A Transformative Concept: From Data Being Passive Objects to Data Being Active Subjects


{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Meeting Societal Data and Knowledge Needs
1.2. From Passive Data Objects to Active Data Subjects
1.3. Structure of The Paper
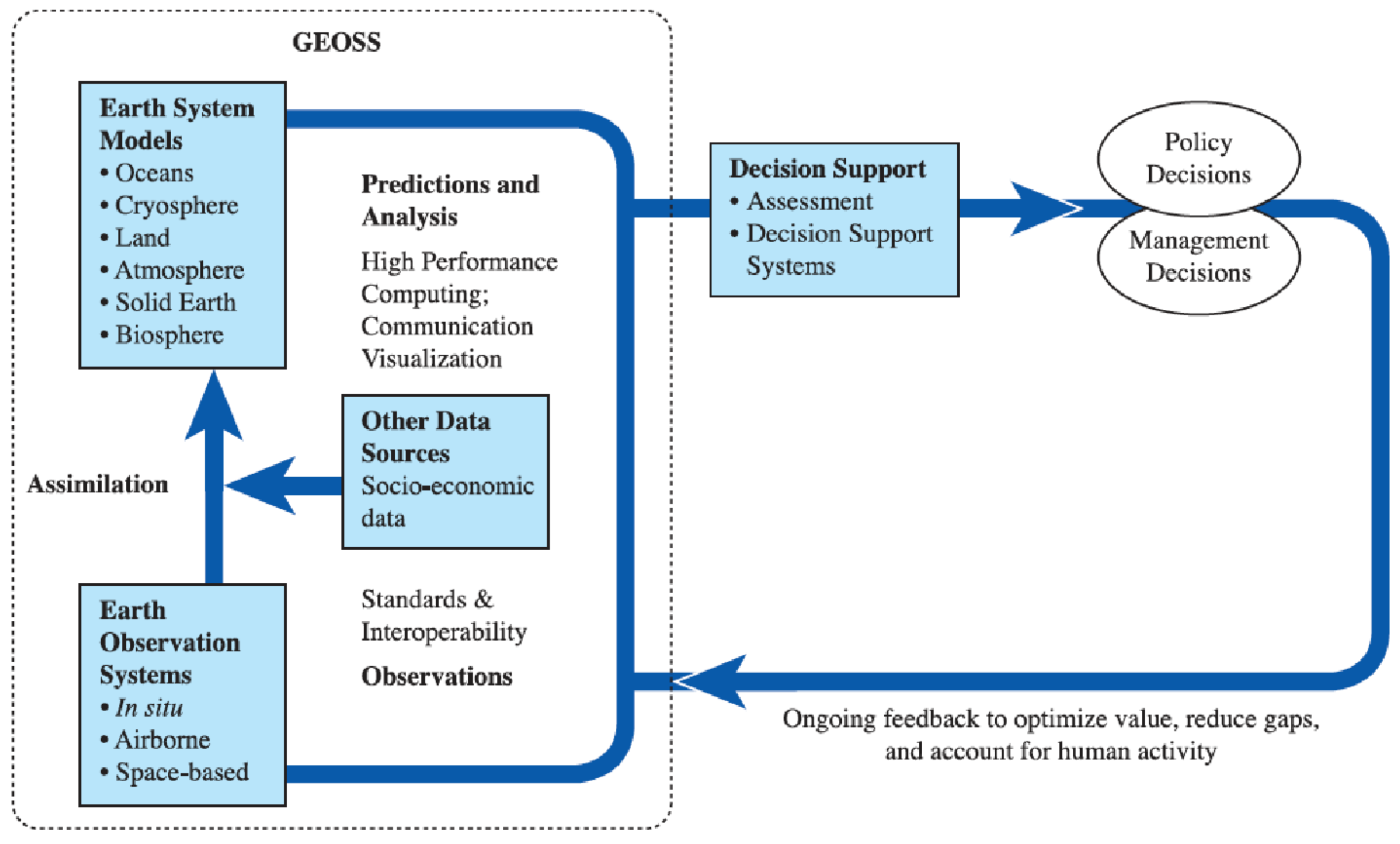
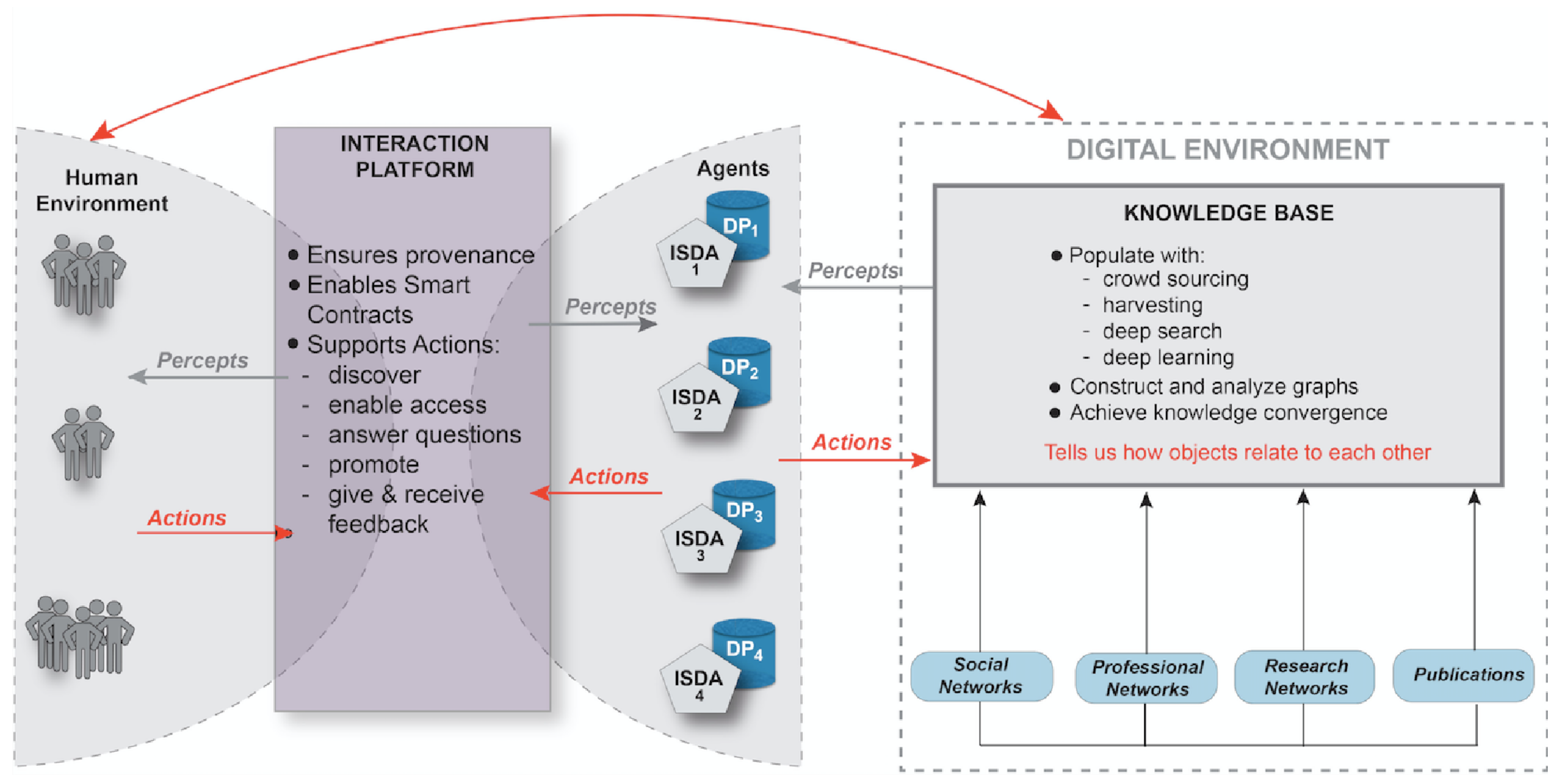
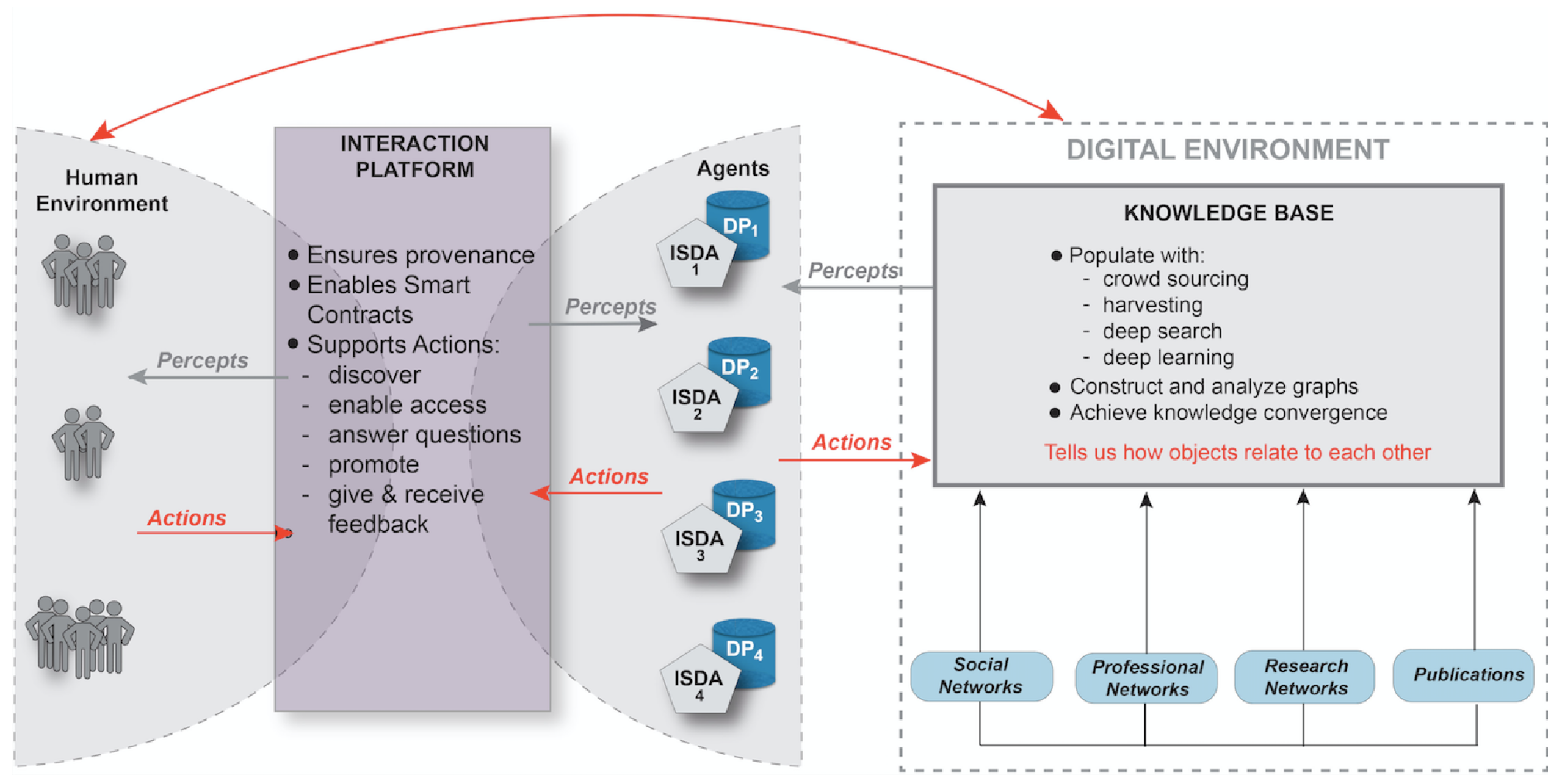
2. The DAS Concept
2.1. Overview
- Intelligent Semantic Data Agents (ISDAs) that are software agents that represent data products. They have the goal to serve potential users and to increase the exploitation of the societal benefits of the data product they represent. To achieve this, an ISDA has comprehensive knowledge about the data product it represents including quality, uncertainties, access conditions, previous uses, user feedbacks, etc. These non-human software agents have the semantic capabilities to communicate with potential users in the human environment and comprehensive graph data in the knowledge base. The ISDAs also have semantic and pragmatic descriptors that allow them to meaningfully interconnected with software agents of other datasets through complex and dynamic relations. These relations are continuously updated as users interact with the data agents and provide feedback on the data.
