A State-Level Socioeconomic Data Collection of the United States for COVID-19 Research

 , , , ,
, , , ,  and
and
Abstract
1. Summary
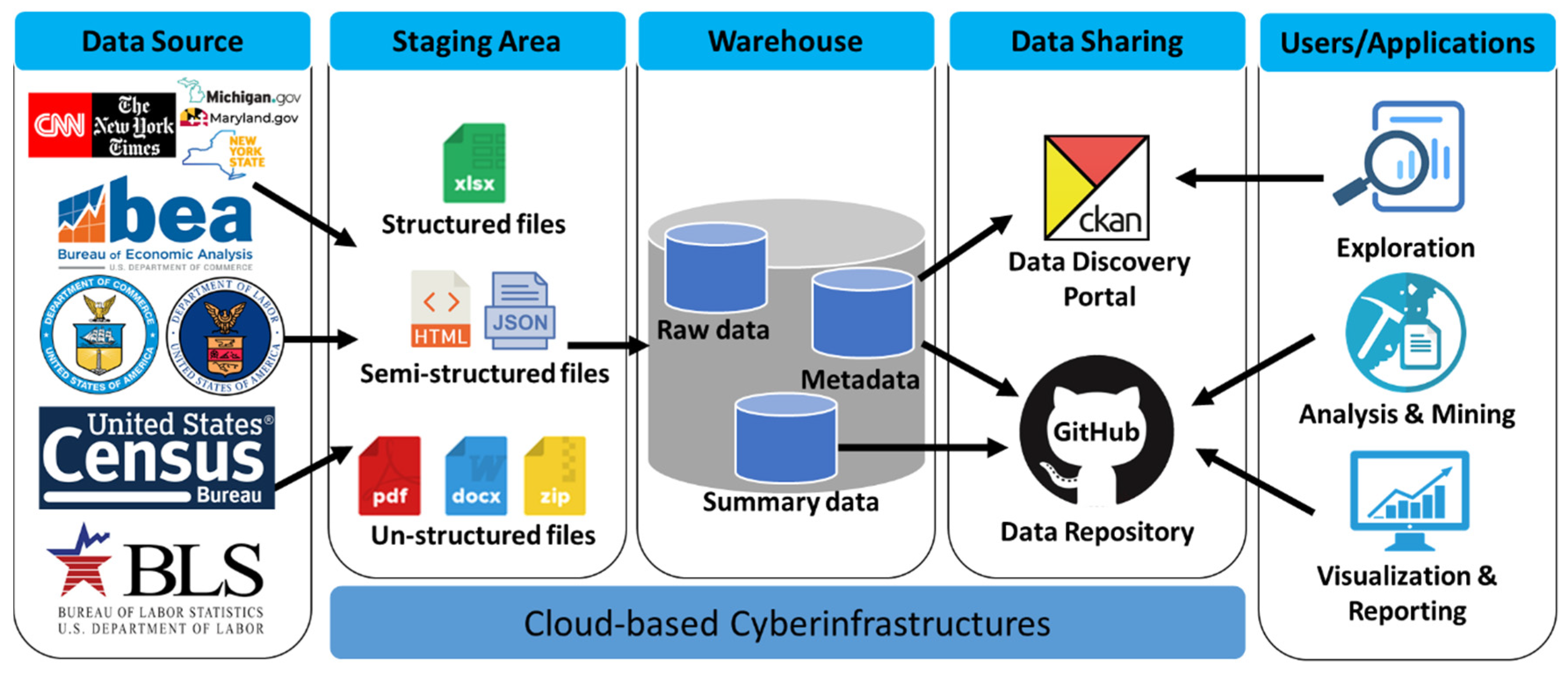
2. Data Sources
2.1. Raw Measurement of Socioeconomic Factors
2.1.1. Qualitative Restriction Policy Orders
2.1.2. Macroeconomic Indicators
2.1.3. Employment
2.1.4. Housing Market
2.1.5. Medical Resources
2.1.6. Census-Based Socioeconomic Data
2.2. Data Description
2.2.1. Daily Policy Stringency Index
2.2.2. Economic Indexes for Multiple Time-Frequency
2.2.3. Socioeconomic Driven Factors/Determinants/Indicators (Control Variable)
3. Methods
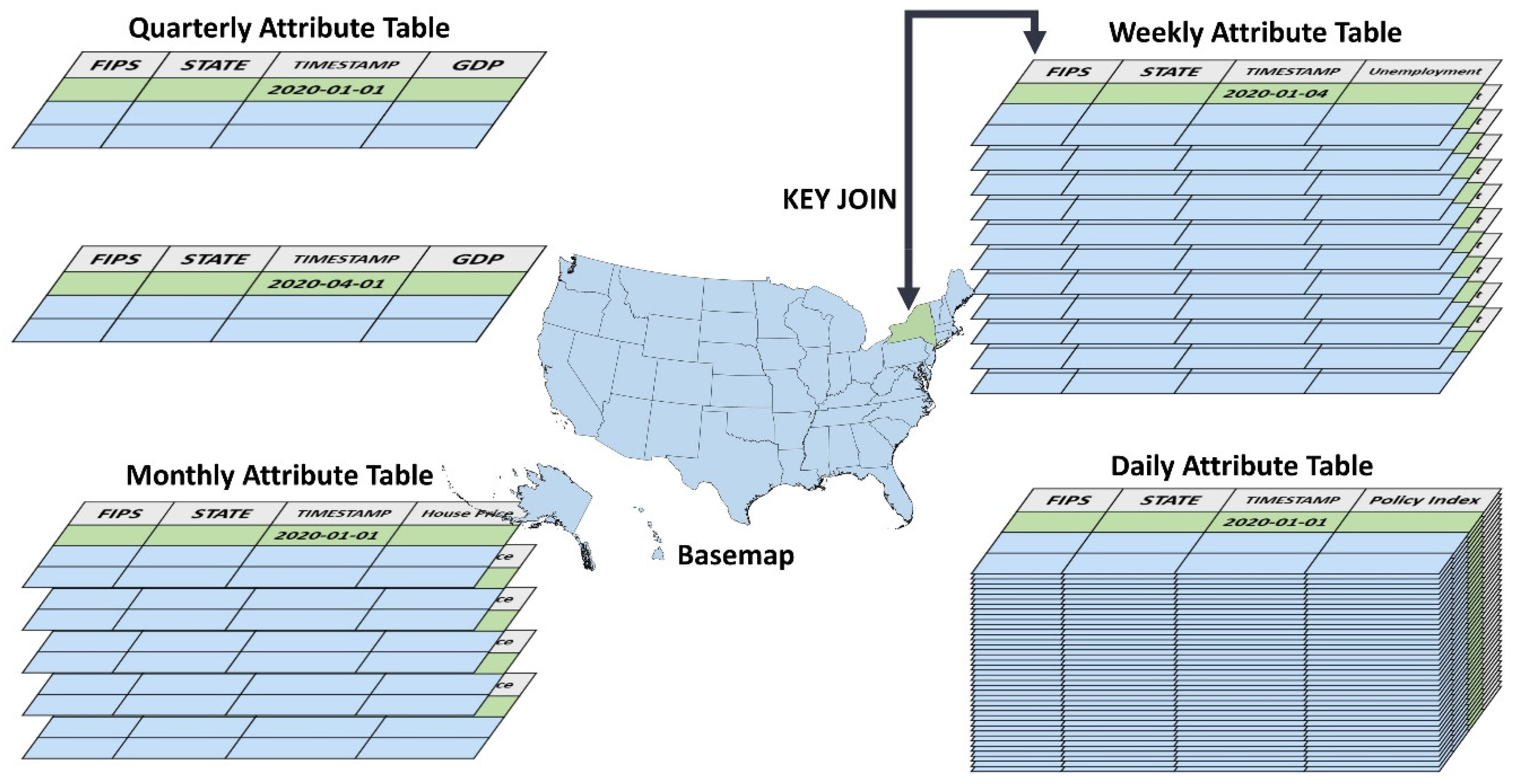
3.1. Cloud-Based Data Warehouse and Spatiotemporal Aggregation
3.2. Policy Index Extraction and Coding Standard
- First, we code the qualitative policy into quantitative numbers (0,1,2) (0 for No measure; 1 for Recommend closing; 2 for Require closing; an additional code of “3” for the category of international travel control) according to the policy’s stringency. For instance, a government’s official announcement that recommends business closure will be coded as 1, and a strict requirement of business closure will be coded as 2. Another example is when there is no policy restricting internal movement, the code would be 0, and if governments recommended movement restrictions (recommend people to stay at home), the code would be 1, and if the government adopted and implemented the “Stay at Home Order” that requires people to stay at home, then the code for this policy’s stringency would be 2. Additionally, there is another code for the national/regional coverage of the specific policy (0 for Targeted region and 1 for General all regions). For example, the code will be 0 if the policy is only targeted at some counties/cities of the state/country, and the code would be changed to 1 if the policy targets the whole state/country.
- Then, the code numbers of each policy category are summed up and rescaled to create a score between 0 and 100.
- In the end, the seven scores are averaged to obtain the overall Stringency Index for that region (as Equation (1) shows). The policy index extraction is conducted manually by the NSF STC group.
