1. Introduction
The development of information and communication technologies (ICTs) in the last several decades has an important role in the world’s socio-economic progress. Countries with higher levels of ICTs adoption enjoy better economic outcomes in return [
1]. Nevertheless, digital society is still an elusive aspiration for some countries, which is, in turn, causing a digital divide both at the individual and at the enterprise level [
2].
In 2003, a World Summit was held in Geneva, which addressed various technological issues, with the digital divide being one of them. A digital divide occurs when groups are formed with different levels of access to specific technological infrastructures, and it is often measured at the level of individual persons. On a psychosocial level, this divide can refer to those that embrace the new digital revolution and those that reject it, for various personal and demographic reasons [
3]. However, recently, the digital divide has substantially decreased for some of the technologies [
4].
On the other hand, new and upcoming technologies contribute to the digital divide among enterprises, which is especially worrisome, since enterprises nowadays heavily depend on ICTs as leverage for increasing their competitiveness. One of such technologies is big data, which is mainly driven by the emergence of Industry 4.0. The notion of Industry 4.0 (or Industrie 4.0), was initially proposed as a concept at the 2011 Hannover Fair, while in 2013, it became a German strategic initiative [
5]. As remarked by Witkowski [
6], the fourth industrial revolution (Industry 4.0) is facilitated with the development of the Internet of Things (IoT) and big data. These technologies enabled the automation and artificial intelligence to be implemented into industrial environments, making them “smart” [
6]. Big data plays one of the most important roles in Industry 4.0 enterprises. The big data algorithms and technologies enable new business insights to be discovered and informed data-driven decisions to be made. Exploiting knowledge hidden in the big data improves organizational performance and competitive advantage [
7]. Therefore, it is not surprising that Akoka et al. reported that 40% of ICT investment growth from 2012 until 2020 would be devoted to big data [
8].
The generally accepted definition of big data refers to the large amounts of structured and unstructured data, usually collected on a real-time basis [
9]. Big data complexity can be summarized by the 3V model of big data characteristics: Volume, Variety, and Velocity [
9,
10]. Volume embodies the size of the data that is measured in terabytes or larger units. Variety refers to diversity in the source and the structure of data. Velocity represents that data is generated, and collected, in streams. According to Brynjolfsson and McAfee, machine learning or deep learning is an inevitable part of the big data systems, due to their ability to learn from big data [
11]. These insights are relevant since it is nearly impossible, if not impossible, for humans to generate any relevant insight from big data without the help of machine learning. For example, using machine learning on big data, businesses can detect and prevent several kinds of fraud, increasing their security and decreasing costs generated by computer crime [
12]. In science, advances have been made in various fields, such as weather forecasting, natural disaster management, medicine, biology, and physics [
13].
The benefits of machine learning and big data have been demonstrated in various industries, such as insurance, chemistry, and energy [
14]. Other examples include customers and market intelligence, financial fraud, and stock market prediction in the financial industry. Big data usage is reported in the public services domain as well, where big data insights can foster innovations. Some of the additional implementations include public safety, smart health, smart grids and eGovernment [
8].
However, one of the most relevant areas of big data utilization is in manufacturing. For instance, big data is used in the smart production process, for the demand planning and inventory management, as parts of supply chain management [
15]. Industry 4.0, which is based on the concept of smart manufacturing, uses the advances in machine learning and big data, combined with advances in robotics, to create a partially autonomous manufacturing infrastructure, self-learning, and self-adapting. Usage of big data allows Industry 4.0 enterprises to integrate different products and platforms in collaborative systems [
6]. Besides, due to the potential value of big data, manufacturing industries are experiencing “servitization” of their business, since the integrated data sources are used in predictive analytics [
6], supporting the customer relationship management systems. Predictive maintenance is an additional area of big data utilization, where the advanced algorithms detect and fix faults, failures, and defects, and learn from past experiences to improve this process [
16,
17,
18,
19,
20,
21,
22].
In the next years, big data is projected to continue its rapid ascent [
23], with the increasing impact on both individuals and enterprises [
24,
25,
26]. Despite the growing importance of big data in business and economic development, big data is still an underrepresented topic in management research [
27]. Current literature mainly discusses big data concepts, methods, and application areas, but mainly from a technical perspective [
10,
23,
27]. However, several questions emerge concerning big data that are operative and are thus relevant to big data adoption. Which data sources are the most used for big data analytics in the enterprise? Are there more differences between enterprises of a different size or between enterprises from different countries according to the big data usage? What is the source of expertise used by the enterprises for using big data; internal or external experts? What are the differences among industries in terms of big data utilization?
