.7 | 12.8 | 23.5 | 88.6 | 12.2 | 43.5 |
| NB | 43.6 | 12.2 | 21.5 | 51.7 | 11.2 | 27.9 |
| XGB | 99.5 | 24.9 | 24.9 | 99.5 | 24.9 | 24.9 |
Table 6.
Stacking classifier performance in Apache Tomcat.
Table 6.
Stacking classifier performance in Apache Tomcat.
| Tomcat | Accuracy in % | Precision in % | Recall in % |
|---|
| Vulnerable | 85.5 | 85.5 | 85.5 |
| Severity | 75.3 | 75.3 | 75.3 |
| Title | 53.1 | 53.1 | 53.1 |
Table 7.
Stacking classifier performance in Apache Struts2-core.
Table 7.
Stacking classifier performance in Apache Struts2-core.
| Struts | Accuracy in % | Precision in % | Recall in % |
|---|
| Vulnerable | 85.8 | 85.8 | 85.8 |
| Severity | 94.1 | 94.1 | 94.1 |
| Title | 98.2 | 98.2 | 98.2 |
Table 8.
Cross-version prediction in Apache Tomcat.
Table 8.
Cross-version prediction in Apache Tomcat.
| Vulnerable | | | |
|---|
| Exp. No. | Accuracy in % | Precision in % | Recall in % |
| 1 | 100 | 100 | 100 |
| 2 | 90.8 | 99.4 | 49.9 |
| 3 | 91.8 | 76.9 | 34.3 |
| 4 | 59.4 | 87.4 | 17.5 |
| 5 | 91.9 | 25.6 | 60 |
| 6 | 97.2 | 0 | 0 |
| Severity | | | |
| 1 | 100 | 100 | 100 |
| 2 | 91.4 | 77.3 | 71.5 |
| 3 | 90.3 | 42.6 | 34.7 |
| 4 | 54.9 | 19.1 | 22.2 |
| 5 | 90.6 | 36.9 | 50.5 |
| 6 | 98.1 | 24.9 | 24.5 |
| Title | | | |
| 1 | 100 | 100 | 100 |
| 2 | 89.9 | 51.5 | 61.5 |
| 3 | 92 | 34 | 32.4 |
| 4 | 51.7 | 4 | 7 |
| 5 | 88.9 | 7 | 8.9 |
| 6 | 97.7 | 97.7 | 97.7 |
Table 9.
Cross-version prediction on Struts2-core.
Table 9.
Cross-version prediction on Struts2-core.
| Vulnerable | | | |
|---|
| Exp. No. | Accuracy in % | Precision in % | Recall in % |
| 1 | 99.8 | 0 | 0 |
| 2 | 100 | 0 | 0 |
| 3 | 100 | 0 | 0 |
| 4 | 99.3 | 0 | 0 |
| 5 | 99.8 | 0 | 0 |
| 6 | 99.2 | 0 | 0 |
| 7 | 99.4 | 30.7 | 100 |
| 8 | 99.5 | 0 | 0 |
| 9 | 99.5 | 28.5 | 50 |
| 10 | 99.4 | 0 | 0 |
| Severity | | | |
| 1 | 99.8 | 99.8 | 99.8 |
| 2 | 100 | 100 | 100 |
| 3 | 100 | 100 | 100 |
| 4 | 99.3 | 99.3 | 99.3 |
| 5 | 99.7 | 99.7 | 99.7 |
| 6 | 99.3 | 99.3 | 99.3 |
| 7 | 99.4 | 99.4 | 99.4 |
| 8 | 99.5 | 99.5 | 99.5 |
| 9 | 99.5 | 99.5 | 99.5 |
| 10 | 99.4 | 99.4 | 99.4 |
| Title | | | |
| 1 | 99.8 | 99.8 | 99.8 |
| 2 | 100 | 100 | 100 |
| 3 | 100 | 100 | 100 |
| 4 | 99.3 | 99.3 | 99.3 |
| 5 | 99.8 | 99.8 | 99.8 |
| 6 | 99.2 | 99.2 | 99.2 |
| 7 | 99.4 | 99.4 | 99.4 |
| 8 | 99.5 | 99.5 | 99.5 |
| 9 | 99.5 | 99.5 | 99.5 |
| 10 | 99.4 | 99.4 | 99.4 |
Table 10.
(Exp 1) Train on Tomcat, test on Struts; (Exp 2) Train on Struts, test on Tomcat.