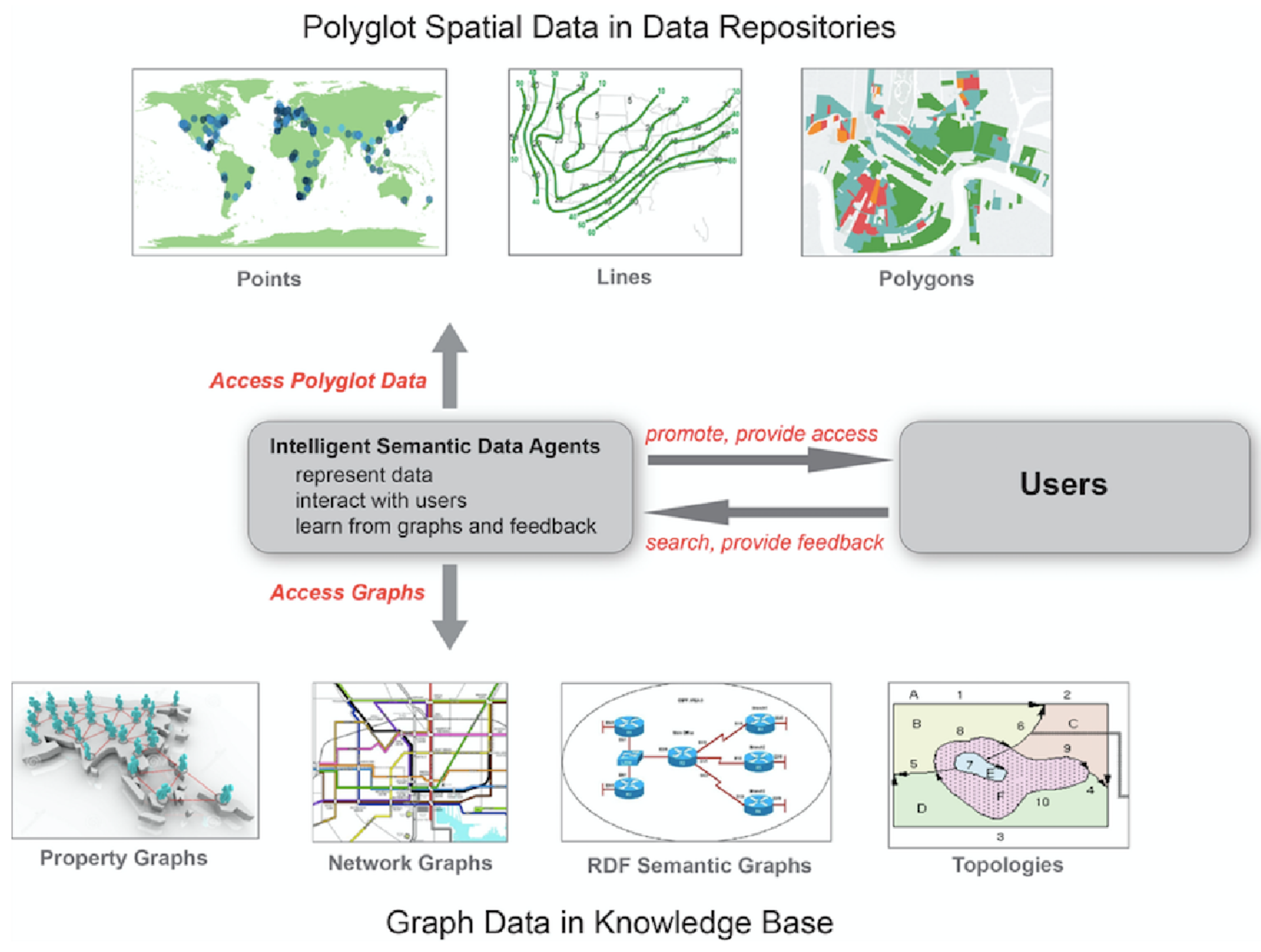
- A knowledge base that can construct and analyze extensive graphs presenting a comprehensive picture of the elements in a community of people, applications, models, tools, and resources. Earth observation (EO) data is mostly polyglot spatial data representing properties at points, lines, or polygones in space and their changes over time (Figure 3). Graph data captures the connections between objects and can consist, e.g., of property graphs linking persons, network graphs linking locations, semantic graphs linking language elements in ontologies, and more generalized graphs linking diverse objects such as data sets, information needs, and societal agents. Polyglot data are helpful in answering questions such as “how did land cover change over time at this point?” Graph data can answer questions such as “which researcher could benefit from land cover data?” The knowledge base will focus on graph data providing links between, e.g., knowledge needs and data types, user types and applications, publications and datasets, processing tools and datasets. None of the objects linked in the graph data resides in the knowledge base.
- An interaction platform to negotiate and execute “contracts” under which users gain access to knowledge extracted from data, access data, modify data, use data and provide feedback on their usage, and to document these interactions in a secure and reliable way maintaining full provenance.