The proliferation of big data occurred due to the increasing amount of data collected from core information technology systems, digital platforms, and Internet traffic. Big data is compounded out of data from web, social media, mobile applications, different types of records and databases, geospatial data, surveys, scanned traditional documents, etc. [
25]. Akoka et al. noted that the main sources of big data are social networks, mobile systems, and IoT devices [
8]. Hence, big data analytics concerning the source of data can be classified into three domains: (i) analyzing their own big data from an enterprise’s smart devices or sensors; (ii) analyzing big data from the geolocation of portable devices; and (iii) analyzing big data generated from social media.
Recent studies have reported on the beneficial impact of big data analytics in diverse industries [
8,
23,
27]. The source of different impact stems from the different nature of the data relevant for different industries, e.g., structured data, textual data, multimedia files, web and social media logs, network logs, internet-of-things, and mobile logs [
10,
28]. Castelo-Branco et al. investigated Industry 4.0 in EU countries [
29]. Their findings suggest that differences in manufacturing digitization could be partially explained by enterprises’ big data maturity.
Since big data acquisition, management, and analytics have recently emerged, the skills relevant to big data are scarce on the labor market, as well as in the curriculum of bachelor and master educational programs [
30]. To fill this gap, abundant massive open online courses and extracurricular courses have been launched, such as “Data Science and Big Data Analytics: Making Data-Driven Decisions” available at MIT [
31]. Rohrbeck discussed that the availability to use internal ICT experts is a significant driver of profitability since such experts have in-depth knowledge about the enterprise data, processes, and strategical goals [
32]. Due to the shortage of big data skills, enterprises likely employ both internal and external big data experts. However, the question emerges if the availability of internal experts could lead to a greater level of big data utilization.
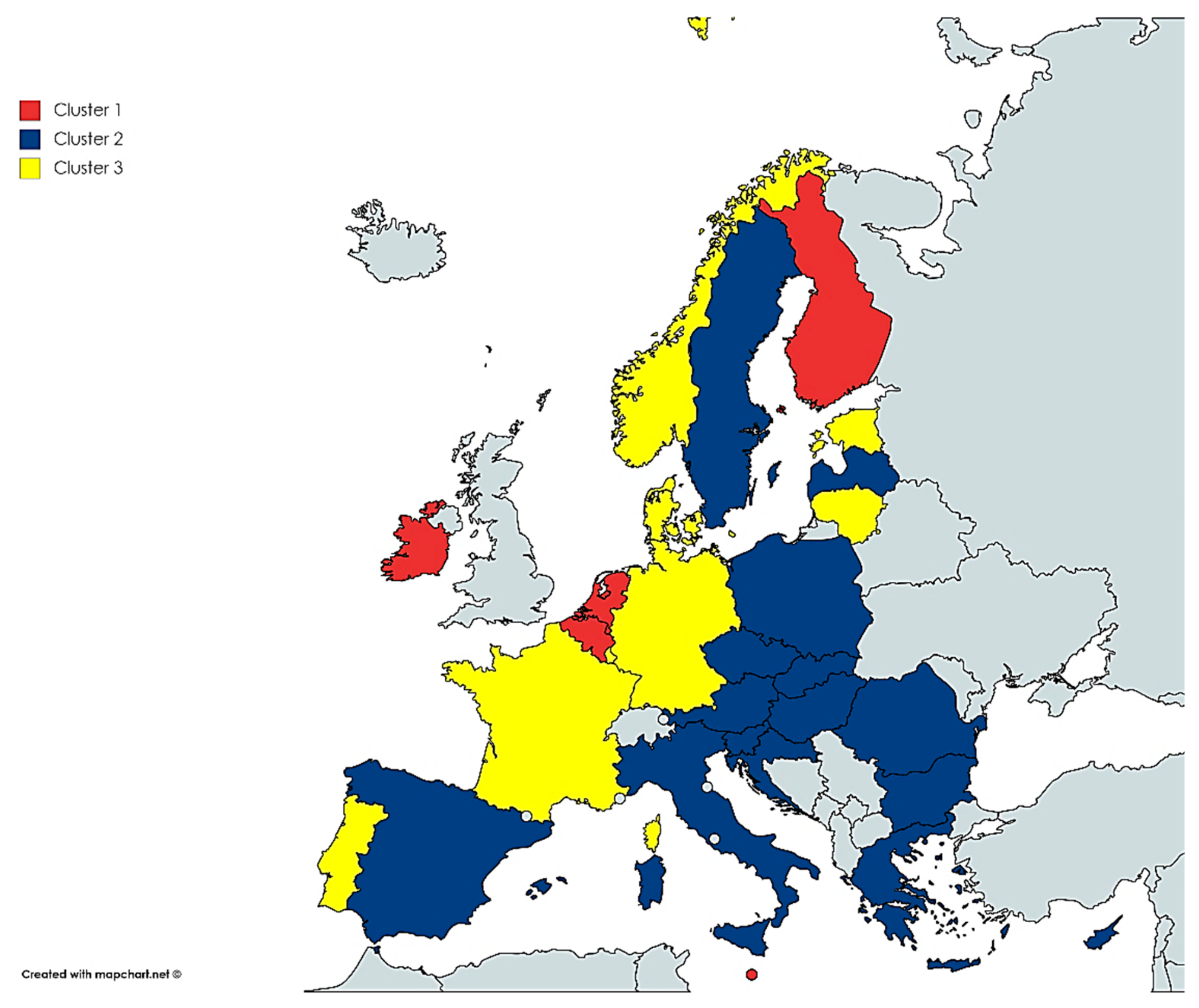
In this work, we focus on the usage of big data in Europe, intending to investigate differences between European countries according to the usage of big data by their enterprises, since the digital divide at the enterprise level has been demonstrated for various ICTs. For that purpose, we analyzed the data about big data usage from Eurostat, which was collected as part of the European ICT usage survey [
33], which includes the information about the overall usage of big data and usage of various big data sources (e.g., social media, internet of things), as well as usage of internal and external big data expertise.