Table 10.
(Exp 1) Train on Tomcat, test on Struts; (Exp 2) Train on Struts, test on Tomcat.
| Exp 1 | Accuracy in % | Precision in % | Recall in % |
|---|
| Vulnerable | 98.2 | 0.6 | 4.5 |
| Severity | 78.4 | 12.4 | 9.8 |
| Title | 0 | 0 | 0 |
| Exp 2 | | | |
| Vulnerable | 62 | 29.1 | 87.4 |
| Severity | 32.3 | 12.1 | 4.8 |
| Title | 20.9 | 3.1 | 1.5 |
Table 11.
Performance in predicting the vulnerable status (undersampled).
Table 11.
Performance in predicting the vulnerable status (undersampled).
| Tomcat | | SFS | | | RFE | |
|---|
| | Accuracy in % | Precision in % | Recall in % | Accuracy in % | Precision in % | Recall in % |
| DT | 72.9 | 37.8 | 85.3 | 72.5 | 36.5 | 86 |
| LR | 84 | 53.3 | 69.9 | 82.4 | 48.7 | 78.1 |
| NB | 83.6 | 52.8 | 60.3 | 83.5 | 50.9 | 63.9 |
| XGB | 94.6 | 78.7 | 94.9 | 95.7 | 81 | 97.9 |
| Struts | | | | | | |
| DT | 79.7 | 0.6 | 55.5 | 71.2 | 0.8 | 90.9 |
| LR | 74.1 | 0.6 | 77.7 | 75.5 | 0.9 | 81.8 |
| NB | 77.5 | 0.4 | 44.4 | 82.4 | 1.1 | 72.7 |
| XGB | 80.6 | 0.6 | 55.5 | 74.7 | 0.9 | 81.8 |
Table 12.
Performance in predicting the severity (undersampled).
Table 12.
Performance in predicting the severity (undersampled).
| Tomcat | | SFS | | | RFE | |
|---|
| | Accuracy in % | Precision in % | Recall in % | Accuracy in % | Precision in % | Recall in % |
| DT | 71.5 | 71.5 | 71.5 | 66.3 | 66.3 | 66.3 |
| LR | 64.2 | 64.2 | 64.2 | 65.2 | 65.2 | 65.2 |
| NB | 28.4 | 28.4 | 28.4 | 21.2 | 21.2 | 21.2 |
| XGB | 71.5 | 71.5 | 71.5 | 68.8 | 68.8 | 68.8 |
| Struts | | | | | | |
| DT | 66.2 | 66.2 | 66.2 | 47.4 | 47.4 | 47.4 |
| LR | 50 | 50 | 50 | 21.6 | 21.6 | 21.6 |
| NB | 37.9 | 37.9 | 37.9 | 28.1 | 28.1 | 28.1 |
| XGB | 39.4 | 39.4 | 39.4 | 25 | 25 | 25 |
Table 13.
Performance in predicting the title of vulnerability (undersampled).
Table 13.
Performance in predicting the title of vulnerability (undersampled).
| Tomcat | | SFS | | | RFE | |
|---|
| | Accuracy in % | Precision in % | Recall in % | Accuracy in % | Precision in % | Recall in % |
| DT | 4.5 | 4.5 | 4.5 | 5 | 5 | 5 |
| LR | 13.6 | 13.6 | 13.6 | 15.4 | 15.4 | 15.4 |
| NB | 8 | 8 | 8 | 5.9 | 5.9 | 5.9 |
| XGB | 13.5 | 13.5 | 13.5 | 12.6 | 12.6 | 12.6 |
| Struts | | | | | | |
| DT | 1.2 | 1.2 | 1.2 | 17.5 | 17.5 | 17.5 |
| LR | 1.3 | 1.3 | 1.3 | 5.1 | 5.1 | 5.1 |
| NB | 0.1 | 0.1 | 0.1 | 0.5 | 0.5 | 0.5 |
| XGB | 0.6 | 0.6 | 0.6 | 0.1 | 0.1 | 0.1 |
Table 14.
Stacking classifier performance in Apache Tomcat (undersampled).
Table 14.
Stacking classifier performance in Apache Tomcat (undersampled).
| Tomcat | Accuracy in % | Precision in % | Recall in % |
|---|
| Vulnerable | 77 | 41.5 | 87.2 |
| Severity | 66.5 | 66.5 | 66.5 |
| Title | 10.6 | 10.6 | 10.6 |
Table 15.
