Korean Tourist Spot Multi-Modal Dataset for Deep Learning Applications

Abstract
:1. Summary
2. Data Description
2.1. Class Structure
2.2. Data Structure
2.2.1. Images
2.2.2. Texts
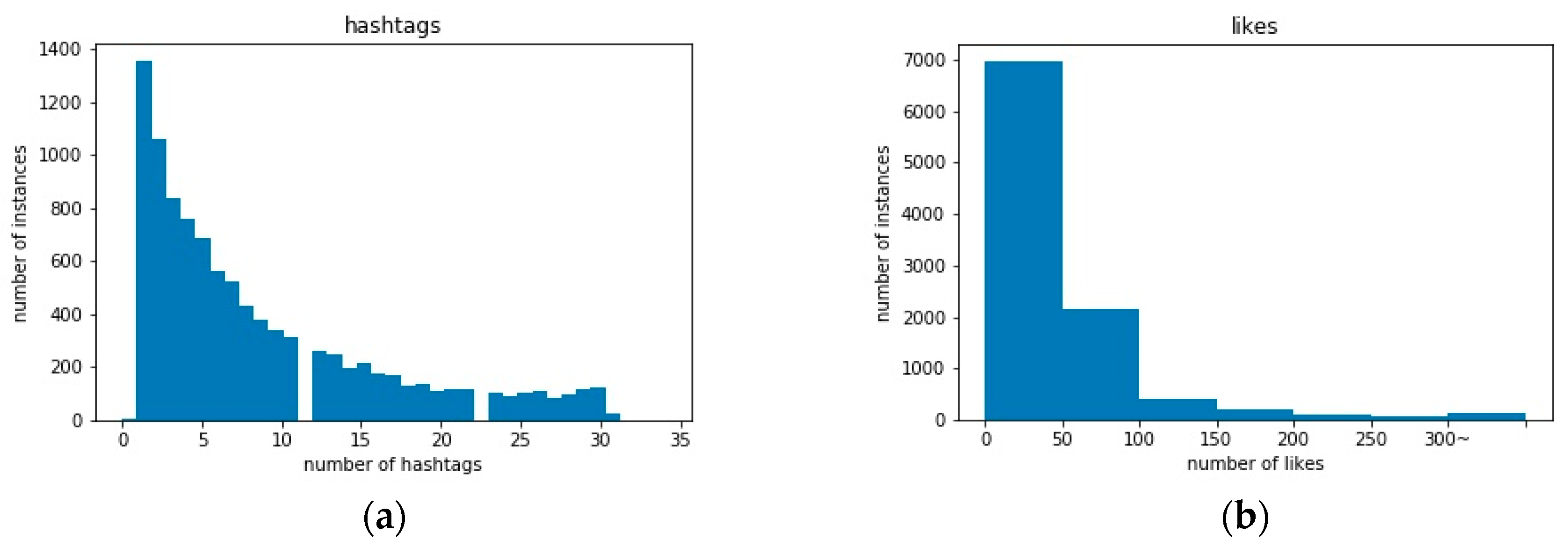
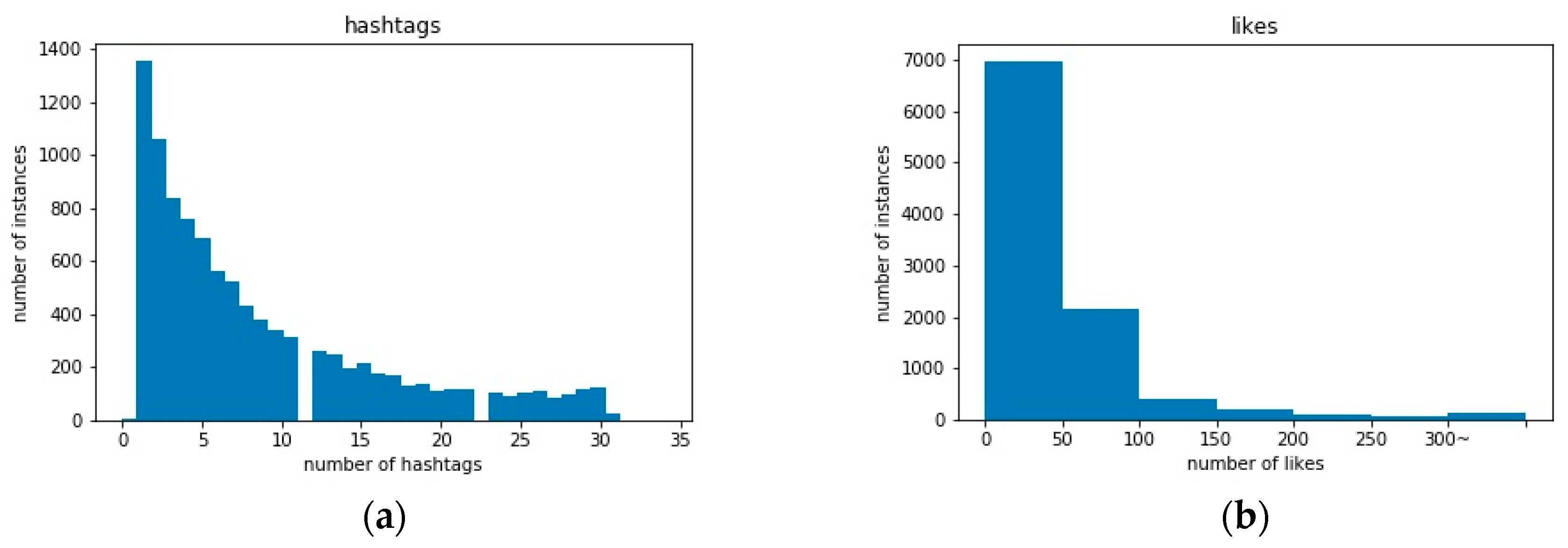
2.2.3. Hashtags and Likes
3. Methods
3.1. Data Collection
