dsCleaner: A Python Library to Clean, Preprocess and Convert Non-Intrusive Load Monitoring Datasets




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- Different File Formats: datasets come in several file formats, text files are the more prominent (e.g., BLUED [7]. Likewise, it is also possible to find datasets that use formats such as FLAC1 [8], WAVE2 [15], and relational databases [16]. Consequently, before conducting any performance evaluation researchers must first understand how the data is formatted and change their algorithms accordingly, including the calculation of performance metrics.
- Different Sampling Rates and Missing Data: datasets come in a variety of sampling rates from 1/60 Hz to several kHz or even MHz in some extreme cases [2]. Furthermore, due to the complexity of the hardware installations to collect such datasets, it is very common to have considerable periods of missing data [14,17]. This often requires the adaptation of algorithms to cope with a different sampling rate, and with missing data since some algorithms may assume the existence of continuous data.
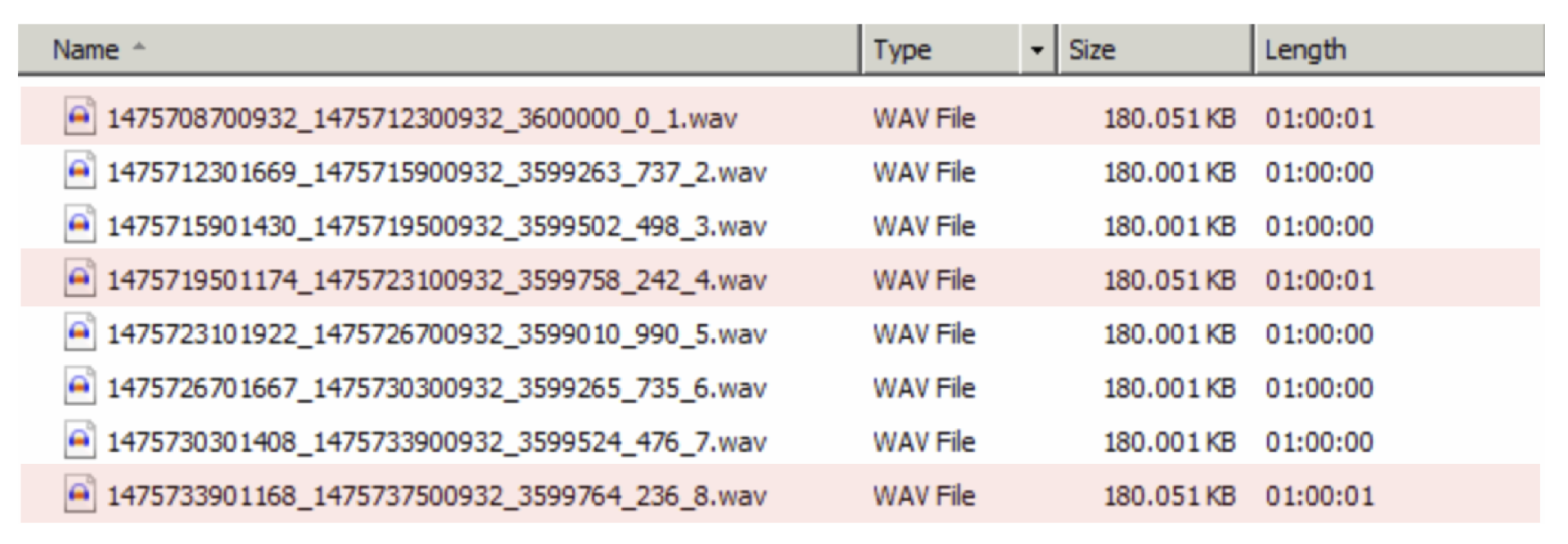
- Number of Files and Folder Structure: datasets are made available in several files and different folder structures. For example, when uncompressed, BLUED takes about 320 GB of disk space, which include 6496 files of distributed across 16 folders. This requires the development of additional code just for data loading, and to cope with different compression strategies. Furthermore, since existing algorithms are likely to support a specific type of data input (e.g., a single file containing all the data, or hourly files), it may be necessary to adapt the algorithms to the new folder structure or vice-versa.