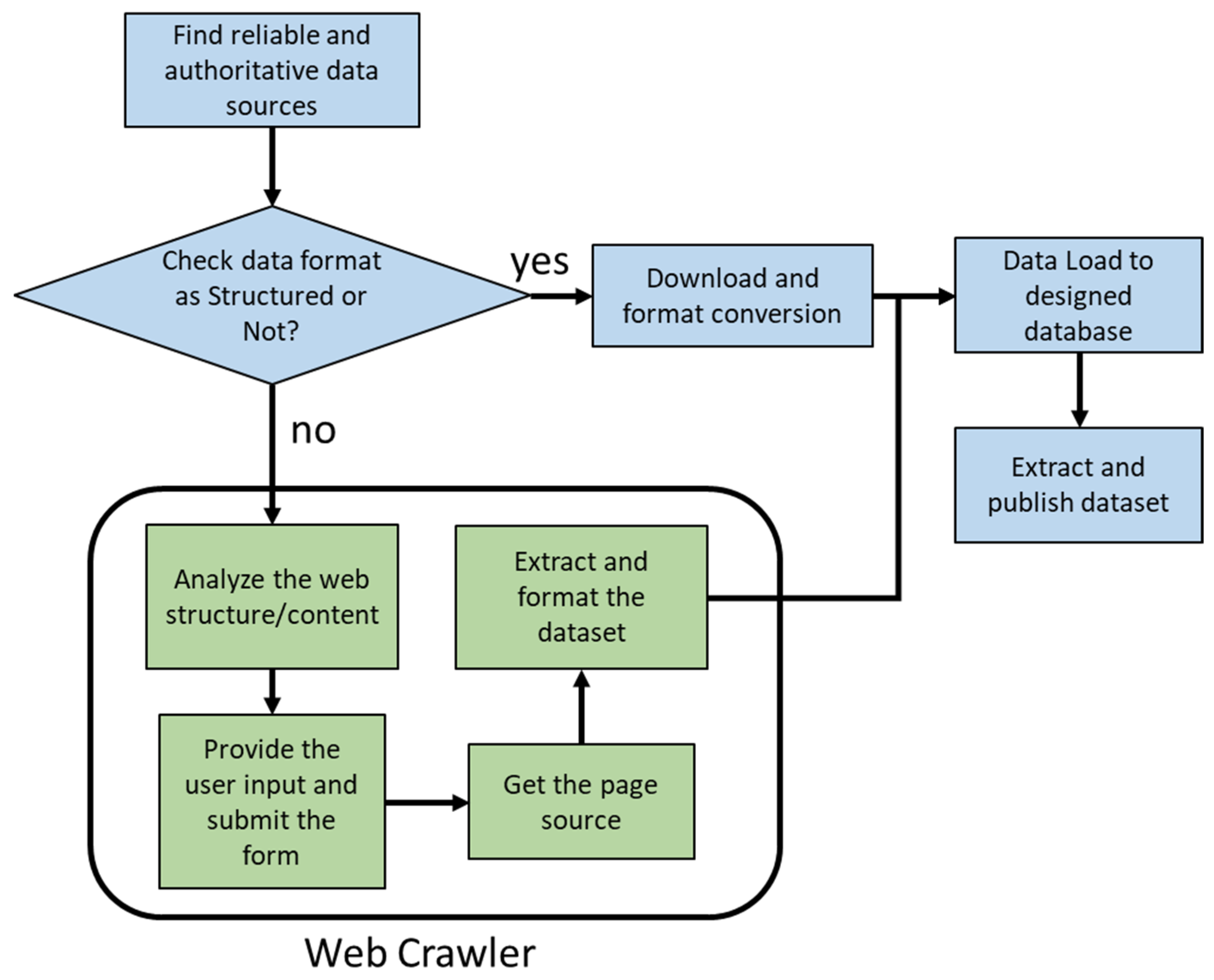
3.3. On-Demand Web Crawler
- First, we interpret and understand the DOM structure.
- The next step is to provide the users with inputs in the required fields and submit the form. This is achieved by selenium API, which automatically interacts with a web page by calling browser drivers such as chrome, gecko (for Firefox), and Internet Explorer (IE). Subsequently, by inspecting the input field web elements (such as textboxes, radio buttons, dropdowns) we provide input values and submit the form using a button click.
- The next step is to obtain the page source. For example, to extract unemployment insurance data from the United States Department of Labor (DOL) website [18], we used selenium to automatically:
- Select the “State” radio button.
- Select “2019” from the drop-down options for the start year.
- Select “2020” from the drop-down options for end year.
- and select all states from the textbox.
- Finally, we submit the form by clicking the Submit button and obtain the page source information.