3.2. Data Preprocessing
3.2.1. Images
3.2.2. Texts and Hashtags
4. Experiments
4.1. Image Classification Using DCNN (Deep Convolutional Neural Networks)
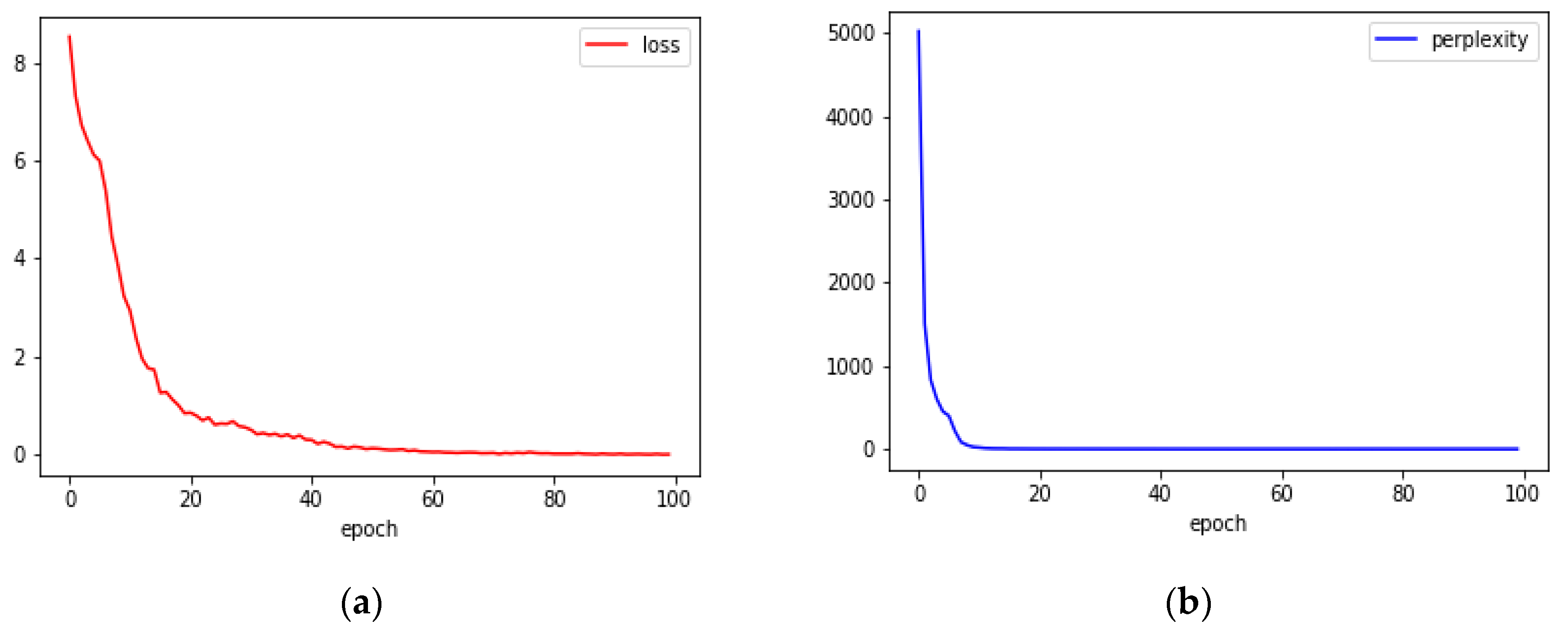
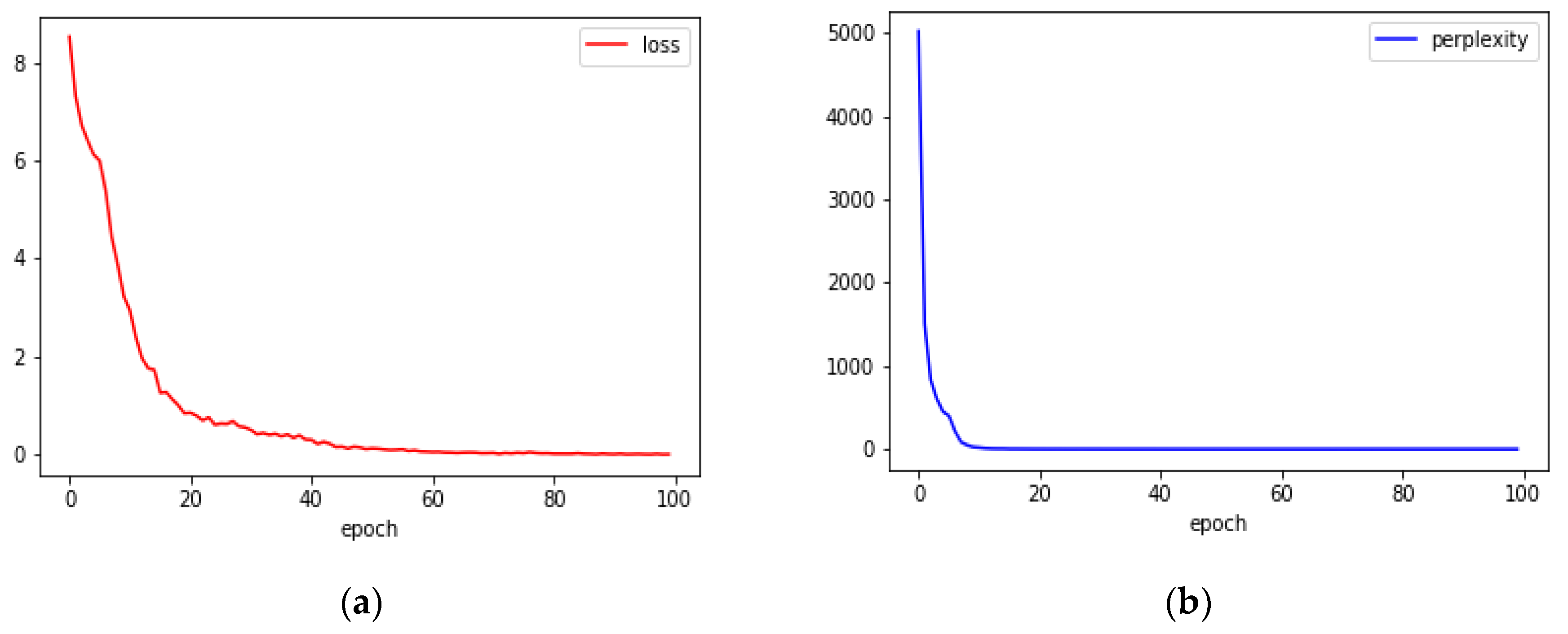
4.2. Image Captioning Using CNN and LSTM (Long Shot Term Memory)
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.-L.; Chen, S.-C.; Iyengar, S.S. A survey on deep learning: Algorithms, techniques, and applications. ACM Comput. Surv. 2018, 51, 92. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Nair, V.; Hinton, G. The CIFAR-10 Dataset. Available online: https://www.cs.toronto.edu/~kriz/cifar.html (accessed on 11 October 2019).