We analyzed these data by using K-means cluster analysis, which is often used for analyzing the digital divide due to its ability to form homogenous groups of cases based on the usage of several variables [
34,
35]. Our analysis generated three clusters, which were in turn compared according to the level of usage of internal or external big data experts, and the level of big data usage in various industries. Results indicate that the big data digital divide is present in European countries, both at the country and industry level. Utilization of experts is also confirmed as a benefit to the big data utilization.
The paper is organized as follows. After the introduction section, the methodology section describes the data and statistical methods used. The third section presents the results of cluster analysis and compares the usage of internal or external big data expertise, and usage of big data in various industries. The final section summarizes the main ideas of the study and provides a discussion of theoretical and practical contributions.
4. Discussion and Conclusion
The goal of the research was to investigate the level of digital divide among European countries according to the big data on the country level, and among different industries. Usage of big data helps enterprises to improve their competitiveness [
7], which can be obtained in the following manner. First, big data allows enterprises to gather information about their customers, from social media and additional online sources, thus contributing to the big data-driven customer intelligence. Second, big data allows enterprises to gather information about their competitors, from the competitors’ websites, and various secondary sources, such as stock exchanges, thus contributing to the big data-driven competitive intelligence. Third, big data supports companies in the utilization of Industry 4.0, thus contributing to the big data-driven process intelligence.
The first research question (RQ1) aims to reveal the differences among enterprises in European countries according to the usage of big data technologies in small, medium, and large enterprises. The results of the analysis revealed that the European countries can be divided into three homogenous clusters with distinctive differences between them according to the level of big data usage. The highest overall usage of big data is observed in Cluster 1, closely followed by Cluster 3, both of which mostly comprise the most developed European countries. The usage of big data is lowest in Cluster 2, which mostly comprises the post-transition developing European countries. Therefore, it can be concluded that the digital divide is present in European countries according to the usage of big data in its enterprise, however, taking into account the fact that a substantial number of enterprises operate in more than one country, such as multinational companies.