- Once we have the page source with the required information, we use the beautifulSoup4 python package to identify the table that holds the unemployment insurance data and extract the text content from the table. The final step is to format the dataset in a standard format.
3.4. Data Quality Control
4. Data Sharing
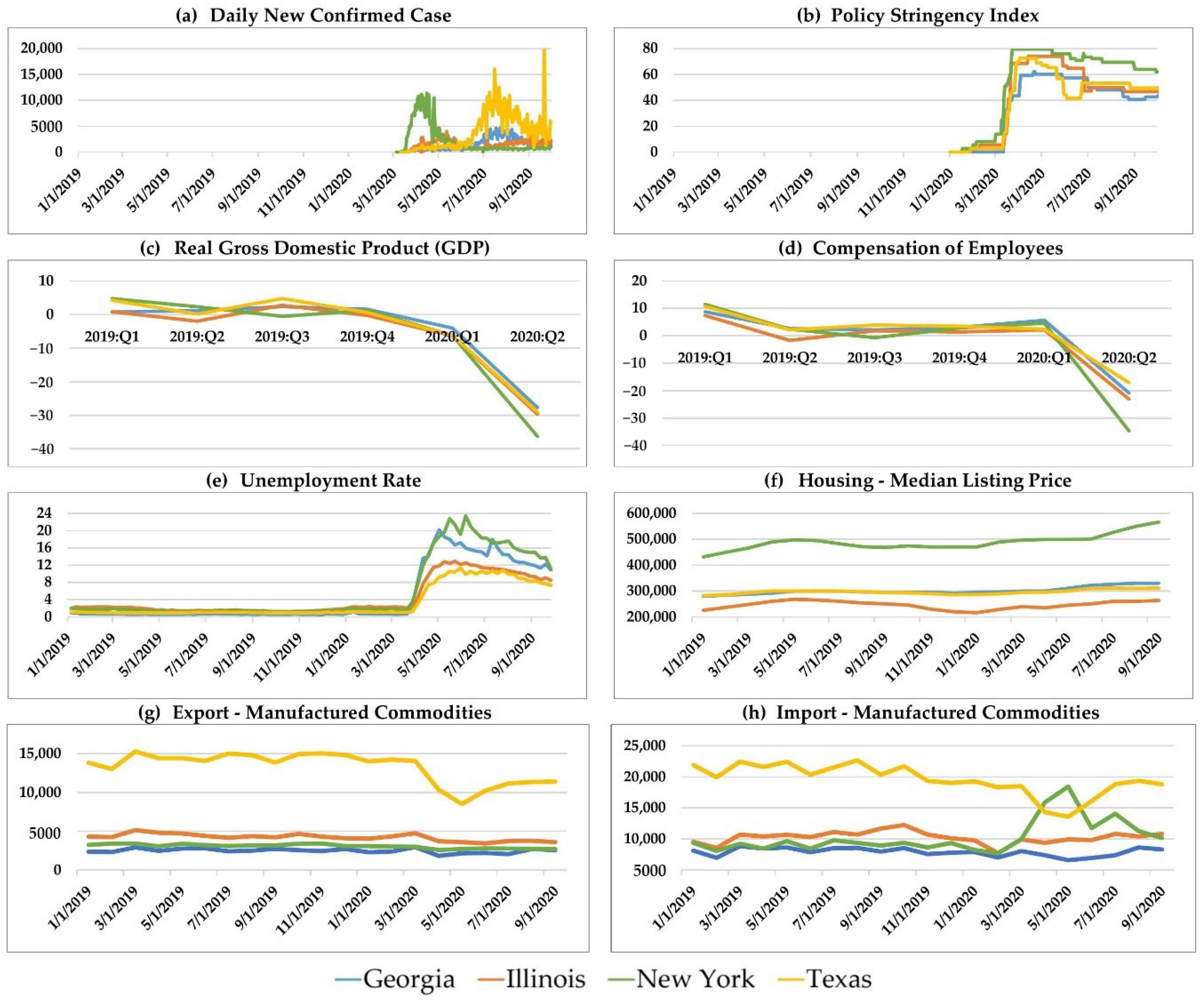
5. Time Trend Analysis of Typical Attributes
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Dong, E.; Du, H.; Gardner, L.M. An interactive web-based dashboard to track COVID-19 in real time. Lancet Infect. Dis. 2020, 20, 533–534. [Google Scholar] [CrossRef]
- McKibbin, W.J.; Fernando, R. The Global Macroeconomic Impacts of COVID-19: Seven Scenarios. SSRN Electron. J. 2020. [Google Scholar] [CrossRef]
- Lenzen, M.; Li, M.; Malik, A.; Pomponi, F.; Sun, Y.-Y.; Wiedmann, T.; Faturay, F.; Fry, J.; Gallego, B.; Geschke, A.; et al. Global socio-economic losses and environmental gains from the Coronavirus pandemic. PLoS ONE 2020, 15, e0235654. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.; Sha, D.; Liu, W.; Houser, P.R.; Zhang, L.; Hou, R.; Lan, H.; Flynn, C.; Lu, M.; Hu, T.; et al. Spatiotemporal Patterns of COVID-19 Impact on Human Activities and Environment in Mainland China Using Nighttime Light and Air Quality Data. Remote Sens. 2020, 12, 1576. [Google Scholar] [CrossRef]
- Yang, C.; Sha, D.; Liu, Q.; Li, Y.; Lan, H.; Guan, W.W.; Hu, T.; Li, Z.; Zhang, Z.; Thompson, J.H.; et al. Taking the pulse of COVID-19: A spatiotemporal perspective. Int. J. Digit. Earth 2020, 13, 1186–1211. [Google Scholar] [CrossRef]
- Franch-Pardo, I.; Napoletano, B.M.; Rosete-Verges, F.; Billa, L. Spatial analysis and GIS in the study of COVID-19. A review. Sci. Total. Environ. 2020, 739, 140033. [Google Scholar] [CrossRef] [PubMed]
- Sun, F.; Matthews, S.A.; Yang, T.-C.; Hu, M.-H. A spatial analysis of the COVID-19 period prevalence in U.S. counties through June 28, 2020: Where geography matters? Ann. Epidemiol. 2020. [Google Scholar] [CrossRef]