Stacking classifier performance in Apache Struts (undersampled).
Table 15.
Stacking classifier performance in Apache Struts (undersampled).
| Struts | Accuracy in % | Precision in % | Recall in % |
|---|
| Vulnerable | 70.4 | 100 | 86.6 |
| Severity | 69.2 | 69.2 | 69.2 |
| Title | 6.4 | 6.4 | 6.4 |
Table 16.
Cross-version prediction performance in Apache Tomcat (undersampled).
Table 16.
Cross-version prediction performance in Apache Tomcat (undersampled).
| Vulnerable | | | |
|---|
| Exp. No. | Accuracy in % | Precision in % | Recall in % |
| 1 | 97.1 | 0 | 0 |
| 2 | 91.7 | 0 | 0 |
| 3 | 96.4 | 0 | 0 |
| 4 | 92.3 | 7 | 100 |
| 5 | 95.1 | 0 | 0 |
| 6 | 95.9 | 0 | 0 |
| Severity | | | |
| 1 | 98.4 | 98.4 | 98.4 |
| 2 | 67.6 | 67.6 | 67.6 |
| 3 | 71.7 | 71.7 | 71.7 |
| 4 | 34.7 | 34.7 | 34.7 |
| 5 | 72 | 72 | 72 |
| 6 | 80 | 80 | 80 |
| Title | | | |
| 1 | 76.9 | 76.9 | 76.9 |
| 2 | 66.3 | 66.3 | 66.3 |
| 3 | 42 | 42 | 42 |
| 4 | 23.9 | 23.9 | 23.9 |
| 5 | 31.4 | 31.4 | 31.4 |
| 6 | 30.9 | 30.9 | 30.9 |
Table 17.
Cross-version prediction performance in Apache Struts (undersampled).
Table 17.
Cross-version prediction performance in Apache Struts (undersampled).
| Vulnerable | | | |
|---|
| Exp. No. | Accuracy in % | Precision in % | Recall in % |
| 1 | 92.6 | 0 | 0 |
| 2 | 95.3 | 0 | 0 |
| 3 | 91.9 | 0 | 0 |
| 4 | 95.4 | 11.8 | 100 |
| 5 | 94.5 | 0 | 0 |
| 6 | 96.6 | 4 | 16.6 |
| 7 | 81 | 1.2 | 100 |
| 8 | 69.3 | 0.1 | 100 |
| 9 | 79.7 | 1.1 | 100 |
| 10 | 79.7 | 0.2 | 33.3 |
| Severity | | | |
| 1 | 96.5 | 96.5 | 96.5 |
| 2 | 95.1 | 95.1 | 95.1 |
| 3 | 91.5 | 91.5 | 91.5 |
| 4 | 94.8 | 94.8 | 94.8 |
| 5 | 70.9 | 70.9 | 70.9 |
| 6 | 92.4 | 92.4 | 92.4 |
| 7 | 6.5 | 6.5 | 6.5 |
| 8 | 54.6 | 54.6 | 54.6 |
| 9 | 70.2 | 70.2 | 70.2 |
| 10 | 56.7 | 56.7 | 56.7 |
| Title | | | |
| 1 | 88 | 88 | 88 |
| 2 | 95 | 95 | 95 |
| 3 | 92 | 92 | 92 |
| 4 | 92.3 | 92.3 | 92.3 |
| 5 | 93 | 93 | 93 |
| 6 | 87.6 | 87.6 | 87.6 |
| 7 | 99.7 | 99.7 | 99.7 |
| 8 | 99.9 | 99.9 | 99.9 |
| 9 | 31.6 | 31.6 | 31.6 |
| 10 | 23.8 | 23.8 | 23.8 |
Table 18.
Cross-project prediction performance (undersampled). (Exp 1) Train on Tomcat, test on Struts; (Exp 2) Train on Struts, test on Tomcat.
Table 18.
Cross-project prediction performance (undersampled). (Exp 1) Train on Tomcat, test on Struts; (Exp 2) Train on Struts, test on Tomcat.
| Exp 1 | Accuracy in % | Precision in % | Recall in % |
|---|
| Vulnerable | 97.5 | 0.1 | 20.4 |
| Severity | 88.4 | 88.4 | 88.4 |
| Title | 0.1 | 0.1 | 0.1 |
| Exp 2 | | | |
| Vulnerable | 67.3 | 31.9 | 83.2 |
| Severity | 29.1 | 29.1 | 29.1 |
| Title | 18.6 | 18.6 | 18.6 |
Table 19.