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- LeCun, Y.; Cortes, C.; Burges, C.J.C. MNIST Handwritten Digit Database. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 11 October 2019).
- Maas, A.L.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1, Portland, OR, USA, 19–24 June 2011; pp. 142–150. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.; Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013. [Google Scholar]
- Zhang, Q.C.; Yang, L.T.; Chen, Z.K.; Li, P. A survey on deep learning for big data. Inf. Fusion 2018, 42, 146–157. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Chua, T.-S.; Tang, J.H.; Hong, R.C.; Li, H.J.; Luo, Z.P.; Zheng, Y.T. NUS-WIDE: A real-world web image database from National University of Singapore. In Proceedings of the ACM International Conference on Image and Video Retrieval, Fira, Greece, 8–10 July 2009. [Google Scholar]
- Yelp Dataset Challenge. 2014. Available online: https://www.yelp.com/dataset/challenge (accessed on 11 October 2019).
- Peng, Y.X.; Huang, X.; Zhao, Y.Z. An overview of cross-media retrieval: Concepts, methodologies, benchmarks, and challenges. IEEE Trans. Circuits Syst. Video. Technol. 2017, 28, 2372–2385. [Google Scholar] [CrossRef]
- Plummer, B.A.; Wang, L.W.; Cervantes, C.M.; Caicedo, J.C.; Hockenmaier, J.; Lazebnik, S. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015. [Google Scholar]
- Instagram. 2010. Available online: https://www.instagram.com (accessed on 11 October 2019).
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, CA, USA, 5–10 December 2013. [Google Scholar]
- WordClouds. Available online: https://www.wordclouds.com/ (accessed on 11 October 2019).
- Python. 1991. Available online: https://www.python.org (accessed on 11 October 2019).
- Beautiful Soup Documentation. Available online: https://www.crummy.com/software/BeautifulSoup/bs4/doc/ (accessed on 11 October 2019).
- Rawat, W.; Wang, Z.H. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef] [PubMed]
- Hossain, M.D.; Sohel, F.; Shiratuddin, M.F.; Laga, H. A comprehensive survey of deep learning for image captioning. ACM Comput. Surv. 2019, 51, 118. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. Available online: https://arxiv.org/abs/1409.1556 (accessed on 10 April 2015).
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.Y.; Gulcehre, C.; Cho, K.Y.; Bengio, Y.S. Gated feedback recurrent neural networks. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2017, arXiv:1412.6980. Available online: https://arxiv.org/abs/1412.6980 (accessed on 30 January 2017).