- Zhang, Z.; Sha, D.; Dong, B.; Ruan, S.; Qiu, A.; Li, Y.; Liu, J.; Yang, C. Spatiotemporal Patterns and Driving Factors on Crime Changing During Black Lives Matter Protests. ISPRS Int. J. Geo-Inf. 2020, 9, 640. [Google Scholar] [CrossRef]
- Li, Y.; Horowitz, M.A.; Liu, J.; Chew, A.; Lan, H.; Liu, Q.; Sha, D.; Yang, C. Individual-Level Fatality Prediction of COVID-19 Patients Using AI Methods. Front. Public Health 2020, 8, 587937. [Google Scholar] [CrossRef]
- Fernandes, N. Economic Effects of Coronavirus Outbreak (COVID-19) on the World Economy. SSRN Electron. J. 2020. [Google Scholar] [CrossRef]
- Paul, A.; Englert, P.; Varga, M. Socio-Economic Disparities and COVID-19 in the USA. SSRN Electron. J. 2020. [Google Scholar] [CrossRef]
- Baric, R.S. SARS-CoV: Lessons for global health. Virus Res. 2008, 133, 1–3. [Google Scholar] [CrossRef] [PubMed]
- Fairlie, R.; Couch, K.; Xu, H. The Impacts of COVID-19 on Minority Unemployment: First Evidence from April 2020 CPS Microdata; Nabr: Cambridge, MA, USA, 2020. [Google Scholar]
- Norouzi, N.; De Rubens, G.Z.; Choupanpiesheh, S.; Enevoldsen, P. When pandemics impact economies and climate change: Exploring the impacts of COVID-19 on oil and electricity demand in China. Energy Res. Soc. Sci. 2020, 68, 101654. [Google Scholar] [CrossRef] [PubMed]
- Mukherji, N. The Social and Economic Factors Underlying the Incidence of COVID-19 Cases and Deaths in US Counties. medRxiv 2020. [Google Scholar] [CrossRef]
- Bartik, A.W.; Bertrand, M.; Cullen, Z.; Glaeser, E.L.; Luca, M.; Stanton, C. The impact of COVID-19 on small business outcomes and expectations. Proc. Natl. Acad. Sci. USA 2020, 117, 17656–17666. [Google Scholar] [CrossRef]
- U.S. Bureau of Economic Analysis Personal Income by State. Available online: https://www.bea.gov/data/income-saving/personal-income-by-state (accessed on 2 November 2020).
- U.S. Department of Labor Unemployment Insurance Weekly Claims. Available online: https://www.dol.gov/ui/data.pdf. (accessed on 15 September 2020).
- United States Census Bureau American Community Survey (ACS). Available online: https://www.census.gov/programs-surveys/acs (accessed on 10 August 2020).