2.2. Intelligent Semantic Data Agents
2.3. The Knowledge Base
2.4. Interaction Platform
3. Discussion
3.1. Current Status and New Contributions
3.2. Validation Through Case Studies
3.3. Considerations For Implementation
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AI | artificial intelligence |
| CDP | Customers Discover Products |
| DAS | Data as Active Subjects |
| DDU | Data Discover Users |
| DFS | Depth-first search |
| DPO | Data as Passive Objects |
| EO | Earth observation |
| FWEN | Food-Water-Energy Nexus |
| GCI | GEOSS Common Infrastructure |
| GDPR | General Data Protection Regulation |
| GEO | Group on Earth Observations |
| GEOSS | Global Earth Observation System of Systems |
| IGOS | Integrated Global Observing Strategy |
| IGOS-P | Integrated Global Observing Strategy Partnership |
| IAEG-SDGs | Inter-Agency and Expert Group on SDG Indicators |
| ISDA | Intelligent Semantic Data Agent |
| LODC | Linked Open Data Cloud |
| PDC | Products Discover Customers |
| RDF | Resource Description Framework |
| SDG | Sustainable Development Goal |
| SEE-IN KB | Socio-Economic and Environmental Information Needs Knowledge Base |
| SIDS | Small Island Developing States |
| UDD | Users Discover Data |
| UNFCCC | United Nations Framework Convention on Climate Change |
| UNSC | United Nations Statistical Commission |
| URR | User Requirements Registry |
References
- Harris, R.; Miller, L. Earth observation and the public good. Space Policy 2011, 27, 194–201. [Google Scholar] [CrossRef]
- Cotton-Barratt, O.; Farquhar, S.; Halstead, J.; Schubert, S.; Snyder-Beattie, A. Global Catastrophic Risks 2016; Technical Report; Global Challenge Foundation, Global Priorities Project: Stockholm, Sweden; Oxford, UK, 2016. [Google Scholar]
- World Economic Forum. Global Risks 2019, 14th ed.; Technical Report; World Economic Forum: Geneva, Switzerland, 2019. [Google Scholar]
- United Nations. Transforming our World: The 2030 Agenda for Sustainable Development; Technical Report A/RES/70/1; United Nations: New York, NY, USA, 2015. [Google Scholar]
- Campbell, J.; Jensen, D.E. The Promise and Peril of a Digital Ecosystem for the Planet; Technical Report; United Nations Environment Programme: Nairobi, Kenya, 2019; Available online: https://medium.com/@davidedjensen_99356/building-a-digital-ecosystem-for-the-planet-557c41225dc2 (accessed on 25 September 2019).
- Ryan, B. Open data for Sustainable Development. Geospatial World, 14 August 2016. [Google Scholar]
- Jules-Plag, S.; Plag, H.P. Supporting Agenda 2030’s Sustainable Development Goals—Agend-Based Models and GeoDesign. ApoGeoSpatial 2016, 31, 24–30. [Google Scholar]
- Taylor, G. Evolution’s Edge—The Coming Collapse and Transformation of our World; New Society Publishers: Gabriola Island, BC, Canada, 2008. [Google Scholar]
- Baum, S.D.; Handoh, I.C. Integrating the planetary boundaries and global catastrophic risk paradigms. Ecol. Econ. 2014, 107, 13–21. [Google Scholar] [CrossRef]
- Keys, P.W.; Galaz, V.; Dyer, M.; Matthews, N.; Folke, C.; Nyström, M.; Cornell, S.E. Anthropocene risk. Nat. Sustain. 2019, 2, 667–673. [Google Scholar] [CrossRef]
- Wang, M.; Hu, C.; Barnes, B.B.; Mitchum, G.; Lapointe, B.; Montoya, J.P. The great Atlantic Sargassum belt. Science 2019, 365, 83–87. [Google Scholar] [CrossRef]
- Steffen, W.; Rockström, J.; Richardson, K.; Lenton, T.M.; Folke, C.; Liverman, D.; Summerhayes, C.P.; Barnosky, A.D.; Cornell, S.E.; Crucifix, M.; et al. Trajectories of the Earth System in the Anthropocene. Proc. Natl. Acad. Sci. USA 2018, 115, 8252–8259. [Google Scholar] [CrossRef] [Green Version]
- Rothman, D.H. Thresholds of catastrophe in the Earth system. Sci. Adv. 2017, 3, e1700906. [Google Scholar] [CrossRef]
- Baum, S.D. The far future argument for confronting catastrophic threats to humanity: Practical significance and alternatives. Futures 2015, 72, 86–96. [Google Scholar] [CrossRef]
- Barnosky, A.D.; Hadly, E.A.; Bascompte, J.; Berlow, E.L.; Brown, J.H.; Fortelius, M.; Getz, W.M.; Harte, J.; Hastings, A.; Marquet, P.A.; et al. Approaching a state shift in Earth’s biosphere. Nature 2012, 486, 52–58. [Google Scholar] [CrossRef]
- Avin, S.; Wintle, B.C.; Weitzdörfer, J.; hÉigeartaigh, S.S.Ó.; Sutherland, W.J.; Rees, M.J. Classifying global catastrophic risks. Futures 2018, 102, 20–26. [Google Scholar] [CrossRef]
- Dahl, A.L. IGOS from the perspective of the global observing systems and their sponsors. In Proceedings of the 27-th International Symposium on Remote Sensing of Environment: Information for Sustainability, Tromsø, Norway, 8–12 June 1998; Norwegian Space Centre: Oslo, Norway, 1998; pp. 92–94. [Google Scholar]
- IGOS-P. The Integrated Global Observing Strategy (IGOS) Partnership Process; Technical Report, IGOS Partnership, 2003; IGOS Process Paper, Version of 19 March 2003; World Meteorological Organization: Geneva, Switzerland, 2003. [Google Scholar]
- IGOS-P Ocean Theme Team. An Ocean Theme for the IGOS Partnership; Technical Report, IGOS Integrated Global Observing Strategy; NASA: Washington, DC, USA, 2001.