2. dsCleaner Library
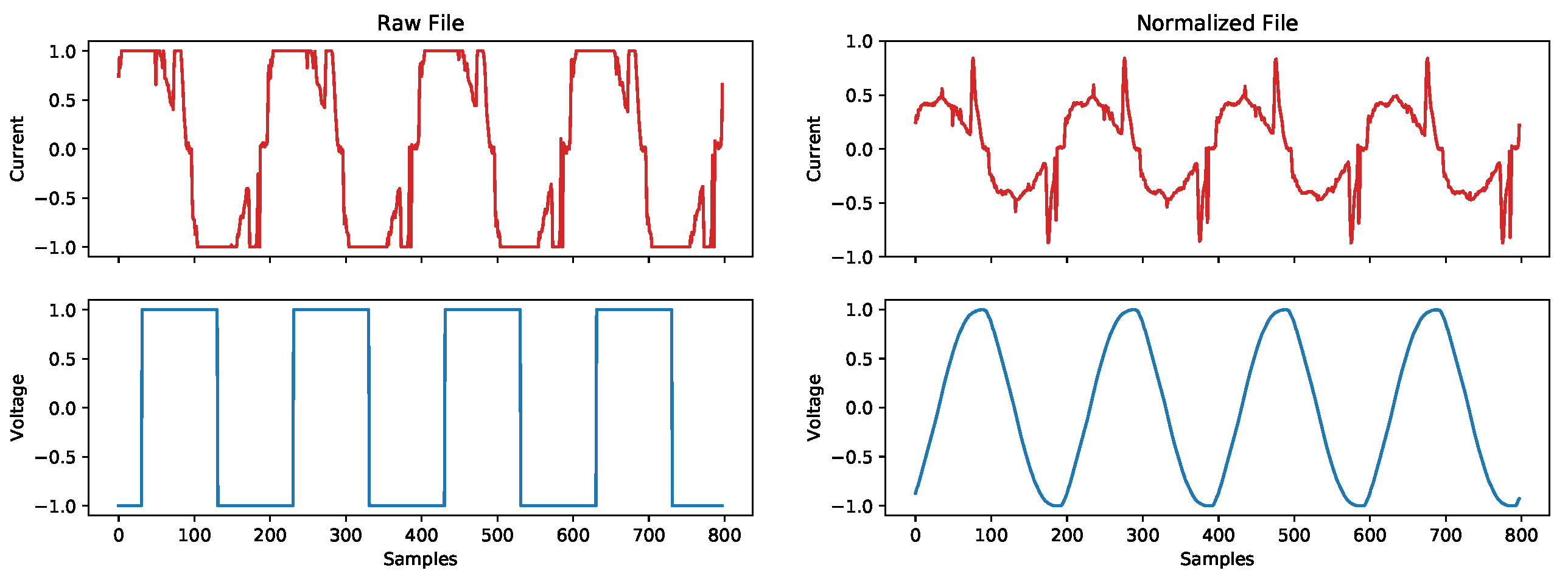
2.1. Data Processing Workflow
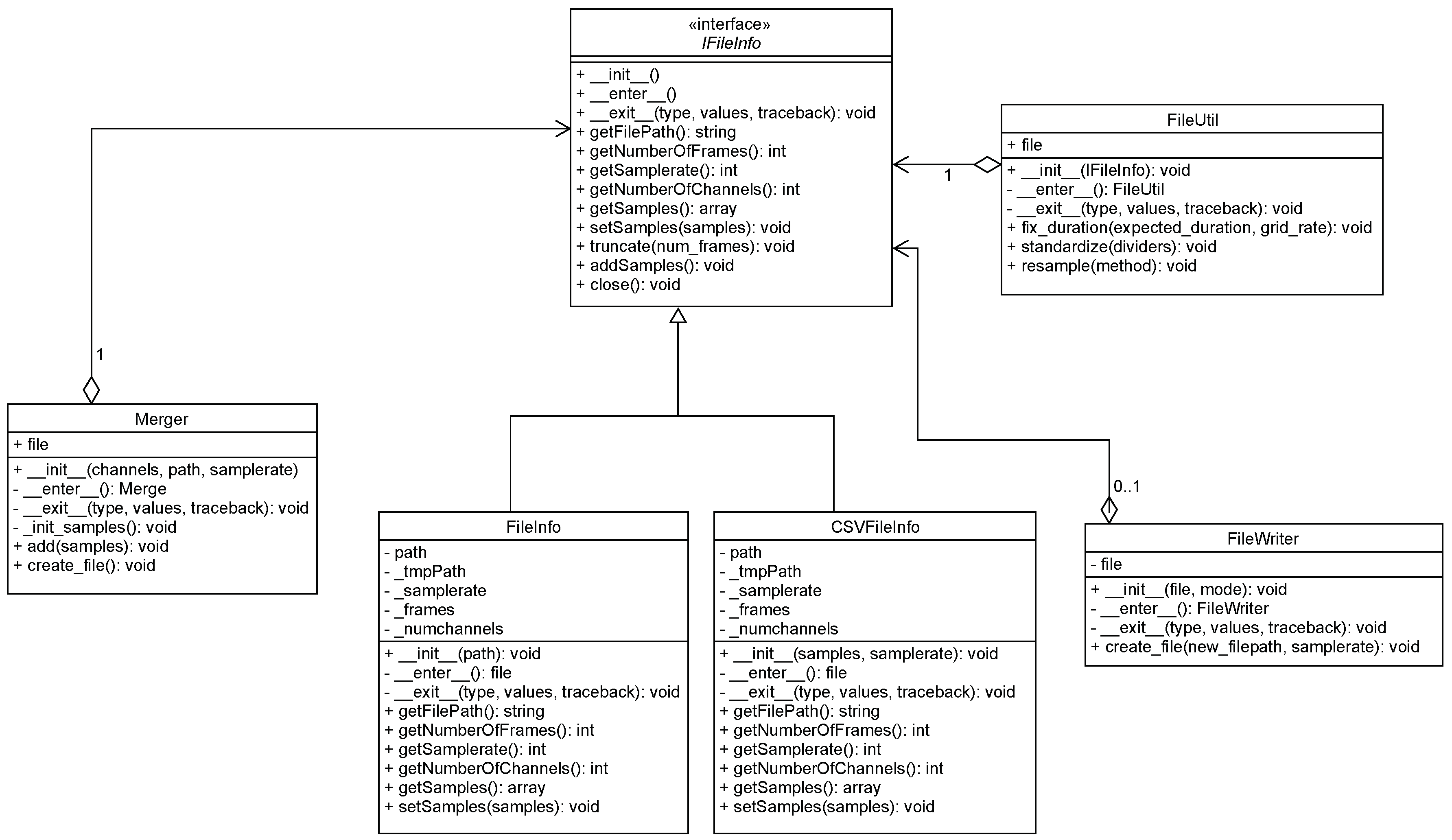
2.2. Library Overview
2.2.1. IFileInfo
2.2.2. FileInfo
2.2.3. CSVFileInfo
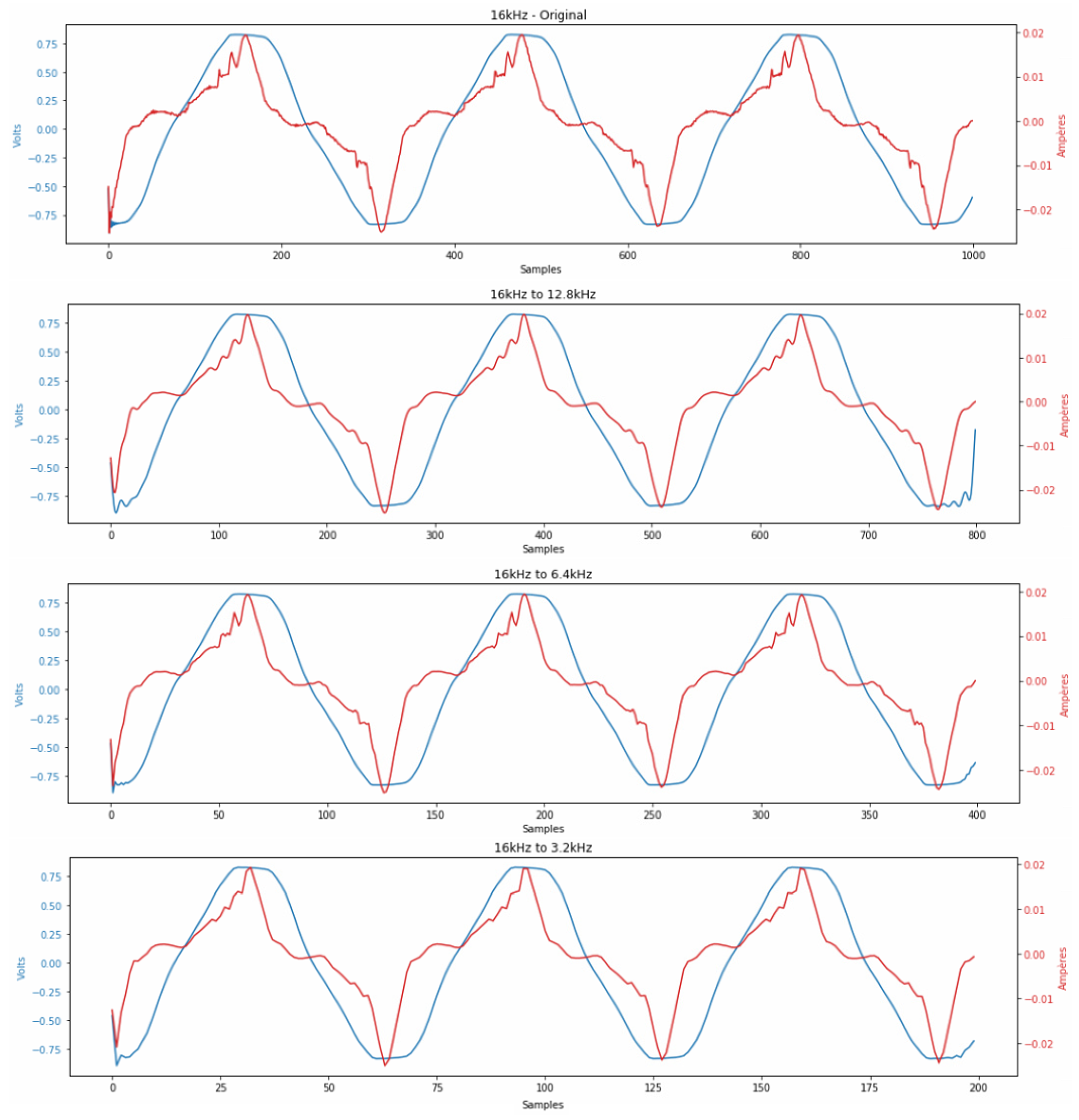
2.2.4. FileUtil
- When there are more samples than expected, the files are truncated to the expected length. Note that the truncate method is defined in the IFileInfo interface. As such, its implementation is required in all the realizations of this interface.
- When there are fewer samples than expected, the first solution is to replicate the samples of the last full cycle until the end of the file. Note that this is only possible when there is no change in power during the last full cycle. Otherwise, this change would propagate until the end of the file. Consequently, the alternative is to replicate the first full cycle of the next file in the dataset. Figure 4 shown an example of the first solution.
2.2.5. FileWriter
- Both formats store the data in separate channels, therefore allowing several different measurements on the same file while still providing a clear way of separating them.
- The resulting files are optimized to have very little overhead. Additionally, since the sampling rate is a fixed value, only the initial timestamp is required to obtain the timestamp of the remaining samples. Hence reducing the file size even further.
- Both are uncompressed lossless formats, i.e., all the original values of the data are kept untouched. Furthermore, it is possible to further compress these formats using lossless compression (e.g., WavePack6.
- Since these are standard formats it is possible to find implementations in most of the existing programming languages. As such, researchers can focus on the actual NILM problem and not in finding ways to interface the datasets.