- Rahman, M.; Ali, G.; Li, X.J.; Paul, K.C.; Chong, P.H. Twitter and Census Data Analytics to Explore Socioeconomic Factors for Post-COVID-19 Reopening Sentiment. arXiv 2020, arXiv:2007.00054. [Google Scholar] [CrossRef]
- Hale, T.; Angrist, N.; Cameron-Blake, E.; Hallas, L.; Kira, B.; Majumdar, S.; Petherick, A.; Phillips, T.; Tatlow, H.; Webster, S. Variation in Government Responses to COVID-19; Blavatnik School of Government: Oxford, UK, 2020. [Google Scholar]
- Stojkoski, V.; Utkovski, Z.; Jolakoski, P.; Tevdovski, D.; Kocarev, L. The Socio-Economic Determinants of the Coronavirus Disease (COVID-19) Pandemic. SSRN Electron. J. 2020. [Google Scholar] [CrossRef]
- Qiu, Y.; Chen, X.; Shi, W. Impacts of social and economic factors on the transmission of coronavirus disease 2019 (COVID-19) in China. J. Popul. Econ. 2020, 33, 1127–1172. [Google Scholar] [CrossRef]
- Bureau of Economic Analysis Gross Domestic Product by State. Available online: https://www.bea.gov/data/gdp/gdp-state/ (accessed on 15 October 2020).
- Parker, K.; Minkin, R.; Bennett, J. About Half of Lower-Income Americans Report Household Job or Wage Loss Due to COVID-19 | Pew Research Center. Available online: https://www.pewsocialtrends.org/2020/04/21/about-half-of-lower-income-americans-report-household-job-or-wage-loss-due-to-covid-19/ (accessed on 2 November 2020).
- Parker, K.; Minkin, R.; Bennett, J. Economic Fallout From COVID-19 Continues To Hit Lower-Income Americans the Hardest | Pew Research Center. Available online: https://www.pewsocialtrends.org/2020/09/24/economic-fallout-from-covid-19-continues-to-hit-lower-income-americans-the-hardest/ (accessed on 2 November 2020).
- Leibovici, F.; Santacreu, A.M. International Trade Policy During COVID-19. Econ. Synop. 2020, 2020. [Google Scholar] [CrossRef]
- COVID-19 and International Trade: Issues and Actions. Available online: https://www.oecd.org/coronavirus/policy-responses/covid-19-and-international-trade-issues-and-actions-494da2fa/ (accessed on 2 November 2020).
- Bartik, A.; Bertrand, M.; Lin, F.; Rothstein, J.; Unrath, M. Measuring the Labor Market at the Onset of the COVID-19 Crisis; Nabr: Cambridge, MA, USA, 2020. [Google Scholar] [CrossRef]
- U.S. Department of Labor Unemployment Insurance Data. Available online: https://oui.doleta.gov/unemploy/ (accessed on 2 November 2020).
- Zhao, Y. US Housing Market during COVID-19: Aggregate and Distributional Evidence. SSRN Electron. J. 2020. [Google Scholar] [CrossRef]
- U.S. Census Bureau New Residential Construction. Available online: https://www.census.gov/construction/nrc/index.html (accessed on 15 October 2020).
- Realtor.com Real Estate Data Library. Available online: https://www.realtor.com/research/data/ (accessed on 15 October 2020).
- Halpern, N.A.; Tan, K.S.; Biostatistician, A.A. United States Resource Availability for COVID-19. Soc. Crit. Care Med. Available online: https://www.sccm.org/Blog/March-2020/United-States-Resource-Availability-for-COVID-19 (accessed on 20 May 2020).
- Sha, D.; Miao, X.; Lan, H.; Stewart, K.; Ruan, S.; Tian, Y.; Tian, Y.; Yang, C. Spatiotemporal analysis of medical resource deficiencies in the U.S. under COVID-19 pandemic. PLoS ONE 2020, 15, e0240348. [Google Scholar] [CrossRef] [PubMed]
- Definitive Healthcare USA Hospital Beds. Available online: https://www.definitivehc.com/ (accessed on 15 October 2020).
- National Council of State Boards of Nursing Number of Active RN Licenses by State. Available online: https://www.ncsbn.org/6161.htm (accessed on 15 October 2020).
- National Plan and Provider Enumeration System NPPES NPI Registry. Available online: https://npiregistry.cms.hhs.gov/ (accessed on 15 April 2020).