- Lawford, R.; The Water Theme Team. A Global Water Cycle Theme for the IGOS Partnership; Technical Report, IGOS Integrated Global Observing Strategy, 2004;Report of the Global Water Cycle Theme Team, April 2004; ESA Publications Division: Noordwijk, The Netherlands, 2004. [Google Scholar]
- Marsh, S.; The Geohazards Theme Team. Geohazards Theme Report; Technical Report, IGOS Integrated Global Observing Strategy; BRGM: Orleans, France, 2004. [Google Scholar]
- Townshend, J.R.; The IGOL Writing Team. Integrated Global Observations of the Land: A Proposed Theme to the IGOS Partnership—Version 2; Technical Report, IGOS Integrated Global Observing Strategy, 2004;Proposal Prepared by the IGOL Proposal Team, May 2004; FAO: Rome, Italy, 2004. [Google Scholar]
- IGOS. A Coastal Theme for the IGOS Partnership—For the Monitoring of our Environment from Space and from Earth; IOC Information Document No. 1220; UNESCO: Paris, France, 2006; 60p. [Google Scholar]
- United Nations Sustainable Development. In Proceedings of the AGENDA 21, United Nations Conference on Environment & Development, Rio de Janerio, Brazil, 3–14 June 1992; Technical Report. United Nations: New York, NY, USA, 1992. Available online: http://sustainabledevelopment.un.org/content/documents/Agenda21.pdf (accessed on 15 August 2019).
- GEO. Global Earth Observing System of Systems GEOSS—10-Year Implementation Plan Reference Document; Technical Report GEO 1000R, Group on Earth Observations; ESA Publications Division: Noordwijk, The Netherlands, 2005; Available online: http://earthobservations.org (accessed on 10 August 2019).
- LeCozannet, G.; Salichon, J. Geohazards Earth Observation Requirements; Technical Report BRGM/RP-55719-FR; BRGM: Orlean, France, 2007. [Google Scholar]
- Zell, E.; Huff, A.K.; Carpenter, A.T.; Friedl, L. A user-driven approach to determining critical earth observation priorities for societal benefit. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1594–1602. [Google Scholar] [CrossRef]
- Plag, H.P.; Rizos, C.; Rothacher, M.; Neilan, R. The global geodetic observing system (GGOS): Detecting the fingerprints of global change in geodetic quantities. In Advances in Earth Observation of Global Change; Springer: Berlin, Germany, 2010. [Google Scholar]
- Plag, H.P.; Ondich, G.; Kaufman, J.; Foley, G.; Pignatelli, F. The GEOSS User Requirement Registry: A Versatile Tool for the Dialog Between Users and Providers. In Proceedings of the 34th International Symposium on Remote Sensing of the Environment, Sydney, Australia, 10–15 April 2011. [Google Scholar]
- Plag, H.P.; Foley, G.; Jules-Plag, S.; Kaufman, J.; Ondich, G. The GEOSS user requirement registry (URR): Linking users of GEOSS across disciplines and societal benefit areas. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium IEEE, Munich, Germany, 23–27 July 2012. [Google Scholar]
- EAG. Results-Oriented GEOSS: A Framework for Transforming Earth Observation Data to Knowledge for Decision Making; Technical Report, Group on Earth Observation, Executive Committee; Report Prepared by the Expert Advisory Group for the 48th Meeting of the Executive Committee; Group on Earth Observation: Geneva, Switzerland, 2019. [Google Scholar]
- Plag, H.; The Workshop Participants. Implementing and Monitoring the Sustainable Development Goals in the Caribbean: The Role of the Ocean, 2018, Saint Vincent, Saint Vincent and the Grenadines, 17–19 January 2018; Technical Report; GEOSS Science and Technology Stakeholder Network (GSTSN): Rossbach, Germany, 2018; Available online: http://www.gstss.org/2018_Ocean_SDGs (accessed on 21 September 2019).
- Group on Earth Observations. Task US-09-01a: Critical Earth Observation Priorities, 2nd ed.; Technical Report; Group on Earth Observations: Geneva, Switzerland, 2012. Available online: http://sbageotask.larc.nasa.gov (accessed on 15 July 2019).
- Valuables. Resources for the Future. Available online: https://www.rff.org/valuables/ (accessed on 15 August 2019).
- UNISDR. Sendai Framework for Disaster Risk Reduction 2015–2030, 1st ed.; Technical Report UNISDR/GE/2015-ICLUX EN5000; UNISDR: Geneva, Switzerland, 2015; Available online: http://www.preventionweb.net/files/43291_sendaiframeworkfordrren.pdf (accessed on 15 July 2019).
- Rittel, H.W.J.; Webber, M.W. Dilemmas in a general theory of planning. Policy Sci. 1973, 4, 155–169. [Google Scholar] [CrossRef]
- UNRISD. Policy Innovations for Transformative Change—Implementing the 2030 Agenda for Sustainable Development; Unrisd Flagship Report 2016; United Nations Research Institute for Social Development: Geneva, Switzerland, 2016. [Google Scholar]
- Nilsson, M.; Griggs, D.; Visbeck, M. Policy: Map the interactions between Sustainable Development Goals. Nature 2016, 534, 320–322. [Google Scholar] [CrossRef] [PubMed]
- Griggs, D.J.; Nilsson, M.; Stevance, A.; McCollum, D. (Eds.) A Guide to SDG Interactions: From Science to Implementation; Technical Report; International Council for Science: Paris, France, 2017. [Google Scholar] [CrossRef]
- Singh, G.G.; Cisneros-Montemayor, A.M.; Swartz, W.; Cheung, W.; Guy, J.A.; Kenny, T.A.; McOwen, C.J.; Asch, R.; Geffert, J.L.; Wabnitz, C.C.; et al. A rapid assessment of co-benefits and trade-offs among Sustainable Development Goals. Mar. Policy 2018, 93, 223–231. [Google Scholar] [CrossRef]
- Alcamo, J.; Chenje, M.; Ghai, A.; Keita-Ouane, F.; Leonard, S.A.; Niamir-Fuller, M.; Nobbe, C. Embedding the Environment in Sustainable Development Goals; UNEP Post-2015 Discussion Paper 1, Version 2; UNEP: Nairobi, Kenya, 2013. [Google Scholar]
- Leadership Council of the Sustainable Development Solutions Network. Indicators for Sustainable Development Goals; Technical Report, Draft Report for Public Hearing; Sustainable Development Solutions Network of the United Nations: New York, NY, USA, 2014. [Google Scholar]
- IAEG-SDGs. Tier Classification for Global SDG Indicators—11 May 2018; Technical Report; Intern-Agency Expert Group for SDG Inidcators, United Nations: New York, NY, USA, 2018. [Google Scholar]
- Jules-Plag, S.; Plag, H.P. Supporting the Implementation of SDGs. Geospatial World. 15 August 2016. Available online: http://www.geospatialworld.net/article/supporting--implementation–sdgs/ (accessed on 10 July 2019).