- Brown, P.F.; Pietra, V.J.D.; Mercer, R.L.; Pietra, S.A.D.; Lai, J.C. An estimate of an upper bound for the entropy of English. Comput. Linguist. 1992, 18, 31–40. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subclass | Image | Text | Hashtag | Likes |
|---|---|---|---|---|
| beach (nature-scene) |  | "이 풍경 실화냐?? 실시간 우도. 제주도 너무 예쁘다. 바다 빛깔도 예술이야." | "#여행" "#우도" "#하고수동해수욕장" | 27 |
| mountain (nature-scene) |  | "죽음의 등산. 오랜만에 등산에 설레서 시작한 등산. 김밥도 싸서 올라갔는데 이게 뭐야.. 너무 힘들어 계단이며 바위며.. 6시간동안 등산하고 몸살났음." | "#등산" "#관악산" "#김밥" "#몸살" "#알배김 | 27 |
| palace (person-made) |  | "2시간 해설 들으면서 덕수궁 탐방, 너무 내 취향이야" | "#덕수궁" "#덕수궁궁궐야행" "#한양길라잡이" "#주말나들이" "#궁궐" | 32 |
| tower (person-made) |  | "대부도에 있는 높은 빌딩 이름하여 시화나래휴게소 달전망대 이름도 참 길다...바닥이 유리로 만들어져서 다 보임! 고소공포증 있는 사람에게는 비추천” | "#대부도" "#대부도여행지" "#대부도전망대" "#시화나래전망대" "#시화호" "#시화방조제" | 54 |
| Super- Class | Person-Made | Nature-Scene | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| sub-class | amusement park | palace | park | restaurant | tower | beach | cave | island | lake | mountain |
| Coarse Label | Fine Label | Example |
|---|---|---|
| person-made | amusement park | 진짜 재밌지만 떨어지는 구간 외에는 그저 추웠다고 한다 |
| palace | 새해 첫날부터 열심히 역사공부, 아픈 역사를 다시 느끼게 해준 설명 | |
| park | 시월의 어느 멋진 날에 용산가족공원. 붙잡고 놓아주기 싫은 가을풍경 | |
| restaurant | 바삭한 에그타르트 맛있어 | |
| tower | 야간 드라이브로 간 빛가람전망대! 맛있는 커피도 마셨다 | |
| nature-scene | beach | 배 한 척 떠 있는 바다. 이마저도 멋있네 |
| cave | 감성적인 느낌이 물씬 나는 울진 성류굴에서 여행 기분을 만끽해본다 | |
| island | 범섬의 아침과 한라산입니다 제주는 오늘도 따뜻합니다 | |
| lake | 경치는 좋았지만 아직은 좀 추웠던…오가는 것도 고생이다 | |
| mountain | 아쉽게도 정상에선 설경을 볼 순 없었지만 소문대로 칼바람 |
| Model | CIFAR-10 | KTS (Ours) |
|---|---|---|
| VGG16 | 0.8668 | 0.9155 |
| ResNet18 | 0.8724 | 0.9025 |
| DenseNet121 | 0.8823 | 0.9160 |
| Sub-Class | Beach | Mountain | Palace | Amusement Park |
|---|---|---|---|---|
| image |  |  |  |  |
| ground truth | 날씨 좋다. 경포대 | 야호! 이 풍경 보려고 등산하지 | 주말나들이 너무 좋다. 경회루도 너무 이쁘다 | 너랑 놀이공원 가고 싶어 |
| caption (prediction) | 겨울바다 너무 좋은 것. 여행은 혼자다. | 어제 도봉산을 올랐어요 ! 날씨가 많이 춥지 않은 덕분에 즐거운 산행을 했지요 ! | 경회루 좋아 멋있어 | 밤되니 이쁘다 회전목마 우리 애기랑 사진한장 찍기가 하늘의 별따기. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, C.; Jang, S.-E.; Na, S.; Kim, J. Korean Tourist Spot Multi-Modal Dataset for Deep Learning Applications. Data 2019, 4, 139. https://doi.org/10.3390/data4040139
Jeong C, Jang S-E, Na S, Kim J. Korean Tourist Spot Multi-Modal Dataset for Deep Learning Applications. Data. 2019; 4(4):139. https://doi.org/10.3390/data4040139
Chicago/Turabian StyleJeong, Changhoon, Sung-Eun Jang, Sanghyuck Na, and Juntae Kim. 2019. "Korean Tourist Spot Multi-Modal Dataset for Deep Learning Applications" Data 4, no. 4: 139. https://doi.org/10.3390/data4040139
APA StyleJeong, C., Jang, S.-E., Na, S., & Kim, J. (2019). Korean Tourist Spot Multi-Modal Dataset for Deep Learning Applications. Data, 4(4), 139. https://doi.org/10.3390/data4040139