- Kouba, Z.; Matoušek, K.; Mikšovský, P. On data warehouse and GIS integration. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin, Germany, 2000; Volume 1873, pp. 604–613. [Google Scholar]
- Sha, D.; Liu, Y.; Qian, L.; Yang, C. A Spatiotemporal Viral Cases Data Collection for COVID-19 Rapid Response. Big Earth Data 2020. [Google Scholar] [CrossRef]
- Liu, Q.; Liu, W.; Sha, D.; Kumar, S.; Chang, E.; Arora, V.; Lan, H.; Li, Y.; Wang, Z.; Zhang, Y.; et al. An Environmental Data Collection for COVID-19 Pandemic Research. Data 2020, 5, 68. [Google Scholar] [CrossRef]
- Mitchell, R. Web Scraping with Python: Collecting More Data from the Modern Web; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2018. [Google Scholar]
- Gupta, S.; Kaiser, G.; Neistadt, D.; Grimm, P. DOM-based content extraction of HTML documents. In Proceedings of the 12th International Conference on World Wide Web, WWW 2003, Budapest, Hungary, 20–24 May 2003; ACM Press: New York, NY, USA, 2003; pp. 207–214. [Google Scholar]
- Yang, C.; Clarke, K.; Shekhar, S.; Tao, C.V. Big spatiotemporal data analytics: A research and innovation frontier. Int. J. Geogr. Inf. Sci. 2020, 34, 1075–1088. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index Name | Description | Example |
|---|---|---|
| State ID | State abbreviation code | MD |
| State | The target state name | Maryland |
| Date | The record date | 2020/3/10 |
| S ID | The coding dimension | S1 |
| Ordinary scale | Ordinary scale records | 2 |
| Binary scale | Binary scale for geographic scope | 1 |
| Notes | The link of policy legal document or news sources as the reference. | shorturl.at/ehuAO |
| Stringency Index | Coded stringency index for this dimension | 100 |
| Attributes | Description | Updated Frequency | Time Range (of Raw Data Source) |
|---|---|---|---|
| Gross Domestic Product (GDP) | |||
| Real GDP | Inflation-adjusted measure that reflects the value of all goods and services produced by an economy in a given year | quarterly | 2004 Q1–2020 Q2 |
| Current-dollar GDP | GDP evaluated at current market prices | quarterly | 2005 Q1–2020 Q2 |
| Chain-type quantity indexes | Eliminate the substitution bias found in indexes with unchanging (or “fixed”) weights, and their movements are not affected by the choice of the reference period. | quarterly | 2006 Q1–2020 Q2 |
| Personal Income | |||
| Overall Compensation | Compensation include all categories | quarterly | 1948 Q1–2020 Q2 |
| Farm Compensation | Compensation for farm relate employees | quarterly | 1948 Q1–2020 Q2 |
| Nonfarm Compensation | Compensation for non-farm relate employees | quarterly | 1948 Q1–2020 Q2 |
| Per capita personal income | Calculated as the total personal income of the residents of a state divided by the population of the state | quarterly | 1948 Q1–2020 Q2 |
| International Trade in Goods and Services | |||
| Export—Manufactured Commodities | Amount of manufactured commodities that export in millions of dollars | monthly | 2006/1–2020/9 |
| Export—Non-Manufactured Commodities | Amount of non-manufactured commodities that export includes agricultural, forestry, fishery products, mineral commodities, scrap, waste and used or second-hand merchandise in millions of dollars | monthly | 2006/1–2020/9 |
| Import—Manufactured Commodities | Amount of manufactured commodities that import in millions of dollars | monthly | 2006/1–2020/9 |
| Import—Non-Manufactured Commodities | Amount of non-manufactured commodities that import includes agricultural, forestry, fishery products, mineral commodities, scrap, waste and used or second-hand merchandise in millions of dollars | monthly | 2006/1–2020/9 |
| Employment | |||
| All employees—Total nonfarm | Number of employees in thousands which are nonfarm related jobs seasonally adjusted | monthly | 1990/1–2020/9 |
| All employees—Manufacturing | Number of employees in thousands which are manufacturing related seasonally adjusted | monthly | 1990/1–2020/9 |
| All employees-Education and Health Services | Number of employees in thousands which are education and health services related seasonally adjusted | monthly | 1990/1–2020/9 |
| Unemployment rate | Number unemployed as a percent of the labor force | monthly | 1976/1–2020/9 |
| Employment | Number of employed persons | monthly | 1976/1–2020/9 |
| Labor force participation rate | Proportion of the population that is in the labor force | monthly | 1976/1–2020/9 |
| Initial unemployment claim | An initial claim is a claim filed by an unemployed individual after a separation from an employer | weekly | 1967/1/7–2020/9/26 |
| Insured Unemployment Rate | The rate computed by dividing Total Unemployed by the Civilian Labor Force | weekly | 1967/1/7–2020/9/26 |
| Continued Claims | A person who has already filed an initial claim and who has experienced a week of unemployment then files a continued claim to claim benefits for that week of unemployment | weekly | 1967/1/7–2020/9/26 |