2.2.6. Merger
3. Application Examples
3.1. UK-DALE

3.2. BLUED

4. Online Resources
4.1. Source Code and Documentation
4.2. Source-Code and Example Datasets
5. Conclusions and Future Work Directions
- Dataset splitting features, such that datasets with large files can be quickly divided into smaller ones;
- File writers for text file formats already being used by the NILM community, e.g., CSV;
- A command line application to provide the main dsCleaner features without the need for additional coding;
- Data compression features from the WavePack library, to further reduce the disk space taken by the resulting datasets;
- More complex application examples and additional metrics to quantify the applicability of dsCleaner. For example, the number of lines of code necessary to preprocess the datasets, or to adapt an existing algorithm to the new data format.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hart, G. Prototype Nonintrusive Appliance Load Monitor; Technical Report; MIT Energy Laboratory Technical Report, and Electric Power Research Institute Technical Report: Concord, MA, USA, 1985. [Google Scholar]
- Pereira, L.; Nunes, N. Performance evaluation in non-intrusive load monitoring: Datasets, metrics, and tools—A review. In Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery; Wiley: New York, NY, USA, 2018. [Google Scholar]
- Zeifman, M.; Roth, K. Nonintrusive appliance load monitoring: Review and outlook. IEEE Trans. Consum. Electron. 2011, 57, 76–84. [Google Scholar] [CrossRef]
- Esa, N.F.; Abdullah, M.P.; Hassan, M.Y. A review disaggregation method in Non-intrusive Appliance Load Monitoring. Renew. Sustain. Energy Rev. 2016, 66, 163–173. [Google Scholar] [CrossRef]
- Nalmpantis, C.; Vrakas, D. Machine learning approaches for non-intrusive load monitoring: From qualitative to quantitative comparation. Artif. Intell. Rev. 2019, 52, 217–243. [Google Scholar] [CrossRef]
- Kolter, Z.; Matthew, J. REDD: A public data set for energy disaggregation research. In Proceedings of the Data Mining Applications in Sustainability (SustKDD), San Diego, CA, USA, 21–24 August 2011. [Google Scholar]
- Anderson, K.; Ocneanu, A.; Benitez, D.; Carlson, D.; Rowe, A.; Berges, M. BLUED: A Fully Labeled Public Dataset for Event-Based Non-Intrusive Load Monitoring Research. In Proceedings of the 2nd KDD Workshop on Data Mining Applications in Sustainability (SustKDD), Beijing, China, 12–16 August 2012; pp. 1–5. [Google Scholar]
- Kelly, J.; Knottenbelt, W. The UK-DALE dataset, domestic appliance-level electricity demand and whole-house demand from five UK homes. Sci. Data 2015, 2, 150007. [Google Scholar] [CrossRef] [PubMed]
- Makonin, S.; Ellert, B.; Bajić, I.V.; Popowich, F. Electricity, water, and natural gas consumption of a residential house in Canada from 2012 to 2014. Sci. Data 2016, 3, 160037. [Google Scholar] [CrossRef] [PubMed]
- Murray, D.; Stankovic, L.; Stankovic, V. An electrical load measurements dataset of United Kingdom households from a two-year longitudinal study. Sci. Data 2017, 4, 160122. [Google Scholar] [CrossRef] [PubMed]
- Makonin, S.; Popowich, F. Nonintrusive load monitoring (NILM) performance evaluation. Energy Effic. 2014, 8, 809–814. [Google Scholar] [CrossRef]
- Mayhorn, E.T.; Sullivan, G.P.; Fu, T.; Petersen, J.M. Non-Intrusive Load Monitoring Laboratory-Based Test Protocols; Technical Report; Pacific Northwest National Laboratory (PNNL): Richland, WS, USA, 2017. [Google Scholar]