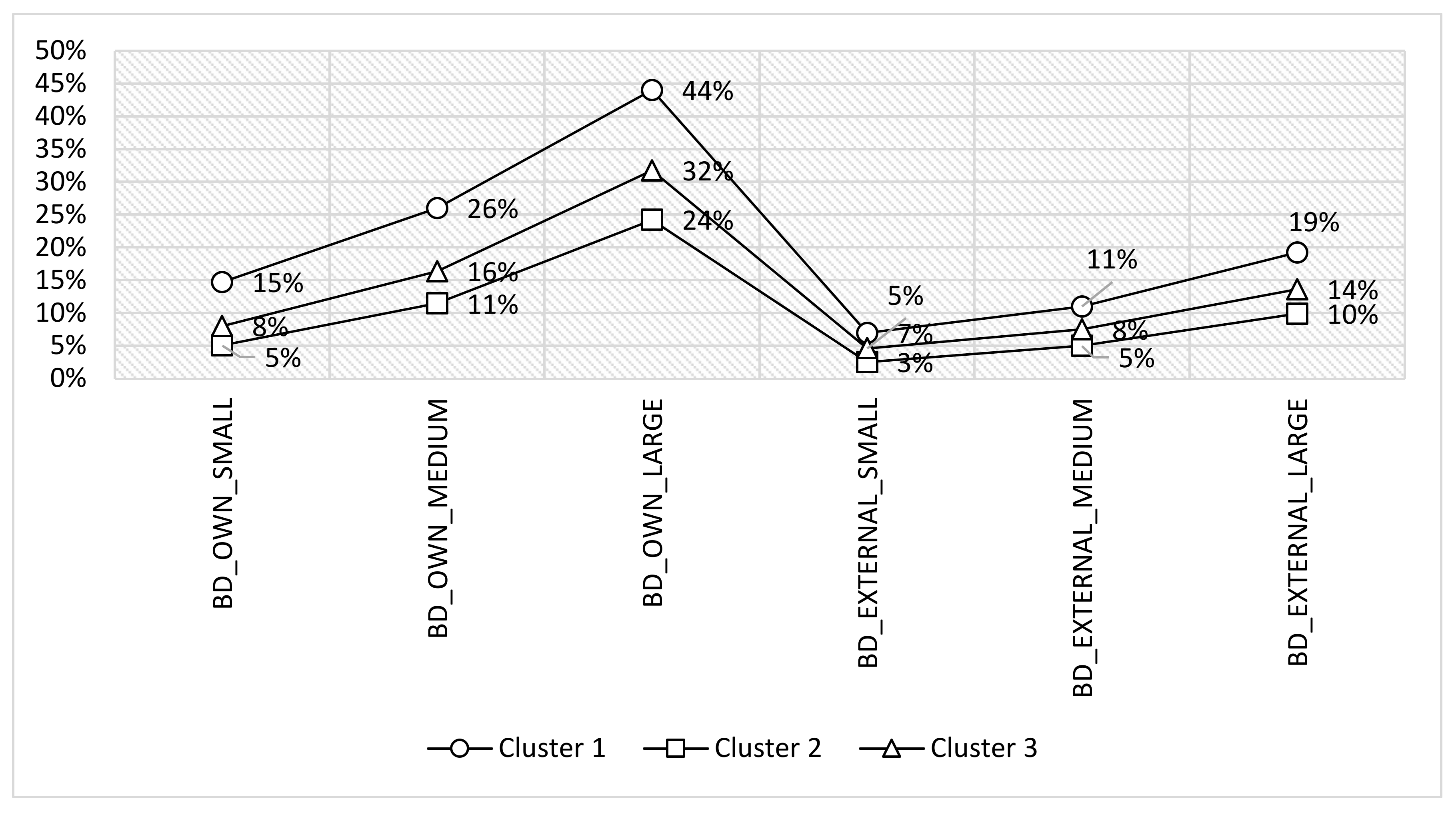
The second research question (RQ2) referred to the impact of using internal or external expertise for big data analysis. The results revealed that enterprises that use big data more often, rely, at the same time, on their internal experts far more than external service providers. This trend is more present in large enterprises compared to small and middle ones.
The third research question (RQ3) referred to the level of big data usage in various industries. The results revealed that in all observed industry types, enterprises belonging to Cluster 1 (the best performing cluster) had the highest average values compared to the other two clusters, while those from Cluster 3 had the lowest ones. Within the Cluster 1 results, the highest average values have been achieved by enterprises in Information and communication industry, followed by the Electricity, gas, steam, air conditioning, and water supply, which leads to the conclusion that such industries are the most efficient in big data utilization and its conversion to business value.