| Housing market | |||
| Total number of housing units | Total number of privately owned housing units unadjusted | monthly | 2019/1–2020/9 |
| Single family house | Total number of single housing units unadjusted | monthly | 2019/1–2020/9 |
| Multi-family units | Total number of multi-unit homes (includes 2, 3, or more) unadjusted | monthly | 2019/1–2020/9 |
| Days on Market | The median number of days property listings spend on the market | monthly | 2019/10–2020/10 |
| Median listing price | The median listing price during the specified month | monthly | 2019/10–2020/10 |
| Price increase count | The count of listings which have had their price increased | monthly | 2019/10–2020/10 |
| All-Transactions | It is based on sales price and appraisal. Values from refinance mortgages are added to the purchase-only data. Units: Index, not seasonally adjusted | quarterly | 1991/1–2020/9 |
| Expanded Data | It is based on sales price information sourced from Enterprise, Federal Housing Administration (FHA), and Real Property County Recorder Data Licensed from DataQuick Units: Index, not seasonally adjusted | quarterly | 1991/1–2020/9 |
| Purchase Only | It is based on more than 6 million repeat sales transactions on the same single-family properties. Units: Index, seasonally adjusted | quarterly | 1991/1–2020/9 |
| Attributes | Description | Unit | Topic |
|---|---|---|---|
| Area Size | the state area measurements, in square kilometers | sq-km | Geographic |
| Population Size | annual estimates of the total population (2019) | # | Demographic |
| Population Density | people per sq. km | # | Demographic |
| Senior Population | population age 65+ (% of total) | % | Demographic—age group |
| Young Population | population ages 0–14 (% of total) | % | Demographic—age group |
| Male Population | population gender male (% of total) | % | Demographic—gender group |
| White Population | population race white (% of total) | % | Demographic—racial group |
| Africa-American Population | population race Africa American (% of total) | % | Demographic—racial group |
| Hispanic Population | population ethnic Hispanic of any race (% of total) | % | Demographic—ethnic group |
| Internet Access | population using the internet and computers (2019 data) | % | Computers and internet subscriptions |
| High School Degree | population with high school and equivalent degrees (% of total) | % | Education |
| Bachelor’s Degrees | population with a bachelor’s degree or higher (% of total) | % | Education |
| Median Household Income | median household income | $ | Income |
| Poverty Rate | poverty rate household income below the poverty line. | % | Poverty |
| Uninsured | population without health care coverage in the United States (% of total) | % | Insurance |
| Household Size | average number of persons in a household | # | Household |
| House Owner | owner-occupied housing (% of total household) | % | Household |
| Hospital | number of hospitals | # | Health resource |
| Hospital bed | number of hospital licensed beds | # | Health resource |
| ICU bed | number of Intensive Care Unit (ICU) beds | # | Health resource |
| Nurses | number of registered nurses (RN) per 1000 population | # | Health resource |
| Medical Doctors | number of medical doctors per 1000 population | # | Health resource |
| ID | Name | Type | Targeted/General |
|---|---|---|---|
| S1 | School Closure | Ordinary | Geographic |
| S2 | Workplace closing | Ordinary | Geographic |
| S3 | Cancel public events | Ordinary | Geographic |
| S4 | Close public transport | Ordinary | Geographic |
| S5 | Public information campaigns | Ordinary | Geographic |
| S6 | Restrictions on internal movement (stay at home) | Ordinary | Geographic |
| S7 | International National travel controls | Ordinary | Geographic |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sha, D.; Malarvizhi, A.S.; Liu, Q.; Tian, Y.; Zhou, Y.; Ruan, S.; Dong, R.; Carte, K.; Lan, H.; Wang, Z.; et al. A State-Level Socioeconomic Data Collection of the United States for COVID-19 Research. Data 2020, 5, 118. https://doi.org/10.3390/data5040118
Sha D, Malarvizhi AS, Liu Q, Tian Y, Zhou Y, Ruan S, Dong R, Carte K, Lan H, Wang Z, et al. A State-Level Socioeconomic Data Collection of the United States for COVID-19 Research. Data. 2020; 5(4):118. https://doi.org/10.3390/data5040118
Chicago/Turabian StyleSha, Dexuan, Anusha Srirenganathan Malarvizhi, Qian Liu, Yifei Tian, You Zhou, Shiyang Ruan, Rui Dong, Kyla Carte, Hai Lan, Zifu Wang, and et al. 2020. "A State-Level Socioeconomic Data Collection of the United States for COVID-19 Research" Data 5, no. 4: 118. https://doi.org/10.3390/data5040118
APA StyleSha, D., Malarvizhi, A. S., Liu, Q., Tian, Y., Zhou, Y., Ruan, S., Dong, R., Carte, K., Lan, H., Wang, Z., & Yang, C. (2020). A State-Level Socioeconomic Data Collection of the United States for COVID-19 Research. Data, 5(4), 118. https://doi.org/10.3390/data5040118