- Plag, H.P.; Jules-Plag, S.A. A Goal-Based Approach to the Identification of Essential Transformation Variables in Support of the Implementation of the 2030 Agenda for Sustainable Development. Int. J. Digit. Earth 2019. [Google Scholar] [CrossRef]
- PANGAEA Team. PANGAEA. Data Publisher for Earth & Environmental Science. Available online: https://pangaea.de (accessed on 28 August 2019).
- McCrae, J.P.; Abele, A.; Buitelaar, P.; Cyganiak, R.; Jentzsch, A.; Andryushechkin, V.; Debattista, J. The Linked Open Data Cloud. Available online: https://www.lod-cloud.net/ (accessed on 27 August 2019).
- Christodoulou, P.; Christodoulou, K.; Andreou, A.S. A real-time targeted recommender system for supermarkets. In Proceedings of the 19th International Conference on Enterprise Information Systems— Volume 2, Porto, Portugal, 26–29 April 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 703–712. [Google Scholar] [CrossRef]
- The Performance Edge, Inc. Feedback Rewards—Guest Feedback and Rewards Program. Available online: http://www.feedbackrewards.com/ (accessed on 27 August 2019).
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach, 2nd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2003. [Google Scholar]
- Weiss, G. Multiagent Systems, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Plag, H.P. Implementing and Monitoring the Sustainable Development Goals in the Caribbean: The Role of the Ocean. Presentated at the Meeting of the Steering Committee of the GEO Initiative “Ocean and Society: Blue Planet”, Saint Vincent, Saint Vincent and the Grenadines, 15 March 2018. [Google Scholar]
- Stevenson, H. Emergence: The Gestalt Approach to Change. Available online: http://www.clevelandconsultinggroup.com/articles/emergence-gestalt-approach-to-change.php (accessed on 15 August 2019).
- Dietz, J. Enterprise Ontology - Theory and Methodology; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Pawlak, Z. Rough sets. Int. J. Parallel Program. 1982, 11, 341–356. [Google Scholar] [CrossRef]
- Bazan, J.; Szczuka, M.; Wojna, A.; Wojnarski, M. On the evolution of rough set exploration system. In Proceedings of the RSCTC 2004, LNAI 3066, Uppsala, Sweden, 1–5 June 2004; Tsumoto, S., Ed.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 592–601. [Google Scholar] [CrossRef]
- Ziarko, W. Rough sets as a methodology for data mining. In Rough Sets in Knowledge Discovery 1: Methodology and Applications; Polkowski, L., Skowron, A., Eds.; Physica-Verlag: Heidelberg, Germany, 1998; pp. 554–576. [Google Scholar]
- Chen, H.; Li, T.; Luo, C.; Horng, S.J.; Wang, G. A decision-theoretic rough set approach for dynamic data mining. IEEE Trans. Fuzzy Syst. 2015, 23, 1958–1970. [Google Scholar] [CrossRef]
- Neukom, R.; Barboza, L.A.; Erb, M.P.; Shi, F.; Emile-Geay, J.; Evans, M.N.; Franke, J.; Kaufman, D.S.; Lücke, L.; Rehfeld, K. Consistent multidecadal variability in global temperature reconstructions and simulations over the Common Era. Nat. Geosci. 2019. [Google Scholar] [CrossRef]
- Tarjan, R.E. Depth-first search and linear graph algorithms. SIAM J. Comput. 1972, 1, 146–160. [Google Scholar] [CrossRef]
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Introduction to Algorithms, 3rd ed.; The MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Soman, J.; Narang, A. Fast community detection algorithm with GPUs and multicore architectures. In Proceedings of the 2011 IEEE International Parallel and Distributed Processing Symposium, Anchorage, AK, USA, 16–20 May 2011; IEEE Computer Society: Washington, DC, USA, 2011. [Google Scholar] [CrossRef]
- Adamic, L.A.; Adar, E. Friends and neighbors on the web. Soc. Netw. 2003, 25, 211–230. [Google Scholar] [CrossRef]
- Newman, M.E.J. Networks: An Introduction; Oxford University Press: Oxford, UK, 2010. [Google Scholar]
- Sniedovich, M. Dijkstra’s algorithm revisited: The dynamic programming connexion. J. Control Cybern. 2006, 35, 599–620. [Google Scholar]
- Cook, J.; Lewandowsky, S. The Debunking Handbook; University of Queensland: St. Lucia, Australia, 2011. [Google Scholar]
- Pennycook, G.; Cheyne, J.A.; Barr, N.; Koehler, D.J.; Fugelsang, J.A. On the reception and detection of pseudo-profound bullshit. Judgm. Decis. Mak. 2015, 10, 549–563. [Google Scholar]
- Plag, H.P.; Adegoke, J.; Bruno, M.; Christian, R.; Digiacomo, P.; McManus, L.; Nicholls, R.; van de Wal, R. Observations as decision support for coastal management in response to local sea level changes. In Proceedings of the OceanObs’09: Sustained Ocean Observations and Information for Society (Volume 2), Venice, Italy, 21–25 September 2009; Hall, J., Harrison, D.E., Stammer, D., Eds.; ESA: Paris, France, 2010. [Google Scholar] [CrossRef]
- Plag, H.P.; McCallum, I.; Fritz, S.; Jules-Plag, S.; Nyenhuis, M.; Nativi, S. The GEOSS Science and Technology Service Suite: Linking S&T Communities and GEOSS. E3S Web Conf. 2013, 1, 28003. [Google Scholar] [CrossRef]