Our research contributes to several lines of research, resulting in the following theoretical contributions: (i) the confirmation of the research results about the leadership of Northern European countries in terms of the technological innovations; (ii) there are substantial differences between the industries in terms of big data usage, with the manufacturing industry lagging, which can be a signal of a worrisome trend of the European countries lagging behind other leaders of Industry 4.0, such as the USA and China; and (iii) large enterprises continue to be the most effective in the utilization of innovative technologies, which is also a signal of substantial obstacles faced by the small companies in the implementation of big data that could, in turn, further curb their growth and competitiveness. These contributions will be elaborated on with more details in the following sections.
First, we confirm the results of the previous research that the Northern European countries are leading according to the utilization of innovative industries, such as big data. Although the information technology development of the European Union is one of the highest in the world, a digital divide is manifested internally, among the member states [
48,
49]. Northern European countries still have a significantly greater percentage of citizens connected to the internet, in part likely to increasing capabilities of the hardware and decreasing cost of electronic goods and services, such as internet services, computer software, and accessories, as well as personal computers [
3]. This indicates that Northern European countries tend to experience fewer negative effects of automation, as the jobs in these countries are more complex and harder to automate. Therefore, a high level of digital development prevents the negative impact of technologies both at the country and enterprise level. On the other side, the low level of digital development reinforces the negative impact of technologies in less developed countries. Although the digital divide has decreased at the personal level among the developed European countries [
49], the digital divide at the country level is decreasing slowly due to its complex relationship with economic development. In the new digital divide, Industry 4.0 will play a significant role, and one of the major disadvantaged groups will be those with low levels of education. This is where the predicted job loss will mostly occur, as routine jobs will be replaced by those requiring analytical and problem-solving skills, flexibility in decision making, and higher levels of education and training in certain topics, such as computer science, mechanical and electronic engineering. Those with a mix of all of these skills, i.e., mechatronic experts, will have a particular advantage in this new industry. Moreover, it is worth noting that it is predicted that jobs requiring social and interpersonal skills, creativity, and innovation will increase [
50].
Second, our results revealed that several industries are leading to big data utilization, such as information technology. However, this is likely to be the result of the overall technical competence of their employees, since our research results revealed that enterprises mostly rely on internal big data experts. On the other hand, it is worrisome that European manufacturing enterprises that should be the leaders in Industry 4.0 revolution are lagging in terms of big data usage.
Third, we confirmed previous research that large companies are leading in the implementation of innovative technologies, such as big data. Therefore, large enterprises will have a great advantage in this regard, as they will possess the top talent and resources, thereby being better able to decide on the right technologies. However, future small enterprises or garage start-ups, due to their groundbreaking new ideas, might be able to compete well on this kind of market as well, as this was the case with top firms, such as Google, Facebook, and Amazon [
50].
The practical implications of our work indicate the need for interventions in educational programs. First, higher education institutions should consider the introduction of a strong bachelor and master curriculum with a focus on big data acquisition, management, and analysis. Second, massive open online courses and life-learning program about big data should be introduced at national levels, since internationally available courses (e.g., Udemy, Coursera) are not sufficient for fulfilling the demand for big data skills. Such programs should be specially tailored for the usage of open source big data software that could be used by small enterprises, to fasten their efficiency in acquiring internal expertise for big data, and at the same time decreasing their costs. Moreover, our results are useful for the enterprises itself, which may be reluctant to hire or educate big data experts due to possible costs. However, our research results indicate that the availability of internal experts is the strongest incentive for the utilization of big data analysis, which is, in turn, a path towards increased competitiveness.
Limitations of this study refer to the fact that the research has been conducted on a sample of selected European countries with different legislations, history, and level of economic development, which can all influence big data usage and acceptance within an enterprise from a certain country. Moreover, we focused our research on country-level data, while the data on an enterprise-level could gain results that could provide more evidence on the efficiency of enterprises in using big data for tactical, operational, and strategic decision-making. Finally, the global economy allows enterprises to operate in more than one country, which should be taken into account when evaluating the results of our research. For these reasons, future research should expand this study to enterprises worldwide, focusing on an enterprise level.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}