- Pereira, L.; Nunes, N. A comparison of performance metrics for event classification in Non-Intrusive Load Monitoring. In Proceedings of the 2017 IEEE International Conference on Smart Grid Communications (SmartGridComm), Dresden, Germany, 23–26 October 2017; pp. 159–164. [Google Scholar]
- Batra, N.; Kelly, J.; Parson, O.; Dutta, H.; Knottenbelt, W.; Rogers, A.; Singh, A.; Srivastava, M. NILMTK: An Open Source Toolkit for Non-intrusive Load Monitoring. In Proceedings of the 5th International Conference on Future Energy Systems, Cambridge, UK, 11–13 June 2014; ACM: New York, NY, USA, 2014; pp. 265–276. [Google Scholar]
- Pereira, L. EMD-DF: A Data Model and File Format for Energy Disaggregation Datasets. In Proceedings of the 4th ACM International Conference on Systems for Energy-Efficient Built Environments, Delft, The Netherlands, 8–9 November 2017. [Google Scholar]
- Batra, N.; Gulati, M.; Singh, A.; Srivastava, M.B. It’s Different: Insights into Home Energy Consumption in India. In Proceedings of the 5th ACM Workshop on Embedded Systems For Energy-Efficient Buildings, Roma, Italy, 11–15 November 2013. [Google Scholar]
- Pereira, L.; Ribeiro, M.; Nunes, N. Engineering and deploying a hardware and software platform to collect and label non-intrusive load monitoring datasets. In Proceedings of the 2017 Sustainable Internet and ICT for Sustainability (SustainIT), Funchal, Portugal, 6–7 December 2017; pp. 1–9. [Google Scholar]
- Kelly, J.; Knottenbelt, W. Metadata for Energy Disaggregation. In Proceedings of the 2014 IEEE 38th International Computer Software and Applications Conference Workshops (COMPSACW 2014), Vasteras, Sweden, 21–25 July 2014. [Google Scholar]
- Kriechbaumer, T.; Jorde, D.; Jacobsen, H.A. Waveform Signal Entropy and Compression Study of Whole-Building Energy Datasets. In Proceedings of the Tenth ACM International Conference on Future Energy Systems, Phoenix, AZ, USA, 25–28 June 2019; pp. 58–67. [Google Scholar]
- Ribeiro, M.; Pereira, L.; Quintal, F.; Nunes, N. SustDataED: A Public Dataset for Electric Energy Disaggregation Research. In Proceedings of the ICT for Sustainability 2016, Bangkok, Thailand, 14–16 Novermber 2016. [Google Scholar]
- Colpaert, P. Publishing Transport Data for Maximum Reuse. Doctor Dissertation, Ghent University, Ghent, Belgium, 2017. [Google Scholar]
- Pereira, L. Hardware and Software Platforms to Deploy and Evaluate Non-Intrusive Load Monitoring Systems. Ph.D. Thesis, Universidade da Madeira, Funchal, Portugal, 2016. [Google Scholar]
| 1 | |
| 2 | |
| 3 | Sony Wave64, http://fileformats.archiveteam.org/wiki/Sony_Wave64 |
| 4 | libsndfile, https://github.com/erikd/libsndfile |
| 5 | Librosa, https://librosa.github.io/librosa/ |
| 6 | WavePack, http://www.wavpack.com/ |
| 7 | MIT License, https://opensource.org/licenses/MIT |
| 8 |






© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pereira, M.; Velosa, N.; Pereira, L. dsCleaner: A Python Library to Clean, Preprocess and Convert Non-Intrusive Load Monitoring Datasets. Data 2019, 4, 123. https://doi.org/10.3390/data4030123
Pereira M, Velosa N, Pereira L. dsCleaner: A Python Library to Clean, Preprocess and Convert Non-Intrusive Load Monitoring Datasets. Data. 2019; 4(3):123. https://doi.org/10.3390/data4030123
Chicago/Turabian StylePereira, Manuel, Nuno Velosa, and Lucas Pereira. 2019. "dsCleaner: A Python Library to Clean, Preprocess and Convert Non-Intrusive Load Monitoring Datasets" Data 4, no. 3: 123. https://doi.org/10.3390/data4030123
APA StylePereira, M., Velosa, N., & Pereira, L. (2019). dsCleaner: A Python Library to Clean, Preprocess and Convert Non-Intrusive Load Monitoring Datasets. Data, 4(3), 123. https://doi.org/10.3390/data4030123