- Michalski, R.S.; Carbonell, J.G.; Mitchell, T.M. (Eds.) Machine Learning: An Artificial Intelligence Approach; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Hartuv, E.; Schmitt, A.O.; Lange, J.; Meier-Ewert, S.; Lehrach, H.; Shamir, R. An algorithm for clustering cDNA fingerprints. Genomics 2000, 66, 249–256. [Google Scholar] [CrossRef] [PubMed]
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson correlation coefficient. In Noise Reduction in Speech Processing, Springer Topics in Signal Processing 2; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar] [CrossRef]
- Hameed, M.A.; Al Jadaan, O.; Ramachandram, S. Collaborative filtering based recommendation system: A survey. Int. J. Comput. Sci. Eng. 2012, 4, 859–876. [Google Scholar]
- Linden, G.; Smith, B.; York, J. Amazon. com recommendations: Item-to-item collaborative filtering. IEEE Internet Comput. 2003, 7, 76–80. [Google Scholar] [CrossRef]
- Houeland, T.G. An efficient random decision tree algorithm for case-based reasoning systems. In Proceedings of the FLAIRS 24th International Florida Artificial Intelligence Research Society Conference, Palm Beach, FL, USA, 18–20 May 2011; AAAI Press: Menlo Park, CA, USA, 2011. [Google Scholar]
- Dalal, S.; Athavale, D.V.; Jindal, K. Case retrieval optimization of case-based reasoning through knowledge-intensive similarity measures. Int. J. Comput. Appl. 2011, 34, 12–18. [Google Scholar]
- Larochelle, H.; Bengio, Y. Classification using discriminative Restricted Boltzmann Machines. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; ACM: New York, NY, USA, 2008; pp. 536–543. [Google Scholar] [CrossRef]
- Lee, H.; Grosse, R.; Ranganath, R.; Ng, A.Y. Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. In Proceedings of the 26th International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; ACM: New York, NY, USA, 2009; pp. 609–616. [Google Scholar]
- Wang, H.; Wang, N.; Yeung, D.Y. Collaborative Deep Learning for Recommender Systems. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; ACM: New York, NY, USA, 2015; pp. 1235–1244. [Google Scholar] [CrossRef]
- Van den Oord, A.; Dieleman, S.; Schrauwen, B. Deep content-based music recommendation. In Advances in Neural Information Processing Systems 26; Burges, C.J.C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2013; pp. 2643–2651. [Google Scholar]
- Forum, W.E. Realizing the Potential of Blockchain—A Multistakeholder Approach to the Stewardship of Blockchain and Cryptocurrencies; Technical Report; World Economic Forum: Davos, Switzerland, 2017; Available online: http://www3.weforum.org/docs/WEF_Realizing_Potential_Blockchain.pdf (accessed on 13 September 2018).
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. 2009. Available online: metzdowd.com (accessed on 10 February 2018).
- Swan, M. Blockchain: Blueprint for a New Economy; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2015. [Google Scholar]
- Van Rijmenam, M. The Top 11 Blockchains for Enterprise Organisations, and Why. Available online: https://vanrijmenam.nl/11-blockchains-enterprise-organisations-why/ (accessed on 13 September 2019).
- Schneier, B. There’s No Good Reason to Trust Blockchain Technology. Wired, 2019. Available online: https://www.wired.com/story/theres-no-good-reason-to-trust-blockchain-technology/ (accessed on 13 September 2019).
- Hijgenaar, S. Not All Blockchains are Created Equal When It Comes to Energy Consumption. Available online: https://www.cgi.com/canada/en/blog/utilities/not-all-blockchains-are-equal-when-it-comes-to-energy-consumption (accessed on 13 September 2019).
- Matthews, K. 4 Ways to Counter Blockchain’s Energy Consumption Pitfall. Available online: https://www.greenbiz.com/article/4-ways-counter-blockchains-energy-consumption-pitfall (accessed on 16 August 2019).
- Boldrini, E.; Craglia, M.; Mazzetti, P.; Nativi, S. The brokering approach for enabling collaborative scientific research. In Collaborative Knowledge in Scientific Research Networks; Diviacco, P., Fox, P., Pshenichny, C., Leadbetter, A., Eds.; IGI Global: Hershey, PA, USA, 2015; pp. 283–304. [Google Scholar] [CrossRef]
- Hsu, L.; Mayorga, E.; Horsburgh, J.; Carter, M.; Lehnert, K.; Brantley, S. Enhancing Interoperability and Capabilities of Earth Science Data using the Observations Data Model 2 (ODM2). Data Sci. J. 2017, 16. [Google Scholar] [CrossRef] [Green Version]
- Hu, Y.; Janowicz, K.; Prasad, S.; Gao, S. Metadata Topic Harmonization and Semantic Search for Linked-Data-Driven Geoportals: A Case Study Using ArcGIS. Trans. GIS 2015, 19, 398–416. [Google Scholar] [CrossRef]
- Khalsa, S.J.S. Data and Metadata Brokering—Theory and Practice from the BCube Project. Data Sci. J. 2017, 16. [Google Scholar] [CrossRef]
- Campbell, J.; Jensen, D.E. Could a Digital Ecosystem for the Environment Have the Potential to Save the Planet? Technical Report; National Council for Science and the Environment: Washington, DC, USA, 2019; Available online: https://science.nasa.gov/national-council-science-and-environment-ncse-2019 (accessed on 25 September 2019).