Performance of all learners in predicting vulnerable status in both datasets. (Weighted-average).
Table 19.
Performance of all learners in predicting vulnerable status in both datasets. (Weighted-average).
| Tomcat | | SFS | | | RFE | |
|---|
| | Accuracy in % | Precision in % | Recall in % | Accuracy in % | Precision in % | Recall in % |
| DT | 77 | 95.6 | 77 | 77 | 95.8 | 77 |
| LR | 83.8 | 95.7 | 83.8 | 84.2 | 95.8 | 84.2 |
| NB | 89.8 | 95.2 | 89.8 | 90.3 | 95.2 | 90.3 |
| XGB | 96.7 | 97 | 96.7 | 95.7 | 96.4 | 95.7 |
| Struts | | | | | | |
| DT | 81.9 | 99.7 | 81.9 | 83.6 | 99.7 | 83.6 |
| LR | 86.9 | 99.6 | 86.9 | 84.7 | 99.7 | 84.7 |
| NB | 14 | 99.5 | 14 | 73.8 | 99.8 | 73.8 |
| XGB | 99.6 | 99.7 | 99.6 | 99.6 | 99.7 | 99.6 |
Table 20.
Performance of all learners in predicting severity in both datasets. (Weighted-average).
Table 20.
Performance of all learners in predicting severity in both datasets. (Weighted-average).
| Tomcat | | SFS | | | RFE | |
|---|
| | Accuracy in % | Precision in % | Recall in % | Accuracy in % | Precision in % | Recall in % |
| DT | 58.7 | 95.9 | 58.4 | 80.1 | 95.8 | 80.1 |
| LR | 85.6 | 95.8 | 85.6 | 82.1 | 99.6 | 82.1 |
| NB | 25.3 | 95.4 | 34.4 | 39.3 | 96 | 39.3 |
| XGB | 68.5 | 96.1 | 66.3 | 70.5 | 96.4 | 70.5 |
| Struts | | | | | | |
| DT | 84.5 | 99.8 | 84.5 | 83.9 | 99.5 | 83.9 |
| LR | 83.7 | 99.7 | 83.7 | 80.2 | 99.4 | 80.2 |
| NB | 19.1 | 99.6 | 19.1 | 80.7 | 99.6 | 80.7 |
| XGB | 88 | 99.7 | 88 | 94 | 99.5 | 94 |
Table 21.
Performance of all learners in predicting title of the vulnerability in both datasets. (Weighted-average).
Table 21.
Performance of all learners in predicting title of the vulnerability in both datasets. (Weighted-average).
| Tomcat | | SFS | | | RFE | |
|---|
| | Accuracy in % | Precision in % | Recall in % | Accuracy in % | Precision in % | Recall in % |
| DT | 8.6 | 1 | 8.6 | 12.4 | 0 | 0 |
| LR | 35.5 | 0 | 0 | 47.1 | 96.1 | 47.1 |
| NB | 9.3 | 92.9 | 9.3 | 35.5 | 96.1 | 35.5 |
| XGB | 61.5 | 96.1 | 61.5 | 66.7 | 96.1 | 66.7 |
| Struts | | | | | | |
| DT | 70.3 | 99.7 | 70.3 | 61.7 | 99.7 | 61.7 |
| LR | 46.6 | 99.6 | 46.6 | 61.2 | 99.6 | 61.2 |
| NB | 31.8 | 99.6 | 31.8 | 43.6 | 99.7 | 43.6 |
| XGB | 95.3 | 99.7 | 95.3 | 91.9 | 99.7 | 91.9 |
Table 22.
Stacking classifier performance in Apache Tomcat. (Weighted-average).
Table 22.
Stacking classifier performance in Apache Tomcat. (Weighted-average).
| Tomcat | Accuracy in % | Precision in % | Recall in % |
|---|
| Vulnerable | 81.5 | 96 | 83.5 |
| Severity | 83 | 95.8 | 83 |
| Title | 89.9 | 95.3 | 89.9 |
Table 23.
Stacking classifier performance in Apache Struts. (Weighted-average).
Table 23.
Stacking classifier performance in Apache Struts. (Weighted-average).
| Struts | Accuracy in % | Precision in % | Recall in % |
|---|
| Vulnerable | 96.5 | 99.8 | 96.5 |
| Severity | 99.4 | 99.8 | 99.4 |
| Title | 99.6 | 99.7 | 99.6 |
Table 24.