- Barrie, L.A.; The IGACO Writing Team. An integrated Global Atmospheric Chemistry Observation Theme for the IGOS Partnership; Technical Report, IGOS Integrated Global Observing Strategy; WMO: Geneva, Switzerland, 2004. [Google Scholar]
- Unninayar, S.; Task Team. GEO Task US-09-01a: Critical Earth Observations Priorities—Water Societal Benefit Area; Technical Report; Group on Earth Observations—User Interface Committee: Geneva, Switzerland, 2016. [Google Scholar]
- Plag, H.P.; Ondich, G.; Kaufman, J.; Foley, G. The GEOSS User Requirement Registry—Supporting a User-Driven Global Earth Observation System of Systems. Imaging Notes 2010, 25, 28–33. [Google Scholar]
- Plag, H.P.; Jules-Plag, S.; Callaghan, C.; McCallum, I. Linking science and technology communities to GEOSS. In Towards a Sustainable GEOSS (Global Earth Observation System of Systems)—Some Results of the EGIDA Project; Nativi, S., Mazzetti, P., Plag, H.P., Eds.; Aíon: Florence, Italy, 2013; pp. 13–34. ISBN 978-88-98262-05-2. [Google Scholar]
- Yang, X.; Blower, J.D.; Bastin, L.; Lush, V.; Zabala, A.; Masó, J.; Cornford, D.; Díaz, P.; Lumsden, J. An integrated view of data quality in Earth observation. Philos. Trans. A Math. Phys. Eng. Sci. 2013, 371, 20120072. [Google Scholar] [CrossRef] [PubMed]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; van Kleef, P.; Auer, S.; et al. DBpedia—A Large-scale, Multilingual Knowledge Base Extracted from Wikipedia. Semant. Web 2012, 6, 167–195. [Google Scholar]
- DBpedia Team. DBpedia—Global and Unified Access to Knowledge. Available online: https://wiki.dbpedia.org/ (accessed on 21 September 2019).
- McCallum, I.; Plag, H.P.; Fritz, S. Data Citation Standard: A Means to Support Data Sharing, Attribution, and Traceability. E3S Web Conf. 2013, 1, 28002. [Google Scholar] [CrossRef]
- W3C. RDF 1.1 Concepts and Abstract Syntax; Technical Report; W3C: Keio, Japan, 2014; Available online: https://www.w3.org/TR/rdf11-concepts/ (accessed on 6 June 2019).
- Oracle. Oracle Big Data Spatial and Graph—Property Graph: Features and Performance; Technical Report, ORACLE Technical Whitepaper; Oracle: Redwood City, CA, USA, 2017. [Google Scholar]
- Levin, K.; Cashore, B.; Bernstein, S.; Auld, G. Overcoming the tragedy of super wicked problems: Constraining our future selves to ameliorate global climate change. Policy Sci. 2012, 45, 123–152. [Google Scholar] [CrossRef]
- Roberts, N. Wicked Problems and Network Approaches to Resolution. Int. Public Manag. Rev. 2000, 1, 1–19. [Google Scholar]
- Obersteiner, M.; Walsh, B.; Frank, S.; Havlík, P.; Cantele, M.; Liu, J.; Palazzo, A.; Herrero, M.; Lu, Y.; Mosnier, A.; et al. Assessing the land resource–food price nexus of the Sustainable Development Goals. Sci. Adv. 2016, 2. [Google Scholar] [CrossRef]
- World Economic Forum. Global Risks 2016, 11th ed.; Technical Report; World Economic Forum: Geneva, Switzerland, 2016. [Google Scholar]
- García, L.E.; Rodríguez, D.J.; Wijnen, M.; Pakulski, I. (Eds.) Earth Observation for Water Resources Management: Current Use and Future Opportunities for the Water Sector; World Bank Group: Washington, DC, USA, 2016. [Google Scholar] [CrossRef]
- Keskinen, M.; Someth, P.; Salmivaara, A.; Kummu, M. Water-Energy-Food Nexus in a Transboundary River Basin: The Case of Tonle Sap Lake, Mekong River Basin. Water 2015, 7, 5416–5436. [Google Scholar] [CrossRef]
- Lehmann, A.; Giuliani, G.; Ray, N.; Rahman, K.; Abbaspour, K.C.; Nativi, S.; Craglia, M.; Cripe, D.; Quevauviller, P.; Beniston, M. Reviewing innovative Earth observation solutions for filling science-policy gaps in hydrology. J. Hydrol. 2014, 518, 267–277. [Google Scholar] [CrossRef] [Green Version]
- Brown, V.A.; Harris, J.A.; Russell, J.Y. (Eds.) Tackling Wicked Problems—Through the Transdisciplinary Imagination; Earthscan: New York, NY, USA, 2010. [Google Scholar]

© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Plag, H.-P.; Jules-Plag, S.-A. A Transformative Concept: From Data Being Passive Objects to Data Being Active Subjects. Data 2019, 4, 135. https://doi.org/10.3390/data4040135
Plag H-P, Jules-Plag S-A. A Transformative Concept: From Data Being Passive Objects to Data Being Active Subjects. Data. 2019; 4(4):135. https://doi.org/10.3390/data4040135
Chicago/Turabian StylePlag, Hans-Peter, and Shelley-Ann Jules-Plag. 2019. "A Transformative Concept: From Data Being Passive Objects to Data Being Active Subjects" Data 4, no. 4: 135. https://doi.org/10.3390/data4040135
APA StylePlag, H.-P., & Jules-Plag, S.-A. (2019). A Transformative Concept: From Data Being Passive Objects to Data Being Active Subjects. Data, 4(4), 135. https://doi.org/10.3390/data4040135