Cross-version prediction performance in Apache Tomcat. (Weighted-average).
Table 24.
Cross-version prediction performance in Apache Tomcat. (Weighted-average).
| Vulnerable | | | |
|---|
| Exp. No. | Accuracy in % | Precision in % | Recall in % |
| 1 | 100 | 100 | 100 |
| 2 | 92.3 | 92.1 | 92.3 |
| 3 | 87.3 | 83.5 | 87.3 |
| 4 | 64.6 | 68.2 | 64.6 |
| 5 | 80.3 | 95.9 | 80.3 |
| 6 | 80.4 | 99.7 | 80.4 |
| Severity | | | |
| 1 | 100 | 100 | 100 |
| 2 | 83.2 | 79.9 | 83.2 |
| 3 | 79.4 | 85.5 | 79.4 |
| 4 | 51 | 44.2 | 51 |
| 5 | 75.1 | 95.9 | 75.1 |
| 6 | 76.9 | 99.7 | 76.9 |
| Title | | | |
| 1 | 100 | 100 | 100 |
| 2 | 76.7 | 75.5 | 76.7 |
| 3 | 80.9 | 82.6 | 80.9 |
| 4 | 44.7 | 37.4 | 44.7 |
| 5 | 70.1 | 95.6 | 70.1 |
| 6 | 63.7 | 99.7 | 63.7 |
Table 25.
Cross-version prediction performance in Apache Struts. (Weighted-average).
Table 25.
Cross-version prediction performance in Apache Struts. (Weighted-average).
| Vulnerable | | | |
|---|
| Exp. No | Accuracy in % | Precision in % | Recall in % |
| 1 | 99.7 | 100 | 99.7 |
| 2 | 99.7 | 100 | 99.7 |
| 3 | 100 | 100 | 100 |
| 4 | 99.3 | 98.7 | 99.3 |
| 5 | 99.3 | 100 | 99.3 |
| 6 | 98.8 | 98.8 | 98.8 |
| 7 | 96.9 | 99.7 | 96.9 |
| 8 | 95.2 | 99.8 | 95.2 |
| 9 | 93.1 | 99.5 | 93.1 |
| 10 | 92.5 | 99.7 | 92.5 |
| Severity | | | |
| 1 | 99.7 | 100 | 99.7 |
| 2 | 99.7 | 100 | 99.7 |
| 3 | 100 | 100 | 100 |
| 4 | 99.3 | 98.7 | 99.3 |
| 5 | 99.6 | 100 | 99.6 |
| 6 | 98.9 | 98.7 | 98.9 |
| 7 | 95.2 | 99.8 | 95.2 |
| 8 | 95.1 | 99.8 | 95.1 |
| 9 | 95 | 99.6 | 95 |
| 10 | 94.2 | 99.6 | 94.2 |
| Title | | | |
| 1 | 99.7 | 100 | 99.7 |
| 2 | 99.7 | 100 | 99.7 |
| 3 | 100 | 100 | 100 |
| 4 | 99.3 | 98.7 | 99.3 |
| 5 | 99.6 | 100 | 99.6 |
| 6 | 98.9 | 98.6 | 98.9 |
| 7 | 95.6 | 99.8 | 95.6 |
| 8 | 94.6 | 99.8 | 94.6 |
| 9 | 94 | 99.7 | 94 |
| 10 | 93.8 | 99.7 | 93.8 |
Table 26.
Cross-project prediction performance in Apache Struts. (Weighted-average). (Exp 1) Train on Tomcat, test on Struts; (Exp 2) Train on Struts, test on Tomcat.
Table 26.
Cross-project prediction performance in Apache Struts. (Weighted-average). (Exp 1) Train on Tomcat, test on Struts; (Exp 2) Train on Struts, test on Tomcat.
| Exp 1 | Accuracy in % | Precision in % | Recall in % |
|---|
| Vulnerable | 95.3 | 99.6 | 95.3 |
| Severity | 90.9 | 99.6 | 90.9 |
| Title | 83.7 | 99.6 | 83.7 |
| Exp 2 | | | |
| Vulnerable | 70.3 | 71.7 | 70.3 |
| Severity | 69.2 | 70 | 69.2 |
| Title | 74.3 | 68.7 | 74.3 |









































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}